exascale challenges for numerical weather...
TRANSCRIPT

This project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 671627
Exascale challenges for Numerical Weather Prediction : the ESCAPE project
O Olivier Marsden

Independent intergovernmental organisation established in 1975 with 19 Member States 15 Co-operating States
European Centre for Medium-Range Weather Forecasts
2

May be one of the best medium-range forecasts of all times!
The success story of Numerical Weather Prediction: Hurricanes
3

NWP: Benefit of high-resolution
Sandy 28 Oct 2012
Mean sea-level pressure AN 30 Oct 5d FC T3999 5d FC T1279 5d FC T639
Precipitation: NEXRAD 27 Oct
4d FC T639 4d FC T1279 4d FC T3999
3d FC: Wave height Mean sea-level pressure 10 m wind speed
4

What is the challenge?
Observations Models
Volume 20 million = 2 x 107 5 million grid points 100 levels 10 prognostic variables = 5 x 109
Type 98% from 60 different satellite instruments
physical parameters of atmosphere, waves, ocean
Observations Models
Volume 200 million = 2 x 108 500 million grid points 200 levels 100 prognostic variables = 1 x 1013
Type 98% from 80 different satellite instruments
physical and chemical parameters of atmosphere, waves, ocean, ice, vegetation
Today:
Tomorrow:
Factor 10 per day Factor 2000 per time step
5

0
1
2
3
4
5
6
7
8
9
0
81
92
16
38
4
24
57
6
32
76
8
40
96
0
49
15
2
57
34
4
65
53
6
73
72
8
81
92
0
90
11
2
98
30
4
10
64
96
11
46
88
12
28
80
13
10
72
13
92
64
Frac
tio
n o
f O
per
atio
nal
Th
resh
old
Number of Edison Cores (CRAY XC-30)
13km Case: Speed Normalized to Operational Threshold (8.5 mins per day)
IFS
NMM-UJ
FV3, single precision
NIM
FV3, double precision
MPAS
NEPTUNE
13km Oper. Threshold
AVEC forecast model intercomparison: 13 km
[Michalakes et al. 2015: AVEC-Report: NGGPS level-1 benchmarks and software evaluation] 6

0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
0
81
92
16
38
4
24
57
6
32
76
8
40
96
0
49
15
2
57
34
4
65
53
6
73
72
8
81
92
0
90
11
2
98
30
4
10
64
96
11
46
88
12
28
80
13
10
72
13
92
64
Frac
tio
n o
f O
per
atio
nal
Th
resh
old
Number of Edison Cores (CRAY XC-30)
3km Case: Speed Normalized to Operational Threshold (8.5 mins per day)
IFS
NMM-UJ
FV3 single precision
FV3 double precision
NIM
NIM, improved MPI comms
MPAS
NEPTUNE
3km Oper. Threshold
Advanced Computing Evaluation Committee (AVEC) to evaluate HPC performance of five Next Generation Global Prediction System candidates to meet operational forecast requirements at the National Weather Service through 2025-30
7
AVEC forecast model intercomparison: 3 km

A spectral transform, semi-Lagrangian, semi-implicit (compressible) hydrostatic model
How long can ECMWF continue to run such a model?
IFS data assimilation and model must EACH run in under ONE HOUR for a 10 day global forecast
8
Technology applied at ECMWF for the last 30 years …

9
IFS ‘today’ (MPI + OpenMP parallel)
IFS = Integrated Forecasting System

October 29, 2014
2 MW 6 MW (for a single HRES forecast)
two XC-30 clusters each with 85K cores
10
Operational requirement
ECMWF require system capacity for 10 to 20 simultaneous HRES forecasts
Predicted 2.5 km model scaling on a XC-30

Numerical methods – Code Adaptation - Architecture
ESCAPE*, Energy efficient SCalable Algorithms for weather Prediction at Exascale: • Next generation IFS numerical building blocks and compute intensive algorithms • Compute/energy efficiency diagnostics • New approaches and implementation on novel architectures • Testing in operational configurations
*Funded by EC H2020 framework, Future and Emerging Technologies – High-Performance Computing Partners: ECMWF, Météo-France, RMI, DMI, Meteo Swiss, DWD, U Loughborough, PSNC, ICHEC, Bull, NVIDIA, Optalysys

Schematic description of the spectral transform method in the ECMWF IFS model
13
Grid-point space -semi-Lagrangian advection -physical parametrizations -products of terms
Fourier space
Spectral space -horizontal gradients -semi-implicit calculations -horizontal diffusion
FFT
LT
Inverse FFT
Inverse LT
Fourier space
FFT: Fast Fourier Transform, LT: Legendre Transform

14
Grid-point space
Fourier space
Spectral space
FFT
LT
Inverse FFT
Inverse LT
Fourier space
FFT: Fast Fourier Transform, LT: Legendre Transform
100 iterations
Time-stepping loop in dwarf1-atlas.F90
DO JSTEP=1,ITERS
call trans%invtrans(spfields,gpfields)
call trans%dirtrans(gpfields,spfields)
ENDDO
Schematic description of the spectral transform warf in ESCAPE
d

An OpenACC port of a spectral transform test (transform_test.F90) Using 1D parallelisation over spectral waves
Contrast with IFS which uses 2D parallelisation (waves, levels)
About 30 routines ported, 280 !$ACC directives
Major focus on FFTs, using NVIDIA cuFFT library
Legendre Transform uses DGEMM_ACC Fast Legendre Transform not ported (need working deep copy)
CRAY provided access to SWAN (6 NVIDIA K20X GPUs) Latest 8.4 CRAY compilers
Larger runs performed on TITAN Each node has 16 AMD Interlagos cores & 1 NVIDIA K20X GPU (6GB)
CRESTA INCITE14 access
Used 8.3.1 CRAY compiler
Compare performance of XK7/Titan node with XC-30 node (24 core Ivybridge)
15
GPU-related work on this dwarf Work carried out by George Mozdzynski, ECMWF

230.6 230.7
207.5
218.4
109.1
86.1
238.9 239.5
0
50
100
150
200
250
300
LTINV_CTL LTDIR_CTL FTDIR_CTL FTINV_CTL
mse
c p
er
tim
e-s
tep
Tc1023 10 km model Spectral Transform Compute Cost (40 nodes, 800 fields)
XC-30
TITAN
16

646.2 645.1
345.3 351.1
189.3
152.9
281.7 281.9
0
100
200
300
400
500
600
700
LTINV_CTL LTDIR_CTL FTDIR_CTL FTINV_CTL
mse
c p
er
tim
e-s
tep
Tc1999 5 km model Spectral Transform Compute Cost (120 nodes, 800 fields)
XC-30
TITAN
17

1024.9
1178.6
428.3 424.6
324.3 279.8
342.3 341.8
0
200
400
600
800
1000
1200
1400
LTINV_CTL LTDIR_CTL FTDIR_CTL FTINV_CTL
mse
c p
er
tim
e-s
tep
Tc3999 2.5 km model Spectral Transform Compute Cost (400 nodes, 800 fields)
XC-30
TITAN
18

100
200
400
800
16003200
0.00
0.20
0.40
0.60
0.80
1.00
1.20
1.40
1.60
T95 T159 T399 T1023 T1279 T2047 T3999 T7999
Re
lati
ve P
erf
orm
ance
Relative FFT performance NVIDIA K20X GPU (v2) v 24 core Ivybridge CRAY XC-30 node (FFT992)
1.40-1.60
1.20-1.40
1.00-1.20
0.80-1.00
0.60-0.80
0.40-0.60
0.20-0.40
0.00-0.20
K20X GPU performance up to 1.4 times faster than 24 Ivybridge core XC-30 node 22

0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40
0.45
0.50
0 1000 2000 3000 4000 5000 6000 7000 8000 9000
Tim
e
FFT length (latitude points)
Comparison of FFT cost for LOT size 100
GPU ver 1
GPU ver 2
FFT992
FFTW 3700
7400
4100
24

Cost very much greater than compute for Spectral Transform test
Tc3999 example follows
XC-30 (Aries) is faster than XK7/Titan (Gemini)
So made prediction for XC-30 comms with K20X GPU
Potential for compute / communications overlap
GPU compute while MPI transfers are taking place
Not done (yet)
25
What about MPI communications?

26
Tc3999 XC-30 TITAN XC-30+GPU Prediction
LTINV_CTL 1024.9 324.3 324.3
LTDIR_CTL 1178.6 279.8 279.8
FTDIR_CTL 428.3 342.3 342.3
FTINV_CTL 424.6 341.8 341.8
MTOL 752.5 4763.0 752.5
LTOM 407.9 4782.9 407.9
LTOG 1225.9 1541.9 1225.9
GTOL 401.5 1658.4 401.5
HOST2GPU** 0.0 655.4 655.4
GPU2HOST** 0.0 650.0 650.0
5844.2 14034.4 5381.4
** included in comms (red) times
Tc3999, 400 nodes, 800 fields (ms per time-step)

27
OpenACC not that difficult, but
Replaced ~10 OpenMP directives (high-level parallelisation)
By ~280 OpenACC directives (low-level parallelisation)
Most of the porting time spent on
Strategy for porting IFS FFT992 interface (algor/fourier)
Replaced by calls to new cuda FFT993 interface
Calling NVIDIA cuFFT library routines
Coding versions of FTDIR and FTINV where FFT992 and FFT993 both ran on same data to compare results
Writing several offline FFT tests to explore performance
Performance issues
Used nvprof, gstats
Spectral transforms experience

Physics dwarf : CloudSC
• Work done by Sami Saarinen, ECMWF
• Adaptation of IFS physics’ cloud scheme (CLOUDSC) to new architectures as part of ECMWF Scalability programme
• Emphasis was on GPU-migration by use of OpenACC directives
• CLOUDSC consumes about 10% of IFS Forecast time
• Some 3500 lines of Fortran2003 –before OpenACC directives
• Focus on performance comparison between
- OpenMP version of CLOUDSC on Haswell
-OpenACC version of CLOUDSC on NVIDIA K40
28

• Given 160,000 grid point columns (NGPTOT) • Each with 137 levels (NLEV) • About 80,000 columns fit into one K40 GPU
• Grid point columns are independent of each other • So no horizontal dependencies here, but ... • ... level dependency prevents parallelization along vertical dim
• Arrays are organized in blocks of grid point columns • Instead of using ARRAY(NGPTOT, NLEV) ... • ... we use ARRAY(NPROMA, NLEV, NBLKS)
• NPROMA is a (runtime) fixed blocking factor
• Arrays are OpenMP thread safe over NBLKS
29
Problem parameters:

• Haswell-node : 24-cores @ 2.5GHz
• 2 x NVIDIA K40c GPUs on each Haswell-node via PCIe • Each GPU equipped with 12GB memory –with CUDA 7.0
• PGI Compiler 15.7 with OpenMP & OpenACC • –O4 –fast –mp=numa,allcores,bind –Mfprelaxed • –tp haswell –Mvect=simd:256 [ -acc ]
• Environment variables • PGI_ACC_NOSHARED=1 • PGI_ACC_BUFFERSIZE=4M
• Typical good NPROMA value for Haswell~ 10 –100
• For GPUs NPROMA up to 80,000 for max performance
30
Details on hardware, compilers, NPROMA:

OpenMP loop around CLOUDSC call:
REAL(kind=8) :: array(NPROMA, NLEV, NGPBLKS)
!$OMP PARALLEL PRIVATE(JKGLO,IBL,ICEND)
!$OMP DO SCHEDULE(DYNAMIC,1)
DO JKGLO=1,NGPTOT,NPROMA! So called NPROMA-loop
IBL=(JKGLO-1)/NPROMA+1 ! Current block number
ICEND=MIN(NPROMA,NGPTOT-JKGLO+1) ! Block length <= NPROMA
CALL CLOUDSC( 1, ICEND, NPROMA, KLEV, &
& array(1,1,IBL), & ! ~ 65 arrays like this
)
END DO
!$OMP END DO
!$OMP END PARALLEL 31
Typical values for NPROMA in OpenMP
implementation: 10 – 100

OpenMP scaling (Haswell, in GFlops)
32

Development of OpenACC/GPU-version
• The driver-code with OpenMP-loop kept roughly unchanged • GPU to HOST data mapping (ACC DATA) added
• OpenACC can (in most cases) co-exist with OpenMP • Allows an elegant multi-GPU implementation
• CLOUDSC was pre-processed with ”acc_insert” –Perl-script • Allowed automatic creation of ACC KERNELS and ACC DATA
PRESENT / CREATE clauses to CLOUDSC
• In addition some minimal manual source code clean-up
• CLOUDSC performance on GPU needs very large NPROMA • Lack of multilevel parallelism (only across NPROMA, not NLEV)
33

Driving OpenACC CLOUDSC with OpenMP
34
!$OMP PARALLEL PRIVATE(JKGLO,IBL,ICEND) & !$OMP& PRIVATE(tid, idgpu) num_threads(NumGPUs) tid = omp_get_thread_num() ! OpenMP thread number idgpu = mod(tid, NumGPUs) ! Effective GPU# for this thread CALL acc_set_device_num(idgpu, acc_get_device_type()) !$OMP DO SCHEDULE(STATIC) DO JKGLO=1,NGPTOT,NPROMA ! NPROMA-loop IBL=(JKGLO-1)/NPROMA+1 ! Current block number ICEND=MIN(NPROMA,NGPTOT-JKGLO+1) ! Block length <= NPROMA !$acc data copyout(array(:,:,IBL), ...) & ! ~22 : GPU to Host !$acc& copyin(array(:,:,IBL)) ! ~43 : Host to GPU
CALL CLOUDSC (... array(1,1,IBL) ...) ! Runs on GPU#<idgpu> !$acc end data END DO !$OMP END DO !$OMP END PARALLEL
Typical values for NPROMA in OpenACC implementation:
> 10,000

Sample OpenACC coding of CLOUDSC
!$ACC KERNELS LOOP COLLAPSE(2) PRIVATE(ZTMP_Q,ZTMP) DO JK=1,KLEV
DO JL=KIDIA,KFDIA ztmp_q = 0.0_JPRB ztmp = 0.0_JPRB !$ACC LOOP PRIVATE(ZQADJ) REDUCTION(+:ZTMP_Q, +:ZTMP) DO JM=1,NCLV-1 IF (ZQX(JL,JK,JM)<RLMIN) THEN ZLNEG(JL,JK,JM) = ZLNEG(JL,JK,JM)+ZQX(JL,JK,JM) ZQADJ = ZQX(JL,JK,JM)*ZQTMST ztmp_q = ztmp_q + ZQADJ ztmp = ztmp + ZQX(JL,JK,JM) ZQX(JL,JK,JM) = 0.0_JPRB
ENDIF ENDDO PSTATE_q_loc(JL,JK) = PSTATE_q_loc(JL,JK) + ztmp_q ZQX(JL,JK,NCLDQV) = ZQX(JL,JK,NCLDQV) + ztmp ENDDO ENDDO !$ACC END KERNELS ASYNC(IBL)
35
ASYNC removes CUDA-thread syncs

OpenACC scaling (K40c, in GFlops)
36
0
2
4
6
8
10
12
100 1000 10000 20000 40000 80000
1 GPU
2 GPUs
NPROMA

37
Timing (ms) breakdown : single GPU
0
2000
4000
6000
8000
10000
12000
10 1000 20000 80000
Other overhead
Communication
Computation
Haswell
NPROMA

Saturating GPUs with more work
38
!$OMP PARALLEL PRIVATE(JKGLO,IBL,ICEND) & !$OMP& PRIVATE(tid, idgpu) num_threads(NumGPUs * 4) tid = omp_get_thread_num() ! OpenMP thread number idgpu = mod(tid, NumGPUs) ! Effective GPU# for this thread CALL acc_set_device_num(idgpu, acc_get_device_type()) !$OMP DO SCHEDULE(STATIC) DO JKGLO=1,NGPTOT,NPROMA ! NPROMA-loop IBL=(JKGLO-1)/NPROMA+1 ! Current block number ICEND=MIN(NPROMA,NGPTOT-JKGLO+1) ! Block length <= NPROMA !$acc data copyout(array(:,:,IBL), ...) & ! ~22 : GPU to Host !$acc& copyin(array(:,:,IBL)) ! ~43 : Host to GPU
CALL CLOUDSC (... array(1,1,IBL) ...) ! Runs on GPU#<idgpu> !$acc end data END DO !$OMP END DO !$OMP END PARALLEL
More threads
here

• Consider few performance degradation facts at present
• Parallelism only in NPROMA dimension in CLOUDSC
• Updating 60-odd arrays back and forth every time step
• OpenACC overhead related to data transfers & ACC DATA
• Can we do better ? YES !
• We can enable concurrently executed kernels through OpenMP !
• Time-sharing GPU(s) across multiple OpenMP-threads
• About 4 simultaneous OpenMP host–threads can saturate a single GPU in our CLOUDSC case
• Extra care must be taken to avoid running out of memory on GPU
• Needs ~ 4X smaller NPROMA : 20,000 instead of 80,000
39
Saturating GPUs with more work

Multiple copies of CLOUDSC per GPU (GFlops)
0
2
4
6
8
10
12
14
16
Copies 1 2 4
1 GPU
2 GPUs
40

nvvp profiler shows time-sharing impact
41
GPU is 4-way time-shared
GPU is fed with work by one OpenMP
thread only
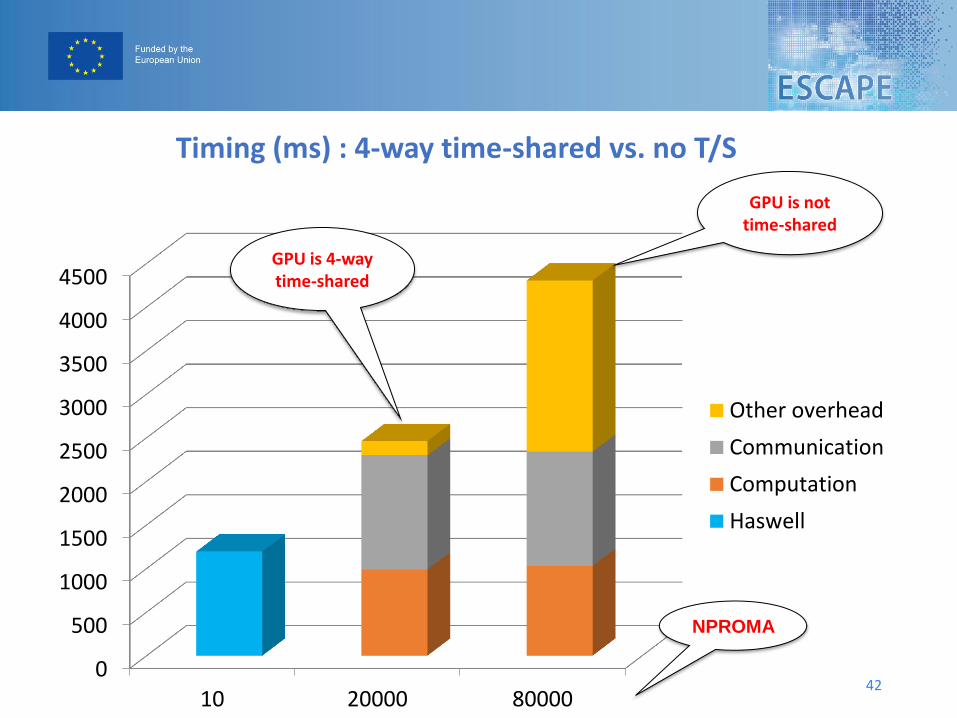
Timing (ms) : 4-way time-shared vs. no T/S
0
500
1000
1500
2000
2500
3000
3500
4000
4500
10 20000 80000
Other overhead
Communication
Computation
Haswell
NPROMA
42
GPU is 4-way time-shared
GPU is not time-shared

24-core Haswell 2.5GHz vs. K40c GPU(s) (GFlops)
0
2
4
6
8
10
12
14
16
18
Haswell
2 GPUs (T/S)
2 GPUs
1 GPU (T/S)
1 GPU
43
T/S = GPUs time-
shared

Conclusions
• CLOUDSC OpenACC prototype from 3Q/2014 was ported to ECMWF’s tiny GPU cluster in 3Q/2015
• Since last time PGI compiler has improved and OpenACC overheads have been greatly reduced (PGI 14.7 vs. 15.7)
• With CUDA 7.0 and concurrent kernels – it seems – time-sharing (oversubscribing) GPUs with more work pays off
• Saturation of GPUs can be achieved not surprisingly by help of multi-core host launching more data blocks onto GPUs
• The outcome is not bad considering we seem to be underutilizing the GPUs (parallelism just along NPROMA)
44

This project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 671627
www.hpc-escape.eu
Thank You!