machine learning based adaptive watermark decoding in view of anticipated attack
TRANSCRIPT

Pattern Recognition 41 (2008) 2594–2610www.elsevier.com/locate/pr
Machine learning based adaptive watermark decoding in view ofanticipated attack
Asifullah Khana,b, Syed Fahad Tahirc, Abdul Majidb, Tae-Sun Choia,∗aDepartment of Mechatronics, Gwangju Institute of Science and Technology, 1 Oryong-Dong, Buk-Gu, Gwangju 500-712, Republic of Korea
bDepartment of Information and Computer Sciences, Pakistan Institute of Engineering and Applied Sciences, Nilore, Islamabad, PakistancFaculty of Computer Science and Engineering, Ghulam Ishaq Khan (GIK) Institute of Engineering Science and Technology, Swabi, Pakistan
Received 20 June 2007; received in revised form 29 November 2007; accepted 5 January 2008
Abstract
We present an innovative scheme of blindly extracting message bits when a watermarked image is distorted. In this scheme, we have exploitedthe capabilities of machine learning (ML) approaches for nonlinearly classifying the embedded bits. The proposed technique adaptively modifiesthe decoding strategy in view of the anticipated attack. The extraction of bits is considered as a binary classification problem. Conventionally, ahard decoder is used with the assumption that the underlying distribution of the discrete cosine transform coefficients do not change appreciably.However, in case of attacks related to real world applications of watermarking, such as JPEG compression in case of shared medical imagewarehouses, these coefficients are heavily altered. The sufficient statistics corresponding to the maximum likelihood based decoding process,which are considered as features in the proposed scheme, overlap at the receiving end, and a simple hard decoder fails to classify them properly.In contrast, our proposed ML decoding model has attained highest accuracy on the test data. Experimental results show that through its trainingphase, our proposed decoding scheme is able to cope with the alterations in features introduced by a new attack. Consequently, it achievespromising improvement in terms of bit correct ratio in comparison to the existing decoding scheme.� 2008 Elsevier Ltd. All rights reserved.
Keywords: Watermarking; Support vector machines (SVM); Artificial neural networks (ANN); Discrete cosine transform (DCT); Bit correct ratio (BCR);Decoding
1. Introduction
Watermarking, closely related to the fields of cryptographyand steganography, is the art of imperceptibly altering a digitalmedium to embed a message about that digital medium. Withthe wide spread and complex use of digital medium, a questionabout the security of the digital medium arises immediately.This concern is effectively addressed by watermarking, owingto its three nice characteristics; imperceptibility, inseparabilityfrom the cover content, and its inherent ability to undergo thesame transformations as experienced by the cover content. Inaddition, it can be employed on many digital mediums like text,audio, images, graphics, movies and 3D models. Its purpose islargely to counter problems like unauthorized handling, copying
∗ Corresponding author.E-mail address: [email protected] (T.-S. Choi).
0031-3203/$30.00 � 2008 Elsevier Ltd. All rights reserved.doi:10.1016/j.patcog.2008.01.007
and reuse of information. Pertinent applications of watermark-ing include ownership assertion, authentication, broadcast mon-itoring and integrity control [1,2].
Watermarking scheme is mostly designed in view of its ap-plications. Decoding of a watermark from the watermarked im-age is an important phase of a watermarking system, especially,when an attack on the watermarked image is highly probable.There is no such watermark decoding scheme that can performwell under all hostile attacks. However, with the growing needof sophisticated watermarking applications, we need a decodingscheme that should perform well under a specific set of conceiv-able attacks. Generally, channel noise and JPEG compressionare the two most common attacks. They can appreciably changethe underlying distribution of discrete cosine transform (DCT)coefficients. The traditional decoders assume that the distri-bution of DCT coefficients is not heavily altered and thus arenot able to retain performance under such attacks. In contrast,the proposed machine learning (ML) decoding models are

A. Khan et al. / Pattern Recognition 41 (2008) 2594–2610 2595
able to learn the distribution of the altered coefficients andachieve a significant margin of improvement. However, thetrained ML decoding model has to be provided at the decod-ing side for blindly extracting the message bits. Dependingupon the nature of the watermarking application, we can makethe trained ML decoding model public. On the other hand, thetrained model can be provided through a private channel or en-crypted along with other secret knowledge of the watermarkingsystem. The encryption layer that overlays above the water-marking layer could be very effective in enhancing the overallsecurity of the watermarking system [3]. In essence, the con-straint of making the trained model private on one side limitsits applications, but on the other side, enhances the securityof the watermarking system [4], especially, if we consider thecomplex security requirement of unauthorized decoding [3].The potential applications of such adaptive ML decoding tech-niques could be like device control, and broadcast monitoring,as in both cases the ML decoding scheme can be employed inhardware form with the capability of adaptively modifying inview of the new attacks. Piracy detection and copyright demon-stration when associated with a copyright authentication centercould also be potential applications.
Recently, support vector machines (SVM) and artificial neu-ral networks (ANN) based ML techniques have been appliedto improve watermarking systems [5–12]. Especially, some re-searchers have concentrated on developing strategies for water-mark detection/decoding by exploiting the learning capabilitiesof ML techniques. However, in the present work, we presenta novel idea of adaptively modifying the decoding strategy inview of a specific application of the watermarking system. Forexample, consider a watermarking application where it is highlyprobable to JPEG compress the watermarked images beforetransmission or storing in an image warehouse, such as, sharedmedical image warehouses utilized for remote diagnostic aidapplications and telesurgery. In such a scenario, it is judiciousto exploit the learning capabilities of ML systems by providinginformation about the distortion caused by the JPEG compres-sion during its training phase. Once the ML decoding model isdeveloped, it can be effectively employed for blindly extractingthe embedded message from the distorted image. Other perti-nent examples of such specific applications consist of a channelcharacterized by Gaussian noise, intentional or unintentionalfiltering, valuematric distortion, etc.
Our main contributions in this regard are as follows:
• Bit extraction is considered as a binary classification prob-lem in view of hostile attacks.• Exploitation of the fact that distortion caused by an at-
tack might have incurred varyingly on different frequencybands.• Employment of SVM and ANN based ML models for
adaptively developing high performance watermark decod-ing in view of its intended application.
The remaining part of this paper is organized such thatSection 2 describes the related research work. Section 3provides a brief overview of ANN and SVM techniques. Our
proposed watermark decoding scheme is described in Section 4.This includes dataset generation as well as the developmentof ML based decoding models. Results and discussion areexplained in Section 5, followed by conclusion in the lastsection.
We use many abbreviations and for reader’s clarity, weexplicitly mention these abbreviations in this section. Theyinclude, support vector machines (SVM), artificial neuralnetworks (ANN), discrete cosine transform (DCT), machinelearning (ML), threshold based decoding (TD) and bit correctratio (BCR).
2. Related research work
Some researchers have put sizable effort to develop newdecoder structures for increasing decoding performance. Forexample, Barni et al. [13] have proposed a new decoding al-gorithm that is powerful in case of non-additive watermark-ing techniques. Likewise, Hernandez et al. [14], Nikolaidis etal. [15] and Briassouli et al. [16,17] have developed nonlin-ear detection/decoding structures that improve on the correla-tion based techniques frequently used in watermarking systems.Their models exploit the properties of probability density func-tions of the transform domain coefficients of the cover work.Nevertheless, these efforts do not present a generic scheme thatcould easily develop a decoder useful in case of a new water-marking application and the subsequent attack. As such, thereis a strong need of easily generating application-specific de-coders. These decoders need to be blind as well as effectiveagainst the conceivable attack.
ML models both in watermarking and steganography are ef-fectively employed at the embedding, detection and decodingstages [5–12]. For instance, very recently, Fridrich et al. [5]have shown improved blind steganalysis by merging Markovand DCT features and utilizing SVM. Fu et al. [6] have appliedSVM for logo detection. The difference in the intensity levelof pixels’ blue components is used for training the SVM. Lyuet al. [7] utilize the learning capabilities of SVM to classifywatermarked images based on the high order statistical mod-els of natural images. Shen et al. [8] employ support vectorregression at the embedding stage for adaptively embeddingthe watermark in the blue channel in view of the human visualsystem. On the other hand, Sang et al. [11] have proposed azero-watermark scheme that employs ANN for feature extrac-tion. Recently, Wang et al. [9] have proposed an ANN controllerfor selecting the strength of the embedded data in view of thehuman audio system. Similarly, Li et al. [12] have used inde-pendent component analysis to extract watermark blindly. Yet,the performance of their system is dependent on the statisticalindependence between the original cover work and the water-mark. Nonetheless, none of these ML based approaches takeinto consideration the intended application and consequentlyare not adaptive toward a new anticipated attack while detect-ing/decoding the watermark.
As far as the applications of genetic programming (GP) inwatermarking are concerned, Khan et al. [19–21] have used GPfor perceptually shaping watermark with respect to both the

2596 A. Khan et al. / Pattern Recognition 41 (2008) 2594–2610
conceivable attacks and cover image at the embedding stage.In a recent work, Khan [18] has proposed the modification ofdecoder structure using GP in accordance to both the cover im-age and conceivable attacks. However, in his proposed scheme,the sufficient statistics of the maximum likelihood based in-formation decoding process are modified using the geneticallyevolved nonlinear mapping function. The modified sufficientstatistics are then presented to a threshold based decoder. Incontrast, in the present work, this nonlinear mapping in viewof the anticipated attack is achieved inherently through thekernel functions in case of SVMs, and hidden layers in caseof ANN.
As far as distortions suffered by a watermarked data are con-cerned, various researchers, e.g. Cox et al. [1] and Barni et al.[2] have studied and categorized these distortions. For exam-ple, addition of different types of noise, signal processing at-tacks such as D/A conversion, color reduction, linear filteringattacks like high pass and low pass filtering, lossy compres-sion, geometric distortions, etc. Keeping in view these distor-tions, researchers have also investigated various approaches tomake watermark system more reliable. They have proposed re-dundant embedding, selection of perceptually significant coef-ficients, spread spectrum modulation and inverting distortion inthe detection phase [1]. Efforts are put in to theoretically eval-uate the performance of a watermarking scheme in presence ofa specific distortion. For instance, the performance of spread-transform dither modulation watermarking system is theoreti-cally evaluated assuming non-additive attacks [22]. In anotherrecent work, Cox et al. [23], incorporate the idea of perceptualshaping into spread-transform dither modulation based water-marking scheme for improving imperceptibility as well as ro-bustness against JPEG compression. In contrast, we exploit thelearning capabilities of both SVM and ANN models for adap-tively modifying the decoding mechanism in view of a specificattack. This is accomplished by training the proposed ML de-coding model in view of the specific attack. Our present workis an extension of our previous work [24], where we have an-alyzed the performance of SVM based decoding only againstGaussian noise attack. However, in the present work, we notonly analyze and compare the performance of different ML de-coding models using both self-consistency and cross-validationtechniques, but also study their performance against diversebenchmark attacks.
3. ML techniques
3.1. ANN models
ANN based ML techniques are extensively used in patternrecognition. They are mostly categorized in terms of super-vised and unsupervised learning algorithms. The ANN net-works present a distinct way to analyze data, and to recognizepatterns within the data [25,26]. A network is characterized byits architecture, learning method and activation function. Ar-chitecture of a neural network describes the pattern in whichthe neurons are interconnected. In this work, we are using su-pervised ANN models in which n input training pairs (xi, yi),
where xi ∈ RN and yi ∈ [−1, 1], are presented to the ANNnetwork.
In order to develop ANN decoding scheme, back-propagationlearning algorithm is employed during training phase. This al-gorithm computes the error e, for output neuron j, as follows:
ej (t)= zj (t)− yj (t), (1)
where zj and yj are the actual and target output for neuronj for iteration t. The average squared error of the network isobtained as
�avg(t)= 1
n
n∑
t=1
�(t), (2)
where, �(t) = 12
∑j∈P e2
j (t), represents instantaneous sum ofsquared errors and P indicates number of neurons in the outputlayer. The average error �avg is a cost function of the network,which helps the network learn using the training samples. Theobjective of the learning process is to adjust the free parameters(weights, learning rate and steepness of the activation function)of the network to minimize �avg.
The weight vector w and the bias b are updated accordingto Levenberg–Marquardt Algorithm [27]. This algorithm worksiteratively in search of weights and biases that minimize the costfunction; mostly the sum-squared of the difference between thetarget and network output responses. While training moderate-sized networks, this algorithm trains neural networks at a rate10–100 times faster than the usual gradient descent based back-propagation method. In this algorithm, the updated weightswn+1 are computed as
wn+1 = wn − [JTJ+ �I]−1JTe, (3)
where � and e denotes a constant scalar and a vector of networkerror, respectively. J represents the Jacobean matrix, which con-tains first derivatives of the network errors with respect to theweights and biases.
3.2. SVM models
SVM is a margin based classifier having excellent general-ization capabilities [28,29]. Such models try to find an optimalseparating hyper-plane between data points of different classesin a high dimensional space. The error in SVM models occurif the data points appear on the wrong side of the boundary. Incase of a linearly separable data, a hyper-plane is determinedby maximizing the distance between the support vectors. Con-sider n training pairs (xi, yi), where xi ∈ RN and yi ∈ [−1, 1],the linear decision surface is defined as
f (x)=n∑
i=1
�iyixTi · x + b, (4)
where �i > 0. In order to find an optimal hyper-plane, the so-lution of the following optimization problem is sought:
�(w, �)= 1
2wTw + C
N∑
i=1
�i (5)

A. Khan et al. / Pattern Recognition 41 (2008) 2594–2610 2597
subject to the condition:
yi(wT�(xi)+ b)�1− �i , �i �0,
where C > 0 is the penalty parameter of the error term∑N
i=1�i
and �(x) is nonlinear mapping. The weight vector w minimizesthe cost function term wTw. Each point �(x) in the new spaceis subject to Mercer’s theorem [29], in which kernel functionsare defined as
f (x)=NS∑
i=1
�iyiK(xi, x)+b =NS∑
i=1
�iyi�(xi) · �(xj )+ b. (6)
In order to obtain different SVM classification models, we haveinvestigated performance of the following three popular kernelfunctions:
• K(xi, xj )= xTi · xj (linear kernel with parameter C)
• K(xi, xj )=exp(−�‖xi−xj‖2) (RBF kernel with parameters�, C)• K(xi, xj )= [� < xi, xj >+ r]d (polynomial kernel with pa-
rameters �, r, d and C).
4. Proposed watermark decoding scheme
For comparative analysis, we have implemented the water-mark scheme proposed by Hernandez et al. [14]. This water-marking technique is oblivious and embeds message into thelow and mid-frequency coefficients of 8× 8 DCT blocks of acover image. In their scheme, they model the DCT coefficientsof each frequency band using generalized Gaussian distribu-tion. One of the reasons for using this watermarking schemein our comparative analysis is that it employs DCT in blocksof 8 × 8 pixels, in a manner similar to the widely used JPEGcompression algorithm. Secondly, this watermarking schemehas strong theoretical foundations [14]. They have employeda TD scheme assuming that the probability density func-tion of the original coefficients remains the same even afterembedding. However, this assumption may not be valid whenattack is performed on the watermarked image. In theirmaximum likelihood based watermark extraction scheme, first,sufficient statistics corresponding to each embedded bit is com-puted and then it is compared with a threshold. In the absenceof an attack, two non-overlapping distributions of the sufficientstatistics, corresponding to ±1 bits are generated as shown inFig. 1a. Under such circumstances, a simple TD model issufficient to decode ±1 bits from the watermarked image.However, we have observed that in case of an attack on thewatermarked image, these distributions overlap as shown inFig. 1b. Consequently, simple TD model is unable to decodethe message bits efficiently.
To address such message decoding problems in watermark-ing, we propose a novel idea of decoding the message bits usingSVM and ANN based ML techniques. We assume that a non-separable message in lower dimensional space might be sepa-rable if it is mapped to higher dimensional space. This mappingto higher dimensional space is what the hidden layers in caseof ANN and the kernel functions in case of SVM are achieving.
20
15
10
5
0-6 -4 -2 0 2 4 6
20
15
10
5
0-0.2 -0.15 -0.1 -0.05 0 0.05 0.1 0.15 0.2
Fig. 1. Distribution of sufficient statistics of the maximum likelihood baseddecoding system corresponding to ±1 bits: (a) before and (b) after Gaussianattack (�= 10).
In our proposed scheme, a generalized dataset is created(Section 4.1) for developing SVM and ANN models. Theirperformance is evaluated by using self-consistency and cross-validation techniques. In self-consistency, the performance ofclassification models is reported using the training dataset.However, in cross-validation, entirely different test dataset isused. In analogy to pattern recognition, a bit corresponds to asample and a message corresponds to a particular pattern ofthese samples.
SVM classification models are developed by using linear,polynomial and RBF kernel functions. The kernel functions inSVM model are optimized by using grid search technique. Ingrid search, optimal values of kernel parameters are obtainedby selecting various values of grid range and step size. ANNmodels based on back-propagation algorithm [27] are also de-veloped. Finally, a comparative analysis of SVMs, ANN andTD models is carried out. Our decoding scheme mainly con-sists of following two modules, as shown in Fig. 2:
(1) Dataset generation module and(2) ML based decoding module.
It should be noted that in the current work, we are focusing onlyon the message retrieval using intelligent techniques and thushave employed the simple but commonly used error correc-tion technique, i.e. repetition coding. Employment of advancederror correction strategies [30,31], for example, trellis [32],low density parity-check [33] and turbo [34] coding, would

2598 A. Khan et al. / Pattern Recognition 41 (2008) 2594–2610
Generation of attacked watermarked images
Formation of Training & Test Datasetusing Data Sampling Techniques
Feature Extraction
Initializing the parameters of SVM
kernel functions
Minimizing Cost function
SVM Module
Tes
ting
Pha
se
Optimized SVM models
Decoding performance (BCR)
Tra
inin
g P
hase Initializing
parameters of feed-forward algorithm
ANN Module
Tes
ting
Pha
seOptimized ANN model
Decoding performance (BCR)
Tra
inin
g P
hase
Tes
ting
Pha
se
Threshold based Decoding
Decoding performance (BCR)
TD Module
Minimizing Cost function
Dat
aset
gen
erat
ion
mod
ule
Mac
hine
lear
ning
bas
ed d
ecod
ing
mod
ule
Fig. 2. Basic block diagram of the proposed ML decoding system.
certainly improve the overall message retrieval performance inall of the cases.
4.1. Proposed dataset generation
In order to analyze the performance of our proposed scheme,we have generated a dataset of 16 000 bits. For this purpose,five different images, each of size 256× 256, are used. Next, amessage of size 128 bits is embedded in each image. The wholeprocess is repeated 25 times by changing the secret key used togenerate the spread spectrum sequence. In this way, it produces125 different messages and consequently, 125 different water-marked images. Gaussian noise attack with �=10 is applied oneach image. Finally, sufficient statistics corresponding to eachembedded bit for every watermarked image is computed. Thisproduces a dataset of 16 000= 125× 128 bits. In this way, weform a dataset representing 125 different messages, being em-bedded in five different types of images generating 16 000 bits.This dataset is assumed to be a generalized one, as we havetaken into account the effect of both the cover image distribu-tion, and the secret key on the sufficient statistics. Table 1 showsthe different parameters of our dataset. A similar approach istaken in case of Wiener and JPEG compression attacks.
4.1.1. Generating attacked watermarked imagesThe underlying watermarking technique that we have used
to analyze ML based decoding is the spread spectrum basedwatermarking approach proposed by Hernandez et al. [14]. Inthis approach, the product of the spread spectrum sequence and
Table 1Parameters of input dataset
Type of images Gray scaleNumber of images 5Name of images Baboon, Lena, Trees, Boat & coupleImage size 256× 256Message size 128 bitsNumber of keys 25Type of attack Gaussian attackSeverity of attack �= 10
expanded message bits is multiplied with a perceptual mask�[k] to obtain the watermark. Let us denote the 2D discreteindices in DCT domain by [k]. The 2D watermark signal W [k]is given as
W [k] = S[k] · b[k] · �[k], (7)
where S[k] is a pseudo-random sequence and b[k] is the rep-etition based expanded code vector, corresponding to the mes-sage to be embedded. Adding this watermark to the originalimage in transformed domain, represented by X[k], performsthe embedding:
Y [k] = X[k] +W[k], (8)
where Y [k] represents the watermarked image.In analogy to communications, the watermark W [k] is our
desired signal, while the cover image X[k] acts as an addi-tive noise. Algorithm 1 contains a high level description for

A. Khan et al. / Pattern Recognition 41 (2008) 2594–2610 2599
generating attacked watermarked images using different imagesand secret keys.
Algorithm 1. Generating attacked watermarked imagedatabase.//We omit the 2-d vector indices [k] for elaboration purpose//x, y: original and watermarked images in spatial domainrespectively//fa: attack function, z: attacked watermarked image//X, Y: original and watermarked images in DCT domainrespectively//W: watermark, S: spread spectrum sequence, b: expandedmessage vector// �: perceptual mask, Imax: No. of images, Qmax: No. ofsecret keys1: Encode the message of size 128 bits using an errorcorrection technique and expand it to form a vector b2: for i ← 1 to Imax do //select different standard
images3: X = DCT2(x) //compute 8×8 block DCT
of the image4: Xi ← X5: �i ← � //compute perceptual
mask of the image6: for q← 1 to Qmax, do //select different secret keys7: generate Sq //generate the spread
spectrum sequence8: W = �i · Sq · b // compute the watermark9: Wi
q ←W10: Yi
q = Xi +Wiq //perform watermark
embedding11: yi
q = invDCT2(Yiq) //perform inverse DCT
12: ziq = fa(yi
q) //perform attack on thewatermarked image
4.1.2. Proposed feature extractionWhen a watermarked image is attacked, the message within
the image is also corrupted. We have computed features corre-sponding to each bit of a message, in two different ways. In thefirst method, the sufficient statistics ri corresponding to eachbit of the maximum likelihood based decoding system acrossall the frequency bands is computed [14]. Therefore, we obtaina random value ri corresponding to each bit as given below:
ri�∑
k∈Gi
|Y [k] + �[k]S[k]|c[k] − |Y [k] − �[k]S[k]|c[k]�[k]c[k] , (9)
where Gi denotes the sample vector of all DCT coefficientsin different 8 × 8 blocks that correspond to a single bit i, �represents the standard deviation of the distribution, while cdictates the shape of generalized Gaussian distribution. Thevalues of c and � are estimated from the received watermarkedimage at the decoding stage. For bipolar signal, b[k] ∈ [−1, 1],the estimated bit b̂i in TD model is computed as follows:
b̂i = sgn(ri) ∀i ∈ {1, 2, . . . , N}. (10)
In the second method, we do not compute sufficient statis-tics across all the frequency bands; rather we compute it acrossthe same channel. In this case, the sample vector Gi used inEq. (9) changes to G
ji , which is defined as the sample vector
of all DCT coefficients in different 8 × 8 blocks that corre-spond to a single bit i and the jth frequency band. This allowsus to keep the sufficient statistics across each frequency bandas a feature itself. Therefore, corresponding to a single bit, thenumber of features is equal to the number of selected frequencybands. As described in detail in Section 6, mostly, we have se-lected 22 frequency bands and consequently, 22 features. Thisis because ML models, as against the TD model, have the ca-pability to exploit the different frequency bands by learningtheir corresponding level of distortion incurred by the attack.Each sample in the training dataset consists of a pair of inputpattern of 22 features and the corresponding target value. Thetarget value consists of the original bit embedded in the im-age. These target values of training dataset are used to makethe SVM model learn the behavior of bits when distorted byan attack. Algorithm 2 describes the main steps involved in ex-tracting features for the proposed ML decoding scheme fromthe attacked watermarked images.
Algorithm 2. Feature extraction for the proposed ML decod-ing model.//We omit the 2-d vector indices [k] for elaboration purpose//x, y: original and watermarked images in spatial domainrespectively//X, Y: original and watermarked images in DCT domainrespectively, ri: sufficient statistics//W: watermark, S: spread spectrum sequence, b: expandedmessage vector//C, �: shape parameter, and standard deviation of the Gen-eralized Gaussian distribution respectively// �: perceptual mask, Imax: No. of images, Qmax: No. ofsecret keys1: for i← 1 to Imax do //select different standard images2: X = DCT2(x) //compute 8×8 block DCT of
the image3: Xi ← X4: �i ← � //compute perceptual mask
for the image5: for q← 1 to Qmax, do //select different secret keys6: generate Sq //generate the spread spec-
trum sequence7: compute C, and � for each frequency band using
maximum likelihood estimation [14]8: compute feature ri corresponding to each bit using
equation (9)
4.1.3. Data sampling techniques utilizedTo investigate the performance analysis of our proposed
decoding scheme, we have employed both the self-consistencyand cross-validation data sampling techniques. The aim of us-ing self-consistency technique is to check the performance oftrained SVM and ANN decoding models on the training dataset.However, cross-validation technique is used to develop a

2600 A. Khan et al. / Pattern Recognition 41 (2008) 2594–2610
-4-2
0
2
4
02
46
810
1214
0.4
0.5
0.6
0.7
0.8
0.9
1
CGamma
BC
R
Fig. 3. BCR performance dependency of RBF-SVM based decoding model on parameters C and �.
generalized decoding model that can perform well even onthe novel data samples. In this technique, the whole dataset isdivided into four equal parts. One part is selected for trainingand the remaining three are kept for test purpose. This processis repeated four times so that whole dataset can be used in4-fold. Finally, average BCR of the classification models arecomputed.
4.2. Developing ML based decoding models
4.2.1. Performance measureIn this work, we have compared the performance of classifi-
cation models in terms of BCR. It is computed as follows:
BCR(M, M ′)=∑Lm
i=1(mi ⊕m′i )Lm
, (11)
where M represents the original, while M ′ represents the de-coded message, Lm is the length of the message and ⊕ repre-sents exclusive-OR operation. It should be noted that (1−BCR)
represents the bit incorrect ratio. Even a small margin of im-provement in BCR can heavily affect the performance of a wa-termarking system.
4.2.2. Developing SVM modelsIn order to develop Linear-, RBF- and Poly-SVM models,
we have used ‘LIBSVM’ toolbox [35]. This toolbox has all thebasic functions for creation and training of SVM models.
4.2.2.1. Parameter optimization of SVM models The perfor-mance of SVM models can be optimized by using various op-timization techniques [29,36–38]. However, we have employedthe most simple but efficient grid search technique, as describedin Ref. [29]. This technique helps to find the optimal values
of SVM kernel parameters by selecting appropriate grid rangeand step size. Poly-SVM has four adjustable parameters d, r,� and C. However, for simplicity, the value of degree, d andcoefficient, r are priori fixed at d = 3, r = 1. By using gridsearch, the optimum value of C is computed in the range of[2−2, 22] with step size of �C = 0.4. Similarly, the optimalvalue of � is computed in the range of [2−2, 28] with step sizeof �� = 0.4. In case of RBF-SVM, the estimated range andstep size of C and � are given as C = [2−2, 22] with �C = 0.4,�= [2−2, 28] with ��= 0.4. The optimal value of C, for linearkernel is obtained by adjusting the grid range of C = [2−2, 25]with step size of �C= 0.4. The overall behavior of RBF-SVMmodel during the optimization of the values of C and � is shownin Fig. 3. This figure shows the relatively high dependency ofRBF-SVM model on the parameter � than that of C.
4.2.3. Developing ANN modelsThe implementation of back-propagation algorithm is carried
out using Neural Network Toolbox of MATLAB 7 [25]. In or-der to use this toolbox, first, we initialize the hidden and outputlayer units, activation functions of hidden and output layers,stopping criterion and the training algorithm. First and secondhidden layers are configured with 25 and 15 neurons, respec-tively. All the necessary parameters setting of ANN model fora dataset of 16 000 bits and exploiting 22 features are shownin Table 2.
The activation functions of ANN models describe the behav-ior of neurons. These functions may be linear and nonlinear.A list of the used linear and nonlinear activation functions isgiven in Table 3.
A block diagram of the ML based watermark extraction pro-cess is shown in Fig. 4. After computing the features, the trainedANN/SVM models are employed to carry out the message ex-traction process.

A. Khan et al. / Pattern Recognition 41 (2008) 2594–2610 2601
Table 2Parameter settings for ANN based decoding model effective against Gaussiannoise attack
Neural network parameters Selected values
1. Input layer neurons 222. Number of hidden layers 2
(a) Neurons in 1st hidden layer 25(b) Neurons in 2nd hidden layer 15
3. Number of neurons in the output layer 14. Activation function of two hidden layers tansig5. Activation function of output layer purelin6. Training algorithm Levenberg–Marquardt7. No of epochs 308. Stopping criterion �avg �0.001
Table 3Activation functions used in the proposed ANN decoding model
Function name Mathematical form Derivatives
Pure linear f (x)= x Constant
Tangent sigmoid f (x)= 2
[1+ exp(−2x)] − 1f ′(x)= 2f (x)[1− f (x)]
Estimation of
Parameter C and σ
Computing Sufficient
Statistics
Pseudo Random
Sequence (PRS)DCT
Perceptual
Shaping
ImageSecret key
yK
S Y
α
Y
DecodedMessage
Trained Ml Decoding
Scheme
Fig. 4. Watermark extraction.
5. Potential applications of proposed ML decoding scheme
In this section, we discuss the potential applications of ourproposed ML based adaptive watermark decoding scheme. Weconceive two scenarios. In the first type of applications, only
trained ML model has to be utilized. On the other hand, in thesecond scenario, we might expect change in type of attack. Inthis 2nd case, the full ML system has to be employed in formof a chip.
In case of shared medical information, such as PACS (Pic-ture Archiving and Communication Systems) [39], and DICOM(Digital Imaging and Communications in Medicine) [40], theimages are compressed to reduce both memory and bandwidthrequirements [41]. In such a scenario, JPEG compression attackis almost inevitable, and therefore, we need to develop an MLbased decoding model for extracting the message blindly. Thetrained ML model could be then deployed as small chip achiev-ing a significant margin of improvement in terms of BCR. Asfar as health related projects are concerned, a small hardwarecost would be of no match to extracting information about thecover data accurately.
Similar approaches needs to be considered in broadcast mon-itoring [42], and device control [43]. The trained ML decodingmodels could be deployed in form of a chip in view of the in-evitable attacks, such as channel noise in case of broadcastingonly, and digital to analog conversion in case of both broad-casting and device control.
Applications related to the second scenario are akin to securedigital camera [44], and those mobiles able to extract hiddeninformation from plain sight [45]. In both of these applicationsimage acquisition and its further processing is involved. How-ever, the user may also be provided with options of focusing,contrast stretching, etc. In such a case of varying attacks, theuser may spare few seconds to let the onboard ML model learnthe distortion occurred due to the new attack.
6. Results and discussion
6.1. Watermark strength and imperceptibility analysis
First, we analyze the strength of the watermark and conse-quently its affect on the imperceptibility. Generally, it is as-sumed that higher the strength of the watermark, the higher willbe the robustness, although it has been practically shown thatthis may not always be the case [20]. However, high strengthmeans high distortion of the original image and thus low im-perceptibility. Therefore, we show that even though keeping afair amount of imperceptibility, our proposed ML models areable to retrieve the embedded message from the attacked wa-termarked image. For this purpose, we first visually analyzethe imperceptibility of the watermarked images as explained inRefs. [19,20]. Figs. 5 and 6 show the original and watermarkedcouple image, respectively. As obvious, the distortion in thewatermarked image is almost impossible to be detected by ahuman eye. It means that imperceptibility is high and conse-quently, low power embedding is performed. This high imper-ceptibility lays down a limit on the capability of the decodingmodels, as robustness usually requires high power embedding.In this connection, Fig. 7 shows the distribution of the water-mark for couple image across both frequency and no. of blocks.It can be easily observed that the amplitude of the watermarkvaries not only from block to block, but also inside each block.

2602 A. Khan et al. / Pattern Recognition 41 (2008) 2594–2610
Fig. 5. Original couple image.
Fig. 6. Watermarked couple image.
In Fig. 7, if we pick a DCT coefficient and vary the blocknumber, then we can realize the watermark strength variationacross a single frequency band. Each of these 22 selected fre-quency bands have different variation in watermark strengthand thus should be dealt with separately.
6.2. Distortion analysis
In this section, we analyze visually, the amount of distor-tion introduced by the attack. This is because small distortion
incurred by a weak attack may not alter the performance ofthe traditional TD model. Therefore, we try to compare theperformance of the decoding systems in a harsh but same en-vironment. Figs. 8 and 9 show the difference in pixel intensi-ties between original and watermarked, and watermarked andattacked images, respectively. This difference is 10 times am-plified for elaboration purpose. It can be observed from Fig. 8that in case of no attack, the difference is not severe and easilyvisible at less sensitive areas like edges. On the other hand, thedifference in case of the attack (Gaussian noise with � = 10)is quite severe. This sort of distortion may easily disturb de-coders based on the statistical characterization of the DCT co-efficients across the different channels. This is the main reasonthat we use two types of feature subsets; in one case, we letthe ML system exploit the sum of the responses from all thechannels, while in the other case, we let it exploit the variousfrequency channels separately as per their corresponding distor-tion. Fig. 10 shows the Gaussian attacked watermarked image,where the imperceptibility is affected strongly by the resultantdistortions.
6.3. Cross-validation based performance comparison
In order to carry out comparative study, the average BCR ofTD model is also computed. The input dataset is divided in thesame fashion as it is used for SVM and ANN decoding models.The experimental results are given in Table 4. This table showsthat in case of TD model, the average BCR of TD model isapproximately the same i.e. 0.984 for both self-consistency andcross-validation techniques.
The BCR performance of SVM models using the same dis-tribution of input dataset is shown in Table 5. It is observedthat Poly-SVM attains maximum value of average BCR, i.e.100% accuracy on the training dataset for the optimized valuesof � = 194 and C = [0.4 − 2]. On the other hand, the perfor-mance of RBF-SVM and Linear-SVM is nearly the same, i.e.0.9877 and 0.9853, respectively.
It is also observed from Table 5 that there is consistencyin decoding performance of SVM models even for novel testdataset. These SVM models have maintained their high per-formance on both the training and test data. However, there issome degradation in the performance of RBF-SVM as com-pared to Poly-SVM. Poly-SVM has achieved 100% decodingperformance by correctly extracting all the 12 000 bits in thetest dataset. This is, indeed, a major achievement as far as adistorted watermark is concerned. From Tables 4 and 5, the or-der of overall BCR performance of SVM and TD models is asfollows: Poly-SVM > RBF-SVM > Linear-SVM > TD model.
Table 6 shows the experimental results of ANN model. Av-erage BCR performance of ANN model is up to 0.999 for thetraining dataset exploiting 22 features. However, in case of testdata, the performance of ANN model degrades up to 0.9746.It is concluded from Tables 5 and 6 that average BCR perfor-mance of Poly-SVM and ANN models are approximately thesame on the training dataset. However, due to its low gener-alization capability, ANN model could not maintain the samehigh performance on the test data. Whereas, SVM models,
A. Khan et al. / Pattern Recognition 41 (2008) 2594–2610 2603
0200
400600
8001000
1200
0
5
10
15
20
25
30
-20
-10
0
10
20
No. of Blocks
Selected DCT Coeficients
Am
plitu
de
Fig. 7. Distribution of the watermark for couple image.
Fig. 8. Pixel intensity difference between original and watermarked images.
especially, Poly-SVM has maintained high performance on bothtraining and test dataset.
The overall performance comparison in terms of bar chartof three decoding models (SVM, ANN and TD) is shown inFig. 11. The order of performance of decoding models ontraining data is as follows; Poly-SVM > ANN > RBF- SVM >
Linear-SVM > TD. On the other hand, in case of test data weobserve, Poly-SVM > Linear-SVM > RBF-SVM > TD > ANN.
Fig. 9. Pixel intensity difference between watermarked and attacked water-marked images.
6.4. Self-consistency based performance comparison
The comparison of the three decoding models is also ana-lyzed using self-consistency as shown in Figs. 12 and 13. Itcan be observed from Fig. 12 that in this case both Poly-SVM,
2604 A. Khan et al. / Pattern Recognition 41 (2008) 2594–2610
Fig. 10. Gaussian noise attacked watermarked couple image.
Table 4BCR performance of TD model using 4-fold cross-validation against Gaussian noise attack
Training data (bits) BCR performance (self-consistency) Test data (bits) BCR performance (cross-validation)
4000 0.9830 12 000 0.984334000 0.9805 12 000 0.985174000 0.98775 12 000 0.982754000 0.98475 12 000 0.98375
Avg. BCR 0.984 – 0.984
Table 5BCR performance of SVM models using 4-fold cross-validation against Gaussian noise attack
SVM kernels C � Training data (bits) BCR Avg. BCR Test data (bits) BCR Avg. BCR
Linear 48.503 – 4000 0.9852 0.9853 12 000 0.9855 0.985548.503 – 4000 0.9832 12 000 0.98617111.43 – 4000 0.9868 12 000 0.9850111.43 – 4000 0.9860 12 000 0.98525
Poly [0.4–2] 194 4000 1.00 1.00 12 000 1.00 1.00[0.4–2] 194 4000 0.9998 12 000 1.00[0.4–2] 194 4000 1.00 12 000 1.00[0.4–2] 194 4000 1.00 12 000 1.00
RBF 0.75786 5.2768 4000 0.9850 0.9877 12 000 0.98483 0.98401.3195 6.9644 4000 0.9875 12 000 0.984751.000 1.7411 4000 0.9868 12 000 0.983332.2974 9.1896 4000 0.9915 12 000 0.98325
Table 6BCR performance of ANN model using 4-fold cross-validation against Gaussian noise attack
Training data (bits) BCR performance (self-consistency) Test data (bits) BCR performance (cross-validation)
4000 0.9992 12 000 0.97624000 0.9998 12 000 0.97274000 0.9998 12 000 0.97684000 0.9998 12 000 0.9727
Avg. BCR 0.9997 – 0.9746
and RBF-SVM have the highest performance. The order ofperformance using self-consistency is as such: Poly-SVM ≈RBF- SVM > ANN > Linear-SVM > TD. Analyzing the perfor-mance of ANN, and RBF-SVM on both self-consistency andcross-validation, it can be concluded that the developed ANN,and RBF-SVM models are not generalized one like the Poly-SVM; achieving high performance both on the self-consistencyand cross-validation cases. In context of our decoding problem,this advantage of Poly-SVM might be due to its learning ca-pability based on the inner product of global data points thatare selected from the training data points. However, the perfor-mance measurement of RBF kernels is based on local Gaussiankernel that might not be suitable for this data.
Fig. 13 compares the performance of the different ML decod-ing models on the various images. This analysis is carried outto examine the generalization property as regards the depen-dency on cover image is concerned. If we imagine a continuouschange from a relatively smooth image e.g. Lena toward a rela-tively textured image e.g. Baboon, then the behavior of the dif-ferent decoding schemes could be analyzed through the surfaceplot. It can be easily observed that both Poly-SVM, and RBF-SVM are independent of the cover image. On the other hand,

A. Khan et al. / Pattern Recognition 41 (2008) 2594–2610 2605
1
0.995
0.99
0.985
0.98
0.975
0.97
0.965
0.96B
CR
TD modelLinear SVM
ANNRbf SVM
Poly SVMTest DataTraining data
Training data
Test Data
Fig. 11. BCR performance comparison using 4-fold cross-validation and 22features.
1
0.995
0.99
0.985
0.98
0.975Linear SVM
ANN model
Poly SVM
Rbf SVM1 feature 22 features
BC
R
Fig. 12. Self-consistency based BCR performance using different featuresubsets.
the performance of ANN, Linear-SVM and TD models suffersfor textured images, especially Baboon image. This is becausein highly textured images, the high frequency content is largeand it is difficult to survive attacks such as Gaussian noise.
Fig. 14 shows the performance comparison of the variousdecoding models using different feature subsets. Using a single
feature, the performance of all the decoding models is approxi-mately the same. However, using 22 features i.e. exploiting the22 frequency bands separately, the performance of SVM andANN models improve appreciably. This behavior underpins thefact that nonlinear ML models are able to exploit the high di-mensional feature space as compared to that of the linear MLmodel like Linear-SVM.
We also have analyzed the performance comparison at differ-ent feature subsets by varying image type. Fig. 15 demonstratesthat at single feature, the performance of all the models under-goes approximately the same decline, as we move from a rela-tively smooth image toward a relatively textured image. That isusing a single feature; collective response of the 22 frequencybands, the models cannot learn the distortion incurred by theattack. Consequently, they cannot cope with the increase in theseverity of the attack as we move from a relatively smooth im-age to a relatively textured image. On the other hand, Fig. 16demonstrates this very fact of the ML model being able to copewith severity of attack by learning the distortion occurred tothe feature space when provided with 22 features. It can be ob-served that the nonlinear ML models, Poly-SVM, RBF-SVM andANN have been able to maintain their performance. Specifically,Poly-SVM, RBF-SVM give outstanding performance achievingBCR up to 1 across all the different types of images.
6.5. Performance comparison against JPEG compression
In order to analyze the adaptability of the proposed MLdecoding system, we change the conceivable attack and retrainthe ML model accordingly. In this case, the attack is JPEGcompression (QF = 80). The sufficient statistics (Eq. (9)) arecomputed in the same way and the ML model is able to learn thenew distortion introduced. Consequently, it is able to extract themessage accurately but blindly (Table 7). The order of perfor-mance is RBF-SVM > Poly-SVM > ANN > Linear-SVM > TD.The training time for Poly-SVM is higher as compared toRBF-SVM and ANN.
6.6. Performance comparison against Wiener attack
We have also analyzed the performance of our adaptivedecoding scheme by changing the conceivable attack fromJPEG compression to Wiener estimation. The ML decodingschemes during their training phase are able to learn the noveldistortion being introduced. Table 8 shows the performancecomparison of the different decoding schemes against theWiener attack. It can be observed from Table 8 that RBF-SVM is able to cope with such change in distortion and offershighest performance, achieving BCR = 1.0 as compared to aBCR = 0.8316 for TD model. The order of performance isRBF-SVM > Poly-SVM > ANN > Linear-SVM > TD.
6.7. Sequence of attacks and small size images
Watermarking performance on small size images (64 × 64)
and against a cascade of attacks is a challenging problem.

2606 A. Khan et al. / Pattern Recognition 41 (2008) 2594–2610
1
0.995
0.99
0.985
0.98
0.975
0.97
0.965Lena
BoatCouple
TreesBaboon
TD model
Linear SVM
ANN model
Poly SVM
Rbf SVM
0.995-1
0.99-0.995
0.985-0.99
0.98-0.985
0.975-0.98
0.97-0.975
0.965-0.97
BC
R
Fig. 13. Self-consistency based performance comparison using features extracted from different images.
1
0.997
0.994
0.991
0.988
0.985
0.982
0.979
0.976
0.973
0.87
BC
R
TD Model ML at 1 Feature ML at 22 Features
TD Model Linear SVM Poly SVM Rbf SVM ANN
Fig. 14. Performance comparison different feature subsets.
Especially, when we consider internet applications, small sizeimages are often communicated for diverse applications. Print-to-Web technology [45] is another example; however, in such
applications; a watermark should be robust enough toward acascade of attacks. Table 9 shows the watermark extractioncomparison for small size images and against a cascade of

A. Khan et al. / Pattern Recognition 41 (2008) 2594–2610 2607
0.995
0.993
0.991
0.989
0.987
0.985
0.983
0.981
0.979
0.977
0.975Lena Couple Boat Trees Baboon
ANN
Rbf SVM
Poly SVM
Linear SVM
TD ModelB
CR
Fig. 15. Self-consistency based performance across increasingly textured images using a single feature.
0.965
0.97
0.975
0.98
0.985
0.99
0.995
1
1.005
Lena Boat Couple Trees Baboon
BC
R
TD1
LinSVM1
PolySVM1
RbfSVM1
ANN1
Fig. 16. Self-consistency based performance across increasingly textured images using 22 features.
Table 7Self-consistency based performance of the decoding models against JPEG compression attack
Type of attack Intensity of attack Data size (bits) Feature set ML models Parameters Time (s) BCR BCR (TD model)
C �
JPEG QF = 80 16 000 22 Linear-SVM 2 128 40 0.9266 0.9119Poly-SVM 2 128 6895 0.9942RBF-SVM 2 128 697 0.9998ANN Hidden layers= 3[8, 4, 2] – 160 0.9431
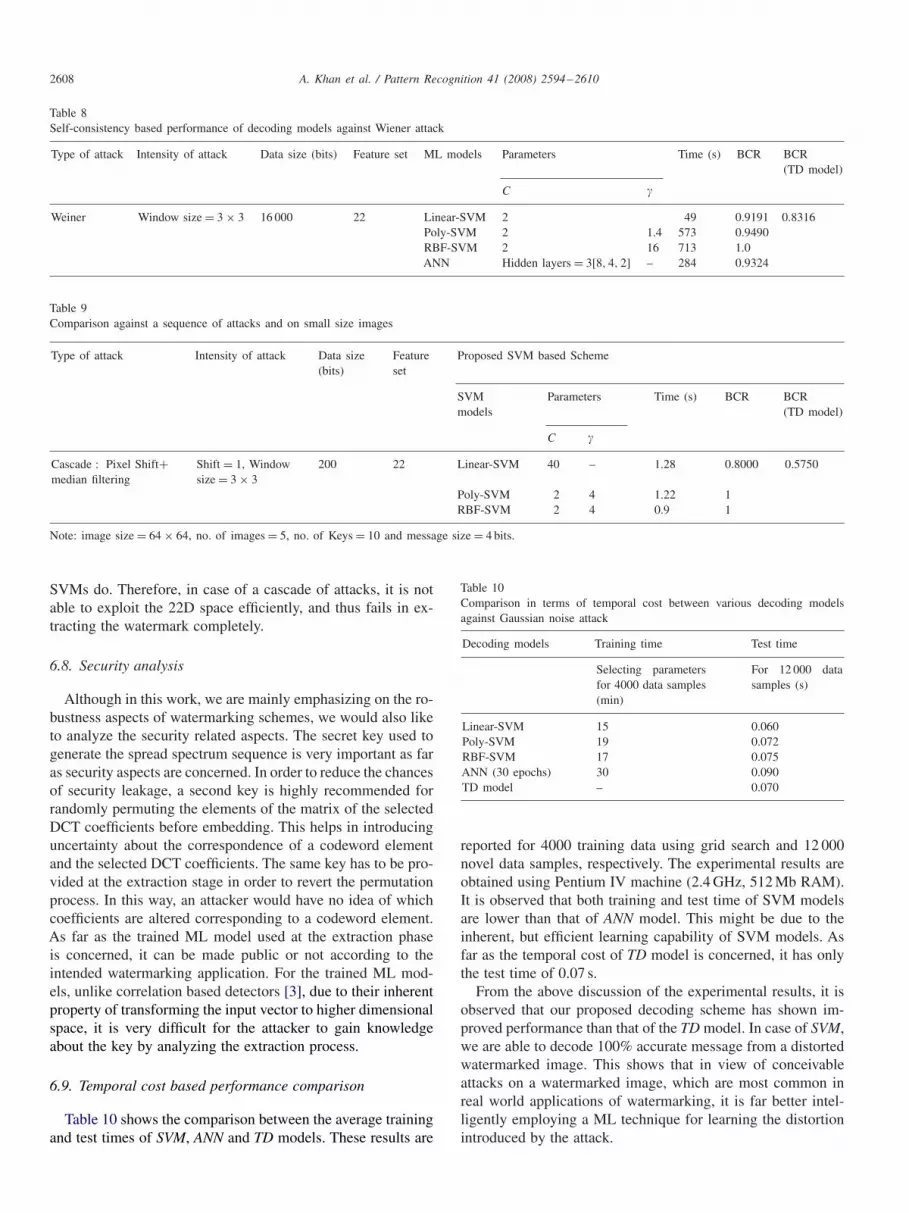
attacks. The cascade of attacks consists of a geometric attack;one pixel shift, and then a median filtering attack. It is observedthat the proposed scheme shows a high margin of improve-ment in BCR as compared to the traditional TD model. TheTD model suffers severely, while the proposed ML decoding
scheme is able to extract the watermark completely. This factalso shows the learning capabilities of nonlinear SVMs, RBF-SVM and Poly-SVM, when provided with 22D feature space.On the other hand, the Linear-SVM does not transform the in-put feature space to a high-dimensional space, as the nonlinear
2608 A. Khan et al. / Pattern Recognition 41 (2008) 2594–2610
Table 8Self-consistency based performance of decoding models against Wiener attack
Type of attack Intensity of attack Data size (bits) Feature set ML models Parameters Time (s) BCR BCR(TD model)
C �
Weiner Window size= 3× 3 16 000 22 Linear-SVM 2 49 0.9191 0.8316Poly-SVM 2 1.4 573 0.9490RBF-SVM 2 16 713 1.0ANN Hidden layers= 3[8, 4, 2] – 284 0.9324
Table 9Comparison against a sequence of attacks and on small size images
Type of attack Intensity of attack Data size Feature Proposed SVM based Scheme(bits) set
SVM Parameters Time (s) BCR BCRmodels (TD model)
C �
Cascade : Pixel Shift+ Shift = 1, Window 200 22 Linear-SVM 40 – 1.28 0.8000 0.5750median filtering size= 3× 3
Poly-SVM 2 4 1.22 1RBF-SVM 2 4 0.9 1
Note: image size= 64× 64, no. of images= 5, no. of Keys= 10 and message size= 4 bits.
SVMs do. Therefore, in case of a cascade of attacks, it is notable to exploit the 22D space efficiently, and thus fails in ex-tracting the watermark completely.
6.8. Security analysis
Although in this work, we are mainly emphasizing on the ro-bustness aspects of watermarking schemes, we would also liketo analyze the security related aspects. The secret key used togenerate the spread spectrum sequence is very important as faras security aspects are concerned. In order to reduce the chancesof security leakage, a second key is highly recommended forrandomly permuting the elements of the matrix of the selectedDCT coefficients before embedding. This helps in introducinguncertainty about the correspondence of a codeword elementand the selected DCT coefficients. The same key has to be pro-vided at the extraction stage in order to revert the permutationprocess. In this way, an attacker would have no idea of whichcoefficients are altered corresponding to a codeword element.As far as the trained ML model used at the extraction phaseis concerned, it can be made public or not according to theintended watermarking application. For the trained ML mod-els, unlike correlation based detectors [3], due to their inherentproperty of transforming the input vector to higher dimensionalspace, it is very difficult for the attacker to gain knowledgeabout the key by analyzing the extraction process.
6.9. Temporal cost based performance comparison
Table 10 shows the comparison between the average trainingand test times of SVM, ANN and TD models. These results are
Table 10Comparison in terms of temporal cost between various decoding modelsagainst Gaussian noise attack
Decoding models Training time Test time
Selecting parametersfor 4000 data samples(min)
For 12 000 datasamples (s)
Linear-SVM 15 0.060Poly-SVM 19 0.072RBF-SVM 17 0.075ANN (30 epochs) 30 0.090TD model – 0.070
reported for 4000 training data using grid search and 12 000novel data samples, respectively. The experimental results areobtained using Pentium IV machine (2.4 GHz, 512 Mb RAM).It is observed that both training and test time of SVM modelsare lower than that of ANN model. This might be due to theinherent, but efficient learning capability of SVM models. Asfar as the temporal cost of TD model is concerned, it has onlythe test time of 0.07 s.
From the above discussion of the experimental results, it isobserved that our proposed decoding scheme has shown im-proved performance than that of the TD model. In case of SVM,we are able to decode 100% accurate message from a distortedwatermarked image. This shows that in view of conceivableattacks on a watermarked image, which are most common inreal world applications of watermarking, it is far better intel-ligently employing a ML technique for learning the distortionintroduced by the attack.

A. Khan et al. / Pattern Recognition 41 (2008) 2594–2610 2609
Overall, the SVM based decoding models performs superi-orly. However, the parameter optimization of SVM has a greatimpact on both the accuracy as well training time of the de-coding model. Once a high performance model is trained, inview of the intended attacks, the computational cost is com-parable to that of TD model during the test phase. Although,we have used 22 frequency bands (7–28 in zigzag order) forwatermark embedding, the proposed scheme has the potentialto be more suitable for effective watermark extraction, if MLbased techniques are allowed to exploit the effect of attack onthe whole 63 frequency bands. In this case, a feature selectionscheme such as genetic algorithm in view of the anticipated at-tack before the ML based decoding approach would be highlydesirable. In future, ML based watermarking schemes are mostlikely to dominate in answering the complex challenges relatedto imperceptibility, robustness, and capacity, that are faced indiverse watermarking applications. Even, application of MLtechniques both at embedding and extraction phases is gainingsignificance in color image watermarking [46–48]. However,for such color image watermarking techniques, avoiding theneed of a reference watermark and the manual selection of itslength for a particular image, is still a challenging problem.
7. Conclusions
We have been able to validate the exploitation of ML con-cepts for decoding purpose. The experimental results havedemonstrated that both SVM and ANN decoding models areable to adopt according to the hostile environment. Especially,SVM has shown highest BCR performance. In addition, theiradaptability characteristics also reduce the risk of the mainsecurity concern; unauthorized decoding. Our proposed intel-ligent decoding scheme has effectively extracted bits of thedistorted watermark and is a generic one—not limited to aspecific set of watermarking schemes. The utilization of ad-vanced error correction strategies [30–34] in conjunction withthe proposed intelligent decoding would be highly desirable,especially, in view of a cascade of conceivable attacks on thewatermarked image. In the current work, we have employedour proposed decoding scheme for image watermarking, butthis technique may also be applied in both audio and videowatermarking. Moreover, the proposed technique is easy toimplement and has strong potential of being utilized in medicalimage watermarking, like remote diagnosis aid applicationsand telesurgery, which utilizes widely distributed sensitivemedical information. In such applications, the performance ofmessage recovery could have severe affect on a patient’s life.
Acknowledgment
This work was supported by the Korea Science and En-gineering Foundation (KOSEF) grant funded by the Koreagovernment (MOST) (No. R01-2007-000-20227-0).
References
[1] I.J. Cox, M.L. Miller, J.A. Bloom, Digital Watermarking andFundamentals, Morgan Kaufmann, San Francisco, 2002.
[2] M. Barni, F. Bartolini, Watermarking Systems Engineering: EnablingDigital Assets Security and Other Application, Marcel Dekker, NewYork, 2004.
[3] I.J. Cox, G. Doërr, T. Furon, Watermarking Is Not Cryptography, LectureNotes in Computer Science, vol. 4283, Springer, Berlin, 2006, pp. 1–15.
[4] L.P. Freire, P. Comesaña, J.R.T. Pastoriza, F. González, Watermarkingsecurity: a survey, Trans. Data Hiding Multimedia Secur. I 4300 (2006)41–72.
[5] J. Fridrich, T. Penvy, Merging Markov and DCT features for multi-classJPEG steganalysis, in: Proceedings of the SPIE Electronic Imaging,Photonics West, January 2007.
[6] Y. Fu, R. Shen, H. Lu, Optimal watermark detection based on supportvector machines, in: Proceedings of the International Symposium onNeural Networks, Dalian, China, August 19–21, 2004, pp. 552–557.
[7] S. Lyu, H. Farid, Detecting Hidden Messages Using Higher-OrderStatistics and Support Vector Machines, Lecture Notes in ComputerScience, vol. 2578, Springer, Berlin, 2002, pp. 340–354.
[8] R. Shen, Y. Fu, H. Lu, A novel image watermarking scheme based onsupport vector regression, J. Syst. Software 78 (1) (2005) 1–8.
[9] H. Wang, L. Mao, K. Xiu, New audio embedding technique basedon neural network, in: Proceedings of First International Conferenceon Innovative Computing, Information and Control, vol. 3, 2006,pp. 459–462.
[10] S. Kırbız, Y. Yaslan, B. Günsel, Robust audio watermark decoding bynonlinear classification, in: European Signal Processing Conference, vol.13, September 2005, pp. 4–8.
[11] J. Sang, X. Liao, M.S. Aslam, Neural-network-based zero-watermarkscheme for digital images, Opt. Eng. 45 (9) (2006).
[12] Z. Li, S. Kwong, M. Choy, W.-W. Xiao, J. Zhen, J.-H. Zhang, Anintelligent watermark detection decoder based on independent componentanalysis, Lecture Notes in Computer Science, vol. 2939, Springer, Berlin,2004, pp. 223–234.
[13] M. Barni, F. Bartolini, A.D. Rosa, A. Piva, A new decoder for theoptimum recovery of nonadditive watermarks, IEEE Trans. ImageProcess. 10 (5) (2001) 755–766.
[14] J.R. Hernandez, M. Amado, F. Perez-Gonzalez, DCT domainwatermarking techniques for still images: detector performance analysisand a new structure, IEEE Trans. Image Process 9 (1) (2000) 55–68.
[15] A. Nikolaidis I. Pitas, Optimal detector structure for DCT and subbanddomain watermarking, in: Proceedings of the IEEE InternationalConference on Image Processing, 2002, pp. 465–467.
[16] A. Briassouli, P.T sakalides, A. Stouraitis, Hidden messages in heavy-tails: DCT domain watermark detection using alpha-stable models, IEEETrans. Multimedia 7 (4) (2005) 700–715.
[17] A. Briassouli, M.G. Strintzis, Locally optimum nonlinearities for DCTwatermark detection, IEEE Trans. Image Process. 13 (12) (2004)1604–1607.
[18] A. Khan, A novel approach to decoding: exploiting anticipated attackinformation using genetic programming, Int. J. Knowl. Based IntelligentEng. Syst. 10 (5) (2006) 337–347.
[19] A. Khan, A.M. Mirza, Genetic perceptual shaping: utilizing cover imageand conceivable attack information during watermark embedding, J. Inf.Fusion 8 (4) (2007) 354–365.
[20] A. Khan, Intelligent perceptual shaping of a digital watermark, Ph.D.Thesis, Faculty of Computer Science, GIK Institute, Pakistan, May 2006.
[21] I. Usman, A. Khan, A.M. Mirza, Robust intelligent watermarking, Journalof Computer Science and Technology, (2007), Submitted for publication.
[22] F. Bartolini, M. Barni, A. Piva, Performance analysis of ST-DMwatermarking in presence of nonadditive attacks, IEEE Trans. SignalProcess 52 (10) (2004) 2965–2974.
[23] Q. Li, G. Doerr, I.J. Cox, Spread-transform dither modulation using aperceptual model, in: Proceedings of the IEEE International Workshopon Multimedia Signal Processing, 2006.
[24] S. Fahad Tahir, A. Khan, A. Majid, A. M. Mirza, Support VectorMachine based Intelligent Watermark Decoding for Anticipated Attack,in: Proceedings of the XV International Enformatika Conference, October22–24, 2006, Barcelona, Spain.
[25] 〈http://www.mathworks.com〉.

2610 A. Khan et al. / Pattern Recognition 41 (2008) 2594–2610
[26] S. Haykin, Neural Networks a Comprehensive Foundation, second ed.,Pearson Education, Canada, 1999.
[27] M.T. Hagan, M. Menhaj, Training feedforward networks with theMarquardt algorithm, IEEE Trans. Neural Networks 5 (6) (1994)989–993.
[28] R.O. Duda, P.E. Hart, D.G. Stork, Pattern Classification, second ed.,Wiley, New York, 2001.
[29] C.W. Hsu, C.C. Chang, C.J. Lin, A practical guide to support vectormachines, Technical Report, Department of Computer Science &Information Engineering, National Taiwan University, 2003.
[30] S. Baudry, J.F. Delaigle, B. Sankur, B. Macq, H. Maitre, Analysesof error correction strategies for typical communication channels inwatermarking, Signal Process. 81 (2001) 1239–1250.
[31] B. Ghoraani, S. Krishnan, Chirp-based image watermarking as error-control coding, in: Proceedings of the International Conference onIntelligent Information Hiding and Multimedia, 2006, pp. 647–650.
[32] E. Esen, A.A. Alatan, Data hiding using trellis coded quantization, in:Proceedings of the IEEE International Conference on Image Processing,2004, pp. 59–62.
[33] F.I. Koprulu, Application to low-density parity-check codes to watermarkchannels, M.S. Thesis, Electrical and Electronics Bogaziei University,Turkey, 2001.
[34] N. Cvejic, D. Tujkovic, T. Seppänen, Increasing robustness of anaudio watermark using turbo codes, in: Proceedings of the IEEEInternational Conference on Multimedia & Expo, Baltimore, MD, 2003,pp. 1217–1220.
[35] C.C. Chang, C.J. Lin, LIBSVM: a library for support vector machines,Available at: 〈http://www.csie.ntu.edu.tw/∼cjlin/libsvm/〉, 2001.
[36] A. Majid, Optimization and combination of classifiers using geneticprogramming, Ph.D. Thesis, Faculty of Computer Science, GIK Institute,Pakistan, May 2006.
[37] O. Chapelle, V. Vapnik, O. Bousquet, S. Mukherjee, Choosing multipleparameters for support vector machine, Machines Learning 46 (1–3)(2002) 131–159.
[38] C. Staelin, Parameter selection for support vector machines, TechnicalReport, HP Labs, Israel, 2002.
[39] T. Wayne, Dejarnette, Web technology and its relevance to PACS andteleradiology, Appl. Radiol. 29 (8) (2000) 9–12.
[40] DICOM (Digital Imaging and Communications in Medicine), Part5(PS3.5-2001): Data Structures and Encoding, Published by NationalElectrical Manufacturers Association, 1300 N. 17th Street Rosslyn, VA22209, USA, 2001.
[41] D. Osborne, Embedded watermarking for image verification intelemedicine, Ph.D. Thesis, University of Adelaide, Australia, 2005.
[42] 〈http://www.research.ibm.com/trl/projects/RightsManagement/〉.[43] M.L. Miller, I.J. Cox, J.A. Bloom, Watermarking in the real world:
an application to DVD, in: Proceedings of Multimedia & SecurityWorkshop, ACM Multimedia, 1998, pp. 71–76.
[44] P. Blythe, J. Fridrich, Secure digital camera, Department of Electricaland Computer Engineering, SUNY Binghamton, Binghamton, NY13902–6000, 2004
[45] 〈http://news.bbc.co.uk/2/hi/technology/6361891.stm〉.[46] Y.G. Fu, R.M. Shen, H.T. Lu, Watermarking scheme based on support
vector machine for color images, Electron. Lett. 40 (16) (2004) 986–987.[47] H.-H. Tsai, D.-W. Sun, Color image watermark extraction based on
support vector machines, Inform. Sci. 177 (2) (2007) 550–569.[48] P.-T. Yu, H.-H. Tsai, J.-S. Lin, Digital watermarking based on neural
networks for color images, Signal Process. 81 (3) (2001) 663–671.
About the Author—ASIFULLAH KHAN received his M.Sc. degree in Physics from University of Peshawar, Pakistan in 1996 and his M.S. degree in NuclearEngineering from Pakistan Institute of Engineering and Applied Sciences (PIEAS), Islamabad, Pakistan, in 1998. He received his M.S. and Ph.D. degrees inComputer Systems Engineering from Ghulam Ishaq Khan Institute of Engineering Sciences and Technology (GIK Institute), Topi, Pakistan, in 2003 and 2006,respectively. He has more than 10 years of research experience and is working as Assistant Professor in Department of Computer and Information Sciencesat PIEAS. Currently he is pursuing his Post-Doc Research at Signal and Image Processing Lab, Department of Mechatronics, Gwangju Institute of Scienceand Technology, South Korea. His research areas include Digital Watermarking, Pattern Recognition, Image Processing, Genetic Programming, Data Hiding,Machine Learning and Computational Materials Science.
About the Author—SYED FAHD TAHIR received his B.S. Eng. in 2005 from COMSATS, Islamabad, Pakistan, and his M.S. degree in Computer SystemsEngineering in 2007 from Ghulam Ishaq Khan Institute of Engineering Sciences and Technology (GIK Institute), Topi, Pakistan. Currently, he is enrolled asa Ph.D. student in Department of Mechatronics, Gwangju Institute of Science and Technology, South Korea. His research interests include Image Processing,Digital Watermarking and Machine learning.
About the Author—ABDUL MAJID received his M.Sc. degree in Electronics from Quaid-i-Azam University, Islamabad, Pakistan in 1991. He received hisM.S. and Ph.D. degrees in Computer Systems Engineering from Ghulam Ishaq Khan Institute of Engineering Sciences and Technology (GIK Institute), Topi,Pakistan, in 2003 and 2006, respectively. He has more than 13 years of research experience and is working as Assistant Professor in Department of Computerand Information Sciences at PIEAS. His research areas include, Pattern Recognition, Image Processing, Machine Learning and Computational Materials Science.
About the Author—TAE-SUN CHOI received his B.S. degree in Electrical Engineering from the Seoul National University, Seoul, Korea, in 1976, and hisM.S. degree in Electrical Engineering from the Korea Advanced Institute of Science and Technology, Seoul, Korea, in 1979, and his Ph.D. degree in electricalengineering from the State University of New York at Stony Brook, in 1993. He is currently a Professor in the Department of Mechatronics at GwangjuInstitute of Science and Technology, Gwangju, Korea. His research interests include Image Processing, Machine/Robot Vision and Visual Communications.