evolution of database services eva dafonte pérez 2014 wlcg collaboration workshop 1
TRANSCRIPT

1
Evolution of database services
Eva Dafonte Pérez2014 WLCG Collaboration Workshop

2
Outline CERN’s databases overview Service evolution
HW Storage Service configuration SW
New database services Replication Database On Demand (DBoD) service Hadoop + Impala Future plans Summary

3
CERN’s databases ~100 Oracle databases, most of them RAC
Mostly NAS storage plus some SAN with ASM ~500 TB of data files for production DBs in total
Example of critical production DBs: LHC logging database ~170 TB, expected growth up to ~70 TB / year
But also as DBaaS, as single instances 120 MySQL Open community databases 11 PostgreSQL databases 10 Oracle11g
And additional tests setups: Hadoop + Impala, CitusDB

4
Our deployment model DB clusters based on RAC
Load balancing and possibility to growth High Availability – cluster survives to node failures Maintenance – rolling interventions
Schema based consolidation Many applications share the same RAC cluster Per customer and/or functionality
Example: CMS offline database cluster
RAC Instance 1
Clusterware
OS
RAC Instance 2
Clusterware
OS
Shared Storage
Public Network
Private Network
Storage Network

5
Service evolution Preparation for RUN2
Changes have to fit LHC schedule New HW installation in BARN
Decommission of some old HW Critical power move from current location to BARN
Keep up with Oracle SW evolution Applications’ evolution - more resources needed Integration with Agile Infrastructure @CERN LS1: no stop for the computing or other DB services
HW Migration
SW upgrade
Stable servicesDecomission
New systems Installation

6
Hardware evolution 100 production servers in the BARN
Dual 8 core XEON e5-2650 128GB/256GB RAM 3x10Gb interfaces
Specific network requirements IP1, ATLAS PIT, Technical Network, routed and non-routed
network New generation of storage from NetApp

7
Storage evolution
FAS3240 FAS8060
NVRAM 1.0 GB 8.0 GB
System memory 8GB 64GB
CPU 1 x 64-bit 4-core 2.33 Ghz
2 x 64-bit 8-core 2.10 Ghz
SSD layer (maximum)
512GB 8TB
Aggregate size 180TB 400TB
OS controller Data ONTAP® 7-mode
Data ONTAP® C-mode
scaling up
scaling out
8
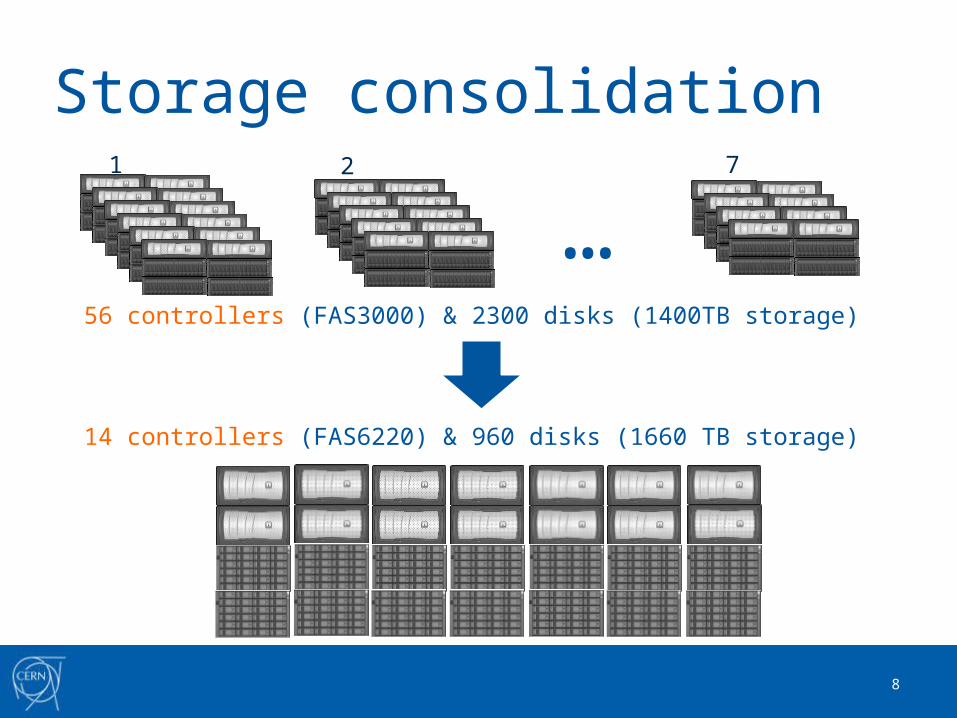
Storage consolidation
56 controllers (FAS3000) & 2300 disks (1400TB storage)
…1 2 7
14 controllers (FAS6220) & 960 disks (1660 TB storage)
9
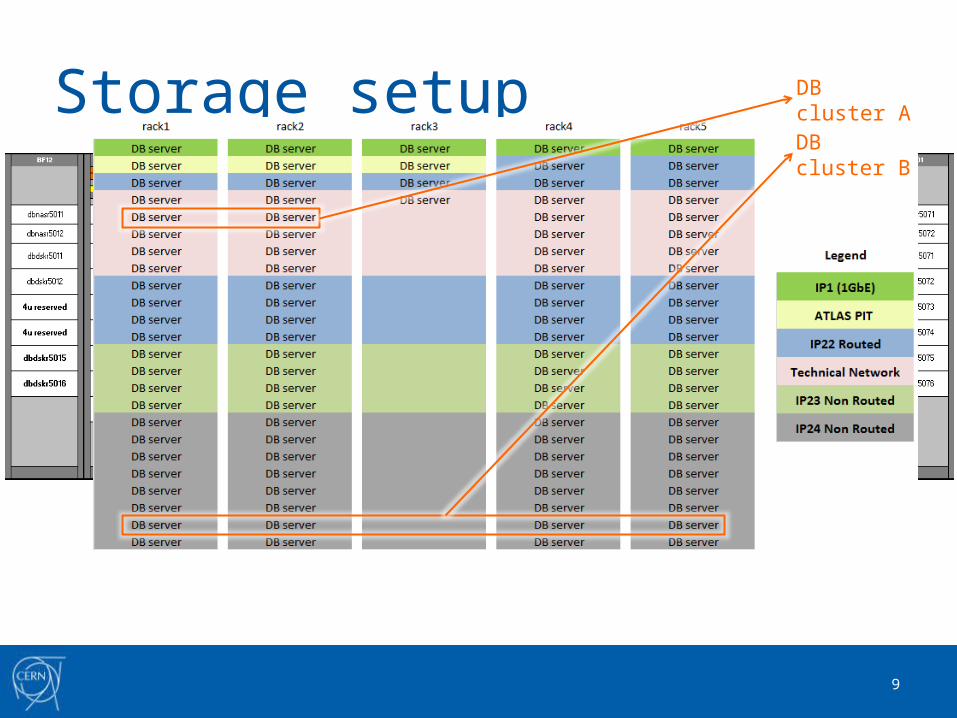
Storage setup DB cluster A
DB cluster B

10
Easy management More capacity Transparent volume move Caching: flash cache and flash pool Performance improvement
~2-3 times more of overall performance Difficulties finding slots for interventions
Storage setup

11
Service configuration - Puppet Following CERN IT’s strategy, IT-DB group adopted Puppet Good occasion to re-think how the services are configured and
managed Rely on the same Syscontrol-LDAP* data source for Quattor-
managed services Developed custom modules for:
Private storage and network configuration Database installation Backups configuration
Removed ssh keys and service accounts in favour of kerberos+sudo Improves traceability & manageability
RHEL 5 8 RHEL 6
* Syscontrol-LDAP for IT-DB: stores configuration for IT-DB services

12
New Oracle releases Production was running on 11.2.0.3 (Oracle 11g) 11.2.0.4
Terminal patch set Additional support fees from January 2016 Extended support ends January 2018
(Oracle 12c) 12.1.0.1 First release Next patch set 12.1.0.2 coming in Q3 2014 Educated Guess: users of 12.1.0.1 will have to upgrade to
12.1.0.2 or higher by 2016
No current Oracle version fits well the entire RUN 2

Oracle upgrade Move IT-DB services to Oracle 12c gradually
Majority of DB services upgraded to 11.2.0.4 Few candidate services upgraded to 12.1.0.1
ATLARC, LHCBR, PDBR, LEMON, CSDB, CSR, COMPR, TIMRAC Compatibility kept to 11.2.0.3
12c Oracle clusterware deployed everywhere Does not conflict with 11g version of RDBMS
Newer 12c releases being/will be tested
13
Create new development DB on 12.1.0.1 – devdb12September 2013
Upgrade devdb11 DB to 11.2.0.4 October 2013
Move integration DBs to new HW November 2013
Upgrade test and integration DBs
December 2013 and January 2014
Test restores & upgrades of prod DBs on new HW
Q1 2014
Move to new HW and/or upgrade of production DBsQ1 and Q2 2014

14
New database services QPSR
Quench Protection System Will store ~150K rows/second (64GB per redo log) 1M rows/second achieved during catch-up tests Need to keep data for a few days (~ 50 TB) Doubtful if previous HW could have handled that
SCADAR Consolidated WinCC/PVSS archive repository Will store ~50-60K rows/second (may increase in the future) The data retention varies depending on the application (from a
few days to 5 years)

15
Replication Plan to deploy Oracle Golden Gate at CERN and Tier1s
In order to replace Oracle Streams replication Streams is phased out Some online to offline setups were already replaced by Oracle Active
Data Guard
Replication Technology Evolution Workshop @CERN in June
Migration plan agreed with experiments and Tier1s Centralised GG configuration
GG software only at CERN Trail files only at CERN No GG management at T1s
A
C
E R
Remote site replica
Downstream cluster
R
R

16
Database On Demand (DBoD)
• Openstack• Puppetdb (MySQL)• Lhcb-dirac• Atlassian databases• LCG VOMS• Geant4• Hammercloud dbs• Webcast• QC LHC Splice• FTS3• DRUPAL• CernVM• VCS• IAXO• UNOSAT• …

17
DBoD evolution PostgreSQL since September 2013 Deprecated virtualization solution based on RHEL + OVM HW servers and storage evolution as for the Oracle
database services Migration to CERN Agile infrastructure
Customized RPM packages for MySQL and PostgreSQL servers High Availability cluster solution based on Oracle clusterware
4 nodes cluster (3 nodes active + 1 as spare) SW upgrades
MySQL currently migrating to 5.6 Oracle 11g migrating towards Oracle 12c multi-tenancy
Tape backups

18
Hadoop Using raw MapReduce for data processing requires:
Abstract decomposition of a problem into Map and Reduce steps Expertise in efficient Java programming
Impala – SQL engine on top of HDFS Alternative solution to MapReduce Data cache available Easy access: JDBC driver provided
Performance benchmarks on synthetic data (early results) Test case: simple CSV table mapping Full scan 36 million rows (small sample): 5.4M rows/sec
Cached: 10x faster Full scan of 3.6 billion rows (100x more): 30M rows/sec
IO: ~3.7GB/s with storage throughput ~4GB/s Cache does not help – too large data set for cache

19
Future plans New HW installations
Second cluster in BARN Wigner (for Disaster Recovery)
SW upgrades First Oracle 12c patch set 12.1.0.2 (Q3 2014)
More consolidation – run different DB services on the same machine Study the use of Oracle Golden Gate for near zero downtime upgrades Quattor decommission DBoD
High density consolidation Cloning and replication Virtualization as OpenStack evolves
Hadoop + Impala Columnar storage (Parquet) Importing data from Oracle into Hadoop Tests with production data (WLCG dashboards, ACC logging, …) Analyze different engines (Shark)

20
Summary HW, Storage, SW and configuration evolution for the DB
service during last year Complex project Many people involved at various levels
Experience gained will be very useful for the new installations
Careful planning is critical Validation is a key to successful change New systems give more capacity and stability for RUN2 New services provided
and more coming Keep looking at new technologies

21
Q&A

22

23
7-mode vs C-mode
Private network
client access
Private network
Cluster interconnect
Cluster mgmt network
client access
24
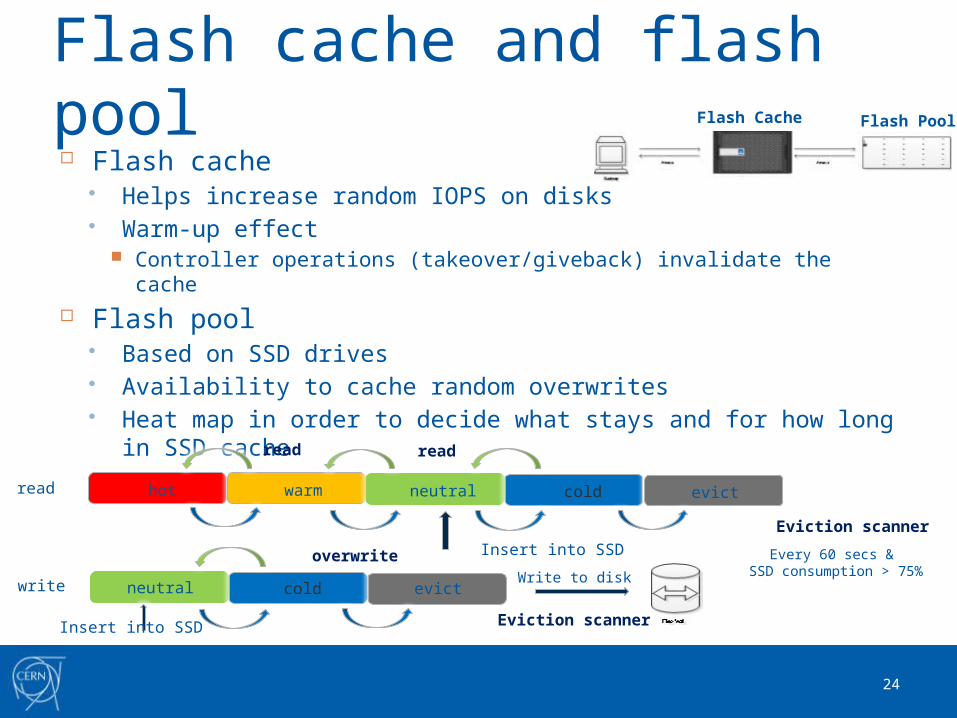
Flash cache and flash pool Flash cache
Helps increase random IOPS on disks Warm-up effect
Controller operations (takeover/giveback) invalidate the cache
Flash pool Based on SSD drives Availability to cache random overwrites Heat map in order to decide what stays and for how long in
SSD cache
Flash Cache Flash Pool
Write to disk
read read
overwrite
Eviction scanner
Eviction scanner
Insert into SSD
Insert into SSD
read
write
Every 60 secs & SSD consumption > 75%
hot warm neutral cold evict
evictcoldneutral

25
Hadoop Sequential data access with Oracle and Hadoop: a performance
comparison Zbigniew Baranowski – CHEP 2013
Test case – counting exotic muons in the collection Oracle performs well for small clusters but scaling ability is limited by
shared storage Hadoop scales very well However, writing efficient Map Reduce code is not trivial

26
Hadoop + Impala 4 nodes each:
Intel Xeon L5520 @2.27GHz (Quad) 24GB RAM
> 40TB storage (sum of single HDDs capacity)
Pros: Easy to setup – works „out of the box” Acceptable performance Promising scalability
Cons: No indexes SQL is not everything on RDBMS!