非線形モデルを利用した解析 - sas institute...非線形モデルを利用した解析...
TRANSCRIPT

非線形モデルを利用した解析
NLMIXEDの応用事例紹介
小林 聡晃
日本たばこ産業株式会社
医薬事業部 臨床開発部 解析チーム

要旨:
NLMIXEDプロシジャの特徴として,被験者を変量効果に設定
すると,被験者ごとの推定を行うことができる。
本発表では非線形混合効果モデルに着目し,NLMIXED
プロシジャのマニュアルに記載されているデータを元に,
解析事例を2つ紹介する。薬物動態解析の事例としてスパース
サンプリングデータでの解析を,生存時間解析の事例として頭痛
発現時間データでの解析を扱う。
特に,生存時間解析の事例では,加速モデルによる解析で
得られた推定結果について,従来の方法(LIFEREGプロシジャ) との比較と考察を行った。
キーワード:薬物動態解析,スパースサンプリング,生存時間解析,
加速モデル,NLMIXED 2

発表の流れ
背景
目的
利用事例(SASマニュアルに記載されたデータを使用)
<スパースサンプリングデータを用いた薬物動態解析>
スパースサンプリングデータとフルスクリーンデータでの推定
結果を比較
<生存時間解析>
LIFEREGとNLMIXEDの推定結果を比較
投与群ごとの推定と被験者ごとの推定を比較
考察 3

背景
Model Based Drug Development(MBDD)に向けて
MBDDとは?
臨床薬理担当者と生物統計担当者間での対話の必要性
NLMIXEDが役立つ場面
4

背景
MBDDとは?
臨床試験の計画段階にて,モデルを活用して臨床試験を
仮想的に行う。複数のシナリオを設定し,不確実性に対応する。 (JPMA News Letter No.140(2010/11))
5
モデルの設定
被験者背景
薬物濃度と
有害事象の関係
シナリオ1
Phase 2
被験者データ シナリオごとに
リスクを評価 シナリオ2
シナリオ3
…
例:Phase 2 試験の計画

モデル化可能な要素の例
患者背景(人口統計学データ) ・投与量と血中薬物濃度の関係(PK)とその影響因子
・血中薬物濃度と薬理効果指標の関係(PD)とその影響因子
・血中薬物濃度と有害反応(発生頻度や重症度)との関係とその影響因子
・薬理効果指標と臨床効果の関係とその影響因子
・標準治療薬(対照薬)における有効性・安全性プロファイルとその影響因子
・プラセボ効果
・病態進行速度
・併用薬・併用治療の影響
・評価項目の観察頻度・観察時期の影響
・症例組み入れ速度と組み入れ時期の影響
・脱落速度
・試験デザイン(並行群間/クロスオーバー,アームの種類や数など)
(JPMA News Letter No.140(2010/11))
背景
6

背景
臨床薬理担当者と生物統計担当者間での対話の必要性
現状,使用しているツールが異なっているため,お互いの理解が進みにくい。(私見)
7
臨床薬理担当者 生物統計担当者
NONMEM
WinNonlin
SAS

背景
NLMIXEDが役立つ場面
被験者を変量効果とした場合,モデルに基づき被験者ごとの
データを生成可能
幅広いモデルの設定ができるため,様々なシナリオに対応可能
8
例:Phase 2 試験の計画
モデルの設定
被験者背景
薬物濃度と
有害事象の関係
シナリオ1
Phase 2
被験者データ シナリオごとに
リスクを評価 シナリオ2
シナリオ3
…

目的
NLMIXEDプロシジャを適切に応用すると,幅広い解析を
行えることを示す。
9

方法
2つの解析事例を扱う(SASマニュアルに記載されたデータを使用)
スパースサンプリングデータを用いた薬物動態解析
生存時間解析
10

2つの利用事例で用いられている方法
①モデルを設定する
②制限付き尤度をDual Quasi-Newton法によって数値
計算を行い,パラメータ推定を行う。
モデルを理解し,適切に応用することが重要である。
11

スパースサンプリングデータを用いた
薬物動態解析
NLMIXEDプロシジャ
<使用データ> Example 51.1のテオフィリン経口投与データ
NONMEMのサンプルデータとしても添付されており,NONMEMを
使用することが多い薬物動態解析担当者と,解析結果について
比較及び議論を行うことができる。
~解析内容~
スパースサンプリングデータを用いて,被験者ごとのAUCの推定が
可能であることを示し,フルスクリーンデータでの推定値と比較する。
12

Phase 1で健康成人を対象とした場合,1日に何回も採血を実施
することがある。
Phase 2試験で患者を対象とした場合,採血が被験者の負担に
なることがあり,採血回数を最小限にすることが求められる。
その際には、より少ないデータで妥当な推定を実施する必要がある。
⇒事前に定めたまばらな(Sparse)時点で採血を実施する。
スパースサンプリングとは
13

テオフィリン経口投与データ
<被験者数> 12人
<測定ポイント>0,0.25,0.5,1,2,3,5,7,9,12,24 (hr)
14
subject time conc dose wt
1 0 0.74 4.02 79.6
1 0.25 2.84 4.02 79.6
1 0.57 6.57 4.02 79.6
1 1.12 10.50 4.02 79.6
1 2.02 9.66 4.02 79.6
1 3.82 8.58 4.02 79.6
1 5.10 8.36 4.02 79.6
1 7.03 7.47 4.02 79.6
1 9.05 6.89 4.02 79.6
1 12.12 5.94 4.02 79.6
1 24.37 3.28 4.02 79.6

C:濃度,D:用量,k:定数,Cl:クリアランス,β:固定効果、b:ランダム効果
※個人間の効果をランダム効果とする
※Cl,kaは対数正規分布に従うと仮定する
3
22
11
exp
exp
exp
expexp
i
i
ii
ii
ii
e
ia
ii
itae
eai
ae
it
k
bk
bCl
etktkkkCl
kDkC
モデルの設定 (経口1-コンパートメントモデル)
15

被験者に対する負担の軽減という観点から,薬物濃度測定用に
採血を実施する回数を減らすことが求められることがある。
今回は,Example 51.1のテオフィリンデータに対して,以下のようなサンプリング計画を立てた。表中の●は採血ポイントであることを
示している。
※1被験者の採血ポイントは4点とする
※吸収相と消失相では薬物濃度推移が被験者間で大きな差が無く,Cmax付近は
共通と考え,交互パネルで設定する
スパースサンプリング計画
16
パネル 被験者 0.5 1 2 4 7 12 24
1 1 - 6 ● ● ● ●
2 7 - 12 ● ● ● ●

cl = exp(beta1 + b1) ;
ka = exp(beta2 + b2) ;
ke = exp(beta3) ;
pred = dose*ke*ka*(exp(-ke*time)
-exp(-ka*time))/cl/(ka-ke)
※NLMIXEDプロシジャで,モデルを複数ステートメントに分けて記述できる。 ※b1,b2はランダム効果を示すパラメータ
解析プログラム モデルの指定
17

model conc ~ normal(pred,s2) ;
random b1 b2 ~
normal([0,0],[s2b1,cb12,s2b2])
subject=subject ;
※血中薬物濃度は正規分布に従うと指定した。
※ランダム効果b1,b2の分布をrandomステートメントで指定した。
ここでは,分散共分散行列の形で指定する。
解析プログラム モデルの指定
18

Time ( hr )
フルスクリーンデータ(推定値) / スパースサンプリングデータ(推定値)
19

AUCのモデル推定結果比較
フルスクリーンデータを基準とした相対誤差
20
subject 相対誤差 %
1 7.1
2 4.3
3 2.1
4 4.3
5 2.3
6 1.7
7 5.9
8 3.3
9 -2.0
10 4.0
11 2.7
12 5.4

スパースサンプリングデータを用いた
薬物動態解析
考察
スパースサンプリングデータのPKパラメータの推定値は、
フルスクリーンデータの推定値とほぼ同じ結果が得られた。
テオフィリンデータでは2つの変量効果を仮定したが、1つの
変量効果で済むのであれば、更なるスパースサンプリング
(1症例3ポイントや2ポイントなど)が可能となるかもしれない。
どのパラメータに変量効果を仮定するかは、個別のプロット
から判断する。 21

生存時間解析
SASのNLMIXEDを生存時間解析に適応
<使用データ>Example 63.5の頭痛鎮痛薬に関する頭痛発現データ
「ハザード」という概念より臨床的に理解しやすい指標として,
「薬剤を投与してから頭痛が改善するまでの時間(頭痛発現時間)」
に着目した。
~解析内容~
accelerated failure time model(加速モデル)を用いて,頭痛発現
時間における改善確率を被験者ごとに推定する。
22

頭痛発現時間
<目的>2種類の頭痛鎮痛薬の効果を比較
被験者数38人を薬剤ごとに2群に割り付け(1群あたり19人)
patient:患者番号,group:群,minutes:頭痛発現時間,
censor=0:打ち切りなし,censor=1:打ち切りあり
23
patient group minutes censor
1 1 11 0
2 1 12 0
3 1 19 0
・・・
37 2 32 1
38 2 20 1

ハザード関数
γ>0,Group 1:X=0 Group 2:X=1,z ~ N (0,σ2)
※ハザード関数はワイブル分布に従うと仮定する
モデルの設定 (加速モデル)
24
)(exp
)(),(
10
1
X
tth
)t(exp),t(G ),t(h),t(G),t(g
確率密度関数 生存分布関数
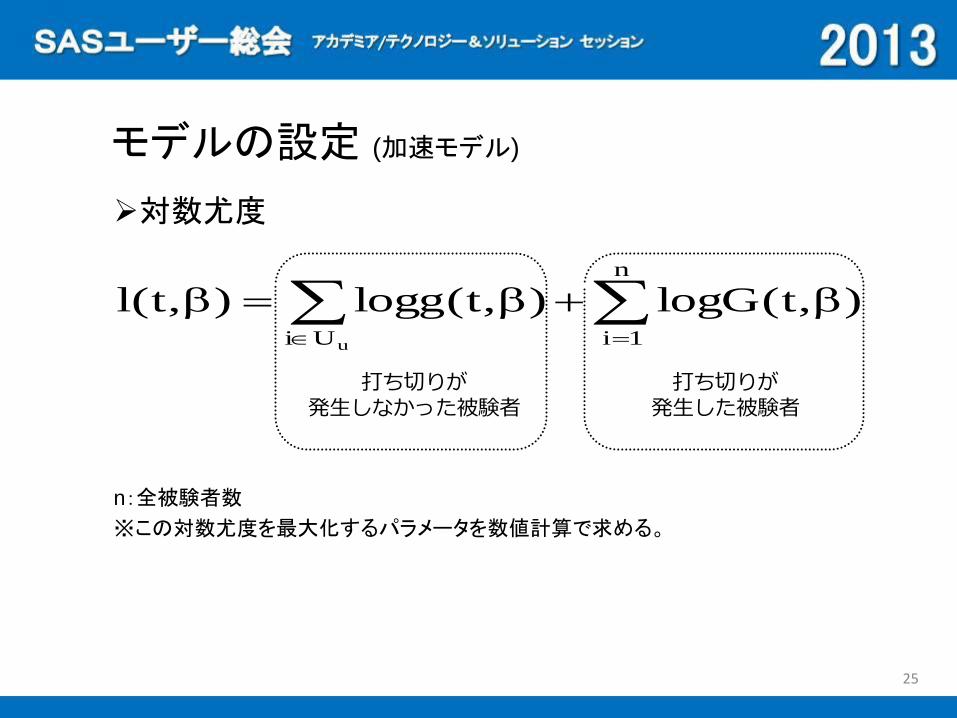
対数尤度
n:全被験者数
※この対数尤度を最大化するパラメータを数値計算で求める。
モデルの設定 (加速モデル)
25
),t(Glog),t(glog),t(ln
1iUi u
打ち切りが
発生しなかった被験者
打ち切りが
発生した被験者

生存時間解析を行うプロシジャとその特徴 SAS Version 9.2
26
機能 LIFEREG NLMIXED
オプション機能で分布指定が可能
〇 ×
幅広い分布の
指定が可能 × 〇
被験者ごとの
推定が可能 × 〇

NLMIXEDプロシジャを利用するにあたって
推奨する手順
27
NLMIXEDプロシジャでのモデルの指定が妥当であることを
確認することが大事
①投与群ごとの推定を行う 。既存のプロシジャ(LIFEREG)との結果の比較を行い,一致することを確認する。
②被験者ごとの変量効果をモデルに追加する。

投与群ごとの推定
28
LIFEREG NLMIXED
proc lifereg data=headache;
class group;
model minutes*censor(1) = group / dist=weibull;
output out=new cdf=prob;
run;
proc nlmixed data=headache;
bounds gamma > 0;
linp = b0 - b1*(group-2);
alpha = exp(-linp);
G_t = exp(-(alpha*minutes)**gamma);
g = gamma*alpha*((alpha*minutes)**(gamma-1))*G_t;
ll = (censor=0)*log(g) + (censor=1)*log(G_t);
model minutes ~ general(ll);
predict 1-G_t out=cdf0;
run;

NLMIXEDプロシジャとLIFEREGプロシジャで推定結果
が一致することを確認できた
Standard
Parameter Estimate Error
gamma 4.7128 0.6742
b0 3.3091 0.05885
b1 -0.1933 0.07856
→モデルに被験者ごとの変量効果を設定する(次のスライド)
投与群ごとの指定
29

赤文字で記載した部分は被験者ごとの変量効果を設定する際に変更した箇所である
ことを示す。
被験者ごとの指定
30
NLMIXED
proc nlmixed data=headache;
bounds gamma > 0;
linp = b0 - b1*(group-2) + z;
alpha = exp(-linp);
G_t = exp(-(alpha*minutes)**gamma);
g = gamma*alpha*((alpha*minutes)**(gamma-1))*G_t;
ll = (censor=0)*log(g) + (censor=1)*log(G_t);
model minutes ~ general(ll);
random z ~ normal(0,exp(2*logsig)) subject=patient out=EB;
predict 1-G_t out=cdf0;
run;

被験者ごとに頭痛回復確率(丸印)と分布関数(線)を推定。
被験者ごとの指定
31 頭痛改善までの時間
頭痛回復確率
投与群 1
投与群 2

被験者ごとの推定の方が保守的な結果を示した。
投与群ごとの推定と被験者ごとの推定を比較
32 頭痛改善までの時間
投与群 1
被験者ごとの推定
投与群 2
被験者ごとの推定
投与群 1
投与群ごとの推定
投与群 2
投与群ごとの推定
頭痛回復確率

生存時間解析
考察
被験者ごとの推定により,該当する被験者と似た背景情報
を持つ被験者に対する薬剤効果を事前に予測できる。
設定するモデルをロジスティック分布やポアソン分布などに
することで,他の分布でも同様の解析を実施できる可能性
がある。
同一被験者で繰り返し発生する事象(有害事象など)の発現
データから,被験者ごとの事象発生確率を推定したい場合
にも適用できる可能性がある。
33

NLMIXEDの応用事例紹介
まとめ
NLMIXEDプロシジャの応用事例を紹介した。
Modeling&Simulationを実施する際に,NLMIXEDプロシジャは
有用な方法となる。
34

NLMIXEDの応用事例紹介
Thank you for your attention!
35