eecc722 - shaaban #1 lec # 2 fall 2002 9-11-2002 simultaneous multithreading (smt) an evolutionary...
Post on 21-Dec-2015
215 views
TRANSCRIPT

EECC722 - ShaabanEECC722 - Shaaban#1 Lec # 2 Fall 2002 9-11-2002
Simultaneous Multithreading (SMT)Simultaneous Multithreading (SMT)• An evolutionary processor architecture originally
introduced in 1995 by Dean Tullsen at the University of Washington that aims at reducing resource waste in wide issue processors.
• SMT has the potential of greatly enhancing processor computational capabilities by:
– Exploiting thread-level parallelism (TLP), simultaneously executing instructions from different threads during the same cycle.
– Providing multiple hardware contexts, hardware thread scheduling and context switching capability.

EECC722 - ShaabanEECC722 - Shaaban#2 Lec # 2 Fall 2002 9-11-2002
SMT IssuesSMT Issues• SMT CPU performance gain potential.• Modifications to Superscalar CPU architecture necessary to support SMT.• SMT performance evaluation vs. Fine-grain multithreading Superscalar, Chip
Multiprocessors.• Hardware techniques to improve SMT performance:
– Optimal level one cache configuration for SMT.– SMT thread instruction fetch, issue policies.– Instruction recycling (reuse) of decoded instructions.
• Software techniques:– Compiler optimizations for SMT.– Software-directed register deallocation.– Operating system behavior and optimization.
• SMT support for fine-grain synchronization.• SMT as a viable architecture for network processors.• Current SMT implementation: Intel’s Hyper-Threading (2-way SMT) Microarchitecture
and performance in compute-intensive workloads.
EECC722 - ShaabanEECC722 - Shaaban#3 Lec # 2 Fall 2002 9-11-2002
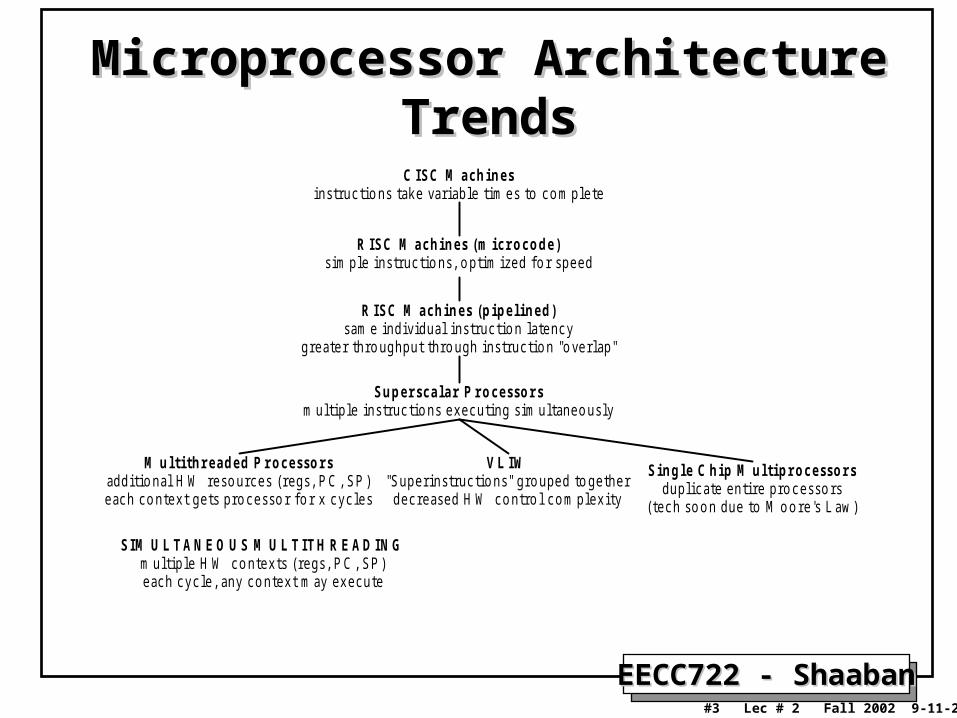
Microprocessor Architecture TrendsMicroprocessor Architecture Trends
C IS C M ac h i n e sins truc tio ns take var iable t im e s to c o m ple te
R IS C M ac h i n e s ( m i c r o c o d e )s im ple ins truc tio ns , o ptim ize d fo r spe e d
R IS C M ac h i n e s ( p i p e l i n e d )s am e individual ins truc tio n late nc y
gre ate r thro ughput thro ugh ins truc tio n "o ve r lap"
S u p e r s c a l ar P r o c e s s o r sm ultiple ins truc tio ns e xe c uting s im ultane o us ly
M u l t i t h r e ad e d P r o c e s s o r saddit io nal H W re so urc e s ( re gs , P C , SP )e ac h c o nte xt ge ts pro c e s so r fo r x c yc le s
V L IW"Supe r ins truc tio ns " gro upe d to ge the r
de c re ase d H W c o ntro l c o m ple xity
S i n g l e C h i p M u l t i p r o c e s s o r sduplic ate e ntire pro c e s so rs
( te c h so o n due to M o o re 's Law)
S IM U L TA N E O U S M U L TITH R E A D IN Gm ultiple H W c o nte xts ( re gs , P C , SP )e ac h c yc le , any c o nte xt m ay e xe c ute
EECC722 - ShaabanEECC722 - Shaaban#4 Lec # 2 Fall 2002 9-11-2002
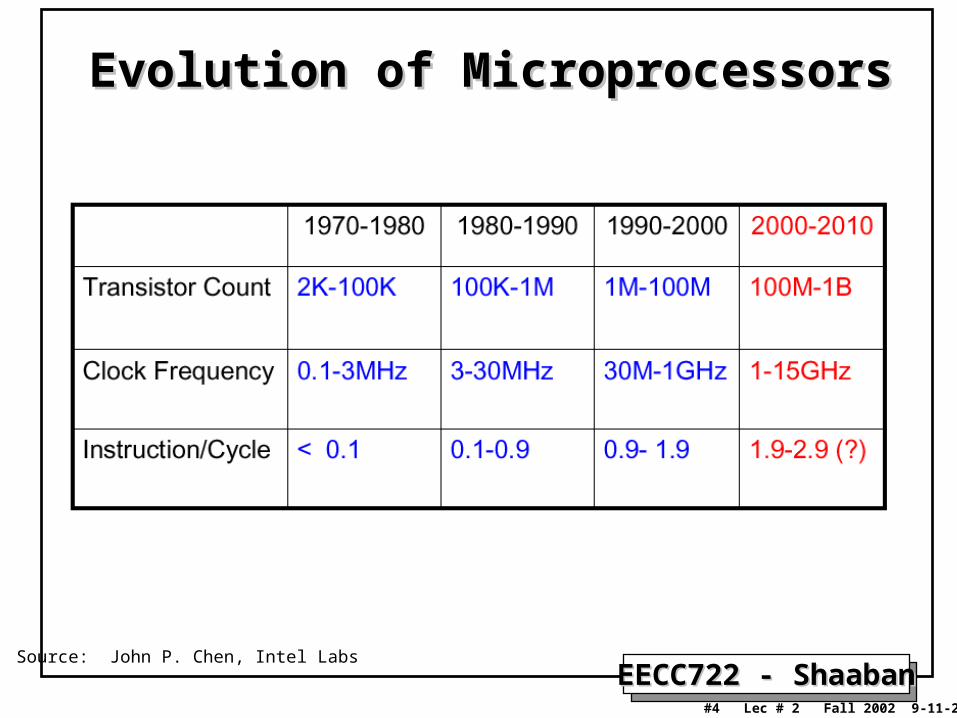
Evolution of MicroprocessorsEvolution of Microprocessors
Source: John P. Chen, Intel Labs

EECC722 - ShaabanEECC722 - Shaaban#5 Lec # 2 Fall 2002 9-11-2002
CPU Architecture Evolution:CPU Architecture Evolution:
Single Threaded/Issue PipelineSingle Threaded/Issue Pipeline
• Traditional 5-stage integer pipeline.• Increases Throughput: Ideal CPI = 1
F etc h M em oryExec uteD ec ode W ritebac k
M em ory Hierarc hy (M anagem ent)
Regis ter F ile
P C
S P

EECC722 - ShaabanEECC722 - Shaaban#6 Lec # 2 Fall 2002 9-11-2002
F etc h i M em ory iExec ute iD ec ode i W ritebac k i
Regis ter F ile
P C
S P
F etc h i+ 1 M em ory i+ 1Exec ute i+ 1D ec ode i+ 1W ritebac k
i+ 1
Mem
ory Hierarchy (M
anagement)
F etc h i M em ory iExec ute iD ec ode i W ritebac k i
CPU Architecture Evolution:CPU Architecture Evolution:
Superscalar ArchitecturesSuperscalar Architectures• Fetch, decode, execute, etc. more than one instruction per cycle (CPI <
1).• Limited by instruction-level parallelism (ILP).
EECC722 - ShaabanEECC722 - Shaaban#7 Lec # 2 Fall 2002 9-11-2002
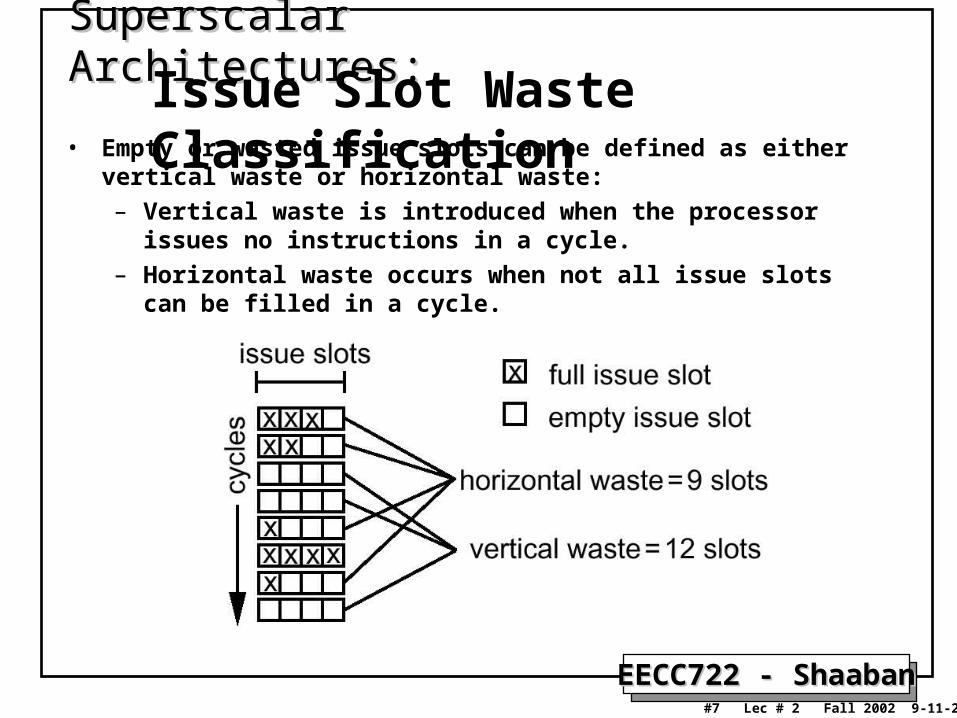
• Empty or wasted issue slots can be defined as either vertical waste or horizontal waste:
– Vertical waste is introduced when the processor issues no instructions in a cycle.
– Horizontal waste occurs when not all issue slots can be filled in a cycle.
Superscalar Architectures:Superscalar Architectures:Issue Slot Waste Classification

EECC722 - ShaabanEECC722 - Shaaban#8 Lec # 2 Fall 2002 9-11-2002
Sources of Unused Issue Cycles in an 8-issue Superscalar Processor.
Processor busy represents the utilized issue slots; allothers represent wasted issue slots.
61% of the wasted cycles are vertical waste, theremainder are horizontal waste.
Workload: SPEC92 benchmark suite.
Source: Simultaneous Multithreading: Maximizing On-Chip Parallelism Dean Tullsen et al., Proceedings of the 22rd Annual International Symposium on Computer Architecture, June 1995, pages 392-403.
EECC722 - ShaabanEECC722 - Shaaban#9 Lec # 2 Fall 2002 9-11-2002
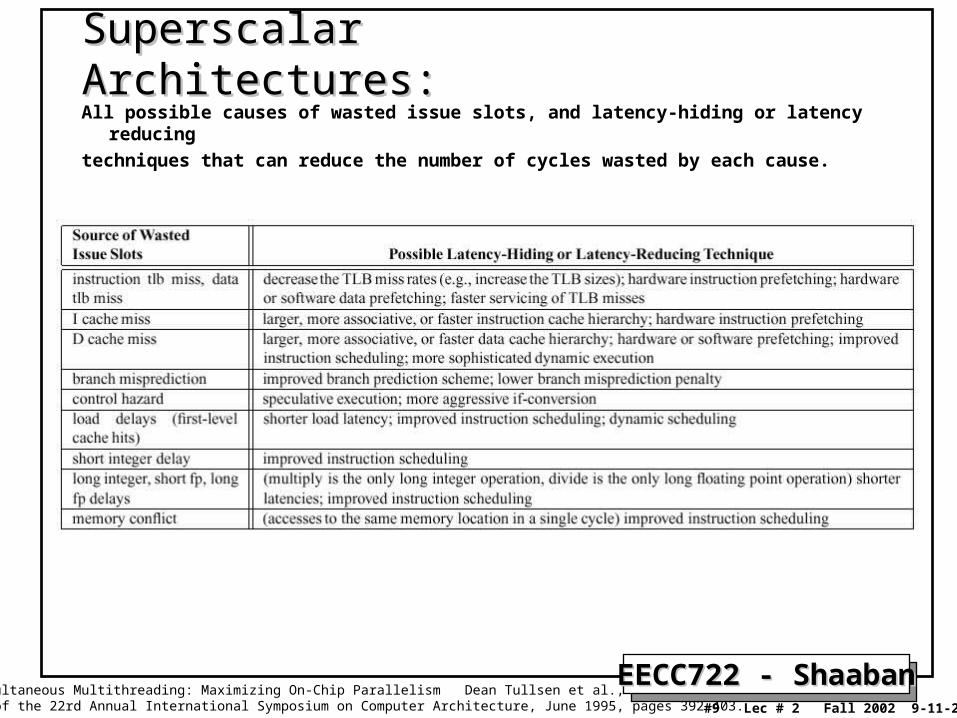
Superscalar Architectures:Superscalar Architectures:All possible causes of wasted issue slots, and latency-hiding or latency reducing
techniques that can reduce the number of cycles wasted by each cause.
Source: Simultaneous Multithreading: Maximizing On-Chip Parallelism Dean Tullsen et al., Proceedings of the 22rd Annual International Symposium on Computer Architecture, June 1995, pages 392-403.

EECC722 - ShaabanEECC722 - Shaaban#10 Lec # 2 Fall 2002 9-11-2002
Fine-grain or Traditional Multithreaded ProcessorsFine-grain or Traditional Multithreaded Processors
• Multiple HW contexts (PC, SP, and registers).
• One context gets CPU for x cycles at a time.
• Limited by thread-level parallelism (TLP):– Can reduce some of the vertical issue slot waste.– No reduction in horizontal issue slot waste.
• Example Architectures: HEP, Tera.
Advanced CPU Architectures:Advanced CPU Architectures:

EECC722 - ShaabanEECC722 - Shaaban#11 Lec # 2 Fall 2002 9-11-2002
VLIW: Intel/HPVLIW: Intel/HP IA-64
Explicitly Parallel Instruction Computing (EPIC)Explicitly Parallel Instruction Computing (EPIC)
• Strengths: – Allows for a high level of instruction parallelism (ILP).– Takes a lot of the dependency analysis out of HW and places focus
on smart compilers.
• Weakness: – Limited by instruction-level parallelism (ILP) in a single thread.– Keeping Functional Units (FUs) busy (control hazards).– Static FUs Scheduling limits performance gains.– Resulting overall performance heavily depends on compiler
performance.
Advanced CPU Architectures:Advanced CPU Architectures:

EECC722 - ShaabanEECC722 - Shaaban#12 Lec # 2 Fall 2002 9-11-2002
Single Chip MultiprocessorSingle Chip Multiprocessor• Strengths:
– Create a single processor block and duplicate.
– Takes a lot of the dependency analysis out of HW and places focus on smart compilers.
• Weakness: – Performance limited by individual thread performance
(ILP).
Advanced CPU Architectures:Advanced CPU Architectures:

EECC722 - ShaabanEECC722 - Shaaban#13 Lec # 2 Fall 2002 9-11-2002
Advanced CPU Architectures:Advanced CPU Architectures:
Regis ter F ile i
P C i
S P i
R e g is t e r F i le i+ 1
P C i+ 1
S P i+ 1
Regis ter F ile n
P C n
S P n
S upers c alar (T w o-w ay) P ipelinei
S upers c alar (T w o-w ay) P ipelinei+ 1
S upers c alar (T w o-w ay) P ipelinen
Mem
ory Hierarchy (M
anagement)
Contro lUnit
i
Contro lUniti+ 1
Contro lUnit
n
Single Chip Multiprocessor

EECC722 - ShaabanEECC722 - Shaaban#14 Lec # 2 Fall 2002 9-11-2002
SMT: Simultaneous Multithreading• Multiple Hardware Contexts running at the same time
(HW context: registers, PC, and SP).
• Reduces both horizontal and vertical waste by having multiple threads keeping functional units busy during every cycle.
• Builds on top of current time-proven advancements in CPU design: superscalar, dynamic scheduling, hardware speculation, dynamic HW branch prediction.
• Enabling Technology: VLSI logic density in the order of hundreds of millions of transistors/Chip.

EECC722 - ShaabanEECC722 - Shaaban#15 Lec # 2 Fall 2002 9-11-2002
SMT
• With multiple threads running penalties from long-latency operations, cache misses, and branch mispredictions will be hidden:– Reduction of both horizontal and vertical waste and thus
improved Instructions Issued Per Cycle (IPC) rate.
• Pipelines are separated until issue stage.
• Functional units are shared among all contexts during every cycle:
– More complicated writeback stage.
• More threads issuing to functional units results in higher resource utilization.

EECC722 - ShaabanEECC722 - Shaaban#16 Lec # 2 Fall 2002 9-11-2002
SMT: Simultaneous Multithreading
Regis ter F ile i
P C i
S P i
R e g is t e r F i le i+ 1
P C i+ 1
S P i+ 1
Regis ter F ile n
P C n
S P n
S upers c alar (T w o-w ay) P ipelinei
S upers c alar (T w o-w ay) P ipelinei+ 1
S upers c alar (T w o-w ay) P ipelinen
Mem
ory Hierarchy (M
anagement)
Control U
nit (Chip-W
ide)

EECC722 - ShaabanEECC722 - Shaaban#17 Lec # 2 Fall 2002 9-11-2002
The Power Of SMTThe Power Of SMT1 1
1
1 1 1 1
1 1
1
1 1
2 2
3 3
4
5 5
1 1 1 1
2 2 2
3
4 4 4
1 1 2
2 2 3
3 3 4 5
2 2 4
4 5
1 1 1 1
2 2 3
1 2 4
1 2 5
Tim
e (p
roce
ssor
cyc
les)
Superscalar Traditional Multithreaded
Simultaneous Multithreading
Rows of squares represent instruction issue slotsBox with number x: instruction issued from thread xEmpty box: slot is wasted

EECC722 - ShaabanEECC722 - Shaaban#18 Lec # 2 Fall 2002 9-11-2002
SMT Performance ExampleSMT Performance Example
Inst Code Description Functional unitA LUI R5,100 R5 = 100 Int ALUB FMUL F1,F2,F3 F1 = F2 x F3 FP ALUC ADD R4,R4,8 R4 = R4 + 8 Int ALUD MUL R3,R4,R5 R3 = R4 x R5 Int mul/divE LW R6,R4 R6 = (R4) Memory portF ADD R1,R2,R3 R1 = R2 + R3 Int ALUG NOT R7,R7 R7 = !R7 Int ALUH FADD F4,F1,F2 F4=F1 + F2 FP ALUI XOR R8,R1,R7 R8 = R1 XOR R7 Int ALUJ SUBI R2,R1,4 R2 = R1 – 4 Int ALUK SW ADDR,R2 (ADDR) = R2 Memory port
• 4 integer ALUs (1 cycle latency)
• 1 integer multiplier/divider (3 cycle latency)
• 3 memory ports (2 cycle latency, assume cache hit)
• 2 FP ALUs (5 cycle latency)
• Assume all functional units are fully-pipelined
EECC722 - ShaabanEECC722 - Shaaban#19 Lec # 2 Fall 2002 9-11-2002
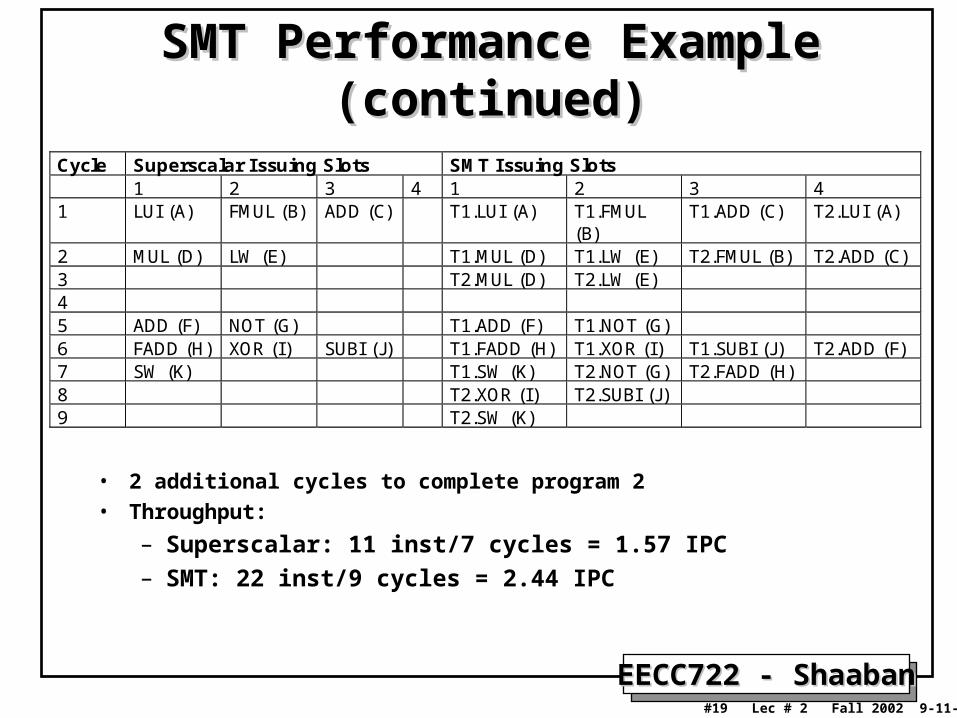
SMT Performance Example SMT Performance Example (continued)(continued)
Cycle Superscalar Issuing Slots SMT Issuing Slots1 2 3 4 1 2 3 4
1 LUI (A) FMUL (B) ADD (C) T1.LUI (A) T1.FMUL(B)
T1.ADD (C) T2.LUI (A)
2 MUL (D) LW (E) T1.MUL (D) T1.LW (E) T2.FMUL (B) T2.ADD (C)3 T2.MUL (D) T2.LW (E)45 ADD (F) NOT (G) T1.ADD (F) T1.NOT (G)6 FADD (H) XOR (I) SUBI (J ) T1.FADD (H) T1.XOR (I) T1.SUBI (J ) T2.ADD (F)7 SW (K) T1.SW (K) T2.NOT (G) T2.FADD (H)8 T2.XOR (I) T2.SUBI (J )9 T2.SW (K)
• 2 additional cycles to complete program 2
• Throughput:
– Superscalar: 11 inst/7 cycles = 1.57 IPC
– SMT: 22 inst/9 cycles = 2.44 IPC

EECC722 - ShaabanEECC722 - Shaaban#20 Lec # 2 Fall 2002 9-11-2002
Modifications to Superscalar CPUs Modifications to Superscalar CPUs Necessary to support SMTNecessary to support SMT
• Multiple program counters and some mechanism by which one fetch unit selects one each cycle (thread instruction fetch policy).
• A separate return stack for each thread for predicting subroutine return destinations.
• Per-thread instruction retirement, instruction queue flush, and trap mechanisms.
• A thread id with each branch target buffer entry to avoid predicting phantom branches.
• A larger register file, to support logical registers for all threads plus additional registers for register renaming. (may require additional pipeline stages).
• A higher available main memory fetch bandwidth may be required.• Larger data TLB with more entries to compensate for increased virtual to
physical address translations.
• Improved cache to offset the cache performance degradation due to cache sharing among the threads and the resulting reduced locality.
– e.g Private per-thread vs. shared L1 cache.

EECC722 - ShaabanEECC722 - Shaaban#21 Lec # 2 Fall 2002 9-11-2002
Current Implementations of SMTCurrent Implementations of SMT• Intel’s recent implementation of Hyper-Threading
Technology (2-thread SMT) in its current P4 Xeon processor family represent the first and only current implementation of SMT in a commercial microprocessor.
• The Alpha EV8 (4-thread SMT) originally scheduled for production in 2001 is currently on indefinite hold :(
• Current technology has the potential for 4-8 simultaneous threads:
– Based on transistor count and design complexity.
EECC722 - ShaabanEECC722 - Shaaban#22 Lec # 2 Fall 2002 9-11-2002
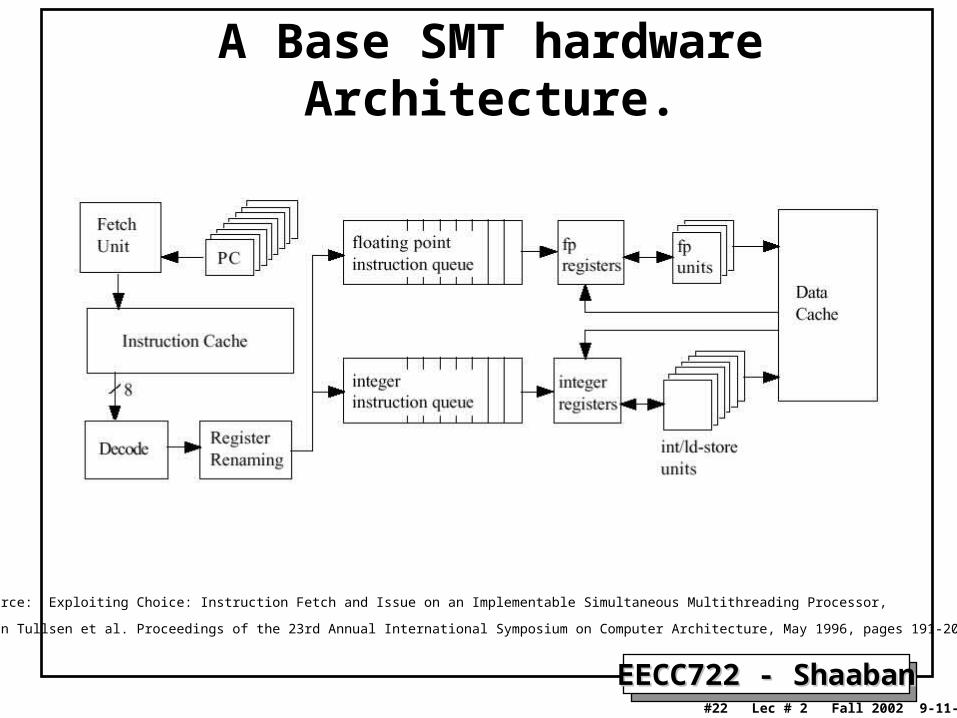
A Base SMT hardware Architecture.
Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,
Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202.

EECC722 - ShaabanEECC722 - Shaaban#23 Lec # 2 Fall 2002 9-11-2002
Example SMT Vs. Superscalar PipelineExample SMT Vs. Superscalar Pipeline
• The pipeline of (a) a conventional superscalar processor and (b) that pipeline modified for an SMT processor, along with some implications of those pipelines.
Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,
Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202.
EECC722 - ShaabanEECC722 - Shaaban#24 Lec # 2 Fall 2002 9-11-2002
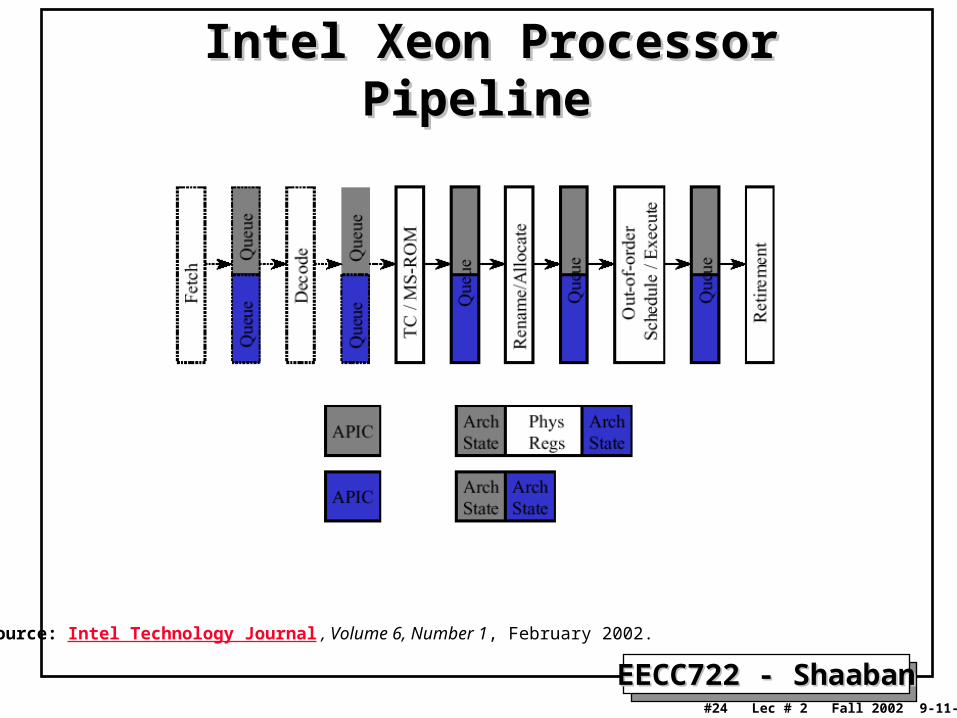
Intel Xeon Processor PipelineIntel Xeon Processor Pipeline
Source: Intel Technology Journal , Volume 6, Number 1, February 2002.

EECC722 - ShaabanEECC722 - Shaaban#25 Lec # 2 Fall 2002 9-11-2002
Intel Xeon Out-of-order Execution Intel Xeon Out-of-order Execution Engine Detailed Pipeline Engine Detailed Pipeline
Source: Intel Technology Journal , Volume 6, Number 1, February 2002.

EECC722 - ShaabanEECC722 - Shaaban#26 Lec # 2 Fall 2002 9-11-2002
SMT Performance ComparisonSMT Performance Comparison• Instruction throughput from simulations by Eggers et al. at The University of Washington, using both multiprogramming and parallel workloads:
Multiprogramming workload
Superscalar Traditional SMTThreads Multithreading 1 2.7 2.6 3.1 2 - 3.3 3.5 4 - 3.6 5.7 8 - 2.8 6.2
Parallel Workload
Superscalar MP2 MP4 Traditional SMTThreads Multithreading 1 3.3 2.4 1.5 3.3 3.3 2 - 4.3 2.6 4.1 4.7 4 - - 4.2 4.2 5.6 8 - - - 3.5 6.1

EECC722 - ShaabanEECC722 - Shaaban#27 Lec # 2 Fall 2002 9-11-2002
Simultaneous Vs. Fine-Grain Multithreading Performance
Instruction throughput as a function of the number of threads. (a)-(c) show the throughput by thread priority for particular models, and (d) shows the total throughput for all threads for each of the six machine models. The lowest segment of each bar is the contribution of the highest priority thread to the total throughput.
Source: Simultaneous Multithreading: Maximizing On-Chip Parallelism Dean Tullsen et al., Proceedings of the 22rd Annual International Symposium on Computer Architecture, June 1995, pages 392-403.
EECC722 - ShaabanEECC722 - Shaaban#28 Lec # 2 Fall 2002 9-11-2002
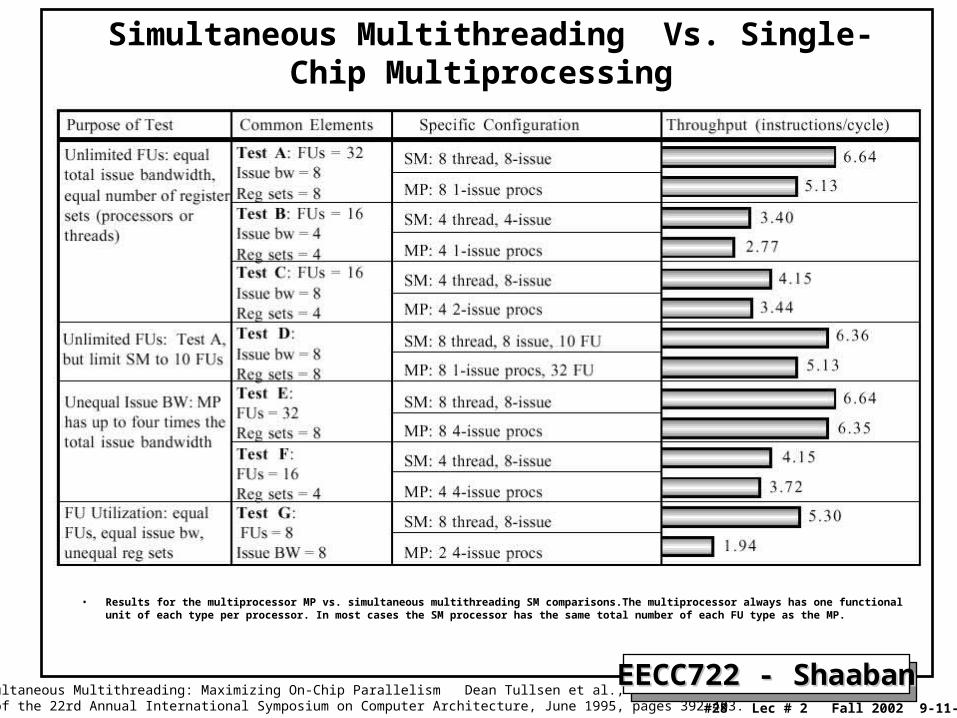
• Results for the multiprocessor MP vs. simultaneous multithreading SM comparisons.The multiprocessor always has one functional unit of each type per processor. In most cases the SM processor has the same total number of each FU type as the MP.
Simultaneous Multithreading Vs. Single-Chip Multiprocessing
Source: Simultaneous Multithreading: Maximizing On-Chip Parallelism Dean Tullsen et al., Proceedings of the 22rd Annual International Symposium on Computer Architecture, June 1995, pages 392-403.

EECC722 - ShaabanEECC722 - Shaaban#29 Lec # 2 Fall 2002 9-11-2002
Impact of Level 1 Cache Sharing on SMT PerformanceImpact of Level 1 Cache Sharing on SMT Performance • Results for the simulated cache configurations, shown relative to the
throughput (instructions per cycle) of the 64s.64p
• The caches are specified as:
[total I cache size in KB][private or shared].[D cache size][private or shared]
For instance, 64p.64s has eight private 8 KB I caches and a shared 64 KB data
Source: Simultaneous Multithreading: Maximizing On-Chip Parallelism Dean Tullsen et al., Proceedings of the 22rd Annual International Symposium on Computer Architecture, June 1995, pages 392-403.

EECC722 - ShaabanEECC722 - Shaaban#30 Lec # 2 Fall 2002 9-11-2002
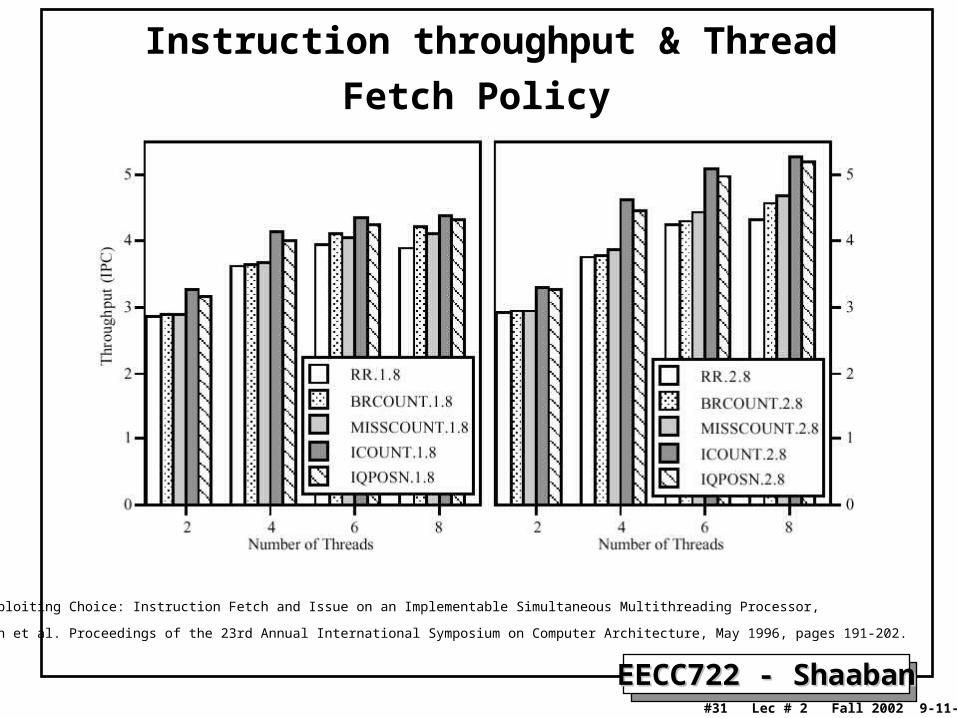
SMT Thread Instruction Fetch Scheduling PoliciesSMT Thread Instruction Fetch Scheduling Policies• Round Robin:
– Instruction from Thread 1, then Thread 2, then Thread 3, etc. (eg RR 1.8 : each cycle one thread fetches up to eight instructions
RR 2.4 each cycle two threads fetch up to four instructions each)
• BR-Count: – Give highest priority to those threads that are least likely to be on a wrong path
by by counting branch instructions that are in the decode stage, the rename stage, and the instruction queues, favoring those with the fewest unresolved branches.
• MISS-Count:– Give priority to those threads that have the fewest outstanding Data cache misses.
• I-Count:– Highest priority assigned to thread with the lowest number of instructions in
static portion of pipeline (decode, rename, and the instruction queues).
• IQPOSN:– Give lowest priority to those threads with instructions closest to the head of either
the integer or floating point instruction queues (the oldest instruction is at the head of the queue).
EECC722 - ShaabanEECC722 - Shaaban#31 Lec # 2 Fall 2002 9-11-2002
Instruction throughput & Thread Fetch Policy
Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,
Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202.
EECC722 - ShaabanEECC722 - Shaaban#32 Lec # 2 Fall 2002 9-11-2002
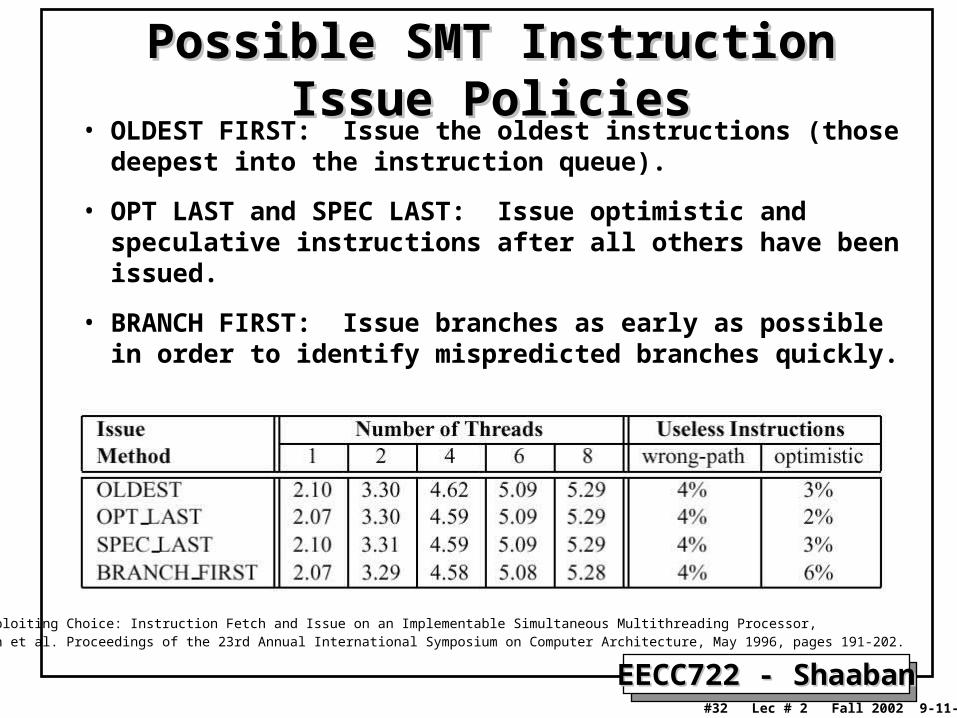
Possible SMT Instruction Issue PoliciesPossible SMT Instruction Issue Policies• OLDEST FIRST: Issue the oldest instructions (those
deepest into the instruction queue).
• OPT LAST and SPEC LAST: Issue optimistic and speculative instructions after all others have been issued.
• BRANCH FIRST: Issue branches as early as possible in order to identify mispredicted branches quickly.
Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202.

EECC722 - ShaabanEECC722 - Shaaban#33 Lec # 2 Fall 2002 9-11-2002
RIT-CE SMT Project GoalsRIT-CE SMT Project Goals• Investigate performance gains from exploiting Thread-
Level Parallelism (TLP) in addition to current Instruction-Level Parallelism (ILP) in processor design.
• Design and simulate an architecture incorporating Simultaneous Multithreading (SMT) including OS interaction (LINUX-based kernel?).
• Study operating system and compiler optimizations to improve SMT processor performance.
• Performance studies with various workloads using the simulator/OS/compiler:– Suitability for fine-grained parallel applications?– Effect on multimedia applications?
EECC722 - ShaabanEECC722 - Shaaban#34 Lec # 2 Fall 2002 9-11-2002
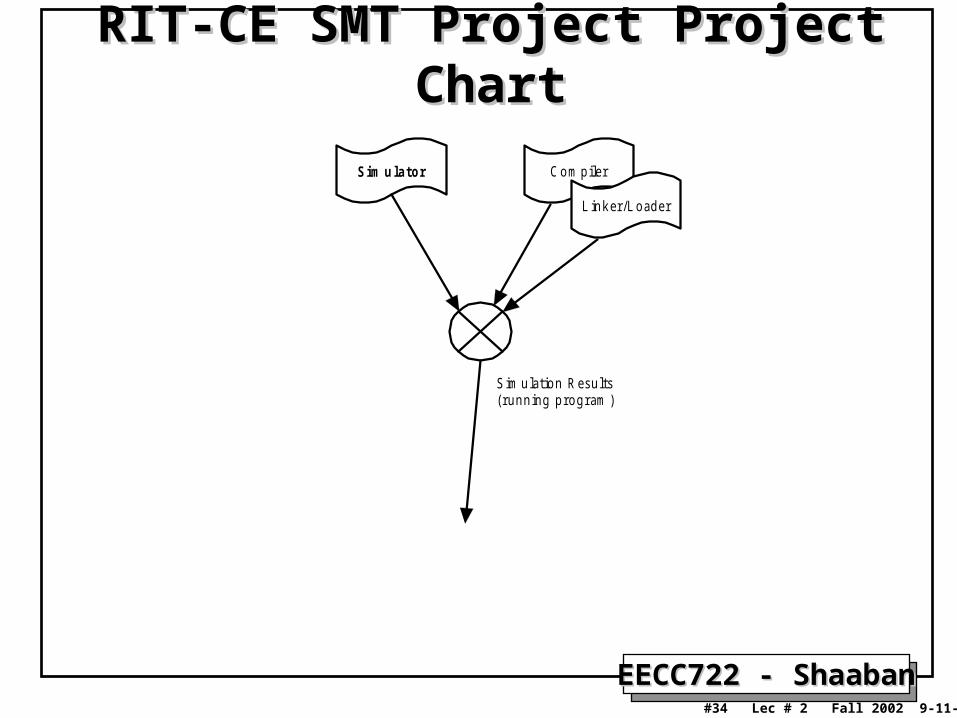
RIT-CE SMT Project Project ChartRIT-CE SMT Project Project Chart
S im u la to r Com piler
Linker/Loader
S im ulation Res ults(running program )
S y s te m C a ll Pro x y(O S s pe cif ic)
Kernel Code
S im ulator w ill repres enthardw are w ith kernelc ontext
Kernel Code w illprovide the threadthat w ill be heldin the HW kernelc ontext
Com piler is s im ply ahac ked vers ion gc c(us ing as s em bler from hos ts ys tem )
P roc es s M anagem entM em ory M anagem ent
S M T Kernel S im ulation

EECC722 - ShaabanEECC722 - Shaaban#35 Lec # 2 Fall 2002 9-11-2002
Simulator (sim-SMT) @ RIT CESimulator (sim-SMT) @ RIT CE• Execution-driven, performance simulator.• Derived from Simple Scalar tool set.• Simulates cache, branch prediction, five pipeline stages• Flexible:
– Configuration File controls cache size, buffer sizes, number of functional units.• Cross compiler used to generate Simple Scalar assembly language.• Binary utilities, compiler, and assembler available.• Standard C library (libc) has been ported.• Sim-SMT Simulator Limitations:Sim-SMT Simulator Limitations:
– Does not keep precise exceptions.– System Call’s instructions not tracked.– Limited memory space:
• Four test programs’ memory spaces running on one simulator memory space
• Easy to run out of stack space

EECC722 - ShaabanEECC722 - Shaaban#36 Lec # 2 Fall 2002 9-11-2002
Simulator Memory Address SpaceSimulator Memory Address Space

EECC722 - ShaabanEECC722 - Shaaban#37 Lec # 2 Fall 2002 9-11-2002
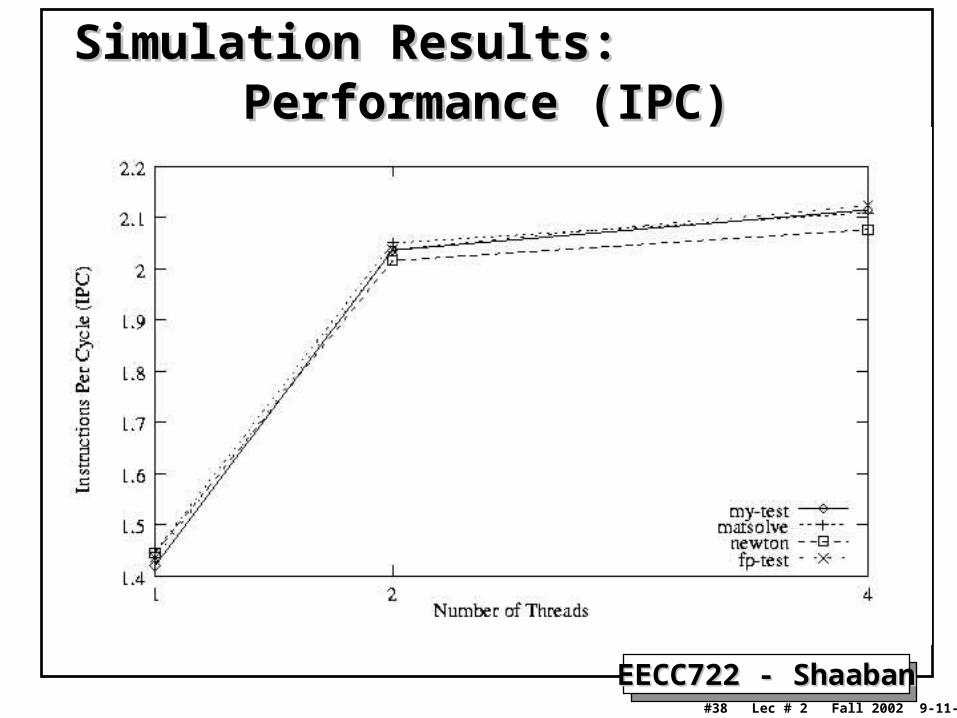
sim-SMTsim-SMT Simulation Runs & Results Simulation Runs & Results• Test Programs used:
– Newton interpolation.– Matrix Solver using LU decomposition.– Integer Test Program.– FP Test Program.
• Simulations of a single program– 1,2, and 4 threads.
• System simulations involve a combination of all programs simultaneously– Several different combinations were run
• From simulation results:– Performance increase:
• Biggest increase occurs when changing from one to two threads.
– Higher issue rate, functional unit utilization.
EECC722 - ShaabanEECC722 - Shaaban#38 Lec # 2 Fall 2002 9-11-2002
Performance (IPC)Performance (IPC)Simulation Results:Simulation Results:

EECC722 - ShaabanEECC722 - Shaaban#39 Lec # 2 Fall 2002 9-11-2002
Simulation Results: Simulation Results: Simulation Time Simulation Time

EECC722 - ShaabanEECC722 - Shaaban#40 Lec # 2 Fall 2002 9-11-2002
Instruction Issue RateInstruction Issue RateSimulation Results:Simulation Results:

EECC722 - ShaabanEECC722 - Shaaban#41 Lec # 2 Fall 2002 9-11-2002
Performance Vs. Issue BWPerformance Vs. Issue BWSimulation Results:Simulation Results:

EECC722 - ShaabanEECC722 - Shaaban#42 Lec # 2 Fall 2002 9-11-2002
Functional Unit UtilizationFunctional Unit UtilizationSimulation Results:Simulation Results:
EECC722 - ShaabanEECC722 - Shaaban#43 Lec # 2 Fall 2002 9-11-2002
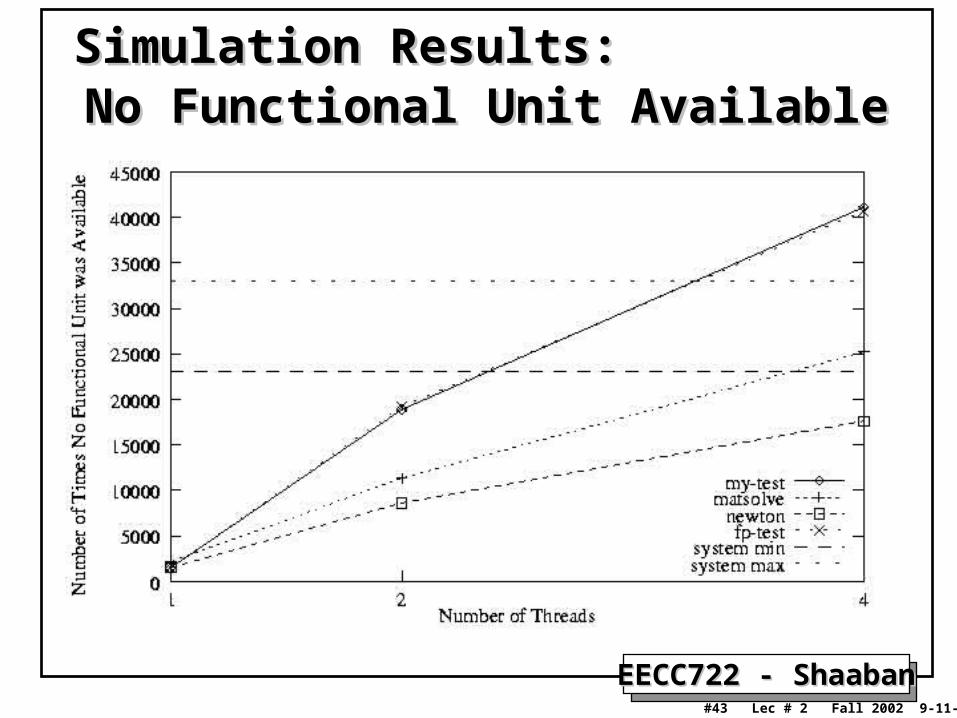
No Functional Unit AvailableNo Functional Unit AvailableSimulation Results:Simulation Results:

EECC722 - ShaabanEECC722 - Shaaban#44 Lec # 2 Fall 2002 9-11-2002
Horizontal Waste RateHorizontal Waste RateSimulation Results:Simulation Results:
EECC722 - ShaabanEECC722 - Shaaban#45 Lec # 2 Fall 2002 9-11-2002
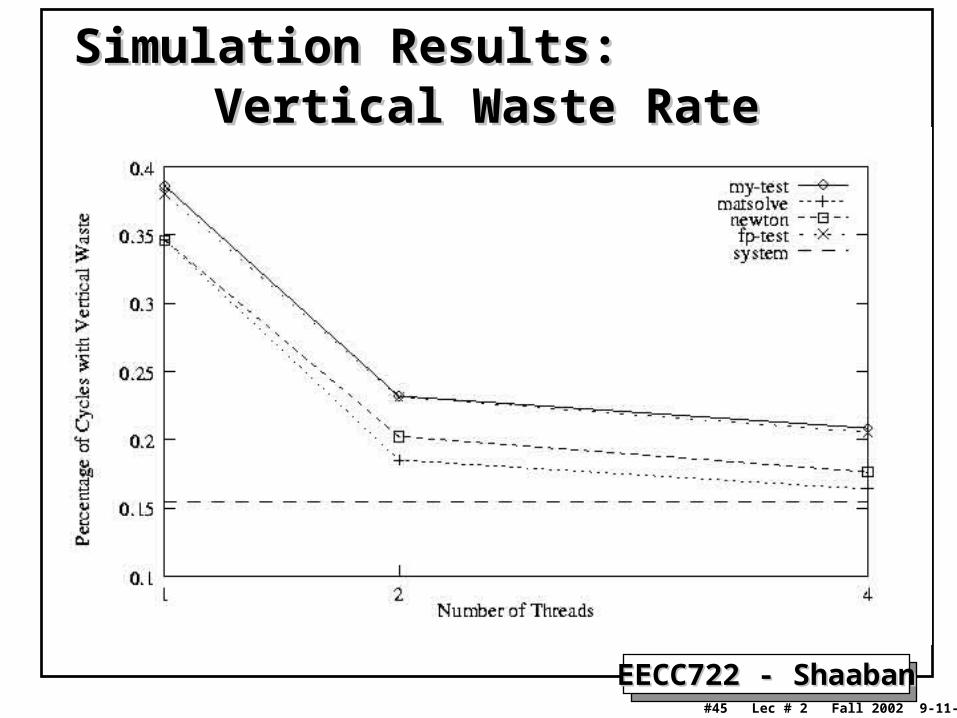
Vertical Waste RateVertical Waste RateSimulation Results:Simulation Results:

EECC722 - ShaabanEECC722 - Shaaban#46 Lec # 2 Fall 2002 9-11-2002
SMT: Simultaneous Multithreading• Strengths:
– Overcomes the limitations imposed by low single thread instruction-level parallelism.
– Multiple threads running will hide individual control hazards (branch mispredictions).
• Weaknesses: – Additional stress placed on memory hierarchy Control unit
complexity.– Sizing of resources (cache, branch prediction, TLBs etc.)– Accessing registers (32 integer + 32 FP for each HW context):
• Some designs devote two clock cycles for both register reads and register writes.