exchange)e*mail)response) service)disruption:)...
TRANSCRIPT

Cornell Information Technology Root Cause Analysis
Exchange E-‐‑Mail Response Root Cause Analysis
Service Disruption: From: October 17, 2011 To: 12:30 AM November 8, 2011
Executive Summary Cornell’s Exchange email system suffered three weeks of increasingly poor response. Microsoft flew a field engineer to Ithaca to assist in diagnosing the problem. With Cornell staff, it was determined that the root cause of the problem was a feature of the network interfaces on the Exchange servers that disrupted communication within the cluster. This triggered a second bug in the Microsoft cluster software that caused lengthy delays in resuming cluster operation following the disruption. Once both of these were addressed, response time returned to normal levels. During the investigation, a number of other potential causes were identified and eliminated. In the end, these other factors were only minor contributors to pushing an unstable system over the edge. Timeline Beginning October 17, users of CIT'ʹs Exchange email system saw increasingly poor response. CIT staff identified and eliminated several apparent contributions to the problem, but ultimately came to an impasse. Paradoxically, while it initially appeared to be a resource load issue, adding additional resources to the cluster made the problem worse. In reviewing the timeline, it is now apparent that the increasing size of the cluster as servers were moved from the Exchange 2007 cluster to the Exchange 2010 cluster caused the network interface errors to reach a critical level. In the first two weeks, a number of factors were identified that appeared to cause the problem. These factors included a set of bad antivirus signatures coinciding with a malware storm, power management settings that reduced CPU clock speeds on the servers, and an Exchange 2010 feature that caused many more mailboxes to be opened than previously. Each seemed at the time to be an isolated problem, and rectifying them provided temporary relief. The problem was escalated to Microsoft, who flew in a Field Engineer on Wednesday, November 2, evening to help us diagnose the problem. The following sections detail the troubleshooting stages.
Network Load Suspected Each Exchange database server (MBX) has two network interfaces that it uses to connect via the Tier 1 and 2 networks to the Client Access Servers (CAS), and to the other MBX servers in the cluster. It has a third that connects to the Tier 3 network for cluster heartbeats and a fourth that connects to the Backup network.

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 2
It was hypothesized that Exchange database replication traffic was overwhelming the client traffic on the Tier 1 and 2 interfaces, causing poor response time. The Microsoft Field Engineer said that this is seen in some large installations of Exchange. He defined large as more than 5,000 users, while we have 20,000. Exchange settings were changed to route replication traffic over the Tier 3 network, which resulted in some improvement in performance issues. This was later determined to be only a tertiary effect on the overall problem.
Clustering Issue The servers continued to report communication errors to their peer servers in the cluster. The physical network was examined for errors or capacity issues, but none were found. The Field Engineer escalated the case to Microsoft internal resources, and eventually engaged a Network Engineer in Austin. This Engineer identified three unreleased hot fixes for the cluster service that appeared relevant to the issue. These fixes addressed issues where cluster timeouts were too short to allow a cluster of our size to restabilize following a transient error, and problems in electing a new cluster manager. Those fixes were applied to the cluster on Thursday night, and made a large improvement in the stability of the system. The issue was related to the number of machines in the cluster. No problems had been observed during the first phase of the 2007 to 2010 migration, when there were only two pairs of mailbox servers in production. Some problems were observed when the third pair was added during the third week of September, and more frequent problems were observed when the fourth pair was added mid-‐‑October. Our analysis now indicates that this was the secondary root cause of the problems. However, the improvement was sufficient that it was believed that the problem was addressed, and the Microsoft field engineer departed at noon on Friday.
Problem with New CAS servers Reports of connection problems on Friday morning appeared to be geographically clustered. Around noon, a connectivity problem between the load balancer and the new CAS servers was suspected. The new servers were removed from rotation. All units that reported problems reported that this resolved their connectivity issues. Analysis now indicates that it was again the combination of the network interface errors and the size of the cluster causing the problem.
Network Interface Issues Communication errors remained present in the cluster, even though the problem of improper responses to those errors by the cluster software had been addressed. While response time seemed improved on Friday, by Monday it was apparent that it was still seriously degraded. CIT staff re-‐‑engaged with the network engineer in Austin, who worked through logs. He first identified a problem with the standby network adaptor invoking power saving mode. This appeared to take the primary adaptor offline momentarily because the system software considered the pair of adaptors a team. Turning off power management again reduced the magnitude of the problem.
Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 3
Finally, using network traces, the engineer identified that heartbeat packets were being corrupted in transit between the systems, and identified a TCP offloading feature of the Broadcom network adaptors as a probable cause. This feature, called NetDMA, was turned off between midnight and 1am on Tuesday morning. Ever since that change, the cluster has been highly responsive, and the CPU utilization on all servers has dropped to normal levels.
Postscript: Network Outage and Load Balancer Problems After the cluster was healthy, a major network outage struck CCC. This affected both load balancers, including the one in Rhodes Hall. People were unable to reach the Exchange system, and after the network was restored, the load balancer did not re-‐‑establish contact with Exchange. Manual intervention was required. This is mentioned in the timeline because of the proximity to the other problems. It is entirely unrelated. Specific Services and Configuration Items Impacted Exchange Actions Taken to Resolve Incident Event Date/Time Action Migrations, 2007 to 2010
9/5/11 12:00 AM
CCAB CHANGE REQUEST: artf35047: Exchange Mailbox Moves CHANGE DESCRIPTION: Migrate Exchange Mailboxes from Exchange 2007 to 2010. TEST PROCEDURE: Process is already underway with select groups of users. NOTE: Migrations completed October 2.
MBXA Added to Cluster
9/20/11 Work was fast-‐‑tracked because of issues with the dual 2007/2010 Exchange environment, as decided in a meeting with Ted and Dave earlier in the month. The CCAB covering the event was inadvertently not filed.
MBXB Added to Cluster
10/14/11 Work was fast-‐‑tracked because of issues with the dual 2007/2010 Exchange environment, as decided in a meeting with Ted and Dave earlier in the month. The CCAB covering the event was inadvertently not filed.
Communication 10/17/11 10:01 AM
CIT posts an alert for Exchange Performance issues (http://www.cit.cornell.edu/services/alert.cfm?id=1500; see Appendix III).
Communication 10/17/11 11:46 AM
CIT posts an alert for the usps.com malware attack (http://www.cit.cornell.edu/services/alert.cfm?id=1503, see

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 4
Actions Taken to Resolve Incident Event Date/Time Action
Appendix III). Communication 10/17/11
9:23 PM CIT posts an update to the Exchange Performance issue (http://www.cit.cornell.edu/services/alert.cfm?id=1500; see Appendix III).
Communication/Description of Service Disruption
10/18/11 1:56 PM
E-‐‑Mail sent to net-‐‑admin-‐‑l:
Please pass this message along to individuals you support who may have been affected by the issues described below. (This message has been sent to Net-‐‑Admin-‐‑L and ITMC-‐‑L.) On Monday, October 17, from approximately 8:15 am to 4:15 pm, the Exchange email and calendar system experienced performance problems related to load, and some individuals reported unstable connections, slow response, reduced functionality, and error messages. It appears that Macintosh clients and BlackBerry devices were most seriously impacted. A few Outlook Web App connections may also have been affected, and response times for Windows Outlook were slow at times. The apparent cause was a significantly higher than normal load triggered by the receipt of tens of thousands of virus-‐‑laden messages. Cornell'ʹs perimeter anti-‐‑virus/anti-‐‑spam defenses kept most of the virus-‐‑laden messages from reaching Exchange, but the ones that got through triggered Exchange 2010'ʹs own anti-‐‑virus defense, which affected overall performance. We are also investigating whether a virus engine update played a role. The virus-‐‑laden messages were from a forged usps.com address, so one defensive step was to temporarily block all usps.com mail until legitimate mail could be distinguished from forged mail. This block resulted in approximately 6 legitimate messages being returned to the sender with a "ʺblacklisted"ʺ alert. At this time, Exchange load is back to typical levels, so we believe individuals should no longer be seeing performance issues. We are investigating why this event had the effects that it did, and what, if anything, could be adjusted in Exchange 2010.
Communication 10/20/11 CIT posts an alert for a 5 minute spike on Exchange servers. The

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 5
Actions Taken to Resolve Incident Event Date/Time Action
10:30 AM issue is closed at 4:13 PM. (http://www.cit.cornell.edu/services/alert.cfm?id=1511, see Appendix III).
Communication 10/20/11 3:54 PM
CIT posts an alert for Exchange authentication errors which had been reported during the previous half hour. (http://www.cit.cornell.edu/services/alert.cfm?id=1512, see Appendix III)
Power Management Settings Turned Off
10/24/11 11:00 AM
CCAB CHANGE REQUEST: artf35973 : Change Power Management Settings on Exchange CHANGE DESCRIPTION: The exchange servers are currently subject to power management which is causing the CPU clock frequencies to be lowered. This is not a recommended setting for exchange and is a contributing factor to the exchange performance issues we have been seeing. This change will change the processors to the maximum power settings. TEST PROCEDURE: Standard Operating system setting. BACKOUT STRATEGY: Revert to current settings
Communication 10/28/11 1:34 PM
CIT posts an alert for Exchange performance which was affected from 10:00 AM to 12:30 PM due to an issue with the server farm switch that morning. (http://www.cit.cornell.edu/services/alert.cfm?id=1526; see Appendix III).
Change Request
10/29/11 5:00 AM
CCAB CHANGE REQUEST: artf36042 : Modify Network settings on Exchange 2010. CHANGE DESCRIPTION: Turn off chimney and rss offloading on the network adapters on the Exchange 2010 mailbox servers. This change is recommended by Microsoft to resolve some database replication problems we have been experiencing in the Exchange 2010 environment. This change will be occurring between 5:00am and 7:00am on Sat for the CCC data center servers followed by 5:00am and 7:00am on Sunday for the Rhodes data center. The actual time to complete this task should only be around 15 minutes. User will not see any downtime as we will always have an available copy of the exchange databases.

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 6
Actions Taken to Resolve Incident Event Date/Time Action
TEST PROCEDURE: These settings have been recommended by Microsoft. BACKOUT STRATEGY: revert to the current settings.
Communication 10/31/11 8:46 AM
CIT posts an alert regarding reports that users cannot access Outlook Web Access (OWA). (http://www.cit.cornell.edu/services/alert.cfm?id=1529; see Appendix III).
Communication 10/31/11 8:54 AM
CIT posts an alert regarding Exchange email and calendar. (http://www.cit.cornell.edu/services/alert.cfm?id=1530; see Appendix III). Updates are provided throughout the day and the cause was believed to be primarily a feature of Exchange Server 2010 SP2 that became apparent when a script for Exchange Groups Accounts was run on the weekend of October 29.
Communication/Description of Service Disruption
10/31/11 7:25 PM
E-‐‑Mail sent to net-‐‑admin-‐‑l: The Exchange performance problems the morning of October 31 have been traced to Outlook 2007/2010 on Windows attempting to connect to all mailboxes to which each user had access. Fixing this problem may have disconnected previously connected shared mailboxes. Affected individuals may need to re-‐‑add the Exchange Group Accounts and other mailboxes they want to see in Outlook. To make Exchange Group Accounts visible again: http://www.cit.cornell.edu/services/ega/howto/config.cfm To make other shared mailboxes visible again: http://www.cit.cornell.edu/services/outlook/howto/email/email-‐‑view-‐‑shared.cfm CIT is adjusting the scripts for Exchange Group Accounts and filing an issue report with Microsoft. -‐‑-‐‑-‐‑-‐‑-‐‑-‐‑-‐‑-‐‑ DETAILS The performance problems are believed to have been primarily caused by a feature introduced by Microsoft in Exchange Server

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 7
Actions Taken to Resolve Incident Event Date/Time Action
2010 SP 2. The feature'ʹs effects were not apparent until scripts for Exchange Group Accounts (which had been in place for two years) were run the weekend of October 29. The feature causes Outlook to automount all mailboxes to which an individual has full access. This behavior creates a huge load on both CornellAD and Exchange. It was primarily responsible for the Exchange performance problems the morning on October 31, as thousands of additional mailbox connections, in aggregate, were made. For individuals with full access to many Exchange Group Accounts or other mailboxes, the start-‐‑up time for Outlook may have taken several minutes. These automounted mailboxes supplanted the accounts that individuals had previously added to Outlook, so when the automounting was stopped, those mailboxes disappeared from view in Outlook. Re-‐‑adding the affected mailboxes resolves the issue for individuals. We apologize for the inconvenience this issue has caused, and appreciate your patience and assistance in helping individuals restore their Outlook views.
Communication 11/1/11 12:02 PM
CIT posts an alert regarding performance issues to Exchange email and calendar. (See http://www.cit.cornell.edu/services/alert.cfm?id=1533; Appendix III). This alert remains open until 9:53 AM on November 10. During this period, approximately 28 updates are provided to this alert.
Microsoft Engineer on Site
11/2/11 9:00 PM
See the narrative description above for the detailed timeline of events. See also Appendix V.
Change Request
11/2/11 2:00 PM
CCAB CHANGE REQUEST: artf36126 (Emergency: Urgent Service Request) Add Exchange Client Access Server to Load Balancer CHANGE DESCRIPTION: Add 4 additional client access servers to the load balancer configuration so they may later be enabled. This will provide additional client access capacity to our exchange environment and should reduce the slow downs and dropped connections users are currently experiencing. TEST PROCEDURE: This is the same procedure used for the

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 8
Actions Taken to Resolve Incident Event Date/Time Action
current client access servers that have been in production for several months. BACKOUT STRATEGY: Revert to previous configuration.
PATCH APPLIED TO SYSTEM
11/3/11 Thursday night, November 3, a patch was applied to the systems. Communication: Wednesday evening, November 2, Microsoft flew in a field engineer. With his help, we first identified a network bottleneck, which reduced but did not eliminate the problem. Digging deeper, a bug was identified in Microsoft'ʹs clustering software that caused the cluster to believe that it was in failure mode, and caused the active mailboxes to flip repeatedly between the redundant Exchange systems in Rhodes and CCC. Since this behavior was related to the number of machines in the cluster, we inadvertently worsened the problem by adding capacity.
CLIENT ACCESS SERVERS REMOVED FROM SYSTEM
11/4/11 Friday morning, November4, pockets of connectivity problems led to discovering that a few of the ten Client Access Servers were not responding to connections; they were removed from the pool. At this time we believe that we have resolved the problems.
Change Request 11/8/11 12:00 AM
CCAB CHANGE REQUEST: artf36210 (Emergency: Urgent Service Request) : Disable NetDMA on Exchange Mailbox Servers CHANGE DESCRIPTION: Microsoft recommends that we disable NetDMA (a feature of the network adapters) on the Exchange Mailbox Servers. NetDMA can cause timing problems with the cluster communications and is a contributing factor to the issues we have been encountering with exchange. The change requires a reboot of the mailbox servers. This process will be done one server at a time so users should not see any additional downtime as a result of this update. These recommendations come out of a Severity 1 case we have open with Microsoft regarding the Exchange performance issues.
Metrics (See Appendix I) Item Time (Hours) Comment
Detection Time (Detection – Incident Occurrence)
Indefinite Difficult to determine when to designate as beginning time (i.e., Incident Occurrence)
Response Time (Diagnosis – Detection) 21 days Repair Time (Recovery – Diagnosis) 30 minutes

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 9
Metrics (See Appendix I) Item Time (Hours) Comment Recovery Time (Restore – Recovery) 0 Time to Repair (Recovery – Incident Occurrence)
~21 days
Root Cause of Incident – The Reason(s) for the Service Disruption The primary cause of this incident was:
• A network interface feature to offload network processing from the CPU caused corruption in heartbeat packets. This caused the cluster to believe communication had been lost and commence failover negotiations. This setting is the default setting for Windows Server 2008R2.
The problem was made worse by:
• An unpublished bug in Microsoft clustering software reacted inappropriately to the missed heartbeat packets, flipping the active cluster node back and forth between Rhodes and CCC.
Two additional factors contributed to triggering the problem, but were not by themselves a problem:
• Power management at the network interface level turned off power to the backup network path, causing interrupted communications. This is the default setting for Windows Server 2008R2.
• Replication network traffic combined with client traffic to increase load on network interfaces on the Exchange database servers.
Issues There was no guidance from Microsoft on avoiding the NetDMA features, despite internal knowledge that there had been problems in cluster environments with these features. There was also no information available to customers or first level Microsoft engineers on the cluster problems resolved by their patches. Both of these have been addressed by Microsoft since our incident. Their knowledgebase article is attached as Appendix VI.
Recommendations
Action Item(s) Created to Address
The following work is identified as important for hardening the Exchange system against failures and improving the performance under load.
• CIT is re-‐‑certifying the four client access servers that were briefly placed in service, and will add their capacity to the service within the next few weeks.
• The work to have the cornell.edu DNS name resolve to the domain controllers is
1,2,3,4,5

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 10
Recommendations
Action Item(s) Created to Address
expected to remove some timeout issues with Exchange management commands.
• CIT is planning on re-‐‑enabling the Forefront antivirus protection on the Exchange servers. This was disabled as a trouble-‐‑shooting step, but was found not to be a contributing factor.
• CIT is planning re-‐‑enabling the host-‐‑based firewalls that were turned off as a trouble-‐‑shooting step.
• CIT is adding additional network interfaces to the Exchange servers, to provide separate paths for replication and user network traffic.
Provide for faster resolution of critical problems by upgrading our Microsoft support contract to provide immediate access to Level 3 engineers.
6
Communicate Root Cause findings to campus and give an opportunity for input; investigate general options for “open” forums or reviews of major service disruptions with strategic customers and users.
9, 10
Perform a yearly risk assessment and health check of our Active Directory and Exchange systems by an outside vendor.
7
Provide checklist for Service Owners of tasks to complete with respect to communication and notification during Service Disruptions.
8
Consider additional options for when the “big red button” should be pushed for similar incidents/problems in the future.
8
Action Plan # Item Responsible Party Completion Date 1 Re-‐‑certify the four client access servers
that were briefly placed in service, and will add their capacity to the service within the next few weeks.
Infrastructure Division -‐‑ Messaging
11/27/2011
2 Modify DNS so that the cornell.edu DNS name resolve to the domain controllers is expected to remove some timeout issues with Exchange management commands.
Infrastructure Division – Identity Management
11/20/2011
3 Re-‐‑enable the Forefront antivirus protection on the Exchange servers. This was disabled as a trouble-‐‑shooting step, but was found not to be a contributing factor.
Infrastructure Division -‐‑ Messaging
12/4/2011
4 Re-‐‑enable the host-‐‑based firewalls that were turned off as a trouble-‐‑shooting step.
Infrastructure Division -‐‑ Messaging/Systems
11/27/2011

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 11
Action Plan # Item Responsible Party Completion Date
Admins 5 Add additional network interfaces to the
Exchange servers, to provide separate paths for replication and user network traffic.
Infrastructure Division -‐‑ Messaging/Systems
1/22/2012
6 Upgrade our Microsoft support contract to provide immediate access to Level 3 engineers.
Infrastructure Division -‐‑ Messaging
1/31/2012
7 Perform a yearly risk assessment and health check of our Active Directory and Exchange systems by an outside vendor.
Infrastructure Division -‐‑ Messaging
3/1/2012
8 Update CIT Process and Procedure 2007-‐‑002 regarding “Sev 1” incidents. Provide awareness to Service Owners and others.
CIT Process Improvement -‐‑ Jim Haustein
1/31/2012
9 Schedule an Exchange SIG to have a review of the incident as one of the topics
Infrastructure Division -‐‑ Messaging
12/31/2011
10 Investigate general options for “open” forums or reviews of major service disruptions with strategic customers and users.
CIT Process Improvement – Jim Haustein
2/28/2012

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 12
Approvals: ___/s/ James R. Haustein________ __ (Submitter) 12/6/2011 Jim Haustein
___e-‐‑mail to Jim Haustein___ __ (Director, Infrastructure) 12/7/2011 Dave Vernon

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 13
APPENDIX I: DESCRIPTION OF METRICS
• Incident Occurrence – when an incident occurs.
• Detection – when IT is made aware of the issue
• Diagnosis – when the diagnosis to determine the underlying cause of the incident has been completed
• Repair – when the incident has been repaired.
• Recovery – when component recovery has been completed.
• Restoration – when normal business operations resume.
Detection Diagnosis Repair Recover Restore
DetectionTime
Repair Time
ResponseTime
Time to Repair (“downtime”)
Time Between Failures
(“uptime”)
Time Between Incidents
IncidentOccurrence
IncidentOccurrence
RecoveryTime

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 14
APPENDIX II: TIMELINE OF EVENTS

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 15
APPENDIX III: COMMUNICATIONS
Performance: Exchange Performance Issues
Date: Oct 17, 2011, 10:01 AM Duration: Unknown
Status: Closed
Description:
We are currently investigating reported connection issues with Exchange. The symptoms include refused connections when sending and or receiving mail. The connections are recovering after a minute but appear to be re-‐‑occurring occasionally. This is affecting client access only we are not seeing delivery issues at this time. After the connection recovers mail is being sent from and to the client.
Timeline:
10/19/2011 11:32 AM: The Exchange servers have been running normally since 4:15pm on Monday.
10/17/2011 09:23 PM: The CIT Exchange Admins report that system performance is much improved this evening. They are still investigating this problem and continue to monitor the issue.
Affected Services: Exchange
Performance: Messaging Malware Attack Block: usps.com
Date: Oct 17, 2011, 11:46 AM Duration: Unknown
Status: Closed
Description:
This morning CIT Messaging staff blocked a large-‐‑scale mail attack purporting to be from addresses at usps.com, carrying malware that could infect client machines. Since it is impossible to distinguish these forged addresses from legitimate usps.com addresses, no mail from usps.com is currently getting through. This action was necessary to protect the Cornell mail system and other IT systems from the attack.
Timeline:
10/17/2011 07:40 PM: The complete block of any email with a @usps.com address has been lifted. We have isolated the appropriate information and we are blocking solely on

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 16
that. Initially due to the volume and variants of the infected email it seemed prudent to block all @usps.com traffic, even though almost all of it was already being blocked by our normal systems. We apologize for any inconvenience this may of caused.
10/17/2011 04:58 PM: The CIT Exchange Admins are still investigating this problem and continue to monitor the issue.
10/17/2011 11:49 AM: We will restore incoming mail from legitimate usps.com addresses as soon as we have a way to do so.
Performance: Problems With Exchange This Morning
Date: Oct 20, 2011, 10:30 AM Duration: Unknown
Status: Closed
Description:
There was a five minute load spike on some of the Exchange servers this morning, causing momentary slowness and denied connections. It appears from reports that some email programs did not recover gracefully from that incident. We recommend quitting and restarted your email program if you are experiencing problems.
Timeline:
10/20/2011 04:13 PM: This problem has been resolved.
10/20/2011 12:48 PM: Exchange experienced a momentary period slowness and denied connections this morning.
Affected Services: Exchange
Performance: Exchange Authentication Errors
Date: Oct 20, 2011, 03:25 PM Duration: Unknown
Status: Closed

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 17
Description:
A issue occurred where some users were unable to authenticate to Exchange. This problem occurred between 3:25pm and 3:30pm. One of our client access servers was unable to authenticate users against Active Directory. We removed the server from service while we investigate and correct the problem. All connections should now have re-‐‑established on the remaining client access servers. In some cases users may have to re-‐‑start their clients.
Timeline:
10/21/2011 03:54 PM: This issue has now been resolved.
10/20/2011 04:16 PM: A issue occurred where some users were unable to authenticate to Exchange.
Affected Services: Exchange
Performance: Exchange Service
Date: Oct 28, 2011, 01:30 PM Duration: Until 10/28/2011 at 2:00 PM
Status: Closed
Description:
Due to the network issue this morning the Exchange system'ʹs performance was affected from 10am to approximately 12:30pm today (10/28). To improve performance we had had split the databases up such that half were primary in Rhodes and half in CCC. The network issue caused databases to fail over and all the databases were on one side instead of being split. Once usage rose up high enough performance suffered.
Timeline:
10/28/2011 01:34 PM: The databases have been split out again and all appears to be well. The Exchange 2007 servers are being rebuilt as Exchange 2010 servers which will increase our overall capacity to better handle these sorts of situations.
Affected Services: Exchange
Unplanned Outage: Outlook Web Access Service (OWA)
Date: Oct 31, 2011, 08:44 AM Duration: Unknown

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 18
Status: Closed
Description:
CIT has received reports that users are unable to access the Outlook Web Access (OWA) service.
Timeline:
10/31/2011 08:46 AM: We are currently investigating this problem and will notify you with updates on this situation.
Affected Services: Outlook Web Access
Unplanned Outage: Exchange Email and Calendar
Date: Oct 31, 2011, 08:52 AM Duration: Unknown
Status: Closed
Description:
The Exchange performance problems the morning of October 31 have been traced to Outlook 2007/2010 on Windows attempting to connect to all mailboxes to which each user had access. Individuals may need to re-‐‑add the Exchange Group Accounts they want to see in Outlook (see http://www.cit.cornell.edu/services/ega/howto/config.cfm).
Timeline:
10/31/2011 05:50 PM: The performance problems are believed to be primarily caused by a feature introduced by Microsoft in Exchange Server 2010 SP 2. The feature'ʹs effects were not apparent until a script for Exchange Group Accounts was run the weekend of October 29. The feature causes Outlook to automount all mailboxes to which an individual has full access. The result was that start-‐‑up time for Outlook may have taken several minutes for some individuals. When the automounting was stopped, the accounts appeared to disappear from Outlook. Re-‐‑adding the affected accounts resolves the issue for individuals. CIT is adjusting the scripts for Exchange Group Accounts and filing an issue report with Microsoft.
10/31/2011 10:10 AM: The load spike has abated this morning. Exchange staff are continuing to work on monitoring the system and addressing the root cause

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 19
10/31/2011 09:10 AM: Some Exchange users are experiencing slow Exchange response or difficulty connecting to Exchange. One of the mailbox servers is experiencing a heavy load spike at this time. Exchange admins are working on determining the source of the load and taking measures to address it.
10/31/2011 08:54 AM: We are currently investigating this problem and will notify you with updates on this situation.
Affected Services: Exchange
Performance: Exchange Email and Calendar
Date: Nov 1, 2011, 12:00 PM Duration: Unknown
Status: Closed
Description:
For the past several days, Cornell'ʹs Exchange email and calendar services have had performance issues. Re-‐‑establishing stable service levels is CIT'ʹs highest priority. Please bear with us as we continue working on the problem.
Timeline:
11/10/2011 09:53 AM: The immediate issues with Exchange have been resolved. Over the next several weeks, additional changes will be made to increase the Exchange'ʹs ability to handle normal growth in load over time and load associated with traffic spikes. A notice to all Exchange users will be sent later today. Please report any issues with Exchange email or calendar to the CIT HelpDesk (255-‐‑8990), noting your email client and OS, and the location from which you observe the problem.
11/08/2011 04:57 PM: Our assessment of today'ʹs experience with the campus Exchange service is that the fixes applied yesterday and early this morning have addressed performance issues seen over the past several days. We have been working on what appear to be pockets of client issues remaining for a limited number of users. We will keep this alert open, however, until more time has elapsed and we can be certain there are no more infrastructure issues remaining. If you have an open ticket with the CIT Help Desk, please update us with your current status. If you see any renewed or continuing problems, please report those to the Help Desk with details including your client and OS, and the location from which you observe the problem. Unfortunately, there was a network outage in the CIT data center this afternoon that impacted Exchange access from about 1:00 to 2:00 PM. During the outage connections were refused. Some clients required a restart before they were able to connect once the network was restored, so some users may have seen problems after 2:00 PM.

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 20
11/08/2011 10:15 AM: After making the recommended changes to the Exchange network configuration, which was complete by 1am today, the Exchange team has seen no recurrence of the server errors that indicate this problem. Spot checks with the community have indicated, in general, much improved performance this morning. If you have an open ticket with the CIT Help Desk, please update us with your current status. If you see any renewed or continuing problems, please report those to the Help Desk with details including your client and OS, and the location from which you observe the problem.
11/07/2011 10:25 PM: We have received some isolated reports of continued problems following the configuration change this afternoon around 4:00 PM, although we'ʹve seen a reduction in server-‐‑side errors. Microsoft has recommended an additional change to the server configuration which we are implementing from 12:00 midnight and 12:15 AM on Tuesday. The change requires rebooting the servers but we do not anticipate a service disruption. If you experienced problems today described in an earlier update (see list below) and continue to see them Tuesday morning, please report them to us. Known symptoms are: sporadic slow or failed logins, failure to send messages, and slow operations (spinning hourglass or beach ball, depending on the client system).
11/07/2011 06:33 PM: Microsoft has recommended that NetDMA be disabled in the Exchange cluster because it is a contributing factor to Cornell'ʹs Exchange issues. From 12 midnight to 12:15 am on Tuesday, November 8, CIT will restart the Exchange mailbox servers to disable NetDMA. This work will be done one server at a time. No outage is expected.
11/07/2011 04:34 PM: CIT has made some changes to network settings on the Exchange cluster at Microsoft'ʹs recommendation. We are monitoring the performance to determine the effects of this change.
11/07/2011 03:49 PM: CIT and Microsoft experts are still diagnosing the cause of cluster communication failures. They are currently analyzing network traces for further information on anomalies identified in the review of Exchange data.
11/07/2011 01:39 PM: CIT staff continue to gather log data for Microsoft engineers to identify the source of the problem, which appears to continue to be in the cluster communications layer. Resolving the issues with Exchange remains the highest priority for both CIT and Microsoft to resolve. The main symptoms are sporadic slow or failed logins, failure to send messages, and slow operations (spinning hourglass or beach ball, depending on the client system). These have appeared a number of times throughout the morning, with a larger interruption from noon to 1pm for users hosted on one of the four mailbox servers. The server became non-‐‑responsive and required a reboot. At this point, we have collected the data we need on client problems. If we need additional data to be reported, a request will be posted here.
11/07/2011 01:12 PM: That database server is now online again. The start time was about 12:30, so it was a half hour from that time.

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 21
11/07/2011 12:51 PM: One of the Exchange databases servers (out of four) went offline and unmounted the mailbox databases. Exchange staff are working to get the databases back online. This problem does appear to be related to the ongoing issue. Expected time to restore the service is 30 minutes.
11/07/2011 09:30 AM: While the patches that were applied to the Exchange cluster on Friday greatly reduced the rate of errors, it'ʹs now apparent that some level of errors still persists. The Exchange team remains engaged with Microsoft to locate the source of these problems. Symptoms include timeouts in connection, refused connections, and errors in using OWA. If you receive these errors, please wait for a short time and retry the operation. The patch applied on Friday makes recovery from such problems much more rapid that before.
11/04/2011 04:45 PM: If people are still seeing problems with their email or calendar, as a first step, they should quit and restart their email client, and give it some time to catch up. In a few cases, it may be necessary to reboot their system. If problems persist, they should contact the CIT HelpDesk with these details: problem description, date and times the problem has occurred, and the operating system and email client being used. Having issues reported is critical. TIME LINE OF ACTIONS TAKEN Early on, CIT staff identified and eliminated several apparent contributions to the problem, but ultimately came to an impasse. Paradoxically, adding additional resources to the cluster made the problem worse. Wednesday evening, November 2, Microsoft flew in a field engineer. With his help, we first identified a network bottleneck, which reduced but did not eliminate the problem. Digging deeper, a bug was identified in Microsoft'ʹs clustering software that caused the cluster to believe that it was in failure mode, and caused the active mailboxes to flip repeatedly between the redundant Exchange systems in Rhodes and CCC. Since this behavior was related to the number of machines in the cluster, we inadvertently worsened the problem by adding capacity. Thursday night, November 3, a patch was applied to the systems, and all the server side problems were eliminated. Friday morning, November 4, pockets of connectivity problems led to discovering that a few of the ten Client Access Servers were not responding to connections; they were removed from the pool. At this time we believe that we have resolved the problems.
11/04/2011 01:41 PM: The root cause of recent Exchange problems has been addressed with hot fixes and reconfiguration of network traffic accomplished last night. Nonetheless, a subset of campus users experienced problems with the service today related to: A brief load spike at 9:00 AM this morning. This resulted in the temporary inability to connect to Exchange for some users. We are still investigating this event. A new problem was introduced with the addition of client access server capacity. These servers were not handling connections properly so we have eliminated them from the rotation. We have been working directly with the IT staff in the units impacted and believe that removing these servers has resolved those cases. We will continue to monitor reports until we are certain that no access issues remain.

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 22
11/04/2011 12:24 PM: Overall, Exchange performance is much improved. However, we are still receiving reports from a subset of users who are having trouble connecting to their accounts. We are working with the Microsoft engineer to diagnose these cases and solve them.
11/04/2011 08:49 AM: CIT staff with the Microsoft engineer who has been assisting us this week have applied patches to the cluster service supporting the Exchange system. These patches have eliminated the network errors and subsequent database restarts that have caused the extremely poor performance this week. At this time the Exchange service appears much healthier. Some email programs may have become confused when the Exchange system became unresponsive. If problems persist, we recommend that you quit and restart your email programs, and contact the CIT Help Desk if problems continue after that.
11/03/2011 09:23 PM: Technical staff working on Exchange performance issues have applied a patch to the server cluster to address a bug that was causing communication failures. This should improve stability and allow the reconfiguration work to proceed.
11/03/2011 07:14 PM: Exchange mailboxes may be temporarily unavailable due to a cluster communications problem we expect this condition to last for less than 30 minutes.
11/03/2011 04:09 PM: We are still working on reconfiguring the network path for Exchange communications to better distribute the traffic. We have engaged additional Microsoft resources over the phone to expedite resolution of issues we'ʹve encountered with this change.
11/03/2011 02:20 PM: We are still working with the Microsoft engineer to accomplish the reconfiguration referenced in the last communication. Although we initially anticipated that work would be completed around 1 PM, we now expect it will take several more hours. We expect these changes will result in a stable service very soon after they are completed but we will continue to take incremental steps to increase capacity to better accommodate future unplanned events.
11/03/2011 10:56 AM: Between now and approximately 1 PM we will be making configuration changes to the Exchange environment to improve performance. The changes themselves are not expected to impact the user community. However, until these changes are complete we may see events similar to those we'ʹve experienced over the past several days that result in access issues for users. Such an event did occur this morning at 10 AM. It affected a significant number of users whose mailboxes live on the affected server. Those users would have experienced performance issues or the momentary inability to connect to their Exchange accounts. We anticipate that very soon after we complete the configuration changes users will see the improvement in service performance.
11/03/2011 07:30 AM: Working in concert with the Microsoft engineer last evening we have made configuration changes to alleviate Exchange performance issues. Measures included client access network reconfiguration, changes to the replication configuration, and deploying four additional client access servers. While we believe we have determined the root cause of these issues we will continue to analyze performance data to confirm.
11/02/2011 03:29 PM: CIT continues to work on resolving the Exchange performance issues. Additional servers will be added to Exchange tonight (November 2) to spread the load. Problems with the replication service are being investigated, including determining whether a Microsoft patch

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 23
would resolve them. A Microsoft engineer will be on site tonight (November 2), and CIT will be taking additional measures based on those recommendations.
11/02/2011 08:55 AM: CIT is continuing to work on solutions to the Exchange performance issues. Our next step is to address a communications problem between the two halves of the Exchange cluster. We are also working to add another Exchange 2010 server as soon as tonight. In our test environment, we will be assessing a newly released Microsoft patch that contains fixes for some of the problems we have been seeing.
11/01/2011 07:22 PM: Exchange performance has been stabilized for the moment. Some Microsoft-‐‑recommended changes to the Active Directory Domain Controllers were implemented, as well as monitors that will capture diagnostic information if the problems return tomorrow during periods of high load. We also have a fourth Exchange database server ready to go into production, which will give us 33% more capacity to deal with load issues. A fifth server will be added in another week. These will have a gradual affect as user mailboxes migrate transparently onto them.
11/01/2011 05:10 PM: CIT understands the importance of email and calendar for your work, and we realize we have fallen short of your expectations. We are working hard to regain those service levels. We have been working with Microsoft and others to understand what is causing these problems. So far the causes have been elusive, appearing at times to be a high CPU load causing poor response time, and at other times seeming to be an intermittent network problem. Several apparent causes have been addressed, including anti-‐‑virus updates, network adapter offload settings, power management settings, and the mailbox automounting setting. Please bear with us as we continue working on the problem.
11/01/2011 04:06 PM: Exchange Admins are actively working with Microsoft to resolve the problem swiftly. Additional information will be posted as it becomes available.
11/01/2011 02:30 PM: CIT is still receiving reports that some users are still unable to access their Exchange email. CIT is still investigating and will provide further updates.
11/01/2011 12:02 PM: We are currently investigating this problem and will notify you with updates on this situation.
Affected Services: Exchange

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 24
APPENDIX IV: CCAB SERVICE DISRUPTION REPORTS The below CCAB Service Disruption reports were completed in conjunction with the Exchange service disruption described in this document.
artf35310 9/15/2011 9:30 PM
(Thursday) 9/15/2011 11:59 PM (Thursday)
Exchange [4236] 2 mailbox DBs on mbcx outage : mailboxdatabases19,22, and the public folder database did not mount after patching last night. It appears possible that this was an early symptom of the communications problem
artf35362 9/19/2011 8:00 AM
(Monday) 9/19/2011 1:30 PM
(Monday) Exchange [4236] Exchange slow response
times : Longer than anticipated run times for a large set of Exchange 2010 migrations coincided with a failed backup run that restarted at the same time. The two activities, neither of which could be halted, combined to slow response time down for client access to Exchange.
artf35567 9/26/2011 7:00 AM
(Monday) 9/26/2011 7:00 PM
(Monday) E-‐‑Mail Routing [3979]
Exchange connections hanging : Connections began to hang on two new Client Access Servers placed into production on Sunday. The problem was resolved when the new servers were removed from service. Only a fraction of Exchange users were affected, and only certain clients had problems. No cause of the problem has yet been determined.
Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 25
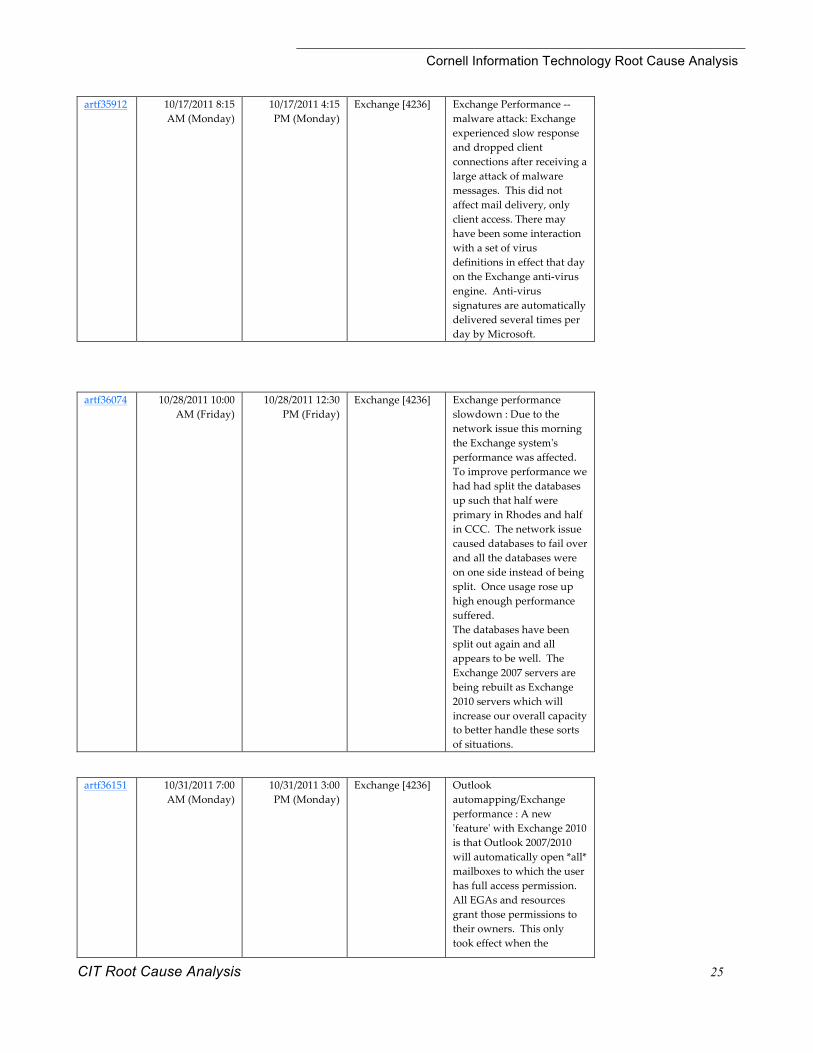
artf35912 10/17/2011 8:15 AM (Monday)
10/17/2011 4:15 PM (Monday)
Exchange [4236] Exchange Performance -‐‑-‐‑ malware attack: Exchange experienced slow response and dropped client connections after receiving a large attack of malware messages. This did not affect mail delivery, only client access. There may have been some interaction with a set of virus definitions in effect that day on the Exchange anti-‐‑virus engine. Anti-‐‑virus signatures are automatically delivered several times per day by Microsoft.
artf36074 10/28/2011 10:00
AM (Friday) 10/28/2011 12:30
PM (Friday) Exchange [4236] Exchange performance
slowdown : Due to the network issue this morning the Exchange system'ʹs performance was affected. To improve performance we had had split the databases up such that half were primary in Rhodes and half in CCC. The network issue caused databases to fail over and all the databases were on one side instead of being split. Once usage rose up high enough performance suffered. The databases have been split out again and all appears to be well. The Exchange 2007 servers are being rebuilt as Exchange 2010 servers which will increase our overall capacity to better handle these sorts of situations.
artf36151 10/31/2011 7:00
AM (Monday) 10/31/2011 3:00 PM (Monday)
Exchange [4236] Outlook automapping/Exchange performance : A new 'ʹfeature'ʹ with Exchange 2010 is that Outlook 2007/2010 will automatically open *all* mailboxes to which the user has full access permission. All EGAs and resources grant those permissions to their owners. This only took effect when the

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 26
permissions for a specific EGA or resource was updated, however a maintenance script over the weekend updated permissions on all EGAs. This resulted in many more connections to mailboxes on Monday morning, contributing to ongoing performance problems. The automatic mounts were removed late in the morning. An unexpected side effect of this was that a previously manually mounted mailbox that was overridden by the automatic mount of the same mailbox was subsequently forgotten. People reported they had 'ʹlost access'ʹ to shared mailboxes, when they had in fact simply been disconnected. The remedy was for them to reopen the shared mailbox.
artf36226 11/01/2011 12:00
AM (Tuesday) 11/07/2011 11:59
PM (Monday) Exchange [4236] Exchange Performance
Problems : Severe performance problems affected Exchange during the time. The underlying symptom was that the cluster repeatedly lost and re-‐‑established quorum. The cause appeared to be communications problems between the cluster nodes. A Microsoft engineer came onsite to assist in diagnosis. A number of steps were taken to eliminate the problems, listed from the apparently most important contributing cause through lesser contributors: -‐‑ Turned off NetDMA on all network adapters. This was causing corrupted heartbeat packets. -‐‑ Applied three hotfixes from Microsoft that improved the cluster resiliency to network errors -‐‑ Turned off power management on the

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 27
network adapters. (The failover NICs were trying to go to sleep.) -‐‑ Ensured that replication traffic does not use the same NIC as MAPI traffic to the CAS servers. -‐‑ Turned off power management on the CPUs.
artf36231 11/08/2011 12:37
PM (Tuesday) 11/08/2011 12:52
PM (Tuesday) Campus Area Network [2208]
Server Farm network disruption : The network switch sfcdist1-‐‑1-‐‑6600 failed at 12:37 and was restored to service at 12:52. A network issue on tier3 prevented the firewalls from failing over properly and the extra tier had no connectivity during this same interval. A second switch sfc1-‐‑1-‐‑5400 also had no connectivity and some single attached servers affected.
artf36227 11/08/2011 12:52
PM (Tuesday) 11/08/2011 2:00 PM (Tuesday)
Exchange [4236] Exchange affected by network outage : Exchange access was affected by the network switch outage. After the end of the outage, the load balancer did not reestablish connections to the CAS servers. Services needed to be stopped and started on the CAS servers before the load balancer would restart the connections. We had many reports that client programs also required a stop/start or reboot before they would let go of their previous connection to Exchange via the load balancer.

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 28
Artf36231 11/08/2011 12:37 PM
11/08/2011 12:52 PM
Campus Area Network [2208]
The network switch sfcdist1-‐‑1-‐‑6600 failed at 12:37 and was restored to service at 12:52. A network issue on tier3 prevented the firewalls from failing over properly and the extra tier had no connectivity during this same interval. A second switch sfc1-‐‑1-‐‑5400 also had no connectivity and some single attached servers affected.

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 29
APPENDIX V: MICROSOFT FINAL REPORT Mail from Microsoft Engineer to CIT team: From: John Chappelle Sent: Tuesday, November 15, 2011 4:40 PM To: [email protected] Cc: Gregg Koop; MSSolve Case Email; Gregg Koop Subject: [REG:111100371705359] Exchange 2010 SP1|Experiencing two databases where the issue is happening frequently. Bill, I am writing to check on your DAG today, and I am also including a summary of our troubleshooting efforts on this case. When we first started, we observed an issue with the cluster losing quorum and the copy queue length changing to a very large number. This was the result of a cluster disconnect. We installed three patches (KB2549472, KB2549448, and 2552040) to allow nodes to join properly when they go offline, as well as to correct an issue with the cluster not regrouping properly following a communication failure. This alleviated the issue for a period of time, although it seems likely at this point that it was really the reboots that brought the cluster back together. Those patches are still important to the proper operation of the cluster, and we recommend them for any 2008R2 cluster that experiences any quorum issues at all. We saw the issue crop up again the next week, and this time we brought in both a Cluster engineer and one of our Networking engineers. From their analysis, we found in the cluster logs: 00001124.00001e84::2011/11/07-‐‑19:36:12.823 INFO [CONNECT] 169.254.7.84:~3343~ from local 169.254.2.231:~0~: Established connection to remote endpoint 169.254.7.84:~3343~. 00001124.00001e84::2011/11/07-‐‑19:36:12.823 INFO [Reconnector-‐‑MBXB-‐‑01] Successfully established a new connection. 00001124.00001e84::2011/11/07-‐‑19:36:12.823 INFO [SV] Route local (169.254.2.231:~43912~) to remote MBXB-‐‑01 (169.254.7.84:~3343~) exists. Forwarding to alternate path. 00001124.00001e84::2011/11/07-‐‑19:36:12.823 INFO [SV] Securing route from (169.254.2.231:~43912~) to remote MBXB-‐‑01 (169.254.7.84:~3343~). 00001124.00001e84::2011/11/07-‐‑19:36:12.823 INFO [SV] Got a new outgoing stream to MBXB-‐‑01 at 169.254.7.84:~3343~ 00001124.00001e84::2011/11/07-‐‑19:36:12.823 INFO [SV] Authentication and authorization were successful 00001124.00001e84::2011/11/07-‐‑19:36:12.838 INFO [SV] Security Handshake successful while obtaining SecurityContext for NetFT driver 00001124.00001e84::2011/11/07-‐‑19:36:12.838 ERR [CORE] mscs::Reconnector::ConnectionEstablished: HrError(0x8009030f)'ʹ because of 'ʹSignature Verification Failed'ʹ 00001124.00001e84::2011/11/07-‐‑19:36:12.838 WARN [Reconnector-‐‑MBXB-‐‑01] Failed to handle new connection with error ERROR_SYSTEM_POWERSTATE_COMPLEX_TRANSITION(783), ignoring connection. In addition, we saw simultaneous TCP Resets that were unexpected. We know this because the remote node in the conversation continued to attempt communication after the resets: 2060 54 0 14:36:12.8425000 13:36:12 07-‐‑Nov-‐‑11 14.4811462 0.0000191 {TCP:41, IPv4:33} 169.254.2.231 169.254.7.84 TCP TCP:Flags=...A.R.., SrcPort=43912, DstPort=3343, PayloadLen=0, Seq=3063920255, Ack=2252985581, Win=0

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 30
(scale factor 0x8) = 0 2061 86 32 14:36:12.8425199 13:36:12 07-‐‑Nov-‐‑11 14.4811661 0.0000199 {TCP:42, IPv4:33} 169.254.7.84 169.254.2.231 TCP TCP:Flags=...AP..., SrcPort=3343, DstPort=43912, PayloadLen=32, Seq=2252985581 -‐‑ 2252985613, Ack=3063920254, Win=514 2062 54 0 14:36:12.8425356 13:36:12 07-‐‑Nov-‐‑11 14.4811818 0.0000157 {TCP:42, IPv4:33} 169.254.2.231 169.254.7.84 TCP TCP:Flags=.....R.., SrcPort=43912, DstPort=3343, PayloadLen=0, Seq=3063920254, Ack=3063920254, Win=0 2063 54 0 14:36:12.8429705 13:36:12 07-‐‑Nov-‐‑11 14.4816167 0.0004349 {TCP:43, IPv4:33} 169.254.7.84 169.254.2.231 TCP TCP:Flags=...A...., SrcPort=3343, DstPort=43912, PayloadLen=0, Seq=2252985613, Ack=3063920255, Win=514 This “POWERSTATE” event and the resets led us to examine the NICs on the server, where we found the power save functions were enabled. We disabled those, and both the “POWERSTATE” and TCP Reset issues abated immediately. Our Cluster engineer also researched the NetDMA settings and determined that they should be disabled, so we turned off NetDMA along with the power save settings. As a side note, I received the information on the Broadcom driver versions, and I am looking around to see if there is a known issue with them. Thank you, John Chappelle Senior Support Escalation Engineer [email protected] 469-‐‑775-‐‑5153 M-‐‑F 0900-‐‑1800 Central My manager: Melissa Stroud [email protected] 469-‐‑775-‐‑7246 Followup email identifying NetDMA as a primary cause: From: William Effinger [mailto:[email protected]] Sent: Friday, November 18, 2011 10:43 AM To: William T Holmes Cc: Gregg Koop; John Chappelle Subject: [REG:111100371705359] Exchange 2010 SP1|Experiencing two databases where the issue is happening frequently Bill, John asked me to give you a shout with a writeup of my notes Looking in your cluster log Node MBXD-‐02 14744 000015d0.000025c0::2011/11/07-‐17:34:50.725 INFO [GUM] Node 2: Processing RequestLock 7:1242 14745 000015d0.00002ad8::2011/11/07-‐17:34:50.725 INFO [GUM] Node 2: Processing GrantLock to 7 (sent by 1 gumid: 80208) 14746 000015d0.00001718::2011/11/07-‐17:35:01.349 WARN [PULLER MBXA-‐02] ReadObject failed with HrError(0x8009030f)' because of 'Signature Verification Failed' 14747 000015d0.00001718::2011/11/07-‐17:35:01.349 ERR [NODE] Node 2: Connection to Node 6 is broken. Reason

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 31
HrError(0x8009030f)' because of 'Signature Verification Failed' 14748 000015d0.00001718::2011/11/07-‐17:35:01.349 WARN [NODE] Node 2: Initiating reconnect with n6. 14749 000015d0.00001718::2011/11/07-‐17:35:01.349 INFO [MQ-‐MBXA-‐02] Pausing 14750 000015d0.000018b0::2011/11/07-‐17:35:01.349 INFO [Reconnector-‐MBXA-‐02] Reconnector from epoch 7 to epoch 8 waited 00.000 so far. 14751 000015d0.000018b0::2011/11/07-‐17:35:01.349 INFO [CONNECT] 169.254.6.224:~3343~ from local 169.254.2.172:~0~: Established connection to remote endpoint 169.254.6.224:~3343~. 14752 000015d0.000018b0::2011/11/07-‐17:35:01.349 INFO [Reconnector-‐MBXA-‐02] Successfully established a new connection. 14753 000015d0.000018b0::2011/11/07-‐17:35:01.349 INFO [SV] Route local (169.254.2.172:~14524~) to remote MBXA-‐02 (169.254.6.224:~3343~) exists. Forwarding to alternate path. 14754 000015d0.000018b0::2011/11/07-‐17:35:01.349 INFO [SV] Securing route from (169.254.2.172:~14524~) to remote MBXA-‐02 (169.254.6.224:~3343~). 14755 000015d0.000018b0::2011/11/07-‐17:35:01.349 INFO [SV] Got a new outgoing stream to MBXA-‐02 at 169.254.6.224:~3343~ 14756 000015d0.000025c0::2011/11/07-‐17:35:01.349 WARN [PULLER MBXB-‐01] ReadObject failed with HrError(0x8009030f)' because of 'Signature Verification Failed' 14757 000015d0.000025c0::2011/11/07-‐17:35:01.349 ERR [NODE] Node 2: Connection to Node 7 is broken. Reason HrError(0x8009030f)' because of 'Signature Verification Failed' 14758 000015d0.000025c0::2011/11/07-‐17:35:01.349 WARN [NODE] Node 2: Initiating reconnect with n7. 14759 000015d0.000025c0::2011/11/07-‐17:35:01.349 INFO [MQ-‐MBXB-‐01] Pausing 15063 000015d0.00001614::2011/11/07-‐17:35:47.681 INFO [GUM] Node 2: Processing GrantLock to 1 (sent by 4 gumid: 80222) 15064 000015d0.00004628::2011/11/07-‐17:35:51.035 INFO [GUM] Node 2: Processing RequestLock 7:1246 15065 000015d0.00003964::2011/11/07-‐17:35:51.035 INFO [GUM] Node 2: Processing GrantLock to 7 (sent by 1 gumid: 80223) 15066 000015d0.00003f7c::2011/11/07-‐17:36:02.704 WARN [PULLER MBXA-‐02] ReadObject failed with HrError(0x8009030f)' because of 'Signature Verification Failed' 15067 000015d0.00003f7c::2011/11/07-‐17:36:02.704 ERR [NODE] Node 2: Connection to Node 6 is broken. Reason HrError(0x8009030f)' because of 'Signature Verification Failed' 15068 000015d0.00003f7c::2011/11/07-‐17:36:02.704 WARN [NODE] Node 2: Initiating reconnect with n6. 15069 000015d0.00003f7c::2011/11/07-‐17:36:02.704 INFO [MQ-‐MBXA-‐02] Pausing 15070 000015d0.00003a78::2011/11/07-‐17:36:02.704 INFO [Reconnector-‐MBXA-‐02] Reconnector from epoch 10 to epoch 11 waited 00.000 so far. 15071 000015d0.00004628::2011/11/07-‐17:36:02.704 WARN [PULLER MBXB-‐01] ReadObject failed with HrError(0x8009030f)' because of 'Signature Verification Failed' 15072 000015d0.00004628::2011/11/07-‐17:36:02.704 ERR [NODE] Node 2: Connection to Node 7 is broken. Reason HrError(0x8009030f)' because of 'Signature Verification Failed' 15073 000015d0.00004628::2011/11/07-‐17:36:02.704 WARN [NODE] Node 2: Initiating reconnect with n7. 15074 000015d0.00004628::2011/11/07-‐17:36:02.704 INFO [MQ-‐MBXB-‐01] Pausing SEC_E_MESSAGE_ALTERED The message or signature supplied for verification has been altered 0x8009030f Doing research with our internal knowledge base I can see that 'Signature Verification Failed' case be caused by one of two reasons Receive Side Scaling, and Network Direct Memory Access features in Windows Server 2008 as you have already turned off RSS we disabled NetDMA Info on this tech http://technet.microsoft.com/sk-‐sk/magazine/2007.01.cableguy(en-‐us).aspx

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 32
How to turn off RSS & NetDMA http://support.microsoft.com/?id=951037 Best Regards, William Effinger | MCP | MCSA | MCSE | MCTS | MCITP EA | Office Hours: Monday - Friday | 7a - 4p | EST ( Phone: 980.776.8887 * Email: [email protected] : Blog: http://blogs.technet.com/askcore/ Alternative Contact Information Local country phone
number found here: http://support.microsoft.com/globalenglish Extension 1168887

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 33
APPENDIX VI: MICROSOFT KNOWLEGEBASE ARTICLE In a post mortem discussion with Microsoft, CIT staff pointed out the lack of information available that would have allowed us to prevent this problem or diagnose it once it occurred. In response, Microsoft published the following article: (http://blogs.technet.com/b/exchange/archive/2011/11/20/recommended-‐‑windows-‐‑hotfix-‐‑for-‐‑database-‐‑availability-‐‑groups-‐‑running-‐‑windows-‐‑server-‐‑2008-‐‑r2.aspx)
Recommended Windows Hotfix for Database Availability Groups running Windows Server 2008 R2
Scott Schnoll [MSFT] 20 Nov 2011 7:41 AM 11 In early August of this year, the Windows SE team released the following Knowledge Base (KB) article and accompanying software hotfix regarding an issue in Windows Server 2008 R2 failover clusters:
KB2550886 - A transient communication failure causes a Windows Server 2008 R2 failover cluster to stop working
This hotfix is strongly recommended for all databases availability groups that are stretched across multiple datacenters. For DAGs that are not stretched across multiple datacenters, this hotfix is good to have, as well. The article describes a race condition and cluster database deadlock issue that can occur when a Windows Failover cluster encounters a transient communication failure. There is a race condition within the reconnection logic of cluster nodes that manifests itself when the cluster has communication failures. When this occurs, it will cause the cluster database to hang, resulting in quorum loss in the failover cluster.
As described on TechNet, a database availability group (DAG) relies on specific cluster functionality, including the cluster database. In order for a DAG to be able to operate and provide high availability, the cluster and the cluster database must also be operating properly.
Microsoft has encountered scenarios in which a transient network failure occurs (a failure of network communications for about 60 seconds) and as a result, the entire cluster is deadlocked and all databases are within the DAG are dismounted. Since it is not very easy to determine which cluster node is actually deadlocked, if a failover cluster deadlocks as a result of the reconnect logic race, the only available course of action is to restart all members within the entire cluster to resolve the deadlock condition.
The problem typically manifests itself in the form of cluster quorum loss due to an asymmetric communication failure (when two nodes cannot communicate with each other but can still communicate with other nodes). If there are delays among other nodes in the receiving of cluster regroup messages from the cluster’s Global Update Manager (GUM), regroup messages can end up being received in unexpected order. When that happens, the cluster loses quorum instead of invoking the expected behavior, which is to remove one of the nodes that experienced the initial communication failure from the cluster.
Generally, this bug manifests when there is asymmetric latency (for example, where half of the DAG members have latency of 1 ms, while the other half of the DAG members have 30 ms latency) for two cluster nodes that discover a broken connection between the pair. If the first node detects a connection loss well before the second node, a race condition can occur:
• The first node will initiate a reconnect of the stream between the two nodes. This will cause the second node to add the new stream to its data.

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 34
• Adding the new stream tears down the old stream and sets its failure handler to ignore. In the failure case, the old stream is the failed stream that has not been detected yet.
• When the connection break is detected on the second node, the second node will initiate a reconnect sequence of its own. If the connection break is detected in the proper race window, the failed stream's failure handler will be set to ignore, and the reconnect process will not initiate a reconnect. It will, however, issue a pause for the send queue, which stops messages from being sent between the nodes. When the messages are stopped, this prevents GUM from operating correctly and forces a cluster restart.
If this issue does occur, the consequences are very bad for DAGs. As a result, we recommend that you deploy this hotfix to all of your Mailbox servers that are members of a DAG, especially if the DAG is stretched across datacenters. This hotfix can also benefit environments running Exchange 2007 Single Copy Clusters and Cluster Continuous Replication environments.
In addition to fixing the issue described above, KB2550886 also includes other important Windows Server 2008 R2 hotfixes that are also recommended for DAGs:
• http://support.microsoft.com/kb/2549472 - Cluster node cannot rejoin the cluster after the node is restarted or removed from the cluster in Windows Server 2008 R2
• http://support.microsoft.com/kb/2549448 - Cluster service still uses the default time-out value after you configure the regroup time-out setting in Windows Server 2008 R2
• http://support.microsoft.com/kb/2552040 - A Windows Server 2008 R2 failover cluster loses quorum when an asymmetric communication fail
Comments
William Holmes 21 Nov 2011 9:59 AM # This helpful article comes about 3 weeks too late. We experienced this issue and have in fact installed the hotfixes. In addition to these fixes you may want to examine other aspects of your networking recomendations. For instance: support.microsoft.com/.../951037 the features mentioned in this KB all contributed to triggering the problems that the hotfixes address. Disabling the features mentioned improved the stability and responsiveness of our entire Exchange Organization.
daliu 21 Nov 2011 5:53 PM # I take it from the kb's these are "Windows" clustering hotfixes & therefore won't be rolled up into Exchange 2010 SP2 later this year, correct?
Marcus L 22 Nov 2011 2:14 AM # This is a question for William Holmes, when you say "Disabling the features mentioned improved stability", which features exactly, all of them?
Martijn 22 Nov 2011 4:33 AM # Will this info be part of the Installation Guide Template - DAG Member? Then it would be clear which hotfixes to install along with the latest Windows 2008 R2 & Exchange 2010 Service Packs and Update Rollups.
Rob A 22 Nov 2011 7:17 AM # MSFT needs to update ExBPA so that we don't have to comb through articles like this for obscure fixes and optimizations. ExBPA makes life easier for us and for PSS. I don't think I have seen an update for ExBPA in a very long time.
Brian Day [MSFT] 22 Nov 2011 8:12 AM # @Rob A, ExBPA updates are released in Service Packs and Update Rollups. If you want to make sure you have the latest ExBPA ruleset in place then install the latest SP and rollup on the machine you are running the ExBPA from.
Eugene 22 Nov 2011 9:33 AM # In our environment, using latest drivers available for IBM x3550 M2 servers and firmware, we can only stabilize a high-throughput server by disabling NetDMA in each and every case.
Eugene 22 Nov 2011 9:34 AM # In fact, IBM has documented recommendations for many of their products to disable NetDMA. But since our drivers are the latest available you'd think we'd expect a feature so heavily recommended by Microsoft perf. tuning guides to fundamentally work, which it fundamentally doesn't. www-304.ibm.com/.../docview.wss

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 35
Serhad MAKBULO�LU 23 Nov 2011 1:46 AM # Thanks. andy 25 Nov 2011 1:03 PM # tried to request the hotfix but got below: The system is currently
unavailable. Please try back later, or contact support if you want immediate assistance When will the hotfix be available from WSUS? We need some quality assurance from Microsoft in order to get it approved on production environment.
William Holmes 25 Nov 2011 7:49 PM # For Marcus: Yes all of them. NetDMA in particular seems to have caused cluster communications to be disrupted. This in turn caused a number of exchange problems as might be expected.

Cornell Information Technology Root Cause Analysis
CIT Root Cause Analysis 36
APPENDIX VII: MICROSOFT CLOSEOUT From: Gregg Koop <[email protected]>
Subject: Recent Exchange/Broadcom case
Date: November 22, 2011 3:13:27 PM EST
To: Chuck Boeheim <[email protected]>, Andrea Beesing <[email protected]>, William T Holmes
<[email protected]> Hi everyone, I am in the process of closing out your case and classifying this as a bug (Broadcom or otherwise) so that you don’t get charged the hours against your contract. Is there anything else you need from the engineers assigned to this case? Otherwise, is it OK to close this out? Thank you. Kind regards, Gregg Koop Sr. Technical Account Manager, MCTS, MBA, PMP, 6σ Black Belt Microsoft US Public Sector Services -‐‑ State and Local Government & Education [email protected] office: (732) 476-‐‑5581 cell: (908) 391-‐‑5656