ee898 lec 3.1 10/8/04 oct. 8, 2004 prof. seok-bum ko electrical engineering university of...
Post on 20-Dec-2015
215 views
TRANSCRIPT

EE898Lec 3.1
10/8/04
Oct. 8, 2004
Prof. Seok-Bum Ko
Electrical Engineering
University of Saskatchewan
EE898.02Architecture of Digital Systems
Lecture 3
Cache Memory

EE898Lec 3.2
10/8/04
CPU-DRAM Gap
• 1980: no cache in µproc; 1995 2-level cache on chip(1989 first Intel µproc with a cache on chip)
Question: Who Cares About the Memory Hierarchy?
µProc60%/yr.
DRAM7%/yr.
1
10
100
1000198
0198
1 198
3198
4198
5 198
6198
7198
8198
9199
0199
1 199
2199
3199
4199
5199
6199
7199
8 199
9200
0
DRAM
CPU198
2
Processor-MemoryPerformance Gap:(grows 50% / year)
Per
form
ance
“Moore’s Law”
“Less’ Law?”
EE898Lec 3.3
10/8/04
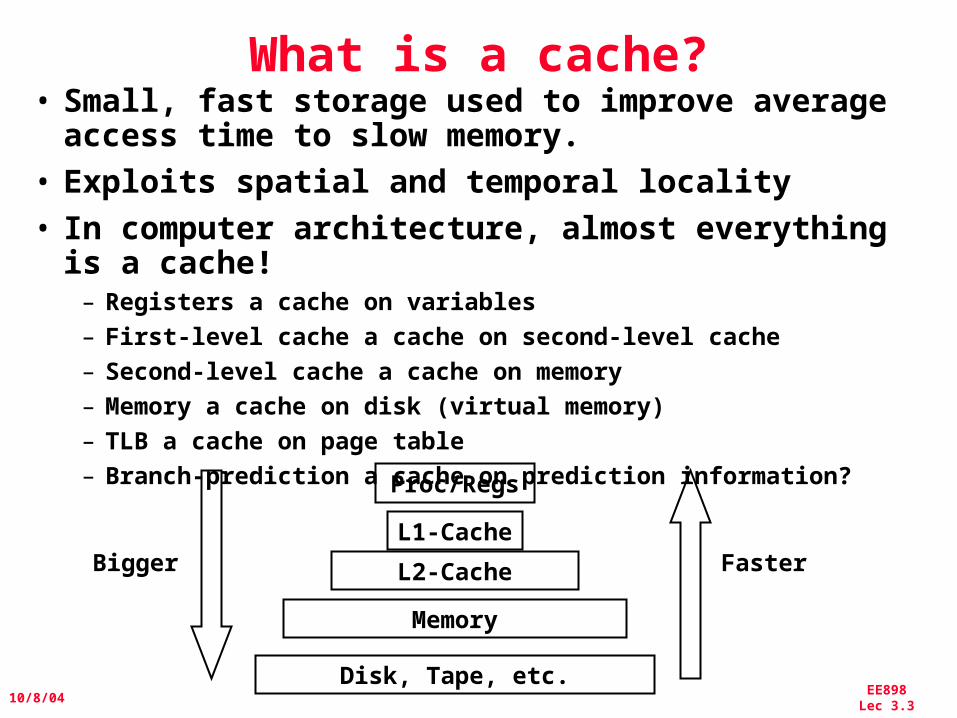
What is a cache?• Small, fast storage used to improve average
access time to slow memory.• Exploits spatial and temporal locality• In computer architecture, almost everything is a
cache!– Registers a cache on variables– First-level cache a cache on second-level cache– Second-level cache a cache on memory– Memory a cache on disk (virtual memory)– TLB a cache on page table– Branch-prediction a cache on prediction information?Proc/Regs
L1-Cache
L2-Cache
Memory
Disk, Tape, etc.
Bigger Faster

EE898Lec 3.4
10/8/04
Levels of the Memory Hierarchy
CPU Registers100s Bytes<1s ns
Cache10s-100s K Bytes1-10 ns$10/ MByte
Main MemoryM Bytes100ns- 300ns$1/ MByte
Disk10s G Bytes, 10 ms (10,000,000 ns)$0.0031/ MByte
CapacityAccess TimeCost
Tapeinfinitesec-min$0.0014/ MByte
Registers
Cache
Memory
Disk
Tape
Instr. Operands
Blocks
Pages
Files
StagingXfer Unit
prog./compiler1-8 bytes
cache cntl8-128 bytes
OS512-4K bytes
user/operatorMbytes
Upper Level
Lower Level
faster
Larger

EE898Lec 3.5
10/8/04
The Principle of Locality
• The Principle of Locality:– Program access a relatively small portion of the address space at any
instant of time.
• Two Different Types of Locality:– Temporal Locality (Locality in Time): If an item is referenced, it will tend
to be referenced again soon (e.g., loops, reuse)– Spatial Locality (Locality in Space): If an item is referenced, items whose
addresses are close by tend to be referenced soon (e.g., straightline code, array access)
• Last 15 years, HW (hardware) relied on locality for speed

EE898Lec 3.6
10/8/04
Memory Hierarchy: Terminology
• Hit: data appears in some block in the upper level (example: Block X)
– Hit Rate: the fraction of memory access found in the upper level
– Hit Time: Time to access the upper level which consists of
RAM access time + Time to determine hit/miss
• Miss: data needs to be retrieved from a block in the lower level (Block Y)
– Miss Rate = 1 - (Hit Rate)– Miss Penalty: Time to replace a block in the upper level +
Time to deliver the block the processor
Lower LevelMemoryUpper Level
MemoryTo Processor
From ProcessorBlk X
Blk Y

EE898Lec 3.7
10/8/04
Cache Measures• Hit rate: fraction found in that level
– So high that usually talk about Miss rate– Miss rate fallacy: as MIPS to CPU performance,
miss rate to average memory access time in memory
• Average memory-access time = Hit time + Miss rate x Miss penalty
(ns or clocks)• Miss penalty: time to replace a block from
lower level, including time to replace in CPU
– access time: time to lower level
= f(latency to lower level)
– transfer time: time to transfer block
= f(between upper & lower levels)

EE898Lec 3.8
10/8/04
Simplest Cache: Direct Mapped
Memory
4 Byte Direct Mapped Cache
Memory Address0
1
2
3
4
5
6
7
8
9
A
B
C
D
E
F
Cache Index
0
1
2
3• Location 0 can be occupied by data
from:– Memory location 0, 4, 8, ... etc.– In general: any memory location
whose 2 LSBs of the address are 0s– Address<1:0> => cache index
• Which one should we place in the cache?
• How can we tell which one is in the cache?

EE898Lec 3.9
10/8/04
1 KB Direct Mapped Cache, 32B blocks
• For a 2 ** N byte cache:– The uppermost (32 - N) bits are always the Cache Tag– The lowest M bits are the Byte Select (Block Size = 2 ** M)
Cache Index
0
1
2
3
:
Cache Data
Byte 0
0431
:
Cache Tag Example: 0x50
Ex: 0x01
0x50
Stored as partof the cache “state”
Valid Bit
:
31
Byte 1Byte 31 :
Byte 32Byte 33Byte 63 :Byte 992Byte 1023 :
Cache Tag
Byte Select
Ex: 0x00
9

EE898Lec 3.10
10/8/04
Two-way Set Associative Cache
• N-way set associative: N entries for each Cache Index
– N direct mapped caches operates in parallel (N typically 2 to 4)
• Example: Two-way set associative cache– Cache Index selects a “set” from the cache– The two tags in the set are compared in parallel– Data is selected based on the tag result
Cache Data
Cache Block 0
Cache TagValid
:: :
Cache Data
Cache Block 0
Cache Tag Valid
: ::
Cache Index
Mux 01Sel1 Sel0
Cache Block
CompareAdr Tag
Compare
OR
Hit

EE898Lec 3.11
10/8/04
Disadvantage of Set Associative Cache
• N-way Set Associative Cache v. Direct Mapped Cache:– N comparators vs. 1– Extra MUX delay for the data– Data comes AFTER Hit/Miss
• In a direct mapped cache, Cache Block is available BEFORE Hit/Miss:
– Possible to assume a hit and continue. Recover later if miss.
Cache Data
Cache Block 0
Cache Tag Valid
: ::
Cache Data
Cache Block 0
Cache TagValid
:: :
Cache Index
Mux 01Sel1 Sel0
Cache Block
CompareAdr Tag
Compare
OR
Hit

EE898Lec 3.12
10/8/04
4 Questions for Memory Hierarchy
• Q1: Where can a block be placed in the upper level? (Block placement)
• Q2: How is a block found if it is in the upper level? (Block identification)
• Q3: Which block should be replaced on a miss?
(Block replacement)• Q4: What happens on a write?
(Write strategy)

EE898Lec 3.13
10/8/04
Q1: Where can a block be placed in the upper level?
• Block 12 placed in 8 block cache:– Fully associative, direct mapped, 2-way set
associative– S.A. Mapping = Block Number Modulo Number
Sets
Cache
01234567 0123456701234567
Memory
111111111122222222223301234567890123456789012345678901
Full MappedDirect Mapped(12 mod 8) = 4
2-Way Assoc(12 mod 4) = 0

EE898Lec 3.14
10/8/04
Q2: How is a block found if it is in the upper level?
• Tag on each block– No need to check index or block offset
• Increasing associativity shrinks index, expands tag
BlockOffset
Block Address
IndexTag

EE898Lec 3.15
10/8/04
Q3: Which block should be replaced on a miss?
• Easy for Direct Mapped• Set Associative or Fully Associative:
– Random– LRU (Least Recently Used)– FIFO (First In First Out)
Ref. fig. 5.6, p. 401 (3rd edition)

EE898Lec 3.16
10/8/04
Q4: What happens on a write?
• Write through—The information is written to both the block in the cache and to the block in the lower-level memory.
• Write back—The information is written only to the block in the cache. The modified cache block is written to main memory only when it is replaced.
– is block clean or dirty?
• Pros and Cons of each?– WT: read misses cannot result in writes– WB: no repeated writes to the same location
• WT always combined with write buffers so that don’t wait for lower level memory

EE898Lec 3.17
10/8/04
A Modern Memory Hierarchy
• By taking advantage of the principle of locality:– Present the user with as much memory as is available in the
cheapest technology.– Provide access at the speed offered by the fastest technology.
Control
Datapath
SecondaryStorage(Disk)
Processor
Registers
MainMemory(DRAM)
SecondLevelCache
(SRAM)
On
-Ch
ipC
ache
1s 10,000,000s (10s ms)
Speed (ns): 10s 100s
100sGs
Size (bytes):Ks Ms
TertiaryStorage
(Disk/Tape)
10,000,000,000s (10s sec)
Ts

EE898Lec 3.18
10/8/04
Example: Harvard Architecture• Unified vs. Separate I&D (Harvard)
• Table on page 384 (2nd edition):– 16KB I&D: Inst miss rate=0.64%, Data miss rate=6.47%– 32KB unified: Aggregate miss rate=1.99%
• Which is better (ignore L2 cache)?– Assume 33% data ops 75% accesses from instructions (1.0/1.33)– hit time=1, miss time=50– Note that data hit has 1 stall for unified cache (only one port)
AMATHarvard=75%x(1+0.64%x50)+25%x(1+6.47%x50) = 2.05
AMATUnified=75%x(1+1.99%x50)+25%x(1+1+1.99%x50)= 2.24
ProcI-Cache-1
Proc
UnifiedCache-1
UnifiedCache-2
D-Cache-1
Proc
UnifiedCache-2

EE898Lec 3.19
10/8/04
Improving Cache Performance
1. Reduce the miss rate,
2. Reduce the miss penalty, or
3. Reduce the time to hit in the cache.

EE898Lec 3.20
10/8/04
Reducing Misses• Classifying Misses: 3 Cs
– Compulsory—The first access to a block is not in the cache, so the block must be brought into the cache. Also called cold start misses or first reference misses.(Misses in even an Infinite Cache)
– Capacity—If the cache cannot contain all the blocks needed during execution of a program, capacity misses will occur due to blocks being discarded and later retrieved.(Misses in Fully Associative Size X Cache)
– Conflict—If block-placement strategy is set associative or direct mapped, conflict misses (in addition to compulsory & capacity misses) will occur because a block can be discarded and later retrieved if too many blocks map to its set. Also called collision misses or interference misses.(Misses in N-way Associative, Size X Cache)
• More recent, 4th “C”:– Coherence - Misses caused by cache coherence.

EE898Lec 3.21
10/8/04
Block Size (bytes)
Miss Rate
0%
5%
10%
15%
20%
25%
16
32
64
12
8
25
6
1K
4K
16K
64K
256K
1. Reduce Misses via Larger Block Size

EE898Lec 3.22
10/8/04
2. Reduce Misses via Higher Associativity
•2:1 Cache Rule: – Miss Rate DM cache size N Miss Rate 2-way
cache size N/2
EE898Lec 3.23
10/8/04
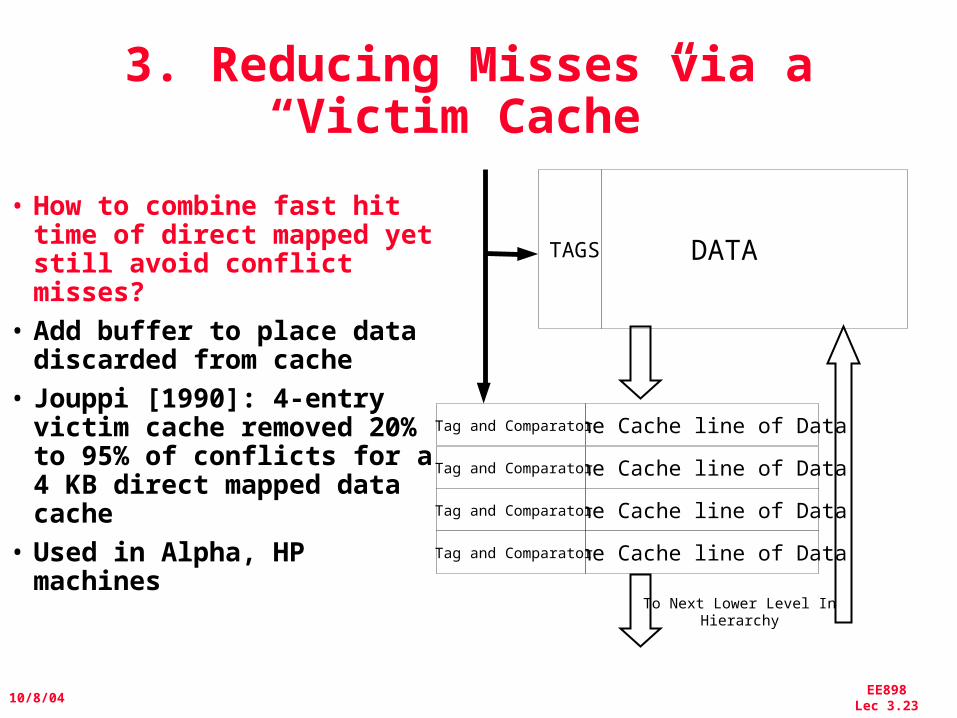
3. Reducing Misses via a“Victim Cache”
• How to combine fast hit time of direct mapped yet still avoid conflict misses?
• Add buffer to place data discarded from cache
• Jouppi [1990]: 4-entry victim cache removed 20% to 95% of conflicts for a 4 KB direct mapped data cache
• Used in Alpha, HP machines
To Next Lower Level InHierarchy
DATATAGS
One Cache line of DataTag and Comparator
One Cache line of DataTag and Comparator
One Cache line of DataTag and Comparator
One Cache line of DataTag and Comparator

EE898Lec 3.24
10/8/04
4. Reducing Misses via “Pseudo-Associativity”
•How to combine fast hit time of Direct Mapped and have the lower conflict misses of 2-way SA cache?
•Divide cache: on a miss, check other half of cache to see if there, if so have a pseudo-hit (slow hit)
•Drawback: CPU pipeline is hard if hit takes 1 or 2 cycles
– Better for caches not tied directly to processor (L2)– Used in MIPS R1000 L2 cache, similar in UltraSPARC
Hit Time
Pseudo Hit Time Miss Penalty
Time

EE898Lec 3.25
10/8/04
5. Reducing Misses by Hardware Prefetching of
Instructions & Data • E.g., Instruction Prefetching
– Alpha 21064 fetches 2 blocks on a miss– Extra block placed in “stream buffer”– On miss check stream buffer
• Works with data blocks too:– Jouppi [1990] 1 data stream buffer got 25% misses
from 4KB cache; 4 streams got 43%– Palacharla & Kessler [1994] for scientific programs
for 8 streams got 50% to 70% of misses from 2 64KB, 4-way set associative caches
• Prefetching relies on having extra memory bandwidth that can be used without penalty

EE898Lec 3.26
10/8/04
6. Reducing Misses by Software Prefetching Data
• Data Prefetch– Load data into register (HP PA-RISC loads)– Cache Prefetch: load into cache (MIPS IV, PowerPC, SPARC
v. 9)– Special prefetching instructions cannot cause faults; a form
of speculative execution
• Prefetching comes in two flavors:– Binding prefetch: Requests load directly into register.
» Must be correct address and register!– Non-Binding prefetch: Load into cache.
» Can be incorrect. Frees HW/SW to guess!
• Issuing Prefetch Instructions takes time– Is cost of prefetch issues < savings in reduced misses?– Higher superscalar reduces difficulty of issue bandwidth

EE898Lec 3.27
10/8/04
7. Reducing Misses by Compiler Optimizations
• McFarling [1989] reduced caches misses by 75% on 8KB direct mapped cache, 4 byte blocks in software
• Instructions– Reorder procedures in memory so as to reduce conflict misses– Profiling to look at conflicts(using tools they developed)
• Data– Merging Arrays: improve spatial locality by single array of
compound elements vs. 2 arrays– Loop Interchange: change nesting of loops to access data in order
stored in memory– Loop Fusion: Combine 2 independent loops that have same
looping and some variables overlap– Blocking: Improve temporal locality by accessing “blocks” of data
repeatedly vs. going down whole columns or rows

EE898Lec 3.28
10/8/04
Merging Arrays Example
/* Before: 2 sequential arrays */int val[SIZE];int key[SIZE];
/* After: 1 array of structures */struct merge {
int val;int key;
};struct merge merged_array[SIZE];
Reducing conflicts between val & key; improve spatial locality

EE898Lec 3.29
10/8/04
Loop Interchange Example
/* Before */for (k = 0; k < 100; k = k+1)
for (j = 0; j < 100; j = j+1)for (i = 0; i < 5000; i = i+1)
x[i][j] = 2 * x[i][j];/* After */for (k = 0; k < 100; k = k+1)
for (i = 0; i < 5000; i = i+1)for (j = 0; j < 100; j = j+1)
x[i][j] = 2 * x[i][j];
Sequential accesses instead of striding through memory every 100 words; improved spatial locality

EE898Lec 3.30
10/8/04
Loop Fusion Example/* Before */for (i = 0; i < N; i = i+1)
for (j = 0; j < N; j = j+1)a[i][j] = 1/b[i][j] * c[i][j];
for (i = 0; i < N; i = i+1)for (j = 0; j < N; j = j+1)
d[i][j] = a[i][j] + c[i][j];/* After */for (i = 0; i < N; i = i+1)
for (j = 0; j < N; j = j+1){ a[i][j] = 1/b[i][j] * c[i][j];
d[i][j] = a[i][j] + c[i][j];}
2 misses per access to a & c vs. one miss per access; improve temporal locality

EE898Lec 3.31
10/8/04
Blocking Example/* Before */
for (i = 0; i < N; i = i+1)
for (j = 0; j < N; j = j+1)
{r = 0;
for (k = 0; k < N; k = k+1){
r = r + y[i][k]*z[k][j];};
x[i][j] = r;
};
• Two Inner Loops:– Read all NxN elements of z[]– Read N elements of 1 row of y[] repeatedly– Write N elements of 1 row of x[]
• Capacity Misses a function of N & Cache Size:
– 2N3 + N2 => (assuming no conflict; otherwise …)
• Idea: compute on BxB submatrix that fits

EE898Lec 3.32
10/8/04
Blocking Example/* After */for (jj = 0; jj < N; jj = jj+B)for (kk = 0; kk < N; kk = kk+B)for (i = 0; i < N; i = i+1)
for (j = jj; j < min(jj+B-1,N); j = j+1){r = 0; for (k = kk; k < min(kk+B-1,N); k = k+1) {
r = r + y[i][k]*z[k][j];}; x[i][j] = x[i][j] + r;};
• B called Blocking Factor• Capacity Misses from 2N3 + N2 to N3/B+2N2
• Conflict Misses Too? • Improve temporal locality by accessing “blocks” of data repeatedly vs. going down
whole columns or rows

EE898Lec 3.33
10/8/04
Summary: Miss Rate Reduction
• 3 Cs: Compulsory, Capacity, Conflict1. Reduce Misses via Larger Block Size2. Reduce Misses via Higher Associativity3. Reducing Misses via Victim Cache4. Reducing Misses via Pseudo-Associativity5. Reducing Misses by HW Prefetching Instr, Data6. Reducing Misses by SW Prefetching Data7. Reducing Misses by Compiler Optimizations
• Prefetching comes in two flavors:– Binding prefetch: Requests load directly into
register.» Must be correct address and register!
– Non-Binding prefetch: Load into cache. » Can be incorrect. Frees HW/SW to guess!
CPUtimeIC CPIExecution
Memory accesses
InstructionMiss rateMiss penalty
Clock cycle time

EE898Lec 3.34
10/8/04
Improving Cache Performance
1. Reduce the miss rate,
2. Reduce the miss penalty, or
3. Reduce the time to hit in the cache.

EE898Lec 3.35
10/8/04
Write Policy:Write-Through vs Write-
Back• Write-through: all writes update cache and underlying
memory/cache– Can always discard cached data - most up-to-date data is in memory– Cache control bit: only a valid bit
• Write-back: all writes simply update cache– Can’t just discard cached data - may have to write it back to memory– Cache control bits: both valid and dirty bits
• Other Advantages:– Write-through:
» memory (or other processors) always have latest data» Simpler management of cache
– Write-back:» much lower bandwidth, since data often overwritten multiple
times» Better tolerance to long-latency memory?

EE898Lec 3.36
10/8/04
Write Policy 2:Write Allocate vs Non-Allocate(What happens on write-miss)
• Write allocate: allocate new cache line in cache– Usually means that you have to do a “read
miss” to fill in rest of the cache-line!– Alternative: per/word valid bits
• Write non-allocate (or “write-around”):– Simply send write data through to underlying
memory/cache - don’t allocate new cache line!

EE898Lec 3.37
10/8/04
1. Reducing Miss Penalty: Read Priority over Write on Miss
writebuffer
CPU
in out
DRAM (or lower mem)
Write Buffer

EE898Lec 3.38
10/8/04
1. Reducing Miss Penalty: Read Priority over Write on
Miss• Write-through with write buffers offer RAW
conflicts with main memory reads on cache misses– If simply wait for write buffer to empty, might increase read miss
penalty (old MIPS 1000 by 50% )– Check write buffer contents before read;
if no conflicts, let the memory access continue
• Write-back also want buffer to hold misplaced blocks
– Read miss replacing dirty block– Normal: Write dirty block to memory, and then do the read– Instead copy the dirty block to a write buffer, then do the read,
and then do the write– CPU stall less since restarts as soon as do read

EE898Lec 3.39
10/8/04
2. Reducing Miss Penalty: Early Restart and Critical
Word First• Don’t wait for full block to be loaded before
restarting CPU– Early Restart—As soon as the requested word of the block
arrives, send it to the CPU and let the CPU continue execution
– Critical Word First—Request the missed word first from memory and send it to the CPU as soon as it arrives; let the CPU continue execution while filling the rest of the words in the block. Also called wrapped fetch and requested word first
• Generally useful only in large blocks, • Spatial locality a problem; tend to want next
sequential word, so not clear if benefit by early restart
block

EE898Lec 3.40
10/8/04
3. Reducing Miss Penalty: Non-blocking Caches to reduce stalls
on misses• Non-blocking cache or lockup-free cache allow data
cache to continue to supply cache hits during a miss– requires F/E bits on registers or out-of-order execution– requires multi-bank memories
• “hit under miss” reduces the effective miss penalty by working during miss vs. ignoring CPU requests
• “hit under multiple miss” or “miss under miss” may further lower the effective miss penalty by overlapping multiple misses
– Significantly increases the complexity of the cache controller as there can be multiple outstanding memory accesses
– Requires multiple memory banks (otherwise cannot support)– Pentium Pro allows 4 outstanding memory misses

EE898Lec 3.41
10/8/04
4. Add a second-level cache
• L2 EquationsAMAT = Hit TimeL1 + Miss RateL1 x Miss PenaltyL1
Miss PenaltyL1 = Hit TimeL2 + Miss RateL2 x Miss PenaltyL2
AMAT = Hit TimeL1 +
Miss RateL1 x (Hit TimeL2 + Miss RateL2 + Miss PenaltyL2)
• Definitions:– Local miss rate— misses in this cache divided by the total number of
memory accesses to this cache (Miss rateL2)– Global miss rate—misses in this cache divided by the total number of
memory accesses generated by the CPU (Miss RateL1 x Miss RateL2)
– Global Miss Rate is what matters

EE898Lec 3.42
10/8/04
Comparing Local and Global Miss Rates
• 32 KByte 1st level cache;Increasing 2nd level cache
• Global miss rate close to single level cache rate provided L2 >> L1
• Don’t use local miss rate• L2 not tied to CPU clock
cycle!• Cost & A.M.A.T.• Generally Fast Hit Times
and fewer misses• Since hits are few, target
miss reduction
Linear
Log
Cache Size
Cache Size

EE898Lec 3.43
10/8/04
Reducing Miss Penalty Summary
• Four techniques– Read priority over write on miss– Early Restart and Critical Word First on miss– Non-blocking Caches (Hit under Miss, Miss under
Miss)– Second Level Cache
• Can be applied recursively to Multilevel Caches
– Danger is that time to DRAM will grow with multiple levels in between
– First attempts at L2 caches can make things worse, since increased worst case is worse
CPUtimeIC CPIExecution
Memory accesses
InstructionMiss rateMiss penalty
Clock cycle time

EE898Lec 3.44
10/8/04
Improving Cache Performance
1. Reduce the miss rate,
2. Reduce the miss penalty, or
3. Reduce the time to hit in the cache.
yMissPenaltMissRateHitTimeAMAT

EE898Lec 3.45
10/8/04
1. Fast Hit times via Small and Simple
Caches• Why Alpha 21164 has 8KB Instruction
and 8KB data cache + 96KB second level cache?
– Small data cache and clock rate
• Direct Mapped, on chip

EE898Lec 3.46
10/8/04
2. Fast hits by Avoiding Address Translation
CPU
TB
$
MEM
VA
PA
PA
ConventionalOrganization
CPU
$
TB
MEM
VA
VA
PA
Virtually Addressed CacheTranslate only on miss
Synonym Problem
CPU
$ TB
MEM
VA
PATags
PA
Overlap $ accesswith VA translation:requires $ index to
remain invariantacross translation
VATags
L2 $

EE898Lec 3.47
10/8/04
2. Fast hits by Avoiding Address Translation
• Send virtual address to cache? Called Virtually Addressed Cache or just Virtual Cache vs. Physical Cache
– Every time process is switched logically must flush the cache; otherwise get false hits
» Cost is time to flush + “compulsory” misses from empty cache
– Dealing with aliases (sometimes called synonyms); Two different virtual addresses map to same physical address
– I/O must interact with cache, so need virtual address
• Solution to aliases– HW guarantees covers index field & direct mapped, they must
be unique; called page coloring
• Solution to cache flush– Add process identifier tag that identifies process as well as
address within process: can’t get a hit if wrong process

EE898Lec 3.48
10/8/04
2. Fast Cache Hits by Avoiding Translation: Index with Physical
Portion of Address• If index is physical part of address, can start
tag access in parallel with translation so that can compare to physical tag
• Limits cache to page size: what if want bigger caches and uses same trick?
– Higher associativity moves barrier to right– Page coloring
Page Address Page Offset
Address Tag Index Block Offset

EE898Lec 3.49
10/8/04
What is the Impact of What You’ve Learned
About Caches?• 1960-1985: Speed
= ƒ(no. operations)• 1990
– Pipelined Execution & Fast Clock Rate
– Out-of-Order execution
– Superscalar Instruction Issue
• 1998: Speed = ƒ(non-cached memory accesses)
• What does this mean for– Compilers?,Operating Systems?, Algorithms?
Data Structures?
1
10
100
1000
1980
1981
1982
1983
1984
1985
1986
1987
1988
1989
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
DRAM
CPU