using humanoid robots to study human behavior
TRANSCRIPT

H U M A N O I D R O B O T I C S
Using Humanoid Robots toStudy Human BehaviorChristopher G. Atkeson, Joshua G. Hale, Frank Pollick, and Marcia Riley, ATR Human Information ProcessingResearch Laboratories
Shinya Kotosaka, Stefan Schaal, Tomohiro Shibata, Gaurav Tevatia, Ales Ude, and Sethu Vijayakumar, Erato Kawato, Dynamic Brain Project
Mitsuo Kawato, ATR Human Information Processing Research Laboratories, ATRI, and the Kawato Dynamic Brain Project, Erato
WE ARE WORKING ON EASIERways to program behavior in humanoidrobots, and potentially in other machines andcomputer systems, based on how we “pro-gram” behavior in our fellow human beings.We have already demonstrated several sim-ple behaviors, including juggling a single ballby paddling it on a racket, learning a folkdance by observing a human perform it,1
drumming synchronized to sounds the robothears (karaoke drumming),2 juggling threeballs (see Figure 1), performing a T’ai Chiexercise in contact with a human,3 and vari-ous oculomotor behaviors.4
Our current robot is DB (which stands forDynamic Brain), a hydraulic anthropomor-phic robot with legs, arms (with palms butno fingers), a jointed torso, and a head (seeFigure 2a and www.erato.atr.co.jp/DB).DB was designed by the Sarcos companyand the Kawato Dynamic Brain Project(www.erato.atr.co.jp) and was built by Sar-cos (www.sarcos.com). The robot is approx-imately 1.85 meters tall, weighs 80 kg, andcontains 25 linear hydraulic actuators and
five rotary hydraulic actuators. It has 30degrees of freedom: three in the neck, two ineach eye, seven in each arm, three in eachleg, and three in the trunk (see Figure 2b).Every DOF has a position sensor and a loadsensor except the eye DOFs, which have noload sensing. The robot is currently mountedat the pelvis, so that we do not have to worryabout balance and can focus our studies onupper-body movement. We plan to explorefull-body motion in the future, probably witha new robot design.
Inverse kinematics andtrajectory formation
One problem that robots with eyes face isvisually guided manipulation—for example,choosing appropriate joint angles that let itreach out and touch a visual target. We uselearning algorithms (described later in the arti-cle) to learn the relationship between wherethe robot senses its limb is using joint sensorsand where the robot sees its limb (referred toin robotics as a model of the forward kine-
OUR UNDERSTANDING OF HUMAN BEHAVIOR ADVANCES AS
OUR HUMANOID ROBOTICS WORK PROGRESSES—AND VICE
VERSA. THIS TEAM’S WORK FOCUSES ON TRAJECTORY
FORMATION AND PLANNING, LEARNING FROM DEMONSTRATION,OCULOMOTOR CONTROL, AND INTERACTIVE BEHAVIORS. THEY
ARE PROGRAMMING ROBOTIC BEHAVIOR BASED ON HOW WE
HUMANS “PROGRAM” BEHAVIOR IN—OR TRAIN—EACH OTHER.
46 1094-7167/00/$10.00 © 2000 IEEE IEEE INTELLIGENT SYSTEMS

Figure 1. DB can juggle three balls, using kitchen funnels for hands.
Figure 2. The humanoid robot DB: (a) the full robot mounted at the pelvis; (b) the robot joints.
(a) (c)(b) (d)
(e) (g)(f) (h)
JULY/AUGUST 2000 47
Arm
(b)
Wrist
Flx/extFlx/ext Ab/ad General rotation
Rotation Flx/ext Ab/ad Pan Tilt
Eye
Hip/knee/ankle
Hip flx/ext Knee flx/ext Ankle flx/ext Flx/ext Ab/ad
Torso
Elbow
Head
Nod Tilt Rotation
Rotation(a)
Key:Flx/ext:Flex/extendAb/ad:Abduct/adduct
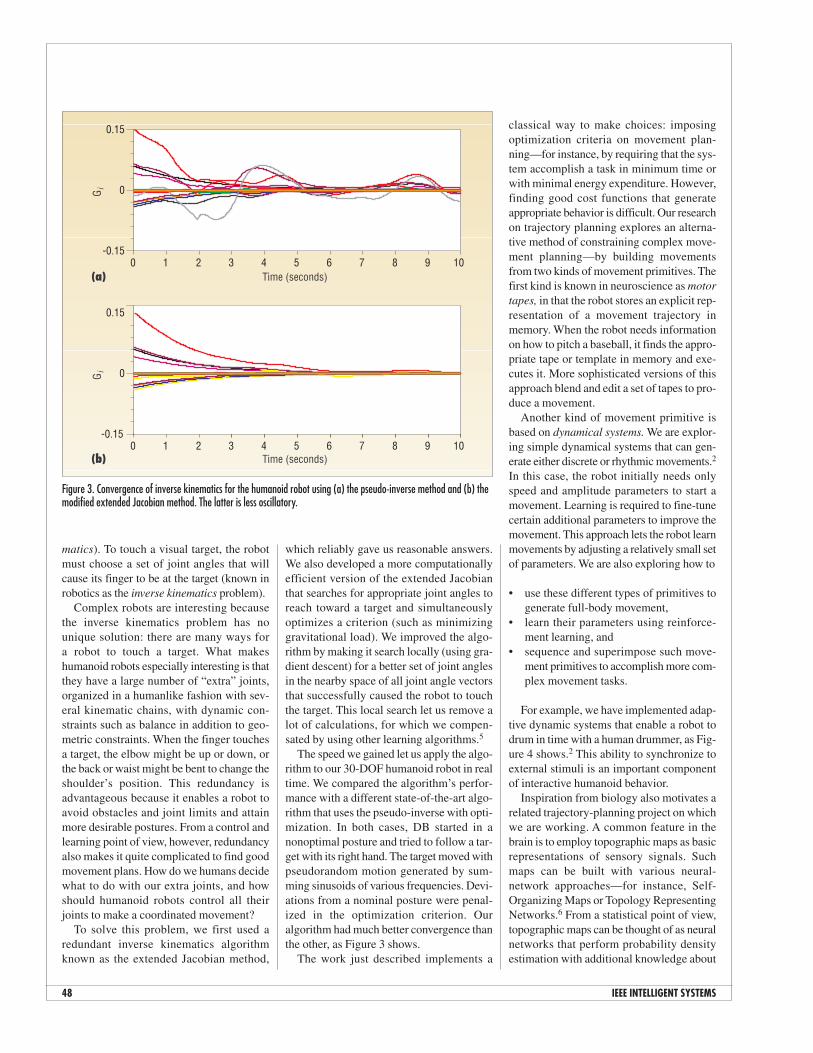
matics). To touch a visual target, the robotmust choose a set of joint angles that willcause its finger to be at the target (known inrobotics as the inverse kinematics problem).
Complex robots are interesting becausethe inverse kinematics problem has nounique solution: there are many ways fora robot to touch a target. What makeshumanoid robots especially interesting is thatthey have a large number of “extra” joints,organized in a humanlike fashion with sev-eral kinematic chains, with dynamic con-straints such as balance in addition to geo-metric constraints. When the finger touchesa target, the elbow might be up or down, orthe back or waist might be bent to change theshoulder’s position. This redundancy isadvantageous because it enables a robot toavoid obstacles and joint limits and attainmore desirable postures. From a control andlearning point of view, however, redundancyalso makes it quite complicated to find goodmovement plans. How do we humans decidewhat to do with our extra joints, and howshould humanoid robots control all theirjoints to make a coordinated movement?
To solve this problem, we first used aredundant inverse kinematics algorithmknown as the extended Jacobian method,
which reliably gave us reasonable answers.We also developed a more computationallyefficient version of the extended Jacobianthat searches for appropriate joint angles toreach toward a target and simultaneouslyoptimizes a criterion (such as minimizinggravitational load). We improved the algo-rithm by making it search locally (using gra-dient descent) for a better set of joint anglesin the nearby space of all joint angle vectorsthat successfully caused the robot to touchthe target. This local search let us remove alot of calculations, for which we compen-sated by using other learning algorithms.5
The speed we gained let us apply the algo-rithm to our 30-DOF humanoid robot in realtime. We compared the algorithm’s perfor-mance with a different state-of-the-art algo-rithm that uses the pseudo-inverse with opti-mization. In both cases, DB started in anonoptimal posture and tried to follow a tar-get with its right hand. The target moved withpseudorandom motion generated by sum-ming sinusoids of various frequencies. Devi-ations from a nominal posture were penal-ized in the optimization criterion. Ouralgorithm had much better convergence thanthe other, as Figure 3 shows.
The work just described implements a
classical way to make choices: imposingoptimization criteria on movement plan-ning—for instance, by requiring that the sys-tem accomplish a task in minimum time orwith minimal energy expenditure. However,finding good cost functions that generateappropriate behavior is difficult. Our researchon trajectory planning explores an alterna-tive method of constraining complex move-ment planning—by building movementsfrom two kinds of movement primitives. Thefirst kind is known in neuroscience as motortapes, in that the robot stores an explicit rep-resentation of a movement trajectory inmemory. When the robot needs informationon how to pitch a baseball, it finds the appro-priate tape or template in memory and exe-cutes it. More sophisticated versions of thisapproach blend and edit a set of tapes to pro-duce a movement.
Another kind of movement primitive isbased on dynamical systems. We are explor-ing simple dynamical systems that can gen-erate either discrete or rhythmic movements.2
In this case, the robot initially needs onlyspeed and amplitude parameters to start amovement. Learning is required to fine-tunecertain additional parameters to improve themovement. This approach lets the robot learnmovements by adjusting a relatively small setof parameters. We are also exploring how to
• use these different types of primitives togenerate full-body movement,
• learn their parameters using reinforce-ment learning, and
• sequence and superimpose such move-ment primitives to accomplish more com-plex movement tasks.
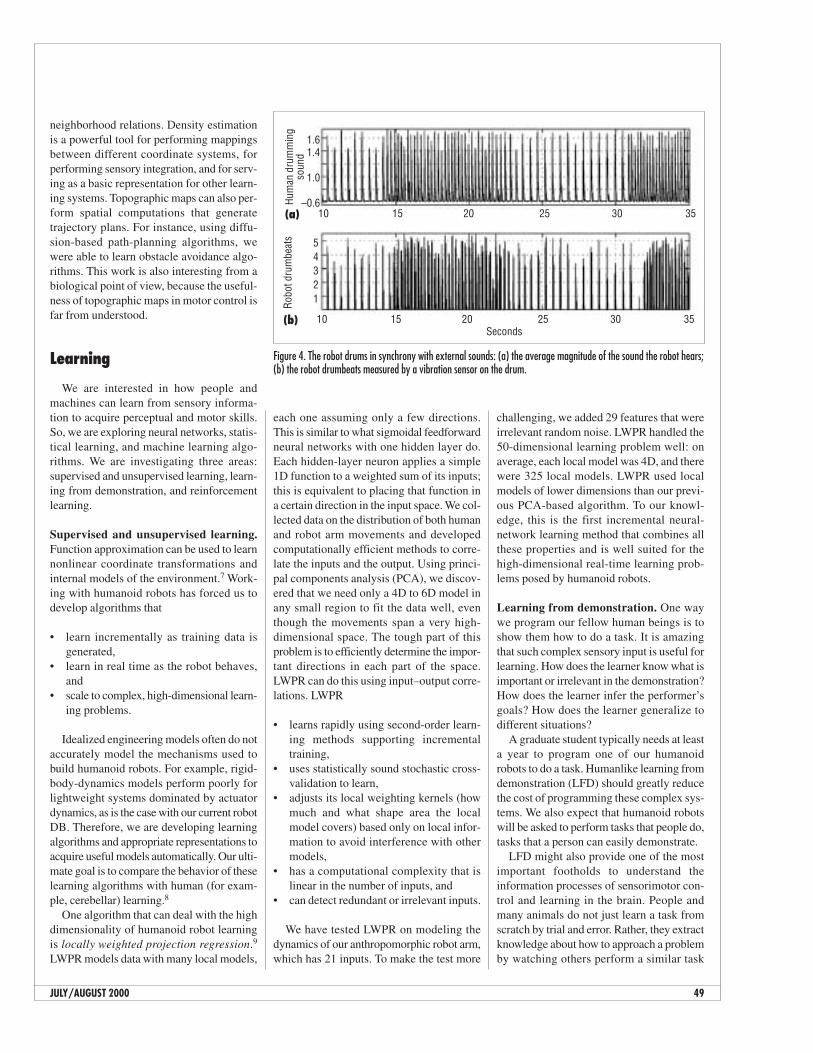
For example, we have implemented adap-tive dynamic systems that enable a robot todrum in time with a human drummer, as Fig-ure 4 shows.2 This ability to synchronize toexternal stimuli is an important componentof interactive humanoid behavior.
Inspiration from biology also motivates arelated trajectory-planning project on whichwe are working. A common feature in thebrain is to employ topographic maps as basicrepresentations of sensory signals. Suchmaps can be built with various neural-network approaches—for instance, Self-Organizing Maps or Topology RepresentingNetworks.6 From a statistical point of view,topographic maps can be thought of as neuralnetworks that perform probability densityestimation with additional knowledge about
48 IEEE INTELLIGENT SYSTEMS
-0.15
0
0.15
0 1 2 3 4 5 6 7 8 9 10
Gi
Time (seconds)
-0.15
0
0.15
0 1 2 3 4 5 6 7 8 9 10
Gi
Time (seconds)
(a)
(b)
Figure 3. Convergence of inverse kinematics for the humanoid robot using (a) the pseudo-inverse method and (b) themodified extended Jacobian method. The latter is less oscillatory.
neighborhood relations. Density estimationis a powerful tool for performing mappingsbetween different coordinate systems, forperforming sensory integration, and for serv-ing as a basic representation for other learn-ing systems. Topographic maps can also per-form spatial computations that generatetrajectory plans. For instance, using diffu-sion-based path-planning algorithms, wewere able to learn obstacle avoidance algo-rithms. This work is also interesting from abiological point of view, because the useful-ness of topographic maps in motor control isfar from understood.
Learning
We are interested in how people andmachines can learn from sensory informa-tion to acquire perceptual and motor skills.So, we are exploring neural networks, statis-tical learning, and machine learning algo-rithms. We are investigating three areas:supervised and unsupervised learning, learn-ing from demonstration, and reinforcementlearning.
Supervised and unsupervised learning.Function approximation can be used to learnnonlinear coordinate transformations andinternal models of the environment.7 Work-ing with humanoid robots has forced us todevelop algorithms that
• learn incrementally as training data isgenerated,
• learn in real time as the robot behaves,and
• scale to complex, high-dimensional learn-ing problems.
Idealized engineering models often do notaccurately model the mechanisms used tobuild humanoid robots. For example, rigid-body-dynamics models perform poorly forlightweight systems dominated by actuatordynamics, as is the case with our current robotDB. Therefore, we are developing learningalgorithms and appropriate representations toacquire useful models automatically. Our ulti-mate goal is to compare the behavior of theselearning algorithms with human (for exam-ple, cerebellar) learning.8
One algorithm that can deal with the highdimensionality of humanoid robot learningis locally weighted projection regression.9
LWPR models data with many local models,
each one assuming only a few directions.This is similar to what sigmoidal feedforwardneural networks with one hidden layer do.Each hidden-layer neuron applies a simple1D function to a weighted sum of its inputs;this is equivalent to placing that function ina certain direction in the input space. We col-lected data on the distribution of both humanand robot arm movements and developedcomputationally efficient methods to corre-late the inputs and the output. Using princi-pal components analysis (PCA), we discov-ered that we need only a 4D to 6D model inany small region to fit the data well, eventhough the movements span a very high-dimensional space. The tough part of thisproblem is to efficiently determine the impor-tant directions in each part of the space.LWPR can do this using input–output corre-lations. LWPR
• learns rapidly using second-order learn-ing methods supporting incrementaltraining,
• uses statistically sound stochastic cross-validation to learn,
• adjusts its local weighting kernels (howmuch and what shape area the localmodel covers) based only on local infor-mation to avoid interference with othermodels,
• has a computational complexity that islinear in the number of inputs, and
• can detect redundant or irrelevant inputs.
We have tested LWPR on modeling thedynamics of our anthropomorphic robot arm,which has 21 inputs. To make the test more
challenging, we added 29 features that wereirrelevant random noise. LWPR handled the50-dimensional learning problem well: onaverage, each local model was 4D, and therewere 325 local models. LWPR used localmodels of lower dimensions than our previ-ous PCA-based algorithm. To our knowl-edge, this is the first incremental neural-network learning method that combines allthese properties and is well suited for thehigh-dimensional real-time learning prob-lems posed by humanoid robots.
Learning from demonstration. One waywe program our fellow human beings is toshow them how to do a task. It is amazingthat such complex sensory input is useful forlearning. How does the learner know what isimportant or irrelevant in the demonstration?How does the learner infer the performer’sgoals? How does the learner generalize todifferent situations?
A graduate student typically needs at leasta year to program one of our humanoidrobots to do a task. Humanlike learning fromdemonstration (LFD) should greatly reducethe cost of programming these complex sys-tems. We also expect that humanoid robotswill be asked to perform tasks that people do,tasks that a person can easily demonstrate.
LFD might also provide one of the mostimportant footholds to understand theinformation processes of sensorimotor con-trol and learning in the brain. People andmany animals do not just learn a task fromscratch by trial and error. Rather, they extractknowledge about how to approach a problemby watching others perform a similar task
JULY/AUGUST 2000 49
Figure 4. The robot drums in synchrony with external sounds: (a) the average magnitude of the sound the robot hears;(b) the robot drumbeats measured by a vibration sensor on the drum.
(a) 10
Hum
an d
rum
min
gso
und
15 20 25 30 35
1.61.4
1.0
–0.6
(b) 10
Robo
t dru
mbe
ats
15 20 25 30 35
54321
Seconds

and by using what they already know. Fromthe viewpoint of computational neuro-science, LFD is a highly complex problemthat requires mapping a perceived action thatis given in an external-coordinate (world)frame of reference into a totally differentinternal frame of reference to activate motorneurons and subsequently muscles. Recentresearch in behavioral neuroscience hasshown that specialized “mirror neurons” inthe frontal cortex of primates seem to be theinterface between perceived movement andgenerated movement; that is, these neuronsfire very selectively when a particular move-ment is shown to the primate, and when theprimate itself executes the movement. Brain-imaging studies with people are consistentwith these results.
Research on LFD also offers tremendouspotential for medical and clinical applica-tions. If we can start teaching machines byshowing, our interaction with machines willbecome much more natural. If a machine canunderstand human movement, it can also beused in rehabilitation as a personal trainerthat watches a patient and provides specificnew exercises to improve a motor skill.Finally, insights into biological motor con-trol that are developed in LFD can help usbuild adaptive prosthetic devices.
We hypothesize that a perceived move-ment is mapped onto a finite set of movementprimitives that compete for perceived action.We can formulate such a process in the
framework of competitive learning: eachmovement primitive predicts the outcome ofa perceived movement and tries to adjust itsparameters to achieve an even better predic-tion, until a winner is determined. In prelim-inary studies with humanoid robots, we havedemonstrated the feasibility of this approach.Nevertheless, many open problems remainfor research. We are also trying to developtheories on how the cerebellum could beinvolved in learning movement primitives.
To explore these issues, we implementedLFD for a number of tasks, ranging from folkdancing to various forms of juggling. Weidentified three key challenges:
• to be able to perceive and understandwhat happens during a demonstration;
• to find an appropriate way to translate thebehavior into something the robot canactually do—it is humanoid, not human,so it has many fewer joints and ways tomove, and it is weaker and slower than ahuman; and
• to enable the robot to fill in missinginformation using learning from prac-tice—many things are hard or impossibleto perceive in a demonstration, such asmuscle activations or responses to errorsthat do not occur in the demonstration.
Solving these challenges is greatly facilitatedby enabling the robot to perceive the teacher’sgoal.
Perceiving human movement. To understanda task demonstration, the robot must be ableto see what is going on. We have focused onthe perception of human movement, exploit-ing our knowledge of how people move toinform our perception algorithms. For exam-ple, one theory is that we move in such a wayas to minimize how fast muscle forceschange.8 We can use this theory about move-ment generation to select the most likelyinterpretation of ambiguous sensory input.10
Our first thought was to borrow motion-capture techniques from the movie and videogame industry. We experimented with opticalsystems that track markers, systems where theteacher wears measurement devices, andvision-based systems with no special markers.However, we found that controlling a physicaldevice rather than drawing a picture requiredsubstantially modifying these techniques.
The organizing principle for our percep-tion algorithms is that they should be able torecreate or predict measured images based onthe recovered information. In addition, wecan make the movement recovery more reli-able by adding what are known as regular-ization terms to be minimized. These termshelp resolve ambiguities in the sensor data.For example, one regularization term penal-izes high rates of estimated muscle forcechange. We also process a large time range ofinputs simultaneously rather than sequen-tially, so we can apply regularization opera-tors across time and easily handle occlusion
50 IEEE INTELLIGENT SYSTEMS
Figure 5. Perceiving human motion. We can see how well our perception algorithms track. (a) A person walks by and his motion is recorded. (b) The perception system lays a graph-ical model on top of the human motion where it believes the person’s body parts are.
(a)
(b)

and noise. Thus, perception becomes anoptimization process, trying to find the under-lying movement or motor program that pre-dicts the measured data and deviates the leastfrom what we know about human movement.
To deal with systems as complex as thehuman body and the humanoid robot, we hadto use a representation with adaptive resolu-tion. We chose B-spline wavelets. Waveletsare removed when their coefficients are smalland added when the prediction error is large.We have also developed large-scale opti-mization techniques that handle the sparserepresentations we typically find in observeddata. We designed these optimization tech-niques to be reliable and robust, using second-order optimization with trust regions and ideasfrom robust statistics. Figure 5 shows anexample of our perception algorithms appliedto frames from a high-speed video camera.
Translating movement and inferring goals.As one test case for LFD, we captured themovements of a skilled performer doing theOkinawan folk dance Kacha-shi.1 Using theperception techniques just described, wefound that the teacher’s motions exceededthe robot’s possible joint movements. We hadto find a way to modify the demonstration topreserve the “dance” but make it possible forthe robot to do. We considered severaloptions:
• Scale and translate the joint trajectoriesto make them fit within robot joint lim-its, without taking into account the Carte-sian location of the limbs.
• Adjust the visual features the robot is try-ing to match until they are all withinreach. This can be done by translating orscaling the images or 3D target locations.How to do this in a principled way is notclear, and the effects on joint motion arenot taken into account.
• Build the joint limits into a special ver-sion of the perception algorithms, so thatthe robot can only “see” feasible posturesin interpreting or reasoning about thedemonstration. This approach trades offjoint errors and Cartesian target errorsstraightforwardly.
• Parameterize the performance in someway (knot-point locations for splines, forexample), and adjust the parameters sothat joint limits are not violated. Humanobservers score how well the original per-formance’s style or essence is preservedand select the optimal set of parameters.
This is very time consuming, unless wecan develop an automatic criterion func-tion for scoring the motion.
We implemented the first option, as shownin Figure 6. Clearly, we should also considerthe alternative approaches. We learned from
this work that we need to develop algorithmsthat identify what is important to preserve inlearning from a demonstration, and what isirrelevant or less important. For example, wehave begun to implement catching based onLFD (see Figure 7), where the learned move-ment must be adapted to new requirements
Figure 6. A frame from a graphics visualization of reconstructed motion using a simple graphical figure. Compared tothe posture the human can achieve (a), the robot’s shoulder and elbow degrees of freedom (b) are constrained.
(a) (b)
JULY/AUGUST 2000 51
Figure 7. A frame of motion showing the end of a catching sequence.
such as the ball’s trajectory.1 In catching, thehand must intercept the ball at the right placein space and at the right time; the joint angletrajectories are secondary.
We have begun to implement learning howto juggle three balls from demonstration,where actuator dynamics and constraints arecrucial. Because the hydraulic actuators limitthe joint velocities to values below thatobserved in human juggling, the robot mustsignificantly modify the observed move-
ments to juggle successfully. We have man-ually implemented several feasible jugglingpatterns; Figure 1 shows one such pattern.
In summary, something more abstract thanmotion trajectories must be transferred inLFD. The robot must perceive the teacher’sgoals to perform the necessary abstraction.We are exploring alternative ways to do this.
Learning from practice using reinforcementlearning. After the robot observes the teacher’s
demonstration, it still must practice the task,both to improve its performance and to esti-mate quantities not easily observable in thedemonstration. In our LFD approach, the robotlearns a reward function from the demonstra-tion that then lets it learn from practice withoutfurther demonstrations.11 The learned functionrewards robot actions that look like theobserved demonstration. This simple rewardfunction does not capture the true goals ofactions, but it works well for many tasks.
Human demonstration 8th trial
-5.00
-4.00
-3.00
-2.00
-1.00
0
1.00
Pend
ulum
ang
le (r
adia
ns)
0.0 0.5 1.0 1.5 2.0 2.5 3.0
-0.15-0.10-0.05
00.050.100.150.20
Hand
pos
ition
(met
ers)
0.5 1.0 1.5 2.0 2.5 3.0Seconds
(a)
3rd trial2nd trial1st trial (imitation)Human demonstration
-5.0
-4.0
-3.0
-2.0
-1.0
0
1.0
0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 2.0
-0.3-0.2-0.1
00.10.20.30.40.5
0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 2.0Seconds
(b)
(c) (d)
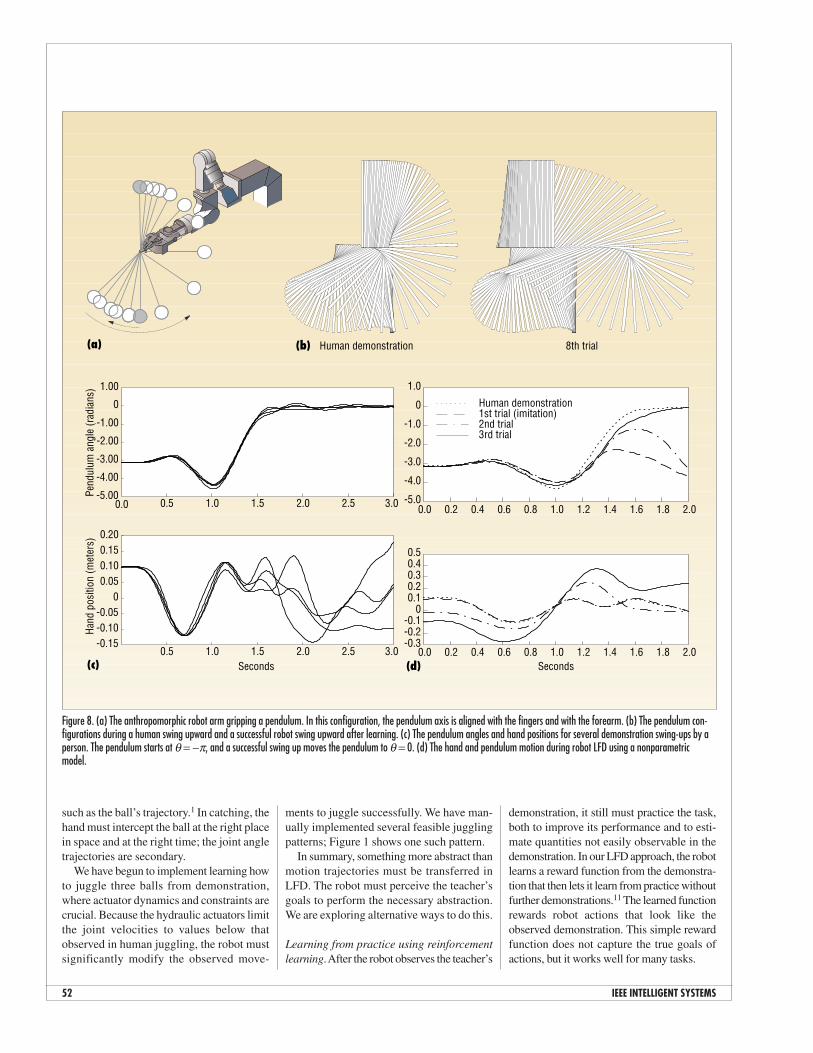
Figure 8. (a) The anthropomorphic robot arm gripping a pendulum. In this configuration, the pendulum axis is aligned with the fingers and with the forearm. (b) The pendulum con-figurations during a human swing upward and a successful robot swing upward after learning. (c) The pendulum angles and hand positions for several demonstration swing-ups by aperson. The pendulum starts at θ = −π, and a successful swing up moves the pendulum to θ = 0. (d) The hand and pendulum motion during robot LFD using a nonparametricmodel.
52 IEEE INTELLIGENT SYSTEMS

The robot also learns models of the taskfrom the demonstration and from its repeatedattempts to perform the task. Knowledge ofthe reward function and the task models letsthe robot compute an appropriate controlmechanism. Using these methods, our robotarm learned how to balance a pole on a fin-ger tip in a single trial. The arm also learnedthe harder task of swinging a pendulum froma downward-pointing position to point up(see Figure 8).
We learned these lessons from theseimplementations:
• Simply mimicking demonstrated motionsis often not adequate.
• Given the differences between the humanteacher and the robot learner and thesmall number of demonstrations, learn-ing the teacher’s policy (what the teacherdoes in every possible situation) is oftenimpossible.
• However, a task planner can use a learnedmodel and a reward function to computean appropriate policy.
• This model-based planning process sup-ports rapid learning.
• Both parametric and nonparametric mod-els can be learned and used.
• Incorporating a task-level direct learningcomponent that is non-model-based, inaddition to the model-based planner, isuseful in compensating for structuralmodeling errors and slow model learning.
Oculomotor control
The humanoid robot’s complexity forcesus to develop autonomous self-calibrationalgorithms. Initially we are focusing oncontrolling eye movements, where percep-tion and motor control strongly interact. Forexample, the robot must compensate for headrotation by counter-rotating the eyes, so thatgaze is stabilized. This behavior is known asthe vestibulo-ocular reflex. Miscalibration ofVOR behavior strongly degrades vision,especially for the robot’s narrow-field-of-view cameras that provide its “foveal” vision.
We are exploring a learning algorithmknown as feedback error learning, where weuse an error signal (in this case an image slipon the retina during head motion) to train acontrol circuit. This approach is modeled onthe adaptive control strategies used by the pri-mate cerebellum. We used eligibility traces, aconcept from biology and reinforcement
learning, to compensate for unknown delaysin the sensory feedback pathway.
In experiments, our humanoid oculomo-tor system (see Figure 9) converged to excel-
JULY/AUGUST 2000 53
Figure 9. A close-up of the robot head, showing the wide-angle and narrow-angle cameras that serve as eyes.
Figure 10. The robot’s (a) head position, (b) eye position, and (c) retinal image slip during vestibulo-ocular reflexlearning.
(a) 0
Eye
(rad
ians
)He
ad(r
adia
ns)
5 10 15 20 25 30 35
0 5 10 15 20 25 30 35
0 5 10 15 20 25 30 35
0.20
–2.0
Retin
al s
lip(r
adia
ns)
(b)
0.20
–2.0
0.20
–2.0(c)
Time (seconds)

lent VOR performance after approximately30 to 40 seconds (see Figure 10), even in thepresence of control system nonlinearities.Our future work will address adding smoothpursuit and saccadic behavior and enablingall these learning systems to run simultane-ously without interfering with each other.
Interactive behaviors
We have explored two kinds of interactivebehavior with DB: catching and a T’ai Chiexercise known as Sticky Hands or PushHands.3 The work on catching forced us todevelop trajectory generation procedures thatcan respond flexibly to demands from theenvironment, such as where the ball is going.The work on Sticky Hands explored robotforce control in contact with a person (seeFigure 11). This task involves the person andthe robot moving together through varied andnovel patterns while keeping the contact forcelow. Sometimes the human “leads” or deter-mines the motion, sometimes the robot leads,
and sometimes it is not clear who leads.A key research issue in generating in-
teractive behaviors is generalizing learnedmotions. It also became clear that when peo-ple interact with a humanoid robot, theyexpect rich and varied behavior from all partsof the body. For example, it is disconcertingif the robot does not exhibit humanlike eyeand head movements or fails to appear to beattending to the task. Interacting with therobot rapidly becomes boring if the robotalways responds in the same way in anygiven situation. How can the robot recognizea particular style of interaction and respondappropriately? If humanoid robots are goingto interact with people in nontrivial ways, wewill need to address these issues as well ascontrol and learning issues.
Understanding humanbehavior
We are using a variety of motion capturesystems to understand the psychophysics ofhuman movement. We are also exploringhow our theories implemented in DB com-pare to human behavior to find out whichmovement primitives biological systemsemploy and how the brain represents suchprimitives. One goniometer-based measure-ment system is the Sarcos Sensuit (see Fig-ure 12), which simultaneously measures 35DOFs of the human body. It can be used forreal-time capture of full-body motion, as anadvanced human–computer interface, or tocontrol sophisticated robotic equipment. Thecomplete Sensuit, worn like an exoskeleton,does not restrict motion for most movements,while an array of lightweight Hall-effect sen-sors records the relative positions of all limbsat sampling rates up to 100 Hz. A platform-independent OpenGL graphical display canbe used to simultaneously show the capturedmotion in real time and to generate and playback animated sequences of stored data files.
Our primary interest is to analyze humandata from the Sensuit and other motion cap-ture and vision systems with respect to cer-tain task-related movements. One key ques-tion we seek to answer in this context is howthe human motor cortex efficiently ana-lyzes, learns, and recalls an apparently infi-nite number of complex movement patternswhile being limited to a finite number ofneurons and synapses. Are there underlyingregularities, invariances, or constraints onhuman behavior? We have already dis-
Figure 11. Sticky-Hands interaction with a humanoid robot.
Figure 12. The Sensuit motion-capture system.
(a) (b)
54 IEEE INTELLIGENT SYSTEMS

cussed how we can reduce the dimension-ality of the movement data in any localneighborhood to under 10 dimensions, andhow we have observed that people tend tomove so as to minimize the rate of changeof muscle forces. These preliminary stud-ies will help us develop new concepts forcontrolling humanoid robotic systems withmany degrees of freedom.
PROGRAMMING HUMANLIKE BE-haviors in a humanoid robot is an importantstep toward understanding how the humanbrain generates behavior. Three levels areessential for a complete understanding ofbrain functions: the computational-hard-ware level, information representation andalgorithms, and computational theory. Weare studying high-level brain functionsusing multiple methods such as neurophys-iological analysis of the basal ganglia andcerebellum, psychophysical and behavioralanalysis of visuo-motor learning, measure-ment of brain activity using scanning tech-niques such as MRI, mathematical analysis,computer simulation of neural networks, androbotics experiments using humanoid robots.For instance, one of our approaches is tryingto have a robot learn a neural-network modelfor motor learning that includes data frompsychophysical and behavioral experimentsas well as from brain MRIs. The robot repro-duces a learned model in a real task, and wecan verify the model’s ability to generateappropriate behavior by checking its robust-ness and performance. This is only oneexample of the attention being given to thestudy of brain functions using humanoidrobots. This body of work should be animportant step toward changing the future ofbrain science.
AcknowledgmentsThis work is a joint project between the ATR
Human Information Processing Research Labora-tories and the Kawato Dynamic Brain Project, anExploratory Research for Advanced Technology(Erato) project funded by the Japan Science and Technology Agency. It was also funded byNational Science Foundation Awards 9710312 and9711770 as well as a University of Southern Cal-ifornia Zumberge grant. This research was par-tially supported by a Human Frontier Science Pro-gram grant and coordination funds for promotingscience and technology of the Japanese Govern-ment’s Science and Technology Agency.
References
1. M. Riley, A. Ude, and C.G. Atkeson, “Meth-ods for Motion Generation and Interactionwith a Humanoid Robot: Case Studies ofDancing and Catching,” Proc. 2000 Workshopon Interactive Robotics and Entertainment,Robotics Inst., Carnegie Mellon Univ., Pitts-burgh, 2000, pp. 35–42.
2. S. Schaal, S. Kotosaka, and D. Sternad, “Non-linear Dynamical Systems as MovementPrimitives,” Proc. Humanoids 2000, IEEE-RAS Int’l Conf. Humanoid Robots, to be pub-lished by IEEE Press, Piscataway, N.J., 2000.
3. J.G. Hale and F.E. Pollick, “ ‘Sticky Hands’Interaction with an Anthropomorphic Robot,”Proc. 2000 Workshop on Interactive Roboticsand Entertainment, Robotics Inst., CarnegieMellon Univ., Pittsburgh, 2000, pp. 117–124.
4. T. Shibata and S. Schaal, “Fast Learning ofBiomimetic Oculomotor Control with Non-parametric Regression Networks,” Proc.IEEE Int’l Conf. Robotics and Automation,IEEE Press, Piscataway, N.J., 2000, pp.3847–3854.
5. G. Tevatia and S. Schaal, “Inverse Kinemat-ics for Humanoid Robots,” Proc. IEEE Int’lConf. Robotics and Automation, IEEE Press,Piscataway, N.J., 2000, pp. 294–299.
6. T. Martinetz and K. Schulten, “Topology Rep-resenting Networks,” Neural Networks, Vol.7, No. 3, 1994, pp. 507–522.
7. S. Schaal, C.G. Atkeson, and S. Vijayakumar,“Real-Time Robot Learning with LocallyWeighted Statistical Learning,” Proc. IEEEInt’l Conf. Robotics and Automation, IEEEPress, Piscataway, N.J., 2000, pp. 288–293.
8. M. Kawato, “Internal Models for Motor Con-trol and Trajectory Planning,” Current Opin-ion in Neurobiology, Vol. 9, 1999, pp.718–727.
9. S. Vijayakumar and S. Schaal, “Fast and Effi-cient Incremental Learning for High-Dimen-sional Movement Systems,” Proc. IEEE Int’lConf. Robotics and Automation, IEEE Press,Piscataway, N.J., 2000, pp. 1894–1899.
10. A. Ude, C.G. Atkeson, and M. Riley, “Plan-ning of Joint Trajectories for HumanoidRobots Using B-spline Wavelets,” Proc. IEEEInt’l Conf. Robotics and Automation, IEEEPress, Piscataway, N.J., 2000, pp. 2223–2228.
11. C.G. Atkeson and S. Schaal, “How Can aRobot Learn from Watching a Human?” Proc.14th Int’l Conf. Machine Learning, MorganKaufmann, San Francisco, 1997, pp. 12–20.
Christopher G. Atkeson is an associate profes-sor in the Georgia Institute of Technology Col-lege of Computing. His research focuses onnumerical approaches to machine learning anduses robotics to explore the behavior of learningalgorithms. He also is applying machine learningto future computer environments. Contact him atthe College of Computing, Georgia Inst. of Tech-nology, 801 Atlantic Dr., Atlanta, GA 30332-0280; [email protected]; www.cc.gatech.edu/fac/Chris.Atkeson.
Joshua G. Hale is a PhD student in computer sci-ence at the University of Glasgow and a memberof the 3D-Matic Faraday Partnership. His researchinterests include human-figure animation, dynamicsimulation, and biomechanics. He received his BAin computation from the University of Oxford andhis MSc in computer science from the Universityof Edinburgh. Contact him at Boyd Orr, Room418, Univ. of Glasgow, Glasgow G12 8QQ, Scot-land; [email protected]; www.dcs.gla.ac.uk/~halej.
Frank Pollick is a lecturer in psychology at theUniversity of Glasgow. From 1991 to 1997 he wasan invited researcher at ATR Human InformationProcessing Research Labs in Kyoto, Japan. Hisresearch interests include the visual control ofaction and the production and perception of humanmovement. He received his PhD in cognitive sci-ences from the University of California, Irvine, hisMSc in biomedical engineering from Case West-ern Reserve University, and a BS degree in physicsand in biology from the Massachusetts Institute ofTechnology. Contact him at the Psychology Dept.,Univ. of Glasgow, 58 Hillhead St., Glasgow G128QB, Scotland; [email protected]; www.psy.gla.ac.uk/frank/home.html.
Marcia Riley is a PhD student at the Georgia Insti-tute of Technology College of Computing. Herresearch interests include generating interestingbehavior for humanoids, and she explores incor-porating techniques and results from human motorcontrol studies and machine learning to createbehaviors. She earned her MS in computer sciencefrom the University of Geneva, Switzerland, andher BS in mathematics from The Johns HopkinsUniversity. Contact her at the College of Comput-ing, Georgia Tech, 801 Atlantic Dr., Atlanta, GA30332-0280; [email protected].
Shinya Kotosaka is a researcher in the KawatoDynamic Brain Project. He received his PhD inmechanical engineering from Saitama University,Japan. He is a member of the Society for Neuro-science, the Japan Society of Mechanical Engi-neers, and the Robotics Society of Japan. Contacthim at 2-2 Hikaridai, Seika-cho, Soraku-gun,Kyoto 619-0288, Japan; [email protected].
JULY/AUGUST 2000 55

Stefan Schaal is an assistant professor of com-puter science and neuroscience at the Universityof Southern California, head of the ComputationalLearning Group of the Kawato Dynamic BrainProject, and an adjunct assistant professor of kine-siology at the Pennsylvania State University. Hisresearch interests include statistical and machinelearning, neural networks, computational neuro-science, nonlinear dynamics, nonlinear control the-ory, and biomimetic robotics. Contact him at theComputational Learning and Motor Control Lab,USC, Hedco Neurosciences Bldg., HNB-103,3614 Watt Way, Los Angeles, CA 90089-2520;[email protected].
Tomohiro Shibata is a researcher at the Japan Sci-ence and Technology Corporation and is workingon the Erato project. He received his PhD in infor-mation engineering from the University of Tokyo.His research focuses on oculomotor control andvisual processing for humans and humanoids. Heis a member of the Society for Neuroscience; theInstitute of Electronics, Information and Commu-nication Engineers; the Robotics Society of Japan;and Japan Cognitive Science Society. Contact himat 2-2 Hikaridai, Seika-cho, Soraku-gun, Kyoto619-0288, Japan; [email protected].
Gaurav Tevatia is a PhD student in computer sci-ence at the University of Southern California. He isa member of the Computational and Motor ControlLab at USC and the Computational Learning Groupof the Kawato Dynamic Brain Project. His researchinterests include statistical and machine learning,neural networks, and nonlinear control theory. Hecompleted his undergraduate studies at Punjab Uni-versity, India. Contact him at the ComputationalLearning and Motor Control Lab, USC, Hedco Neu-rosciences Bldg., HNB-103, 3614 Watt Way, LosAngeles, CA 90089-2520; [email protected].
Ales Ude is an Science & Technology Agency fel-low in the Kawato Dynamic Brain Project and aresearcher at the Jozef Stefan Institute in Ljubl-jana, Slovenia. His research focuses on computervision and robotics. He studied applied mathe-matics at the University of Ljubljana, Slovenia,and received his PhD in computer science from theUniversity of Karlsruhe, Germany. Contact him at2-2 Hikaridai, Seika-cho, Soraku-gu, Kyoto 619-0288 Japan; [email protected].
Sethu Vijayakumar is a researcher at the Com-putational Learning and Motor Control Lab at the
University of Southern California and holds a part-time affiliation with the Riken Brain Science Insti-tute, Japan. His research interests include statisti-cal and machine learning, neural networks, andcomputational neuroscience. He received his BE incomputer science from the Regional EngineeringCollege, Tiruchirapalli, India, and his master’s andPhD from the Tokyo Institute of Technology. Con-tact him at the Computational Learning and MotorControl Lab, USC, Hedco Neurosciences Bldg.,HNB-103, 3614 Watt Way, Los Angeles, CA90089-2520; [email protected].
Mitsuo Kawato is a project leader of the AdvancedTelecommunications Research International, adepartment head in the ATR Human InformationProcessing Research Laboratories, and the directorof the Kawato Dynamic Brain Project, Erato, JapanScience and Technology Corporation. He receivedhis BS in physics from Tokyo University and hisME and PhD in biophysical engineering fromOsaka University. Contact him at Dept. 3,ATR HIPLabs, 2-2-2 Hikaridai, Seika-cho, Soraku-gun,Kyoto 619-0288, Japan; [email protected];www.hip.atr.co.jp/departments/dept3.html.
56 IEEE INTELLIGENT SYSTEMS
2000 Editorial CalendarJanuary-March Multimedia Computing and Systems
April-June Virtual World Heritage
July-September Multimedia Tools and Applications
October-December Multimedia Computer Supported Cooperative Work
http://computer.org/multimedia