why does africa need sinclair?
TRANSCRIPT

WHY DOES AFRICA NEED SINCLAIR?
Gilles-Maurice de Schryver: Department of African Languages and Cultures, GhentUniversity; Xhosa Department, University of theWestern Cape; and TshwaneDJe HLT([email protected])
Abstract
John Sinclair’s impact on lexicography in English as well as his pioneering work in
corpus linguistics is well known. What is less widely known is his impact on dictionary
making for languages other than English. In this article it is shown how Sinclair’s
revolutionary insights are being adopted and developed in the production of bilingual
dictionaries for Bantu languages. This work has proceeded from a Ciluba–Dutch lear-
ner’s dictionary ten years ago to an online Swahili–English work and a Northern Sotho–
English school dictionary. The latter has features that transcend the monolingual level,
as corpus-based analyses in different languages have to be mapped onto one another.
New questions arise as a result, which focus on the need to show idiomatic bilingual
example sentences. A frequency-based approach to lexical and grammatical gaps is
adopted, with a seamlessly integrated ‘corpus-based dictionary mini-grammar’. Not
all problems have been solved, but the compilers find time and again that analysis of
real data provides insights unavailable in an ‘armchair-linguistics’ approach. It is excit-
ing to join those riding the wave that was set in motion by Sinclair.
1. Looking Up
Back in 1997, just weeks after I had started in lexicography, I stumbled upon a
copy of Looking Up (Sinclair 1987c), which gives an account of the Cobuild
project in lexical computing. In it, I recognized the potential of corpus analysis
to lift Bantu-language lexicography out of its colonial tradition, a tradition in
which it had been stuck for over a century. Although I became a disciple of
Sinclair’s synchronic empiricism overnight, the full implications for bilingual
dictionary making would only become apparent with practice.
In this article, the focus is on the latest dictionary compiled within this
framework, a bilingual Northern Sotho–English school dictionary. Reference
is also made to other corpus-based Bantu-language dictionaries compiled
during the past decade, particularly one for Ciluba, and one for Swahili.
It should be clear from the outset that without Sinclair’s Cobuild project as
an example, these reference works would never have seen the light.
International Journal of Lexicography, Vol. 21 No. 3. Advance access publication 12 August 2008� 2008 Oxford University Press. All rights reserved. For permissions,please email: [email protected]
doi:10.1093/ijl/ecn024 267

2. Beknopt woordenboek Ciluba' ^Nederlands
The first task in compiling a corpus-based dictionary for any language is to
build or to have access to a corpus. Today, this task is greatly facilitated by the
availability of the Internet—which can be used for corpus building or simply as
a corpus—even for under-resourced languages (see De Schryver 2002, Scannell
2007). Ten years ago, however, there was no option other than to build one
from scratch for a language such as Ciluba. A well-defined target user group
was identified for a Ciluba–Dutch dictionary, namely language acquisition
students at Ghent University, and a modest corpus suitable for their needs,
consisting of just 300,000 words and comprising both general language and
textbook material, was assembled. The main purpose during that first project
was to use the corpus to draw up a lemma list. This was done manually by
running through the most frequent orthographic words and lemmatizing them.
The top 3,000 lemmas were selected as dictionary entries. Lemmas included not
just words but also word stems and even grammatical affixes and circumfixes.
During dictionary compilation, any lemmas with an uneven spread across sub-
corpora were either labelled as belonging to a particular field or deleted (as too
idiosyncratic).
A sample page of the published dictionary (De Schryver and Kabuta 1998)
is shown in Addendum 1. From that sample page it can be seen that the textual
condensation is rather high, which necessitated the inclusion of two different
explanatory running footers. On the odd pages is a legend to the Luba grammar;
on the even pages (not shown) is a summary of the Luba concordial agreement
system. On the macrostructural level, frequency bands divide the lexicon into
four groups: the 200 most frequent lemmas, for instance, are preceded by a
circled number 1. This is a direct calque of the filled vs. hollow diamonds in
Cobuild2 (Sinclair and Fox 1995). The intransitive verb stem -enda ‘go; walk;
run’, for instance, belongs to the top-frequency band.
Turning to the microstructural level, an idiomatic expression may follow a
translation equivalent. Decisions on inclusion versus omission of such expres-
sions were based on overall corpus frequencies. Given that Ciluba has a rich
and complex verbal morphology, special attention was devoted to verbs and
their grammatical constructions, with illustrative examples. These grammatical
constructions are always preceded by a hollow square, as seen at -enda. The
examples here are of the textbook type, as at -enda: Ngamonu ne uvwa wenda
ufııka munda ‘I noticed that (s)he started to become angry’ and Ukaadi wenda
umvwa anyı? ‘Do you start to understand now?’ These examples come from
grammar books, for which they were selected from the living language. They
are not necessarily representative, however, as they are meant to exemplify
grammatical points (which is why they are accompanied by codes). Some
dictionary articles end with a so-called ‘frequency-based tail slot’, which lists
all the frequent lemmas derived from the current one. At the articles for each of
268 Gilles-Maurice de Schryver

those derivations, a cross-reference was worked in (under -enzekela ‘occur’, for
instance, it is stated that this form is the stative plus applicative form of -enza).
To summarize, in this first corpus-based dictionary for Ciluba the micro-
structure displays both traditional and corpus approaches.1
3. The Online Swahili^English Dictionary
One often hears that lemmatization issues should only really play a role in
paper dictionaries, where dictionary citation forms serve as entry points to
sometimes very large paradigms of inflected forms. In an electronic environ-
ment, by contrast, where storage space is not an issue, one could, the argument
goes, equally well treat all orthographic forms as entries.
Dictionaries of Bantu languages traditionally give only word stems as
entries, not full orthographic forms. For the online Swahili–English dictionary
(Hillewaert et al. 2004) a hybrid approach was followed. Entries were given for
full word forms as well as word stems, and translations were provided for all
of these. Selection of headwords was based on a frequency list derived from a
15-million-word Swahili corpus. Concordance lines were selected from the
corpus for each of the frequent orthographic words, and the various translation
equivalents were ordered according to frequency. The result was that users
were able to look up words as they are spoken or written, with translations
ordered from most likely to least likely, and that more precise meanings could
be conveyed.
As Sinclair pointed out:
The organisation of meanings around ‘headwords’—lemmas in computa-
tional linguistics—carries an assumption that, by and large, the inflected
forms of a word do not have distinctive meanings. This view is now
regarded as rather suspect (Tognini-Bonelli 1995), and it is to be expected
that a new generation of dictionary will arise where the indexing is through
the form and not the lemma. (Sinclair 1998: 4)
The Swahili project was an attempt to do just that. Additionally, there was an
assumption that such a procedure would satisfy most dictionary users, assum-
ing a direct correlation between frequency of occurrence (as seen in a large
corpus) and dictionary lookup probability (as logged by usage modules
attached to an online dictionary; see De Schryver et al. 2006). The outcome
was rather surprising, however, given that only a minor correlation could be
found between corpus frequency and lookup frequency, and this only for the
top few thousand words (up to around 3,000 for Swahili, and up to around
5,000 for English). Beyond that point no correlation could be seen.2 In other
words, this research result means that it is impossible to ‘predict’ which full
orthographic words will be of interest to the dictionary user.
Why Does Africa Need Sinclair? 269

The implication of all this is that lemmatization into headwords remains a
necessity in lexicography. Not only for a paper dictionary, where it is a sine qua
non given the physical limitations of books, but also for electronic reference
works, unless one has access to unlimited human resources to compile literally
hundreds of thousands of dictionary articles, many of which would be highly
repetitive and miss important generalizations. Even with additional software
modules for electronic dictionaries, modules which for example take care of
morphological decomposition, it will always be necessary to decompose down
to a canonical form for which the meaning is stored.
4. Oxford Bilingual School Dictionary: Northern Sotho and English
4.1 Dictionaryplanning
In order for South Africa’s eleven-way bilingualism to transcend the current lip
service paid to all but two (English and Afrikaans) of the official languages, it
was felt that new, modern dictionaries are needed. Bilingual Bantu diction-
aries—e.g. for Zulu–English3—are at least fifty years old, and the better ones
are far too complex for the layman, as is the case for Northern Sotho.4
The task is thus daunting: Not only is it necessary to compile new dictionaries
for all nine Bantu languages, but also each dictionary must aim to reach as wide
an audience as possible. Thus, the bilingual lexicographer must try to compress
up to eight dictionaries into a single volume: for use by mother-tongue speakers
of both languages (actually also by third-language speakers, given the complex
multilingual background of many South Africans), and for both decoding
(receptive) and encoding (active) use.Moreover, the two sides must be published
simultaneously and compressed into one volume. In addition, each dictionary
must try to meet the needs of several different levels of users (basic, intermedi-
ate, advanced). This is not quite as impossible as it sounds, since different users
look up different words for different purposes; the lexicographers must try to
predict which users are likely to need what kind of information.
Negotiations with OUP yielded a plan and commitment for a new bilingual
series, with Northern Sotho being the first Bantu language to be targeted. Two
years later, the result is a 600-page bidirectional, bilingual Northern Sotho–
English dictionary (De Schryver 2007), aimed primarily at a junior target user
group (but also with more advanced users in mind).
4.2 Macrostructure
Each side of the dictionary aimed at a selection of 5,000 articles. With a decade
of lemmatization studies as background (De Schryver et al. 2004), drawing
up the macrostructure for Northern Sotho (henceforth NS) was rather straight-
forward. A frequency list was derived from a corpus of 7.5 million NS words,
270 Gilles-Maurice de Schryver
and the top section was lemmatized.5 As will become apparent from the
extracts below, the corpus contains both a wide variety of general-language
material and ‘customized’ material taken from school textbooks.
For the English macrostructure, the full NS!English side was reversed
automatically, with every translation equivalent becoming a candidate
English entry. For this, one of the standard functions of the dictionary compi-
lation software, the TshwaneLex Suite (Joffe et al. 2008), was activated.
Example sentences were also reversed, as well as combinations and gramma-
tical constructions. Multiple NS translation equivalents for the same candidate
English entry (originating from different articles in the NS!English side)
were brought together, with the NS corpus frequencies also being brought
over (see below). The result was ‘cleaned up’, as not all the translation equiva-
lents from the NS!English side were suitable as headwords in English. This
produced a first version for the English!NS side of the dictionary with about
3,000 articles. It was also decided to include around 300 so-called ‘curriculum
words’ in the English!NS side (see below). The remainder of the entries,
roughly 1,700 items, consisted of the top 1,700 English lemmas that were not
yet in the list. BNC frequencies (Kilgarriff 1996) were used to pinpoint those.
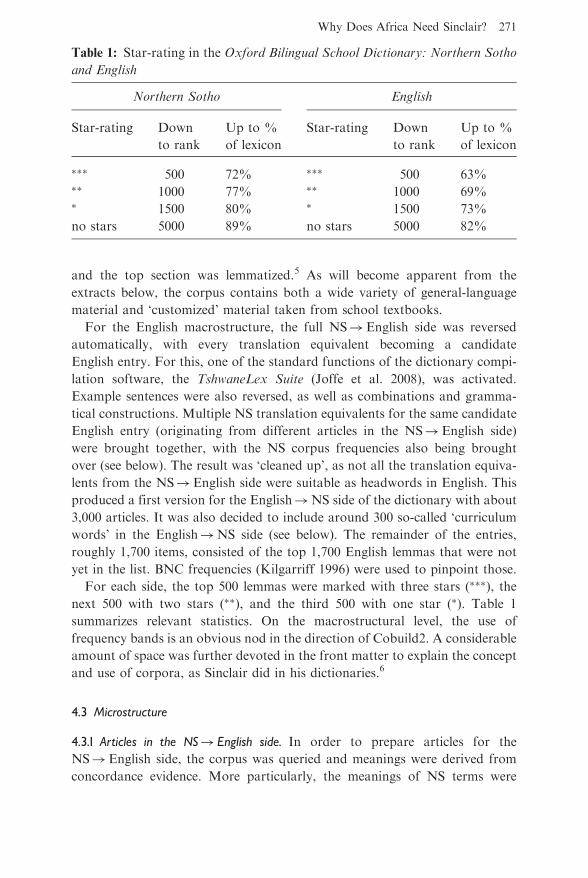
For each side, the top 500 lemmas were marked with three stars (���), the
next 500 with two stars (��), and the third 500 with one star (�). Table 1
summarizes relevant statistics. On the macrostructural level, the use of
frequency bands is an obvious nod in the direction of Cobuild2. A considerable
amount of space was further devoted in the front matter to explain the concept
and use of corpora, as Sinclair did in his dictionaries.6
4.3 Microstructure
4.3.1 Articles in the NS!English side. In order to prepare articles for the
NS!English side, the corpus was queried and meanings were derived from
concordance evidence. More particularly, the meanings of NS terms were
Table 1: Star-rating in the Oxford Bilingual School Dictionary: Northern Sotho
and English
Northern Sotho English
Star-rating Down
to rank
Up to %
of lexicon
Star-rating Down
to rank
Up to %
of lexicon
��� 500 72% ��� 500 63%�� 1000 77% �� 1000 69%� 1500 80% � 1500 73%
no stars 5000 89% no stars 5000 82%
Why Does Africa Need Sinclair? 271

mapped onto use, following the procedure set out for English by Hanks (2002).
These meanings were then translated into English and ordered by frequency.
Usually one example per meaning was selected from the corpus as an illustra-
tion and translated into English. Figure 1 shows an example.
The first example at mosepelo was taken verbatim from the corpus: a clear
sign of this is that it starts with ‘therefore’. We had lengthy discussions with the
publisher about examples such as these, the publisher arguing that example
sentences should not start with words such as ‘therefore’, ‘moreover’, or ‘but’.
We disagreed, arguing (with Fox 1987: 144) that: ‘Real-text examples . . . carry
a lot of loose ends—they follow on from what has been said and they lead in to
what will be said.’ The dispute resulted in some examples being adapted after
all (see Sections 5.3 and 5.4 below). The source of the second example can also
easily be pinpointed: It is a phrase from the South African constitution.
The attempt to be faithful to corpus evidence also generated entries that are
not found in any other dictionary of NS. Figure 2 is an example. In a tradi-
tional (stem-based) dictionary, the user is expected to be able to cut off the
relative marker and the passive, perfect, causative and double-applicative
extensions in order to be able to associate this word with boa ‘come back;
return’. In such dictionaries it is further expected that the user can reverse
engineer the analysis and add the meaning of the various morphemes just cut
off, in order to be able to produce the word boeleditswego with the meaning
‘who/which was/were repeated’.
The verb shown in Figure 3 is a core word in NS. The form kwe is derived
from the verb stem kwa. There is a single broad NS sense here, which, for kwa,
might be translated roughly as ‘to sense’, but does not include seeing. There is
therefore a usage note: ‘This verb, with the overall meaning ‘‘to sense’’, refers
to all the senses except for sight (‘‘to see’’).’ In cases such as this, the entire
English series of partial equivalents is given, but as one sense, even though, in
English, these are of course four different senses.7
Figure 1: A basic noun in the NS!E side.
Figure 2: A basic verb in the NS!E side.
272 Gilles-Maurice de Schryver

Figure 3 also shows how grammar was brought into the dictionary by means
of grammatical constructions. The verb form kwe means, on a generic level,
‘(must) sense’, but when it is preceded by one of the negative morphemes ga, sa
or se, its meaning is ‘not to sense’.
Thirdly, Figure 3 also shows how combinations are treated. These are pre-
ceded by a hollow diamond. While compiling an article such as kwe, frequent
combinations of course ‘jump out’ from the concordance lines. Notice that a
straightforward derivation such as kweng is treated under the form from which
it is derived. Derivations are preceded by a filled right-pointing arrow. Despite
our aim to stick rigidly to corpus evidence, there are some cases where we
deviated for didactic purposes. Figure 4 shows an example. As a last example
of the NS!English side of the dictionary, consider Figure 5, in which a more
complex grammatical construction is the focus, viz. the verbal relative construc-
tion. This construction has a fixed pattern: ‘demonstrative (DEM) of any kind,
Figure 3: A complex verb in the NS!E side.
Figure 4: Didactic examples in the NS!E side.
Figure 5: Grammatical constructions in the NS!E side.
Why Does Africa Need Sinclair? 273

in concordial agreement with the noun’ plus ‘subject concord (SC), in concor-
dial agreement with the noun’ plus ‘verb, followed by the attached relative
suffix -go’.8 The English equivalent of such constructions is generally an adjec-
tive. The number of such codes the dictionary user needs to master has been
kept to an absolute minimum—there are just three: PC (for possessive
concord), SC, and DEM. In the dictionary’s mini-grammar (see below),
three quarters of a page is devoted to adjectives and ‘other constructions
that describe nouns’.
The use of such grammatical constructions, whereby an entire paradigm of
items is conflated, is a novelty in Bantu dictionaries, the only other example of
their use being in the dictionary for Ciluba described in Section 2 above. These
grammatical constructions have both decoding and encoding functions, and in
a way they too can be related to an early observation by Sinclair:
The item quarry which collocates with chase, corner, hunter, etc. will also
collocate frequently with a grammatical class we could call possessive. The
exponents could be his, their, Bill’s, etc., and the lexical description would
be more accurate if these varying exponents could be conflated. (Sinclair
1966: 430)
4.3.2 Articles in the English!NS side. In Section 4.2 it was mentioned that the
English side of the dictionary consists of three distinct sections: (a) material
that has been reversed, (b) curriculum words, and (c) new data. In reality, the
distinction is not always so clear-cut, with overlaps between these sections. The
new data was provided by the publisher, having been extracted from the
English!Afrikaans side of the Afrikaans bilingual dictionary in the series
(Louw 2007).9 At its most basic, then, using this data simply meant to translate
an ‘English template’. Figure 6 is an example (compare the last section of
Figure 5).10
The Bantu languages only have a handful of adjectives, typically between
twenty and thirty. NS adjectives are made up of an adjective stem, in most
cases preceded by a class prefix, with a demonstrative in front of that.
For a ‘true NS adjective’ it is thus possible to give the full forms. Figure 7
shows an example, where all the material was reversed, using the information
Figure 6: An adjective in the E!NS side, which is not an adjective in NS.
274 Gilles-Maurice de Schryver

found in the NS!English side in the articles for bantsi, mentsi, mantsi, ntsi,
dintsi, bontsi, mmalwa, gantsi and kae.11 In the English!NS side of the
dictionary, different parts of speech for the same word are brought together
whenever the meanings are also related. In such cases, each part-of-speech
group is preceded by a filled bullet, as may be seen in Figure 8. The examples
again show that the material has been reversed, and this includes the ‘com-
binations’ listed at the end. The first, bolaisa, is simply the causative form.
While most NS verb prefixes are written separately, three kinds are
attached to the verb. Rather than expecting that learners will remember
all the morphophonological rules that need to be applied to arrive at those
forms, the dictionary lists all frequent ones, here mmolaya (the object concord
of class 1þ bolaya) and mpolaya (the object concord of the first person
Figure 7: An adjective in the E!NS side, which is also an adjective in NS.
Figure 8: Part-of-speech groups in the E!NS side.
Why Does Africa Need Sinclair? 275

singularþ bolaya). The third kind takes the reflexive prefix, which for bolaya is
ipolaya ‘kill oneself’. That form, however, is found as a combination under the
lemma ‘kill’.
So far all the dictionary extracts for the English!NS side showed either
translated data or reversed material. Figure 9 shows an example of an article
with a ‘curriculum meaning’. As can be seen, a curriculum meaning is accom-
panied by a definition in both English and NS, and is preceded by a subject
label. Because many of the curriculum words are also new to NS (e.g. biome,
black economic empowerment (BEE), critical outcome, global warming, green-
house effect), it was decided not to reverse these concepts.12
Particularly challenging in bilingual lexicography are lexical gaps. These
occur in both directions of the dictionary, of course. Figure 10 shows an exam-
ple for malome, rangwane, and ramogolo, all brought together under the
English lemma ‘uncle’. Neither malome, rangwane or ramogolo corresponds
to the English concept ‘uncle’, nor do they when considered together
Figure 9: A curriculum sense in the E!NS side.
Figure 10: English lexical gaps in the E!NS side.
276 Gilles-Maurice de Schryver

(Cobuild2: ‘Someone’s uncle is the brother of their mother or father, or the
husband of their aunt’). Conversely, neither malome, rangwane, nor ramogolo
is lexicalized in English.
Above (see Figure 3), kwa can be mapped exactly onto
‘{hearþ feelþ tasteþ smell}’, which is why all these translation equivalents
are presented in a single entry. This is not the case in Figure 10, where each
partial equivalent is presented as a separate (partial) sense. Note that such
equivalents, here and elsewhere, are presented in frequency order (578, 368,
and 115 occurrences for malome, rangwane and ramogolo respectively in the
7.5-million-word NS corpus). When the ‘neutral’ English concept of ‘uncle’
needs to be translated, malome is the one that is usually used.
Interesting variants of lexical gaps are cases where words in one language
correspond to grammatical affixes in another. Figure 11 shows one such case,
where the English ‘each other’ is conveyed in NS by means of the addition of
the reciprocal extension ‘-an-’ to verbal stems. An item like this cannot be
reversed, and the lexicographer has no option other than to discuss it in the
mini-grammar (which was done). Finally, there are cases such as for, quite, and
off, where the lexicographer is ready to give up. The preposition and adverb
‘off’ has rank 123 in this dictionary, so omitting it is not an option. The
solution that was adopted for off can be seen in Figure 12.
Figure 11: A NS lexical gap in the E!NS side (1).
Figure 12: A NS lexical gap in the E!NS side (2).
Why Does Africa Need Sinclair? 277

5. Evaluation against some Sinclairian research findings
5.1 Onnormalrealizations and patterns ofco-selection
In 1966 Sinclair showed astonishing foresight and insight in his aptly named
article, ‘Beginning the Study of Lexis’. He knew exactly what was needed: he
built a small corpus and started to calculate collocation frequencies. He
complained, ‘there is no easy way of collecting a few thousand occurrences
of any lexical item’ (Sinclair 1966: 412). Four decades later, concordance lines
for a lemma can be generated automatically in a dictionary-writing system such
as TshwaneLex, and with a single keystroke any number of corpus lines may be
attached to the appropriate sense (De Schryver and De Pauw 2007).
Collocation statistics, too, may be calculated automatically, building on the
work pioneered by Church and Hanks (1989).
In his 1998 article on ‘The Lexical Item’, Sinclair summarized his research
findings—for English—of the intervening decades as follows:
(a) many, if not most, meanings require the presence of more than one word
for their normal realization;
(b) patterns of co-selection among words, which are much stronger than any
description has yet allowed for, have a direct connection with meaning.
(Sinclair 1998: 4)
These findings are valid for the Bantu languages as well. For example, take the
first article that has so-called ‘combinations’ in the NS!English dictionary—
the verb akga. In Addendum 2 all the KWIC lines for the form akga in the
7.5-million-word NS corpus are shown, sorted to the right of the node. In the
first five lines akga is used as an interjection, the frequency of which is too low
to be included in this school dictionary. The data for all the other lines is
summarized in Table 2. Table 2 shows that the verb akga collocates most
frequently with diatla ‘hands’ and dinao ‘feet’. See lines 9–41 and 69–70,
compared with lines 6–7, 42–67 and 95 in Addendum 2. Note that this verb
collocates only with plural forms here. Thus, the normal realization of the verb
akga is in collocation with either diatla (38% of the cases) or dinao (32%). The
meanings are shown in Figure 13.
Table 2: Collocates of the NS verb akga (with N¼ 92; f¼ frequency;
OC¼object concord)
278 Gilles-Maurice de Schryver

The collocations in Figure 13 account for 70% of all occurrences of the verb
akga, which illustrates point (a) in the Sinclair quote. If one now considers the
right half of Table 2, then one sees that instead of hands, arm(s) may also
co-occur (9%þ 12%), at which point the meaning becomes ‘work diligently’.
See lines 8, 71–78, 85–93 and 97. Also, instead of feet, legs/feet may co-occur
(7%), with the same meaning ‘walk very quickly’. See lines 79–84. As observed
by Sinclair, see point (b), these patterns of co-selection indeed have a direct
bearing on the meaning. Compared to the normal realizations, however, the
frequencies for the alternatives were deemed too low, and those combinations
were not included in the dictionary.
Thus, there is very little room to attribute a meaning to akga in isolation.
It is impossible to ascertain with certainty whether the hapaxes dinkatana
‘underwear’, molala ‘neck’ and themo ‘chisel’ truly contribute to the meaning.
Given the extremely low frequency of a meaning for akga in isolation—if it
exists at all—no such meaning was given in the dictionary. This stands in sharp
contrast to other dictionaries for NS, where ‘throw; swing; sling; hurl’ is
presented as the main meaning of akga. The corpus evidence shows that
such a ‘meta-meaning’—if it indeed exists—is of little use to the intended
target user group.13
While akga is an extreme case, in that no meaning was assigned to it in
isolation, most entries are given one or more meanings. In order to pinpoint
the words that typically collocate with each lemma, straightforward collocation
statistics were used during the project. As an example, Table 3 lists the raw
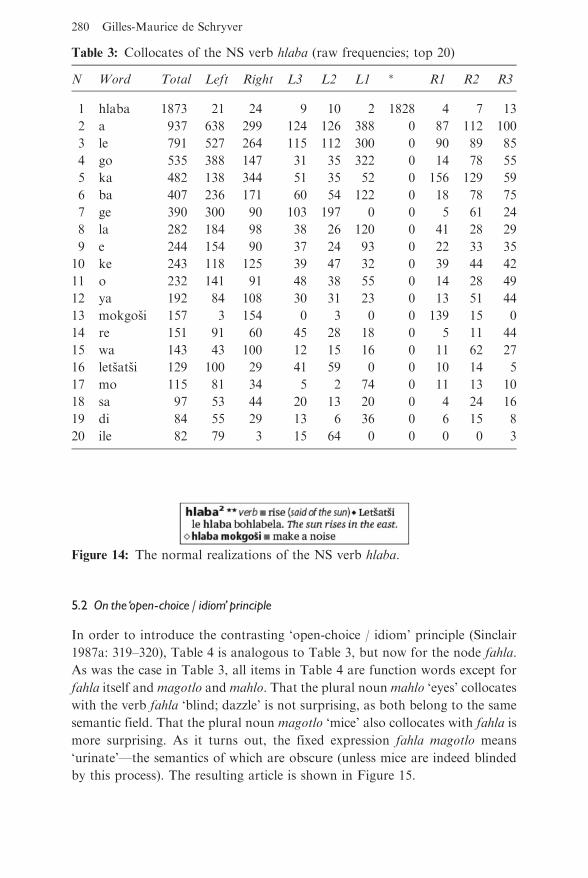
frequencies of the most frequent words collocating in a span of three words
to the left and three words to the right of the node hlaba. In Table 3, all items
are function words except for hlaba itself and mokgosi ‘noise’ and letsatsi
‘sun; day’. There are two verbs hlaba, one meaning ‘stab; slaughter’, the
other ‘rise’. The latter sense, however, is only activated when collocation
with letsatsi is either present or implied. When hlaba collocates with mokgosi,
the meaning is simply ‘make a noise’. Figure 14 shows how cases such as these
were treated.14
Figure 13: The normal realizations of the NS verb akga.
Why Does Africa Need Sinclair? 279
5.2 On the‘open-choice / idiom’principle
In order to introduce the contrasting ‘open-choice / idiom’ principle (Sinclair
1987a: 319–320), Table 4 is analogous to Table 3, but now for the node fahla.
As was the case in Table 3, all items in Table 4 are function words except for
fahla itself and magotlo and mahlo. That the plural noun mahlo ‘eyes’ collocates
with the verb fahla ‘blind; dazzle’ is not surprising, as both belong to the same
semantic field. That the plural noun magotlo ‘mice’ also collocates with fahla is
more surprising. As it turns out, the fixed expression fahla magotlo means
‘urinate’—the semantics of which are obscure (unless mice are indeed blinded
by this process). The resulting article is shown in Figure 15.
Table 3: Collocates of the NS verb hlaba (raw frequencies; top 20)
N Word Total Left Right L3 L2 L1 � R1 R2 R3
1 hlaba 1873 21 24 9 10 2 1828 4 7 13
2 a 937 638 299 124 126 388 0 87 112 100
3 le 791 527 264 115 112 300 0 90 89 85
4 go 535 388 147 31 35 322 0 14 78 55
5 ka 482 138 344 51 35 52 0 156 129 59
6 ba 407 236 171 60 54 122 0 18 78 75
7 ge 390 300 90 103 197 0 0 5 61 24
8 la 282 184 98 38 26 120 0 41 28 29
9 e 244 154 90 37 24 93 0 22 33 35
10 ke 243 118 125 39 47 32 0 39 44 42
11 o 232 141 91 48 38 55 0 14 28 49
12 ya 192 84 108 30 31 23 0 13 51 44
13 mokgosi 157 3 154 0 3 0 0 139 15 0
14 re 151 91 60 45 28 18 0 5 11 44
15 wa 143 43 100 12 15 16 0 11 62 27
16 letsatsi 129 100 29 41 59 0 0 10 14 5
17 mo 115 81 34 5 2 74 0 11 13 10
18 sa 97 53 44 20 13 20 0 4 24 16
19 di 84 55 29 13 6 36 0 6 15 8
20 ile 82 79 3 15 64 0 0 0 0 3
Figure 14: The normal realizations of the NS verb hlaba.
280 Gilles-Maurice de Schryver
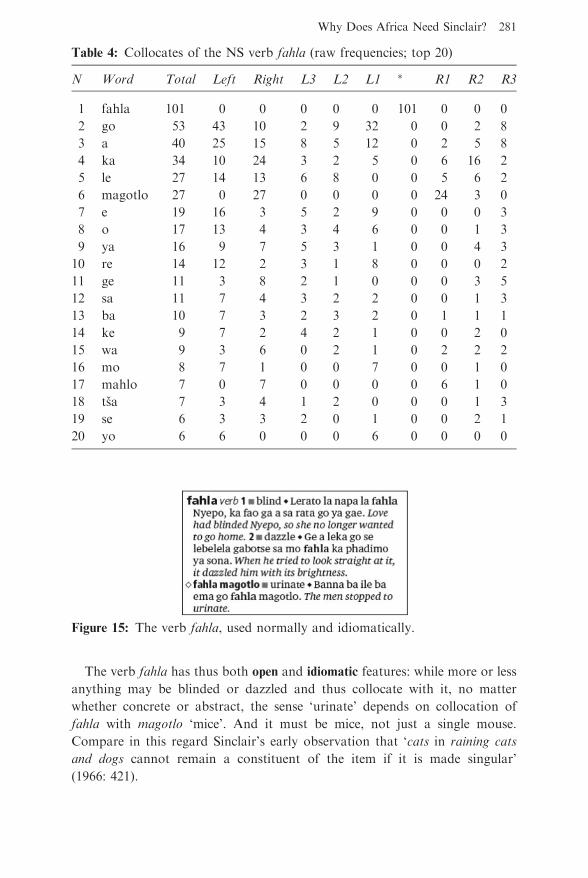
The verb fahla has thus both open and idiomatic features: while more or less
anything may be blinded or dazzled and thus collocate with it, no matter
whether concrete or abstract, the sense ‘urinate’ depends on collocation of
fahla with magotlo ‘mice’. And it must be mice, not just a single mouse.
Compare in this regard Sinclair’s early observation that ‘cats in raining cats
and dogs cannot remain a constituent of the item if it is made singular’
(1966: 421).
Table 4: Collocates of the NS verb fahla (raw frequencies; top 20)
N Word Total Left Right L3 L2 L1 � R1 R2 R3
1 fahla 101 0 0 0 0 0 101 0 0 0
2 go 53 43 10 2 9 32 0 0 2 8
3 a 40 25 15 8 5 12 0 2 5 8
4 ka 34 10 24 3 2 5 0 6 16 2
5 le 27 14 13 6 8 0 0 5 6 2
6 magotlo 27 0 27 0 0 0 0 24 3 0
7 e 19 16 3 5 2 9 0 0 0 3
8 o 17 13 4 3 4 6 0 0 1 3
9 ya 16 9 7 5 3 1 0 0 4 3
10 re 14 12 2 3 1 8 0 0 0 2
11 ge 11 3 8 2 1 0 0 0 3 5
12 sa 11 7 4 3 2 2 0 0 1 3
13 ba 10 7 3 2 3 2 0 1 1 1
14 ke 9 7 2 4 2 1 0 0 2 0
15 wa 9 3 6 0 2 1 0 2 2 2
16 mo 8 7 1 0 0 7 0 0 1 0
17 mahlo 7 0 7 0 0 0 0 6 1 0
18 tsa 7 3 4 1 2 0 0 0 1 3
19 se 6 3 3 2 0 1 0 0 2 1
20 yo 6 6 0 0 0 6 0 0 0 0
Figure 15: The verb fahla, used normally and idiomatically.
Why Does Africa Need Sinclair? 281

5.3 On textualwell-formedness
Among the many innovations in the Cobuild dictionaries is the use of corpora
not only for analysis, but also as a source of examples. One of Sinclair’s core
concerns was textual well-formedness, and in Sinclair (1984) he contrasts this
with the problematic idiomaticity and naturalness in invented examples often
found in English-language course books. In her chapter on examples in
Cobuild1 (Sinclair and Hanks 1987), Fox (1987) says:
One reason why dictionaries have not in the past helped learners to use
natural language is that most of the examples given have been full sentences,
prepared for being presented in isolation rather than being thought of as
extracts from a text. (1987: 141)
If a word typically occurs in a sentence which is grammatically complex or
alongside vocabulary items that are infrequent, it would be misleading of a
dictionary to present that word in a very simple clause or sentence with
easy vocabulary. (Fox 1987: 138)
According to this view, the best examples for learners are unedited ones, taken
verbatim from the corpus, no matter whether they are embedded in complex
grammatical constructions or accompanied by infrequent words. Examples
must be normal, representative, and typical—and thus authentic, natural,
and real.
Sinclair and Fox were focusing on monolingual lexicography. In bilingual
dictionaries, at least two new concerns surface. Firstly, it is one thing to select a
real example to exemplify a particular sense; it is a different thing entirely to
hope that the translation of that example will also be ‘real’ in the translated
language. Actually, by definition, it will not and cannot be real! What one can
try to achieve is idiomaticity, however: the lexicographer attempts to make the
translation sound idiomatic.
What happened in practice for the NS!English side of the dictionary
was that the NS mother-tongue compilers would pass their English translations
of the examples to a grammarian well versed in both languages. That gram-
marian would then check that all aspects of the original examples were indeed
conveyed in the translation. Next, the material was sent to an English mother-
tongue speaker at the publishing house, who checked the idiomaticity of the
English. His or her input was noted in the file and sent back to the grammarian,
whose task was now to realign the translation and the original. When running
into problems, the file had to be sent back to either the NS or the English
mother-tongue speaker, or both. As a result, although the original idea was to
leave corpus examples untouched, adaptations were made—punctuation was
added, difficult words were replaced by easier ones, and long sentences were
282 Gilles-Maurice de Schryver

shortened. As one can imagine, the tension between the dictionary develop-
ment team and the publisher was often palpable—and despite the frequent
to-ing and fro-ing, it was not always possible to please everyone. Figure 16
is a case in point, where the publisher would have preferred the more idiomatic
If rhyme has been used properly in the poem, it will not be easily forgotten. That
would have implied too much rewriting of the real example, however, for
methaladi ‘lines’ is what is referred to in the NS.
Similarly, the NS translations of the English template were also piped
between the translators, grammarians, and idiomaticity checkers. Take for
instance the extract shown in Figure 17. Although the example at sense 3 is
grammatically correct, some mother-tongue speakers felt that it is not idiomatic
enough, as a back translation might result in something like I have enough work
which will use me for a month.
A second area of concern was a direct result of using corpora, namely that
the example sentences and their translations often contain words that are not
covered in the dictionary’s macrostructures. This matter was given serious
thought: Should one only choose examples where all words are also covered
in the dictionary? Should this only apply to the original example, or to both the
original and its translation? Could one perhaps agree on a system whereby, say,
up to two unlemmatized words per example are permissible?
With Sinclair’s principle of well-formedness in mind, we decided to simply
keep the number of such ‘missing words’ to a minimum. The reasoning was
that the context, in combination with the translation, should give enough clues
as to the meaning of those missing words. In order to enable the compilers to
keep track of potential problems in this area, the dictionary compilation soft-
ware used has a feature (‘Highlight undefined words in examples’) which auto-
matically marks such cases. For example, Figure 18 shows the first article on
Figure 16: Chasing bilingual idiomaticity (1).
Figure 17: Chasing bilingual idiomaticity (2).
Why Does Africa Need Sinclair? 283

page 2 of the published dictionary. During compilation in TshwaneLex, both
the NS motswiri and the English leadwood were marked as missing.15
5.4 On semanticprosody
Despite the best efforts, occasionally it all went wrong. The entry for the verb
ipona (the reflexive form of bona ‘see; look’), in Figure 19, is an example.
Close inspection reveals that most of the information in this article was
invented by introspection, not based on corpus analysis. Firstly, in 7.5 million
words of running NS text there is not a single instance of ipona and maemo
‘status’ as collocates, even using a 10-word window. The example sentence
illustrating sense 2 prompts criticism in Fox’s terms (1987: 143): ‘It gives us
far too much information, and so carries too much meaning content for one
sentence.’ In the corpus there are only three instances of ipona and seipone
‘mirror’ collocating. The meaning at sense 2 appears to have been constructed
rather than observed in the corpus, and the example was handcrafted to fit that
constructed meaning. Moving on to sense 3, motho wa go ipona ‘a person who
boasts’ is also absent from the corpus. The fixed expression at the end of the
article (ipona molato), however, is very frequent. If a Sinclairian approach had
been adopted, that one fixed expression might have led to a better treatment of
this lemma. This is expounded in the next paragraphs.
Sinclair (1987b: 155–156) shows that the most striking feature of the
phrasal verb set in is the nature of its subjects, which generally refer to
Figure 18: Chasing bilingual idiomaticity (3).
Figure 19: Getting it wrong.
284 Gilles-Maurice de Schryver

unpleasant state of affairs (rot, decay, malaise, despair, etc.). The definition in
Cobuild1 for set in reads: ‘If something unpleasant sets in, it begins and seems
likely to continue or develop.’
Sinclair (1998: 16–22) takes the idea of hidden associations affecting the
neutrality of language to a new level, supported by a detailed analysis of
budge. He proposes five categories of co-selection as components of a lexical
item: obligatory core and semantic prosody, and optional collocation, colliga-
tion, and semantic preference. Taking the example of ipona above, it is exactly
the application of the notion of semantic prosody which suggests that the article
in Figure 19 was created in a corpus vacuum. Studying the 400þ corpus lines
for ipona, one soon realizes that there are very few instances where this
verb is semantically positive. The most salient collocates are molato ‘guilt,
fault, problem, trouble’, phoso ‘mistake’, botlaela ‘stupidity; foolishness’, and
molahlego ‘lostness’. Looking back at all the positives in Figure 19 we have to
conclude, with Fox, that ‘we cannot trust native speakers to invent sentences
except in a proper communicative context—where they are actually using
language rather than sitting thinking about it.’ (Fox 1987: 144)
6. Looking ahead
Just as isolated, handcrafted example sentences don’t fare well, dictionary
A-to-Z sections don’t do well on their own either. In the NS dictionary,
front, middle, and back matter support the two A-to-Z sections. An innovative
extra section is the corpus-based dictionary mini-grammar, placed in the centre
of the dictionary, and presented in both NS and English. This short grammar
was specifically written to be used with the dictionary: it is seamlessly inte-
grated with the information in the A-to-Z sections. Not only is all the data
drawn from the corpus, but in selecting topics the frequencies of the various
grammatical phenomena were considered. The ten most salient phenomena,
bridging the grammars of NS and English, were withheld. This was our contri-
bution to the growing body of corpus-driven linguistics and lexicographical
studies.16
Another integrated section found in the extra matter of the NS dictionary is
called ‘Dictionary activities’. The need for this, and the decision to bundle it
with the A-to-Z sections of the dictionary, has to be seen against the back-
ground of virtually absence of dictionary culture in Africa. An accompanying
bilingual dictionary workbook (Taljard et al. 2008) has recently also been added
to the series as supporting material.
Following a decade of building, analyzing, and extracting data from corpora
for lexicographic purposes of the African languages, it is hard to imagine how
anyone could even attempt to compile a dictionary without them. Corpora,
even small ones, allow fast-tracked production of reference works, act as arbi-
ters on what to include in and what to omit from both the macro- and
Why Does Africa Need Sinclair? 285

microstructures, enable mother-tongue speakers to map meanings onto use,
while all along the raw material may be lifted out of the corpora and dropped
straight into the dictionary. Idiomaticity and corpus statistics drive this entire
process. All of this, then, is not only Sinclair’s contribution to modern lexico-
graphy, but also why Africa needs Sinclair.
Acknowledgements
Thanks are due to Elsabe Taljard, without whose help we would not have got
this far in applying to Northern Sotho the groundbreaking work of John
Sinclair and Patrick Hanks.
Notes
1 For a comprehensive account of the issues involved in compiling this dictionary, see De
Schryver (1999).2 For a full report, see De Schryver et al. (2006).3 See for instance Doke and Vilakazi (1953): Zulu!English, set in an old spelling, and Doke
et al. (1958): English!Zulu, set in a newer, but nevertheless old spelling.4 See for instance Ziervogel andMokgokong (1975): Northern Sotho!Afrikaans and English.5 For at least a hundred items grammarians were consulted, who pinpointed the word class and
sometimes the meaning or function. These items, although frequent, had never been recorded by
anyone anywhere.6 In an ideal world, it would have been scientifically sound to re-reverse the (new)
English!NS side of the dictionary, but tight deadlines unfortunately did not allow for this.
This is especially unfortunate as TshwaneLex offers dedicated tools to help balance the two sides.
These tools include ‘Linked View’, whereby, when a lexicographer is working on a particular
lemma in one side, all related lemmas on the other side are automatically shown. Another feature is
‘Translation Equivalent Fanout’, which automatically shows lemmas related to the current one via
a shared translation equivalent (i.e. all other articles in the same side that share a translation
equivalent that appears within the current article).7 This aspect also led to extensive discussions with the publisher. Wherever we did not bow to
pressure, equivalents in such series are separated by semicolons (so that dictionary users will not be
led to infer that these options are synonymous). Unfortunately, there are also instances where we
ended up splitting after all. In such cases the target language exercised an unfortunate influence on
the source language.8 For a more detailed discussion, see De Schryver (2006).9 In that dictionary, and for that side, a serious influence by the target language (Afrikaans) on
the source language (English) can be observed, and one of the first tasks was therefore an attempt
to undo that. This was only partially successful. In addition, the senses had not always been
ordered according to their frequencies in an English corpus, so the structure for many articles was
also reworked in this regard.10 From Figures 5 and 6 one may conclude that parts of speech do not correspond
across languages. This is hardly surprising. The publisher insisted that we ‘align’ them wherever
possible, so that, say, a verb in one language would also be a verb in the other. We felt this
often resulted in unnatural translations, however, and of course in some cases it is simply
impossible to do it.11 In Figure 7, the juxtaposition seen in the first example sentence for class 10, under sense 1 of
‘many’, is clearly one that the proofreaders missed. This, too, was an area which caused some
friction, with the dictionary compilation team being convinced that one should faithfully reflect
286 Gilles-Maurice de Schryver

what the corpus and thus culture show, while the publisher would rather ‘invent’ neutral examples
to rid the dictionary text of all potentially politically incorrect information.12 Actually, it is hoped that the suggestions offered in this dictionary will end up being used by
the community, after which it will also make sense to lemmatize them in NS lexicons.13 Further note that the first meaning in Figure 13 was exemplified with KWIC line 27, used
verbatim, while the second meaning was illustrated with line 53, shortened slightly.14 Also observe that function words such as those in Table 3 are not merely ‘noise’,
as they are often important constituents of grammatical constructions. Compare with
Figure 5.15 In Figure 18 one can also see one of the techniques that were sometimes used in trying to
achieve translated idiomaticity while remaining true to the original: In NS the possessive abo most
definitely includes the notion of ‘place/family/homestead’, while the English translation of the
example would be better without it—hence the use of the brackets, in an attempt to sit on two
(language) chairs simultaneously.16 For a detailed expose, see De Schryver and Taljard (2007).
References
A. Dictionaries
De Schryver, G.-M. 2007. Oxford Bilingual School Dictionary: Northern Sotho andEnglish. Cape Town: OUP.
De Schryver, G.-M. and N. S. Kabuta. 1998. Beknopt woordenboek Ciluba – Nederlands.Ghent: Recall.
Doke, C. M. et al. 1958. English–Zulu Dictionary. Johannesburg: WUP.Doke, C. M. and B. W. Vilakazi. 1953. Zulu–English Dictionary. Johannesburg: WUP.Hillewaert, S. et al. 2004. Online Swahili–English Dictionary. http://africanlanguages.
com/swahili/Louw, P. 2007. Oxford English–Afrikaans School Dictionary. Cape Town: OUP.Sinclair, J. M. and G. Fox. 1995. Collins COBUILD English Dictionary. London:
HarperCollins.Sinclair, J. M. and P. Hanks. 1987. Collins COBUILD English Language Dictionary.
London: HarperCollins.
Ziervogel, D. and P. C. Mokgokong. 1975. Comprehensive Northern Sotho Dictionary.Pretoria: Van Schaik.
B. Other references
Church, K. W. and P. Hanks. 1989. ‘Word Association Norms, Mutual Information and
Lexicography’ in Proceedings of ACL’89, 76–83.De Schryver, G.-M. 1999. Bantu Lexicography and the Concept of Simultaneous
Feedback. (MA dissertation.) Ghent: UGent.De Schryver, G.-M. 2002. ‘Web for/as Corpus: A Perspective for the African
Languages.’ Nordic Journal of African Studies 11.2: 266–282.
De Schryver, G.-M. 2006. ‘Compiling Modern Bilingual Dictionaries for BantuLanguages: Case Studies for Northern Sotho and Zulu’ in Proceedings ofEuralex’06, 515–525.
De Schryver, G.-M. et al. 2004. ‘The Lexicographic Treatment of the DemonstrativeCopulative in Sesotho sa Leboa—An Exercise in Multiple Cross-referencing.’
Lexikos 14: 35–66.De Schryver, G.-M. et al. 2006. ‘Do Dictionary Users Really Look Up Frequent Words?
– On the Overestimation of the Value of Corpus-based Lexicography.’ Lexikos 16:
67–83.
Why Does Africa Need Sinclair? 287

De Schryver, G.-M. and G. De Pauw. 2007. ‘Dictionary Writing System(DWS)þCorpus Query Package (CQP): The case of TshwaneLex.’ Lexikos 17:
226–246.De Schryver, G.-M. and E. Taljard. 2007. ‘Compiling a Corpus-based Dictionary
Grammar: An example for Northern Sotho.’ Lexikos 17: 37–55.
Fox, G. 1987. ‘The Case for Examples’ in Sinclair (ed.), 137–149.Hanks, P. 2002. ‘Mapping Meaning onto Use’ in Correard (ed.) Lexicography and
Natural Language Processing, 156–198.
Joffe, D. et al. 2008. TshwaneLex Suite. http://tshwanedje.com/tshwanelex/Kilgarriff, A. 1996. BNC Database and Word Frequency Lists. http://www.kilgarriff.
co.uk/bnc-readme.htmlScannell, K. P. 2007. ‘The Crubadan Project: Corpus building for under-resourced
languages’ in Fairon et al. (eds.) Building and Exploring Web Corpora. Louvain-la-Neuve: PUL, 5–15.
Sinclair, J. M. 1966. ‘Beginning the Study of Lexis’ in Bazell et al. (eds.) In Memory of J.
R. Firth. London: Longman, 410–430.Sinclair, J. M. 1984. ‘Naturalness in Language’ in Aarts and Meijs (eds.) Corpus
Linguistics. Amsterdam: Rodopi, 203–210.
Sinclair, J. M. 1987a. ‘Collocation: a Progress Report’ in Steele and Threadgold (eds.)Language Topics. Amsterdam: Benjamins, 319–331.
Sinclair, J. M. 1987b. ‘The Nature of the Evidence’ in Sinclair (ed.), 150–159.Sinclair, J. M. (ed.) 1987c. Looking Up, An account of the COBUILD Project in lexical
computing and the development of the Collins COBUILD English LanguageDictionary. London: Collins.
Sinclair, J. M. 1998. ‘The Lexical Item’ in Weigand (ed.) Contrastive Lexical Semantics.
Amsterdam: Benjamins, 1–24.Taljard, E. et al. 2008. Oxford Bilingual School Dictionary Workbook: Northern Sotho
and English. Cape Town: OUP.
Tognini-Bonelli, E. 1995. ‘Italian Corpus Linguistics: Practice and Theory.’ Textus 8.2:391–412.
288 Gilles-Maurice de Schryver

Addendum 1: Sample page from the Beknopt woordenboek Ciluba–
Nederlands
Why Does Africa Need Sinclair? 289

Addendum 2: KWIC lines for akga in a 7.5-million-word Northern Sotho
corpus
290 Gilles-Maurice de Schryver

Addendum 2: Continued
Why Does Africa Need Sinclair? 291