
Lecture 4:Gene Annotation& Gene Ontology
June 11, 2015

Gene lists in a manuscript
• Official gene ID, symbol and name• Fold-change• Additional annotation
– Role in cell, protein domain, predicted function, ect

p38MAPK-dependent factors are expressed in the TME of breast cancer (BC) lesions.
Elise Alspach et al. Cancer Discovery 2014;4:716-729

Gene lists from RNAseq analysis
What do you do with a list of 100s of genes that contain only the following information?• Gene name or symbol• Ratio between groups (UP or DOWN)• One or more database IDs (accession numbers)
How do you figure out the role of the genes in the model you are studying?

Sequence databases
Genbank EMBL-EBI
GenPep trEMBL
Joe/Jill lab geek
Hans/Heidi lab geek
automatic translation
error correction & limited annotation
RefSeq UniprotKB/ trEMBL
Expert annotation from literature
Gene DB UniprotKB/SwissProt
Removal of seqs >90% identical
NCBI NR
DNA sequence
DNA sequence
Proteins
ENSEMBL

Most common database IDs
• Refseq records (NCBI)– NM_ (mRNA) & NP_ (proteins), ~61 million records
• ENSEMBL records (EBI)– ENSG (gene), ENST (transcript), ENSP (proteins)
• Gene database (NCBI or Entrez)– Gene DB IDs are all digits, ranging in length from 2->10 – Started with human genes, ~11 million records
• Uniprot database (EMBL-EBI, SIB and PIR)– Q####, P####, ect; – Focused on high-quality annotations of proteins~550,000 out of ~50 million proteins in TrEMBL

Identifying the genes
• For most downstream analyses, you will want to use a database ID rather than gene symbols
• Why?– Database IDs (Gene, Refseq, Uniprot) more stable– Less likely to be misinterpreted – Same gene symbol used in more than one organism
• Which database ID?– NCBI Gene DB (or Entrez Gene ID)– Uniprot (only proteins)– Refseq (redundancy from transcript isoforms)– ENSEMBL, less commonly used

Converting database IDs
bioDBnet (db2db) http://biodbnet.abcc.ncifcrf.gov/All types of gene products
EBI BioMart (Tools -> id conversion)http://www.biomart.org/Biased towards protein-coding
DAVID bioinformatics (Gene ID conversion)http://david.abcc.ncifcrf.gov/Biased towards protein-coding

Types of genes
• RNAseq not biased towards protein-coding genes, so you will get data from non-coding RNA, pseudo-genes and others.
• Can obtain data from bioDBnet and use Excel to categorize your list by type of gene product

Gene annotation
Process of assigning descriptions to a transcript or gene product. Includes:
– Official gene symbol & name– Protein features: domains, functional elements such as
nuclear localization signals– Predicted molecular function, biological process and
cellular location– Experimentally derived information function, process
and cellular location– References– ....

Who does the gene annotation?
• Refseq & Gene databases– NCBI staff
• Ensemble databases – http://useast.ensembl.org– EMBL & Welcome Trust at Sanger Institute
• Uniprot– Staff at European Bioinformatics Institute (EBI), Swiss
Institute of Bioinformatics (SIB) and the Protein Information Resource (PIR)
• Yeast DB, FlyBase, Mouse Genome Informatics (MGI) & other organism specific databases

Gene record for BEST1

Ensembl Gene record for BEST1

Uniprot record for BEST1

Gene, Ensembl or Uniprot?
• What information are you looking for?• Comfort level with the interface• All have a little to LOTS of information• Use as a starting point

Dealing with gene lists
• How can you efficiently categorize the genes in in some biologically meaningful way?
• Batch download data from Gene or Uniprot and do a lot of reading?
• PubMed?
• One approach is to use meta-data in the form of terms assigned to each gene that describe its molecular function, participation in a biological process and its location in a cellular component

Gene Ontology
• Set of standard biological phrases (terms) which are applied to genes/proteins:– protein kinase– apoptosis– Membrane
• Attempt to standardize the representation of genes and gene product attributes across species and databases
• Maintained by Gene Ontology consortium – http://geneontology.org/– Individual groups contribute taxonomic specific terms
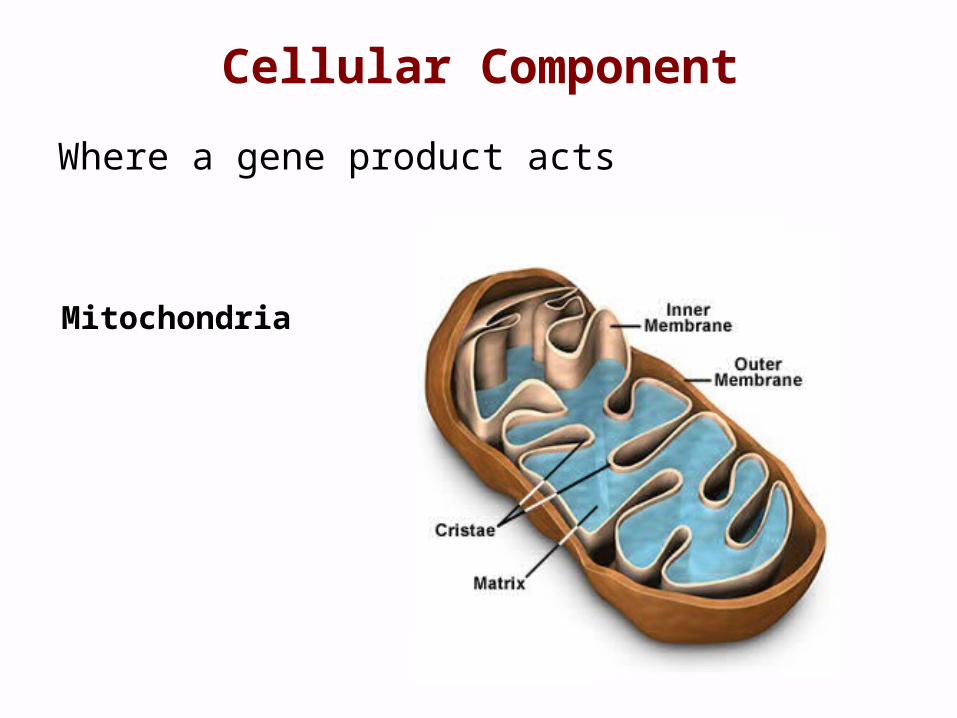
Cellular Component
Where a gene product acts
Mitochondria
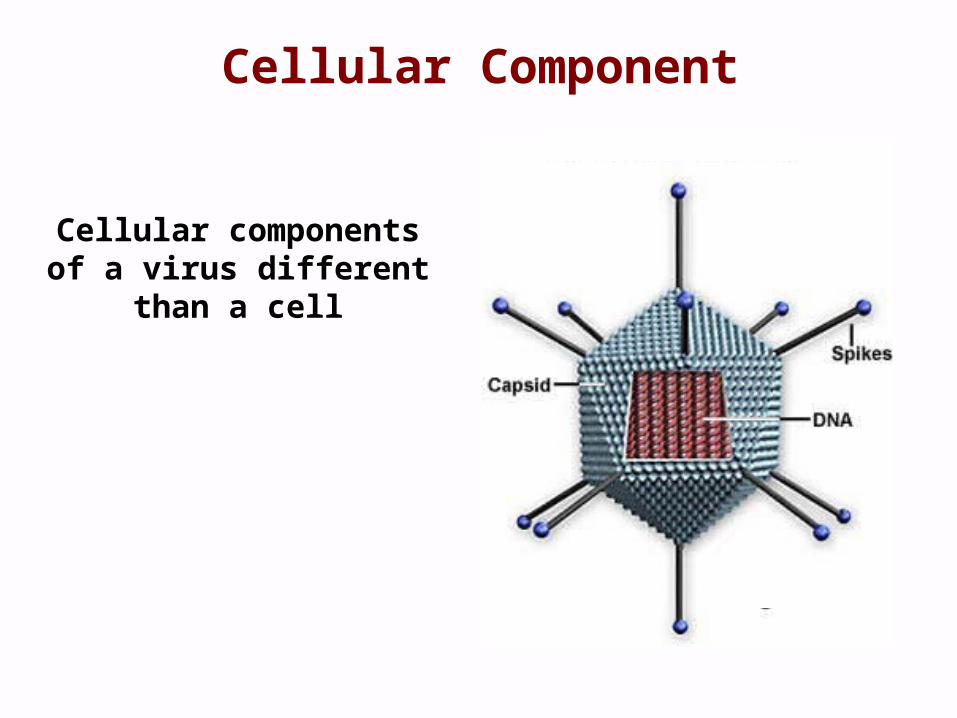
Cellular Component
Cellular components of a virus different than a cell

Cellular Component
Enzyme complexes in the component ontology refer to places, not activities.

Molecular Function
Activities or “jobs” of a gene product
glucose-6-phosphate isomerase activity
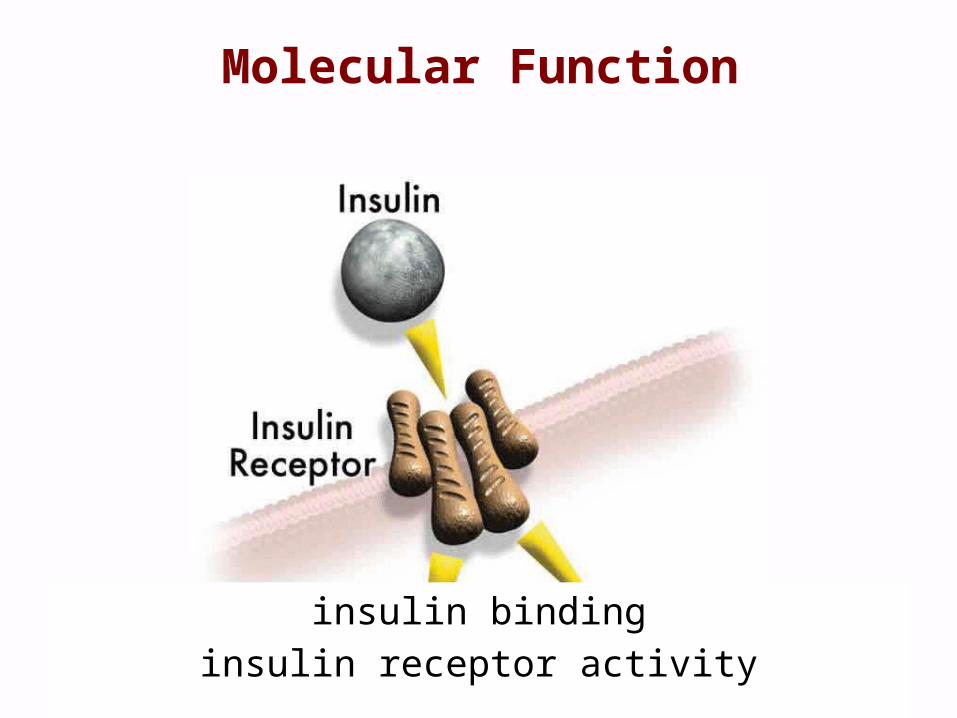
Molecular Function
insulin bindinginsulin receptor activity

Molecular Function
• A gene product may have several functions• Sets of functions make up a biological process.

Biological Process
a commonly recognized series of events
cell division
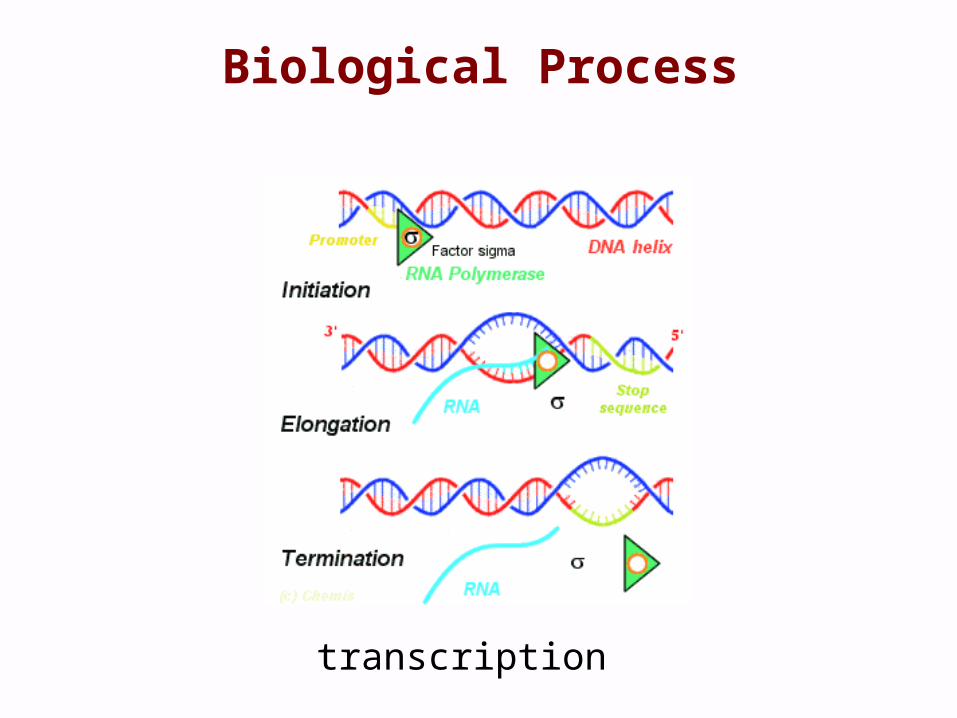
Biological Process
transcription

Biological Process
regulation of gluconeogenesis
Biological Process
limb development

Biological Process
courtship behavior

Why use gene ontology?
• Allows biologists to make queries across large numbers of genes without researching each one individually
• Can find all the PI3 kinases in a given genome or find all proteins involved in oxidative stress response without prior knowledge of every gene

From the Ex 2 gene list• BEST1
– Bestrophin 1– What is its role in the cell?
• Gene ontology biological process:– Chloride transmembrane transport– Regulation calcium ion transport– Visual perception
• GO molecular function:– Chloride channel activity
• GO cellular component– Basolateral plasma membrane– Chloride channel complex

CCL23 from Ex2 list
• Chemokine (C-C motif) ligand 23• Function:
– chemokine receptor binding• Processes include:
– G-protein coupled receptor signaling– Cellular calcium homeostasis– Monocyte chemotaxis
• Component:– Extracellular space


• Generally biological process terms are more useful for putting gene lists into a context
• There are more GO terms assigned to process than to function or component
• Fewest terms assigned to component• Function in the absence of any process
information can imply a biological role– i.e. you are looking for transcription factors responsible
for some response

Ontology Structure
• Terms are linked by two relationships– is-a – part-of
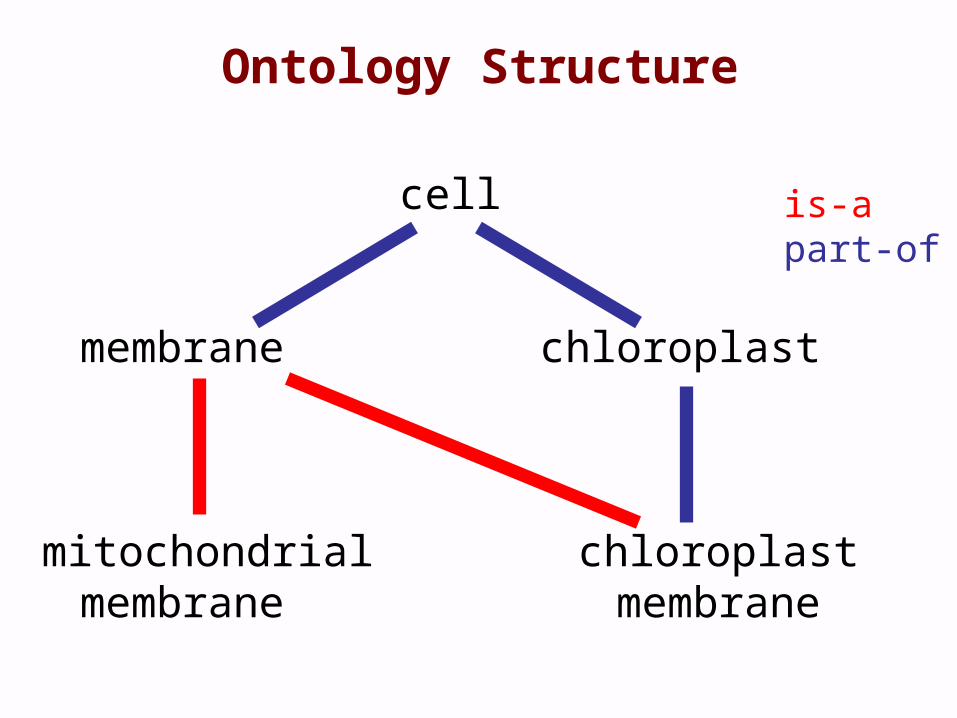
Ontology Structure
cell
membrane chloroplast
mitochondrial chloroplastmembrane membrane
is-apart-of
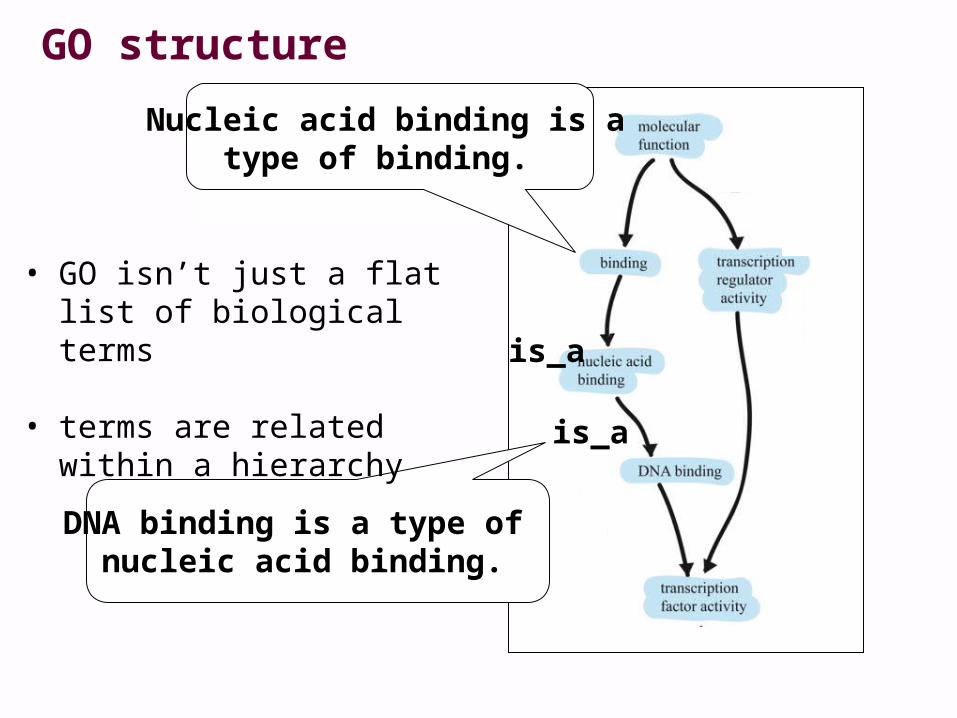
is_a
is_a
DNA binding is a type of nucleic acid binding.
GO structure
• GO isn’t just a flat list of biological terms
• terms are related within a hierarchy
Nucleic acid binding is atype of binding.
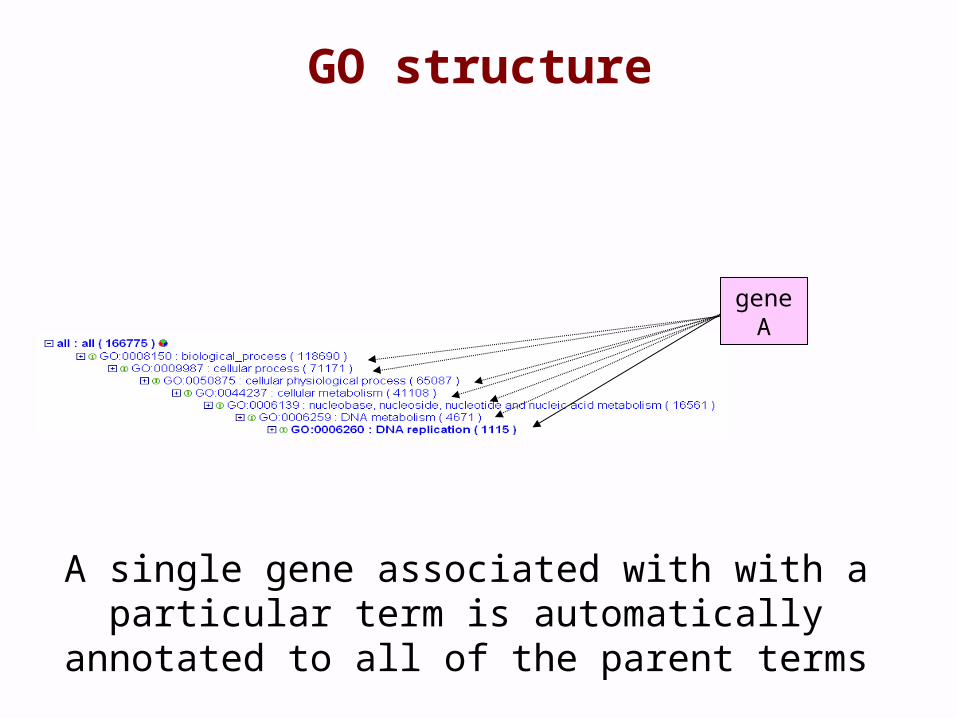
GO structure
gene A
A single gene associated with with a particular term is automatically annotated to all of the parent terms

GO structure
• This means genes can be grouped according to user-defined levels
• Allows broad overview of gene set or genome
• You can use the level of granularity that makes most sense

GO terms
• a name
term: transcription initiation
definition: Processes involved in the assembly of the RNA polymerase complex at the promoter region of a DNA template resulting in the subsequent synthesis of RNA from that promoter.
• a definition
id: GO:0006352
• an ID number
Eachconcept has:

GO terms assigned to BEST1

Types of evidence codes
Experimental:

Computational:
Types of evidence codes

Other evidence codes
Types of evidence codes

Manual annotation
In this study, we report the isolation and molecular characterization of the B. napus PERK1 cDNA, that is predicted to encode a novel receptor-like kinase. We have shown that like other plant RLKs, the kinase domain of PERK1 has serine/threonine kinase activity, In addition, the location of a PERK1-GTP fusion protein to the plasma membrane supports the prediction that PERK1 is an integral membrane protein…these kinases have been implicated in early stages of wound response…
Molecular function
Cellular componentBiological process
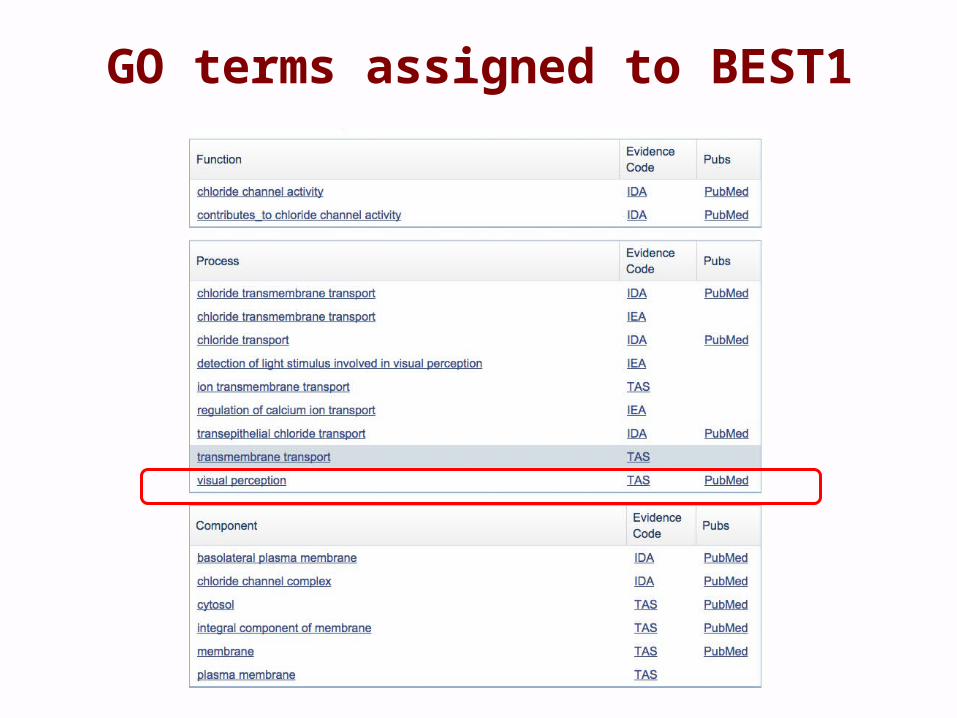
GO terms assigned to BEST1
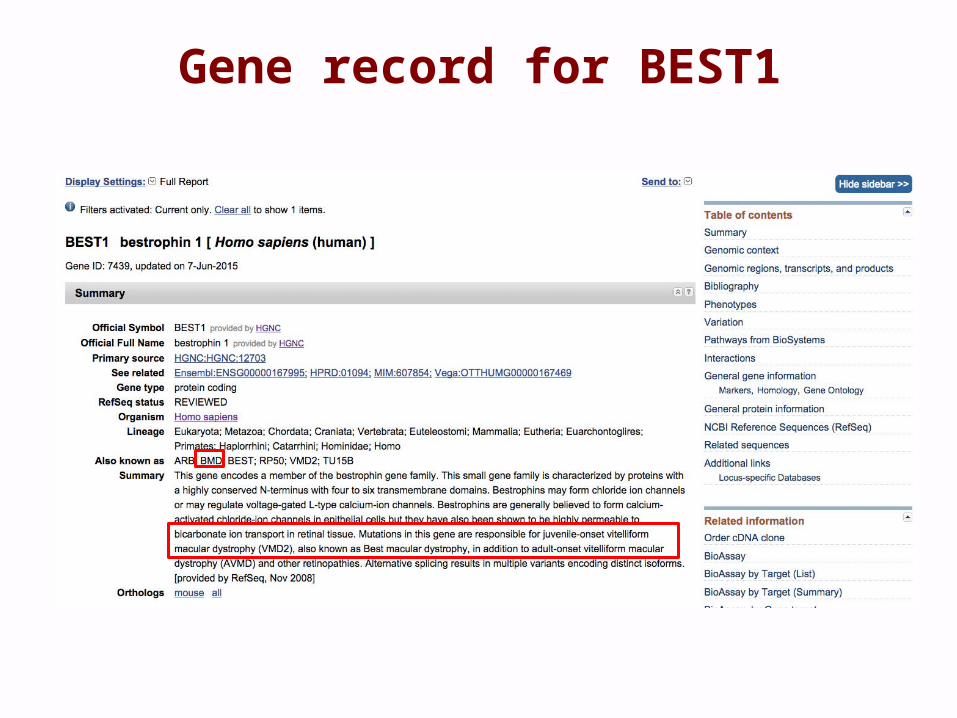
Gene record for BEST1

Electronic Annotation• Annotation derived without human validation
– mappings file e.g. interpro2go, ec2go.– Blast search ‘hits’
• Lower ‘quality’ than manual codes • Used in non-model organisms

GO & analysis of gene lists
• Many tools exist that use GO to find common biological functions from a list of genes
• WebGestalt, gProfiler, Onto-Express, and GSEA to name a few
• Partek Genomics Suite has built-in GO enrichment• We’ll use PGS and either the web-based
WebGestalt or gProfiler as a comparison

GO tools
• input a gene list • shows which GO categories have most genes
associated with them or are “enriched” • provides a statistical measure to determine
whether enrichment is significant

Using GO in practice
• statistical measure – how likely your differentially regulated genes fall into
that category by chance
microarray
1000 genes experiment100 genes differentially regulated
mitosis – 80/100apoptosis – 40/100Cell proliferation – 30/100glucose transport – 20/100
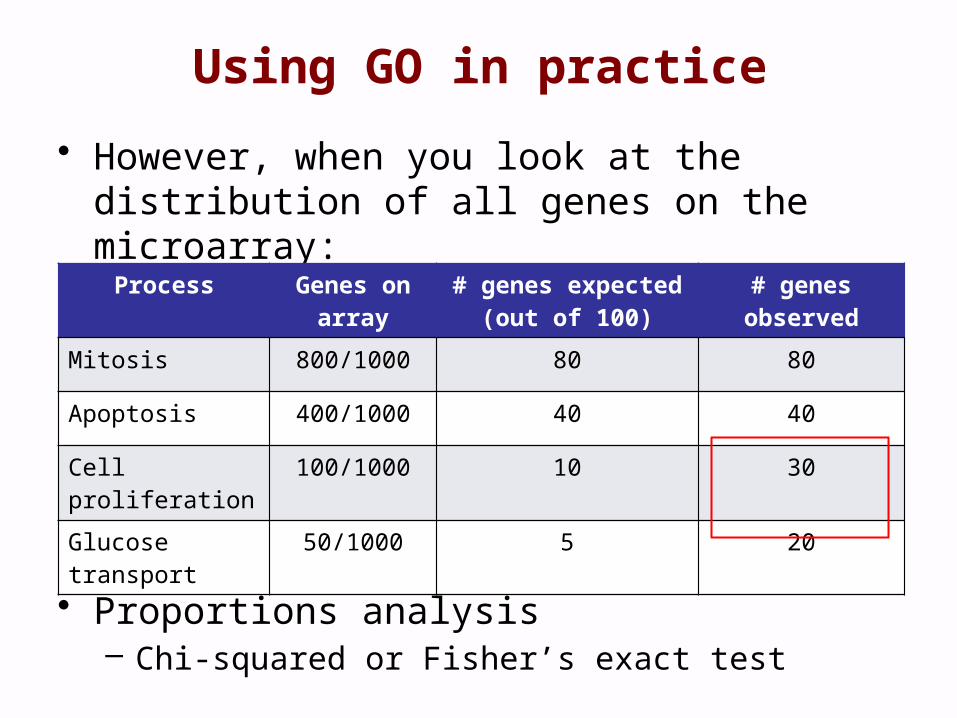
Using GO in practice
• However, when you look at the distribution of all genes on the microarray:
• Proportions analysis – Chi-squared or Fisher’s exact test
Process Genes on array
# genes expected (out of 100)
# genes observed
Mitosis 800/1000 80 80
Apoptosis 400/1000 40 40
Cell proliferation
100/1000 10 30
Glucose transport
50/1000 5 20

Other sources of annotation
• Uniprot (Swiss-Prot) keywords• Protein domain databases
– PFAM, Panther, PDB, PROSITE, ect• GeneDB summaries from NCBI• Protein-protein interactions databases• Pathway databases
– KEGG, BioCarta, BBID, Reactome
DAVID incorporates annotation from all of these and clusters the redundant terms

Today & next Tuesday in computer lab
• Managing gene lists with various online database tools
• Filtering your gene list from Ex. 2 so that you have only protein-coding genes and the database IDs or accession numbers you need for later analyses
• Tutorial on different tools for GO enrichment analysis
• Conduct GO enrichment on your list of genes using PGS, DAVID and one other GO tool (web based)







