enabling knowledge management in the agronomic domain
TRANSCRIPT

Enabling knowledge management in the Agronomic Domain
Pierre Larmande Ins-tute of Computa-onnal Biology
(IBC) [email protected]
Mul7-‐scale omics integra7on
BIG DATA
Research areas
Workflow management
Seman7c web

Outline
• Data integration challenges in the Life Sciences"
• Ontologies/ Semantic Web Technologies"
• Agronomic Linked Data project"
• NGS Big Data project"

Data landscape in the Life Sciences
• The availability of biological data has increased"
• Advancements in:"• computational biology"• genome sequencing"• high-throughput technologies "
• Integrative approaches are necessary to understand the functioning of biological systems"

• Lack of effective approaches to integrate data that has created a gap between data and knowledge"
• Need for an effective method to bridge gap between data and underlying meaning"
• Harvest the power of overlaying different data sets"
Data integration challenges

• Today’s Web content is suitable for human consumption"
• Collection of documents"• the existence of links that establish connections
between documents"
• Low on data interoperability and lacks semantics."
Today’s Web

• Ontologies are formal representations of knowledge - definitions of concepts, their attributes and relations between them."
• To integrate data, improve machine interoperability and data analysis required a conceptual scaffold."
• Ontological terms used across databases"• provide cross-domain common entry points in the description."
• An array of ontologies are being used to bring structured integration of various datasets."
• The Open Biomedical Ontologies (OBO) initiative:"• serves as an umbrella for well structured orthogonal
ontologies."• Ontologies represented in OBO format and OWL"
Ontologies

Semantic Web Technology
• An extension of the current Web technologies."
• Enables navigation and meaningful use of digital resources."
• Support aggregation and integration of information from diverse sources."
• Based on common and standard formats."

Resource Description Framework (RDF)
• Framework for representing information about resources on the Web"
• Provides a labeled connection between two resources"
• Uses Unique Resource Identifiers (URI)"
• Statements take the form of triples:"
Subject Predicate Object
<Gene_A> <codes_for> <Protein_A>
RDF Triple

• Combining the triples results in a directed, labeled graph."
<Gene_A>
<Protein_A> <has_func7on>
<BP_A>
<MF_A>
<Gene_X>
<regulates>

SPARQL
• Language which allows querying RDF models (graphs) "
• Powerful, flexible"
• Its syntax is similar to the one of SQL"

Agronomic Linked Data (AgroLD)
• Semantic web based system that captures knowledge pertaining to plant data"
• Aim:"
• Capability to answer complex real life questions"
• Efficient information integration / retrieval"
• Easy extensibility"

AgroLD – Phase I
• AgroLD will be developed in phases – "
• Phase I: includes data on Oryza sps. and Arabidopsis thaliana!
• SPARQL endpoint: http://bioportal.lirmm.fr:8081/test/ "
AgroLD

• Integrates information from:"
• Ontologies: Gene Ontology, Plant Ontology, Plant Trait Ontology, Plant Environment Ontology, Crop Ontology"
• Other information sources: "
• Gene/Protein information: GOA, Gramene, Tair, OryzaBase, UniPort "
• QTL information: Gramene"
• Pathway information: RiceCyc, AraCyc"
• Germplasm information: Oryza Tag Line"
• Homology prediction: GreenPhyl"
Information in AgroLD

Biological process Cellular
Component
Molecular Function
Interaction
Gene
Taxon
Protein
protein
Modification
Pathway
has_par7cipant
contains
has_func7on
has_agent
acts_on
is_member_of
codes_for
occurs_in
has_source
protein
Target Gene
Knowledge representation in AgroLD

Future directions
• Phase II: having both wider and deeper coverage to promote comparative analysis"• Include varied data types – gene expression data, protein-protein
interaction, Transcription factor- target gene "
• Developing methods to aid the process of hypotheses generation - e.g. inference rules."
• Pluggable with workflow platforms e.g.: Galaxy, OpenAlea (VirtualPlants)."
• Engage with biologists to mobilise ‘user-pull’:"• Develop real world use cases – studying the molecular mechanism
of panicle differentiation in rice"

Gigwa: Genotype Inves7gator for Genome Wide Analyses

Aims of Gigwa
• Manage genomic, transcriptomic and genotyping data resul-ng from NGS analyses
• Handle large VCF files to filter, query and extract data
• Provide a web user interface to make the system accessible for all

Main features
o Based on NoSQL technology o Handles VCF files (Variant Call Format) and annota-ons
o Supports mul-ple variant types: SNPs, InDels, SSRs, SV
o Powerful genotyping queries o Easily scalable with MongoDB sharding
o Transparent access

Demo – Database selec7on
Mul--‐database with restricted access

Demo – datatypes selec7on
Several types of selection: Variant search is restricted to the selected reference sequences and subset of individuals

Demo -‐ Queries
Predefined queries

Demo – Filters selec7on
Several filters
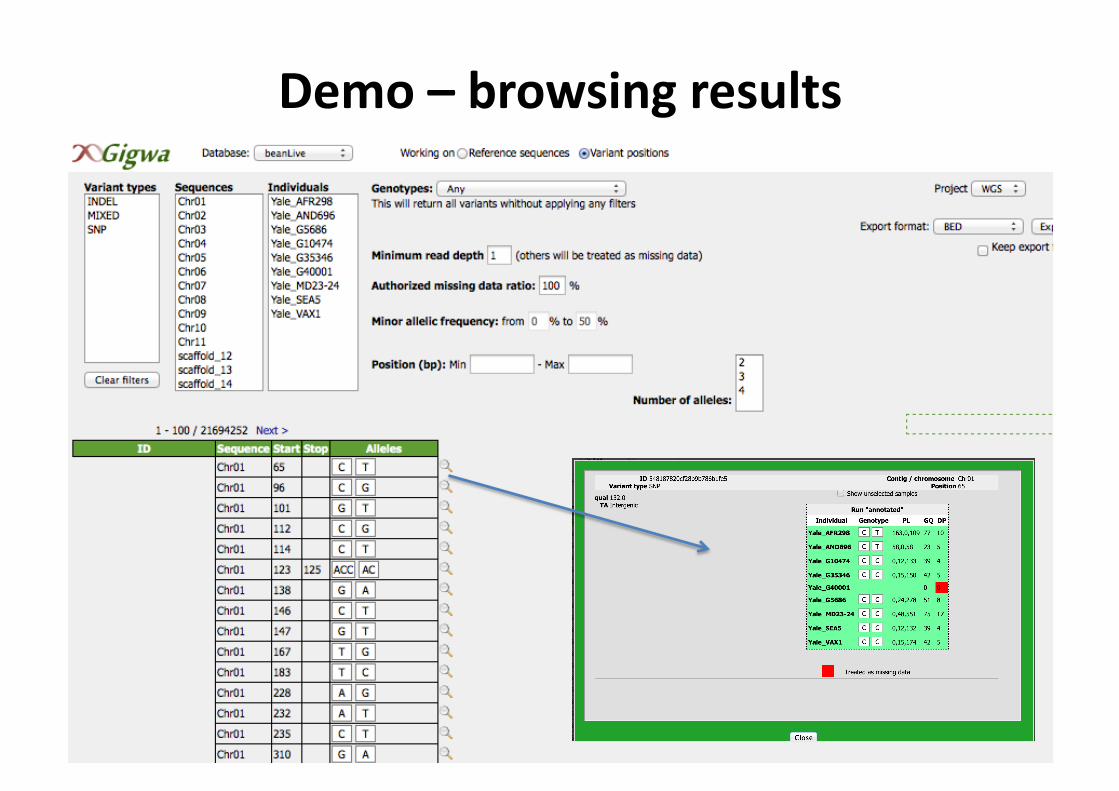
Demo – browsing results

Acknowledgements
Dr. Patrick Valduriez!
Dr. Clement Jonquet
Dr. Manuel Ruiz! Guilhem Sempéré!
Alexis Dereeper Gautier Sarah Dr. Aravind Venkatesan
Florian Philippe Contact: [email protected]