
OSC Graduate Student Workshop/Conference, August, 2000
1
Using the Linux Cluster at OSCScience & Technology Support and Systems Staff
High Performance Computing
The Ohio Supercomputer Center1224 Kinnear Road
Columbus,Ohio 43212

OSC Graduate Student Workshop/Conference, August, 2000
2
Contents• Introduction
• Accessing the Linux Cluster at OSC
• User Environment
• Development Environment
• Job Scheduling
• Cluster Parallel Programming

OSC Graduate Student Workshop/Conference, August, 2000
3
Introduction• Linux clusters are becoming mature
• Scientists at NASA Goddard started the Beowulf idea, see http://www.
beowulf.org – Variation on an old theme, NOW’s, Cow,s, etc...
• Rich tool environment, free and commercial
• Third-party adoption– LS-Dyna, Fluent and other scientific codes– Large choice of commercial compilers– Integrators

OSC Graduate Student Workshop/Conference, August, 2000
4
Tutorial Objectives• Logging into the cluster
• Understanding the layout and hardware of the OSC cluster
• Compiling a program
• Submitting a job to the batch queue system
• Compiling and running parallel programs
OSC Graduate Student Workshop/Conference, August, 2000
5
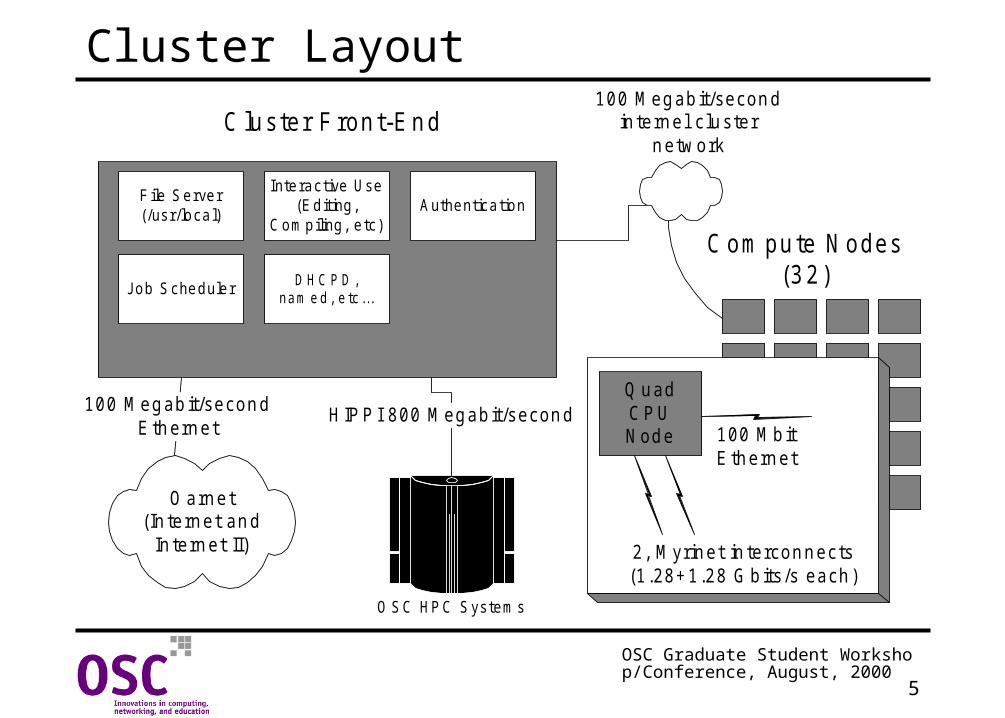
Cluster Layout
F ile S erve r( /usr / loca l)
Inte rac t ive Use(E d it ing ,
C om p iling , e tc )A uthent ica t ion
C luster F ron t-E nd
O arn et(In tern et an d
In tern et II)
100 Meg ab it/secon dE th ern et
O S C HP C S ys tem s
HIPPI 800 Meg ab it/secon d
Job S chedule r
C om pu te N odes(32 )
Q u adCPUNod e
100 Meg ab it/secon din tern el c lu ster
n etwork
D H C P D ,nam e d , e tc ...
100 Mb itE th ern et
2, Myrin et in tercon n ects(1.28+1.28 G b its/s each )

OSC Graduate Student Workshop/Conference, August, 2000
6
Hardware IntroductionThe OSC Beowulf cluster consists of the following:
• A front-end node for interactive use, compiling, testing, etc.
• Several (currently 32) compute nodes used by parallel jobs.
• A high-speed system area network (SAN) for inter-node communication.
• External network access.

OSC Graduate Student Workshop/Conference, August, 2000
7
Front End Node Configuration• Quad Intel Pentium III Xeon processors running at 550 MHz with
512kB of L2 cache.
• 2 GB RAM.
• Dual UW SCSI controllers supporting 72 GB of SCSI disk (mirrored system disk, /usr/local for cluster-wide software).
• Dual Fast Ethernet interfaces.
• HIPPI interface for fast access to the OSC mass storage server (mss.osc.edu).

OSC Graduate Student Workshop/Conference, August, 2000
8
Processor PerformanceAll of the nodes in the OSC Beowulf cluster use the Intel Pentium III
Xeon processor with a 550 MHz clock:
• x86 instruction decoder in front of a RISC-style super-scalar execution core with out-of-order execution.
• 32 kB L1 instruction cache, 32 kB L1 data cache, and 512 kB unified L2 cache.
• 5 execution units: 2 integer units, 2 load/store units, and 1 floating-point unit.
• 14-stage pipeline.
• 550 MFLOPs peak, ~120 MFLOPs on Linpack 100x100.

OSC Graduate Student Workshop/Conference, August, 2000
9
Memory PerformanceAll of the nodes in the OSC Beowulf cluster use 100MHz SDRAM
memory:
• 64-bit wide data path.
• 6ns latency.
• 800 MB/s peak, 300 MB/s on stream_d memory copy.

OSC Graduate Student Workshop/Conference, August, 2000
10
Cluster Interconnect• Myrinet interconnects are full duplex, 1.28+1.28 Gbit/Second
channels, 2.0+2.0 Gbit/Second channels are available today.
• The driver provides user level, OS bypass communication primitives.– Memory registration to implement zero copy protocols.– Communication primitives provided through GM, Glens’ Messages.
Use Level ProgramsUse Level Programs
GM
MPI, ch_gm

OSC Graduate Student Workshop/Conference, August, 2000
11
Accessing the Linux Cluster at OSC• There are several ways to remotely access the front end node of the
Linux cluster, oscbw.osc.edu.
• You can use telnet:telnet oscbw.osc.edu
• rsh and rlogin are also available:rlogin oscbw.osc.edu -l myuserid
• However, we encourage you to use ssh if possible:ssh oscbw.osc.edu -l myuserid
• ssh sends your commands over an encrypted stream, so your passwords and all data transferred can’t be sniffed over the network.
• Another benefit of ssh is also the recommended method if you will be using the interactive batch queue (required for parallel debugging).

OSC Graduate Student Workshop/Conference, August, 2000
12
Remote X Display from the Beowulf Cluster• You can run applications which use the X Window System on the
front end node and have them displayed on your remote workstation or PC.
• If you use ssh, you should be able to display X applications remotely with no further work; ssh does all the necessary steps itself.
• If you use telnet, rlogin, or rsh, you need to set an environment variable called DISPLAY in your session on the front end node to point to your workstation:export DISPLAY=“mypc.some.edu:0.0” ( for ksh users)
setenv DISPLAY mypc.some.edu:0.0 (for csh users)
• You also need to tell your workstation that the front end node is allowed to display to it:xhost +oscbw.osc.edu

OSC Graduate Student Workshop/Conference, August, 2000
13
User Environment• Shells supported at OSC on the cluster are,
– ksh– bash– tcsh and csh
• The “modules” interface is a way to allow multiple versions of software to coexist.
• They allow you to add or remove software from your environment without having to manually modify environment variables.
• This is a “Cray-ism” which OSC has adopted for all of our HPC systems; the OSC Beowulf uses a modules implementation from Los Alamos National Lab.

OSC Graduate Student Workshop/Conference, August, 2000
14
Using modules• You can get a list of modules you currently have loaded by running
module list: oscbw:~> module list
Currently Loaded Modulefiles:
1) pbs_2_2_0
2) pgi_3_1
3) modules_0_2
4) mpich_gm
• To get a list of all available modules, run module avail:oscbw:~> module avail
---------- /usr/local/lanl-modules-0.2/modules ----------
hdf -> hdf_4_1_2
pbs -> pbs_2_1_13
…list continues...

OSC Graduate Student Workshop/Conference, August, 2000
15
Using Modules (con’t)• To add a software module to your environment, run module load
<modulename>:oscbw:~> module load scmsoscbw:~> which scms/usr/local/scms/bin/scmsoscbw:~> module listCurrently Loaded Modulefiles: …scms…
• To remove a software package from your environment, run module unload <modulename>:oscbw:~> module unload scmsoscbw:~> which scmsscms: Command not found.oscbw:~> module listCurrently Loaded Modulefiles: …no scms…

OSC Graduate Student Workshop/Conference, August, 2000
16
Development EnvironmentPortland Group Compilers:
• Vendor of Compilers for traditional HPC systems.
• Contracted by DOE and Intel to provide compilers for Intel ASCI Red.
• Optimizing compiler for Intel P6 core.
• Linux, Solaris and MS Windows (X86 only).
• Compiler suite includes,– C (pgcc)– C++ (pcCC)– Fortran 77 (pgf77)– Fortran 90 (pgf90)– High Performance Fortran - HPF (pghpf)
• Link compatible with GCC objects and libraries.
• Includes debugger and profiler (can use GDB).

OSC Graduate Student Workshop/Conference, August, 2000
17
Portland Group Compilers: C Options• -B (allows C++ style comments)• -mp (enables support for OpenMP and SGI-style PCF pragmas for
parallelization)• -Xa (enforces strict ANSI C compliance)• -Xc (enforces loose ANSI C compliance)• -Xs (enforces strict K&Rv1 C compliance)• -Xt (enforces loose K&Rv1 C compliance)
Recommended flags: -Xa -fast -tp p6 -Mvect=assoc
-Mvect=cachesize:524288

OSC Graduate Student Workshop/Conference, August, 2000
18
Portland Group Compilers: Common OptionsMost of these are identical to their counterparts in the GNU compilers• -c (compile only; do not link) • -DMACRO[=value] (defines preprocessor macro MACRO with
optional value; default value is 1)• -g (generate symbols for debugging; disables optimization)• -I/dir/name (add /dir/name to the list of directories to be
searched for #included files)• -lname (add library libname.{a|so} to the list of libraries to be
linked)• -L/dir/name (add /dir/name to the list of directories to be
searched for library files)• -o outfile (name resulting output file outfile; default is
a.out)• -UMACRO (removes definition of MACRO from preprocessor)

OSC Graduate Student Workshop/Conference, August, 2000
19
Portland Group Compilers: C++ Options• -A (enforces strict ANSI C++ compliance)• --exceptions (enables ANSI C++ exceptions)• -mp (enables support for OpenMP and SGI-style PCF pragmas for
parallelization)• --prelink-objects (enables support for template libraries
within template libraries)• -tall (forces all templates to be instantiated)• -tlocal (forces template instantiations to be local)• -tnone (forces no templates to be instantiated)• -tused (instantiates only those templates used)
Recommended flags: -A -fast -tp p6 -Mvect=assoc
-Mvect=cachesize:524288 --prelink-objects

OSC Graduate Student Workshop/Conference, August, 2000
20
Portland Group Compilers: F77/F90 Options• -byteswapio (uses byte-swapping unformatted I/O compatible
with Sun and SGI systems)• -i4 (assumes 4-byte INTEGERs; default)• -i8 (assumes 8-byte INTEGERs)• -module /dir/name (adds /dir/name to the list of directories
searched for F90 modules)• -mp (enables support for OpenMP and SGI-style PCF directives for
parallelization)• -r4 (assumes 4-byte REALs; default)• -r8 (assumes 8-byte REALs)• -Mcray=pointer (forces compatibility with Cray CF77 pointer
semantics)
Recommended flags: -fast -tp p6 -Mvect=assoc
-Mvect=cachesize:524288

OSC Graduate Student Workshop/Conference, August, 2000
21
Optimization Usage• Vectorizor can optimize for countable loops with large arrays.
• Use -Minfo=loop to have the compiler report what optimizations were applied to the loops, unrolling and vectorized.
• Cache size can be specified to maximize cache re-use, -Mvect:cachesize=…
• Use -Mneginfo=loop to provide information about why a loop was not a candidate for vectorization.
• Can specify number of times to unroll a loop.
• Can use -Minline to inline functions. This can improve the performance of calls to functions inside of subroutines.
– Is not useful for functions that have an execution time >> penalty for the jump.
– This option will sacrifice code compactness for efficiency.

OSC Graduate Student Workshop/Conference, August, 2000
22
Optimizations Usage (cont.)• All command line optimizations are available through directives or
pragmas.
• Can be used to enable or disable specific optimizations.

OSC Graduate Student Workshop/Conference, August, 2000
23
Caveats for Portland Compilers• F77 and F90 are separate front-ends.
• Debugger cannot display floating point registers.
• Code compiled with Portland Compiler is compatible with GDB– Initial listing of code does not work.– Set break point or watch point where desired.
• Profiler can be difficult or impossible to use on parallel codes.
• Complete compiler suite documentation can be found at, http://www.pgroup.com/docs.htm

OSC Graduate Student Workshop/Conference, August, 2000
24
MPI Compiler WrappersThe MPICH/GM implementation of MPI uses a set of compiler scripts to
keep users from having to remember how to set include and library paths for the their MPI compiles. These scripts call the system compilers to do the actual compilation. The scripts support the following languages:
• C (mpicc -- wrapper for pgcc)
• C++ (mpiCC -- wrapper for pgCC)
• Fortran 77 (mpif77 -- wrapper for pgf77)
• Fortran 90 (mpif90 -- wrapper for pgf90)
These compiler scripts accept the same arguments as the compiler they wrap, i.e. mpicc accepts the same arguments as pgcc, mpif77 accepts the same arguments as pgf77, etc.

OSC Graduate Student Workshop/Conference, August, 2000
25
MPI Compiler Wrappers (con’t.)The MPI compiler wrappers also accept a few command line arguments
of their own:
• -mpilog (generates MPE log files compatible with the jumpshot MPI profiler)
• -mpitrace (prints trace messages on entry and exit to all MPI routines)

OSC Graduate Student Workshop/Conference, August, 2000
26
When the MPI Compiler Wrappers Break• Occasionally, a program’s build process will make make assumptions
about quoting around the arguments for compilers that will not work with the MPI compiler wrappers (which are after all only shell scripts). In these cases, you should use the Portland Group compilers directly and use the following environment variables:
• Compile with– $MPI_CFLAGS (C)– $MPI_CXXFLAGS (C++)– $MPI_FFLAGS (F77)– $MPI_F90FLAGS (F90)
• Link with $MPI_LIBS

OSC Graduate Student Workshop/Conference, August, 2000
27
LibrariesThe OSC Beowulf cluster has several Fortran numerical libraries installed
which can be used in conjunction with the Portland Group compilers:
• BLAS (link with -lblas)
• LAPACK (link with -llapack -lblas)
• LAPACK90 (link with -L/usr/local/lib -llapack90 -llapack -lblas)
• BLACS, PBLAS, and ScaLAPACK (compile with mpif77 or mpif90, link with ${SCALAPACK} ${PBLAS} ${FBLACS})
• A public domain version of Cray’s libsci FFT routines (link with -L/usr/local/lib -lsci)
• PETSC (module load petsc to use, look at the examples’ Makefiles in $PETSC_ROOT/examples for how to build programs which use it)

OSC Graduate Student Workshop/Conference, August, 2000
28
Libraries (con’t)The OSC Beowulf cluster also has several I/O libraries installed for
writing files in platform independent formats:
• HDF (module load hdf to use, compile with $HDF_INCLUDE, link with $HDF_LIBS)
• HDF5 (module load hdf5 to use, compile with $HDF5_INCLUDE, link with $HDF5_LIBS)
• NetCDF (link with -lnetcdf for C or Fortran, or -lnetcdf_c++ for C++)

OSC Graduate Student Workshop/Conference, August, 2000
29
Job SchedulingWhy Job Scheduling Software:• In an ideal world, users would coordinate with each other and no
conflicts would be encountered when running jobs on a cluster.
• Unfortunately in real life we have limited resources (processors, memory and network interfaces)
– Users, faced with time deadlines of their own, will want to execute jobs on the cluster as it fits with their schedule
– High throughput users can swamp the whole system, if allowed– Users can check for CPU availability (system load), but how many will
check memory or network interface availability
• Job scheduling system allows you to enforce a system policy– Policy can be established by management or peer review– Enforcement of policy will control what are the maximum resources
available, and in what order jobs will be allocated these resources

OSC Graduate Student Workshop/Conference, August, 2000
30
Job Scheduling Software for ClustersThere are several batch queuing systems available for Linux-based
clusters, depending on what your needs are. Here are just a few:
• Condor (http://www.cs.wisc.edu/condor/)
• DQS (http://www.scri.fsu.edu/~pasko/dqs.html)
• Generic NQS (http://www.gnqs.org/)
• Job Manager (http://bond.imm.dtu.dk/jobd/)
• GNU Queue (http://www.gnu.org/software/queue/queue.html)
• LSF (http://www.platform.com/ -- commercial)
• Portable Batch System (PBS) (http://pbs.pbspro.com/)

OSC Graduate Student Workshop/Conference, August, 2000
31
Introduction to PBS• PBS is short for “Portable Batch System”; it is an open source batch
queuing system.
• It is an outgrowth/extension of the NQS batch queuing system from the NAS project at NASA Ames Research Center.
• PBS is available for virtually anything that is UNIX-like, including Linux, the BSDs, UNICOS, IRIX, Solaris, AIX, HP/UX, and Digital UNIX.

OSC Graduate Student Workshop/Conference, August, 2000
32
How PBS Handles a Job• User determines resource requirements for a job and writes a batch
script.
• User submits job to PBS with the qsub command.
• PBS places the job into a queue based on its resource requests and runs the job when those resources become available.
• The job runs until it either completes or exceeds one of its resource request limits.
• PBS copies the job’s output into the directory from which the job was submitted and optionally notified the user via email that the job has ended.

OSC Graduate Student Workshop/Conference, August, 2000
33
Determining Job Requirements• For single CPU jobs, PBS needs to know at least two resource
requirements:– CPU time– memory
• For multiprocessor parallel jobs, PBS also needs to know how many nodes/CPUs are required.
• Other things to consider:– Job name?– Working in /tmp or $TMPDIR?– Where to put standard output and error output?– Should the system email when the job completes?

OSC Graduate Student Workshop/Conference, August, 2000
34
PBS Job Scripts• An PBS job script is just a regular shell script with some comments
(the ones starting with #PBS) which are meaningful to PBS. These comments are used to specify properties of the job.
• PBS job scripts always start in your home directory, $HOME. If you need to work in another directory, your job script will need to cd to there.
• Every PBS job has a unique temporary directory, $TMPDIR. This in on each compute node’s local disk array and thus is much faster than your home directory, which is mounted over the network from the mass storage server. For best I/O performance, you should try to copy all the files you need into $TMPDIR, do your work there, and then copy any files you want to keep back to your home directory.

OSC Graduate Student Workshop/Conference, August, 2000
35
PBS Job Scripts (con’t)• Useful PBS options:
-e errfile (redirect standard error to errfile)
-I (run as an interactive job)
-j oe (combine standard output and standard error)
-l cput=N (request N seconds of CPU time; N can also be in hh:mm:ss form)
-l mem=N[KMG][BW] (request N {kilo|mega|giga}{bytes|words} of memory)
-l nodes=N:ppn=M (request N nodes with M processors per node)
-m e (mail the user when the job completes)
-m a (mail the user if the job aborts)
-o outfile (redirect standard output to outfile)
-N jobname (name the job jobname)
-S shell (use shell instead of your login shell to interpret the batch script; must include a complete path)
-V (job inherits the full environment of the current shell, including $DISPLAY)

OSC Graduate Student Workshop/Conference, August, 2000
36
A First Batch Script• Here is a simple batch job:
#PBS -l cput=40:00:00
#PBS -l nodes=1:ppn=1
#PBS -N cdnz3d
#PBS -j oe
#PBS -S /bin/ksh
cd $HOME/Beowulf/cdnz3d
cp *.dat cdnz3d.in cdnz3dxyz.bin $TMPDIR
cd $TMPDIR
/usr/bin/time ./cdnz3d > cdnz3d.hist
cp cdnz3d.out cdnz3dq.bin $HOME/Beowulf/cdnz3d
• This job asks for one CPU on one node, and 40 hours of CPU time. Its name is “cdnz3d”.

OSC Graduate Student Workshop/Conference, August, 2000
37
Monitoring a Job• The status of all the jobs running on the Beowulf cluster can be shown
with the qstat command:
oscbw:~> qstat -aoscbw.cluster.osc.edu:
Req'd Req'd Elap
Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time
--------------- -------- -------- ---------- ------ --- --- ------ ----- - -----
80.oscbw.clust osu2376 serial h1.com 1207 1 1 64mb 16:40 R 01:05 node01
86.oscbw.clust troy serial cdnz3d 776 1 1 36mb 40:00 R 00:00 node02
93.oscbw.clust cls022 serial NAME 787 1 1 128mb 11:06 R 00:00 node04
101.oscbw.clus cls022 SMP imid1 6542 1 2 64mw 10:00 R 00:40 node01

OSC Graduate Student Workshop/Conference, August, 2000
38
qstat Output Fields• Job Id (request number)• Username (userid)• Queue (queue the job is in)• Jobname (name of the job)• SessId (job identifier)• NDS (number of nodes requested)• TSK (number of CPUs per node requested)• Req’d Memory (memory requested [if waiting] or used [if running])• Req’d Time (CPU time requested)• S (status)
– R (running)– Q (queued and waiting)
• Elap Time (time the job has been running)
• nodes the job is running on

OSC Graduate Student Workshop/Conference, August, 2000
39
Killing a Job• If, for whatever reason, you need to delete a queued job or kill a
running job, use the qdel command.
• Usage: qdel request_number

OSC Graduate Student Workshop/Conference, August, 2000
40
SMP JobsSo far, the job scripts we’ve seen have been serial, uniprocessor jobs.
The following is an example of a job that used more than one processor on a single node:
oscbw:~/Beowulf/omp> more smp.pbs
#PBS -N smp
#PBS -j oe
#PBS -S /bin/ksh
#PBS -l nodes=1:ppn=4
#PBS -l cput=0:01:00
cd $HOME/Beowulf/omp
export OMP_NUM_THREADS=4
/usr/bin/time ./matmul-omp

OSC Graduate Student Workshop/Conference, August, 2000
41
More on SMP and Serial Jobs• The only real difference between a uniprocessor job and an SMP job
(at least from PBS’s point of view) is the -l nodes=1:ppn=4 limit in the SMP job. This tells PBS to allow the job to run four processes (or threads) concurrently on one node.
• If you simply request a number of nodes (eg. -l nodes=1), PBS will assume that you want one processor per node.

OSC Graduate Student Workshop/Conference, August, 2000
42
Parallel JobsBoth serial and SMP jobs run on only 1 node. However, most MPI
programs should be run on more than 1 node. Here is an example of how to do that:
#PBS -N nblock
#PBS -j oe
#PBS -l nodes=4:ppn=4
#PBS -l cput=1:00:00
cd ~/Beowulf/mpi-c
mpiexec ./nblock

OSC Graduate Student Workshop/Conference, August, 2000
43
mpiexec Formatmpiexec [OPTION]... executable [args]...
-n numproc Use only the specified number of processes (optional)
-tv, -totalview Debug using totalview (does not work with ch_gm)
-perif Allocate only one process per myrinet interface
This flag can be used to ensure maximum communication
bandwidth available to each process
-pernode Allocate only one process per compute node. For SMP
nodes, only one processor will be allocated a job.
This flag is used to implement multiple level parallelism
with MPI between nodes, and threads within a node

OSC Graduate Student Workshop/Conference, August, 2000
44
Other Sources of Information• OSC technical information server, http://oscinfo.osc.edu
• OSC state-wide software licenses, http://oscinfo.osc.edu/software/ssd.html
• Linux Fortran web page, http://studbolt.physast.uga.edu/templon/fortran.html
• Cygnus/FSF GCC homepage, http://gcc.gnu.org
• Scientific Applications on Linux, http://SAL.KachinaTech.COM/index.shtml
• Myricom homepage, http://www.myri.com







