
1
Parallel Scientific Computing: Algorithms and Tools
Lecture #2
APMA 2821A, Spring 2008Instructors: George Em Karniadakis
Leopold Grinberg

2
Memory Bits: 0, 1; Bytes: 8 bits Memory size
PB – 10^15 bytes; TB – 10^12 bytes; GB – 10^9 bytes; MB – 10^6 bytes; KB – 10^3 bytes
Memory performance measures: Access time, or response time, latency: interval between time of
issuance of memory request and time when request is satisfied. Cycle time: minimum time between two successive memory
requests
t0 t1 t2Memory request
requestsatisfied
Access time: t1-t0 Cycle time: t2-t0
If there is another request at t0 < t < t2, memory is busy and will not respond; have to wait until t > t2
Memory busy t0 < t < t2DRAM only

3
Memory HierarchyMemory can be fast (costly) or slow (cheaper).Increase overall performance: use locality of
referenceFaster memory (also smaller) closer to CPU; slower memory (also larger) farther away from CPU.Have often-used data in fast memory; leave less-
often-used data in slow memory.Key: When lower levels of hierarchy send value
at location x to higher levels, also send content at x+1, x+2, etc. i.e. send a block of dataCache line

4
Memory Hierarchy
Performance of different levels can be very different e.g. access time for L1 cache can be 1 cycle, L2 can be 5 or 6
cycles, while main memory can be dozens of cycles and secondary memory can be orders of magnitude slower.
Registers
Level-1 cache
Level-2 cache
Main memorySecondary memory
(hard disk)
Network storage
… …
Cache: a piece of fast memoryExpensive, CA$H ?
Increasing speedIncreasing costDecreasing size
Decreasing speedDecreasing costIncreasing size

5
How Memory Hierarchy Works(RISC processor) CPU works only on data in
registers. If data is not in register, request data from memory
and load to register …Data in register come only from and go only to
L1 cache.When CPU requests data from memory, L1 cache
takes over;If data is in L1 cache (cache hit), return data to CPU
immediately; end memory access;If data is not in L1 cache (cache miss) …

6
How Memory Hierarchy Works If data is not in L1 cache, L1 cache forwards memory
request down to L2 cache. If L2 cache has the data (cache hit), it returns the data to L1
cache, which in turn returns data to CPU; end memory access; If L2 cache does not have the data (cache miss) …
If data is not in L2 cache, L2 cache forwards memory request down to main memory. If data is in main memory, main memory passes data to L2
cache, which then passes data to L1 cache, which then passes data to CPU.
If data is not in memory … Then request is passed to OS to read data from
secondary storage (disk), which then is passed to memory, L2 cache, L1 cache, register.

7
Cache Line A cache line is the smallest unit of data that can be
transferred to or from memory (and L2 cache). usually between 32 and 128 bytes May contain several data items
When L2 cache passes data to L1 cache, or when main memory passes data to L2 cache, a cache line, instead of a single piece of data, is transferred. When the data in variable X is requested from memory, the
cache line containing X (and adjacent data) is transferred to cache.
X[10] X[11] X[12] X[13]X[9] X[14]
Cache line Cache line
Assume: 32-byte cache line, X[11] is requested by CPUResult: X[10] – X[13] is brought into cache from memory.

8
Cache Effect on PerformanceCache miss degrading performance
When there is a cache miss, CPU is idle waiting for another cache line to be brought from lower level of memory hierarchy
Increasing cache hit rate higher performanceEfficiency directly related to reuse of data in cache
To increase cache hit rate, access memory sequentially; avoid strides, random access, and indirect addressing in programming.
for(i=0;i<100;i++) y[i] = 2*x[index[i]];
for(i=0;i<100;i++) y[i] = 2*x[i];
for(i=0;i<100;i=i+4) y[i] = 2*x[i];
sequential access
strides Indirect addressing

9
Where in Cache to Put Data from MemoryCache is organized into cache lines.Memory is also logically organized into cache
lines.
…32-byte cache line
1 MB (32,768 cache lines)
…
2 GB (67,108,864 cache lines)
cache
Main memory
Memory size >> cache size
Number of cache lines in memory >> number of cache lines in cache.
Many cache lines in memory correspond to one cache line in cache.

10
Cache ClassificationDirect-mapped cache
Given a memory cache line, it is always placed in one specific cache line in cache.
Fully associative cacheGiven a memory cache line, it can be placed
in any of the cache lines in cache.N-way set associative cache
Given a memory cache line, it can be placed in any of a set of N cache lines in cache.

11
Direct-Mapped Cache A set of memory cache lines always correspond to exactly the same
cache line in cache. Cheap to implement in hardware; May cause cache thrashing: repeatedly displacing and loading
cache lines.
…
… … … …
8 KB
0 8K 16K … 2G
Line-Index = Mod (mem-cache-line-index, tot-cache-lines-in-cache)

12
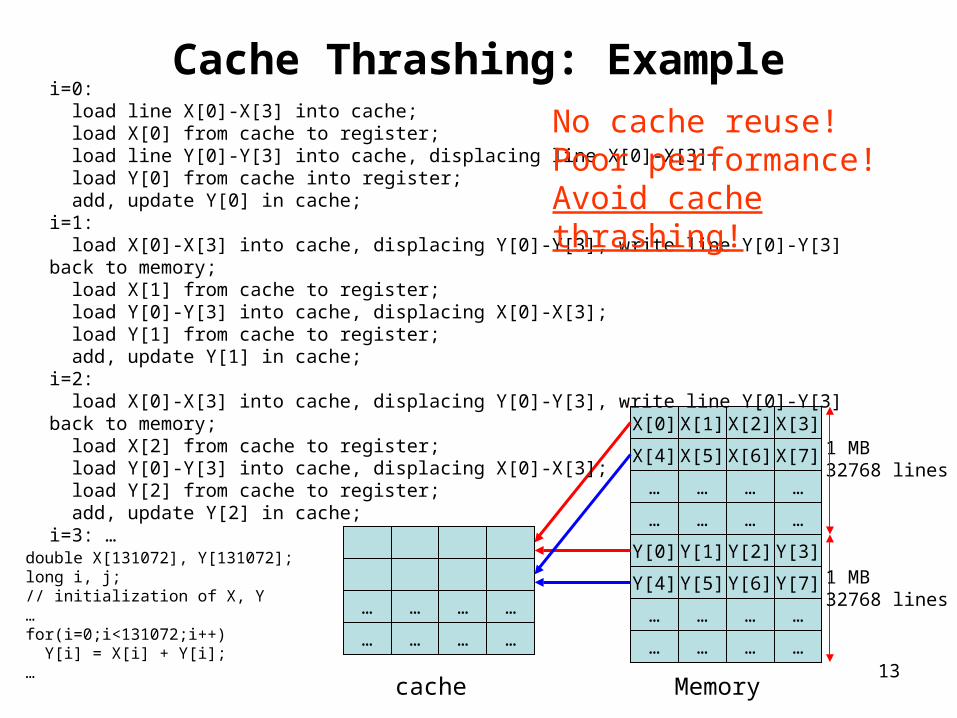
Cache Thrashing: ExampleAssumptions:
Direct-mapped cache;Cache size: 1 MB;Cache line: 32 bytes;
double X[131072], Y[131072];long i, j;// initialization of X, Y…for(i=0;i<131072;i++) Y[i] = X[i] + Y[i];…
1 double value = 8 bytes131072 double values = 1 MB1 cache line = 32 bytes = 4 double values
X[131072]: 1 MB memoryY[131072]: 1 MB memory
13
Cache Thrashing: Example
1 MB32768 lines
X[0] X[1] X[2] X[3]
X[4] X[5] X[6] X[7]
… … … …
… … … …
Y[0] Y[1] Y[2] Y[3]
Y[4] Y[5] Y[6] Y[7]
… … … …
… … … …
… … … …
… … … …
cache Memory
1 MB32768 lines
i=0: load line X[0]-X[3] into cache; load X[0] from cache to register; load line Y[0]-Y[3] into cache, displacing line X[0]-X[3]; load Y[0] from cache into register; add, update Y[0] in cache;i=1: load X[0]-X[3] into cache, displacing Y[0]-Y[3], write line Y[0]-Y[3] back to memory; load X[1] from cache to register; load Y[0]-Y[3] into cache, displacing X[0]-X[3]; load Y[1] from cache to register; add, update Y[1] in cache;i=2: load X[0]-X[3] into cache, displacing Y[0]-Y[3], write line Y[0]-Y[3] back to memory; load X[2] from cache to register; load Y[0]-Y[3] into cache, displacing X[0]-X[3]; load Y[2] from cache to register; add, update Y[2] in cache;i=3: …
No cache reuse!Poor performance!Avoid cache thrashing!
double X[131072], Y[131072];long i, j;// initialization of X, Y…for(i=0;i<131072;i++) Y[i] = X[i] + Y[i];…

14
Fully Associative CacheA cache line from memory can be placed
anywhere in cache;No cache thrashing; but costly.Direct-mapped cache at one extreme of
spectrum; fully associative cache at another extreme of spectrum.
Disadvantage: search entire cache to determine if a specific cache line is present.

15
N-Way Set Associative Cache Compromise between direct-mapped cache and fully associative
cache The cache lines in cache is divided into a number of sets; Each set
contains N cache lines. Given a cache line from memory, the index of set it belongs to is
first calculated; Then it is placed in one of the N cache lines in this set.
…
2 GB (67,108,864 cache lines)
…
1 MB 32,768 cache lines16,384 setsEach set has 2 lines
cache
Main memory
2-way set associative cache
Less likely to cause cache thrashing;Less costly;
Direct-mapped cache is 1-way set associative cache;Fully associative cache is N_c way set associative cache; N_c is total number of cache lines in cache.

16
Instruction/Data Cache
CPU may have separate instruction cache and data cache (split cache).
CPU may have a single cache, for both instructions and data from memory (unified cache).

17
Remember …
Efficiency directly related to cache reuseCache thrashing is eliminated by padding
arrays (array dimensions should not be a multiple of cache line – avoid powers of 2)
To improve cache reuse,Access memory sequentially as much as
possibleAvoid stride, random access, indirect addressingAvoid cache thrashing.

18
Example
Large stride in memory access pattern results in not only cache miss/poor reuse, but also TLB miss.
double X[1024][1024], Y[1024][1024];int i,j;…
for(j=0;j<1024;j++) for(i=0;i<1024;i++) X[i][j] = Y[i][j];
X[0][0]
X[0][1]
X[0][1023]
X[1][0]
X[1][1]
……
X[1023][1023]
……
Y[0][0]
Y[0][1]
Y[0][1023]
Y[1][0]
Y[1][1]
……
Y[1023][1023]
……
stride 1024or 8KB

19
Virtual Memory, Memory Paging
… …
0
4KB
8KB
2GB
… …
0
4KB
8KB
2GB
… …
… …
0
1024KB
1028KB
1032KB
1036KB
1040KB
1044KB
1048KB
4GB
Program #1
Program #2
Physical Memory
Modern computers use virtual memory;
Memory address seen in a program (virtual address) is not the actual address in physical memory;
Memory is divided into pages (e.g. 4KB);
A memory page in program’s address space corresponds to a page in physical memory;
To access memory, need to translate program’s virtual address to the actual address in physical memory.
This is done using a page table;

20
Translation Look-aside Buffer (TLB)
TLB is a special cache for the page tables Faster access to TLB for virtual-physical translation.
When program accesses a memory location, the translation between virtual and physical pages is loaded into TLB (if it is not already there);
If program exhibits locality of references, entries in TLB can be reused TLB hit better performance
Otherwise TLB miss performance degrades. Large stride in memory access pattern TLB miss (and
cache miss).

21
Remedies
Use large memory page sizeOn some systems, the memory page size can
be modified by user programs, e.g. IBM SP, HP machines
Avoid large stride in memory access; Sequential access to memory as much as possible.

22
Interleaved Memory Memory interleaving: alleviating the impact of memory cycle time.
Total memory divided into a set of memory banks; Contiguous memory addresses reside on different banks.
When accessing memory sequentially, effect of memory cycle time minimized When current bank is busy, next bank is idle and can be accessed immediately.
Stride in memory access not favorable may access the same bank repeatedly, need to wait due to cycle time poor performance
Total 2GB memoryDivide into 4 memory banksEach bank: 512 MBCache line: assumed 32 bytes0-31
128-159
…
32-63
160-191
…
64-95
192-223
…
96-127
224-255
…
Bank 1 Bank 2 Bank 3 Bank 4
1 cache line(32 bytes)







