virtualizing network i/o on end-host operating system: operating system support fornetwork control...
TRANSCRIPT

Virtualizing Network I/O on End-Host OperatingSystem: Operating System Support for
Network Control and Resource ProtectionTakashi Okumura and Daniel Mosse, Member, IEEE Computer Society
Abstract—In the recent past, with the advent of more powerful networks, computations have become more distributed in nature and
control of network resources has become essential for Operating Systems (OS). Nevertheless, proposed primitives for network control
at end-host OS are designed without an OS design perspective and have been in disagreement with existing OS constructs, causing a
variety of problems. In this paper, we propose a new OS service for network control, namely, hierarchical virtualization of network
interface. The virtual network interface is hierarchically structured and attached to various OS constructs, such as threads, processes,
and sockets, for the control of their network I/O. We show that our proposed mechanism provides the following properties: 1) flexible
control granularity, 2) resource protection, 3) reasonable abstraction and Application Programming Interface (API), and 4) various
types of packet scheduling and control in a single framework, such as work-conserving and non-work-conserving, in accordance with
existing OS mechanisms. For a proof of concept, we present an implementation on a PC-Unix, using the file system abstraction, and
carry out systematic profiling. The system exhibited the expected control behavior, that is, good responsiveness to the control
commands while keeping the performance penalty small.
Index Terms—Operating systems, process management, network communication.
�
1 INTRODUCTION
IN this age of computer communications, applicationprogramshaveavarietyof requirements for theunderlying
communication infrastructure. For example, a video stream-ing server may require a reservation of bandwidth on theentire path, while an interactive application may need jitterguarantees for proper communication quality. Hence, anenormous effort has been dedicated in the research andindustrial communities to meet these requirements for thenetwork Quality of Service (QoS) and, to realize the requiredlevel of service, further commitment of end-host OperatingSystems is expected for a variety of reasons.
First of all, there have been more and more networkapplications that require QoS support. They may need sucha service even in a network without QoS capabilities, suchas wireless networks, where traffic control can be achievedonly by the cooperation of end-nodes. Second, increasingthe volume of network traffic has been demanding higherswitching performance for core routers, which cannotafford detailed traffic inspection and control that end-hostapplications may want. Thus, the pressure for involvementof the end-host in the control would continuously increase.Third, increased processor power currently allows end-hosts to saturate attached network resources and, therefore,requires efficient means to manage their resource consump-tion within that host. Last, new types of distributedapplications may presuppose a controlled network load
for proper functionality, for example, in the grid-computingand factory automation area.
All of these trends lead to the need for traffic control byend-host operating systems, in addition to the traditionalnetwork control mechanisms. However, the design andimplementation of the new Operating System (OS) servicehas not been addressed appropriately in the context of itsdesign principle. For illustration, we may consider the casesof existing implementations [19], [2], [11], which have beenin use for many years. These implementations are built withthe traditional network control model, in which an almightynetwork administrator controls flow of packets in themiddle of communication. This implies that an ordinaryuser on the system, without such a privilege, cannot controlnetwork I/O of their applications, even though the systemdoes have mechanisms for such a purpose. Indeed, it issurprising to realize, in the network age, that there is nostandardized way for application programs to control theirgenerating traffic, or receiving traffic.
We ascribe this misfortune mainly to two functionaldeficiencies of the existing OSs: controllability of networkI/Oand its protection semantics. The objective of this paper isto establish the general principle that aids in the design ofnetwork-aware general-purpose end-host OSs for thesefunctionalities. For this purpose, we propose a new OSservice, hierarchical virtualization of network interface. Thevirtualized network interfaces are hierarchically structuredand attached to terminating entities on the end-host such asprocesses and sockets to control their network I/O.We showthat this simplemechanism has desirable properties as anOScore service and provides a smart solution for the problem.
The remainder of this paper is organized as follows:First, we clarify the problem of OS support for networkcontrol and define its requirements (Section 2). Then, we
IEEE TRANSACTIONS ON COMPUTERS, VOL. 53, NO. 10, OCTOBER 2004 1303
. The authors are with the Department of Computer Science, Sennott Square,University of Pittsburgh, Pittsburgh, PA 15260. T. Okumura is also withAsahikawa Medical College, Japan. E-mail: {taka, mosse}@cs.pitt.edu.
Manuscript received 30 July 2003; revised 4 Mar. 2004; accepted 17 Mar.2004.For information on obtaining reprints of this article, please send e-mail to:[email protected], and reference IEEECS Log Number TC-0109-0703.
0018-9340/04/$20.00 � 2004 IEEE Published by the IEEE Computer Society

propose the concept of hierarchical virtual network interface(Section 3) and address system interface issue (Section 4).After the conceptual foundations have been laid, we presentour prototype implementation on FreeBSD [10] and showperformance profiles to validate the model (Section 5). Next,we show applications and lessons we learned (Section 6).Last, we give a brief review of related work (Section 7) andoffer concluding remarks (Section 8).
2 OS SUPPORT FOR NETWORK CONTROL
The field of operating system research has been workingtoward proper abstraction of various system resources.Hence, to address the problem of operating system supportfor network control and protection, the simplest approach isto abstract the communication and provide control over theabstraction. However, we contend that this straightforwardapproach, abstraction of end-to-end communication, has funda-mental shortcomings.
2.1 Problem in the Abstraction of End-to-EndCommunication
We begin the discussion by presenting two antitheticalapproaches: low-level abstraction and high-level abstraction.
2.1.1 Low-Level Abstraction
One way to control network traffic is to provide controlservices that work directly over flows. For example, we mayextend the socket abstraction so that users can set bandwidthlimitations. Admittedly, the low-level control over eachconnection is useful for some applications. However, as weillustrate below, there is some room for improvement.
First, such an interface can easily contradict the resourcemanagement semantics of the operating system. For example, anetwork-intensive low-priority process with a large band-width limit can easily starve higher priority processes thatrequire network I/O. We call this situation, caused by thelack of a resource protection mechanism, network priorityreversal. This compromises the resource managementsemantics of the OS and, clearly, resource protection withproper access control is needed for the system to be safe.
Second, the low-level abstraction is not scalable. Supposethat we have 1,000 concurrent connections with intermittenttraffic. It is quite inefficient to designate fixed networkresources to each of them. In this case, proper trafficaggregation can greatly improve the resource utilization, aswell as the quality of each session. Likewise, if we have1,000 successive short connections, we may want to assignan aggregate flow specification for all of them. Clearly,aggregation is needed.
Third, the low-level abstraction scheme presupposesknowledge of independent connections, which is not alwayspossible. For instance, if we are to control output of a Webbrowser, we need to know how many connections thebrowser makes and when. To address the problem, we needanother system service to properly locate the connectionsthey make and monitor the usage. This would probablyincrease the design complexity of the system and causeextra overhead and latency.
Last, in the area of network resource management, theservice model is still an open problem. For example, we mighthave service models such as IntServ and DiffServ, but thereare also models for authentication and accounting. Themost probable scenario is coexistence of various models in
which each administrative domain chooses its own modelsand services to offer, based upon its own needs andresource constraints. Hence, in this scheme, we would needto configure a resource management algorithm with thelow-level primitives, severely compromising the portabilityof the control program.
As shown above, although the low-level abstraction offlows provides fine-grain control, it is not always the mostdesirable solution. Consequently, we need a higher level ofabstraction.
2.1.2 High-Level Abstraction
On the other extreme, the operating system might provide ahigher abstraction. For example, we may attempt to create acommunication abstraction under /dev/network/, with asignaling API for end-to-end bandwidth reservation andproper abstraction for aggregation of the traffic. Althoughthis sounds promising, it is not as simple as it may seem at acursory examination. The fundamental problems of thisscheme are threefold.
First is the lack of controllability of the network. Althoughthe network interface is one of the major I/O devices of amodern computer, the network I/O differs from typical I/Oaccess, such as those for hard drives and serial ports, in thatmost of the network I/O involve remote resources. Forexample, the bandwidth guaranteemight require output rateregulation at the host and a path bandwidth reservation,which has to be supported by the network. This fact does notmake a single and consistent abstraction by the end-host OSimpossible, but clearly makes it harder to achieve.
Second, from the OS perspective, we need a standardizedabstraction and interface, mostly for programming efficiency.However, there have been numerous network protocols andthose of future networks are unpredictable. For example,unicast, multicast, and anycast differ greatly and, thus, it ishard to converge toward a single abstraction. There arevarious tricky protocols, such as the Real Time StreamingProtocol (RTSP) [20], which has a connection for datastreaming and keeps another for a health check of the stream.It is hard to statically define a single standardized abstractionand system service to satisfy these various needs.
Third, such service with abstraction of end-to-endcommunication requires close cooperation of kernel anduser-level applications. Let us take the example of pathbandwidth reservation. We may employ an RSVP [18]module at the user level for end-to-end signaling, but, insome cases, we also need a kernel module to regulate thehost’s network I/O. This poses another question of how toseparate the functionalities between kernel and user-space.
As briefly illustrated, it is quite challenging to have asystem service of high-level abstraction for end-to-endcommunication.
2.2 Requirements for Alternative Approach
The conclusion we reach from the two perspectivespresented in the preceding section is that there is a needfor a new OS service paradigm for network control. And,according to the discussion, it has to meet the followingrequirements:
2.2.1 Resource Protection Model
We need a resource protection model for the system to bedependable. For example, once we grant some resource,
1304 IEEE TRANSACTIONS ON COMPUTERS, VOL. 53, NO. 10, OCTOBER 2004

say, to a process, its network I/O activity should not exceedthe specified limit, regardless of the number of childrenprocesses and open sockets.
In addition, we need a proper access control model. Forexample, a resource granted to a user should not be utilizedby other users, except perhaps for the system administrator,who has privileges to do so.
2.2.2 Flexible Control Granularity
We stated above that fine grain control (controlling indivi-dual flows) is useful, while aggregation of flows (coarse graincontrol) is indispensable. This suggests that the operatingsystem service should provide flexible control granularity sothat it works on a flow, as well as on a set of flows.
2.2.3 Useful Abstraction and System Interface
Last, a standardized abstraction and interface should exist toaccommodate control for all the requirements stated above.
In the following sections, we present a novel approach inoperating system support for network control that meets allof these requirements.
3 HIERARCHICAL VIRTUALIZATION OF NETWORK
INTERFACE
3.1 Introduction
To meet the requirements, we propose a new systemabstraction, called hierarchical virtual network interface (VIF).Fig. 1 gives a conceptual overview of the approach. Physicalmachines (rectangular boxes) are shown with physicalnetwork interfaces (cylinders at bottom). Circles denoteprocesses and arrows are data flows. A dashed boxwrapping the circles is a virtual machine (VM), an illusionof possessing their own machine by the execution entities.
In a legacy setting (Fig. 1a), every process shares aphysical network interface (a shadowed cylinder). Thenetwork is transparent to the processes and the best-effortprinciple governs every I/O activity. Unfortunately, thismodel has serious drawbacks—lack of protection andcontrol for the network I/O—and, thus, causes problemslike network priority reversal, as illustrated in Section 2.1.Existing mechanisms proposed to give network controlcapabilities [19], [2], [11] share the same limitation sincethey lack protection semantics for their control. We believethat this is a serious flaw that compromises the resourceprotection principle of a modern operating systems.
To solve this problem, we virtualize the network interface(Fig. 1b). Each process (virtual machine) now possesses itsown virtual interface (shadowed cylinders) with the illusionof possessing its own machine. Then, we allow each processto configure the specification of its virtual interface. Thisway, processes can control their network I/O whileintroducing proper partitioning, that is, providing resourceprotection.
3.2 Meeting Requirements
Next, to meet the requirements in Section 2.2, we extend thesimple idea of virtual network interfaces proposed above.
First, we are able to provide better protection by makinga child process inherit a virtual network interface of itsparent process (Fig. 2). This way, all the process activity isbound by the granted resource. For example, once we set abandwidth limit for a VIF, the entire process familyconforms to the limit, even if they spawn child processesor initiate new sessions.
Second, we realize flexible control granularity. Our(natural) solution is to allow processes to create childinterfaces connected to the original VIF and to attach theinterfaces to processes’ subunits, such as threads.
In Fig. 3a, we see three threads (wavy lines in a processcircle) each having dedicated interfaces, thereby partition-ing the resource of the common interface lying on theVM boundary.
It is easy to extend the concept above for resource unitslarger than processes, such as process groups (Fig. 3b).Suppose that two processes are cooperating toward acommon task. It is natural that we allocate a single virtualinterface for both and give a certain amount of resources tothe group.
OKUMURA AND MOSS�EE: VIRTUALIZING NETWORK I/O ON END-HOST OPERATING SYSTEM: OPERATING SYSTEM SUPPORT FOR... 1305
Fig. 1. Conceptual overview of the virtual network interface: (a) legacy
system and (b) proposed system.
Fig. 2. Inheritance of virtual network interface.
Fig. 3. Hierarchical structuring of the virtual interfaces.

As illustrated, hierarchical structuring and attachment ofvirtual network interfaces provides a clear and naturalsolution for flexible control granularity. Note that we talkabout processes and threads here simply for presenting theoverall idea of hierarchical virtual network interfaces; theproposed scheme is applicable to process, threads, sockets,and other OS-supported management entities. For simpli-city of presentation, we will use “processes” instead of “OS-supported entities” in the rest of this paper.
Third, although not a requirement drawn in Section 2, itis clear that an operating system should provide amechanism as general as possible for its control. In thisregard, it is desirable that the network control primitiverealizes various types of network control, such as packetshaping and fair queuing, in a single framework.
Toward this end, we extend the model so that eachinterface can employ its own packet scheduler. For example, ifa process needs an output rate control for its traffic, it mayassign a packet shaper scheduler. If it wants high resourceutilization, a work-conserving scheduler may be employed.This way, by allowing users to select a scheduler for eachvirtual interface, we can realize various types of networkcontrol and provide great freedom in network control, eachwithin its own protection domain.
3.3 Remarks
Our proposed OS service, a virtual network interface withslight extension for hierarchical structuring and deploy-ment of various schedulers, has the following properties.
First, it provides a consistent mechanism for resourcemanagement and protection. Second, the cascade of inter-faces provides simple solution for flexible control granu-larity within the limits of the allocated resource. Third, italso provides great freedom in the control of network I/O.
In addition to the these features, this local mechanismworks independent of application protocols and of thecommunication topology (such as unicast and multicast).
Moreover, this strategy is backward compatible (or retro-fitting), where existing programs can benefit from theproposed mechanismwithout modification, as we will showin Section 6. In other words, retrofitting existing applicationsto work with our scheme is a simple configuration task thatrequires no source code and no recompilation.
On the other hand, we have not addressed an importantissue: Although the VIFs provide an upper limit on resourceusage by processes, the present model cannot give a simplesolution for resource guarantees (lower limit). This isbecause the model lacks the means to specify resourceallocation policies. This topic is yet to be explored in themodel and we will revisit the issue in Section 6.
4 SYSTEM INTERFACE
A system interface that meets the requirements in Section 2.2was another challenge we face. How can we express thehierarchical nature of the VIF tree? How can we provideaccess capability to users or realize access rights on VIFs?They are indispensable for the system to be sound, but weneed to avoid increased complexity of the system andconflict with existing mechanisms. In this section, weaddress this interface problem and demonstrate that filesystem abstraction can be a simple but powerful solution.
To clarify our presentation, we start by presenting asample scenario in which we control the network with theVIF concept. Then, we propose a new system interface torealize the control, based on the process file systemabstraction (procfs) [23], [7]. Last, the operation model ispresented using common file management mechanisms.The strength of the design will become clearer as the paperprogresses. Note that this is a low-level API and we offerhigher-level commands that wrap the low-level systemservice, as we show in Section 6.
4.1 Sample Scenario
Let us consider a VIF-based control for a typical clientmachine. In Fig. 4, there are two daemon processes (p1 andp2) for network file system access. Suppose that they aremounting a file server on the local network and have burstytraffic pattern (e.g., file transfers). On the right is a Webbrowser process (p3), accommodating several threads, oneof which is reserved for data streaming. Note that burstytraffic by the network file system occasionally saturates thereal network interface and starves the web browser processflows. (In fact, the work presented in this paper wasoriginally motivated by a similar problem we had in ourdepartment network [14].)
Our goal is to give proper protection to the processes andprovide better quality of service to system users. To thisend, we show below how to configure the VIFs.
First, we reserve a certain amount of bandwidth for thestreaming application. This is achieved by limiting the filesystem traffic and, thus, we configure the flow specificationof VIF 3 so that the bursty traffic is bound by somepredefined bandwidth (e.g., 4Mbps). Next, we give fairshares to the file system processes for better utilization ofthe limited bandwidth; for instance, 50 percent of VIF 3 toeach VIF 1 and VIF 2.
VIF 4 and VIF 5 are for Web browsing. Let us supposethat VIF 4 is for the streaming and VIF 5 for TCPconnections. Again, to assure the streaming quality, itwould be better to limit the bandwidth usage of VIF 5,leaving room for VIF 4 to receive the time-sensitive data.
4.2 File System Abstraction
Next, we show how to carry out the configuration of thesystem, utilizing the file system abstraction. For a briefdescription of the process file system, readers are referred tomanual page of procfs on any Unix system.
1306 IEEE TRANSACTIONS ON COMPUTERS, VOL. 53, NO. 10, OCTOBER 2004
Fig. 4. Configuration sample of a hierarchical virtual network interface
structure.

To illustrate the abstraction strategy, we show in Fig. 5 a
sample directory representation for the VIF configuration
shown in Fig. 4. A directory under /proc/network/
represents a VIF. The root VIF is named as fxp0, which
corresponds to the name of a real network interface on the
machine, marked as interface 6 in Fig. 4. The VIF has three
VIFs under it: VIF 3, VIF 4, and VIF 5. Files under a VIF (e.g.,
bandwidth and stat) contain configuration parameters for
the virtual interface (for simplicity, only some of them are
shown in the figure).Directories under /proc/[pid]/ are process entries, as
usual. We added a sockets directory under each process
entry. As shown, process 1 (p1) and process 2 (p2) have one
socket each and process 3 (p3) has two sockets. Directory
names (such as 1 and 2) for the sockets correspond to the
file descriptors they are assigned to.Under each individual socket directory there is a link
named fxp0 (e.g., directory /proc/[p3]/sockets/1/
fxp0/), indicated by the @ mark in Unix convention. The
links denote attachment of the VIFs to the particular
resources. For example, we can see that p3 has its
network I/O capped by a VIF represented as /proc/
network/fxp0/ and the two sockets of p3 are connected
to VIF 4 and VIF 5.The association of a VIF and an OS-supported entity
(e.g., a process or a socket) is represented by a link with the
same name as the real interface (in this case, fxp0). This
convention is chosen because we may have several network
interfaces, like fxp0 and fxp1. (We will revisit this
multiple interface issue later.)In summary, there is a directory for configuration of the
VIF structure. And, each process entry possesses a sockets
subdirectory for VIF association. Under that directory are
subdirectories for each socket and software links pointing
to their respective target VIFs.
4.3 Operation Model
The operation model is briefly described next. We first show
how the system interface is used by applications, and discuss
some other issues related to the operation of the API.
4.3.1 Low-Level Interface
For control of the VIF system, we use common file manage-ment system calls, such as directory creation, soft linking, fileread, and write. Since they are just files and directories, wemay also control the VIF system using correspondingcommands, such as mkdir and ln. Although we do notexpect users to use the file management commands for VIFoperation, we use such commands for simplicity of theillustration, here. First, to create a VIF, the mkdir command(or system call, to be exact) is used under /proc/networkdirectory. Likewise, the ln command (a system call, to beexact, again) is used to attach aVIF to a process or a socket. Forexample, the operation ln -s /proc/network/fxp0/5
issued in directory /proc/[p3]/sockets/2/ will attachthe VIF 5 to the second socket of process 3. Analogously,detachment and removal of VIF is possible with rm andrmdir.
In this procfs abstraction, it is easy to support variousattributes for a VIF through parameter files. To set anyvalue to a certain parameter, simply write an ASCII value toa representing parameter file. To read the values, simplyread the file content.
4.3.2 Extensibility of Functionality
To extend the model to realize various types of trafficcontrol and packet scheduling, we simply create an entry inthe VIF directory that keeps the scheduler type so that eachvirtual interface can specify its own packet scheduler (notshown in the figures). For specification, users write ascheduler ID onto the handle.
It is possible to further extend the interface. For example,we may allow users to add their own packet schedulercode. Or, we may create a file to describe some rule forpacket filtering. We can observe that the directory structureis a natural representation of a VIF, where files correspondto “attributes” of each VIF object.
4.3.3 Multiple Network Interfaces
We need to address the situation where there are multiplenetwork interfaces on a system. Suppose that a machine hastwo interfaces (fxp0 and fxp1) connecting the machine todifferent networks. A process on the machine might want to
OKUMURA AND MOSS�EE: VIRTUALIZING NETWORK I/O ON END-HOST OPERATING SYSTEM: OPERATING SYSTEM SUPPORT FOR... 1307
Fig. 5. Directory structure for the sample VIF configuration in Fig. 4.

use fxp0 heavily, but might need moderate usage of fxp1.In this case, we need to have separate VIF structures for thetwo interfaces. Note that this is not a rare case since everyUnix system has a loopback interface at least, in addition toany physical interface.
In our proposed scheme, each interface has its own VIFstructure under /proc/network. (Fig. 5 shows just oneinterface for simplicity.) Accordingly, each process hasindependent attachments to each one of the VIFs, under/proc/[pid]/sockets. It is natural to designate thename of the real interface for the associations to discrimi-nate each independent VIF structure. Note that we canavoid the trouble of managing the associations just byhaving control commands which hide the API detail, as wereview in Section 6.
4.3.4 Rules for Consistency
To assure consistency of the VIF system, we just needsimple rules.
First, users can only remove leaf VIFs. Second, users canonly attach a process (a resource unit) to a VIF that is adescendant of the VIF originally attached. Third, users canonly modify parameters and directory structures they own,whereas system administrators have privileges to access/modify any part of the system. Last, we define that theattachment of a VIF implies “access allowed” and lack ofVIF attachment “access denied.” Hence, if the parent doesnot have an access to an interface, children are not allowedto use it. Conversely, if the parent has access, the childrenare allowed to use the interface.
Following these rules, we can assure the consistency ofthe system and make resource units to conform to theresource limit granted originally. If any violating operationis performed, the system returns file system errors, such aspermission denied.
4.4 Remarks
The abstraction presented in this section is powerful for thefollowing reasons:
First, the hierarchical structure of the virtual interfacesand its operation are intuitively represented, which is moreadvantageous than a system call-based approach. Second,the resource protection model is naturally realized withexisting file permission semantics, that is, users can onlycontrol their own resources. Third, the abstraction enablesvarious types of network control in a single consistentinterface, for example, work-conserving and non-work-conserving. Fourth, it supports controls of various types ofOS abstractions (or resource units) representable in theprocess file system, not limited to process and sockets. Last,but also very important, all the above advantages are validfor any programming environment that supports commonfile management API, even without system call interface,such as shell scripts.
The primary drawback of the scheme is its performanceoverhead compared with another possible interface with aset of dedicated system calls. For example, we needinvocation of extra system calls, open() and close(),just for a parameter inspection. However, we believe thatthis is not a serious shortcoming, and give simple empiricalqualification in Section 5.2.
5 IMPLEMENTATION AND PERFORMANCE
EVALUATION
We have discussed the model of the hierarchical virtualnetwork interfaces. Contrary to the simplicity of the model,the implementation of this concept is quite challengingsince it requires a flexible hierarchical packet scheduler thatsupports work-conserving and non-work-conserving sche-duling. This section addresses the issue by showing anactual implementation of the concept we developed onFreeBSD [10].
In this section, we first present an implementationoverview of the kernel module for FreeBSD. Then, weshow how our results of the performance evaluation on theimplemented prototype validate the model.
5.1 Implementation
The implementation overview is given in Fig. 6. We brieflydescribe the functional components of interest.
5.1.1 Packet Hook
The four thin arrows in the figure denote packet entry andexit points of the hierarchical virtual network interface tree.The packet hook mechanism resides between the networklayer and the network interface layer. For example, ifInternet Protocol (IP) is the network layer protocol, wecapture incoming packets before they reach the IP inputfunction and outgoing packets after they are processed bythe IP output function.
For each outgoing packet, after processing of networkprotocol (typically, by ip_output()), the kernel calls afunction for interface output routine, that is, a function thatwill forward the packet to an appropriate interface. In ourimplementation, the function pointer for if_output() isreplaced by vif_input() and the system redirectspackets into the VIF subsystem.
The VIF subsystem consists of VIF data structures andtwo global schedulers, one for incoming traffic and theother for outgoing. A VIF data structure, struct vifnet,includes queue data structures, statistics variables, andscheduling parameters. Packets are inserted and travelthrough the VIF data structure connected to each other ina tree shape, as shown below. After proper scheduling in
1308 IEEE TRANSACTIONS ON COMPUTERS, VOL. 53, NO. 10, OCTOBER 2004
Fig. 6. Implementation overview.

the VIF tree, packets are again directed, by vif_output()
function, to the original outgoing function (if_output()).Likewise, input packets are hooked from their normal
path using function pointer stealing. In FreeBSD, when apacket arrives at a real interface, the kernel initiates asoftware timer for further processing by ipintr(). Weoverwrite this by vif_intr() to divert the input packet.This way, input packets are redirected into the VIF tree andprocessed for further scheduling. After they reach theappropriate leaf VIF, the packets are returned to the regularupward processing stream.
5.1.2 Packet Scheduling
The main reason for stealing packets into the VIF treestructure is to be able to control the data traffic, typically bydelaying or reordering the packets (packet scheduling).Below we describe our scheduling framework.
The goal of the scheduler is to realize a singlehierarchical scheduling framework that is able to houseboth Work-Conserving (WC) scheduling and Non-Work-Conserving (NWC) scheduling modes. A Work-Conservingscheduler is one that processes packets whenever they areavailable in the queues, thereby contributing to better linkutilization. A Non-Work-Conserving scheduler may deferthe processing for better control of bursty traffic andpredictability in its output.
The two different scheduling paradigms are unified in asingle framework by two mechanisms. First, the systememploys different drainage strategies for work-conservingVIF and non-work-conserving VIF. Second, a VIF iscomprised of two queues—proximal and distal queue.Fig. 7 shows a pictorial and pseudocode description of thehierarchical multidiscipline scheduling framework in whichpackets smartly travel through the VIF tree. An explanationof the algorithm, and of the combined behavior, follows.
At the top of the figure is a VIF structure, where two VIFshave a common parent VIF (at bottom). As shown, a VIF iscomprised of two queues, proximal queue and distal queue,labeled as p_queue and d_queue. Arrows in the figureshow the enqueue and drainage (dequeue) relationshipamong VIFs, which is labeled WC and NWC. The numbersin parentheses next to the labels correspond to packetdequeuing operation of the scheduler (Lines 11-14).
Now, we show how the system works, following thecode. Suppose that the system enqueues a packet (a circleon the top) into the upper left VIF (in a shadowed oval). Thesystem enqueues the packet into p_queue of the VIF(Line 3). Then, a global scheduler function, vif_sched(),is called (Line 4) to regulate the rate at which VIFs will beserviced; vif_sched() starts a software timer that callsvif_dequeue() function for each VIF at the appropriatetime for packet dequeuing. The scheduling time of thedequeue operation is calculated from the packet length andbandwidth of the virtual interface. When the software timerexpires, the system initiates drainage operation by callingthe VIF dequeuing function.
In the dequeue function (Line 7) invoked by the softwaretimer, packets are handled differently based on schedulertypes of the VIFs (NWC and WC). Below, we illustrate thealgorithm through a couple of scenarios.
An NWC VIF is chosen to generate constant bit rate flowand, for this purpose, packets are simply enqueued into thenextp_queueat someconfigured rate. For example, let anewpacket arrive at anNWCVIF (shadowed oval in Fig. 7), when
all VIFs are empty. First, the system enqueues the packet intop queue1 (Line 3), and schedules the VIF for dequeuing (Line4). Then, at the appropriate time, the scheduler callsvif_dequeue() at Line 7, which will find d queue1 empty(Line 11). Therefore, it falls through the if statement andfinds the enqueued packet in the vif->p_queue (Line 13).The algorithm then goes to the switch statement at Line 20and sends the packet to output (Line 23) if the VIF is a root,or enqueues the packet into the next VIF, p queue2, atLine 25. In other cases, the do statement at Line 10 may finda packet in a different queue (there are three possibilities, asshown), but an NWC VIF always sends it to p_queue of thenext VIF.
OKUMURA AND MOSS�EE: VIRTUALIZING NETWORK I/O ON END-HOST OPERATING SYSTEM: OPERATING SYSTEM SUPPORT FOR... 1309
Fig. 7. Algorithm of the VIF drainage.

AWCVIF is used forwork-conserving scheduling, such asfair queuing and priority queuing, where packets are sentwhenever the link is available. For this purpose, the VIFutilizes a special purposewait queue,d_queue. TheVIFputspackets ready to be serviced in the queue and wakes up thenext VIF for their drainage. To demonstrate this, let a newpacket arrive at aWCVIF, when all VIFs are empty. First, thesystem enqueues the packet into p queue1 (Line 3) andschedules theVIF for dequeuing (Line 4). Then, the schedulercalls vif_dequeue() at Line 7 and, in the do statement(Line 10), we find the packet at Line 13. The algorithm thengoes to the switch statement at Line 20 for the nextoperation, and inserts the packet into d_queue of itself atLine 28, scheduling the next VIF for future drainage (Line 29).In other cases, thedo statement at Line 10may find apacket ina different queue (there are twopossibilities, as shown), but italways sends it to d_queue of itself, leaving the dequeuingoperation (vif_dequeue()) to the next VIF. The dequeuefunction is called when the next VIF finishes its currentoperation, thereby realizing the work-conserving behaviorof the VIFs.
5.1.3 Packet Marking
Since the overhead of packet classification can be over-whelming, we use a packet marking mechanism. Thismechanism is also used for the routing of the packets inthe VIF tree, as follows.
We modified the OS internal data structure for processesand sockets to include a pointer to the attached VIF datastructure.1 We copy this pointer onto each outgoing packetwhen the kernel allocates buffers for the data. Then, whenthe packet enters the VIF subsystem, the kernel traverses theVIF tree from the associated VIF down to the root VIF,creating a list of VIFs on the path. The list is attached to eachpacket, which is, in turn, enqueued into the correspondingVIF. The dequeue function, called by the scheduler, simplychecks the list for the next VIF without any detailedinspection of the packet for classification and, then,enqueues into the next VIF by calling vif_enqueue().
Incoming packets are handled differently since theymust be put into the root VIF first and traverse the VIF treeto reach a leaf VIF attached to the destination socket.Clearly, exploring the entire VIF tree would yield a severeperformance penalty. Thus, we utilize early demultiplexing.When the packets emerge from the interface input routine,we first look up the Protocol Control Block hash table (inBSD terminology) and find the destination socket. Second,we find the VIF associated with the particular destinationsocket by using the pointer for its attached VIF. Third, weget the VIF path from the socket down to the root VIF. Byreversing the order, we get the VIF list on the path from theinterface upward to the target socket.
5.1.4 Performance Improvement
So far, we have presented a simplified overview of theimplementation for algorithmic clarity. However, since theVIF system lies in the packet processing path, it incurs extraoverhead for system performance. Here, we state several
strategies we have found useful to improve performanceand suggest some points that can be exploited.
First, we can cache the list of the VIFs on the path foreach VIF to save the CPU cycles for the costly path listcreation. Second, in many cases, we can process consecutivepackets together to avoid the number of costly andinaccurate software timer events. Third, we can demultiplexincoming packets at the VIF entry stage of the packetprocessing and can save the packet classification data (apointer to Protocol Control Block) for future use to avoid aredundant lookup operation later in the original location.Fourth, we can greatly simplify the processing for theincoming packets since the upward path of the VIF tree hasjust a single data source (the root VIF), as opposed to theoutgoing flows. Note that, if there are two sources, we haveto choose a packet to process next each time, causing extraoverhead, which is the case with the outgoing traffic. Fifth,we can avoid the per-packet memory management cost bypreallocating data space for VIF control on each packetwhen the packets are created.
In our experience, a faithful implementation of thepresented algorithm has caused a performance penalty ofas much as one fourth of the peak throughput or evenworse. Meanwhile, as we demonstrate in the followingsection, the optimizations contributed to make it approxi-mately 10 percent in the worst case and usually better inmost cases, making it a practical option for most systems.
5.2 Performance Profiling
In this section, we evaluate the performance of theimplementation. First, we show that the traffic patterngenerated by the system complies with the VIF specifica-tions. This is followed by statistics on control overhead and,then, we show the packet scheduler overhead.
The hardware specification used in the experiments is:Processor: Intel Celeron processor (2.0Ghz), Memory:512MB, Hard Disk Drive: Maxtor 6E040L0 (40GB, IDE),Network interface: Intel Pro/100 Ethernet (10/100baseTX),Motherboard: GIGABYTE GA-8INXP (Chipset E7205).
5.2.1 Traffic Profile
First, we conducted a simple experiment to verify if trafficgenerated by the implemented mechanism complied withVIF specifications. In the experiment, we connected twoidentical machines with a switch (D-Link DI-604), installeda modified kernel (NETNICE) and a normal FreeBSD kernel(GENERIC), and generated traffic.
We structured the VIFs as shown in Fig. 4 andconfigured the VIFs as follows: VIFs 1 and 2 receive66 percent and 33 percent of VIF 3’s bandwidth share,respectively. VIF 3 is limited to 4,096Kbps, VIF 4 to8192Kbps, and VIF 5 to 2,048Kbps. The root vif (VIF 6) isconfigured as 1,000Mbps, which is much bigger than thehardware capability to avoid bottlenecks.
The simulation scenario is as follows: A process attachedto VIF 5 continuously sends packets as background traffic.From time 20 to 39 and 30 to 49, VIF 1 and VIF 2 sendpackets through VIF 3. Additionally, to demonstrateregulation of input traffic, the sink machine is configured tosend burst data toward a process connected to VIF 4, fromtime 5 to 14.
We captured the traffic on the destination machine, usingthe tcpdump command, and plotted the throughput (Fig. 8).
1310 IEEE TRANSACTIONS ON COMPUTERS, VOL. 53, NO. 10, OCTOBER 2004
1. Since we need to handle multiple physical interfaces, as mentioned inSection 4, we actually attached a pointer to a list of VIFs associated with thesender, which is copied onto each packet. This list is used later to choose theVIF to enqueue when the packet enters into the VIF system, based on therouting information provided by the network layer.
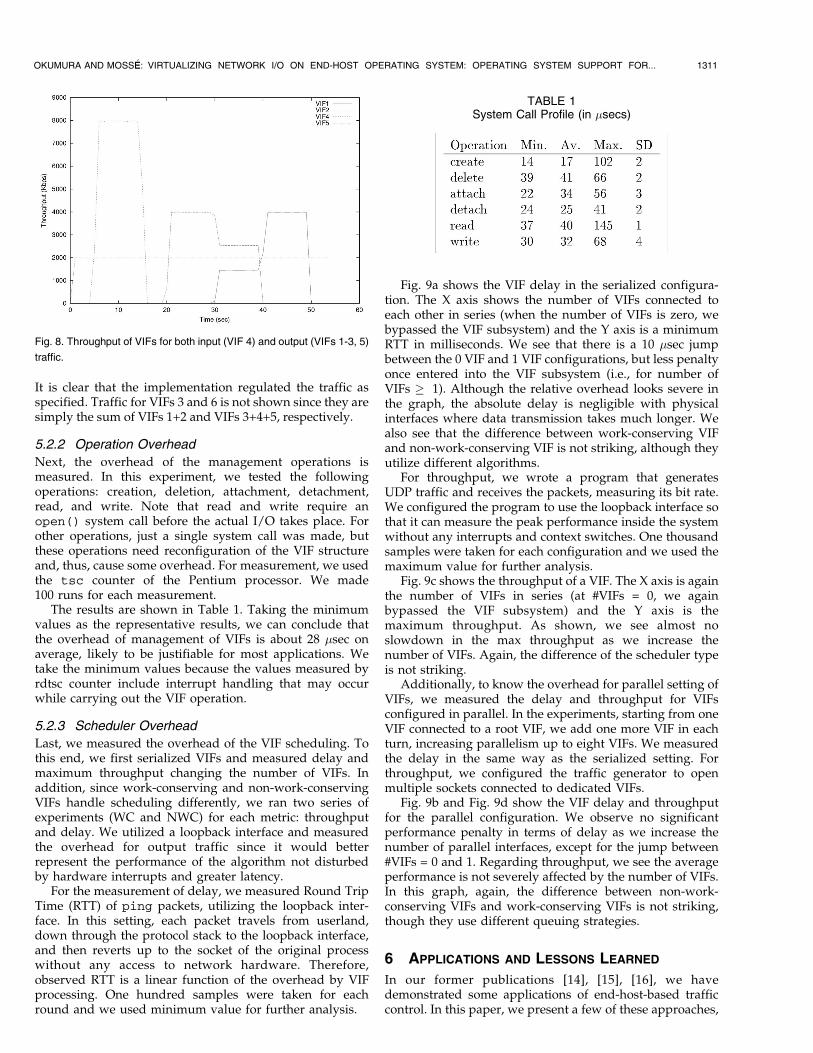
It is clear that the implementation regulated the traffic asspecified. Traffic for VIFs 3 and 6 is not shown since they aresimply the sum of VIFs 1+2 and VIFs 3+4+5, respectively.
5.2.2 Operation Overhead
Next, the overhead of the management operations ismeasured. In this experiment, we tested the followingoperations: creation, deletion, attachment, detachment,read, and write. Note that read and write require anopen() system call before the actual I/O takes place. Forother operations, just a single system call was made, butthese operations need reconfiguration of the VIF structureand, thus, cause some overhead. For measurement, we usedthe tsc counter of the Pentium processor. We made100 runs for each measurement.
The results are shown in Table 1. Taking the minimumvalues as the representative results, we can conclude thatthe overhead of management of VIFs is about 28 �sec onaverage, likely to be justifiable for most applications. Wetake the minimum values because the values measured byrdtsc counter include interrupt handling that may occurwhile carrying out the VIF operation.
5.2.3 Scheduler Overhead
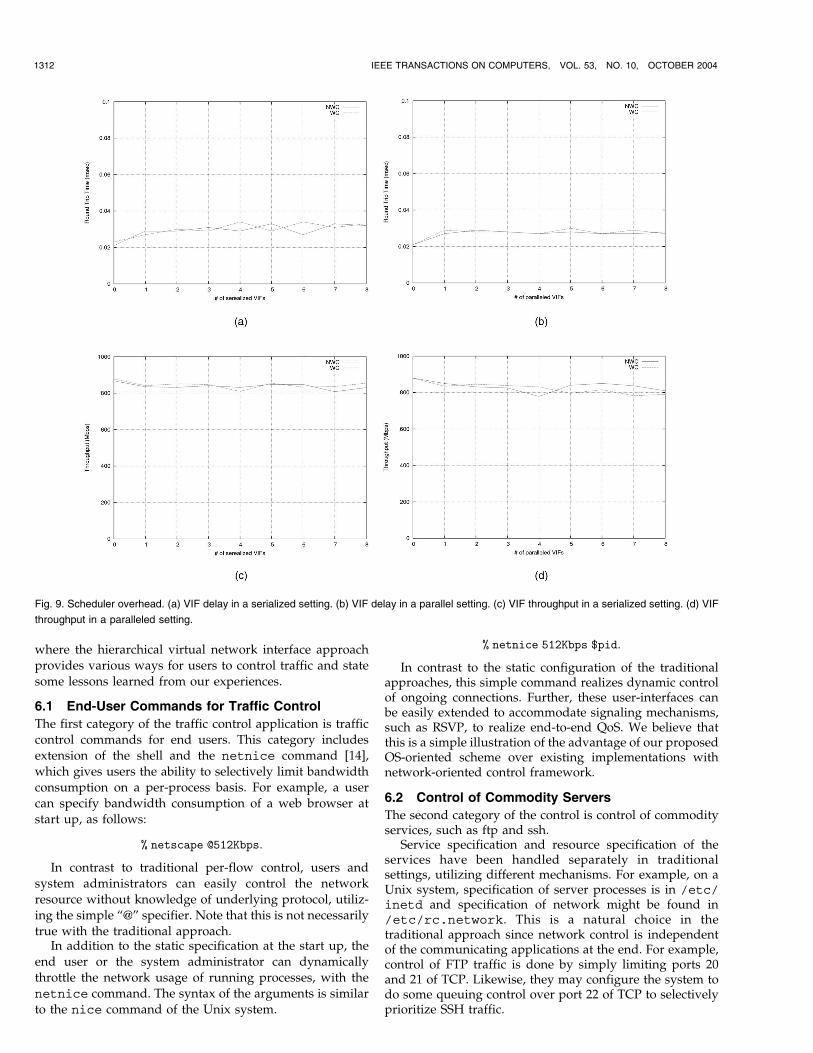
Last, we measured the overhead of the VIF scheduling. Tothis end, we first serialized VIFs and measured delay andmaximum throughput changing the number of VIFs. Inaddition, since work-conserving and non-work-conservingVIFs handle scheduling differently, we ran two series ofexperiments (WC and NWC) for each metric: throughputand delay. We utilized a loopback interface and measuredthe overhead for output traffic since it would betterrepresent the performance of the algorithm not disturbedby hardware interrupts and greater latency.
For the measurement of delay, we measured Round TripTime (RTT) of ping packets, utilizing the loopback inter-face. In this setting, each packet travels from userland,down through the protocol stack to the loopback interface,and then reverts up to the socket of the original processwithout any access to network hardware. Therefore,observed RTT is a linear function of the overhead by VIFprocessing. One hundred samples were taken for eachround and we used minimum value for further analysis.
Fig. 9a shows the VIF delay in the serialized configura-tion. The X axis shows the number of VIFs connected toeach other in series (when the number of VIFs is zero, webypassed the VIF subsystem) and the Y axis is a minimumRTT in milliseconds. We see that there is a 10 �sec jumpbetween the 0 VIF and 1 VIF configurations, but less penaltyonce entered into the VIF subsystem (i.e., for number ofVIFs � 1). Although the relative overhead looks severe inthe graph, the absolute delay is negligible with physicalinterfaces where data transmission takes much longer. Wealso see that the difference between work-conserving VIFand non-work-conserving VIF is not striking, although theyutilize different algorithms.
For throughput, we wrote a program that generatesUDP traffic and receives the packets, measuring its bit rate.We configured the program to use the loopback interface sothat it can measure the peak performance inside the systemwithout any interrupts and context switches. One thousandsamples were taken for each configuration and we used themaximum value for further analysis.
Fig. 9c shows the throughput of a VIF. The X axis is againthe number of VIFs in series (at #VIFs = 0, we againbypassed the VIF subsystem) and the Y axis is themaximum throughput. As shown, we see almost noslowdown in the max throughput as we increase thenumber of VIFs. Again, the difference of the scheduler typeis not striking.
Additionally, to know the overhead for parallel setting ofVIFs, we measured the delay and throughput for VIFsconfigured in parallel. In the experiments, starting from oneVIF connected to a root VIF, we add one more VIF in eachturn, increasing parallelism up to eight VIFs. We measuredthe delay in the same way as the serialized setting. Forthroughput, we configured the traffic generator to openmultiple sockets connected to dedicated VIFs.
Fig. 9b and Fig. 9d show the VIF delay and throughputfor the parallel configuration. We observe no significantperformance penalty in terms of delay as we increase thenumber of parallel interfaces, except for the jump between#VIFs = 0 and 1. Regarding throughput, we see the averageperformance is not severely affected by the number of VIFs.In this graph, again, the difference between non-work-conserving VIFs and work-conserving VIFs is not striking,though they use different queuing strategies.
6 APPLICATIONS AND LESSONS LEARNED
In our former publications [14], [15], [16], we havedemonstrated some applications of end-host-based trafficcontrol. In this paper, we present a few of these approaches,
OKUMURA AND MOSS�EE: VIRTUALIZING NETWORK I/O ON END-HOST OPERATING SYSTEM: OPERATING SYSTEM SUPPORT FOR... 1311
Fig. 8. Throughput of VIFs for both input (VIF 4) and output (VIFs 1-3, 5)
traffic.
TABLE 1System Call Profile (in �secs)
where the hierarchical virtual network interface approach
provides various ways for users to control traffic and state
some lessons learned from our experiences.
6.1 End-User Commands for Traffic Control
The first category of the traffic control application is trafficcontrol commands for end users. This category includes
extension of the shell and the netnice command [14],
which gives users the ability to selectively limit bandwidth
consumption on a per-process basis. For example, a user
can specify bandwidth consumption of a web browser at
start up, as follows:
% netscape @512Kbps:
In contrast to traditional per-flow control, users and
system administrators can easily control the network
resource without knowledge of underlying protocol, utiliz-
ing the simple “@” specifier. Note that this is not necessarily
true with the traditional approach.In addition to the static specification at the start up, the
end user or the system administrator can dynamically
throttle the network usage of running processes, with the
netnice command. The syntax of the arguments is similar
to the nice command of the Unix system.
% netnice 512Kbps $pid:
In contrast to the static configuration of the traditionalapproaches, this simple command realizes dynamic controlof ongoing connections. Further, these user-interfaces canbe easily extended to accommodate signaling mechanisms,such as RSVP, to realize end-to-end QoS. We believe thatthis is a simple illustration of the advantage of our proposedOS-oriented scheme over existing implementations withnetwork-oriented control framework.
6.2 Control of Commodity Servers
The second category of the control is control of commodityservices, such as ftp and ssh.
Service specification and resource specification of theservices have been handled separately in traditionalsettings, utilizing different mechanisms. For example, on aUnix system, specification of server processes is in /etc/
inetd and specification of network might be found in/etc/rc.network. This is a natural choice in thetraditional approach since network control is independentof the communicating applications at the end. For example,control of FTP traffic is done by simply limiting ports 20and 21 of TCP. Likewise, they may configure the system todo some queuing control over port 22 of TCP to selectivelyprioritize SSH traffic.
1312 IEEE TRANSACTIONS ON COMPUTERS, VOL. 53, NO. 10, OCTOBER 2004
Fig. 9. Scheduler overhead. (a) VIF delay in a serialized setting. (b) VIF delay in a parallel setting. (c) VIF throughput in a serialized setting. (d) VIF
throughput in a paralleled setting.

However, since network resource management is aninseparable part of the service specification for servers, theseparation has been limiting resource allocation strategy forbetter quality of service. Hence, as a counterpart to thetraditional control model, we have proposed the extended-inetdmodel (originally presented in [14]). In this scheme, wewrap each process with a dedicated virtual networkinterface and dynamically control the traffic specificationof each service. With our implementation, system admin-istrators can specify the allocation of network resources inthe service specification file (/etc/inetd.conf, in Unixtradition) as follows. Note that the example does not showall the fields required.
# inetd @512K
# cat /etc/inetd.conf
FTP tcp /usr/libexec/ftpd ftpd -l
login tcp /usr/libexec/rlogind rlogind @32K
telnet tcp /usr/libexec/telnetd telnetd @32K
#
This configuration example works like this: First, we give512Kbps limitation to the commodity service handled byinetd, simply leaving the rest of the bandwidth to otheractivities on the system. Second, when interactive trafficcomes, it invokes an appropriate server program and wrapsit with a VIF which has 32Kbps bandwidth. Last, the rest ofthe bandwidth is fairly (evenly) shared by ftp connectionsfor the bulk data transfers.
We believe that this is another illustration that suggeststhe advantage of our proposed scheme over the existingnetwork-oriented approaches.
6.3 QoS Manager
To further explore the advanced traffic control realized withthe VIF scheme, we have also implemented a multipurposeQoS manager [16]. Originally designed for traffic control ofload-balancing clusters, the netnice daemon realizes a varietyof end-host oriented traffic control through scripting of trafficcontrol algorithms. The latest version provides a JavaScriptscripting environment with a standard class library andevent-driven control framework.
To illustrate the simplicity and strength of a trafficcontrol script, we give an example for fair-sharing ofavailable bandwidth in a wireless network below (seeFig. 10). For this control, we simply deploy the netniced
on each node with the sample script.The system object is an object representing the control
system and get_root() is a method that returns a VIFobject connected to the physical interface, given an interfacename (Line 1). The VIF object instantiates a virtualizednetwork interface, which allows easy control of networktraffic. The tuple object is a simple abstract for interdaemoncommunication (Line 2). In this example, a tuple object isused to count the number of neighbors on a segment atLine 7. A function, timer(), is an event-handler which isautomatically called when the QoS manager raises aperiodic Timer event, thereby realizing easy polling-basedcontrol. At Lines 6-7, the fair share of the bandwidth iscalculated and the bandwidth parameter of VIF is config-ured accordingly. Combined together, this short scriptrealizes automatic fair sharing of the wireless bandwidth.
Although primitive, we believe that the simple scriptillustrates the ease and the power traffic control scriptingbased on the VIF model. Further examples are given in [16].
6.4 Lessons Learned
We have introduced three different ways of utilizing thehierarchical virtualization serviceofnetwork interface,whichdid not require modification of the applications we control.Hence, they were clear illustrations of the “retrofitting”property of theOS service. On the other hand, there aremanyother possibilities and advantages of the OS service, particu-larly for network applications, such as Web servers andstreaming servers. Although we have not explored the fieldsufficiently, we state several observations we have madeabout the traffic control service for such applications.
One of the most noteworthy advantages of end-hostcontrol comes from its stateful nature. Consider a server forElectronic Commerce, where customers who have started tochoose items have a higher priority to customers at check-out. Attempting to implement this policy at intermediatenodes would require extensive inspection of every flow andsemantic knowledge of different types of payload. End-hostcontrol can exploit the local information of each transactionfor efficient stateful control, thus significantly reducing theprocessing overhead. This would hold for any process thathas several connections and wants to differentiate theconnections. Another example is a Web server that wants togive higher priority to HTML documents over large datatransfer for pictures and files.
The second advantage is about traffic aggregation. Forexample, RTSP [20] utilizes a connection for datastreaming and another for health check of the stream.Because intermediate nodes cannot easily recognize thedifferent flows as being bundled, only the originator ofthese flows would have enough information to performproper control over the session. Our per-process networkcontrol facilitates this.
Last, our approach can provide simple receiver-sidebandwidth regulation, for flow controlling protocol, such asTCP. As we demonstrated (see VIF 4 in Fig. 8), the sender ofTCP traffic throttles its flow to conform to the bottleneckbandwidth if we limit the rate of a VIF at the receiverprocess. This is because the arrival of the incoming packetsare paced by the VIF and, thus, acknowledgments for eachpacket (or groups of packets) are delayed, complying withthe bandwidth configured.
OKUMURA AND MOSS�EE: VIRTUALIZING NETWORK I/O ON END-HOST OPERATING SYSTEM: OPERATING SYSTEM SUPPORT FOR... 1313
Fig. 10. Simple script for fair-sharing of wireless network bandwidth.

Although some of these controls can be realized with thetraditional approaches (e.g., intermediate node control andflow-based control), the traffic control API can ease the taskof network control in a more sophisticated manner. Weadmit that traffic control by end-nodes cannot solve all theproblem inside the network. However, we think that thecontrol at the end-hosts and inside the network isorthogonal and the OS approach would be a more reason-able way of addressing the problem at the end-host side, aswe have been claiming throughout the paper.
Another lessonwe learned in the implementation is that itis quite easy to extend the system to support new protocolswith this approach since the function hooks (entry points ofthe VIF structure) are localized and located between theinterface layer and the network layer. Further, any newnetwork interface card works without source code modifica-tion. For example, we found that it was relatively easy tosupport the new version of Internet Protocol, IPv6, in ourprototype implementation and we were able to use a newGigabit Ethernet card without any system modification.
Second, we realized that the utilization of early demulti-plexing can serve different purposes. For example, [12], [4]exhibited that early demultiplexing protects CPU cyclesfrom malicious network interrupts, although it violates thecustomary layering rules. We believe that faithful imple-mentation of protocol layering at end-hosts is becomingobsolete for system security and I/O controllability and thatthe hierarchical virtual network interface approach isanother illustration that justifies early demultiplexing onmodern operating system.
Last, since thehierarchical virtual network interfacemodelpresented in this paper provides mainly upper-boundregulation, some readers might claim that the OS shouldplay a more active role in network resource management,particularly to support lower-boundguarantee.However,weare skeptical about such an attempt at this point. First of all,end-to-endQoS guarantee is possible onlywhen the networkarchitecture does support network-wide QoS. Second, evenwith an assumption that the network provides such guaran-tees and controller interfaces, it is hard to devise acomprehensive mechanism that can accommodate all needsat the kernel level. Third, system design principles suggestthat core functionalitymeets themost commonneeds, leavingothers to extension mechanisms. Hence, it is much morenatural to use an extension mechanism, such as user-spacelibraries or kernel expansionmodules [8], [5], tomeet specificrequests for guarantee service.
7 RELATED WORK
Several works are related to and have inspired ourhierarchical virtual network interface approach. We startwith the virtualization of network interfaces, which hasbeen addressed in several contexts, and describe relatedwork, particularly those about network control by end-hostOSs, network protection, and file system abstraction.
First, the virtualization of network interface has beenused to realize virtual machines on PC-based workstations.VMware [24] is a notable effort toward PC emulation ongeneral purpose operating system and virtualization ofnetwork interfaces has been argued in [22] to attainpractical performance for high-bandwidth I/O. Our workdiffers from these approaches in that their primary goal is
virtualization of hardware to execute a host OS, whereasours is control of network traffic inside the end-host OS.
Second, there have been continuing efforts towardstandardization of virtualized network interface [6]. Thishas been motivated to provide raw access to networkinghardware for clustering applications that require extremelyhigh bandwidth communication channel. Our approachgreatly differs from this approach in that their primary goalis increased performance at the cost of the compromisedsystem protection for specific application, while we aim atproviding network control and protection as a standardservice of general purpose OSs.
Third, there have been several commercial products thatprovide virtualization service of hosts and network inter-faces, particularly for virtual Web hosting applications, suchas [3].Wediffer in thatwe aimat providing a general purposeoperating systems support for network control, althoughthey aim at providing specific solution for server hosting.
Network control on end-host OS has been exploredmainly in two approaches. The first aims at providing amechanism to realize some specific control on the network[2], [19], [11]. Their fundamental drawback is that they arebuilt with the traditional network control model in which analmighty network administrator controls flow of packets inthe middle of communication. Because of this model, thecontrol is made through privileged commands and ordin-ary users and user applications cannot utilize the controlservice. In short, they are designed as administrative tools,not as an OS service with which users and applicationssafely control the system activity. On the other hand, ourmechanism allows application programs to control theirnetwork I/O, working on entities terminating communica-tion. Further, to the best of our knowledge, existingimplementations utilize just a flat structure for their queueorganization and, thus, do not provide hierarchical packetscheduling. Note that CBQ [9] and some other advancedqueuing disciplines provide hierarchical specification ofresource allocation, but their queue structures are flat. Thevirtual network interfaces form hierarchical queues andpackets travel through the hierarchically structured queues.
The second approach for end-host network control tries toprovide a general mechanism for such control by increasingprogrammability of the network subsystem of the end-host.In this category, two opposite approaches have beenexplored: expanded programmability in kernel [8] anduser-space protocol processing [5]. Although they providegeneral and flexible means to solve problems in networkcontrol, they tend to lack proper abstraction and protectionmodel,whichwe contend that anOS service needs topossess.
The protection of network resources on end-host OSs hasbeen addressed in several former studies. To review them,we classify them using two dimensions, namely, 1) whattype of traffic we want to protect (output or input) and2) how incremental or radical the approach is (see Table 2).
1314 IEEE TRANSACTIONS ON COMPUTERS, VOL. 53, NO. 10, OCTOBER 2004
TABLE 2Studies for Protection of Network Resource on OS

Resource protection for outgoing traffic deals with thepartitioning and fair allocation of CPU cycles consumed toprocess communications. Since these computations areexecuted in kernel mode, they tend to cause unfairdistribution of CPU resources among processes, particu-larly when they are network-bound computation and theload is high.
An important representative of the incremental approachfor output control is presented in [1]. The architecture ofmany high-performance server applications has beenshifting from the traditional “process-per-connection ser-ver” model toward the “single-process event-driven server”or “single-process multithreaded server,” to eliminatecostly overhead of heavyweight processes and contextswitching. Nevertheless, operating systems have beenassuming that resource protection needs to be done in aprocess-oriented manner. Consequently, the operatingsystem cannot assure fair allocation of various resourcesand this causes an “application versus operating systemmismatch.” To address the problem, they suggest toseparate the protection domain and resource principal,and provide finer resource controllability by a newoperating system abstraction, called a resource container,for network-intensive high-performance computing.
A radical approach for the output control problem is toredesign much of the operating system, as the ScoutOperating System [13] proposed. They use a noteworthyprotection paradigm, called path, which is applicable tolayered systems to optimize the resource used by theprocessing entity penetrating the layers.
The need for system protection from input traffic has beenexplored mainly in the context of denial of service attack. Thishas recently drawn much attention because any host on thenetwork can initiate an attack on a target host by sendingmany packets and forcing the target host to spend most ofits CPU cycles on interrupt processing. This creates afundamental and easily exploitable security hole.
Reference [12] addresses the receive livelock problem, inwhich applications can make no progress due to the higharrival rate of interrupts caused by the incoming packets.The work had been strengthened by the proposal of theLazy Receiver Processing (LRP) [4]. Both [12] and [4] fallinto the incremental approach in the sense that they arerealized as an extension of an existing network subsystemof a kernel.
Interestingly, a radical solution for input traffic control isfound again in [21], as a demonstration of the ScoutOperating System. The paper addressed defense againstthe denial of service attacks, utilizing the path concept.
All of these approaches share certain similarities in thatthe operating system should play a central role forprotection of network resources and should realize parti-tioning of CPU utilization for network-intensive high-performance computing.
The approaches mentioned above contrast with ourproposed approach in three main ways. First of all, theproposed abstractions are basically units of CPU utilization,whereas VIF is a mechanism to process packets that utilizeCPU resources. Note that the hierarchical CPU schedulersthey utilized and the hierarchical packet schedulers we areproposing are a completely different notion. HierarchicalCPU schedulers are to give CPU cycles to the schedulers ofthe subunits, which themselves work on the cycles given.
On the other hand, a hierarchical packet scheduler is anentity which emulates hierarchical movements of packetsbetween queues, as we demonstrated in Section 5. Second,the target application of these proposals is high-perfor-mance server applications, such as Web servers. In contrast,we are addressing the design principle of general-purposeoperating systems, used by client machines as well asservers. Third, they tend to lack protection in terms ofbandwidth specification.
File system abstraction of process and its resources firstappeared in [23]. The process file system has evolved as it isported onto new operating systems [7]. The idea of filesystem abstraction for network resources first appeared in[17]. The system represented a network connection by adirectory and provided several control files for its manage-ment. We owe this work for the file system abstractioncoupled with an ASCII interface. However, we differ in thatwe pay major attention to higher degree of freedom innetwork control while still providing system protection, aswe argued throughout the paper. Also, it should be notedthat we exploited the hierarchical nature of the file systemto naturally represent the tree structure of the VIF system.
8 CONCLUSION
We explored the design principle of operating systemsupport for network control and presented the hierarchicalvirtual network interface concept, which realizes flexiblecontrol granularity, resource protection, and a variety ofcontrol in a single framework.
Further, for its control API, we proposed using the filesystem abstraction of the virtual interfaces. This proved to bea reasonable and powerful approach, conforming toprotection semantics and syntax of underlying operatingsystem. Utilizing the hierarchical virtual network interfaceswith the file system interface, every system user andadministrator can conveniently control their network I/Osafely with great flexibility, which was not possible withany other approach.
We implemented a hierarchical packet scheduler withboth work-conserving and non-work-conserving schedul-ing support on FreeBSD. The systematic profiling re-vealed that the algorithm can control the traffic asexpected and the performance penalty is kept small.Additionally, the proposed primitive has been demon-strated in various QoS applications and has shownvarious advantages in network control.
We conclude that the hierarchical virtual network inter-face approach is a reasonable and promising direction totake for general-purpose operating systems that requirecontrol for their network I/O. We have made our prototypeimplementation open to the public (see the project home-page at http://www.netnice.org or a mirror site at http://www.cs.pitt.edu/NETNICE) and will continue to explorethe advanced network control possible with the novelservice on end-host OS.
ACKNOWLEDGMENTS
The authors would like to thank Dr. Mark Moir andDr. Manas Saksena for giving detailed comments on anearlier version of the work. Takashi Okumura thanksDr. Akira Kato, Dr. Hiroshi Esaki, Dr. Osamu Nakamura,Dr. Masaki Minami, Dr. Ikuo Takeuchi, Dr. Takashi
OKUMURA AND MOSS�EE: VIRTUALIZING NETWORK I/O ON END-HOST OPERATING SYSTEM: OPERATING SYSTEM SUPPORT FOR... 1315

Sakamoto, Dr. Hiroyuki Hirokawa, Dr. Hiroshi Yamakami,Mr. Tomoya Okazaki, and Mr. Masaki Ikeda for theirassistance in the research. This research was supported inpart by the US National Science Foundation under grantsANI-0087609, ANI-0125704, and ANI-0121658, by theTelecommunications Advancement Organization of Japanunder JGN-P122518, and by the Information-technologyPromotion Agency, Japan.
REFERENCES
[1] G. Banga, P. Druschel, and J.C. Mogul, “Resource Containers: ANew Facility for Resource Management in Server Systems,” Proc.Third USENIX Symp. Operating Systems Design and Implementation(OSDI), Oct. 1999.
[2] K. Cho, “A Framework for Alternate Queueing: Towards TrafficManagement by PC-UNIX Based Routers,” Proc. USENIX Ann.Technical Conf., pp. 247-258, June 1998.
[3] Ensim Corp., http://www.ensim.com/, 1998.[4] P. Druschel and G. Banga, “Lazy Receiver Processing (LRP): A
Network Subsystem Architecture for Server Systems,” Proc.Second USENIX Symp. Operating Systems Design and Implementation(OSDI), Feb. 1996.
[5] T. Eicken, A. Basu, V. Buch, and W. Vogels, “U-Net: A User-LevelNetwork Interface for Parallel and Distributed Computing,” Proc.SIGOPS ’95, 1995.
[6] T. Eicken and W. Vogels, “Evolution of the Virtual InterfaceArchitecture,” Computer, vol. 31, no. 11, pp. 61-68, Nov. 1998.
[7] R. Faulkner and R. Gomes, “The Process File System and ProcessModel in UNIX System V,” Proc. Winter 1991 USENIX Conf.,pp. 243-252, 1991.
[8] M.E. Fiuczynski and B.N. Bershad, “An Extensible ProtocolArchitecture for Application-Specific Networking,” Proc. 1996Winter USENIX Conf., pp. 55-64, 1996.
[9] S. Floyd and V. Jacobson, “Link-Sharing and Resource Manage-ment Models for Packet Networks,” IEEE/ACM Trans. Networking,vol. 3, no. 4, pp. 365-386, Aug. 1995.
[10] The Free BSD Project, http://www.freebsd.org/, 1995.[11] B. Hubert, “Linux Advanced Routing and Traffic Control,”
http://www.lartc.org/, 2000.[12] J.C. Mogul, “Eliminating Receive Livelock in an Interrupt-Driven
Kernel,” Proc. USENIX 1996 Annual Tech. Conf., Oct. 1996.[13] D. Mosberger and L.L. Peterson, “Making Paths Explicit in the
Scout Operating System,” Proc. Second USENIX Symp. OperatingSystems Design and Implementation (OSDI), Feb. 1996.
[14] T. Okumura, M. Moir, and D. Mosse, “Netnice: Nice Is Not Onlyfor CPUs,” Proc. Ninth Int’l Conf. Computer Comm.n and Network(ICCCN2000), Oct. 2000.
[15] T. Okumura, D. Mosse, M. Minami, and O. Nakamura, “Operat-ing System Support for Network Control,” Proc. 10th Int’lWorkshop Quality of Service (IWQoS2002), May 2002.
[16] T. Okumura, D. Mosse, M. Minami, and O. Nakamura, “Quality ofService Manager for Load-Balancing Clusters: An End-HostRetrofitting Event-Handler Approach by Netniced,” Proc. ThirdIEEE/ACM Int’l Symp. Cluster Computing and the Grid (CCGrid2003), May 2003.
[17] D. Presotto and P. Winterbottom, “The Organization of Networksin Plan 9,” Proc. Winter 1993 USENIX Tech. Conf., pp. 271-280,1993.
[18] E.R. Braden, RFC 2205: Resource ReSerVation Protocol (RSVP)-Version 1. IETF, Sept. 1997.
[19] L. Rizzo, “Dummynet: A Simple Approach to the Evaluation ofNetwork Protocols,” Computer Comm. Rev., vol. 27, no. 1, pp. 31-41,Jan. 1997.
[20] H. Schulzrinne and R. Lanphier, RFC2326: Real Time StreamingProtocol (RTSP). The Internet Soc., 1998.
[21] O. Spatscheck and L.L. Peterson, “Defending against Denial ofService Attacks in Scout,” Proc. Third USENIX Symp. OperatingSystems Design and Implementation (OSDI), Oct. 1999.
[22] J. Sugerman, G. Venkitachalam, and B.H. Lim, “Virtualizing I/ODevices on VMware Workstation’s Hosted Virtual MachineMonitor,” Proc. 2001 USENIX Ann. Technical Conf., June 2001.
[23] D. Verma, H. Zhang, and D. Ferrari, “Processes as Files,” Proc.USENIX Assoc. Conf., pp. 203-207, 1984.
[24] VMware, http://www.vmware.com/, 1998.
Takashi Okumura received the BA (policymanagement) and MA (sociology) degrees fromKeio University in 1996 and 1998, respectively,and the MS (computer science) degree from theUniversity of Pittsburgh in 2000. He is currentlyworking toward the PhD degree in computerscience at the University of Pittsburgh andtoward the MD degree at Asahikawa MedicalCollege, concurrently. His research interestsinclude end-host operating system support for
network control, semantics-based Quality of Service control for medicalnetworks, and methodology of interdisciplinary computer networkstudies. He is a member of the Widely Integrated DistributedEnvironment (WIDE) project, Japan, serving as a chair of the Netniceworking group, and a student member of the ACM.
Daniel Mosse received the BS degree inmathematics from the University of Brasilia in1986 and the MS and PhD degrees in computerscience from the University of Maryland in 1990and 1993, respectively. He joined the faculty ofthe University of Pittsburgh in 1992, where he iscurrently an associate professor. His researchinterests include fault-tolerant and real-timesystems, as well as networking. The majorthrust of his research in the new millenium is
systems integration, power-aware issues, and security. He has servedon program committees for all major IEEE-sponsored real-time relatedconferences and as program and general chair for RTAS and RTEducation Workshop. Typically funded by the US National ScienceFoundation and the US Defense Advanced Research Projects Agency,his projects combine theoretical results and implementations. He hasbeen an associate editor of the IEEE Transactions on Computers and iscurrently a member of the IEEE Computer Society and of the ACM.
. For more information on this or any computing topic, please visitour Digital Library at www.computer.org/publications/dlib.
1316 IEEE TRANSACTIONS ON COMPUTERS, VOL. 53, NO. 10, OCTOBER 2004