
Tapping Hadoop, Kafka, and Spark to Turbocharge Your Big Data Analytics
#SeizeTheData#HighPerformanceAnalytics
Ben Vandiver, Architect, HPE SW Big Data
Jeff Healey, Director of Product Marketing, HPE SW Big Data

Agenda
What it is
What it does
How it works Example

Agenda
–Simple analytics on events
– Time series
– Patterns
–Geospatial
–Live Aggregate Projections
–Flex Tables
–Kafka Streaming
–Text and Unstructured
–Advanced Analytics & UDx
–Hadoop and Data Lakes

Time series/Event series

Time series basics
What you can do:
– Process events in chronological order, cleaning, joining, looking for patterns, etc.
How it works:
– Vertica partitions the data into independent sets (across nodes/CPUs), orders the data into sequences, then does stream analysis.
Example:
– We have meter readings that come in at irregular intervals. Convert it to regular intervals for charting purposes.
0
2
4
6
8
10
12
14
0 2 4 6 8 10 12
Irregular Intervals
0
2
4
6
8
10
12
14
0 2 4 6 8 10 12
Regular Intervals

Event series joins
What you can do:
– Correlate events across streams when the times do not line up
How it works:
– Co-partition and order the sequences, join the streams together, interpolate
Example:
– Stock bids and asks come in at different times… calculate the spread from the prior ask/bid.
32.1 32.5
32.4
32.4
32.3 32.4
32.5
32.6
32.7
Input
32.1 32.5
32.1 32.4
32.4 32.4
32.3 32.4
32.5 32.4
32.5 32.6
32.7 32.6
FULL OUTER
32.1 32.5
32.3 32.4
INNER
LEFT OUTER
32.1 32.5
32.4 32.4
32.3 32.4
32.5 32.4
32.7 32.6
32.1 32.5
32.1 32.4
32.3 32.4
32.5 32.6
RIGHT OUTER

Event windows
What you can do:
– Break a sequence into subsequences based on certain events or changes
How it works:
– Increases a number when a condition is met, or a value changes
Examples:
– Break a log into parts when based on system restarts. Break a user’s clicks into sessions when there are 15-minute gaps in activity.

Pattern matching
What you can do:
– Find matching subsequences of events, compare the frequency of event patterns
How it works:
– Assign labels to events. Find the events within an ordered partition, and pull out any sequences that match the patterns.
Example:
– Identify referring URL for clickstream sessions that begin with an ENTRY to the site, then have a series of ONSITE page views, and end with a PURCHASE.
SELECT uid, sid, refurl, pageurl,
action, event_name()
FROM clickstream_log
MATCH( PARTITION BY user_id
ORDER BY timestamp
DEFINE
ENTRY as RefURL NOT ILIKE ‘%amazon%’
and PageURL ILIKE ‘%amazon%’
ONSITE as PageURL ILIKE ‘%amazon%’
and Action = ‘V’
PURCHASE as PageURL ILIKE ‘%amazon%’
and Action = ‘P’
PATTERN P as (ENTRY ONSITE+ PURCHASE)
ROWS MATCH FIRST EVENT);

Geospatial(Highlights)

Distance functions
– Point to point, or geometry to geometry
– Planar, Spherical, Elliptical
– Example: We’re seeing fraud issues with cloned cell phone SIM cards. Find all SIM cards that appear to have moved faster than could be explained by jet airline travel.
– Solution: Partition event data by ID, and order by time. Compute spherical distance using a lag version of the sequence; ignore short moves; divide by time, compare to speed of a jet.
id lat lng t
1 42.36 71.01 2016-03-06 19:30:00-05
1 37.62 122.38 2016-03-07 02:13:00-05
1 37.62 122.38 2016-03-12 01:12:00-05
1 42.36 71.01 2016-03-12 07:45:00-05
2 42.36 71.01 2016-03-08 12:30:00-05
2 -6.57 -13.32 2016-03-08 12:35:00-05
2 42.36 71.01 2016-03-08 12:40:00-05

Region classification
– Classify points into known regions quickly
– How it works
– Build an index from geometry (DFS, replicated)
– Classify millions of points per second, per node
– Examples
– Measure activity by state/territory
– Find cell phones that aren’t connected to the nearest tower
– Geofencing – keep records of which region points were in, calculate new regions for moved points, use pattern matching to debounce, generate alert list
SELECT STV_Intersect(location
USING PARAMETERS
index=‘/dat/states.idx’),
COUNT(*)
FROM calls
GROUP BY 1;

Live aggregate projections

Phone bills Smart meters Financial trades
Optimize known queries using live aggregate projections
Old Pace:Monthly batch billing
New Pace:
Need to report roaming within 15 minutes
Impersonal:Here’s your bill!
Personal:
Here’s your usage by time, compare rating plans
Analytics:Here are the trends…
Real-Time:
Here’s the spread right now

Feature design
– Define aggregated projection: SUM, COUNT, MIN, MAX, LIMIT (Top-K), Custom UDTs
– Just like any other projection: ROS storage, transactionally consistent, tuple mover, B/R, etc.
– Supports DROP PARTITION, but not DELETE/UPDATE
– Query projection directly, or let optimizer do it for you
Call log table Total minutes used this month (Sum)
Length of most recent call (Top-K)
Table data
Aggregates

Example: Counting Distinct Recent UsersCount distinct visitors in the last <n> days
SELECT DISTINCT visitor FROM events WHERE visit_time >
current_timestamp - 5;
CREATE PROJECTION recent_visits AS
SELECT visitor, MAX(visit_time) recent_visit
FROM events
GROUP BY visitor;
SELECT COUNT(*) FROM recent_visits
WHERE recent_visit > current_timestamp - 5;
Proportional to
number of events
Proportional to
number of visitors

Flex Tables
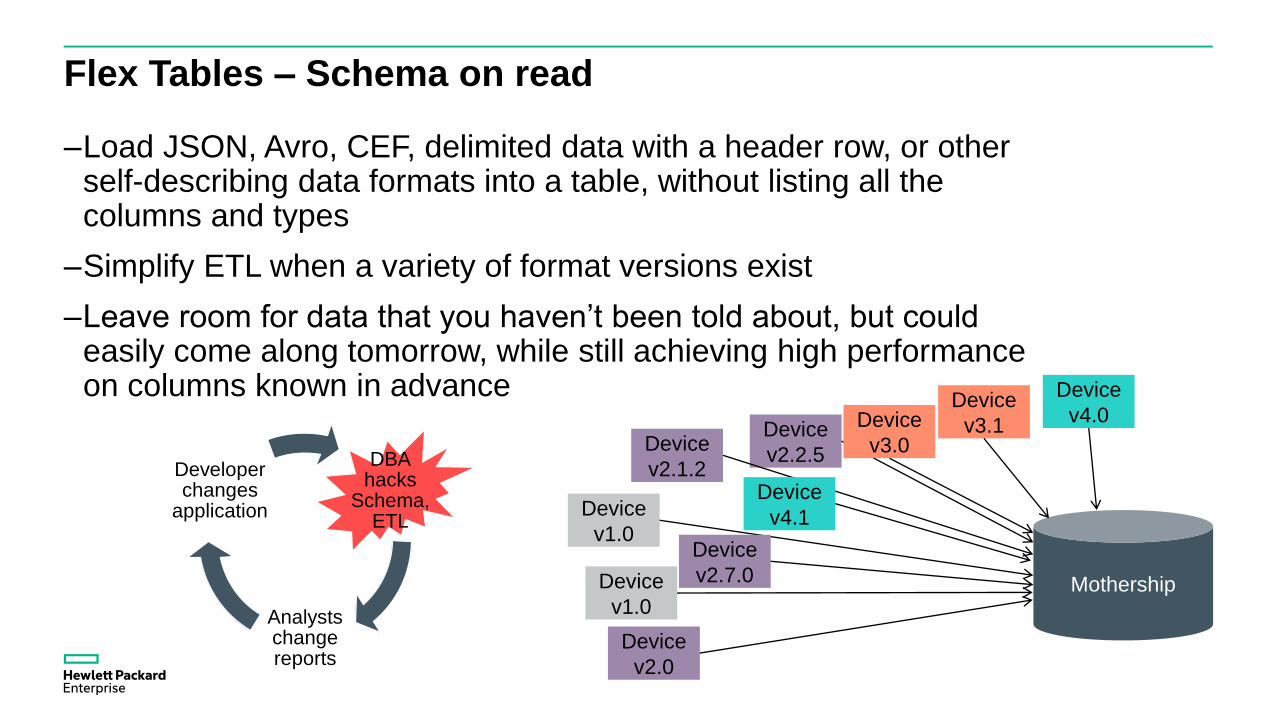
Flex Tables – Schema on read
–Load JSON, Avro, CEF, delimited data with a header row, or other self-describing data formats into a table, without listing all the columns and types
–Simplify ETL when a variety of format versions exist
–Leave room for data that you haven’t been told about, but could easily come along tomorrow, while still achieving high performance on columns known in advance
Device
v1.0
MothershipDevice
v1.0
Device
v2.0
Device
v2.1.2
Device
v2.2.5
Device
v2.7.0
Device
v3.1
Device
v4.0
Device
v4.1
Device
v3.0DBA
hacksSchema,
ETL
Analystschangereports
Developerchanges
application

How Flex Tables work
–Each row has an associated Flex Zone bucket (__raw__ column)
–Flex loaders put name/value pairs in the bucket; known “real” columns are extracted
–References to undeclared columns look in the bucket
–No match returns null
–Auto-generated VIEWs can be used to simplify
–ALTER TABLE … ADD COLUMN can be used to optimize more columns
JSONMAP
KeyValue
TableFlex
Zone
Parse Serialize
Delimited
???

Example – Message data
–How to store this data in a table?
–Some fields are fixed, but some are optional
–New ones (e.g. spam level) could be added
–We could store the whole thing as a string, but that’s hard to query
–Flex is a good compromise
Sender: Chuck <[email protected]>
Recipient: Darren <[email protected]>
Date: 6/17/2015 15:30:02-04
Received: 6/17/2015 19:30:05+00
Subject: Clustering + DAH
...
Body:
How does that work?
Just curious...
~CB
Sender Recipients CC Date Received Subject Body __raw__
John Doe [email protected] 06/17/15 06/17/15 Miracles can happen! Super pills will... {spam=10.0}
Chuck Darren Daniel 06/17/15 06/17/15 Clustering + DAH How does that...
Chuck Reuse 06/17/15 06/17/15 [reuse] Jade Flower Anyone want it? {priority=low; attachment=plant.jpg}
John Doe [email protected] 06/17/15 06/17/15 Miracles can happen! Super pills will... {spam=10.0}
Eileen Chuck 06/17/15 06/17/15 Legal Hold – DO NOT DISCARD We have been sued... {delivery_confirmation=true}
John Doe [email protected] 06/17/15 06/17/15 Miracles can happen! Super pills will... {spam=10.0}

Kafka streaming

Kafka - What you can do with it
– Take advantage of a non-SQL data exchange ecosystem
– Avoid complexities of COPY command scheduling
– Deliver data once and only once, across a variety of systems
– Scale out
– TBs per hour
– Handle bursts and downtime
– Keep latency low
Kafka
Raw Data
Apps
Stream Engines
Vertica
Hadoop
Analytics Archive
Kafka
Apps Logs Social Media

Kafka Streaming – How it works
– Vertica schedules loads to continuously consume from Kafka
– Priority scheduling for multiple tables/topics
– Batches commit atomically with new offset records
– JSON, Avro, etc. data formats handled by Vertica
– CLI for easy setup
– In-database monitoring
– Vertica can also produce -- export query results Kafka to close the processing loop
Kafka Data @ Offset X
Data inserted into Vertica
New offsets stored In Vertica
Commit
Microbatch (µB)
Scheduler
KafkaKafkaKafka
Vertica
Kafka Plugin
Vertica
Kafka Plugin
Vertica
Kafka Plugin
CLI
Load
Export

Structured + UnstructuredIndexing and searching text

Text search
What it is:
– Indexing to speed up searches in Vertica text fields, compared to LIKE, or regex scan of the whole string field
How it works:
– A separate table stores the “inverted index” of terms (or n-grams) to containing documents and positions
– As data comes in, the text field is tokenized, stop words are eliminated, stemming is performed, etc., and an inverted index is built
– Using SQL (or the AdvancedTextSearch pack, which generates SQL), Vertica is queried and does joins to retrieve matching documents
Example:
– HPE Operations Analytics uses Vertica for log data
Log table Index tableLoad data Tokenize
Join
Search query result
Log messages
& other dataSearch
matches

IDOL integration
What it does:
– Handles ALL the data
How it works:
– Connect to data sources
– Extract text/content
– Preprocess to identify important entities & topics, perform categorization, etc.
– Send data to Vertica, IDOL, or both
– Query IDOL, Vertica, or both together (use SQL with embedded IDOL calls)
Modular:
– Use alternate ingest processing, like Storm or Kafka
– Store machine data in Vertica
– Store+index full content in IDOL
– Store+index short content or metadata in Vertica
CFSText
Audio
Video
Enrichment
KeyView
Policy
Alt Pipelines
IDOL Content
+
DIH & DAH
VerticaMachine
Sensor
Structured
Various -
ETL,
Streams,
etc.
UQL / ACI
SQL / xDBC
Flex/Text

Usage example – Financial fraud
Communications Archive(Legally Required)
Categorize Internal/External, Extract Symbols
People, Trades, Reports, etc.
Metadata IndexEntity Index
Structured DataSocial Graph
Messages to review w/ risk
scores
Financial institutions have different departments that are not supposed to talk to each other, and must therefore monitor and archive internal communications.
Looking at a message in isolation will miss a lot of things.
Example:
– The research department released a report on XYZ co on March 4. Find all traders who opened positions within three days prior to the release of the report, and review their communications to ensure that they did not have advance information about the content of the report.

Advanced analytics

HPE Vertica Analytics Platform SDK A framework for Open Source / Third-party plug-in analytics
Simple
– Concise APIs and examples
– Deployment in Java, C++, or R
Powerful
– Scalar (UDF)
– Multi-row transforms (UDT) – for complex analytics
– User-defined load (UDL) – great for scalable, custom ingest
Scalable
– Supports parallel execution throughout the cluster
Flexible configuration for C++ extensions
– Highly-efficient in-process “Unfenced” mode
– Safe out-of-process “Fenced” mode
Lots of interesting functionality built on top, see– https://github.com/vertica/Vertica-Extension-Packages
HP Vertica Server
Client
SD
K A
PI
“Fenced”
mode
user code
SD
K A
PI
In-process
“Unfenced”
user code

HPE Vertica Connector for Apache SparkApache Kafka + Spark + HPE Vertica for both Batch and Streaming Analytics
HPE Vertica
Analytics Platform
Analytics /
ReportingData
Generation
OLTP/ODS
Apache
Spark
Logs
(Apps, Web,
Devices)
User
tracking
Operational
Metrics
Apache
Kafka
Distributed
Messaging
System
ETL
MapReduce
replacement
ETL
Stream
processing

HPE Vertica Connector for Apache SparkOperationalize Spark Machine learning models in HPE Vertica
Business
Problem
Model and
EvaluatePrepare Data
Explore Data
Operationalize
and
Monitor
HPE Vertica HPE Vertica
HPE Vertica
Vertica standalone cluster
Vertica SQL on Hadoop
Vertica Cloud Deployments
Vertica OnDemand
HPE Vertica
HPE Vertica

ML Lib
– Classification models
– Regression models
– Clustering modelsPMML
Operationalize predictive modelsDeploy Spark ML models in PMML for in-database scoring
PMML MODELS
Node 1
PMML MODELS
Node 2
PMML MODELS
Node 3
HPE Vertica

HPE Vertica Connector for Spark
Store data in RDDs in HPE Vertica
native columnar format for high-
speed interactive SQL analytics
Fast access to HPE Vertica data in
Spark RDDs and data frames with
filter and predicate push-down
Executor
Task
Task
Task
WORKER NODE
Executor
Task
Task
Task
WORKER NODE
Node 1
Node 2
Node 3
HPE Vertica
Beta download at https://saas.hpe.com/marketplace/haven/hpe-vertica-connector-apache-spark

SQL on HadoopData lake integration

Would you rather…
1. Ask a question
2. Get some people started buildingdata collection
3. Wait for data to come in
4. Then get an answer (6-12 months later)?
1. Ask a question
2. Have some folks explore the“Big Data” lake
3. To get an answer in a week?
OR

Another tool in the box
– MapReduce Connector
– HDFS connector
– HCatalog Connector (SerDe)
– Native ORC parser (Parquet coming soon)
– Kerberos support
– Store ROS in HDFS
– Mix and match Hadoop distros (Cloudera, Hortonworks, MapR)
– Use as many tools, formats, and languages (Map/Reduce, Hive, Spark, Kafka, Vertica, Flex, SQL, etc.) as it takes to get the job done
HC
ata
log
HDFS
json csv
HDFS
txt orc
HDFS
ROS ROS
HPE Vertica

– Incremental Load; Simultaneous Query
– Better workload management, concurrency, etc.
– Available “Plan B”: Spin out a mart
– Also: More formats, more distros, and less tweaking
Up to 7x
faster
ComparableUp to 2x
slower
43 queries more!
0x
1x
2x
3x
4x
5x
6x
7x
8x
Rela
tive
sp
ee
d-u
p
Queries
Faster, more features

Thank you
Month day, year #SeizeTheData







