spatial perspective choice in asl
TRANSCRIPT

Spatial perspective choice in ASL
</SECTION "opt"><SECTION "art" TITLE "Articles">
Sign Language & Linguistics 5:1 (2002), 3–26.
issn 1387–9316 / e-issn 1569–996X�©John Benjamins Publishing Company
<TARGET "emm" DOCINFO
AUTHOR "Karen Emmorey and Barbara Tversky"
TITLE "Spatial perspective choice in ASL"
SUBJECT "SL&L, Volume 5:1"
KEYWORDS "spatial perspective, shared space, classifiers"
SIZE HEIGHT "240"
WIDTH "170"
VOFFSET "4">
Karen Emmorey and Barbara TverskyThe Salk Institute for Biological Studies / Stanford University
Two studies investigated the ramifications of encoding spatial locations via signingspace for perspective choice in American Sign Language. Deaf signers (“speakers”)described the location of one of two identical objects either to a present addressee orto a remote addressee via a video monitor. Unlike what has been found for Englishspeakers, ASL signers did not adopt their addressee’s spatial perspective whendescribing locations in a jointly viewed present environment; rather, they producedspatial descriptions utilizing shared space in which classifier and deictic signs werearticulated at locations in signing space that schematically mapped to both thespeaker’s and addressee’s view of object locations within the (imagined) environ-ment. When the speaker and addressee were not jointly viewing the environment,speakers either adopted their addressee’s perspective via referential shift (i.e., loca-tions in signing space were described as if the speaker were the addressee) or speak-ers expressed locations from their own perspective by describing locations fromtheir view of a map of the environment and the addressee’s position within thatenvironment. The results highlight crucial distinctions between the nature of per-spective choice in signed languages in which signing space is used to convey spatialinformation and spoken languages in which spatial information is conveyed bylexical spatial terms. English speakers predominantly reduce their addressee’s cogni-tive load by adopting their addressee’s perspective, whereas in ASL shared space canbe used (there is no true addressee or speaker perspective) and in other contexts,reversing speaker perspective is common in ASL and does not increase the addres-see’s cognitive load.
Keywords: spatial perspective, shared space, classifiers
1. Introduction
When English speakers talk about locations within a scene that they are both viewing,they are often faced with a coordination problem with respect to reference frames.That is, speakers must choose a particular spatial perspective from which to describethe locations of objects. What is on the left from one person’s point of view might be

4 Karen Emmorey and Barbara Tversky
in front of or on the right from another person’s point of view. For example, speakerscan describe object locations from their own viewpoint, e.g. “Pick the one that’sfarthest fromme” or “It’s the one on my right,” or they can adopt the point of view oftheir addressee, saying “Pick the one closest to you,” or “It’s the one on your left.”Speakers may also adopt amore neutral perspective by describing object locations withrespect to other objects or landmarks, e.g. “Pick the one near the water cooler” or “It’sthe one next to the door.” In the experiments reported here, we investigate the natureof spatial perspective choice in American Sign Language (ASL).
Signed languages generally convey spatial information using “classifier” construc-tions in which spatial relations are expressed by where the hands are placed in signingspace or with respect to the body (e.g. Supalla 1982; Engberg-Pedersen 1993).1
Classifier predicates are complex forms in which the handshape is a morpheme thatencodes information about object type, and the movement and position of the handmay specify the movement and location of a referent (see papers in Emmorey in pressa, for an in-depth discussion of classifier constructions in various signed languages).For these constructions, there is a schematic correspondence between the location ofthe hands in signing space and the position of physical objects in the world (e.g.Emmorey & Herzig in press). When describing spatial scenes, the identity of eachobject is usually indicated by a lexical sign (e.g. table, t-v, chair). The location ofobjects, their orientation, and their spatial relation vis-a-vis one another is indicatedby where the appropriate classifier predicates are articulated. Where English usesprepositions and directional terms to express spatial relations, ASL uses the visuallayout displayed by classifier signs positioned in signing space. Figure 1 provides anillustrative example of a room description in ASL.
In the example in Figure 1, neither the addressee nor the signer is currentlyobserving the room that is being described. In this situation, spatial descriptions arealmost always produced from the signer’s (the “speaker’s”) perspective. “Speaker” willbe used here to refer to the person who is signing, in order to parallel the speaker/addressee contrast for English. In Figure 1, the speaker describes a scene where a tableis on his left as he enters a room. He uses the sign glossed as i-enter at the beginningof the discourse which signals that the scene should be understood from his perspec-tive. The speaker indicates that the table is to the left by producing the classifier signappropriate for tables at a spatial location on his left. Because the addressee is usuallyfacing the speaker, the spatial location for table is actually positioned on the addressee’sright. There is a mismatch between the location of the table in the room beingdescribed (the table is on the left as seen from the entrance) and what the addresseeactually observes in signing space (the classifier sign for table is produced to the
1.�The status of handshape as a classifier in these constructions has been recently called intoquestion (see papers in Emmorey in press a).

Spatial perspective choice in ASL 5
addressee’s right). The addressee must mentally transform the spatial location of the
Room layout Description of layout using classi er constructionsW
I-ENTER TABLE IS - THERE TV IS - THERE CHAIR IS - THERE
Figure 1.�Example of an ASL spatial description. An English translation of the ASL would be “Ienter the room. There is a table to the left, a T.V. on the far side, and a chair to the right.”
table in signing space to match the perspective of the speaker. Previous research hasindicated that such a transformation is not difficult for ASL signers and that in thissituation, addressees prefer spatial descriptions from the speaker’s perspective(Emmorey, Klima & Hickok 1998).
Specifically, Emmorey et al. (1998) noted that spatial scenes are most oftendescribed from the speaker’s perspective, such that an addressee facing the speakermust perform what amounts to a 180° mental rotation to correctly comprehend thedescription. However, scenes can also be described, non-canonically, from theaddressee’s perspective, in which case no rotation is required. To investigate whethermental rotation during sign language processing was difficult for signers, we askedDeaf ASL signers to decide whether a signed descriptionmatched a room presented onvideotape. If the room description was introduced with the non-canonical sign glossedas you-enter, the signing space in which the room layout was described was “rotated”180° so that the addressee was “at the entrance” of the room. In this case, the spatialarrangement of the signs, as viewed by the addressee, exactly matched the spatialarrangement of the objects in the room as viewed from the entrance. In contrast, whenthe room descriptions were introduced with the more canonical sign i-enter, thedescription was from the speaker’s point of view, and the addressee had to perform amental transformation to correctly comprehend the description (e.g., if the speakerdescribed the table as on her left, the actual table in the roomwould appear on the right ofthe videoscreenbecause the roomwasfilmed from the entrance). The results revealed thatsubjects were more accurate when scenes were described from the speaker’s perspective(even though rotation was required) than from the addressee’s perspective (norotation required). This result indicates that not only speakers but addressees as wellprefer spatial descriptions from the speaker’s point of view — despite the mentalrotation requirements for the addressee when this viewpoint is adopted.
However, what happens when both the speaker and the addressee are in theenvironment, observing the same scene, as in the English examples cited earlier? Wehypothesize that in such situations, ASL signers use what Emmorey (2002) has termedshared space. Figure 2 provides an illustration of what is meant by shared space. In the

6 Karen Emmorey and Barbara Tversky
situation depicted, the speaker (the signer) and addressee are facing each other, andbetween them are two boxes. Suppose the box on the speaker’s right is the one that hewants to identify. If the speaker uses signing space (rather than just pointing to theactual box), he would indicate the desired box by placing the appropriate classifier signon the right side of signing space. Note that in this situation, nomental transformationis required by the addressee. The speaker’s signing space is simply “mapped” onto thejointly observed physical space — the right side of the speaker’s signing space mapsdirectly to the actual box on the left side of the addressee (see Figure 2a). However, if thespeaker were to adopt the addressee’s spatial perspective, producing the classifier sign onhis left, the location in signing space would conflict with the location of the target boxobserved by the addressee (see Figure 2b). We predict that in such situations, signerswill use shared space, rather than adopt their addressee’s spatial viewpoint.
It is not impossible to adopt the addressee’s viewpoint when physical space isjointly observed by both interlocutors. For example, the speaker could describe anaction of the addressee. In this case, the speakerwould indicate a referential shift througha break in eye gaze, and within the referential shift, the signer could sign lift-box usinga handling classifier construction articulated toward the left of signing space. Thesigning space in this case would reflect the addressee’s view of the environment (i.e.,the box is to the addressee’s left).
In general, however, for situations in which the speaker and addressee are bothobserving and discussing a jointly viewed physical environment, there is no truespeaker versus addressee point of view in signed descriptions of that environment. Thesigning space is shared in the sense that it maps to the observed space and to both thespeaker’s and addressee’s perspective of the physical space. Furthermore, the speaker’sdescription of the box would be the same regardless of where the addressee wasstanding (e.g. placing the addressee to the signer’s left in Figure 2, would not alter thespeaker’s description or the nature of the mapping from signed space to physicalspace). Thus, in this situation, an ASL signer (unlike an English speaker) does not needto take into account where his addressee is located and can simply describe what hesees. This difference between languages derives from the fact that signers use the actualspace in front of them to represent observed physical space.
To investigate the nature of perspective choice in ASL, we adapted a task developedby Mainwaring, Tversky & Schiano (1996) to elicit spatial descriptions. In thisexperimental task (adapted from Schober 1993), subjects are invited to join a “SecretOperations Agency” in which the subject must communicate with another secret agent(Agent Z) about the locations of various objects (e.g. a bomb, microfilm). The subjectis given maps of various simple scenes with a description of each situation (seeFigure 3). English speakers in the Mainwaring et. al (1996) study were told that forsecurity reasons they must communicate via an “Encoder Pad” which allows Agent Zto send the subject a simple question that the subject can answer with a short written

Spatial perspective choice in ASL 7
message. For the example situation shown in Figure 3, an English speaker might write
X X
X X
Addressee Addressee
Speaker Speaker
A) Shared Space * B) Addressee viewpoint
Figure 2.�Illustration of a speaker using (a) shared space and (b) using the addressee’s spatialviewpoint to indicate the location of the box marked with an “X” (the asterisk indicates thatsigners reject this type of description). By convention, the half circle represents the signing spacein front of the speaker. The “X” represents the location of the classifier sign used to representthe target box (e.g. a hooked 5 handshape).
“It’s on my right,” “It’s on your left,” or “It’s near the water cooler.” The results fromMainwaring et al. (1996) indicate that English speakers generally preferred to adopttheir addressee’s perspective. Overall, 81% of spatial descriptions adopted the addres-see’s viewpoint, and the percentage rose to 92%when no landmark was present in theenvironment. In contrast, we predict that ASL signers will not adopt their addressee’sspatial perspective but will use shared space.
For English speakers, the presence of a relevant landmark in the environmentaltered the tendency to adopt the addressee’s perspective (in these situations, 23% ofthe descriptions were perspective-neutral and used the landmark to locate the targetobject) (Mainwaring et al. 1996). We investigate whether the presence of a landmarkalso affects the nature of spatial descriptions for ASL signers. Another factor thataffects perspective choice for English speakers is whether they are conversing withactual conversational partners or with imaginary addressees (Schober 1993). Speakersare less likely to adopt their addressee’s perspective when their addressee is actuallypresent, rather than imaginary: 2% versus 13% of spatial descriptions were from thespeaker’s perspective for present vs. imaginary addressees, respectively (Schober 1993).Our experiments also investigate the effects of real vs. imaginary addressees for spatial

8 Karen Emmorey and Barbara Tversky
perspective choice in ASL. Experiment 1 parallels the Mainwaring et al. (1996) study,
Figure 3.�An example scenario from Experiment 1.
except that the addressee is actually present in the (imagined) environment and asksthe speaker for information regarding target locations (e.g. “Where are the docu-ments?”; Figure 3). However, in Experiment 2, the speaker communicates with animaginary addressee via a videophone. We predict that, unlike English speakers, thepresence of an addressee does not increase the use of speaker perspective. Rather, whenthe addressee is present, we predict that ASL signers are much more likely to useshared space.
Finally, it is important to point out that we are comparing communication inwritten English to signed communication with an actual addressee in Experiment 1.

Spatial perspective choice in ASL 9
Our previous research with English speakers producing spoken descriptions ofenvironments revealed that speakers often use gesture to indicate perspective(Emmorey, Tversky & Taylor 2000). In their speech, subjects adopted either a routeperspective (addressees were taken on a tour of the environment) or a survey perspec-tive (the environment was described from one, unchanging, viewpoint). Speakers’gestures generally mirrored the spatial perspective of the spoken description; forexample, 3-D gesture space was used for route descriptions as if moving through anenvironment, and 2-D planar gesture space was used for survey descriptions, as ifillustrating the environment on a blackboard. In addition, there were no differences inperspective choice for the spoken descriptions from Emmorey, Tversky, and Taylor(2000) and the written descriptions of the same environments from Taylor andTversky (1996). These results suggest that the ability to gesture does not change thenature of perspective choice for English speakers, at least when comparing route andsurvey perspectives. Thus, it is not unreasonable to compare the results from Main-waring et al. (1996) with those of the present study, even though we are comparing aprimary language mode (ASL) with a derived language mode (written English).
2. Experiment 1: Co-present situation
Experiment 1 was designed to test our predictions concerning perspective choice byASL signers and to investigate the nature of spatial descriptions in ASL. As with theMainwaring et al. (1996) study, we asked subjects to imagine themselves in variousenvironments (e.g. an office, a zoo, a casino). However, unlike the English speakers,Deaf ASL signers communicated with an actual addressee who took on the role ofAgent Z andmoved to different locations within the room. For each environment andscenario, subjects were told to imagine that they were in a particular environment withAgent Z, as depicted on a set of maps.
2.1 Method
2.1.1 SubjectsTwenty Deaf subjects participated in the experiment. 15 subjects had Deaf families andwere native signers of ASL, and 5 subjects were near-native signers, exposed to ASL ata mean age of 6 years. 14 subjects were deaf from birth, and 6 became deaf before age3. Subjects were tested either at Gallaudet University in Washington, D.C., at the SalkInstitute in San Diego, or at California State University, Northridge.

10 Karen Emmorey and Barbara Tversky
2.1.2 Materials and procedureSubjects were first shown an instructional videotape in which a native ASL signer(dressed in suit and tie) welcomed the subject into the Secret Organization andidentified himself as its head. He explained that the subject’s mission was to help AgentZ accomplish various dangerous but important tasks in a variety of environments.Subjects were told that there would be two parts to their job. For the first part, thesubject would meet Agent Z in the same location, and the person in the room withthem now was Agent Z (the Deaf research assistant in the experiment room). It wasnot feasible to use “encoder pads” as in the English study because we were interested insigned, rather than written responses. Furthermore, pilot research indicated that signersoverwhelmingly preferred to sign to a live addressee, rather than to imagine an addresseeas present in the environment. In the second part (Experiment 2 below), subjects weretold theywouldworkwith another secret agent and that thismissionwould be explainedlater. Subjects were told to use ASL as their “secret language” and that Agent Z wouldonly be able to ask a simple question, and subjects must provide a short answer. AgentZ would not be able to ask for clarification so their answer must be clear and concise.
Subjects were given a set of maps, and for each map the Agency head describedtheir mission and the environment in ASL on videotape. Subjects were told that “you”indicated where they were standing and that “Z” indicated where Agent Z was standing(see Figure 3, but note that for ASL subjects, maps were only labeled with the name ofthe location, e.g. “Blackmailer’s office;” the English description was not printed on themap). The map always matched the real world scene, i.e. youwas always at the bottomof the map representing the subject’s view (subjects stayed in one position), and theDeaf research assistant moved to the appropriate locations indicated on the map forAgent Z (i.e. to the side or directly across from the subject). After each scene descrip-tion, Agent Z would ask the subject for information (e.g. “Where’s the microfilm?”).All subjects’ responses were recorded on videotape for later analysis.
Eachmap description included a brief key to the diagram (e.g. “the squares are thewine vats, and the arrow points to the poisoned one”). For all maps, two containerswere shown as identical filled squares with an arrow pointing to the target container.If a scenario included a landmark, it was shown as an unfilled circle.
Subjects were presented with 16maps. Eight maps corresponded to the “baseline”condition of Mainwaring et al. (1996) which only depicted Agent Z and the twocontainers (no landmark or compass direction), and eight contained a landmark whichwas skewed toward either the target container or the non-target container. For half ofthe maps, Agent Z was facing the subject, and for the other half, Agent Z was either tothe left or right of the subject. Finally, the container squares were either aligned withthe direction that the subject was facing (i.e. one in front of the other from thesubject’s view, as shown in Figure 4) or perpendicular to the subject (i.e. side-by-sidefrom the subject’s view, as shown in Figure 3).

Spatial perspective choice in ASL 11
2.2 Results and discussion
2.2.1 Response codingEach ASL description was coded by a native ASL signer as using shared space, as takingthe addressee’s or the speaker’s perspective, or as using the landmark to locate thetarget object. Figure 5 below provides an illustration of each response type for a singlescene. A description was coded as using shared space if the subject located the targetobject by articulating classifier signs or deictic signs within signing space, such that thespecified locations were isomorphic with the imagined environment in front of thesigner. Figure 4a and 4b provide examples of ASL descriptions using shared space(actual subject responses are illustrated in all of the figures, unless otherwise noted).Subjects either articulated appropriate classifier signs at specific locations in signingspace (Figures 4a and 6), or they articulated deictic pointing signs or other deictic signsin signing space or toward the imagined environment (Figures 4b and 5a).
Responses were coded as from the addressee’s viewpoint if the target location waslexically described with respect to the addressee’s position (e.g. near you, seeFigure 5b). A response would also have been coded as from the addressee’s perspectiveif locations in the speaker’s signing space represented the addressee’s view of theenvironment, e.g. locating the target object on the left side of signing space, if theobject was on the addressee’s left; however, no subject produced such a description,which would have been analogous to the starred description in Figure 2b.
Responses were coded as from the speaker’s viewpoint if the target location waslexically described with respect to the speaker (e.g. near me, see Figure 5c for anotherexample). The use of shared space also reflects the speaker’s perspective of theenvironment and could be thought of as a description from the speaker’s point of view.However, the use of shared space also reflects the addressee’s view of the imaginedscene, as illustrated in Figure 2. Again, we suggest that when shared space is used, thereis no true addressee vs. speaker perspective.
Finally, when a landmark was present, signers produced some neutral non-spatialdescriptions, such as the one shown in Figure 5d, but more often signers described thelocation of a target with respect to the landmark using shared space. Figure 6 providesan example in which the signer describes the location of two slot machines and aroulette wheel in a casino. She indicates the location of target slot machine with respectto the landmark (a roulette wheel). The locations in signing space representing the slotmachines and the roulette wheel correspond to the locations indicated on the map(and thus to the locations in the imagined environment) and with the addressee’s viewof the imagined environment. Thus, although the target location is described withrespect to a landmark, the signer expresses this relationship using shared space.

12 Karen Emmorey and Barbara Tversky
2.2.2 Analysis of perspective choice
Figure 4a.�Example of an ASL description using shared space and classifier signs. The subjectdescribed the location of the target car as depicted in the scenario shown on the map.
Figure 4b.�Example of an ASL description using shared space and deictic signs. The subjectdescribed the location of the target car as depicted in the scenario in Figure 4a.
Re-descriptions were excluded from the analysis — the first response was consideredprimary. For example, if a subject used shared space to indicate the location of a targetobject, and then added “on your right,” this would be counted as a shared spacedescription, and the re-description with the addressee perspective would be excluded.The percent of all responses from each perspective is shown in Table 1. Figure 5 provides
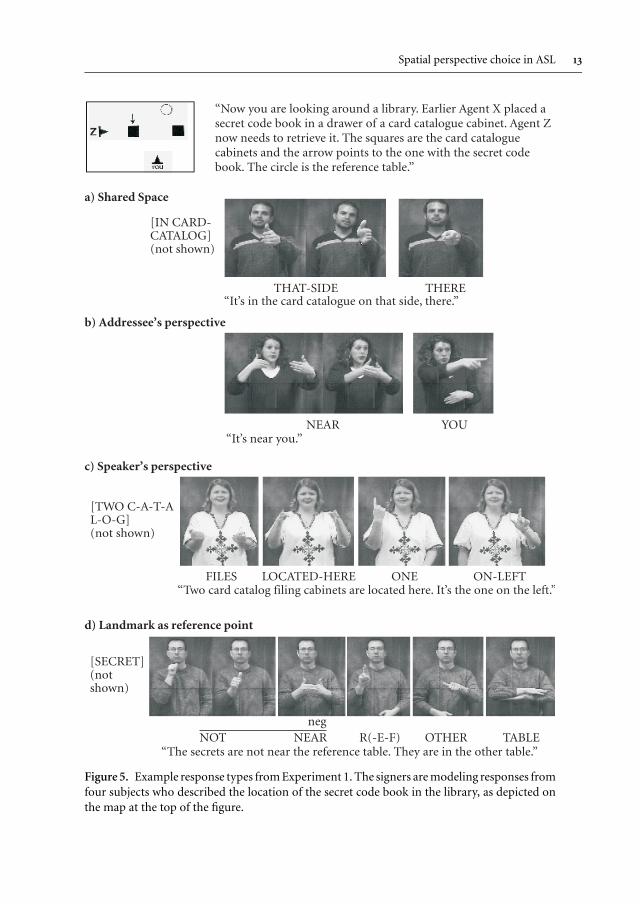
Spatial perspective choice in ASL 13
“Now you are looking around a library. Earlier Agent X placed asecret code book in a drawer of a card catalogue cabinet. Agent Znow needs to retrieve it. The squares are the card cataloguecabinets and the arrow points to the one with the secret codebook. The circle is the reference table.”
[IN CARD-CATALOG](not shown)
THAT-SIDE THERE“It’s in the card catalogue on that side, there.”
NEAR YOU“It’s near you.”
[TWO C-A-T-AL-O-G](not shown)
FILES LOCATED-HERE ONE ON-LEFT“Two card catalog filing cabinets are located here. It’s the one on the left.”
[SECRET](notshown)
NOT NEAR R(-E-F) OTHER TABLEneg
“The secrets are not near the reference table. They are in the other table.”
a) Shared Space
b) Addressee’s perspective
c) Speaker’s perspective
d) Landmark as reference point
Figure 5.�Example response types fromExperiment 1. The signers aremodeling responses fromfour subjects who described the location of the secret code book in the library, as depicted onthe map at the top of the figure.

14 Karen Emmorey and Barbara Tversky
examples of each type of description for a singlemap. There was a total of 160 descriptionsin the landmark condition, and 158 descriptions in the no landmark condition.2
As can be seen from Table 1, ASL signers overwhelmingly preferred to express
Table 1.�Percent of descriptions from each point of view for the co-present condition(Experiment 1)
No landmark Landmark present
Shared SpaceAddressee’s Point of ViewSpeaker’s Point of ViewLandmark
84.2�7.6�8.2N/A
a79.4a
�8.8�5.0b�6.8b
a�Percent of descriptions that used shared space in combination with referencing a landmark element (seeFigure 6).b�Percent of descriptions that referenced a landmark and did not use shared space (see Figure 5d).
locative information using shared space when the addressee was present in theenvironment. When subjects adopted the addressee’s perspective, they produceddescriptions that did not make use of locations within signing space. As noted, nosubject adopted the spatial perspective of the addressee using referential shift to “takeon the role” of Agent Z. In such a description, the locations in signing space wouldrepresent the locations in the environment as observed by Agent Z. For example, forthe situation depicted in Figure 3, no signer indicated the location of the incriminatingdocuments by articulating a classifier or deictic sign on the left of signing space.
When shared space was not used to describe target locations, descriptions werefairly evenly divided between those that adopted the addressee’s viewpoint and thosethat adopted the speaker’s viewpoint. In contrast, the English descriptions in theMainwaring et al. (1996) study were most often from the addressee’s perspective. Inthe baseline (no landmark) condition, 92% of the descriptions adopted the addressee’sviewpoint (only 8% adopted the speaker’s viewpoint), and in the (skewed) landmarkcondition, 70% of the descriptions adopted the addressee’s viewpoint, 8% adopted thespeaker’s viewpoint, and 23% used the landmark to indicate the target location.However, for ASL signers, choice of addressee vs. speaker viewpoint was affected bywhether the target location was nearest the addressee (as in Figure 5). For thesescenarios, 12% of the descriptions were from the addressee’s perspective, and only 1%of descriptions adopted the speaker’s perspective.When the target location was nearestthe speaker, descriptions were evenly divided between addressee (8.8%) and speaker(8.8%) viewpoints.
2.�One subject’s description utilized an absolute reference frame and was excluded (this subjectindicated that the target was the “North barn” assuming North was at the top of the map), and asecond subject misunderstood the firstmap and did not produce a description for that environment.

Spatial perspective choice in ASL 15
In sum, most ASL signers produced spatial descriptions in which classifier signs
Figure 6.�Example of a description using shared space with the landmark as the reference object.
and deictic signs were articulated at locations in signing space that schematicallymapped to both the speaker’s and addressee’s view of object locations within theimagined environment. When shared space was not used to express spatial informa-tion, ASL signers exhibited a preference for descriptions from the addressee’s perspec-tive, but only when the target location was nearest the addressee. Otherwise, neitherthe speaker’s nor the addressee’s perspective was preferred. This pattern of perfor-mance contrasts with English speakers who overwhelmingly prefer to produce

16 Karen Emmorey and Barbara Tversky
descriptions from their addressee’s perspective. However, ASL signers have an optionthat is unavailable to English speakers: signing space.
3. Experiment 2: Remote “control room” situation
In Experiment 1, signers communicated with an actual, rather than imaginary,addressee. However, in the Mainwaring et al. (1996) study, English speakers commu-nicated with an imaginary addressee, and as noted earlier, Schober (1993) found thatthe tendency to adopt the addressee’s perspective decreases with a live addressee. InExperiment 2, we investigated whether and how perspective choice in ASL changeswhen the speaker communicates with a non-present, imaginary addressee. For thispart of the study, subjects were told that they are now in a control room at the SecretAgency’s headquarters. They are now working with Agent Y who is out in the field.Agent Z (the Deaf research assistant) has been demoted and is now simply in charge ofworking the VCR pause button. The subject has a set of maps that indicate thelocations of various objects and the current location of Agent Y within each environ-ment. The subject communicates with Agent Y through a type of videophone. Subjectsare told that Agent Y has a small TV monitor which receives video from the cameralocated in front of them. As in Experiment 1, the subject’s addressee (Agent Y) cannotask for clarification— the videophone only broadcasts, it does not receive. Subjects aretherefore asked to be clear and concise.
As in Experiment 1, the head of the Secret Agency described each scenario in ASL.An example map and scenario is given in Figure 7. For scenarios that include only thelocation of Agent Y on the map (i.e. there is no landmark object), English speakerswould have just one natural way to describe the location of the target object. That is,English speakers must adopt the addressee’s perspective, e.g. saying something like“It’s the one in front of you” for the scenario in Figure 7. In contrast, ASL signers haveat least three options for choosing a spatial perspective, as outlined in Figure 7a-c.
Like English speakers, ASL signers could adopt the addressee’s perspective usingeither a lexical expression (near you) or by using referential shift. If the signerindicates that the spatial description is from Agent Y’s (the addressee’s) perspective,then the signer’s body represents Agent Y (via referential shift), and locations insigning space represent the locations of objects as observed by the addressee (Agent Y).For the greenhouse map shown in Figure 7, the signer would indicate that the locationnearest his or her body corresponds to the location of the poisonous plant bed, asillustrated in Figure 7a. Another possibility for ASL signers is to describe the targetlocation based on their view of the map (see Figure 7b). In this case, the signerindicates the location of Agent Y in relation to the location of the target object. Thistype of description uses signing space to represent the speaker’s view of the map, and

Spatial perspective choice in ASL 17
the addressee (Agent Y) must perform a mental transformation of locations observedin the speaker’s signing space to correspond to locations observed in the field (e.g. thetarget object is in front of Agent Y, rather than to the left as observed on the video-screen). A mental transformation is also required when the speaker adopts Agent Y’sperspective via referential shift (Figure 7a). The addressee (Agent Y) is facing thespeaker via the videophone screen. Thus, a location observed as farthest away from theaddressee on the video screen (closest to the speaker) must be understood as closest tothe addressee (Agent Y) in the actual environment.
A third possible way of describing the environment to Agent Y would be to assume
Figure 7.�Illustration of three possible spatial perspectives that a speaker could adopt todescribe the greenhouse scenario depicted at the top of the figure.
shared space. That is, speakers know that Agent Y is facing the videomonitor, and theyimagine that Agent Y is facing them in the room. In this case, speakers must mentallytransform the location of Agent Y on the map so that Agent Y is now facing them, asillustrated in Figure 7c. In this case, the addressee does not need to perform anytransformation of the speaker’s signing space. The locations observed in signing spaceon the videoscreenmap directly to the locations observed in the environment, e.g. thetarget location observed as closest to the addressee (Agent Y) on the video screen isalso closest to the addressee in the actual environment (for the scenario in Figure 7).
In sum, for the situation in which the speaker and addressee are not in the sameenvironment, ASL signers have several options for describing the location of targetobjects. A speaker can express the spatial viewpoint of the addressee by using referen-tial shift, or the speaker can express his or her view of the map, describing the locationof the addressee with respect to the target object. Both of these options require sometype of mental transformation on the part of the addressee who is facing the speaker onthe videoscreen. The final option is to use shared space by imagining the addressee as

18 Karen Emmorey and Barbara Tversky
opposite the speaker (via the videophone). If this option is chosen, the addressee neednot perform any type of mental transformation, but the speaker must mentallytransform the locations observed on the map such that the locations correspond witha shared space situation (see Figure 7c). Experiment 2 examines which spatial perspec-tive is chosen most often by ASL signers.
3.1 Method
3.1.1 SubjectsThe same subjects from Experiment 1 participated in Experiment 2.
3.1.2 Materials and procedureSubjects were told that they were now working with Agent Y, an expert spy who worksout in the field, and that Agent Y has a small TV monitor that receives informationfrom the camera in front of them. As in Experiment 1, subjects were presented with 16maps. Eight maps depicted only Agent Y and the two containers (no landmark), andeight contained a landmark which was skewed toward either the target object or thenon-target object. For half of the maps, Agent Y was at the top of the map “above” theobjects (e.g. Figure 9), and for the other half, Agent Y was either to the left or right ofthe objects (from the speaker’s view of the map). Finally, the container squares wereeither aligned horizontally (as in Figure 7) or vertically (as in Figure 8).
3.2 Results and discussion
3.2.1 Response codingEach ASL description was coded by a native ASL signer as adopting the addressee’spoint of view, the speaker’s point of view (of the map), or using shared space (via thevideo connection). Descriptions were coded as from the addressee’s viewpoint if thetarget location was described lexically from the addressee’s point of view (e.g. nearyou) or if the locations in signing space represented Agent Y’s view of the environ-ment. Descriptions were coded as from the speaker’s viewpoint if the locations insigning space represented the subject’s view of the map. No subject lexically describeda target location from their viewpoint as speaker (e.g. near me) because the subjectwas not in the environment. Examples of spatial descriptions from the addressee’sperspective and from the speaker’s view of the map are given in Figure 8.
Descriptions were coded as using shared space if the subject indicated that he orshe imagined the addressee (Agent Y) as facing them, either by physically rotating themap so that Agent Y was located at the top (effectively facing the subject) or bydescribing the location of the target object as if Agent Y were facing the subject (asillustrated in Figure 7c). In addition, shared space could be indicated by articulating

Spatial perspective choice in ASL 19
The Central Plaza subway station has two entrances. Agent Q has spray painted animportant invisible message on one of the entrances. Agent Y has a special camerathat can photograph the message. The squares indicate the entrances. The arrowpoints to the entrance with the invisible message. The “Y” indicates where Agent Yis standing now. Agent Y is now ready to take the picture. Tell Agent Y where themessage has been written.
“[Now you see two] entrances located here and here. It’s the second entrance. On that side.”
A) Addressee’s viewpoint
YOU
WHERE THIS-ONE
STAND THATENTRANCES-LOCATED-HERE
“You are standing here. The entrances are located here.You know where that one (you want) is? It’s this one.”
ENTRANCE-HERE
ENTRANCE-HERE THAT-SIDE
ENTRANCE-HERE SECOND
B) Speaker’s viewpoint (of the map)
Figure 8.�Illustration of descriptions from (a) the addressee’s point of view and (b) thespeaker’s view of the map (from Experiment 2).
20 Karen Emmorey and Barbara Tversky
signs outward from the speaker, as if creating a signing space between Agent Y and thespeaker. An example is shown in Figure 9.
Descriptions were coded as “landmark only” if the subject produced a perspectiveneutral description of the location of the target object with respect to the landmark(e.g. near water fountain). If the description referenced the landmark, but signingspace clearly reflected the subject’s view of the map, then the description was coded asfrom the speaker’s viewpoint. Similarly, if the description referenced the landmark, butsigning space clearly reflected the addressee’s perspective, then the description wascoded as from the addressee’s viewpoint.
Finally, a few subjects produced a small number of descriptions that expressed atype of “mixed” perspective that we had not anticipated. For these descriptions, thelocations in signing space reflected the speaker’s view of the map, but the identity ofthe target location was specified lexically from the addressee’s point of view. In theexample shown in Figure 10, the subject indicates that the target location is on theaddressee’s left by signing on your left, but the sign left is articulated in signingspace with respect to the subject’s view of the target location on the map.
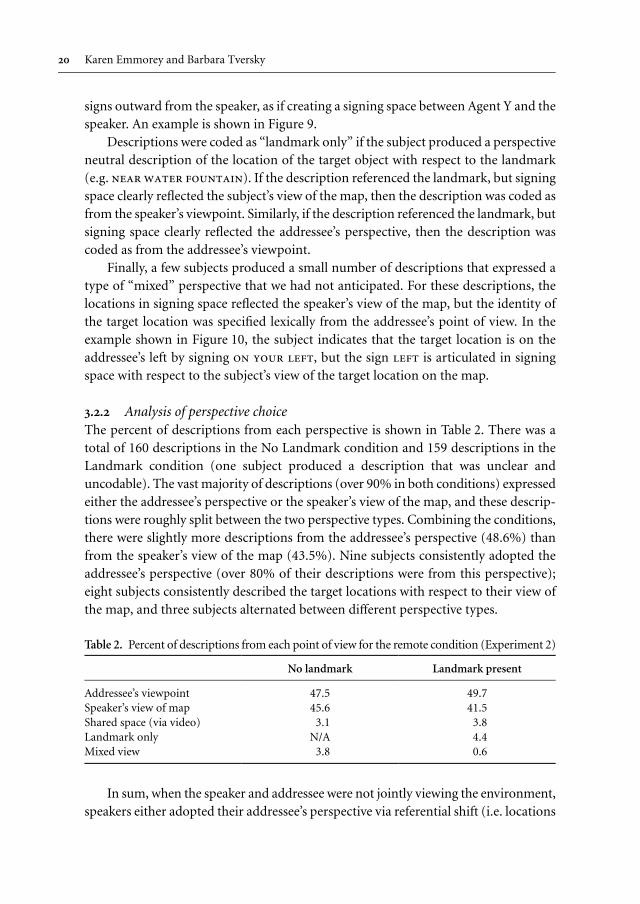
3.2.2 Analysis of perspective choiceThe percent of descriptions from each perspective is shown in Table 2. There was atotal of 160 descriptions in the No Landmark condition and 159 descriptions in theLandmark condition (one subject produced a description that was unclear anduncodable). The vast majority of descriptions (over 90% in both conditions) expressedeither the addressee’s perspective or the speaker’s view of the map, and these descrip-tions were roughly split between the two perspective types. Combining the conditions,there were slightly more descriptions from the addressee’s perspective (48.6%) thanfrom the speaker’s view of the map (43.5%). Nine subjects consistently adopted theaddressee’s perspective (over 80% of their descriptions were from this perspective);eight subjects consistently described the target locations with respect to their view ofthe map, and three subjects alternated between different perspective types.
In sum, when the speaker and addressee were not jointly viewing the environment,
Table 2.�Percent of descriptions from each point of view for the remote condition (Experiment 2)
No landmark Landmark present
Addressee’s viewpointSpeaker’s view of mapShared space (via video)Landmark onlyMixed view
47.545.6�3.1N/A�3.8
49.741.5�3.8�4.4�0.6
speakers either adopted their addressee’s perspective via referential shift (i.e. locations

Spatial perspective choice in ASL 21
in signing space were described as if the speaker were Agent Y) or speakers expressed
HAVE TWO TABLES(not shown)
TABLE-LOCATED-HERE
TABLE-LOCATED-HERE (THAT) -POINT
“There are two tables, located here and here. That’s the one [with the gun underneath it]”
Figure 9.�Example of a description using shared space from Experiment 2. The model hascopied the signing of a participant.
locations from their own perspective by describing locations on the map and Agent Y’sposition in the environment. Two-thirds of the participants consistently adopted asingle perspective for most scenarios (either addressee or speaker perspective), andone-third of the participants varied perspective choice across scenarios. Unlike Englishspeakers, we found no general bias toward adopting the addressee’s perspective.Participants rarely chose to use shared space to describe locations. The use of sharedspace occurred when speakers imagined the addressee as facing them (either in theimagined environment or via the videophone). Perspective neutral descriptionsreferencing the landmark were also relatively rare. In general, when landmarks werementioned, signing space clearly reflected either the speaker’s view of the map or theaddressee’s view of the environment. Finally, for a few location descriptions (4%) theperspective indicated by signing space and the perspective indicated by lexical formswere not the same (Mixed View descriptions; see Figure 10).

22 Karen Emmorey and Barbara Tversky
4. General Discussion
VIDEO-TAPE HIDE(not shown)
ON
LEFT
YOUR
“The videotape is hiddenin the one on your left.”
Figure 10.�Illustration of a mixed perspective (see text). The model has copied the signing of aparticipant.
Signed languages differ from spoken languages because signing space can be used toconvey spatial information, usually via classifier forms and other signs directed towardor articulated at specific locations in space. This spatialization of linguistic form hasclear ramifications for how speakers and addressees negotiate spatial perspective.When a speaker communicates with a live addressee about a jointly viewed (imagined)environment, English speakers most frequently adopt their addressee’s perspective(Mainwaring et al. 1996; and evenmore so when the addressee is not present, Schober1993). In contrast, ASL speakers use shared space to describe jointly-viewed environ-ments and rarely adopt their addressee’s perspective. In Experiment 1, speakers neverused referential shift to indicate that locations in signing space reflected their addres-see’s view of the environment. Speakers occasionally used lexical expressions toindicate either their own perspective (e.g. near me; 6.6% of descriptions) or theiraddressee’s perspective (e.g. on your left; 8.2% of descriptions). Thus, unlike Englishspeakers, ASL signers do not exhibit a strong preference for producing descriptionsfrom their addressee’s perspective. This difference between languages is clearly drivenby differences in language modality.
English encodes spatial relationships via lexical spatial terms and phrases, such as‘on the left’ or ‘in front of ’. ASL encodes spatial relationships via where classifier and

Spatial perspective choice in ASL 23
deictic signs are positioned in signing space. Although lexical encoding via spatialterms and phrases is also possible, it is not the preferred means of expressing spatialinformation.When interlocutors are present in an environment, there is a relationshipbetween signing space and the environment (whether imagined or real). Locations insigning space associated with referent objects must map to the location of objects inthe environment described and to the interlocutors’ views of that environment. Theselocations reflect a shared view of the environment and do not strictly reflect either thespeaker’s or the addressee’s perspective. Lexical encoding (in either ASL or English)tends to force the adoption of a particular viewpoint (e.g. ‘my left’ vs. ‘your right’),unless a neutral perspective is available (e.g. ‘near the fountain’). The use of signingspace neutralizes the need to adopt a particular perspective when describing jointlyviewed (or imagined) environments.
In a separate study, Emmorey (in press b) examined how signing space was usedwhen ASL interlocutors were not discussing a present environment. ASL signers(speakers) memorized the locations of landmarks in a town (from a map) anddescribed these locations to an addressee who was later asked to draw a map of thetown. All but one of the eleven speakers in this study described the environment fromtheir own perspective, i.e. from their view of the map. When addressees asked aquestion or re-described the locations of landmarks (e.g. for clarification), they“reversed” the locations in the speaker’s signing space. For example, speakers describedMaple Street as looping to the left (observed as to the right by the addressee facing thespeaker), and when addressees subsequently described Maple Street, they alsoindicated that Maple Street looped to the left in their signing space. Both speakers andaddressees generally described the map of the town as if they were each looking at themap. Thus, locations observed on the addressee’s right (i.e. locations on the speaker’sleft) were described as on the left by the addressee.
In addition, addressees in the study by Emmorey (in press b) produced re-descrip-tions and questions that utilized a form of shared space. In these instances, the addresseeand speaker did not maintain separate signing spaces. In one type of shared space, anaddressee referred directly to referent locations by directing a pronoun or classifiersign toward the appropriate location in the speaker’s signing space. Such shared spaceis common for non-spatial discourse when an addressee points toward a location inthe speaker’s space in order to refer to the referent associated with that location.In another type of example from Emmorey (in press b), the signing space of thespeaker and addressee physically overlapped. For both of these example types, signingspace is shared because both interlocutors use the same locations in signing space torefer to locations and/or referents associated with those locations.
In sum, the notion of shared space derives primarily from how the addresseeinterprets the speaker’s signing space. The addressee shares the speaker’s signing spaceeither because it maps to the addressee’s view of present objects (as in the present

24 Karen Emmorey and Barbara Tversky
study) or because the addressee uses the same locations within the signer’s space torefer to non-present objects (as in the Emmorey in press b study). Because addresseescan share the speaker’s signing space, speakers rarely produce spatial descriptions thatare from the addressee’s spatial viewpoint, i.e. in which locations in signing spacematch the addressee’s view of an environment, rather than the speaker’s view.
Experiment 2 investigated the unusual situation in which a speaker describedlocations in an environment to an addressee who was in that environment via a typeof videophone. In our scenario, the speakers imagined themselves in a control roomwith maps of various environments, while the addressee was imagined as present inthese environments, communicating with the speaker via amonitor and video camera.This situation highlighted the unusual difference between spoken and signed languag-es. For environments in which speakers know only the location of the target object andthe position of the addressee (Agent Y), English speakers can only naturally describethe location of the target object from the addressee’s perspective. However, as we havediscussed, ASL signers have at least three perspective choices: they can describelocations from the addressee’s viewpoint, from their own view of the map, or they canuse shared space via the videophone. The results indicated that perspective choice wasroughly split between addressee and speaker viewpoints.
Adoption of the speaker’s viewpoint lessens the cognitive communication load forthe speaker who does not need to perform a spatial mental transformation becauselocations on the map are directly mapped to locations in signing space, but thecognitive burden is greater for the addressee whomust perform amental transforma-tion to map locations in the speaker’s signing space to locations in the observedenvironment (see Figure 7). The cognitive load for the speaker is greater when theaddressee’s perspective is adopted, but the addressee must still perform a mentaltransformation (because the addressee is facing the speaker), but this “reversal”transformation occurs frequently during sign conversations and does not appear to bedifficult for addressees (see Emmorey et al. 1998). Given the even split in perspectivechoice, it suggests that ASL speakers know that the reversal transformation required oftheir addressee is not difficult. In contrast, English speakers appear to know thatreversing left and right (e.g. “my right is your left”) is difficult for their addressee, andthey avoid producing descriptions that require this transformation (Tversky 1996).
In conclusion, these studies highlight some of the consequences of using signingspace to represent space for choice of viewpoint in spatial descriptions. The fact thatsigners can view both the environment and the speaker’s signing space allows forspeaker and addressee points of view to be “combined” via shared space. Becausespatial notions are encoded by lexical items and phrases in English, these speakersmust adopt a particular viewpoint (most often the addressee’s viewpoint), and thelocation of the addressee will affect which spatial terms are chosen. Experiment 2revealed that the use of signing space permits additional points of view in situations

Spatial perspective choice in ASL 25
where English allows only one. An unusual aspect of Experiment 2 was that theaddressee was not allowed to respond to the speaker (being imaginary). It is possiblethat choice of perspective might change if the speaker and addressee were communi-cating using a true videophone. In this case, we might find that speakers and address-ees make use of “virtual” shared space (e.g. referring to locations in signing spaceobserved on the videoscreen). Further researchmay reveal other factors that influencethe nature of perspective choice in signed languages and how speakers and addresseesnegotiate the use of signing space with respect to these spatial viewpoints.
Acknowledgments
This research was supported by grants from the National Institutes of Health (NICHD RO1–13249)and the National Science Foundation (SBR-9809002) awarded to Karen Emmorey, and by grantsfrom the Office of Naval Research (N00014-PP-1–0659 and N000140110717) awarded to BarbaraTversky. We thank Scott Mainwaring for the use of his stimulus materials, and Brenda Falgier andMelissa Herzig for help with data coding and with testing Deaf subjects. We also thank Sam Hawk,Helsa Borinstein, and Kelly Gunderson for help with the ASL illustrations.
References
Emmorey, K. (ed). (in press a). Perspectives on classifier constructions in sign languages.Mahwah, NJ:Lawrence Erlbaum Associates.
Emmorey, K. (in press b). “The effects of modality on spatial language: How signers and speakerstalk about space.” In R.P. Meier. D.G. Quinto & K.A. Cormier (eds),Modality and structure insigned and spoken languages. Cambridge: University Press.
Emmorey, K. (2002). Language, cognition, and the brain: Insights from sign language research.Mahwah, NJ: Lawrence Erlbaum Associates.
Emmorey, K. & M. Herzig (in press). “Categorical versus gradient properties of classifier construc-tions in ASL.” In K. Emmorey (ed.), Perspectives on classifier constructions in signed languages.Mahwah, NJ: Lawrence Erlbaum Associates.
Emmorey, K., E.S. Klima & G. Hickok (1998). “Mental rotation within linguistic and nonlinguisticdomains in users of American Sign Language.” Cognition 68: 221–246.
Emmorey, K., B. Tversky & H. Taylor (2000). “Using space to describe space: Perspective in speech,sign, and gesture.” Spatial cognition and computation 2: 157–180.
Engberg-Pedersen, E. (1993). Space in Danish Sign Language: The semantics and morphosyntax of theuse of space in a visual language. International studies on sign language research and communi-cation of the deaf, Vol. 19. Hamburg, Germany: Signum-Verlag.
Mainwaring, S., B. Tversky & D. Schiano (1996). “Perspective choice in spatial descriptions.” IRCTechnical Report 1996–06. Palo Alto, CA: Interval Research Corporation.
Neidle, C., J. Kegl, D. MacLaughlin, B. Bahan & R.G. Lee, (2000). The syntax of American SignLanguage: Functional categories and hierarchical structure. Cambridge, MA: The MIT Press.
Schober, M.F. (1993). “Spatial perspective-taking in conversation.” Cognition 47: 1–24.

26 Karen Emmorey and Barbara Tversky
Supalla, T. (1982). Structure and acquisition of verbs of motion and location in American SignLanguage. Doctoral dissertation, University of California, San Diego.
Taylor, H.A. & B. Tversky (1996). “Perspective in spatial descriptions.” Journal of Memory andLanguage 35(3): 371–391.
Tversky, B. (1996). “Spatial perspective in descriptions.” In P. Bloom, M.A. Peterson, L. Nadel &M.Garrett (eds.), Language and Space, pp. 463–492. Cambridge, MA: The MIT Press.
Corresponding author’s address
Karen EmmoreyLaboratory for Cognitive NeuroscienceThe Salk Institute for Biological Studies10010 North Torrey Pines Rd.La Jolla, CA [email protected]: (858) 452–7052Phone: (858) 453–4100
</TARGET "emm">