
The Semantic Web:New-style data-integration
(and how it works for life-scientists too!)
Frank van HarmelenAI Department
Vrije Universiteit Amsterdam

What’s the problem?
(data-mess in bio-inf)

The Study of Genes...
• Chromosomal location
• Sequence
• Sequence Variation
• Splicing
• Protein Sequence• Protein Structure

… and Their Function
• Homology
• Motifs
• Publications
• Expression
• HTS
• In Vivo/Vitro Functional Characterization
Understanding Mechanisms of Disease
Metabolic and
regulatory pathway induction

Development of Drugs, Vaccines, Diagnostics
Differing types of Drugs, Vaccines, and Diagnostics• Small molecules• Protein therapeutics• Gene therapy• In vitro, In vivo diagnostics
Development requires• Preclinical research• Clinical trials• Long-term clinical research
All of which often feeds back into ongoing Genomics research and discovery.

Sample Problem: Hyperprolactinemia
Over production of prolactin– prolactin stimulates mammary gland
development and milk production
Hyperprolactinemia is characterized by:– inappropriate milk production– disruption of menstrual cycle– can lead to conception difficulty

Understanding transcription factors for prolactin production
“Show me all genes in the public literature that are putatively related to hyperprolactinemia, have more than 3-fold expression differential between hyperprolactinemic and normal pituitary cells, and are homologous to known transcription factors.”
“Show me all genes that are homologous to known transcription factors”
SEQUENCE
1Q“Show me all genes that have more than 3-fold expression differential between hyperprolactinemic and normal pituitary cells”EXPRESSION
2Q
“Show me all genes in the public literature that are putatively related to hyperprolactinemia”
LITERATURE
3Q
(Q1Q2Q3)

The Industry’s Problem
Too much unintegrated data:– from a variety of incompatible sources
– no standard naming convention
– each with a custom browsing and querying mechanism (no common interface)
– and poor interaction with other data sources

ESTC Sept, 2008
Andy Law’s First Law
“The first step in developing a new genetic analysis algorithm is to decide how to make the input data file format different from all pre-existing analysis data file formats.”
ESTC Sept, 2008

ESTC Sept, 2008
Andy Law’s Second Law
“The second step in developing a new genetic analysis algorithm is to decide how to make the output data file format incompatible with all pre-existing analysis data file input formats.”
ESTC Sept, 2008

What are the Data Sources?
• Flat Files• URLs• Proprietary Databases• Public Databases• Data Marts• Spreadsheets• Emails• …
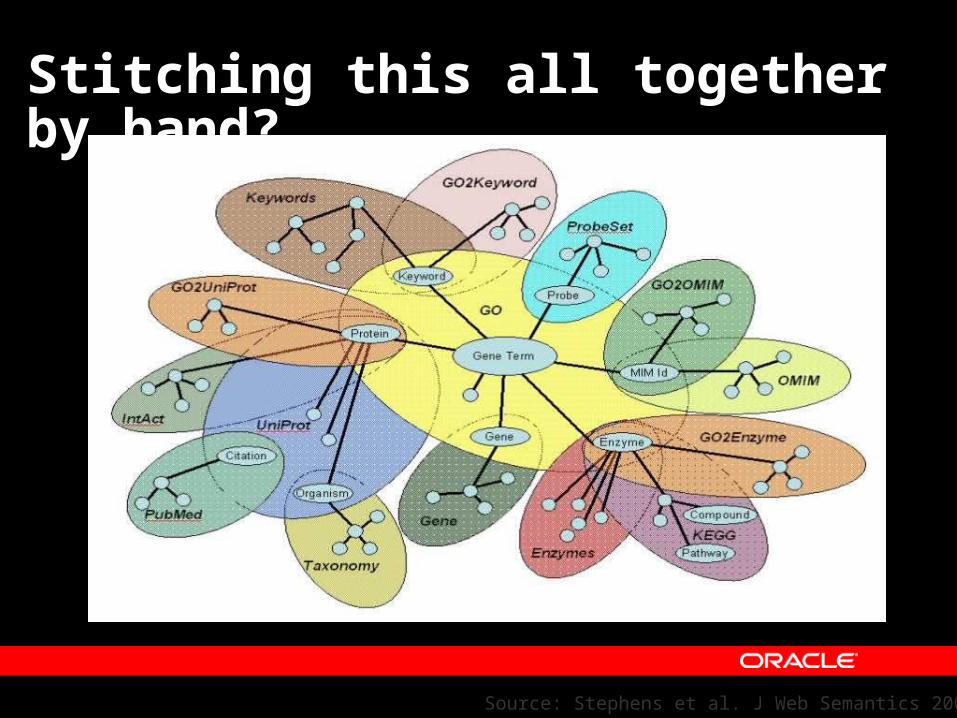
Stitching this all together by hand?
Source: Stephens et al. J Web Semantics 2006

Why would Semantic Web
technology help?

Semantic Web Approach1. Convert all data sources to
RDF representation (local or distributed)2. Optional: Collect the data to scalable
semantic repository3. Apply light-weight reasoning to specify
formal interpretations of the data, e.g.: remove redundancy, establish equalities, etc
4. Derive new implicit knowledge
ESTC Sept, 2008
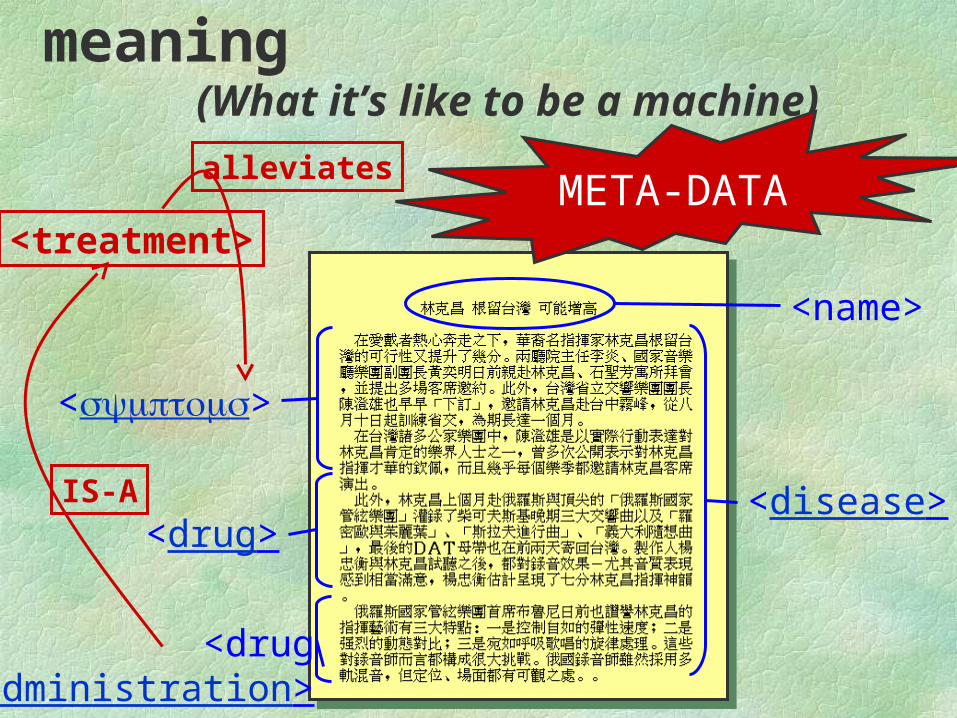
machine accessible meaning (What it’s like to be a machine)
<name>
<symptoms>
<drug>
<drugadministration>
<disease>
<treatment>
IS-A
alleviatesMETA-DATA

What is meta-data?
it's just datait's data describing other dataits' meant for machine consumption
disease
name
symptoms
drug
administration

Required are:1. one or more standard vocabularies
so search engines, producers and consumersall speak the same language
2. a standard syntax, so meta-data can be recognised as such
3. lots of resources with meta-data attached
mechanisms for attribution and trust

no shared understanding
Conceptual and terminological confusion
Actors: both humans and machines
Agree on a conceptualization
Make it explicit in some language.
world
concept
language
What are ontologies &what are they used for

standard vocabularies (“Ontologies”)Identify the key concepts in a domainIdentify a vocabulary for these
conceptsIdentify relations between these
conceptsMake these precise enough
so that they can be shared between humans and humans humans and machines machines and machines

Real life examples handcrafted
music: CDnow (2410/5), MusicMoz (1073/7) biomedical: SNOMED (200k), GO (15k),
Emtree(45k+190kSystems biology
ranging from lightweight Yahoo, UNSPC, Open directory (400k)
to heavyweight (Cyc (300k))
ranging from small (METAR) to large (UNSPC)

Biomedical ontologies (a few..) Mesh
Medical Subject Headings, National Library of Medicine 22.000 descriptions
EMTREE Commercial Elsevier, Drugs and diseases 45.000 terms, 190.000 synonyms
UMLS Integrates 100 different vocabularies
SNOMED 200.000 concepts, College of American Pathologists
Gene Ontology 15.000 terms in molecular biology
NCBI Cancer Ontology: 17,000 classes (about 1M definitions),

Remember “required are”: one or more standard vocabularies
so search engines, producers and consumersall speak the same language
2. a standard syntax, so meta-data can be recognised as such
3. lots of resources with meta-data attached

Stack of languages
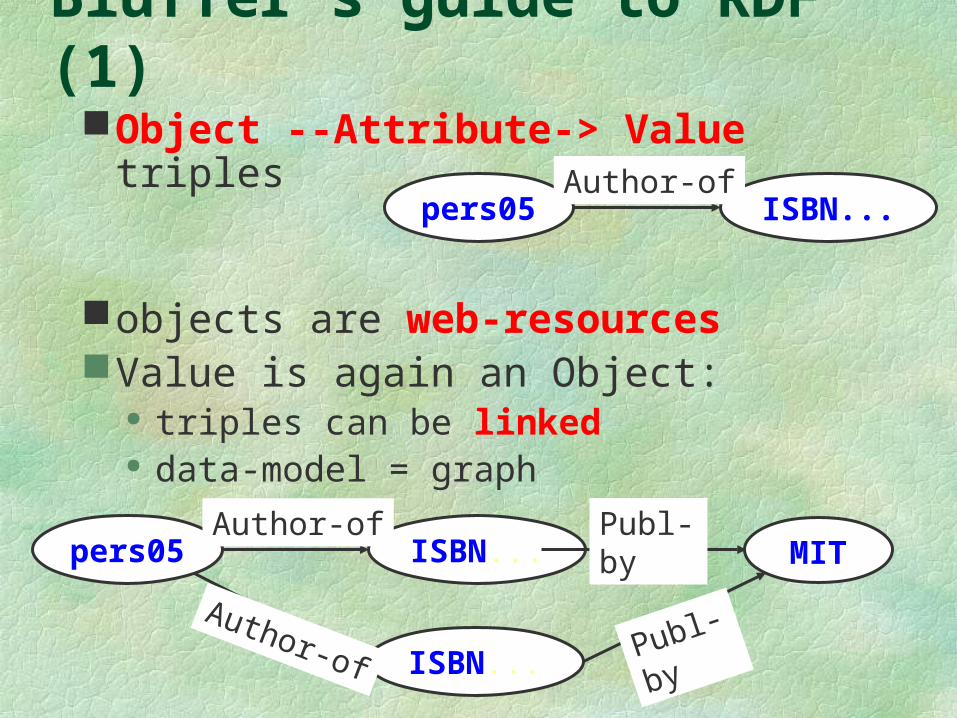
Bluffer’s guide to RDF (1)Object --Attribute-> Value triples
objects are web-resourcesValue is again an Object:
triples can be linked data-model = graph
pers05 ISBN...Author-of
pers05 ISBN...Author-of
MIT
ISBN...
Publ-by
Author-of Publ-
by
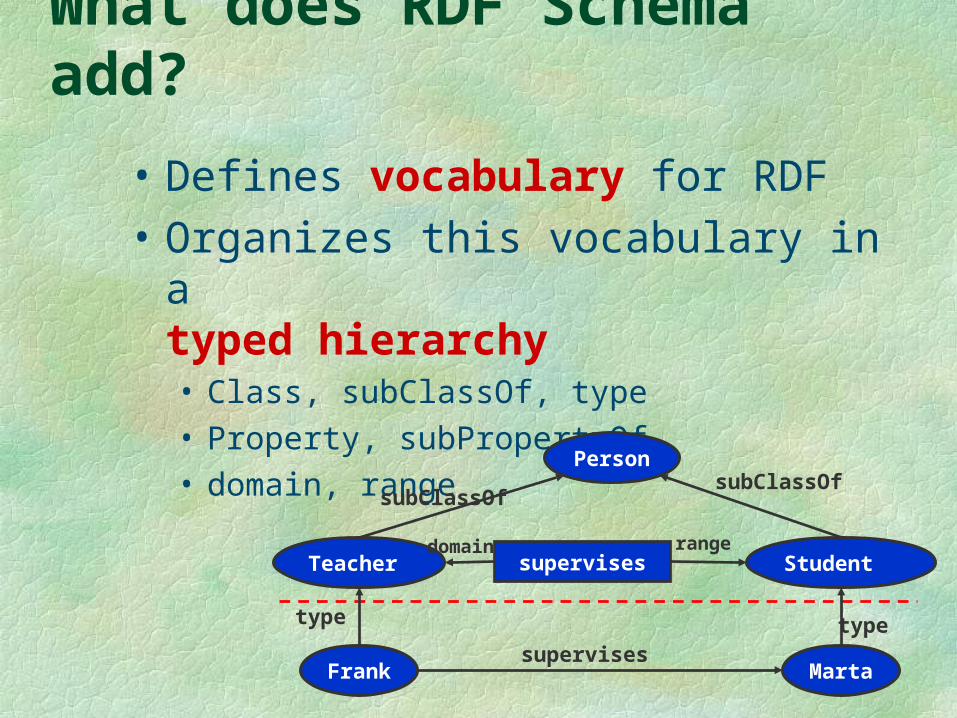
What does RDF Schema add?
• Defines vocabulary for RDF• Organizes this vocabulary in a
typed hierarchy• Class, subClassOf, type• Property, subPropertyOf• domain, range
Person
Teacher Student
subClassOfsubClassOf
Marta
type
supervisesdomain range
Frank
type
supervises
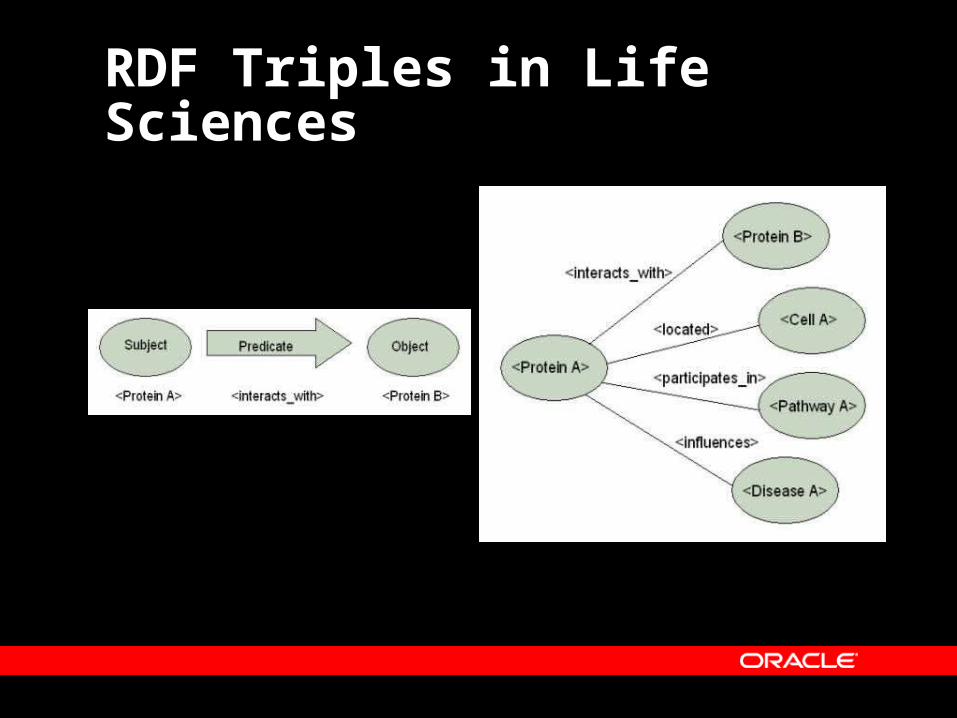
RDF Triples in Life Sciences

OWL: things RDF Schema can’t doequalityenumerationnumber restrictions
Single-valued/multi-valued Optional/required values
inverse, symmetric, transitiveboolean algebra
Union, complement…
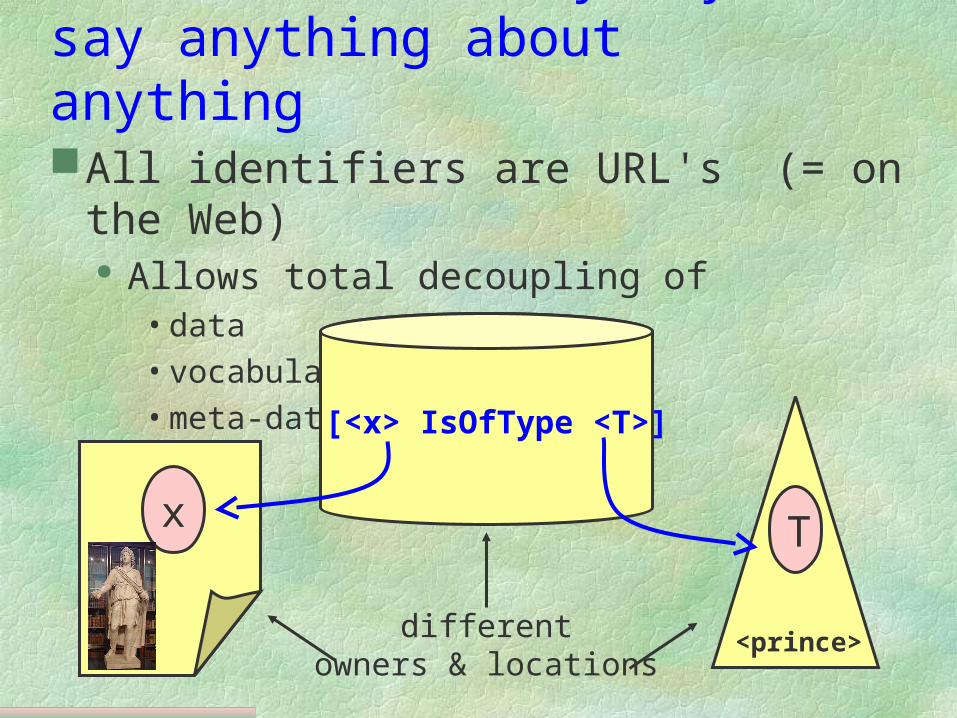
Web of Data: anybody can say anything about anythingAll identifiers are URL's (= on the
Web) Allows total decoupling of
• data• vocabulary • meta-data
x T
[<x> IsOfType <T>]
differentowners & locations
<prince>

RDF(S) have a (very small) formal semanticsDefines what other statements are
implied by a given set of RDF(S) statements
Ensures mutual agreement on minimal contentbetween parties without further contact
In the form of “entailment rules”Very simple to compute
(and not explosive in practice)
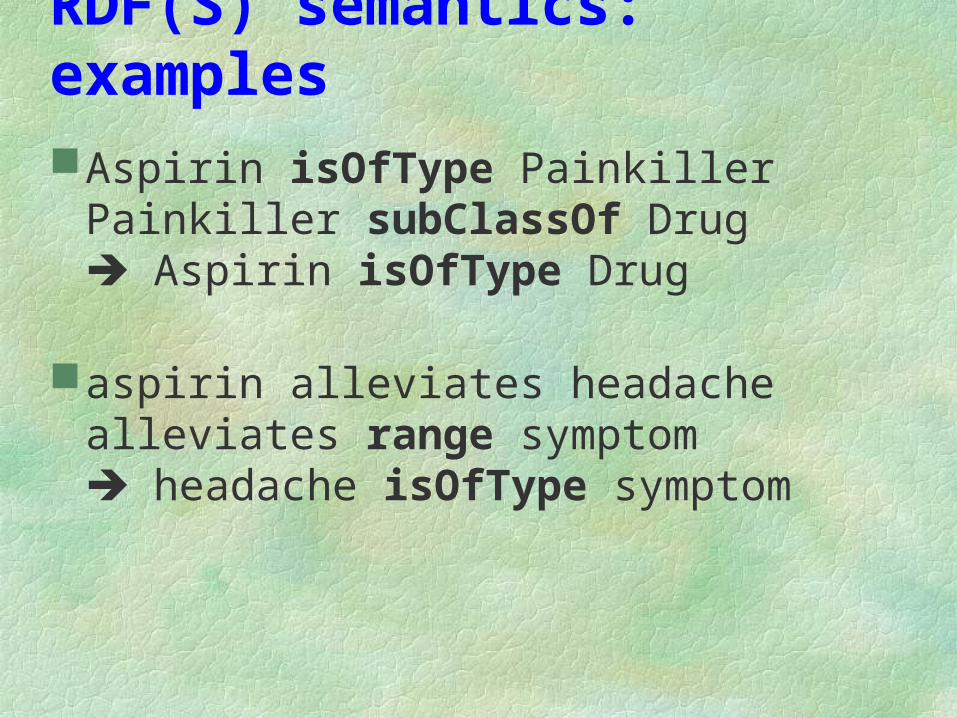
RDF(S) semantics: examplesAspirin isOfType Painkiller
Painkiller subClassOf Drug Aspirin isOfType Drug
aspirin alleviates headachealleviates range symptom headache isOfType symptom

RDF(S) semantics: examplessp isOfType
subClassOf sp isOfType
sptstts range symptom isOfType symptom

RDF(S) semanticsX R Y + R domain T X IsOfType TX R Y + R range T Y IsOfType TT1 SubClassOf T2 +
T2 SubClassOf T3 T1 SubClassOf T3
X IsOfType T1 +T1 SubClassOf T2 X IsOfType T1

OWL also has a formal semantics
Defines what other statements are implied by a given set of statements
Ensures mutual agreement on content(both minimal and maximal)between parties without further contact
Can be used for integrity/consistency checking
Hard to compute (and rarely/sometime/always explosive in practice)

OWL semantics: minimalvanGogh isOfType Impressionist
Impressionist subClassOf Painter vanGogh isOfType Painter
vanGogh painter-of sunflowerspainter-of domain painter vanGogh isOfType painter

OWL semantics: maximalvanGogh isOfType Impressionist
Impressionist disjointFrom Cubist NOT: vanGogh isOfType Cubist
painted-by has-cardinality 1sun-flowers painted-by vanGoghPicasso different-individual-from vanGogh NOT: sun-flowers painted-by Picasso

Remember “required are”: one or more standard vocabularies
so search engines, producers and consumersall speak the same language
a standard syntax, so meta-data can be recognised as such
3. lots of resources with meta-data attached

Question: who writes the ontologies?Professional bodies, scientific
communities, companies, publishers, ….
See previous slide on Biomedical ontologies Same developments in many other fields
Good old fashioned Knowledge Engineering
Convert from DB-schema, UML, etc.

Question:Who writes the meta-data ?
- Automated learning- shallow natural language analysis- Concept extraction
amsterdam
trade
antwerp europe
amsterdam
merchant
city town
center
netherlandsmerchant
city town
Example: Encyclopedia Britannica on “Amsterdam”

Remember “required are” one or more standard vocabularies
so search engines, producers and consumersall speak the same language
a standard syntax, so meta-data can be recognised as such
lots of resources with meta-data attached
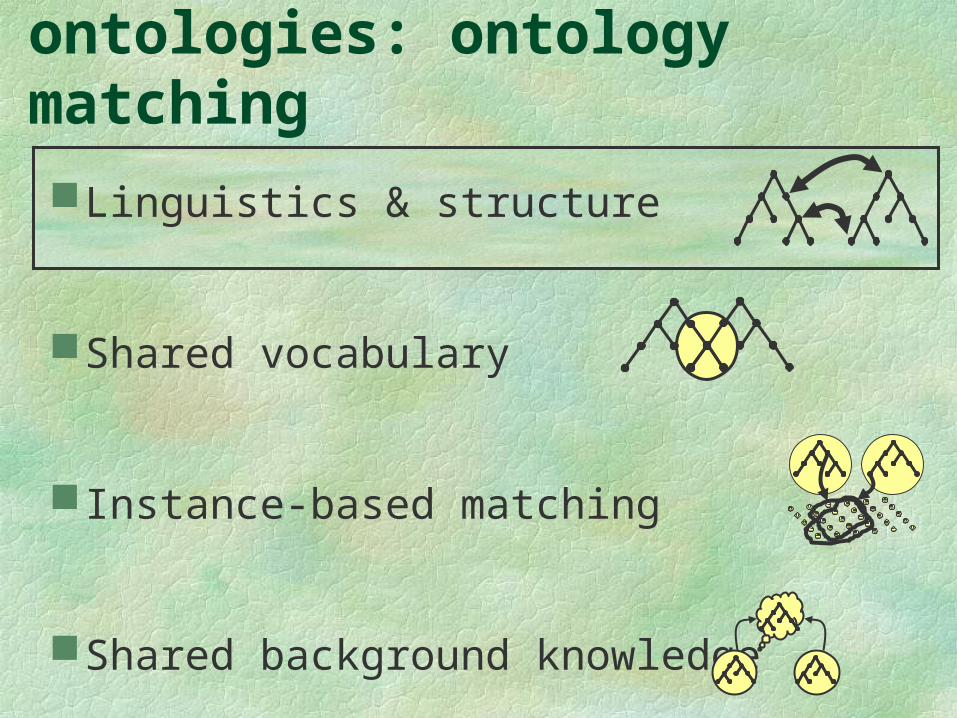
How to handle multiple ontologies: ontology matching
Linguistics & structure
Shared vocabulary
Instance-based matching
Shared background knowledge
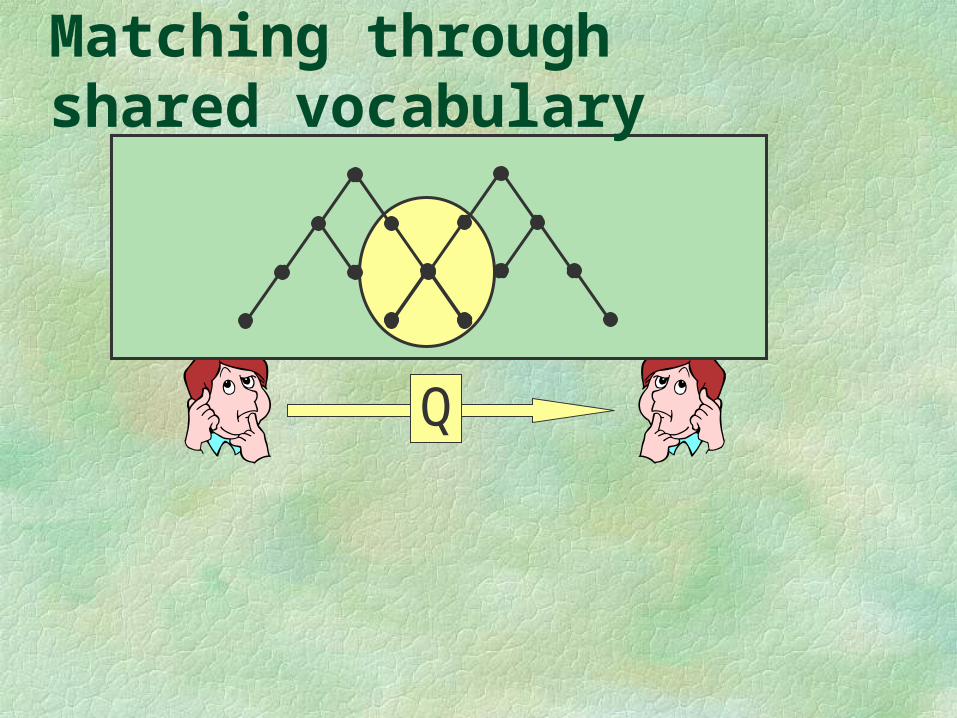
Q
Matching through shared vocabulary
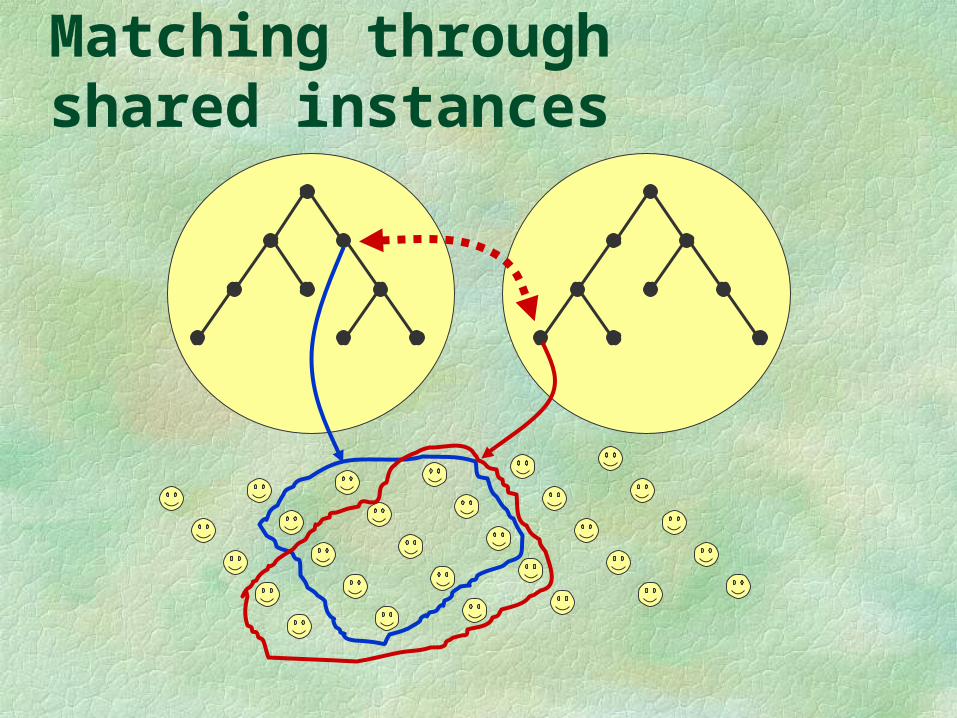
Matching through shared instances

sharedbackgroundknowledge
Matching using shared background knowledge
ontology 1 ontology 2

Some working examples?
• Linked Life Data http://www.linkedlifedata.com
• DOPE• HCLS http://www.w3.org/2001/sw/hcls/

ESTC Sept, 2008
Linked Life Data Overview
• LinkedLifeData - statistics:– Number of statements: 1,159,857,602 – Number of explicit statements: 403,361,589 – Number of entities: 128,948,564
• Platform to automate the process:– Infrastructure to store and inferences – Transform the structured data sources to RDF– Provide web interface to access the data
• Currently operates over OWLIM semantic repository
• Publicly available at: http://www.linkedlifedata.com
ESTC Sept, 2008
ESTC Sept, 2008
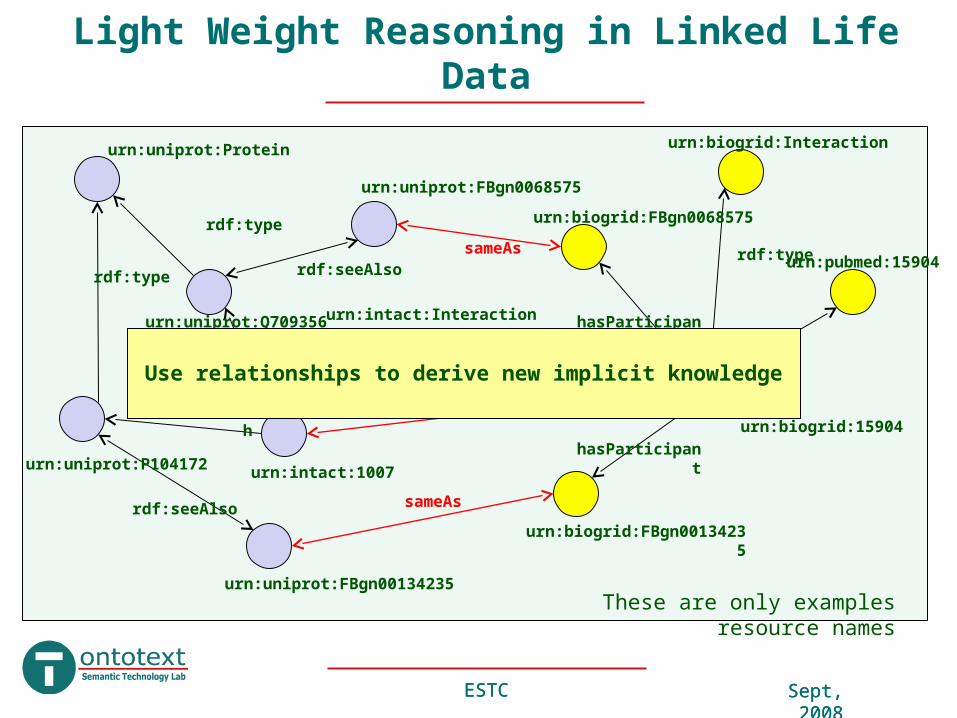
Light Weight Reasoning in Linked Life Data
ESTC Sept, 2008
rdf:type
rdf:type rdf:seeAlso
rdf:seeAlso
urn:intact:1007urn:uniprot:P104172
urn:uniprot:Protein urn:biogrid:Interaction
urn:biogrid:15904
urn:biogrid:FBgn00134235
urn:biogrid:FBgn0068575
urn:pubmed:15904
urn:uniprot:FBgn0068575
urn:uniprot:FBgn00134235
rdf:type
urn:intact:Interactionurn:uniprot:Q709356
interactsWith
interactsWith
hasParticipant
hasParticipant
rdf:typesameAs
sameAs
sameAs
Resolve the syntactic differences in the identifiersUse relationships to derive new implicit knowledge
These are only examples resource names

ESTC Sept, 2008ESTC Sept, 2008
Database Dataset Schema Description
Uniprot Curated entries
Original by the provider Protein sequences and annotations
Entrez-Gene Complete Custom RDF schema Genes and annotation
iProClass Complete Custom RDF schema Protein cross-references
Gene Ontology Complete Schema by the provider Gene and gene product annotation thesaurus
BioGRID Complete BioPAX 2.0 (custom generated) Protein interactions extracted from the literature
NCI - Pathway Interaction Database
Complete BioPAX 2.0 (original by the provider)
Human pathway interaction database
The Cancer Cell Map Complete BioPAX 2.0 (original by the provider)
Cancer pathways database
Reactome Complete BioPAX 2.0 (original by the provider)
Human pathways and interactions
BioCarta Complete BioPAX 2.0 (original by the provider)
Pathway database
KEGG Complete BioPAX 1.0 (original by the provider)
Molecular Interaction
BioCyc Complete BioPAX 1.0 (original by the provider)
Pathway database
NCBI Taxonomy Complete Custom RDF schema Organisms

Some working examples?
• Linked Life Data http://www.linkedlifedata.com
• DOPE• HCLS http://www.w3.org/2001/sw/hcls/

The Data Document repositories:
ScienceDirect: approx. 500.000 fulltext articles
MEDLINE: approx. 10.000.000 abstracts
Extracted Metadata The Collexis Metadata Server: concept-
extraction ("semantic fingerprinting")
Thesauri and Ontologies EMTREE:
60.000 preferred terms 200.000 synonyms


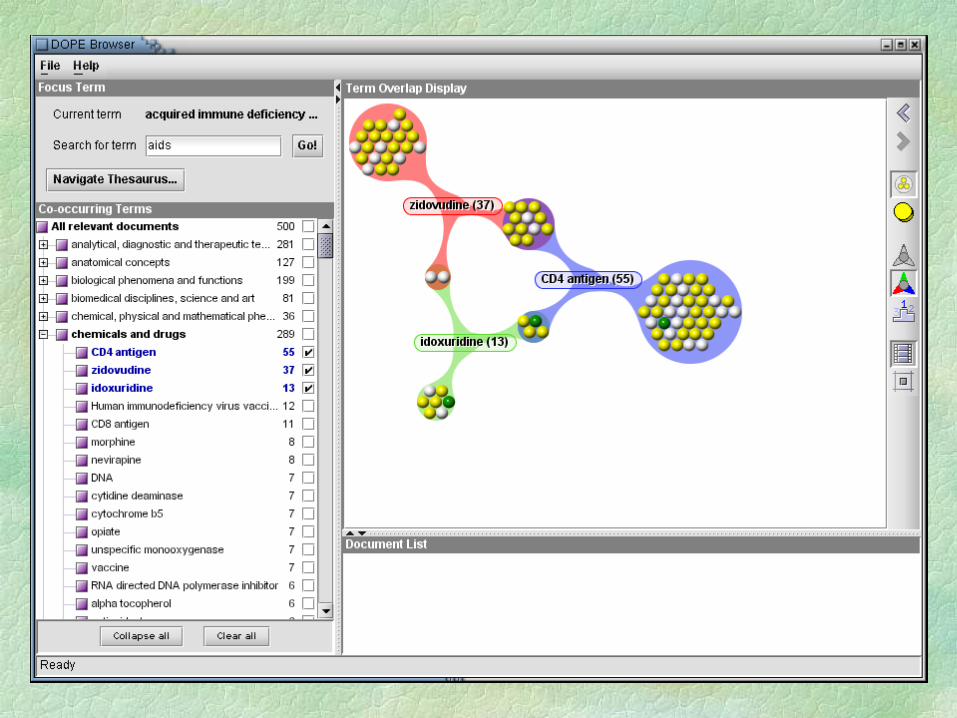
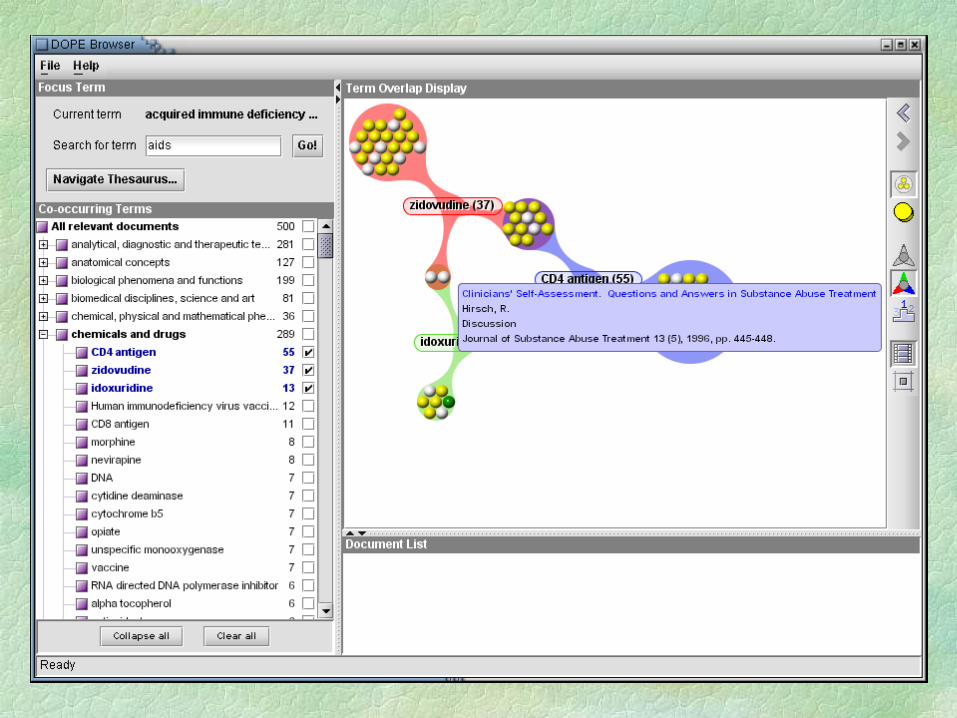



Summarising… Data integration on the Web:
machine processable data besides human processable data
Syntax for meta-data (not discussed in any detail)
Vocabularies for meta-data Lot’s of them in bio-inf.
Actual meta-data: Lot’s in bio-inf.
Will enable: Better search engines (recall, precision,
concepts) Combining information across pages (inference) …

Things to do for you Practical:
Use existing software to construct new use-scenario’s
Conceptual:Create on ontology for some area of bio-medical expertise
from scratch as a refinement of an existing ontology
Technical:Transform an existing data-set in meta-data format, and provide a query interface (for humans and machines)







