performance analysis of explicit group parallel algorithms for distributed memory multicomputer
TRANSCRIPT

Available online at www.sciencedirect.com
Parallel Computing 34 (2008) 427–440
www.elsevier.com/locate/parco
Performance analysis of explicit group parallel algorithmsfor distributed memory multicomputer
Kok Fu Ng *, Norhashidah Hj. Mohd Ali
School of Mathematical Sciences, Universiti Sains Malaysia, 11800 Penang, Malaysia
Received 14 December 2006; received in revised form 7 July 2007; accepted 16 October 2007Available online 7 November 2007
Abstract
Since their introduction, the four-point explicit group (EG) and explicit decoupled group (EDG) methods in solvingelliptic PDE’s have been implemented on various parallel computing architectures such as shared memory parallel com-puter and distributed computer systems. However, no detailed study on the performance analysis of these algorithmswas done in any of these implementations. In this paper we developed performance models for these explicit group meth-ods and present detailed study of their hypothetical implementation on two distributed memory multicomputers with dif-ferent computation speed and communication bandwidth. Detailed performance analysis based on these models predicteddifferent theoretical performance if the methods were implemented on the clusters. This was confirmed by the experimentalresults performed on the two distinct clusters. Theoretical analysis and experimental results indicated that both explicitgroup methods are scalable with respect to number of processors and the problem size.� 2007 Published by Elsevier B.V.
Keywords: Performance analysis; Explicit group (EG) method; Explicit decoupled group (EDG) method; Distributed memory multico-mputer; Poisson equation; MPI
1. Introduction
Partial differential equations (PDE’s) form the basis of many mathematical models in such diverse applica-tion in physical and scientific phenomena. A particularly important class of PDE’s is that of linear equation ofsecond order in two independent variables, and Poisson’s equation is one typical representative of this classwhich arises in many physical phenomena such as electrostatic, heat conduction and fluid mechanics. A numberof numerical methods have been formulated to solve the equation with emphasis on explicit methods since theyare suitable to be implemented on parallel computing environments [1,2,5,11,12]. In a recent paper [3], two suchmethods, explicit group (EG) and explicit decoupled group (EDG), were parallelized and implemented on acluster of Sun workstations using PVM with maximum six processors. However, the results indicated some
0167-8191/$ - see front matter � 2007 Published by Elsevier B.V.
doi:10.1016/j.parco.2007.10.004
* Corresponding author. Tel.: +60 125620179; fax: +60 44218582.E-mail addresses: [email protected] (K.F. Ng), [email protected] (N.H.M. Ali).

428 K.F. Ng, N.H.M. Ali / Parallel Computing 34 (2008) 427–440
slight deterioration for certain problem size due to a significant communication overheads in the proposedstrategies. Moreover an implementation of the methods on a different computing cluster [4] showed differentand contradicting results. A detailed and rigorous analysis on these methods is therefore very much in need.
In this paper, we present a detailed performance analysis of EG and EDG methods implemented using MPIprogramming environment [6,7] on two distinct distributed memory multicomputer architectures, each by twodifferent parallelization strategies. We proceed as follows. In Section 2, we describe the model problem and theexplicit group methods in solving the problem, followed by a discussion of the parallelization strategies. Thecomputational and communication complexity of these methods along with the performance methods is devel-oped in Section 3. The scalability analysis is presented in Section 4. We present in Section 5 the numericalresults of experiments and conclude with some remarks.
2. Parallel explicit group algorithms
Consider the following Poisson equation in two-space dimension
o2u
ox2þ o
2uoy2¼ f ðx; yÞ; x; y 2 X ð2:1Þ
with Dirichlet boundary conditions on oX, where oX is the boundary of the unit square [0 6 x,y 6 1]. Theproblem is solved numerically by discretising the domain X uniformly in both x and y directions with a gridsize h = 1/n, where n is an arbitrary positive integer. The solutions of (n � 1)2 internal grid points (x,y) areapproximated by the standard five-point finite difference discretization and the rotated (skewed) five-point fi-nite difference discretization from which the four-point EG and EDG methods are derived [1,3,12] usingblocks of four points. We only present the ultimate explicit equations in this paper.
2.1. Explicit group (EG) method
Applying standard five-point finite difference to blocks of four points yields the following explicit four pointEG equation [12]
ui;j
uiþ1;j
uiþ1;jþ1
ui;jþ1
26664
37775 ¼ 1
24
7 2 1 2
2 7 2 1
1 2 7 2
2 1 2 7
26664
37775
ui�1;j þui;j�1 �h2fi;j
uiþ2;j þuiþ1;j�1 �h2fiþ1;j
uiþ2;jþ1 þuiþ1;jþ2 �h2fiþ1;jþ1
ui�1;jþ1 þui;jþ2 �h2fi;jþ1
26664
37775; ð2:2Þ
where subscripts i and j represent x and y directions respectively. The solution for the domain X is obtained byiteratively evaluating (2.2) in blocks of four points until a desired accuracy is achieved. The computationalmolecule is shown in Fig. 1.
Fig. 1. Computational molecule of EG method.

K.F. Ng, N.H.M. Ali / Parallel Computing 34 (2008) 427–440 429
2.2. Explicit decoupled group (EDG) method
Similarly, applying rotated (skewed) five-point finite difference discretization to blocks of four points yieldsthe following explicit four point EDG equation [1]:
ui;j
uiþ1;jþ1
uiþ1;j
ui;jþ1
26664
37775 ¼ 1
15
4 1 0 0
1 4 0 0
0 0 4 1
0 0 1 4
26664
37775
ui�1;j�1 þuiþ1;j�1 þui�1;jþ1 �2h2fi;j
uiþ2;j þuiþ2;jþ2 þui;jþ2 �2h2fiþ1;jþ1
ui;j�1 þuiþ2;j�1 þuiþ2;jþ1 �2h2fiþ1;j
ui�1;j þui�1;jþ2 þuiþ1;jþ2 �2h2fi;jþ1
26664
37775; ð2:3Þ
which can be decoupled into a system of 2 · 2 equations
ui;j
uiþ1;jþ1
� �¼ 1
15
4 1
1 4
� �ui�1;j�1 þuiþ1;j�1 þui�1;jþ1 �2h2fi;j
uiþ2;j þuiþ2;jþ2 þui;jþ2 �2h2fiþ1;jþ1
" #; ð2:4Þ
uiþ1;j
ui;jþ1
� �¼ 1
15
4 1
1 4
� �ui;j�1 þuiþ2;j�1 þuiþ2;jþ1 �2h2fiþ1;j
ui�1;j þui�1;jþ2 þuiþ1;jþ2 �2h2fi;jþ1
" #: ð2:5Þ
Note that from their corresponding computational molecules in Fig. 2, it is obvious that the evaluation of(2.4) and (2.5) can be performed independently, thus saving the execution time by nearly half. The solution forthe half of the domain X (either points of • or j) is obtained by iteratively evaluating either (2.4) or (2.5) inblocks of four points until a desired accuracy, after which the remaining half of the domain (either points of j
or •) can be computed directly once using standard five-point formula. In this paper we solve points of •iter-atively and points of j directly.
We now describe two strategies to parallelize the above methods in a distributed memory multicomputerenvironment. In both strategies, the decomposition of domain is the same as in [3] but the implementationin terms of communication complexity is different for EDG method in parallel strategy 1, and for both meth-ods in parallel strategy 2 [4]. The complexity detail is given in Section 3. Note that one dimensional domaindecomposition is used in both parallelizing strategies in [3,4].
2.3. Parallel strategy 1 (Panels A&B)
In parallel strategy 1, the domain X is decomposed into alternating horizontal panels assigned to availableprocessors as shown in Fig. 3. Each panel contains two rows of domain points to form a strip of four-pointgroups. The groups are labeled A and B, and the discretized Eqs. (2.2) and either (2.4) or (2.5) are evaluated onthese grouped points in natural order, that is in increasing order of i and j. Fig. 3 shows the evaluation orderfor n = 13 and number of processors, p = 3.
The evaluation of u in a single iterative step is done in two stages. Stage 1 updates all group A’s and Stage 2updates all group B’s. It can be shown [2,3] that the updates of u involved in each stage are independent and
Fig. 2. Independent computational molecules of EDG method.

Fig. 3. Domain decomposition and arrangement of 4-point groups for parallel strategy 1.
Table 1Sequential tasks in a complete single iterative step of parallel strategy 1
Stage Sequential task
1a Transfer boundary row of group B’s to adjacent processor1b Update points on group A’s and check local convergence2a Transfer boundary row of group A’s to adjacent processor2b Update points on group B’s and check local convergenceConvergence test Check global convergence by reducing all local convergence values
430 K.F. Ng, N.H.M. Ali / Parallel Computing 34 (2008) 427–440
therefore can be done in parallel. Since the update of group A’s (or group B’s) requires the values of somepoints in group B’s (or group A’s), communication need to be carried out to send values of local domainboundary points to adjacent processors. So a complete single iterative step in every processor will consistof a series of sequential tasks as listed in Table 1.
The computational and communication costs in each stage will be analyzed in Section 3.
Fig. 4. Domain decomposition and arrangement of 4-point groups for parallel strategy 2.

K.F. Ng, N.H.M. Ali / Parallel Computing 34 (2008) 427–440 431
2.4. Parallel strategy 2 (Panels AC&DB)
In parallel strategy 2, the domain X is also decomposed into alternating horizontal panels, each comprisingtwo rows of domain points to form a strip of four-point groups. However the groups are labeled A, B, C andD as shown in Fig. 4.
The evaluation of u in an iteration is done in four stages: Stage 1 (all group As), followed by Stage 2 (allgroup B’s), Stage 3 (all group C’s), and finally Stage 4 (all group D’s). It also can be shown [2,3] that the com-putations within each stage are independent and can be carried out in parallel. So a complete single iterativestep in every processor will consist of a series of sequential tasks as shown in Table 2.
3. Computational and communication complexity
In this section, we develop performance models for EG and EDG methods based on computational andcommunication complexity in one iterative step. The speedup of the methods can then be approximated tothe speedup calculated from the performance models in this one iterative step [8].
3.1. Parallel strategy 1 (Panel A&B)
3.1.1. EG method
The computational cost of EG method is obtained from (2.2).From (2.2), we obtain
TableSequen
Stage
1a1b2a2b3a3b4a4bConve
ui;j
uiþ1;j
uiþ1;jþ1
ui;jþ1
26664
37775 ¼ 1
24
7 2 1 2
2 7 2 1
1 2 7 2
2 1 2 7
26664
37775
r1
r2
r3
r4
26664
37775; ð3:1Þ
where
r1
r2
r3
r4
26664
37775 ¼
ui�1;j þui;j�1 �h2fi;j
uiþ2;j þuiþ1;j�1 �h2fiþ1;j
uiþ2;jþ1 þuiþ1;jþ2 �h2fiþ1;jþ1
ui�1;jþ1 þui;jþ2 �h2fi;jþ1
26664
37775: ð3:2Þ
Thus, the update equation for an individual point say uij is given by
~ui;j ¼1
24½7r1 þ 2ðr2 þ r4Þ þ r3� ð3:3Þ
2tial tasks in a complete single iterative step of parallel strategy 2
Sequential task
Transfer boundary row of group D’s to adjacent processorUpdate points on group A’s and check local convergenceTransfer boundary row of group C’s to adjacent processorUpdate points on group B’s and check local convergenceTransfer boundary row of group B’s to adjacent processorUpdate points on group C’s and check local convergenceTransfer boundary row of group A’s to adjacent processorUpdate points on group D’s and check local convergence
rgence test Check global convergence by reducing all local convergence values

432 K.F. Ng, N.H.M. Ali / Parallel Computing 34 (2008) 427–440
and the SOR iterative scheme is given by
uðkþ1Þi;j ¼ uðkÞi;j þ x ~ui;j � uðkÞi;j
� �: ð3:4Þ
Since an update stage is done in groups of four points, the values of ri for i = 1,4 are calculated only oncebefore computing those four points of u. This results in seven additions and four multiplications for a singlepoint, provided the constants 1/24 and h2 fij are computed and stored beforehand. Let ta and tm be the costs ofa floating point addition and multiplication respectively of a specific machine. Thus, the update cost of a singlepoint in EG method is given by
tEG1-update ¼ 7ta þ 4tm: ð3:5Þ
One might leave the update cost expression as indicated in (3.5) and benchmark the parameter ta and tmseparately. However we treat the whole expression as a single parameter, tEG-update, and carefully benchmarkit for the difference parallel strategies and computing cluster. This results in a more stable and reliable perfor-mance model for the specific parallel implementation. Therefore the computational cost of EG method in onecomplete iterative step, dependent on the problem size, n, and number of processors, p, is given by
T EG1-compðn; pÞ ¼ðn� 1Þ2
ptEG1-update: ð3:6Þ
The communication cost for message passing of m data words in a distributed memory multicomputer ismodeled approximately by
tsend ¼ ts þ mtd; ð3:7Þ
where ts is the startup time or message latency, and td is the time to send one double-type data or word cost[7,9,10].The computation molecule (Fig. 1) of EG method requires n � 1 points to be passed to the adjacent pro-cessor in each Stage 1 and Stage 2 of an iteration. Furthermore, at the end of an iteration, a reduce commu-nication is required to check for global convergence of the methods from all participating processes. The MPIcollective communication function, MPI_Allreduce, is used here to reduce a logical variable using MPI_LAND operation which cost is modeled as a binary-tree structured communication approximately as
T allreduce ¼ treducelog2p; ð3:8Þ
where treduce is the cost of performing a logical operation and communicating it.Therefore the total communication cost of EG method in a single iterative step, consisting of two sequentialpoint-to-point communications and one global collective communication (Table 1), is given by
T EG1-commðnÞ ¼ 2ts þ 2ðn� 1Þtd þ treducelog2p: ð3:9Þ
As such, the total costs of an iteration in EG method of parallel strategy 1 isT EG1ðn; pÞ ¼ðn� 1Þ2
ptEG1-update þ 2ts þ 2ðn� 1Þtd þ treducelog2p: ð3:10Þ
3.1.2. EDG method
The computational cost of EDG method is obtained from (2.4).From (2.4), we obtain
ui;j
uiþ1;jþ1
� �¼ 1
15
4 1
1 4
� �r1
r2
� �; ð3:11Þ
where
r1
r2
� �¼ ui�1;j�1 þuiþ1;j�1 þ ui�1;jþ1 �2h2fi;j
uiþ2;j þuiþ2;jþ2 þ ui;jþ2 �2h2fiþ1;jþ1
" #: ð3:12Þ

K.F. Ng, N.H.M. Ali / Parallel Computing 34 (2008) 427–440 433
Thus, the update equation for an individual point say uij is given by
~ui;j ¼1
15½4r1 þ r2� ð3:13Þ
and the SOR iterative scheme is given by
uðkþ1Þi;j ¼ uðkÞi;j þ x ~ui;j � uðkÞi;j
� �: ð3:14Þ
Since the update stage is done in groups of two points, the values of ri for i = 1,2 are calculated only oncebefore computing those two points of u. This results in six additions and three multiplications for a singlepoint, provided the constants 1/15 and 2h2 fij are computed and stored beforehand. Thus the update costof a single point in EDG method is given by
tEDG1-update ¼ 6ta þ 3tm: ð3:15Þ
As with EG method, we benchmark tEDG-update as a whole parameter. Take note that the EDG methodinvolves only half of the domain, therefore the computational cost of a single iterative step, as a functionof problem size, n, and number of processors, p, is given by
T EDG1-compðn; pÞ ¼ðn� 1Þ2
2ptEDG1-update: ð3:16Þ
It can be seen from (3.16) and (3.6) that the computational cost of EDG method is less than half (9/22to be exact if ta = tm) of the computational cost of EG method. However we expect the experimental ratioto be much higher due to some overheads such as loop initialization and address calculation in EDGmethod.
The communication required in EDG method is exactly the same as in EG method except that only half ofthe (n � 1) points (see computation molecule of Fig. 2) are required to be sent to the adjacent processor in eachStage 1 and Stage 2 of an iteration. Therefore the communication cost of EDG method in a single iterativestep is given by
T EDG1-commðnÞ ¼ 2ts þ ðn� 1Þtd þ treducelog2p: ð3:17Þ
It can be seen from (3.17) and (3.9) that the communication cost of EDG method is approaching half of thecommunication cost of EG method for large n.Therefore, the total costs of an iteration in EDG method of parallel strategy 1 is
T EDG1ðn; pÞ ¼ðn� 1Þ2
2ptEDG1-update þ 2ts þ ðn� 1Þtd þ treducelog2p: ð3:18Þ
In the performance equation derived above (3.10) and (3.18), the machine-dependent characteristic param-eters tEG1�update, tEDG1-update, ts, td and treduce will be evaluated by experiments on two test clusters.
3.2. Parallel strategy 2 (Panels AC&DB)
The computational expressions of EG (3.6) and EDG (3.16) methods described above remains unchangedin Parallel Strategy 2. As such we might assume both strategies have equal computational cost per iterationstep. However since Strategy 2 doubles the computation stages compared to Strategy 1 hence the extra over-heads, we would expect higher update costs. Therefore we benchmark the point update cost for parallel strat-egy 2 separately from parallel strategy 1.
The communication cost of both methods increases in Strategy 2 as there are now four stages of commu-nication (Table 2). Besides, since each update stage involves only alternating group of four points, so only(n � 1)/2 points of local boundary need to be sent to adjacent processors. Figs. 5 and 6 illustrate this require-ment for EG and EDG method respectively.
Therefore using the same performance model developed in Section 3.1, the total cost of an iterative step forEG and EDG methods of parallel strategy 2 is as follows:

Fig. 5. (EG method) Update of A groups in Processor 3 requires (n � 1)/2 local boundary points from Processor 2.
Fig. 6. (EDG method) Update of A groups in Processor 3 requires (n � 1)/2 local boundary points from Processor 2.
434 K.F. Ng, N.H.M. Ali / Parallel Computing 34 (2008) 427–440
T EG2ðn; pÞ ¼ðn� 1Þ2
ptEG2-update þ 4ts þ 2ðn� 1Þtd þ treducelog2p: ð3:19Þ
T EDG2ðn; pÞ ¼ðn� 1Þ2
2ptEDG2-update þ 4ts þ 2ðn� 1Þtd þ treducelog2p: ð3:20Þ
3.3. Benchmarking
Although it is difficult to obtain reliable estimates for various parameters in any performance models, werun several benchmarking tests on two computing clusters available at the School of Computer Science, Uni-versiti Sains Malaysia, in which the experiments of explicit group methods are to be carried out. The two clus-ters are
(a) Stealth cluster consists of 1 unit of Sun Fire 280R with 2 processors (900 MHz UltraSPARC� III CuSuperscalar SPARC� V9), 2GB RAM, 8MB L2 Cache, and 4 unit of Sun Fire V210 each with 2 pro-cessors (1002 MHz UltraSPARC IIIi), 2 GB RAM, 1 MB of level 2 cache. The operating system usedis Solaris9 (SunOS 2.9) with Sun HPC ClusterTools 5 and Sun MPI 6.0.
(b) Aurora cluster consists of 1 unit of PC with two 1.36 GHz CPUs, 1.96 GB RAM, and 16 units of PCeach with two 1.36 GHz CPUs, 0.98 GB RAM. The PCs are connected back to back via Gigabit Ether-net NICs. The OS used is Linux 2.4.21-20.ELsmp (·86) and MPICH installation.
Both clusters are isolated from other network traffic and put under exclusive use during the experimentsto ensure the accuracy of the tests. Based on our developed performance model (3.10) and (3.18), we per-form the measuring of the four different characteristic parameters for each cluster, and the results are pre-sented in Table 3.
The values obtained from the benchmarking shows that Stealth cluster is a slower computing cluster com-pared to Aurora cluster which has smaller computational cost. On the other hand, Stealth cluster has much
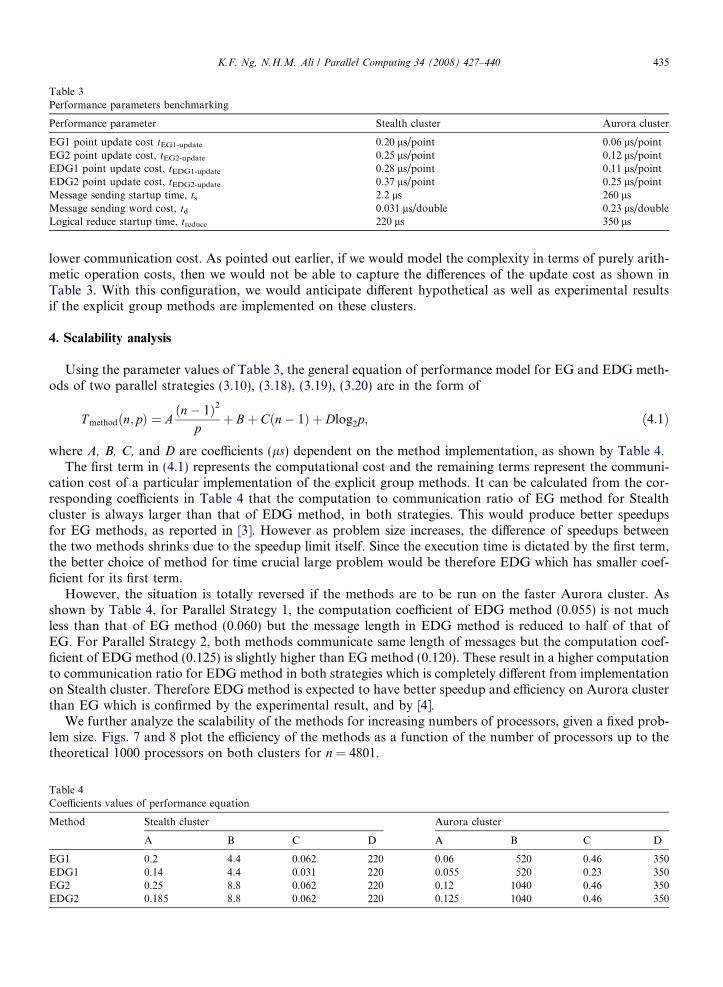
Table 3Performance parameters benchmarking
Performance parameter Stealth cluster Aurora cluster
EG1 point update cost tEG1-update 0.20 ls/point 0.06 ls/pointEG2 point update cost, tEG2-update 0.25 ls/point 0.12 ls/pointEDG1 point update cost, tEDG1-update 0.28 ls/point 0.11 ls/pointEDG2 point update cost, tEDG2-update 0.37 ls/point 0.25 ls/pointMessage sending startup time, ts 2.2 ls 260 lsMessage sending word cost, td 0.031 ls/double 0.23 ls/doubleLogical reduce startup time, treduce 220 ls 350 ls
K.F. Ng, N.H.M. Ali / Parallel Computing 34 (2008) 427–440 435
lower communication cost. As pointed out earlier, if we would model the complexity in terms of purely arith-metic operation costs, then we would not be able to capture the differences of the update cost as shown inTable 3. With this configuration, we would anticipate different hypothetical as well as experimental resultsif the explicit group methods are implemented on these clusters.
4. Scalability analysis
Using the parameter values of Table 3, the general equation of performance model for EG and EDG meth-ods of two parallel strategies (3.10), (3.18), (3.19), (3.20) are in the form of
TableCoeffic
Metho
EG1EDG1EG2EDG2
T methodðn; pÞ ¼ Aðn� 1Þ2
pþ Bþ Cðn� 1Þ þ Dlog2p; ð4:1Þ
where A, B, C, and D are coefficients (ls) dependent on the method implementation, as shown by Table 4.The first term in (4.1) represents the computational cost and the remaining terms represent the communi-
cation cost of a particular implementation of the explicit group methods. It can be calculated from the cor-responding coefficients in Table 4 that the computation to communication ratio of EG method for Stealthcluster is always larger than that of EDG method, in both strategies. This would produce better speedupsfor EG methods, as reported in [3]. However as problem size increases, the difference of speedups betweenthe two methods shrinks due to the speedup limit itself. Since the execution time is dictated by the first term,the better choice of method for time crucial large problem would be therefore EDG which has smaller coef-ficient for its first term.
However, the situation is totally reversed if the methods are to be run on the faster Aurora cluster. Asshown by Table 4, for Parallel Strategy 1, the computation coefficient of EDG method (0.055) is not muchless than that of EG method (0.060) but the message length in EDG method is reduced to half of that ofEG. For Parallel Strategy 2, both methods communicate same length of messages but the computation coef-ficient of EDG method (0.125) is slightly higher than EG method (0.120). These result in a higher computationto communication ratio for EDG method in both strategies which is completely different from implementationon Stealth cluster. Therefore EDG method is expected to have better speedup and efficiency on Aurora clusterthan EG which is confirmed by the experimental result, and by [4].
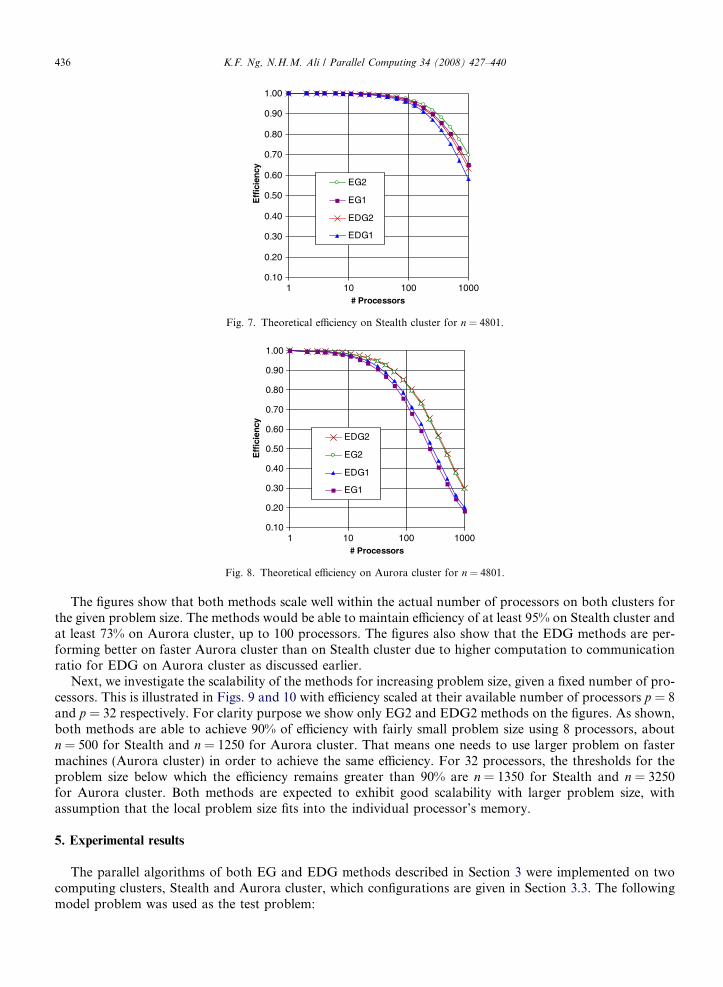
We further analyze the scalability of the methods for increasing numbers of processors, given a fixed prob-lem size. Figs. 7 and 8 plot the efficiency of the methods as a function of the number of processors up to thetheoretical 1000 processors on both clusters for n = 4801.
4ients values of performance equation
d Stealth cluster Aurora cluster
A B C D A B C D
0.2 4.4 0.062 220 0.06 520 0.46 3500.14 4.4 0.031 220 0.055 520 0.23 3500.25 8.8 0.062 220 0.12 1040 0.46 3500.185 8.8 0.062 220 0.125 1040 0.46 350
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
1 10 100 1000# Processors
Eff
icie
ncy
EG2
EG1
EDG2
EDG1
Fig. 7. Theoretical efficiency on Stealth cluster for n = 4801.
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
1 10 100 1000# Processors
Eff
icie
ncy
EDG2
EG2
EDG1
EG1
Fig. 8. Theoretical efficiency on Aurora cluster for n = 4801.
436 K.F. Ng, N.H.M. Ali / Parallel Computing 34 (2008) 427–440
The figures show that both methods scale well within the actual number of processors on both clusters forthe given problem size. The methods would be able to maintain efficiency of at least 95% on Stealth cluster andat least 73% on Aurora cluster, up to 100 processors. The figures also show that the EDG methods are per-forming better on faster Aurora cluster than on Stealth cluster due to higher computation to communicationratio for EDG on Aurora cluster as discussed earlier.
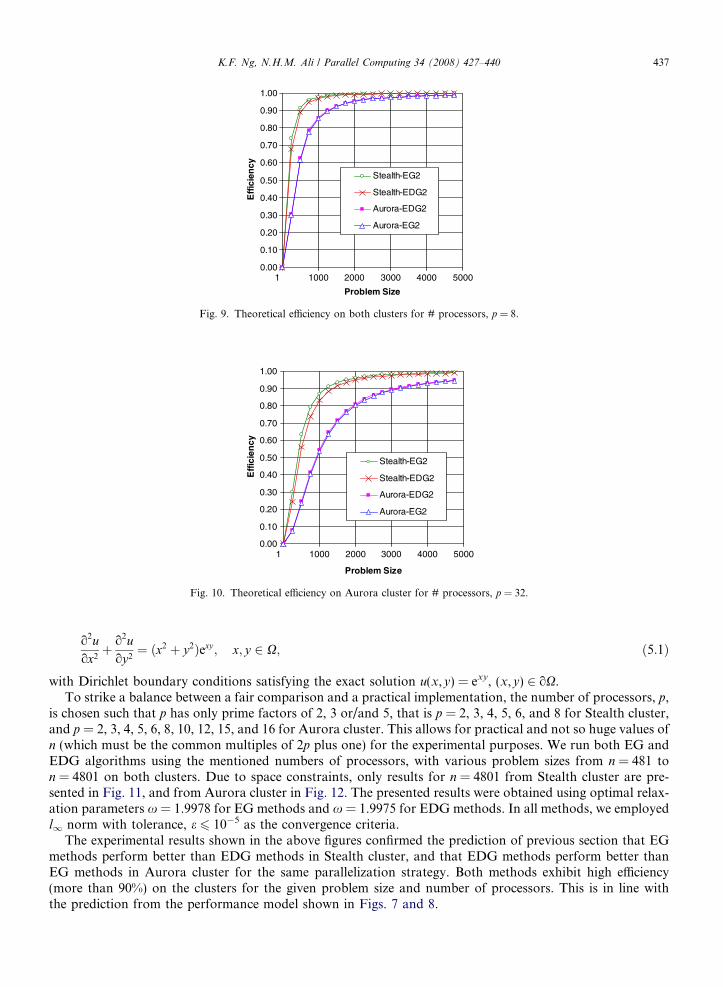
Next, we investigate the scalability of the methods for increasing problem size, given a fixed number of pro-cessors. This is illustrated in Figs. 9 and 10 with efficiency scaled at their available number of processors p = 8and p = 32 respectively. For clarity purpose we show only EG2 and EDG2 methods on the figures. As shown,both methods are able to achieve 90% of efficiency with fairly small problem size using 8 processors, aboutn = 500 for Stealth and n = 1250 for Aurora cluster. That means one needs to use larger problem on fastermachines (Aurora cluster) in order to achieve the same efficiency. For 32 processors, the thresholds for theproblem size below which the efficiency remains greater than 90% are n = 1350 for Stealth and n = 3250for Aurora cluster. Both methods are expected to exhibit good scalability with larger problem size, withassumption that the local problem size fits into the individual processor’s memory.
5. Experimental results
The parallel algorithms of both EG and EDG methods described in Section 3 were implemented on twocomputing clusters, Stealth and Aurora cluster, which configurations are given in Section 3.3. The followingmodel problem was used as the test problem:
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
1 1000 2000 3000 4000 5000
Problem Size
Eff
icie
ncy
Stealth-EG2
Stealth-EDG2
Aurora-EDG2
Aurora-EG2
Fig. 10. Theoretical efficiency on Aurora cluster for # processors, p = 32.
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
1 1000 2000 3000 4000 5000
Problem Size
Eff
icie
ncy
Stealth-EG2
Stealth-EDG2
Aurora-EDG2
Aurora-EG2
Fig. 9. Theoretical efficiency on both clusters for # processors, p = 8.
K.F. Ng, N.H.M. Ali / Parallel Computing 34 (2008) 427–440 437
o2uox2þ o2u
oy2¼ ðx2 þ y2Þexy ; x; y 2 X; ð5:1Þ
with Dirichlet boundary conditions satisfying the exact solution u(x,y) = exy, (x,y) 2 oX.To strike a balance between a fair comparison and a practical implementation, the number of processors, p,
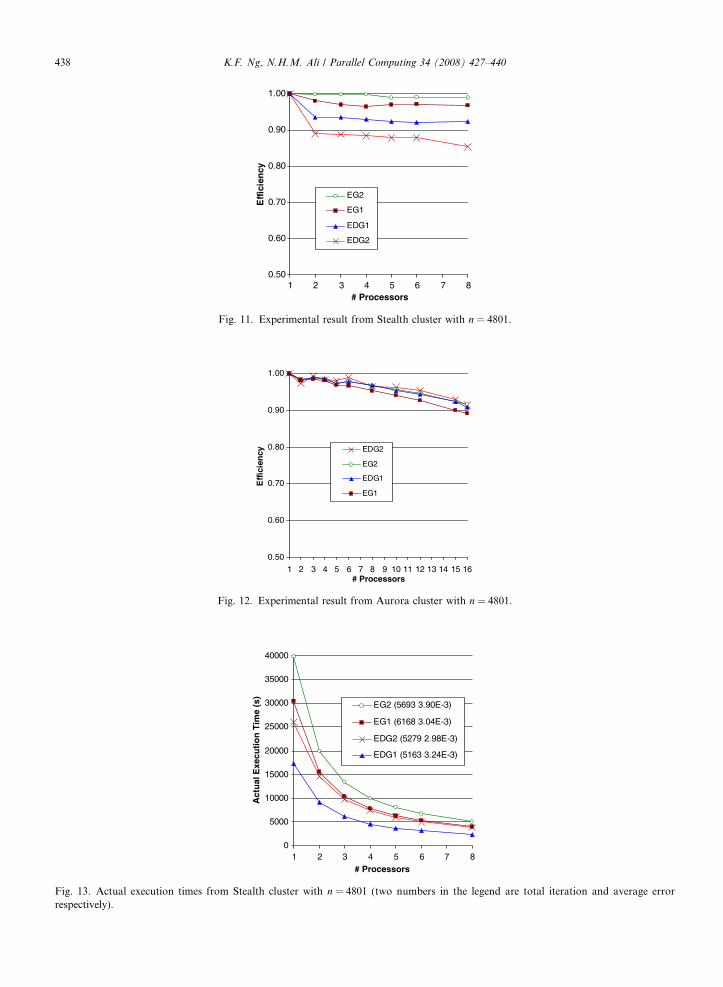
is chosen such that p has only prime factors of 2, 3 or/and 5, that is p = 2, 3, 4, 5, 6, and 8 for Stealth cluster,and p = 2, 3, 4, 5, 6, 8, 10, 12, 15, and 16 for Aurora cluster. This allows for practical and not so huge values ofn (which must be the common multiples of 2p plus one) for the experimental purposes. We run both EG andEDG algorithms using the mentioned numbers of processors, with various problem sizes from n = 481 ton = 4801 on both clusters. Due to space constraints, only results for n = 4801 from Stealth cluster are pre-sented in Fig. 11, and from Aurora cluster in Fig. 12. The presented results were obtained using optimal relax-ation parameters x = 1.9978 for EG methods and x = 1.9975 for EDG methods. In all methods, we employedl1 norm with tolerance, e 6 10�5 as the convergence criteria.
The experimental results shown in the above figures confirmed the prediction of previous section that EGmethods perform better than EDG methods in Stealth cluster, and that EDG methods perform better thanEG methods in Aurora cluster for the same parallelization strategy. Both methods exhibit high efficiency(more than 90%) on the clusters for the given problem size and number of processors. This is in line withthe prediction from the performance model shown in Figs. 7 and 8.
0.50
0.60
0.70
0.80
0.90
1.00
1 2 3 4 5 6 7 8# Processors
Eff
icie
ncy
EG2
EG1
EDG1
EDG2
Fig. 11. Experimental result from Stealth cluster with n = 4801.
0.50
0.60
0.70
0.80
0.90
1.00
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16# Processors
Eff
icie
ncy EDG2
EG2
EDG1
EG1
Fig. 12. Experimental result from Aurora cluster with n = 4801.
0
5000
10000
15000
20000
25000
30000
35000
40000
1 2 3 4 5 6 7 8# Processors
Act
ual
Exe
cuti
on
Tim
e (s
)
EG2 (5693 3.90E-3)
EG1 (6168 3.04E-3)
EDG2 (5279 2.98E-3)
EDG1 (5163 3.24E-3)
Fig. 13. Actual execution times from Stealth cluster with n = 4801 (two numbers in the legend are total iteration and average errorrespectively).
438 K.F. Ng, N.H.M. Ali / Parallel Computing 34 (2008) 427–440
0
5000
10000
15000
20000
25000
30000
35000
40000
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16# Processors
Act
ual
Exe
cuti
on
Tim
e (s
) EG2 (5693 3.90E-3)
EDG2 (5279 2.98E-3)
EG1 (6168 3.04E-3)
EDG1 (5163 3.24E-3)
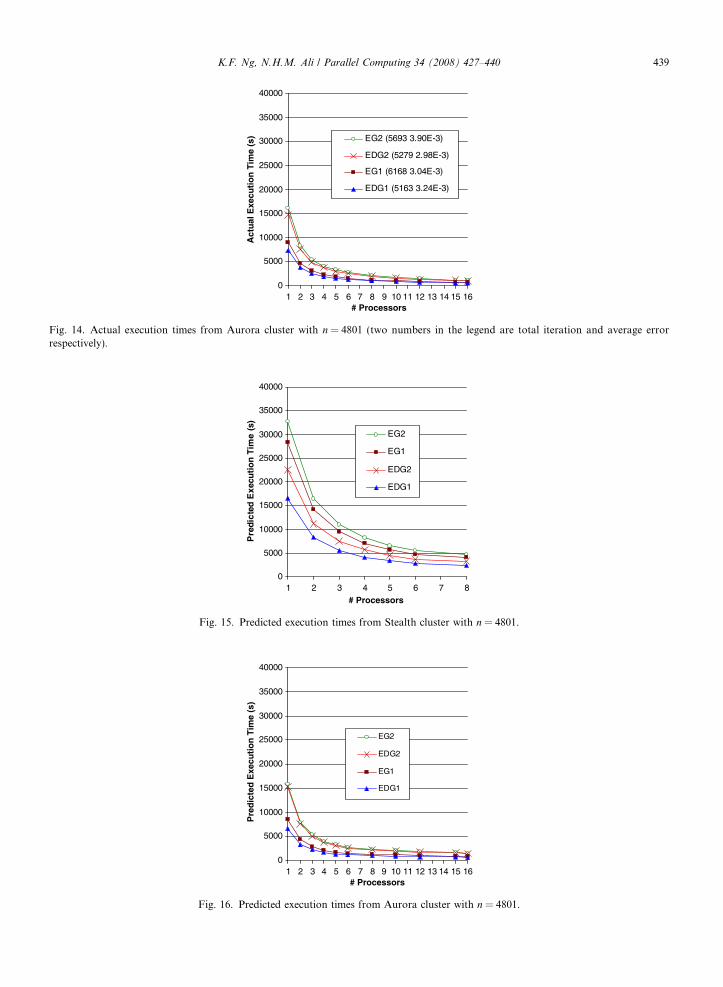
Fig. 14. Actual execution times from Aurora cluster with n = 4801 (two numbers in the legend are total iteration and average errorrespectively).
0
5000
10000
15000
20000
25000
30000
35000
40000
1 2 3 4 5 6 7 8# Processors
Pre
dic
ted
Exe
cuti
on
Tim
e (s
)
EG2
EG1
EDG2
EDG1
Fig. 15. Predicted execution times from Stealth cluster with n = 4801.
0
5000
10000
15000
20000
25000
30000
35000
40000
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16# Processors
Pre
dic
ted
Exe
cuti
on
Tim
e (s
)
EG2
EDG2
EG1
EDG1
Fig. 16. Predicted execution times from Aurora cluster with n = 4801.
K.F. Ng, N.H.M. Ali / Parallel Computing 34 (2008) 427–440 439

440 K.F. Ng, N.H.M. Ali / Parallel Computing 34 (2008) 427–440
The experimental results indicate the EDG methods, especially with parallel strategy 2, are better solversfor the Poisson equation than EG methods in terms of accuracy, convergence rate and efficiency. TheEDG methods converge more rapidly than EG methods while producing solutions with less average errorand within shorter execution time. Figs. 13 and 14 show the actual execution times of all methods for Stealthand Aurora clusters respectively. The total iteration numbers and the average error for each method are listedin the respective lines in the legend. For comparison purpose, we present the predicted execution times in Figs.15 and 16, which are calculated from the cost per iterative step Eq. (4.1) using coefficients values from Table 4and the corresponding total iteration numbers from the experimental results. The predicted execution timesare found to be very close to the actual execution times.
6. Conclusion
In this paper, we have presented the theoretical performance analysis and experimental results of the par-allel explicit group methods on two distinct computing clusters, implemented in MPI environment. The the-oretical execution times and efficiency values obtained from the performance models are found to be inagreement with the experimental results for both EG and EDG methods implemented on two different clus-ters. The algorithms turn out to be efficient solvers for the Poisson equation on distributed memory multicom-puter with high scalability. We have shown that both explicit group methods exhibit good parallelperformance with the EDG as the better method with higher accuracy, convergence rate and efficiency, espe-cially if implemented on cluster with high computation speed. Both theoretical and experimental results showthat the methods scale well as the number of processors increases for large scale problems.
References
[1] A.R. Abdullah, The four point explicit decoupled group (EDG) method: a fast Poisson solver, Int. J. Comput. Math. 38 (1991) 61–70.[2] A.R. Abdullah, N.M. Ali, The comparative study of parallel strategies for the solution of elliptic PDE’s, Parallel Algor. Appl. 10
(1996) 93–103.[3] N.H.M. Ali, R. Abdullah, K.J. Lee, A comparative study of explicit group iterative solvers on a cluster of workstations, Parallel
Algor. Appl. 19 (4) (2004) 237–255.[4] N.H.M. Ali, K.F. Ng, Explicit group PDE solvers in an MPI environment. In: Paper presented at the International Conference on
Mathematical Modelling and Computation, Universiti Brunei Darussalam, 5 June, 2006.[5] D.J. Evans, W.S. Yousif, The implementation of the explicit block iterative methods on the Balance 8000 parallel computer, Parallel
Comput. 16 (1990) 81–97.[6] W. Gropp, E. Lusk, A. Skjellum, Using MPI: portable parallel programming with the message-passing interface, second ed., MIT
Press, Cambridge, MA, 1999.[7] P.S. Pacheco, Parallel Programming with MPI, Morgan Kaufmann Publishers, San Francisco, CA, 1997.[8] D. Petcu, The performance of parallel iterative solvers, Comput. Math. Appl. 50 (2005) 1179–1189.[9] L.R. Scott, T. Clark, B. Bagheri, Scientific Parallel Computing, Princeton University Press, Princeton, 2005.
[10] B. Wilkinson, M. Allen, Parallel Programming: Techniques and Applications Using Networked Workstations and ParallelComputers, Prentice Hall, Upper Saddle River, NJ, 1999.
[11] W.S. Yousif, D.J. Evans, Explicit decoupled group iterative methods and their parallel implementation, Parallel Algor. Appl. 7 (1995)53–71.
[12] W.S. Yousif, D.J. Evans, Explicit group over-relaxation methods for solving elliptic partial differential equations, Math. Comput.Simul. 28 (1986) 453–466.