Download - Big Data Science - hype?

Big Data ScienceHype?
Levente TörökBlinkbox Music Ltd ... GE Hungary

Disclaimer
All statements appearing in slides or in the presentation represent my personal opinion. They are not in connection to any companies nor any person I had or have connection to.
I reserve these statements with risk of error.

Summary
- Big data? Data Science? Hype?
- Continuous improvement of Online Systems
- A/B testing

Data Science, hype?Harvard Business Review in 2012
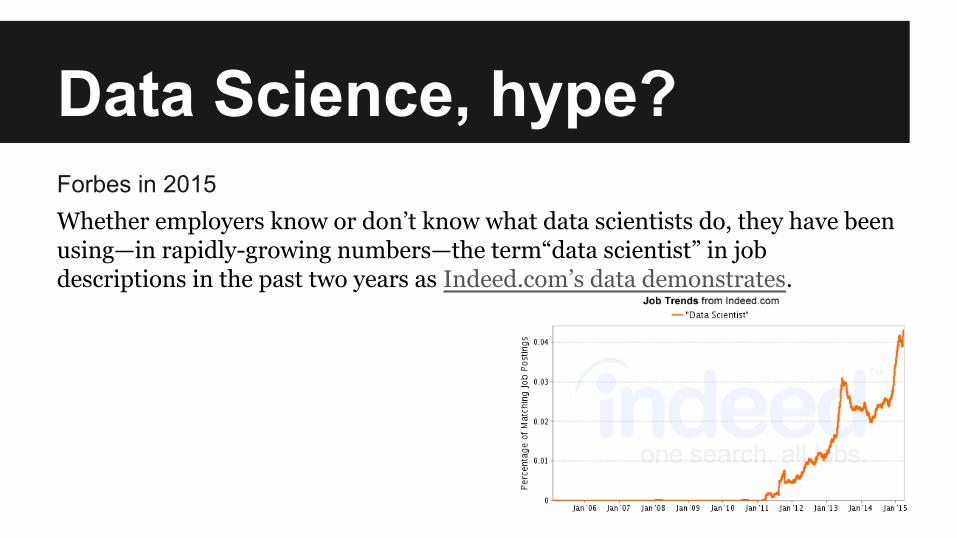
Data Science, hype?Forbes in 2015Whether employers know or don’t know what data scientists do, they have been using—in rapidly-growing numbers—the term“data scientist” in job descriptions in the past two years as Indeed.com’s data demonstrates.


“Data Science” in mediaYahoo Finance:
“If you take a cue from the Harvard Business Review, the title goes to data scientists. That’s right. Data scientist, as in, the type of person who can write computer code and harness the power of big data to come up with innovative ways to use it for companies like Google (GOOG), Amazon (AMZN), and Yahoo! (YHOO).”
“Data Science” in mediaNature Jobs:

Data Science, what is this?Wikipedia“Data Science is the extraction of knowledge from data, which is a continuation of the field data mining and predictive analytics”

Data? Science... ?1) Big Data Engineer
- Hive, Yarn, Spark, Impala
2) Data Miner- SAS, Knime, Rapid Miner, Weka,
IBM Clementine
3) Big Data & Data Miner- Apache - Mahout- Spark - MLlib, Spark - GraphX- Apache - Giraph- GraphLab ?

Data Scientist?Big data - big failure:
If an algo doesn’t work on small data, it wont work on big data.
4) Data Scientist is a real scientist:Follows scientific principles in data modeling:
- conjectures hypothesis on statistical structure of data- validates it offline and online- improves model iteratively


Tools: verdictother -> R -> python = 0.44 * 0.26 = 0.11other -> python -> R = 0.23 * 0.18 = 0.04
Is this correct?
However ... what?

Improving Online SystemsExamples
Recommender systems (ie. RecSys)What to listen next?What ad to display?
Anomaly detection:Is this user/system behaviour “normal”?Does this system going to fail soon?

Data Flow in Online Sys
Online sys -> log -> daily aggregation -> long term -> batch model bld. storage
queue -> async online model updates
near optimal online data model

The major difficultydaily aggregates
data
sou
rce
batch model training
online model training
1. batch model training starts: 4:00, finishes 4:302. new online model updates starts at 4:30, would finish at 5:10 with all the events from 0:00
to 4:30 but new events arrived in the mean time.... -> streaming architectures
queue

Offline data modelling
Train Test
Model Prediction
Parameters

Offline modeling1. Data splits for train / test / quiz
- time based: eg 2 weeks / 1 day / 1 day- entity based: set of users- session: set of sessions of users
Test data preparation:- manual pos/neg sample data points labeled, or injected
2. Train by batch trainingGiven a data set, we try to fit the model to the data set controlled by model
parameters.

Offline data modelling3. Prediction phase: Given a model
- for each users we met in train, we give predictions- for each event we can see in test set, we predict likelihood
4. Evaluation phase: prediction and test data similarity is measured- RecSys: NDCG, Recall, Precision, AUC, ... 20 different metrics- Artificially labelled data set for anomaly detection: C2B (AUC),
weighted AUC ...- Sanity check! -> Q/A team

Offline data modelling4. Parameter search in parallel
The output of the searching is the parameter vector (+ model id) that returns the optimal solution offline according to our belief
NB: usually we are unsure which offline measure is going to reflect the best online results, so we have number of optimal parameter vectors according to different offline measures.

A/B testing
Train_A Model_A Online pred_A Performance_A
Model_B Online pred_B Performance_B Train_B
??

Online performance tuning
Train_A Model_A Online pred_A
Parameters
Performance_A
Model_B Online pred_B Performance_B Train_B

Online traffic split adj.
Train_A Model_A Online pred_A Performance_A
Model_B Online pred_B Performance_B Train_B

Offline-Online matching
Model NDCG AUC ... Avg Sess Len
A 1 1 1
B 2 3 3
C 3 2 2
Offline measures Online measure
compare with Pearsons corr. coeff.

On-line testing5. A/B testing
- control model- tested model (model with an offline optimal parameter set)
6. Evaluation of online results:Measures:
- Session length, station length- Return rate, CLTV
Filter and compare models -> wow!

On-line testing7. Run many models one-by-one according phase 4.
8. Figure out the best offline metrics:Compare order statistics of offline and online models
(ie Pearsons correlation) to figure out which of the offline metrics matter the most in online performance.

Model comparisonsProblems:1. Day 1 A is better, Day 2 B is better
2. The version with the longest session length != the version with the highest full play ratio of tracks
3. Outliers are dominates the session length average:- Number of users listen the service “forever”- Bouncing users pollutes the session length average with high noise

A/B testing1. Version A: Control group2. Version B: Treatment group
With n_A, n_B users, we have successes of k_A, k_B.
Is it enough if I compare k_A / n_A with k_B / n_B ?

A/B testing?Questions:
- What if one day A wins, next the B wins?- How many users should I use for testing?- How long should I run test?- What if we have A, B, C ... versions we want to test?

Classical StatisticsHypothesis testing:
- Does treatment B have any effect?- up to probability: (1-alpha)- given: a sample size of N
Even the most well known A/B testing platforms can lead you illusory results.
Command: “Sample size estimator”

Binomial ?Note that:
Binomial distribution: Beta distribution: where
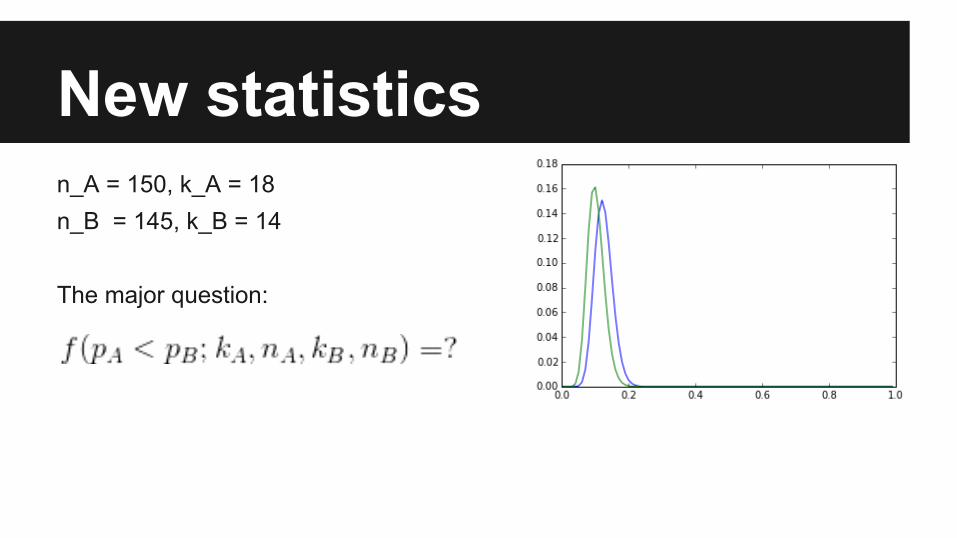
New statisticsn_A = 150, k_A = 18n_B = 145, k_B = 14
The major question:

New statisticsn_A = 150, k_A = 18n_B = 145, k_B = 14
The major question:
Chance2beat:x
f_A(x;...) f_B(x;...)

Chance 2 beat- This is a probability, we want to increase by testing. For example:
- Can be: - Gaussians, - distributions w/ priors- empiric distributions, or - small sample size data sets directly
- Sometimes it is not enough: use bootstrapping!

Thanks







