instruction window size trade-offs and characterization of program parallelism
TRANSCRIPT

IEEE TRANSACTIONS ON COMPUTERS, VOL. 43, NO. 4, APRIL 1994 43 I
Instruction Window Characterization of
Pradeep K. Dubey, George B. Adams,
Abstract-Detecting independent operations is a prime objec- tive for computers that are capable of issuing and executing multiple operations simultaneously. The number of instructions that are simultaneously examined for detecting those that are independent is the scope of concurrency detection. This paper presents an analytical model for predicting the performance impact of varying the scope of concurrency detection as a func- tion of available resources, such as number of pipelines in a superscalar architecture. The model developed can show where a performance bottleneck might be: insufficient resources to exploit discovered parallelism, insufficient instruction stream par- allelism, or insufficient scope of concurrency detection.
The cost associated with speculative execution is examined via a set of probability distributions that characterize the inherent parallelism in the instruction stream. These results were derived using traces from a Multiflow TRACE SCHEDULINGm com- pacting FORTRAN 77 and C compilers. The experiments provide misprediction delay estimates for 11 common application-level benchmarks under scope constraints, assuming speculative, out- of-order execution and run time scheduling. The throughput prediction of the analytical model is shown to be close to the measured static throughput of the compiler output.
Index Terms- concurrency detection, cost of parallelism, in- struction window, misprediction delay, parallelism analysis, per- formance model, speculative execution, superscalar.
I. INTRODUCTION
DENTIEYING independent operations that can be sched- I uled for execution in parallel has always been a key to execution speed enhancement. At the instruction level, detection of concurrent operations begins by examining a consecutive set of instructions from a serial execution se- quence, or Iinstruction stream. The instruction stream can be analyzed either at compile time or at execution time. Whether concurrency detection is done at compile time or at run time has an effect on the amount of available parallelism and the cost of its extraction. At compile time, several hundreds of instructions may be examined at a time for dependencies. At run time, however, simultaneous dependence analysis on so many instructions may imply expensive hardware support. The number of instructions simultaneously examined to detect a concurrent subset is the scope of concurrency detection.
Manuscript received January 27, 1992; revised January 7, 1993. This work
P. K. Dubey is with IBM, T.J. Watson Research Center, Yorktown Heights,
G. B. Adams, 111 is with hrdue University, School of Electrical Engineer-
M. J. Flynn is with Stanford University, Department of Electrical Engineer-
IEEE Log Number 9214055. TRACE SCHEDULINGTM is a trademark of Multiflow Computer, Inc.
was supported in part by NASA under Contract NAG2-248.
NY 10598.
ing, West Lafayette, IN 47907.
ing, Stanford, CA 94305.
Size Trade-offs and Program Parallelism 111, and Michael J. Flynn, Fellow, ZEEE
On computers that do run-time concurrency detection, the instruction window comprises the set of instructions examined for possible simultaneous execution. The larger the scope, the greater the probability of detecting a subset of instructions of a given size that can be scheduled for concurrent execution.
The conditional branch instructions of a program partition it into a collection of basic blocks,' or instruction stream segments each ending with a conditional branch. A conditional branch directs the execution sequence along one of two or more possible paths and the direction taken is known only at run time. Yet, concurrency detection must precede execution and assumes the availability of a consecutive set of instructions of size equal to the desired scope. This dilemma can be overcome by using branch prediction to identify the most likely execution sequence. Concurrency detection can then proceed using the instruction stream as assumed by the branch prediction method.
Conditional branch predictions will occasionally be incor- rect. Therefore, any concurrency detection scheme that groups operations across conditional branches (i.e., beyond basic blocks) must also have a mechanism to undo the effect of executed operations, if any, that do not lie on the actual execution path.
A variety of studies have been done to assess the perfor- mance potential of concurrency detection techniques. While some studies, based on idealistic hardware resource assump- tions, report a speedup potential in the range of 50 to 100 [21], [17], others report a speedup potential of only 1.5 to 10 for specific architectures and specific sets of applications. In the latter category, studies considering only concurrency detection within basic blocks, such as those by Tjaden and Flynn [25], Weiss and Smith [28], Acosta et al. [l], and Sohi and Vajapeyam [24], report speedup of about 1.5 to 2.5. Wedig [27] and Smith et al. [23] assume concurrency detection beyond basic blocks and find potential speedup of about 2 to 4. A recent study by Butler et al. [3] reports a throughput of 2.0 to 5.8 instructions per cycle for the SPEC benchmark suite, assuming out-of-order scheduling and execution. Using simulation-based techniques, Acosta et al. [l], Smith et al. [23], Butler et al. [3], and Wall [26] have also reported the performance impact of instruction window size on dynamic concurrency detection. Finally, the studies [ 131, [15], [ll], [4], [16] rely on compile-time support to enhance speedup potential and have reported speedups in the range of 4 to 8.
Performance studies can be broadly classified as either simulation-based or analytical. Most of the work on processor
' The reader should note our atypical use of the term, basic block. We ignore unconditional branches in determining the block.
0018-9340/94$04.00 0 1994 IEEE

432 lEEE TRANSACTIONS ON COMPUTERS, VOL. 43, NO. 4, APRIL 1994
performance has concentrated on the simulation-based ap- proach, The research presented in this paper is intended to complement previous work by providing an alternative ap- proach to study processor performance based on relatively sim- ple analytical models. Such models, when validated through comparison with existing simulation-based performance pre- dictions and with empitical data, when available, can provide valuable additional insights into performance potential. In particular, while simulation provides good overall measures of performance, such as expected run time, it may not clearly reveal the underlying reasons for the behavior. The analytical model developed in this paper allows identification of spe- cific program characteristics and machine features that cause performance bottlenecks, leading to additional understanding.
Architects of next generation processors are often required to provide an accurate-as-is-feasible performance estimate of the proposed design. Here, next generation means a follow- on design to an existing instruction set architecture. Common performance estimates these days for microprocessors are numbers such as the SPECmark89, which is the geometric mean of the SPEC ratios for the 10 CPU-intensive benchmarks that comprise the SPEC benchmark suite. A SPEC ratio is the ratio of execution time for a given benchmark relative to the execution time of that benchmark on a VAX 11/780 running the ULTRIX 3.1 B operating system. The traditional performance modelling approach is to run traces of the bench- marks on a low level simulation model of the proposed next generation machine. While the simulation of the new machine must be detailed enough to provide a sufficiently accurate prediction, it has to be abstract enough to have a feasible run time.
The simulation predicament can be resolved by noting that in assessing a next generation machine design it is the machine architecture only that is being redefined; the benchmark traces input to the simulation need not change. There are two good reasons for this. First, new compiler tricks and optimizations will typically lag the appearance of a next generation of a given computer architecture, appearing as an upgrade to the installed base of the new systems. Secondly, many users will want to run third-party application programs that are provided in binary form. As the next generation machine will most likely maintain machine language compatibility for marketplace reasons, the users’ favorite applications will have the same traces until such time as the vendors issue new versions that are compiled with a new compiler. Performance evaluation of a new generation machine may actually be more informative for the designers if stable binary traces are used. Therefore, if the benchmarks can be abstracted or characterized, there is no need to go through tedious clock- by-clock simulation. There are several ways to characterize a machine architecture, such as the number of pipelines and processors, cache size and design, branch delay, and so on, that can be useful for estimating performance potential. A set of program features that can serve as an indicator of potential to exceed conventional uniprocessor sequential execution speed has received little attention. The need for such a program characterization serves as a counterpoint motivation for this work.
The following section describes the analytical model used to study the performance trade-offs associated with instruction window size, and introduces a measure of the available amount of parallelism in an instruction stream. In Section 111, different costs associated with conditional branches are introduced and a measure of the cost of extracting the available parallelism is defined. Experimental results are presented in Section IV. Sec- tion V describes the issues to improve performance prediction accuracy. Section VI contains some concluding remarks and the last sections provides some recommendations for future work in this area.
11. mE ANALYTICAL PERFORMANCE MODEL A necessary condition for two instructions I, and I k to be
schedulable for simultaneous execution is that they have no mutual dependencies. An instruction is dependent on another if it uses the result of the other, if it overwrites a value to be read by the other, or if it overwrites the result of the other. The two types of dependencies caused by overwriting may be avoided if sufficient storage locations are available and used. An instruction dependent on another cannot be executed prior to or simultaneously with the instruction it depends upon without changing the meaning of the program. The sufficient condition for scheduling I, and I k together is that there must also be no instruction I3 in the instruction stream between I, and on which I k depends. If such an I3 exists, then I k must execute after that 13, and by implication, after I,.
Consider an instruction window of size W consisting of a dynamic stream of instructions labeled IO, 11, I,,..., I W - ~ , where IO is the first instruction in the window. Because in- struction IO may always be dispatched, consider the remaining instructions in terms of whether they are scheduled together with IO or not. Let I z , k represent the event that instructions I, and I k are mutually independent. p ( I z , k ) denotes the probability of the event I,$. Also, let I, : y represent the event that instruction I, is scheduled with IO, and let I, : TZ
represent the event that instruction I, is not scheduled with lo. Because I, can be scheduled with IO only if I, is independent of all the preceding instructions between IO and I,,
p(IZ : Y) = p ( l Z - l , C , I2-2,27 I2-3,2,. ’ . > I0,z)
= p(Iz - 1 ,z ) p(Iz - 2 ,z I Iz - 1 ,z ) p(Iz - 3 ,z 11,- 1 ,z, 1%- 2 ,Z ) . . . ~ ( ~ 0 , 2 l ~ 2 - 1 , , , L - Z , , , . . . ,Il,J (1)
Let p, ,k = p ( I z , k l I j , k , for all j such that z < j < k) (see Fig. 1). This pz,k is the conditional independence probability of instructions I, and I k . Thus
2
P ( L : Y) = Pz-m, , . m= 1
Let us assume that the instruction stream exhibits equilibrium on intervals, that is, the probability of instruction indepen- dence is independent of the instruction window position with respect to the instruction stream over some long sequence of consecutively executed instructions. In addition to yield- ing mathematical simplification, this assumption is motivated primarily by the fact that in this paper we are mainly interested in measuring and predicting average throughput over long

DUBEY ef aL: INSTRUCTION WINDOW SIZE TRADE-OFFS AND CHARACTERIZ .ATION 433
and
Sequential Instruction Stream
Fig. 1. Illustration of dependencies determining conditional independence probability, pa,,,. Each single arc indicates a pair of instructions that are given to be independent. The double arc denotes the dependence in question for p , ,k .
sequences of execution. Therefore, for prograh environments where such an assumption does not hold well, our predicted as well as measured throughputs would have large variances associated with them, corresponding to the different phases of program execution with their own distinct curves of scheduling probabilities. This assumption is discussed later in the paper also. Thus, pi,k is a function only of the distance between Ii and 4. Hence, pa,k may be written p6, where S = k - i. Then,
i
6=1
If pg were constant, then i
P(I2 : y) = c p 6 = p . p - . . p = p a . . 6=1
A constant pa does not mean that any two instructions, say I1 and 110, are equally likely to be independent of a third instruction, say IO. Rather it does mean that I1 and 110 are equally likely to be independent of IO, provided that 110 is not already dependent on an intermediate instruction, I,, for 1 5 m 5 9. (2) above also implies that scheduling probability, P(I; : y) is determined by its constituent pa probabilities. Hence, pg is a more inherent measure of the amount of parallelism in a given program sequence. Here, the program sequence is an assembly language sequence.
Recall that the instruction window is lo,Il , . . . , Iw-1. Let pk (IO,Il, . . . , IW - 1 ) denote the probability of dispatching exactly k instructions from the window (including IO, which is always dispatched). Then,
Pk(IO,Il, ' . ' , I W - l ) =pk-l(IO,Il, " * , I W - 2 )
x PVw-1 : 9)
x P(Iw-1 : n) -k pk (IO 7 I1 , ' , I W - 2 )
Pl(I0) =1 po(Io,Il,. . . , Iw-1) =o
At run time, the probability of being able to dispatch at least k instructions is of more interest than the probability of having exactly k dispatchable instructions. The probability of having at least k dispatchable instructions including Io is
w-1
The above equation cab also be written in the following form, which may be more computationally efficient
P>l(IO, 1 1 , . . ., Iw-1) = 1 k-1
p>k (10711 7 ' . . , IW-1) = 1 - pj (10, I1 , . ' ' > I W - l ) , j=1
for k > 1.
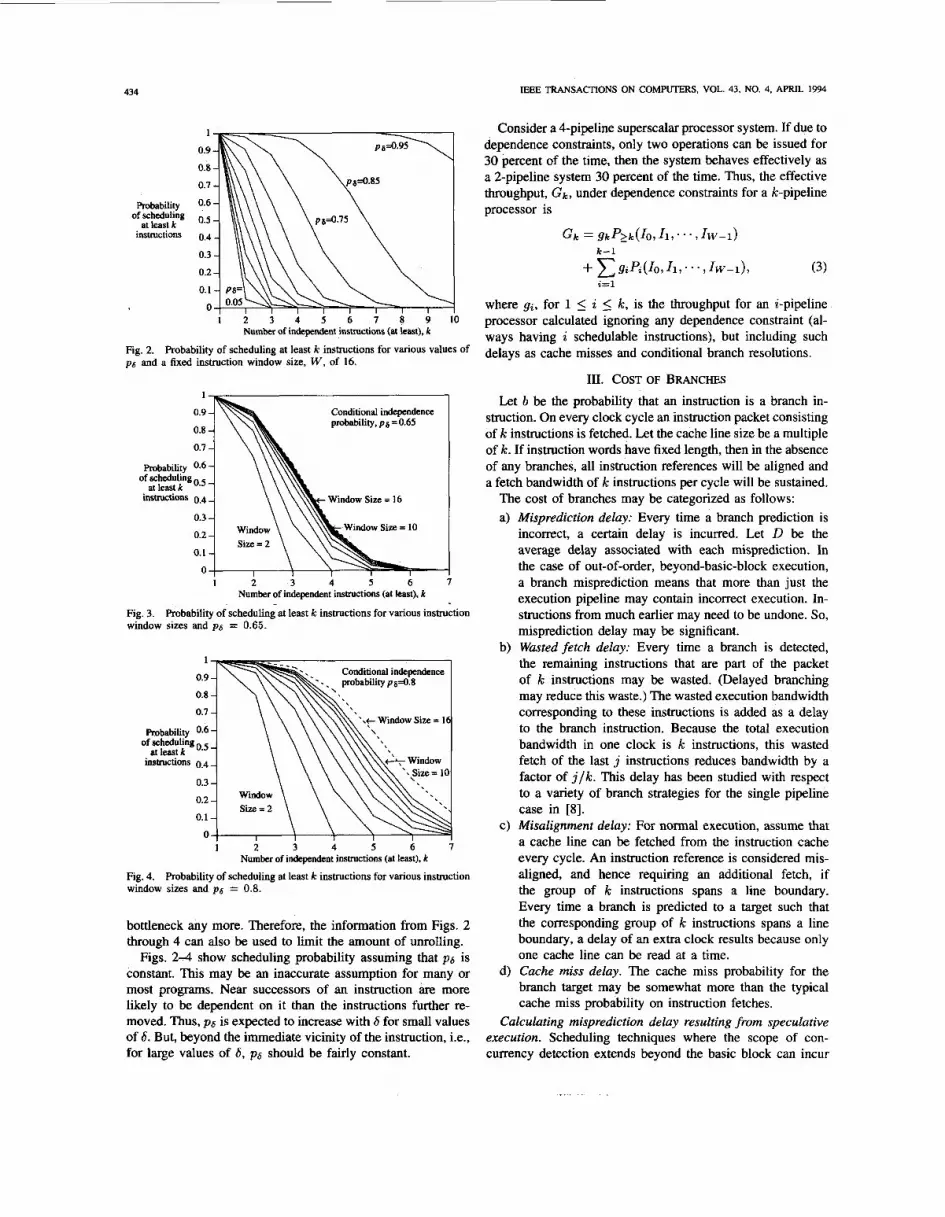
Fig. 2 through 4 depict PLk as a function of p6 and W. The following observations can be made:
1) Fig. 2 shows that there is a window (a set of values of k) for which changing p6 does not change the probability much. For the larger values of pg. the window is larger and shifted towards the higher values of k. For example, a compile-time effort to increase (say, by register renaming) from 0.55 to 0.65 to improve the scheduling probability for dispatching at least k instructions, would be only somewhat useful for k = 2, most useful for k = 3, and of significant help for k = 4. An increase in pg from 0.75 to 0.85 although unnoticed for k = 2, is significant when k = 4, even more significant for k = 5, and again very marginal for k = 10. Intuitively, increasing the parallelism in the instruction stream does not improve performance when the number of resources or the scope of concurrency detection is the bottleneck.
2) Larger window size can only be justified with an ac- companying compile-time effort to reduce dependence by increasing the conditional independence probability, as is evident from Figs. 3 and 4. For example, better scheduling probabilities are achieved with p g = 0.8 and w = 5 than With pg = 0.65 and w = 16.
Plots such as in Figs. 2-4 can be useful in isolating execution performance bottlenecks. Based on the operating point, the plots reveal whether the bottleneck is insufficient inherent parallelism in the stream (low pg, suggesting more compiler effort to reduce instruction dependencies), or not examining enough instructions (suggesting increased window size which might further indicate the need to do beyond- basic-block scheduling), or insufficient resources for utilizing available parallelism (suggesting good payoff for additional hardware). The operating point for a new processor design can be determined at an early stage, so Figs. 2 4 can be useful in guiding the design effort. Sometimes loop unrolling is used at compile time, to increase the scope of concurrency detection. There is no performance gain in unrolling beyond the point where scope of concurrency detection is not a performance
434 IEEE TRANSACTIONS ON COMPUTERS, VOL. 43. NO. 4, APRIL 1994
Robability of scheduling
at least k instructions
I I I I I I I I 1 2 3 4 5 6 7 8 9 10
Number of independent instructions (at least), k
Fig. 2. pa and a fixed instruction window size, w, of 16.
Probability of scheduling at least k instructions for various values of
Conditional independence probability, p 6 =0.65
indow Size = 16
Window Size = 10
1 2 3 4 5 6 1 Number of independent instructions (at least), k
Fig. 3. window sizes and p,5 = 0.65.
Probability of scheduling at least k instructions for various instruction
1 2 3 4 5 6 1 Number of independent instructions (at least), k
Fig. 4. window sizes and pa = 0.8.
Probability of scheduling at least k instructions for various instruction
bottleneck any more. Therefore, the information from Figs. 2 through 4 can also be used to limit the amount of unrolling.
is constant. This may be an inaccurate assumption for many or most programs. Near successors of an instruction are more likely to be dependent on it than the instructions further re- moved. Thus, p6 is expected to increase with 6 for small values of 6. But, beyond the immediate vicinity of the instruction, i.e., for large values of 6, pa should be fairly constant.
Figs. 2 4 show scheduling probability assuming that
Consider a 4-pipeline superscalar processor system. If due to dependence constraints, only two operations can be issued for 30 percent of the time, then the system behaves effectively as a 2-pipeline system 30 percent of the time. Thus, the effective throughput, G k , under dependence constraints for a k-pipeline processor is
Gk = g k P > k ( l O , 117 ’ . * 7 I W - 1 ) k - 1
+ C ~ i ~ i ( 1 0 , 1 1 , . . . , l w - 1 ) , (3) i = l
where g i , for 1 5 i 5 IC, is the throughput for an i-pipeline processor calculated ignoring any dependence constraint (al- ways having i schedulable instructions), but including such delays as cache misses and conditional branch resolutions.
III. COST OF BRANCHES
Let b be the probability that an instruction is a branch in- struction. On every clock cycle an instruction packet consisting of IC instructions is fetched. Let the cache line size be a multiple of IC. If instruction words have fixed length, then in the absence of any branches, all instruction references will be aligned and a fetch bandwidth of IC instructions per cycle will be sustained.
The cost of branches may be categorized as follows: Misprediction delay: Every time a branch prediction is incorrect, a certain delay is incurred. Let D be the average delay associated with each misprediction. In the case of out-of-order, beyond-basic-block execution, a branch misprediction means that more than just the execution pipeline may contain incorrect execution. In- structions from much earlier may need to be undone. So, misprediction delay may be significant. Wasted fetch delay: Every time a branch is detected, the remaining instructions that are part of the packet of IC instructions may be wasted. (Delayed branching may reduce this waste.) The wasted execution bandwidth corresponding to these instructions is added as a delay to the branch instruction. Because the total execution bandwidth in one clock is k instructions, this wasted fetch of the last j instructions reduces bandwidth by a factor of j/k. This delay has been studied with respect to a variety of branch strategies for the single pipeline case in [8]. Misalignment delay: For normal execution, assume that a cache line can be fetched from the instruction cache every cycle. An instruction reference is considered mis- aligned, and hence requiring an additional fetch, if the group of IC instructions spans a line boundary. Every time a branch is predicted to a target such that the corresponding group of IC instructions spans a line boundary, a delay of an extra clock results because only one cache line can be read at a time. Cache miss delay. The cache miss probability for the branch target may be somewhat more than the typical cache miss probability on instruction fetches.
Calculating misprediction delay resulting from speculative execution. Scheduling techniques where the scope of con- currency detection extends beyond the basic block can incur

DUBEY ef aL: INSTRUCTION WINDOW SEE TRADE-OFFS AND CHARACTERIZATION 435
Portion of a program tree 0 - a basic block
Wide instruction words for the trace
A scheduled trace with numbered instructions
Fig. 5. A program tree, a scheduled trace of execution from the tree, and an assembly of wide instruction words for the trace with beyond-basic-block scheduling (compensation code not shown).
additional delay for an incorrect branch prediction. This is because such scheduling techniques may need to undo the damage, if any, caused by the speculative execution of in- structions outside the current basic block. The cost of undoing a wrongfully executed instruction depends on the specific repair mechanism implemented. Since the damage undoing normally involves restoring the user-visible machine state, the repair is typically independent of the speculatively executed operation, i.e., independent of the specific instruction type. Let the time cost of undoing the damage of a wrongfully executed instruction be ,u cycles. While some machines require a constant delay per instruction for undoing the damage due to a wrongfully executed instruction, other machines may be capable of undoing the damage due to more than one wrongfully executed instructions in a constant amount of time.
Consider a program tree where each node represents a basic block and imagine following a program trace using some branch prediction mechanism (see Fig. 5) . Let p, be the probability that an instruction is scheduled with an instruction from a basic block that is w levels earlier in the program tree. Assume p , is independent of depth in the program tree. Also assume that the scope of concurrency detection extends to the end of the program (feasible at compile time but not at run time). The branch misprediction cost, Dj. associated with the basic block that is j levels deep is
N m-1 ." - D j = 'y,
n=j+ l w=n-j
where N is the average program tree depth and l / b is the expected size of a basic block. For example, suppose the conditional branch prediction associated with the basic block five levels deep is in error. Then all the instructions from the basic blocks at depth six and greater that were scheduled with instructions from basic blocks at depths 5 , 4, 3, 2, and 1 need to be undone. Assuming conditional branch prediction at any depth is equally likely to be in error, the average cost of a misprediction is
. N N n-1
(4)
Because the probability of scheduling an instruction x levels earlier in the program tree cannot exceed that of scheduling z - 1 levels earlier, p , must be a monotonically decreasing
qrangingfromO.1 to0.8
14
misprediction. D (clocks) 8
2 48 or, I I , , I I I I 10 20 30 40 50 60 70 80 90 100
Program tree depth, N
Fig. 6. Average misprediction delay versus program tree depth for brand frequency, b = 0.2, average cost of damage undoing per percolation, p = 1, and various percolation-distance distribution parameter. q. values. The parameter q is a measure of beyond-basic-block scheduling probability .
N function of w . Also, since Cw=op, = 1, p , must be a non- linear function of w. On the basis of these observations, p, may be approximated by a truncated geometric distribution with parameters K and empirically determined q such that
p , = KqW(l - q ) , where K = 1
E,"==, sW(1 - 4) * The experimentally collected results for p, for the set of benchmarks exhibit geometric distribution characteristics. As- suming K = 1 (as would be the case for large N ) , ( 1 - q) represents the probability of within-basic-block scheduling for an instruction. Thus, (4) can be rewritten as
D = - c l N 5 n-l KqW(l - q),u N h
In closed form
+ Nq") . q ( 1 - q N ) - q N - l ( q - N - 1 ) ( N - 1 - q q - 1 - 1
Fig. 6 illustrates D as a function of program tree depth, N . For values of q in the range of 0.1 to 0.6 the average misprediction delay, D, is essentially constant for N 2 20. Even for q as large as 0.8, D is nearly stable for N 2 50. Since the scope of concurrency detection in (4) is assumed to be infinite (extending up to the end of the program), D as computed above is an upper bound. Even in the worst case the average branch misprediction delay is about the same as a typical cache miss processing delay, 10 to 20 clocks.
Dynamic scheduling with finite lookahead. Since a machine can only dedicate a finite amount of chip area to keeping the history of speculatively executed operations, there is a limit to the amount of lookahead in terms of basic blocks. Let L be the scope of lookahead measured in number of basic blocks ( L = 0 for within-basic-block scheduling). Then the average misprediction delay is approximately
L L
D=C Ed. b (5 ) j=1 w=j

436 IEEE TRANSACTIONS ON COMPUTERS, VOL. 43, NO. 4, APRIL 1994
where p , represents the p , distribution truncated at a distance of L basic blocks.
A finite lookahead in terms of basic blocks also implies that the instruction window size, W , is a variable, as it gets truncated to the size of L basic blocks whenever the combined size of L pending basic blocks is less than W instructions. The distribution for W in such a case can be computed using the basic block size distribution.
Alternative computation for p,. Assuming fixed size basic blocks of size B = Lg + 0.51 and that P ( l j : y) exhibits equilibrium on intervals (as explained in Section 2), p , can be computed from P(l j : y):
TABLE I BENCHMARKS USED IN THIS STUDY
Benchmark stanford
spice fPPP
aPPlu tair
cgm fftpde mgrid mdg
Description Collection of various application programs, also known as the Stanford Integer Suite Analog circuit simulation package Quantum chemistry benchmark that measures performance on a two-electron integral derivative computation Transonic airfoil analysis program Coupled partial differential equations Conjugate gradient solver
Simple multigrid solver Driver for molecular dynamic simulation of a flexible water molecule
3-D FFT PDE
mg3d
bdna
Nonlinear algebraic systems solvers and ODE solvers for signal processing ODE solvers for chemical and physical models i=o j = i + ( w - l ) B + l
Note that P ( l j : y) = 0 for j 5 0. A value for parameter p , computed as above would not be
as accurate as one empirically collected, because the above calculation is based on the very simplistic assumption of fixed basic block size. This can be improved by using the basicblock size distribution instead. Assuming p,5 (and hence P ( l j : y)) to be independent of the size of basic blocks, p , computed using the basic block size distribution should be approximately same as that empirically collected. Thus an alternate characterization of parallelism can be in terms of p6 and basic block size distribution instead of p6 and p,.
IV. EXPERIMENTAL RESULTS There are two key input parameters in the model developed
in the previous two sections: p,5 and p, . The parameter pg provides a measure of how often two instructions at positions S apart in the instruction stream are found to be independent. Two different pairs of independent instructions separated by a fixed distance 6 in the instruction stream may have very different costs for simultaneous scheduling, depending on the distance as measured in basic blocks. The parameter p , captures this additional cost, giving a more realistic performance estimate.
Experiments have been conducted on a set of benchmarks (see Table I) using the Multiflow TRACE SCHEDULING compacting FORTRAN 77 and C compilers, for a TRACE 28/200 computer. This compiler [ 101 does beyond-basic-block scheduling. The goal of these experiments was two-fold. First, to establish the nature of the p6 and p , parameters and to determine their capability for characterizing program parallelism; second, to show that this characterization can be used to predict program performance under scope and resource constraints.
The hardware of the TRACE [7] can initiate 28 operations per instruction. Thus, the collected values for p6 and p , are not resource constrained when considering less than the available number of resources of the TRACE 28/200.
The Multiflow compiler has the ability to generate de- tailed trace schedules, such that the operations being grouped for simultaneous execution are also tagged to indicate their position in the original sequential instruction stream. This information is used for calculating the scheduling probability,
Note: Stanford is written in C, rest of the benchmarks are in FORTRAN.
P(I; : y) which is used for predicting the static throughput, as explained in Section 11. The model makes no attempt to discover parallelism in addition to that found by the Multiflow compiler ([22] explores the loop-level parallelism that was left undiscovered by Multiflow compilers). Collected traces for the benchmarks are post-processed to simulate a run-time scheduling environment. The target environment assumes that on every scheduling cycle W instructions from the dynamic stream of instructions are examined for dependence. Those found independent, say k ( 5 W), are scheduled together and dispatched, and another IC instructions are moved into the instruction window. The post-processing consists of the fol- lowing phases:
1) renumbering instructions in a trace to represent a con-
2) dynamically adjusting distances between instructions as
3) weighting data from each routine in proportion to the
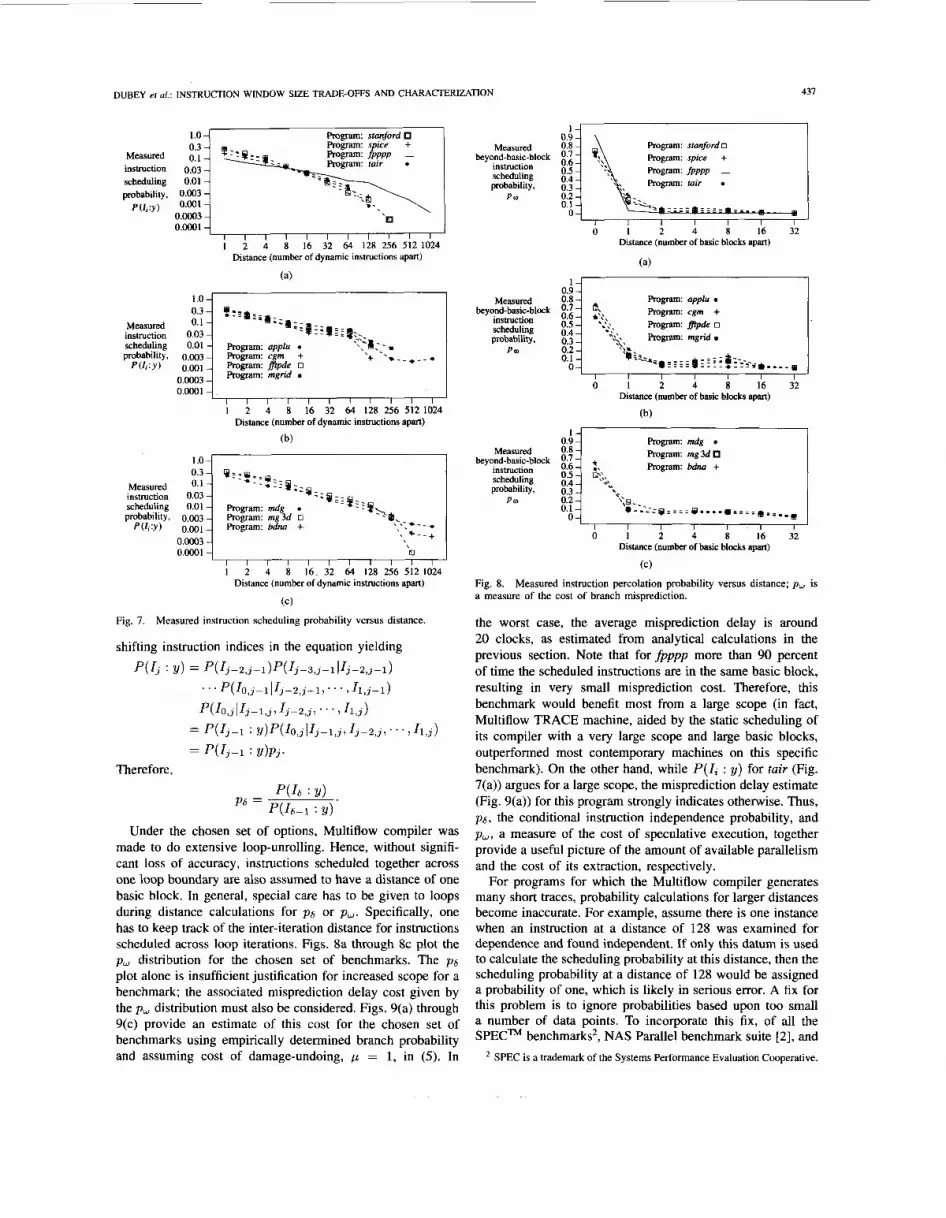
Fig. 7(a)-(c) plot P(I; : y) for the chosen set of bench- marks. Note the distinctive nature of the fpppp benchmark. Unlike the others, it has a relatively small scheduling proba- bility for adjacent instructions ( 6 = 1) and has a small but non-negligible probability of scheduling even at distances of more than 512. Three other benchmarks, applu, mdg and bdna, also exhibit small but non-negligible probability of scheduling even at distances of more than 512 instructions.
The p,5 values can be obtained from the scheduling proba- bilities in the following manner. Restating (l),
tinuous dynamic sequence,
the execution proceeds, and
fraction of run time spent in that routine.
Equilibrium on intervals for the distribution of instruction independence probability, P(l i ,k) , as assumed earlier, allows
437 DUBEY et al.: INSTRUCTION WINDOW SIZE TRADE-OFFS AND CHARACTERIZATION
1.0 - Program: stanford Program: spice +
Measured 0.1
probability, 0.003 - P ( I , : y ) 0.001 -
0.0003 - 0.0001-
I I I I I I I I ~ I I 1 2 4 8 16 32 64 128 256 512 1024
Distance (number of dynamic instructions apart)
Measured instruction scheduling probability, P ui: Y )
Measured instruction scheduling probability. P (1, : y )
1 2 4 8 16 32 64 128 256 512 1024 Distance (number of dynamic instructions apart)
(b)
1.04
0.003 0.001
0.0003 0.0001 0
I I I I I I I I I I I I 2 4 8 16. 32 64 128 256 512 1024
Distance (number of dynamic instructions apart)
(C)
Measured instruction scheduling probability versus distance. Fig. 7.
Under the chosen set of options, Multiflow compiler was made to do extensive loop-unrolling. Hence, without signifi- cant loss of accuracy, instructions scheduled together across one loop boundary are also assumed to have a distance of one basic block. In general, special care has to be given to loops during distance calculations for p6 or p, . Specifically, one has to keep track of the inter-iteration distance for instructions scheduled across loop iterations. Figs. 8a through 8c plot the p , distribution for the chosen set of benchmarks. The p6 plot alone is insufficient justification for increased scope for a benchmark; the associated misprediction delay cost given by the p , distribution must also be considered. Figs. 9(a) through 9(c) provide an estimate of this cost for the chosen set of benchmarks using empirically determined branch probability and assuming cost of damage-undoing, p = 1, in (5). In
0.9 Rogram: stunford o
beyo!%%block i!! 1 "\% Program: spice + Program: @ppp -
I , Program: ?air
instruction scheduling O3 probability, g::
o i i 4 S 1 6 3 2 Distance (number of basic blocks apart)
(a)
Program: applu beyond-basic-block Program: cgm +
F": I.%* 0 ":<, Program: mgrid . instruction g:: scheduling 0.4 probability, 0.3 I. I
, I I I I I I
0 1 2 4 8 1 6 3 2 Distance (number of basic blocks apart)
Program: Rogram: Measured i/i
instruction 0.6 :, scheduling t:: ";:\
probability, 0.3 ''\. Program: beyond-basic-block O.'
P W 0.2 '\@ - - i .---= @ ~ = = 0.1
mdg m g M bdna+
I I
0 1 2 4 8 1 6 3 2 Distance (number of basic blocks apart)
I I I I I I
(C)
Fig. 8. a measure of the cost of branch misprediction.
the worst case, the average misprediction delay is around 20 clocks, as estimated from analytical calculations in the previous section. Note that for fpppp more than 90 percent of time the scheduled instructions are in the same basic block, resulting in very small misprediction cost. Therefore, this benchmark would benefit most from a large scope (in fact, Multiflow TRACE machine, aided by the static scheduling of its compiler with a very large scope and large basic blocks, outperformed most contemporary machines on this specific benchmark). On the other hand, while P(I; : y) for tuir (Fig. 7(a)) argues for a large scope, the misprediction delay estimate (Fig. 9(a)) for this program strongly indicates otherwise. Thus, pg , the conditional instruction independence probability, and p,, a measure of the cost of speculative execution, together provide a useful picture of the amount of available parallelism and the cost of its extraction, respectively.
For programs for which the Multiflow compiler generates many short traces, probability calculations for larger distances become inaccurate. For example, assume there is one instance when an instruction at a distance of 128 was examined for dependence and found independent. If only this datum is used to calculate the scheduling probability at this distance, then the scheduling probability at a distance of 128 would be assigned a probability of one, which is likely in serious error. A fix for this problem is to ignore probabilities based upon too small a number of data points. To incorporate this fix, of all the SPECm benchmarks', NAS Parallel benchmark suite [2], and
Measured instruction percolation probability versus distance; p , is
SPEC is a trademark of the Systems Performance Evaluation Cooperative.

438 IEEE TRANSACTlONS ON COMPUTERS, VOL. 43. NO. 4, APRIL 1994
Predicted misprediction
delay, D (clocks)
.................... . . Program: Stanford
m3ram: fPPPP - . Program: tair
0 2 4 6 8 10 12 14 16 18 20 22 242628 3032 Lookahead (number of basic blocks)
(a)
Predicted misprediction
delay, D (clocks)
...................... ......................... ......................... ~~~~~ooooooooooooooonnnnnno
Program: applu Program: c m + Program: o Program: mgrid
0 2 4 6 8 10 12 14 16 18 20 22 24 2628 3032 Lookahead (number of basic blocks)
1 I I I I I I I I I I I I I I I
I
0 2 4 6 8 10 12 14 16 18 20 22 242628 3032 Lookahead (number of basic blocks)
(C)
Fig. 9. Model-predicted misprediction delay based on the empirically col- lected p , distribution as a function of the amount of dynamic lookahead.
Perfect Benchmarksm [6], only those benchmarks3 that had at least 200 data points in their growing throughput range have been selected. (This is why not all of the SPEC, NAS Parallel, and Perfect Benchmarks are members of the chosen set of benchmarks.)
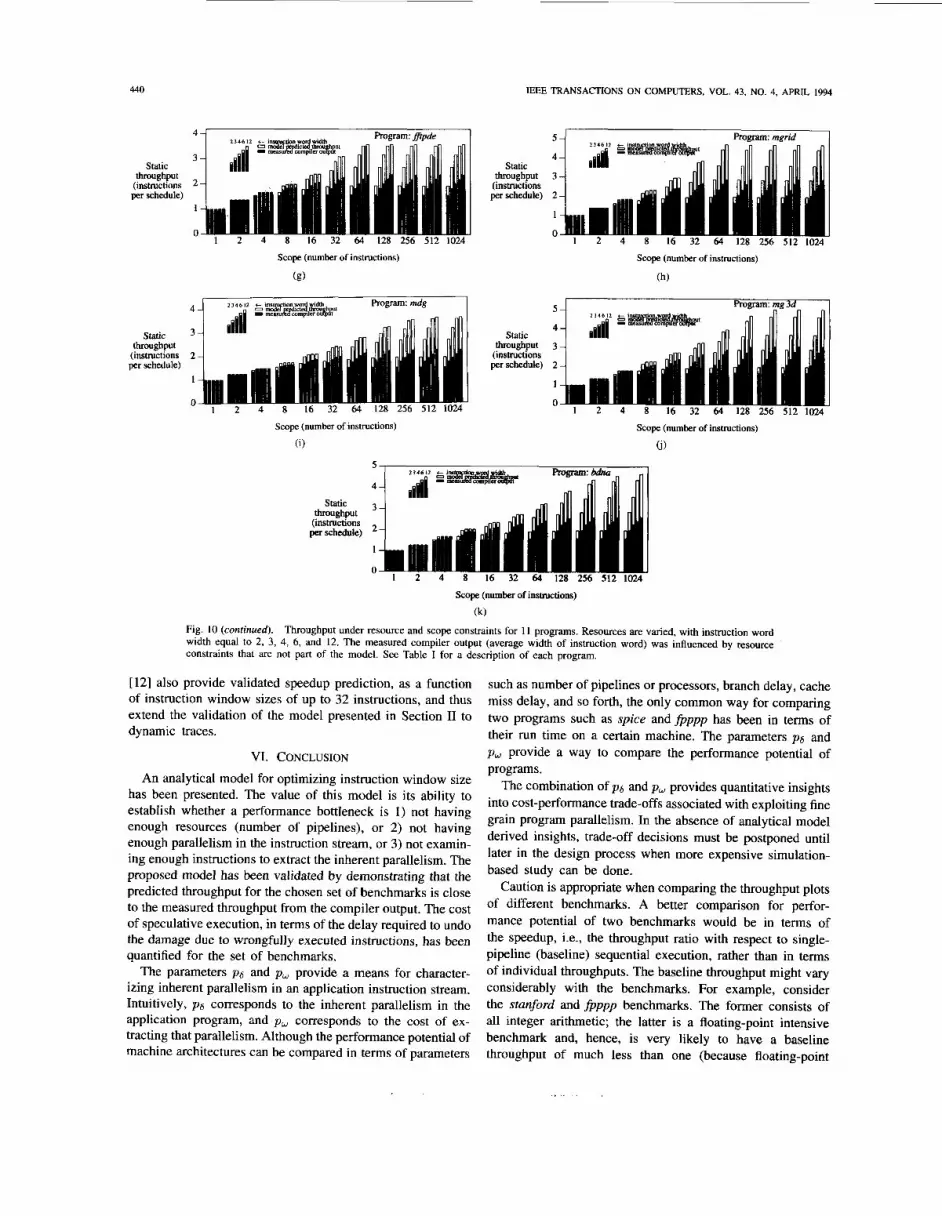
Fig. 10(a)-(k) show analytical model predicted through- put and measured static throughput (average width of an instruction word) from the compiler output as a function of scope of concurrency detection and instruction word width. Model predicted throughput is calculated using the empirically calculated scheduling probability P(I i : y) values (Fig. 7) as input to the analytical model developed in Section 11. Measured static throughput is estimated as the average width of schedules (wide instruction words) in the traces output by the Multiflow compiler. The throughputs (both measured and predicted) do not take into account run-time delays, including, branch misprediction delay, D. More specifically, Fig. 10(a)-(k) assume gi = 1, in (3). The compiler throughput estimate also does not take into account memory delays, such as, cache miss, etc. which are not part of the analytical model either.
Purdue University SPEC License No. 310. Perfect Benchmarks is a trademark of The Board of Trustees of the University of Illinois.
An important reason for the discrepancy between the model prediction and the compiler output is due to the basic dif- ference between a symmetric superscalar and an asymmetric superscalar or a VLIW machine. The model is based on a sym- metric superscalar architecture. Consequently, two instructions that are data-independent of each other are always assumed schedulable on two available resources (pipelines). But in an asymmetric superscalar or VLIW environment (such as that of the Multiflow), there are resource type restrictions, as each functional unit is not a complete execution pipeline. For example, on a VLIW machine, two independent floating point adds may be forced to wait if only integer adders are available. Such resource constraints are not part of the analytical model. As a result, model predictions are always optimistic (i.e., higher throughput). Moreover, this optimism impacts more and more instruction pairs, as the instruction window size increases. Therefore, Figs. 10a through 10k show increasing discrepancy between measured and predicted throughputs as the scope of concurrency detection increases.
For a window size of 32, the average difference between the model predicted throughput and measured compiler output is 20 percent and the worst case difference is 43 percent; whereas, for a window size of 1024, the average and worst case differences are 47 percent and 79 percent, respectively. More importantly, the throughput curves for both the model and the measured values have very similar shape. Reference [DAF9 11 contains additional data on the benchmarks used here, as well as some other SPEC benchmarks and Perfect Benchmarks.
Experience with these benchmarks confirms that the longer the traces, the more data points, and hence more credible the probabilities and better the performance prediction. For example, the tuir andfpppp benchmarks gave relatively longer traces and the model predicted throughput was particularly close to the measured compiler output. Almost all the bench- marks (an important exception being fpppp) attain almost all of their potential speedup with a scope of about 64 instructions and an instruction word width of six.
v . POTENTIAL IMPROVEMENTS TO THE MODEL INPUT There are three predominant sources of inaccuracy in the
input to the analytical model. First, a trace scheduling compiler schedules instructions
subject to the available hardware resources in the target computer. The analytical model depends on experimentally gathered data for its input probabilities. As indicated in the previous section, the target of the Multiflow compiler is a resource-categorized machine, i.e., functional units are non- uniform. Also the finiteness of resources of Multiflow TRACE machine implies that the empirical data presented in this paper cannot be meaningfully used for predicting performance for set of resources larger than that of TRACE 28/200. Hence, the pg probabilities inferred from the scheduled VLIW instruction stream omit some cases of instructions schedulable with instruction Io. Thus, the measured P(I; : y) or pg values are a lower bound on the actual values. Hence the performance
3The SPEC benchmarks and NAS parallel benchmarks were compiled using version 1.6.1 of the TRACE C and FORTRAN 77 compilers. The Perfect Benchmarks were compiled using version 2.2 of the TRACE FORTRAN 77 compiler.
derived using these values should be viewed as conservative estimates Of the performance potentia' Of next generation machines on these benchmarks. We do not know

DUBEY et al.: INSTRUCTION WINDOW SIZE TRADE-OFFS AND CHARACTERIZATION 439
Scope (number of instructions)
(a)
3 static
(instructions throughput 2
p e r a w
1 2 4 8 16 32 64 128 256 512 1024
Scope (number of instructions)
(C)
3
4 static
(instructions perschedule) 2
1
throughput
1 2 4 8 16 32’ 64 128 256 512 1024
Scope (number of instructions)
(e)
2 static
throughput (instructions perschedule)
n ” 1 2 4 8 16 32 64 128 256 512 1024
Scope (number of instructions)
(b)
3
static 2 throughput
(im’tructions perschedule) 1
1 2 4 8 16 32 64 128 256 512 1024
Scope (number of instructions)
(d)
3 static
(instructions per schedule)
h g h P U l 2
1
0 1 2 4 8 16 32 64 128 256 512 I024
Scope (number of instructions)
(0 Fig. 10. Throughput under resource and scope constraints for 1 1 programs. Resources are varied, with instruction word width equal to 2, 3, 4, 6, and 12. The measured compiler output (average width of instruction word) was influenced by resource constraints that are not part of the model. See Table I for a description of each program.
of a parallelizing compiler that assumes an infinite resource environment and provides a detailed schedule, with mapping between the original sequential stream and the new compacted (parallelized) schedule.
Second, the collected set of pg statistics is a subset of the total statistics due to missing dependence information from the compiler. For example, when any compiler schedules I8 with Io, it can be concluded that independent instruction pairs were detected at a distance of 8, 7, 6, . . . , and 1, because 18 can be scheduled with IO only if 18 is independent of not only IO but also of 17, I, . . e, and II. However, if I8 is not scheduled with IO, it is not possible to determine the responsible dependent instruction pair(s). Therefore, the collected statistics for sched- uled instructions as a function of distance is a subset of the statistics corresponding to all possible schedulable instruction pairs as a function of their distance.
Finally, the analytical performance prediction model as- sumes a continuous instruction stream (the dynamic instruction stream) with the given pg characteristics, whereas the Mul- tiflow compiler output produces several, potentially many, disjoint traces. (It is quite reasonable for the compiler to do this.) The analysis combines the p6 values for all the traces, weighted by the estimated time spent executing each trace. This is an approximation of the dynamic pg values.
Fixes for the first and second issues require dependence analysis tools specially designed for collecting pg values. The second issue would also benefit from complete dependence information available from run-time traces. A remedy for the problem of continuous instruction stream requires gen- erating combined traces and collecting pg using dependence analysis on dynamic instruction streams. Analyzing dynamic instruction streams can also solve the problem of short traces mentioned in the previous section. Subsequent work of two of us [ 121 has addressed some of these issues along the suggested lines. The conceptual framework for [12] is based on the ana- lytic model introduced in this paper. In contrast to the method of static program analysis used in this paper, [12] describes a set of tools for dynamic program analysis. These tools are capable of dynamically collecting pg and provide p6 plots for four science/engineering application benchmarks (including fpppp, mgnd, and spice), up to a distance of 32 instructions. The pg plots in [12] support our hypothesis in Section 2 that p s should be fairly constant for larger values of 6. These measurements also suggest that pg values typically remain constant over several millions of executed instructions and then change over a much shorter interval to new values that are then sustained for millions of executed instructions. Using dynamic traces from the four benchmarks, the experiments of
440 IEEE TRANSACTIONS ON COMPUTERS, VOL. 43, NO. 4, APRIL 1994
1 2 4 8 16 32 64 128 256 512 1024
Scope (number of instructions)
(9)
Scope (number of instructions)
(h)
4
static 3 throughput
(instructions 2 per schedule)
1
0 1 2 4 8 16 32 64 128 256 512 1024
Scope (number of instructions)
( 0
Scope (number of instructions)
ci) 5
4
Static throughput (instructions per schedule)
1
0 1 2 4 8 16 32 64 128 256 512 1024
Scope (number of instructions)
(k) Fig. 10 (conrinued). Throughput under resource and scope constraints for 11 programs. Resources are varied, with instruction word width equal to 2, 3, 4, 6, and 12. The measured compiler output (average width of instruction word) was influenced by resource constraints that are not part of the model. See Table I for a description of each program.
[I21 also provide validated speedup prediction, as a function of instruction window sizes of up to 32 instructions, and thus extend the validation of the model presented in Section I1 to dynamic traces.
VI. CONCLUSION An analytical model for optimizing instruction window size
has been presented. The value of this model is its ability to establish whether a performance bottleneck is 1) not having enough resources (number of pipelines), or 2) not having enough parallelism in the instruction stream, or 3) not examin- ing enough instructions to extract the inherent parallelism. The proposed model has been validated by demonstrating that the predicted throughput for the chosen set of benchmarks is close to the measured throughput from the compiler output. The cost of speculative execution, in terms of the delay required to undo the damage due to wrongfully executed instructions, has been quantified for the set of benchmarks.
The parameters p s and p , provide a means for character- izing inherent parallelism in an application instruction stream. Intuitively, pg corresponds to the inherent parallelism in the application program, and p , corresponds to the cost of ex- tracting that parallelism. Although the performance potential of machine architectures can be compared in terms of parameters
such as number of pipelines or processors, branch delay, cache miss delay, and so forth, the only common way for comparing two programs such as spice andfbppp has been in terms of their run time on a certain machine. The parameters pg and p , provide a way to compare the performance potential of programs.
The combination of pg and p , provides quantitative insights into cost-performance trade-offs associated with exploiting fine grain program parallelism. In the absence of analytical model derived insights, trade-off decisions must be postponed until later in the design process when more expensive simulation- based study can be done.
Caution is appropriate when comparing the throughput plots of different benchmarks. A better comparison for perfor- mance potential of two benchmarks would be in terms of the speedup, i.e., the throughput ratio with respect to single- pipeline (baseline) sequential execution, rather than in terms of individual throughputs. The baseline throughput might vary considerably with the benchmarks. For example, consider the stunford and fbppp benchmarks. The former consists of all integer arithmetic; the latter is a floating-point intensive benchmark and, hence, is very likely to have a baseline throughput of much less than one (because floating-point

DUBEY er al.: INSTRUCTION WINDOW SIZE TRADE-OFFS AND CHARACTERIZATION 441
arithmetic operations typically take multiple execution cycles to complete). Therefore, although Stanford andfippp may both have a throughput of around 1.6 for a window-size of 16, the latter implies a much higher speedup than the former.
Finally, the performyme prediction approach presented in this paper is meant primarily for actual applications (including “dusty decks”) as opposed to kemels or small benchmarks. Full applications yield longer traces. The longer the traces, the more credible and meaningful the probability calculations, and hence the better the performance prediction. Providing predictions about the speed of real applications, rather than of kemels, is a strength of the approach here.
VII. FUTURE WORK
Studying the cost-pelformanee trade-offs for concurrency detection in different phases of execution. Before execution, any end-user task goes through stages of transformation from the level of algorithm formulation to high level language specification, followed by assembly and possibly microcode translations. In an ideal sense, the available parallelism in- creases as the transformation proceeds from the algorithm level to the microcode level. For example, in an ideal sense it should be possible, at the microcode level, to overlap two independent internal register moves belonging to two independent sort operations specified at the algorithm level. But while these independent sort operations may be only a few lines apart at the level of high level language specification, they would be many lines apart at the microcode level, due to intervening translation steps. Thus, as we move towards latter stages of program transformation, potential parallelism goes up along with the scope required for its detection. Con- sequently, exploitation of the additional amount of available parallelism at the latter stages of transformation has additional cost associated with it. This implies a cost-performance design trade-off aimed at extracting a large amount of parallelism without incurring prohibitive cost.
Machines have been built with parallelism detection and scheduling at all of the stages of transformations (previously mentioned). Systolic architectures [ 141 exploit concurrency at the algorithm level, data flow architectures [20] attempt con- currency detection at the level of microcode, and recent VLIW [5] and superscalar [ 191 architectures detect concurrency at the level of assembly-level instructions. The ability to quantify the amount of parallelism and the cost of its extraction, as discussed in this paper (using p6 and the p , distribution) can be a useful tool in analyzing the cost-performance trade-off for the proper level of concurrency detection. This paper provides the plots for these statistics for a VLIW machine (Multiflow) and efforts are underway to collect the same data at the level of high level language specification.
There are two other factors that influence the available parallelism and its cost of exploitation. First is the language used for specification at the high level or at the assembly level. There may be built-in dependencies in the specification syntax. For example, if there are separate instructions used for setting the condition code and branching, then almost invariably condition code setting would be followed by a branch that is dependent on the preceding instruction that
set the condition code. Such built-in dependencies limit the amount of parallelism for a given scope. By collecting p6 and the p , distribution for a variety of languages on a common set of application tasks, a quantitative comparison of languages can be made. Future research is targeted at comparing different high level languages (such as FORTRAN and C) as well as some assembly level instruction sets (such as those for the Intel x86, Motorola 68x, IBM RS6000, and Sun Sparc).
Second, whether concurrency detection is done at compile time or run time has an effect on the amount of available parallelism and the cost of its extraction. At compile time, a scope as large as several hundreds of instructions can have an affordable space and ,compilation time cost. At run time, how- ever, such a large scope would seriously compromise clock cycle time and increase the hardware needed for maintaining history to support misprediction undoing.
Other measures for distance between instruction pairs: This paper analyzes instruction window size trade-offs for a ma- chine with dynamic (run time) scheduling and speculative execution. The input for run-time schedulers is the dynamic instruction sequence. Consequently the density of available parallelism and the cost of its extraction have been estimated as a function of the number of such instructions being examined (W) and the number of pending branches (L) . There is another reason for describing pa and p , in terms of the number of intervening instructions. As indicated in Section 11, intuitively one would assume that the output of an instruction is more likely to be consumed in the immediate vicinity than much farther. At the assembly or microcode level, this immediate vicinity can be quantified in terms of the number of following instructions. But at the level of high level languages, this may not be a good measure of immediate vicinity. For example, consider a machine capable of directly executing instructions specified in a high level language, such as the two pieces of code in Fig. 11. Intuitively one would assume B[i , j] to be equally likely to be dependent on A[i - l,j] and A[Z,j - 11. But in terms of number of run-time intervening instructions, the dependent instructions in Example 1) are separated by six instructions, whereas, those in Example 2 ) are separated by 51 instructions. Although different iteration instances of an instruction may be at varying distances, the probability of dependence for any pair should be expected to be close if they are equidistant along any one of the dimensions. Thus at the level of high level language specification, when multi-dimensional references are involved, the immediate vicinity may be better characterized using some measure that treats equally every dimension. Such measures of parallelism can also be used as heuristics in choosing the dimensions that would be most profitable to unroll in loop quantization techniques discussed in [ 181. Finally, for machines doing static scheduling, a better distance measure between two instructions may be the number of arcs in the uncompacted program tree.
ACKNOWLEDGMENT The authors thank J. T. Kuehn and his colleagues at the
Supercomputing Research Center in Bowie, Maryland, and thank the University Computing Center at Califomia State

442 IEEE TRANSACTIONS ON COMPUTERS, VOL. 43, NO. 4, APRIL 1994
Example - i for i=l to 10 forj=l to 10 1: 1: 2: 2: 3: A[ij] := C[ij] 4: B[ij] := A[ij-l] 5 : 5:
Example - ii for i=l to 10 for j=l to 10
3: A[i,j] := C[ij] 4: B[ij] := A[i-lj]
end; end;
Fig. 11. Dependence across iterations.
end; end;
University, Sacramento, California, for making their Multiflow computers available. The authors also thank the reviewers for their valuable suggestions.
REFERENCES
[22] M. Schuette, “Exploitation of instruction-level parallelism for detection of processor execution errors,” Res. Rep. No. CMUCDS-91-7, Camegie- Mellon Univ., 1991.
[23] M. D. Smith, M. Johnson and M. A. Horowitz, “Limits multiple instruction issue,” in Proc. of ASPLOS I l l , Apr. 1989, pp. 290-302.
[24] G. S. Sohi and S. Vajapeyam, “Instruction issue logic in high- performance interruptible pipelined processors,” in Pmc. 14th Annu. Symp. on Computer Architecture. June 1987, pp. 27-34.
[25] G. S. Tjaden and M. J. Flynn, “Detection and parallel execution of independent instructions,” IEEE Trans. Comput., vol. C-19, pp. 889-895. Oct. 1970.
[26] D. W. Wall, “Limits of instruction-level parallelism,” in Proc. 4th Int. Con$ Architectural Support for Programming Languages and Operating Syst., April 1991, pp. 17&188.
[27] R. G. Wedig, “Detection of concurrency in directly executed language instruction streams,” Ph.D. dissertation, Stanford Univ., June 1982.
1281 S. Weiss and J. E. Smith, “Instruction issue logic in pipelined super- computers,” Proc. I Ith Annu. Symp. Comput. Architecture. June 1984, pp. 11G118.
R. D. Acosta, J. Kjelstrup and H. C. Tomg, “An instruction issuing ap- proach to enhancing performance in multiple functional unit processors,” IEEE Trans. Comput., vol. C-35, pp. 815-828, Sept. 1986. D. Bailey, J. Barton, T. Lasinski, and H. Simon, “The NAS parallel benchmarks,” Rep. RNR-91-002, NASA Ames Res. Ctr., Jan. 1991. M. Butler, T. Yeh, Y. Patt, M. Alsup, H. Scales, and M. Shebanow, “Single instruction stream parallelism is greater than two,” in Proc. 18th Annu. Symp. Comput. Architecture, May 1991, pp. 276-286. R. Cohn, T. Gross, M. Lam, and P. S. Tseng, “Architecture and compiler trade-offs for a long instruction word microprocessor,” in Proc. of ASPLOS I l l , Apr. 1989, pp. 2-14. R. P. Colwell, W. E. Hall, C. S. Joshi, D. B. Papworth, P. K. Rodman, and J. E. Tomes, “Architecture and implementation o f a VLIW supercomputer,” Proc. of Supercomputing ’90, Nov. 1990, pp. 910-919. G. Cybenko, L. Kipp, L. Pointer, and D. Kuck, “Supercomputer per- formance evaluation and the PERFECT benchmarks,” CSRD Rep. No. 965, Univ. of Illinois, Urbana, IL, Mar. 1990. R. P. Colwell, R. P. Nix, J. J. O’Donnell. D. B. Papworth, and P. K. Rodman, “A VLIW architecture for a trace scheduling compiler,” IEEE Trans. Comput. vol. 37, pp. 967-979, Aug. 1988. P. K. Dubey and M. J. Flynn, “Branch strategies: Modelling and optimization.” IEEE Trans. Comput.. vol. 40, pp. 1159-1 167. Oct. 1991. P. K. Dubey, G. B. Adams, 111, and M. J. Flynn, “Exploiting fine-grain concurrency: analytical insights in superscalar processor design,” Tech. Rep. No. TI -EE 91-31, School of Elect. Eng., Purdue Univ., Aug. 1991. J . A. Fisher, “Trace scheduling: A technique for global microcode compaction,” IEEE Trans. Comput., vol. C-30, pp. 478490, July 1981. P. Y. T. Hsu and E. S. Davidson, “Highly concurrent scalar process- ing,’’ Proc. 13th Annu. Symp. on Comput. Architecture, June 1986, pp. 38&395. R. A. Kamin, G. B. Adams, 111, and P. K. Dubey. “Dynamic trace analysis for analytic modeling of superscalar performance,” to appear in a Special Issue of Performance Evaluation (the Performance Modeling of Parallel Processing Systems). D. Kuck, Y. Muraoka, and S. Chen, “On the number of operations simultaneously executable in Fortran-like programs and their resulting speedup,” IEEE Trans. Comput., vol. C-21, pp. 1293-1310, Dec. 1972. H. T. Kung, “Why systolic architectures?,” Computer, vol. 15, no. 1, pp. 3 7 4 6 , Jan. 1982. M. Lam. “Software pipelining: An effective scheduling technique for VLIW machines,” in Proc. SIGPLAN ’88 Conj Prog. h g . Design and Implementation, June 1988, pp. 3 1&328. T. Nakatani and K. Ebcioglu, “Using a lookahead window in a com- paction based parallelizing compiler,” Proc. 23rd Annu. Workshop Mi- croprogramming, Nov. 1990, pp. 57-68. A. Nicolau and J. Fisher, “Measuring the parallelism available for very long instruction word architectures,” IEEE Trans. Comput., vol. C-33, pp. 968-976, Nov. 1984. A. Nicolau, “Uniform parallelism exploitation in ordinary programs,” in Proc. Int. Con$ Parallel Processing, Aug. 1985, pp. 61&618. R. R. Oehler and R. D. Groves, “IBM RISC System/6ooO processor architecture,” IBM J. Res. Develop., pp, 23-36, Jan. 1990. Y. N. Patt, W.-M. Hwu, and M. Shebanow, “HPS, a new microar- chitecture: Rationale and introduction,” in Proc. 18th Annu. Workshop Microprogramming, pp. 103-108, Dec. 1985. E. M. Riseman and C. C. Foster, “The inhibition of potential paral- lelism,” IEEE Trans. Comput., vol. C-21, pp. 1405-1411, Dec. 1972.
Pradeep K. Dubey received the B.S. degree in electronics, with distinction from Birla Institute of Technology, Mesra, India, in 1982, the M.S. degree in electrical and computer engineering from Univer- sity of Massachusetts at Amherst, in 1984, and the Ph.D. degree in electrical engineering from Purdue University in 1991.
He is currently a research staff member at IBM Thomas J. Watson Research Center in the Advanced RISC Systems group. From 1984 to 1991, he worked at Intel Corporation, Santa Clara, CA
and was a member of the 80386, 80486, and the Pentium design teams. His research interests include computer architecture and performance modeling.
George B. A d a m , I11 (S’76-M-85) received the B.S.E.E. with distinction from Virginia Polytechnic Institute and State University in 1978, the M.S.E.E. degree and the Ph.D. degree in electrical engineering from Purdue University in 1980 and 1984, respec- tively.
In 1983, he joined the Research Institute for Advanced Computer Science (RIACS) at the NASA Ames Research Center. Since 1987, he has been an Assistant Professor with the School of Electrical Engineering, Purdue University. He was a Visiting
Scientist with RIACS during the summers of 1988 and 1989. During 1986, he was also a Visiting Lecturer with the Department of Electrical Engineering, Stanford University. His research interests include computer architecture, parallel processing, interconnection network design, parallel processing al- gorithms, and modeling and analysis of computer systems. He holds a patent for the Extra Stage Cube fault-tolerant interconnection network.
Michael J. Flynn (M’56-SM’79-F‘80) is a Profes- sor of Electrical Engineering at Stanford University. His experience includes ten years at IBM Corp. working in computer organization and design. He was also a faculty member at Northwestern and Johns Hopkins University, and the director of Stan- ford’s Computer Systems Laboratory from 1977 to 1983.
He is well known for his research in parallel processors and computer arithmetic, and has pub- lished widely in these areas. Flynn has served as
vice president of the Computer Society and was founding chairman of CS’s Technical Committee on Computer Architecture, as well as ACM’s Special Interest Group on Computer Architecture.
Dr. Flynn was the 1992 recipient of the ACMlIEEE Eckert-Mauchly Award for his work in computer architecture.