
Analyse von Querschnittsdaten
Vom theoretischen Modell zum empirischen Ergebnis
Beispiele sozialwissenschaftlicher Datenanalysen

Warum geht es in den folgenden Sitzungen?
Vorarbeiten
Logistische Regression07.02.2007
Regression mit Dummy-Variablen31.01.2007
Heteroskedastizität24.01.2007
Spezifikation der Regressionsfunktion17.01.2007
Spezifikation der unabhängigen Variablen10.01.2007
Signifikanztests II20.12.2006
Signifikanztests I13.12.2006
Statistische Inferenz06.12.2006
Multiple Regression29.11.2006
Kontrolle von Drittvariablen22.11.2006
Bivariate Regression15.11.2006
Variablen08.11.2006
Daten25.10.2006
Beispiele18.10.2006
Einführung18.10.2006
VorlesungDatum

Gliederung
1. Theorie und Modell: ein einführendes Beispiel aus der Ökonomie
2. Theorie und Modell: ähnliches Vorgehen in anderen Disziplinen
3. Kein theoretisches Modell, aber gute Hypothesen: auch ein Beispiel
4. Schritte der Datenanalyse

Höhe der Konsumausgaben• We shall therefore define what we shall call the propensity to
consume as the functional relationship X between Y, a given level of income and C the expenditure on consumption out of that level of income, so that C = X(Y).
• The amount that the community spends on consumption depends (i) partly on the amount of its income, (ii) partly on other objectiveattendant circumstances, and (iii) partly on the subjective needs and the psychological propensities and habits of the individualscomposing it ...
• The fundamental psychological law upon which we are entitled to depend with great confidence [...] is that men are disposed [...] to increase their consumption as income increases, but not as much as the increase in their income. That is [...] dC/dY is positive and lessthan unity.
• But [...] it is also obvious that a higher absolute level of income will tend as a rule to widen the gap between income and consumption.

Keynes (1936): General Theory ...
• Aussagen über erklärende Variablen– C = f(income, circumstances, needs/habits)
• Aussagen über deren Effekte– je höher Einkommen, desto höher Konsum
• Aussagen über funktionale Form
0 und 10 wenn ,erfüllt 0 :consume topropensity average :2 Bedingung
10 :consume topropensity marginal :1 Bedingung
><<+=⇒<
<<
αββα
β
YCd(C/Y)/dY

Empirische Überprüfung• Daten
– Konsumausgaben– Einkommen– circumstances ?– needs, habits ?– Aggregatdaten (oder Mikrodaten?)– Stichprobe oder Totalerhebung?
• Statistisches Modell–
• Ergebnisse– geschätzte marginale Konsumquote:
uxy ++= 10 ββ
1β̂
600
700
800
900
1000
Rea
l per
sona
l con
sum
ptio
n ex
pend
iture
750 800 850 900 950 1000Real disposable personal income
Consume Fitted values
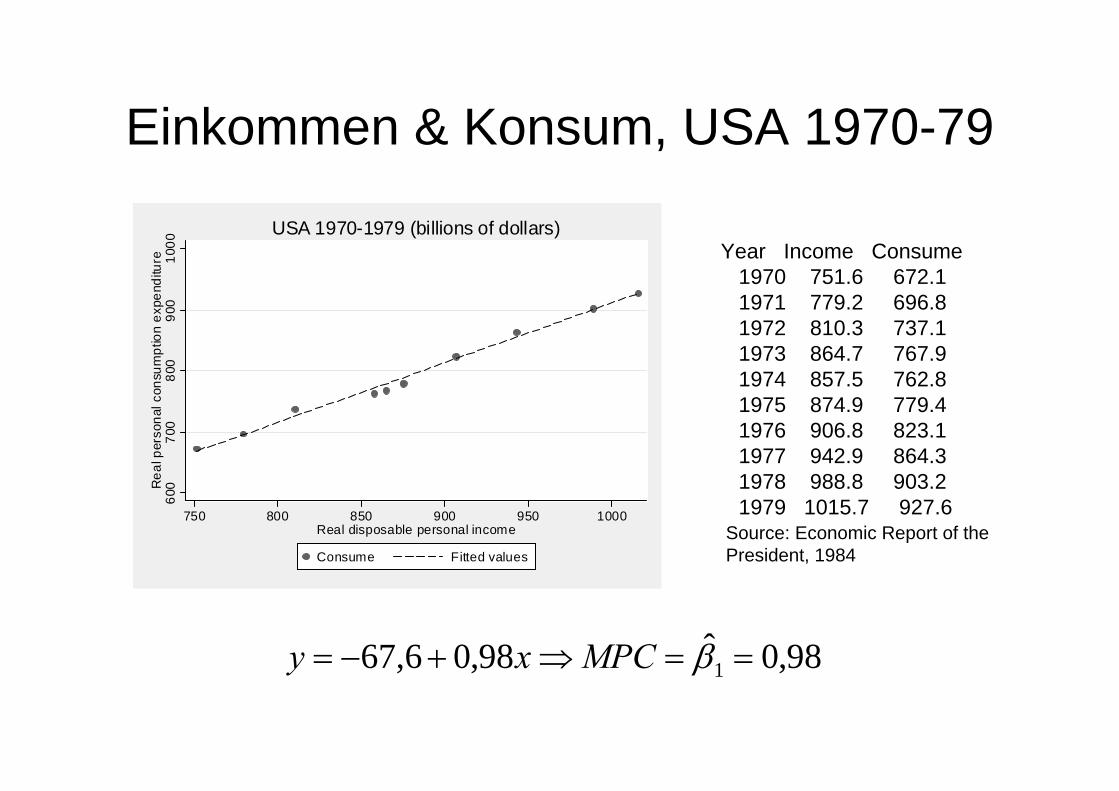
USA 1970-1979 (billions of dollars)Year Income Consume
1970 751.6 672.1 1971 779.2 696.8 1972 810.3 737.1 1973 864.7 767.9 1974 857.5 762.8 1975 874.9 779.4 1976 906.8 823.1 1977 942.9 864.3 1978 988.8 903.2 1979 1015.7 927.6
Einkommen & Konsum, USA 1970-79
98,0ˆ 98,06,67 1 ==⇒+−= βMPCxy
Source: Economic Report of thePresident, 1984

Vorgehen allgemein
1. Theoretisches (Ökonomisches) Modell2. Statistisches (Ökonometrisches) Modell3. Schätzung der Modellparameter mit
empirischen Daten4. Interpretation

Gliederung
1. Theorie und Modell: ein einführendes Beispiel aus der Ökonomie
2. Theorie und Modell: ähnliches Vorgehen in anderen Disziplinen
3. Kein theoretisches Modell, aber gute Hypothesen: auch ein Beispiel
4. Schritte der Datenanalyse

Beispiele
1. Bildungsökonomie: Bildungsrenditen• Kölner Zeitschrift für Soziologie und
Sozialpsychologie: Blossfeld (1984)
2. Politologie: Wahlbeteiligung• American Political Science Review: Riker /
Ordeshok (1968)
3. Soziologie: Scheidungen• Journal of Mathematical Sociology: Brüderl /
Kalter (2001)

Höhe der Erwerbseinkommen• Menschen investieren in Ausbildung zwecks Erzielung
höherer Einkommen– Schul- und Berufsausbildung– allgemeine berufs- und betriebsspezifische Kenntnisse („on the
job“, Weiterbildung)• Gewinn: höheres Erwerbseinkommen• Kosten: entgangenes Einkommen während der
Ausbildung• Investitionen lohnen sich insbesondere zu Beginn des
Erwerbslebens• Wertverlust der Investition: Veraltung des Wissens,
Vergessen mit biologischem Altern

Humankapitaltheorie (Mincer, Schultz, Becker)• Aussagen über erklärende Variablen
• Einkommen = f(Ausbildung, Berufserfahrung)
• Aussagen über deren Effekte• je höher Ausbildung, desto höher Einkommen• je höher Berufserfahrung, desto höher Einkommen• mit zunehmendem Lebensalter entwertet Kapital
• Aussagen über funktionale Form• Erwerbseinkommen (w, w0), Ausbildungsdauer (S),
Berufserfahrung (E), Rendite (ρ), Erfahrung (α1, α2)
0,0,0mit )ln()ln(
21
2210
<>>⋅+⋅+⋅+=
ααααρ
ρEESww

Exkurs: funktionale Form
ρρρρρρρρ
ρρρ
ρρρρρρ
swwsww
ww
wwwwwwwwwww
ss
s
ss
+=⇔=≈+====
+++=
++=+=⇔−=+=⇔−=
)ln()ln()exp( :giltdann )exp()1( und wenn
)1()1)(1(
)1)(1()1(/)()1(/)(
00
21
210
2102121122
1010011
K
K

Empirische Überprüfung• Daten
– Erwerbseinkommen– Dauer der Schul- und Berufsausbildung– Erwerbserfahrung– Kontrollvariablen (Alter, Geschlecht, Branche usw.)– Mikrodaten (Aggregatdaten?)– Stichprobe
• Statistisches Modell–
• Ergebnisse– z.B. geschätzte Bildungsrendite:
uxxy +++= 22110 βββ
1β̂

Schätzergebnisse
• Mincer, J. (1974): Schooling, experienceand earnings. New York: Columbia University PressBildungsrendite: 10,7% pro Ausbildungsjahr
285,00012,0018,0107,020,6)ln(
2
2
=⋅−⋅+⋅+=
REESw

Wahlbeteiligung• Wahlbeteiligung ist ein Ergebnis einer
Nutzenabwägung• Nutzenkomponenten:
– Parteiendifferential (Benefit): positiv– Bürgerpflicht (Duty): positiv– Kosten der Wahlbeteiligung (Cost): negativ
• Der erwartete relative Vorteil (Benefit), den der Wahlsieg einer Partei gegenüber dem Wahlsieg einer anderen Partei erbringt, ist nur dann verhaltenswirksam, wenn die Wahrscheinlichkeit (Probability), mit der eigenen Stimme den Wahlsieg der favorisierten Partei herbeizuführen, hoch eingeschätzt wird.

Theorie des rationalen Wählers (Downs)• Aussagen über erklärende Variablen
• Voting = f(Benefit, Duty, Cost, Probability)
• Aussagen über deren Effekte• je höher Kosten, desto geringer Wahlbeteiligung• usw.
• Aussagen über funktionale Form• CDBPV −+⋅=

Empirische Überprüfung• Daten
– Wahlbeteiligung (ja, nein)– B: Indikatoren für Kompetenzen der Parteien– D: Indikatoren für verinnerlichte Wahlnorm– C: Indikatoren für Kosten der Wahlbeteiligung– P: wahrgenommene Bedeutung der eigenen Stimme– Mikrodaten, Stichprobe
• Statistisches Modell– siehe nächste Seite
• Ergebnisse– Effekte der einzelnen Nutzenkomponenten

Statistisches Modell
)exp(1)exp()1Pr(
:verteiltextremwert wenn
ligung) Wahlbeteikeine Nutzen, (negativer 0wenn 0ligung) WahlbeteiNutzen, (positiver 0wenn 1
: und zwischen ngZusammenha
nein)! (ja, ligung Wahlbeteiebeobachtetdirekt über nur Daten Daten! keine der Wahl,n Nettonutzerer beobachtbadirekt nicht :
22110
22110
*
*
*
22110*
kk
kk
*
kk
xxxxxxy
u
yy
y
yy
yy
uxxxy
ββββββββ
ββββ
+++++++++
==
⎩⎨⎧
<≥
=
+++++=
K
K
K

Schätzergebnisse
• Riker, W.H. / Ordeshook, P.C. (1968): A theoryof the calculus of voting. American PoliticalScience Review 62: 25-42
• Kühnel, S. (1997): Gibt es den rationalen Wähler? Eine Logitanalyse zur Erklärungskraft des Rational-Choice-Ansatzes in der empirischen Wahlforschung. S. 403-429 in: Andreß, H.J. / Hagenaars, J.A. / Kühnel, S.: Analyse von Tabellen und kategorialen Daten. Berlin et al.: Springer

Eheschließung und Scheidung• Personen heiraten, wenn für sie der Nutzen der
Lebensform „Ehe“ größer ist als die Summe ihrer Nutzen in alternativen Lebensformen.
• Eine Scheidung tritt dann auf, wenn der Ehenutzen geringer ist.
• Aufgrund unvollständiger Information zum Zeitpunkt der Heirat kann der Ehenutzenüberschätzt werden.
• Der Nutzen der Ehe steigt mit ehespezifischenInvestitionen.

Theorie der Ehestabilität (Becker)
• Aussagen über erklärende Variablen• Scheidungsrisiko = f(Information, Investition)
• Aussagen über deren Effekte• je höher ehespezifische Investitionen, desto
geringer das Scheidungsrisiko• usw.
• Aussagen über funktionale Form• z.B. über den zeitlichen Verlauf des
Scheidungsrisikos („verflixtes siebtes Jahr“)

Empirische Überprüfung• Daten
– Scheidung (ja, nein)– Ehedauer– Indikatoren für Informationen über Ehepartner (z.B. Dauer der
Bekanntschaft)– Indikator für ehespezifische Investitionen (z.B. Kinder,
Hauseigentum– Mikrodaten, Stichprobe
• Statistisches Modell– Modell für Zeitdauern– Problematik zensierter Beobachtungen
• Ergebnisse– Determinanten der Ehescheidung

Schätzergebnisse
• Brüderl, J. / Kalter, F. (2001): Thedissolution of marriages: the role of information and marital-specific capital. Journal of Mathematical Sociology 25: 403-421

Zwischenresümee• Es gibt einen Unterschied zwischen
statistischem und theoretischem Modell.• Das statistische Modell beschreibt das, was
angesichts der vorliegenden Daten und der verfügbaren statistischen Methoden möglich ist.
• Das theoretische Modell formalisiert Aussagen der zugrunde liegenden Theorie.
• Es gibt außerdem Anregungen für das statistische Modell (Variablen, Hypothesen, funktionale Form).

Gliederung
1. Theorie und Modell: ein einführendes Beispiel aus der Ökonomie
2. Theorie und Modell: ähnliches Vorgehen in anderen Disziplinen
3. Kein theoretisches Modell, aber gute Hypothesen: auch ein Beispiel
4. Schritte der Datenanalyse

Einkommensungleichheit• Alderson, A.S. / Nielsen, F. (2002): Globalization
and the Great U-Turn: Income Inequality Trends in 16 OECD Countries. American Journal of Sociology 107: 1244-1299Abstract: The debate on the resurgence of incomeinequality in some advanced industrial societies has often focused on the impact of an increasingly integratedworld economy, typified by growing capital mobility, heightened international competition, and an increase in migration. This study represents one of the firstsystematic, cross-national examinations of the role of globalization in the inequality “U-turn.”

Vorgehen (1)• Studium der relevanten Literatur• Sammlung möglicher Einflussfaktoren
– Kapitalflucht– Nord-Süd-Handel– Migration– Sektor-Dualismus (Landwirtschaft / Industrie)– institutionelle Faktoren (Gewerkschaften, Arbeitsmarkt)– usw.
• Formulierung von Hypothesen– Beispiel: Je geringer der gewerkschaftliche Organisationsgrad,
desto höher die Einkommensungleichheit• Daten für OECD-Länder (jeweils verschiedene Jahre)• Schätzung eines linear-additiven Regressionsmodells


Vorgehen (2)
Vorhersagen der Theorie manchmal nicht eindeutig
funktionale Form ergibt sich häufig aus der Theorie
Datenfit und statistische Kriterien entscheiden über funktionale Form
relevante Variablen sind bekannt (behauptet Theorie)
Anzahl unabhängiger Variablen offen (abhängig von
Literatursuche)
Deduktion aus konsistentem theoretischen Ansatz
Addition vorliegender Forschungsergebnisse
vorherige BeispieleAldersen / Nielsen

Gliederung
1. Theorie und Modell: ein einführendes Beispiel aus der Ökonomie
2. Theorie und Modell: ähnliches Vorgehen in anderen Disziplinen
3. Kein theoretisches Modell, aber gute Hypothesen: auch ein Beispiel
4. Schritte der Datenanalyse

Schritte der Datenanalyse
1. Literaturstudium2. Wenn möglich: Theoretisches Modell3. Mindestens: Hypothesen4. Erhebung / Auswahl geeigneter Daten5. Statistisches Modell6. Schätzung der Modellparameter7. Darstellung und Interpretation der Ergebnisse8. Publikation

Davon in dieser Veranstaltung
1. Literaturstudium2. Wenn möglich: Theoretisches Modell3. Mindestens: Hypothesen4. Erhebung / Auswahl geeigneter Daten5. Statistisches Modell6. Schätzung der Modellparameter7. Darstellung und Interpretation der Ergebnisse8. Publikation

Zum Schluss

Literatur• Wooldridge, J. (2003): Introductory econometrics: a
modern approach. South Western College Publishing.– Teile von Kapitel 1 (WO 1-5) geben einen Überblick über
theoretische (ökonomische) und statistische (ökonometrische) Modelle mit Beispielen.
• Berndt, E.R. (1991): The practice of econometrics: classic and contemporary. Reading, MA: Addison-Wesley– Sehr schöne Sammlung von Anwendungen für Ökonomen, z.B.
Kapitel 5 mit Analysen der Determinanten von Erwerbseinkommen.
• Andreß, H.J. / Hagenaars, J.A. / Kühnel, S.: Analyse von Tabellen und kategorialen Daten. Berlin et al.: Springer– Kapitel 6-9 beinhalten Anwendungen kategorialer Datenanalyse,
u.a. zu Determinanten des Wahlverhaltens.







