executing provenance-enabled queries over web data
TRANSCRIPT

24th International World Wide Web Conference, 21st May 2015, Florence, Italy
Executing Provenance-Enabled Queries over Web Data
Marcin Wylot1, Philippe Cudré-Mauroux1, and Paul Groth2
1) eXascale Infolab, University of Fribourg, Switzerland 2) Elsevier Labs, Amsterdam, Netherlands

Research Question
How RDF databases can efficiently support
provenance-enabled queries?
2

Outline
➢ Motivation
➢ Provenance-Enabled Queries
➢ Query Execution Strategies
➢ Results
3

Data Provenance
“Provenance is information about
entities, activities, and people involved
in producing a piece of data or thing, which can be used to form
assessments about its quality, reliability or trustworthiness.”
Which pieces of data were combined to produce
the result?
4

Data Integration
➢ Integrated and summarized data
➢ Trust, transparency, and cost
➢ Capability to store and track provenance data (WWW 2014)
➢ Capability to tailor queries with provenance information (WWW 2015)
5

Querying Linked Datause data following a provenance specification
6

Provenance-Enabled Query
A Workload Query is a query producing results a user is interested in. These results are referred to as workload query results.
A Provenance Query is a query that selects a set of data from which the workload query results should originate.
A Provenance-Enabled Query is a pair consisting of a Workload Query and a Provenance Query, producing results a user is interested in (as specified by the Workload Query) and originating only from data pre-selected by the Provenance Query.
7

Provenance-Enabled Query: Example
SELECT ?t WHERE {?a <type> <article> .?a <tag> <Obama> .?a <title> ?t . }
➢ ensure that the articles come from sources attributed to the governmentSELECT ?ctx WHERE { ?ctx prov:wasAttributedTo <government> . }
➢ ensure that the data used to produce the answer was associated a “SeniorEditor” and a “Manager”
SELECT ?ctx WHERE {?ctx prov:wasGeneratedBy <articleProd>.<articleProd> prov:wasAssociatedWith ?ed .?ed rdf:type <SeniorEdior> .<articleProd> prov:wasAssociatedWith ?m .?m rdf:type <Manager> . }
8

Executing Provenance-Enabled Queries
A workload and a provenance query are given as input to a triplestore, which produces results for both queries and then combine them to obtain the final results.
9

TripleProv: Query Execution Pipeline
input: provenance-enable query
➢ execute the provenance query ➢ optionally pre-materializing or co-locating data➢ optionally rewrite the workload queries➢ execute the workload queries➢output: the workload query results, restricted to those which were derived from data specified by the provenance query 10

Physical Storage Models
A molecule collocates objects related to a given subject; it is composed of a subject, and a series of predicate and object related to that subject.
Extended for provenance data a molecule collocates the context values with the predicate-object pairs.
This avoids the duplication of the same context value, while at the same time collocating all data about a given subject in one structure.
11
➢ composed of a subject, and a series of related predicates and objects
➢ collocates the context values with the predicate-object pairs
➢ avoids data duplication
RDF molecule
basic data unit

Query Execution Strategies
1. Post-Filtering
2. Query Rewriting
3. Full Materialization
4. Pre-Filtering
5. Partial Materialization
12

Post-Filtering
➢ the baseline strategy➢ executes both the workload and the provenance query independently. ➢ the provenance and workload queries can be executed in any order➢ the results from the provenance query are used to filter a posteriori
the results of the workload query based on their provenance
13
➢ the baseline strategy
➢ workload and provenance queries executed independently
➢ results filtered a posteriori

Query Rewriting
➢ efficient from the provenance query execution side
➢ can be suboptimal from the workload query execution side
14
execute the provenance query
rewrite the query plan; add provenance constraints
return restricted results
➢ efficient from the provenance query execution side
➢ can be suboptimal from the workload query execution side
It can be implemented in two ways by the triplestores, either by modifying the query execution process, or by rewriting the workload queries in order to include constraints on the named graphs.

Full Materialization
15
We implemented a basic view mechanisms in TripleProv. These mechanisms allow us to project, materialize and utilize as a secondary structure the portions of the molecules that are following the provenance specification.

Full Materialization
➢ outperforms all other strategies when executing the workload queries
➢ materializing is be expensive
16
execute the provenance query
materialize data for the provenance query
execute workload queries on the materialized view
➢ This strategy will outperform all other strategies when executing the workload queries, since they are executed as is on the relevant subset of the data.
➢ Materializing all potential tuples based on the provenance query can be expensive, both in terms of storage space and latency.
➢ Implementing this strategy requires either to manually materialize the relevant tuples and modify the workload queries accordingly, or to use a triplestore supporting materialized views.

Pre-Filtering
➢ Dedicated provenance index collocates, for each context values, the ids (or hashes) of all tuples belonging to this context.
➢ The index is created upfront when the data is loaded.
17

Pre-Filtering
➢ provenance index ➢ inspects only molecules that are
compatible with the provenance specification
18
execute the provenance query
execute workload queries, including early filtering with the provenance index
➢ The provenance index is looked up during the query execution to filter molecules that are compatible with the provenance specification.
➢ This strategy requires to create a new index structure in the system, and to modify both the loading and the query execution processes.

Partial Materialization
➢ This strategy introduces a trade-off between the performance of the provenance query and that of the workload queries.
➢ While executing the provenance query, the system builds a temporary structure maintaining the ids of all molecules belonging to the context values returned by the provenance query.
19

Partial Materialization
➢ partially materializes relevant molecules
➢ early filters out irrelevant molecules
➢ executes query processing operations can reduce number of elements20
execute the provenance query and partially materialize molecules
execute workload queries, including early filtering based on pre-materialized set of molecules
➢ The system dynamically (and efficiently) looks-up all molecules and can filter them out early in case they do not appear in the temporary structure.
➢ Query processing operations can be executed faster on a reduced number of elements.
➢ The implementation of this strategy requires the introduction of an additional data structure at the core of the system, and the adjustment of the query execution process in order to use it.

Experiments
What is the most efficient query
execution strategy for provenance-
enabled queries?
21

Datasets
➢ Two collections of RDF data gathered from the Web
○ Billion Triple Challenge (BTC): Crawled from the linked open data
cloud
○ Web Data Commons (WDC): RDFa, Microdata extracted from
common crawl
➢ Typical collections gathered from multiple sources
➢ Sampled subsets of ~40 million triples each; ~10GB each
➢ Added provenance specific triples (184 for WDC and 360 for BTC); that
the provenance queries do not modify the result sets of the workload
queries
22

Workloads
➢ Queries defined for BTC○ T. Neumann and G. Weikum. Scalable join processing on very large rdf
graphs. In Proceedings of the 2009 ACM SIGMOD International Conference on Management of data, pages 627–640. ACM, 2009.
➢ Two additional queries with UNION and OPTIONAL
clauses
➢ 7 various new queries for WDC
http://exascale.info/provqueries23

Results for BTC
➢ Full Materialization: 44x faster than the vanilla version of the system
➢ Partial Materialization: 35x faster
➢ Pre-Filtering: 23x faster
➢ Adaptive Partial Materialization executes a provenance query and materialize data 475 times faster than Full Materialization
➢ Query Rewriting and Post-Filtering strategies perform significantly slower
24
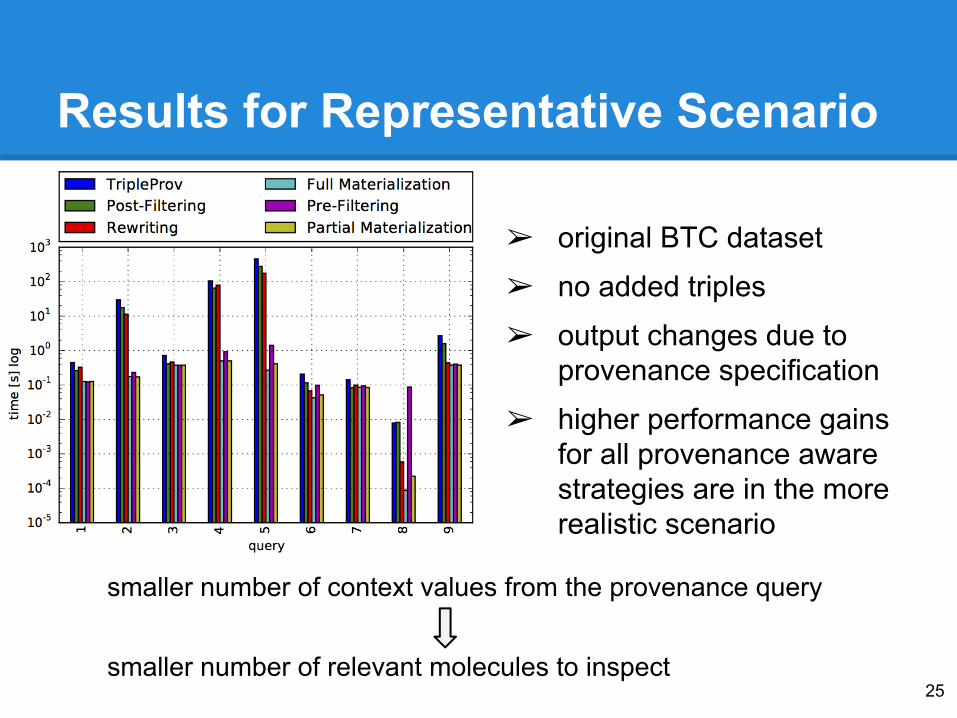
Results for Representative Scenario
➢ original BTC dataset
➢ no added triples
➢ output changes due to provenance specification
➢ higher performance gains for all provenance aware strategies are in the more realistic scenario
25
smaller number of context values from the provenance query smaller number of relevant molecules to inspect

Data Analysis
➢ How many context values refer to how many triples? How selective it is?
➢ 6'819'826 unique context values in the BTC dataset.
➢ The majority of the context values are highly selective.
26
➢ average selectivity
○ 5.8 triples per context value
○ 2.3 molecules per context value

Conclusions
➢ Querying provenance data does not necessarily introduce a performance overhead.
➢ Queries tailored with provenance data can be executed faster.
➢ Provenance information is highly selective.
➢ Partial Materialization represents the best trade-off for provenance-enabled queries, but it introduces a materialization cost and is not trivial to implement.
27

Summary
➢ provenance-enabled queries: to tailor queries with provenance information
➢ five provenance aware query execution strategies
➢ TripleProv: an efficient triplestore allowing to store, track, and query provenance
➢ experimental evaluation and data analysis
★ http://exascale.info/provqueries★ http://exascale.info/tripleprov
28
❖ email: [email protected]❖ twitter: @mwylot