
Ana Andrade Machado
Selecao de Variaveis em Modelos de
Regressao Logıstica
Niteroi - RJ, Brasil
10 de dezembro de 2018

Universidade Federal Fluminense
Ana Andrade Machado
Selecao de Variaveis em Modelos deRegressao Logıstica
Trabalho de Conclusao de Curso
Monografia apresentada para obtencao do grau de Bacharel emEstatıstica pela Universidade Federal Fluminense.
Orientadora: Profa. Dra. Patrıcia Lusie Velozo da Costa
Corientadora: Profa. Dra. Mariana Albi de Oliveira Souza
Niteroi - RJ, Brasil
10 de dezembro de 2018


Ficha catalográfica automática - SDC/BIMEGerada com informações fornecidas pelo autor
Bibliotecário responsável: Ana Nogueira Braga - CRB7/4776
M149s Machado, Ana Andrade Seleção de Variáveis em Modelos de Regressão Logística: / Ana Andrade Machado ; Drª. Patrícia Lusié Velozo daCosta, orientador ; Drª. Mariana Albi de Oliveira Souza,coorientador. Niterói, 2018. 57 p.
Trabalho de Conclusão de Curso (Graduação emEstatística)-Universidade Federal Fluminense, Instituto deMatemática e Estatística, Niterói, 2018.
1. Regressão logística. 2. Métodos de seleção devariáveis bayesianos. 3. Lasso. 4. SSVS. 5. Produçãointelectual. I. Lusié Velozo da Costa, Drª. Patrícia,orientador. II. Albi de Oliveira Souza, Drª. Mariana,coorientador. III. Universidade Federal Fluminense. Institutode Matemática e Estatística. IV. Título.
CDD -

Resumo
Este trabalho apresenta o modelo de regressao logıstica e alguns metodos de avaliacaode ajuste deste modelo, como testes para avaliar se as estimativas para os coeficientes deregressao sao significativas. Posteriormente, sao apresentados alguns metodos de selecaode variaveis nos quais modelos hierarquicos sao utilizados para selecionar as variaveisexplicativas. Comparam-se alguns metodos classicos com outros bayesianos. Sob oenfoque bayesiano, a inferencia sob os parametros desconhecidos do modelo e realizadaatraves de algoritmos de metodos de Monte Carlo via Cadeias de Markov (MCMC).
Palavras-chaves: Regressao logıstica; metodos de selecao de variaveis bayesianos; MCMC;Lasso; SSVS.

Sumario
Lista de Figuras
Lista de Tabelas
Lista de Abreviacoes p. 10
1 Introducao p. 1
2 Objetivos p. 4
3 Materiais e Metodos p. 5
3.1 Famılia Exponencial . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 5
3.2 Modelo de Regressao Linear . . . . . . . . . . . . . . . . . . . . . . . . p. 6
3.3 Modelo Linear Generalizado . . . . . . . . . . . . . . . . . . . . . . . . p. 7
3.4 Modelo de Regressao Logıstica . . . . . . . . . . . . . . . . . . . . . . . p. 7
3.4.1 Estimacao dos Parametros . . . . . . . . . . . . . . . . . . . . . p. 10
3.4.1.1 Estimacao Classica dos Parametros . . . . . . . . . . . p. 10
3.4.1.2 Estimacao Bayesiana dos Parametros . . . . . . . . . . p. 11
3.5 Metodos de Monte Carlo via Cadeias de Markov aplicado a Inferencia
Bayesiana . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 12
3.5.1 Cadeias de Markov . . . . . . . . . . . . . . . . . . . . . . . . . p. 13
3.5.2 Algoritmo de Metropolis-Hastings . . . . . . . . . . . . . . . . . p. 13
3.5.3 Algoritmo Amostrador de Gibbs . . . . . . . . . . . . . . . . . . p. 14
3.6 Medidas de Qualidade de Ajuste do Modelo . . . . . . . . . . . . . . . p. 15

3.7 Testes de Hipoteses para os Coeficientes de Regressao . . . . . . . . . p. 16
3.7.1 Teste de Wald . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 17
3.7.2 Teste de Razao de Verossimilhanca . . . . . . . . . . . . . . . . p. 17
3.7.3 Teste de Razao de Chances a Posteriori . . . . . . . . . . . . . p. 18
3.8 Metodos de Selecao de Variaveis Bayesianos . . . . . . . . . . . . . . . p. 19
3.8.1 Selecao de Variaveis via Busca Estocastica (SSVS) . . . . . . . . p. 20
3.8.2 Operacao de Selecao e Contracao com Penalidade em Valor
Absoluto (Lasso) . . . . . . . . . . . . . . . . . . . . . . . . . . p. 23
4 Analise dos Resultados p. 26
4.1 Aplicacao em Dados Simulados . . . . . . . . . . . . . . . . . . . . . . p. 26
4.2 Aplicacao em Dados Reais . . . . . . . . . . . . . . . . . . . . . . . . . p. 38
5 Conclusao p. 42
Referencias p. 44

Lista de Figuras
1 Aplicacao da funcao de ligacao logito em um vetor de probabilidades. . p. 8
2 Curvas de densidade de distribuicao normal com medias zero e variancias
0,2 e 2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 21
3 Curvas de densidade para cada valores simulados ao longo das cadeias
para cada βj utilizando o metodo proposto por Chipman et al.(2001) [1]. p. 23
4 Histograma das Probabilidades dos Dados Simulados . . . . . . . . . . p. 27
5 Distribuicoes a priori para β utilizadas nos algoritmos Monte Carlo via
cadeias de Markov (MCMC) . . . . . . . . . . . . . . . . . . . . . . . . p. 28
6 Box-Plot dos valores estimados para β1 dentre as replicacoes obtidas
atraves dos diferentes metodos. . . . . . . . . . . . . . . . . . . . . . . p. 32
7 Box-Plot dos valores estimados para β2 dentre as replicacoes obtidas
atraves dos diferentes metodos. . . . . . . . . . . . . . . . . . . . . . . p. 32
8 Box-Plot dos valores estimados para β3 dentre as replicacoes obtidas
atraves dos diferentes metodos. . . . . . . . . . . . . . . . . . . . . . . p. 32
9 Box-Plot dos valores estimados para β4 dentre as replicacoes obtidas
atraves dos diferentes metodos. . . . . . . . . . . . . . . . . . . . . . . p. 33
10 Box-Plot dos valores estimados para β5 dentre as replicacoes obtidas
atraves dos diferentes metodos. . . . . . . . . . . . . . . . . . . . . . . p. 33
11 Box-Plot dos valores estimados para β6 dentre as replicacoes obtidas
atraves dos diferentes metodos. . . . . . . . . . . . . . . . . . . . . . . p. 33
12 Box-Plot dos valores estimados para β7 dentre as replicacoes obtidas
atraves dos diferentes metodos. . . . . . . . . . . . . . . . . . . . . . . p. 34
13 Box-Plot dos valores estimados para β8 dentre as replicacoes obtidas
atraves dos diferentes metodos. . . . . . . . . . . . . . . . . . . . . . . p. 34

14 Box-Plot dos valores estimados para β1 dentre as replicacoes obtidas
atraves dos diferentes metodos. . . . . . . . . . . . . . . . . . . . . . . p. 37
15 Box-Plot dos valores estimados para β2 dentre as replicacoes obtidas
atraves dos diferentes metodos. . . . . . . . . . . . . . . . . . . . . . . p. 37
16 Box-Plot dos valores estimados para β3 dentre as replicacoes obtidas
atraves dos diferentes metodos. . . . . . . . . . . . . . . . . . . . . . . p. 37
17 Box-Plot dos valores estimados para β8 dentre as replicacoes obtidas
atraves dos diferentes metodos. . . . . . . . . . . . . . . . . . . . . . . p. 38

Lista de Tabelas
1 Estimativa Maxima Verossimilhanca, via MCMC com diferentes
distribuicoes a priori e Selecao de Variaveis via Busca Estocastica (SSVS)
referente a primeira simulacao. . . . . . . . . . . . . . . . . . . . . . . . p. 29
2 Percentagem de vezes que o verdadeiro valor do parametro esta contido
no intervalo estimado nos metodos de Maxima Verossimilhanca, via
MCMC com diferentes distribuicoes a priori e SSVS. . . . . . . . . . . p. 30
3 Percentagem de vezes que o valor zero esta contido no intervalo estimado
nos metodos de Estimativa Maxima Verossimilhanca, via MCMC com
diferentes distribuicoes a priori e SSVS. . . . . . . . . . . . . . . . . . p. 30
4 Proporcao de vezes em que a hipotese nula nao foi rejeitada no teste de
Wald. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 31
5 Estimativa via Lasso Bayesiano referente a primeira simulacao. . . . . . p. 35
6 Medidas de Qualidade e Testes de Hipoteses para Estimativa de Maxima
Verossimilhanca e via MCMC com diferentes distribuicoes a priori. . . p. 36
7 Estimativas de Maxima Verossimilhanca, via MCMC com diferentes
distribuicoes a priori , SSVS e Lasso Bayesiano. . . . . . . . . . . . . . p. 39
8 Estimativas atraves do Lasso Bayesiano utilizando uma distribuicao a
priori impropria para λ . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 40
9 Teste de Wald aplicado aos dados reais . . . . . . . . . . . . . . . . . . p. 41

10
Lista de Abreviacoes
iid independentes e identicamente distribuıdas
MCMC Monte Carlo via cadeias de Markov
MLG modelos lineares generalizados
SSVS Selecao de Variaveis via Busca Estocastica
TRCP Teste de Razao de Chances a Posteriori
TRV Teste de Razao de Verossimilhanca
HPD Highest Posterior Density Interval

1
1 Introducao
Em diversas areas de conhecimento muitos pesquisadores buscam analisar a relacao
entre diversos fatores. Na area da saude, por exemplo, pode-se verificar a relacao entre a
quantidade de vitamina D no organismo e a quantidade de sol que uma pessoa toma por
dia; ja na area financeira, e possıvel associar a renda de uma empresa com a capacidade
de pagamento desta empresa para uma avaliacao de credito. Modelos de regressao sao
uma opcao para estas analises, pois contemplam situacoes em que a variavel de interesse
e explicada por um conjunto de variaveis explicativas, tambem chamadas de variaveis
independentes.
Modelos de regressao logıstica relacionam variaveis de interesse dicotomicas com
variaveis explicativas modelando a probabilidade da variavel de interesse. Este modelo
pode ser aplicado em diversas areas, como a financeira, para calcular a probabilidade de
o contribuinte ser inadimplente; e a de saude, associando caracterısticas fısicas com a
probabilidade de um indivıduo desenvolver uma determinada doenca.
Nos dias de hoje, a quantidade de dados disponıveis e extremamente grande. O
termo big data vem se popularizando cada vez mais e com isso diversas tecnicas com
fundamentos estatısticos para analise de dados e modelagem vem surgindo. Em algumas
situacoes a quantidade de variaveis explicativas e tao grande que pode-se levantar o
questionamento de quais variaveis deve-se utilizar para explicar a variavel resposta. O
excesso de informacao pode atrapalhar a efetividade do ajuste, pois o fato de utilizar
todas as variaveis disponıveis nao necessariamente indica um bom modelo. Por exemplo,
com o grande numero de covariaveis, aumenta a possibilidade de existencia de correlacao
entre elas, dando origem a um problema denominado multicolinearidade.
Na literatura sao propostos diversos metodos em que e possıvel medir a qualidade de
um modelo em relacao a outro proposto. O grande problema destes metodos e que para
cada ajuste proposto estas medidas devem ser calculadas e posteriormente comparadas.

1 Introducao 2
Quando ha dois modelos possıveis, isto e uma tarefa facil; porem, se tratando de um
exemplo em que ha vinte possıveis ajustes, esta tarefa se torna bem trabalhosa.
No sentido de reduzir o numero de variaveis explicativas e mantendo ainda aquelas
que trazem mais informacoes sobre a variavel resposta, uma serie de metodos estatısticos
vem sendo propostos na literatura, dando origem aos chamados metodos de selecao de
variaveis. Estes metodos buscam sempre o modelo mais parcimonioso, ou seja, aquele
que melhor explique o comportamento da variavel resposta e use a menor quantidade de
parametros possıvel.
Neste estudo, metodos de selecao de variaveis foram aplicados em um modelo de
regressao logıstica.
Os modelos de regressao logıstica vem tendo um uso extremamente grande nas
industrias financeiras, e com sua alta utilizacao sao propostas diferentes tecnicas de
ajuste. Em um estudo sobre a hepatite A, Santos et al. (2005) [2] utilizaram redes neurais
artificiais para ajustar um modelo de regressao logıstica. Mais recentemente o blog Curso-
R [3] feito por um grupo de cinco estatısticos e de um cientista da computacao de Sao
Paulo publicou um post utilizando tecnicas de deep learning para ajuste do modelo de
regressao logıstica.
Com o questionamento de quais variaveis usar para explicar melhor a variavel resposta,
a proposta deste trabalho e estudar alguns metodos de selecao de variaveis bayesianos
em que sao atribuıdas distribuicoes a priori de contracao para os parametros associados
as covariaveis a serem estimados no modelo. Este trabalho concentrou-se nos seguintes
metodos: Selecao de Variaveis via Busca Estocastica SSVS (George e McCulloch (1993))
e Operacao de Selecao e Contracao com penalidade em valor absoluto, conhecido por
Lasso (Tibshirani (1996) [4]). Tambem foram estudados alguns testes em que e possıvel
verificar a significancia das estimativas dos coeficientes associados as covariaveis, como o
teste de Wald e de Razao de Chances a posteriori.
Sob o enfoque bayesiano, a inferencia sobre os parametros desconhecidos do modelo
e realizada atraves da distribuicao a posteriori. Muitas vezes essa distribuicao nao possui
forma analıtica conhecida e recorrer aos metodos bayesiano de MCMC para avaliar
esta distribuicao, e uma solucao. Dentre esses metodos: o amostrador de Gibbs o de
Metropolis-Hastings foram utilizados neste trabalho.
Neste trabalho, no Capıtulo 2 sao apresentados brevemente os objetivos a serem
alcancados. No Capıtulo 3, e realizada uma revisao bibliografica sobre os metodos

1 Introducao 3
utilizados neste estudo, alem disso, tambem ha uma descricao dos materiais utilizados.
No Capıtulo 4 e apresentado um estudo simulado em que as variaveis independentes
foram geradas de distribuicoes conhecidas e o vetor de parametro de interesse tambem e
conhecido, e posteriormente e apresentada uma aplicacao dos metodos estudados em um
conjunto de dados reais; ao final sao comparados os metodos classicos com os metodos
bayesianos. Por fim, o Capıtulo 5 sao apresentadas as conclusoes referentes as aplicacoes
feitas no Capıtulo 4.

4
2 Objetivos
O objetivo deste trabalho e discutir como selecionar variaveis em modelos de regressao
logısticos atraves de uma abordagem bayesiana. Para isso, foram utilizados metodos
de selecao de variaveis nos quais foram atribuıdas distribuicoes a priori de contracao,
concentradas no zero, para os preditores lineares.
A discussao se da atraves de um estudo simulado no qual uma grande quantidade
de covariaveis e utilizada para gerar dados atraves de um modelo de regressao logıstica,
e, a seguir, metodos de selecao de variaveis e estimacao bayesiana foram utilizados para
selecionar e estimar os parametros do modelo e comparados com o metodo classico da
maxima verossimilhanca.

5
3 Materiais e Metodos
Neste capıtulo sao apresentados todos os materiais e metodos utilizados ao longo
deste trabalho. Inicialmente e apresentada uma breve definicao de Famılia Exponencial
na Secao 3.1 e em seguida dos modelos de regressao linear (Secao 3.2) e generalizado
(Secao 3.3). Posteriormente o modelo de regressao logıstica e descrito na Secao 3.4. Ao
propor um modelo, e desejado inferir sobre parametros desconhecidos e por isso e feita
uma revisao sobre estimacao classica e bayesiana na Subsecao 3.4.1. Na Secao 3.5 sao
descritos os algoritmos MCMC que sao utilizados para realizar a estimacao bayesiana de
parametros desconhecidos neste trabalho. A Secao 3.6 apresenta medidas de qualidade de
um ajuste. A Secao 3.7 apresenta testes de hipotese, tanto classicos quanto bayesianos,
que julgam a significancia dos parametros em modelos de regressao. A Secao 3.8 discute
os metodos de selecao de variaveis bayesianos, sendo eles: SSVS (Subsecao 3.8.1) e o Lasso
(Subsecao 3.8.2).
3.1 Famılia Exponencial
Dizemos que uma famılia de distribuicoes pertence a famılia exponencial se sua funcao
de densidade de probabilidade (ou funcao de probabilidade) pode ser expressa da seguinte
forma:
f(y|θ) = exp
k∑
j=1
aj(y)bj(θ)
s(y)t(θ) (3.1)
em que θ e um vetor de parametros, s(·) e t(·) sao funcoes reais nao-negativas conhecidas
e aj(·) e bj(·), j = 1, . . . , k, sao funcoes reais conhecidas.
A famılia exponencial inclui distribuicoes de extrema importancia como a Poisson
e a normal. Outra distribuicao muito utilizada que pertence a famılia exponencial e a
distribuicao binomial, que representa o numero de sucessos, y, emN ensaios independentes

3.2 Modelo de Regressao Linear 6
da distribuicao de Bernoulli com probabilidade de sucesso π, cuja funcao de probabilidade
de y e escrita da seguinte forma:
f(y|π) =
(N
y
)πy(1− π)N−y, y = 0, 1, . . . , N. (3.2)
Note que N − y e o numero de fracassos em N repeticoes. Considerando N conhecido
e π desconhecido, e possıvel organizar a expressao (3.2) na forma de famılia exponencial
dada pela equacao (3.1):
f(y|π) = exp
ln
(N
y
)+ yln(π) + (N − y)ln(1− π)
= exp y(ln(π)− ln(1− π))
(N
y
)exp Nln(1− π) (3.3)
e assim tem-se que s(y) =(Ny
), t(π) = exp Nln(1− π), a(y) = y e b(π) = ln(π) −
ln(1− π).
Maiores detalhes podem ser vistos em Casella e Berger (2002) [5] e em Migon et al
(2014) [6].
3.2 Modelo de Regressao Linear
Em diversas areas de conhecimento, modelos de regressao sao amplamente usados para
tentar explicar uma relacao entre duas ou mais variaveis. Em um modelo de regressao
linear tem-se a seguinte relacao
Yi = XTi β + ei, i = 1, . . . , n, (3.4)
em que Yi e variavel aleatoria chamada de variavel resposta ou dependente, XTi =
(xi1, . . . , xip) e um vetor contendo p covariaveis (tambem chamadas de variaveis
explicativas ou independentes ou preditoras), β = (β1, . . . , βp)T e um vetor contendo
os efeitos das covariaveis e ei representa um efeito aleatorio, i e o ındice da unidade
amostral e n e o tamanho da amostra.
Alem disso costuma-se supor que os efeitos aleatorios sao independentes e
normalmente distribuıdos com media zero e uma variancia constante σ2. Nesse caso, tem-
se que as variaveis respostas, condicionadas nas covariaveis e nos parametros θ = (β, σ2),
sao independentes e identicamente distribuıdas (iid) e tem-se a seguinte distribuicao
Yiiid∼ N(XT
i β, σ2), i = 1, . . . , n. (3.5)

3.3 Modelo Linear Generalizado 7
Em geral, modelos de regressao linear sao utilizados quando a variavel resposta e
contınua e possui uma associacao linear com cada covariavel.
Maiores detalhes podem ser vistos em Casella e Berger (2002) [5].
3.3 Modelo Linear Generalizado
Quando a variavel resposta nao e contınua, nao e apropriado o uso do modelo de
regressao linear. Por isso, Nelder e Wedderburn (1972) [7] generalizaram os modelos
de regressao linear simples propondo os modelos lineares generalizados (MLG) que sao
caracterizados por terem
1. uma variavel aleatoria dependente Yi, i = 1, . . . , n, com funcao de densidade
de probabilidade (ou funcao de probabilidade) f(y | θ) pertencendo a famılia
exponencial;
2. um conjunto de variaveis independentes XTi = (xi1, . . . , xip) e um preditor linear
ηi = XTi β, sendo β um vetor com p componentes;
3. uma funcao monotona e diferenciavel, g(·), chamada de funcao de ligacao, que
relaciona as variaveis dependentes com as independentes da seguinte forma
g(µi) = ηi = XTi β, (3.6)
sendo µi = E[Yi].
Os vetores θ e β podem ter valores conhecidos ou desconhecidos.
Um caso particular dos modelos lineares generalizados e o modelo de regressao linear,
apresentado na Secao 3.2, que pode ser obtido atraves da funcao de ligacao identidade,
ou seja, considerando que g(µi) = µi = XTi β.
3.4 Modelo de Regressao Logıstica
Em um modelo de regressao linear, definido na Secao 3.2, a variavel resposta
Yi geralmente e contınua. Suponha um modelo que tenha uma variavel dependente

3.4 Modelo de Regressao Logıstica 8
dicotomica, ou seja, que assume apenas dois valores. Sendo assim, a variavel resposta
tem o seguinte formato:
Yi =
1, com probabilidade πi,
0, com probabilidade 1− πi(3.7)
em que πi e uma probabilidade explicada pelas variaveis explicativas Xi. Logo, Yi ∼Bern(πi).
Caso um modelo de regressao linear seja ajustado, nesse caso, como a variavel resposta
assume apenas dois valores, o grafico de dispersao ficara com alguns pontos concentrados
em 1 e outros em 0 e esses pontos provavelmente terao uma alta dispersao da reta ajustada
atraves do metodo dos mınimos quadrados. Portanto, neste caso, faz-se necessario recorrer
aos modelos lineares generalizados.
O modelo de regressao logıstica e um caso particular dos MLG (descritos na Secao 3.3)
e e utilizado para variaveis com distribuicao Bernoulli conforme descritas pela Equacao
(3.7). Como Yi ∼ Bern(πi), entao tem-se que o valor esperado da variavel dicotomica e
µi = E[Yi] = πi. Recorrendo a funcao de ligacao logito tem-se a seguinte relacao
g(µi) = ln
(πi
1− πi
)= XT
i β = ηi. (3.8)
Note que a funcao logito e o logaritmo natural da razao de chances e que essa funcao
associa a cada probabilidade πi (que possui valores limitados no intervalo [0, 1]) um
valor real de forma que esses valores passem a pertencer a reta. A Figura 1 ilustra a
transformacao das probabilidade πi atraves da funcao de ligacao g(µi):
Figura 1: Aplicacao da funcao de ligacao logito em um vetor de probabilidades.

3.4 Modelo de Regressao Logıstica 9
Aplicando a exponencial e isolando πi, na Equacao (3.8), tem-se que:
(3.9)
exp
ln
(πi
1− πi
)= exp
XT
i β
⇒ πi1− πi
= expXT
i β
⇒ πi =exp
XT
i β
1 + exp XTi β
=1
1 + exp −XTi β
Assim, o modelo de regressao logıstica pode ser definido como:
Yi =
1, com probabilidade
1
1 + exp −XTi β
,
0, com probabilidade 1− 1
1 + exp −XTi β
(3.10)
Para melhor compreensao deste modelo, suponha o seguinte exemplo:
Exemplo 3.4.1 Um banco de fomento deseja estimar a probabilidade, de uma empresa
que solicita credito, pagar este emprestimo. Com esta probabilidade calculada, a i-esima
empresa sera classificada como boa (Yi = 1) ou ma (Yi = 0) pagadora. Para tal calculo,
foi proposto o seguinte modelo:
πi = P (Yi = 1) =1
1 + exp −(2, 5− 6×X2 + 0, 5×X3)
em que:
• X2 - Variavel binaria que indica se a empresa tem restricoes no mercado (“nome
sujo”), assumindo 1 para sim e 0 para nao.
• X3 - Variavel quantitativa que indica o tempo, em anos, que a empresa tem no
mercado.
Usando o exemplo citado, uma empresa que possui restricoes e tem 3 anos de mercado
tera a seguinte probabilidade de pagar o emprestimo em dia:
P (Yi = 1) =1
1 + exp −(2, 5− 6× 1 + 0, 5× 3)=
1
1 + exp −(−2)= 0, 1192.
Entao esta empresa tera aproximadamente 12% de probabilidade de ser uma boa
pagadora. Geralmente na area de credito brasileira, para uma empresa ser classificada
como boa pagadora, essa probabilidade deve ser maior ou igual a 95%. Neste exemplo
fica claro que o cliente seria classificado como mau pagador.

3.4 Modelo de Regressao Logıstica 10
Outro cenario seria a empresa nao ter “nome sujo” e ter 10 anos de mercado:
P (Yi = 1) =1
1 + exp −(2, 5− 6× 0 + 0, 5× 10)=
1
1 + exp −(7, 5)= 0, 9994.
Com esta situacao, em que ha aproximadamente 99% de chances do emprestimo ser
pago, a empresa sera classificada como boa pagadora.
Para mais esclarecimentos sobre o modelo de regressao logıstica apresentado, sugere-se
ver o material de Hosmer e Lemeshow (2000) [8] e de Dobson (2002) [9].
3.4.1 Estimacao dos Parametros
Nesta subsecao sao apresentadas duas formas de se estimar os parametros de um
modelo de regressao logıstica. A primeira forma e atraves da inferencia classica, em
que e utilizado o metodo da maxima verossimilhanca, e a segunda maneira e atraves
da inferencia bayesiana, em que neste estudo sao utilizados metodos de Monte Carlo via
Cadeias de Markov. Referente a estimacao bayesiana, esta subsecao e apenas introdutoria,
pois os metodos aqui utilizados sao apresentados de maneira mais profunda na Secao 3.5.
3.4.1.1 Estimacao Classica dos Parametros
Usualmente em regressao linear os estimadores para cada βj sao calculados atraves
do metodo dos mınimos quadrados, como mostra Neter et al (1996) [10]. Porem, ao
tentar estimar os parametros do modelo de regressao logıstica usando este mesmo metodo,
os coeficientes encontrados acabam nao tendo algumas propriedades desejaveis de um
estimador. Por exemplo, Hosmer e Lemeshow (2000) [8] citam que a soma das diferencas
dos valores observados e dos valores ajustados nem sempre sera zero ao se utilizar o
metodo dos mınimos quadrados.
Sendo assim, no modelo logıstico a estimacao classica usualmente e feita atraves do
metodo da maxima verossimilhanca (Neter et al (1996) [10]), em que e encontrada uma
combinacao de coeficientes que maximizam a funcao de verossimilhanca. No modelo
em questao, segundo a equacao (3.10), quando Yi = 1 a contribuicao para a funcao de
verossimilhanca sera πi e quando Yi = 0 a contribuicao para a funcao de verossimilhanca

3.4 Modelo de Regressao Logıstica 11
sera o complementar da anterior, 1 − πi. Entao a funcao de verossimilhanca, assumindo
que as variaveis sao independentes, sera definida como:
`(β;y) =n∏
i=1
[πyii (1− πi)1−yi
], (3.11)
sendo y = (y1, . . . , yn) os valores amostrados da variavel resposta.
Aplicando a funcao logarıtmica, obtemos a funcao de log verossimilhanca da forma:
ln [`(β;y)] =n∑
i=1
[yiln(πi) + (1− yi)ln(1− πi)] . (3.12)
Desenvolvendo as contas tem-se o seguinte resultado:
ln [`(β;y)] =n∑
i=1
[yiln
(exp
XT
i β)− ln
(1 + exp
XT
i β)]
Para continuar o metodo, a equacao anterior deve ser derivada em relacao a cada
coeficiente e igualada a zero, resultando em um conjunto de equacoes nao lineares onde
pode-se recorrer a metodos iterativos que sao rapidamente resolvidos atraves de algum
software estatıstico.
3.4.1.2 Estimacao Bayesiana dos Parametros
A inferencia bayesiana tambem permite que parametros de um determinado modelo
possam ser estimados. Antes de apresentar a estimacao bayesiana, vale a pena reforcar
alguns conceitos, como os de distribuicao a priori e distribuicao a posteriori.
A distribuicao a priori e uma distribuicao que expressa a incerteza sobre o vetor
de parametros desconhecidos, que no caso da regressao logıstica e denotado por β,
representando o conhecimento previo que se tem sobre β antes de observar a amostra.
Ela deve sempre respeitar o espaco parametrico de β. Em casos de variaveis regressoras,
usualmente e atribuida a distribuicao normal como distribuicao a priori para os efeitos
das regressoras.
A distribuicao a posteriori incorpora tanto as informacoes a priori quanto as
informacoes fornecidas pelos dados atraves da funcao de verossimilhanca. Com auxılio do
Teorema de Bayes, a distribuicao a posteriori pode ser definida como:
p(β | y) =`(β;y)p(β)
p(y)(3.13)

3.5 Metodos de Monte Carlo via Cadeias de Markov aplicado a Inferencia Bayesiana 12
onde p(β) denota a distribuicao a priori de β, `(β;y) a funcao de verossimilhanca de β
e p(y) e a distribuicao marginal de y.
E comum em inferencia bayesiana o uso da proporcionalidade, definida pelo sımbolo
∝. Em uma distribuicao a posteriori p(β | y) os valores que nao dependem do parametro
desconhecido, neste caso β, sao tratados como constantes e podem ser retirados da
equacao, permanecendo apenas o nucleo da distribuicao. Note que p(y)−1 nao dependera
de β e desta forma a equacao anterior pode ser reescrita como:
p(β | y) ∝ `(β;y)p(β). (3.14)
Supondo entao que β tem distribuicao a priori normal com vetor de medias nulas e
uma matriz de covariancia Σ, tem-se que a distribuicao a posteriori de β e proporcional
a:
(3.15)p(β | y) ∝n∏
i=1
[(1
1 + exp −XTi β
)yi (1− 1
1 + exp −XTi β
)1−yi]
× exp
−1
2
(βTΣ−1β
).
Note que a distribuicao acima nao possui nucleo de alguma distribuicao conhecida.
Uma forma de estimar o parametro β usando essa distribuicao e recorrendo aos metodos
de Monte Carlo via Cadeias de Markov, que serao discutidos a seguir.
3.5 Metodos de Monte Carlo via Cadeias de Markov
aplicado a Inferencia Bayesiana
Suponha uma situacao em que ha uma distribuicao que nao possui forma analıtica
conhecida e que se deseja simular amostras desta distribuicao. Os metodos de MCMC
podem auxiliar nesta tarefa. Os metodos MCMC sao algoritmos de simulacao iterativas
em que a ideia e obter amostras de distribuicoes de interesse.
No contexto deste trabalho, as distribuicoes de interesse sao as distribuicoes a
posteriori dos parametros estudados. Assim, e obtida uma amostra da distribuicao a
posteriori baseada em cadeias de Markov, fazendo com que os valores gerados para compor
a amostra sejam independentes.

3.5 Metodos de Monte Carlo via Cadeias de Markov aplicado a Inferencia Bayesiana 13
3.5.1 Cadeias de Markov
Uma cadeia de Markov de primeira ordem e uma sequencia de variaveis aleatorias
Z1, Z2, . . . em que para todo evento A, a distribuicao de Zt dados os valores anteriores
Z1, . . . , Zt−1 depende apenas do instante imediatamente anterior Zt−1. Matematicamente,
P (Zt ∈ A | Z1, . . . , Zt−1) = P (Zt ∈ A | Zt−1), ∀t.
Os metodos MCMC exigem que as cadeias de Markov tenham algumas caracterısticas:
devem ser homogeneas implicando nas probabilidades de transicao de um estado para o
outro nao mudarem ao longo das iteracoes; irredutıvel (sem estados isolados), isto e, todo
estado podera ser atingido a partir de qualquer outro em um numero finito de iteracoes; e
por ultimo, aperiodica, sem estados absorventes, ou seja, no momento em que o processo
entra em um determinado estado ele deve ser capaz de deixar tal estado.
Os metodos MCMC sao muito utilizados na estatıstica bayesiana para simular uma
amostra da distribuicao a posteriori, e apos um numero finito e suficientemente grande
de iteracoes a cadeia converge para a distribuicao de interesse. Discutiremos adiante dois
metodos de MCMC: o algoritmo de Metropolis-Hastings e o Amostrador de Gibbs.
3.5.2 Algoritmo de Metropolis-Hastings
O algoritmo de Metropolis-Hastings, proposto por Metropolis et al (1953) [11] e
Hastings (1970) [12], tem como proposta simular amostras de uma distribuicao em que
nao e possıvel obter sua forma fechada. O algoritmo tem a ideia similar aos metodos de
aceitacao e rejeicao, ou seja, e gerado um valor de uma distribuicao auxiliar q e aceita-se
esse valor com uma certa probabilidade que depende da distribuicao de interesse. Desta
forma, e garantida a convergencia da cadeia para a distribuicao de equilıbrio, neste caso,
a distribuicao a posteriori p(θ | y).
A distribuicao auxiliar q e chamada de distribuicao proposta e pode depender do
estado atual da cadeia (θt−1), e neste caso denotamos q(· | θt−1) . Desta forma, o
algoritmo pode ser especificado como:
1. Inicialize o contador de iteracoes t = 1 e especifique um valor inicial θ0;
2. gere um novo valor θp da distribuicao proposta q;

3.5 Metodos de Monte Carlo via Cadeias de Markov aplicado a Inferencia Bayesiana 14
3. calcule a probabilidade de aceitacao
α(θt−1,θp) = min
1,
p(θp | y)q(θt−1 | θp)p(θt−1 | y)q(θp | θt−1)
e gere u ∼ U(0, 1);
4. se u < α, aceite θp fazendo θt=θp; caso contrario, rejeite e faca θt=θt−1;
5. incremente o contador de t para t+ 1 e volte ao passo 2 ate atingir a convergencia.
Os valores simulados para a cadeia apos a convergencia representarao uma amostra
da distribuicao de interesse.
3.5.3 Algoritmo Amostrador de Gibbs
Outro metodo para simular amostras de distribuicoes desconhecidas e o amostrador de
Gibbs, proposto por Geman e Geman (1990) [13] e introduzido a comunidade estatıstica
por Gelfand e Smith (1990) [14]. A ideia e que cada θj, tanto uni quanto multidimensional,
seja gerado da sua distribuicao condicional completa a posteriori, definida como
p(θj | θ−j,y), onde θ−j = (θ1,θ2, . . . ,θj−1,θj+1, . . . ,θJ).
Repare que neste metodo a distribuicao condicional completa devera ser conhecida,
pois e atraves dela que sera feita a transicao de um estado para o outro. Assim a
distribuicao condicional completa de cada θj dependera de todas as componentes de θ,
exceto o proprio θj. O algoritmo pode ser escrito como:
1. Inicialize o contador de iteracoes t = 1 e especifique um valor inicial
θ0 = (θ01, . . . ,θ0J);
2. gere um novo valor de θt a partir de θt−1 atraves da geracao sucessiva de valores:
θt1 ∼ p(θ1 | θt−12 ,θt−13 , . . . ,θt−1J ,y)
θt2 ∼ p(θ2 | θt1,θt−13 , . . . ,θt−1J ,y)
...
θtJ ∼ p(θJ | θt1,θt2, . . . ,θtJ−1,y)
3. incremente o contador de t para t+ 1 e volte ao passo 2 ate atingir a convergencia.

3.6 Medidas de Qualidade de Ajuste do Modelo 15
Apos a convergencia, os valores resultantes formam uma amostra da distribuicao
conjunta de θ, p(θ | y).
O algoritmo de Metropolis-Hastings pode ser utilizado em conjunto com amostrador
de Gibbs quando uma ou mais distribuicoes condicionais completas a posteriori forem
desconhecidas.
Maiores detalhes sobre os metodos de MCMC podem ser vistos em Gamerman e Lopes
(2006) [15].
3.6 Medidas de Qualidade de Ajuste do Modelo
Conforme Bozdangan (1987) [16], a escolha do modelo apropriado, ou seja, do
“melhor” modelo e extremamente importante na analise de dados. Depois que um
modelo e ajustado, e necessario avaliar a qualidade daquele ajuste. Em qualquer
modelagem e buscado o modelo mais parcimonioso, ou seja, aquele que melhor explique
o comportamento da variavel resposta e use menos parametros possıveis.
Existem diversos metodos de comparacao de modelos. A seguir sao apresentadas
algumas medidas bastante utilizadas.
O Criterio de Informacao de Akaike (AIC) proposto por Akaike (1987) [17] e o Criterio
de Informacao Bayesiano (BIC) proposto por Schwarz et al.(1978) [18], podem ser escritos,
respectivamente, como:
AIC = −2ln(`(θ;y)) + 2p (3.16)
BIC = −2ln(`(θ;y)) + pln(n) (3.17)
em que `(θ;y) e a funcao de verossimilhanca avaliada nos parametros estimados, p e o
numero de parametros e n o tamanho da amostra. Repare que tanto o AIC quanto o
BIC sao baseados na funcao de verossimilhanca. Outra medida conhecida e o Criterio de
Informacao Baseado no Desvio (DIC) proposto por Spiegelhalter et al (2002) [19]:
DIC = D(θ) + pD (3.18)
em que D(θ) e o desvio medio a posteriori definido como D(θ) = 21
G
G∑g=1
ln[`(θ;y)] −
ln[`(θ(g);y)], em que `(θ;y) e a funcao de verossimilhanca com os parametros estimados
e `(θ(g);y) a funcao de verossimilhanca com os parametros estimados em cada iteracao;

3.7 Testes de Hipoteses para os Coeficientes de Regressao 16
e pD o numero de parametros efetivos no modelo estimado definido como pD = D(θ) −2ln[`(θ;y)]. Assim, o DIC tambem pode ser definido como DIC = −2D(θ)−2ln[`(θ;y)].
O DIC e extremamente usado na selecao de modelos ajustados de forma bayesiana, cuja
distribuicao a posteriori dos modelos e alcancada atraves de metodos MCMC.
Para essas tres medidas apresentadas, os valores mais baixos indicam um melhor
ajuste.
Suponha que em determinado estudo ha apenas duas covariaveis em que se deseja
ajustar um modelo de regressao, assim, ha quatro ajustes possıveis (22). Desta forma
para avaliar qual ajuste e mais parcimonioso, estas medidas deveriam ser calculadas para
cada um dos quatro modelos. Nesta situacao, nao parece haver nenhum inconveniente.
Porem estas medidas nao se tornam praticas a partir do momento em que se tem um
numero maior de covariaveis, quanto maior a quantidade de colunas da matriz de valores
observadosX, mais modelos sao possıveis de serem ajustados. Desta forma sera trabalhoso
calcular estas medidas para cada um dos ajustes. Por exemplo, em um estudo que ha
15 covariaveis disponıveis, e possıvel ajustar 215 = 32.768 modelos, se tornando inviavel
calcular o AIC, BIC ou DIC para cada ajuste. Desta maneira, os metodos de selecao de
variaveis bayesianos, que serao vistos na Secao 3.7, sao uma saıda para este problema.
Estes metodos realizam um unico ajuste, e com o auxılio de variaveis indicadoras mostram
se o parametro βj e significativo ou nao no modelo e assim ressaltando a importancia da
variavel independente Xj associada aquele βj.
3.7 Testes de Hipoteses para os Coeficientes de
Regressao
Nesta secao sao apresentados alguns testes de hipoteses que julgam a significancia de
um determinado βj. Se βj = 0, entao a variavel correspondente aquele coeficiente nao
e significativa no modelo de regressao. Assim, alguns destes testes devem ser realizados
para cada um dos coeficientes.

3.7 Testes de Hipoteses para os Coeficientes de Regressao 17
3.7.1 Teste de Wald
O teste de Wald e um teste classico bem simples. Nele e verificado para cada
parametro a sua importancia no modelo de regressao, utilizando as seguintes hipoteses:H0 : βj = 0
H1 : βj 6= 0
Sua estatıstica de teste sob H0 verdadeiro e dada por Wj =βj
SE(βj)em que SE(βj)
e o erro padrao do estimador e βj e o proprio estimador em questao. A estatıstica Wj
segue, aproximadamente, uma distribuicao normal padrao.
Uma das formas de decidir a rejeicao da hipotese nula em testes de hipotese, e atraves
do p-valor. Segundo Greenland et al (2016) [20] o p-valor e a probabilidade de que a
estatıstica de teste teria sido pelo menos tao grande quanto seu valor observado se todas as
suposicoes estivessem corretas, incluindo a hipotese do teste. Por ser uma probabilidade,
o p-valor esta contido no intervalo [0,1]. Assim para tomar uma decisao em um teste de
hipotese e utilizado o p-valor. Se esta medida for menor que o nıvel de significancia do
teste (geralmente e utilizado 0, 05% de nıvel de significancia), e rejeitada a hipotese nula,
caso contrario nao e rejeitada a hipotese nula.
No teste de Wald, se a hipotese nula nao for rejeitada, significa que aquele parametro e
estatisticamente igual a zero e a covariavel associada a ele nao traz informacoes relevantes
para o modelo ajustado. No caso em que a hipotese nula nao e rejeitada, ha indıcios de
que a covariavel associada ao respectivo parametro e relevante no ajuste.
Hauck e Donner (1977) [21] registraram que o teste de Wald falha frequentemente
em rejeitar coeficientes que sao estatisticamente significativos, desta forma sugerem que
se teste novamente os coeficientes sinalizados como nao significativos atraves do teste da
razao de verossimilhanca.
3.7.2 Teste de Razao de Verossimilhanca
No caso de modelos de regressao logıstica, o teste da razao de verossimilhanca compara
a funcao de verossimilhanca baseada nos valores observados com os valores preditos do

3.7 Testes de Hipoteses para os Coeficientes de Regressao 18
modelo proposto com e sem um determinado conjunto de variaveis independentes. Assim
e possıvel verificar se determinada covariavel influencia no modelo. Suas hipoteses sao:H0 : β ∈ Ω0
H1 : β ∈ Ω1
Usualmente a hipotese nula, no caso de selecao de variaveis corresponde a testar se
o conjunto dos possıveis valores de β muda de Rp para Ru tornando u componentes de
β iguais a zero. Por exemplo, suponha um modelo com cinco parametros e que deseja-se
testar se β3 e estatisticamente igual a zero, assim tem-se βj ∈ R, j = 1, . . . , 5 com j 6= 3
e β3 = 0, sob H0.
Tal comparacao e feita com base no logaritmo da funcao de verossimilhanca:
D = −2ln`(β−j;y)
`(β;y)
em que `(β−j;y) e a funcao de verossimilhanca do vetor β sem a j-esima componente e
`(β;y) e a funcao de verossimilhanca com do vetor β com a j-esima componente.
A estatıstica de teste tem, aproximadamente, distribuicao qui-quadrado com µ graus
de liberdade, sendo µ o numero de parametros que esta sendo testado. Se o p-valor
correspondente a estatıstica de teste for menor que o nıvel de significancia proposto,
rejeita-se a hipotese nula assumindo que tal variavel e significativa no modelo.
3.7.3 Teste de Razao de Chances a Posteriori
O teste de razao de chances a posteriori e uma versao bayesiana do teste de razao de
verossimilhanca. Desta forma as hipoteses podem ser definidas como:H0 : β ∈ Ω0
H1 : β ∈ Ω1
As hipoteses sao testadas atraves da chances a posteriori, definida como:
p(H0 | y)
p(H1 | y)︸ ︷︷ ︸Chances a Posteriori
=p(y | H0)
p(y | H1)︸ ︷︷ ︸Fator de Bayes
× p(H0)
p(H1)︸ ︷︷ ︸Chances a Priori

3.8 Metodos de Selecao de Variaveis Bayesianos 19
Se a medida anterior for maior que 1, assume-se que H0 se ajustou melhor aos dados,
caso contrario, o melhor ajuste foi representado em H1.
3.8 Metodos de Selecao de Variaveis Bayesianos
Suponha um modelo com muitas covariaveis. Usualmente ajusta-se o modelo proposto
com todas as covariaveis disponıveis e depois elimina-se as covariaveis que nao sao
estatisticamente significativas. Porem, ao retirar um determinado conjunto de covariaveis,
nao ha garantias de que sera obtido o modelo mais parcimonioso. Pode-se entao ajustar
os dados com diferentes subconjuntos de covariaveis e calcular o AIC, BIC e DIC para
cada um dos ajustes feitos, mas essa forma acaba sendo muito custosa. Os metodos de
selecao de variaveis bayesianos sao uma otima saıda, pois sao mais praticos, nao sendo
necessario realizar todos os possıveis ajustes.
Na literatura ha diversos metodos bayesianos utilizados para ajustar modelos. Kuo
e Mallick (1998) [22] propuseram um metodo que possui uma variavel auxiliar γj que
identifica a presenca (γj = 1) ou a ausencia (γj = 0) de um determinado βj. Outro
metodo e o metodo de Selecao de variaveis de Gibbs, proposto por Carlin e Chibi (1995)
[23] e aperfeicoado por Dellaportas et al (2002) [24] em que e atribuıda uma mistura de
distribuicoes normais como distribuicao a priori de β.
O primeiro metodo apresentado, e o metodo de Selecao de Variaveis via Busca
Estocastica proposto por George e McCulloch (1993)[25], que possui propostas
semelhantes aos metodos propostos por Kuo e Mallick (1998) [22] e de Carlin e Chibi
(1995) [23]. Neste metodo e atribuıda uma mistura de distribuicoes normais a priori para
βj com a ajuda de uma variavel auxiliar γj, que indica de qual parte desta mistura de
distribuicoes βj sera estimado.
Na Subsecao 3.8.2 e apresentado um metodo de contracao conhecido como Lasso
Bayesiano. Inicialmente este metodo, proposto por Tibshirani (1996) [4], foi criado para
ser aplicado em modelos de regressao em que a variavel resposta tem distribuicao normal.
Este metodo penaliza o procedimento de estimacao por mınimos quadrados, e a variancia
de β, τ 2, tem distribuicao a priori exponencial com parametro λ, o que da uma outra
interpretacao da estimativa do Lasso.
Posteriormente e apresentado um aperfeicoamento deste metodo aplicado a regressao
logıstica, proposto por Huang et al.(2013) [26]. Este aperfeicoamento sugere um modelo

3.8 Metodos de Selecao de Variaveis Bayesianos 20
hierarquico em tres nıveis, em que e feita uma aproximacao de Laplace para a distribuicao
a posteriori de β.
Ambos os metodos apresentados propoem modelos hierarquicos em que sao utilizadas
distribuicoes a priori nao informativas para β. Sao utilizados metodos MCMC para
simular amostras das distribuicoes condicionais completas a posteriori e as estimativas
sao baseadas na media (a posteriori) destes valores.
3.8.1 Selecao de Variaveis via Busca Estocastica (SSVS)
Neste metodo, proposto por George e McCulloch (1993) [25], e buscada a selecao
de variaveis para modelos de regressao em que Y ∼ N(Xβ, σ2). A ideia do metodo e
atribuir uma mistura de distribuicoes normais a priori para cada βj com auxılio de uma
variavel γj que indica de qual parte desta mistura de distribuicoes cada βj sera estimado.
Se γj = 1 e assumido que a covariavel associada a este βj e relevante, e assim βj e gerado
de uma distribuicao normal centrada no zero com uma variancia grande que espalhe a
distribuicao e estime valores distantes do zero. Se γj = 0 e assumido que a covariavel
associada a este βj nao e relevante, e desta forma βj e gerado de uma distribuicao normal
com media zero e variancia bem pequena, para que os valores fiquem bem proximos de
zero.
George e McCulloch (1993) [25] propuseram este metodo para modelos de regressao
normais. Desta forma, a estrutura hierarquica a priori para os parametros pode ser
definida como:
Yi ∼ N(µi, σ2)
µi = β1Xi1 + β2Xi2 + . . .+ βpXip
βj | γj ∼ γjN(0, υ1) + (1− γj)N(0, υ0)
γj ∼ Bern(ρj)
σ2 ∼ IG(a, b)
em que i = 1, . . . , n, j = 1, . . . , p e υ1, υ0, ρj, a e b serao fixados.
Note que υ1 e υ0 sao responsaveis, respectivamente, por espalhar e comprimir a
distribuicao a priori de βj. A Figura 2 ilusta duas curvas de densidade normal: a linha
tracejada proveniente de uma distribuicao N(0; 0, 2) e a linha contınua de uma distribuicao
N(0; 2). Note que quanto maior o valor da variancia, mais espalhada e a distribuicao.

3.8 Metodos de Selecao de Variaveis Bayesianos 21
Figura 2: Curvas de densidade de distribuicao normal com medias zero e variancias 0,2 e
2.
Chipman et al.(2001) [1] abordaram algoritmos MCMC para selecao de variaveis em
modelos logısticos. Estes algoritmos aplicaram a abordagem do SSVS para selecionar
as variaveis e, alem disso, determinar a estrutura dos efeitos aleatorios na matriz de
covariancia e variancia.
Aqui β teve uma outra distribuicao a priori. Como uma forma de modificacao do
metodo para a regressao logıstica, foi proposto uma distribuicao multivariada a priori
para β | γ:
Yi ∼ Bern(πi)
πi =1
1 + exp −ηiηi = β1Xi1 + β2Xi2 + . . .+ βjXij
β | γ ∼ N(b, V ), V −1 = k
((1− γ)XTW
X
n+ γdiag
(XTW
X
n
))γj ∼ Bern(ρj)
em que ρj e a probabilidade de inclusao a priori para cada βj e γ a matriz diagonal
com estas probabilidades, X e a matriz com os valores observados em que cada coluna
representa uma covariavel, b e o vetor de medias da distribuicao a priori, XTWX e a
informacao total de Fisher (valor esperado com base nos dados) para o respectivo peso
W , n o numero de observacoes, k e o escalar com o peso dado a priori (Chipman
et al.(2001) [1] recomendam que seja 0,01), e W a matriz diagonal em que Wjj =
probabilidade de sucesso× (1− probabilidade de sucesso). Esta probabilidade de sucesso
nada mais e que a probabilidade de sucesso observada na variavel resposta.

3.8 Metodos de Selecao de Variaveis Bayesianos 22
Com isto, foi implementado um algoritmo MCMC com as respectivas distribuicoes a
priori. O software R [27] possui um pacote chamado BoomSpikeSlab que auxilia neste
metodo.
Para uma melhor compreensao, suponha que:
y =
0
0
0
0
1
1
1
1
1
1
10×1
, X =
1 1 2 3 5 9 1
1 4 2 4 2 2 3
1 2 2 3 2 3 1
1 2 2 5 1 9 3
1 5 5 3 5 5 1
1 3 2 1 9 1 1
1 5 3 1 2 3 4
1 4 2 2 3 1 2
1 5 1 4 9 3 2
1 4 3 2 5 1 5
10×7
, bT =
0
0
0
0
0
0
0
0
0
0
10×1
e k = 0, 01.
Note que a matriz X possui 7 colunas, assim serao estimados 7 coeficientes (sendo β1
o intercepto). Apos 100.000 iteracoes obtem-se a matriz V :
V =
0, 0024 0, 0042 0, 0029 0, 0034 0, 0052 0, 0036 0, 0028
0, 0042 0, 0338 0, 0107 0, 0113 0, 0190 0, 0098 0, 0097
0, 0029 0, 0107 0, 0163 0, 0077 0, 0119 0, 0077 0, 0067
0, 0034 0, 0113 0, 0077 0, 0226 0, 0134 0, 0108 0, 0071
0, 0052 0, 0190 0, 0119 0, 0134 0, 0622 0, 0132 0, 0113
0, 0036 0, 0098 0, 0077 0, 0108 0, 0132 0, 0403 0, 0086
0, 0028 0, 0097 0, 0067 0, 0071 0, 0113 0, 0086 0, 0166
7×7
A figura 3 mostra as curvas de densidade com base nos valores simulados ao longo
da cadeia. Veja que o algoritmo se comporta da mesma forma que o metodo proposto
originalmente por George e McCulloch (1993) [25], os valores simulados referentes a β2
e β6 estao bem concentrados no zero, indicando a insignificancia das covariaveis X2 e
X6; ja os valores para β1 e β4 formam uma curva de densidade achatada mostrando as
estimativas destes coeficientes estao longe do zero, e as covariaveis associadas a eles sao
importantes.

3.8 Metodos de Selecao de Variaveis Bayesianos 23
Figura 3: Curvas de densidade para cada valores simulados ao longo das cadeias para
cada βj utilizando o metodo proposto por Chipman et al.(2001) [1].
3.8.2 Operacao de Selecao e Contracao com Penalidade emValor Absoluto (Lasso)
Do ingles, Least Absolute Shrinkage and Selection Operator, o Lasso e um penalizador
do procedimento de mınimos quadrados, proposto por Tibshirani (1996) [4]. Esta tecnica
minimiza a soma dos quadrados dos resıduos com uma restricao nos coeficientes β a serem
estimados. Desta forma, a estimativa de β utilizando o metodo Lasso e:
minβ
= (y −Xβ)T (y −Xβ) + λ
p∑i=0
| βj | (3.19)
em que y = y − yIn, X =
X11 X12 . . . X1p
X21 X22 . . . X2p
......
. . ....
Xn1 Xn2 . . . Xnp
n×p
e β =
β1
β2...
βp
p×1
O parametro λ na equacao (3.19) e um parametro de sintonia fundamental para
a restricao a ser imposta. E o λ que vai indicar a regiao que os parametros a serem
estimados nao poderao estar. Originalmente o Lasso foi desenvolvido para uma aplicacao
classica, porem nesta subsecao sera apresentada sua forma bayesiana. Tibshirani (1996)
[4] ressalta que o Lasso pode ser interpretado como a moda a posteriori estimada quando
as componentes de β possuem distribuicao a priori Laplace independentes. A distribuicao
de Laplace pode ser expressa como uma mistura de distribuicoes normais cujas variancias
seguem distribuicoes exponenciais independentes.

3.8 Metodos de Selecao de Variaveis Bayesianos 24
Park e Casella (2008) [28] propuseram o amostrador de Gibbs para o metodo Lasso
Bayesiano em um modelo de regressao linear. Se tratando de regressao logıstica, Yi nao
seguira uma distribuicao normal, e sim uma distribuicao Bernoulli. Assim, neste trabalho,
o modelo hierarquico para o Lasso Bayesiano sera baseado no modelo proposto por Huang
et al.(2013) [26]:
Yi ∼ Bern(πi)
πi =1
1 + exp −ηiηi = β1Xi1 + β2Xi2 + . . .+ βjXij
βj | τ 2j ∼ N(0, τ 2j )
τ 2j | λ ∼ Exp(λ)
λ ∼ Gama(a, b)
em que i = 1, . . . , n e j = 1, . . . , p e a e b sao fixados.
Huang et al.(2013) [26] nomearam este modelo de regressao logıstica com normal-
exponencial-gama (NEG) como BLasso-NEG.
A distribuicao a priori de τ 2j pode ser encontrada fazendo:
p(τ 2j ) =
∞∫0
p(τ 2j | λ)p(λ)dλ =a
b
(τ 2jb
+ 1
)(a+1). (3.20)
Definindo τ 2 = [τ 21 , τ22 , . . . , τ
2p ]T e y = [y1, y2, . . . , yn]T , a distribuicao a posteriori de
(β, τ 2) e dada por:
p(β, τ 2 | y) ∝ p(y | β)p(β | τ 2)p(τ 2) (3.21)
em que p(y | β) =n∏
i=1
[(1
1 + exp −ηi
)yi (1− 1
1 + exp −ηi
)1−yi]
e p(β | τ 2) e uma
distribuicao normal com vetor de medias zero e matriz de covariancias τ 2I, sendo I a
matriz diagonal de ordem p.
Como a expressao em (3.21) e difıcil de ser integrada em β para se obter a distribuicao
a posteriori marginal de τ 2, nao sera facil estimar τ 2 diretamente maximizando sua
funcao de densidade de probabilidade a posteriori. Para contornar este problema, Huang
et al.(2013) [26] sugeriram empregar um sistema iterativo que se baseia na aproximacao
de Laplace para a distribuicao a posteriori de β.

3.8 Metodos de Selecao de Variaveis Bayesianos 25
Huang et al.(2013) [26] mostram todas as contas e cada passo do algoritmo criado que
sera utilizado neste trabalho. O pacote com este algoritmo e o EBglmnet e esta disponıvel
no software R [27].

26
4 Analise dos Resultados
Este Capıtulo apresenta a aplicacao dos materiais e metodos discutidos no Capıtulo 3.
Primeiramente esta aplicacao e feita em um conjunto de dados simulados, pois desta forma
sao conhecidos os verdadeiros valores dos parametros e quais covariaveis influenciam a
variavel resposta possibilitando avaliar o desempenho dos metodos aplicados. Em seguida,
e aplicado em um conjunto de dados reais que tambem foi utilizado por Huang et al.(2013)
[26].
4.1 Aplicacao em Dados Simulados
Li et al. (2010) [29] propuseram um interessante estudo simulado, em que foram
aplicadas algumas tecnicas de selecao de variaveis, incluindo o Lasso Bayesiano, para o
modelo de regressao quantılica. Foram feitas diversas simulacoes em que β era conhecido
e a partir de β e de uma matriz de covariaveis X foram geradas as variaveis respostas.
Entre essas simulacoes alguns valores de β eram nulos, e, desta forma, esperava-se que
as covariaveis associadas a estes valores nulos nao fossem significativas no ajuste. Neste
artigo foi mostrado que os metodos bayesianos superaram o metodo classico no quesito
de selecao de variaveis.
Neste trabalho foi feito um estudo semelhante ao de Li et al. (2010) [29], porem
aplicado a regressao logıstica juntamente com os metodos vistos no Capıtulo 3. Neste
estudo os verdadeiros valores de β sao conhecidos e alguns destes valores sao iguais a
zero, indicando a insignificancia das variaveis associadas a estes βj nulos. Desta forma
e possıvel analisar como cada metodo se comporta e sua eficiencia, pois os verdadeiros
valores dos parametros sao conhecidos. Para este estudo foi utilizado o software R [27].
Alem disso, foi fixada uma “semente” (2000), na simulacao de dados, caso o leitor deseje
reproduzir o estudo em questao.
Foram criadas 8 covariaveis, com 1.000 observacoes cada, e 8 coeficientes, sendo β1 o
intercepto.

4.1 Aplicacao em Dados Simulados 27
Por β1 ser o intercepto, X1 e definido como um vetor em que todas suas observacoes
sao iguais a um. As variaveis independentes X2, . . . , X8 foram criadas de maneira aleatoria
de uma distribuicao uniforme discreta:
• X2 ∼ U1, 2, 3, 4, 5
• X3 ∼ U6, 7, 8, 9, 10
• X4 ∼ U8, 9, 10, 11, 12
• X5 ∼ U15, 16, 17, 18, 19, 20
• X6 ∼ U1, 2, 3, 4, . . . , 10
• X7 ∼ U7, 8, 9
• X8 ∼ U11, 12, 13, 14
Os valores para β foram:
β = [β1 β2 β3 β4 β5 β6 β7 β8]T = [3 1, 5 − 0, 7 0 0 0 0 − 2]T .
Perceba que os coeficientes β4, β5, β6 e β7 sao iguais a zero, desta forma as covariaveis
associadas a estes coeficientes, ou seja, X4, X5, X6 e X7, nao deveriam ser relevantes ao
ajuste.
A Figura 5 exibe o histograma com os mil valores de probabilidades de sucesso geradas:
Figura 4: Histograma das Probabilidades dos Dados Simulados

4.1 Aplicacao em Dados Simulados 28
As maiores concentracoes estao entre a classe de 0 a 0,1 e a de 0,9 a 1, e ainda
ha probabilidades espalhadas em menor quantidade nos outros intervalos. Com essas
probabilidades, foram geradas 1.000 amostras provenientes de uma distribuicao Bernoulli,
cada uma de tamanho 1.000. Desta forma cada metodo foi aplicado 1.000 vezes. Vale
ressaltar que para todos os metodos iterativos foi fixado o valor de 10.000 iteracoes e as
estimativas foram baseadas na media a posteriori dos valores simulados, retirada uma
amostra de aquecimento (burn-in) de tamanho 1.000.
O software R [27] possui um pacote disponıvel chamado MCMCpack que possui
uma funcao, MCMCLogit, que gera amostras de uma distribuicao a posteriori usando
um passeio aleatorio no algoritmo de Metropolis-Hastings, e estima, atraves dos valores
simulados, os coeficientes em um modelo de regressao logıstica. Nesta funcao tambem
e possıvel utilizar diferentes distribuicoes a priori para os coeficientes do modelo de
regressao logıstica. Neste metodo foram testadas tres distribuicoes a priori para o vetor
de coeficientes β: normal padrao, t-Student com 3 graus de liberdade e normal assimetrica
com o coeficiente de assimetria δ = 5. Com estas escolhas como distribuicoes a priori
para β, tem-se distribuicoes nao informativas. Desta forma as estimativas para β podem
assumir valores ao longo da reta. A figura 4.1 mostra as curvas de densidades destas tres
distribuicoes.
Figura 5: Distribuicoes a priori para β utilizadas nos algoritmos MCMC
Veja que as distribuicoes a priori estao distribuıdas ao longo da reta. Note que a
distribuicao normal assimetrica nao abrange os valores negativos da mesma forma que as
outras distribuicoes, porem espera-se que os algoritmos MCMC consigam se “esquecer”
de suas distribuicoes a priori.

4.1 Aplicacao em Dados Simulados 29
Para a aplicacao do SSVS foi utilizada a funcao Logit.spike do pacote BoomSpikeSlab.
Para aplicacao desta funcao foram utilizados os valores padrao do pacote, pois de acordo
com Chipman et al (2001) [1] estes valores geralmente apresentam desempenhos melhores
e caracterizam uma distribuicao a priori nao informativa para β. Foi atribuida a priori
igual probabilidade para cada βj, ou seja, γ ∼ Bern (ρ = 0, 5) e para k foi atribuıdo vetor
de 0,01. Como dito antes, W e a matriz diagonal em que Wjj = probabilidade de sucesso∗(1 − probabilidade de sucesso) para cada um dos conjuntos simulados, desta forma para
cada conjunto simulado foi utilizado um W diferente com base na amostra observada.
Para b, que e o vetor de medias da distribuicao a priori de β, foi atribuıdo zero para
todas as coordenadas.
Nesta primeira parte do estudo foram testados tres metodos, o metodo classico da
maxima verossimilhanca, e os metodos bayesianos atraves da funcao MCMCLogit com
diferentes distribuicoes a priori, e o metodo do SSVS. O metodo do Lasso Bayesiano
sera visto mais a frente. A Tabela 1 mostra as estimativas para β baseada na primeira
replicacao para cada um dos metodos:
Tabela 1: Estimativa Maxima Verossimilhanca, via MCMC com diferentes distribuicoes
a priori e SSVS referente a primeira simulacao.
CoeficienteVerdadeiro
Valor
Maxima
Verossimilhanca
Normal
PadraoT-Student
Normal
AssimetricaSSVS
β1 3 3,0917 3,0890 3,1507 3,1870 3,1873
β2 1,5 1,2321 1,2512 1,2553 1,2518 1,2372
β3 -0,7 -0,5854 -0,5899 -0,5931 -0,5998 -0,5897
β4 0 -0,0423 -0,0398 -0,0387 -0,0477 0,0000
β5 0 0,0496 0,0533 0,0492 0,0539 -0,0001
β6 0 0,0171 0,0188 0,0162 0,0158 0,0000
β7 0 -0,0427 -0,0389 -0,0466 -0,0476 0,0000
β8 -2 -1,8224 -1,8491 -1,8604 -1,8552 -1,8413
As estimativas para a primeira replicacao em todos os metodos propostos na Tabela
1 ficaram bem proximas aos verdadeiros valores de β. Note que o metodo do SSVS
apresentou os valores mais proximos de zero para β4, β5, β6 e β7.
A Tabela 2 mostra a percentagem de vezes em que o verdadeiro valor dos parametros
estava contido nos percentis de 2, 5% e de 97, 5% estimados para o metodo da maxima
verossimilhanca, e a percentagem que estava contido nos intervalos de credibilidade de

4.1 Aplicacao em Dados Simulados 30
maxima densidade a posteriori (do ingles Highest Posterior Density Interval (HPD)) de
95% nos metodos bayesianos:
Tabela 2: Percentagem de vezes que o verdadeiro valor do parametro esta contido no
intervalo estimado nos metodos de Maxima Verossimilhanca, via MCMC com diferentes
distribuicoes a priori e SSVS.
CoeficienteMaxima
Verossimilhanca
Normal
PadraoT-Student
Normal
AssimetricaSSVS
β1 94, 5% 93, 7% 93, 5% 93, 5% 95, 8%
β2 94, 4% 92, 7% 92, 4% 92, 1% 94, 3%
β3 94, 7% 93, 2% 92, 9% 92, 6% 94, 6%
β4 96, 5% 95, 0% 95, 3% 95, 1% 100, 0%
β5 95, 1% 92, 3% 92, 4% 92, 3% 100, 0%
β6 92, 9% 91, 7% 91, 9% 92, 7% 100, 0%
β7 94, 8% 93, 3% 92, 9% 92, 4% 100, 0%
β8 95, 4% 92, 9% 93, 1% 91, 9% 95, 8%
Os metodos aplicados tiveram comportamento bem semelhantes, porem o SSVS
apresentou um melhor desempenho novamente em relacao aos βj′s com valores nulos,
pois em todas as replicacoes os intervalos de credibilidade estimados continham o zero. A
Tabela 3 indica a frequencia dos intervalos que contem o valor zero:
Tabela 3: Percentagem de vezes que o valor zero esta contido no intervalo estimado nos
metodos de Estimativa Maxima Verossimilhanca, via MCMC com diferentes distribuicoes
a priori e SSVS.
CoeficienteMaxima
Verossimilhanca
Normal
PadraoT-Student
Normal
AssimetricaSSVS
β1 0, 0% 0, 0% 0, 0% 0, 0% 0, 001%∗
β2 0, 0% 0, 0% 0, 0% 0, 0% 0, 0%
β3 0, 0% 0, 0% 0, 0% 0, 0% 0, 0%
β4 96, 5% 95, 0% 95, 3% 95, 1% 100, 0%
β5 95, 1% 92, 3% 92, 4% 92, 3% 100, 0%
β6 92, 9% 91, 7% 91, 9% 92, 7% 100, 0%
β7 94, 8% 93, 3% 92, 9% 92, 4% 100, 0%
β8 0, 0% 0, 0% 0, 0% 0, 0% 0, 0%

4.1 Aplicacao em Dados Simulados 31
Vale ressaltar que em * na Tabela 3 o limite inferior do intervalo de credibilidade
HPD para β1 em apenas uma unica replicacao era zero, desta forma foi contabilizado a
presenca do valor nulo neste intervalo.
Na Tabela 3 nota-se que os metodos aplicados nao indicam que as estimativas pontuais
diferentes de zero para β1, β2, β3 e β8 possam ser nulo, reforcando ainda mais a ideia de
que as covariaveis X2, X3 e X8 sao significativas nestes ajustes.
O teste de Wald apresentado na Secao 3.7.1 indica se o coeficiente βj, estimado
via maxima verossimilhanca, e significativo ou nao, ou seja, se aquele parametro e
estatisticamente igual a zero ou nao. A Tabela 4 mostra a nao rejeicao da hipotese nula
(βj = 0) do teste de Wald ao longo das replicacoes. Note que este teste nao acertou em
todas as repeticoes para os coeficientes que realmente possuem zero como verdadeiro valor,
apresentando alguns erros maiores que 5, 0% (que foi o nıvel de significancia utilizado),
porem o teste nao deixou de rejeitar esta hipotese nenhuma vez para os outros coeficientes
diferentes de zero. Sendo assim, o teste de Wald teve comportamento semelhante a
percentagem de vezes que o valor zero esteve contido no intervalo estimado nos metodos
de estimativa de maxima verossimilhanca, no ajuste bayesiano e no SSVS conforme pode
ser visto comparando as Tabelas 3 e 4.
Tabela 4: Proporcao de vezes em que a hipotese nula nao foi rejeitada no teste de Wald.
Coeficiente β1 β2 β3 β4 β5 β6 β7 β8
Verdadeiro valor 3 1,5 -0,7 0 0 0 0 -2
Teste de Wald 0% 0% 0% 96, 5% 95, 1% 93, 1% 94, 8% 0%
As Figuras 6 a 13 mostram os box-plots dos valores ajustados ao longo das replicacoes
para os metodos da maxima verossimilhanca e as estimativas calculadas atraves de
modelos bayesianos. Nos graficos foi tracada uma linha pontilhada preta para o verdadeiro
valor dos βj′s.

4.1 Aplicacao em Dados Simulados 32
Figura 6: Box-Plot dos valores estimados para β1 dentre as replicacoes obtidas atraves
dos diferentes metodos.
Figura 7: Box-Plot dos valores estimados para β2 dentre as replicacoes obtidas atraves
dos diferentes metodos.
Figura 8: Box-Plot dos valores estimados para β3 dentre as replicacoes obtidas atraves
dos diferentes metodos.
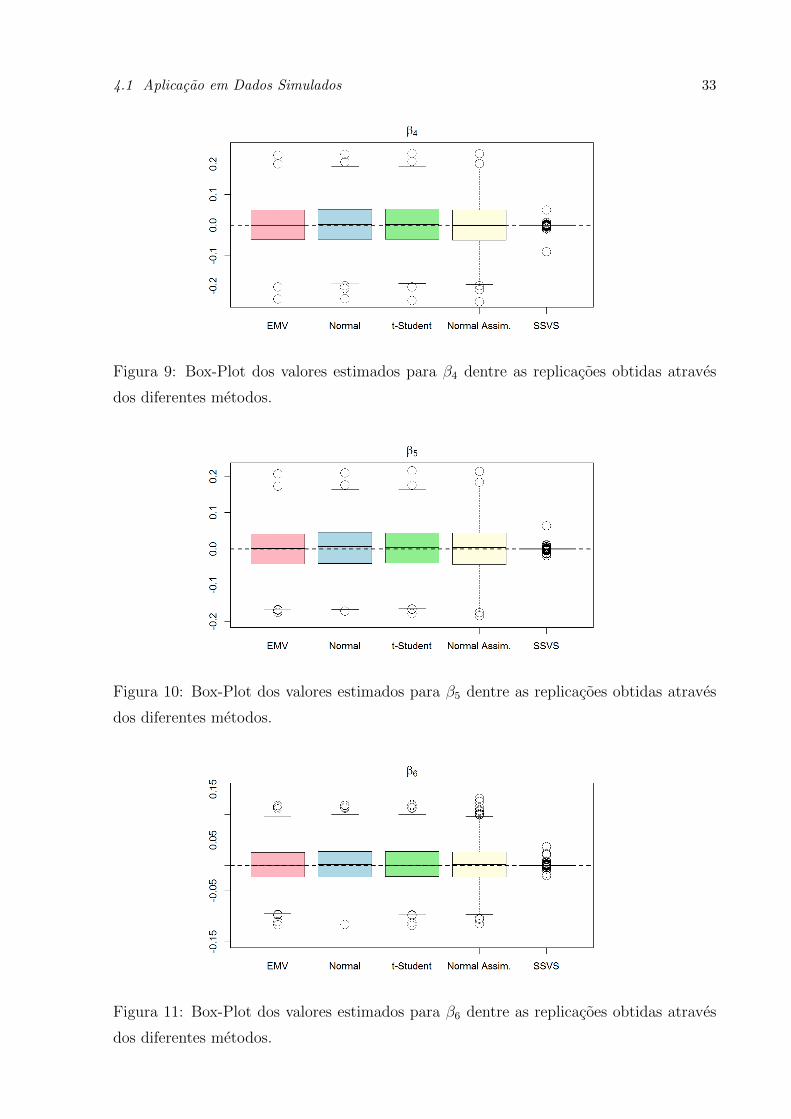
4.1 Aplicacao em Dados Simulados 33
Figura 9: Box-Plot dos valores estimados para β4 dentre as replicacoes obtidas atraves
dos diferentes metodos.
Figura 10: Box-Plot dos valores estimados para β5 dentre as replicacoes obtidas atraves
dos diferentes metodos.
Figura 11: Box-Plot dos valores estimados para β6 dentre as replicacoes obtidas atraves
dos diferentes metodos.

4.1 Aplicacao em Dados Simulados 34
Figura 12: Box-Plot dos valores estimados para β7 dentre as replicacoes obtidas atraves
dos diferentes metodos.
Figura 13: Box-Plot dos valores estimados para β8 dentre as replicacoes obtidas atraves
dos diferentes metodos.
Nos tres metodos aplicados as estimativas para todos os coeficientes ficaram bem
similares, alem disso, proximas aos verdadeiros valores. Para os βj′s = 0 as estimativas
tambem ficaram proximas de zero, porem o metodo do SSVS teve um destaque visto que
suas estimativas para os coeficientes nulos ficaram bem mais concentradas em torno de
zero.
O ultimo metodo aplicado e o Lasso Bayesiano discutido na Secao 3.8.2. Para isso foi
definido λ ∼ Gama(a = 0, 01; b = 0, 01), fazendo com que λ variancia grande( ab2
= 100)
,
caracterizando assim uma distribuicao a priori nao informativa. As estimativas para β
referente ao primeiro conjunto de dados estao na Tabela 5:

4.1 Aplicacao em Dados Simulados 35
Tabela 5: Estimativa via Lasso Bayesiano referente a primeira simulacao.
Coeficiente β1 β2 β3 β4 β5 β6 β7 β8
Verdadeiro valor 3 1,5 -0,7 0 0 0 0 -2
Estimativa 3,0139 1,1840 -0,5466 - - - - -1,7673
O Lasso Bayesiano tambem apresentou estimativas bem proximas para a primeira
simulacao. Note que as estimativas para β4, β5, β6 e β7 foram consideradas nao
significativas e o pacote descartou estas estimativas. Dentre as 1.000 replicacoes deste
metodo, a funcao utilizada nao considerou as estimativas para β4, β5, β6 e β7, indicando
que as covariaveis X4, X5, X6 e X7 nao sao relevantes em nenhum dos ajustes. Com
isso, na aplicacao do Lasso Bayesiano, nao se torna relevante avaliar os intervalos de
credibilidade, visto que o metodo selecionou corretamente as covariaveis relevantes em
todas as simulacoes.
Para o metodo de maxima verossimilhanca e o da estimacao bayesiana usando
diferentes distribuicoes a priori, foram feitos tambem ajustes usando apenas as covariaveis
X1, X2, X3 e X8, que estao associadas aos βj 6= 0. Apos isto, foram calculados o AIC,
o BIC e o Teste de Razao de Verossimilhanca (TRV) para o metodo classico; o DIC e
o Teste de Razao de Chances a Posteriori (TRCP) para os metodos bayesianos. Estas
medidas foram calculadas para ambos ajustes, tanto o geral (com todas as covariaveis)
quanto o simples (apenas com X1, X2, X3, X8). Com isto, foi calculado qual o percentual
de vezes, dentre as 1.000 replicacoes, estas medidas selecionaram cada modelo (simples
ou geral). A Tabela 6 mostra os resultados:

4.1 Aplicacao em Dados Simulados 36
Tabela 6: Medidas de Qualidade e Testes de Hipoteses para Estimativa de Maxima
Verossimilhanca e via MCMC com diferentes distribuicoes a priori.
CoeficienteMedida/
Teste
Modelo
Geral
Modelo
Simples
Estimativa Maxima Verossimilhanca AIC 10, 6% 89, 4%
Estimativa Maxima Verossimilhanca BIC 0% 100%
Estimativa Maxima Verossimilhanca TRV 5, 7% 94, 3%
Media a posteriori distribuicao Normal DIC 0% 100%
Media a posteriori distribuicao t-Student DIC 0% 100%
Media a posteriori distribuicao Normal Assimetrica DIC 0% 100%
Media a posteriori distribuicao Normal TRCP 1, 0% 99, 0%
Media a posteriori distribuicao t-Student TRCP 0, 5% 99, 5%
Media a posteriori distribuicao Normal Assimetrica TRCP 1, 3% 98, 7%
O AIC nao mostrou tanta eficiencia em escolher o modelo mais simples, pois errou
em 10, 6% das vezes. Porem o BIC e DIC se mostraram extremamente eficientes, pois em
nenhuma das 1.000 replicacoes selecionou o modelo geral.
Para o teste de Razao de Verossimilhanca, seu percentual de escolhas do modelo
geral, ou seja, o menos parcimonioso, e semelhante ao nıvel de significancia de 5, 0%, o
que era esperado. Apesar do teste de Razao de Chances a Posteriori nao possuir nıvel de
significancia, note que a percentagem de escolhas do modelo geral e bem menor do que
feita pelo teste de Razao de Verossimilhanca, indicando um melhor desempenho do teste
bayesiano em identificar o modelo mais parcimonioso.
Nas Figuras 14 a 17 estao os boxplots contento as estimativas para β no modelo
simples (somente com as covariaveis X1, X2, X3 e X8) dos metodos da maxima
verossimilhanca e via MCMC com diferentes distribuicoes a priori, juntamente com as
estimativas do Lasso Bayesiano, que apesar de ter sido feito com todas as covariaveis,
indicou as covariaveis X4, X5, X6 e X7 como irrelevantes e assim nao apresentou
estimativas para β4, β5, β6 e β7.
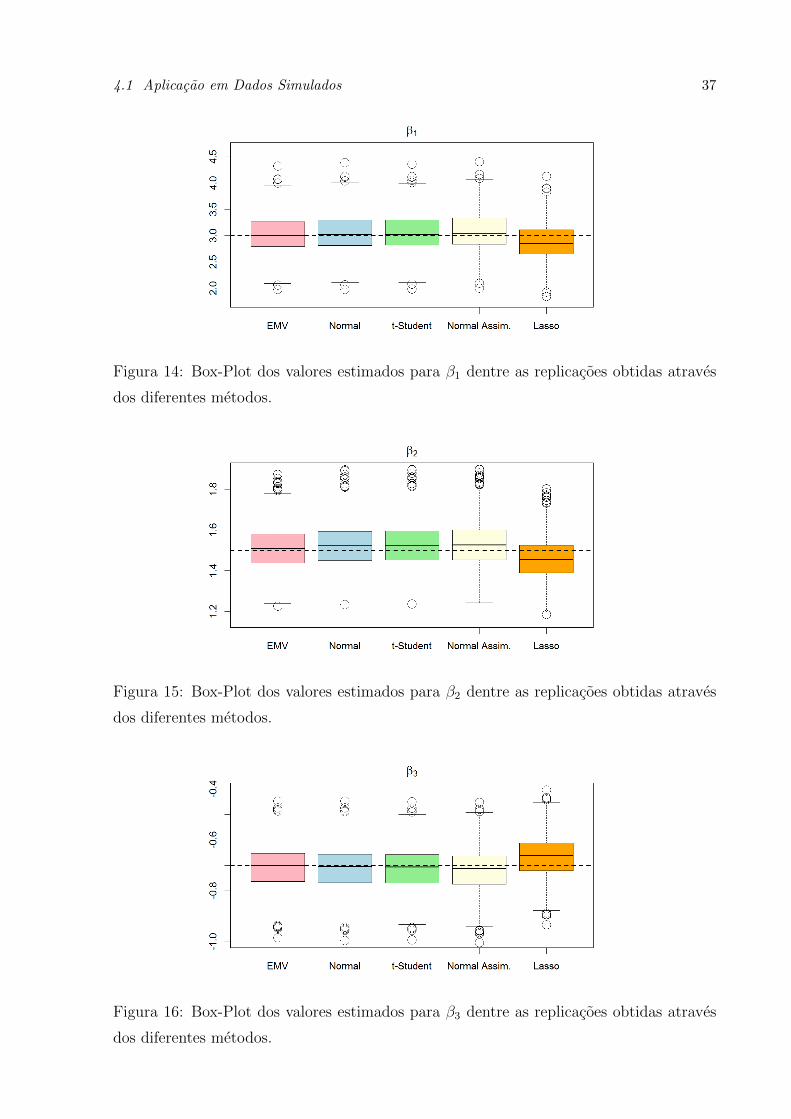
4.1 Aplicacao em Dados Simulados 37
Figura 14: Box-Plot dos valores estimados para β1 dentre as replicacoes obtidas atraves
dos diferentes metodos.
Figura 15: Box-Plot dos valores estimados para β2 dentre as replicacoes obtidas atraves
dos diferentes metodos.
Figura 16: Box-Plot dos valores estimados para β3 dentre as replicacoes obtidas atraves
dos diferentes metodos.

4.2 Aplicacao em Dados Reais 38
Figura 17: Box-Plot dos valores estimados para β8 dentre as replicacoes obtidas atraves
dos diferentes metodos.
Todos os valores estao bem proximos do verdadeiro valor, representado pela linha
preta tracejada. A estimativa do Lasso Bayesiano ficou um pouco superior, porem vale
ressaltar que este ajuste foi feito com todas as covariaveis e se tratando de selecao de
variaveis este metodo teve exito.
4.2 Aplicacao em Dados Reais
A aplicacao em dados reais foi feita em um conjunto de dados de um banco alemao.
Este conjunto esta disponıvel no pacote Fahrmeir do software R. A base de dados possui
diversas informacoes dos clientes deste banco e com base nisso deseja-se modelar a
probabilidade de um cliente nao pagar um possıvel emprestimo. Esta base possui 1.000
observacoes, as variaveis disponıveis sao:
• Yi – Variavel resposta que indica se o cliente i e bom ou mau pagador.
• Risco da Conta – Indica se o cliente possui uma boa movimentacao (Bom func.),
ma movimentacao (Mau func.) ou nao utiliza a conta.
• Quant. parcelas – Duracao do emprestimo em meses, ou seja, quantidades de
parcelas a serem pagas.
• Hist. do cliente – Indica se o cliente possui um bom (Bom pagador) ou mau (Mau
pagador) historico de pagamento.
• Uso – Variavel que indica a finalidade do emprestimo, se e de uso profissional ou
privado.

4.2 Aplicacao em Dados Reais 39
• Valor – Valor do emprestimo.
• Sexo – Sexo do cliente (Feminino ou Masculino).
• Estado civil – Indica se o cliente vive sozinho ou nao.
Das 1.000 observacoes, 300 se tratam de maus clientes e 700 de bons clientes. Este
conjunto de dados tambem foi analisado por Tucher (2008) [30], porem ela acrescentou
variaveis fictıcias em seu estudo.
Foram feitos ajustes atraves dos metodos: da maxima verossimilhanca; estimacao
bayesiana usando diferentes distribuicoes a priori(normal padrao, t-Student com 3 graus
de liberdade e normal assimetrica com o coeficiente de assimetria δ = 5); com o SSVS; e
por ultimo, com o Lasso Bayesiano. Os hiperparametros utilizados no SSVS e no Lasso
Bayesiano foram os mesmos do estudo simulado. A Tabela 8 apresenta as estimativas
obtidas:
Tabela 7: Estimativas de Maxima Verossimilhanca, via MCMC com diferentes
distribuicoes a priori , SSVS e Lasso Bayesiano.
CoeficienteMaxima
Verossimilhanca
Normal
PadraoT-Student
Normal
AssimetricaSSVS
Lasso
Bayesiano
Intercepto -1,1780 -1,1750 -1,1750 -1,1830 -1,1921 -1,0909
Risco da conta
Bom func. -1,9520 -1,9770 -1,9560 -1,9860 -1,7026 -1,6379
Mau func. -0,6346 -0,6442 -0,6405 -0,6466 -0,0925 -
Quant. parcelas 0,0350 0,0350 0,0351 0,0353 0,0364 0,0345
Hist. do cliente
Mau pagador 0,9884 1,0200 0,9803 1,0110 0,8648 -
Uso
Profissional 0,4744 0,4699 0,4718 0,4850 0,0097 -
Valor 0,0000 0,0000 0,0000 0,0000 0,0000 -
Sexo
Masculino -0,2235 -0,2361 -0,2410 -0,2277 -0,0038 -
Estado civil
Vive sozinho 0,3854 0,3666 0,3733 0,3717 0,0394 -
Note que os quatro primeiros ajustes apresentaram estimativas bem proximas. O
SSVS apresentou diferencas nas variaveis que indicam o uso do emprestimo, o sexo e o

4.2 Aplicacao em Dados Reais 40
estado civil, estimando um coeficiente bem menor que os metodos anteriores, indicando
a possıvel irrelevancia destas covariaveis.
O metodo do Lasso selecionou ainda menos covariaveis, indicando que apenas duas,
sendo o bom funcionamento da conta e a duracao do emprestimo, sao relevantes para o
modelo. Na elaboracao do BLasso-NEG Huang et al.(2013) [26] atribuem uma distribuicao
a priori Gama(a, b) para λ e pelas propriedades da distribuicao Gama, a e b devem ser
maiores que zero. Porem mostram que utilizando uma distribuicao impropria para λ,
aplicando −1, 5 < α ≤ 0, a estimacao dos parametros apresentam melhores resultados.
Aplicando a = −0, 8 e b = 0, 1, obtem-se o seguinte resultado:
Tabela 8: Estimativas atraves do Lasso Bayesiano utilizando uma distribuicao a priori
impropria para λ
Lasso
Bayesiano
Intercepto -1,2801
Risco da conta
Bom func. -1,8648
Mau func. -0,5231
Quant. parcelas 0,0368
Hist. do cliente
Mau pagador 0,9086
Uso
Profissional 0,3804
Valor -
Sexo
Masculino -
Estado civil
Vive sozinho 0,4487
Assim foram estimados parametros mais distantes de zero, como foi o caso da variavel
historico do cliente, que tinha sido considerada irrelevante com os parametros anteriores.
A Tabela 9 apresenta o Teste de Wald para os parametros:

4.2 Aplicacao em Dados Reais 41
Tabela 9: Teste de Wald aplicado aos dados reais
CoeficienteMaxima
VerossimilhancaP-Valor
Intercepto -1,1780 0,0000
Fator de risco da conta
Bom funcionamento -1,9520 < 2e− 16
Mau funcionamento -0,6346 0,0003
Quant. parcelas (meses) 0,0350 0,0000
Historico do cliente
Mal pagador 0,9884 0,0000
Uso do emprestimo
Profissional 0,4744 0,0031
Valor do emprestimo 0,0000 0,3309
Sexo
Masculino -0,2235 0,3115
Estado civil
Vive sozinho 0,3854 0,0789
Usando o nıvel de significancia de 0, 05% o teste nao rejeitou a hipotese nula para o
valor do emprestimo, para o sexo e para o estado civil, indicando que essas covariaveis
sao estatisticamente insignificantes no ajuste. Note que os valores estimados para estes
parametros nem sempre foram proximos de zero. Estas mesmas variaveis ja tinham sido
excluıdas do ajuste feito atraves do Lasso e o SSVS estimou valores bem proximos de zero
para os parametros associados.

42
5 Conclusao
Este trabalho tinha por objetivo avaliar os diferentes metodos de selecao de variaveis
bayesianos aplicados ao modelo de regressao logıstica. Foram aplicados dois metodos:
Selecao de Variaveis via Busca Estocastica (SSVS) e Operacao de Selecao e Contracao
com Penalidade em Valor Absoluto (Lasso).
Os metodos de selecao de variaveis bayesianos sao uma otima saıda quando nos
deparamos com um numero grande de variaveis explicativas, pois sao mais praticos, nao
sendo necessario realizar todos os possıveis ajustes para decidir posteriormente qual o
mais parcimonioso.
No exercıcio de simulacao apresentado na Secao 4.1, pudemos perceber que as
estimativas encontradas atraves da maxima verossimilhanca e as estimativas encontradas
atraves dos modelos propostos para a regressao logıstica usando diferentes distribuicoes a
priori e modelos hierarquicos, sao bem proximas. O fato de utilizar diferentes distribuicoes
a priori para β mostra que a estimacao bayesiana nao foi sensıvel em relacao a escolha
destas distribuicoes.
Tanto o metodo da maxima verossimilhanca quanto o metodo bayesiano encontraram
estimativas bem proximas de zero para β4, β5, β6 e β7 o que era desejado, pois
seus valores reais eram zero para todos estes coeficientes. Porem o metodo SSVS
apresentou estimativas para estes βj′s bem mais concentradas em zero, e seus intervalos
de credibilidade para as 1.000 replicacoes reforcavam o fato das covariaveis X4, X5, X6
e X7 nao serem relevantes no ajuste. O metodo do Lasso Bayesiano tambem apresentou
vantagens, indicando que as covariaveis X4, X5, X6 e X7 tambem eram irrelevantes no
ajuste.
Em relacao ao metodo classico, o AIC indicou uma percentagem de erros mais alta
do que o BIC, que escolheu em todas as 1.000 replicacoes, o modelo simples. Em relacao
ao metodo bayesiano, o DIC teve desempenho identico ao BIC, escolhendo em todas as
1.000 replicacoes o modelo mais simples.

5 Conclusao 43
O teste de Razao de Chances a Posteriori se mostrou extremamente efetivo na escolha
do ajuste com as variaveis relevantes, diferente do teste de Razao de Verossimilhanca, que
em 5, 7% das 1.000 replicacoes escolheu o modelo geral.
A aplicacao em dados reais mostrou que o metodo do Lasso e do SSVS conseguiram
indicar a irrelevancia de determinadas covariaveis a partir das estimativas dos parametros.
Ja no metodo da maxima verossimilhanca foi necessario realizar o teste de Wald para
poder verificar a relevancia das variaveis estudadas.

44
Referencias
[1] CHIPMAN, H. A.; GEORGE, E.; MCCULLOCH, R. The practical implementation ofbayesian model selection. Model Selection IMS Lecture Notes -Monograph Series, v. 38,01 2001.
[2] SANTOS, A. M. dos et al. Usando redes neurais artificiais e regressao logıstica napredicao da hepatite a. Revista Brasileira de Epidemiologia, v. 8, n. 2, p. 117–126,2005.
[3] DAMIANI, A. P. et al. Curso-R:Regressao Logıstica em: A menor Deep Learningdo Mundo. 2018. Disponıvel em: <https://www.curso-r.com/blog/2017-07-29-segundo-menor-dl/>.
[4] TIBSHIRANI, R. Regression shrinkage and selection via the lasso. Journal of theRoyal Statistical Society (Series B), v. 58, p. 267–288, 1996.
[5] CASELLA, G.; BERGER, R. Statistical Inference. [S.l.]: Thomson Learning, 2002.(Duxbury advanced series in statistics and decision sciences).
[6] MIGON, H.; GAMERMAN, D.; LOUZADA, F. Statistical Inference: An IntegratedApproach, Second Edition. [S.l.]: Taylor & Francis, 2014. (Chapman & Hall/CRC Textsin Statistical Science).
[7] NELDER, J. A.; WEDDERBURN, R. W. M. Generalized linear models. Journal ofthe Royal Statistical Society. Series A (General), [Royal Statistical Society, Wiley],v. 135, n. 3, p. 370–384, 1972.
[8] HOSMER, D. W.; LEMESHOW, S. Applied logistic regression (Wiley Series inprobability and statistics). 2. ed. [S.l.]: Wiley-Interscience Publication, 2000.
[9] DOBSON, A. J. Book. An introduction to generalized linear models / Annette J.Dobson. 2nd ed.. ed. [S.l.]: Chapman & Hall/CRC Boca Raton, 2002.
[10] NETER, J. et al. Applied Linear Statistical Models. [S.l.]: Irwin, 1996.
[11] METROPOLIS, N. et al. Equation of state calculations by fast computing machines.Journal of Chemical Physics, v. 21, n. 6, p. 1087–1092, 1953.
[12] HASTINGS, W. K. Monte Carlo sampling methods using Markov chains and theirapplications. Biometrika, v. 57, p. 97–109, 1970.
[13] GEMAN, S.; GEMAN, D. Stochastic relaxation, Gibbs distribution and theBayesian restoration of images. IEEE Transactions on Pattern Analysis and MachineIntelligence, n. 6, p. 721–741, 1990.

Referencias 45
[14] GELFAND, A. E.; SMITH, A. F. M. Sampling-based approaches to calculatingmarginal densities. Journal of the American Statistical Association, v. 85, n. 410, p.398–409, 1990.
[15] GAMERMAN, D.; LOPES, H. Markov Chain Monte Carlo: Stochastic Simulationfor Bayesian Inference, Second Edition. [S.l.]: Taylor & Francis, 2006. (Chapman &Hall/CRC Texts in Statistical Science).
[16] BOZDOGAN, H. Model selection and akaike’s information criterion (aic): Thegeneral theory and its analytical extensions. Psychometrika, v. 52, n. 3, p. 345–370,1987.
[17] HIROTUGU, A. Factor analysis and aic. Psychometrika, v. 52, n. 3, p. 317–332,1987.
[18] SCHWARZ, G. et al. Estimating the dimension of a model. The annals of statistics,v. 6, n. 2, p. 461–464, 1978.
[19] SPIEGELHALTER, D. J. et al. Bayesian measures of model complexity and fit.Journal of the Royal Statistical Society: Series B (Statistical Methodology), WileyOnline Library, v. 64, n. 4, p. 583–639, 2002.
[20] GREENLAND, S. et al. Statistical tests, p values, confidence intervals, and power: aguide to misinterpretations. European Journal of Epidemiology, v. 31, n. 4, p. 337–350,Apr 2016.
[21] JR., W. W. H.; DONNER, A. Wald’s test as applied to hypotheses in logit analysis.Journal of the American Statistical Association, Taylor & Francis, v. 72, n. 360a, p.851–853, 1977.
[22] KUO, L.; MALLICK, B. Variable selection for regression models. Sankhya: TheIndian Journal of Statistics, Series B (1960-2002), Springer, v. 60, n. 1, p. 65–81,1998.
[23] CARLIN, B. P.; CHIB, S. Bayesian model choice via markov chain monte carlomethods. Journal of the Royal Statistical Society. Series B (Methodological), [RoyalStatistical Society, Wiley], v. 57, n. 3, p. 473–484, 1995.
[24] DELLAPORTAS, P.; FORSTER, J. J.; NTZOUFRAS, I. On bayesian model andvariable selection using mcmc. Statistics and Computing, v. 12, n. 1, p. 27–36, Jan2002.
[25] GEORGE, E. I.; MCCULLOCH, R. E. Variable selection via gibbs sampling. Journalof the American Statistical Association, Taylor & Francis, v. 88, n. 423, p. 881–889,1993.
[26] HUANG, A.; XU, S.; CAI, X. Empirical bayesian lasso-logistic regression for multiplebinary trait locus mapping. BMC Genetics, v. 14, n. 1, p. 5, Feb 2013.
[27] R Development Core Team. R: A Language and Environment for StatisticalComputing. Vienna, Austria, 2009. ISBN 3-900051-07-0. Disponıvel em:<http://www.R-project.org>.

Referencias 46
[28] PARK, T.; CASELLA, G. The Bayesian Lasso. Journal of the American StatisticalAssociation, v. 103, n. 482, p. 681–686, jun. 2008.
[29] LI, Q.; XI, R.; LIN, N. Bayesian regularized quantile regression. Bayesian Anal.,International Society for Bayesian Analysis, v. 5, n. 3, p. 533–556, 09 2010.
[30] TUCHLER, R. Bayesian variable selection for logistic models using auxiliary mixturesampling. Journal of Computational and Graphical Statistics, Taylor & Francis, v. 17,n. 1, p. 76–94, 2008.
[31] CELEUX, G. et al. Deviance information criteria for missing data models. BayesianAnal., International Society for Bayesian Analysis, v. 1, n. 4, p. 651–673, 12 2006.
[32] PAWITAN, Y. In All Likelihood: Statistical Modelling and Inference UsingLikelihood. [S.l.]: OUP Oxford, 2001. (Oxford science publications).
[33] TIBSHIRANI, R. et al. Sparsity and smoothness via the fused lasso. Journal of theRoyal Statistical Society Series B, p. 91–108, 2005.
[34] MEIER, L.; GEER, S. V. D.; BuHLMANN, P. The group lasso for logistic regression.Journal of the Royal Statistical Society: Series B (Statistical Methodology), v. 70, n. 1,p. 53–71.
[35] AGRESTI, A. Categorical data analysis. [S.l.]: Wiley, 1990. XV, 558 S. p. (A Wiley-Interscience publication).
[36] GEORGE, E. I.; MCCULLOCH, R. E. Approaches for bayesian variable selection.Statistica Sinica, p. 339–374, 1997.







