
from the
TRENCHESTRENCHES
what you should know before you go to production
AWS LAMBDAAWS LAMBDA

hi, I’m Yan Cui

hi, I’m Yan CuiAWS user since 2009







apr, 2016

hidden complexities and dependencies
low utilisation to leave room for traffic spikes
EC2 scaling is slow, so scale earlier
lots of cost for unused resources
up to 30 mins for deployment
deployment required downtime

- Dan North
“lead time to someone saying thank you is the only reputation
metric that matters.”


“what would good
look like for us?”

be small be fast
have zero downtime have no lock-step
DEPLOYMENTS SHOULD...

FEATURES SHOULD...be deployable independently
be loosely-coupled

WE WANT TO...minimise cost for unused resources
minimise ops effort reduce tech mess
deliver visible improvements faster

nov, 2016

170 Lambda functions in prod
1.2 GB deployment packages in prod
95% cost saving vs EC2
15x no. of prod releases per month

timeis a good fit

1st function in prod!time
is a good fit
?
timeis a good fit
1st function in prod!
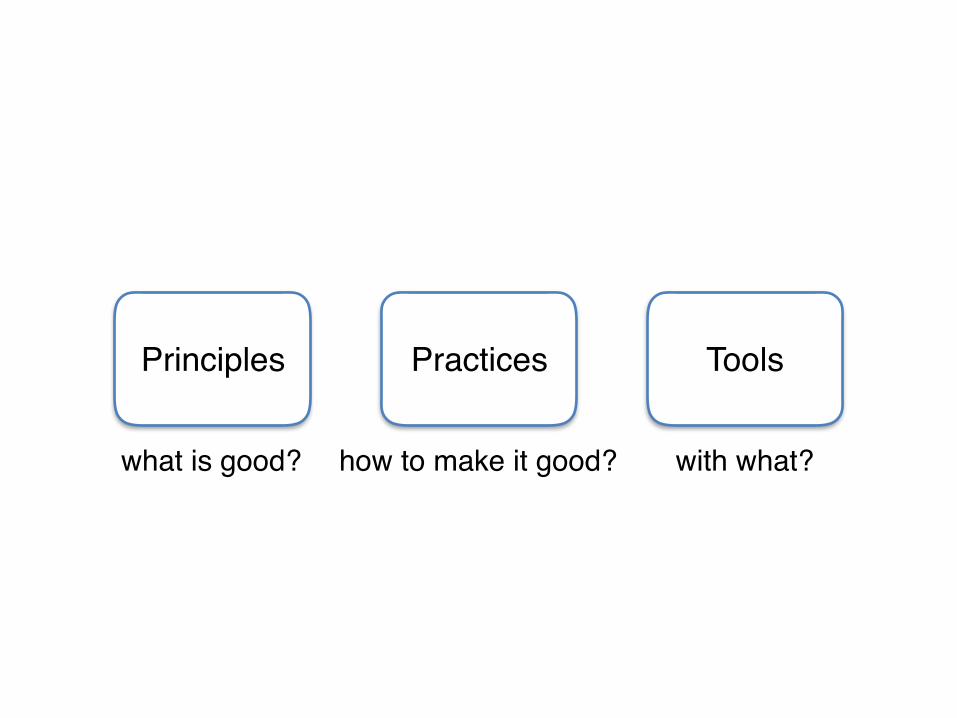
Practices ToolsPrinciples
what is good? how to make it good? with what?

Principles outlast Tools

ALERTING
CI / CD
TESTING
LOGGING
MONITORING

170 functions
WOOF!
? ?
timeis a good fit
1st function in prod!

SECURITY
DISTRIBUTEDTRACING
CONFIGMANAGEMENT

evolving the PLATFORM

rebuilt search
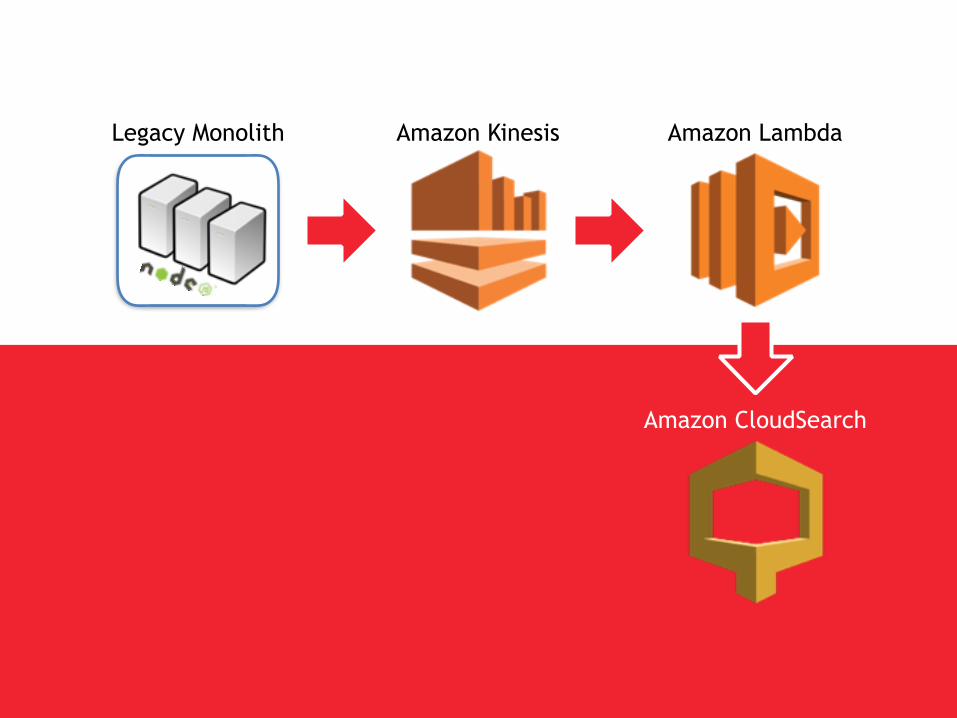
Legacy Monolith Amazon Kinesis Amazon Lambda
Amazon CloudSearch

Legacy Monolith Amazon Kinesis Amazon Lambda
Amazon CloudSearchAmazon API Gateway Amazon Lambda

new analytics pipeline

Legacy Monolith Amazon Kinesis Amazon Lambda
Google BigQuery

Legacy Monolith Amazon Kinesis Amazon Lambda
Google BigQuery
1 developer, 2 daysdesign production
(his 1st serverless project)

Legacy Monolith Amazon Kinesis Amazon Lambda
Google BigQuery“nothing ever got done
this fast at Skype!”
- Chris Twamley

- Dan North
“lead time to someone saying thank you is the only reputation
metric that matters.”

Rebuiltwith Lambda







Rebuiltwith Lambda

BigQuery

BigQuery

grapheneDB
BigQuery

grapheneDB
BigQuery

grapheneDB
BigQuery

getting PRODUCTION READY

CHOOSE A
FRAMEWORK
DEPLOYMENT


https://github.com/awslabs/serverless-application-model






TESTING


Level of Testing
1.Unitdo our objects do the right thing?are they easy to work with?


Level of Testing
1.Unit2.Integrationdoes our code work against code we can’t change?
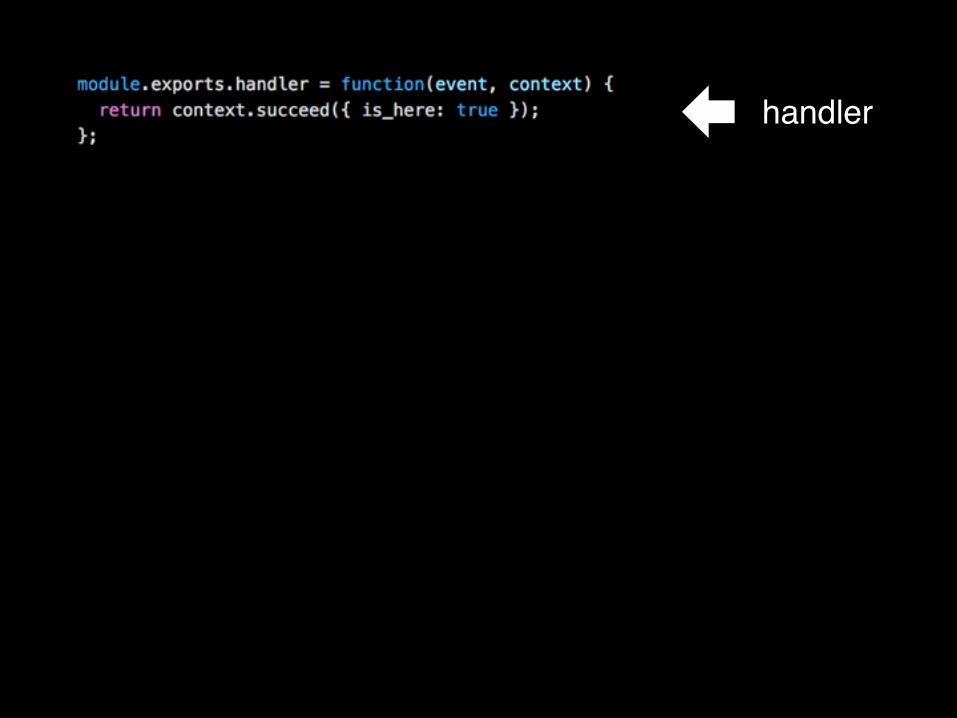
handler

handler
test by invoking the handler

Level of Testing
1.Unit2.Integration3.Acceptancedoes the whole system work?

Level of Testing
unit
integration
acceptance
feedb
ack
confidence

“…We find that tests that mock external libraries often need to be complex to get the code into the right state for the functionality we need to exercise.
The mess in such tests is telling us that the design isn’t right but, instead of fixing the problem by improving the code, we have to carry the extra complexity in both code and test…”
Don’t Mock Types You Can’t Change

“…The second risk is that we have to be sure that the behaviour we stub or mock matches what the external library will actually do…
Even if we get it right once, we have to make sure that the tests remain valid when we upgrade the libraries…”
Don’t Mock Types You Can’t Change

Don’t Mock Types You Can’t ChangeServices

Paul Johnston
The serverless approach to testing is different and may
actually be easier.
http://bit.ly/2t5viwK

LambdaAPI Gateway DynamoDB

LambdaAPI Gateway DynamoDB
Unit Tests
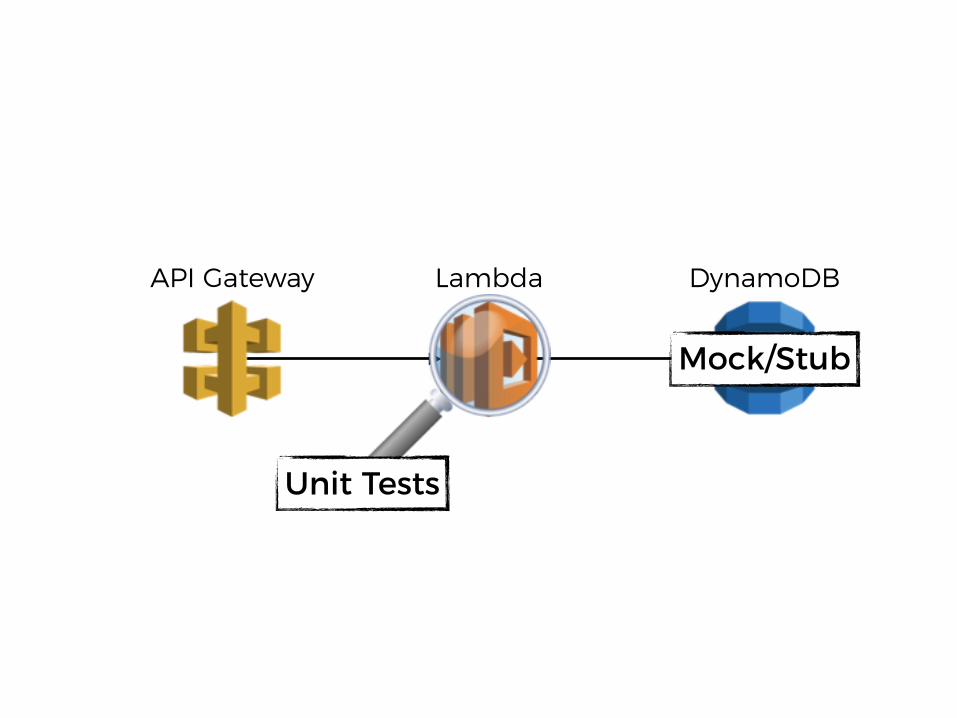
LambdaAPI Gateway DynamoDB
Unit Tests
Mock/Stub

is our request correct?
is the request mapping set up correctly?is the API resources
configured correctly?
are we assuming the correct schema?
LambdaAPI Gateway DynamoDB
is Lambda proxy configured correctly?
is IAM policy set up correctly?
is the table created?
what unit tests will not tell you…


most Lambda functions are simple have single purpose, the risk of
shipping broken software has largely shifted to how they integrate with
external services
observation


But it slows down my feedback loop…
IT’S NOT ABOUT YOU!


IT’S CHINA. NOT SCHINA.







me
Your users shouldn’t be the ones to pay the price for your
faster feedback loop. Optimise for working software.
Test your software end-to-end.

“…Wherever possible, an acceptance test should exercise the system end-to-end without directly calling its internal code.
An end-to-end test interacts with the system only from the outside: through its interface…”
Testing End-to-End
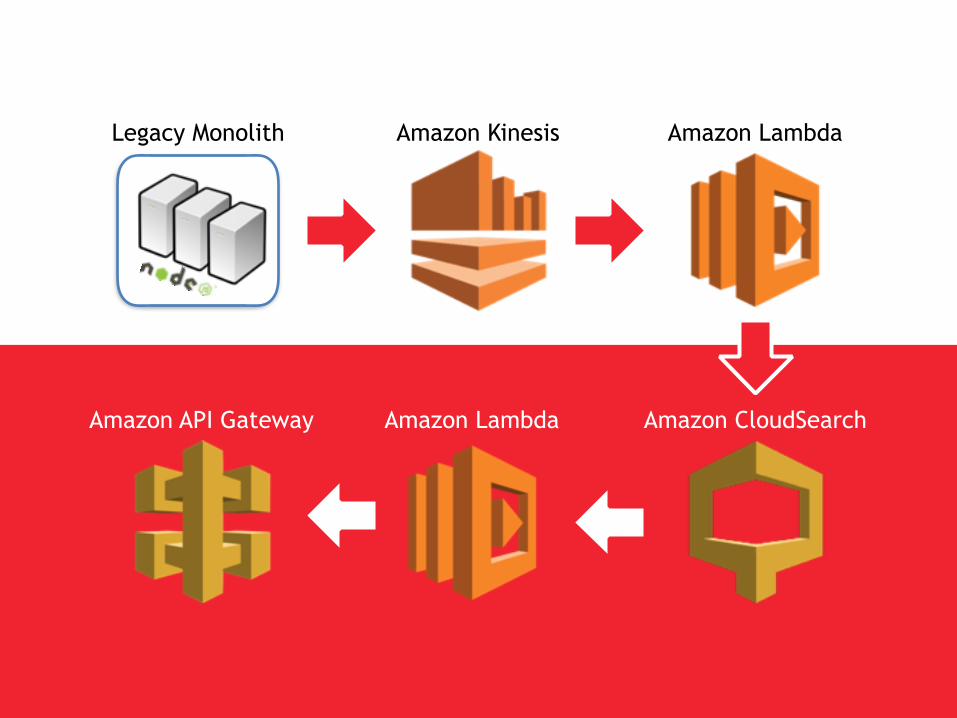
Legacy Monolith Amazon Kinesis Amazon Lambda
Amazon CloudSearchAmazon API Gateway Amazon Lambda

Legacy Monolith Amazon Kinesis Amazon Lambda
Amazon CloudSearchAmazon API Gateway Amazon Lambda
Test Input

Legacy Monolith Amazon Kinesis Amazon Lambda
Amazon CloudSearchAmazon API Gateway Amazon Lambda
Test Input
Validate

integration tests exercise system’s Integration with its
external dependencies

acceptance tests exercise system End-to-End from
the outside

integration tests differ from acceptance tests only in HOW the
Lambda functions are invoked
observation




CI + CD PIPELINE

“the earlier you consider CI + CD, the more time you save in the long run”
- me

“…We prefer to have the end-to-end tests exercise both the system and the process by which it’s built and deployed…
This sounds like a lot of effort (it is), but has to be done anyway repeatedly during the software’s lifetime…”
Testing End-to-End

“deployment scripts that only live on the CI
box is a disaster waiting to happen”
- me
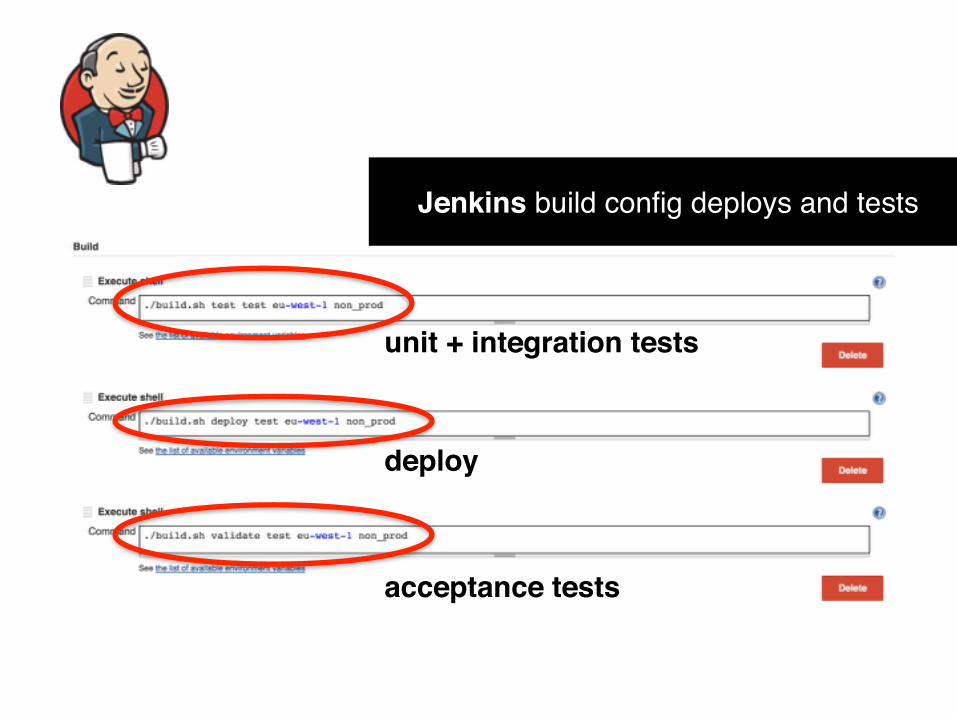
Jenkins build config deploys and tests
unit + integration tests
deploy
acceptance tests

if [ "$1" = "deploy" ] && [ $# -eq 4 ]; then STAGE=$2 REGION=$3 PROFILE=$4
npm install AWS_PROFILE=$PROFILE 'node_modules/.bin/sls' deploy -s $STAGE -r $REGION elif [ "$1" = "int-test" ] && [ $# -eq 4 ]; then STAGE=$2 REGION=$3 PROFILE=$4
npm install AWS_PROFILE=$PROFILE npm run int-$STAGE elif [ "$1" = "acceptance-test" ] && [ $# -eq 4 ]; then STAGE=$2 REGION=$3 PROFILE=$4
npm install AWS_PROFILE=$PROFILE npm run acceptance-$STAGE else usage exit 1 fi

build.sh allows repeatable builds on both local & CI

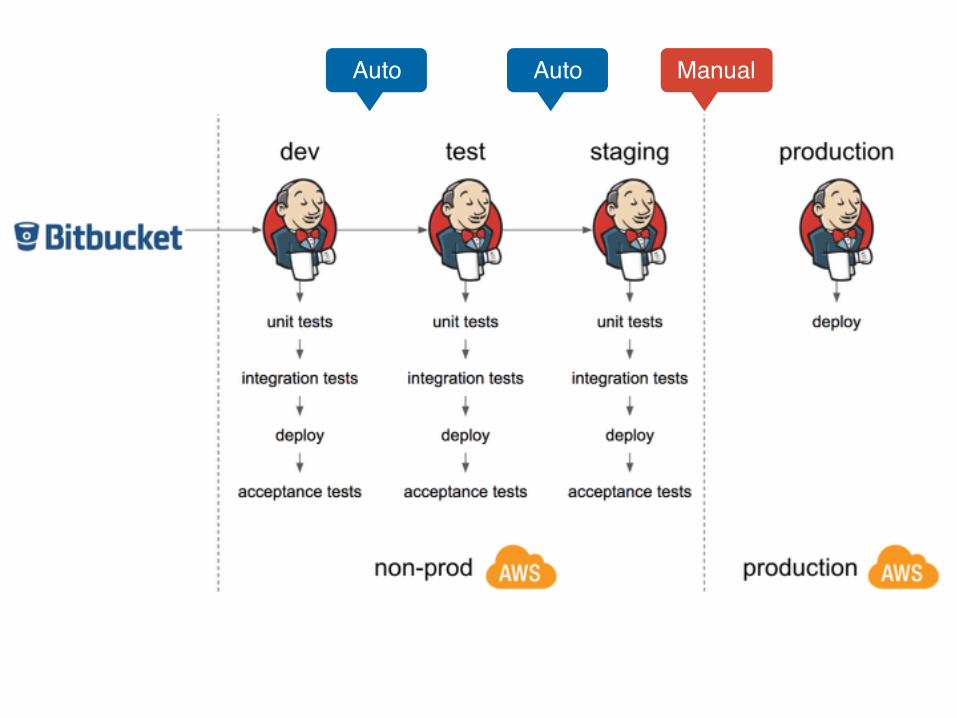
Auto Auto Manual

LOGGING


2016-07-12T12:24:37.571Z 994f18f9-482b-11e6-8668-53e4eab441ae GOT is off air, what do I do now?

2016-07-12T12:24:37.571Z 994f18f9-482b-11e6-8668-53e4eab441ae GOT is off air, what do I do now?
UTC Timestamp API Gateway Request Id
your log message

function name
date
function version

LOG OVERLOAD

CENTRALISE LOGS

CENTRALISE LOGS
MAKE THEM EASILYSEARCHABLE

+ +the elk stack

CloudWatch Logs

CloudWatch Logs AWS Lambda ELK stack

CloudWatch Events



DISTRIBUTED TRACING


“my followers didn’t receive my new post!”
- a user

where could the problem be?

correlation IDs*
* eg. request-id, user-id, yubl-id, etc.

ROLL YOUR OWNCLIENTS

kinesis client
http client
sns client
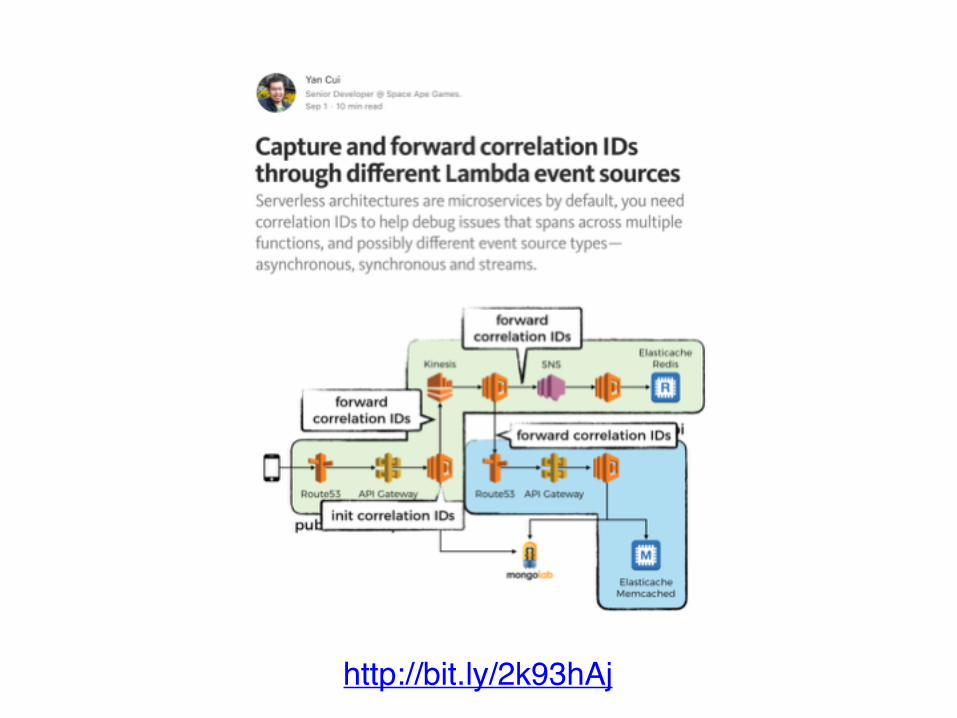

ROLL YOUR OWNCLIENTS
X-RAY

Amazon X-Ray
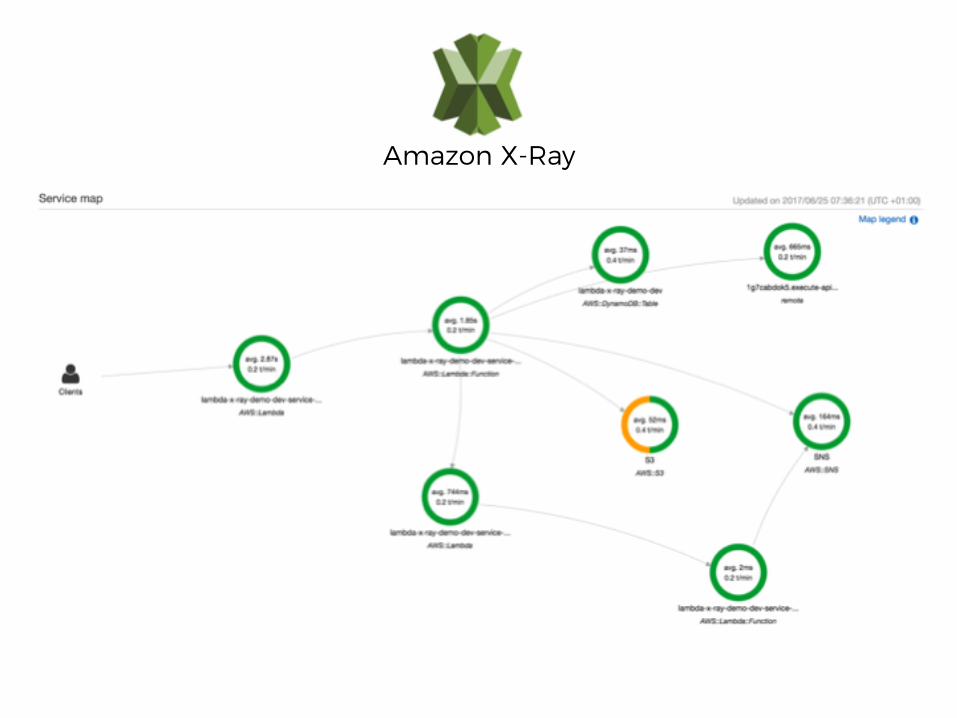
Amazon X-Ray

traces do not span over API Gateway

MONITORING + ALERTING

“where do I install monitoring agents?”

you can’t

• invocation Count• error Count• latency• throttling• granular to the minute• support custom metrics

• same metrics as CW• better dashboard• support custom metrics
https://www.datadoghq.com/blog/monitoring-lambda-functions-datadog/


“how do I batch up and send logs in the
background?”

you can’t (kinda)

console.log(“hydrating yubls from db…”);
console.log(“fetching user info from user-api”);
console.log(“MONITORING|1489795335|27.4|latency|user-api-latency”);
console.log(“MONITORING|1489795335|8|count|yubls-served”);
timestamp metric value
metric type
metric namemetrics
logs

CloudWatch Logs AWS Lambda
ELK stacklogs
metrics
CloudWatch


DASHBOARDS

DASHBOARDS
SET ALARMS

DASHBOARDS
SET ALARMS
TRACK APP-LEVELMETRICS

Not Only CloudWatch


“you really don't want your monitoring
system to fail at the same time as the
system it monitors” - me

CONFIG MANAGEMENT

easily and quickly propagate config changes


CENTRALISEDCONFIG SERVICE

config servicegoes here



SSM Parameter
Store

sensitive data should be encrypted in-flight, and at rest
(credentials, connection string, etc.)

role-based access

SSM Parameter Store
HTTPS
role-based access
encrypted in-flight

SSM Parameter Store
encrypt
role-based access

SSM Parameter Store
encrypted at-rest

HTTPS
role-based access
SSM Parameter Store
encrypted in-flight

CENTRALISEDCONFIG SERVICE
CLIENT LIBRARY

fetch & cache at Cold Start

invalidate at interval + signal


PRO TIPS
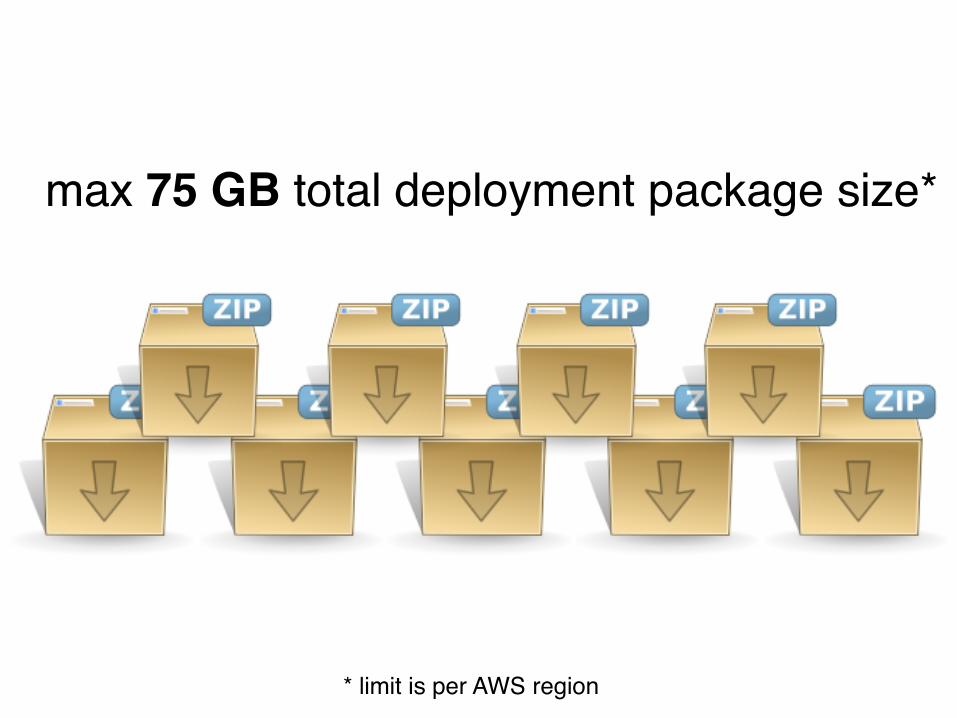
max 75 GB total deployment package size*
* limit is per AWS region

Janitor Monkey


disable versionFunctions in

install Serverless framework as dev dependency at project level
dev dependencies are excluded since 1.16.0



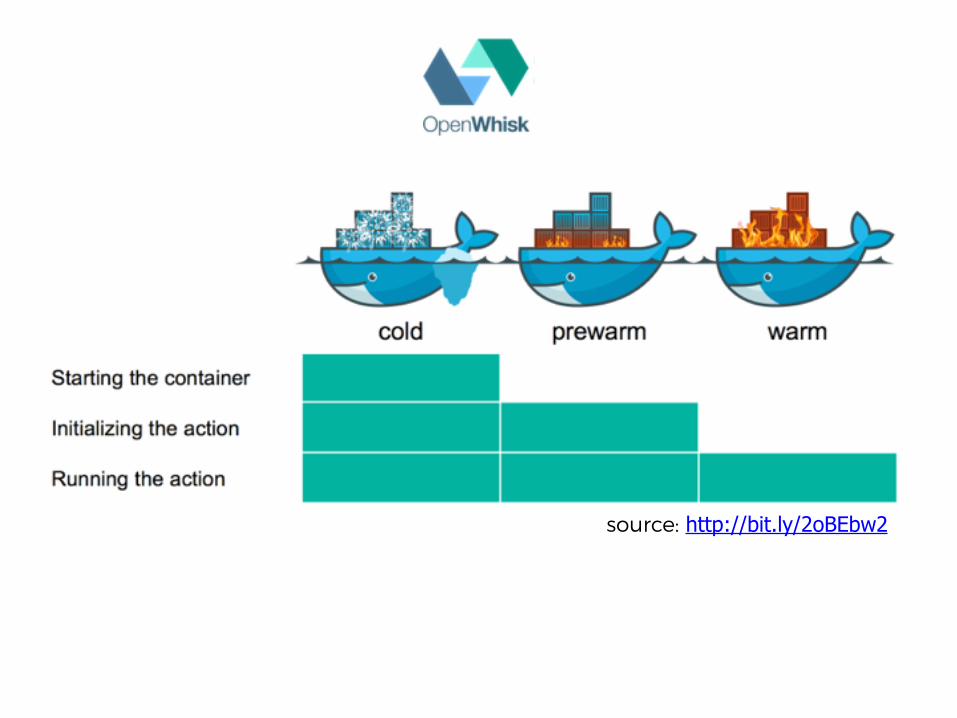
UNDERSTANDCOLDSTARTS

Amazon X-Ray1st invocation
2nd invocation
cold start

EMBRACENODE.JS & PYTHON





what about type safety?


complexity ceiling of a Node.js app
com
plex
ity

complexity ceiling of a Node.js app
com
plex
ity
referential transparencyimmutability as default
type inferenceoption typesunion types
…

for managing complexity
complexity ceiling of a Node.js app
com
plex
ity
referential transparencyimmutability as default
type inferenceoption typesunion types
…

complexity ceiling of a Node.js app
com
plex
ity
complexity ceiling of a Node.js Lambda function

if you can limit the complexity of your solution, maybe you
won’t need the tools for managing that complexity.me

AVOID HARDASSUMPTIONS
ABOUT FUNCTIONLIFETIME

USE STATE FOR
OPTIMISATION

AVOIDCOLDSTARTS

CloudWatch Event AWS Lambda

CloudWatch Event AWS Lambda
ping
ping
ping
ping

CloudWatch Event AWS Lambda
ping
ping
ping
ping

CloudWatch Event AWS Lambda
ping
ping
ping
ping
HEALTH CHECKS?

max 5 mins execution time

USE RECURSIONFOR LONG
RUNNING TASKS

CONSIDERPARTIAL
FAILURES

“AWS Lambda polls your stream and invokes your Lambda function. Therefore, if
a Lambda function fails, AWS Lambda attempts to process the erring batch of
records until the time the data expires…”
http://docs.aws.amazon.com/lambda/latest/dg/retries-on-errors.html

should function fail on partial/any failures?

SNS
Kinesis
SQS
after 3 attempts
share processing logic
events are processed in chronological order
failed events are retried out of sequence

PROCESS SQSWITH RECURSIVE
FUNCTIONS


AVOID HOTKINESS
STREAMS

“Each shard can support up to 5 transactions per second for reads, up to a maximum total data
read rate of 2 MB per second.”
http://docs.aws.amazon.com/streams/latest/dev/service-sizes-and-limits.html

“If your stream has 100 active shards, there will be 100 Lambda functions running concurrently. Then, each
Lambda function processes events on a shard in the order that they arrive.”
http://docs.aws.amazon.com/lambda/latest/dg/concurrent-executions.html

when no. of processors goes up…

ReadProvisionedThroughputExceeded
can have too many Kinesis read operations…

ReadRecords.IteratorAge
unpredictable spikes in read ‘latency’…

can kinda workaround…


clever, but costly

for subsystems that don’t have to be realtime, or are task-
based (ie. order doesn’t matter), consider other
triggers such as S3 or SNS.me

@theburningmonktheburningmonk.comgithub.com/theburningmonk

@theburningmonktheburningmonk.comgithub.com/theburningmonk
http://bit.ly/2yQZj1H
all my blog posts on Lambda








