drbl-live-hadoop at tslc
TRANSCRIPT

利用 DRBL live 快速佈署簡易型 Hadoop 叢集
蔡育欽 國家高速網路中心

Outline● DRBL / Clonezilla● DRBL-live● Hadoop● Drbl-live-hadoop● [Video | Live ] Demo● Hadoop commands

國網中心自由軟體開發高速計算技術及經驗發展之核心技術
企鵝龍 DRBL 再生龍Clonezilla
適用完整系統備份、裸機還原或災難復原
是自由!不僅是免費…使用、複製、修改與再散播軟體的自由。免費是附加價值。人人皆可自由享用。
無碟環境,適合將整個電腦教室轉換成純自由軟體環境
(Diskless Remote Boot in Linux)
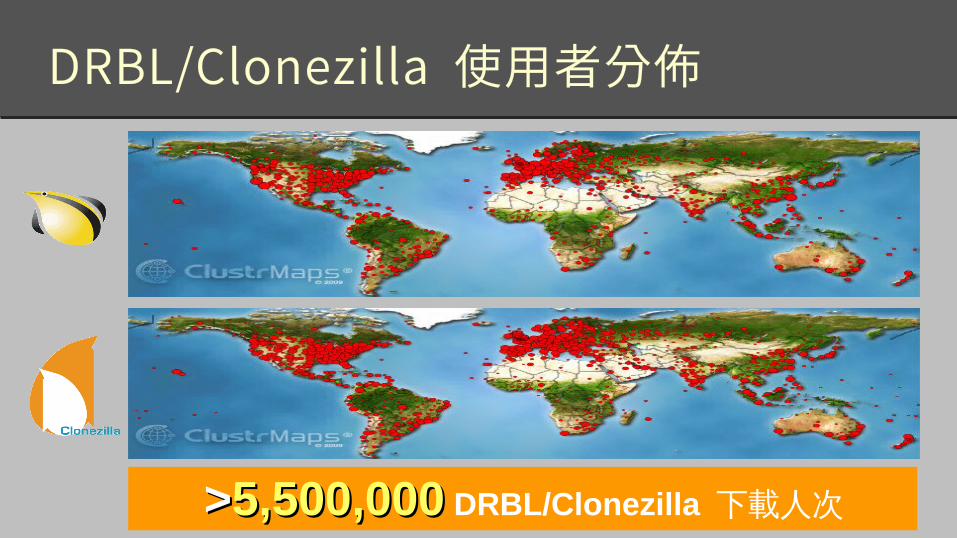
>>5,500,0005,500,000 DRBL/Clonezilla 下載人次
DRBL/Clonezilla 使用者分佈

● Clonezilla [OCS (Opensource Clone System)]● Clonezilla 是一完整的硬碟資料複製的工具 , 類似 Ghost®(Symantec) 或是 Rembo(Acquired by IBM Tivoli® software)/ Acronis®(True Image)● 處理元件包含 :
– 實體資料 : 分割區資料、 LVM2– 隱藏磁區
● Block base 備份方式– 只備份有使用之區塊 , 提高備份還原效能– Smart copying– 支援 Grub 1/2 ( 恢復、重建 )– 檔案式架構之印象檔 : 格式通透、公開、標準格式 ; 易於彈性調整
Clonezilla

+ +=
ServerDisklessPC
image source: www.mren.com.tw
DiskfullPC
DRBL

DRBL - Diskless Remote Boot in Linux● pxe/etherboot + nfs + nis – 站在巨人的肩膀上● 支援多元化的電腦教學 - Linux 與微軟 Windows 可同時並存● DRBL 環境下, OS 存在 server 端, client 端的作業系統可保留● 簡化管理工作● 所有的服務集中在 server 管理,減少檢視每台 client 軟體的困擾● 作業系統與軟體只需要在 server 上安裝一遍即可● 硬體與安裝雖簡化,軟體卻完整● 軟體和逐一安裝的機器一樣,沒有任何偷工減料

DRBL EnvironmentDRBL erver
switch 1
node001 node013 node040node027
NIC 4NIC 3NIC 2
switch 2 switch 3
node014 ~ node028 ~
private IP private IP private IP
~

DRBL 的建議規格以下所列的規格僅供參考,採購時可依據經費與當時最佳的設備來採購,中央政府各機關、學校委託的中央信託局集中採購案中有符合使用的設備高效能計算 (HPC) 的需求是永無止境的
伺服器最低規格 :CPU 450 MHz,記憶體 256 MB, fast ethernet(100Mbps)網路卡多張。
建議規格 :CPU 2.6 GHz,記憶體 1 GB,Gigabits網路卡 4張。
客戶端最低規格 :CPU 300 MHz,記憶體 128 MB, 100Mbps網路卡,若是新購電腦的話建議直接買有支援網路開機 (PXE)的網卡或是內建 PXE功能網卡的主機板。
網路連接設備最低需求 :100Mbps的交換器。
建議規格 :以 40人的電腦教室為例,兩台 24埠 100Mbps的交換器,每台上面另外個別有 2個Gigabits ports。

Modes of DRBL/ClonezillaFull DRBL Full Clonezilla DRBL SSI Clonezilla Box
/etc, /var of client NFSbased NFSbased Tmpfsbased Tmpfsbased
Kept Kept Gone Gone
~ 50 100 MB* ~ 50100MB* 0 0
253 253 253 253* depends on the packages installed in the server
Files in /etc and /var of client after reboot
Extra space in server/clientMax client #/ethernet card in server

DRBL-live● DRBL live
– 透過光碟或者隨身碟直接開機– 當一台 DRBL 伺服器– 所有的程式不需要裝在那台電腦的硬碟中。
● 圖形介面 XFCE● 不需要安裝 直接操作 所有 DRBL功能

Hadoop

Hadoop● 以 Google App Engine平台為仿效對象● 創始者 Doug Cutting
– Apache Lucene文字搜尋引擎, Java 設計的高效能文件索引引擎 API– 進而開發了 Apache Nutch
● 以 Java 開發● 自由軟體● 上千個節點與 Petabyte等級的資料量● 為 Apache 軟體基金會的 top level project

起源 :2002-2004● Lucene
– 用 Java 設計的高效能文件索引引擎 API– 索引文件中的每一字 ,讓搜尋的效率比傳統– 逐字比較還要高的多
● Nutch– nutch 是基於開放原始碼所開發的 web search– 利用 Lucene函式庫開發– 在Nutch 0.8版之後, Hadoop為獨立項目演變為獨立的 Hadoop開發套件

起源 :Google論文● Google File System
– 可擴充的分散式檔案系統– 設計目的在於可以給大量的用戶提供總體性– 能較高的服務– 適用於分散式、對大量資訊進行存取的應用– 可運作在一般的普通主機上 ,且提供錯誤容忍的能力
● “The Google File System“ 發表於 SOSP' 03 October, 並將設計的概念公開● Dong Cutting 開始參考論文來實做

起源 :2004~● Dong Cutting 開始參考論文來實做● Added DFS & MapReduce implement to Nutch● Nutch 0.8版之後 ,Hadoop為獨立項目● Yahoo 於 2006年僱用 Dong Cutting 組隊專職開發
– Team member = 14 (engineers, clusters, users, etc. )● Hadoop命名的概念也非常類似當年Google命名的由來, Google 是英文單詞「 Googol」按照通常的英語拼法改寫而來的。 Googol 是一個大數的名稱,也就是10的 100次方,表示 1後面加上 100個零。

系統特色● 巨量 - 擁有儲存與處理大量資料的能力● 經濟 - 可以用在由一般PC 所架設的叢集環境內● 效率 - 籍由平行分散檔案的處理以致得到快速的回應● 可靠 - 當某節點發生錯誤 , 系統能即時自動的取得備份資料以及佈署運算資源● 定位 - 是用來處理與保存大量資料的雲端運算平台● Hadoop主要核心完全使用 Java 開發,而使用者端則提供 C++/Java/Shell/Command等程式開發介面,目前可執行於Linux 、 Mac OS/X 、 Windows 和 Solaris 作業系統,以及一般商用等級的伺服器

Hadoop 元件● Hadoop 中包含了最著名的分散式檔案系統(HDFS) 、 MapReduce框架、儲存系統 (HBase)等元件,以及根據 Hadoop延伸發展的其他子專案:
– Core:一組用於分散式檔案系統和一般性 I/O 之用的元件和介面。– ZooKeeper:分散式且高可用性的協調服務,可為建置分散式系統提供分散式鎖定等原始鎖定功能。– Hive:分散式資料倉儲,透過 Hiave 可管理存放於 HDFS 的資料,並提供根據SQL 發展的查詢語言來查詢資料。– Pig:超大資料集的資料流語言以及執行環境,可在 HDFS 和 MapReduce叢集環境中執行。– Avro:提供高效能、跨語言以及可保存資料的 RPC 資料序列化系統。– Chukwa:分散式資料收集和分析系統,其會執行收集器以便在 HDFS 中儲存資料,且會使用 MapReduce 來產生報表

Hadoop 架構雲端應用程式
Hbase 儲存系統 Map Reduse 框架
分散式檔案系統 HDFS
叢集伺服器

MapReduce( MRv2/YARN) ● 新的 Hadoop MapReduce 框架命名為
MapReduceV2 或者叫 Yarn● MRv2 最基本的設計思想是將
JobTracker 的兩個主要功能,即資源管理和作業調度 / 監控分成兩個獨立程序。包含幾個部分:– ResourceManager ( RM )
● 調度器( Scheduler )● 應用管理器
(ApplicationsManager , ASM )– ApplicationMaster ( AM )
● 一個具體的框架庫,它的任務是與RM 協商獲取應用所需資源和與NM (NodeManager) 合作,以完成執行和監控 task 的任務

背景與動機● 電腦教室一般使用率不到30%● 個人電腦叢集一般使用量都非常高● 應該妥善利用電腦教室閒暇時間● 完善的電腦教室管理與使用機制是需要的 -> DRBL

drbl-live-hadoop● 整合 DRBL 與 Hadoop 環境● 自動化佈署Hadoop● 彈性擴充節點● 有效運用計算資源

DIY● Tuxboot● Drbl-live● CD-Rom or Usb boot● Drbl-live-hadoop● Boot clients (datanode)● http://127.0.0.1:50070● http://127.0.0.1:8088

DRBL-live CD 下載

選擇架構

使用 Tuxboot
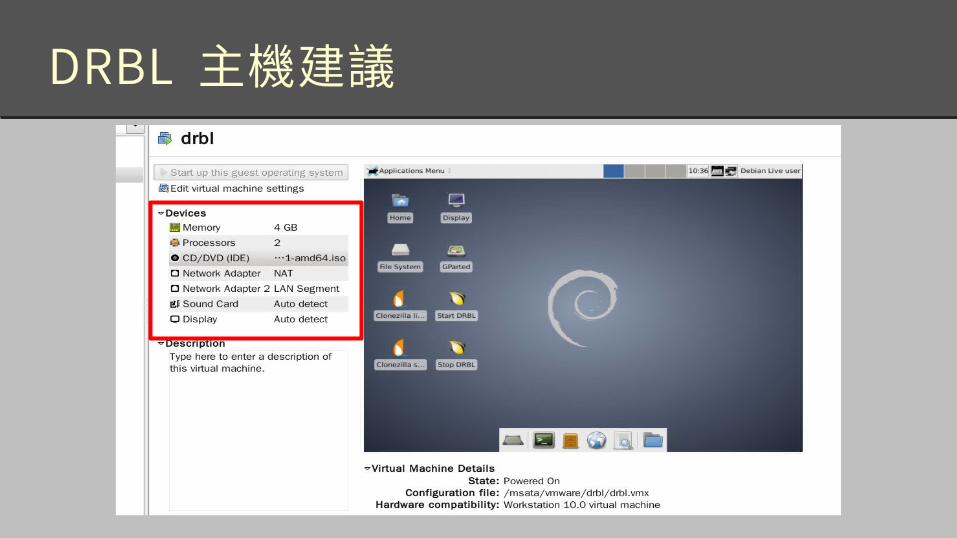
DRBL 主機建議

開機

鍵盤、語言

確認對外網路

執行 drbl-live-hadoop

設定網路

固定 IP
準備安裝 hadoop

下載中

Hadoop Cluster done

Data node Spec

BIOS 網路開機設定

開啟 Datanode
開啟狀態

JPS

確認完成

任務完成

todo● Storm● HBase● Zookeeper● Clonezilla-hadoop● DRBL-hadoop

Related Projects and Developers● DRBL● Clonezilla● Partclone● Tuxboot● Tux2Live● Cloudboot
● Steven Shiau● Ceasar Sun● Thomas Tsai● Jimmy Chuang
DEMO

F&Q
Thank You