donedeal - aws data analytics platform
TRANSCRIPT

DoneDeal -‐ Data Pla+orm April 2016
Mar6n Peters ([email protected] / @mar6nbpeters)
DoneDeal Analy6cs Team Manager

If you don’t understand the details of your business you are going to fail.
If we can keep our competitors focused on us while we stay focused on the customer, ultimately we’ll turn out all right.
- Jeff Bezos, Amazon

What do these companies have in Common?

Data is …
With the right set of information, you can make business decisions with higher levels of confidence, as you can audit and attribute the data you used for the decision-making process.
- Krish Krishnan, 2014
one of our biggest assets.

Business Intelligence 101
For small companies the gap is oNen filled with custom ad hoc solu6ons with limited and rather sta6c repor6ng capability.

What and why BI?
As a company grows, the Availability, Accuracy and Accessibility requirements of data increases.

Some terminology: ETL process
Extrac6on
Extracts data from homogeneous or heterogeneous data sources.
Transforma6on:
Process, Blend, merge and conform the data
Loading:
Store in the proper format or structure for the purposes of querying and analysis.

April 2015 -‐ April 2016

Timeline: 2014-‐2017
2014 2015 2016 2017
Silo’d Data
Manual/ErrorProne Blending
Value of BI/Datanot understood
Platform Design
Implementation
Storage Layer
Batch Layer
Traditional BI
Serving Layer
Speed Layer
Real Time Analytics

Business Goals & Objec6ves1. Build a future proof data analy2cs pla5orm that will scale with the company over the next 5 years.
2. Take ownership of our data. Collect more data.
3. Replace exis2ng repor2ng tool.
4. Provide a holis2c view of our users (buyers and sellers), ads, products
5. Use our data in a smarter manner and provide recommenda2ons in a 2mely fashion.

Apollo Team
Data EngineerData Analyst
ArchitectDevOpsBI Consultants
Solution Architect
• Analy2cs Pla5orm that includes Event Streaming, Data Consolida2on, Cleansing & Warehousing, Data Visualisa2on, Business Intelligence and Data Product Delivery.
• Apollo brings agility and flexibility in our data model, data ownership is key and allows us to blending data more conveniently
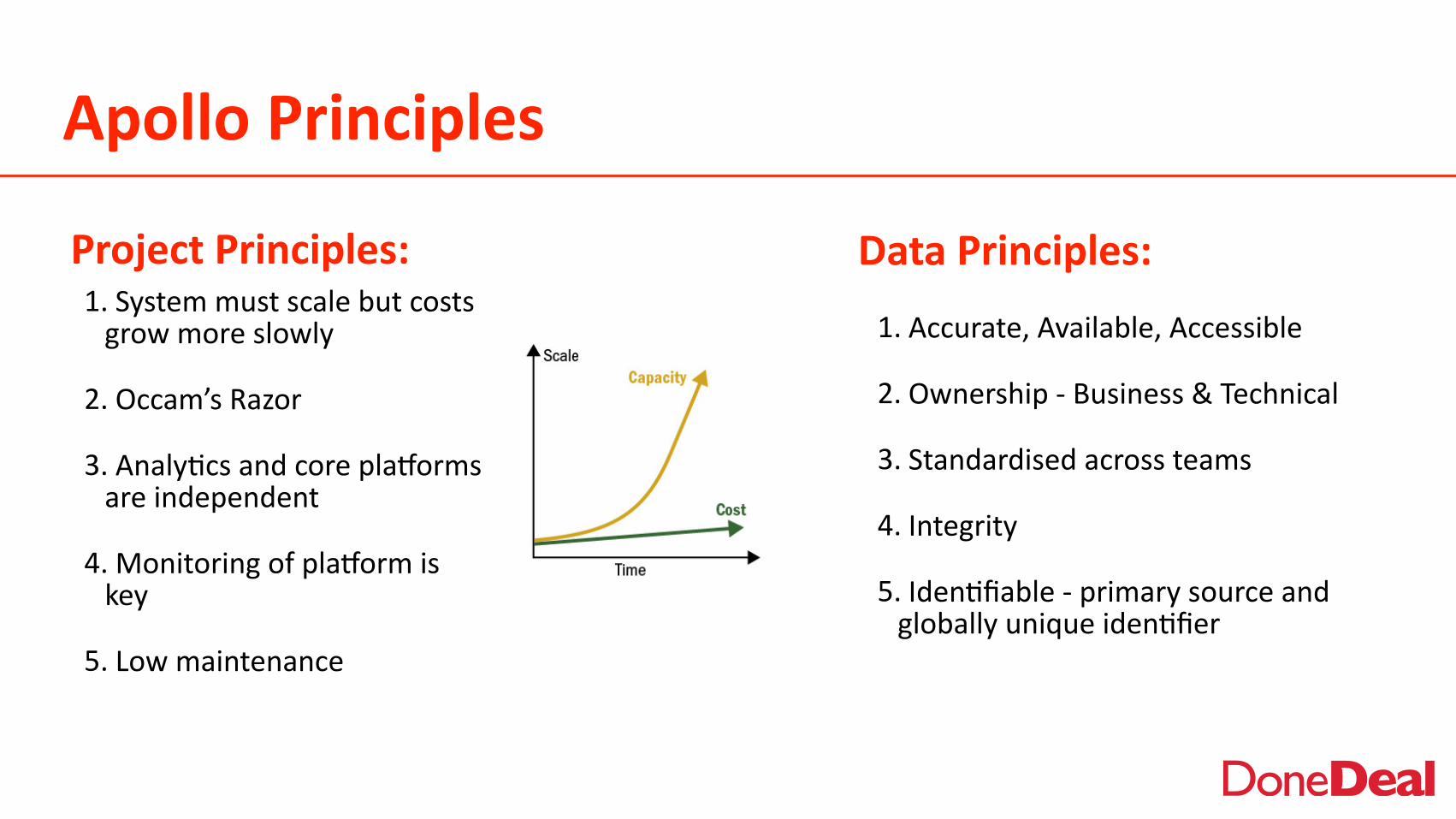
Apollo Principles
1. System must scale but costs grow more slowly
2. Occam’s Razor
3. Analy2cs and core pla5orms are independent
4. Monitoring of pla5orm is key
5. Low maintenance
Project Principles: Data Principles:
1. Accurate, Available, Accessible
2. Ownership -‐ Business & Technical
3. Standardised across teams
4. Integrity
5. Iden2fiable -‐ primary source and globally unique iden2fier

Apollo Architectural Principles
www.slideshare.net/AmazonWebServices/big-data-architectural-patterns-and-best-practices-on-aws
• Decoupled “data bus”
• Use the right tool/service for the job
➡ Data structure, latency, throughput, access pa\erns
• Use Lambda architecture ideas
➡ Immutable (append-‐only), batch, [speed, serving] layers
• Leverage AWS Managed Services
➡ Scalable/elas2c, available, reliable, secure, no/low admin
• Big data != Big Cost

Tools/Services in Produc6on
DataScience
Business Users
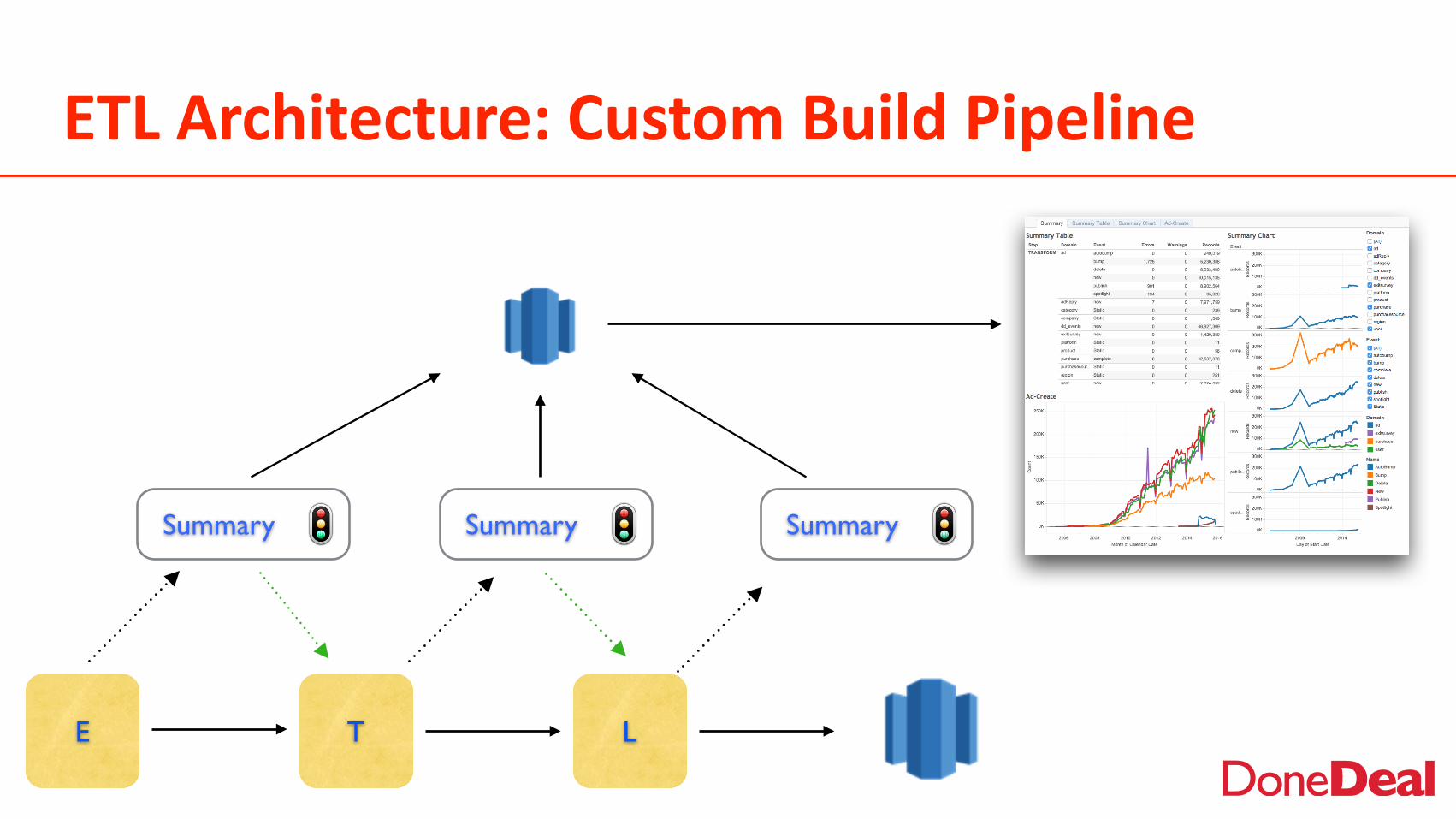
ETL Architecture: Custom Build Pipeline
E T L
Summary Summary Summary

ETL: Control over complex dependencies
• Allows control of ETL pipelines with complex dependencies
• Easy plug-in of new datasource
• Orchestration with Data Pipeline and Common Status or Summary Files
• Idempotent Pipeline• Historical data extracted
as simulated stream

ETL: By the numbers• Extrac6on
-‐ 4000 days processed
-‐ 7 different data sources
-‐ 14 domains
-‐ 13 event types
• Orchestra6on
-‐ 1200 processing days
-‐ 4GB/day
-‐ 3 Environments
-‐ 15 data pipelines
• Data Lake
-‐ 11M events streamed/day
-‐ 3 million files
-‐ 3 TB of data stored over 7 buckets
• RedshiN
-‐ 7B records in produc6on
-‐ 6 Schemas (core and aggregate)
-‐ 86 Tables in core schema

Kinesis Streams• 1 Stream with 4 Shards
• Data reten6on of 24hrs
• KCL on EC2 writes data to S3 ready for Spark
• Max size of 1MB data blog
• 1,000 records/sec per shard write
• 5 transac6ons/sec read or 2MB/sec
• Server side API Logging from 7 applica6on servers using Log4JAppender
• Event Buffering at source [in progress]
Put records Requests

S3
• Simple Storage Service provides secure, highly-scalable, durable cloud storage
• Native support for Spark, Hive

S3
• A strongly defined naming convention• YYYY/MM/DD prefix used
• Avro format used for OLTP data/ JSON otherwise - probably the right choice (schema evolution), although we haven’t take any advantages for those yet.
• Allow easy retrieval of data from a particular time period
• Easy to maintain and browse• Handling of summaries from E, T & L steps

Spark on EMR
• AWS’s managed Hadoop framework that can interact with data from S3, DynamoDB, etc.
• Apache Spark -‐ Fast, general purpose engine for large-‐scale in-‐memory data processing. Runs on Hadoop/EMR and can read from S3.
• PySpark + SparkSQL was the focus in Apollo.
• Streaming and ML will be the focusing the months ahead.
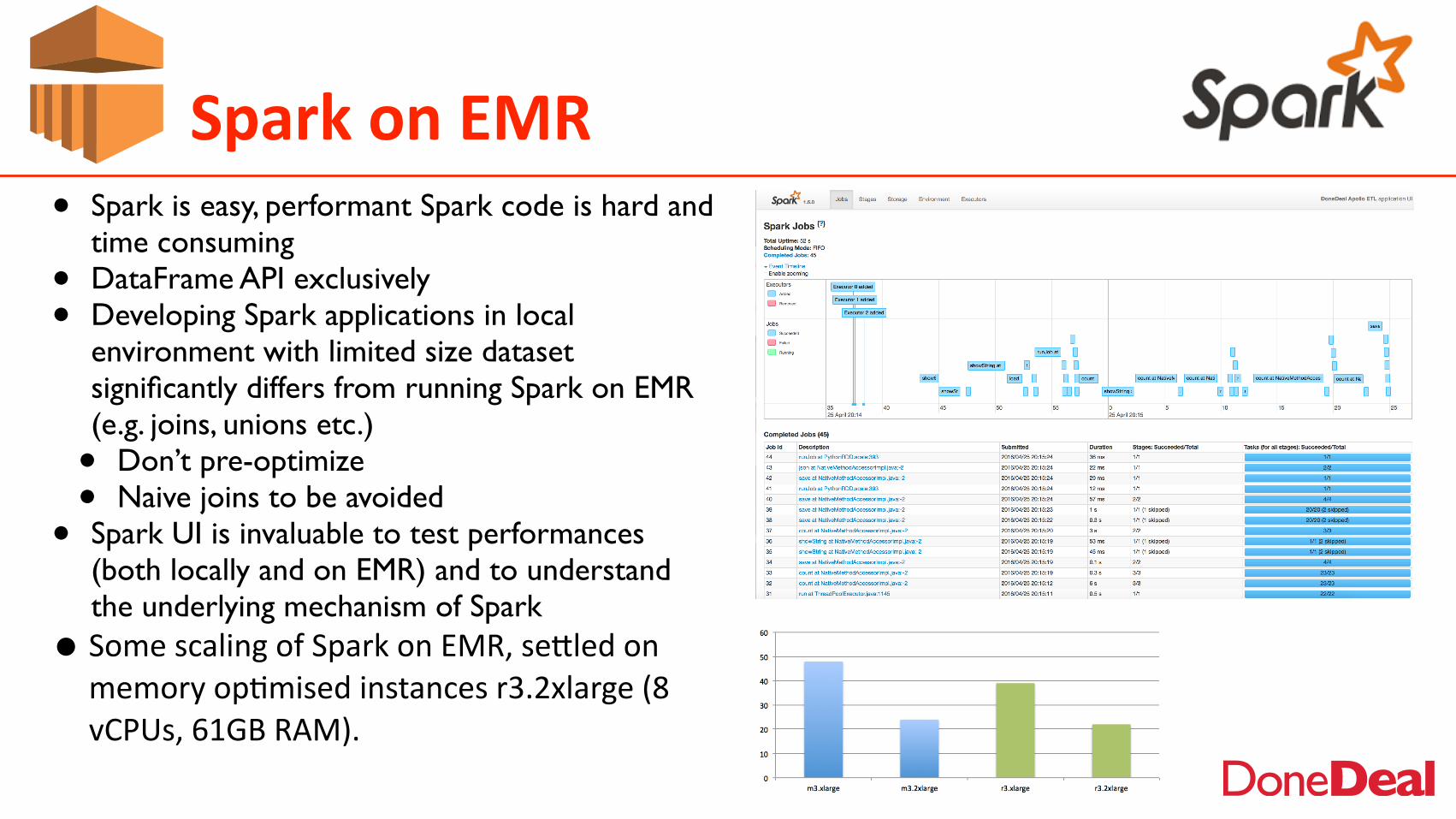
• Spark is easy, performant Spark code is hard and time consuming
• DataFrame API exclusively • Developing Spark applications in local
environment with limited size dataset significantly differs from running Spark on EMR (e.g. joins, unions etc.)• Don’t pre-optimize• Naive joins to be avoided
• Spark UI is invaluable to test performances (both locally and on EMR) and to understand the underlying mechanism of Spark
• Some scaling of Spark on EMR, se\led on memory op2mised instances r3.2xlarge (8 vCPUs, 61GB RAM).
Spark on EMR

Data Pipeline + Simple No6fica6on Service• Pipeline is a service to reliably process and
move between AWS applica6ons (e.g. S3, EMR, DynamoDB)
• Pipelines run on schedule and alarms are issued with Simple No6fica6on Service (SNS)
• EMR/Spark used for compute and EC2 used for loading data in RedshiN
• Debugging can be a challenge

RedshiN• Dense Compute or Dense Storage? -‐ Single ds2.xlarge instance -‐ Right balance between storage/memory/
compute and cost/hr
• Strict ETL, no transforma2on is carried out in DW, an Append Only Strategy -‐ Leverage power and scalability of EMR and
Insert speed of Redshif -‐ No Updates in DW, Drop and Recreate
• Tuning is a 2me consuming task & requires rigorous tes2ng.
• Define Sort, Distribu2on, Interleaved keys as early as possible.
• Reserved Nodes will be used in future
Test Dev Prod
Core cmtest cmdev cmprod
Agg agtest agdev agprod
Test Dev Prod
Core cmtest cmdev cmprod
Agg agtest agdev agprodread permissions
Kimball Star Schema: Conformed dimensions across all data sources

Tableau on EC2
• Tableau Server runs on EC2 (c3.2xlarge) inside AWS Environment.
• Tableau Desktop used to develop dashboards that are published to the server.
• Connec2on to Redshif Data Warehouse -‐ JDBC/ODBC Connector.
• Maps support is poor for countries outside the US
http://www.slideshare.net/AmazonWebServices/analytics-on-the-cloud-with-tableau-on-aws

Up Next?• Increase number of data
streams/Remove dependence on OLTP
• Tradi2onal BI/Repor2ng -‐ More dashboards
• [In progress] Data Products with Spark ML/Amazon ML, DynamoDB, Lambda & API Gateway
• Trials of Kinesis Firehose, Kinesis Analy2cs, Quicksight
• Improved Code Deployment with Code Pipeline and Code Commit

DoneDeal Image Service Upgrade
• Image Storage & Transforming moved to AWS
• Over 4.5M images migrated to S3
• ECS + ELB used for image resizing
• Autoscaling group enables adding new image sizes
• We now run docker in produc2on thanks to ECS
• Inves2ga2ng uses for AWS Lambda and image processing
For more info: @davidconde

DoneDeal Dynamic Test Environments
• QA can now run any feature branch of DoneDeal directly from our CI server
• Uses Jenkins / Docker (Machine + Compose) / EC2 & Route 53
• Enables rapid tes2ng without server conten2on
• Also used by the mobile team to develop against & test new APIs
For more info: @davidconde

Q&A Session
Nigel Creighton CTO at DNM
Martin Peters BI Manager at DoneDeal
