
Design of Optimal Multiple Spaced Seeds for Homology Search
Jinbo XuSchool of Computer Science, University
of WaterlooJoint work with D. Brown, M. Li and B.
Ma

Overview
Seed-based homology search Optimal multiple spaced seeds LP based randomized algorithm Experimental results Future work

Homology Search
Exhaustive search algorithm e.g. Smith-Waterman algorithm 100% sensitivity infeasible if the database is large
Suffix tree Seed-based algorithm, e.g. BLAST,
PatternHunter
Given: database of DNA sequences, query sequence QTask: extract all homologous sequences of Q from the database.

Region and Seed
S1: AGCTTGCCGTAAACCGS2: ACGTAGCACTGAGCTGRegion model: 1001011001010101
seed: 10010010111: a required match0: “don’t care”seed length M: length of the stringseed weight W: the number of 1 in the seed

Seed-based Hit
ACGCGTGGGAAACC
CAATGTGGGCAATT11011011
00001111101100
seed
region
Given a seed, a query sequence hits another sequence ifand only if the seed hits a region model of both sequences.
Query:
A seed S hits a region R at position i if and only ifR[i+j]=1 for every position j where s[j]=1

Single Seed Based Algorithm
Query: GGAAGCTTGCCGTATGCCATAGS1: CCAGGCTAGCCATAGGCCTTCT
Seed:101110111011011101
Length=18, weight=13
Query: GGAAGCTTGCCGTATGCCATAGS2: CCAGGCATGCAGTAGGCCTTCT
S1 hit, but S2 missed.

Multiple Seeds Based Algorithm
Query: GGAAGCTTGCCGTATGCCATAGS1: CCAGGCTAGCCATAGGCCTTCT
seed1:101110111011011101
Length=18, weight=13
Query: GGAAGCTTGCCGTATGCCATAGS2: CCAGGCATGCAGTAGGCCTTCT
seed2:101101110111011101
Both S1 and S2 are hit

Optimal Multiple Seeds (OMS) Problem
Given: random region R under certain distribution, two integers M and W, and an integer k.Find: set of k seeds with weight W and length no more than M to maximize the hit probability of R.

Mandala (J. Buhler et al.) Hill Climbing, good for small k, no result
reported for k>4 Greedy + Monte Carlo sampling
Greedy Algorithm (M. Li and B. Ma et al.) Given i seeds (i=1,2,…,k-1), search for the
next seed by maximizing the incremental sensitivity
Vector Seeds (B. Brejova et al.)
Related Work

Seed Specific OMS problem: Given a random region R, a set of m seeds , and an integer k, find a set of k seeds out of , to maximize the hit probability of R.
Seed-Region Specific OMS problem: Given a set of m seeds , an integer k and a set of
regions , find a set of k seeds, to maximize the hits of .
Variants of OMS
msss ,...,, 21
msss ,...,, 21
msss ,...,, 21
NRRR ,...,, 21
NRRR ,...,, 21

Main Results:1. Approximation ratio by a greedy algorithm
(D.S. Hochbaum)2. Same approximation ratio by linear programming based
randomized algorithm 3. is tight unless P=NP (U. Feige)
Given a ground set H and its subsets and an integer k, Find k sets out of to cover H as much as possible.
Maximum Coverage (MC) problem
632.01 1 e
mHHH ,...,, 21
11 e
mHHH ,...,, 21

OMS vs. MC ProblemOMS
Region Sampling
Seed Specific OMS
Seed-Region Specific OMS=MC Problem
Seed Enumeration
iS seedby hit regions ofset the:iH

Region Model
3-bits
000 001 010 011 100 101 110 111
p .1426
.0573
.1236
.0660
.0710
.0364
.2335
.2696
1. PH: length 64 and each bit independently set to 1 with probability 0.7 (B. Ma et al.)
2. M3: length 64 and each bit independently set to 1 with probability 0.8 if i%3=1 or 2, 0.5 otherwise (B. Brejova et al.)
3. M8: length 63 and each codon satisfy a certain distribution (B. Brejova et al.)
4. HMM: average length 90, two adjacent codons are not independent (B. Brejova et al.)

Observations
1. PH model: the hit probability of any seed with weight 11 and length 18 is at least 0.30
2. M3 model: the hit probability of any seed with weight 11 and length 18 is at least 0.27
3. HMM model: the hit probability of any seed with weight 11 and length 18 is at least 0.70

Variant of MC Problem
possible. asmuch as cover to
,...,, ofout sets find elements, ||least at contains
whichofeach ,,...,, subsets its and set ground aGiven
21
21
H
HHHkH
HHHH
m
m
Can we have a better approximation ratio?

If the sensitivity of each seed is at least and the optimal linear solution is , then the LP based randomized algorithm guarantees to generate a solution with approximation ratio at least
for the seed-region specific OMS problem.
Better Approximation Ratio
)1)(1()1( 1
)1()1( *
*
*
*
ee
lklkk
lklk
*l
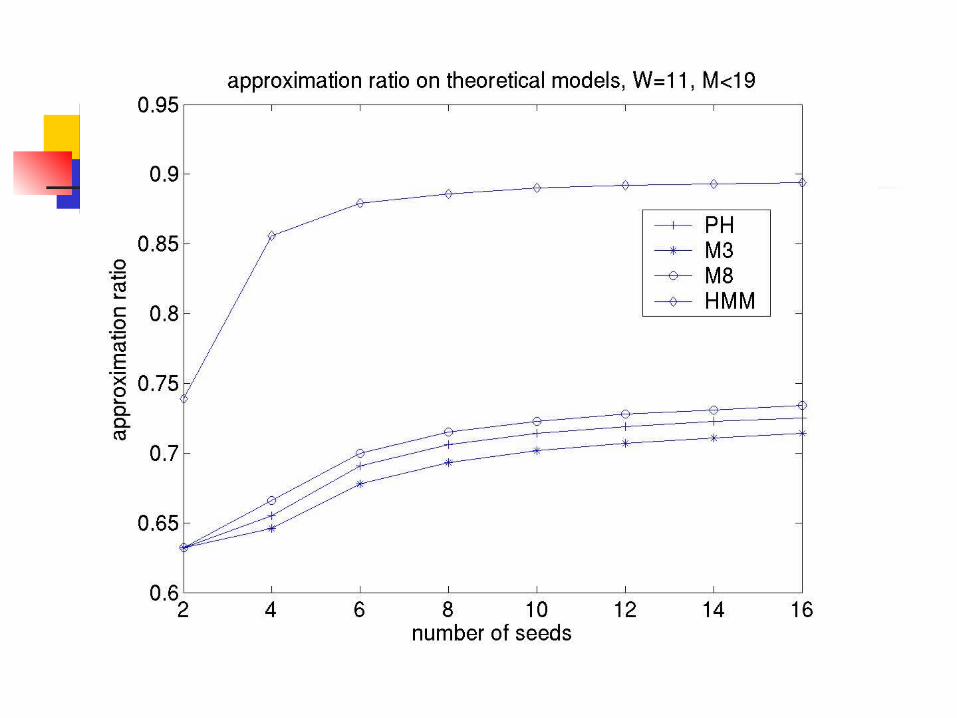
Theoretical Results

Practical Approximation Ratio
)11( 02146.0
)(
)(
)(**
l
Ap
AP
Ap
the optimal seed set for the random region R the best seed set found by the LP based algorithm
*AA
with probability 0.99
If 5000 regions are sampled, then we have
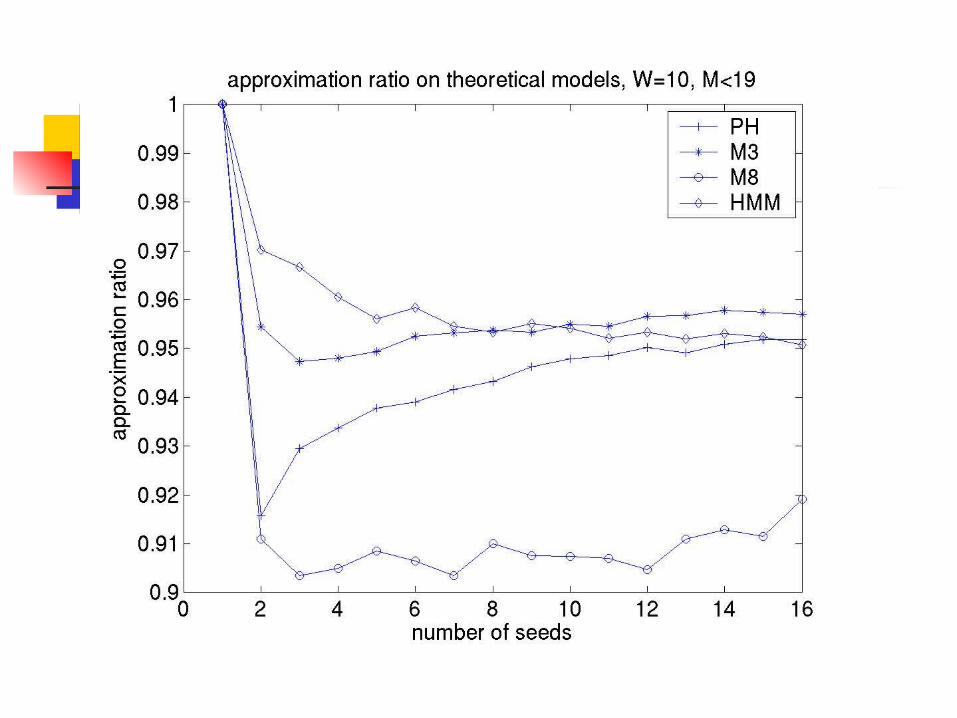
Practical Approximation Ratio (W=10)

Practical Approximation Ratio (W=11)

Test Data
All-against-all comparison between mouse EST sequences and human EST sequences by Smith-Waterman algorithm
3346700 pairs found with local alignment score no less than 16
score
16-20
20-30
30-40
40-50
50-60
60-70
70-80
80-90
>90
ratio 93 6.3 0.26 0.06 0.06 0.02 0.01 0.02 0.28
label
1 2 3 4 5 6 7 8 9

Performance of PH Seeds

Performance of HMM Seeds
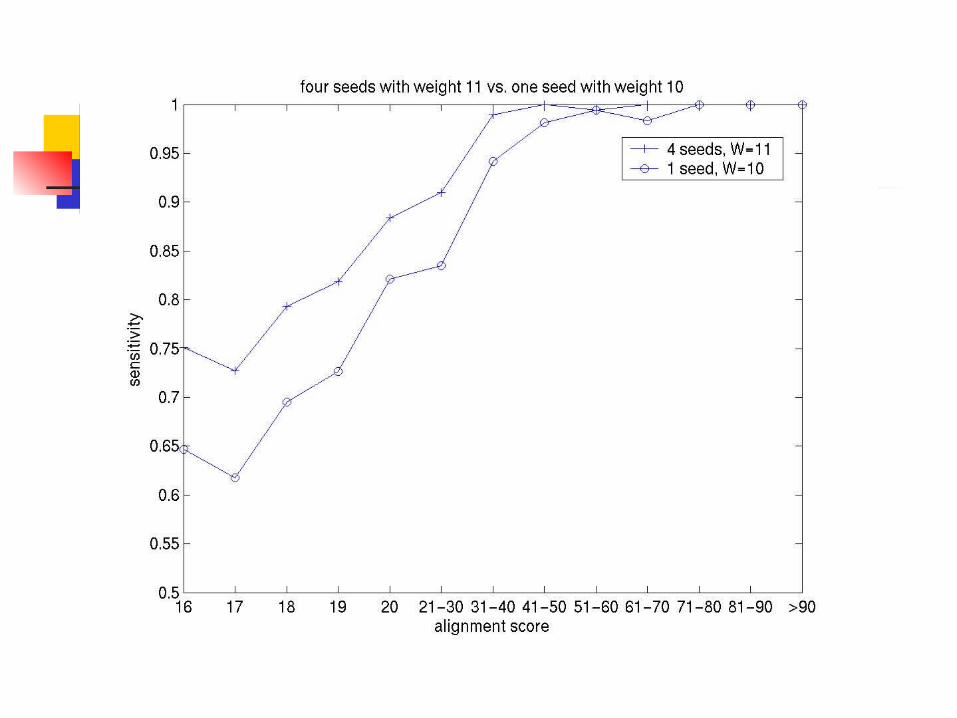
4 HMM Seeds vs. 1 HMM Seed

Greedy vs. LP

LP-based algorithm gives a mathematical foundation
LP-based algorithm is also good in practice Time complexity is exponential to . Is there
an approximation algorithm without enumerating seeds?
Better approximation ratio by Greedy algorithm?
Summary and Future Work
WM 2






