
MaxEnt POS TaggingShallow Processing Techniques for NLP
Ling570November 21, 2011

RoadmapMaxEnt POS Tagging
Features
Beam Searchvs Viterbi
Named Entity Tagging

MaxEnt Feature TemplateWords:
Current word: w0
Previous word: w-1
Word two back: w-2
Next word: w+1
Next next word: w+2
Tags:Previous tag: t-1
Previous tag pair: t-2t-1
How many features? 5|V|+|T|+|T|2

Representing Orthographic Patterns
How can we represent morphological patterns as features?Character sequences
Which sequences? Prefixes/suffixes e.g. suffix(wi)=ing or prefix(wi)=well
Specific characters or character typesWhich?
is-capitalized is-hyphenated

MaxEnt Feature Set

Examples
well-heeled: rare word

Examples
well-heeled: rare wordJJ prevW=about:1 prev2W=stories:1 nextW=communities:1 next2W=and:1 pref=w:1 pref=we:1 pref=wel:1 pref=well:1 suff=d:1 suff=ed:1 suff=led:1 suff=eled:1 is-hyphenated:1 preT=IN:1 pre2T=NNS-IN:1

Finding FeaturesIn training, where do features come from?
Where do features come from in testing?
w-1 w0 w-1w0 w+1 t-1 y
x1(Time)
<s> Time <s>Time flies BOS N
x2 (flies)
Time flies Time flies like N N
x3 (like)
flies like flies like an N V

Finding FeaturesIn training, where do features come from?
Where do features come from in testing?tag features come from classification of prior word
w-1 w0 w-1w0 w+1 t-1 y
x1(Time)
<s> Time <s>Time flies BOS N
x2 (flies)
Time flies Time flies like N N
x3 (like)
flies like flies like an N V

Sequence Labeling

Sequence LabelingGoal: Find most probable labeling of a sequence
Many sequence labeling tasksPOS taggingWord segmentationNamed entity taggingStory/spoken sentence segmentationPitch accent detectionDialog act tagging

Solving Sequence Labeling

Solving Sequence Labeling
Direct: Use a sequence labeling algorithmE.g. HMM, CRF, MEMM

Solving Sequence Labeling
Direct: Use a sequence labeling algorithmE.g. HMM, CRF, MEMM
Via classification: Use classification algorithm Issue: What about tag features?

Solving Sequence Labeling
Direct: Use a sequence labeling algorithmE.g. HMM, CRF, MEMM
Via classification: Use classification algorithm Issue: What about tag features?
Features that use class labels – depend on classification
Solutions:

Solving Sequence Labeling
Direct: Use a sequence labeling algorithmE.g. HMM, CRF, MEMM
Via classification: Use classification algorithm Issue: What about tag features?
Features that use class labels – depend on classification
Solutions:Don’t use features that depend on class labels (loses
info)

Solving Sequence Labeling
Direct: Use a sequence labeling algorithmE.g. HMM, CRF, MEMM
Via classification: Use classification algorithm Issue: What about tag features?
Features that use class labels – depend on classification
Solutions:Don’t use features that depend on class labels (loses
info)Use other process to generate class labels, then use

Solving Sequence Labeling
Direct: Use a sequence labeling algorithmE.g. HMM, CRF, MEMM
Via classification: Use classification algorithm Issue: What about tag features?
Features that use class labels – depend on classificationSolutions:
Don’t use features that depend on class labels (loses info)Use other process to generate class labels, then usePerform incremental classification to get labels, use labels
as features for instances later in sequence
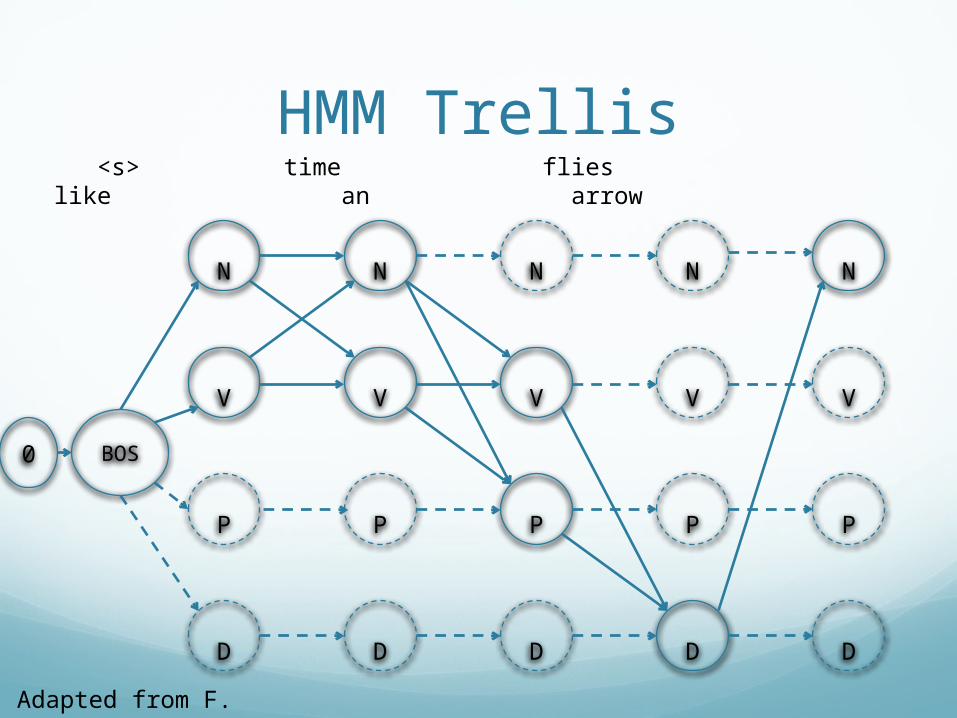
HMM Trellis
D
P
V
N
D
P
V
N
D
P
V
N
D
P
V
N
D
P
V
N
BOS
<s> time flies like an arrow
Adapted from F. Xia
0

ViterbiInitialization:
Recursion:
Termination:
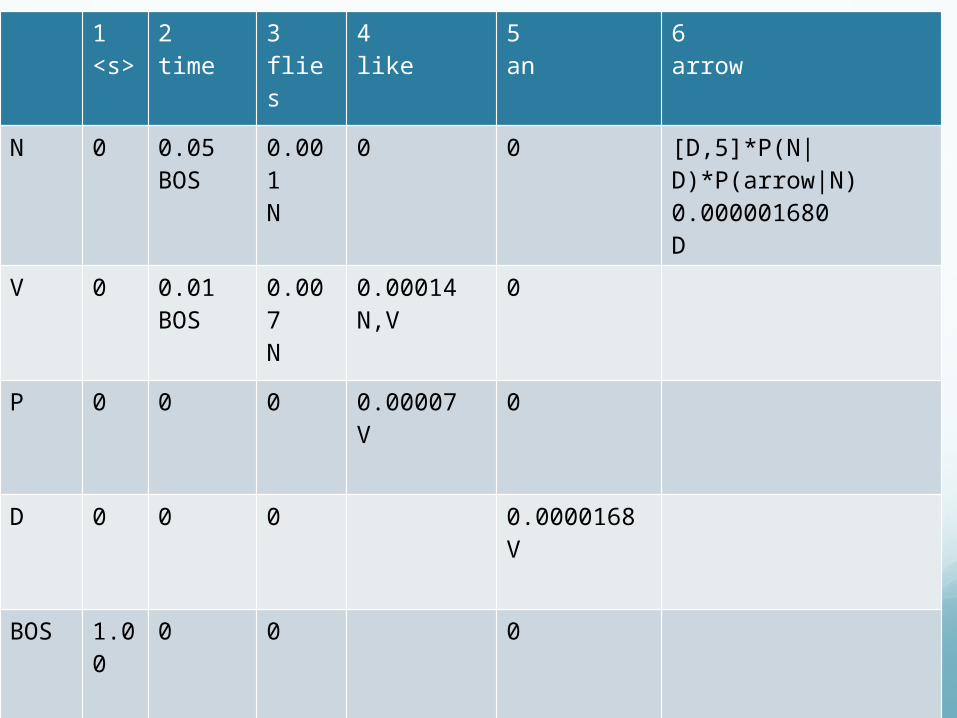
1<s>
2time
3flies
4like
5an
6arrow
N 0 0.05BOS
0.001N
0 0 [D,5]*P(N|D)*P(arrow|N)0.000001680D
V 0 0.01BOS
0.007N
0.00014N,V
0
P 0 0 0 0.00007V
0
D 0 0 0 0.0000168V
BOS 1.00
0 0 0

DecodingGoal: Identify highest probability tag sequence

DecodingGoal: Identify highest probability tag sequence
Issues:Features include tags from previous words
Not immediately available

DecodingGoal: Identify highest probability tag sequence
Issues:Features include tags from previous words
Not immediately available
Uses tag historyJust knowing highest probability preceding tag
insufficient

DecodingApproach: Retain multiple candidate tag
sequencesEssentially search through tagging choices

DecodingApproach: Retain multiple candidate tag
sequencesEssentially search through tagging choices
Which sequences?

DecodingApproach: Retain multiple candidate tag
sequencesEssentially search through tagging choices
Which sequences?All sequences?

DecodingApproach: Retain multiple candidate tag
sequencesEssentially search through tagging choices
Which sequences?All sequences?
No. Why not?

DecodingApproach: Retain multiple candidate tag
sequencesEssentially search through tagging choices
Which sequences?All sequences?
No. Why not? How many sequences?

DecodingApproach: Retain multiple candidate tag
sequencesEssentially search through tagging choices
Which sequences?All sequences?
No. Why not? How many sequences?
Branching factor: N (# tags); Depth: T (# words)NT

DecodingApproach: Retain multiple candidate tag
sequencesEssentially search through tagging choices
Which sequences?All sequences?
No. Why not? How many sequences?
Branching factor: N (# tags); Depth: T (# words)NT
Top K highest probability sequences

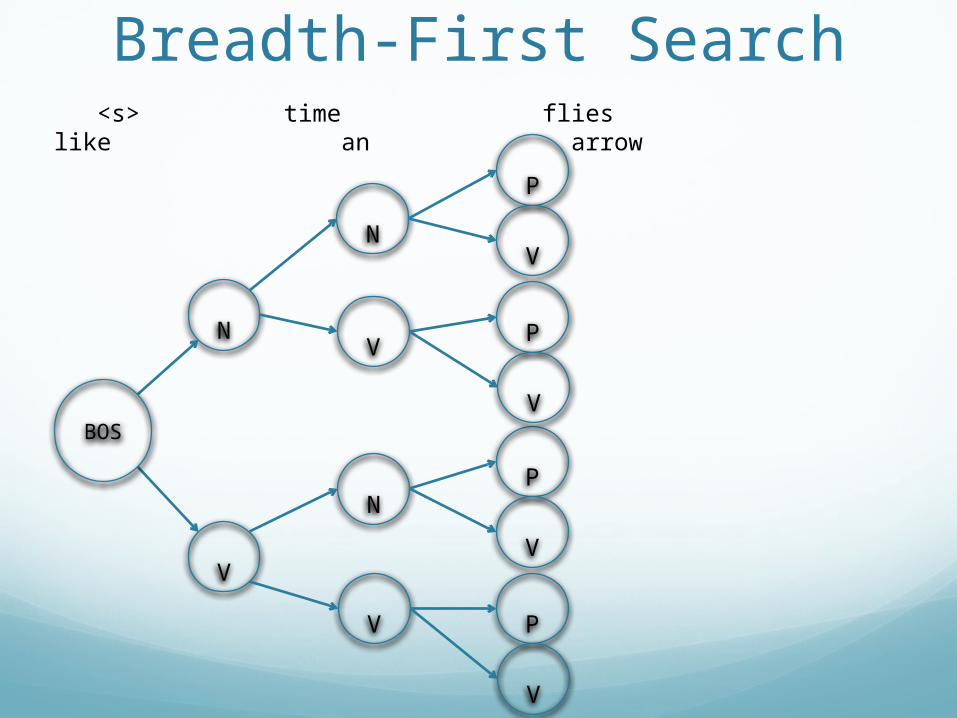
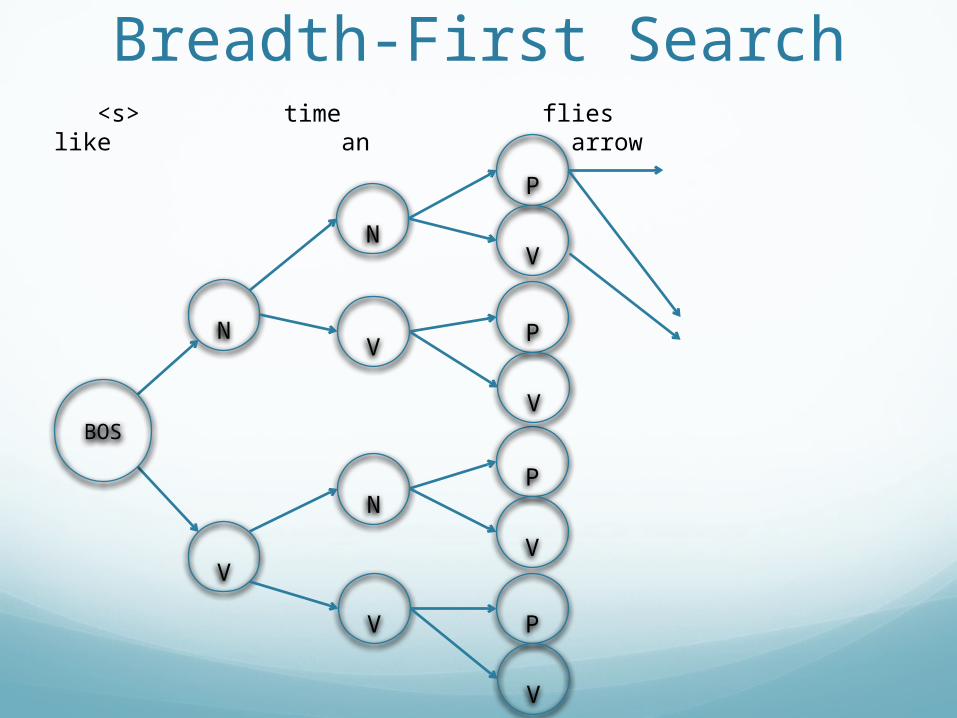
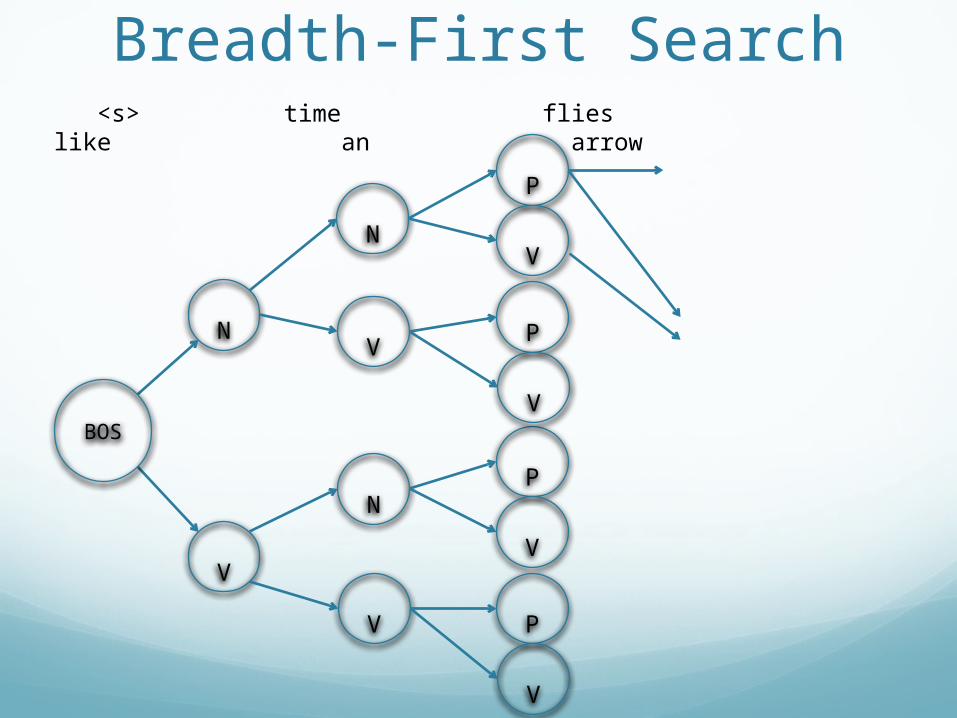
Breadth-First Search <s> time flies like an arrow
BOS
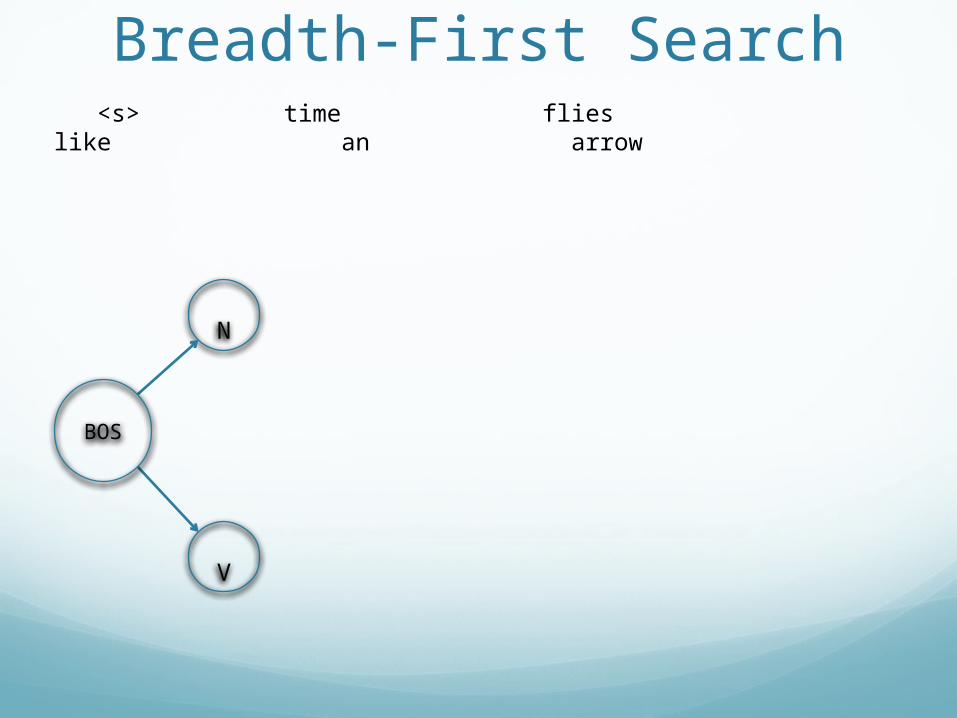
Breadth-First Search
V
N
<s> time flies like an arrow
BOS
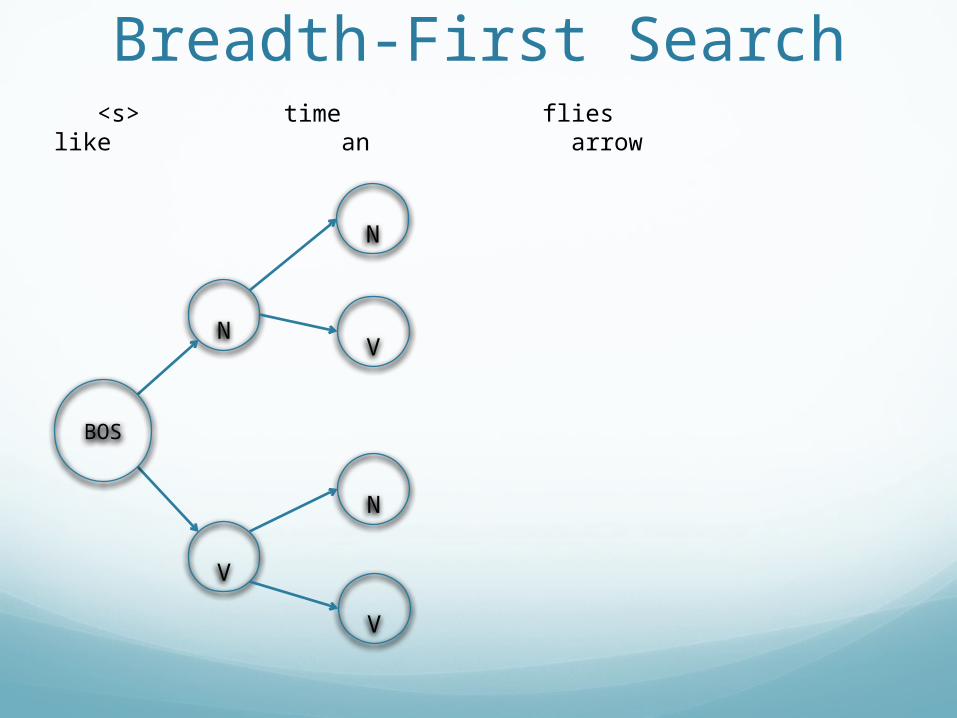
Breadth-First Search
V
N
<s> time flies like an arrow
BOS
N
V
N
V
Breadth-First Search
V
N
<s> time flies like an arrow
BOS
N
V
N
V
P
V
P
V
P
V
P
V
Breadth-First Search
V
N
<s> time flies like an arrow
BOS
N
V
N
V
P
V
P
V
P
V
P
V
Breadth-First Search
V
N
<s> time flies like an arrow
BOS
N
V
N
V
P
V
P
V
P
V
P
V

Breadth-first SearchIs breadth-first search efficient?

Breadth-first SearchIs it efficient?
No, it tries everything

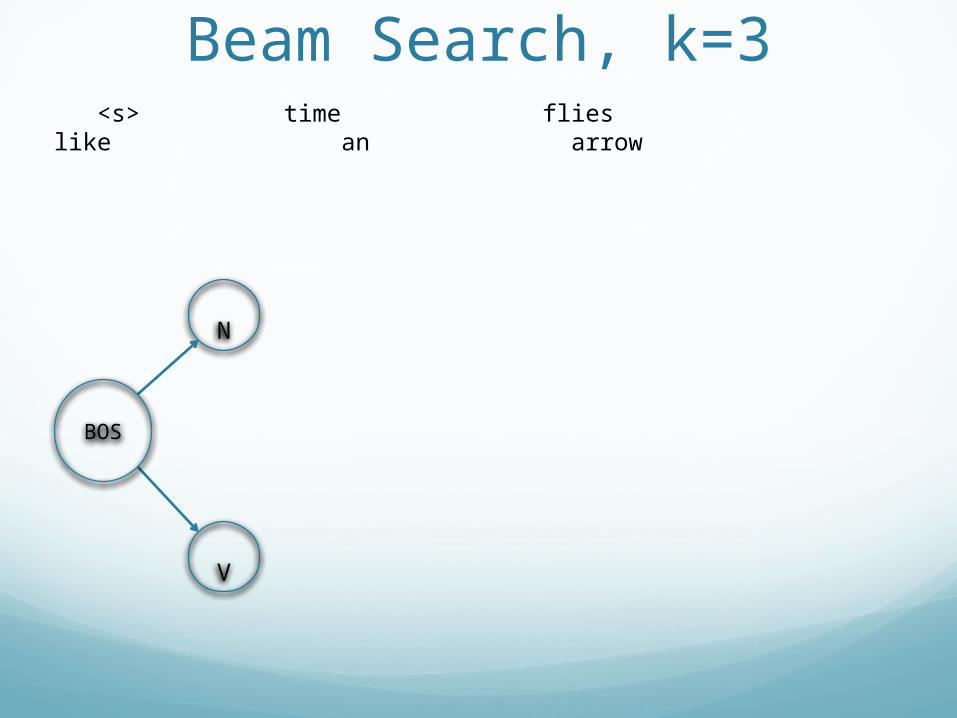
Beam SearchIntuition:
Breadth-first search explores all paths

Beam SearchIntuition:
Breadth-first search explores all pathsLots of paths are (pretty obviously) badWhy explore bad paths?

Beam SearchIntuition:
Breadth-first search explores all pathsLots of paths are (pretty obviously) badWhy explore bad paths?Restrict to (apparently best) paths
Approach:Perform breadth-first search, but

Beam SearchIntuition:
Breadth-first search explores all pathsLots of paths are (pretty obviously) badWhy explore bad paths?Restrict to (apparently best) paths
Approach:Perform breadth-first search, butRetain only k ‘best’ paths thus fark: beam width

Beam Search, k=3 <s> time flies like an arrow
BOS
Beam Search, k=3
V
N
<s> time flies like an arrow
BOS
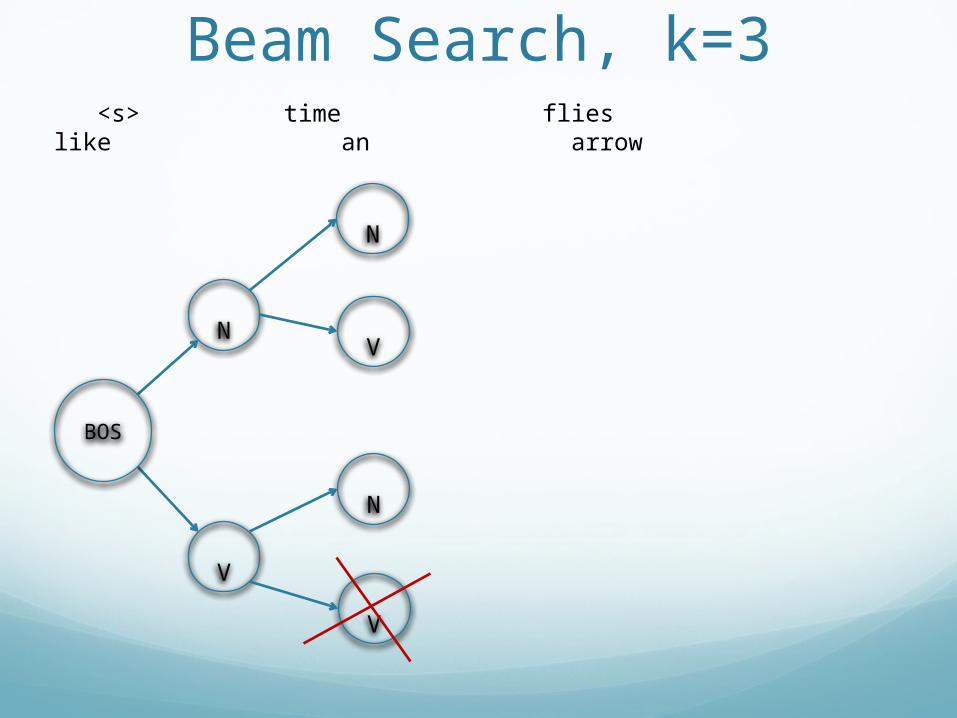
Beam Search, k=3
V
N
<s> time flies like an arrow
BOS
N
V
N
V
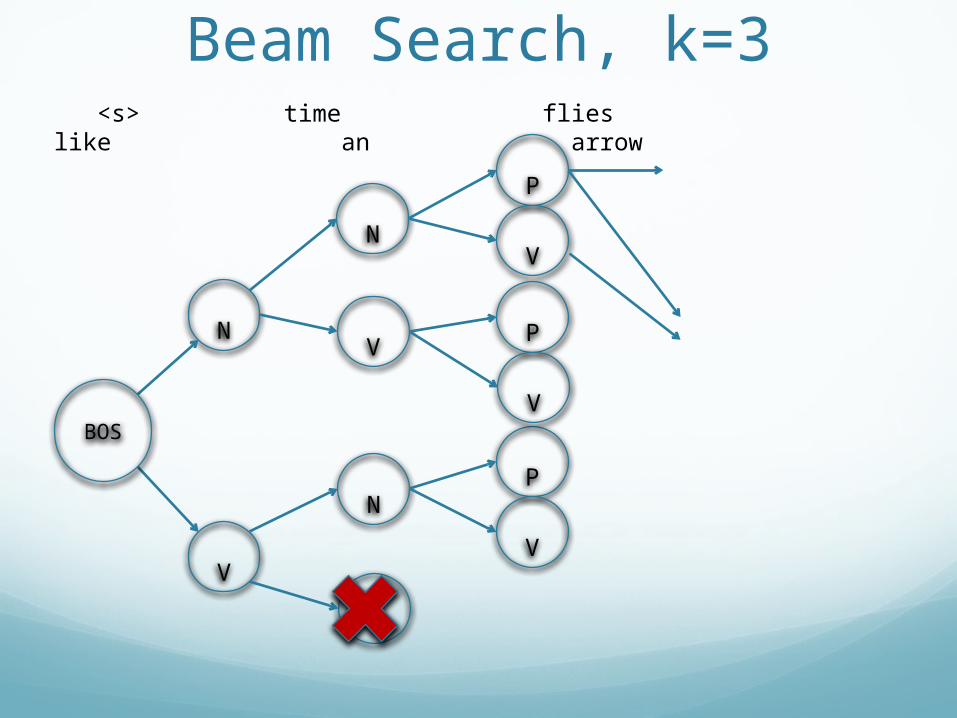
Beam Search, k=3
V
N
<s> time flies like an arrow
BOS
N
V
N
V
P
V
P
V
P
V
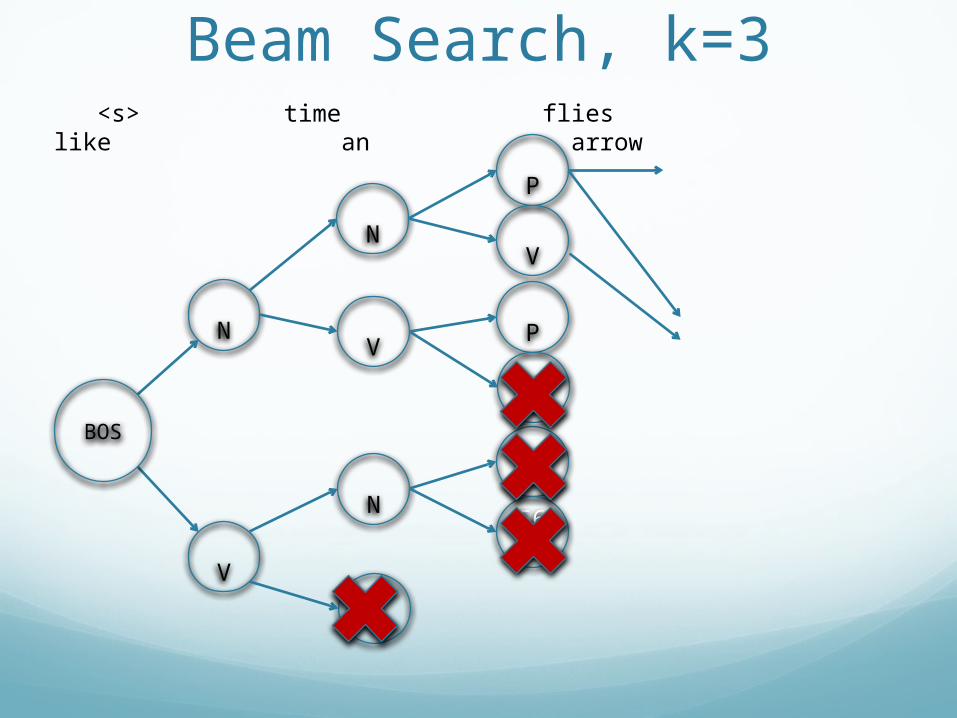
Beam Search, k=3
V
N
<s> time flies like an arrow
BOS
N
V
N
V
P
56V
P
V
P
V

Beam SearchW={w1,w2,…,wn}: test sentence

Beam SearchW={w1,w2,…,wn}: test sentence
sij: jth highest prob. sequence up to & inc. word wi

Beam SearchW={w1,w2,…,wn}: test sentence
sij: jth highest prob. sequence up to & inc. word wi
Generate tags for w1, keep top k, set s1j accordingly

Beam SearchW={w1,w2,…,wn}: test sentence
sij: jth highest prob. sequence up to & inc. word wi
Generate tags for w1, keep top k, set s1j accordingly
for i=2 to n:

Beam SearchW={w1,w2,…,wn}: test sentence
sij: jth highest prob. sequence up to & inc. word wi
Generate tags for w1, keep top k, set s1j accordingly
for i=2 to n:Extension: add tags for wi to each s(i-1)j

Beam SearchW={w1,w2,…,wn}: test sentence
sij: jth highest prob. sequence up to & inc. word wi
Generate tags for w1, keep top k, set s1j accordingly
for i=2 to n:Extension: add tags for wi to each s(i-1)j
Beam selection: Sort sequences by probabilityKeep only top k sequences

Beam SearchW={w1,w2,…,wn}: test sentence
sij: jth highest prob. sequence up to & inc. word wi
Generate tags for w1, keep top k, set s1j accordingly
for i=2 to n:Extension: add tags for wi to each s(i-1)j
Beam selection: Sort sequences by probabilityKeep only top k sequences
Return highest probability sequence sn1

POS TaggingOverall accuracy: 96.3+%
Unseen word accuracy: 86.2%
Comparable to HMM tagging accuracy or TBL
ProvidesProbabilistic frameworkBetter able to model different info sources
Topline accuracy 96-97%Consistency issues

Beam SearchBeam search decoding:
Variant of breadth first searchAt each layer, keep only top k sequences
Advantages:

Beam SearchBeam search decoding:
Variant of breadth first searchAt each layer, keep only top k sequences
Advantages:Efficient in practice: beam 3-5 near optimal
Empirically, beam 5-10% of search space; prunes 90-95%

Beam SearchBeam search decoding:
Variant of breadth first searchAt each layer, keep only top k sequences
Advantages:Efficient in practice: beam 3-5 near optimal
Empirically, beam 5-10% of search space; prunes 90-95%
Simple to implementJust extensions + sorting, no dynamic programming

Beam SearchBeam search decoding:
Variant of breadth first searchAt each layer, keep only top k sequences
Advantages:Efficient in practice: beam 3-5 near optimal
Empirically, beam 5-10% of search space; prunes 90-95%
Simple to implementJust extensions + sorting, no dynamic programming
Running time:

Beam SearchBeam search decoding:
Variant of breadth first searchAt each layer, keep only top k sequences
Advantages:Efficient in practice: beam 3-5 near optimal
Empirically, beam 5-10% of search space; prunes 90-95%Simple to implement
Just extensions + sorting, no dynamic programmingRunning time: O(kT) [vs. O(NT)]
Disadvantage: Not guaranteed optimal (or complete)

Viterbi DecodingViterbi search:
Exploits dynamic programming, memoizationRequires small history window
Efficient search: O(N2T)
Advantage:

Viterbi DecodingViterbi search:
Exploits dynamic programming, memoizationRequires small history window
Efficient search: O(N2T)
Advantage:Exact: optimal solution is returned
Disadvantage:

Viterbi DecodingViterbi search:
Exploits dynamic programming, memoizationRequires small history window
Efficient search: O(N2T)
Advantage:Exact: optimal solution is returned
Disadvantage:Limited window of context

Beam vs ViterbiDynamic programming vs heuristic search

Beam vs ViterbiDynamic programming vs heuristic search
Guaranteed optimal vs no guarantee

Beam vs ViterbiDynamic programming vs heuristic search
Guaranteed optimal vs no guarantee
Different context window

MaxEnt POS TaggingPart of speech tagging by classification:
Feature designword and tag context featuresorthographic features for rare words

MaxEnt POS TaggingPart of speech tagging by classification:
Feature designword and tag context featuresorthographic features for rare words
Sequence classification problems:Tag features depend on prior classification

MaxEnt POS TaggingPart of speech tagging by classification:
Feature designword and tag context featuresorthographic features for rare words
Sequence classification problems:Tag features depend on prior classification
Beam search decodingEfficient, but inexact
Near optimal in practice

Named Entity Recognition

RoadmapNamed Entity Recognition
Definition
Motivation
Challenges
Common Approach

Named Entity RecognitionTask: Identify Named Entities in (typically)
unstructured text
Typical entities:Person namesLocationsOrganizationsDatesTimes

ExampleMicrosoft released Windows Vista in 2007.

ExampleMicrosoft released Windows Vista in 2007.
<ORG>Microsoft</ORG> released <PRODUCT>Windows Vista</PRODUCT> in <YEAR>2007</YEAR>

ExampleMicrosoft released Windows Vista in 2007.
<ORG>Microsoft</ORG> released <PRODUCT>Windows Vista</PRODUCT> in <YEAR>2007</YEAR>
Entities:Often application/domain specific
Business intelligence:

ExampleMicrosoft released Windows Vista in 2007.
<ORG>Microsoft</ORG> released <PRODUCT>Windows Vista</PRODUCT> in <YEAR>2007</YEAR>
Entities:Often application/domain specific
Business intelligence: products, companies, featuresBiomedical:

ExampleMicrosoft released Windows Vista in 2007.
<ORG>Microsoft</ORG> released <PRODUCT>Windows Vista</PRODUCT> in <YEAR>2007</YEAR>
Entities:Often application/domain specific
Business intelligence: products, companies, featuresBiomedical: Genes, proteins, diseases, drugs, …

Why NER?Machine translation:

Why NER?Machine translation:
Person

Why NER?Machine translation:
Person names typically not translatedPossibly transliteratedWaldheim
Number:

Why NER?Machine translation:
Person names typically not translatedPossibly transliteratedWaldheim
Number: 9/11: Date vs ratio911: Emergency phone number, simple number

Why NER?Information extraction:
MUC task: Joint ventures/mergersFocus on

Why NER?Information extraction:
MUC task: Joint ventures/mergersFocus on Company names, Person Names (CEO),
valuations

Why NER?Information extraction:
MUC task: Joint ventures/mergersFocus on Company names, Person Names (CEO),
valuations
Information retrieval:Named entities focus of retrieval In some data sets, 60+% queries target Nes

Why NER?Information extraction:
MUC task: Joint ventures/mergersFocus on Company names, Person Names (CEO),
valuations
Information retrieval:Named entities focus of retrieval In some data sets, 60+% queries target NEs
Text-to-speech:

Why NER? Information extraction:
MUC task: Joint ventures/mergersFocus on Company names, Person Names (CEO),
valuations
Information retrieval: Named entities focus of retrieval In some data sets, 60+% queries target NEs
Text-to-speech: 206-616-5728
Phone numbers (vs other digit strings) , differ by language

ChallengesAmbiguity
Washington chose

ChallengesAmbiguity
Washington choseD.C., State, George, etc
Most digit strings

ChallengesAmbiguity
Washington choseD.C., State, George, etc
Most digit strings
cat: (95 results)

ChallengesAmbiguity
Washington choseD.C., State, George, etc
Most digit strings
cat: (95 results)CAT(erpillar) stock tickerComputerized Axial TomographyChloramphenicol Acetyl Transferasesmall furry mammal

EvaluationPrecision
Recall
F-measure

ResourcesOnline:
Name listsBaby name, who’s who, newswire services
Gazetteersetc
ToolsLingpipeOpenNLPStanford NLP toolkit







