elasticsearch - life inside a cluster
TRANSCRIPT

Elasticsearch - Life Inside a Cluster
@farhan_faruque

Cluster
A cluster is a group of nodes with the same cluster.name that are working together to share data and to provide failover and scale, although a single node can form a cluster all by itself.

ScalabilityReal scalability comes from horizontal scale—the ability to add more nodes to the cluster and to spread load and reliability between them.
Elasticsearch is distributed by nature: it knows how to manage multiple nodes to provide scale and high availability. This also means that applications doesn’t need to care about it.

An Empty Cluster A cluster with one empty node

An Empty ClusterOne node in the cluster is elected to be the master node, which is in charge of managing cluster-wide changes like creating or deleting an index, or adding or removing a node from the cluster.
Any node can become the master.
As users, we can talk to any node in the cluster, including the master node

Cluster Healthcluster health, which reports a status of either green , yellow , or red GET /_cluster/healthreturns{
"cluster_name": "elasticsearch","status": "green","timed_out": "false",…..
}
green - All primary and replica shards are active.yellow - All primary shards are active, but not all replica shards are active.red - Not all primary shards are active.

Add an IndexAn index is just a logical namespace that points to one or more physical shards.A shard is a low-level worker unit that holds just a slice of all the data in the index.a shard is a single instance of Lucene, and is a complete search engine in its own right.Documents are stored in shards, and shards are allocated to nodes in cluster. As cluster grows or shrinks, Elasticsearch will automatically migrate shards between nodes so that the cluster remains balanced.

Add an IndexA shard can be either a primary shard or a replica shard.A replica shard is just a copy of a primary shard.
Replicas are used to provide redundant copies of data to protect against hardware failure, and to serve read requests.
The number of primary shards in an index is fixed at the time that an index is created, but the number of replica shards can be changed at any time.

ExampleLet’s create an index called blogs in our empty one-node cluster.PUT /blogs{
"settings" : {"number_of_shards" : 5,"number_of_replicas" : 1
}}
All five primary shards have been allocated to Node 1.(one replica of every primary shard)

A single-node cluster with an indexA single-node cluster with an index

Add Failoverstart a new node in exactly the same way as started the first one.
As long as the second node has the same cluster.name as the first node (see the ./config/elasticsearch.yml file), it should automatically discover and join the cluster run by the first node.
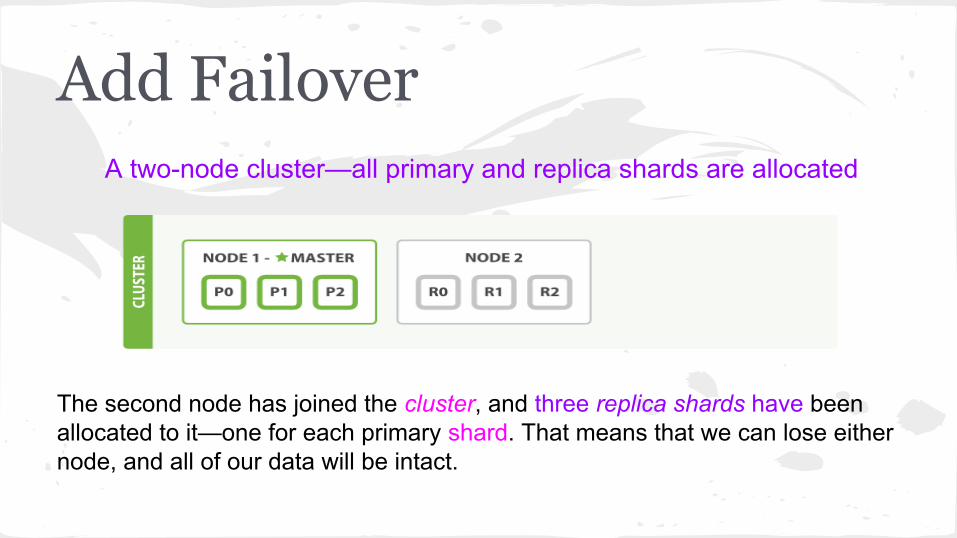
Add FailoverA two-node cluster—all primary and replica shards are allocated
The second node has joined the cluster, and three replica shards have been allocated to it—one for each primary shard. That means that we can lose either node, and all of our data will be intact.

Scale HorizontallyA three-node cluster— shards have been reallocated to spread
the load

Then Scale Some More
The number of primary shards is fixed at the moment an index is created.read requests—searches or document retrieval—can be handled by a primary or a replica shard, so the more copies of data ,the more search throughput.The number of replica shards can be changed dynamically : PUT /blogs/_settings{ "number_of_replicas" : 2}

Increasing ReplicaIncreasing the number_of_replicas to 2

Coping with Failure
Cluster after killing one node

Reference