
Accelerating Big Data with Hadoop (HDFS, MapReduce and HBase) and Memcached
Dhabaleswar K. (DK) Panda
The Ohio State University
E-mail: [email protected]
http://www.cse.ohio-state.edu/~panda
Talk at HPC Advisory Council Lugano Conference (2013)
by

Big Data
• Provides groundbreaking opportunities for enterprise
information management and decision making
• The rate of information growth appears to be exceeding
Moore’s Law
• The amount of data is exploding; companies are capturing
and digitizing more information that ever
• 35 zettabytes of data will be generated and consumed by
the end of this decade
Courtesy: John Gantz and David Reinsel, "The Digital Universe Decade
– Are You Ready?" May 2010.
http://www.emc.com/collateral/analyst-reports/idc-digital-
universe-are-you-ready.pdf
2 HPC Advisory Council Lugano Conference, Mar '13

Frequency of Big Data – An Example
Graph of 1026 Twitter users whose tweets contain ‘big data’ https://nodexlgraphgallery.org/Pages/Graph.aspx?graphID=1266
Tweets made over a period of 8 hours and 24 minutes
3 HPC Advisory Council Lugano Conference, Mar '13

HPC Advisory Council Lugano Conference, Mar '13 4
Trends of Networking Technologies in TOP500 Systems
Interconnect Family – Performance Share Interconnect Family – Systems Share

HPC and Advanced Interconnects
• High-Performance Computing (HPC) has adopted advanced interconnects and protocols
– InfiniBand
– 10 Gigabit Ethernet/iWARP
– RDMA over Converged Enhanced Ethernet (RoCE)
• Very Good Performance
– Low latency (few micro seconds)
– High Bandwidth (100 Gb/s with dual FDR InfiniBand)
– Low CPU overhead (5-10%)
• OpenFabrics software stack with IB, iWARP and RoCE interfaces are driving HPC systems
• Many such systems in Top500 list
5 HPC Advisory Council Lugano Conference, Mar '13

• Message Passing Interface (MPI)
• Parallel File Systems
• Storage Systems
• Almost 12 years of Research and Development since
InfiniBand was introduced in October 2000
• Other Programming Models are emerging to take
advantage of High-Performance Networks
– UPC
– OpenSHMEM
– Hybrid MPI+PGAS (OpenSHMEM and UPC)
6
Use of High-Performance Networks for Scientific Computing
HPC Advisory Council Lugano Conference, Mar '13

• Focuses on large data and data analysis
• Hadoop (HDFS, HBase, MapReduce) environment is gaining
a lot of momentum
• Memcached is also used for Web 2.0
7
Big Data/Enterprise/Commercial Computing
HPC Advisory Council Lugano Conference, Mar '13

Can High-Performance Interconnects Benefit Enterprise Computing?
• Most of the current enterprise systems use 1GE
• Concerns for performance and scalability
• Usage of High-Performance Networks is beginning to draw interest
– Oracle, IBM, Google are working along these directions
• What are the challenges?
• Where do the bottlenecks lie?
• Can these bottlenecks be alleviated with new designs (similar to the designs adopted for MPI)?
8 HPC Advisory Council Lugano Conference, Mar '13

• Overview of Hadoop (HDFS, MapReduce and HBase) and Memcached
• Challenges in Accelerating Enterprise Middleware
• Designs and Case Studies – Hadoop
• HDFS
• MapReduce
• HBase
• Combination (HDFS + HBase)
– Memcached
• Conclusion and Q&A
Presentation Outline
9 HPC Advisory Council Lugano Conference, Mar '13

Big Data Processing with Hadoop
• The open-source implementation of MapReduce programming model for Big Data Analytics
• http://hadoop.apache.org/
• Framework includes: MapReduce, HDFS, and HBase
• Underlying Hadoop Distributed File System (HDFS) used by MapReduce and HBase
• Model scales but high amount of communication during intermediate phases
10 HPC Advisory Council Stanford Conference, Mar'13

Hadoop Distributed File System (HDFS)
• Primary storage of Hadoop;
highly reliable and fault-tolerant
• Adopted by many reputed
organizations
– eg:- Facebook, Yahoo!
• NameNode: stores the file system namespace
• DataNode: stores data blocks
• Developed in Java for platform-
independence and portability
• Uses sockets for communication!
(HDFS Architecture)
HPC Advisory Council Lugano Conference, Mar '13 11

Network-Level Interaction Between Clients and Data Nodes in HDFS
12
High
Performance
Networks
(HDD/SSD)
(HDD/SSD)
(HDD/SSD)
...
...
(HDFS Data Nodes)(HDFS Clients)
...
...
HPC Advisory Council Stanford Conference, Mar '13

HPC Advisory Council Lugano Conference, Mar '13 13
HBase
• Apache Hadoop Database
(http://hbase.apache.org/)
• Semi-structured database,
which is highly scalable
• Integral part of many
datacenter applications
– eg:- Facebook Social Inbox
• Developed in Java for platform-
independence and portability
• Uses sockets for
communication!
ZooKeeper
HBase
Client
HMaster
HRegion
Servers
HDFS
(HBase Architecture)

Network-Level Interaction Between HBase Clients, Region Servers and Data Nodes
14
(HBase Clients) (HRegion Servers) (Data Nodes)
(HDD/SSD)
(HDD/SSD)
(HDD/SSD)
...
......
... ...
...
High
Performance
Networks
High
Performance
Networks
HPC Advisory Council Stanford Conference, Mar '13
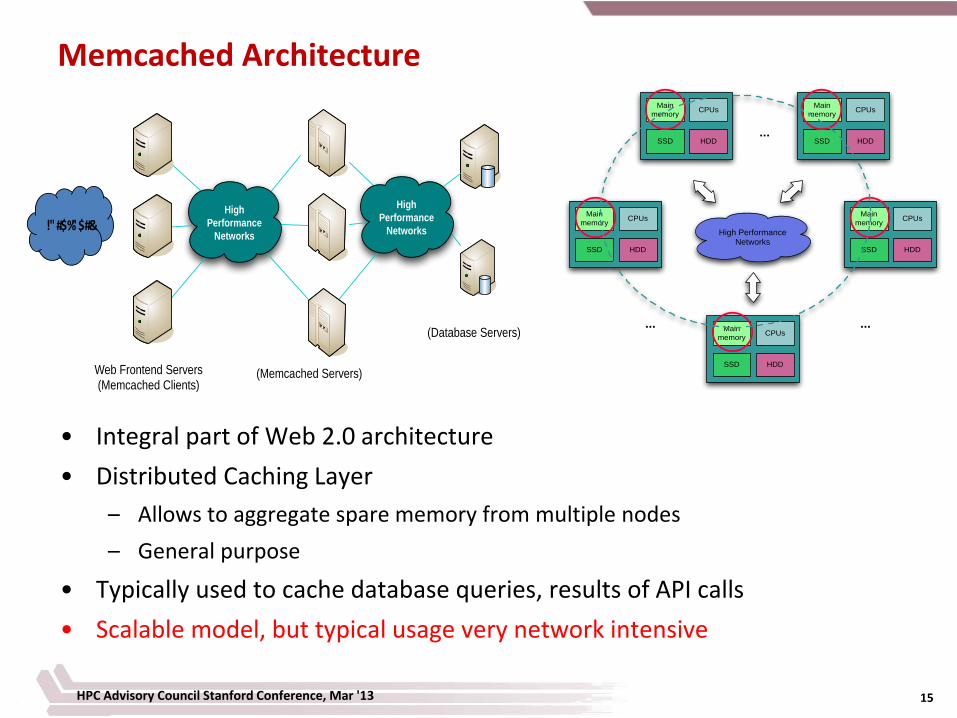
Memcached Architecture
• Integral part of Web 2.0 architecture
• Distributed Caching Layer
– Allows to aggregate spare memory from multiple nodes
– General purpose
• Typically used to cache database queries, results of API calls
• Scalable model, but typical usage very network intensive
15
!"#$%"$#&
Web Frontend Servers (Memcached Clients)
(Memcached Servers)
(Database Servers)
High
Performance
Networks
High
Performance
Networks
Main
memoryCPUs
SSD HDD
High Performance Networks
... ...
...
Main
memoryCPUs
SSD HDD
Main
memoryCPUs
SSD HDD
Main
memoryCPUs
SSD HDD
Main
memoryCPUs
SSD HDD
HPC Advisory Council Stanford Conference, Mar '13

• Overview of Hadoop (HDFS, MapReduce and HBase) and Memcached
• Challenges in Accelerating Enterprise Middleware
• Designs and Case Studies – Hadoop
• HDFS
• MapReduce
• HBase
• Combination (HDFS and HBase)
– Memcached
• Conclusion and Q&A
Presentation Outline
16 HPC Advisory Council Lugano Conference, Mar '13

Designing Communication and I/O Libraries for Enterprise Systems: Challenges
HPC Advisory Council Lugano Conference, Mar '13 17
D at ac e n t e r M i ddl e war e (H D F S , H Ba s e , M a pRe duc e , M e m c a c he d)
N e t w orki ng T e c hnol ogi e s (Infi ni Ba nd, 1/ 10/ 40 G i G E ,
RN ICs & Int e l l i ge nt N ICs )
S t ora ge T e c hnol ogi e s (H D D or S S D )
P oi nt -t o-P oi nt
Com m uni c a t i on
Q oS
T hre a di ng M ode l s a nd
S ync hroni z a t i on
F a ul t T ol e ra nc e I/ O a nd F i l e s ys t e m s
Com m u n i c at i on an d I / O L i br ar y
P r ogr am m i n g M ode l s (S oc ke t )
Appl i c at i on s
Com m odi t y Com put i ng S ys t e m
A rc hi t e c t ure s (s i ngl e , dua l , qua d, ..)
M ul t i / M a ny-c ore A rc hi t e c t ure
a nd A c c e l e ra t ors

Common Protocols using Open Fabrics
18
Application
Verbs Sockets
Application Interface
SDP
RDMA
SDP
InfiniBand Adapter
InfiniBand Switch
RDMA
IB Verbs
InfiniBand Adapter
InfiniBand Switch
User
space
RDMA
RoCE
RoCE Adapter
User
space
Ethernet Switch
TCP/IP
Ethernet Driver
Kernel Space
Protocol
InfiniBand Adapter
InfiniBand Switch
IPoIB
Ethernet Adapter
Ethernet Switch
Adapter
Switch
1/10/40 GigE
iWARP
Ethernet Switch
iWARP
iWARP Adapter
User
space IPoIB
TCP/IP
Ethernet Adapter
Ethernet Switch
10/40 GigE-TOE
Hardware Offload
RSockets
InfiniBand Adapter
InfiniBand Switch
User
space
RSockets
HPC Advisory Council Lugano Conference, Mar '13

Can Big Data Processing Systems be Designed with High-Performance Networks and Protocols?
19
Enhanced Designs
Application
Accelerated Sockets
10 GigE or InfiniBand
Verbs / Hardware Offload
Current Design
Application
Sockets
1/10 GigE Network
• Sockets not designed for high-performance
– Stream semantics often mismatch for upper layers (Memcached, HBase, Hadoop)
– Zero-copy not available for non-blocking sockets
Our Approach
Application
OSU Design
10 GigE or InfiniBand
Verbs Interface
HPC Advisory Council Lugano Conference, Mar '13

Interplay between Storage and Interconnect/Protocols
• Most of the current generation enterprise systems use the
traditional hard disks
• Since hard disks are slower, high performance
communication protocols may not have impact
• SSDs and other storage technologies are emerging
• Does it change the landscape?
20 HPC Advisory Council Lugano Conference, Mar '13

• Overview of Hadoop (HDFS, MapReduce and HBase) and Memcached
• Challenges in Accelerating Enterprise Middleware
• Designs and Case Studies – Hadoop
• HDFS
• MapReduce
• HBase
• Combination (HDFS + HBase)
– Memcached
• Conclusion and Q&A
Presentation Outline
21 HPC Advisory Council Lugano Conference, Mar '13

HDFS-RDMA Design Overview
• JNI Layer bridges Java based HDFS with communication library written in native code
• Only the communication part of HDFS Write is modified; No change in HDFS architecture
22
HDFS
IB Verbs
InfiniBand
Applications
1/10 GigE, IPoIB Network
Java Socket Interface
Java Native Interface (JNI)
Write Others
OSU Design
HDFS Write involves
replication; more
network intensive
HDFS Read is mostly
node-local
Enables high performance RDMA communication, while supporting traditional socket interface
HPC Advisory Council Lugano Conference, Mar '13

Communication Times in HDFS
• Cluster B with 32 HDD DataNodes
– 30% improvement in communication time over IPoIB (32Gbps)
– 87% improvement in communication time over 1GigE
• Similar improvements are obtained for SSD DataNodes
0
10
20
30
40
50
60
70
80
90
100
2GB 4GB 6GB 8GB 10GB
Co
mm
un
icat
ion
Tim
e (s
)
File Size (GB)
1GigE
IPoIB (QDR)
OSU-IB (QDR)
Reduced by 30%
N. S. Islam, M. W. Rahman, J. Jose, R. Rajachandrasekar, H. Wang, H. Subramoni, C. Murthy and D. K. Panda ,
High Performance RDMA-Based Design of HDFS over InfiniBand , Supercomputing (SC), Nov 2012
23 HPC Advisory Council Lugano Conference, Mar '13

Evaluations using TestDFSIO
• Cluster with 32 HDD DataNodes
– 13.5% improvement over IPoIB (32Gbps) for 8GB file size
• Cluster with 4 SSD DataNodes
– 15% improvement over IPoIB (32Gbps) for 8GB file size
0
50
100
150
200
250
300
350
2 4 6 8 10
Thro
ugh
pu
t (M
ega
Byt
es/
s)
File Size (GB)
1GigE IPoIB (QDR) OSU-IB (QDR)
0
20
40
60
80
100
120
140
2 4 6 8 10
Thro
ugh
pu
t (M
ega
Byt
es/
s)
File Size (GB)
1GigE IPoIB (QDR) OSU-IB (QDR)
Cluster with 32 HDD Nodes Cluster with 4 SSD Nodes
Increased by 13.5%
Increased by 15%
24 HPC Advisory Council Lugano Conference, Mar '13

Evaluations using TestDFSIO
• Cluster with 4 DataNodes, 1 HDD per node
– 10% improvement over IPoIB (32Gbps) for 10GB file size
• Cluster with 4 DataNodes, 2 HDD per node
– 16.2% improvement over IPoIB (32Gbps) for 10GB file size
• 2 HDD vs 1 HDD
– 2.01x improvement for OSU-IB (32Gbps)
– 1.8x improvement for IPoIB (32Gbps)
Increased by 16.2%
0
50
100
150
200
250
300
350
2 4 6 8 10
Ave
rage
Th
rou
ghp
ut
(Meg
aByt
es/s
)
File Size (GB)
1GigE (1HDD) IPoIB(1HDD) OSU-IB (1HDD)
1GigE (2HDD) IPoIB (2HDD) OSU-IB (2HDD)
25 HPC Advisory Council Lugano Conference, Mar '13

Evaluations using YCSB (Single Region Server: 100% Update)
• HBase using TCP/IP, running over HDFS-IB
• HBase Put latency for 360K records
– 204 us for OSU Design; 252 us for IPoIB (32Gbps)
• HBase Put throughput for 360K records
– 4.42 Kops/sec for OSU Design; 3.63 Kops/sec for IPoIB (32Gbps)
• 20% improvement in both average latency and throughput
Put Latency Put Throughput
HPC Advisory Council Lugano Conference, Mar '13 26
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
120K 240K 360K 480K
Thro
ugh
pu
t (M
ega
Byt
es/
s)
Number of Records (Record Size = 1KB)
1GigE IPoIB (QDR) OSU-IB (QDR)
0
50
100
150
200
250
300
350
400
450
500
120K 240K 360K 480K
Ave
rage
Lat
en
cy (
us)
Number of Record (Record Size = 1KB)
1GigE IPoIB (QDR) OSU-IB (QDR)

Evaluations using YCSB (32 Region Servers: 100% Update)
Put Latency Put Throughput
• HBase using TCP/IP, running over HDFS-IB
• HBase Put latency for 480K records
– 201 us for OSU Design; 272 us for IPoIB (32Gbps)
• HBase Put throughput for 480K records
– 4.42 Kops/sec for OSU Design; 3.63 Kops/sec for IPoIB (32Gbps)
• 26% improvement in average latency; 24% improvement in throughput
HPC Advisory Council Lugano Conference, Mar '13 27
0
50
100
150
200
250
300
350
400
120K 240K 360K 480K
Ave
rage
Lat
en
cy (
us)
Number of Records (Record Size = 1KB)
1GigE IPoIB (QDR) OSU-IB (QDR)
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
120K 240K 360K 480K
Thro
ugh
pu
t (K
op
s/se
c)
Number of Records (Record Size = 1KB)
1GigE IPoIB (QDR) OSU-IB (QDR)

• Overview of Hadoop (HDFS, MapReduce and HBase) and Memcached
• Challenges in Accelerating Enterprise Middleware
• Designs and Case Studies – Hadoop
• HDFS
• MapReduce
• HBase
• Combination (HDFS + HBase)
– Memcached
• Conclusion and Q&A
Presentation Outline
28 HPC Advisory Council Lugano Conference, Mar '13

HPC Advisory Council Lugano Conference, Mar '13 29
MapReduce-RDMA Design Overview
• Enables high performance RDMA communication, while supporting traditional socket interface
RDMA-enabled MapReduce
IB Verbs
RDMA Capable Networks
(IB, 10GE/ iWARP, RoCE ..)
OSU-IB Design
Applications
1/10 GigE Network
Java Socket Interface
Java Native Interface (JNI)
Job
Tracker
Task
Tracker
Map
Reduce
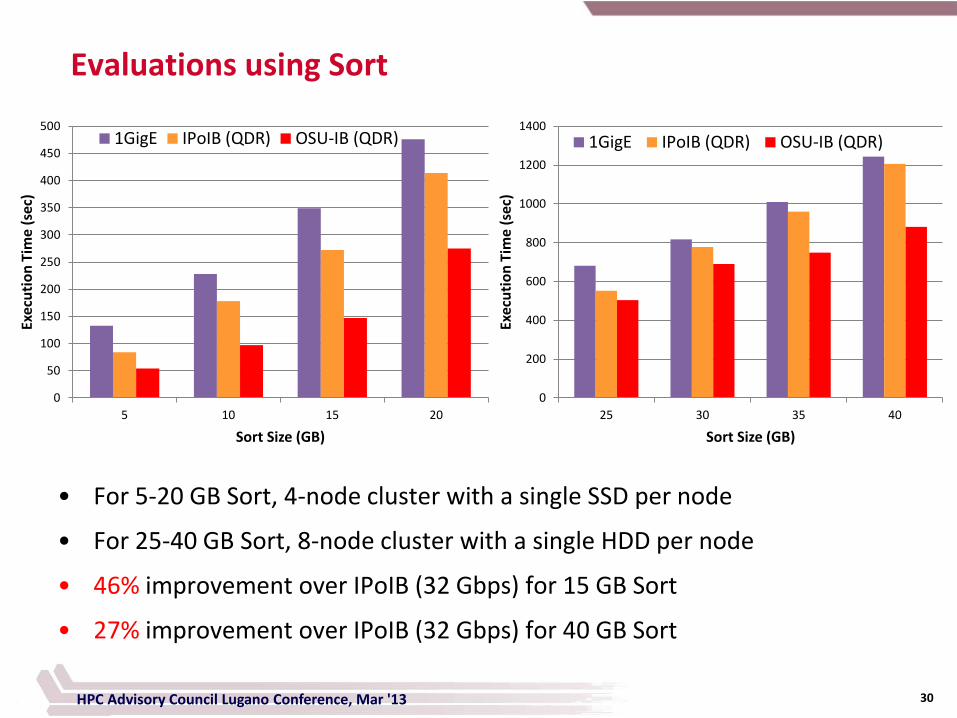
• For 5-20 GB Sort, 4-node cluster with a single SSD per node
• For 25-40 GB Sort, 8-node cluster with a single HDD per node
• 46% improvement over IPoIB (32 Gbps) for 15 GB Sort
• 27% improvement over IPoIB (32 Gbps) for 40 GB Sort
Evaluations using Sort
0
50
100
150
200
250
300
350
400
450
500
5 10 15 20
Exec
uti
on
Tim
e (s
ec)
Sort Size (GB)
1GigE IPoIB (QDR) OSU-IB (QDR)
0
200
400
600
800
1000
1200
1400
25 30 35 40
Exec
uti
on
Tim
e (s
ec)
Sort Size (GB)
1GigE IPoIB (QDR) OSU-IB (QDR)
30 HPC Advisory Council Lugano Conference, Mar '13
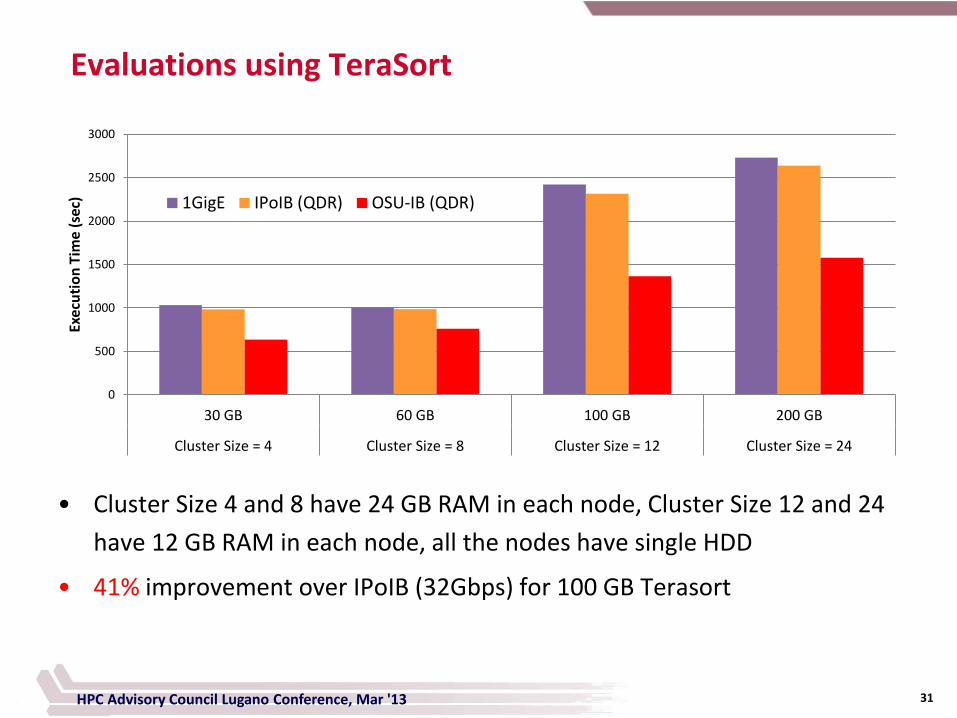
• Cluster Size 4 and 8 have 24 GB RAM in each node, Cluster Size 12 and 24
have 12 GB RAM in each node, all the nodes have single HDD
• 41% improvement over IPoIB (32Gbps) for 100 GB Terasort
Evaluations using TeraSort
0
500
1000
1500
2000
2500
3000
30 GB 60 GB 100 GB 200 GB
Cluster Size = 4 Cluster Size = 8 Cluster Size = 12 Cluster Size = 24
Exec
uti
on
Tim
e (s
ec) 1GigE IPoIB (QDR) OSU-IB (QDR)
31 HPC Advisory Council Lugano Conference, Mar '13

• The DataSet for these workloads are taken from PUMA (Purdue MapReduce
Benchmark Suite)
• 46% improvement in Adjacency List over IPoIB (32Gbps) for 30 GB data size
• 33% improvement in Sequence Count over IPoIB (32 Gbps) for 50 GB data
size
Evaluations using PUMA Workload
0
500
1000
1500
2000
2500
3000
Adjacency List (30GB) Self Join (30 GB) Word Count (50 GB) Sequence Count (50 GB) Inverted Index (50 GB)
Exec
uti
on
Tim
e (s
ec)
Workloads
IPoIB (QDR) OSU-IB (QDR)
HPC Advisory Council Lugano Conference, Mar '13 32

• Overview of Hadoop (HDFS, MapReduce and HBase) and Memcached
• Challenges in Accelerating Enterprise Middleware
• Designs and Case Studies – Hadoop
• HDFS
• MapReduce
• HBase
• Combination (HDFS + HBase)
– Memcached
• Conclusion and Q&A
Presentation Outline
33 HPC Advisory Council Lugano Conference, Mar '13

HPC Advisory Council Lugano Conference, Mar '13 34
HBase Put/Get – Detailed Analysis
• HBase 1KB Put – Communication Time – 8.9 us – A factor of 6X improvement over 10GE for communication time
• HBase 1KB Get – Communication Time – 8.9 us – A factor of 6X improvement over 10GE for communication time
0
50
100
150
200
250
300
1GigE IPoIB 10GigE OSU-IB
Tim
e (
us)
HBase Put 1KB
0
50
100
150
200
250
1GigE IPoIB 10GigE OSU-IB
Tim
e (
us)
HBase Get 1KB
Communication
Communication Preparation
Server Processing
Server Serialization
Client Processing
Client Serialization
W. Rahman, J. Huang, J. Jose, X. Ouyang, H. Wang, N. Islam, H. Subramoni, Chet Murthy and D. K. Panda, Understanding the Communication Characteristics in HBase: What are the Fundamental Bottlenecks?, ISPASS’12

HPC Advisory Council Lugano Conference, Mar '13 35
HBase-RDMA Design Overview
• JNI Layer bridges Java based HBase with communication library written in native code
• Enables high performance RDMA communication, while supporting traditional socket interface
HBase
IB Verbs
RDMA Capable Networks
(IB, 10GE/ iWARP, RoCE ..)
OSU-IB Design
Applications
1/10 GigE Network
Java Socket Interface
Java Native Interface (JNI)
HPC Advisory Council Lugano Conference, Mar '13 36
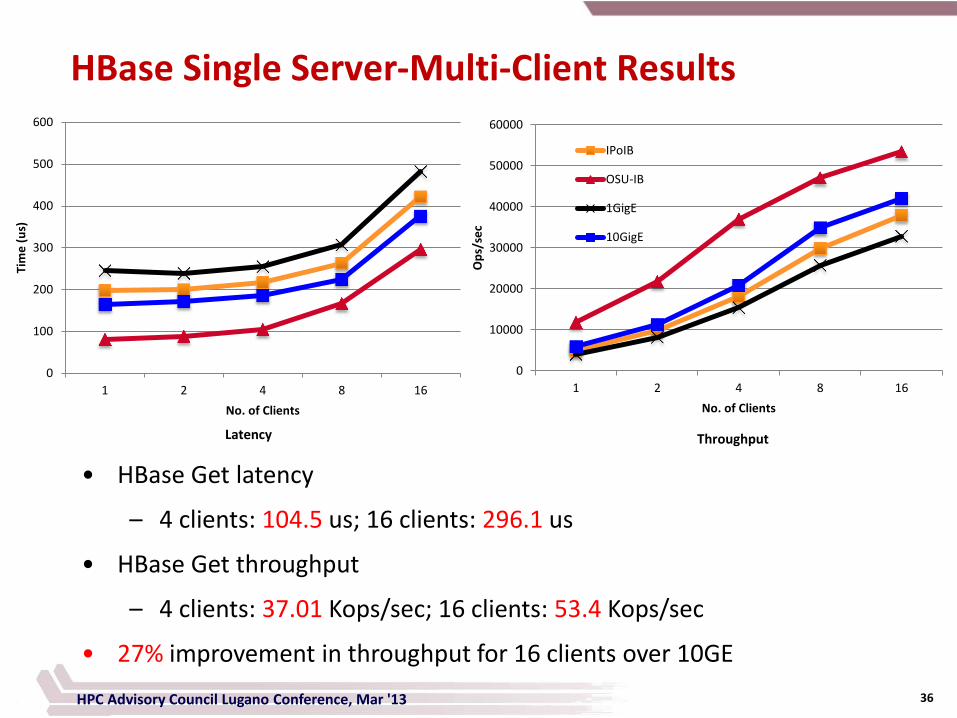
HBase Single Server-Multi-Client Results
• HBase Get latency
– 4 clients: 104.5 us; 16 clients: 296.1 us
• HBase Get throughput
– 4 clients: 37.01 Kops/sec; 16 clients: 53.4 Kops/sec
• 27% improvement in throughput for 16 clients over 10GE
0
100
200
300
400
500
600
1 2 4 8 16
Tim
e (
us)
No. of Clients
0
10000
20000
30000
40000
50000
60000
1 2 4 8 16
Op
s/se
c
No. of Clients
IPoIB
OSU-IB
1GigE
10GigE
Latency Throughput

HPC Advisory Council Lugano Conference, Mar '13 37
HBase – YCSB Read-Write Workload
• HBase Get latency (Yahoo! Cloud Service Benchmark)
– 64 clients: 2.0 ms; 128 Clients: 3.5 ms
– 42% improvement over IPoIB for 128 clients
• HBase Get latency
– 64 clients: 1.9 ms; 128 Clients: 3.5 ms
– 40% improvement over IPoIB for 128 clients
0
1000
2000
3000
4000
5000
6000
7000
8 16 32 64 96 128
Tim
e (
us)
No. of Clients
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
8 16 32 64 96 128
Tim
e (
us)
No. of Clients
IPoIB OSU-IB
1GigE 10GigE
Read Latency Write Latency
J. Huang, X. Ouyang, J. Jose, W. Rahman, H. Wang, M. Luo, H. Subramoni, Chet Murthy and D. K. Panda, High-Performance Design of HBase with RDMA over InfiniBand, IPDPS’12

• Overview of Hadoop (HDFS, MapReduce and HBase) and Memcached
• Challenges in Accelerating Enterprise Middleware
• Designs and Case Studies – Hadoop
• HDFS
• MapReduce
• HBase
• Combination (HDFS + HBase)
– Memcached
• Conclusion and Q&A
Presentation Outline
38 HPC Advisory Council Lugano Conference, Mar '13

• YCSB Evaluation with 4 RegionServers (100% update)
• HBase Put Latency and Throughput for 360K records
- 37% improvement over IPoIB (32Gbps)
- 18% improvement over OSU-IB HDFS only
HDFS and HBase Integration over IB (OSU-IB)
0
50
100
150
200
250
300
350
400
450
120K 240K 360K 480K
Late
ncy
(u
s)
Number of Records (Record Size = 1KB)
1GigE IPoIB (QDR)
OSU-IB (HDFS) - IPoIB (HBase) (QDR) OSU-IB (HDFS) - OSU-IB (HBase) (QDR)
0
1
2
3
4
5
6
120K 240K 360K 480K
Thro
ugh
pu
t (K
op
s/se
c)
Number of Records (Record Size = 1KB)
1GigE IPoIB (QDR)
OSU-IB (HDFS) - IPoIB (HBase) (QDR) OSU-IB (HDFS) - OSU-IB (HBase) (QDR)
39 HPC Advisory Council Lugano Conference, Mar '13

• Overview of Hadoop (HDFS, MapReduce and HBase) and Memcached
• Challenges in Accelerating Enterprise Middleware
• Designs and Case Studies – Hadoop
• HDFS
• MapReduce
• HBase
• Combination (HDFS + HBase)
– Memcached
• Conclusion and Q&A
Presentation Outline
40 HPC Advisory Council Lugano Conference, Mar '13

Memcached-RDMA Design
41
• Memcached applications need not be modified; uses verbs interface if available
• Memcached Server can serve both socket and verbs clients simultaneously
• Native IB-verbs-level Design and evaluation with
– Memcached Server: 1.4.9
– Memcached Client: (libmemcached) 0.52
Sockets Client
RDMA Client
Master Thread
Sockets Worker Thread
Verbs Worker Thread
Sockets Worker Thread
Verbs Worker Thread
Shared
Data
Memory Slabs Items
…
1
1
2
2
HPC Advisory Council Lugano Conference, Mar '13

42
• Memcached Get latency
– 4 bytes RC/UD – DDR: 6.82/7.55 us; QDR: 4.28/4.86 us
– 2K bytes RC/UD – DDR: 12.31/12.78 us; QDR: 8.19/8.46 us
• Almost factor of four improvement over 10GE (TOE) for 2K bytes on
the DDR cluster
Intel Clovertown Cluster (IB: DDR) Intel Westmere Cluster (IB: QDR)
0
20
40
60
80
100
120
140
160
180
1 2 4 8 16 32 64 128 256 512 1K 2K
Tim
e (
us)
Message Size
0
20
40
60
80
100
120
140
160
180
1 2 4 8 16 32 64 128 256 512 1K 2K
Tim
e (
us)
Message Size
SDP IPoIB
OSU-RC-IB 1GigE
10GigE OSU-UD-IB
Memcached Get Latency (Small Message)
HPC Advisory Council Lugano Conference, Mar '13

HPC Advisory Council Lugano Conference, Mar '13 43
Memcached Get TPS (4byte)
• Memcached Get transactions per second for 4 bytes
– On IB QDR 1.4M/s (RC), 1.3 M/s (UD) for 8 clients
• Significant improvement with native IB QDR compared to SDP and IPoIB
0
200
400
600
800
1000
1200
1400
1600
1 2 4 8 16 32 64 128 256 512 800 1K
Tho
usa
nd
s o
f Tr
ansa
ctio
ns
pe
r se
con
d (
TPS)
No. of Clients
SDP IPoIB
OSU-RC-IB 1GigE
OSU-UD-IB
0
200
400
600
800
1000
1200
1400
1600
4 8
Tho
usa
nd
s o
f Tr
ansa
ctio
ns
pe
r se
con
d (
TPS)
No. of Clients

HPC Advisory Council Lugano Conference, Mar '13 44
Application Level Evaluation – Olio Benchmark
• Olio Benchmark
– RC – 1.6 sec, UD – 1.9 sec, Hybrid – 1.7 sec for 1024 clients
• 4X times better than IPoIB for 8 clients
• Hybrid design achieves comparable performance to that of pure RC design
0
500
1000
1500
2000
2500
64 128 256 512 1024
Tim
e (
ms)
No. of Clients
0
20
40
60
80
100
120
1 4 8
Tim
e (
ms)
No. of Clients
SDP
IPoIB
OSU-RC-IB
OSU-UD-IB
OSU-Hybrid-IB

HPC Advisory Council Lugano Conference, Mar '13 45
Application Level Evaluation – Real Application Workloads
• Real Application Workload – RC – 302 ms, UD – 318 ms, Hybrid – 314 ms for 1024 clients
• 12X times better than IPoIB for 8 clients • Hybrid design achieves comparable performance to that of pure RC design
0
20
40
60
80
100
120
1 4 8
Tim
e (
ms)
No. of Clients
SDP
IPoIB
OSU-RC-IB
OSU-UD-IB
OSU-Hybrid-IB
0
50
100
150
200
250
300
350
64 128 256 512 1024
Tim
e (
ms)
No. of Clients
J. Jose, H. Subramoni, M. Luo, M. Zhang, J. Huang, W. Rahman, N. Islam, X. Ouyang, H. Wang, S. Sur and D. K.
Panda, Memcached Design on High Performance RDMA Capable Interconnects, ICPP’11
J. Jose, H. Subramoni, K. Kandalla, W. Rahman, H. Wang, S. Narravula, and D. K. Panda, Scalable Memcached
design for InfiniBand Clusters using Hybrid Transport, CCGrid’12

Designing Communication and I/O Libraries for Enterprise Systems: Solved a Few Initial Challenges
HPC Advisory Council Lugano Conference, Mar '13 46
D at ac e n t e r M i ddl e war e (H D F S , H Ba s e , M a pRe duc e , M e m c a c he d)
N e t w orki ng T e c hnol ogi e s (Infi ni Ba nd, 1/ 10/ 40 G i G E ,
RN ICs & Int e l l i ge nt N ICs )
S t ora ge T e c hnol ogi e s (H D D or S S D )
P oi nt -t o-P oi nt
Com m uni c a t i on
Q oS
T hre a di ng M ode l s a nd
S ync hroni z a t i on
F a ul t T ol e ra nc e I/ O a nd F i l e s ys t e m s
Com m u n i c at i on an d I / O L i br ar y
P r ogr am m i n g M ode l s (S oc ke t )
Appl i c at i on s
Com m odi t y Com put i ng S ys t e m
A rc hi t e c t ure s (s i ngl e , dua l , qua d, ..)
M ul t i / M a ny-c ore A rc hi t e c t ure
a nd A c c e l e ra t ors
Upper level
Changes?

• Presented initial designs to take advantage of InfiniBand/RDMA
for HDFS, MapReduce, HBase and Memcached
• Results are promising
• Working on Integrated designs of all components
• Many other open issues need to be solved including design
changes at the upper layers
• Will enable BigData community to take advantage of modern
clusters and Hadoop middleware to carry out their analytics in a
fast and scalable manner
HPC Advisory Council Lugano Conference, Mar '13
Concluding Remarks
47

HPC Advisory Council Lugano Conference, Mar '13
Web Pointers
http://www.cse.ohio-state.edu/~panda
http://nowlab.cse.ohio-state.edu
MVAPICH Web Page
http://mvapich.cse.ohio-state.edu
48







