
Creating Knowledge out of Interlinked Data
LOD2 Presentation . 02.09.2010 . Page http://lod2.euAKSW, Universität Leipzig
Norman Heino
Browsing and Editing RDF Knowledge bases with OntoWiki and RDFauthor
OntoWiki

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
Schedule
Semantic Wikis
OntoWiki
Semantics Aware Editing with RDFauthor
Use Cases
2
Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
Semantic Wikis
3

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
Wikiwiki Concepts
Everyone can edit anything
Content is edited in the same way as structure is
Activity can be watched and reviewed by everyone
Ward Cunningham
4

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
Semantic Wikis
Two approaches:
• Text-based wiki w/ semantic layer (e.g. Semantic MediaWiki)
• Form-based RDF data wiki (e.g. OntoWiki)
5

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
Semantic MediaWiki
Semantic
store
MediaWiki DB
(MySQL)
Storage
Abstraction
Storage
Implementation
Parsing RenderingInline
QueriesSetup
Lan-
guage
Java-
Scripts
+
CSS
OWL
Export...
Datatype API
Data processing
Type:String
Type:Date
Type:Number
...
Page display and
manipulation
Special
pages
DB interface
MediaWiki
Webserver (Apache)
Semantic
MediaWiki
Setu
pLanguage
syste
m
Fig. 1. Architecture of SMW’s main components in relation to MediaWiki.
Semantic MediaWiki (SMW) is a semantically enhanced wiki engine that enablesusers to annotate the wiki’s contents with explicit, machine-readable information.Using this semantic data, SMW addresses core problems of today’s wikis:
• Consistency of content: The same information often occurs on many pages. Howcan one ensure that information in di↵erent parts of the system is consistent,especially as it can be changed in a distributed way?• Accessing knowledge: Large wikis have thousands of pages. Finding and com-
paring information from di↵erent pages is challenging and time-consuming.• Reusing knowledge: Many wikis are driven by the wish to make information
accessible to many people. But the rigid, text-based content of classical wikiscan only be used by reading pages in a browser or similar application.
SMW is free software, available as an extension of the popular wiki engine Media-Wiki. Figure 1 provides an overview of SMW’s core components which we willdiscuss in more detail throughout this paper. The integration between MediaWikiand SMW is based on MediaWiki’s extension mechanism: SMW registers for cer-tain events or requests, and MediaWiki calls SMW functions when needed. SMWthus does not overwrite any part of MediaWiki, and can be added to existing wikiswithout much migration cost. Usage information about SMW, installation instruc-tions, and the complete documentation are found at SMW’s homepage. 1
Next, Section 2 explains how structural information is collected in SMW, and howthis data relates to the OWL DL ontology language. Section 3 surveys SMW’s mainfeatures for wiki users: semantic browsing, semantic queries, and data exchangeon the Semantic Web. Queries are the most powerful way of retrieving data fromSMW, and their syntax and semantics is presented in detail. The practical use ofSMW is the topic of Section 4, where we consider existing usage patterns in (non-semantic) Wikipedia, usage statistics from a medium-sized SMW site, and typicalcurrent uses of SMW. Section 5 focusses on performance, first by discussing mea-
1 http://ontoworld.org/wiki/SMW
2
• Semantic extension to MediaWiki
• Page-centric
• Pre-configured properties
• Queryable semantic overlay graph
6

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
OntoWiki
6 Heino, Dietzold, Martin, Auer
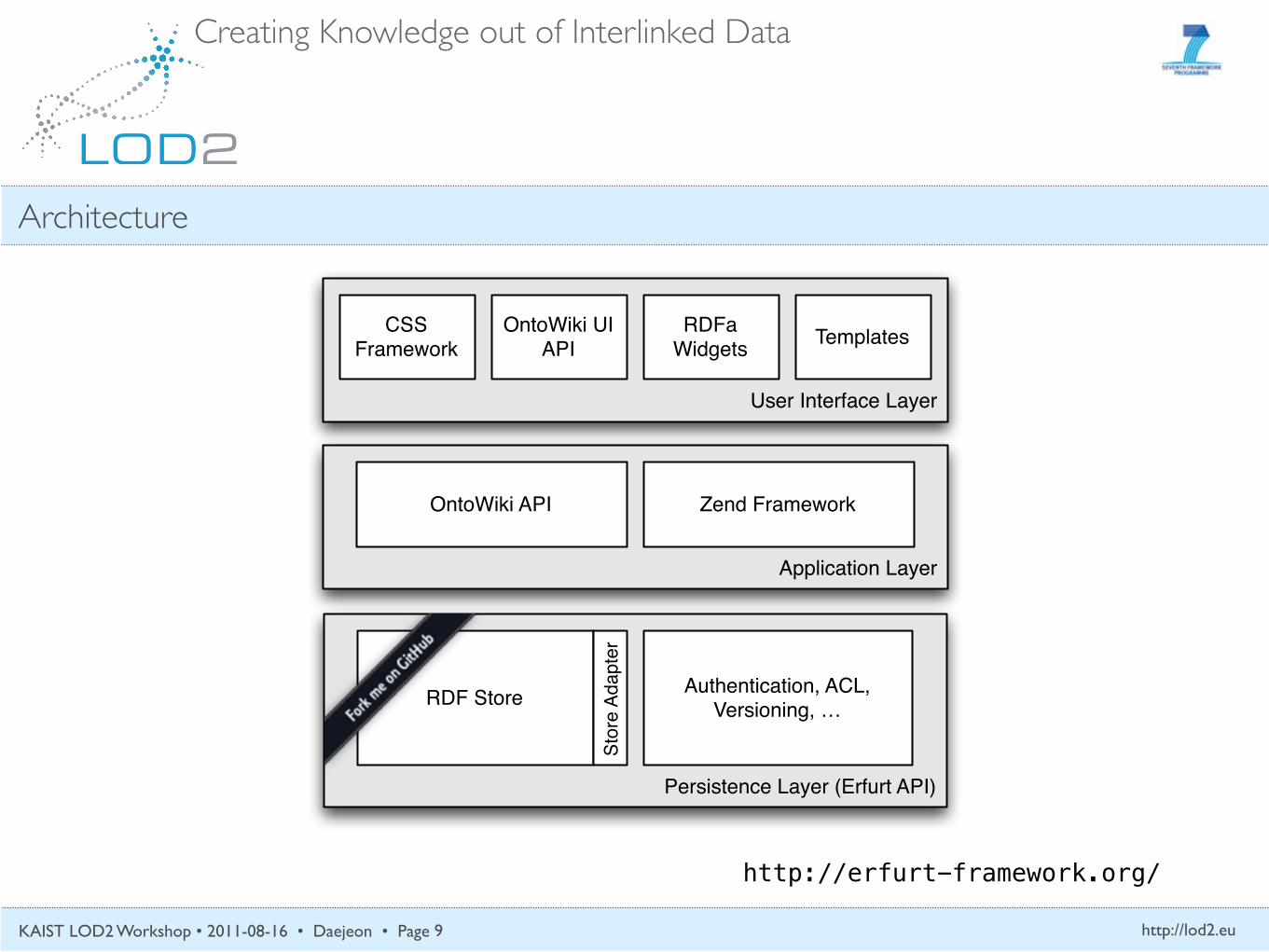
2.1 Architecture Overview
As depicted in figure 2, the OntoWiki Application Framework consists ofthree separate layers. The persistence layer consists of the Erfurt API whichprovides an interface to di↵erent RDF stores. In addition to the Erfurt API,the application layer is built by a) the underlying Zend Framework1 and b) anAPI for OntoWiki extension development. With the exception of templates,the user interface layer is primarily active on the client side, providing theCSS framework, a JavaScript UI API, RDFa widgets and HTML templatesgenerated on the Web-server side.
Application Layer
OntoWiki API Zend Framework
Persistence Layer (Erfurt API)
RDF Store
Sto
re A
da
pte
r
Authentication, ACL, Versioning, …
User Interface Layer
CSS Framework
OntoWiki UI API
RDFa Widgets
Templates
Fig. 2 The OntoWiki Application Framework with its three layers: persistence layer,application layer, user interface layer
2.2 Persistence Layer
Persistent data storage as well as associated functionality such as versioningand access control are provided by the Erfurt API. This API consists of thecomponents described in the subsequent paragraphs.
1http://framework.zend.com/
http://erfurt-framework.org/
• RDF data wiki
• Resource centric
• Generic and custom views
• Façet and set-based browsing
• Collaborative authoring
• based on Erfurt framework
7

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
OntoWiki
8
Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
Architecture
Application Layer
OntoWiki API Zend Framework
User Interface Layer
CSS Framework
OntoWiki UI API
RDFa Widgets
Templates
9
Persistence Layer (Erfurt API)
RDF Store
Sto
re A
da
pte
r
Authentication, ACL, Versioning, …
http://erfurt-framework.org/

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
Vision
Generic data wiki for RDF models
• no data model mismatch (structured vs. unstructured)
Application framework for:
• Knowledge-intensive applications
• Distributed user groups
10

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
Interfaces
SPARQL Endpoint
Linked Data Endpoint
WebDAV
REST API
Command Line Interface
LDAP
11

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
Extensibility
Plugins
Views/Templates
Themes
Localizations
12

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
Access Control
Model (graph) based
• partitioning via owl:imports
Action based (predefined)
• register new user
• reset password
13

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
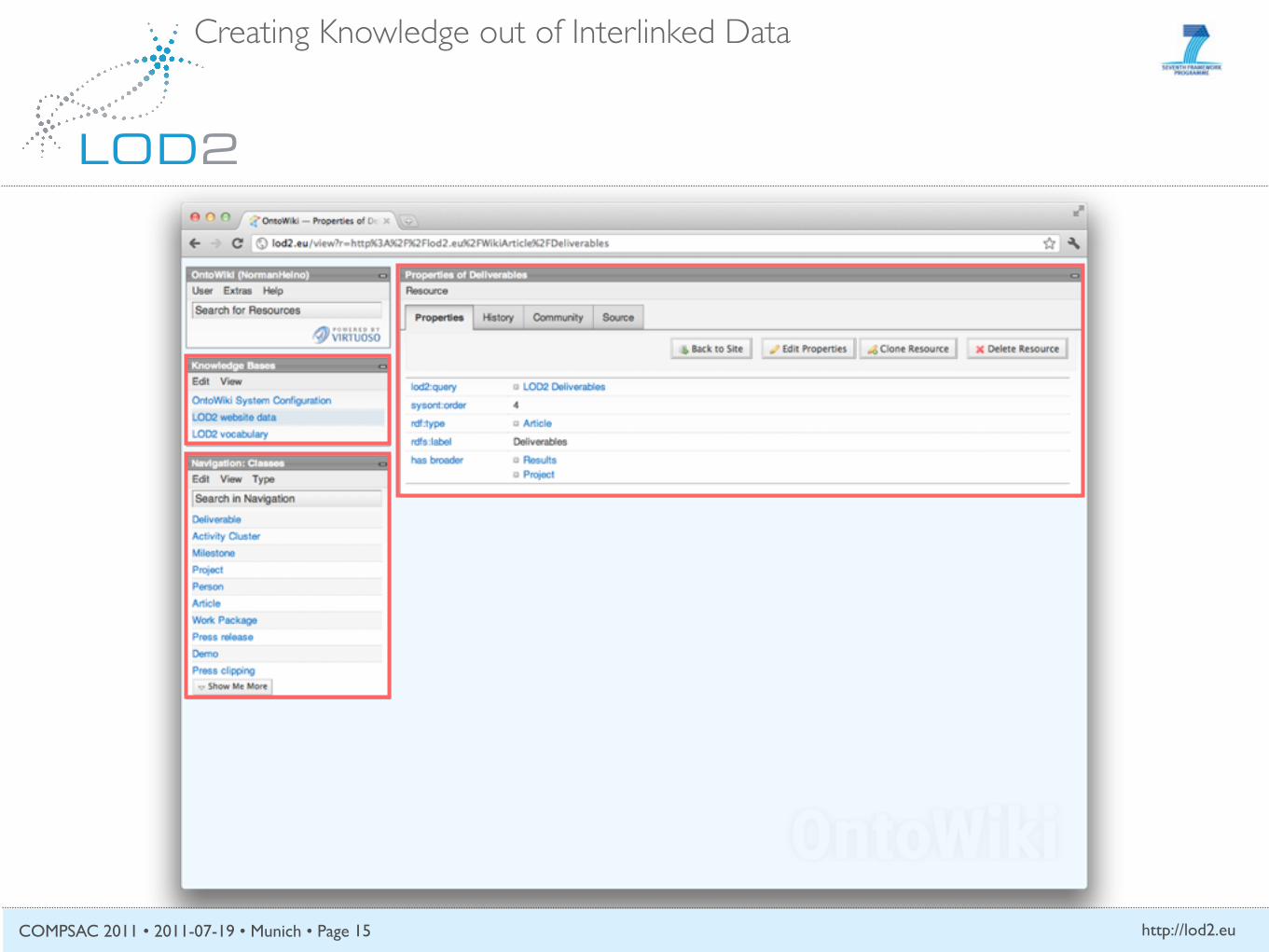
Other Features
Facet-based browsing
Inline editing
Auto-adaptive user interface
Resource auto-suggestion
SPARQL Query Editor
14
Creating Knowledge out of Interlinked Data
COMPSAC 2011 • 2011-07-19 • Munich • Page http://lod2.eu15

Creating Knowledge out of Interlinked Data
COMPSAC 2011 • 2011-07-19 • Munich • Page http://lod2.eu16

Creating Knowledge out of Interlinked Data
COMPSAC 2011 • 2011-07-19 • Munich • Page http://lod2.eu17

Creating Knowledge out of Interlinked Data
COMPSAC 2011 • 2011-07-19 • Munich • Page http://lod2.eu18

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
RDFauthor
19

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
RDFa
Images: http://www.w3.org/TR/xhtml-rdfa-primer/
Annotating XML documents with RDF
Human and machine-readable
MVC – declare view in model language
20

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
Knowledge Engineering with RDFa
XHTML+
RDFaWeb
Server+
RDF Store
Edit
SPARQL/Update
HTTP
RDFa page, updatable knowledge store
"Intelligent" editing components (widgets)
Supporting the user
21

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
Implementation
HTML Form• Widget selection/form creation
RDF Store
• Update propagation
Extracted Triples
• Client-side page processing XHTML
+RDFa
• Page creation
22

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
Use Case I
23

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
Web content and Linked Data
Same content
• readable by humans
• processable by machines
Strategy: OntoWiki as backend, custom frontent
24

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
OntoWiki Site Extension
Erfurt Framework
RDFa
RDFauthor Zend Framework(Zend_View)
Linked Data
Virtuoso RDF Store
BibSonomy
RSS/Atom
Blog Posts Twitter
Site Vocabulary(foaf, doap)
Instance Data
Taxonomy(skos)
expressed in expressed in
consumes
uses
exposes
imports
syndicates
updates
exposed as
exposed as
uses
is built upon
SPARQL Software component
Exchange format/practice
External service
Represented knowledge
Figure 1. OntoWiki-CMS overall architecture and building blocks.
narios. It makes no assumptions on the data model and canthus be used with any RDF knowledge base. For managingWeb content, we developed a core ontology (see Section IV),a skos-based taxonomy for navigation and populated bothwith instance data representing the Web site content andmetadata. OntoWiki provides a configureable navigationhierarchy that can be used to display skos hierarchies. Inaddition, it has search capabilities and leverages resourceinterlinks in order to provide different paths for browsingknowledge bases. Being a wiki, it also fosters versioningof changes to a resource, discussion and editing, which aredescribed below.
The OntoWiki backend automatically creates pages anno-tated with RDFa. For editing content, these builtin semanticannotations are leveraged to automatically create an editingform. The system in use here has been made availableseparately as RDFauthor [9]. To this end, it incorporatesseveral technologies:
• semantics-aware widgets that support the user whileediting content by automatically suggesting resourcesto link to based on queries to the local knowledge storeand Sindice2.
• Updates are sent back the the RDF store via SPAR-QL/Update – an update extension to the current speci-fication currently in standardization.Extensibility: OntoWiki started as an RDF-based data
wiki with emphasis on collaboration but has meanwhileevolved into a comprehensive framework for developingSemantic Web applications [1]. This involved not only thedevelopment of a sophisticated extension interface allowingfor a wide range of customizations but also the additionof several access and consumption interfaces allowing On-
2http://sindice.com/
toWiki installations to play both a provider and a consumerrole in the emerging Web of Data.
Evolution: The loosely typed data model of RDF en-courages continuous evolution and refinement of knowledgebases. With EvoPat, OntoWiki supports this in a declarative,pattern-based manner [10]. Such basic evolution patternsconsist of three components: a set of variables, a SPARQLselect query selecting a number of resources under evolution,and a SPARQL/Update query template that is executed foreach resulting resource of the select query. In addition, basicpatterns can be combined to form compound patterns –suitable for more complex evolution scenarios.
C. Access Interfaces
In addition to human-targeted graphical user interfaces,OntoWiki supports a number of machine-accessible datainterfaces. These are based on established Semantic Webstandards like SPARQL or accepted best practices likepublication and consumption of Linked Data.
Worth mentioning are a SPARQL Endpoint, allowing allresources managed in an OntoWiki be queried over the Web,a Linked Data interface for publishing resources accordingto accepted publication principles3, as well as SemanticPingback [11] which adapts the pingpack idea to LinkedData providing a notification mechanism for resource usage.
D. Exploration Interfaces
For exploring semantic content, OntoWiki provides sev-eral exploration interfaces that are appropriate for a widerange of use cases. For instance, it offers generic views,domain-specific browsing interfaces, facet-based browsingand graphical query builders in addition to full-text and
3http://sites.wiwiss.fu-berlin.de/suhl/bizer/pub/LinkedDataTutorial/
Architecture of the approach
25

Load and render
template
Load CBD, interpret
properties
Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
Linked Data request
Forwardapplication/rdf+xml, text/turtle, …
Export RDF
http://lod2.eu/Welcome.rdf
Forward and rewrite
internal links
text/html
http://lod2.eu/Welcome.htmlAccept?
404
yes
no
∃ URI?Request
http://lod2.eu/Welcome
26

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
Use Case II
27

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
Orchestra-tion
Service
Virtuoso FOX
CMS
Wrapper
push (content) annotations (RDF) – async
text
annotations
OntoWiki injection
crawlednews
optional
Extraction and Storage Layer
Wrapper Layer
Orchestration and Curation Layer
push (curation changes)
28

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
a scms:Request
a sioc:Item
xsd:string
xsd:string
xsd:string
scms:document
dc:title
dc:description
content:encoded
scms:annotate
scms:annotate
a rdf:Resource
scms:callbackEndpoint
29

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
Text
broadly used vocabularies Annotea20 and Autotag 21. In particular, we addedthe following constructs:
– scms:beginIndex denotes the index in a literal value string at which a par-ticular annotation or keyphrase begins;
– scms:endIndex stands for the index in a literal value string at which aparticular annotation or keyphrase ends;
– scms:means marks the URI assigned to a named entity identified for anannotation;
– scms:tool provides the URI of tool that found the annotation and– scmsann is the namespace for the annotation classes, i.e, location, person,
organization and miscellaneous.
Thanks to the multi-core architecture of current servers, FOX is almost asfast as the slowest tool in its pipeline and thus as time-e⇥cient as state-of-the-arttools, given that the overhead due to the merging of the results via the neuralnetwork is of only a few milliseconds. Still, as our evaluation shows, these fewmilliseconds overhead can lead to an increase of more than 13% F-Score (seeSection 6). The output of FOX for our example is shown in Listing 3. This isthe output that is forwarded to the orchestration service, which adds provenanceinformation to the RDF before sending an answer to the callback URI providedby the wrapper. By these means, we ensure that the wrapper can write the RDFain the write segment of the item content.
a ann:Annot
ation
a rdf:Resour
ce
xsd:string
scms:means
ann:body
xsd:integer
xsd:integer
scms:beginIndex
scms:endIndex
a rdf:Resour
cescms:tool
(a) named entity annotation
a ctag:AutoT
ag
a rdf:Resour
ce
ctag:means
xsd:string
ctag:label
a rdf:Resour
cescms:tool
anyProp
(b) keyword annotation
Fig. 5. Vocabularies used by FOX for representing named entities (a) and keywords(b)
20 http://www.w3.org/2000/10/annotation-ns#21 http://commontag.org/ns#
30

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu31

Creating Knowledge out of Interlinked Data
KAIST LOD2 Workshop • 2011-08-16 • Daejeon • Page http://lod2.eu
resulting reference data contained 20 location, 78 organization and 11 persontokens. Note that both data sets are of very di�erent nature as the first containsa large number of organizations and a relatively small number of locations whilethe second consists mainly of locations. In both cases, the annotation was carriedout independently from the automatic extraction of named entities.
The results of our evaluation are shown in Table 1. CS follows a very con-servative strategy, which leads to it having very high precision scores of up to100% in some experiments. Yet, its conservative strategy leads to a recall whichis mostly significantly inferior to that of SCMS. The only category within whichCS outperforms SCMS is the detection of persons in the actors profile data.This is due to it detecting 6 out of the 11 person tokens in the data set, whileSCMS only detected 5. In all other cases, SCMS outperforms CS by up to 13%F-score (detection of organizations in the country profiles data set). Overall,SCMS outperform CS by 7% F-score on country profiles and almost 8% F-scoreon actors.
Country Profiles Actors Profiles
Entity Type Measure FOX CS FOX CS
Location Precision 98% 100% 83.33% 100%Recall 94.23% 78.85% 90% 70%F-Score 96.08% 88.17% 86.54% 82.35%
Organization Precision 73.33% 100% 57.14% 90.91%Recall 68.75% 40% 69.23% 47.44%F-Score 70.97% 57.14% 62.72% 62.35%
Person Precision – – 100% 100%Recall – – 45.45% 54.55%F-Score – – 62.5% 70.59%
Overall Precision 93.97% 100% 85.16% 98.2%Recall 91.60% 74.79% 70.64% 52.29%F-Score 92.77% 85.58% 77.22% 68.24%
Table 1. Evaluation results on country and actors profiles. The superior F-score foreach category is in bold font.
7 Conclusion
In this paper, we presented the SCMS framework for extracting structured datafrom CMS content. We presented the architecture of our approach and explainedhow each of its components work. In addition, we explained the vocabulariesutilized by the components of our framework. The flexibility of our approach isensured by the combination of RDF messages that can be easily extended and
32


![[MBF2] Webinar API Crédit Agricole Store #1](https://cdn.vdocuments.mx/doc/165x107/55a64dca1a28abf6028b4857/mbf2-webinar-api-credit-agricole-store-1.jpg)




