planning under uncertainty for coordinating infrastructural maintenance
TRANSCRIPT

Planning under Uncertainty for CoordinatingInfrastructural Maintenance⇤
Joris Scharpff Matthijs T.J. Spaan Leentje Volker Mathijs de WeerdtDelft University of Technology, Delft, The Netherlands
{j.c.d.scharpff, m.t.j.spaan, l.volker, m.m.deweerdt}@tudelft.nl
ABSTRACTWe address efficient planning of maintenance activities on infras-tructural networks, inspired by the real-world problem of servicinga highway network. A road authority is responsible for the quality,throughput and maintenance costs of the network, while the actualmaintenance is performed by autonomous, third-party contractors.
From a (multi-agent) planning and scheduling perspective, manyinteresting challenges can be identified. First, planned maintenanceactivities might have an uncertain duration due to unexpected de-lays. Second, since maintenance activities influence the traffic flowin the network, careful coordination of the planned activities is re-quired in order to minimise their impact on the network throughput.Third, as we are dealing with selfish agents in a private-values set-ting, the road authority faces an incentive design problem to truth-fully elicit agent costs, complicated by the fact that it needs to bal-ance multiple objectives.
The main contributions of this work are: 1) implicit multi-agentcoordination on a network level through a novel combination ofplanning under uncertainty and dynamic mechanism design, ap-plied to real-world problems, 2) accurate modelling and solving ofthe maintenance planning problem and 3) empirical exploration ofthe complexities that arise in these problems. Using two real-worldapplication examples we introduce a formal model of the problemdomain, present experimental insights and identify open challengesfor both the planning and scheduling as well as the mechanism de-sign communities.
Categories and Subject DescriptorsI.2.11 [Distributed Artificial Intelligence]: Multiagent systems
General TermsAlgorithms, Experimentation
KeywordsMultiagent systems, Planning and Scheduling, Coordination
1. INTRODUCTIONThe planning and scheduling of maintenance activities on large
infrastructural networks, such as a national highway network, is a
⇤This work will also appear in the Proceedings of the ICAPS 2013conference [20].
Appears in The Eighth Annual Workshop on Multiagent SequentialDecision-Making Under Uncertainty (MSDM-2013), held in con-junction with AAMAS, May 2013, St. Paul, Minnesota, USA.
challenging real-world problem. While improving the quality of theinfrastructure, maintenance causes temporary capacity reductionsof the network. Given the huge impact of time lost in traffic on theeconomic output of a society, planning maintenance activities in away that minimises the disruption of traffic flows is an importantchallenge for the planning and scheduling field. In this paper, weaddress this challenge by a novel combination of stochastic multi-agent planning, captured in Markov Decision Processes (MDPs),and dynamic mechanism design.
Maintenance activities in infrastructural networks not only incurmaintenance costs, but also incur social costs based on the effectsmaintenance has on the throughput of the network. Put simply, clos-ing off a main highway will lead to traffic delays, resulting in quan-tifiable losses in economic activity. For instance, an hour of timelost in traffic is valued between §10 for leisure traffic and §40 forbusiness traffic [22]. Since maintenance activities are unavoidable,traffic delays are inevitable. However, they can be minimised usingplanning and scheduling techniques. In our work, we use planning-under-uncertainty methodology to schedule maintenance activitiesacross the entire network, taking into account the effect that roadclosures have on traffic on nearby road segments.
A powerful real-world example of the benefits that careful main-tenance planning can provide is the summer 2012 closure of theA40 highway in Essen, Germany. Instead of choosing for the de-fault option of restricting traffic to fewer lanes for 2 years, authori-ties fully closed off a road segment for 3 months and diverted traf-fic to parallel highways. Traffic conditions on the other highwayshardly worsened, while an estimated §3.5M in social costs due totraffic jams were avoided (besides lowering building costs) [9].
As maintenance activities often have an uncertain duration dueto delays in construction, it is important to take uncertainty into ac-count while planning. Also, there may be multiple ways to performa certain maintenance action by varying the amount of resourcesdedicated to it, leading to options that have different duration, cost,risk and effect on asset quality. Furthermore, long-term planning isrequired to ensure overall network quality. Markov Decision Pro-cesses provide a suitable framework to model and solve these typesof planning-under-uncertainty problems [19].
A complicating factor, however, is that while a single public roadauthority is responsible for the quality, throughput and costs ofthe network, the actual maintenance is performed by autonomouscontractors, typically third-party companies interested primarily inmaximising their profits. Road authorities face the problem of align-ing objectives; we introduce monetary incentives for the contractorsto consider global objectives. But an agent servicing one part of thenetwork also influences agents in other parts as his work has a neg-ative impact on the traffic flow. As a consequence, the paymentswe introduce lead to very high throughput penalties for all agents if
1

they do not coordinate their maintenance plans on a network level.In this work we focus on socially optimal joint maintenance plan-
ning that maximises the sum of contractor utilities, in the presenceof such monetary incentives, and therefore we have chosen a cen-tralised coordination approach. The authority is given the responsi-bility to develop socially optimal plans, while considering the indi-vidual interests of all contractors expressed through cost functions.However, as these cost functions are private information, optimalcoordination and hence outcomes can only be achieved if the con-tractors report these costs truthfully. Ensuring this truthfulness isthe key motivation to combine stochastic planning with mechanismdesign.
Our main contribution is the application of a combination ofstochastic planning and dynamic mechanism design to realise truth-ful coordination of autonomous contractors in a private-values set-ting. Typical one-shot mechanisms often used to elicit private val-ues are not suitable for contingent and repeated settings. Insteadwe focus on dynamic mechanisms that define payments over all ex-pected outcomes such that in expectation it is in the agent’s bestinterest to be truthful during the entire plan period. Applying dy-namic mechanism design to (real-world) settings such as the onewe consider is relatively unexplored territory [6].
Related WorkOther approaches towards solving the problems discussed here havebeen considered, although they can not be applied to our setting forvarious reasons. Multi-agent MDP [4] assumes co-operative agentsthat are willing to share private information and have the same util-ity functions. This is not the case with decentralised MDP [3], how-ever agent decisions are made solely on locally available informa-tion and are therefore inadequate in optimising network objectives.Moreover, both methods are not suitable when agents misreporttheir private information to ‘cheat’ the center into different out-comes. Non-cooperative settings have been studied in the classicalplanning literature [5, 14, 23], but uncertainty is not addressed.
Multi-machine scheduling has also been considered for the plan-ning of maintenance activities, but we found this infeasible forour contingent setting. Moreover, finding optimal policies in multi-machine problems with general cost functions is highly intractable.The only work we are aware of in this area is [10], in which onlynon-decreasing regular step functions are considered. In our prob-lem agents could both profit as well as suffer from concurrent main-tenance, therefore our cost functions do not have the non-decreasingproperty.
Another interesting related approach is that of reinforcement learn-ing [15, 16] and in particular Collective Intelligence [25]. In this anapproach agents learn how and when to coordinate and, in the caseof collective intelligence, strive to optimise a global goal, withoutsubstantial knowledge of the domain model. Nevertheless, the ab-sence of domain knowledge makes it impossible for such methodsto provide theoretical guarantees regarding agent and system per-formance – crucial if this method is to be applied in practice (e.g.as part of a dynamic contracting procedure) – and will most likelynot produce socially optimal solutions.
Applying mechanism design to large multi-agent systems is chal-lenging. First, few results are known for dynamic settings (but see[21]), but taking into account changes in the state of the system iscrucial for planning ahead. Second, for large systems, computingoptimal solutions might not be possible. When resorting to approx-imate solutions, however, standard theory for strategy-proof mech-anisms does not immediately apply [18]. Finally, existing generalsolutions fail to apply in settings with actuation uncertainty. For in-stance, fault-tolerant mechanism design has been proposed to take
into account that agents might not be able to accomplish an as-signed activity [17], but no techniques exist for the quite generalforms of uncertainty that we address.
Both stochastic planning and mechanism design have been wellstudied independently, however only a handful of papers addressdynamic mechanism design and/or a combination of the two. [2]proposed a dynamic variant of the VCG mechanism for repeatedallocation, implementing the mechanism desiderata in a within-period, ex-post Nash equilibrium. [1] studied a dynamic variantof the AGV mechanism [8] that is budget-balanced in the weakerBayes-Nash equilibrium solution concept. Highly related is the workby [7], in which the authors also study dynamic mechanism designto obtain desirable outcomes in multi-agent planning with privatevaluations. However, the focus is on allocation problems that canbe modelled as multi-armed bandit problems, instead of the richerproblem domains with dynamic states that we consider.
OutlineIn the next section, we present a theoretical framework for mainte-nance planning obtained and refined through interviews and discus-sions with public road and rail network authorities, as well as assetmanagers of several larger contractors. We then introduce the theo-retical background of both stochastic planning and mechanism de-sign (Section 3), and show how to combine work on planning withuncertainty and dynamic mechanism design to solve two exam-ple applications, derived from practice (in Section 4). We presentexperimental insights where we compare this with uncoordinatedagents as well as with best-response (Section 5). In our conclusion,we summarise our findings and present open challenges for boththe planning and scheduling as well as the mechanism design com-munities (Section 6).
2. MAINTENANCE PLANNINGCommonly in infrastructural maintenance planning there is one
(public) institution responsible for the network on behalf of the net-work users. This road authority is given the task to maintain a high(i) network quality and (ii) throughput (iii) at low costs (althoughother objectives are also possible, e.g. environmental concerns, ro-bustness, etc.). To this end, network maintenance has to be per-formed with minimal nuisance. However, the actual maintenanceis performed by several autonomous, independent contractors andtherefore some coordination of maintenance activities is required.
The maintenance planning problem discussed in this paper is partof the dynamic contracting procedure introduced in [24]. Here wefocus on the execution phase, i.e. the planning and execution ofmaintenance activities. The assessment, pricing and allocation ofmaintenance activities is performed in the preceding procurementphase, not discussed in this paper.
In the infrastructural maintenance planning problem we are givena network of roads E. On this network we have a set N of agents(the contractors), with each agent i 2 N responsible for the main-tenance of a disjoint subset Ei ✓ E of roads over a set of discreteperiods T . An edge ek 2 E has a quality level qe
k
2 [0, 1] anda function q̂ : q ⇥ T ! q that models the quality degradationof a road given the current state and time (new roads degrade lessquickly, seasons influence degradation).
For each edge ek 2 Ei, an agent i has a set of possible main-tenance activities Ak that have been identified and assigned in theaforementioned procurement phase. We write Ai to denote all pos-sible activities by an agent i, i.e. Ai = [{k|e
k
2Ei
}Ak. Each ofthe activities k 2 Ak has a duration dk 2 Z+, a quality impactfunction �qk : qe
k
⇥ T ! qek
that depends on the current road
2

quality and time, and a constant revenue wk 2 R that is obtainedupon completion of the activity. Moreover, the agent has a (private)cost function ci : Ai⇥T ⇥Z+ ! R that represents the cost of per-forming an activity k 2 Ai at time t 2 T for a duration d 2 Z+.The dependency on time enables modelling of different costs forexample for different seasons, or for periods where the agent hasfewer resources available.
We model the limited resources (machinery, employees, etc.)available to an agent by allowing at most one activity at a time.This restriction does not have much impact on the model we pro-pose here but does greatly simplify resource reasoning and there-fore the complexity of finding optimal maintenance plans.
Each agent strives to plan their maintenance activities in such away that their profits are maximised, but plan execution is unlikelyto be perfect. Uncertainties in various forms – for example delays,unknown asset states, failures, etc. – may be encountered duringexecution and hence ‘offline optimal’ plans might lead to ratherpoor results. To this end we focus on contingent plans, or policies,that dictate the best action to take in expectation for all possibleagent states. Note that actions here are operations available to thecontractors (e.g. start activity, do nothing, etc.) and states containall relevant information for its planning problem. We formalise allthese concepts in Section 3.1, for now it is sufficient to know thatwe can always obtain contractor plans by evaluating the most-likelypath of a policy (i.e. the sequence of actions that in expectationoptimise the contractor reward). We use (k, t) 2 ⇡i to denote thatfrom the policy ⇡i we can derive that starting activity k at time t isexpected to yield the highest reward.
Given a policy ⇡i, the expected profit for agent i is defined as
Ci(⇡i) =X
(k,t)2⇡i
w̄k �X
(k,t)2⇡i
ci(k, t, dk) (1)
with w̄k being wk if the activity is completed within the period Tand 0 otherwise. As activity rewards follow directly from the pro-curement, we assume that agents in expectation are always ableto achieve a positive profit for completing their activities, other-wise they would not have bid on the activity during procurement.Note that we do not explicitly require all activities of an agent tobe planned or that they can be completed within the period T , butbecause agents will not receive rewards wk for each uncompletedactivity k they will be stimulated to complete them.
For the agents to also consider the global objectives, we intro-duce payments such that their profits depend on the delivered qual-ity and additional congestion caused by their presence. The qualitypayment Qi for each agent i can be both a reward as well as apenalty, depending on the final quality state of its roads (e.g. basedon contracted demands). Again given a policy ⇡i, we can determinethe resulting quality state qTe at the end of the period T using therecursive formula
qt+1
ek
=
(
�qk(qtek
, t) if (k, t) 2 ⇡i
q̂ek
(qtek
, t) otherwise(2)
with (given) initial quality q0ek
. Consequentially, we define thequality payment for agent i as a result of his policy by Qi(⇡i) =P
e2Ei
Qi(qTe ).
Congestion payments, i.e. social costs, cannot be considered fromjust the single agent perspective because network throughput de-pends on the planning choices of all agents. Let At denote the setof activities performed by all agents at time t, then the social costof this combination is captured by `(At). The impact of an indi-vidual agent, given the choices made by others, can be determined
by `i(At) = `(At)�`(At
�i) in which At�i denotes the set of activ-
ities performed at time t minus any activity by agent i. The socialcost function can for example capture the costs of traffic jams dueto maintenance activities. In realistic scenarios where a good esti-mate of origins and destinations of the traffic flow is known, thesecosts can be learned empirically.
Recapitulating the above, each agent i is interested in maximis-ing its expected profit, trivially comprised of only maintenancerewards and costs Ci. In order to stimulate agents to plan main-tenance in favour of global objectives, we introduce quality andthroughput payments such that their profit ui, given the joint pol-icy ⇡ =
S
i2N ⇡i, is now given by:
ui(⇡) = Ci(⇡i) +Qi(⇡i) + `i(⇡) (3)
in which `i(⇡) =P
t2T `i(At). Here, At can be easily derived
from ⇡ considering planned start times and activity durations asbefore.
Now given the utility function of Eq. 3, how should we definethese payments such that the right balance is made between thesecosts and the agents’ private costs, which are not known to the roadauthority? This is exactly a mechanism design problem. As the sce-narios both contain a form of uncertainty and thus dynamics, thereare few known mechanisms that can be applied; we are aware ofonly two (dynamic-VCG [2, 6] and dynamic AGV [1]). Both re-quire an optimal solution (in expectation) of the planning problem,otherwise agents can benefit from (deliberately) misreporting theirprivate costs.
In the next section we therefore start by discussing how to com-pute optimal solutions to the problem variants introduced in thissection, followed by a summary of how this can be combined witha dynamic mechanism.
3. BACKGROUNDWe briefly introduce the two concepts our work builds on, plan-
ning under uncertainty and dynamic mechanism design.
3.1 Planning under UncertaintyTo deal with uncertainties we model the planning problem using
Markov Decision Processes (MDPs), which capture this type of un-certainty rather naturally [19]. For each agent i 2 N we have anMDP Mi = hSi,Ai, ⌧i, rii that defines its local planning problem.In this definition, Si is the set of states and Ai a set of available ac-tions (see Sections 4.3 and 4.4). The function ⌧i : Si ⇥ Ai !�(Si) describes the transition probabilities where ⌧i(si,Ai, s
0i)
denotes the probability of transitioning to state s0 if the currentstate is si and action Ai is taken. Finally, ri : Si ⇥Ai ! R is thereward function where ri(si, a) denotes the reward that the agentwill receive when action a 2 Ai is taken in state si (e.g. the utilityof Eq. 3). We formalise the rewards and actions for the agents inSection 4, as they depend on the encoding used to solve the MDP.
Solutions to MDPs are policies ⇡ : S ! A that dictate thebest action to take in expectation, given the current state it is in.Formally, the optimal policy ⇡⇤ is defined such that for all startstates s 2 S:
⇡⇤(s) = argmax⇡2⇧
V 0(⇡, s) (4)
with
V t0(⇡, s) = E
h
1X
t=t0
�tr(st,⇡(st))) | st0 = si
(5)
in which st is the state at time t and � 2 [0, 1) is a shared dis-
3

count factor commonly used to solve problems with infinite hori-zons.
We can obtain the individual policies ⇡i for each agent by solv-ing its local plan problem MDP Mi. However, in order to developan (optimal) joint policy ⇡⇤, required to consider throughput pay-ments, we need to solve the multi-agent MDP that results fromcombining all individual MDPs. Formally, the joint MDP is definedby M = hS,A, r, ⌧i where S = ⇥i2NSi is the joint state spacecontaining in each state s 2 S a local state si for all agents i 2 N ,A is the set of combined actions, r the reward function defined as8s 2 S, a 2 A : r(s, a) =
P
i2N ri(si, ai) and ⌧ the combinedtransition probability function. The joint action set can always beobtained by including an action for each element of the Cartesianproduct set of all individual action spaces but smarter constructioncan greatly reduce the joint action set. For planning problems (atleast) we have developed a two-stage MDP encoding that effec-tively reduces the joint action set size from exponential to linearin the number of players and their action sets. This is discussed indetail in Section 4.2.
3.2 Dynamic mechanism designAlthough MDPs facilitate modelling uncertainties, they assume
global knowledge of all these uncertainties, as well as costs andrewards. As the maintenance activities are performed by different,usually competing companies, we cannot assume that this knowl-edge is globally available. We therefore aim to design a game suchthat utility-maximising companies behave in a way that (also) max-imises the global reward. This is exactly the field of mechanismdesign, sometimes referred to as inverse game theory.
Formally, in a static or one-shot game, each agent i 2 N hassome private information ✓i usually known as its type. In so-calleddirect mechanisms, players are asked for their type, and then a de-cision is made based on this elicited information. Groves mecha-nisms [12] take the optimal decision (⇡⇤) and define payments Tsuch that each player’s utility is maximised when it declares its typetruthfully.
Dynamic mechanisms extend ‘static’ mechanisms to deal withgames in which the outcome of actions is uncertain and private in-formation of players may evolve over time. In each time step t,players need to determine the best action (in expectation) to takewhile considering current private information and possible futureoutcomes. Private rewards are therefore defined depending on thestate and the policy, given by ri(s
t,⇡(st))), in which the state con-tains the player’s type. This type is denoted by ✓ti to express thepossibility of this changing over time. With ✓t we denote the typeof all players at time t which are encoded in the state st.
An extension of Groves mechanisms for such a dynamic and un-certain setting is dynamic-VCG [2, 6]. For dynamic-VCG the deci-sion policy is the optimal one maximising the reward of all players,identical to Eq. 4 when the types ✓t are encoded into the state st.We denote this optimal policy for time step t given the reportedtypes ✓t encoded in state st by ⇡⇤(st). A policy optimised for thegame with all players except i is denoted by ⇡⇤
�i(st) and we define
ri(sti,⇡
⇤�i(s
ti)) = 0.
In every time step each player i pays the expected marginal costhe incurs on other players j for the current time step. This is de-fined as the difference between the reward of the other playersfor the socially optimal decision for the current time step t, i.e.P
j 6=i rj(st,⇡⇤(st)) and their expected reward optimised for just
them in future time steps, i.e. V t+1(⇡⇤�i, s
t+1) (Eq. 5) minus theexpected reward of the other players for a policy optimised for themfor all time steps including the current one, i.e. V t(⇡⇤
�i, st). Sum-
marising, the payment Ti(✓t) for an agent i at time step t given that
reports ✓t are encoded in state st is thus is defined as
Ti(✓t) =
X
j 6=i
rj(st,⇡⇤(st)) + V t+1(⇡⇤
�i, st+1)� V t(⇡⇤
�i, st)
(6)The dynamic-VCG mechanism yields maximum revenue among
all mechanisms that satisfy efficiency, incentive compatibility andindividual rationality in within-period, ex-post Nash equilibrium.This means that at all times for each player the sum of its expectedreward and its expected payments is never more than when declar-ing its true type.
4. COORDINATING MAINTENANCE PLAN-NING
In this work we combine existing work on planning under uncer-tainty and dynamic mechanism design to solve the complex prob-lem of maintenance planning where agents are selfish and execu-tion is uncertain. Using the dynamic VCG mechanism we ensurethat agents are truthful in reporting their costs. Then, using these re-ports to model agent rewards, we apply planning-under-uncertaintytechniques to find efficient policies and finally we determine thepayments of the mechanism, as discussed in the previous section.Basically this approach can be seen as a series of auctions in whichagents bid activities and their associated costs for an assignment oftime-slots.
An important condition for the dynamic VCG mechanism is thatthe chosen policy is optimal. If it is not, the payments are not guar-anteed to achieve truthful cost reports and agents may want to devi-ate. Therefore we focus on exact solving methods in our approach.
We implemented our mechanism using the SPUDD solver [13]to determine optimal policies. The SPUDD solver allows for a verycompact but expressive formulation of MDPs in terms of algebraicdecision diagrams (ADDs) and uses a structured policy iterationalgorithm to maximally exploit this structure. This allows it to findoptimal solutions to moderately sized problems. We note, however,that our mechanism is independent of the particular MDP solverused, as long as it returns optimal solutions.
4.1 MDP models for maintenance planningRecall that we want to find an efficient joint policy ⇡⇤ that max-
imises the sum of all agent utilities ui (Eq. 3). However, this utilityfunction cannot be directly translated into an equivalent MDP en-coding. Although in our model C, Q and ` can be general functions,encoding general functions in the MDP formulation potentially re-quires exponential space. Hence to be able to use the SPUDD solverin our experiments, we necessarily restricted ourselves to only lin-ear functions.
The current state of the network, i.e. the quality levels qe, aremodelled using a 5 star classification (from (0) very bad to (5) ex-cellent) are encoded as discrete variables [0, 5]. Road degradationfunctions q̂ are modelled using decision diagrams that probabilisti-cally decrease the road quality in each time slot by one state. Com-pleting an activity k0 increases the corresponding road quality q0kby a specified number of states (additive), corresponding to its ef-fect �q0k.
Encoding the social cost ` can be cumbersome, depending on thecomplexity of the chosen cost model. Again, general cost modelscould result in exponential MDP encoding sizes. Using only unaryand binary rules to express social cost, we can overcome this ex-ponential growth. (at the cost of losing some expressiveness). Theunary rules l : A ! R express the marginal latency introduced byeach activity independently. Dependencies between activities areexpressed using binary relations l : Ai ⇥ Aj ! R that specify the
4

additional social cost when both activities are planned concurrently.The costs incurred by the set of chosen activities At can be com-puted using `(At) =
P
k2At
l(k)+P
k1
2At
P
k2
6=k1
2At
l(k1
, k2
).
4.2 Avoiding exponentially-sized action spacesFactored MDP solvers are typically geared towards exploiting
structure in transition and reward models, but scale linearly with thenumber of actions. In multi-agent problem domains such as ours,however, a naive construction of the joint action set – such as enu-merating all elements of the Cartesian product of individual actionsets – can be exponential in the number of agents. To overcome thisissue, we model each time step in the real world by two stages in themulti-agent MDP, resulting in a larger number of search backupsdue to additional variables, but crucially avoiding exponentially-sized action spaces. Note that the encoding technique we discuss inthis section is not restricted to our problem; they can be applied onany multi-agent decision problem MDP formulation in which agentactions are dependent only through their rewards.
In our MDP encoding we have used a two-stage approach foreach time step in the plan problem length T . In the first step agentsdecide on the activity to perform (or continue) and this activityis then ‘executed’ in the second stage (illustrated in Sections 4.3and 4.4 for two example scenarios). We implement this separationthrough the use of additional variables that for each agent state theactivity to perform in the current time step. These variables canbe set independent from the actions available to other players (un-like the Cartesian product action space). The second stage then en-codes the ‘execution’ of their choices using one additional action.Still there are multiple ways in which this first-stage activity selec-tion can be implemented. Again enumeration is possible (althoughobliterating the purpose of the two-stage approach) but we have de-veloped two smarter encodings: action chains and activity chains.
The action chain encoding exploits the fact that we can decide onan action for each player sequentially, instead of deciding on themall at once (as with enumeration). Through the use of a player to-ken, each agent gets a ‘turn’ to determine his action within a singletime step. Therefore we require only |Ai| actions for each agent i,one for each activity it can choose, and hence a total of
P
i2N |Ai|states (and one additional variable), instead of the
Q
i2N |Ai| ac-tions needed for enumerating the Cartesian product.
For activity chains we exploit a similar idea. We group the ac-tivities of agents into activity chains to obtain an even smaller setof joint MDP actions. Let D = maxi2N |Ai| be the size of thelargest activity set of any player, then the activity chains are de-fined as ACm =
S
i2N km 2 Ai for m = 1, 2, . . . , D. Hence wegroup all m-th activities of each player into set ACm. If a player ihas no m-th activity, i.e. m > |Ai|, we exclude the player from thisactivity chain using a high penalty. Again using the player token weenforce that each player sequentially chooses an activity from oneof these chains. This encoding requires exactly D actions in thejoint MDP for the first stage and is therefore often more compactthan the
P
i2N |Ai| actions required for action chains.In the second stage we model the execution of these choices, i.e.
apply maintenance effects, and compute the sum of utilities (Eq. 3)for this time step as the reward. Note that we only proceed in timeafter the second stage, hence both stages are effectively within onetime slot t 2 T .
So far we have introduced a general encoding for maintenancescheduling problems. Now we will go into the the specifics for tworeal-world application we have chosen to study in this paper: onewith unit-time activities that may fail, and one where activities al-ways succeed, but possibly have a much longer duration. A sum-mary of the main differences can be found in Table 1.
repeat duration successprob.
delaydur.
delayprob.
dk ↵k hk �k
1 yes 1 [0, 1] 0 02 no Z+ 1 Z+ [0, 1]
Table 1: The differences between scenario 1 and 2
4.3 Scenario 1: Activities with failuresAs a step towards network maintenance, we first focus on schedul-
ing repeatable unit-time activities with possible failures. Althoughthis problem is conceptually rather simple, it captures essential partsof real-world applications such as factory scheduling and supplychain planning problems. In this scenario, activities k 2 Ai are re-peatable, of unit-time (dk = 1) and succeed with probability ↵k 2[0, 1]. It is possible for any activity k 2 Ai to fail with probability1�↵k. Whether an activity fails will become apparent at its actualexecution time. When an activity fails, it has no positive effect onthe quality but its associated maintenance and throughput costs arestill charged. If the agent still wants to perform the maintenance ithas to include the activity in his plan again at a later time.
Because activities in this scenario are unit-time and repeatable,we can directly translate these into actions of the single-agent MDPs.For each activity k 2 Ai of agent i we create an action ak with re-ward c(k, t, 1). This action improves the quality level qk by thenumber of levels corresponding to �qk with probability ↵k. Thuswith probability 1� ↵k the maintenance fails and the quality levelremains unchanged.
4.4 Scenario 2: Portfolio ManagementPortfolio management is a second variant of our model. Inspired
by real-world consequences of signing a maintenance contract, inthis setting agents have to perform each activity exactly once, al-though multiple alternatives exists for the activity, and instead ofactivity failure we consider delays. More formally, for each activ-ity k we now additionally have a delay duration hk and delay prob-ability �k.
Encoding the portfolio management planning in an MDP re-quires a substantially greater effort as we can no longer translateactivities directly to actions. This problem is more complex becauseof (1) possible non-unit activity durations, (2) activities can be de-layed, (3) for each road we can only choose one activity to perform,and (4) each road can be serviced only once. The latter two are eas-ily resolved by introducing a variable that flags whether a road hasbeen serviced and using corresponding penalties to prohibit plan-ning of these activities in a later time; the first two require morework.
From the single agent MDP perspective, non-unit activity du-rations (including possible delay) do not pose any difficulties. Wecould use actions that update the time variable t according to theactivity duration. For the joint MDP however, this time variable isshared over all the agents. Increasing the time by the activity dura-tion makes it impossible for other agents to start their activities inthis time period.
Our solution is to decompose each activity k into a series of unit-time MDP actions {startk, dok, delayk, donek} and use a timervariable to keep track of the remaining activity duration and its de-lay status (pending, no or yes). The startk action marks the be-ginning of the activity. This action sets the delay status to pendingand the activity timer to the duration dk. In subsequent time steps,the agent has to perform a dok action until the activity timer reacheszero. At this point, the activity delay status is pending and the activ-
5

ity is delayed with probability �k (also updating the delay status).If the activity is not delayed, the donek action is executed and
the associated road ek is flagged as serviced. When an activity isdelayed however, we set the activity timer to the delay duration hk
and continue with dok actions until again the timer reaches zero, atwhich point the stopk action is executed (not delayk again becauseof the delay status value).
Important to keep in mind is that during the search for optimalpolicies, a solver might decide on any order of these actions. Hencewe need to constrain the actions such that only feasible action se-quences are considered. For example, the dok action can only bechosen if the activity timer is greater than zero, otherwise a highpenalty results.
Rewards are encoded using the two-stage approach as before.In the first stage, each agent chooses a start, do, delay or stopaction. Then the second stage implements these actions and incursmaintenance, quality and social costs for the current time step t.
4.5 Planning MethodsUsing the encodings we discussed, we can find the optimal pol-
icy ⇡⇤ that minimises costs over all three objectives. In the experi-ments, we then compare this centralised computation that relies ontruthful reporting to (1) the approach where each agent plans itsown actions optimally individually, i.e. disregarding other agents,and (2) a best-response approach [14].
In the best-response approach, agents alternatingly compute theirbest plan (in expectation) in response to the current (joint) planof the others. This approach allows us to solve much easier singleagent problems but still consider agent dependencies (e.g. socialcost). Of course, the downside of this approach is that we will haveto settle for Nash equilibria (if they exist).
5. EVALUATIONThe combination of planning under uncertainty and mechanism
design has been studied in only a handful of papers, their focusmainly on theoretical aspects. Little is known about application ofsuch a combination on practical problems. We have performed asubstantial number of experiments to gain insight into this previ-ously uncharted area.
For both problem scenarios we have generated large benchmarksets on which we tested the various planning approaches and theirencodings discussed in the previous section. These experiments aremainly of an exploratory nature in which we study the effect ofeach of the problem variables.
The solver used in these experiments has been implemented inJava, using SPUDD as its internal MDP solver. All experimentshave been run on a system with an 1.60 Ghz Intel i7 processor.
5.1 Activities with failuresIn the first series of experiments we have been mainly interested
in exploring the computational limits of solving the problem cen-trally using an exact algorithm. To this end we generated a set ofsimple instances that vary in both the number of players N (2-5)and activity set Ai sizes (1-15). We solved these instances usingdifferent planning period lengths T (1-46). From these experimentswe identify the parameters that contribute the most to the complex-ity of the problem.
Activity sets are generated using random, linear, time-dependentcost functions and always increase the quality level of the associ-ated road by one. Quality cost functions are also generated for eachroad. Road quality is decreasing linearly in the quality with a ran-dom factor from [1, 3], which is fixed per road. Recall from Section4.1 that linearity of this and other cost functions is a restriction not
2 3 4 5100
102
104Runtime
Number of players
Run
time
inse
cond
2 3 4 5104
106
108Memory usage
Number of players
Num
bero
fnod
es
EnumerationAction chainActivity chain
Figure 1: Comparison of runtime (left) and memory use (right)for different encoding methods and number of player, |Ai| = 3,|T | = 46, |Q| = 6 (both log scale).
0 5 1010�2
100
102
104
Activity set size
Run
time
(s)
0 10 20 30 40 5010�2
100
102
104
Period length
Run
time
(s)
|N| = 2|N| = 3|N| = 4|N| = 5
Figure 2: Runtime for different activity set sizes with T = 46(left) and plan period lengths with |Ai| = 10 (right) using theactivity chain encoding (again both log scale).
imposed by our model but is required to combat a potential expo-nential MDP encoding size.
The choice of activity and quality cost functions mostly influencethe rewards players can obtain, their impact on the computationalcomplexity is negligible (unless very complex models are used tocompute costs). Regarding the social costs ` we study the worst-case where all activities always interfere and define these costs us-ing randomly chosen (marginal) cost l(k1, k2) 2 [1, 10] for eachk1
2 Ai and k2
2 Aj where i 6= j. We do not consider themarginal cost for individual actions, i.e. l(k) = 0.
In Figure 1 we have depicted both the runtime (left) and thememory (right) required to solve each of these instances, under dif-ferent encoding methods. The memory required is expressed in thenumber of nodes SPUDD generates.
Not surprisingly this figure illustrates that the performance of thesolver is exponential in both time and memory, and greatly dependson the structure of its input. By exploiting the problem structure, theactivity chain encoding is able to greatly reduce the required run-time. With it we have been able to solve instances with 5 playersand 3 activities per player within the time limit of 3 hours, whereasthe other two failed on such instances. Observe that activity chainencoding requires slightly more memory, but this will be of no bur-den to most modern day computer systems.
For the reasons stated above, we have illustrated the results ofthe remaining experiments only using the activity chain encoding(which indeed outperformed the others in all tests). In Figure 2 wehave plotted the required runtime for solving instances using activ-ity chains for various activity set sizes and period lengths.
From the figure we can conclude that the runtime is only lin-early affected by the number of activities each player has. The planperiod length shows almost the same: although the required run-time increases rapidly at first, for larger plan horizons the increaseis again almost linear. It is expected that instances with small planlengths are easily solvable because only a small number of plans
6
100
200
300
400
Activity success probability
Cos
t
� = 0.2 � = 0.6� = 0.4 � = 0.8 � = 1
Individual
Best-response
Centralised
Figure 3: Total cost using different planning approaches for theactivities with failure problems (lower is better).
is possible. Increasing the plan length introduces an exponentialnumber of new possible plans and therefore the computation timeincreases rapidly, up to the point where the roads reach maximumquality. From this time on, agents have to consider planning an ac-tivity only when the quality degrades.
Having identified the computational boundaries of the centralisedproblem, we compared the performance of different planning ap-proaches discussed in Section 4.5 in terms of total reward obtained.For these experiments we have used 60 generated two-player in-stances in which each player is responsible for one road.
The activity set of each player contains the no-operation and 1,2 or 3 available maintenance operations that improve the qualityof the road by 1, 2 or 3 levels respectively. The cost of each ac-tion k 2 Ai is drawn randomly from [1, 3 ⇤ �qk] and is thereforeindependent from its execution time.
We have generated 20 instances for each different activity setsize and we ran our planning algorithms from Section 4.5. In theseexperiments all activities have the same success rate ↵ and wesolved all the instances with rates [0.2, 0.4, 0.6, 0.8, 1]. For thebest-response algorithm we have used 3 iterations and in each ofthese iterations the order of agents is randomly determined. Smallerexperiments support our choice for 3 iterations: less iterations resultin far worse results while more iterations only slightly improve thequality but increase the runtime substantially. Note that we haveno guarantee that the best-response approach will converge to anequilibrium at this point. This is an issue that remains open at thispoint, however early experiments have shown that best-responsealmost always improves the initial solution at least.
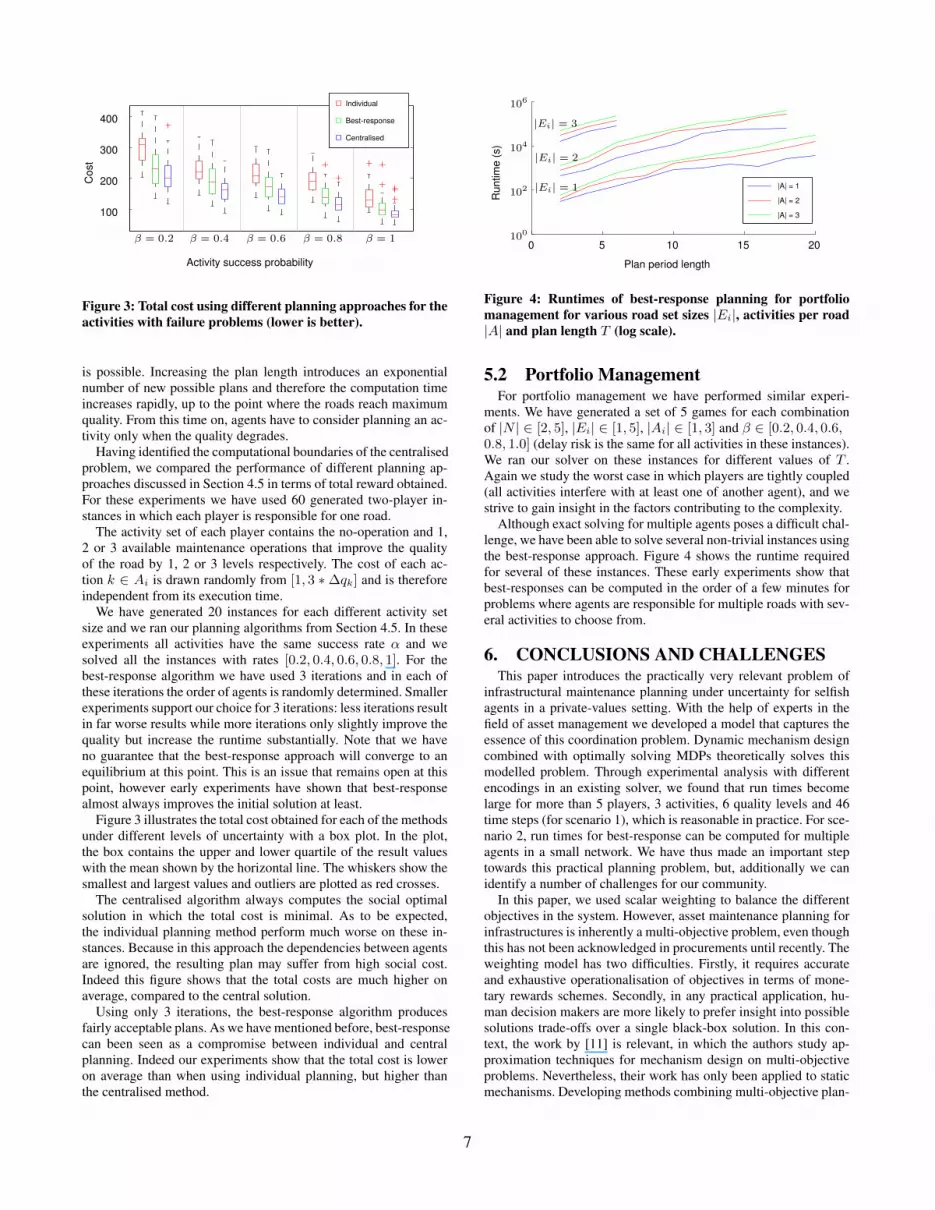
Figure 3 illustrates the total cost obtained for each of the methodsunder different levels of uncertainty with a box plot. In the plot,the box contains the upper and lower quartile of the result valueswith the mean shown by the horizontal line. The whiskers show thesmallest and largest values and outliers are plotted as red crosses.
The centralised algorithm always computes the social optimalsolution in which the total cost is minimal. As to be expected,the individual planning method perform much worse on these in-stances. Because in this approach the dependencies between agentsare ignored, the resulting plan may suffer from high social cost.Indeed this figure shows that the total costs are much higher onaverage, compared to the central solution.
Using only 3 iterations, the best-response algorithm producesfairly acceptable plans. As we have mentioned before, best-responsecan been seen as a compromise between individual and centralplanning. Indeed our experiments show that the total cost is loweron average than when using individual planning, but higher thanthe centralised method.
0 5 10 15 20100
102
104
106
Plan period length
Run
time
(s)
|A| = 1
|A| = 2
|A| = 3
|Ei
| = 3
|Ei
| = 2
|Ei
| = 1
Figure 4: Runtimes of best-response planning for portfoliomanagement for various road set sizes |Ei|, activities per road|A| and plan length T (log scale).
5.2 Portfolio ManagementFor portfolio management we have performed similar experi-
ments. We have generated a set of 5 games for each combinationof |N | 2 [2, 5], |Ei| 2 [1, 5], |Ai| 2 [1, 3] and � 2 [0.2, 0.4, 0.6,0.8, 1.0] (delay risk is the same for all activities in these instances).We ran our solver on these instances for different values of T .Again we study the worst case in which players are tightly coupled(all activities interfere with at least one of another agent), and westrive to gain insight in the factors contributing to the complexity.
Although exact solving for multiple agents poses a difficult chal-lenge, we have been able to solve several non-trivial instances usingthe best-response approach. Figure 4 shows the runtime requiredfor several of these instances. These early experiments show thatbest-responses can be computed in the order of a few minutes forproblems where agents are responsible for multiple roads with sev-eral activities to choose from.
6. CONCLUSIONS AND CHALLENGESThis paper introduces the practically very relevant problem of
infrastructural maintenance planning under uncertainty for selfishagents in a private-values setting. With the help of experts in thefield of asset management we developed a model that captures theessence of this coordination problem. Dynamic mechanism designcombined with optimally solving MDPs theoretically solves thismodelled problem. Through experimental analysis with differentencodings in an existing solver, we found that run times becomelarge for more than 5 players, 3 activities, 6 quality levels and 46time steps (for scenario 1), which is reasonable in practice. For sce-nario 2, run times for best-response can be computed for multipleagents in a small network. We have thus made an important steptowards this practical planning problem, but, additionally we canidentify a number of challenges for our community.
In this paper, we used scalar weighting to balance the differentobjectives in the system. However, asset maintenance planning forinfrastructures is inherently a multi-objective problem, even thoughthis has not been acknowledged in procurements until recently. Theweighting model has two difficulties. Firstly, it requires accurateand exhaustive operationalisation of objectives in terms of mone-tary rewards schemes. Secondly, in any practical application, hu-man decision makers are more likely to prefer insight into possiblesolutions trade-offs over a single black-box solution. In this con-text, the work by [11] is relevant, in which the authors study ap-proximation techniques for mechanism design on multi-objectiveproblems. Nevertheless, their work has only been applied to staticmechanisms. Developing methods combining multi-objective plan-
7

ning under uncertainty with dynamic mechanism design is a hardchallenge for the community, but with high potential payoffs interms of real-world relevance.
Scaling MDP solvers in terms of number of actions has not re-ceived large amounts of attention, but is crucial for solving multi-agent problems that suffer from exponential blow up of their actionspace. Furthermore, the best-response approach that we employedis not guaranteed to converge to the optimal solution, except forspecial cases such as potential games [14]. Bounding the loss, e.g.,by building on those special cases, will provide benefits to the adop-tion of best-response methods.
Finally, as mentioned in the related work section, approximatesolutions often preclude many of the theoretical mechanism-designresults to apply. A major challenge here is to identify mechanismsthat are more robust to such approximations.
With respect to the implications of our work, it is clear thatthe planning and coordination of (maintenance) activities in thepresence of uncertainty is a complex problem. However, applica-tions exist in several other domains such as bandwidth allocationor smart power grids, and hence the need for a practical solution ishigh.
The concept of traffic time loss can also be used to stimulatemarket parties in rethinking current working methods. By adjustingtendering criteria to specific needs on certain areas of the network,bidders can distinguish themselves by offering innovative propos-als with limited traffic loss hours. The road authority and severalprovinces are currently experimenting with this method.
AcknowledgementsThis research is part of the Dynamic Contracting in Infrastructuresproject and is supported by Next Generation Infrastructures andAlmende BV. Matthijs Spaan is funded by the FP7 Marie CurieActions Individual Fellowship #275217 (FP7-PEOPLE-2010-IEF).
7. REFERENCES[1] S. Athey and I. Segal. An efficient dynamic mechanism.
Technical report, UCLA Department of Economics, 2007.[2] D. Bergemann and J. Valimaki. Efficient dynamic auctions.
Cowles Foundation Discussion Papers, 2006.[3] D. S. Bernstein, R. Givan, N. Immerman, and S. Zilberstein.
The complexity of decentralized control of Markov decisionprocesses. Mathematics of Operations Research,27(4):819–840, 2002.
[4] C. Boutilier. Planning, learning and coordination inmultiagent decision processes. In Proc. of 6th Conf. onTheoretical Aspects of Rationality and Knowledge, pages195–201, 1996.
[5] R. I. Brafman, C. Domshlak, Y. Engel, and M. Tennenholtz.Planning games. In Proc. Int. Joint Conf. on ArtificialIntelligence, pages 73–78, 2009.
[6] R. Cavallo. Efficiency and redistribution in dynamicmechanism design. In Proc. of 9th ACM conference onElectronic commerce, pages 220–229. ACM, 2008.
[7] R. Cavallo, D. C. Parkes, and S. Singh. Optimal coordinatedplanning amongst self-interested agents with private state. InProc. of Conf. on Uncertainty in Artificial Intelligence, pages55–62, 2006.
[8] C. d’Aspremont and L. Gérard-Varet. Incentives andincomplete information. Journal of Public Economics,11(1):25–45, 1979.
[9] Der Spiegel. A40: Autobahn nach dreimonatiger sperrefreigegeben, 2012. Online, Sep 30.
[10] B. Detienne, S. Dauzère-Pérès, and C. Yugma. Schedulingjobs on parallel machines to minimize a regular step totalcost function. Journal of Scheduling, pages 1–16, 2009.
[11] F. Grandoni, P. Krysta, S. Leonardi, and C. Ventre.Utilitarian mechanism design for multi-objectiveoptimization. In Proc. of 21st Annual ACM-SIAMSymposium on Discrete Algorithms, pages 573–584. Societyfor Industrial and Applied Mathematics, 2010.
[12] T. Groves. Incentives in teams. Econometrica,41(4):617–631, 1973.
[13] J. Hoey, R. St-Aubin, A. Hu, and C. Boutilier. Spudd:Stochastic planning using decision diagrams. In Proc. ofConf. on Uncertainty in Artificial Intelligence, pages279–288, 1999.
[14] A. Jonsson and M. Rovatsos. Scaling up multiagentplanning: A best-response approach. In Int. Conf. onAutomated Planning and Scheduling, pages 114–121, 2011.
[15] J. R. Kok, P. Hoen, B. Bakker, and N. Vlassis. Utilecoordination: Learning interdependencies among cooperativeagents. In Proc. Symp. on Computational Intelligence andGames, pages 29–36, 2005.
[16] F. S. Melo and M. Veloso. Learning of coordination:Exploiting sparse interactions in multiagent systems. InProceedings of The 8th International Conference onAutonomous Agents and Multiagent Systems-Volume 2, pages773–780. International Foundation for Autonomous Agentsand Multiagent Systems, 2009.
[17] R. Porter, A. Ronen, Y. Shoham, and M. Tennenholtz. Faulttolerant mechanism design. Artificial Intelligence,172(15):1783–1799, 2008.
[18] D. Procaccia and M. Tennenholtz. Approximate mechanismdesign without money. In Proc. of ACM Conf. on ElectronicCommerce, pages 177–186, 2009.
[19] M. L. Puterman. Markov Decision Processes—DiscreteStochastic Dynamic Programming. John Wiley & Sons, Inc.,New York, NY, 1994.
[20] J. Scharpff, M. T. J. Spaan, L. Volker, and M. M. de Weerdt.Planning under Uncertainty for Coordinating InfrastructuralMaintenance. In Proc. of the International Conference onAutomated Planning and Scheduling (ICAPS), 2013. Toappear.
[21] S. Seuken, R. Cavallo, and D. Parkes. Partially-synchronizedDEC-MDPs in dynamic mechanism design. In Proc. ofNational Conf. on Artificial Intelligence, pages 162–169,2008.
[22] J. Snellen, D. Ettema, and M. Dijst. Activiteitenpatronen enreistijdwaardering (dutch). Technical report, Transumo,December 2007.
[23] R. P. van der Krogt, M. M. de Weerdt, and Y. Zhang. Ofmechanism design and multiagent planning. In M. Ghallab,C. D. Spyropoulos, N. Fakotakis, and N. Avouris, editors,European Conf. on Artificial Intelligence, pages 423–427,2008.
[24] L. Volker, J. Scharpff, M. De Weerdt, and P. Herder.Designing a dynamic network based approach for assetmanagement activities. In Proc. of 28th Annual Conferenceof Association of Researchers in Construction Management(ARCOM), 2012.
[25] D. H. Wolpert, K. Tumer, and J. Frank. Using collectiveintelligence to route internet traffic. In Proceedings of the1998 conference on Advances in neural informationprocessing systems II, pages 952–958. MIT Press, 1999.
8