
Content-based image and video analysis
Event Recognition
21.06.2010

What is an event?
“a thing that happens or takes place” ,
Oxford Dictionary
Examples:
Human gestures
Human actions (running, drinking, etc.)
Human interaction (gunfight, car-crash, etc.)
Sports event (tennis, soccer, etc.)
Nature event (fire, storm, etc.)
…
Content-based image and video retrieval 1

Why event recognition?
Huge amounts of video available
Event recognition useful for:
Content-based browsing
“Fast forward to the next goal scoring scene”
Video search
“Show me all videos with Bush and Putin shaking hands”
2Content-based image and video retrieval

Human actions
Human actions are major events in moviecontent
Meaning hidden within visual representation
4Content-based image and video retrieval

What are human actions?
Definition 1:
Physical body motion:
KTH action Database
(http://www.nada.kth.se/cvap/actions/)
5Content-based image and video retrieval

What are human actions?
Definition 2:
Interaction with environment on specific purpose
Same physical motion – different action depending on the context
6Content-based image and video retrieval

Challenges
Variations:
Lighting, appearance, view, background
Individual motion, camera motion
Difference in shape
Difference in motion
Both actions are similar in
overall shape (human
posture) and motion
(hand motion)
Drinking
Smoking
7Content-based image and video retrieval

Challenges
Problems:
Existing datasets contain few action classes, captured in controlled and simplified settings
Lots of (realistic) training data needed
Idea:
Realistic human actions are frequent events within movies
Perform automatic labeling of video sequences based on movie scripts
8Content-based image and video retrieval

Action event dataset
“Coffee and Cigarettes” dataset
159 annotated “Drinking” samples
149 annotated “Smoking” samples
KeyframeFirst framehead rectangle
torso rectangle
Temporal annotationSpatial annotation
Last frame
http://www.irisa.fr/vista/Equipe/People/Laptev/actiondetection.html
9Content-based image and video retrieval

Challenges
Problems:
Existing datasets contain few action classes, captured in controlled and simplified settings
Lots of (realistic) training data needed
Idea:
Realistic human actions are frequent events within movies
Perform automatic labeling of video sequences based on movie scripts
Hollywood Human actions (HOHA) dataset
10Content-based image and video retrieval

Script-based annotation
Problems:
No time information available
Use subtitles to align scripts with the video
Described actions do not always correspond to movie scene
Assign an alignment score to scene description:
a = (#matched words)/(#all words)
Apply a Threshold (eg. a>0.5)
Variability of action expressions in text
Use regularized Perceptron to classify action description
11Content-based image and video retrieval
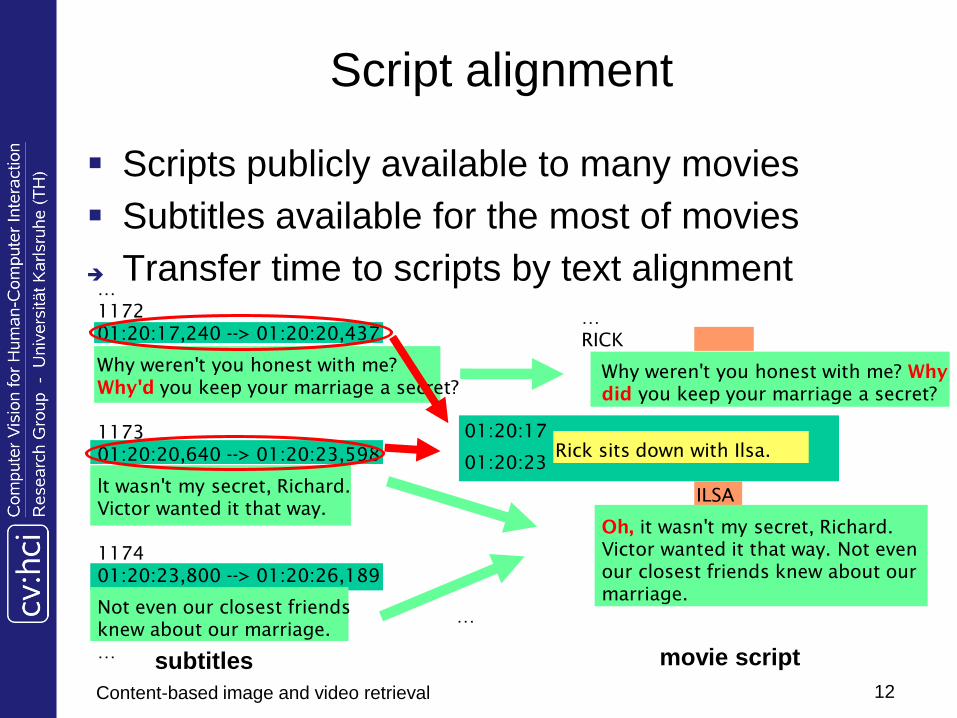
Script alignment
…
1172
01:20:17,240 --> 01:20:20,437
Why weren't you honest with me?
Why'd you keep your marriage a secret?
1173
01:20:20,640 --> 01:20:23,598
lt wasn't my secret, Richard.
Victor wanted it that way.
1174
01:20:23,800 --> 01:20:26,189
Not even our closest friends
knew about our marriage.
…
…
RICK
Why weren't you honest with me? Why
did you keep your marriage a secret?
Rick sits down with Ilsa.
ILSA
Oh, it wasn't my secret, Richard.
Victor wanted it that way. Not even
our closest friends knew about our
marriage.
…
01:20:17
01:20:23
Scripts publicly available to many movies
Subtitles available for the most of movies
Transfer time to scripts by text alignment
subtitles movie script
12Content-based image and video retrieval

Script alignment: Problems
Perfect alignment does not guarantee perfect action annotation in video
From 147 action with correct alignment (a=1), only 70% did match the video
Errors
Temporal misalignment (10%)
Ouside FOV (10%)
Completely missing in video (10%)
Example of false positive for “get out of car”, Action is not visible in video!
(a: quality of subtitle-script matching)
A black car pulls up, two army
officers get out.
14Content-based image and video retrieval

Script-based Annotation
Pros:
Realistic variation of actions
Many examples per class, many classes
No extra overhead for new classes
Character names may be used to resolve “who is doing what?”
Problems:
No spatial localization
Temporal localization may be poor
Script does not always follow the movie
Automatic annotation useful for training, but not precise enough for evaluation
15Content-based image and video retrieval

Retrieving actions in movies
Ivan Laptev and Patric Perez
ICCV 2007
Content-based image and video retrieval 16

Actions == space-time objects?
“atomic”
actions
car exit phoning smoking hand shaking drinking
Take
advantage
of space-
time shape
time time time time
“stable-
view”
objects
17Content-based image and video retrieval
Tem
pora
l slic
e

Actions == space-time objects?
Can actions be considered as space-time objects?
Transfer object detectors to action recognition
Here: only atomic actions considered (i.e. simple actions)
Temporal slice of same action under different circumstances similar
So, (atomic) actions = space-time objects
Content-based image and video retrieval 18

Action features
Action volume = space-time cuboid region around the head (duration of action)
Encoded with block-histogram features f(), = (x,y,t,dx,dy,dt,,), defined by
Location (x,y,t)
Space-time extent (dx,dy,dt)
Type of block ()
el Plane, Temp-2, Spat-4
Type of histogram ()
Histogram of optical flow (HOF)
Histogram of oriented gradient (HOG)
Content-based image and video retrieval 19
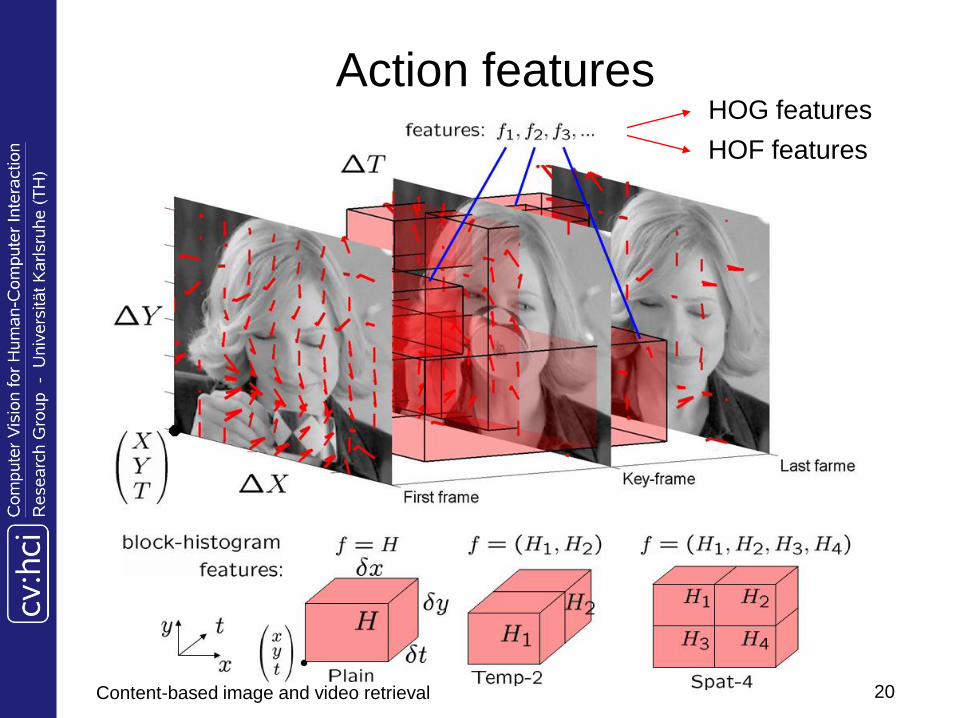
Action featuresHOG features
HOF features
20Content-based image and video retrieval

Histogram features
(simplified) Histogram of oriented gradient:
Apply gradient operator to each frame within sequence (eg. Sobel)
Bin gradients discretized in 4 orientations to block-histogram
Histogram of optical flow:
Calculate optical flow (OF) between frames
Bin OF vectors discretized in 4 direction bins (+1 bin for no motion) to block-histogram
Normalized action cuboid has size 14x14x8 with units corresponding to 5x5x5 pixels
More than 1 Mio. possible features f()
Content-based image and video retrieval 21
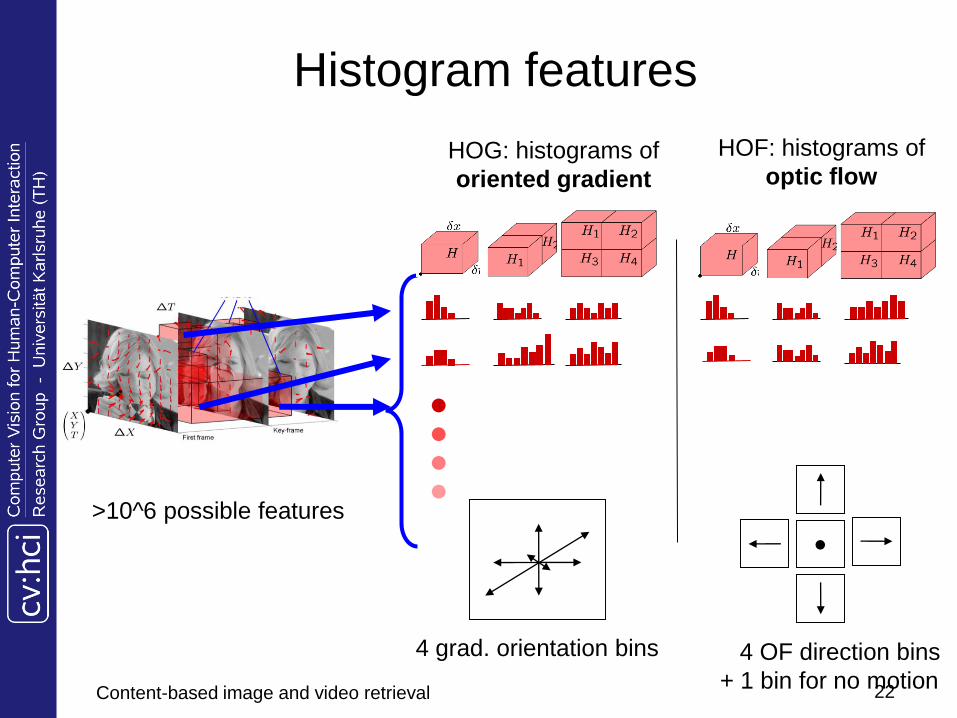
Histogram features
HOG: histograms of
oriented gradient
HOF: histograms of
optic flow
>10^6 possible features
4 grad. orientation bins
4 OF direction bins
+ 1 bin for no motion22Content-based image and video retrieval

Action learning
Use boosting method (eg. AdaBoost) to classify features within an action volume
Features:
Block-histogram features
Content-based image and video retrieval 23
boosting
selected features
weak classifier
• Efficient discriminative classifier [Freund&Schapire’97]
• Good performance for face detection [Viola&Jones’01]AdaBoost:

Action learning: Boosting
A weak classifier h is a classifier with accuracy only slightly better than chance
Boosting: combine a number of weak classifiers so that the ensemble is arbitrarily accurate
Allows the use of simple (weak) classifiers without the loss if accuracy
Selects features and trains the classifier
Content-based image and video retrieval 24
selected features
weak classifier

Action learning: Boosting
Weak classifier ht:
In case of one dimensional features
select an optimal decision threshold
E.g. for Haar-filter responses (Viola&Jones face detector)
Here: m-dimensional features
Project data on one dimension using Fisher’s Linear Discriminant (FLD), then select optimal threshold in 1-D
Content-based image and video retrieval 25
Haar
features
Histogram
features
Use FLD, select
opt. threshold
optimal
threshold
pre-aligned
samples

Action classification test
Comparison of:
Static keyframe classifier with spatial HOG features (BH-Grad4)
Use Boosting to classify action using features from keyframes (= frame when hand reaches the mouth) only
Space-time action classifier with HOF features (STBH-OF5)
Space-time action classifier with HOF and HOG features (STBH-OFGrad9)
Content-based image and video retrieval 28

Action classification testRandom
motion
patterns
Additional shape information does not seem to improve the space-time classifier
Space-time classifier and static key-frame classifier might have complementary properties
29Content-based image and video retrieval

Classifier properties
Space-time classifier (HOF) Static keyframe classifier(HOG)
Training output: Accumulated feature maps
Space-time classifier and static keyframe classifier might have complementary features
30Content-based image and video retrieval

Classifier properties
Region of selected features show most “active” parts of classifier
High activity at beginning and end of sequence, but low activity at keyframe
Less accuracy expected when only classifying keyframes
Space-time classifier selects most features around hand region
Keyframe classifier selects most features in upper part of the key-frame
Idea: Use complementary properties to combine classifiers (-> keyframe priming)
Content-based image and video retrieval 31

Keyframe priming
Combination of static key-frame classifier with space-time classifier
Motivated by complementary properties of both classifiers
Bootstrap space-time classifier and apply it to keyframes detected by the keyframe detector (boosted space-time window classifier)
Speeds up detection
Combines complementary models
32Content-based image and video retrieval

Keyframe priming
Apply keyframe detector (HOG classification on single frame) to all positions, scales and frames while being set to a high false positive rate
Generate space-time blocks aligned with detected keyframes and with different temporal extent
Run space-time classifier on each hypothesis
33Content-based image and video retrieval

Keyframe priming
Training
Positive
training
sample
Negative
training
samples
Test
34Content-based image and video retrieval
Keyframe-primed
event detectionKeyframe detections

Action detection
Keyframe
priming
No
Keyframe
priming
Test on 25min from “Coffee and Cigarettes” with 38 drinking actions
No overlap with the training set in subjects or scenes
Keyframe priming is faster and leads to significant better results
35Content-based image and video retrieval

Action detection
36Content-based image and video retrieval

Learning realistic human actions from movies
Ivan Laptev, Marcin Marszalek, Cordelia Schmid and
Benjamin Rozenfeld
CVPR 2008
Content-based image and video retrieval 37

Action recognition in real-world videos
Humans can do more than just “drinking” and “smoking”
Robust detection and classification of all kinds of human actions needed
38Content-based image and video retrieval

Space-Time Features: Detector
[Laptev, IJCV 2005]
39Content-based image and video retrieval

Space-Time Features: Detector
Space-Time Interest Points (STIP):
Space-Time Extension of Harris Operator
Add dimensionality of time to the second moment matrix
Look for maxima in extended Harris corner function H
Detection depends on spatio-temporal scale
Extract features at multiple levels of spatio-temporal scales (dense scale sampling)
40Content-based image and video retrieval

Space-Time Features: Descriptor
Histogram of oriented spatial
grad. (HOG)
Histogram of optical
flow (HOF)
3x3x2x4bins HOGdescriptor
3x3x2x5bins HOF descriptor
Public code available at www.irisa.fr/vista/actions
Multi-scale space-time patches from corner detector
41Content-based image and video retrieval

Space-Time Features: Descriptor
Compute histogram descriptors of space-time volumes in neighborhood of detected points:
Compute a 4-bin HOG for each cube in 3x3x2 space-time grid
Compute a 5-bin HOF for each cube in 3x3x2 space-time grid
Size of each volume related to detection scales
Content-based image and video retrieval 42
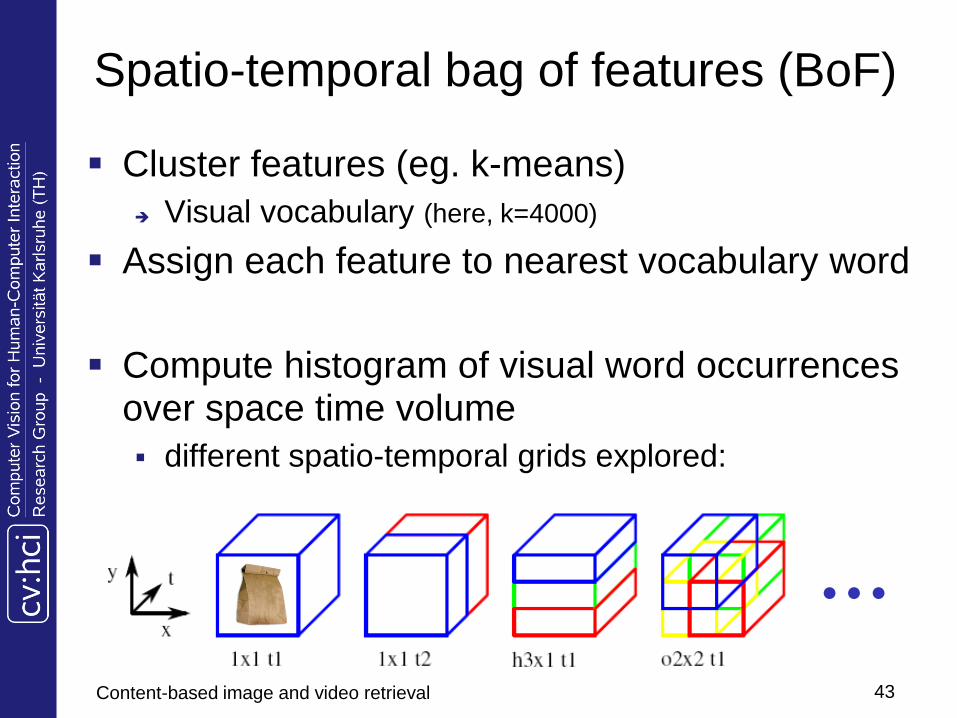
Spatio-temporal bag of features (BoF)
Cluster features (eg. k-means)
Visual vocabulary (here, k=4000)
Assign each feature to nearest vocabulary word
Compute histogram of visual word occurrences over space time volume
different spatio-temporal grids explored:
43Content-based image and video retrieval

Action classification
Use SVMs with multi-channel chi-square kernel:
“Channel” c is a combination of a spatio-temporal grid and a descriptor (HoG or HoF)
D is 2 distance between the BoF-histograms
A is mean value of distances between all training samples
One-against-all approach in case of multi-class classification
44Content-based image and video retrieval

Results on KTH actions dataset
Examples of all six classes and all four scenarios
45Content-based image and video retrieval
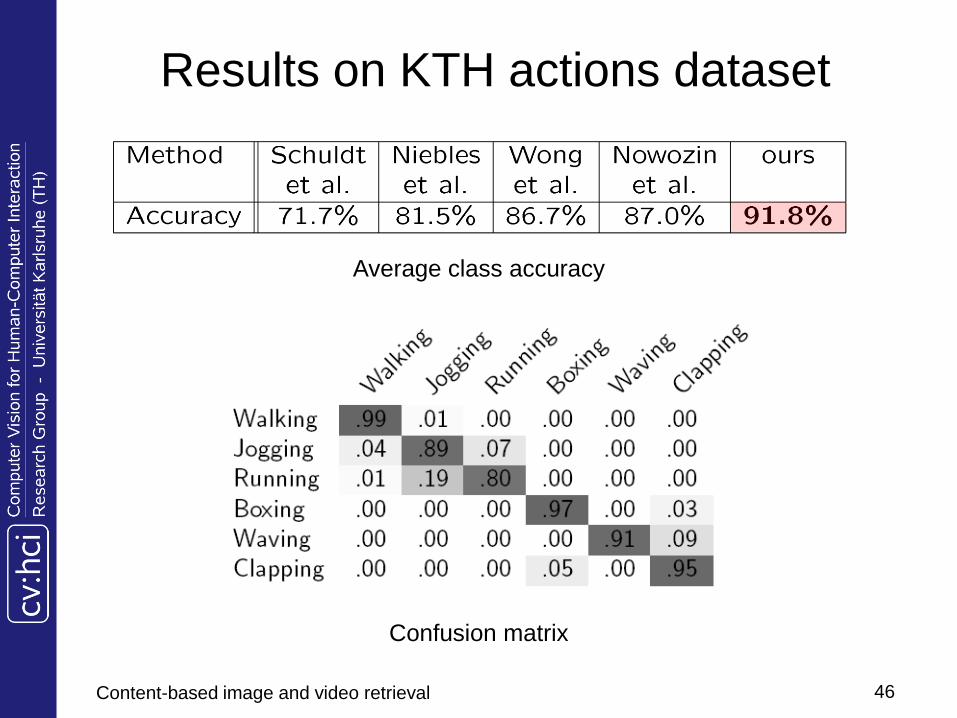
Results on KTH actions dataset
Average class accuracy
Confusion matrix
46Content-based image and video retrieval

Results on HOHA dataset
Average Precision for each action class
Comparison of results for annotated (clean) and automatic training data
Chance denotes results of a random classifier47Content-based image and video retrieval

Results on HOHA dataset
48Content-based image and video retrieval

Visual Event Recognition in News Video using Kernel Methods with Multi-Level Temporal Alignment
Dong Xu and Shih-Fu Chang
CVPR 2007
Content-based image and video retrieval 49

Event recognition in news broadcast
Challenging task:
Complex motion, cluttered backgrounds, occlusions, geometric variations of objects
HOF/HOG approaches are sensitive to high-motion regions only
News events may have relatively low motion (eg. fire)
Broadcast news less constrained domain than human actions
Event usually consists of different sub-clips
E.g. “riot” may consist of scenes of fire and smoke at different locations
50Content-based image and video retrieval

Temporally aligned pyramid matching
Algorithm overview:
each frame is represented by one feature vector
decompose video into sub-clips using hierarchical clustering
on each hierarchy level, calculate Earth Mover’s Distance (EMD) between frame features and use it within SVM framework
Constrain EMD that frames from one sub-clip can only be matched to fames from one other sub-clip (alignment)
fuse SVM outputs from all levels
51Content-based image and video retrieval

Temporally aligned pyramid matching
52Content-based image and video retrieval

Decomposition of video into sub-clips
Temporal-constrained Hierarchical Agglomerative Clustering (T-HAC):
First each feature-vector forms a cluster
Construct clusters iteratively by combining existing clusters based on their distances (EMD)
Only merge neighboring clusters in temporal dimension
Clusters form a pyramid like structure (dendrogram)
53Content-based image and video retrieval

Features
Low-level global features:
Grid Color Moment (GCM)
First three moments for each grid region (eg. 5X5 grid)
Gabor Texture feature (GT)
Edge Direction Histogram (EDH) (same as HoG)
Apply Sobel operator and histogram edge directions quantized at 5 degrees
Mid-level feature: Concept Score (CS)
N-dimensional vector (eg. N=108)
each component represents confidence score from a semantic concept classifier (SVMs)
55Content-based image and video retrieval

Temporal alignment
Content-based image and video retrieval 58
Matching in single-level EMD (a) and temporally aligned pyramid matching
(TAPM) (b)

Classification
SVM Classification with Earth Movers Distance (EMD) Kernel:
D(P,Q): EMD between features from sequence P and Q
A: hyper-parameter set empirically through cross-validation
59Content-based image and video retrieval

Fusion
Fuse Information from different levels directly:
L: number of sub-clip levels
g: decision values from the SVMs at different levels l
h: level weights (eg. all weights equal to 1)
Similar to logistic regression/perceptron
60Content-based image and video retrieval

Experiments
Test with LSCOM concepts on TRECVID-2005
56 events/activities annotated (449 total concepts)
10 events chosen
Relatively high occurrence frequency
May be recognized from visual cues intuitively
Number of positive samples for each class: 54-877
61Content-based image and video retrieval

Results
Comparison of single-level EMD (SLEMD) with key-frame classification on different features
62Content-based image and video retrieval
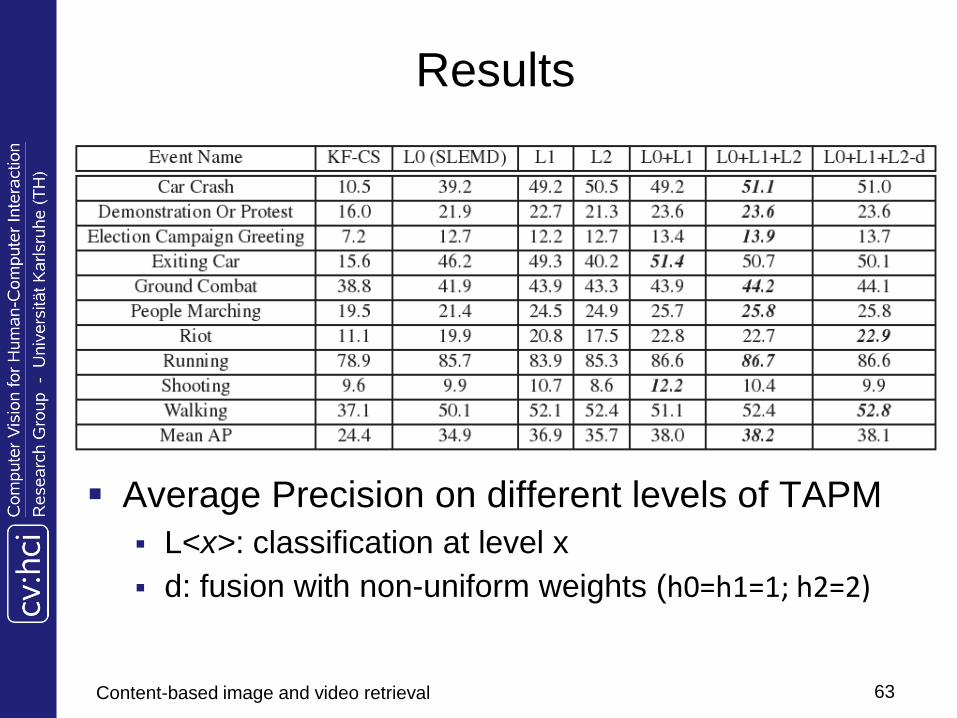
Results
Average Precision on different levels of TAPM
L<x>: classification at level x
d: fusion with non-uniform weights (h0=h1=1; h2=2)
63Content-based image and video retrieval

Summary
Paper1: “Retrieving actions in movies”
Atomic human actions: smoking, drinking
Histogram of oriented gradients (HoG), histograms of oriented flow (HoF), at different spatio-temporal positions & scales + grid-types, ..
Boosting to select good features and to build classifier
Paper2: “Learning realistic human actions from movies”
Eight atomic human actions: Kiss, AnswerPhone, GetOutCar, ..
HoG / HoF at space-time interest points, bag of features
SVM for classification
Paper 3: “Visual event recognition in news videos…”
Decomposes video into sub-clips
Temporal alignment improves classification
Low- and mid-level features, SVM for classification
64Content-based image and video retrieval

References
I. Laptev and P. Perez. Retrieving actions in movies. ICCV '07
I. Laptev, M. Marszalek, C. Schmid and B. Rozenfeld. Learning realistic human actions from movies. CVPR '08
D. Xu and SF. Chang. Visual Event Recognition in News Video using Kernel Methods with Multi-Level Temporal Alignment. CVPR '07
65Content-based image and video retrieval

References
http://www.irisa.fr/vista/Equipe/People/Ivan.Laptev.html
P. Viola and M. Jones. Rapid object detection using a boosted cascade of simple features. CVPR '01
R. Schapire, Y. Freund, P. Bartlett and WS. Lee. Boosting the margin: A new explanation for the effectiveness of voting methods. ICML '97
66Content-based image and video retrieval

Hiwi
Interested in action recognition?
We are currently looking for a motivated student to teach Armar-III how to recognize situations within rooms (eg. cooking, cleaning)
Required skills:
Interest in Computer Vision
C++ programming experience under Linux
Email [email protected] for more details
Content-based image and video retrieval 67







