Download - Lecture 04 IBL

Lecture 04: KNN, IBL and CBR

2
Instance-based learning
• One way of solving tasks of approximating discrete or real valued target functions
• Have training examples: (xn, f(xn)), n=1..N.
• Key idea: • just store the training examples• when a test example is given then find the closest matches

3
• 1-Nearest neighbour:Given a query instance xq, • first locate the nearest training example xn
• then f(xq):= f(xn)
• K-Nearest neighbour:Given a query instance xq, • first locate the k nearest training examples • if discrete values target function then take
vote among its k nearest nbrs else if real valued target fct then take the mean of the f values of the k nearest nbrs
k
xfxf
k
i iq
1)(
:)(

4
The distance between examples • We need a measure of distance in order to know who are
the neighbours
• Assume that we have T attributes for the learning problem. Then one example point x has elements xt , t=1,…T.
• The distance between two points xi xj is often defined as the Euclidean distance:
T
ttjtiji xxd
1
2][),( xx
5
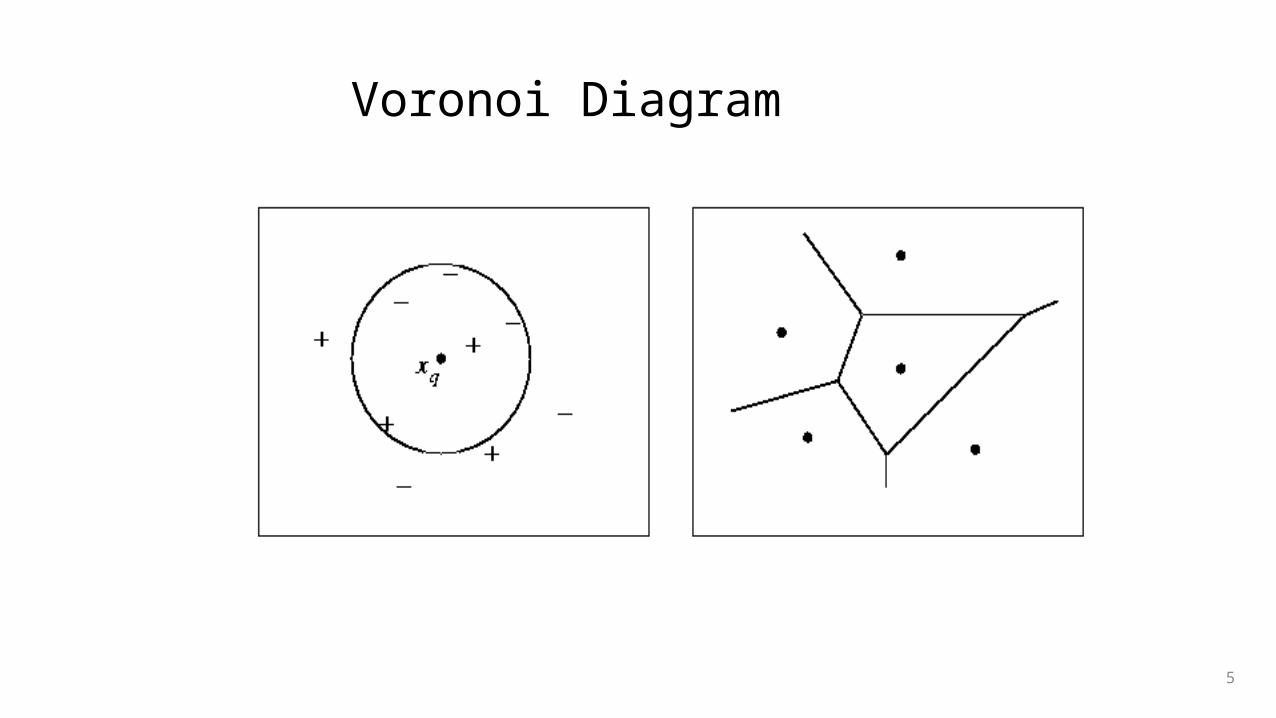
Voronoi Diagram

6
Characteristics of Instance based Learning• An instance-based learner is a lazy-learner and does all the work when
the test example is presented. This is opposed to so-called eager-learners, which build a parameterised compact model of the target.
• It produces local approximation to the target function (different with each test instance)

7
When to consider Nearest Neighbour algorithms?
• Instances map to points in• Not more then say 20 attributes per instance• Lots of training data• Advantages:
• Training is very fast• Can learn complex target functions• Don’t lose information
• Disadvantages:• ? (will see them shortly…)
n
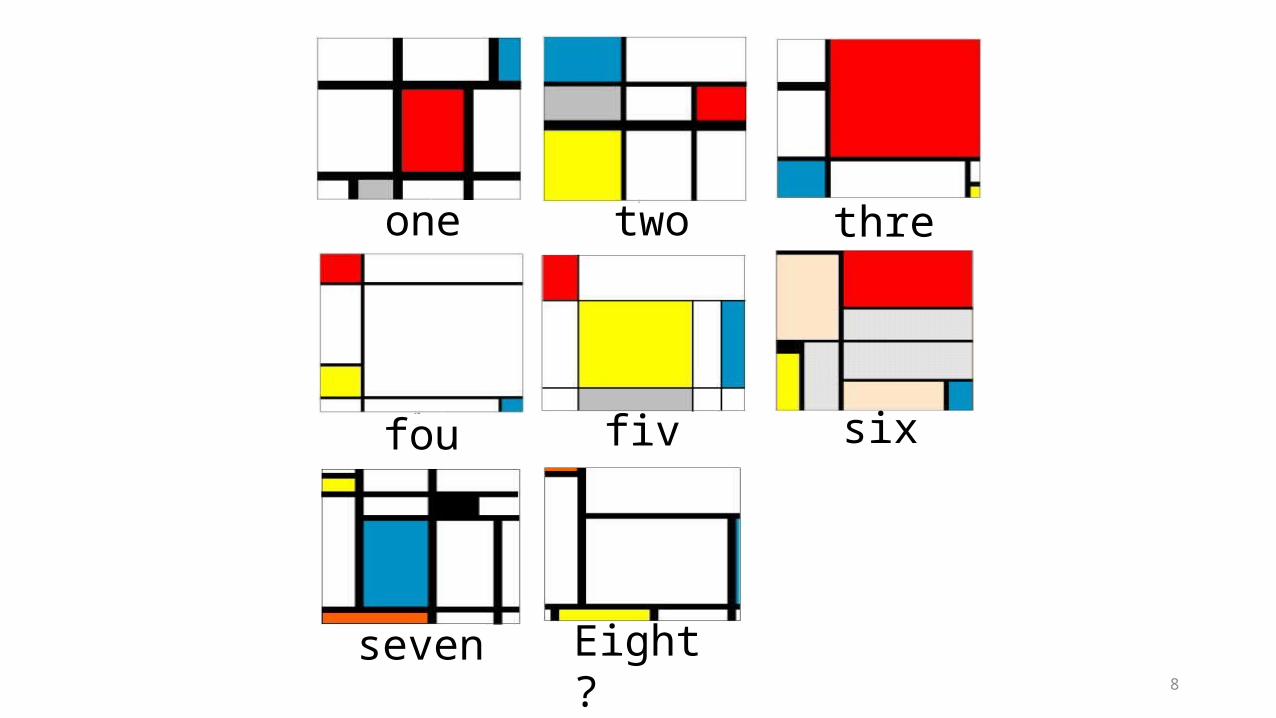
8
twoone
four
three
five six
seven Eight ?
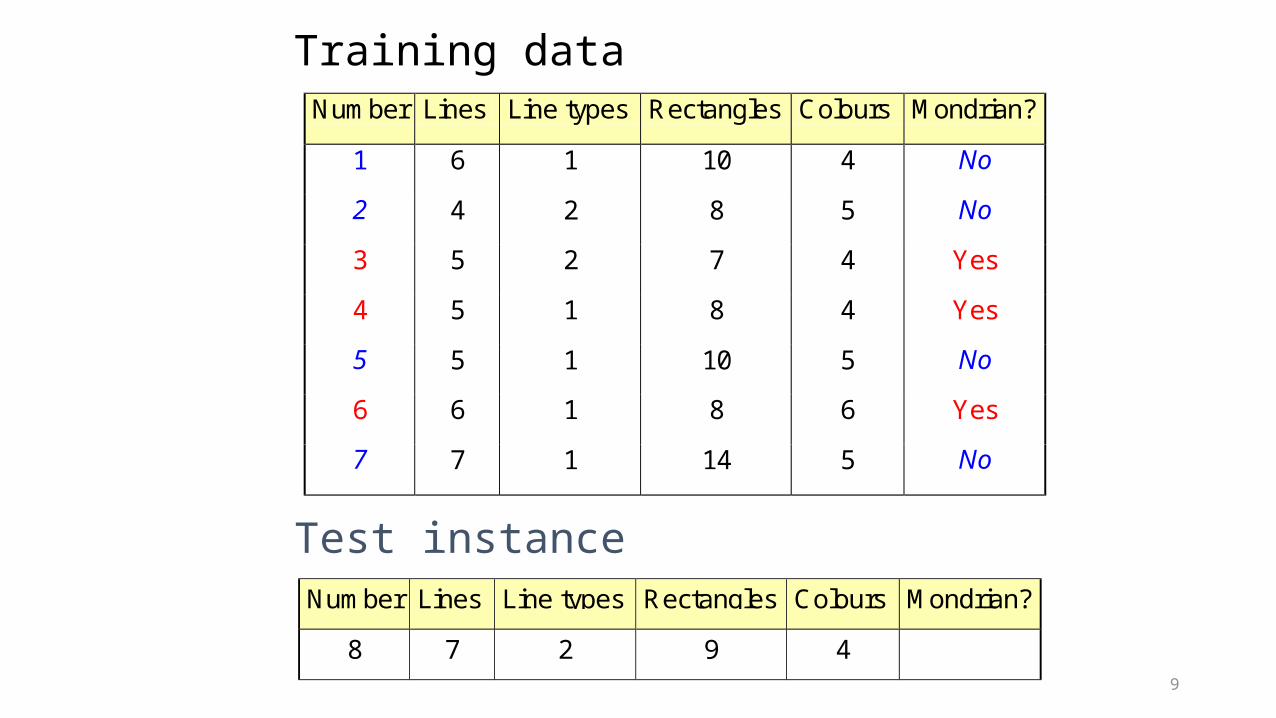
9
Training dataNumber Lines Line types Rectangles Colours Mondrian?
1 6 1 10 4 No
2 4 2 8 5 No
3 5 2 7 4 Yes
4 5 1 8 4 Yes
5 5 1 10 5 No
6 6 1 8 6 Yes
7 7 1 14 5 No
Number Lines Line types Rectangles Colours Mondrian?
8 7 2 9 4
Test instance

10
Keep data in normalised formOne way to normalise the data ar(x) to a´r(x) is
t
ttt
xxx
'
attributestofmeanx thr
attributestofdeviationndardsta tht
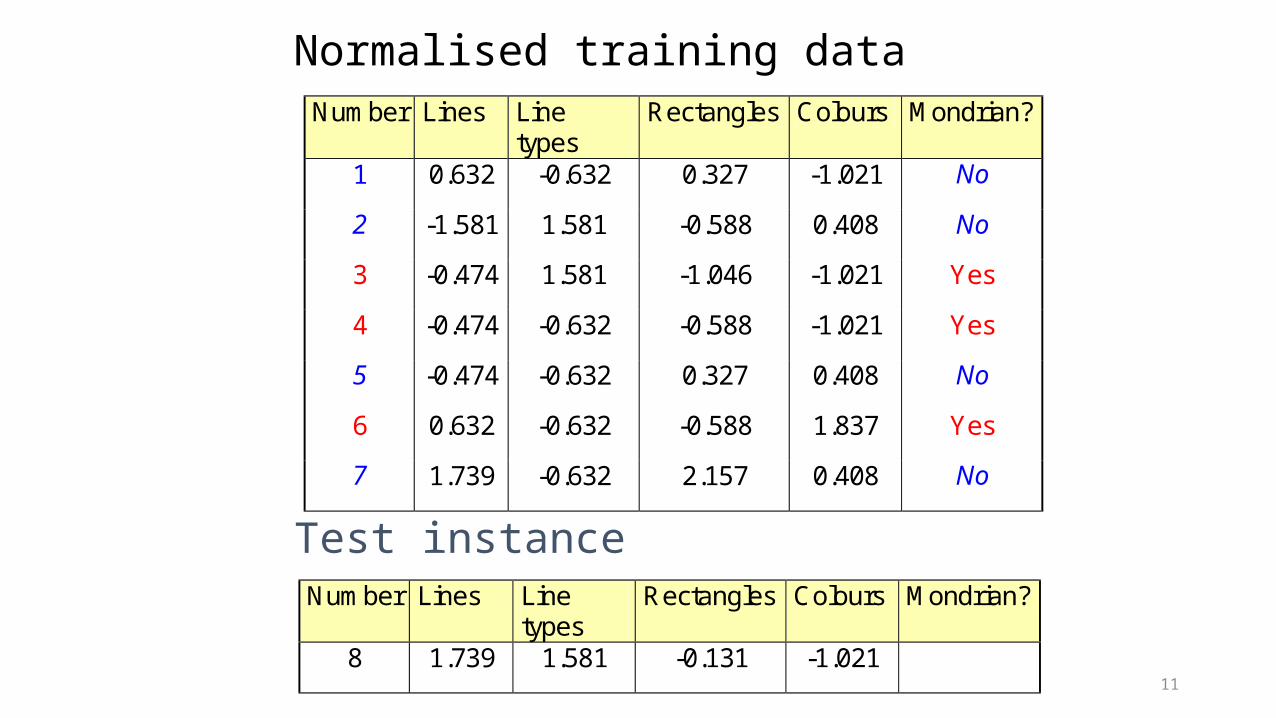
11
Normalised training dataNumber Lines Line
types Rectangles Colours Mondrian?
1 0.632 -0.632 0.327 -1.021 No
2 -1.581 1.581 -0.588 0.408 No
3 -0.474 1.581 -1.046 -1.021 Yes
4 -0.474 -0.632 -0.588 -1.021 Yes
5 -0.474 -0.632 0.327 0.408 No
6 0.632 -0.632 -0.588 1.837 Yes
7 1.739 -0.632 2.157 0.408 No
Number Lines Line types
Rectangles Colours Mondrian?
8 1.739 1.581 -0.131 -1.021
Test instance
12
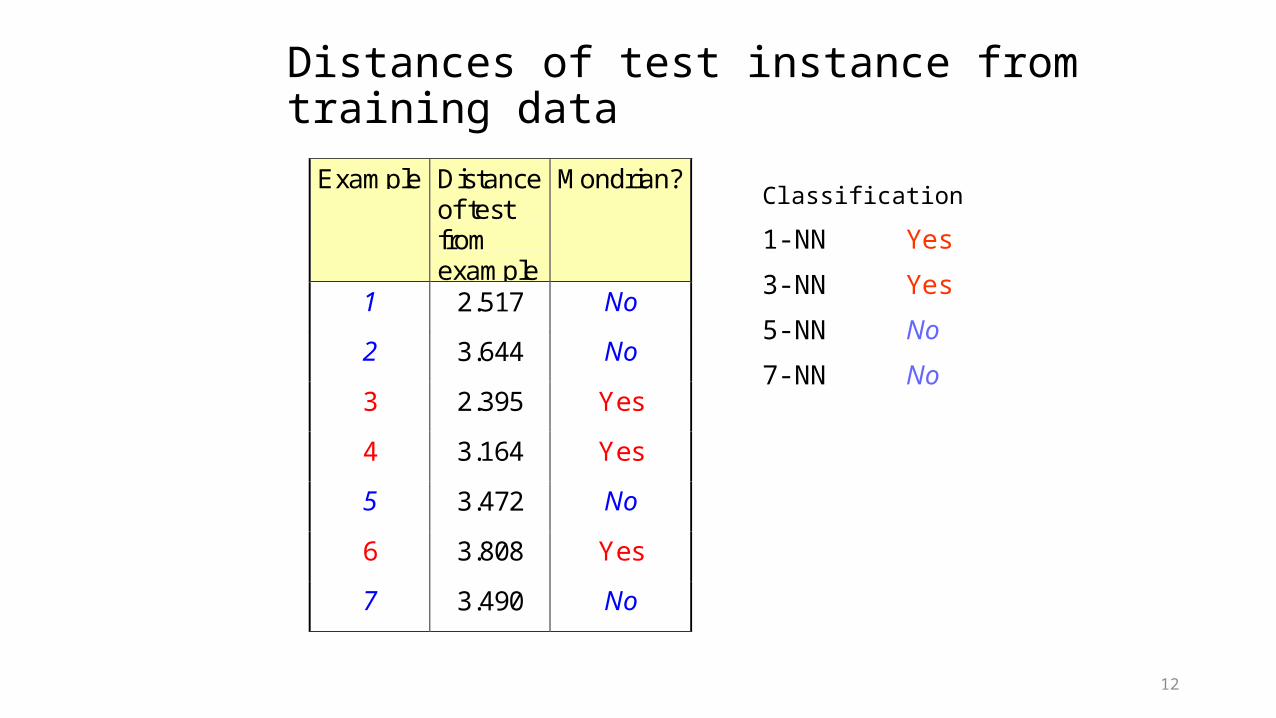
Distances of test instance from training data
Example Distanceof testfromexample
Mondrian?
1 2.517 No
2 3.644 No
3 2.395 Yes
4 3.164 Yes
5 3.472 No
6 3.808 Yes
7 3.490 No
Classification
1-NN Yes
3-NN Yes
5-NN No
7-NN No

13
What if the target function is real valued?
• The k-nearest neighbour algorithm would just calculate the mean of the k nearest neighbours

14
Variant of kNN: Distance-Weighted kNN
• We might want to weight nearer neighbors more heavily
• Then it makes sense to use all training examples instead of just k (Stepard’s method)
2
1
1
),(
1 where
)(:)(
iqik
i i
k
i iiq d
ww
fwf
xx
xx

15
Difficulties with k-nearest neighbour algorithms
• Have to calculate the distance of the test case from all training cases
• There may be irrelevant attributes amongst the attributes – curse of dimensionality

16
Case-based reasoning (CBR)
• CBR is an advanced instance based learning applied to more complex instance objects
• Objects may include complex structural descriptions of cases & adaptation rules

17
• CBR cannot use Euclidean distance measures • Must define distance measures for those complex
objects instead (e.g. semantic nets)• CBR tries to model human problem-solving
• uses past experience (cases) to solve new problems• retains solutions to new problems
• CBR is an ongoing area of machine learning research with many applications

18
Applications of CBR• Design
• landscape, building, mechanical, conceptual design of aircraft sub-systems
• Planning• repair schedules
• Diagnosis• medical
• Adversarial reasoning• legal
19
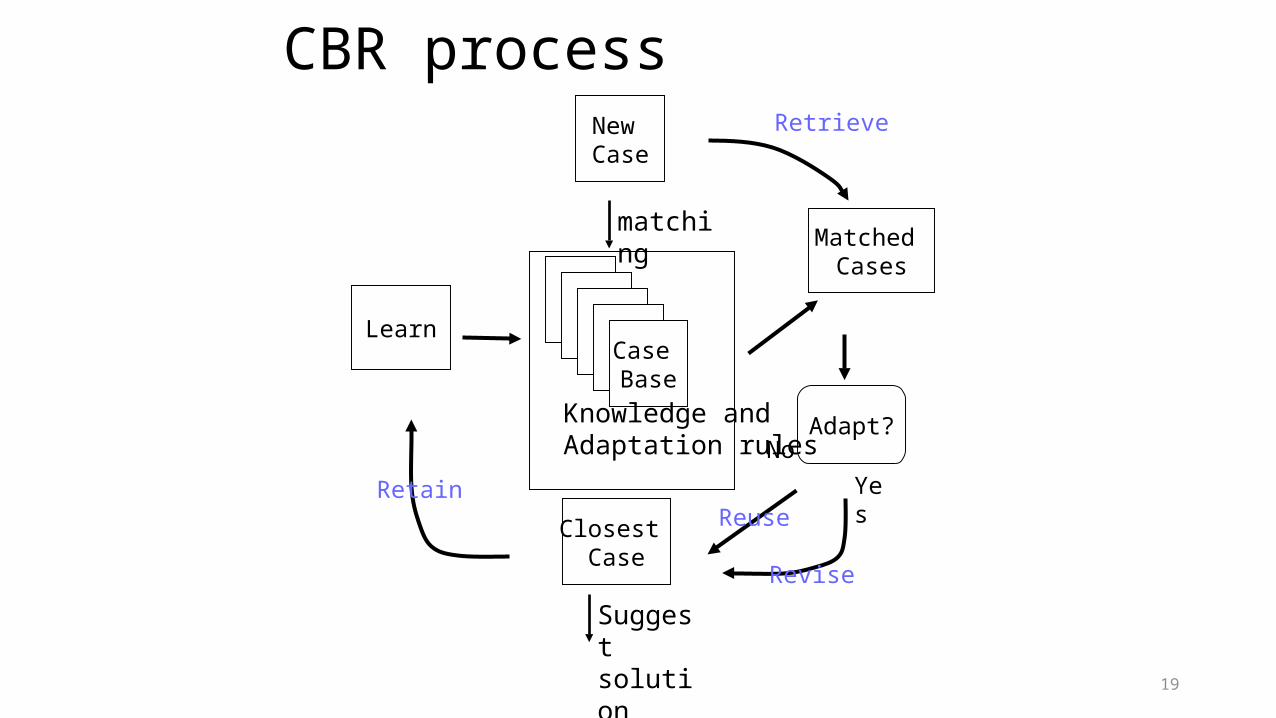
CBR processNew Case
matchingMatched
Cases
Retrieve
Adapt?No
Yes
Closest Case
Suggest solution
Retain
Learn
Revise
Reuse
Case Base
Knowledge and Adaptation rules
20
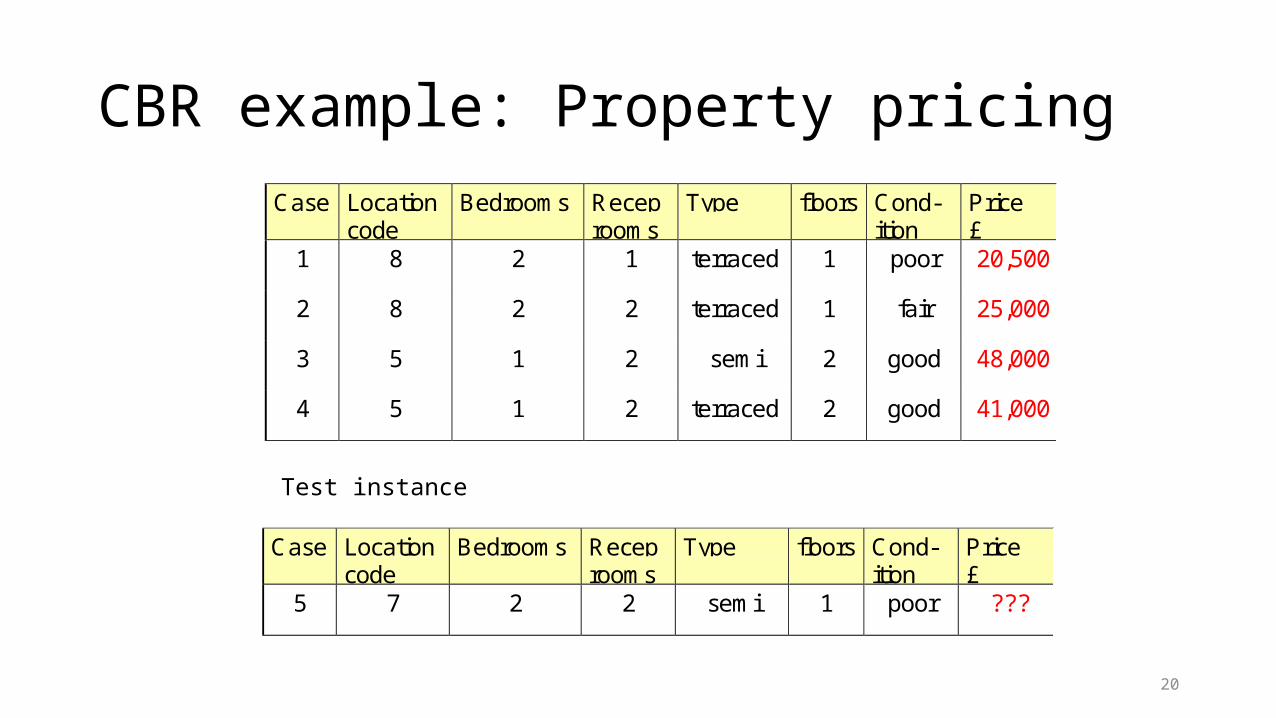
CBR example: Property pricingCase Location
codeBedrooms Recep
roomsType floors Cond-
itionPrice£
1 8 2 1 terraced 1 poor 20,500
2 8 2 2 terraced 1 fair 25,000
3 5 1 2 semi 2 good 48,000
4 5 1 2 terraced 2 good 41,000
Case Locationcode
Bedrooms Receprooms
Type floors Cond-ition
Price£
5 7 2 2 semi 1 poor ???
Test instance

21
How rules are generated• There is no unique way of doing it. Here is one
possibility:• Examine cases and look for ones that are almost
identical• case 1 and case 2
• R1: If recep-rooms changes from 2 to 1 then reduce price by £5,000
• case 3 and case 4• R2: If Type changes from semi to terraced then reduce price
by £7,000

22
Matching
• Comparing test instance • matches(5,1) = 3• matches(5,2) = 3• matches(5,3) = 2• matches(5,4) = 1
Estimate price of case 5 is £25,000

23
Adapting
• Reverse rule 2• if type changes from terraced to semi then increase price by £7,000
• Apply reversed rule 2 • new estimate of price of property 5 is £32,000

24
Learning
• So far we have a new case and an estimated price• nothing is added yet to the case base
• If later we find house sold for £35,000 then the case would be added• could add a new rule
• if location changes from 8 to 7 increase price by £3,000

25
Problems with CBR
• How should cases be represented?• How should cases be indexed for fast retrieval?• How can good adaptation heuristics be developed?• When should old cases be removed?

26
Advantages
• A local approximation is found for each test case• Knowledge is in a form understandable to human beings• Fast to train

27
Summary
• K-Nearest Neighbours• Case-based reasoning• Lazy and eager learning

28
Lazy and Eager Learning• Lazy: wait for query before generalizing
• k-Nearest Neighbour, Case based reasoning
• Eager: generalize before seeing query• Radial Basis Function Networks, ID3, …
• Does it matter?• Eager learner must create global approximation• Lazy learner can create many local approximations







