european the association e l elra ra
TRANSCRIPT

Signed articles represent the views of their authors and do not necessarily reflect the position of theEditors, or the official policy of the ELRABoard/ELDAstaff.
Editor in Chief:Khalid Choukri
Editors:Valérie MapelliHélène Mazo
Layout:Valérie Mapelli
Contributors:Martine Adda-DeckerNicoletta CalzolariKhalid ChoukriThierry DeclerckLaurence DevillersEleni EfthimiouOlivier FerretCarmen García-MateoOlivier GalibertBente MaegaardValérie MapelliJean-Claude MartinStelios PiperidisMike RosnerSophie RossetBjörn Schuller
ISSN: 1026-8200
ELRA/ELDASecretary General: KhalidChoukri55-57, rue Brillat Savarin75013 Paris - FranceTel: (33) 1 43 13 33 33Fax: (33) 1 43 13 33 30E-mail: [email protected] sites:http://www.elra.info orhttp://www.elda.org
The ELRANewsletter January - June
2010A
ELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
LREC 2010 Special Issue
7th International Conference on LanguageResources and Evaluation
Vol.15 n.1 & 2

- 2 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
Contents
Message from ELRA President and Secretary General.................................................................Page 3
Intr oduction by Nicoletta Calzolari, Conference Chair.................................................................Page 4
Opening Ceremony Speeches
Stelios Piperidis, the ELRAPresident.......................................................................................Page 6
Khalid Choukri, ELRASecretary General and ELDAManaging Director.............................Page 7
Mike Rosner, Chair of the Local Organizing Committee.........................................................Page 9
Antonio Zampolli Prize Award Ceremony
Stelios Piperidis.........................................................................................................................Page 10
Oral Session Summaries
O3 - Dialogue and Evaluation, Sophie Rosset.........................................................................Page 11
O8 - Sign Language, Eleni Efthimiou.......................................................................................Page 11
O13 - Ontologies, Thierry Declerck .........................................................................................Page 12
O23 - Broadcast News, Carmen García-Mateo........................................................................Page 12
O25 - Emotion, Sentiment - Special Session, Laurence Devillers............................................Page 13
O31- Multimodal Annotation, Jean-Claude Martin .................................................................Page 14
O39 - Information Extraction, Martine Adda-Decker..............................................................Page 14
PosterSession Summaries
P14 - Word Sense Disambiguation and Evaluation, Olivier Ferret.........................................Page 15
P27 - Evaluation of Speech Recognition and Speech Synthesis, Olivier Galibert...................Page 15
Workshop Summaries
Legal Issues for Sharing Language Resources: Constraints and Best Practices,
Valérie Mapelli..........................................................................................................................Page 17
Emotion 2010 - On Recent Corpora for Research on Emotion and Affect,
Björn Schuller and Laurence Devillers....................................................................................Page 18
LR and HLT for Semitic Languages, Khalid Choukri and Bente Maegaard ...........................Page 18
Conference Survey Report.................................................................................................................Page 19
New Resources....................................................................................................................................Page 20

Dear Colleagues,
Like every two years, this is the special issue of the ELRAnewsletter devoted to the Language Resources and EvaluationConference (LREC). The Seventh edition of the Language Resources and Evaluation Conference took place last May inValletta (Malta) under the Distinguished Patronage of Dr George Abela, President of Malta and with the support ofHerman Van Rompuy, President of the European Council.
This edition has been again very popular: 1246 participants coming from 61 countries registered to the main conference,workshops and tutorials. This time, Germany brought the highest number of participants, but the participation fromAmerica and Asia was also significant.
For LREC 2010, three major changes were introduced:
• The LRE-Map, a new mechanism intended to monitor the use and creation of language resources by collecting infor-mation on both existing and newly-created resources during the submission process. Nearly 2000 language resourceforms have been filled in. Apart from providing a portrait of the existing or under-development language resources andtools, of their uses and usability, the LRE Map intends to be a measuring instrument for monitoring the field of HumanLanguage Technologies.
• The EC Village, an initiative to encourage EC-sponsored projects to gain visibility by showing their objectives, pro-gress and activities, either through demos, or through brochures or posters for projects still at their early stages. 15 pro-jects took part in this Village. Both ELRAand LDC were present and took this opportunity to highlight their role withinthe community.
• The Special sessions, a new experiment of oral sessions on "hot topics", with dedicated time slots left for more exchan-ge and discussions between the authors, chairpersons and audience.
A joint COCOSDA/WRITE workshop on Language Technology Issues for International Cooperationwas held onSaturday, May 22nd 2010. This meeting was organised jointly by COCOSDA, the International Committee for Co-ordi-nation and Standardisation of Speech Databases, WRITE International Committee for Written Resources Infrastructure,Technology, and Evaluation, and FLaReNet. It aimed at reporting on existing initiatives (worldwide) and internationalcooperation among various initiatives and communities around the world, within and around the field of LanguageResources and Technologies.
Six years ago, the ELRABoard created the Zampolli Prize, a prize for "Outstanding Contributions to the Advancementof Language Resources and Language Technology Evaluation", to honour the memory of its co-founder and first presi-dent, Antonio Zampolli. In 2010, the Antonio Zampolli Prize was awarded to Mark Liberman, from the University ofPennsylvania (USA). We made Mark Liberman's presentation available on-line, from the LREC home page:
www.lrec-conf.org/lrec2010
Now concerning the content of this ELRAnewsletter dedicated to LREC2010, a few sessions' summaries are proposed along with the OpeningCeremony speeches. A short report on participants' feedback is also avai-lable.
Last but not least, the new resources added to the ELRAcatalogue arelisted at the end of this newsletter.
Stelios Piperidi, PresidentKhalid Choukri, Secretary General
- 3 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010

- 4 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
INTRODUCTION
by Nicoletta Calzolari, LREC 2010 Conference Chair
Let me first express to His ExcellencyDr George Abela, President of Malta,the gratitude of the Program
Committee and of all LREC participantsfor his Distinguished Patronage of LREC2010. We thank him also for having kindlyoffered us the Presidential summer resi-dence, the beautiful Verdala Palace, for ourwelcome reception.
This is the 7th LREC. LREC is still youngin comparison to other conferences of thefield, but after only 12 years we have esta-blished a new record: we received 930submissions and have accepted 662papers. We have 22 Workshops and 9Tutorials. These figures are a confirmationthat the field of Language Resources andEvaluation is flourishing more than ever.In support of this statement is the fact thatalso ACL and COLING this year decidedto have a specific Track called "LanguageResources".
So far more than 1100 people have alreadyregistered. LREC thus continues to be - asmany say - "the conference where youhave to be and where you meet everyone".The high acceptance rate is an importantcharacteristic that gives LREC its specialflavour, even more important consideringthe flaws of the reviewing system of mainconferences. But mostly we don't want justthe "peaks" (if we can speak about peaks),we want to provide a global vision of thefield (the "lay of the land"), with its manyfeatures (and for many languages): LRECis therefore the event where we gather abroad representation of the current trendsof the field. The preparation of this yearprogram was as usual a challenge, like abig puzzle, but also quite an interestingtask giving the perception of the hugerange of topics in which our community isengaged. Some of this year main trends:
•Semantics and Knowledge, in all itsvariations, from annotation of anaphoric,temporal, spatial information, to ontolo-gies and lexicons, to disambiguation,named entities recognition, informationextraction, and so on.
•Subjectivity, declined in various nuances:emotions, opinions, sentiments. Itbecomes almost a workshop track insidethe main conference.
•Machine Translation and multilingua-lism, almost another track.
• Infrastructural initiatives, strategies,national and international projects areof major interest, as usual inside theLREC community.
•Both Lexicons and Corpora keeptheir strong position.
•Tools and systems for text analysis atmany levels.
•Dialogue and discourse, with contri-butions from both the Speech and Textcommunities.
•Speech and Multimodal databases,tools, systems.
•And finally evaluation and validationmethodologies, as a topic per se and asan important part of quite many papers.
A problem we still have to face is therelatively small number of submissionsfrom the Speech and Multimodal com-munities. We have always thought thatit is important for the field to integratework from the Written, Spoken and
Multimodal areas, and to have a conferen-ce where these communities may cometogether. But the tradition of separateconferences makes this objective difficultto meet. We need to do more in this res-pect.
It is interesting to notice how, while all theother topics occur in all major conferences(maybe in different proportions), a charac-teristic of LREC is the relevance of whatwe can call "meta-research" issues. I thinkthis reflects a peculiarity of the LanguageResources and Evaluation community,which has recognised since some time theimportance for the field of promotinginfrastructural activities. These are consi-dered not so rewarding from the typicalresearcher viewpoint, but are of extremeimportance for the field as a whole. Usingan ecological metaphor, the majority ofresearchers tend to look after their indivi-dual tree (individual benefits), but somemust take care of the forest (the best for thefield)! I think this is a great merit of ourcommunity, which is now starting to berecognised also outside. Why this?Probably because language resources andevaluation themselves have an infrastruc-tural nature, they are in need of coopera-
Nicoletta Calzolari

- 5 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
tion, and this reinforces the awareness ofthe importance of joint efforts and coordi-nating actions. It is a fact that initiativestowards standardisation, distribution, reu-sing, integration and now sharing mostlycome from this community.
LREC has also introduced innovations inthe style of our conferences: posters (pre-viously used mostly in Speech conferencesand used at LREC since its first edition,thanks to the insistence of Joseph Mariani)are now used in every conference. Manycolleagues even like poster sessions morethan oral sessions.
This year we introduce other innovations.We make an experiment of two "specialsessions" on hot topics - Temporal and spa-tial annotation, and Emotion and senti-ments (this is even a special track) - wherethe last slot is left for discussion, to beintroduced, stimulated and moderated bythe chair. If successful we may have morespecial sessions in the next edition.
The LREC Map
This year's biggest innovation is theLREC Map, which finds its proper placeinside the infrastructural actions. I wasthinking about this already two years ago,but it was too late to introduce it.Somehow it is even better to start nowbecause of the coincidence of new impor-tant initiatives around LanguageResources in the last years and of newwindows of opportunities. What is theMap? As all the authors know, we haveasked to provide some basic informationabout all the resources (in a broad sense,i.e. also tools, standards, evaluation pac-kages, etc.) - either used or created - des-cribed in their papers. Without all theauthors' efforts the Map wouldn't exist,but now they gain much more: the wholeMap will be available to everyone!
Lack of information and documentationabout resources is, in the e-science para-digm, a very critical issue. With the Mapwe aim not only at starting to fill this gap,but also at encouraging the needed "chan-ge in culture". We need in fact to makeeach and every researcher aware of theimportance of his/her personal engage-ment in documenting resources. It is a taskas important as creating new resources andis not an accessory to be disregarded. It isthe necessary service to the whole commu-nity that we all have to provide (again, theforest and not only the tree!).
Even if it is a simple idea, it has a greatpotential for many uses, in addition tobeing an information gathering tool:
• It may become a great instrument formonitoring the evolution of the field(useful also for funders), if applied indifferent contexts and times.
• It can be seen as a huge joint effort,the beginning of an even larger coope-rative action not just among a few lea-ders but among all the researchers.
• It can thus become also an "educatio-nal" means towards the broad acknow-ledgment of the need of meta-researchactivities with the active involvementof many.
• It is also instrumental in introducingthe new notion of "citation ofresources" that could provide an awardand a means of scholarly recognitionfor researchers engaged in resourcecreation.
I am proud of the fact that the Map isalready being adopted in othercontexts. The Language Resources andEvaluationJournal will also make useof it, as announced in the new SpecialIssue LREC 2008: Selected papers(freely accessible to all LREC partici-pants). And quite recently alsoCOLING 2010 has decided to makeuse of the Map. The Map is taking itsfirst steps outside home!
Acknowledgments
The final section is dedicated, as usual,to the acknowledgments to all thosewho made this LREC possible andhopefully successful.
I thank first the Program Committee,and recognise their dedication in thehuge task of selecting the papers, butalso in the various aspects aroundLREC. Among them a particularthanks goes to Jan Odijk and JosephMariani, who have been very helpful inthe preparation of the program. And toKhalid Choukri, who is in charge of somany organisational aspects aroundLREC.
I thank ELRA, which is the promoterof LREC, its own conference.
I am particularly grateful to Mr.Herman Van Rompuy, President of theEuropean Council, for his support to
LREC2010 and his interest in multilingua-lism, a great topic in LREC.
I thank our impressively large ScientificCommittee, composed of 537 colleagues.They did a wonderful job, succeeding tocomplete their reviews on time for somany papers. Also on behalf of theProgram Committee, I warmly thank allthe various Committees that have providedsupport to this LREC, the InternationalAdvisory Board and the Local AdvisoryBoard.
A particular thanks goes to the LocalOrganising Committee, and especially toMike Rosner and Claudia Borg, who haveworked very hard for many months to findthe best solutions to many local issues.
I am grateful to authorities, associations,organisations, committees, agencies andcompanies that have supported LREC invarious ways, for their important coopera-tion.
I express my gratitude to all the sponsorsthat have believed in the importance of ourconference, and have helped with financialsupport.
I thank the workshop, tutorial, and panelorganisers, who complement LREC of somany interesting events.
A big thanks goes to all the authors, whoprovide the "substance" to LREC, and giveus such a broad picture of the field.
I finally thank the two institutions thathave provided economic support anddedicated so much effort, in terms ofmanpower, to this LREC, as to the pre-vious ones, i.e. ELDAin Paris and mygroup at ILC-CNR in Pisa. Without theircommitment LREC would not have beenpossible. The last, but not least thanks,are thus devoted, with all my sympathy,to the people of these institutions whohave worked so intensely to make thisLREC possible in all its details: RobertoBartolini, Olivier Hamon, VincenzoParrinelli, Valeria Quochi, Sergio Rossi,and in particular Irene Russo (substitutingthis time Sara Goggi in maternity leave)and Hélène Mazo, a pillar of LREC. I cansay for sure that without their daily workand real commitment for many months,LREC would not have happened. Wehave solved together the many big andsmall problems of such a large conferen-ce. They, together with other youngresearchers of these two institutions and

- 6 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
Nicoletta Calzolari ZamoraniIstituto di Linguistica Computazionaledel CNRVia Moruzzi 156124 Pisa, [email protected]
with a number of volunteers, will assistyou during the conference.
Now LREC is in your hands, the partici-pants. You are the protagonist of LREC,you will make this LREC great. So, at thevery end, my greatest thanks go to youall. I may not be able to speak with eachone of you during the Conference (I'lltry). I hope that you learn something, thatyou perceive and touch the excitement,fervour and liveliness of the field, thatyou have fruitful conversations (confe-rences are useful also for this) and mostof all that you profit of so many contactsto organise new exciting work and pro-jects in the field of Language Resourcesand Evaluation, which you will show atthe next LREC.
I particularly hope that funding agen-cies all over the world will be impres-sed by the quality and quantity of theinitiatives in our sector that LREC dis-plays, and by the fact that the fieldattracts practically all the best groupsof R&D from all continents. This is asign they must take into account intheir programmes and funding strate-gies, and I recognise that they havestarted to do so. The success of LRECfor us actually means the success of thefield of Language Resources andEvaluation.
The tradition of holding LREC in won-derful locations with a Mediterraneanflavour continues, and Malta is a proto-type of the typical LREC location! I'm
sure you will enjoy Malta during theLREC week. And I hope that Malta willenjoy the invasion of LRECers!
With all the Programme Committee, I wel-come you at LREC 2008 in such a won-derful country as Malta and wish you afruitful Conference.
Enjoy LREC 2010 in Malta!
Message from Stelios Piperidis, the ELRAPresident
Stelios Piperidis
LREC 2010 Opening Ceremony Speeches
Let me first express, on behalf of theELRA Board and Members, our pro-found gratitude to His Excellency Dr
George Abela, President of Malta, for hisDistinguished Patronage of LREC 2010and for honoring us with his presence. Ourgratitude is also extended to HisExcellency M. Herman Van Rompuy,
President of the European Council forthe importance that the EC confer tomultilingualism, one of the corners-tones of our conference.
This 7th edition of LREC coincideswith ELRA's fifteenth anniversary.ELRA was established in 1995, in asetting where data-driven techniqueshad just started rising, numerical andlearning methods had not prevailed inthe language technology field. It wasthe work and strategic thought of a fewvisionary people to set up an associa-tion that would take care of identifying,archiving, and distributing languagedata, as well as cater for language tech-nology evaluation. Initial goals werelater on extended into production andvalidation of language data, productionof technology evaluation packages, aswell as into offerings of specific ser-vices (upon demand) and organisationof specific events, LREC being themajor such event since 1998. Andevery LREC edition seems to outper-form the previous one in a range ofdimensions, most notably in numbersof submissions and participants.
Today, we live in a totally different set-ting. No need to stress the importanceof data any longer. Data Intensive
Science and Research is the new paradigmand Digital Data Deluge a new term thatchallenges the minds of many of us.Infrastructures, detailed machine-readablemetadata and documentation of languagedata and tools, data and metadata exchan-ge and harvesting, processing tools in theform of web services, static or dynamicworkflows were just unknown terms 10years ago in our field. Yet, today, they arepart of our daily vocabulary and appearhigh in our research and developmentagendas, as you will notice in the nextthree days.
Throughout this period, from 1995 to2010, ELRA has achieved to establishitself as a high-quality data centre, as amain player in the field of languageresources and evaluation, while it alsoenjoys a steady base of membership. Intimes changing at a dazzling speed, ELRAis constantly responding to new challengesand adapting to new cultures and trends.ELRA has recast its definition of resourcesby extending it to encompass tools that are,by contemporary methods, used in the LRproduction, validation, and evaluation pro-cesses. As announced at a previous LREC,besides its ever evolving catalogue of lan-guage data with clear distribution rightsand licences, ELRAhas set up theUniversal Catalogue, a bottom-up, com-

- 7 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
munity-built resource radar, a catalogue ofresources, data and tools, irrespective ofwhether these can be acquired throughELDA, ELRA's Distribution Agency, ornot. In a similar vein, through its cata-logues, ELRAreinforces its cooperationlinks with major data centres around theworld, notably LDC and NICT, trying tounify all component catalogues into aGlobal Inventory of LRs. Likewise,ELRA's resources are now harvestable byOLAC.
To achieve these goals, ELRAis restructu-ring its activities along three axes : a)infrastructural, taking care of identifica-tion, cataloguing, updating metadata-basedLR description and documentation, andnew simpler distribution mechanisms, b)scientific, taking care of LRs production &validation, and evaluation, and c) promo-tion, taking care of marketing and promo-tion activities like LREC and informationaggregation services.
Along the infrastructural line, LREC andELRA are proud of having initiated, imple-mented and supported the LREC 2010Map. As will be discussed in various otheropportunities during the conference, thisnew concept is yet another concerted efforttowards a new culture, it constitutes a veryrich source of information, that I am prettycertain will be re-used many times, and
functions as a unique tool for monito-ring progress, identifying specificgaps, highlighting trends. The LREC2010 Map is a truly community-builtinformation base, and we are deeplyindebted to all of you for embracing theidea and making it happen. The Map isthe common achievement of all of us,our first shared meta-resource.
ELRA, through its operational bodyELDA, is also proud of being a foun-ding member of the newly launchedMETA-NET, a Network of Excellencededicated to fostering the technologicalfoundations of the European multilin-gual information society. In the frame-work of META-NET, by its nature andobjectives, ELRAwill play an impor-tant role in META-SHARE, an open,integrated, secured and interoperableexchange facility for language data andtools for the Human LanguageTechnologies domain and all otherapplicative domains (e.g., digital libra-ries, cognitive systems, robotics, etc),where language plays a critical role.
[…]
I would like to take the opportunity tothank all those who have worked sohard to make this conference a big suc-cess; the LREC Programme
Committee, chaired by Nicoletta Calzolari,the Scientific Committee, the InternationalAdvisory Committee, Nicoletta's group inPisa, Khalid Choukri and the ELDAstaffin Paris. Particular thanks go to MikeRosner and his Local OrganisingCommittee for taking care of the myriad ofissues that pop up when undertaking theorganisation of such a complex anddemanding conference as LREC, aHerculean task.
Dear LREC Participants,
The Conference is now in your hands.With your active participation in the oralsessions, your lively discussions with thepresenters at the poster sessions, yourvisits to the EC Village to discuss with theinvestigators of the research projects fun-ded by the European Commission, LREC2010 will be yet another success.
I welcome you all to LREC 2010 in Maltaand wish you a fruitful conference.
Stelios PiperidisILSP/ R.C. "Athena"Epidavrou & Artemidos 6Marousi 151 25 Athens, [email protected]
Message from Khalid Choukri, ELRASecretary General and ELDAManaging Director
Khalid Choukri
Welcome to Malta and LREC'2010;Merhba lil Malta u LREC'2010;
Welcome to the celebration of ELRA15th anniversary; your presence here isthe best gift that friends can bring forsuch a wonderful event; thank you allfor your contribution to make this hap-pen;
But let me first express, on behalf ofthe ELDAteam, our profound gratitudeto His Excellency Dr George Abela,President of Malta, for hisDistinguished Patronage of LREC2010and for honoring us with his presence.Our gratitude is also extended to HisExcellency M. Herman Van Rompuy,President of the European Council forthe importance that the EC confer tomultilingualism, one of the corners-tones of our conference.
The patronage of His Excellency DrGeorge Abela, President of Malta high-lights the importance his Excellenceattributes to this field and the encoura-
gements of his Excellence to the diversityof our topics and I know that this is also atrue commitment to see the languages rein-force the foundations of intercultural com-prehensions and diversities in Europe andbeyond. So in the name of ELRAand ofthe LREC Program Committee, and I amsure I can speak on their behalf, let meexpress to his Excellence our gratitude forhis support and extend this gratitude to hisExcellency, president Van Rompuy, assu-ring him with our dedication to help withthe huge challenge of Multilingualism onhis agenda.
I am particularly proud to welcome you inMalta where many of our visions are sha-red by the country highest authorities butalso where our main concerns are explicit-ly imprinted everywhere. Maltese (Malti)is the only Semitic language that is an offi -cial language of the European Union, it hasall the roots and grammar paradigms of aSemitic language while it borrowed from

- 8 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
Italian, Sicilian, and more recently fromEnglish a large amount of its vocabularyand uses Latin alphabet for its writing. Thecountry population lives the multilingua-lism at a very high degree, mostly bilin-gual (Maltese, English), the population hasa good command of Italian, a nice scenarioto mimic at other corners of the EuropeanUnion and beyond.
We are happy that this 7th LREC is takingplace in that context; ELRAand its part-ners are very proud to continue the organi-sation of such a major event where one canmeet all active players from both academiaand industry. Going back to the 1998vision initiated by Joseph Mariani andAntonio Zampolli for the need of a scienti-fic event dedicated to LRs and Evaluation,I remember that we welcomed less than500 participants in Granada (1998) follo-wed by Athens (2000), Las Palmas (2002),Lisbon (2004), Genoa (2006) andMarrakech (2008) with increasing interestfrom the HLT community. We, the organi-zing team, felt that we reached the highesttarget in terms of number of participants,papers and submissions, workshops but wehave broken a new record with more than1100 registered participants a month befo-re the Conference, about 9 tutorials and 24workshops.
This stresses how dynamic our field is butalso how vital it is in particular for a conti-nent like Europe attempting to establish aMultilingual Union that fundamentallyrequires HLT to help overcoming the lan-guage barriers and bringing a crucial sup-porting tool for the Challenge ofMultilingualism. ELRA has committed tosuch a vision from that start and will conti-nue being supportive to all activities andinitiatives that help making LRs availableto the R&D communities and also provi-ding the necessary resources and the infra-structures for the evaluation of technolo-gies.
As you know ELRAis driven by its mem-bers and enjoyed over the last 15 years themembership of more than 70 activeplayers in average, each year. Gatheringsuch members, that enjoy all ELRAmem-bership benefits, helped also ELRAtodesign and tune its strategy and orienta-tion. I am particularly happy to welcomethe 150 participants to this edition andcoming from institutions, members ofELRA.
To offer useful services to its membersmeant for ELRA to devote human
resources to the identification of usefulLRs and making them availablethrough its LRs catalogue. From a"centralised" archiving house, as wasinitially established, ELRAshifted itsoperations towards brokerage of LRswith strong focus on distribution andlicensing. This required, in addition tothe negotiation of distribution rightswith providers, the drafting of reliableand understandable licences and licen-sing schemas, ensuring that use (andre-use) of LRs is not hindered by legalbarriers. With the support of legalexperts, the ELRAteam acquired thenecessary legal knowledge to handlethe basic legal issues involved.
Over the 15 years of activities, morethan 1000 resources have been catalo-gued and made available, thanks toover 250 distribution agreements (withproviders from all over the world);ELRA distributed over 3500 resourcesfor HLT development (respectively48% for research purposes by acade-mia, 37% for Research and technologydevelopment by industry, and 16% forevaluation of technologies), not tomention an additional 1500 copies dis-tributed within evaluation campaigns.The availability of such resourceswithin easy, trustable, and fair legaland exchange frameworks boosted thedevelopment of Human LanguageTechnologies and the deployment ofapplications.
In addition to the over 1000 items avai-lable off the shelf from ELRAcata-logue, ELRA has also continued itswork on identifying existing LRs andcollected useful information on over1700 resources that constitute theELRA Universal Catalogue, an ante-chamber to the ELRAcatalogue andthe ancestor of the LREC Map.
A number of HLT evaluation campai-gns have been initiated, others havebeen strongly supported ensuring thatthe community get a clear picture ofthe state of the art but also ensuringthat all used resources are assembledafterwards and offered to the commu-nity as "Evaluation Packages", with allrequired datasets, tools, methodolo-gies, to conduct similar experiments.More than 20 technologies have beenevaluated with that contexts and over40 Packages are available within theELRA Catalogue. In order to ensurethat the community has access to all
available information on Evaluation initia-tives, ELRAhas set up a portal collectingand compiling all sorts of information rela-ted to evaluation with quick and easy refe-rence about protocols, metrics, tasks,resources, projects, campaigns, etc.(http://www.hlt-evaluation.org).
ELRA has also conducted the productionof LRs, either on its internal funds or com-missioned by partners. Many of these pro-ductions took place in the framework ofEuropean and international projects. So farELRA compiled LRs in more than 25 lan-guages, with processes that ensure highquality. Such LRs target different techno-logies. Some of the recent achievementscovered audio/speech data for a variety oflanguages (e.g. Hindi, Korean, ColloquialArabic(s), Canadian French, US Spanish,etc.), Broadcast News Speech Corpus forArabic, French, Spanish, etc. Corpora forlanguages such as Turkish, Romanian,Kazak, Catalan, etc. aligned textual corpo-ra for Machine Translation (several lan-guages), video annotations with audiotranscriptions, etc. etc.
Most of these resources are intended to bepart of the ELRACatalogue, even if, whencommissioned, all the rights includingownership remain with the commissioningparty.
Last but not least, ELRAcontinues itswork on providing useful forums for theHLT community to debate on currentsituations, new trends, and shared visionsfor the future. In addition to LREC, esta-blished as a major milestone within ourcommunity, ELRA continues to supportthe organization of the Langtech events(the European exhibition on languagetechnologies, previous one in Rome 2008,next one very likely in 2011), the organi-zation of what is now known as the"European Language Resources andTechnologies Forum" (held in the frame-work of the EC funded project FLaReNetin Vienna, 2009 and Barcelona, 2010), theorganization of specialized events(MEDAR conferences on Arabic langua-ge, workshops on Less-ResourcedLanguages (last one in Poznan, in conjunc-tion with LTC'09), etc. Such events allowthe community to gather and discuss thehot topics and ensure a useful stream ofinformation dissemination and awareness.
Now that many of the original core goalshave been achieved, others expanded, andmany activities are running smoothly,ELRA is moving to a new stage. After an

- 9 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
establishment and consolidation period,ELRA is now well equipped to tackle thenew challenges emerging from the newtrends within our community.
ELRA is reshaping its visions and mis-sions throughout a number of infrastructu-ral changes that will offer our communitynew services centred on LRs andEvaluation, taking into account new scena-rios of LRs "consumption behaviours",while keeping in mind the rationalesbehind its establishment.
The core activity centred on identificationof Language Resources, negotiation of dis-tribution rights and cataloguing such LRson our online catalogue will remain as ourbackbone. The modus operandi will stron-gly take into consideration new mecha-nisms of sharing and distributing LRs,combining all Web 2.0 features and inspi-ring both from "open source" principlesand professional Business-to-Businessapproaches.
Part of this vision will be driven by thestrong implication of ELRA, throughELDA, in some major European and inter-national initiatives. An international initia-tive is ongoing to secure the largest Globalcatalogue of LRs, partnering with LDC,NICT, and others. Others will be driven bya number of EC newly funded projects thathave just started e.g. META-NET andPANACEA to name the crucial ones;META-NET, a network of excellence that
will design "an open, integrated, secu-red and interoperable exchange facilityfor language data and tools for theHuman Language Technologiesdomain" called META-SHARE. Ourexpectations within META-SHARE isto make more resources sharablethrough open and integratedRepositories that share similar prin-ciples of community servicing andwhich would benefit from ELRA's 15years of expertise. The other importantproject, PANACEA, is addressingissues related to cost-effectiveness ofthe production of LRs and its automa-tion through adequate web-servicebased "factories".
Another reason to offer a forum for dis-cussion like LREC is to ensure thatneeds, trends, expectations, plans, part-nerships, co-operations can be discus-sed and brought one step forward.Given the number of initiatives, pro-jects, committees, that address some ofthe issues of paramount importance toour community, it is becoming essen-tial to harmonize and coordinate theactivities of international organiza-tions. I know that many of us share thisview and I would like to take thisopportunity to issue a public invitationto coordinate our efforts, through an"informal" umbrella organization, to allinterested organizations (ACL,COLING, IAMT, ISCA, EAFT, LDC,GSK, AFNLP, COCOSDA/ORIEN-
TAL-COCOSDA, etc.). LREC'2010 couldbe the right place to start such an initiative.
If you would like to learn more aboutELRA and ELDA, the ELRA/ELDAstaffis available during the conference. Youwill also find more information on our websites, at www.elra.info and www.elda.org.
On behalf of ELRAand ELDA, and onyour behalf, I would like to warmly thankthe local team in Malta as well as theMaltese advisory committee.
ELRA and the Organizing Committeehave made every effort to ensure the suc-cess of LREC 2010, making, both thescientific part and the social events fruitfuland enjoyable. Suggestions to improve anyaspects of the conference are welcome,and if you need any assistance to make ofthis event a more memorable one, pleasedo not hesitate to contact our staff, whowill be very pleased to help.
Once again, welcome to Malta, welcometo LREC 2010.
Khalid ChoukriELRA / ELDA55/57, rue Brillat Savarin75013 Paris, [email protected]
Dear LREC 2010 Participants,
On behalf of the Local AdvisoryCommittee, the Local OrganisingCommittee, and all the other participa-ting organisations I would first of alllike to express my profound gratitudeto His Distinguished Excellency Dr.George Abela, President of Malta, forso kindly agreeing to honour the LREC2010 by His Patronage and for his offerto assist with the training of a sign-lan-guage specialist. I also thank thePresident of the European Union, Mr.Herman Van Rompuy, for the supporthe has offered.
About ten years ago, the late AntonioZampolli had asked me if I would beinterested in exploring the possibility
of organising LREC 2002 in Malta. Iexplored for about ten seconds. "I am sorryAntonio", I said, "It's impossible. Therewould be no support for that kind of confe-rence over here. Come back in ten yearsand we'll see". With an answer like that Ithought I was pretty safe. But it was not tobe.
As Chairman of the Local OrganisingCommittee, I am now very proud to ack-nowledge the help we have received fromlocal organisations and individuals that hasmade this event possible. In particular, Iwould like to mention generous financialand material support that has been forthco-ming from the Ministry of Finance, theUniversity of Malta, the Malta TouristAuthority, and Air Malta.
In addition to these institutions there is along list of local individuals to whom we
Message from Mike Rosner, Chair of the Local Organizing Committee
Mike Rosner

- 10 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
are indebted for the hard work that has tur-ned LREC 2010 from an idea into the rea-lity that you now see unfurling before you.Let us hope it does not unravel complete-ly! I cannot mention them all, but I wouldlike to single out a few in particular: Prof.Juanito Camilleri, Rector of theUniversity, colleagues from the Faculty ofInformation and CommunicationTechnology, from my own Department ofIntelligent Computer Systems, and fromthe Institute of Linguistics; RosetteMicallef and her team, who run thismagnificent Mediterranean ConferenceCentre, Rachel Borg Cardona andAleksandra Radulovic, of Gollcher Travel,our local destination management compa-ny, Nadine Brincat, of the Malta TouristAuthority, Claudia Borg, my personalassistant throughout, who has had to facethe hot fires of disagreement coming from
all directions simultaneously on seve-ral occasions, and last but not least, thestudent volunteers who are assistingthroughout.
I am extremely pleased to have inaugu-rated a Local Advisory Committeewhose members reflect a broad crosssection of those having interests thatintersect with those of the LREC com-munity. It is my sincere hope that theactivities of this Committee will endu-re beyond the short week of thisConference and will help to establish apermanent home here for languageresources, particularly for the MalteseLanguage.
Of course, all this local support hasbeen received in the context of a trulyEuropean collaboration that has provi-ded us with constant guidance and
includes all the other members of theProgramme Committee, Khalid Choukri,Helene Mazo and ELRAstaff in Paris, andthe Pisa team headed by NicolettaCalzolari.
Let me conclude by welcoming you all toMalta. I sincerely hope you all enjoy yourvisit, and that the arrangements we havemade will serve to make LREC 2010 apleasant and memorable experience bothscientifically and socially.
Michael RosnerHead Department Intelligent ComputerSystemsUniversity of Malta Msida MSD 2080, [email protected]
LREC 2010 Antonio Zampolli Prize
J ust a few words about the Antonio Zampolli Prize, the prize created by the ELRABoard in order to honour our founder andfirst president who did so much for the field of language resources. Citing the prize articles: "The Antonio Zampolli Prize isintended to recognize the outstanding contributions to the advancement of Human Language Technologies through all issues
related to Language Resources and Evaluation. In awarding the prize we are seeking to reward and encourage innovation and inven-tiveness in the development and use of language resources and evaluation of HLTs". At the LREC2010 conference, the Prize willbe awarded for the fourth time. The ELRABoard has been very happy to receive nominations made by outstanding people in thefield, and we recognize there are several persons who are eligible for this prestigious prize.
The LREC2010 prize is awarded to a very important linguist. A linguist that has been involved and has been fighting with a rangeof research areas from phonology and phonetics to gestural, prosodic morphological and syntactic ways of marking focus and theiruse in discourse, to formal models of linguistic annotation, to information retrieval and information extraction from text. Recentlyhe has been working on the organization of spoken communication in the human brain, especially in relation to the evolutionarysubstrates for speech and language, and to analogous systems in other animals; he has also worked on agent-based models of lan-guage evolution and learning. His research is frequently conducted through computational analyses of linguistic corpora.Recognising the need for centres offering services around language data, he founded the first data centre. To terminate the agony,ladies and gentlemen please welcome this LREC's Antonio Zampolli Prize winner, Professor Mark Liberman.
Speech given at the Opening Ceremony by Stelios Piperidis
The presentation given by Mark Liberman, entitled
“The Future of Computational Linguistics: or, What Would Antonio Zampolli Do?”,
can be viewed from the LREC 2010 web site:www.lrec-conf.org/lrec2010
This year, the Antonio Zampolli Prize was awarded to:
Mark LibermanTrustee Professor of Phonetics in the Department of Linguistics and Professor in the Department of Computer
and Information Sciences, University of Pennsylvania.
From the Prize statutes:
“The Antonio Zampolli Prize is intended to recognize the outstanding contributions to the advancement ofHuman Language Technologies through all issues related to Language Resources and Evaluation.”

- 11 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
LREC 2010 Oral Session Summaries
O3 - Dialogue and EvaluationSophie Rosset____________________________________________________________________________________
The references given in the summaries all point to papers presented in each session. For the completereferences, we invite you to refer to the LREC 2010 Proceedings, which are available online:
http://www.lrec-conf.org/proceedings/lrec2010/index.html
T his session on "Dialogue andEvaluation" was very interesting andoffered a large panel of work
conducted in this domain. Speaking ofevaluation in the dialog systems field leadsto different points of view. One can consi-der evaluating specific modules of a dialogsystem or evaluating and predicting theuser satisfaction, or overall dialogue.
Gordon and Passonneau in their paper "AnEvaluation Framework for NaturalLanguage Understanding in SpokenDialogue Systems" describe experiments forevaluating different approaches for naturallanguage understanding in two different dia-log systems. Their proposed evaluation fra-mework addresses different questions suchas "is the NLU approach robust to recogni-zer error?" or "what is the maximum level ofnoise an NLU can robustly accommodate?"which are important questions when develo-ping NLU modules for spoken dialog sys-tem. The paper compares, given differentword error rates, the results obtained by twocompletely different approaches (CFG-based grammar and SVM-based classifiers)in two completely different domains. Theresults are discussed given the task difficul-ty and the word error rate.
User satisfaction is one of the most impor-tant metrics for measuring the performanceof spoken dialogue systems. Differentmethods have been proposed and most ofthem rely on objective features among them
the speech recognition accuracy. Hara,Kitaoka and Takeda in their paper"Estimation Method of User SatisfactionUsing N-gram-based Dialog HistoryModel for Spoken Dialog System" pro-pose to estimate user satisfactionthrough a N-gram model based on dialogacts sequences (user, system oruser+system). The best results concernthe simpler classification task (completeor incomplete task). It seems obviousthat the history context is useful even forthe more complex task that is the dia-logue classification between satisfactionlevel classes (5 levels).
The need to evaluate overall dialoguesand not only user satisfaction or speci-fic modules is considered more andmore important, specifically when thetask or the domain is not well defined.Two papers address this question. Thefirst one ("Dialogues in Context: AnObjective User-Oriented EvaluationApproach for Virtual HumanDialogue" by Robinson, Roque andTraum) proposes a descriptive codingscheme with as objective to allow qua-litative evaluations of the dialogue qua-lity itself, for example is the kind ofanswer, silence or utterance, appropria-te given the situation. What is interes-ting in this paper is that the evaluationframework allows dialogue evaluationfrom a dialogue perspective itself andnot from a system perspective.
"Evaluating Human-MachineConversation for Appropriateness"(Webb, Benyon, Hansen and Mival) isconcerned, as the previous one, by thenotion of appropriateness and propose touse this notion as a measure of conversa-tion quality. A coding scheme is proposedregarding the appropriateness of the sys-tem (7 classes) or user (5 classes) utte-rances. Using this scheme, the scoresoffer objective and subjective performan-ce measures which allow to show impro-vements over the different version of thesystems.
The work described in "Constructing theCODA Corpus: A Parallel Corpus ofMonologues and Expository Dialogues"by Stoyanchev and Piwek is slightly moredifferent and concern the notion of dia-logue itself as opposed to a monologue.The paper presents the construction of aparallel corpus of monologues and exposi-tory dialogues where the monologues areparaphrases of the dialogues. The dia-logues are annotated with dialogue actsand the monologues with rhetorical struc-tures. Guidelines and a tool for annotationand translation are presented.
Sophie RossetLIMSI-CNRSBP13391403 Orsay Cedex, [email protected]
O8 - Sign LanguageEleni Efthimiou __________________________________________________________________________________
cons and appropriately created and annota-ted corpora. Since SLs are natural lan-guages articulated in the 3D space, simulta-neously using multiple channels in order toexpress the linguistic message, SLcorporaare collections of video. SLvideo-corporacomprise the necessary resource, whichallows for the development of language
T here has been a tradition of success-ful Sign Language workshops (thisyear's workshop was the 4th of a
series) organised in the framework ofLREC, which indicate the steadily raisinginterest of the HLT community for SignLanguage. However, it was Session O8 ofLREC 2010, which introduced Sign
Language for the first time, among thesubjects covered within the main confe-rence. The session included 5 oral pre-sentations, which gave light to a numberof Sign Language (SL) related issues. Amajor aspect in Sign Language researchis the existence of language resourcesincluding vocabularies, electronic lexi-

- 12 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
enough place for discussion was given. Wenoticed during this session the increasingimportance of partially structured (multi-lingual) sources like Wikipedia.Advantages and problems of such a"monopolistic" approach to semi-structu-red sources have also been discussed.
O13 - OntologiesThierry Declerck __________________________________________________________________________________
Thierry DeclerckDFKI GmbHLanguage Technology LabStuhlsatzenhausweg 3D-66123 Saarbrücken, [email protected]
models of SLs. But the importance of SLcorpora becomes evident also in respect tothe development of the so-called SLTechnologies, from Sign LanguageRecognition and Generation to SignLanguage Machine Translation systems.
The Sign Language session provided theopportunity to a number of national andinternational research teams and a SLNetwork to present their work and highlightthe points of focus in their research.Discussion included reference to methodo-logies and practice in creation of SLcorpo-ra, annotation procedures and exploitationperspectives of annotated data, the state-of-the-art in SL technologies and how the
various SLTechnology oriented pro-jects address the currently open issuesof Sign Language Processing, SignLanguage Recognition, Sign LanguageGeneration and Sign Language MachineTranslation, but also various organisa-tional and policy issues relating to cor-pus maintenance practices, standards forannotation and metadata, informantconsensus protocols and IPR issues.
The list of presentations provided arepresentative picture of work done inEurope towards creation, maintenanceand standardisation of SLresources, aswell as development of SLtechnologies.Reference was made to the FP7 Sign-
Speak and DICTA-SIGN projects, thenational projects Creagest and SignCom,and the scope and objectives of the SignLinguistics Corpora Network (SLCN).Finally, the session brought to light thenecessity of provision for interpreting fromand into SL, in the case a public eventaddresses Deaf as well as hearing audience.
Eleni EfthemiouILSP/ R.C. "Athena"Epidavrou & Artemidos 6Marousi 151 25 Athens, [email protected]
T he session O13 on ontologies had afocus on the relation between naturallanguage and semantic resources.
How to combine them in applications, howto use one type of resource in order to enri-ch the other one? Those were broadly thetopics discussed by four presentations, in awell filled auditorium. The four paperswere:
Inducing Ontologies from Folksonomiesusing Natural Language Understanding,Marta Tatu and Dan Moldovan
WikiNet: A Very Large Scale Multi-LingualConcept Network, Vivi Nastase, Michael
Strube, Benjamin Boerschinger,Caecilia Zirn and Anas Elghafari
Cross-lingual Ontology Alignmentusing EuroWordNet and Wikipedia,Gosse Bouma
A Semi-supervised Type-basedClassification of Adjectives:Distinguishing Properties andRelations, Matthias Hartung andAnette Frank
All papers have been presented in agood setting, and all the speakers res-pected the time for presentation, so that
The EPAC Corpus: Manual and AutomaticAnnotations of Conversational Speech inFrench Broadcast News, Thierry Bazillon,Jean-Yves Antoine, Frédéric Béchet andJérôme Farinas
This paper presents the EPAC corpuswhich is composed by a set of 100 hours ofconversational speech manually transcri-bed and by the outputs of automatic tools(automatic segmentation, transcription,POS tagging, etc.) applied on the entireFrench ESTER 1 audio corpus: thisconcerns about 1700 hours of audio recor-dings from radiophonic shows. The EPACcorpus will be useful to researchers whowant to work on such data without havingto develop and deal with such tools. These
O23 - Broadcast NewsCarmen García-Mateo ______________________________________________________________________________
I n this session four papers were presen-ted. Each paper was presented by oneof the authors and get comments and
questions by the audience. The paperscover different languages and techniquesbut all of them try to cope with the pro-blem about how to get high-quality speechresources in the area of Broadcast News.Next, a reduced summary of each paper ispresented.
KALAKA: A TV Broadcast SpeechDatabase for the Evaluation of LanguageRecognition Systems, Luis JavierRodríguez-Fuentes, Mikel Penagarikano,Germán Bordel, Amparo Varona andMireia Díez.
The process of designing, collectingdata and building the training, develop-ment and evaluation datasets ofKALAKA is described. This speechdatabase was created to support theAlbayzin 2008 Evaluation of LanguageRecognition Systems, organized by theSpanish Network on SpeechTechnologies from May to November2008. This evaluation involved fourtarget languages: Basque, Catalan,Galician and Spanish (official lan-guages in Spain), and included speechsignals in other (unknown) languagesto allow open-set verification trials.Also, results attained in the Albayzin2008 LRE are presented as a means ofevaluating the database.

- 13 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
sis of DiSCo, a German corpus for the eva-luation of speech and speaker recognitionon challenging material from the broadcastdomain. One of the key requirements forthe design of this corpus was a good cove-rage of different types of programmesbeyond clean speech and planned speechbroadcast news. Corpus annotationencompasses manual segmentation, anorthographic transcription, and labellingwith speech mode, dialect, and noise type.Results from ASR, speech search, andspeaker recognition on the new corpus arealso presented.
automatic annotations are various: seg-mentation and speaker diarization, one-best hypotheses from the LIUM automaticspeech recognition system with confidencemeasures, but also word-lattices andconfusion networks, named entities, part-of-speech tags, chunks, etc.
Online Temporal Language ModelAdaptation for a Thai Broadcast NewsTranscription System, KwanchivaSaykham, Ananlada Chotimongkol andChai Wutiwiwatchai
This paper investigates the effectiveness ofonline temporal language model adapta-tion when applied to a Thai broadcast newstranscription task. The adaptation schemeworks as follows: first an initial languagemodel is trained with broadcast newstranscription available during the develop-
ment period. Then the language modelis adapted over time with more recentbroadcast news transcription and onli-ne news articles available duringdeployment especially the data fromthe same time period as the broadcastnews speech being recognized. It isfound that the data that are closer intime are more similar in terms of per-plexity and are more suitable for lan-guage model adaptation.
DiSCo - A German Evaluation Corpusfor Challenging Problems in theBroadcast Domain, Doris Baum,Daniel Schneider, Rolf Bardeli, JochenSchwenninger, Barbara Samlowski,Thomas Winkler and Joachim Köhler
This paper reports on the design,construction, and experimental analy-
•sharing multi-level annotated resourceswith emotion, sentiment and opinion anno-tations
•creating open-source tools/libraries:praat, openEAR, lexical resources
• finding measures for qualifying resources(stat & meta-data)
•using multiple corpora collected in diffe-rent contexts to train models, combine lin-guistic and paralinguistic information
•collecting multilingual and multiculturaldata
•building further benchmarks and evalua-tions: larger databases, real-life emotionaldata, challenge including emotion, senti-ment and opinion
One of the conclusions drawn from thisdiscussion was the proposal for a commonworkshop on Corpora for research onEmotion, Sentiment and Opinions atLREC 2012.
The Special session 025 "Emotion andSentiments" has consisted of the presenta-tion of 4 papers and of 20 minutes of dis-cussion at the end of the session. This spe-cial session has enclosed three sessionsdeclining in various nuances Emotionsfrom speech and Opinions and Sentimentsfrom text:
017 Opinion Mining and Emotions - PaoloRosso
021 Emotion, sentiment - Inma HernaezRioja
025 Emotion, sentiment - LaurenceDevillers
During these three sessions, the number ofpapers was balanced between both speechand text approaches.
•7 papers were related to Text: Resourcesfor opinion mining (news, movies, productreviews), Sentiment /opinion classifier(negative, positive, neutral).
•6 papers dealt with Speech (using alsosometimes the lexical content): Persuasivepower (political dialogs), Spotting proble-matic dialog situations, Integration ofemotional strategies into spoken dialoguemanagement, Cross-corpora study, Cross-cultural difference.
There are some obvious links betweenemotion, sentiment and opinion.
In opinion/sentiment mining, wordscan be ambiguous without an emotio-nal context analysis. For example:
"I am afraid in the dark" -> emotion
"I am afraid I don't understand whatyou have said" -> politeness
When it comes to emotion detection,sentiment and opinion analysis combi-ned with emotion detection is very use-ful in conversation analysis to detectfor example:
• the satisfaction of the customers(Voxfactory project (LIMSI)),
• the probability of the task being com-pleted (WITcHCRafT "a workbenchfor intelligent exploration of human-computer conversations").
The discussion of the special sessionfocused on the best practices for impro-ving research in emotion, sentimentand opinion, such as:
•sharing the annotations schemes andannotated data
O25 - Emotion, Sentiment - Special SessionLaurence Devillers ________________________________________________________________________________
Laurence DevillersLIMSI-CNRSBP13391403 Orsay Cedex, [email protected]
Carmen García MateoETSI TelecomunicacionUniversity of Vigo, CampusUniversitario 36310, Vigo, [email protected]

- 14 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
O39 - Information Extraction Martine Adda-Decker ______________________________________________________________________________
They use the text of the articles as a textualinformation source to annotate images, andimage captions as a ground truth to evalua-te their annotation algorithm. Their annota-tion method identifies relevant named enti-ties in the texts, and associates them withhigh-level visual concepts detected in theimages (in this paper, faces and logos).
The fourth paper was presented byFrancesca D'Errico about Types of Nods:the Polysemy of a Social Signal. Theauthors analyse the head nod, a down-upmovement of the head, as a polysemic-social signal, that is, a signal with a numberof different meanings which all share somecommon semantic element. Based on theanalysis of 100 nods drawn from theSSPNet corpus of TV political debates, atypology of nods is presented that distin-guishes Speaker's, Interlocutor's and ThirdListener's nods, with their subtypes (confir-mation, agreement, approval, submissionand permission, greeting and thanks, back-channel giving and backchannel request,emphasis, ironic agreement, literal and rhe-toric question, and others).
T he session on "MultimodalAnnotation" included 4 presentationscovering several burning issues of the
domain: standards for dialog act annotation,dialogue and their multimodal expression,annotation of combined text and image, andpolysemy / function of head nods.
The first paper by Harry Bunt et al. was pre-sented by David Traum: Towards an ISOStandard for Dialogue Act Annotation. Thispaper describes an ISO project which aimsat developing a standard for annotating spo-ken and multimodal dialogue with semanticinformation concerning the communicativefunctions of utterances, the kind of seman-tic content they address, and their relationswith what was said and done earlier in thedialogue. The proposed annotation schemadistinguishes 9 orthogonal dimensions,allowing each functional segment in dia-logue to have a function in each of thesedimensions, thus accounting for the multi-functionality that utterances in dialogueoften have. A number of core communicati-ve functions is defined in the form of ISOdata categories; they are divided into"dimension-specific" functions, which canbe used only in a particular dimension, suchas Turn Accept in the Turn Managementdimension, and "general-purpose" func-tions, which can be used in any dimension,such as Informant Request. An XML-basedannotation language, "DiAML" is defined.More information can be found at:http://semantic-annotation.uvt.nl/.
The second paper was presented byVolha Petukhova and aims at AnIntegrated Scheme for SemanticAnnotation of Multimodal DialogueData. It shares some research goals withthe first talk. The authors investigate theapplicability of existing dialogue actannotation schemes to the semanticannotation of multimodal data, and theway a dialogue act annotation schemecan be extended to cover dialogue phe-nomena from multiple modalities. Thegeneral conclusion of their explorativestudy is that a multidimensional dia-logue act taxonomy is usable for thispurpose when some adjustments aremade. They proposed a solution foradding these aspects to a dialogue actannotation scheme without changing itsset of communicative functions, in theform of qualifiers that can be attached tocommunicativefunction tags.
The third paper was presented by PierreTirrilly about News Image Annotationon a Large Parallel Text-Image Corpus.He presented a multimodal parallel text-image corpus, and proposed an imageannotation method that exploits the tex-tual information associated with images.Their corpus contains news articlescomposed of a text, images and imagecaptions, and is significantly larger thanthe other news corpora proposed inimage annotation papers (27,041articles and 42,568 captionned images).
Jean-Claude MartinLIMSI-CNRSBP13391403 Orsay Cedex, [email protected]
paper of D. Fišer addressed the problem ofDefinition learning, and the authors arguedin favor of starting with structuredresources (here Slovene Wikipedia corpus)to acquire knowledge, which can then beused for less structured data. The thirdpaper by Italian colleagues (S. Biggio etal.) reported on research on Entity MentionDetection EMD, which is an extension ofNamed Entity Detection, to nominal andpronominal mentions. The system wasapplied among others to annotate theItalian Wikipedia and has been evaluatedin the framework of the Italian Evalita2009. The work presented by colleagues
T he Session 039 on InformationExtraction, which took place thethird day in the morning, attracted a
relatively large audience (the room wasalmost filled at the beginning of the ses-sion). It was a very interesting sessionwith a nice mix of papers addressing bothgeneral and more specific issues: EventExtraction (R. Grishman), GeographicalRelation Extraction (A. Blessing et al.)Slovene Definition mining (D. Fi¨er et al.),Entity Mention Detection (S. Biggio etal.). A last paper dealt with English L2proficiency to evaluate Dutch-speakingusers on PubMed searches (K. Vanopstal et
al.). The focus of this paper was felt abit marginal with respect to the overallsession scope. The quality of the pre-sentations was globally very high.
The paper by R. Grishman aimed atstudying the influence of corpus andtask on event extraction systems (theirdesign and evaluation). The author dis-cussed major event extraction evalua-tions in English (ACE, MUC...) basedon various news sources. His claim isthat the characteristics of the corporaneed to be understood to better unders-tand the event extraction task. The
O31 - Multimodal AnnotationJean-Claude Martin ________________________________________________________________________________

- 15 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
Martine Adda-DeckerLIMSI-CNRSBP13391403 Orsay Cedex, [email protected]
from Stuttgart University aimed at enhan-cing context-aware systems by extractinggeographical relations on a fine-grainedlevel. The application made use of structu-red and unstructured data from the GermanWikipedia (German towns/ditrict loca-tions). The work by researchers from theFlemish Gent University addressed the
problem of information access in scien-tific English databases (PubMed) bynon-native English (Flemish nursingand midwifery students). The doubleproblem of language skills and scienti-fic competence was investigated acrosstwo test groups with different levels ofeducation.
LREC 2010 Poster Session Summaries
The references given in the summaries all point to papers presented in each session. For the completereferences, we invite you to refer to the LREC 2010 Proceedings which are available online:
http://www.lrec-conf.org/proceedings/lrec2010/index.html
P14 - Word Sense Disambiguation and EvaluationOlivier Ferret ____________________________________________________________________________________
other domains; the second one turns theACD into a lexical network and presentsan activation propagation procedure onthis network for performing WSD. A thirdarticle in this set, (Rakko & Constant),investigates a large set of linguistic fea-tures to determine their impact on WSDresults. Finally, only one article concernedthe application of WSD: (Laparra &Rigau) aim at connecting WordNet andFrameNet by disambiguating the LexicalUnits of the FrameNet's frames with thesynsets of WordNet as reference senses.
F rom a global viewpoint, work pre-sented at the Word SenseDisambiguation (WSD) and
Evaluation poster session can be classifiedinto three main categories. The first oneaccording to the number of its articlesconcerns the problem of building trainingand evaluation corpora for WSD, which isknown to be a difficult and expensive task.A classical way to reduce the cost of buil-ding an evaluation corpus in this field is touse the pseudo-word paradigm. This is theissue addressed by (Otrusina & Smrz) andScheible: the first one focuses on the use ofsemantic similarity measures to choosewords to conflate into pseudo-words forhaving the most possible realistic evalua-tion; the second one applies this paradigmto the evaluation of verb clustering. Thetwo other articles in this first category
were dedicated to the manual buildingof evaluation corpora: (Rehbein &Ruppenhofer) explores the use ofActive Learning for selecting the mostuseful new examples for a word sense,claiming that more data is not alwaysuseful if these data bring nothing new;(Görög and Vossen) focuses in its caseon bootstrapping techniques for anno-tating a large Dutch corpus for wordsenses. A second set of articles tackledmore directly the WSD issue.(Tsutsumida et al.) and (Okamoto &Ishizaki) both rely on the same resour-ce, the Associative Concept Dictionary(ACD), a dictionary of associations, forperforming WSD: the first one uses itfor enriching the context vectors asso-ciated to each word to disambiguate,which is a to favor the transposition to
Olivier FerretCEA - LISTCentre de Fontenay-aux-Roses18, rue du PanoramaBP6 - 92265 Fontenay aux RosesCedex - [email protected]
P27 - Evaluation of Speech Recognition and Speech Synthesis Olivier Galibert __________________________________________________________________________________
that the generated variants can beemployed to improve name recognition,and that the obtained accuracy is compa-rable to what is achieved with transcrip-tions made by a human expert. They alsoshow that the knowledge of the linguisticorigins of both the proper name and thespeaker are critical clues to obtain goodresults.
TTS evaluation campaign with a commonSpanish database by Sainz, Navas, Hernáez,
T he "Evaluation of SpeechRecognition and Speech Synthesis"session was comprised of a set of
three posters around the topic of speechrecognition, synthesis and spoken interac-tion.
Improving proper name recognition byadding automatically learned pronuncia-tion variants to the lexicon by Réveil,Martens and van den Heuvel, deals withthe task of large vocabulary proper name
recognition. In order to accommodate awide diversity of possible name pro-nunciations (due to non-native nameorigins or speaker tongues) a multilin-gual acoustic model is combined with alexicon comprising 3 grapheme-to-phoneme transcriptions built for 3 dif-ferent languages and 4 variant genera-tors (phoneme-to-phoneme transdu-cers) keyed on the speaker tongue andthe linguistic origin of the propername. The experimental results show

- 16 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
As a whole, the session presented comple-mentary studies on varied points of theinteraction loop. Proper name recognitionis essential for most interactive applica-tions, being primary designators of theobjects we want the system to manipulate.Speech intelligibility and naturalness is arequirement from the user to continue witha spontaneous interaction. And finally,evaluating in which cases a well-designedspeech interface can be more efficient thana remote control helps focus the researchon what will be considered useful.
Bonafonte and Campillo, describes the firstTTS evaluation campaign designed to com-pare approaches for Spanish synthesis.Seven research institutions took part in theevaluation campaign and developed a voicefrom a common speech database providedby the organisation. A common set of sen-tences were generated and some of the syn-thesised test audio files were subjectivelyevaluated via an online test according to thefollowing criteria: similarity to the originalvoice, naturalness and intelligibility. Whilethe results show that a considerable marginfor improvement still exists, twoapproaches obtain significantly betterresults, allowing to conclude that some kindof spectral control is needed when buildingvoices with a medium size database forunrestricted domains.
DICIT: Evaluation of a Distant-talkingSpeech Interface for Television by Sowa,
Arisio and Cristoforetti, presents anevaluation of the final prototype of avoice and remote-controlled manage-ment interface for an interactive TV.Voice, in that case, includes both natu-ral language and command-and-control-style speech input. The task-oriented evaluation involved naive testpersons and consisted of a subjectivepart with a usability questionnaire andan objective part covering speech com-ponent performance, interface designand user awareness, and finally task-based effectiveness and usability. Theevaluation revealed a quite positivesubjective assessment of the systemand reasonable objective results. Inaddition to pointing specific design-related issues, a usability advantage ofvoice over remote control has beenshown for certain types of tasks.
Olivier GalibertLaboratoire National de métrologie etd'Essais29 rue Roger Hennequin78190 Trappes, [email protected]
Opening Session with KhalidChoukri, Nicoletta Calzolari,
Joseph Mariani, Roberto Cencioni,Stelios Piperidis
Republic Hall

- 17 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
LREC 2010 Workshop Summaries
The references given in the summaries all point to papers presented in each session. For the completereferences, we invite you to refer to the LREC 2010 Proceedings which are available online:
http://www.lrec-conf.org/proceedings/lrec2010/index.html
Legal Issues for Sharing Language Resources: Constraints and Best PracticesValérie Mapelli ____________________________________________________________________________________
•Denise DiPersio (Linguistic DataConsortium - LDC, USA), "SomeImplications of US Initiatives for 'FairResearch' and Open Access on theDevelopment and Distribution ofLanguage Resources": She presented his-torical facts concerning recent US initia-tives with respect to legal questions lin-ked to the use of data for Research. Inparticular, she presented the legal frame-work of the latest Fair Research inCopyright Act and Federal ResearchPublic Access Act.
•Gilles Adda (LIMSI), "Languageresources and Amazon Mechanical Turk:legal, ethical and other issues": He pre-sented the legal and ethical questions thatcan be raised from a researcher's point ofview with respect to the production ofLanguage Resources through a crowd-sourcing system.
•Christina Bankhardt (Institut fürDeutsche Sprache, Germany),"Processing Language Resources on thebasis of the Consent - European point ofview": She elaborated on an IPR criterioncalled "Consent" and which is linked tothe processing of Language Resourcesthat include personal data.
At last, Khalid Choukri and Marc Kupietzlaunched a panel discussion with the invi-ted speakers.
T his half-day workshop took placeon Monday 17th May, 2010. Itaimed at enlightening the often
fuzzy knowledge around legal issues thathave to be dealt with at each step of theproduction and dissemination of aLanguage Resource. It also aimed at sho-wing new lines of work in that field, aswell as new possible cooperation topics.The workshop was a good opportunity forall interested parties to air their views andhave an open discussion.
The workshop was organised by KhalidChoukri (ELDA, France), DeniseDiPersio (Linguistic Data Consortium,USA), Marc Kupietz (Institut fürDeutsche Sprache, Germany) and ValérieMapelli (ELDA, France) and was suppor-ted by FLaReNet (Fostering LanguageResources Network - http://www.flare-net.eu).
Before introducing the workshop, KhalidChoukri first presented an overview ofthe vision of ELRAabout Legal Issueswith respect to Language Resourcesthroughout ELRA's 15 years of activity.
The workshop was divided into 3 parts,the first one being open to 3 invited talks,the second one to short talks and the lastone to a panel discussion on the subject.
• Isabelle Gavanon (FIDAL, working asELDA consultant, France) gave the firsttalk, entitled "Sharing Or Not Sharing?That Is the Legal Question". She focusedon the restrictions of the current legal sys-tem in particular in the French law vis-à-vis the specific field of LanguageResources, and showed the variety ofexisting licenses such as CreativeCommons or GNU...
•Erik Ketzan (Attorney at Law,USA)'s presentation, entitled"Translation licensing and copyrightissues under United States law",aimed to raise questions on authorright limitations with respect to theproduction/exchange/distribution ofautomatically translated works. Heparticularly focussed on the US "fairuse" and "implied license" practicesfor copyrighted works and the adapta-tion of this practice with respect toLanguage Technology. He also brieflyshowed the difference between USand European laws.
•Prodromos Tsiavos (The LondonSchool of Economics and PoliticalScience, United Kingdom) gave a talkentitled "Extracting value from openlicensing arrangements". This talkaimed at presenting the CreativeCommons licenses, showing thevarious questions that needed to bedealt with when creating the variousCreative Commons licensing models.
Then, four short talks were givenduring the second session:
•John Hendrik Weitzmann (EEAR -European Academy of Law andComputing, Germany), "Licensingand Sharing Language Resources: AnApproach Inspired by CreativeCommons and Open Science DataMovements": He introduced the legalwork being carried out within theMETA-SHARE project which aims atbecoming a universal exchange plat-form for Language Resources andLanguage Technology. He focussed onthe use and adaptation of the CreativeCommons license to this field of acti-vity.
Valérie MapelliELDA55-57 rue Brillat-Savarin75013 Paris, [email protected]
http://workshops.elda.org/lislr2010

- 18 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
Emotion 2010 - On Recent Corpora for Research on Emotion and AffectBjörn Schuller and Laurence Devillers ________________________________________________________________
non-restricted, natural in terms of emotion,though studio recorded, labelled in 15 classesor 4 dimensions by 4 annotators, contain 38speakers with more of them being femaleproducing 6h of speech that would result in3,6k instances. Yet, it would be proprietaryand not feature a defined partitioning.Overall, the obvious positive trends by thatare that more and more languages are cove-red; and more natural databases labelled inmore complex models seem to be expectableas available to the community. At the sametime, increasingly more multimodalresources are to be expected.
Finally, as an agreement of the concludingpanel session, further synergies from thepresently partly co-existing fields of emo-tion, opinion, and sentiment research areemerging. Follow-up initiatives could fur-ther help foster combined community effortsfor merging and common labelling ofresources and make such desperately neededlarger amounts of resources accessible.
T he 2010 International Workshop onEmotion - Corpora for Research onEmotion and Affect - organized by L.
Devillers, B. Schuller, R. Cowie, E. DouglasCowie and A. Batliner, was the third in aseries started in 2006 in association withLREC 2010. Its previous two workshopshave helped to consolidate the field, andthere generally now is growing experienceof not only building databases but also usingthem to build systems. By that, this work-shop aimed to continue the process, and laidemphasis on databases for practical usage.
In the 15 papers accepted for and presentedat the workshop, a total of 21 databases werepresented covering 7 languages (distributedover English (32%), French (26%), German(22%), Hebrew, Hungarian, Italian andRussian (5%, each)) and two non-speechsets. Considering the type of the spokencontent, in 24% of the corpora a fixed suchwas selected as opposed to 76% of the setsfeaturing non-constrained speech. The natureof the contained emotion was acted in only23%, induced in 32%, and natural in themajority of the sets at 45% clearly reflectingthe current preference of more realistic dis-play of emotion in resources. However, stu-dio recording still prevails looking at 87% ofthe sets discussed being recorded in such anenvironment and only 13% in real-life sur-roundings (call centre and medical operation
room). A prevailing problem also seemsto be the accessibility of data looking at47% being of proprietary nature, 24%available under a license, and 29% beingfreely available. Looking at the model ofemotion, the ratio was 3:2 in favour ofcategorical versus dimensional, wherebythe minimum of categories was 5, andthat of dimensions 2. In addition, a 3:1ratio was given for utilizing one of theseschemas exclusively versus using both.The trend behind these figures illustratesthe increasing popularity of dimensionalor more complex modelling. The accor-ding number of annotators in these setsvaried from only 1 (in 7% of the sets) to17 leading to a mean of 4 annotators (2and 3 to 6 in 37% of cases, each, andmore than 10 in 19% of the cases). At thesame time, the number of contained indi-viduals reached from 4 to 100, with atotal of 530 and a mean of 38, wherebythe female to male ratio was at 4:3. Interms of size, the recorded speech timevaried between 47 minutes and 22 hours,leading to a total of 69 hours and a meanof 6 hours per corpus resembling a mini-mum of 120 to 13,731 instances per setand 3,641 on average.
If one judged exclusively from thesedatabases, the 2010 average emotion cor-pus would be English spoken, verbally
Björn Schuller & Laurence DevillersLIMSI-CNRSBP13391403 Orsay Cedex, [email protected]
http://emotion-research.net/sigs/speech-sig/emotion-workshop
LR and HLT for Semitic LanguagesKhalid Choukri and Bente Maegaard __________________________________________________________________
http://workshops.elda.org/sl2010
the poster sessions to allow for more interac-tions and discussions.
The workshop presentations covered manyaspects of Arabic Language Processing(from low morphology levels to seman-tics/wordnet aspects), a few issues regardingAmharic (in particular a dependency gram-mar), Semitic verbal morphology, anapproach to a light morphology of Amazigh(though not a semitic language), an approa-ch to enrichment of the Named Entities inArabic WordNet, etc.
The first oral session focused on corpusaspects for Arabic including syntax and par-sing, semantics/Wordnet, etc. It also featureda paper on issues regarding Amharic (in par-
T he workshop aimed at addressing allissues related to language technologieshandling the Semitic language family.
The Semitic family includes languages anddialects spoken by a large number of nativespeakers (around 300 million). Prominentmembers of this family are Arabic (and itsvarieties), Hebrew, Amharic, Tigrinya,Aramaic, Maltese and Syriac. Their sharedancestry is apparent through pervasivecognate sharing, a rich and productive pat-tern-based morphology, and similar syntac-tic constructions. In addition, several lan-guages which are used in the same geogra-phic area such as Amazigh or Coptic, which,while not Semitic, have common featureswith Semitic languages, such as borrowedvocabulary.
The Workshop intended to follow ontopics of paramount importance forSemitic-languages NLPthat were dis-cussed at previous events (LREC,MEDAR/NEMLAR Conferences, theworkshops of the ACL Special InterestGroup for Semitic languages, etc.) andwhich are worth revisiting.
The workshop was organized as a one-day workshop consisting of two oral ses-sions, three poster sessions, and a generaldiscussion on a "Cooperation Roadmap",prepared within the MEDAR project, forbuilding a sustainable Human LanguageTechnologies for the Arabic languagewithin and outside the Arabic world. Alarge number of papers were assigned to

- 19 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
HLT - a short presentation was made - andother roadmaps were mentioned as well.
The discussion was structured along the fol-lowing themes: tools for reading support,fighting illiteracy through LT, teaching dia-lects (and focussing on dialects in LRT),standards, repositories for free resources,sharing and collaboration, evaluation, net-works for the field. An extensive report onthe discussion can be found at the MEDARwebsite www.medar.info.
ticular a dependency grammar). The secondone addressed issues related to MT, elabora-ting on approaches to create parallel and ali-gned corpora for MTas well as use of suchalignment tools to construct bilingual lexica.
The three poster sessions were customisedto address specific areas of NLP. The firstand second ones focused on topics related tobasic levels of language processing e.g.morphology, tagging, language annotation,and their use in applications (QA, searchtool, etc.). A paper elaborated on an approa-ch to enrich Wordnet using an ontology. Aninteresting paper addressed the use ofMechanical Turk to develop resources forArabic (a corpus of summaries in this case).A session was devoted to speech and relatedresources and described several collections
of Arabic dialects, e.g. Algerian,Maltese, etc.
Two papers focused on Amazighe lan-guage spoken in Morocco and the adap-tation of existing annotation and taggingtools from semitic languages.
The General Discussion aimed at descri-bing the MEDAR proposal for aCooperation Roadmap for building sus-tainable Human Language Technologiesfor the Arabic language within and outsi-de the Arabic world. The purpose of thediscussion was to determine some of thecommon interests among the participantswhich could serve as a basis for futurecollaboration. MEDAR has suggested acooperation roadmap for Arabic LR and
Bente MaegaardCentre for Language TechnologyUniversity of CopenhagenNjalsgade 802300 Copenhagen S, [email protected]
LREC 2010 Conference Survey Report
Finally, more or less half of the respon-dents found that the main conference pro-gramme was well-balanced as opposed tonearly one third who considered the pro-gramme as too heavy.
For this edition, 3 new initiatives havebeen introduced and the survey was ques-tioning the participants on those initiatives.
The LREC Map, the new mechanism formonitoring the use and creation of langua-ge resources, was found useful by 53% ofthe respondents and they were almost 60%to assess that they were ready to enter suchinformation in the LREC Map in the futu-re. The implementation of the Map in otherconferences was approved by nearly 50%of the respondents.
For the EC-Village as well as the SpecialSessions, there was a majority of "No ans-wer" whether "no opinion" or "did notattend" which made difficult to draw clearconclusions. Those respondents whoactually answered considered that the ECVillage was a "good idea" and that this ini-tiative could become a global (rather thanEuropean) HLT projects village in futureeditions. Those who attended the SpecialSessions found them interesting.
Many respondents wrote personalizedcomments, some very detailed, most ofthem reflecting positive spirits, congratu-lating the organizers for the work done andtheir dedication. These responses are veryuseful as they are more specific than thesurvey questions and often convey interes-ting suggestions.
F ollowing each edition of theConference, ELRAconducts anonline survey of LREC participants.
ELRA uses responses from that survey toimprove the overall organization of theevent and to address the concerns andneeds of LREC participants.
This year's survey received 302 respon-dents (over 1246 registered participants) asopposed to 202 in 2008. The surveycontained 13 questions related to theConference Organization and theConference Content.
The first part of the survey covered thevarious aspects of the conference organiza-tion. The overall results show that a greatmajority of respondents were satisfied orvery satisfied by the conference organiza-tion. The online registration is acknowled-ged as a "good" (52%) even "excellent"(33%) process and the on-site registrationprocess' score is even higher. The confe-rence web site with a 15% "fair" opinionrate has certainly suffered from the latepublishing of the conference programmewhich, according to some participants,have triggered practical issues in their per-sonal organization. Finally, the conferencesupport staff has carried the day with a90% "good" and "excellent" opinion score.A number of very nice comments on theorganization have also been expressed,stressing the smooth sequence of the ses-sions and within the sessions.
The second part of the survey dealt withthe content and structure of the conference.
Here again, the impression given bythe overall results confirm the satisfac-tion of most participants. LRECremains the place where the HLT com-munity can gather, allowing contactsnetworking, meetings and discussions.Nevertheless, if the quality of theLREC 2010 programme is generallyacknowledged by the respondents(nearly 70% state that the papers mettheir expectations), comments showthat there is still room for improvingeach paper's quality and the overallquality of the programme by reaching ahomogeneous level for all acceptedpapers.
This year, for the second time, PosterSessions have been organized in paral-lel with Oral Sessions. From therespondents' point of view, it seemsthat this structure should be kept "as is"for future editions. The current LRECformat which was also questioned inthe survey appears to be also the pre-ferred one (51%): that is maintainingthe satellite workshops and tutorials (2days) before and after the main confe-rence (3 days). From a content perspec-tive, some respondents have foundoverlaps in topics between the confe-rence and workshops and are callingfor a better selection/distribution of thetopics. Other suggested that "workshophopping" is proposed by implementinga new feeing system that would allowparticipants to switch between differentworkshops instead of registering toindividual events.

- 20 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
NEW RESOURCES
Monolingual Lexicons from the general domain
ELRA-L0086 Persian Multext-East framework lexiconThis is a Persian (Farsi) morphosyntactic lexicon derived from the Persian 1984 corpus (Multext-East framework) (see ELRA-W0054). It contains the full inflectional paradigms of a superset of lemmas that appear in the Persian 1984 corpus. Each entry givesthe word-form, its lemma and morphosyntactic description. The lexicon contains 13,247 entries.
ELRA members Non-membersFor research use 45 Euro 45 EuroFor commercial use 500 Euro 2,000 Euro
ELRA-L0087 Persian lexiconThis is a Persian (Farsi) lexicon of more than 40,000 entries of non-inflected forms of words. Each word is transliterated based onthe proposed framework from MBROLA(Text-To-Speech synthesizer). The database includes a large variety of descriptors for eachentry (plural, homograph, ...).This lexicon has been made out from a corpus of newspaper publications collected during a period of six months from the SharghNewspaper, a publication containing articles from diverse topics: art, culture, policy, social, sport, etc. Due to its coverage, this lexi-con can be in particular interesting for Persian TTS systems, as the pronunciation of Persian words cannot be derived directly fromtheir transcription due to the omission of short vowels in Persian writing systems.The number of records is distributed as follows: 11,955 adjectives, 2,047 adverbs, 164 classifiers, 129 conjunctions, 85 indexes,36,651 names, 88 numbers, 455 verbs with past stem, 435 verbs with present stem, 223 prepositions, 141 pronouns, 352 semi-sen-tences.The lexicon is provided in a MS Access database.
ELRA members Non-membersFor research use 500 Euro 700 EuroFor commercial use 5,000 Euro 7,000 Euro
Written Corpora from the general and specific domains
ELRA-W0053 Catalan-Spanish Parallel CorpusThis corpus contains more than 100 million words and it contains 10 years of bilingual articles from “El Periódico de Catalunya”.Both language data are rather close as the Catalan text is a translation of the Spanish one, partly achieved by means of Machinetranslation and then post-edited.The data are aligned at sentence level and stored in textfiles, in a one sentence per line basis. The data are pro-vided in plain text, with no encoding whatsoever.
ELRA members Non-membersFor research use 2,000 Euro 3,000 EuroFor commercial use 20,000 Euro 24,000 Euro
ELRA-W0054 Persian 1984 corpus (Multext-East framework)This corpus contains the Persian (Farsi) translation of a part of the novel “1984” (G. Orwell) annotated in the Multext-East frame-work (Multilingual Text Tools and Corpora for Eastern and Central European Languages). The aim of the Multext-East project wasto develop standardized language resources.The package comprises:(i) the specifications for morphosyntactic encoding of Persian Language, based on the EAGLES/MULTEXT model and specificresources of MULTEXT-East,(ii) the annotated Persian version of Orwell’s 1984 corpus.The corpus contains extensive headers and markup for document structure, sentences, and various sub-sentence annotations in theXML-format following the TEI guidelines. Annotation includes POS (part-of-speech) and lemmas. The corpus contains approxi-mately 100,000 words (6,604 sentences, 13,247 lem-mas) and can easily be aligned with other corpora in theMULTEXT-East framework.
ELRA members Non-membersFor research use 45 Euro 100 EuroFor commercial use 2,000 Euro 5,000 Euro

- 21 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
ELRA-T0374 Terminology database of natural sciencesThis dictionary covers the three kingdoms: Animal, Vegetal, Mineral. It contains 50,000 species with numerous synonyms in French,English and Latin and many breeds and varieties. Minerals are given with their chemical formula. About 7,900 definitions in French areincluded.This dictionary gathers many disciplines and topics such as: Mammals, Fishes, Birds, Insects, Reptiles, Shellfishes, Trees, Plants,Flowers, Fruits, Vegetables, Minerals, Rocks, Gems, etc. It also includes synonyms and linguistic variants.Languages : French - English (GB, US) - LatinNumber of entries: 133,500Number of terms per language: between -20% and -25% approx. with respect to the number of entries (i.e. ca. 50,000 terms)Disciplines: about 105Format: .DBF files, sorted alphabetically in French and EnglishA viewer is also available upon demand for an additional cost of 2676 euros. This software enables a spontaneous search French =>English and English => French in the database according to different criteria:- by beginning of term,- by included word,- by discipline,- by class,- by kingdom,- through a free search: French, English, Latin words and synonyms in the 3 languages, chemical formula, i.e. 435,000 access points. Foreach term obtained, the database corpus is instantly displayed with the total of terminological data available for that term.Viewing format: .FIC (Windev)Please note that the prices indicated here are dependent from the number of entries available which is growing constantly. Please contactus for further details.
ELRA members Non-membersFor research use 53,400Euro 66,750 EuroFor commercial use 66,750 Euro 80,100 Euro
Terminology Resource in Natural Sciences
ELRA-S0307 BABEL Polish databaseThe BABELPolish Database is a speech database that was produced by a research consortium funded by the European Union under theCOPERNICUS programme (COPERNICUS Project 1304). The project began in March 1995 and was completed in December 1998.The objective was to create a database of languages of Central and Eastern Europe in parallel to the EUROM1 databases produced bythe SAM Project (funded by the ESPRITprogramme).The BABELconsortium included six partners from Central and Eastern Europe (who had the major responsibility of planning and car-rying out the recording and labelling) and six from Western Europe (whose role was mainly to advise and in some cases to act as host toBABEL researchers). The five databases collected within the project concern the Bulgarian, Estonian, Hungarian, Polish, and Romanianlanguages.The Polish database consists of the basic "common" set which is:• The Many Talker Set: 30 males, 30 females; each to read 100 numbers, 3 connected passages and 5 “filler” sentences (or 4 passages ifno fillers needed).• The Few Talker Set: 5 males, 5 females, normally selected from the above group: each to read 5 blocks of 100 numbers, 15 passagesand 25 filler sentences ( or 20 passages if fillers not needed), and 5 lists of syllables.• The Very Few Talker Set: 1 male, 1 female, selected from many-talker set: 5 blocks of syllables, with and without carrier sentences.
Desktop/Microphone Resources
ELRA members Non-membersFor research use 300Euro 600 EuroFor commercial use 4,000 Euro 6,000 Euro

- 22 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
ELRA-S0308 Egyptian Arabic Speecon databaseThe Egyptian Arabic Speecon database is divided into 2 sets:1) The first set comprises the recordings of 550 adult Egyptian speakers of Modern Standard Arabic as spoken in Egypt (273 males, 277females), recorded over 4 microphone channels in 4 recording environments (office, entertainment, car, public place).2) The second set comprises the recordings of 50 child Egyptian speakers of Modern Standard Arabic as spoken in Egypt (24 boys, 26girls), recorded over 4 microphone channels in 1 recording environment (children room).This database is partitioned into 25 DVDs (first set) and 4 DVDs (second set).The speech databases made within the Speecon project were validated by SPEX, the Netherlands, to assess their compliance with theSpeecon format and content specifications. Each of the four speech channels is recorded at 16 kHz, 16 bit, uncompressed unsigned inte-gers in Intel format (lo-hi byte order). To each signal file corresponds an ASCII SAM label file which contains the relevant descriptiveinformation.Each speaker uttered the following items (over 290 items for adults and over 210 items for children):
The following age distribution has been obtained:Adults: 290 speakers are between 15 and 30, 166 speakers are between 31 and 45, 94 speakers are over 46.Children: 24 speakers are between 8 and 10, and 26 speakers are between 11 and 14.A pronunciation lexicon with a phonemic transcription in SAMPA is also included.
Broadcast Resource
ELRA members Non-membersFor research use 300Euro 600 EuroFor commercial use 4,000 Euro 6,000 Euro
Calibration data:•6 noise recordings•The “silence word” recordingFree spontaneous items (adults only):5 minutes (session time) of free spontaneous, rich context items(story telling) (an open number of spontaneous topics out of a setof 30 topics)17 Elicited spontaneous items (adults only):3 dates, 2 times, 3 proper names, 2 city names, 1 letter sequence, 2answers to questions, 3 telephone numbers, 1 languageRead speech:•30 phonetically rich sentences uttered by adults and 60 uttered bychildren•5 phonetically rich words (adults only)•4 isolated digits•1 isolated digit sequence
•4 connected digit sequences•1 telephone number•3 natural numbers•1 money amount•2 time phrases (T1 : analogue, T2 : digital)•3 dates (D1 : analogue, D2 : relative and general date, D3 : digital)•3 letter sequences•1 proper name•2 city or street names•2 questions•2 special keyboard characters•1 Web address•1 email address•204 application specific words and phrases per session (adults)•74 toy commands, 14 phone commands and 34 general com-mands (children)
Evaluation Packages from CLEF
ELRA-E0036 CLEF AdHoc-News Test Suites (2004-2008) – Evaluation PackageThe Cross-Language Evaluation Forum (CLEF) promotes R&D in multilingual information access (MLIA) by (i) developing an infra-structure for the testing, tuning and evaluation of information retrieval systems operating on European languages in both monolingualand cross-language contexts, and (ii) creating test-suites of reusable data which can be employed by system developers for benchmar-king purposes.The CLEF AdHoc-News Test Suites (2004-2008) contain the data used for the main AdHoc track of the CLEF campaigns carried outfrom 2004 to 2008. This track tested the performance of monolingual, bilingual and multilingual Information Retrieval (IR) systems onmultilingual news collections.The CLEF Test Suite is composed of:•News Data Collections•Topics•Guidelines•Relevance assessments•Official campaign results•Working notes papers

- 23 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
For evaluation use ELRA members Non-membersBy an academic org. 150Euro 300 EuroBy a commercial org. 500Euro 1,000 Euro
The News Data Collections consist of the following datasets:
The full package consists of 2.43 Gb and is stored on 1 DVD.
•Bulgarian- Sega 2002 (33,356 documents, 120 Mb)- Standart 2002 (35,839 documents, 93 Mb)
•Czech- Mladna frontaDnes (68,842 documents, 143 Mb)- Lidove Noviny (12,893 documents, 35 Mb)
•Dutch- NRC Handelsblad 1994/95 (84,121 documents, 299 Mb)- Algemeen Dagblad 1994/95 (106,483 documents, 241 Mb)
•English- Glasgow Herald 1995 (56,472 documents, 154 Mb)- Los Angeles Times 1994 (113,005 documents, 425 Mb)- Los Angeles Times 2002 (135,153 documents, 434 Mb)
•Finnish- Aamulehti late-1994/95 (55,344 documents, 137 Mb)
•French- Le Monde 1994 (44,013 documents, 157 Mb)- Le Monde 1995 (47,646 documents, 156 Mb)- SDAFrench 1994 (43,178 documents, 86 Mb)- SDAFrench 1995 (42,615 documents, 88 Mb)
•German- Frankfurter Rundschau 1994 (139,715 documents, 320 Mb)- Der Spiegel 1994/95 (13,979 documents, 63 Mb)
- SDAGerman 1994 (71,677 documents, 144 Mb)- SDAGerman 1995 (69,438 documents, 141 Mb)
•Hungarian- Magyar Hirlap 2002 (49,530 documents, 105 Mb)
• Italian- La Stampa 1994 (58,051 documents, 193 Mb)- SDAItalian 1994 (50,527 documents, 85 Mb)- SDAItalian 1995 (48,980 documents, 85 Mb)
•Persian- Hamshahri 1996-2002 (166,774 documents, 611 Mb)
•Portuguese- Público 1994 (51,751 documents, 164 Mb)- Público 1995 (55,070 documents, 176 Mb)- Folha de São Paulo 1994 (51,875 documents, 108 Mb)- Folha de São Paulo 1995 (52,038 documents, 116 Mb)
•Russian- Izvestia 1995 (16,716 documents, 68 Mb)
•Spanish- EFE 1994 (215,738 documents, 509 Mb)- EFE 1995 (238,307 documents, 577 Mb)
•Swedish- Tidningarnas Telegrambyrå 1994/95 (142,819 documents,352 Mb)
ELRA-E0037 CLEF Domain Specific Test Suites (2004-2008) – Evaluation PackageThe Cross-Language Evaluation Forum (CLEF) promotes R&D in multilingual information access (MLIA) by (i) developing an infra-structure for the testing, tuning and evaluation of information retrieval systems operating on European languages in both monolingualand cross-language contexts, and (ii) creating test-suites of reusable data which can be employed by system developers for benchmar-king purposes.The CLEF Domain SpecificTest Suites (2004-2008) contain the data used for the Domain Specific track of the CLEF campaigns carriedout from 2004 to 2008. This track tested the performance of monolingual, bilingual and multilingual Information Retrieval (IR) systemson multilingual collections of scientific articles.The CLEF Test Suite is composed of:•Data Collections•Topics•Guidelines•Relevance assessments•Official campaign results•Working notes papersThe Data Collections consist of the following datasets:•German Indexing and Retrieval Test database (302,638 documents, 524 Mb):Data collection (social sciences) including a German corpus (151,319 documents) and a pseudo-English corpus which is in fact a trans-lation of the German corpus into English (does not contain as much textual information as the German version).•Cambridge Scientific Abstracts - Sociological Abstracts (20,000 documents, 38.5 Mb):Database of Sociological Abstracts from Cambridge Scientific Abstracts.
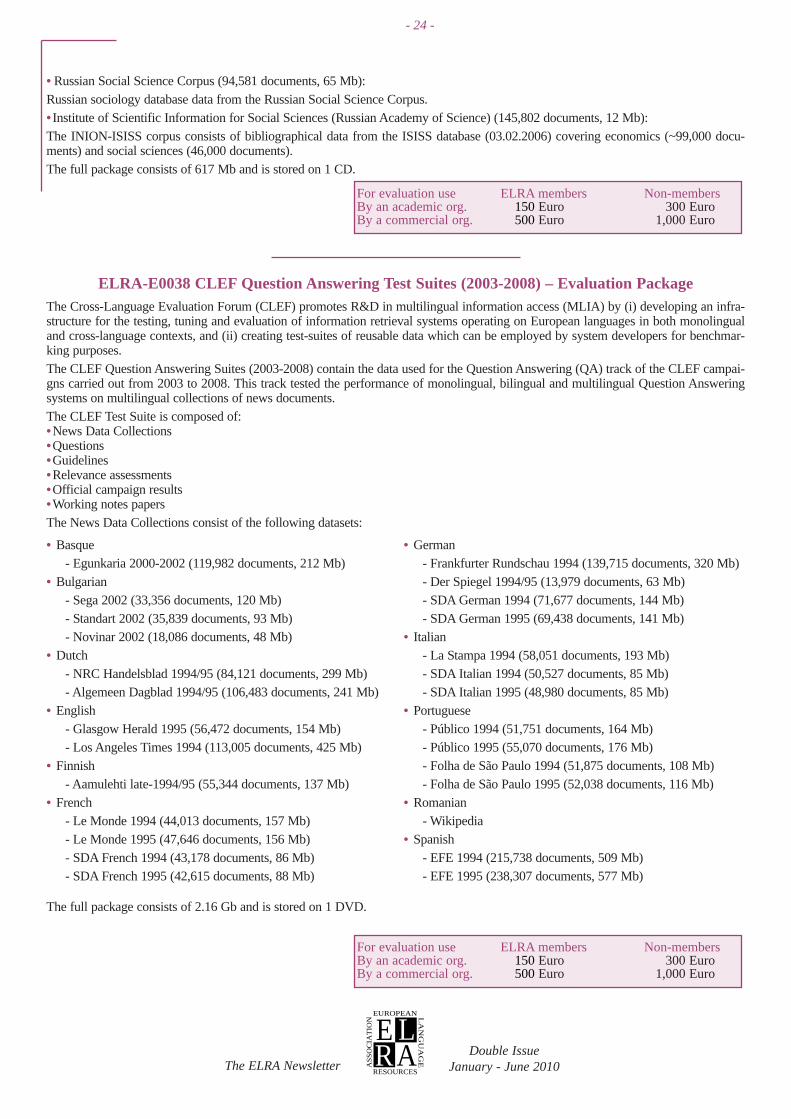
- 24 -
AELR
EUROPEAN
RESOURCES
LA
NG
UA
GE
AS
SO
CIA
TIO
N
The ELRANewsletterDouble Issue
January - June 2010
•Russian Social Science Corpus (94,581 documents, 65 Mb):Russian sociology database data from the Russian Social Science Corpus.•Institute of Scientific Information for Social Sciences (Russian Academy of Science) (145,802 documents, 12 Mb):The INION-ISISS corpus consists of bibliographical data from the ISISS database (03.02.2006) covering economics (~99,000 docu-ments) and social sciences (46,000 documents).The full package consists of 617 Mb and is stored on 1 CD.
For evaluation use ELRA members Non-membersBy an academic org. 150Euro 300 EuroBy a commercial org. 500Euro 1,000 Euro
ELRA-E0038 CLEF Question Answering Test Suites (2003-2008) – Evaluation PackageThe Cross-Language Evaluation Forum (CLEF) promotes R&D in multilingual information access (MLIA) by (i) developing an infra-structure for the testing, tuning and evaluation of information retrieval systems operating on European languages in both monolingualand cross-language contexts, and (ii) creating test-suites of reusable data which can be employed by system developers for benchmar-king purposes.The CLEF Question Answering Suites (2003-2008) contain the data used for the Question Answering (QA) track of the CLEF campai-gns carried out from 2003 to 2008. This track tested the performance of monolingual, bilingual and multilingual Question Answeringsystems on multilingual collections of news documents.The CLEF Test Suite is composed of:•News Data Collections•Questions•Guidelines•Relevance assessments•Official campaign results•Working notes papersThe News Data Collections consist of the following datasets:
The full package consists of 2.16 Gb and is stored on 1 DVD.
• Basque- Egunkaria 2000-2002 (119,982 documents, 212 Mb)
• Bulgarian- Sega 2002 (33,356 documents, 120 Mb)- Standart 2002 (35,839 documents, 93 Mb)- Novinar 2002 (18,086 documents, 48 Mb)
• Dutch- NRC Handelsblad 1994/95 (84,121 documents, 299 Mb)- Algemeen Dagblad 1994/95 (106,483 documents, 241 Mb)
• English- Glasgow Herald 1995 (56,472 documents, 154 Mb)- Los Angeles Times 1994 (113,005 documents, 425 Mb)
• Finnish- Aamulehti late-1994/95 (55,344 documents, 137 Mb)
• French- Le Monde 1994 (44,013 documents, 157 Mb)- Le Monde 1995 (47,646 documents, 156 Mb)- SDAFrench 1994 (43,178 documents, 86 Mb)- SDAFrench 1995 (42,615 documents, 88 Mb)
• German- Frankfurter Rundschau 1994 (139,715 documents, 320 Mb)- Der Spiegel 1994/95 (13,979 documents, 63 Mb)- SDAGerman 1994 (71,677 documents, 144 Mb)- SDAGerman 1995 (69,438 documents, 141 Mb)
• Italian- La Stampa 1994 (58,051 documents, 193 Mb)- SDAItalian 1994 (50,527 documents, 85 Mb)- SDAItalian 1995 (48,980 documents, 85 Mb)
• Portuguese- Público 1994 (51,751 documents, 164 Mb)- Público 1995 (55,070 documents, 176 Mb)- Folha de São Paulo 1994 (51,875 documents, 108 Mb)- Folha de São Paulo 1995 (52,038 documents, 116 Mb)
• Romanian- Wikipedia
• Spanish- EFE 1994 (215,738 documents, 509 Mb)- EFE 1995 (238,307 documents, 577 Mb)
For evaluation use ELRA members Non-membersBy an academic org. 150Euro 300 EuroBy a commercial org. 500Euro 1,000 Euro