dr. ike nassi, founder, tidalscale at mlconf nyc - 4/15/16
TRANSCRIPT

SCALE | SIMPLIFY | OPTIMIZE | EVOLVE
05/01/2023 TidalScale Proprietary & Confidential 1
Comparing a Virtual Supercomputer with a Cluster for Spark in-memory
Computations

05/01/2023 2
Why Run Spark?
Spark originated as in-memory alternative to Hadoop
Run huge analytics on clusters of commodity servers
Enjoy the hardware economy of “scale-out”
Apply a rich set of transformations and actions
Operate out of memory as much as possible
TidalScale Proprietary & Confidential

05/01/2023 3
Today’s Conundrum: Scale Up vs. Scale Out?
TidalScale Proprietary & Confidential
Scale Up Scale Out
Software Simplicity
HW Cost?
✔ ✗✗ ✔

05/01/2023 4
TidalScale – The Best of Both
TidalScale Proprietary & Confidential
Software Simplicity HW Cost
✔ ✔
Easy to say, but this is a ridiculously difficult problem!

05/01/2023 5
Key takeawaysSimplicity of Scale up:
• We allow the simplicity of scale-up – you can run multi-terabyte analytics on a single Spark node.
Scale out “under the hood”• We offer a new class of virtual supercomputers to host
Spark – we hide the complexity of scale-out “under the hood”.
TidalScale Proprietary & Confidential

05/01/2023 6
Traditional Spark in two layers
TidalScale Proprietary & Confidential
Programming Paradigm RDD – Resilient Distributed Dataset / DataFrame
Parallel in-memory execution
Lazy, repeatable evaluation thanks to ”wide dependencies”
Rich set of operators beyond just Map-Reduce
Implementation Plumbing Clusters – standalone, Mesos, Yarn
Data – HDFS, Dataframes
Memory management

05/01/2023 7
Alternative Spark in two layers
TidalScale Proprietary & Confidential
Programming Paradigm RDD – Resilient Distributed Dataset / DataFrame
Parallel in-memory execution
Lazy, repeatable evaluation thanks to ”wide dependencies”
Rich set of operators beyond just Map-Reduce
TidalScale as alternate plumbing!
05/01/2023 8
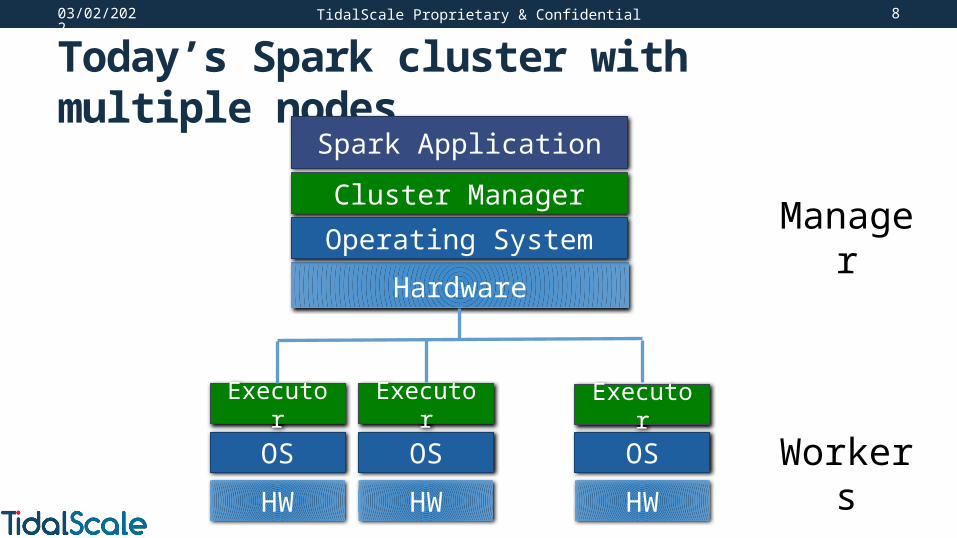
Today’s Spark cluster with multiple nodes
TidalScale Proprietary & Confidential
Hardware
Spark Application
Cluster Manager
Operating System
OS
HW
OS
HW
OS
HW
Executor Executor Executor
Manager
Workers
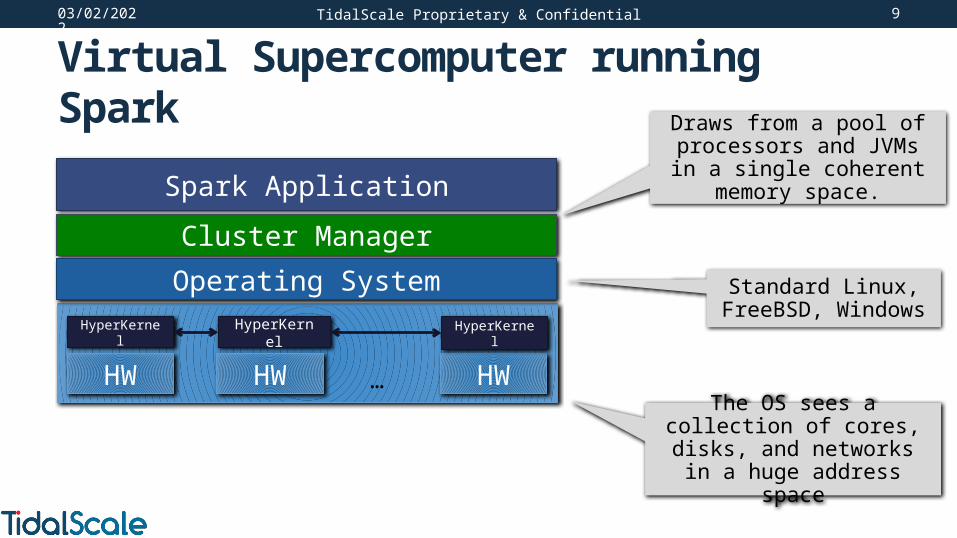
05/01/2023 9
Virtual Supercomputer running Spark
TidalScale Proprietary & Confidential
Spark Application
HW HW HW…
HyperKernel HyperKernel HyperKernel
Cluster Manager
Operating System
Draws from a pool of processors and JVMs in a single
coherent memory space.
Standard Linux, FreeBSD, Windows
The OS sees a collection of cores, disks, and networks in a
huge address space
05/01/2023 10
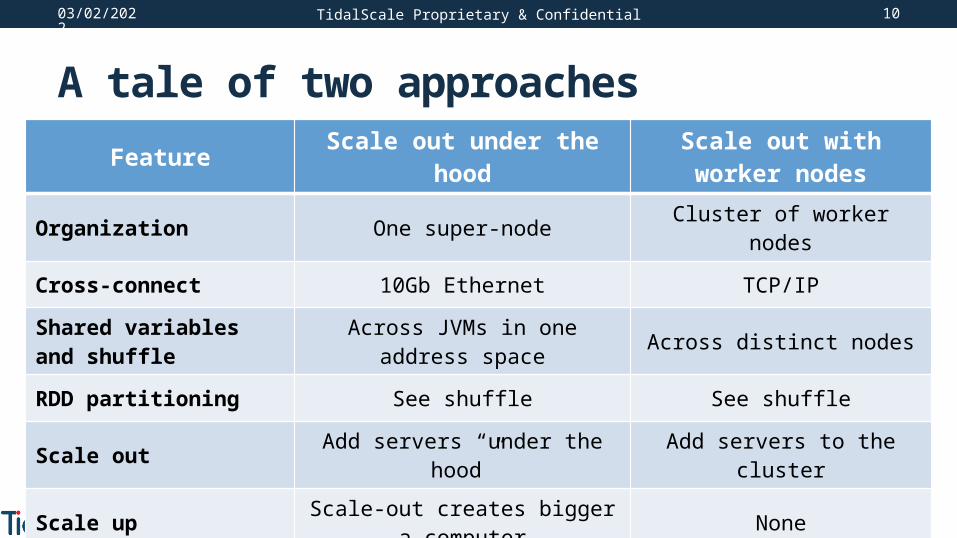
A tale of two approaches
TidalScale Proprietary & Confidential
Feature Scale out under the hood Scale out with worker nodes
Organization One super-node Cluster of worker nodes
Cross-connect 10Gb Ethernet TCP/IP
Shared variables and shuffle Across JVMs in one address space Across distinct nodes
RDD partitioning See shuffle See shuffle
Scale out Add servers “under the hood” Add servers to the cluster
Scale up Scale-out creates bigger a computer None
Reuse Run any application Other cluster techs like Hadoop

May 1, 2023 11
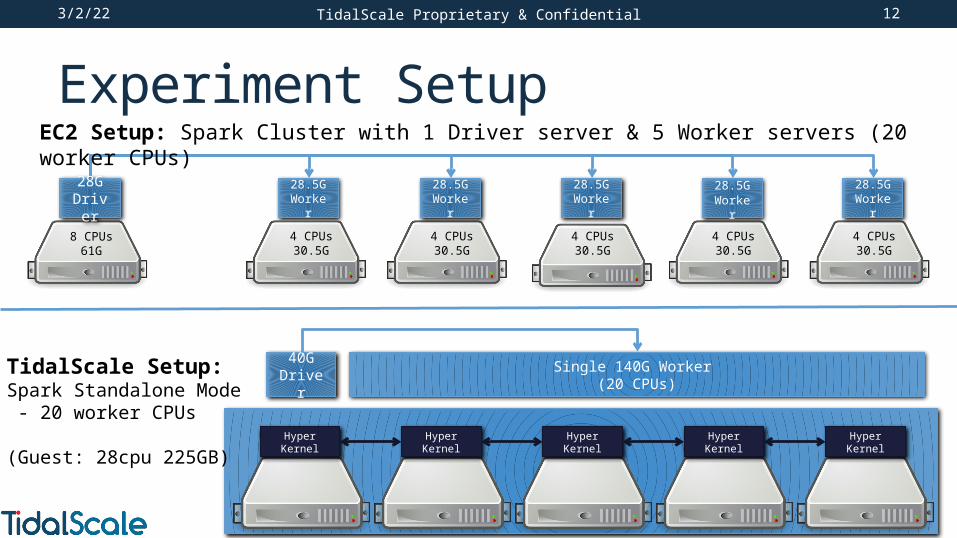
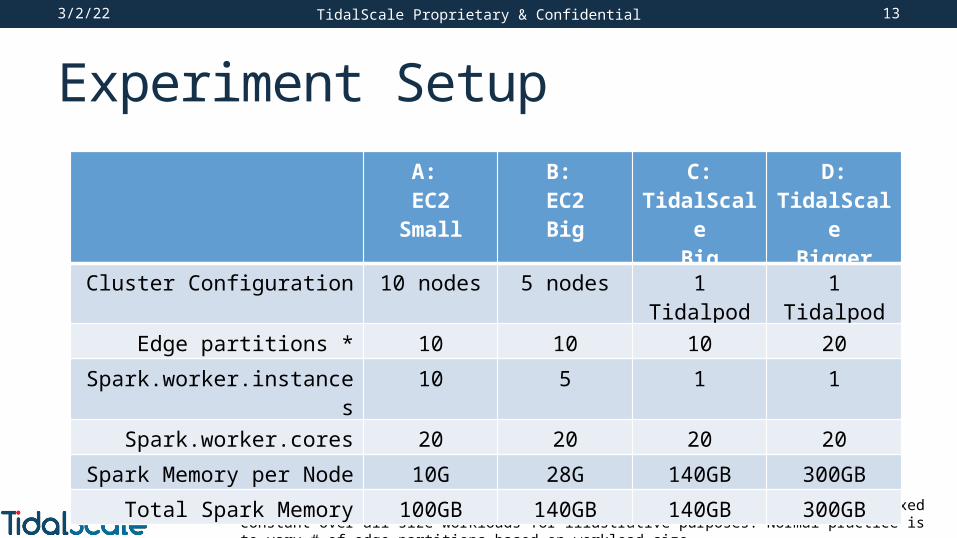
Experiment SetupSynthBenchmark benchmark from Apache.org
• git://git.apache.org/spark.git (spark-1.6.1-bin-hadoop2.6.tgz)• Applies the PageRank algorithm to a generated graph • Benchmark scaled from 15GB to 150GB by number of vertices
Scale Out Spark Configuration on EC2: • 1 Master: ec2 r3.2xlarge (8 cpus, 61G)• 5 Workers: r3.xlarge (4 cpus, 28.5G)• 4 Intel E5 2670 CPUs x 5 servers = 20 CPUs total allocated to Spark
Scale Up Spark Configuration on TidalScale: • TidalScale TidalPod with 5 nodes• 20 Intel E5 2643 v3 CPUs allocated to Spark
TidalScale Proprietary & Confidential
May 1, 2023 12
Experiment SetupTidalScale Proprietary & Confidential
28.5G Worker
28GDriver
8 CPUs61G
EC2 Setup: Spark Cluster with 1 Driver server & 5 Worker servers (20 worker CPUs)
4 CPUs30.5G
28.5GWorker
28.5GWorker
28.5G Worker
28.5G Worker
4 CPUs30.5G
4 CPUs30.5G
4 CPUs30.5G
4 CPUs30.5G
Single 140G Worker (20 CPUs)
40G Driver
HyperKernel
HyperKernel
HyperKernel
HyperKernel
HyperKernel
TidalScale Setup:Spark Standalone Mode - 20 worker CPUs
(Guest: 28cpu 225GB)
May 1, 2023 13
Experiment SetupTidalScale Proprietary & Confidential
* Note: The number of edge partitions in this example have been set to a fixed constant over all size workloads for illustrative purposes. Normal practice is to vary # of edge partitions based on workload size.
A: EC2
Small
B: EC2Big
C: TidalScale
Big
D: TidalScale
Bigger
Cluster Configuration 10 nodes 5 nodes 1 Tidalpod 1 Tidalpod
Edge partitions * 10 10 10 20
Spark.worker.instances 10 5 1 1
Spark.worker.cores 20 20 20 20
Spark Memory per Node 10G 28G 140GB 300GB
Total Spark Memory 100GB 140GB 140GB 300GB
May 1, 2023 14
Experiment ResultsTidalScale Proprietary & Confidential
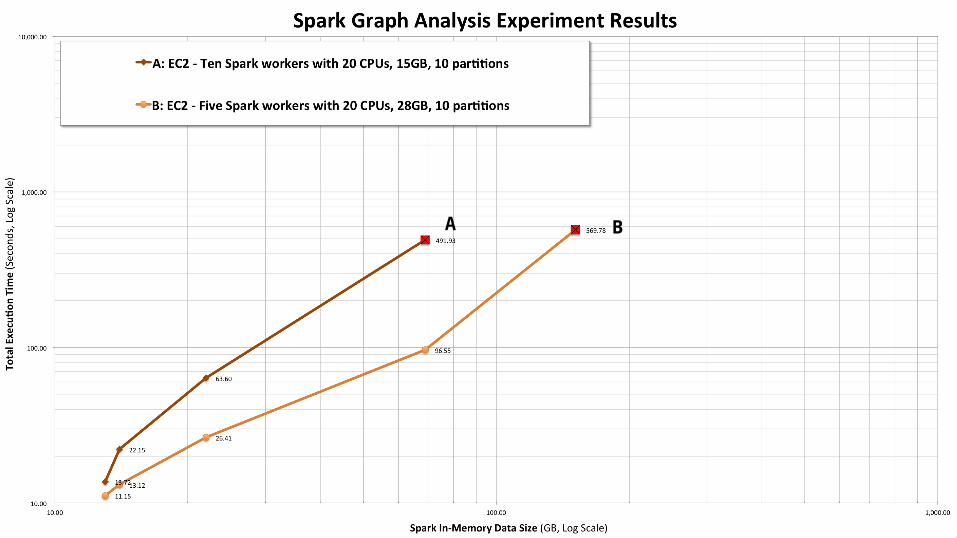
A B
May 1, 2023 15
Experiment ResultsTidalScale Proprietary & Confidential
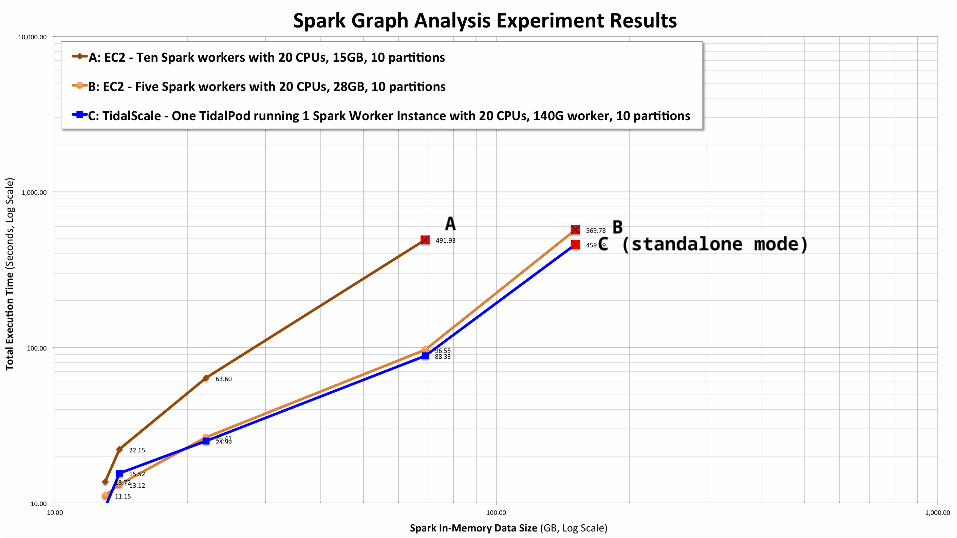
A BC (standalone mode)
May 1, 2023 16
Experiment ResultsTidalScale Proprietary & Confidential
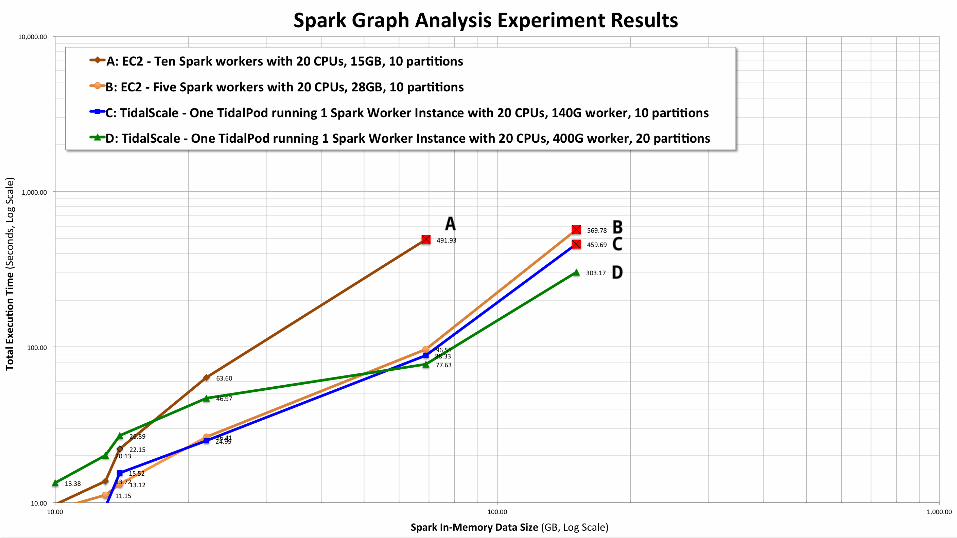
A BCD

May 1, 2023 17
Experiment ObservationsTuning Spark is complex
• We spent most of our time tuning Spark parameters• We are not sure we’ve tuned optimally for either the ec2 spark distributed
cluster or the TS spark standalone case, but parameters were the same in both
Choice of the number of data partitions really matters• A suboptimal choice can have 2-3x performance impact• We used 10 edge partitions for both ec2 and TidalScale configurations
TidalScale Proprietary & Confidential
05/01/2023 18
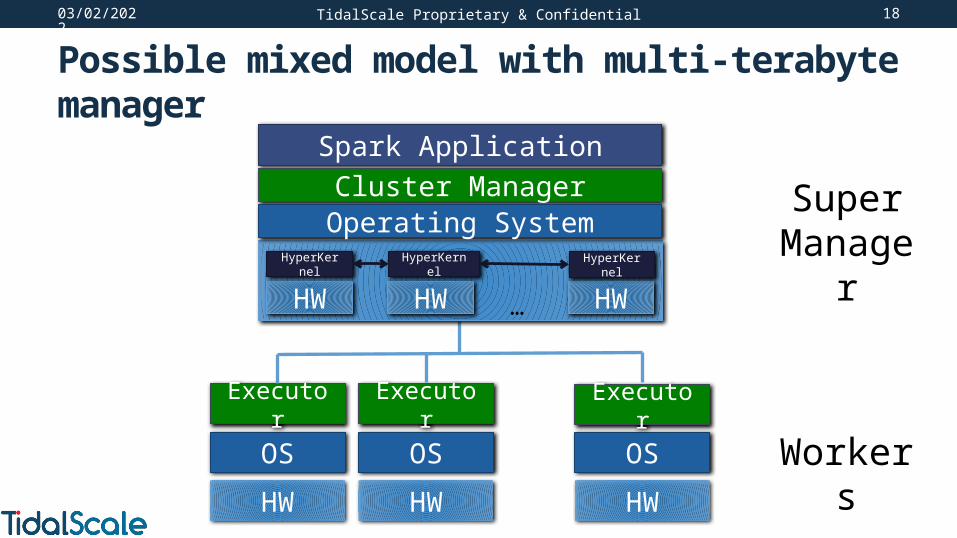
Possible mixed model with multi-terabyte manager
TidalScale Proprietary & Confidential
OS
HW
OS
HW
OS
HW
Executor Executor Executor
SuperManager
Workers
Spark Application
HW HW HW…
HyperKernel HyperKernel HyperKernel
Cluster ManagerOperating System

May 1, 2023 19
Conclusions & RecommendationsSpark standalone on TidalScale performs similarly to a clusterWithout TidalScale, larger workloads can run out of memory without careful Spark tuningWe recommend using both scale up and scale out
TidalScale Proprietary & Confidential

05/01/2023 20
Key messages – more obvious now?
A new class of virtual supercomputers to host Spark
Run multi-terabyte analytics on a single Spark node
TidalScale Proprietary & Confidential

05/01/2023 21
Value PropositionScale:
• Aggregates compute resources for large scale in-memory analysis and decision support• Scales like a cluster using commodity hardware at linear cost• Allows customers to grow gradually as their needs develop
Simplify: • Dramatically simplifies application development• No need to distribute work across servers• Existing applications run as a single instance, without modification, as if on a highly flexible
mainframeOptimize:
• Automatic dynamic hierarchical resource optimizationEvolve:
• Applicable to modern and emerging microprocessors, memories, interconnects, persistent storage & networks
TidalScale Proprietary & Confidential

SCALE | SIMPLIFY | OPTIMIZE | EVOLVE
05/01/2023 TidalScale Proprietary & Confidential 22
Contact: Ike [email protected]