
Financial Time SeriesCassandra 1.2
Jake Luciani and Carl YeksigianBlueMountain Capital

Know your problem.
1000s of consumers..creating and reading data as fast as possible..consistent to all readers..and handle ad-hoc user queries..quickly..across datacenters.

Know your data.AAPL price
MSFT price

Know your queries.Time Series Query
start (10am)
end (2pm)
1 minute periods
Start, End, Periodicity defines query
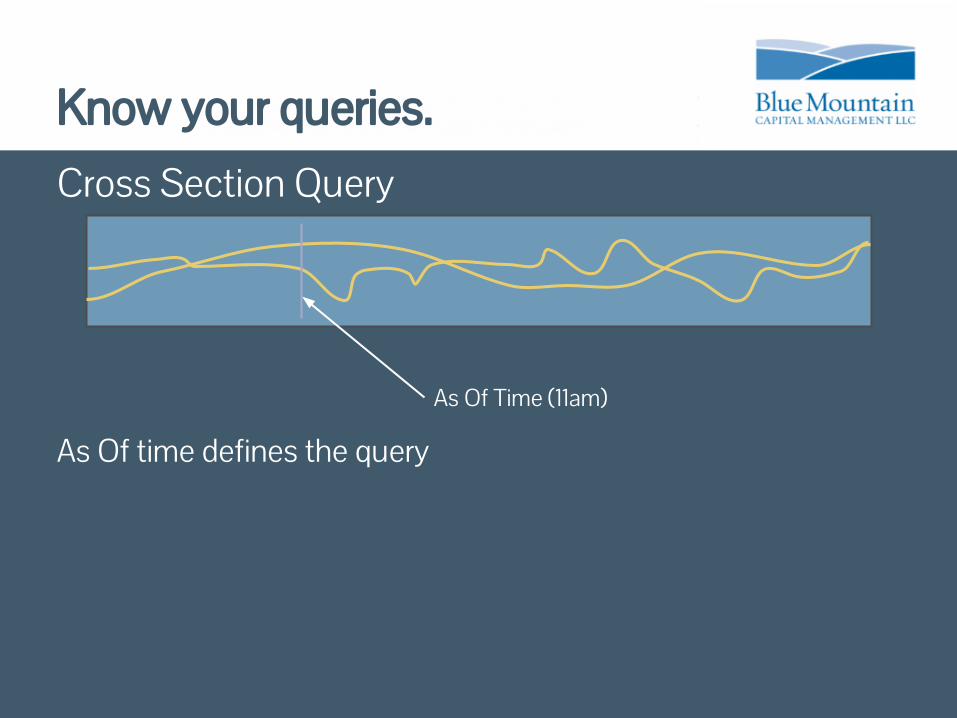
Know your queries.Cross Section Query
As Of time defines the query
As Of Time (11am)

Know your queries.
● Cross sections are for random data● Storing for Cross Sections means thousands of
writes, inconsistent queries● We also need bitemporality, but it's hard, so let's
ignore it in the query

Know your users.
A million, billion writes per second..and reads are fast and happen at the same time..and we can answer everything consistently..and it scales to new use cases quickly..and it's all done yesterday

Since we can't optimize for everything.
Let's optimize for Time Series.

Data Model (in C* 1.1)
AAPL lastPrice:2013-03-18:2013-03-19 0E-34-88-FF-26-E3-2C
lastPrice:2013-03-19:2012-03-19
lastPrice:2013-03-19:2013-03-20
0E-34-88-FF-26-E3-3D
0E-34-88-FF-26-E3-4E

But we're using C* 1.2.CQL3
V-nodesJBOD
Pooled Decompression buffers
SSD Aware
Parallel CompactionOff-Heap Bloom Filters
Metrics!Concurrent Schema Creation

CREATE TABLE tsdata (id blob,property string,asof_ticks bigint,knowledge_ticks bigint,value blob,PRIMARY KEY(id,property,asof_ticks,knowledge_ticks)
)WITH COMPACT STORAGEAND CLUSTERING ORDER BY(asof_ticks DESC, knowledge_ticks DESC)
Data Model (CQL 3)

SELECT * FROM tsdataWHERE id = 0x12345AND property = 'lastPrice'AND asof_ticks >= 1234567890AND asof_ticks <= 2345678901
CQL3 Queries: Time Series

CQL3 Queries: Cross Section
SELECT * FROM tsdataWHERE id = 0x12345AND property = 'lastPrice'AND asof_ticks = 1234567890AND knowledge_ticks < 2345678901LIMIT 1

Data Overload!
All points between start and endEven though we have a periodicity
All knowledge timesEven though we only want latest

A Service, not an app
C*
Olympus
Olympus
Olym
pusOly
mpu
s
Olympus
Olympus Olympus
OlympusApp
App
App
App
App
App
App
App
App
App

Filtration
Filter everything by knowledge time
Filter time series by periodicity
200k points filtered down to 300
ServiceFilter
AAPL:lastPrice:2013-03-18:2013-03-19AAPL:lastPrice:2013-03-19:2013-03-19AAPL:lastPrice:2013-03-19:2013-03-20AAPL:lastPrice:2013-03-20:2013-03-20AAPL:lastPrice:2013-03-20:2013-03-21
AAPL:lastPrice:2013-03-18:2013-03-19AAPL:lastPrice:2013-03-19:2013-03-20AAPL:lastPrice:2013-03-20:2013-03-21Cassandra Reads

Pushdown Filters
● To provide periodicity on raw data, downsample on write
● There are still cases where we don't know how to sample
● This filtering should be pushed to C*● The coordinator node should apply a filter to the
result set

Complex Value Types
Not every value is a doubleSome values belong togetherBid and Ask should come back together

Thrift
Thrift structures as valuesTyped, extensible schemaUnion types give us a way to deserialize any type
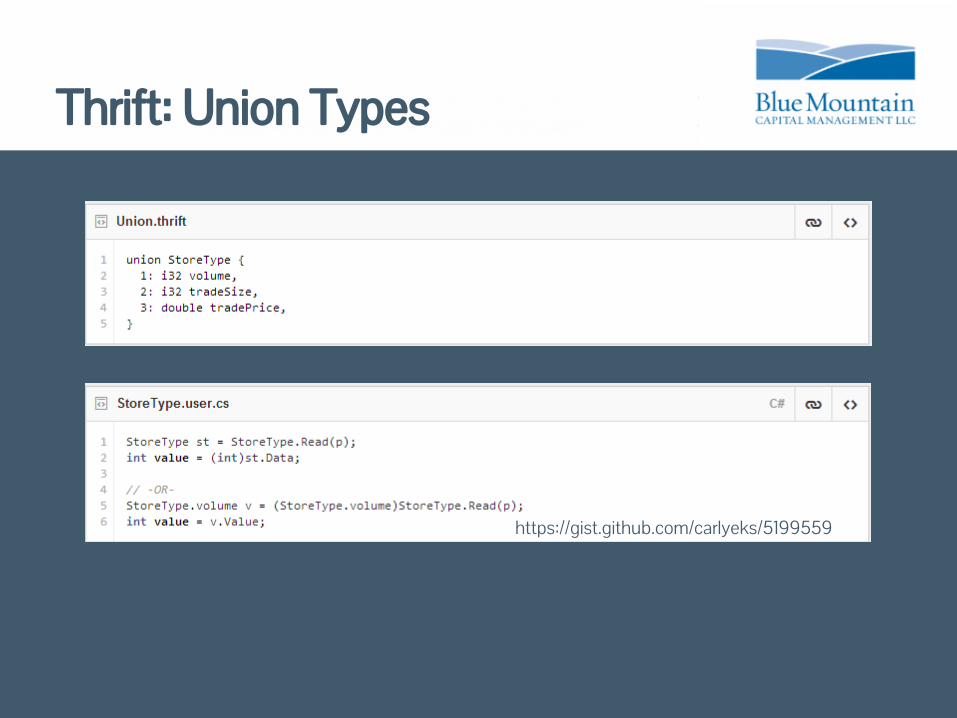
Thrift: Union Types
https://gist.github.com/carlyeks/5199559

But that's the easy part...

Scaling...
The first rule of scaling is you do not just turn eveything to 11.

Scaling...
Step 1 - Fast Machines for your workloadStep 2 - Avoid Java GC for your workloadStep 3 - Tune Cassandra for your workloadStep 4 - Prefetch and cache for your workload

Can't fix what you can't measure
Riemann (http://riemann.io)Easily push application and system metrics into a single systemWe push 4k metrics per second to a single Riemann instance

Metrics: Riemann
Yammer Metrics with Riemann
https://gist.github.com/carlyeks/5199090

Metrics: Riemann
Push stream based metrics libraryRiemann Dash for Why is it Slow?
Graphite for Why was itSlow?

VisualVM-The greatest tool EVER
Many useful plugins...Just start jstatd on each server and go!

Scaling Reads: Machines
SSDs for hot dataJBOD configAs many cores as possible (> 16)10GbE networkBonded network cardsJumbo frames

JBOD is a lifesaver
SSDs are great until they aren't anymore
JBOD allowed passive recovery in the face of simultaneous disk failures (SSDs had a bad firmware)

Scaling Reads: JVM
-Xmx12G-Xmn1600M-XX:SurvivorRatio=16-XX:+UseCompressedOops
-XX:+UseTLAB yields ~15% Boost!(Thread local allocators, good for SEDA architectures)
JVM
Magic!

Scaling Reads: Cassandra
Changes we've made:● Configuration● Compaction● Compression● Pushdown Filters

Scaling Cassandra: Configuration
Hinted HandoffHHO single threaded, 100kb throttle

Scaling Cassandra: Configuration
memtable size2048mb, instead of 1/3 heap
We're using a 12gb heap; leaves enough room for memtables while the majority is left for reads and compaction.

Scaling Cassandra: Configuration
Half-Sync Half-Async serverNo thread dedicated to an idle connectionWe have a lot of idle connections

Scaling Cassandra: Configuration
Multithreaded compaction, 4 coresMore threads to compact means fastToo many threads means resource contention

Scaling Cassandra: Configuration
Disabled internode compressionCaused too much GC and Latency
On a 10GbE network, who needs compression?

Leveled Compaction
Wide rows means data can be spread across a huge number of SSTablesLeveled Compaction puts a bound on the worst case (*)Fewer SSTables to read means lower latency, as shown below; orange SSTables get read
L0
L1
L2
L3
L4
L5
* In Theory

Leveled CompactionBreaking Bad
L0
L1
L2
L3
L4
L5
Under high write load, forced to read all of the L0 files

Hybrid CompactionBreaking Better
L0
L1
L2
L3
L4
L5
{HybridCompaction
Size Tiered
Leveled
Size Tiering Level 0

Better Compression:New LZ4Compressor
LZ4 Compression is 40% faster than Google's Snappy...
LZ4 JNI
Snappy JNI
LZ4 Sun Unsafe
Blocks in Cassandra are so small we don't see the same in production but the 95% latency is improved and it works with Java 7

CRC Check Chance
CRC check of each compressed block causes reads to be 2x SLOWER.Lowered crc_check_chance to 10% of reads.
A move to JNI would cause a 30x boost

Current Stats
● 12 nodes● 2 DataCenters● RF=6● 150k Writes/sec at EACH_QUORUM● 100k Reads/sec at LOCAL_QUORUM● > 6 Billion points (without replication)● 2TB on disk (compressed) ● Read Latency 50%/95% is 1ms/10ms

Questions?
Thank you!
@tjake and @carlyeks







