estimação e previsão de volatilidade em períodos de crise ...£o 2010.pdf · conseqüente...
TRANSCRIPT

Estimação e Previsão de Volatilidade em Períodos de Crise:
Modelos Aditivos Semi-Paramétricos Versus Modelos GARCH
Douglas Gomes dos Santos*
Flávio Augusto Ziegelmann**
Abstract
In this paper, we compare additive and GARCH models in terms of their capability to estimate and
forecast volatility during crisis periods. Comparisons are made through Monte Carlo studies. Our
results indicate a better performance for GARCH models when their functional forms do not differ
from that of the specified Data Generating Process (DGP). However, if they differ from the DGP,
the results suggest the superiority of additive models. Additionally, we perform an empirical
application in three selected periods of high volatility of Ibovespa returns series. Given two
forecast evaluation statistics, one suggests the equivalence of the models and the other indicates a
superior performance for a GARCH model.
Keywords: Volatility, Additive Models, GARCH Models, Crisis.
JEL Classification: C14; C22; C52; C53.
1. Introdução
Em razão da relevância de temas como risco e incerteza na teoria
econômica moderna, métodos capazes de modelar uma variância condicional que
evolui ao longo do tempo têm sido propostos na literatura. Neste contexto, o
* Programa de Pós-Graduação em Economia (UFRGS). Endereço: Av. João Pessoa, 52, 3º andar, 90040-000, Porto Alegre – RS – Brasil. E-mail: [email protected] ** Departamento de Estatística e Programa de Pós-Graduação em Economia (UFRGS).

2
modelo ARCH (Autoregressive Conditional Heteroskedastic) de Engle (1982) e
as extensões da família GARCH destacam-se por sua ampla utilização. Inúmeros
trabalhos envolvendo os modelos GARCH aparecem na literatura nas últimas
décadas, levando a diversas inovações nos mesmos. Estas inovações visam, em
sua maioria, a descrever de forma mais apropriada as regularidades empíricas
observadas em séries de tempo financeiras. Para revisões abrangentes, ver
Bollerslev (2008), Bollerslev, Chou e Kroner (1992), Bollerslev, Engle e Nelson
(1994), Rydberg (2000), entre outros.
Em contraste aos modelos GARCH paramétricos, a principal motivação
para a modelagem não paramétrica surge quando não se possui conhecimento
suficiente sobre o processo gerador explicativo, permitindo desta forma que os
dados “falem por si mesmos” (para revisões sobre estes métodos, ver Fan e
Gijbels (1996), Fan e Yao (2003), Wand e Jones (1995), entre outros). Assim,
parte-se para a análise dos dados supondo-se modelos menos rígidos. De acordo
com Ziegelmann (2002a), a única condição que deve ser especificada para os
estimadores não paramétricos está relacionada à definição de um certo grau de
suavidade para as funções a serem estimadas. Pode-se dizer que a principal
vantagem dos modelos não paramétricos está relacionada a sua flexibilidade e à
conseqüente diminuição do risco de errar na especificação do modelo. Contudo,
os custos desta maior flexibilidade se apresentam em taxas de convergência mais
lentas, perda do poder de extrapolação e a dificuldade de estimação em alta
dimensionalidade (curse of dimensionality).
Sob o enfoque multivariado, onde há a presença de mais de uma variável
defasada na regressão, o modelo saturado (ou totalmente não paramétrico)

3
destaca-se como a opção mais flexível na redução do viés de especificação.
Todavia, ressalta-se que problemas de estimação relacionados a espaços de alta
dimensão são freqüentes (curse of dimensionality). Este leva à perda da noção de
vizinhança local, essencial em modelagem não paramétrica, o que abre espaço
para o uso de modelos semi-paramétricos. Os últimos, por sua vez, impõem algum
tipo de restrição nas funções a serem estimadas. Por essa razão, são mais rígidos
que o modelo não paramétrico saturado, mas substancialmente mais flexíveis que
os paramétricos. Discussões abrangentes sobre modelos semi-paramétricos podem
ser encontradas em Fan e Yao (2003), Gao (2007), Hastie e Tibshirani (1990),
Horowitz (1998), entre outros.
O modelo aditivo semi-paramétrico, amplamente discutido em Hastie e
Tibshirani (1990), é uma alternativa ao problema da alta dimensionalidade. Neste,
a idéia é modelar aditivamente funções univariadas, o que claramente é ainda
menos restritivo do que assumir o pressuposto da linearidade definido no modelo
de regressão linear. A motivação principal do modelo aditivo é permitir que
componentes do modelo de regressão assumam formas não pré-determinadas e
possivelmente não lineares. Estes superam o problema em espaços de alta
dimensão devido ao método de estimação ser construído a partir de suavizadores
univariados. Nota-se ainda que as suposições sobre o erro do modelo são
substancialmente relaxadas.
Existe uma vasta literatura que abrange o uso de modelos de volatilidade
em geral e a comparação entre eles. Com relação aos modelos GARCH, ver como
exemplo Ederington e Guan (2005), Hansen e Lunde (2005), e uma gama de
estudos avaliados em Poon e Granger (2003). Já Carroll, Härdle e Mammen

4
(2002), Kim e Linton (2004), Levine e Li (2007) e Linton e Mammen (2005) são
algumas das referências que utilizam os modelos aditivos (ou suas versões
generalizadas) em estimação de volatilidade.
Objetiva-se comparar neste artigo os modelos aditivos e os modelos
GARCH quanto à capacidade de estimar e prever a volatilidade de retornos em
períodos de crise. Os momentos de turbulência no mercado financeiro podem
oferecer um bom indicativo do potencial dos modelos aditivos, em relação aos
modelos da classe GARCH, na medida em que ajudem a exacerbar as fraquezas
ou virtudes dos modelos confrontados. As comparações baseiam-se em um estudo
de Monte Carlo e em um estudo empírico.
Nas simulações de Monte Carlo, são especificados dois processos
geradores de dados (PGD) distintos, com duas distribuições para os erros em cada
um. Ainda, seis modelos têm suas estimativas e previsões comparadas em
momentos selecionados de alta volatilidade nos diferentes cenários. Na aplicação
empírica, utiliza-se uma série de retornos diários do Ibovespa. As comparações
entre os modelos ocorrem em três períodos de crise definidos para a série.
Em ambos os estudos, duas medidas de erro são utilizadas para avaliar o
desempenho dos modelos dentro e fora da amostra:
i. Raiz do Erro Quadrático Médio (REQM)
( )1 2
22 2
1
1ˆ
T
t tt
REQMT
σ σ=
= − ∑ , (1.1)
ii. Erro Absoluto Médio (EAM)
2 2
1
1ˆ
T
t tt
EAMT
σ σ=
= −∑ . (1.2)

5
Nas expressões (1.1) e (1.2), 2
1
T
t tσ
= representa a série de variâncias condicionais
verdadeiras1, T é o número de dias estimados ou previstos e 2
1ˆ
T
t tσ
= denota a
série de estimativas ou previsões um passo à frente da variância condicional de
um determinado modelo.
As simulações de Monte Carlo indicam uma melhor performance dos
modelos GARCH quando suas formas funcionais não diferem da especificada no
Processo Gerador dos Dados (PGD). Contudo, na medida em que diferem, obtêm-
se resultados que sugerem uma substancial superioridade dos modelos aditivos.
No estudo empírico, os resultados sugerem uma equivalência entre os modelos
pela medida EAM, ao passo que pela estatística REQM, um dos modelos GARCH
apresenta desempenho superior. Interpretando os resultados deste estudo, sugere-
se que os modelos GARCH parecem ser uma boa expressão para o PGD do
Ibovespa e que o modelo aditivo tem um bom desempenho frente aos GARCH,
mesmo com os últimos representando adequadamente o PGD.
O restante do artigo é estruturado da seguinte forma: a seção 2 engloba a
metodologia utilizada; a seção 3 reúne as aplicações numéricas; e, por fim, as
considerações finais são apresentadas na seção 4.
1 No estudo empírico, ao invés das volatilidades verdadeiras (desconhecidas), são utilizados seus estimadores teóricos: os quadrados dos resíduos.

6
2. Metodologia
2.1 Modelos GARCH
Considere uma série de tempo univariada ty , com 1t−Ω representando o
conjunto de informação no período 1t − . Assim, pode-se definir sua forma
funcional como
( )1 ,t t t ty E y ε−= Ω + (2.1)
onde ( )E ⋅ ⋅ denota o operador de esperança condicional e tε representa o termo
de erro com ( ) 0tE ε = e ( ) 0 , t sE t sε ε = ∀ ≠ . A expressão (2.1) representa a
equação da média, normalmente modelada por uma estrutura ARMA, e o termo
tε é chamado de inovação do processo. Engle (1982) define como um processo
auto-regressivo com heteroscedasticidade condicional (ARCH) todo tε da
seguinte forma:
,t t tzε σ= (2.2)
onde ( ). . . 0,1tz i i d D∼ , com ( )D ⋅ uma função densidade de probabilidade. Por
definição, tε é serialmente não correlacionado com média igual a zero, mas sua
variância condicional é igual a 2tσ , portanto, pode mudar ao longo do tempo.
O modelo ( )ARCH q tradicional pode ser definido como:
2 2
1
,
t t t
q
t i t ii
zε σ
σ ω α ε −=
=
= +∑ (2.3)
onde ( ). . . 0,1tz i i d D∼ . Nota-se que, mesmo se a variância condicional varie no
tempo, ( )2 21t t tEσ ε ψ −= , sob estacionariedade a variância não condicional de tε é

7
constante, isto é, desde que 0ω > e 1
1q
iiα
=<∑ , tem-se que
( ) ( )2 2
11
q
t iiEσ ε ω α
=≡ = −∑ . Evidências empíricas mostram que modelos
ARCH de ordens elevadas devem ser selecionados para poder captar a dinâmica
da variância condicional, desta forma, envolvendo a estimação de diversos
parâmetros. O modelo ARCH Generalizado (GARCH) de Bollerslev (1986) surge
como resposta ao problema.
O modelo ( ),GARCH p q pode ser expresso como
2 2 2
1 1
q p
t i t i j t ji j
σ ω α ε β σ− −= =
= + +∑ ∑ , (2.4)
e utilizando o operador defasagem, pode-se reescrever o mesmo como
( ) ( )2 2 2t t tL Lσ ω α ε β σ= + + , tal que ( )
1
q iii
L Lα α=
=∑ e ( )1
p jjj
L Lβ β=
=∑ . Se
todas as raízes do polinômio ( )1 0Lβ− = estiverem fora do círculo unitário,
tem-se ( ) ( ) ( )1 12 21 1t tL L Lσ ω β α β ε− −= − + − , que pode ser visto como um
( )ARCH ∞ devido à variância condicional depender de todo o histórico de
quadrados dos resíduos. Algumas restrições são necessárias para garantir que a
variância condicional seja positiva para todo t . Bollerslev (1986) mostra que é
suficiente impor 0ω > , 0iα ≥ para 1,...,i q= , e 0jβ ≥ para 1,...,j p= .
O modelo ( ),GJR p q , proposto por Glosten, Jagannathan e Runkle (1993),
tem sua versão generalizada dada por
( )2 2 2 2
1 1
q p
t i t i i t i t i j t ji j
Sσ ω α ε γ ε β σ−− − − −
= =
= + + +∑ ∑ , (2.5)

8
onde tS − é uma variável dummy. Neste modelo, é assumido que o impacto de 2tε
em 2tσ é distinto, dependendo se tε é positivo ou negativo.
O modelo ( ),TS GARCH p q− de Taylor (1986) e Schwert (1989)
parametriza o desvio padrão condicional como uma defasagem distribuída dos
resíduos absolutos e dos desvios padrão condicionais defasados:
1 1
q p
t i t i j t ji j
σ ω α ε β σ− −= =
= + +∑ ∑ . (2.6)
Esta especificação mitiga a influência de grandes (em termos absolutos)
observações quando se compara ao modelo ( ),GARCH p q tradicional.
O pacote computacional2 utilizado na estimação dos modelos GARCH
utiliza na implementação dos modelos ( ),GJR p q e ( ),TS GARCH p q− o
modelo ( ),APARCH p q de Ding, Granger e Engle (1993). Este pode ser
expresso como
( )1 1
q p
t i t i i t i j t ji j
δδ δσ ω α ε γ ε β σ− − −= =
= + − +∑ ∑ , (2.7)
onde 0δ > e ( )1 1 1,...,i i qγ− < < = . Para especificar o modelo ( ),GJR p q ,
define-se ( )2δ = , e para o ( ),TS GARCH p q− , define-se 1δ = e
( )0 1,...,i i qγ = = .
Discussões a respeito das propriedades assintóticas dos estimadores de
máxima verossimilhança condicional para os modelos GARCH podem ser
encontradas em Hall e Yao (2003), e de forma compacta em Fan e Yao (2003).
2 Pacote fGarch do software livre R.

9
2.2 Métodos Não Paramétricos
A literatura reúne distintos métodos não paramétricos para modelar
estruturas explicativas, dentre eles, podem ser citados a suavização kernel e
splines. As técnicas de suavização kernel podem ser encontradas em referências
como Bowman e Azzalini (1997), Fan e Gijbels (1996) e em Fan e Yao (2003).
No arcabouço de regressão não paramétrica, o estimador polinomial local
de suavização kernel é amplamente utilizado. A partir deste, estima-se a função de
regressão, em um ponto particular, ajustando localmente um polinômio de ordem
p via mínimos quadrados ponderados. Na apresentação do método, considere a
seqüência de variáveis aleatórias bidimensionais3 ( ),t tY X , 1,...,t T= . A
esperança condicional e a variância condicional são definidas respectivamente
como ( ) ( )t tm x E Y X x= = e ( ) ( )2 0t tx Var Y X xσ = = > , 1,...,t T= . Supõe-se
um modelo que relaciona as variáveis ( ),t tY X com a seguinte forma:
( ) ( )t t t tY m X Xσ ε= + , (2.8)
onde ( ) 0t tE Xε = e ( ) 1t tVar Xε = . Considerando um ponto de interesse x no
domínio da variável aleatória X , pode-se definir o estimador polinomial local de
( )m x como ( ) 0ˆˆ pm x β= , com 0β dado pela solução do problema de mínimos
quadrados ponderados que segue:
( ) ( ) ( )0 1
2
0 1, ,...,
1 0
ˆ ˆ ˆ, ,..., arg minp
pTi
p t i t h tt i
Y X x K X xβ β β
β β β β= =
= − − −
∑ ∑ , (2.9)
3 No contexto de séries temporais, tX representa 1tY − .

10
onde ( )K ⋅ é uma função densidade de probabilidade simétrica em ℜ ,
( ) ( ) ( )1hK u h K u h= , e 0h > é o parâmetro de suavização ou janela
(bandwidth). Quando 1p = , obtém-se o estimador linear local.
Utiliza-se neste artigo, com 1p = , o suavizador loess de Cleveland (1979),
versão não robusta4. Em loess, as vizinhanças locais são determinadas por uma
janela baseada em vizinhos próximos. Complementarmente, 0 1f< ≤ expressa
uma fração dos dados ( )n a serem incluídos em cada vizinhança, de tal forma que
f representa o parâmetro de suavização (span).
Em regressão múltipla, foca-se a atenção na relação estrutural entre a
variável resposta Y e o vetor de covariáveis ( )1 2, ,..., dX X X ′ . Desta maneira,
pode-se estender o modelo (2.8) ao caso multivariado, onde X passa a ser um
vetor de dimensão-d em dℜ (em séries de tempo ( )1 2, ,...,t t t dY Y Y− − −′=tX ) e Y um
escalar em ℜ . A esperança e a variância condicionais são representadas como
( ) ( )m E Y=x X = x e ( ) ( )2 0Var Yσ = >x X = x , respectivamente. O modelo
(2.8) assume a forma
( ) ( )t tY m σ ε= +t tX X , (2.10)
onde ( ) 0tE ε =tX e ( ) 1tVar ε =tX . Como principal desvantagem em regressão
múltipla não paramétrica, cita-se o problema da alta dimensionalidade. As
soluções para este problema costumam estar relacionadas a algum mecanismo de
redução de dimensão, como os modelos aditivos semi-paramétricos.
4 Versão disponível no Pacote gam, do software livre R.

11
Para apresentar o modelo aditivo, considere primeiramente o modelo geral
de regressão múltipla discutido em Fan e Gijbels (1996),
( ) ,Y m ε= +X (2.11)
onde ( ) 0E ε = , ( ) 2Var ε σ= e ε é independente do vetor de covariáveis X . No
modelo de regressão linear múltipla a função de regressão ( )m ⋅ é assumida como
linear, e portanto aditiva nas variáveis explicativas. Nos modelos aditivos, o
pressuposto de linearidade é abandonado, mas a forma aditiva é mantida. A idéia
de um modelo aditivo, como sugerido por Friedman e Stuetzle (1981) e
substancialmente desenvolvido por Hastie e Tibshirani (1990), é a de permitir que
componentes do modelo de regressão linear assumam formas não paramétricas, o
que leva ao modelo
( )1
,d
j jj
Y g Xα ε=
= + +∑ (2.12)
onde 1,..., dg g são funções univariadas desconhecidas. Para evitar constantes
livres nas funções, garantindo a identificabilidade do modelo, é requerido que
( ) 0 , 1,..., .j jE g X j d= = (2.13)
Isto implica que ( )E Y α= . Se o modelo aditivo é válido, tem-se que
( ) ( ) , 1,..., .j j k k kj k
E Y g X X g X k dα≠
− − = =
∑ (2.14)
Isto sugere um algoritmo iterativo que permite a estimação das funções
univariadas 1,..., dg g . Ainda, para α dado e para funções , jg j k≠ dadas, a
função kg pode ser estimada através de uma simples regressão univariada

12
baseada nas observações ( ) , : 1,...,ik iX Y i n= . O suavizador univariado arbitrário
de kg é definido por kS . Este representa o suavizador loess, nas aplicações deste
artigo. Para obedecer à condição (2.13), a estimativa ( ) ( )ˆ de k kg g⋅ ⋅ , obtida por
meio de kS , é substituída por sua versão centralizada
( ) ( ) ( )1
1ˆ ˆ ˆ
n
k k k jkj
g g g Xn
∗
=⋅ = ⋅ − ∑ . (2.15)
Uma escolha inicial das funções univariadas, 0kg , é necessária, bem como
um esquema de iteração. Este procedimento leva ao algoritmo backfitting5, que
segue os próximos passos:
Passo 1- Inicialização: 1 0
1ˆ ˆ, , 1,..., .
n
i k kin Y g g k dα −
== = =∑
Passo 2- Para cada 1,..., ,k d= obter ( )ˆˆ ˆk k j j kj k
g S Y g X Xα≠
= − −
∑ e obter
( )ˆkg∗ ⋅ como em (2.15).
Passo 3- Repetir o passo 2 até convergir.
A idéia básica do algoritmo é a de através da regressão inicial, calcular os resíduos
parciais desta, e regredir novamente. Para estimar volatilidade, o modelo aditivo é
especificado da seguinte forma:
( ) ( )1
2
0
d
i t ii
f Xσ α−
−=
= +∑tX , (2.16)
onde ( )1 1, ,...,t t t dX X X− − +′=tX é o vetor de covariáveis.
5 Ver Hastie e Tibshirani (1990) para o estimador Backfitting e Linton e Nielsen (1995) para o método alternativo de Integração Marginal.

13
O estimador de volatilidade adotado neste artigo é baseado nos resíduos
(estimador em dois passos), cujo nome é estimador residual da volatilidade.
Alguns autores como Fan e Yao (1998), Ruppert, Wand, Holst e Hössjer (1997) e
Ziegelmann (2002b, 2008, 2010) apresentam implementações sobre a técnica.
Resumidamente, pode-se dizer que o método consiste em reescrever o modelo
(2.10) como ( ) ( )t tY m σ ε− =t tX X , tal que tomando-se a esperança condicional
dos resíduos ao quadrado, ( ) ( )22 2 2t t tr Y m σ ε = − = t tX X , obtém-se
( ) ( )2 2tE r σ=t tX X . Assim, pode-se estimar ( )2σ tX a partir de uma regressão
de 2tr contra tX , onde ( ) 22ˆ ˆt tr Y m = − tX . Nesta situação, 2tr representa a nova
variável resposta, substituindo tY nos modelos anteriores.
Sobre os métodos não paramétricos abordados, destaca-se que a teoria
assintótica relativa ao estimador polinomial local pode ser encontrada em Fan e
Gijbels (1996) e em Fan e Yao (2003)6. Para informações referentes à
convergência do algoritmo Backfitting, ver Hastie e Tibshirani (1990). Cabe
salientar que de forma comparativa, as taxas de convergência dos estimadores não
paramétricos são mais lentas que as dos estimadores paramétricos.
3. Aplicação Numérica
3.1 Estudo de Monte Carlo
Nesta seção busca-se comparar por meio de simulações de Monte Carlo os
modelos da família GARCH e os Modelos aditivos. Nos experimentos são geradas
50 séries de tempo com 2.500 observações, sendo que a partir da observação
6 Nesta referência, ver especificamente o Teorema 6.3, p. 238.

14
1.500 (ponto de corte) de cada série, procura-se nas 1.000 posições restantes o
período (com 50 observações) mais volátil. Destaca-se que as avaliações de
estimação e previsão um passo à frente atualizadas são realizadas somente nos
momentos que contém as 50 observações. Ademais, na medida em que se define o
intervalo composto das 50 observações mais voláteis, define-se automaticamente
a extensão da série de tempo. Assim, pode-se avaliar também, implicitamente, o
comportamento dos estimadores frente às amostras de tamanhos distintos.
Os Processos Geradores de Dados (PGD) são os seguintes:
i. 1PGD
1 2
2 2 21 2
0,2 0,1
0,1 0,5 0,2 ,
t t t t t
t t t
y y y zσ
σ ε ε
− −
− −
= + +
= + + (3.1)
ii. 2PGD
1 2
21 2
0,2 0,1
0,1 0,5 0,2 ,
t t t t t
t t t
y y y zσ
σ ε ε
− −
− −
= + +
= + + (3.2)
onde t t tzε σ= , sendo especificadas duas distribuições para tz ,
( )0,1tz N∼ e ( )6tz t∼ .
Para cada série de tempo gerada, por ambos os PGDs, calculam-se as
estimativas e previsões a partir de seis modelos distintos. Conhecendo o número
de defasagens dos processos geradores, são analisados os modelos
( )2 (2)AR ARCH− , ( )2AR − Aditivo, ( )2AD − Aditivo7, ( ) ( )2 1,1AR GARCH− ,
7 Modelo Aditivo com duas funções univariadas tanto para a esperança condicional como para a variância condicional. Ainda, destaca-se que em ambos os modelos aditivos o span foi mantido constante, span=0,8, devido à performance ter sido equivalente a dos modelos com span variável (por série de tempo) e devido à redução do tempo computacional.

15
( ) ( )2 1,1AR GJR− e ( ) ( )2 1,1AR TS GARCH− − . As estimativas e previsões de
volatilidade oriundas destes estimadores são utilizadas em conjunto com as
volatilidades verdadeiras para calcular, para cada uma das 50 séries de tempo, as
medidas de erro. A partir das estatísticas iREQM e iEAM , para 1,...,50i = , pode-
se apresentar na FIG. 1 e FIG. 2 os box plots que comparam os seis modelos
citados (dentro e fora da amostra) para o 1PGD e 2PGD , respectivamente.
Adicionalmente, a TAB. 1 do APÊNDICE reúne as estatísticas dos experimentos.
A FIG. 1 indica um melhor desempenho, de acordo com ambas as
medidas, do modelo ( )2 (2)AR ARCH− , que possui a mesma especificação do
processo gerador. Este é seguido de perto pelos outros dois modelos cuja forma
funcional depende de quadrados de resíduos, o ( )1,1GARCH e o ( )1,1GJR . O
modelo ( )1,1TS GARCH− apresenta comportamento inferior em relação aos
últimos. Para o 1PGD , o pior desempenho é atribuído aos modelos aditivos, que
indicam performance similar entre si.
A FIG. 2 reúne as comparações entre os seis estimadores para o 2PGD .
Nesta, fica clara a superioridade dos modelos aditivos. Pela REQM, o modelo
( )1,1TS GARCH− apresenta o segundo melhor resultado. Os demais modelos da
família GARCH, cuja forma funcional difere da especificada no 2PGD ,
destacam-se pelo pior desempenho. De acordo com o EAM, os modelos
(2)ARCH , ( )1,1GARCH e ( )1,1GJR ainda são os piores estimadores em termos
de viés e variância. Segundo a mesma estatística, pode-se dizer que a performance

16
do modelo ( )1,1TS GARCH− é equivalente a dos modelos aditivos, mesmo
apresentando variância ligeiramente superior para a distribuição ( )6t .
Os resultados gerais do estudo de Monte Carlo sugerem um melhor
desempenho dos modelos da família GARCH, notadamente aqueles especificados
via quadrados de resíduos, para o primeiro processo ( 1PGD ). Contudo, tendo em
vista sua dependência à forma funcional previamente especificada, são incapazes
de se adaptar a processos distintos ( 2PGD ). Os modelos aditivos, por sua vez,
baseados em funções livres, são capazes de se adaptar aos diferentes processos.
Embora com pior performance no 1PGD , são nitidamente superiores no 2PGD .
3.2 Estudo Empírico
Utilizando dados reais, procura-se comparar mais uma vez os modelos
GARCH e os Modelos aditivos. Para isto, utiliza-se a série de tempo composta
dos preços de fechamento diários do Ibovespa e seus respectivos retornos diários,
definidos como 1ln lnt t ty X X −= − (onde tX é o preço do ativo no tempo t ).
Baseando-se na amostra completa dos retornos, são selecionados os modelos mais
adequados para a estimação da volatilidade do índice. Após, os modelos têm suas
estimativas e previsões comparadas em períodos denominados de crise no
mercado financeiro internacional. Foram definidos três anos recentes com crise no
mercado financeiro, sendo a análise delimitada aos momentos de alta volatilidade
de 2001, 2002 e 2007.

17
3.2.1 Características dos Dados
A amostra completa dos retornos do Ibovespa contém 3.212 observações,
de 03/01/1995 até 28/12/2007. A evolução do índice e de seus retornos segue na
FIG. 3. A série compreende um período posterior à crise do México (fim de 1994)
e atravessa momentos de alta volatilidade, como as crises da Ásia (1997) e da
Rússia (1998). A partir de 2001, notam-se turbulências decorrentes do atentado de
11 de setembro nos Estados Unidos, e mais à frente, em 2002, os meses de
setembro e outubro refletem os desdobramentos da bolha das empresas de alta
tecnologia. Para completar o período amostral, nos meses de julho e agosto de
2007, o índice sofre influência da crise no mercado hipotecário subprime norte-
americano.
Quanto às regularidades empíricas, pode-se visualizar evidências de
caudas pesadas em relação à distribuição normal, nos itens (a) e (b) da FIG. 4. No
item (d), observa-se que a função de autocorrelação dos quadrados dos retornos é
significativa, e no item (c), aparentemente não há autocorrelação nos retornos.
A escolha dos modelos aditivos bem como os da família GARCH se dará
sobre a amostra completa dos retornos. Após a seleção dos melhores modelos
ajustados, serão efetuadas as estimativas e previsões das volatilidades em três sub-
amostras. As estimativas e previsões um passo à frente atualizadas serão
calculadas sobre períodos de cem dias de negociação após a última observação de
cada sub-amostra. A primeira partição dos dados do Ibovespa compreende os
retornos de 03/01/1995 até 31/08/2001, ou seja, até o último dia do mês anterior
ao ataque terrorista nos Estados Unidos. A segunda sub-amostra engloba os dados
de 03/01/1995 até 30/08/2002. Nesta situação o objetivo é mensurar o

18
comportamento dos modelos a partir do mês de setembro de 2002, cuja
volatilidade nos mercados financeiros é elevada. Por fim, a terceira partição dos
dados inicia em 03/01/1995 e se estende até 29/06/2007. Este período antecede os
desdobramentos da crise no mercado hipotecário subprime nos EUA, que se
intensificam ao final de julho e durante as primeiras semanas de agosto. São
apresentadas no APÊNDICE as principais estatísticas descritivas.
A partir da TAB. 2 do APÊNDICE, observa-se uma autocorrelação nos
retornos da amostra completa do Ibovespa via estatísticas Q de Ljung-Box. Além
disso, as três partições restantes também apresentam autocorrelação significativa.
Em relação aos quadrados dos retornos, pode-se dizer que todos os períodos
avaliados revelam a existência de autocorrelação.
3.2.2 Modelos
Ao iniciar a modelagem pela série completa do Ibovespa, deve-se ressaltar
a exclusão de doze observações8, dentre elas: cinco mínimas e sete máximas. As
datas específicas e os valores das observações podem ser encontrados na TAB. 3
do APÊNDICE. A eliminação dos outliers faz-se necessária em virtude da
estrutura bastante flexível dos modelos aditivos que, ajustados localmente via
suavizadores, acabam tendo as estimativas de volatilidade para estes valores
extremos prejudicadas pela ausência de vizinhança local. A manutenção dos
outliers leva à obtenção de estimativas negativas para volatilidade ou a não-
convergência do algoritmo backfitting. Note que, apesar disso, a abordagem de
8 O limite para definição dos outliers foi especificado de forma arbitraria por meio da observação da média e do desvio padrão da série dos retornos. Ainda, nenhuma das observações extremas pertence aos períodos de crise avaliados e estimou-se tanto os modelos aditivos como os GARCH com os mesmos dados.

19
estimação é robusta a outliers, com exceção das estimativas em cima destes
valores.
Observando uma autocorrelação significativa nos retornos, ajustou-se uma
estrutura para a esperança condicional. Devido ao método definido para
comparação das estimativas e previsões de volatilidade entre os modelos aditivos
e os GARCH, ou seja, por meio do quadrado do retorno corrigido pela média,
optou-se por utilizar uma estrutura ARMA na equação da média condicional para
ambos os modelos, preservando a base de comparação. Como indicado nas
simulações, as estimativas de volatilidade dos modelos aditivos são equivalentes,
não dependendo do estimador utilizado na equação da esperança condicional.
Através dos procedimentos tradicionais de identificação em séries
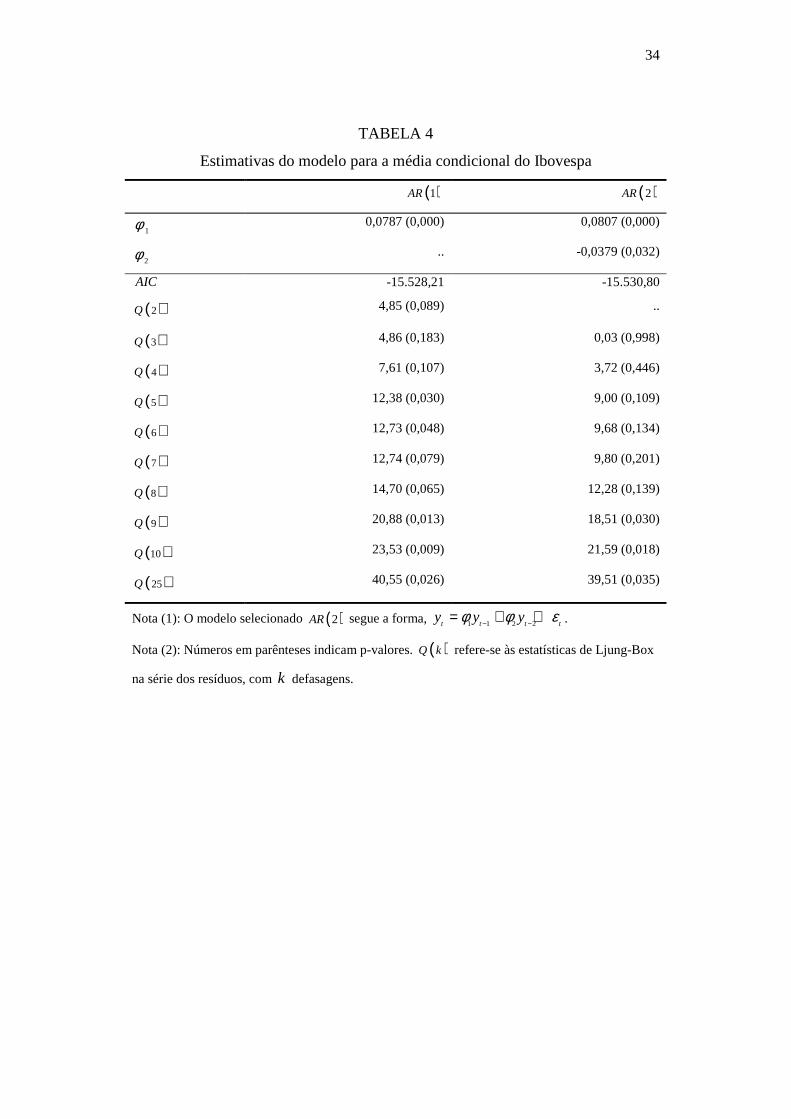
temporais, selecionou-se um modelo ( )2AR para filtrar a série dos retornos,
sendo os resultados reunidos na TAB. 4 do APÊNDICE. Adicionalmente, a FIG. 5
reúne as funções de autocorrelação e autocorrelação parcial dos retornos (sem
outliers), bem como a função de autocorrelação dos resíduos estimados do modelo
( )2AR e seus quadrados. Pode-se perceber no item (c) da FIG. 5 que a estrutura
de autocorrelação dos resíduos é mais fraca em relação à ilustrada no item (a).
Porém, pelo item (d), os quadrados dos resíduos permanecem correlacionados.
Sendo assim, os resíduos do modelo ( )2AR são utilizados para se obter as
estimativas da volatilidade do Ibovespa.
Na estimação da volatilidade por meio dos modelos aditivos foram levados
em consideração diversos resultados, sejam quantitativos ou visuais, ao longo do
processo de inferência. Contudo, o teste F aproximado e o critério de

20
informação aproximado de Akaike9 (AIC) servem como principais guias na
escolha entre modelos alternativos. Desta forma, buscou-se de forma simultânea a
definição do número de funções univariadas a serem incluídas no modelo aditivo
bem como o parâmetro de suavização (span) que minimizasse o critério AIC.
Modelos compostos de uma até nove funções foram testados. Adicionalmente,
selecionou-se de forma automática o span, cuja amplitude10 variou de 0,5 até 0,8,
com incrementos de 0,05. Os modelos com seis funções ou mais apresentaram
problemas de convergência ou estimativas negativas para volatilidade, assim,
foram excluídos da análise. A TAB. 5 reúne de forma ilustrativa os resultados dos
testes F bem como os critérios AIC aproximados para os melhores modelos.
9 Ver Hastie e Tibshirani (1990), bem como Hastie (1993). 10 Nota-se que a amplitude definida gera funções estimadas mais suaves e resultados superiores.
TABELA 5
Seleção dos modelos aditivos para o Ibovespa
SQR resdf Teste F AIC
Modelo aditivo (1; 0,5) 0,0023673 3.186,80 -35.992,57
Modelo aditivo (2; 0,5) 0,0022609 3.181,59 28,75 (0,000) -36.129,03
Modelo aditivo (3; 0,55) 0,0021716 3.177,54 32,20 (0,000) -36.249,53
Modelo aditivo (4; 0,6) 0,0021385 3.174,14 14,49 (0,000) -36.291,88
Modelo aditivo (5; 0,7) 0,0021246 3.173,49 31,60 (0,000) -36.311,31
Nota (1): Nos modelos aditivos: (número de funções; span).
Nota (2): No teste F os números em parênteses indicam os p-valores.

21
Da TAB. 5 percebe-se que a inclusão sucessiva de componentes funcionais
se mostra significativa até a quinta defasagem. Os critérios AIC aproximados
reforçam os resultados do teste F , que indicam a superioridade do modelo com
cinco funções. A FIG. 6 apresenta a descrição visual das contribuições de cada
função univariada para a explicação da variável resposta. Nesta, pode-se notar
uma assimetria nas funções em relação à ocorrência de resíduos positivos ou
negativos de mesma magnitude. As funções indicam uma maior inclinação na
presença de resíduos negativos e, conseqüentemente, sugerem uma maior resposta
da volatilidade na ocorrência dos mesmos.
A FIG. 7 reúne as medidas de ajuste do modelo aditivo (5). Pode-se
observar no item (d) que as autocorrelações dos quadrados dos resíduos corrigidos
por heterocedasticidade apresentam uma redução expressiva quando comparadas
as dos quadrados dos resíduos do ( )2AR , contidos no item (d) da FIG. 5.
Todavia, percebe-se uma estrutura de autocorrelação remanescente nos quadrados,
indicando que nem toda a não-linearidade foi captada pelo modelo.
Para os modelos GARCH, buscou-se selecioná-los através dos critérios de
informação de Akaike (AIC) e de Schwarz (BIC) e a partir do valor máximo do
log-verossimilhança. Na estimação via função de verossimilhança condicional
foram supostas duas distribuições condicionais para os erros padronizados, a
normal e a t-Student. A TAB. 6 reúne os modelos comparados.

22
Apresenta-se na TAB. 6 somente os modelos com os parâmetros da
equação da variância significativos. Ainda, foram eliminados aqueles cujas
estimativas não convergiram. Optou-se por selecionar um modelo ( )ARCH q e
outra parametrização entre os GARCH. Desta forma, foram selecionados os
modelos ( )7ARCH e ( )1,1GJR , ambos com distribuição t-Student para os erros.
As estimativas dos parâmetros (erros padrão entre parênteses) seguem nas
expressões (3.3) e (3.4), respectivamente.
( ) ( )
( ) ( ) ( ) ( ) ( )
( ) ( )
1 20,01780 0,01801
2 2 2 2 21 2 3 4
0,000013 0,02197 0,02617 0,02824 0,02607
2 25 6
0,02317 0,02436 0,02
0,0570 0,0289 , ,
0,00015 0,0734 0,0999 0,1454 0,1094
0,0712 0,0836 0,1025
t t t t t t t
t t t t t
t t
y y y zε ε σ
σ ε ε ε ε
ε ε
− −
− − − −
− −
= − + =
= + + + +
+ + +( )
27
661 .tε −
(3.3)
TABELA 6
Seleção dos modelos GARCH para o Ibovespa
Normal t-Student
Modelo AIC BIC Max [Log L] AIC BIC Max [Log L]
ARCH(4) -5,012862 -4,999582 8.027,58 -5,031154 -5,015977 8.057,85
ARCH(5) -5,020398 -5,005221 8.040,64 -5,037489 -5,020415 8.068,98
ARCH(6) -5,021547 -5,004473 8.043,48 -5,040811 -5,021840 8.075,30
ARCH(7) -5,028058 -5,009087 8.054,89 -5,044984 -5,024116 8.082,98
ARCH(8) -5,025449 -5,004581 8.051,72 .. .. ..
GARCH(1,1) -5,048393 -5,038907 8.082,43 -5,062752 -5,051369 8.106,40
TS-GARCH(1,1) -4,935124 -4,925639 7.901,20 -5,031985 -5,020602 8.057,18
GJR(1,1) -5,071723 -5,060340 8.120,76 -5,082759 -5,069479 8.139,42
Nota: Em negrito, os melhores modelos e [..] indica que as estimativas não convergiram.

23
No modelo ( )7ARCH , o segundo termo auto-regressivo da equação da
média condicional, quando estimado conjuntamente aos demais parâmetros da
equação da variância, não se mostrou significativo. Contudo, decidiu-se por sua
manutenção no modelo para garantir a eqüidade nas comparações posteriores.
( ) ( )
( ) ( ) ( ) ( )
1 20,01817 0,01822
2
2 21 1 1
0,000003 0,01410 0,1568 0,01684
0,0626 0,0156 , ,
0,00002 0,0605 0,5850 0,8819 .
t t t t t t t
t t t t
y y y zε ε σ
σ ε ε σ
− −
− − −
= − + =
= + − +
(3.4)
No modelo ( )1,1GJR , o segundo coeficiente do ( )2AR não se mostrou
significativo. Mais uma vez, optou-se por sua manutenção. A assimetria na
volatilidade (sugerida anteriormente no modelo aditivo) foi captada, onde o
parâmetro ( )0,5850 0> indica a presença do efeito leverage. Adicionalmente, a
FIG. 8 destaca as estimativas de volatilidade para a amostra do Ibovespa.
3.2.3 Comparações nos períodos de crise
As comparações entre os modelos aditivos e GARCH são realizadas a
partir das três primeiras partições da série dos retornos do Ibovespa, apresentadas
na TAB. 2 do APÊNDICE. Para comparar o desempenho dos modelos dentro da
amostra, os mesmos são estimados incorporando as observações contidas nos
momentos de crise (cem dias de negociação). Este período é definido em 2001 de
(03.09.2001-04.02.2002), em 2002 de (02.09.2002-24.01.2003) e em 2007 de
(02.07.2007-26.11.2007).
Para a análise fora da amostra, as previsões um passo à frente atualizadas
são efetuadas nos mesmos momentos referenciados de cem dias. Sendo assim, os

24
modelos são estimados até o período t , e então são obtidas as previsões para 1t + .
Em 1t + , os modelos são reestimados e as previsões são obtidas para 2t + , e
assim sucessivamente. As medidas de erro, REQM e EAM, são calculadas
somente sobre as estimativas e previsões do intervalo de cem dias de negociação,
sendo que os resultados são apresentados via intervalos de confiança para as duas
estatísticas, somando e diminuindo dois desvios padrão.
Apresenta-se na TAB. 7 o desempenho, dentro da amostra, dos modelos
selecionados para os três momentos de crise. Segundo a métrica REQM, o modelo
aditivo tem performance superior em 2001, ao passo que o modelo ( )1,1GJR é o
de melhor desempenho nas crises de 2002 e 2007. Ainda, nos períodos de 2002 e
2007, o modelo aditivo é o que mais erra. Pela medida EAM, os três modelos são
equivalentes nos três períodos, apresentando intervalos com valores em comum.
Os resultados comparativos dos estimadores quanto à capacidade preditiva,
contidos na TAB. 8, indicam o mesmo comportamento apresentado dentro da
amostra.

25
TABELA 7
Desempenho dos modelos (dentro da amostra) para o Ibovespa
M. Aditivo (5) ( )7ARCH ( )1,1GJR
Crise de 2001
REQM [0,0008413; 0,0008506] [0,0009120; 0,0009230] [0,0008692; 0,0008797]
EAM [-0,0008093; 0,0018586] [-0,0008201; 0,0020019] [-0,0008032; 0,0019133]
Crise de 2002
REQM [0,0007059; 0,0007109] [0,0006862; 0,0006916] [0,0006805; 0,0006856]
EAM [-0,0005122; 0,0015098] [-0,0004929; 0,0014666] [-0,0005300; 0,0014675]
Crise de 2007
REQM [0,0005040; 0,0005059] [0,0004981; 0,0004999] [0,0004864; 0,0004883]
EAM [-0,0002844; 0,0010468] [-0,0002379; 0,0010166] [-0,0002903; 0,0010165]
Nota: Valor em negrito denota a melhor medida.
TABELA 8
Desempenho dos modelos (fora da amostra) para o Ibovespa
M. Aditivo (5) ( )7ARCH ( )1,1GJR
Crise de 2001
REQM [0,0008488; 0,0008582] [0,0009195; 0,0009305] [0,0008726; 0,0008830]
EAM [-0,0008220; 0,0018764] [-0,0008229; 0,0020172] [-0,0008076; 0,0019209]
Crise de 2002
REQM [0,0007131; 0,0007181] [0,0006916; 0,0006971] [0,0006812; 0,0006863]
EAM [-0,0005146; 0,0015243] [-0,0004958; 0,0014778] [-0,0005287; 0,0014683]
Crise de 2007
REQM [0,0005082; 0,0005100] [0,0004996; 0,0005014] [0,0004870; 0,0004889]
EAM [-0,0002855; 0,0010549] [-0,0002392; 0,0010200] [-0,0002918; 0,0010182]
Nota: Valor em negrito denota a melhor medida.

26
4. Considerações Finais
Buscou-se comparar os modelos aditivos com os modelos GARCH quanto
à capacidade de estimar e prever volatilidade em períodos turbulentos (crise).
Primeiramente, realizou-se um experimento de Monte Carlo, em que foram
supostos dois processos geradores de dados. No primeiro ( 1PGD ), baseado em
quadrados de resíduos, os modelos GARCH com a mesma especificação do
processo foram superiores. No segundo ( 2PGD ), baseado em resíduos absolutos,
os modelos aditivos são os de melhor desempenho. Os modelos GARCH, cujas
formas funcionais dependem de quadrados, apresentam os piores resultados.
Adicionalmente, realizou-se um estudo empírico, avaliando a performance
dos modelos na série de retornos do Ibovespa. Neste, a medida REQM indica a
superioridade do modelo ( )1,1GJR , tanto dentro quanto fora da amostra. Todavia,
os três modelos comparados são estatisticamente equivalentes segundo o EAM.
Como última consideração, cabe salientar que os modelos aditivos também
podem ser entendidos como complementares aos modelos paramétricos,
fornecendo sugestões de assimetrias (como ocorre neste estudo) e não linearidades
a serem incorporadas nestes modelos.
Referências
BOLLERSLEV, T. Generalized Autoregressive Conditional Heteroskedasticity.
Journal of Econometrics, v. 31, p. 307–327, 1986.
BOLLERSLEV, T. Glossary to ARCH (GARCH). Disponível em:
<http://ssrn.com/abstract=1263250>. Acesso em: 20 set. 2008.

27
BOLLERSLEV, T.; CHOU, R. Y.; KRONER, K. F. ARCH Modeling in Finance:
A Review of the Theory and Empirical Evidence. Journal of Econometrics, v.
52, p. 5-59, 1992.
BOLLERSLEV, T.; ENGLE, R. F.; NELSON, D. B. ARCH Models. In: ENGLE,
R. F.; MCFADDEN, D. L. Handbook of Econometrics. Amsterdam: Elsevier
Sciences B. V., v. IV, cap. 49, 1994.
BOWMAN, A.; AZZALINI, A. Applied Smoothing Techniques for Data
Analysis: The Kernel Approach with S-Plus Illustrations. Oxford: Oxford
University Press, 1997.
CARROLL, R. J.; HÄRDLE, W.; MAMMEN, E. Estimation in an Additive
Model when the Components are Linked Parametrically. Econometric Theory,
v. 18, p. 886-912, 2002.
CLEVELAND, W. Robust Locally Weighted Regression and Smoothing
Scatterplots. Journal of the American Statistical Association, v. 74, p. 829-836,
1979.
DING, Z.; GRANGER, C.W.J.; ENGLE, R.F. A Long Memory Property of Stock
Market Returns and a New Model. Journal of Empirical Finance, v.1, p. 83–
106, 1993.
EDERINGTON, L.H.; GUAN, W. Forecasting Volatility. The Journal of Futures
Markets, v.25, n. 5, p. 465-490, 2005.
ENGLE, R. F. Autoregressive Conditional Heteroskedasticity with Estimates of
the Variances of U.K. Inflation. Econometrica, v. 50, n. 4, p. 987-1008, 1982.
FAN, J.; GIJBELS, I. Local Polynomial Modeling and Its Applications. London:
Chapman and Hall, 1996.

28
FAN, J.; YAO, Q. Efficient Estimation of Conditional Variance Functions in
Stochastic Regression. Biometrika, v. 85, p. 645-660, 1998.
FAN, J.; YAO, Q. Nonlinear Time Series: Nonparametric and Parametric
Methods. New York: Springer-Verlag, 2003.
FRIEDMAN, J. H.; STUETZLE, W. Projection Pursuit Regression. Journal of the
American Statistical Association, v. 76, p. 817-823, 1981.
GAO, J. Nonlinear Time Series: Semiparametric and Nonparametric Methods.
Boca Raton: Chapman and Hall, 2007.
GLOSTEN, L. R.; JAGANNATHAN, R.; RUNKLE, D. On the Relation Between
the Expected Value and the Volatility of the Nominal Excess Return on Stocks.
Journal of Finance, v. 48, p. 1779–1801, 1993.
HALL, P.; YAO, Q. Inference in ARCH and GARCH models with heavy-tailed
errors. Econometrica, v. 71, p. 285-317, 2003.
HANSEN, P.R.; LUNDE, A. A Forecast Comparison of Volatility Models: Does
Anything Beat a GARCH(1,1)? Journal of Applied Econometrics, v. 20, p. 873-
889, 2005.
HASTIE, T. J. Generalized additive models. In: CHAMBERS, J. M.; HASTIE, T.
J. Statistical Models in S. London: Chapman and Hall, cap. 7, 1993.
HASTIE, T. J.; TIBSHIRANI, R. J. Generalized Additive Models. London:
Chapman and Hall, 1990.
HOROWITZ, J. L. Semiparametric Methods in Econometrics. New York:
Springer-Verlag, 1998.
KIM, W.; LINTON, O. The Live Method for Generalized Additive Volatility
Models. Econometric Theory, v. 20, n. 6, p. 1094-1139, 2004.

29
LEVINE, M.; LI, J. Local Instrumental Variable (LIVE) Method for the
Generalized Additive-Interactive Nonlinear Volatility Model. Technical Report,
2007.
LINTON, O.; MAMMEN, E. Estimating Semiparametric ARCH (∞) Models by
Kernel Smoothing Methods. Econometrica, v. 73, 771-836, 2005.
LINTON, O.; NIELSEN, J. P. A Kernel Method of Estimating Structured
Nonparametric Regression based on Marginal Integration. Biometrika, v. 82, p.
93-100, 1995.
POON, S-H.; GRANGER, C. Forecasting Volatility in Financial Markets: A
Review. Journal of Economic Literature, v. XLI, p. 478-539, 2003.
RYDBERG, T. Realistic Statistical Modelling of Financial Data. International
Statistics Review, v. 68, p. 233-258, 2000.
RUPPERT, D.; WAND, M. P, HOLST, U.; HÖSSJER, O. Local Polinomial
Variance Function Estimation. Technometrics, v. 39, p. 262-273, 1997.
SCHWERT, G.W. Why Does Stock Market Volatility Change Over Time?
Journal of Finance, v. 44, p. 1115-1153, 1989.
TAYLOR, S. Modelling Financial Time Series. New York: Wiley, 1986.
WAND, M. P.; JONES, M. C. Kernel Smoothing. Chapman and Hall: London,
1995.
ZIEGELMANN, F. A. Estimation of Volatility Functions: Nonparametric and
Semi-Parametric Methods. PhD thesis - Department of Statistics, University of
Kent at Canterbury (UK), 2002a.
ZIEGELMANN, F. A. Estimation of Volatility Functions: The Local Exponential
Estimator. Econometric Theory, v. 18, n. 4, p. 985-992, 2002b.

30
ZIEGELMANN, F. A. A Local Linear Least-Absolute-Deviations Estimator of
Volatility. Communications in Statistics-Simulation and Computation, v. 37, p.
1543-1564, 2008.
ZIEGELMANN, F. A. Semiparametric Estimation of Volatility: Some Models
and Complexity Choice in the Adaptive Functional-Coefficient Class. Journal
of Statistical Computation and Simulation, to appear, 2010.

31
Apêndice
TABELA 1
Estatísticas das medidas de erro
1PGD 2PGD
Modelos Estimativas Previsões Estimativas Previsões
N(.) t(.) N(.) t(.) N(.) t(.) N(.) t(.)
AR(2)-ARCH(2)
M 0.227 0.333 0.227 0.336 0.347 0.410 0.345 0.408 REQM
DP 0.085 0.179 0.085 0.183 0.116 0.184 0.114 0.181
M 0.116 0.153 0.116 0.153 0.189 0.205 0.187 0.205 EAM
DP 0.042 0.072 0.042 0.071 0.049 0.075 0.048 0.073
AR(2)-ADITIVO
M 0.435 0.658 0.448 0.669 0.156 0.178 0.164 0.185 REQM
DP 0.201 0.403 0.204 0.395 0.046 0.046 0.049 0.049
M 0.207 0.276 0.212 0.282 0.114 0.125 0.118 0.129 EAM
DP 0.084 0.136 0.086 0.138 0.032 0.028 0.033 0.030
AD(2)-ADITIVO
M 0.436 0.698 0.447 0.711 0.159 0.182 0.166 0.189 REQM
DP 0.189 0.431 0.194 0.425 0.048 0.047 0.050 0.050
M 0.208 0.288 0.212 0.294 0.116 0.127 0.120 0.131 EAM
DP 0.083 0.137 0.085 0.138 0.031 0.028 0.032 0.030
AR(2)-GARCH(1,1)
M 0.246 0.358 0.246 0.361 0.349 0.413 0.348 0.412 REQM
DP 0.094 0.183 0.094 0.187 0.114 0.183 0.113 0.182
M 0.126 0.164 0.126 0.164 0.190 0.206 0.189 0.205 EAM
DP 0.044 0.076 0.044 0.075 0.050 0.079 0.049 0.077
AR(2)-GJR(1,1)
M 0.250 0.362 0.252 0.366 0.354 0.437 0.353 0.437 REQM
DP 0.098 0.205 0.098 0.208 0.117 0.201 0.115 0.205
M 0.129 0.167 0.129 0.167 0.192 0.214 0.191 0.214 EAM
DP 0.045 0.083 0.045 0.082 0.050 0.080 0.048 0.078
AR(2)-TS-GARCH(1,1)
M 0.359 0.506 0.360 0.511 0.190 0.210 0.189 0.209 REQM
DP 0.162 0.270 0.162 0.272 0.059 0.088 0.058 0.085
M 0.167 0.217 0.167 0.220 0.120 0.128 0.119 0.127 EAM
DP 0.063 0.096 0.064 0.098 0.028 0.047 0.027 0.045
Nota: M e DP indicam média e desvio padrão, respectivamente.

32
TABELA 2
Estatísticas descritivas dos retornos diários do Ibovespa
03.01.1995–
31.08.2001
03.01.1995–
30.08.2002
03.01.1995–
29.06.2007
03.01.1995–
28.12.2007
Média 0,000663 0,000466 0,000821 0,000840
Mediana 0,001342 0,001070 0,001406 0,001438
Desvio padrão 0,027950 0,027288 0,023675 0,023520
Assimetria 0,745545 0,690969 0,593462 0,572547
Curtose 16,02324 15,58598 17,14970 16,98146
Máximo 0,288325 0,288325 0,288325 0,288325
Mínimo -0,172082 -0,172082 -0,172082 -0,172082
Observações 1650 1893 3090 3212
Jarque-Bera 11.813,18 (0,000) 12.644,97 (0,000) 25.958,95 (0,000) 26.337,37 (0,000)
( )11Q 3,98 (0,046) 5,87 (0,015) 7,67 (0,006) 7,42 (0,006)
( )16Q 31,64 (0,000) 32,46 (0,000) 39,85 (0,000) 39,55 (0,000)
( )136Q 86,81 (0,000) 84,94 (0,000) 104,20 (0,000) 103,73 (0,000)
( )21Q 66,18 (0,000) 76,49 (0,000) 131,75 (0,000) 136,32 (0,000)
( )26Q 262,57 (0,000) 301,34 (0,000) 534,47 (0,000) 555,06 (0,000)
( )236Q 409,12 (0,000) 475,26 (0,000) 905,52 (0,000) 944,52 (0,000)
ADF -38,66 (0,000) -41,15 (0,000) -52,84 (0,000) -53,97 (0,000)
Phillips-Perron -38,62 (0,000) -41,09 (0,000) -52,79 (0,000) -53,93 (0,000)
Fonte: Dados da Economatica.
Nota (1): Os testes ADF e PP também rejeitam a hipótese nula na presença de um termo constante
e tendência linear.
Nota (2): Números em parênteses indicam p-valores. ( )1Q k e ( )2
Q k referem-se às estatísticas
de Ljung-Box nas séries dos retornos e retornos ao quadrado com k defasagens, respectivamente.

33
TABELA 3
Observações extremas excluídas da série completa dos retornos do Ibovespa
Data do retorno Mínimas Máximas
23/02/1995 .. 0,113426
10/03/1995 .. 0,228116
14/03/1995 .. 0,121814
27/10/1997 -0,162137 ..
12/11/1997 -0,107646 ..
27/08/1998 -0,104786 ..
10/09/1998 -0,172082 ..
11/09/1998 .. 0,125571
15/09/1998 .. 0,171289
23/09/1998 .. 0,104140
14/01/1999 -0,105024 ..
15/01/1999 .. 0,288325
Fonte: Dados da Economatica.
34
TABELA 4
Estimativas do modelo para a média condicional do Ibovespa
( )1AR ( )2AR
1φ 0,0787 (0,000) 0,0807 (0,000)
2φ .. -0,0379 (0,032)
AIC -15.528,21 -15.530,80
( )2Q 4,85 (0,089) ..
( )3Q 4,86 (0,183) 0,03 (0,998)
( )4Q 7,61 (0,107) 3,72 (0,446)
( )5Q 12,38 (0,030) 9,00 (0,109)
( )6Q 12,73 (0,048) 9,68 (0,134)
( )7Q 12,74 (0,079) 9,80 (0,201)
( )8Q 14,70 (0,065) 12,28 (0,139)
( )9Q 20,88 (0,013) 18,51 (0,030)
( )10Q 23,53 (0,009) 21,59 (0,018)
( )25Q 40,55 (0,026) 39,51 (0,035)
Nota (1): O modelo selecionado ( )2AR segue a forma, 1 1 2 2t t t ty y yφ φ ε− −= + + .
Nota (2): Números em parênteses indicam p-valores. ( )Q k refere-se às estatísticas de Ljung-Box
na série dos resíduos, com k defasagens.

35
FIGURA 1 – Medidas de erro de estimação e previsão para o 1PGD
Nota: A figura exclui o pequeno número existente de outliers.
FIGURA 2 – Medidas de erro de estimação e previsão para o 2PGD
Nota: A figura exclui o pequeno número existente de outliers.

36
a)
010.00020.00030.00040.00050.00060.00070.000
2/1/95 2/1/98 2/1/01 2/1/04 2/1/07
b)
-0,2
-0,1
0
0,1
0,2
0,3
0,4
3/1/95 3/1/98 3/1/01 3/1/04 3/1/07
FIGURA 3 - Evolução do Ibovespa e seus retornos: a) Índice; b) Retornos.
Fonte: Dados da Economatica.
FIGURA 4 – Fatos estilizados dos retornos do Ibovespa: a) Histograma dos retornos
padronizados; b) Gráfico QQ-normal dos retornos padronizados; c) Função de autocorrelação dos
retornos; d) Função de autocorrelação dos quadrados dos retornos.
FIGURA 5 – Funções de autocorrelação: a) Autocorrelação dos retornos (sem outliers); b)
Autocorrelação parcial dos retornos (sem outliers); c) Autocorrelação dos resíduos do AR(2); d)
Autocorrelação dos quadrados dos resíduos do AR(2).

37
FIGURA 6 – Funções univariadas do Modelo aditivo (5)
Nota (1): Os termos ret1, ret2,..., ret5 indicam as defasagens da variável explicativa.
FIGURA 7 – Medidas de ajuste do Modelo aditivo (5): a) Histograma dos resíduos
padronizados; b) Gráfico QQ-normal dos resíduos pad.; c) Função de autocorrelação dos resíduos
pad.; d) Função de autocorrelação dos quadrados dos resíduos pad.
FIGURA 8 – Resíduos ao quadrado e volatilidade estimada do Ibovespa: a) Resíduos do AR(2)
ao quadrado; b) Modelo aditivo (5); c) Modelo GJR(1,1); d) Modelo ARCH(7).
Nota: Áreas sombreadas denotam os períodos de crise de 2001, 2002 e 2007.