predicting mbti personality type of twitter users - rucore
TRANSCRIPT

PREDICTING MBTI PERSONALITY TYPE OF TWITTER USERS
By
WEILING LI
A thesis submitted to the
Graduate School-Camden
Rutgers, The State University of New Jersey
In partial fulfillment of the requirements
For the degree of Master of Arts
Graduate Program in Psychology
Written under the direction of
Dr. Daniel Hart
And approved by
______________________________
Dr. Daniel Hart
______________________________ Dr. Sarah R. Allred
______________________________
Dr. I-Ming Chiu
Camden, New Jersey
May 2021

ii
THESIS ABSTRACT
Predicting MBTI Personality Type of Twitter Users
by WEILING LI
Thesis Director:
Dr. Daniel Hart
As the internet becomes more pervasive, people shift their self-expression and social
interaction activities towards online platforms. It is therefore relevant to relate personality
traits to behavior in social media domains. In this study, I investigated the relationship
between one’s social media profiles and their MBTI personalities. I performed this
research based on 4000 Twitter users who self-report their personalities and 425,752
tweets these users posted. I extracted 26 features that map into five categories of the
user’s social media activities: Social Connections, Social Activities, Content Topic,
Content Sentiment, and Temporal Patterns of Activities. I used two-sample t-tests and
stepwise logistic regressions to examine the association between people’s social media
activities and their personality traits. Then I used machine learning methods to predict
one’s personality based on their social media profiles. Findings indicate that: 1) there are
strong associations between personality and social media activities; 2) MBTI personality
could be predicted by social media data and the best model achieved an average testing
accuracy of 67.6%. I discuss the implications for further research in broader domains.
Keywords: MBTI, Personality, Social Media, Twitter, Prediction, Machine Learning

1
Introduction
Personality, defined as a bundle of traits in people’s behavior, cognition, and
emotion, is an important topic in psychological studies (Mischel, Shoda, & Ayduk,
2007). Personality traits are related to a wide range of topics in psychological studies,
including identity, depression, anxiety, abuse, and poor health (Bagby, Quilty, & Ryder,
2008). For example, studies find strong associations between depression and three
personality traits – neuroticism, extraversion, and conscientiousness (Klein, Kotov, &
Bufferd, 2011), and matching the patient’s personality with different types of treatments
(pharmacotherapy or psychotherapy) will maximize the response (Bagby & Quilty,
2007). In addition, personality has been used to solve many practical problems in various
industry domains such as security, advertising, and human resources (Celli, Massani, &
Lepri, 2017; Turban et al., 2017). For example, substantial evidence reveals that
personality constructs are strong predictors for work performance (Hurtz & Donovan,
2000) and workplace antisocial behavior (Lee, Ashton, & Shin, 2005). Therefore,
according to Psychology Today, more than 80 percent of Fortune 500 companies use
some forms of personality tests for job screening, leadership development, team building,
and sales training (Dattner, 2008).
Traditionally, questionnaires have been used for personality assessment. As the
internet becomes more pervasive, people shift their self-expression and social interaction
activities towards online platforms. As a result, there is a growing trend of studies that
focus on using users’ online profiles and behaviors to predict their personalities
(Bachrach et al., 2012; Gosling et al., 2011; Qiu et al., 2012; Quercia et al., 2012; Wang,
Qu, & Sun, 2013). For example, Bachrach et al. (2012) found that there are significant

2
associations between users’ personalities as measured by questionnaire and
characteristics of their Facebook profiles such as the size and density of friendship
network, the number of uploaded photos, and the number of events attended. Moreover,
they found the accuracy of algorithm prediction is comparable to, or at least not worse
than, assessment using questionnaires. Similarly, a study by Back et al. (2010) found the
profile and behavior in online social media reflect one’s actual personality instead of an
idealized projected image that one prefers. These results constitute the foundation of the
proposed study and make it possible to harness the power of big data and computational
models to make automatic assessment of people’s personalities.
Assessing personality via predictive models has benefits compared to assessing
personality via questionnaires. On the one hand, people’s social media language and
behavior are rich with psychological content. Building an accurate personality prediction
model could facilitate psychological studies by providing alternative personality
measures that could be easily used with large unstructured data sets such as those found
in social media. Moreover, people’s social media activities happen in a natural social
setting and capture real interactions among friends and acquaintances, making
automatically assessed personalities less affected by experimental bias. Lastly, social
media provides longitudinal data, making it much easier for researchers to retroactively
access historical records and measure changes in one’s activities to facilitate prospective
studies that are usually very expensive and hard to conduct. On the other hand, the
automatically accessed personalities could be used in various practical applications such
as disease prevention, online dating, targeted advertising, and personalized
recommendation systems. For example, monitoring and detecting deviance of one’s

3
social media language from his/her personality (such as a surge of expressions that reflect
anxiety, depression, or suicide attempt) could help introduce early interventions that
alleviate the negative impact of such deviance.
In this study, I propose to investigate the relationship between individual’s social
media content and their Myers-Briggs Type Indicator (MBTI). This study seeks to not
only identify the association relationships between people’s personality traits and their
social media profiles but also build an accurate prediction model. In order to do that, I
collected 4000 users’ profiles, activities, friendships, posts, and their associated MBTI
personality types from Twitter between January 2019 to September 2019. Based on
previous research, I mined 26 features that fall into five categories: Social Connections,
Social Activities, Content Topic, Content Sentiment, and Temporal Patterns of Activities.
Two sample t-test and stepwise regression are used to examine the association
relationship, and different machine learning models are tested to build the prediction
model.
The Myers-Briggs Type Indicator (MBTI) Personality Test
The Myers-Briggs Type Indicator (MBTI) (Myers & McCaulley, 1988) is one of
the world’s most popular personality tests. It is based on the conceptual work of Carl
Jung, who proposed that four cognitive functions (sensation vs. intuition, feeling vs.
thinking) as well as two polar orientations (extraversion vs. introversion) are dominant
and reflect people’s preference for attending the world and making decisions (Jung,
1923). Briggs and Myers extend Jung’s work by adding two more indicators (judging vs.
perception) into the framework to form the MBTI that is known to our days (Myers &
McCaulley, 1988). Since its birth, the MBTI has been translated into 29 languages and

4
adopted in 115 countries1. General uses of MBTI are in education facilities and human
resource departments for occupation planning, team building, and leadership
development (Boyle, 1995). There are more than two million assessments are completed
each year (Quenk, 2009).
The MBTI defines four orthogonal dimensions: Extraversion vs. Introversion (E-I
indicator), Sensing vs. Intuition (S-N Indicator), Thinking vs. Feeling (T-F Indicator),
Judging vs. Perception (J-P Indicator). The E-I indicator is designed to reflect whether
one’s general attitude toward the world is oriented outward to other persons/objects (E)
or is internally oriented (I). The S-N indicator focuses on whether a person prefers to rely
on observable facts acquired through five senses (S) or intuition (N). The T-F indicator
contrasts people’s reliance on logical thinking (T) or interpersonal feeling (F). The J-P
indicator distinguishes a preference for planning and organized activities (J for judgment)
versus a preference for flexibility and spontaneous activities (P for perception).
Compared with the Five-Factor personality model or the ”Big Five” (Costa & McCrae,
1985) that retains continuous dimensional scores, The MBTI model categorizes people
into 16 personality types and represents each personality in a four-letter coding (e.g.,
ENFP). Generally, the Big Five model is more widely used and accepted in academic
settings (Funder, 2001), whereas the MBTI model is more popular and widely used in the
industry and in the online environment due to its simplicity.
Multiple empirical findings suggest convergent validity between the Big Five
model and the MBTI model (Furnham, 1996; Furnham, Moutafi, & Crump, 2003;
McCrae & Costa, 1989). For all the Big Five factors, there are corresponding indicators
1 https://www.themyersbriggs.com/en-US/Products-and-Services/Myers-Briggs

5
in the MBTI personality model. For example, a study reported significant strong
correlation between Extraversion and the Extraversion/Introversion (E-I indicator)
(McCrae & Costa, 1989). This means when a person scores high in Extraversion, he or
she is very likely to be an extravert when evaluating using the MBTI personality test.
Similar relationships were also found between the Openness and the Sensing/Intuition (S-
N indicator), Agreeableness and Thinking/Feeling (T-F indicator), Conscientiousness and
Judging /Perception (J-P indicator), and between Neuroticism and
Extraversion/Introversion (E-I indicator) (Furnham, 1996; McCrae & Costa, 1989).
Predicting Personality Using Social Media Profiles
Previous studies have paid much attention to the relationship between people’s
personality traits and their profiles and behaviors in social media. Because the Big Five
model is one of the most widespread models of personality and widely accepted in
academia, most studies in this area used it for prediction. For example, the earliest
research could be traced back to 2006, in which researchers successfully predicted blog
users’ personalities using different sets of words used in the blog content (Oberlander &
Nowson, 2006). However, this and most other pioneering works are limited by small
sample size (usually less than hundreds) and homogeneous samples (usually college
students). More recently, scholars have focused on improving the accuracy of predictions
with the help of various machine learning algorithms (Lima & de Castro, 2013; Liu &
Zhu, 2016; Ortigosa, Carro, & Quiroga, 2014). In the meantime, the sample sizes have
become relatively larger (usually hundreds) and the data sources have become more
diverse from English-based social media such as Facebook and Twitter, to social media
in other cultures and languages (Liu & Zhu, 2016).

6
Previous studies have identified significant correlations between different
personality traits and three aspects of people’s social media usage: people’s social
connections, social activities, and their use of words. Social connections are features
related to people’s online friendship networks, such as number of followers, number of
followings, the density of their friendship networks, etc. Social activities are features
related to the level of people’s social media usage, such as the number of activities
attended, the total number of posts, etc. The use of words relates to the frequency of
specific linguistic words people use in their posts, such as the number of times people use
“work”, “family”, “food”, etc. Content sentiment are features related to the frequency of
sentiment words used in their posts, such as the number of times people use “happy”,
“sad”, “sorry”, etc. I only summarize the use of these features in previous studies and
their findings. More details about the use of these features in the focal study can be found
in the Method section.
People’s social connections and social activities were the most widely used
predictive features and were shown to be connected with many personality traits. For
example, studies found there were significant correlations between the Big Five
personality and features of user’s Facebook profile and activities including: (1) Openness
is positively related to the number of Facebook users’ likes, group associations and status
updates; (2) Conscientiousness is negatively correlated with the number of likes and
group membership, but positively correlated with the number of uploaded photos; (3)
Extraversion is positively related to the number of friends; (4) Agreeableness is
negatively connected with the number of likes; (5) Neuroticism is positively associated
with the number of likes and number of groups attended (Bachrach et al., 2012).

7
At the same time, different words used in the content of people’s social media posts were
also examined and found to be correlated with personality traits including Extraversion,
Agreeableness, and Openness in the Five-Factor Model. In a study that investigated the
relationship between the Big Five personality traits and linguistic features in the content
of the owner’s tweets (Qiu et al., 2012), scholars found that: (1) Extraversion is positively
related to the number of times people use assent words (such as ”agree”, ”ok”, ”yes”), but
negatively associated with the number of functional words (such as ”work”, ”job”, ”eat”)
and impersonal pronouns (such as ”it”, ”she”, ”he”); (2) Agreeableness is negatively
connected with negation, exclusive and sexual words (such as ”no”, ”but”, ”love”); (3)
Openness is negatively correlated with adverbs, swear words, affect words and non-fluent
words (such as ”very”, ”damn”, ”fuck”), but positively correlated with prepositions (such
as ”to”, ”above”, ”with”).
Substantial connections between the Five-Factor Model and the MBTI model
enable us to directly apply findings in previous literature that connect social media and
the Big Five model to the proposed study. At the same time, I try to overcome some
drawbacks of previous studies by adding temporal patterns of people’s posting behavior
and extracting some high-level features from the content of posts using Machine
Learning Algorithms. Specifically, I propose to extract Content Sentiment and Content
Topics using Sentiment Analysis (Loria et al., 2014) and Topic Modeling (Blei, Ng, &
Jordan, 2003). I propose to do that because the meaning of words depends on the context
and the same word could have multiple meanings or even the opposite meaning (e.g.,
when you’re trying to be sarcastic). By preprocessing the posts using advancements in

8
machine learning, we could better interpret the meaning of people’s posts and the feeling
they try to convey.
Research Questions and Hypotheses
In this study, I seek to answer the following research questions:
What aspects of individuals’ social media profile and activities are related to MBTI
indicators?
Based on the previous literature, I extracted five aspects of features that
summarize one’s social media profile and activities: Social Connections, Social
Activities, Content Topic, Content Sentiment, and Temporal Pattern of Activities. Among
these five aspects, Social Connections information is widely used in previous studies and
found to be positively related to Extraversion (E-I indicator) and Agreeableness (T-F
indicator). Social Activities information are positively related to Conscientiousness (J-P
indicator). Therefore, for these features, I find the counterpart indicator in the MBTI
personality system and hypothesize:
● the number of one’s social connections will be positively related to Extraversion
(E in the E-I indicator);
● the number of one’s social connections will be positively related to related to
Feeling (F in the T-F indicator);
● the number of one’s social activities will be positively related to Perception (P in
the J-P indicator);
Following the same logic, I draw the following hypotheses for features in Content
Topic and Content Sentiment.
● the content topics will be related to the Extraversion/Introversion (E-I indicator);

9
● the content topics will be related to the Sensing/Intuition (S-N indicator);
● a high sentiment score of user’s tweets will be positively related to the
Extraversion (E in the E-I indicator);
● a high sentiment score of user’s tweets will be positively related to Intuition (N in
the S-N indicator);
● a high sentiment score of user’s tweets will be positively related to Feeling (F in
the T-F indicator);
Distinct from previous studies, I also propose to extract the temporal pattern of
users’ activities. The temporal pattern of user’s activities may be an important predictor
for Conscientiousness (or the Judging/Perceiving (J-P indicator)). Because conscientious
people tend to be efficient and organized as opposed to easy-going and disorderly, their
posting behavior tends to be more regularized than the posting behavior of people who
are low in conscientious. For example, I expect a disorganized person to post more
frequently in the middle of night, but hardly have the same expectation for a disciplined
person. For the same reason, I predict fewer posting behaviors for conscientious people in
workdays and in early mornings. Therefore, I hypothesize:
● the temporal pattern will be related to the Judging/Perceiving (J-P indicator).
Figure 1 shows the summary of the mapping relationships among independent
variables, personality traits in the Five-Factor model and indicators in the MBTI model.

10
Figure 1.
Hypotheses and mapping relationships among independent variables, personality traits
in the Five-Factor model and indicators in the MBTI model.
Method
Data Description
Established in July 2006, Twitter is one of the most successful and popular social
network sites in the world. As of 2018, the website had more than 321 million active
users (Molina, 2017). To examine my hypotheses, I performed an archival research based
on a sample of Twitter users who self-reported their MBTI personality types. This study
is possible because an online personality test called “16Personalities” became popular on
Twitter. After taking this personality test, users posted their test results on Twitter to
share with their friends. A typical Tweet, in which the user self-reports his/her MBTI
personality type, contains information such as the user’s username, time of the post,
his/her personality, a link to an introduction page of his/her personality type, and a
hashtag of the testing tool “#16Personalities”. Figure 2 shows an example of a Twitter
user’s post revealing his/her personality type.

11
Figure 2.
An example Tweet contains the user’s self-report MBTI personality
I mainly considered two criteria when conducting the data collection process.
First, since previous studies have the drawbacks of small samples (sample size of 100 to
200) and homogenous samples (data usually collected from college students), I wanted a
sample of several thousand (I set the total sample size to be 4000) to generate more
robust findings. Second, as the hot topics and the users’ language habits are constantly in
flux in social media, I wanted users in my sample actively posting in a relatively small
period of time so there are relatively fewer changes in their language habits (I set the time
limit to one year). In considering the two criteria listed above, I first collected all the
tweets written in English and contain the hashtag “#16Personalities” between January 1st,
2019, to September 31st, 2019, using the Twitter public API2. The detailed data
collection procedures were as follows. I wrote a python program to send queries to the
Twitter API and the API returned data that satisfied my queries (tweets written in English
and contain the hashtag “#16Personalities”). The program queried on a daily basis started
on September 31st, 2019. After successfully gathering one day’s data, the program
counted the total number of users in my sample and if the number was less than 4000, it
continued to send queries to retrieve data in the previous day. The program stopped when
the sample size reached 4000.
2 Application Program Interface (API) is a set of routines, protocols, and tools for data transfer between machines based on queries.
12
After successfully collecting 4000 users in the observing period, I extracted the
username in each Tweet and removed duplicated usernames. For each user, I further
collected their user descriptions, number of followers, number of followings, number of
favorites sent, and all the tweets the user ever posted. Each Tweet will also contain
information including time, content, the number of retweets, and the number of favorites
it received. After all these procedures, I collected 3,995 Twitter users with their self-
report MBTI personality types, and 425,752 tweets these users posted.
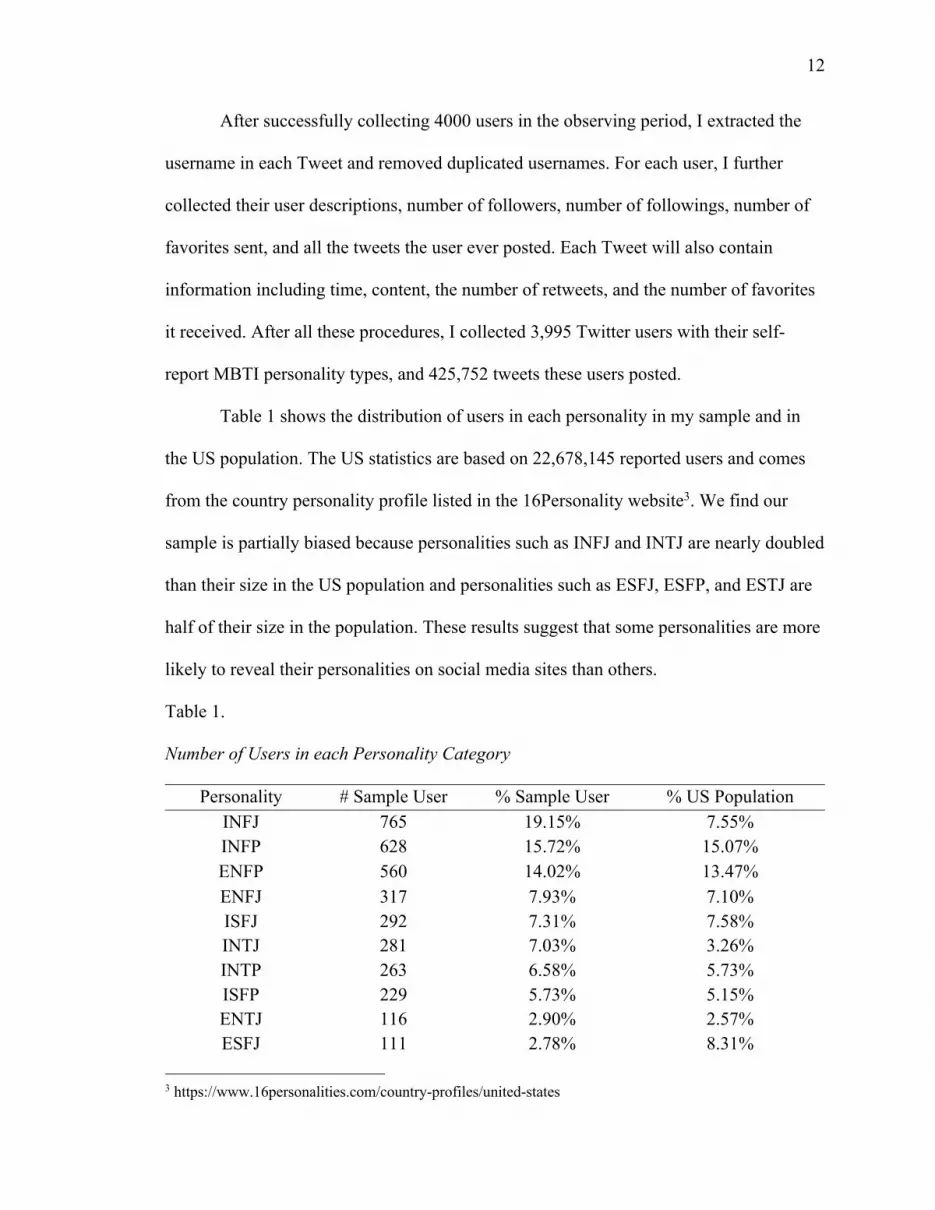
Table 1 shows the distribution of users in each personality in my sample and in
the US population. The US statistics are based on 22,678,145 reported users and comes
from the country personality profile listed in the 16Personality website3. We find our
sample is partially biased because personalities such as INFJ and INTJ are nearly doubled
than their size in the US population and personalities such as ESFJ, ESFP, and ESTJ are
half of their size in the population. These results suggest that some personalities are more
likely to reveal their personalities on social media sites than others.
Table 1.
Number of Users in each Personality Category
Personality # Sample User % Sample User % US Population INFJ 765 19.15% 7.55% INFP 628 15.72% 15.07% ENFP 560 14.02% 13.47% ENFJ 317 7.93% 7.10% ISFJ 292 7.31% 7.58% INTJ 281 7.03% 3.26% INTP 263 6.58% 5.73% ISFP 229 5.73% 5.15% ENTJ 116 2.90% 2.57% ESFJ 111 2.78% 8.31%
3 https://www.16personalities.com/country-profiles/united-states

13
ESFP 100 2.50% 4.79% ENTP 99 2.48% 4.69% ISTJ 81 2.03% 3.56% ISTP 62 1.55% 2.25% ESTJ 61 1.53% 3.80% ESTP 30 0.75% 2.32%
The focal study does not require an IRB approval because I used an existing
dataset (archival data) and the users in my sample do not satisfy the definition of Human
Subject. Based on the IRB requirements, a Human Subject is a living individual about
whom an investigator conducting research obtains (1) data through intervention or
interaction with the individual or (2) identifiable private information4. This study does not
need an IRB approval because (1) it does not involve intervention or interaction with
individual users in my sample; (2) the data I will use have been made public and will not
link to one’s identity.
Measurements: Independent Variables
I extracted a comprehensive set of features that fall into five categories, which
reflect one’s social media profiles and activities: Social Connections, Social Activities,
Content Topic, Content Sentiment, Temporal Pattern of Activities.
Number of Social Connections. The number of social connections is widely used
in previous studies and found to be positively related to Extraversion/Introversion (E-I
indicator) and Thinking/Feeling (T-F indicator). Such information on Twitter is
represented in the number of followings or followers the user has. It could also be
embedded in the number of favorites the user sends and receives since the more people
4 https://www.bu.edu/researchsupport/compliance/human-subjects/determining-if-irb-approval-is-needed/

14
the user connected with, the more favorites he or she is likely to send and receive. For the
same reason, it could also be represented in the number of @5 used in the content of their
tweets. I, therefore, extracted the number of friends, the number of followers, the number
of favorites sent, the number of @ used and the number of favorites received to represent
the number of user’s online social connections. Meanwhile, I used log transformation to
account for highly skewed distributions of variables including number of friends, the
number of followers, the number of favorites sent.
Number of Social Activities. Variables related to the number of social activities
are also widely used and were predicted to be positively related to the Judging/Perceiving
(J-P indicator). Such information on Twitter is represented in many aspects of the user’s
posting behaviors. For example, the number of hashtags or links used might represent the
number of activities the user had attended. Also, the number of tweets and the number of
words used in each Tweet were thought to represent the user’s level of engagement -- the
more tweets or more words the user used, the more engaged he or she was in social
media. Therefore, I extract the number of hashtags, the number of links, the number of
tweets, and the average number of words used to represent the number of user’s online
social activities.
Content Topics. The Sensing/Intuition (S-N indicator) in MBTI is thought to
reveal how people gather and interpret information and was predicted to be correlated to
Openness in the Five-Factor Model. Based on previous studies, people with different
openness scores will be interested in different topics and, therefore, talk about different
5 @ in Twitter context represents the user notify other users (been at-ed) to look at the post he or she just sent.

15
topics in their tweets. For example, the number of times people mention “work” is a
significant predictor for Openness (Lima & de Castro, 2013). Similarly, sensation-
oriented people and intuition-oriented people may be interested in different topics. For
example, a sensation-oriented person may be more comfortable at handling concrete
things, such as sports and music. In contrast, an intuition-oriented person is more
interested in symbolic meaning and looking forward to the future. Hence, they may post
more tweets related to politics, art, or culture. To extract the content topics of each
Tweet, I used the Latent Dirichlet Allocation (LDA) (Blei et al., 2003) method of Topic
Modeling. LDA is a generative probabilistic model to extract latent topics from
unstructured text. It is based on the promise that a sentence could be represented as a
probabilistic distribution over a set of topics, and each topic is also a probabilistic
distribution over a set of words. The model proceeds as follows. First, each Tweet is
inspected and group keywords that frequently appeared together to form a set of topics
are identified. For example, the topic “universe” could be represented as a combination of
frequent important keywords such as “space”, “sphere”, “earth”, “launch”, “moon”, etc.
Then for each Tweet, the model calculates the probability that the sentence belongs to
each topic based on what words it mentions and use the topic with the highest probability
as the topic of the sentence.
I used the LDA model in the Gensim package (Radim Rehurek, 2010) in Python
and asked the program to extract ten topics given the 425,752 tweets I collected. Gensim
is a widely used Natural Language Processing package in Python for syntax analysis,
sentiment analysis, and topic modeling. When conducting the topic analysis, I found that
some tweets are written in languages other than English, making these tweets more easily
16
clustered together. This is understandable because multilingual Tweeter users are likely
to use multiple languages when posting tweets. To solve this problem, I used the Fasttext
package (Joulin et al., 2016), an automatic language detection tool, to identify and rule
out tweets written in other languages. After this procedure, there are 317,170 tweets left
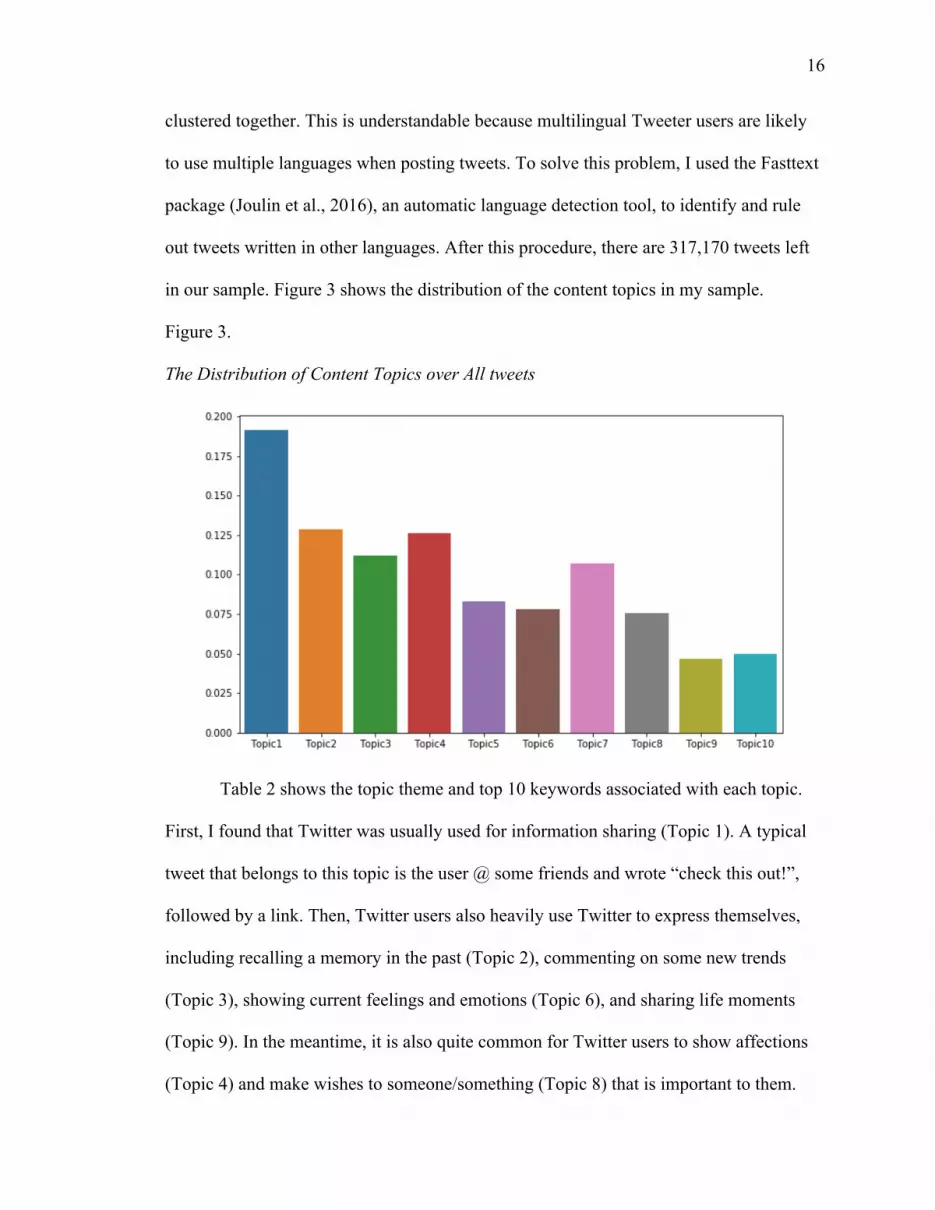
in our sample. Figure 3 shows the distribution of the content topics in my sample.
Figure 3.
The Distribution of Content Topics over All tweets
Table 2 shows the topic theme and top 10 keywords associated with each topic.
First, I found that Twitter was usually used for information sharing (Topic 1). A typical
tweet that belongs to this topic is the user @ some friends and wrote “check this out!”,
followed by a link. Then, Twitter users also heavily use Twitter to express themselves,
including recalling a memory in the past (Topic 2), commenting on some new trends
(Topic 3), showing current feelings and emotions (Topic 6), and sharing life moments
(Topic 9). In the meantime, it is also quite common for Twitter users to show affections
(Topic 4) and make wishes to someone/something (Topic 8) that is important to them.
17
Last, there are also a significant number of tweets that people describe their work and
study (Topic 5), tool sharing and lotteries (Topic 7), and write about time and numbers
(Topic 10).
Table 2.
Topic Themes and Associated Keywords
Topic 1 Topic 2 Topic 3 Topic 4 Topic 5 Share Information Memory Make Comments Love Work & Study
links people person check live
follow 16person automat world share
links time life
back friend read fuck show every call
make feel
thing really don tri
pleas give
always someone
love links good watch miss song girl little made omg
links great learn
change free story
support job
write sign
Topic 6 Topic 7 Topic 8 Topic 9 Topic 10 Feeling RightNow Lottery Wishes Share Life Time & Number
links beautiful
night lot
man wow big
school run
sleep
At person win
agree chance enter
giveaway latest
exactly seventeen
tag
At person links happy
lol hope
birthday ye
haha hahaha enjoy
links today work play game start post wait
photo long
links day year
2 week video
3 1 5 4
After the model extracted the topic of each Tweet, I defined a set of variables, the
frequencies of topics, to represent the distribution of topics interests of the user. The
frequency of topic N is calculated by the number of tweets belonging to that topic divided
by the total number of tweets the user posted. For example, Share Information: 0.2 means
20 percent of the user’s tweets are related to information sharing. After processing all ten
topics, I get a vector of frequencies over all the topics to indicate the user’s areas of
interest.

18
Content Sentiment. The content sentiment is likely to relate to the
Thinking/Feeling (F-T indicator) as feeling-oriented people tend to use more words with
strong emotion (Qiu et al., 2012). I used the pre-trained sentiment analysis model in the
TextBlob package in Python to extract two sentiment related variables: content sentiment
and content subjectivity. The content sentiment score is number ranging from -1 to 1,
with -1 represent extremely negative and 1 represent extremely positive. The content
subjectivity score represents how likely the sentence is subjective other than objective
(need an example here). TextBlob (Loria et al., 2014) is a widely used text processing
package and has been used in previous studies to assess content sentiment in the Twitter
context (Hasan et al., 2018). The pre-trained model is a Naive Bayesian model that
contains sentiment score and subjectivity score for common words in English. Following
the Bayes rule, the model calculates sentiment or subjectivity score of a Tweet by
multiplying the pre-trained sentiment/subjectivity score of each word it contains. More
intuitively, “this is a great movie!” will have a higher sentiment score than “this is a good
movie!”, and “this is a very great movie!” will have a higher subjectivity score than “this
is a great movie!” I use the average sentiment score and the average subjectivity score to
represent the user’s content sentiment. Meanwhile, I also extract the variance of
sentiment score and the variance of subjectivity score to represent the variation of the
user’s content sentiment.
Temporal Pattern of Activities. The temporal pattern of the user’s posting
activities is also be relevant as it may be a strong predictor for the J-P indicator. I,
therefore, defined the frequency of late-night posts (12 am to 4 am), the frequency of
early morning posts (5 am to 8 am), the frequency of workday posts (Monday to Friday)

19
to represent the temporal pattern of the user’s activities. For example, the frequency of
late-night posts will be the number of posts that the user sent from 12 am to 4 am divided
by the total number of posts. With this encoding, I may misclassify some people who
don’t work in a Monday to Friday, 9am to 5pm job, but with the exceptionally large
sample size, I believe the effects of those people will be decreased.
Measurements: Dependent Variable
I extracted each user’s MBTI personality type by matching whether personalities
show up in the text or links of one’s tweets. In order to let the model recognize these
personalities, I further defined a set of binary variables (extraversion, intuition, feeling,
and judgment) that encode different indicators. For example, if the user is an ENFP,
his/her corresponding dependent variables will be {Extraversion:1, Intuition:1, Feeling:1,
and Judgment:0}.
The total variables used and their definitions are summarized in Table 3.
Table 3.
Variable Definitions
Variables Definition Dependent Variables Extraversion Binary, whether the user is an extravert Intuition Binary, whether the user is an intuition-oriented person Feeling Binary, whether the user is a feeling-oriented person Judgment Binary, whether the user is a judgment-oriented person Social Connections Number of Followings The log transformation of the number of followings the user has Number of Followers The log transformation of the number of followers the user has Number of @ Used The log transformation of the number of @ the user used Number of Favorites Received
The log transformation of the number of favorites the user received from others
Number of Favorites Sent The number of favorites the user sent to others Social Activities Number of Hashtags The number of hashtags the user used Number of Links The number of links the user used Number of tweets The total number of tweets the user sent Ave Num of Words Used The average number of words used in all posts Content Topics Frequency of Topic N The number of posts belongs to topic N divided by the total number of posts
20
Content Sentiment Sentiment Mean The average sentiment score of the user's tweets Subjectivity Mean The average subjectivity score of user's tweets Sentiment Variance The variance of sentiment score of the user’s tweets Subjectivity Variance The variance of subjectivity score of the user’s tweets Temporal Pattern of Activities Freq of Late Night Posts The number of late-night posts (12 am to 5 am) divided by the total number of
posts Freq of Early Morning Posts
The number of early morning posts (5 am to 8 am) divided by the total number of posts
Freq of Workday Posts The number of workday posts (Mon - Fri) divided by the total number of posts
Descriptive Statistics
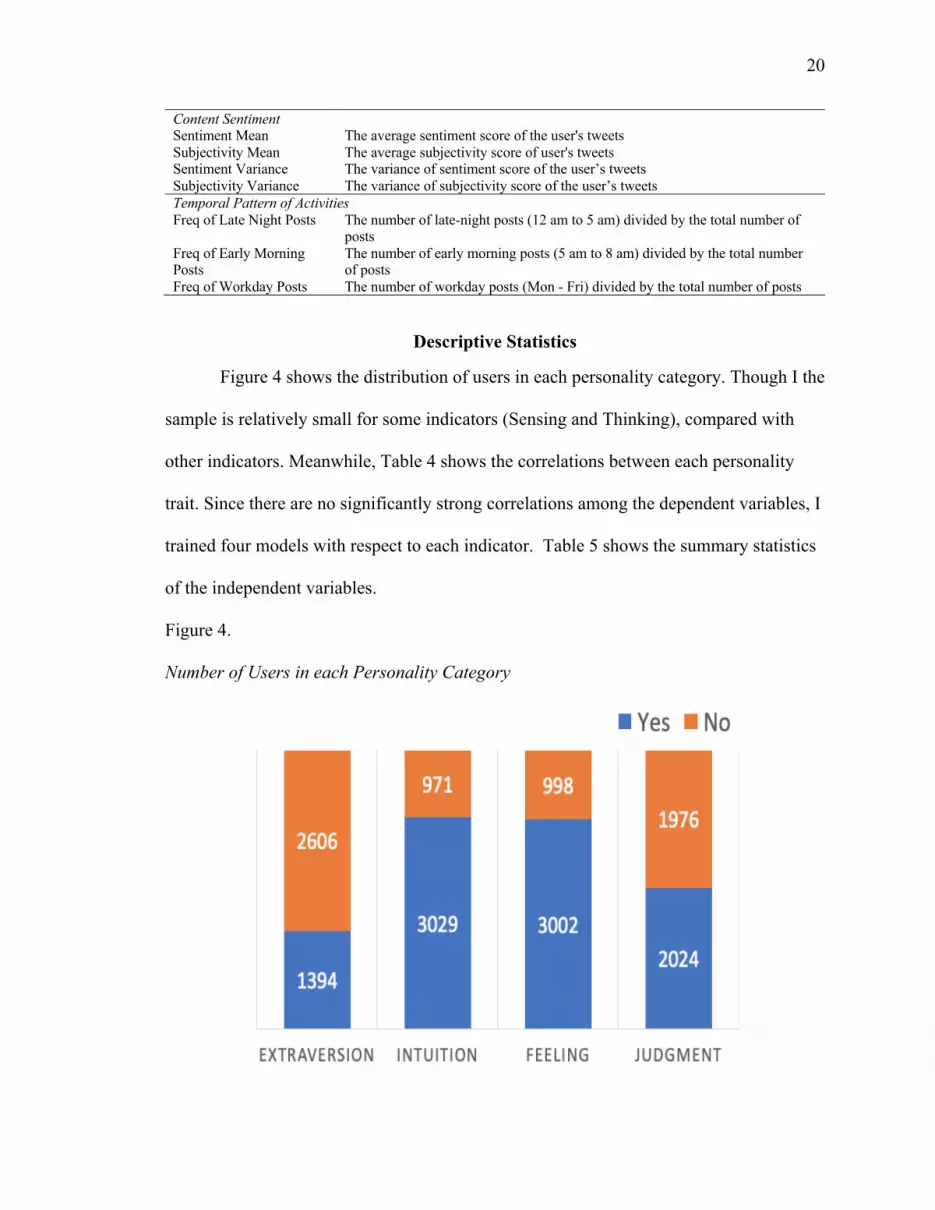
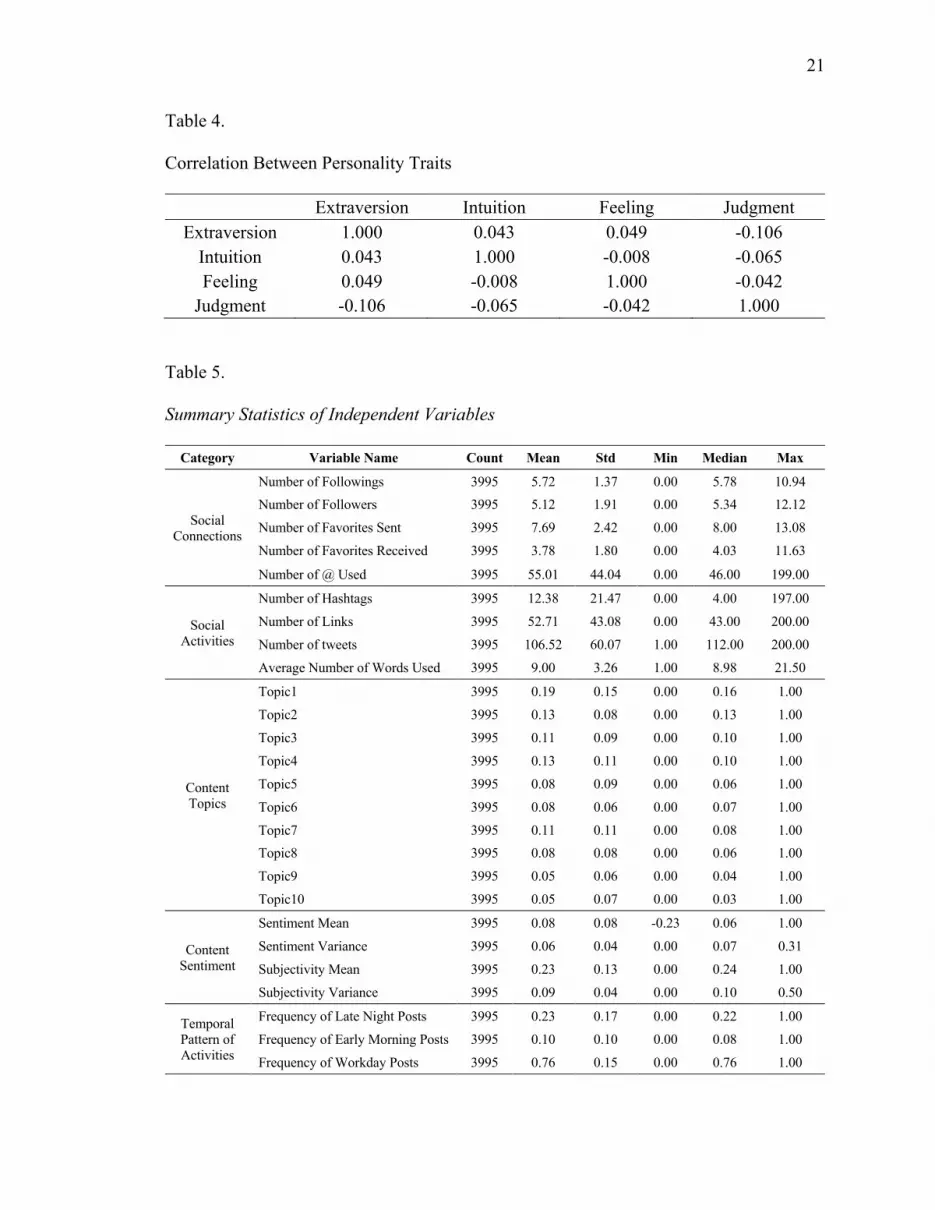
Figure 4 shows the distribution of users in each personality category. Though I the
sample is relatively small for some indicators (Sensing and Thinking), compared with
other indicators. Meanwhile, Table 4 shows the correlations between each personality
trait. Since there are no significantly strong correlations among the dependent variables, I
trained four models with respect to each indicator. Table 5 shows the summary statistics
of the independent variables.
Figure 4.
Number of Users in each Personality Category
21
Table 4.
Correlation Between Personality Traits
Extraversion Intuition Feeling Judgment Extraversion 1.000 0.043 0.049 -0.106
Intuition 0.043 1.000 -0.008 -0.065 Feeling 0.049 -0.008 1.000 -0.042
Judgment -0.106 -0.065 -0.042 1.000
Table 5.
Summary Statistics of Independent Variables
Category Variable Name Count Mean Std Min Median Max
Social Connections
Number of Followings 3995 5.72 1.37 0.00 5.78 10.94 Number of Followers 3995 5.12 1.91 0.00 5.34 12.12
Number of Favorites Sent 3995 7.69 2.42 0.00 8.00 13.08
Number of Favorites Received 3995 3.78 1.80 0.00 4.03 11.63
Number of @ Used 3995 55.01 44.04 0.00 46.00 199.00
Social Activities
Number of Hashtags 3995 12.38 21.47 0.00 4.00 197.00
Number of Links 3995 52.71 43.08 0.00 43.00 200.00
Number of tweets 3995 106.52 60.07 1.00 112.00 200.00
Average Number of Words Used 3995 9.00 3.26 1.00 8.98 21.50
Content Topics
Topic1 3995 0.19 0.15 0.00 0.16 1.00
Topic2 3995 0.13 0.08 0.00 0.13 1.00
Topic3 3995 0.11 0.09 0.00 0.10 1.00
Topic4 3995 0.13 0.11 0.00 0.10 1.00
Topic5 3995 0.08 0.09 0.00 0.06 1.00
Topic6 3995 0.08 0.06 0.00 0.07 1.00
Topic7 3995 0.11 0.11 0.00 0.08 1.00 Topic8 3995 0.08 0.08 0.00 0.06 1.00
Topic9 3995 0.05 0.06 0.00 0.04 1.00
Topic10 3995 0.05 0.07 0.00 0.03 1.00
Content Sentiment
Sentiment Mean 3995 0.08 0.08 -0.23 0.06 1.00
Sentiment Variance 3995 0.06 0.04 0.00 0.07 0.31
Subjectivity Mean 3995 0.23 0.13 0.00 0.24 1.00
Subjectivity Variance 3995 0.09 0.04 0.00 0.10 0.50
Temporal Pattern of Activities
Frequency of Late Night Posts 3995 0.23 0.17 0.00 0.22 1.00
Frequency of Early Morning Posts 3995 0.10 0.10 0.00 0.08 1.00
Frequency of Workday Posts 3995 0.76 0.15 0.00 0.76 1.00

22
Results
I began with a set of two-sample t-tests to compare people with and without
certain personality traits. Table 6 shows the test results and values whose significance
level exceed 0.05 are marked in bold. For example, I found that the mean value of the log
transformation of the following for an extrovert person was 5.809, which was
significantly larger than an introverted person. Similarly, I found that extroverted person
had more followers on social media, while introverted people sent more favorites to
others than extroverts. About people’s topic interests, I found that extroverts posted more
content about work and study, whereas introverts liked to make comments on things and
send others their wishes. In general, the results confirmed all the hypotheses except the
hypothesis that a high sentiment score of user’s tweets would be positively related to
Extraversion. Moreover, the results are in support of other association relationships that
are not identified in previous literature. For example, I found that the content topics also
related to other personality traits including Feeling/Thinking and Judging/Perceiving and
different content topics were associated with different personality traits.

23
Table 6.
Two-sample t-test results, values with significance (p-value<5%) are marked in bold
Extraversion Intuition Feeling Judgment
Yes No Tstast Yes No Tstast Yes No Tstast Yes No Tstast
Num of Followings 5.81 5.67 3.18 5.76 5.59 3.44 5.73 5.67 1.20 5.71 5.72 -0.23
Num of Followers 5.31 5.02 4.62 5.16 4.98 2.69 5.13 5.08 0.66 5.21 5.02 3.09
Num of Favorites Sent 7.53 7.78 -3.16 7.76 7.49 3.04 7.77 7.45 3.61 7.61 7.79 -2.38
Num of Favorites Received 3.81 3.77 0.62 3.85 3.55 4.55 3.78 3.80 -0.30 3.79 3.77 0.28
Num of @Used 56.19 54.38 1.25 55.66 52.98 1.63 53.94 58.25 -2.58 54.69 55.34 -0.47
Num of Hashtags 13.01 12.04 1.34 12.60 11.67 1.13 12.64 11.58 1.38 13.62 11.11 3.70
Num of Links 55.77 51.07 3.19 54.34 47.58 4.32 53.08 51.57 0.98 54.82 50.53 3.15
Num of tweets 109.00 105.19 1.92 107.81 102.49 2.37 105.78 108.78 -1.37 108.05 104.96 1.63
MeanNumWordsUsed 9.02 8.99 0.27 9.20 8.38 6.84 9.02 8.95 0.59 9.16 8.84 3.05
Topic1 ShareInfor 0.19 0.19 0.83 0.19 0.20 -2.68 0.19 0.19 0.34 0.20 0.19 1.75
Topic2 Memory 0.13 0.13 0.42 0.13 0.13 1.53 0.13 0.13 1.21 0.13 0.13 -2.27
Topic3 MakeComment 0.11 0.12 -2.77 0.12 0.10 3.68 0.11 0.11 1.12 0.11 0.12 -3.90
Topic4 Love 0.13 0.13 -0.30 0.12 0.14 -3.16 0.13 0.12 1.71 0.13 0.13 -0.70
Topic5 Work/Study 0.09 0.08 2.40 0.09 0.08 2.86 0.08 0.09 -3.34 0.09 0.07 6.02
Topic6 FeelingNow 0.08 0.08 1.53 0.08 0.08 1.29 0.08 0.08 0.04 0.08 0.08 -1.05
Topic7 Lottery 0.11 0.11 1.60 0.11 0.11 -0.98 0.10 0.12 -2.81 0.10 0.11 -1.74
Topic8 Wishes 0.07 0.08 -2.47 0.08 0.08 0.20 0.08 0.07 2.36 0.07 0.08 -1.71
Topic9 ShareLife 0.05 0.05 -0.91 0.05 0.04 1.47 0.05 0.05 0.96 0.05 0.05 1.52
Topic10 Time/Number 0.05 0.05 -1.88 0.05 0.05 1.10 0.05 0.05 1.40 0.05 0.05 0.40
Sentiment Mean 0.08 0.08 -0.54 0.08 0.07 2.66 0.08 0.07 4.91 0.08 0.07 1.98
Sentiment Variance 0.06 0.06 -0.55 0.07 0.06 3.63 0.07 0.06 3.79 0.06 0.06 -1.09
Subjectivity Mean 0.22 0.23 -1.95 0.23 0.20 5.58 0.23 0.21 3.83 0.22 0.23 -1.10
Subjectivity Variance 0.09 0.09 0.34 0.09 0.09 5.03 0.09 0.09 3.19 0.09 0.09 -1.83
Freq LateNightPosts 0.23 0.24 -0.96 0.23 0.23 0.95 0.23 0.23 1.00 0.23 0.24 -2.12
Freq EarlyMorningPosts 0.10 0.10 0.42 0.10 0.11 -2.10 0.10 0.10 -0.21 0.10 0.10 -0.94
Freq WorkdayPosts 0.77 0.75 2.33 0.76 0.76 0.24 0.76 0.76 0.23 0.75 0.76 -1.96
After comparing differences between groups, I performed four sets of Stepwise
Logistic Regressions in order to explore associated relationships between people’s social
media usage and their personality traits. Table 7 shows the results of the Stepwise
Logistic Regression.
Table 7.
Step-wise Logistic Regression Results (p<0.1 *, p<0.05 **, p<0.01 ***)
Extraversion Intuition Feeling Judgment Num of Followings -0.235 *** Num of Followers 0.296 *** 0.322 *** Num of Favorites Sent -0.283 *** 0.114 *** 0.153 *** Num of Favorites Received -0.061 * Num of @Used -0.186 *** Num of Hashtags 0.051 *

24
Num of Links 0.055 * 0.071 ** 0.115 *** Num of tweets Mean Num Words 0.209 *** 0.132 *** Topic1 Share Information 0.110 *** 0.070 * Topic2 Memory 0.092 *** Topic3 Make Comment -0.077 *** Topic4 Love -0.102 *** 0.100 *** Topic5 Work/Study 0.081 *** -0.125 *** 0.167 *** Topic6 Feeling RightNow 0.081 *** Topic7 Lottery 0.138 *** Topic8 Wishes 0.096 *** Topic9 Share Life Topic10 Time/Number Sentiment Mean 0.242 *** 0.122 *** Sentiment Variance -0.146 *** Subjectivity Mean -0.225 *** -0.184 *** Subjectivity Variance 0.218 *** 0.206 *** Freq Late Night Posts Freq Early Morning Posts Freq Workday Posts 0.079 *** -0.086 ***
Intercept -0.644 *** 1.170 *** 1.137 *** 0.02936
Num of Observation 3995 3995 3995 3995
DF 3983 3988 3986 3984
AIC 5079.7 4354.3 4414.6 5450.7
Interpreting the above results, I find that most features from all five aspects are
significant predictors of different personality traits. In general, extroverts, comparing to
their introvert counterpart, are more likely to be someone who has more followers, less
likely to send favorites to others, more likely to use links, and more likely to post on
workdays. They tend to use social media to share information, recall past experiences,
share current feelings, talk about work, and post lotteries. Meanwhile, they also tend to
talk more objectively, but the objectivity has a larger variance. Compared with their
sensation-oriented counterparts, intuition-oriented people are more likely to send more

25
favorites, use more links, and write more words in their posts. They are less likely to
show affections on Twitter and have a larger variance on the sentiment value and
subjectivity value of their posts. Feeling-oriented people, comparing with their Thinking-
oriented counterparts, are more likely to send favorites to others, less likely to @
someone, and more likely to use links. Meanwhile, they tend to use Twitter to share
information, show affection, send wishes, and less likely to talk about work and study.
Their posts tend to have relatively stronger emotions. Judgment-oriented people,
comparing with their perception-oriented counterparts, are more likely to have more
followers, fewer followings, and less likely to receive favorites from others and post on
workdays. They tend to engage in social activities, write longer posts, write about work
and study, and not comment on others. Their posts tend to have higher sentiment values
and be more objective.
Since the task is a binary classification problem, I then apply five classifiers to
each personality trait. I used the classifiers implemented in Python Scikit-learn package
(Pedregosa et al., 2011) with default configurations. Scikit-learn package is one of the
most popular machine learning packages in Python and has been widely used in empirical
studies in different domains (Hao & Ho, 2019). Specifically, I applied Logistic
Regression, K-Nearest Neighbor (KNN) (Cover & Hart, 1967), Decision Tree (Breiman
et al., 1984), Support Vector Machine (Suykens & Vandewalle, 1999), and Random
Forests Model (Breiman, 2001) methods. To fully examine the model’s prediction power,
I used five-fold cross-validation and used accuracy as the evaluation metric. K fold cross-
validation is a standard procedure in machine learning to estimate the model’s predictive
power given unseen data (Stone, 1974). The procedure goes as follows. Given the

26
original dataset, I first randomly separate all samples into five equal-sized subsamples. I
then leave out one subsample as the testing dataset and combine the rest subsamples as
the training dataset. Third, I train the model using the training dataset and test its
accuracy using the testing dataset. Fourth, I repeat the above steps four times with each
subsample used exactly once as the testing dataset. Finally, the testing accuracy is the
average value of all testing accuracy collected during the procedure.
Table 8 shows the testing accuracy of each model on different personality traits.
First, I found the model achieved higher predicting accuracy on Intuition, Feeling,
Extraversion than Judgement. This indicates some personality traits are easier to predict
than others based on people’s social media usage. Second, I found that non-linear models
(KNN, Decision Tree, Random Forests) generally outperformed linear models (Logistic
Regression and SVM). Third, I find that the best model (Random Forests) has a 2% to
17% increase in the testing accuracy comparing with the baseline model (Logistic
Regression). This suggests that indeed we could significantly improve the model’s
predictive power using some advanced models in machine learning. Overall, the best
model achieves an average prediction accuracy of 67.6%.
Table 8.
Testing Accuracy Comparison
Extraversion Intuition Feeling Judgment Logistic Regression 0.562 0.577 0.569 0.535 KNN 0.611 0.731 0.723 0.499 Decision Tree 0.556 0.637 0.644 0.507 SVM 0.513 0.503 0.540 0.524 Random Forests 0.647 0.755 0.748 0.555

27
Discussion
To reiterate, the aims of this study were to (1) examine the association
relationships between people’s social media activities and their MBTI personality traits,
(2) explore to what extent we could accurately predict people’s personality using their
social media activities. Using the latest advances in machine learning and natural
language processing, I explored high-level features other than simple characteristics of
people’s social media usage. Specifically, I extended previous literature by adding
language features, including specifically the content topics and content sentiment
features.
Regarding the first aim, I found that my results confirm most of the findings
identified in previous studies but also yield some associations that are not established in
previous studies (content topics). This suggests the superiority of using advanced natural
language processing methods in similar research. The LDA model summarizes and
generates high-level features (content topics) that could better portray the sentiment
meaning of the user’s tweets, helping us identify a set of associations that could not be
uncovered when using individual words as independent variables. Regarding the second
aim, the prediction results suggest that people’s personality traits could be effectively
predicted using social media profiles, their use of language, and their behavioral patterns.
I find that the model’s predicting accuracy increased by using more sophisticated models
that better at capturing the non-linear relationships between variables. This suggests that
one could potentially achieve higher predicting accuracy by using more advanced models
that are designed to capture intricate, non-linear relationships between variables such as

28
Neural Networks (LeCun, Bengio, & Hinton, 2015) and Gradient Boosting Tree (Chen &
Guestrin, 2016).
Limitations and Future Directions
This study is a step toward understanding how people with different personalities
express themselves on social media. There are many possible next steps. First, I find that
the distribution of personalities in my sample is slightly different than the distribution of
personalities in the US population. To overcome this, one may resample the dataset by
randomly removing observations from over-represent personalities or replicate
observations in the under-represent personalities. One may also acquire a larger dataset or
deliberately collect observations in the under-represented personalities to reconstruct the
data. Second, when I conduct the topic modeling process, I find that using the text of
many tweets may not enough to reveal its content topic. For example, a Twitter post may
only contain a string of text “check this” followed by a link and an image. In this case,
important topic features are hidden in the link or the image associated with the post.
Thus, future studies may further query information relate to the associated link and use
image processing techniques to extract features from the image. Third, one may also use
the follower/following relationships to construct a social network of users and exploit
users’ network properties to improve the model’s prediction power.
Implications
One potential implication of this study is to apply such methods to the study of
stereotyping and social bias. For example, we tend to believe that an extrovert should be
talkative, happy, and popular, whereas an introvert tends to be shy, blue, and unpopular.
However, I find there is no significant difference in the number of posts or the sentiment

29
value of their posts between extroverts and introverts. Introverts are as active and
emotional revealing as extroverts. Similarly, we tend to think that a feeling-oriented
person tends to be more nostalgic and therefore post more content about memory in the
past. Still, the results do not support such propositions. Therefore, similar methods could
be applied to social psychology to investigate a wide range of social bias issues. With
machine learning, researchers could utilize abundant social media data to test results they
get using laboratory experiments. Conversely, one may also use social media data to
conduct exploratory studies to derive insights that could be casually examined using
controlled experiments.
Another implication relates to the accurate prediction of people’s personalities.
On the positive side, psychological researchers could use the automatic assessed
personality as an alternative measure when assessing using questionnaires are not
available. Such personality feature could also be used in the health area to improve our
understanding of how people with different personalities may have different health risks.
Moreover, it could also be used to develop health applications that focus on early
protection, intervention, and proper treatment of various physical and mental health
issues such as depression, obesity, and suicide. Similarly, there are also abundant
opportunities to use such predicted personalities in the industry to develop various
applications such as personalized recommendation systems, online dating, and job
screening. On the negative side, the accurate prediction of people’s personality raises the
concern regarding data privacy. Progressive data protection laws such as European
General Data Protection Regulation (GDPR) may, to some extent, alleviate such risks,
but they cannot resolve privacy concerns when personal data was used to generate

30
second-order predictions, which the user may consider as more private and does not want
to disclose. Therefore, it is critical for users to be made aware of the usage of their
personal data, including both the direct usage and applications/predictions that these data
produce. In this way, the user could make better decisions about who uses their data, for
what purposes, and whether to give in their data privacy for better services.

31
References
Bachrach, Y., Kosinski, M., Graepel, T., Kohli, P., & Stillwell, D. (2012). Personality and patterns of Facebook usage. Proceedings of the 4th Annual ACM Web Science Conference, 24–32. ACM.
Back, M. D., Stopfer, J. M., Vazire, S., Gaddis, S., Schmukle, S. C., Egloff, B., & Gosling, S. D. (2010). Facebook profiles reflect actual personality, not self-idealization. Psychological Science, 21(3), 372–374.
Bagby, R. M., & Quilty, L. C. (2007). The impact of personality and personality disorders on the treatment of depression: A brief commentary on Gabbard and Simonsen. Personality and Mental Health, 1(2), 176–178. doi:10.1002/pmh.24
Bagby, R. M., Quilty, L. C., & Ryder, A. C. (2008). Personality and depression. The Canadian Journal of Psychiatry, 53(1), 14–25.
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent Dirichlet Allocation. Journal of Machine Learning Research: JMLR, 3(Jan), 993–1022.
Boyle, G. J. (1995). Myers-Briggs type indicator (MBTI): Some psychometric limitations. Australian Psychologist, 30(1), 71–74. doi:10.1111/j.1742-9544.1995.tb01750.x
Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5–32. doi:10.1023/A:1010933404324
Breiman, L., Friedman, J., Stone, C. J., & Olshen, R. A. (1984). Classification and regression trees. CRC press.
Celli, F., Massani, P. Z., & Lepri, B. (2017). Profilio: psychometric profiling to boost social media advertising. Proceedings of the 25th ACM International Conference on Multimedia, 546–550. ACM.
Chen, T., & Guestrin, C. (2016, August 13). XGBoost: A Scalable Tree Boosting System. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 785–794. Presented at the San Francisco, California, USA. doi:10.1145/2939672.2939785
Costa, P. T., & McCrae, R. R. (1985). The NEO personality inventory.
Cover, T., & Hart, P. (1967). Nearest neighbor pattern classification. IEEE Transactions on Information Theory / Professional Technical Group on Information Theory, 13(1), 21–27. doi:10.1109/TIT.1967.1053964
Dattner, B. (2008, June 13). The use and misuse of personality tests for coaching and development. Psychology Today. Retrieved from

32
http://www.psychologytoday.com/blog/credit-and-blame-work/200806/the-use-and-misuse-personality-tests-coaching-and-development
Funder, D. C. (2001). Personality. Annual Review of Psychology, 52(1), 197–221.
Furnham, A. (1996). The big five versus the big four: the relationship between the Myers-Briggs Type Indicator (MBTI) and NEO-PI five factor model of personality. Personality and Individual Differences, 21(2), 303–307.
Furnham, A., Moutafi, J., & Crump, J. (2003). The relationship between the revised NEO-personality inventory and the Myers-Briggs type indicator. Social Behavior and Personality: An International Journal, 31(6), 577–584.
Gosling, S. D., Augustine, A. A., Vazire, S., Holtzman, N., & Gaddis, S. (2011). Manifestations of personality in online social networks: Self-reported Facebook-related behaviors and observable profile information. Cyberpsychology, Behavior and Social Networking, 14(9), 483–488.
Hao, J., & Ho, T. K. (2019). Machine Learning Made Easy: A Review of Scikit-learn Package in Python Programming Language. Journal of Educational and Behavioral Statistics: A Quarterly Publication Sponsored by the American Educational Research Association and the American Statistical Association, 44(3), 348–361. doi:10.3102/1076998619832248
Hasan, A., Moin, S., Karim, A., & Shamshirband, S. (2018). Machine Learning-Based Sentiment Analysis for Twitter Accounts. Mathematical & Computational Applications, 23(1), 11.
Hurtz, G. M., & Donovan, J. J. (2000). Personality and job performance: the Big Five revisited. The Journal of Applied Psychology, 85(6), 869–879. doi:10.1037/0021-9010.85.6.869
Joulin, A., Grave, E., Bojanowski, P., Douze, M., Jégou, H., & Mikolov, T. (2016). FastText.zip: Compressing text classification models. Retrieved from http://arxiv.org/abs/1612.03651
Jung, C. G. (1923). Psychological Types. Retrieved from https://play.google.com/store/books/details?id=y7nCBQAAQBAJ
Klein, D. N., Kotov, R., & Bufferd, S. J. (2011). Personality and depression: explanatory models and review of the evidence. Annual Review of Clinical Psychology, 7, 269–295. doi:10.1146/annurev-clinpsy-032210-104540
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436–444.

33
Lee, K., Ashton, M. C., & Shin, K.-H. (2005). Personality correlates of workplace antisocial behavior. Applied Psychology Psychologie Appliquee, 54(1), 81–98. doi:10.1111/j.1464-0597.2005.00197.x
Lima, A. C., & de Castro, L. N. (2013). Multi-label semi-supervised classification applied to personality prediction in Tweets. 2013 BRICS Congress on Computational Intelligence and 11th Brazilian Congress on Computational Intelligence, 195–203. IEEE.
Liu, X., & Zhu, T. (2016). Deep learning for constructing microblog behavior representation to identify social media user’s personality. PeerJ Computer Science, 2, e81.
Loria, S., Keen, P., Honnibal, M., Yankovsky, R., Karesh, D., Dempsey, E., & Others. (2014). Textblob: simplified text processing. Secondary TextBlob: Simplified Text Processing.
McCrae, R. R., & Costa, P. T., Jr. (1989). Reinterpreting the Myers-Briggs type indicator from the perspective of the five-factor model of personality. Journal of Personality, 57(1), 17–40.
Mischel, W., Shoda, Y., & Ayduk, O. (2007). Introduction to personality: Toward an integrative science of the person. John Wiley & Sons.
Molina, B. (2017). Twitter overcounted active users since 2014, shares surge on profit hopes. USA Today.
Myers, I. B., & McCaulley, M. H. (1988). Myers-Briggs type indicator: MBTI. Consulting Psychologists Press Palo Alto.
Oberlander, J., & Nowson, S. (2006). Whose thumb is it anyway? Classifying author personality from weblog text. Proceedings of the COLING/ACL 2006 Main Conference Poster Sessions, 627–634.
Ortigosa, A., Carro, R. M., & Quiroga, J. I. (2014). Predicting user personality by mining social interactions in Facebook. Journal of Computer and System Sciences, 80(1), 57–71.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., … Duchesnay, É. (2011). Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research: JMLR, 12(Oct), 2825–2830.
Qiu, L., Lin, H., Ramsay, J., & Yang, F. (2012). You are what you tweet: Personality expression and perception on Twitter. Journal of Research in Personality, 46(6), 710–718.
Quenk, N. L. (2009). Essentials of Myers-Briggs Type Indicator Assessment. Retrieved from https://play.google.com/store/books/details?id=th_gTxfPdlgC

34
Quercia, D., Lambiotte, R., Stillwell, D., Kosinski, M., & Crowcroft, J. (2012). The personality of popular facebook users. Proceedings of the ACM 2012 Conference on Computer Supported Cooperative Work, 955–964. ACM.
Radim Rehurek, P. S. (2010). Software Framework for Topic Modelling with Large Corpora. IN PROCEEDINGS OF THE LREC 2010 WORKSHOP ON NEW CHALLENGES FOR NLP FRAMEWORKS. Citeseer.
Stone, M. (1974). Cross-validatory choice and assessment of statistical predictions. Journal of the Royal Statistical Society. Series B, Statistical Methodology, 36(2), 111–133.
Suykens, J. A. K., & Vandewalle, J. (1999). Least Squares Support Vector Machine Classifiers. Neural Processing Letters, 9(3), 293–300.
Turban, D. B., Moake, T. R., Wu, S. Y.-H., & Cheung, Y. H. (2017). Linking extroversion and proactive personality to career success: The role of mentoring received and knowledge. Journal of Career Development, 44(1), 20–33.
Wang, L., Qu, W., & Sun, X. (2013). An analysis of microblogging behavior on Sina Weibo: Personality, network size and demographics. International Conference on Cross-Cultural Design, 486–492. Springer.
Yarkoni, T., & Westfall, J. (2017). Choosing Prediction Over Explanation in Psychology: Lessons From Machine Learning. Perspectives on Psychological Science: A Journal of the Association for Psychological Science, 12(6), 1100–1122. doi:10.1177/1745691617693393