integrated handwriting recognition and interpretation using finite-state models
TRANSCRIPT

May 28, 2004 14:48 WSPC/115-IJPRAI 00334
International Journal of Pattern Recognitionand Artificial IntelligenceVol. 18, No. 4 (2004) 519–539c© World Scientific Publishing Company
INTEGRATED HANDWRITING RECOGNITION AND
INTERPRETATION USING FINITE-STATE MODELS∗
A. H. TOSELLI
Instituto Tecnologico de Informatica,Universidad Politecnica de Valencia, Camino de Vera s/n, 46022 Valencia, Spain
A. JUAN†, J. GONZALEZ, I. SALVADOR, E. VIDAL and F. CASACUBERTA
Departamento de Sistemas Informaticos y Computacion,Universidad Politecnica de Valencia, Camino de Vera s/n, 46022 Valencia, Spain
D. KEYSERS‡ and H. NEY
Lehrstuhl fur Informatik VI, Computer Science Department,RWTH Aachen, University of Technology, 52056 Aachen, Germany
The interpretation of handwritten sentences is carried out using a holistic approach inwhich both text image recognition and the interpretation itself are tightly integrated.Conventional approaches follow a serial, first-recognition then-interpretation schemewhich cannot adequately use semantic–pragmatic knowledge to recover from recognitionerrors. Stochastic finite-sate transducers are shown to be suitable models for this inte-gration, permitting a full exploitation of the final interpretation constraints. Continuous-density hidden Markov models are embedded in the edges of the transducer to accountfor lexical and morphological constraints. Robustness with respect to stroke verticalvariability is achieved by integrating tangent vectors into the emission densities of thesemodels. Experimental results are reported on a syntax-constrained interpretation taskwhich show the effectiveness of the proposed approaches. These results are also shownto be comparatively better than those achieved with other conventional, N-gram-basedtechniques which do not take advantage of full integration.
Keywords: Handwriting recognition and interpretation; hidden Markov models; sto-chastic finite-state transducers; preprocessing and feature extraction; tangent vectors.
1. Introduction
The recognition of a handwritten sentence, i.e. decoding its symbolic representation
in terms of characters, digits and/or words, is not the ultimate purpose in many
∗Work supported by the Spanish MCT under grant TIC2000-1703-CO3-01.
519

May 28, 2004 14:48 WSPC/115-IJPRAI 00334
520 A. H. Toselli et al.
tasks involving handwritten input. On the contrary, in these tasks, the handwritten
text is often used just as an intermediate means to express some semantic message.
The goal of an ideal automatic system in these cases is to obtain an adequate
interpretation of the handwritten message, rather than achieving a good recognition
of the individual text constituents of this message. This is clearly illustrated in two
prominent tasks: postal address processing and bank check reading.
A system for postal address processing uses knowledge about postal domains
and tries to guess the correct destination even if only incomplete or contradictory
information appears or can be recognized in the postal address. Here recognition
would consist in getting adequate hypotheses about the words and numbers written
in the envelope; interpretation, in contrast, should yield a unique entry to the
postal database containing the right addresses. Similarly, a bank check reading
system has to interpret the legal amount (written in letters) to determine the
real numeric sum (and to optionally verify whether this sum matches the cour-
tesy amount — written in digits). Here recognition would consist in getting ad-
equate hypotheses about the written words, while the goal of interpretation is
to come out with a numeric expression which, overall, reflects what was written
in letters as accurately as possible. It is not of great importance whether all the
words comprising the legal amount were correctly written or whether they can be
exactly recognized or not; only the reliability of the interpreted numeric result really
matters.
From this point of view, the role of an interpretation system is to map input
images into adequate target meanings and the written words or numbers should be
considered just as intermediate results or hidden variables.
Under this paradigm, accurate handwriting interpretation requires a tight co-
operation of lexical, syntactic and semantic/pragmatic knowledge. Each source of
knowledge adds valuable, possibly redundant information which is best exploited
in conjunction with that obtained from the other sources. This is just the very
same situation that appears in the field of continuous speech recognition.16 In this
field, knowledge integration benefits are attained by following three basic principles:
(i) adopt simple, homogeneous and easily understandable models for all the know-
ledge sources; (ii) formulate the problem as one of searching for an optimal path
through an adequate structure based on these models; and (iii) use appropriate
techniques to learn the different models from training data. These principles are
actually the basis of those systems developed using finite-state devices such as
hidden Markov models and stochastic finite-state grammars.17
Inspired by the success of finite-state technology in continuous speech recogni-
tion, several systems based on this technology have been proposed or adapted for
handwritten input in the last few years (e.g. see Refs. 10 and 12, and the refer-
ences therein). However, these systems often break the above-mentioned principles
at the lexical or the syntactic levels. A typical example violating these principles at
the lexical level is given by those systems based on the segmentation of sentences
into single words (or even into individual characters). Clearly, it is quite difficult to

May 28, 2004 14:48 WSPC/115-IJPRAI 00334
Integrated Handwriting Recognition and Interpretation using Finite-State Models 521
locate individual characters or words in a sentence without considering lexical or
syntactic knowledge. Moreover, it is even harder to recover from errors produced
during segmentation and hence this approach is generally unreliable and the more
recent, advanced systems do not rely on word segmentation1 (see also Ref. 9).
Although adequate, homogeneous, finite-state based solutions have been re-
cently developed for handwriting recognition, no such solutions have been yet
proposed for the more general problem of handwriting interpretation. For instance,
the approach followed by Kaufmann and Bunke7 for check processing is to first
decode the handwritten legal amount into a word sequence and then translate this
recognized sentence into a digit string. No attempt is made to do recognition and
interpretation simultaneously and, in fact, it is difficult to do so since the authors use
a translation scheme which is not easily amenable to integration into a finite-state
framework. As in the case of systems relying on word segmentation, this is another
example breaking the basic principles described above. In this case, however, these
principles are broken at the semantic level, thereby preventing semantic knowledge
to be fully exploited in the whole process.
Other works (concerning legal amount handwriting recognition) which also
break these principles in some way or another are worth mentioning. The approaches
followed by Paquet–Lecourtier14 and Gillevic–Suen6 are directly based on recog-
nition of previously segmented words (belonging to a restricted lexicon) using
structural and morphological features. The former approach uses a template
matching word classifier, whereas the latter uses a Bayesian word classier. Further,
the approach proposed by Gillevic–Suen6 also supported the idea of the above-
mentioned three different levels of knowledge to get more accuracy at the inter-
pretation level, but only preliminary results with integration only up to the lexical
level were reported.
In this paper, we propose the integration of handwriting recognition and in-
terpretation via finite-state models. As usual, images of handwritten text are
modeled at the lexical level by continuous density, left-to-right hidden Markov
models. To achieve integration of recognition and interpretation, we advocate the
use of stochastic finite-state transducers. The details of the proposed techniques
are given in Sec. 3. A syntax-constrained interpretation task resembling legal
amount interpretation for bank checks is adopted as an illustrative example. In
Sec. 4, experimental results are reported showing the effectiveness of the proposed
approach. This approach is also shown to clearly outperform a conventional,
N -gram based scheme which cannot easily take advantage of full integration.
Overall, the results constitute a significant improvement over previous (prelimi-
nary) results obtained for the same task.4 Apart from the benefits of integration,
this improvement is due to two refinements: on the one hand we included elaborate
preprocessing and feature extraction techniques (Sec. 2). And on the other hand, we
introduced the use of tangent vectors in the emission densities of the hidden Markov
models to help cope with the vertical variability of the input images (Sec. 3.3).

May 28, 2004 14:48 WSPC/115-IJPRAI 00334
522 A. H. Toselli et al.
2. Preprocessing and Feature Extraction
Preprocessing of handwritten text lines has not yet been given a general, standard
solution and it can be said that each handwriting recognition (interpretation)
system has its own, particular solution. There are, however, generic preprocessing
operations such as skew and slant correction for which robust, more or less equiva-
lent techniques are available.15 But in many cases, other not so generic preprocessing
operations are also needed to compensate for a weakness in the ability of the system
to model pattern variability. In particular, this is the case of approaches like ours
that use (one-dimensional) hidden Markov models for a handwritten text line image.
Although these models do properly model (nonlinear) horizontal image distortions,
they are to some extent limited for vertical distortion modeling. Therefore, apart
from the usual skew and slant correction preprocessing steps, we have decided to
include a third step aimed at reducing a major source of vertical variability: the
height of ascenders and descenders. These steps are discussed hereafter. See Fig. 1
for an illustrative example.
Skew correction processes an original image to put the text line into horizontal
position. As each word or multiword segment in the text line may be skewed at
a different angle, the original image is divided into segments surrounded by wide
blank spaces and skew correction is applied to each segment separately. This is not
to obtain a segmentation of the text line into words and it is not necessary for
each segment to contain exactly one word. The complete skew correction process
is carried out in four steps: (a) horizontal run-length smoothing of the segments
comprising the original image (panel b.1 in Fig. 1); (b) computation of the upper
and lower contours for each segment (panel b.2); (c) eigenvector line fitting of
the contours (panels b.3 and b.4); and (d) segment deskewing in accordance to
the average angle of the contour lines (panel b.5). Although this process involves
significant computing time, we have found it to be more robust than other simpler
approaches.5
Slant correction shears the deskewed image horizontally to bring the writ-
ing in an upright position. Following the procedure proposed by Yanikoglu and
Sandon,18 the dominant slant angle of the writing is obtained by computing the
slant histogram using Sobel edge operators.
As said above, the third step is aimed at reducing a major source vertical vari-
ability: the height of ascenders and descenders (not that of the main text body). The
reference lines computed for each image segment during skew correction are updated
and joined together to separate the main text body from the zones with ascenders
and descenders. Then, each of these zones is linearly scaled in height to a size de-
termined as a percentage of the main body vertical size (30% for ascenders and
15% for descenders). This percentage was empirically determined through simple
informal tests. Since these zones are often large, nearly blank areas, this scaling
operation has the effect of filtering out most of the uninformative background. It
also compensates for the large variability of the ascenders and descenders height as
compared with that of the main text body.

May 28, 2004 14:48 WSPC/115-IJPRAI 00334
Integrated Handwriting Recognition and Interpretation using Finite-State Models 523
�
�����
��� �
��� �
��� �
���
�
�
Fig. 1. Preprocessing and feature extraction example. From top to bottom: (a) original image(“four millions” in Spanish); (b) skew angle estimation and correction (block of 5 joint panels);(c) slant correction; (d) height normalization for ascenders and descenders; and (e) extractedsequence of feature vectors (normalized gray levels, horizontal and vertical derivatives). Fromtop to bottom in the block of five joint panels describing skew angle estimation and correction:(b.1) horizontal run-length smoothing of the two segments (words) comprising the original image;(b.2) upper and lower contours; (b.3) eigenvector line fitting of the contours; (b.4) fitted lines;and (b.5) deskewed image.
As with any approach based on (one-dimensional) hidden Markov models, fea-
ture extraction is required to transform the preprocessed image into a sequence of
(fixed-dimension) feature vectors. To do this, the preprocessed image is first divided
into a grid of square cells whose size is a small fraction of the image height (such as
1/16, 1/20, 1/24 or 1/28). We call this fraction vertical resolution. Then each cell is
characterized by the following features: normalized gray level, horizontal gray-level
derivative and vertical gray-level derivative. To obtain smoothed values of these

May 28, 2004 14:48 WSPC/115-IJPRAI 00334
524 A. H. Toselli et al.
features, feature extraction is extended to a 5 × 5 window centered at the cur-
rent cell weighted with a Gaussian function. The derivatives are computed by least
squares fitting of a linear function.
Columns of cells are processed from left to right and a feature vector is built for
each column by stacking the features computed in its constituent cells (panel e in
Fig. 1). This process is similar to that followed by Bazzi et al.1
3. Integrated Recognition and Interpretation via
Finite-State Models
3.1. Probabilistic framework
In order to develop a true holistic approach to interpretation, it is useful to think
of recognition as a hidden process and start facing the basic problem, i.e. to search
for an optimal interpretation
t = arg maxt
P (t | x) (1)
where x is the sequence of feature vectors extracted from an image of handwritten
text, and P (t | x) is the posterior probability for t to be the correct interpretation
of x in the semantic or target language.a
To uncover the underlying recognition process, P (t | x) can be seen as a marginal
of the joint probability function P (s, t | x), where s is a decoded sentence in the
sourcea language. Using the Bayes rule and assuming that in practice, P (x | s, t) is
independentb of t, we have
t = argmaxt
∑s
P (s, t | x) (2)
= argmaxt
∑s
P (x | s, t)P (s, t) (3)
= argmaxt
∑s
P (x | s)P (s, t) . (4)
It is convenient to approximate the sum in Eq. (4) by the max operator to
facilitate the search for t:
t ≈ argmaxt
maxs
P (x | s)P (s, t) . (5)
Moreover, this simplification also permits to simultaneously search for both t
and its associated most probable decoding, s:
(s, t) ≈ argmax(s,t)
P (x | s)P (s, t) . (6)
aIn the context of bank check legal amount interpretation a “target language” is any adequateformal representation of numeric amounts; e.g. decimal digit sequences (see Sec. 3.4) and the“source language” is the language used to write legal (worded) amounts.bThat is the writing style of the source text is not conditioned by the overall numerical meaning.

May 28, 2004 14:48 WSPC/115-IJPRAI 00334
Integrated Handwriting Recognition and Interpretation using Finite-State Models 525
This optimization problem serves as the basis for our integrated approach to
handwriting recognition and interpretation via finite-state models. On the one hand,
we adopt conventional hidden Markov models, extended with tangent vectors for in-
creased robustness, to estimate P (x | s) (Sec. 3.2). On the other hand, we advocate
the use of stochastic finite-state transducers to model P (s, t) (Sec. 3.4). Thanks to
the homogeneous finite-state nature of these models, they can be easily integrated
into a single global finite-state network, and both recognition and interpretation
can be efficiently performed at the same time by solving (6), using the well-known
Viterbi algorithm (Sec. 3.5).
3.2. Hidden Markov Models
Hidden Markov Models (HMMs) have received significant attention in handwriting
recognition during the last years. As speech recognizers do for acoustic data,7,16
HMMs are used to estimate the probability for a sequence of feature vectors to be
seen as an “image realization” of a given text sentence. Sentence models are built by
concatenation of word models which, in turn, are often obtained by concatenation of
continuous left-to-right HMMs for individual characters. Figure 2 shows an example
of character HMM.
Basically, each character HMM is a stochastic finite-state device that models
the succession, along the horizontal axis, of (vertical) feature vectors which are
extracted from instances of this character. Each HMM state generates feature
vectors following an adequate parametric probabilistic law; typically, a mixture of
Gaussian densities. The required number of densities in the mixture depends, along
with many other factors, on the “vertical variability” typically associated with each
state. This number needs to be empirically tuned in each task.
0.3
0.7 0.8
0.2
0.9
0.1
0.8
0.2
0.7
0.3
Fig. 2. HMM modeling of instances of the character “a” within the word “cuarenta”. The statesare shared among all the instances of a same character class.

May 28, 2004 14:48 WSPC/115-IJPRAI 00334
526 A. H. Toselli et al.
The number of states that is adequate to model a certain character depends on
the underlying horizontal variability. For instance, to ideally model a capital “E”
character, only two states might be enough (one to model the vertical bar and the
other for the three horizontal strokes), while three states may be more adequate to
model a capital “H” (one for the left vertical bar, another for the central horizontal
stroke and the last one for the right vertical bar). Note that the possible or optional
blank space that may appear between characters should be also modeled by each
character HMM. In many cases the adequate number of states for a given task may
be conditioned by the available amount of training data.
Once an HMM “topology” (number of states and structure) has been adopted,
the model parameters can be easily trained from continuously handwritten text
(without any kind of segmentation) accompanied by the transcription of this text
into the corresponding sequence of characters. This training process is carried
out using a well-known instance of the EM algorithm called forward-backward or
Baum-Welch re-estimation.16
3.3. Tangent vectors in Hidden Markov Models
Even with our treatment of ascenders and descenders described in Sec. 2, vertical
shift variability remains difficult to model in left-to-right one-dimensional HMMs.
As an additional effective method for coping with this problem we propose the use
of tangent vectors.13 Tangent vectors can be used to enhance tolerance with respect
to small variations of the input patterns in a classifier. Their name is due to the
fact that they are computed as derivatives of these transformations and therefore
tangential to the manifold a transformed pattern is described in pattern space.
Tangent vectors have been successfully applied to various pattern recognition tasks,
most notably (isolated) handwritten digit recognition. The method is especially
suitable for integration into Gaussian models as can be shown to be equivalent to
a modification of the covariance matrix in the Gaussian case.8
For the use of tangent vectors in our task, let µ denote a mean vector of one
Gaussian emission density of one HMM state. Let further f(µ, α) denote a trans-
formation of µ, e.g. vertical shift, that depends on a parameter α. This transforma-
tion can be approximated by a linear subspace for small values of α using a Taylor
expansion around α = 0:
f(µ, α) = µ + αv +O(α2) ≈ µ + αv . (7)
The tangent vector v that spans the resulting subspace is the partial derivative of
the transformation f with respect to the parameter α, i.e. v = ∂f(µ, α)/∂α. Using
this first-order approximation, we obtain the probability density for an observation
vector x:
p(x | µ, α,Σ) = N (x | µ + αv, Σ) . (8)
Now, by integrating out the parameter α and assuming that the distribution of α
is N (0, γ2) and independent of µ and Σ, we obtain the following expression8:

May 28, 2004 14:48 WSPC/115-IJPRAI 00334
Integrated Handwriting Recognition and Interpretation using Finite-State Models 527
p(x|µ,Σ) =
∫p(α) · p(x|µ, α,Σ) dα = N (x|µ,Σ′), Σ′ = Σ + γ2vvT . (9)
Here, we want the character HMMs to be robust with respect to small vertical
shifts. This can be achieved by applying the following procedure to each Gaussian
density N (µ,Σ) of each mixture of the trained HMMs:
• calculate the tangent vector v as the vertical derivative of the mean vector µ;
• modify the covariance matrix Σ by setting Σ← Σ + γ2vvT , where the factor γ
controls the variance along the tangent vector direction.
The increased variance in the direction of the tangent vectors leads to emission
densities which assign higher probability to slightly transformed feature vectors.
This has the effect that the resulting model is more robust with respect to this
transformation, in this case with respect to vertical variability.
3.4. Stochastic finite-state transducers
As discussed in Sec. 3.1, in this work we propose the use of stochastic finite-state
transducers (stochastic FSTs, SFSTs) to model P (s, t) in Eq. 6. Basically, a SFST
is a finite-state network whose transitions are labeled by three items2,17:
(a) an input symbol (a word from the source lexicon);
(b) an output string (a sequence of tokens from the target symbol set); and
(c) a transition probability.
In addition, each state has associated a probability to be an initial state and a
probability to be a final state.
If a SFST is unambiguous, P (s, t) is computed as the product of the probabilities
of the transitions of the unique path that matches (s, t). Otherwise, it is the sum of
the probabilities computed for all paths matching (s, t). In most cases of interest,
this sum can be conveniently approximated by the maximum.
FSTs can be automatically learned from training data,11 or they can be built
by hand in accordance with previous knowledge about the task. A key factor of the
difficulty of manually (or automatically) building a FST is the degree of monoto-
nicity or “sequentiality” between source and target subsequences of the considered
task.17 The simplest case is where translation may proceed from left to right, in
a sequential sweep that considers only one source word at a time, producing a
bounded number of output tokens. This kind of tasks can be properly modeled by
Sequential Transducers,2 a kind of FST that is amenable to manual construction.
If the required mapping source/target is more complex, Subsequential Transducers2
can be used though, in this case, manual construction often becomes exceedingly
difficult even for small, nontrivial tasks.
For illustration purposes, let us consider a simple syntax-constrained interpre-
tation task that will be also considered for the experiments reported in Sec. 4.
It consists of interpreting the Spanish numbers from 0 to 1012 − 1, i.e. translating

May 28, 2004 14:48 WSPC/115-IJPRAI 00334
528 A. H. Toselli et al.
doscientos+(200
mil+(1000)
sesenta+60
...
veinte+20
...
ydos+2
...
mil)*1000
mil)*1000
Fig. 3. A piece of the hand-designed numbers transducer. Solid-line edges correspond to a paththat accepts “doscientos sesenta y dos mil veinte” (two hundred sixty two thousand and twenty),yielding “+(200 + 60 + 2 ) ∗ 1000 + 20”.
instances of these numbers in text form to their corresponding numerical representa-
tion. It will be referred to as the Spanish numbers task. The source-target mapping
underlying this task is a typical case of Subsequential Transduction.17 However, we
can slightly modify the task specification in order to allow for a simple sequential
mapping.
The source lexicon of this modified task comprises Spanish words such as
“uno”, “dos”, “diez”, “sesenta”, “cien”, “mil”, “millon”, etc. (one, two, ten, sixty,
hundred, thousand, million, etc.). The target set of symbols consists of the ten digits
plus four arithmetic operators: “(, ), +, ∗”. For instance, given the source (Spanish
number) sentence: “doscientos sesenta y dos mil veinte” (two hundred sixty two
thousand and twenty), the corresponding target sequence should be the arithmetic
expression: “+ (200+ 60+ 2) ∗ 1, 000+ 20”. Clearly, from this expression the target
(decimal) number (262, 020) can be readily computed.
For this modified task, we wrote a simple sequential SFST that accepts any text
Spanish number in the range given above and outputs an arithmetic expression
giving its corresponding numerical value. A small fragment of this transducer is
shown in Fig. 3. Its basic features are: 51 source words, 14 target symbols, 32 states
and 660 transitions. Its source language (test-set) perplexity is 6.2.
3.5. Recognition and interpretation as a best path search
Trained character HMMs and the SFST chosen for the task can be easily integrated
into a global finite-state recognition network. To this end each edge of the SFST
is expanded by a concatenation of the HMMs of the successive characters which
constitute the source-language word of this edge. To deal with possible inter-word
white space (as a complement to the inter-caracter blank-space modeling mentioned
in Sec. 3.2), a blank (“@”) special HMM can be trained and also integrated in the
network. This network expansion, illustrated in Fig. 4, realizes the integration,
discussed in Sec. 3.1, of character, lexical and syntactic-semantic levels.
Given an input sequence of feature vectors x, the pair (s, t) in Eq. (6) is obtained
by searching for a best path in the integrated network. This global search process
is very efficiently carried out by the well known (beam-search-accelerated) Viterbi
algorithm.16 This technique allows integration to be performed “on the fly” during
the search process. In this way, only the memory strictly required for the search is
actually allocated.

May 28, 2004 14:48 WSPC/115-IJPRAI 00334
Integrated Handwriting Recognition and Interpretation using Finite-State Models 529
m i l@
u
d
n o@
o s
Fig. 4. A small piece of an integrated finite-state model, using three-state character HMMs. Thepart shown stands for the sentences “mil”, “mil uno” and “mil dos” (1,000; 1,001; 1,002 ). Outputarithmetic-expression tokens are omitted for the sake of clarity.
Table 1. Some details about the imagedatabase and the training and test partitions.
Training Test Total
# writers 18 11 29# sentences 298 187 485# words 1,300 827 2,127# letters 9,220 5,852 15,072# digits 1,543 2,480 4,023
4. Experiments
The proposed approach was empirically evaluated on the Spanish numbers task
described in Sec. 3.4. It was also compared with a more conventional approach
based on a serial combination of word recognition using N -gram syntactic modeling,
followed by text-to-number translation based on a perfect text-to-number trans-
ducer. To acquire a database of handwritten sentences of Spanish numbers, two
independent lists of numbers were randomly generated: one of 10,000 items (L1)
and other of 300 items (L2), and 29 writers were asked to write numbers from these
lists. Each writer was given a blank sheet of paper and a pencil, and asked to write
numbers in well-separated lines to facilitate their segmentation. Filled sheets were
scanned at 300 dpi in 8-bit grayscale. After segmentation of the scanned sheets, 485
images of handwritten numbers were collected, from which 298 were transcribed
from list L1 by 18 writers and 187 from list L2 by the remaining 11 writers.c
Some examples are shown in Fig. 7. For the experiments reported hereafter, the
298 sentence images were employed as a training set and the 187 sentence images
as a test set. Details about this database and the partitions used in the experi-
ments are shown in Table 1. In addition, the text-only sentences of L1 were used to
train N -gram language models in some of the comparative experiments described
in Sec. 4.2.
Two measures are used to assess the empirical results: Word Error Rate (WER)
and Digit Error Rate (DER). Both measure the percentage of tokens that have to
cThe acquired database is available upon request. To our knowledge, there are no publicly avai-lable databases of syntax-constrained handwritten text and thus it may be useful for researchersinterested in handwriting recognition and interpretation.

May 28, 2004 14:48 WSPC/115-IJPRAI 00334
530 A. H. Toselli et al.
be substituted, inserted or deleted in the system hypotheses in order to match the
corresponding reference sequences. Tokens are words for WER and decimal digits for
DER. WER and DER measure recognition and interpretation errors, respectively. It
should be noted that, for practical application to the proposed task, WER values are
of little interest. In practice, the output of a legal amount reading system generally
needs to be compared with the result of a digit recognizer, which provides a comple-
mentary hypothesis of the check sum, based on the courtesy amount. The automatic
(or manual) work needed to compare and eventually correct the results, is directly
related with the number of digit errors. Therefore, since this is a digit-by-digit
comparison, it is the DER measure what actually matters. In principle, WER and
DER are not directly comparable measures. For the Spanish numbers, for instance,
the average number of words in a text sentence of our database is 5.6, while the
average number of digits in the corresponding decimal representation is 8.3. So, at
first sight, DER might be expected to be lower than WER. However, many typical
single-word errors correspond to two or more digit errors. For instance, mistaking
“diez” for “dos” (a typical error in our system) in a sentence like “mil dos”
corresponds to changing “1002” into “1010”, which entail two digit errors. And
mistaking the word “noventa” for “millones” in a sentence such as “mil millones”
corresponds to changing “1000000000” into “1090”; i.e. seven digit errors! On the
average, for a good system, DER is expected to be somewhat lower than WER
(for Spanish number sentences), the difference approaching to zero with increasing
system accuracy.
4.1. Training feature extraction and HMMs parameters
There are three main parameters that need to be adjusted to design an accurate
Spanish numbers recognizer/interpreter in accordance with our approach. They are
the vertical resolution (VR) for feature extraction, and the number of states (NS )
and Gaussian densities per state (NG) for each character HMM. Automatically
determining optimal values for these parameters is not an easy task. In particular,
it is difficult to determine independent, optimal values of NS and NG for each
character HMM. For simplicity, we decided to use the same values of NS and NG
for all HMMs. Taking into account previous (preliminary) results for the Spanish
numbers database,4 we decided to test the following parameter values: VR = 1/16,
1/20, 1/24 and 1/28; NG = 8, 16, 32 and 64; and NS = 4, 5, 6, 7, 8 and 9. First,
we observed the influence of these parameters without using tangent vectors, which
introduce an additional parameter, the variance factor γ.
The acquired database was preprocessed as described in Sec. 2. Then, feature
extraction was applied to the preprocessed database to obtain a sequence of
(3 ·VR)-dimensional feature vectors for each handwritten number image (Sec. 2).
As discussed in Sec. 3.2, left-to-right continuous-density HMMs of NS states and
NG Gaussian densities per state were used for character modeling. These HMMs
were trained through four iterations of the Baum–Welch algorithm. This algorithm
May 28, 2004 14:48 WSPC/115-IJPRAI 00334
Integrated Handwriting Recognition and Interpretation using Finite-State Models 531
6
8
10
12
14
16
18
20
22
1/16 1/20 1/24 1/28
WER(%)
VR
NG=8163264
6
8
10
12
14
16
18
20
22
4 5 6 7 8 9
WER(%)
NS
NG=8163264
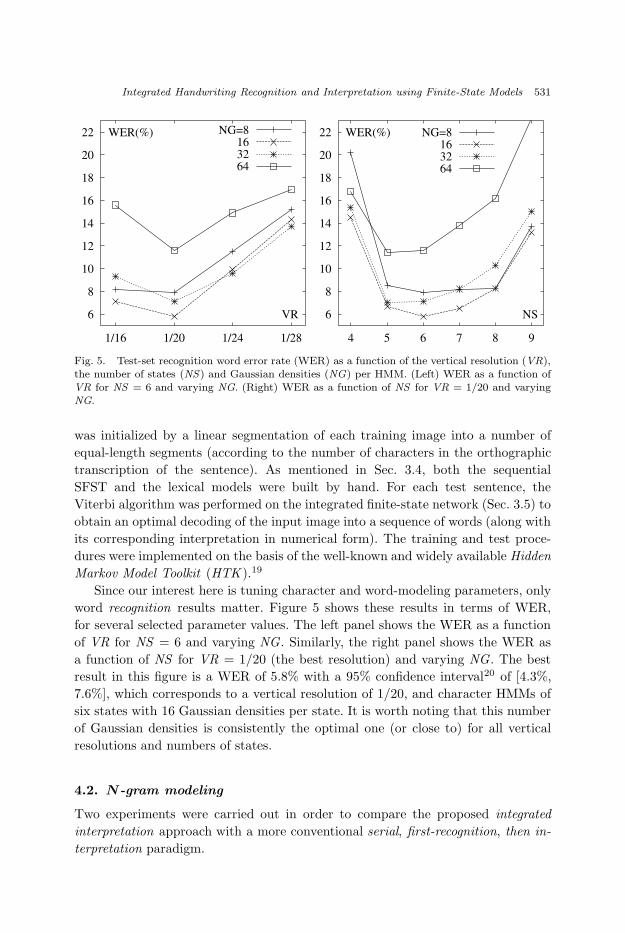
Fig. 5. Test-set recognition word error rate (WER) as a function of the vertical resolution (VR),the number of states (NS) and Gaussian densities (NG) per HMM. (Left) WER as a function ofVR for NS = 6 and varying NG. (Right) WER as a function of NS for VR = 1/20 and varyingNG.
was initialized by a linear segmentation of each training image into a number of
equal-length segments (according to the number of characters in the orthographic
transcription of the sentence). As mentioned in Sec. 3.4, both the sequential
SFST and the lexical models were built by hand. For each test sentence, the
Viterbi algorithm was performed on the integrated finite-state network (Sec. 3.5) to
obtain an optimal decoding of the input image into a sequence of words (along with
its corresponding interpretation in numerical form). The training and test proce-
dures were implemented on the basis of the well-known and widely available Hidden
Markov Model Toolkit (HTK ).19
Since our interest here is tuning character and word-modeling parameters, only
word recognition results matter. Figure 5 shows these results in terms of WER,
for several selected parameter values. The left panel shows the WER as a function
of VR for NS = 6 and varying NG . Similarly, the right panel shows the WER as
a function of NS for VR = 1/20 (the best resolution) and varying NG . The best
result in this figure is a WER of 5.8% with a 95% confidence interval20 of [4.3%,
7.6%], which corresponds to a vertical resolution of 1/20, and character HMMs of
six states with 16 Gaussian densities per state. It is worth noting that this number
of Gaussian densities is consistently the optimal one (or close to) for all vertical
resolutions and numbers of states.
4.2. N-gram modeling
Two experiments were carried out in order to compare the proposed integrated
interpretation approach with a more conventional serial, first-recognition, then in-
terpretation paradigm.
May 28, 2004 14:48 WSPC/115-IJPRAI 00334
532 A. H. Toselli et al.
4
6
8
10
12
14
16
18
20
4 8 16 32 64
NG
WER (%)
DER (%)
4
6
8
10
12
14
16
4 8 16 32 64
NGWER (%)
DER (%)
4
6
8
10
12
14
16
4 8 16 32 64
NG
WER (%)
DER(%)
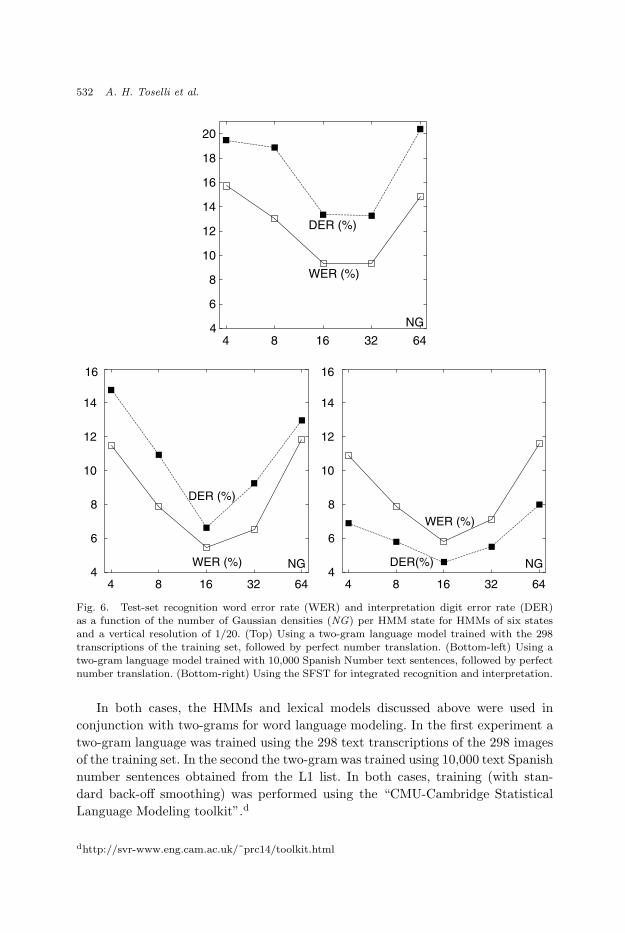
Fig. 6. Test-set recognition word error rate (WER) and interpretation digit error rate (DER)as a function of the number of Gaussian densities (NG) per HMM state for HMMs of six statesand a vertical resolution of 1/20. (Top) Using a two-gram language model trained with the 298transcriptions of the training set, followed by perfect number translation. (Bottom-left) Using atwo-gram language model trained with 10,000 Spanish Number text sentences, followed by perfectnumber translation. (Bottom-right) Using the SFST for integrated recognition and interpretation.
In both cases, the HMMs and lexical models discussed above were used in
conjunction with two-grams for word language modeling. In the first experiment a
two-gram language was trained using the 298 text transcriptions of the 298 images
of the training set. In the second the two-gram was trained using 10,000 text Spanish
number sentences obtained from the L1 list. In both cases, training (with stan-
dard back-off smoothing) was performed using the “CMU-Cambridge Statistical
Language Modeling toolkit”.d
dhttp://svr-www.eng.cam.ac.uk/˜prc14/toolkit.html

May 28, 2004 14:48 WSPC/115-IJPRAI 00334
Integrated Handwriting Recognition and Interpretation using Finite-State Models 533
Using Viterbi search with these models, the test images were optimally recog-
nized in terms of word sequences. The resulting sentences were translated into
numerical form by means of the very same SFST used in our integrated interpreta-
tion experiments. Test-set recognition WER and the corresponding interpretation
DER are shown in Fig. 6 (top and bottom-left, respectively). They are plotted as a
function of NG for the best values of NS and VR found in the previous experiments
(NS = 6 and VR = 1/20). As expected, the WERs for the two-gram trained with
the small training set are clearly worse than those of the two-gram trained with
10,000 text sentences. It is worth noting that, in both cases, DER is systematically
worse than WER.
4.3. Integrated transduction
One experiment was carried out to assess the impact of integrated interpretation
following the approach proposed in Sec. 3. This experiment is similar to the one
presented in Sec. 4.1 for VR = 1/20, NS = 6 and varying NG . Here, integrated
recognition and interpretation was carried out using the SFST outlined in Sec. 3.4
(the same used as a back-end in the serial, two-gram experiments).
As in the previous subsection, both test-set recognition WER and interpretation
DER are shown in Fig. 6 (bottom-right), plotted as a function of NG . WER results
are similar to those obtained with the two-gram model trained with 10,000 text
sentences. However, in contrast with the two-gram serial approach, here the DER is
systematically better than the WER. The best result is a DER of 4.6% (with a 95%
confidence interval of [3.6%, 5.7%]; this corresponds to a 3.6% of digit substitution
errors, 0.7% deletions and 0.3% insertions). If compared with this result, the best
DER of the two-gram serial approach was worse by 44% relative.
Three examples of sentences recognized and interpreted by both the integrated
system and the two-gram serial approach are shown in Fig. 7. The first one
was perfectly recognized and interpreted by the SFST integrated system, but the
�������������� ���������������������������� !�����"�����$#��% &� ��' !����()���� �� !�����
�*������+ ,�-�.)/ 0�1�.1324������5� !�!���6�� &7�$���!���' �78��)��9��7�5���;:������' !���)�&9�� < =�� �������+ !�!������������ ����>�!���$���' �?8@�A�&9��7�7�6�;:����6�� ����)��9�� ,�-�.)/ 0�1�.�*������+ -�0�/ 0�.'B'/ 0�1�C
1324������5� �7���;���D:����� &E8@�!���6���5���;:������' !��#���� < =�� �������+ �$���$���' �?�5�����6�������>�)��9����' �E8��$���F�>�7���G:������' !�6#��)� -�0�/ 0�.�-)/ 0�1)H�*������+ H�/ 0�0�0)/ -)HD1
1324������5� #)�"�7�6���6���I�$���6���������' !�����A�)��� H�/ 0�0�0)/ -)HD1 =�� �������+ #)�"�7�6���6���"�A�&9��A���6���� ����>�)�)�J� H�/ 0�0�0)/ .)HD1
Fig. 7. Examples of test sentences (correctly and/or incorrectly) recognized and interpreted byboth the two-gram serial approach and the integrated system.
May 28, 2004 14:48 WSPC/115-IJPRAI 00334
534 A. H. Toselli et al.
two-gram recognizer produced a word sequence with a single word error (“treinta”
for “trescientos”). This error, however, makes the sequence syntactically incor-
rect, thereby preventing the words-to-numbers transducer to provide an adequate
numeric output. The second example corresponds to a rather bad-quality sentence
which is missrecognized by both systems. Here the two-gram recognizer produces a
syntactically incorrect sentence, with many (5) word errors, which can neither be
adequately parsed into numeric form. In contrast, the integrated approach produces
a syntactically correct sentence with only two errors and a corresponding digit
sequence having also two errors. The last example shows a sentence that is correctly
recognized and interpreted by the serial two-gram method but is slightly missrec-
ognized by the integrated approach (with only one word and one digit errors).
As these examples illustrate, a significant number of digit errors of the two-gram
serial approach are due to the incapability of the words-to-numbers translator to
parse syntactically incorrect word sequences. However, in some of these cases there
are segments (typically the final parts) of the word sequences provided by the two-
gram recognizer which do admit some parsing. While this never leads to correct
digit sequences, it would at least provide a few digit hypotheses rather than a null
output. We have recomputed the DER for some of the best results in Fig. 6 (bottom,
left) by parsing the two-gram word sequences in the above suggested error-tolerant
manner. This produced noticeable improvements, but the best DER achieved was
still larger than the corresponding WER and clearly worse than the best DER
obtained with the integrated approach.
4.4. Impact of tangent vectors
Starting with the above result, we incorporated the tangent vectors into the trained
HMMs in order to increase robustness of the approach with respect to changing
4
4.5
5
5.5
6
0.001 0.01 0.1 1 10 100 1000
γ
WER(%)
DER(%)
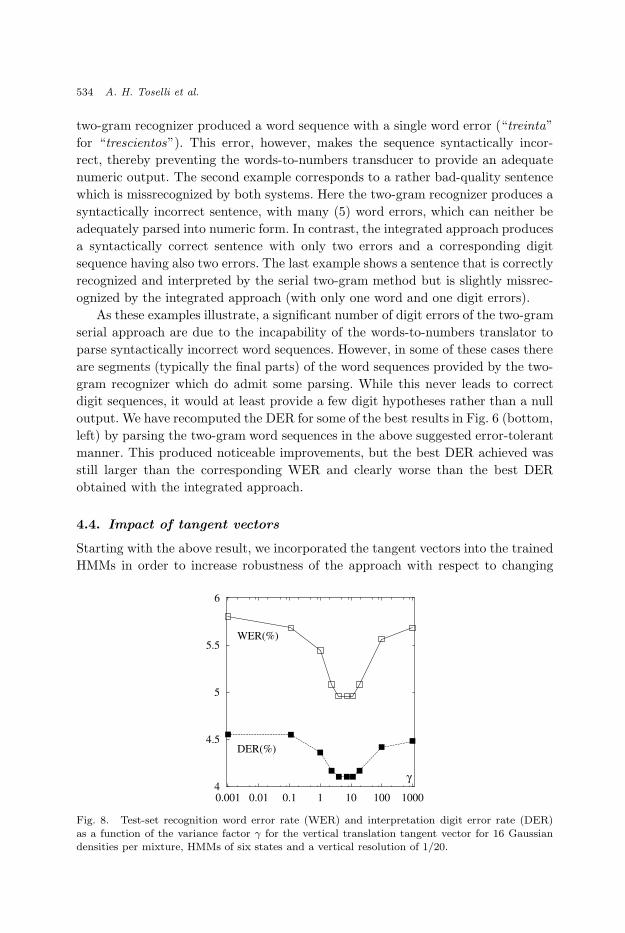
Fig. 8. Test-set recognition word error rate (WER) and interpretation digit error rate (DER)
as a function of the variance factor γ for the vertical translation tangent vector for 16 Gaussiandensities per mixture, HMMs of six states and a vertical resolution of 1/20.

May 28, 2004 14:48 WSPC/115-IJPRAI 00334
Integrated Handwriting Recognition and Interpretation using Finite-State Models 535
Fig. 9. Examples of new sentences which have been correctly recognized by the system: 5,225and 5,457.
vertical shift within each word. Recognition results are given in Fig. 8 as a function
of the variance factor γ. Using this method, the WER was reduced to 5.0% (with a
95% confidence interval of [3.6%, 6.8%]), which is a relative improvement of about
14%. The digit error rate could be further reduced from 4.6% to 4.1% (with a 95%
confidence interval of [3.2%, 5.2%]) which corresponds to a relative improvement of
about 10%. This accuracy can be considered as very satisfactory given the difficulty
of the task.
4.5. Additional field tests
The purpose of all the experiments described in the previous subsections was two-
fold. In the first place, they were aimed at showing the impact of the different system
design choices and paramenters on the results. But, as a result, in the second place,
we end up with a tuned system prepared to do real work in the task it has been
studied for.
This system recently underwent an informal field test in which 100 new images
of Spanish number sentences (411 words)e were processed. These sentences were
written by a large number of writters, completely disjoint from those in our
database, and were scanned and segmented using scanners and segmentation soft-
ware different from those used in our database. This resulted in images of much
lower quality, as shown in Fig. 9. The results were encouraging. Only a couple of
sentences failed in the preprocessing phase and more than half of the remaining
images were perfectly recognized. Most of the misrecognized sentences contained
just one word error. It should be mentioned that, by varying (some of) the recogni-
tion parameters, the accuracy did not vary significantly. This confirms that the
values of these parameters, tuned throughout the experiments reported in this
section, are adequate for using the system in real-world applications.
5. Conclusions
Integrated recognition and interpretation of handwriting text via finite-state models
has been proposed. We advocate the use of HMMs with tangent vectors for increased
robustness with respect to vertical shift and stochastic finite-state transducers for
their adequacy to globally model all the relevant constraints. A syntax-constrained
interpretation task resembling legal amount interpretation for bank checks has
eProvided by a company potentially interested in this technology.

May 28, 2004 14:48 WSPC/115-IJPRAI 00334
536 A. H. Toselli et al.
been adopted as an illustrative example. Experimental results have been reported
showing the effectiveness of the proposed approach. They constitute a significant
improvement over previous (preliminary) results obtained in the same task.4 Apart
from the impact of integrated processing, this improvement is due to the inclusion
of elaborated preprocessing and feature extraction techniques.
References
1. I. Bazzi, R. Schwartz and J. Makhoul, An omnifont open-vocabulary OCR system forEnglish and Arabic, IEEE Trans. PAMI 21 (1999) 495–504.
2. J. Berstel, Transductions and Context-Free Languages (Teubner, 1979).3. R. O. Duda and P. E. Hart, Pattern Classification and Scene Analysis (John Wiley,
1973).4. J. Gonzalez, I. Salvador, A. H. Toselli, A. Juan, E. Vidal and F. Casacuberta, Off-line
recognition of syntax-constrained cursive handwritten text, in Proc. S+SSPR 2000,Alicante, Spain, 2000, pp. 143–153.
5. D. Guillevic, Unconstrained Handwriting Recognition Applied to the Processing ofBank Cheques, Ph.D. thesis, Concordia University, 1995.
6. D. Guillevic and C. Y. Suen, Cursive script recognition: a sentence level recognitionscheme, in Proc. 3rd Int. Workshop on Frontiers in Handwriting Recognition, 1994,pp. 216–223.
7. X. D. Huang, Y. Ariki and M. A. Jack, Hidden Markov Models for Speech Recognition,Edinburgh Information Technology Series, 1990.
8. F. Jelinek, Statistical Methods for Speech Recognition (MIT Press, 1998).9. G. Kaufmann and H. Bunke, Amount translation and error localization in check
processing using syntax-directed translation, in Proc. ICPR’98, Vol. 2, Brisbane,Australia, 1998, pp. 1530–1534.
10. D. Keysers, W. Macherey, J. Dahmen and H. Ney, Learning of variability for invari-ant statistical pattern recognition, in Proc. ECML 2001, Freiburg, Germany, 2001,pp. 263–275.
11. U.-V. Marti and H. Bunke, Handwritten sentence recognition, in Proc. ICPR’00,Vol. 3, Barcelona, Spain, 2000, pp. 467–470.
12. G. Nagy, Twenty years of document image analysis in PAMI, IEEE Trans. PAMI 22
(2000) 38–62.13. J. Oncina, P. Garcıa and E. Vidal, Learning subsequential transducers for pattern
recognition interpretation tasks, IEEE Trans. PAMI 15 (1993) 448–458.14. T. Paquet and Y. Lecourtier, Recognition of handwritten sentences using a restricted
lexicon, Patt. Recogn. 26 (1993) 391–407.15. R. Plamondon and S. N. Srihari, On-line and off-line handwriting recognition: a
comprehensive survey, IEEE Trans. PAMI 22 (2000) 63–84.16. L. Rabiner and B.-H. Juang, Fundamentals of Speech Recognition (Prentice-Hall PTR,
1993).17. P. Simard, Y. Le Cun, J. Denker and B. Victorri, Transformation Invariance in
Pattern Recognition — Tangent Distance and Tangent Propagation, Lecture Notesin Computer Science, Vol. 1524 (Springer, 1998), pp. 239–274.
18. P. Slavik, Equivalence of different methods for slant and skew corrections in wordrecognition applications, IEEE Trans. PAMI 23 (2001) 323–326.
19. E. Vidal, Language learning, understanding and translation, in CRIM/FORWISSWorkshop on Progress and Prospects of Speech Research and Technology, in Proc.Art. Intell., eds. R. de Mori, H. Niemann and G. Hanrieder, Infix, 1994, pp. 131–140.

May 28, 2004 14:48 WSPC/115-IJPRAI 00334
Integrated Handwriting Recognition and Interpretation using Finite-State Models 537
20. B. Yanikoglu and P. A. Sandon, Segmentation of off-line cursive handwriting usinglinear programming, Patt. Recogn. 31 (1998) 1825–1833.
21. S. J. Young, P. C. Woodland and W. J. Byrne, HTK: Hidden Markov Model ToolkitV1.5, Technical Report, Cambridge University Engineering Department Speech Groupand Entropic Research Laboratories Inc., 1993.
Alejandro H. Toselli
received the M.S. degreein electrical engineer-ing from UniversidadNacional de Tucuman(Argentina) in 1997 andthe Ph.D. degree incomputer science fromUniversidad Politecnicade Valencia (Spain) in
2004.Dr. Alejandro is a member of the Spanish
Society for Pattern Recognition and ImageAnalysis (AERFAI) and the InternationalAssociation for Pattern Recognition (IAPR).
His current research interest lies in theareas of pattern recognition, computer visionand human language technology.
Jorge Gonzalez re-ceived the M.S. degree
in computer science fromthe Universidad Poli-tecnica de Valencia(UPV), in 1999. Hehas been a graduateresearch assistant from2000 to 2003. Now heis under a contract on a
research project.His research interests are in the areas of
speech recognition and machine translation.
Alfons Juan receivedthe M.S. and Ph.D. de-grees in computer sci-ence from the Universi-dad Politecnica de Va-lencia (UPV), in 1991and 2000, respectively.He is a Professor atthe UPV since 1995.Dr. Juan is a member of
the Spanish Society for Pattern Recognitionand Image Analysis (AERFAI) and the Inter-national Association for Pattern Recognition(IAPR).
His research interests are in the areasof pattern recognition, computer vision andhuman language technology.
Ismael Salvador re-ceived the M.S. in com-puter science engineer-ing from PolytechnicUniversity of Valenciain 1999. He startedhis Ph.D. studies inpattern recognition in1999. In 2002 he ob-tained the Advanced
Studies Diploma. He worked for 3 years on acomputer vision system to recognize identifi-cation digits in containers and he is currentlyresearching fast nearest neighbors methods.
His research interests are in computervision, image processing and patternrecognition.

May 28, 2004 14:48 WSPC/115-IJPRAI 00334
538 A. H. Toselli et al.
Enrique Vidal re-ceived the Licenciadodegree in physics in1978 and the Doctor enCiencias Fısicas (Ph.D.in physics) degree in1985, both from theUniversitat de Valencia.
From 1978 to 1986he was with this univer-
sity serving in computer system program-ming and teaching positions. In the sameperiod he coordinated a research group inthe fields of pattern recognition and auto-matic speech recognition. In 1986 he joinedthe Departamento de Sistemas Informaticos yComputacion of the Universidad Politecnicade Valencia (UPV), where he is until nowserving as a full professor of the Facultad deInformatica. In 1995 he joined the InstitutoTecnologico de Informatica, where he hasbeen coordinating several projects on patternrecognition and machine translation. He is co-leader of the Pattern Recognition and HumanLanguage Technology group of the UPV.
Dr. Vidal is a member of the SpanishSociety for Pattern Recognition and ImageAnalysis (AERFAI) and the InternationalAssociation for Pattern Recognition (IAPR).
His current fields of interest include statis-tical and syntactic pattern recognition, andtheir applications to language, speech andimage processing. In these fields, he haspublished more than one hundred papers injournals, conference proceedings and books.
Daniel Keysers re-ceived the Dipl. degreein computer science(with honors) from theRWTH Aachen Univer-sity, Germany, in 2000.Since then, he has beena Ph.D. student andresearch assistant at theDepartment of Com-
puter Science of the RWTH, where hecurrently is the Head of the Image Processingand Object Recognition Group at the Chairof Computer Science VI.
His research interests include statisticalmodeling for pattern recognition, invariancein image object recognition and computervision, and (medical) image retrieval.
Francisco Casacu-
berta received theMaster and Ph.D. de-grees in physics fromthe University of Va-lencia, Spain, in 1976and 1981, respectively.From 1976 to 1979, heworked with the De-partment of Electricity
and Electronics at the University of Valen-cia as an FPI fellow. From 1980 to 1986, hewas with the Computing Center of the Uni-versity of Valencia. Since 1980, he has beenwith the Department of Information Systems
and Computation of the Polytechnic Univer-sity of Valencia first as an Associate Professorand from 1990 as a Full Professor. Since 1981,he has been an active member of a researchgroup in the fields of automatic speechrecognition and machine translation.
Dr. Casacuberta is a member of theSpanish Society for Pattern Recognition andImage Analysis (AERFAI), which is anaffiliate society of IAPR, the IEEE ComputerSociety and the Spanish Association for Ar-tificial Intelligence (AEPIA).
His current research interest lies in theareas of speech recognition, machine transla-tion, syntactic pattern recognition, statisticalpattern recognition and machine learning.

May 28, 2004 14:48 WSPC/115-IJPRAI 00334
Integrated Handwriting Recognition and Interpretation using Finite-State Models 539
Hermann Ney re-ceived the Dipl. degreein physics from the Uni-versity of Goettingen,Germany, in 1977 andthe Dr.-Ing. degree inelectrical engineeringfrom the TU Braun-schweig (University ofTechnology), Germany,
in 1982.In 1977, he joined Philips Research Labo-
ratories (Hamburg and Aachen, Germany)where he worked on various aspects of speakerverification, isolated and connected wordrecognition and large vocabulary continuous-speech recognition. In 1985, he was appointedhead of the Speech and Pattern Recognitiongroup. In 1988–1989 he was a visiting scien-tist at AT&T Bell Laboratories, Murray Hill,NJ. In July 1993, he joined RWTH Aachen
(University of Technology), Germany, as aprofessor for computer science. His work isconcerned with the application of statisti-cal techniques and dynamic programming fordecision-making in context.
His current interests cover pattern recogni-tion and the processing of spoken and writtenlanguage, in particular signal processing,search strategies for speech recognition,language modeling, automatic learning andlanguage translation.