guia de uso básico de spss
TRANSCRIPT

Guía de uso básico de SPSS
0. Introducción
El objetivo de esta guía es que el estudiante aprenda a preparar los datos, interpretar
los resultados y formular sus conclusiones mediante SPSS. Los temas a cubrir son:
Importación y propiedades de variables.
Comparación de muestras de una población.
Asociación de variables.
Construcción de gráficos multivariados.
Para realizar los ejercicios se usarán siguientes documentos: (1) Organizaciones.xls,
con datos de organizaciones económicas de la SAGARPA; (2) Seguros, con datos de
aseguradoras; (3) Rehabilitacion.sav, con datos de una población de reclusos; (4)
Leche.sav, con datos de los lecheros de los Altos de Jalisco, y (5) Graficos1.xls y
Graficos2.xls que contienen datos para la construcción de gráficos.
1. Preparación de datos
El análisis de datos casi siempre comienza en una hoja de cálculo, aunque es posible
hacerlo también en la hoja de datos de SPSS. Si se decide comenzar en MS Excel,
entonces debe colocar en la primera fila el nombre de las variables y en las filas
siguientes los datos. Al finalizar se recomienda hacer una inspección de las celdas con
el propósito de asegurarse que ha introducido los datos correctamente.
Las tareas de preparación consisten en: (a) auditar los datos, (b) documentar variables,
(c) transformación de variables (recodificar), y (d) verificación de escalas de medida.
Estas tareas se dividen en dos fases: la primera usualmente se realiza mediante MS
Excel, mientras que las demás en SPSS.
Durante el Taller se usará MS Excel para la adquisición de datos, su auditoría y su
documentación correspondiente. Por su parte, en SPSS se usará el procedimiento para
importar datos, transformación de variables y verificación de escalas de medida1.
1 Las opciones para Excel son Calc de OpenOffice y Gnumeric; las alternativas para SPSS son SAS, BMP (de también de SAS), eViews, STATA, StatGraphics, PSPP, MyStat, MathLab y una gran cantidad de macros programadas para Excel como AnalizeIt, EZAnalize, NumXL, XLStat y XLStatistics. Para elaborar gráficos de negocios las opciones son BMP, SPSS y Origin, entre muchas otras.
2
Abra el documento “Organizaciones.xls”, que contiene tres hojas: Hoja1 (base de datos
de las organizaciones de la SAGARPA), Aspectos del IDO (componentes del índice de
desarrollo organizacional) y VarDescr (descripción de variables).
1.1. Auditoría de datos
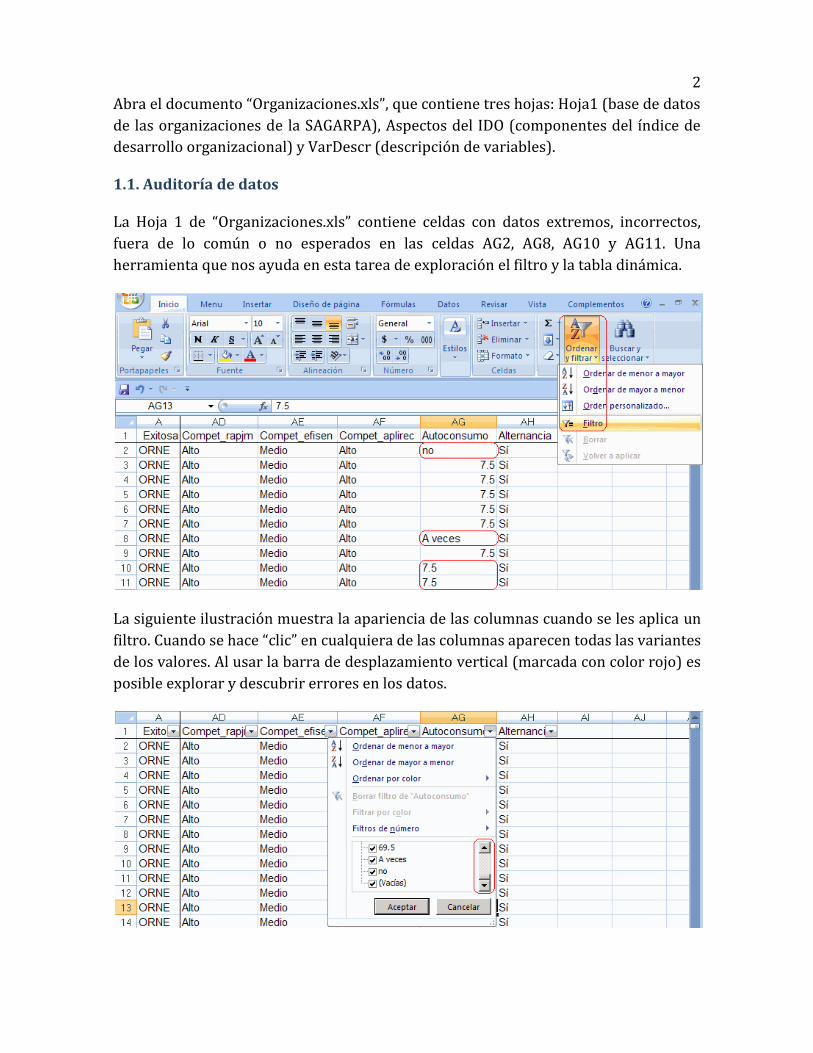
La Hoja 1 de “Organizaciones.xls” contiene celdas con datos extremos, incorrectos,
fuera de lo común o no esperados en las celdas AG2, AG8, AG10 y AG11. Una
herramienta que nos ayuda en esta tarea de exploración el filtro y la tabla dinámica.
La siguiente ilustración muestra la apariencia de las columnas cuando se les aplica un
filtro. Cuando se hace “clic” en cualquiera de las columnas aparecen todas las variantes
de los valores. Al usar la barra de desplazamiento vertical (marcada con color rojo) es
posible explorar y descubrir errores en los datos.
3
1.2. Documentación de variables
Con frecuencia es necesario trabajar con datos que prepararon otras personas, de modo
que se dificulta su análisis porque no se está familiarizado con la estructura de la hoja
de cálculo, las variables ni los valores que adoptan. Por eso es necesario documentar la
hoja de datos.
Para documentar una hoja de cálculo en MS Excel existen dos posibilidades. La primera
es añadir comentarios tanto en los títulos de las variables como en sus valores. Note
que los comentarios no alteran las propiedades numéricas de los datos.
La siguiente ilustración muestra los nombres de las variables (los cuales usualmente
son muy cortos para optimizar el espacio visual), que sólo las entiende el autor o quien
las preparó, pero dificulta que otras personas comprendan la estructura de esa hoja de
cálculo. Aquí también se describe el procedimiento para añadir comentarios.
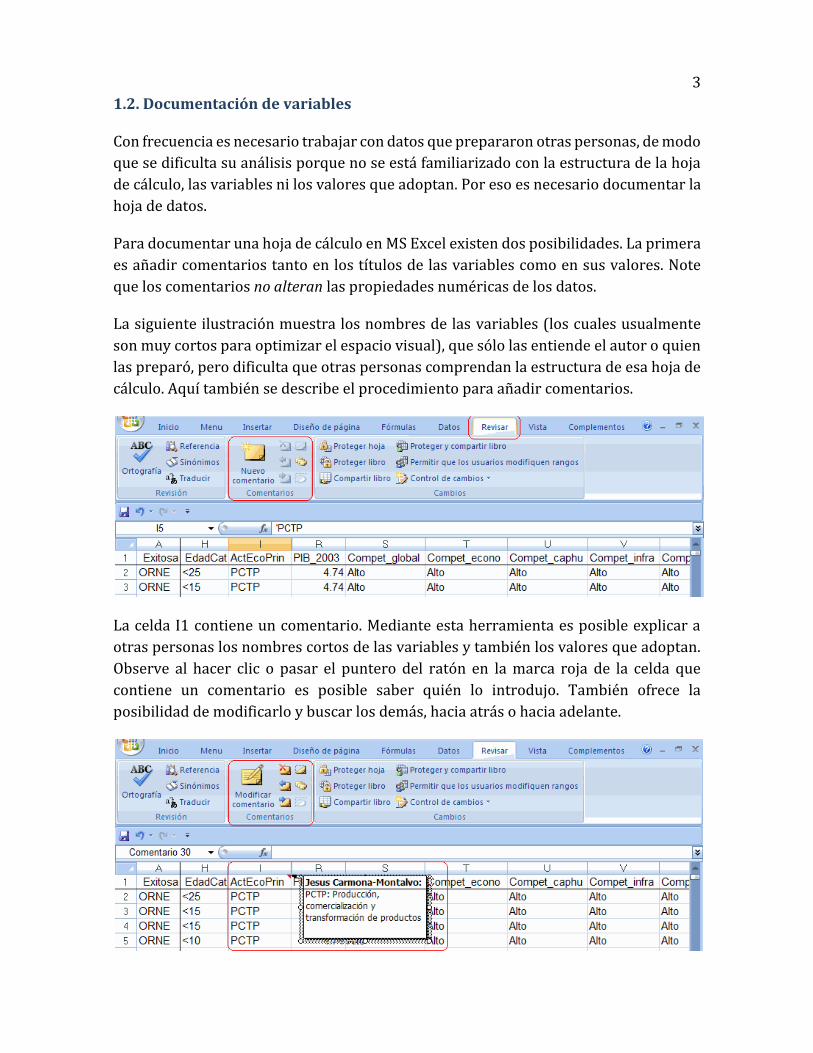
La celda I1 contiene un comentario. Mediante esta herramienta es posible explicar a
otras personas los nombres cortos de las variables y también los valores que adoptan.
Observe al hacer clic o pasar el puntero del ratón en la marca roja de la celda que
contiene un comentario es posible saber quién lo introdujo. También ofrece la
posibilidad de modificarlo y buscar los demás, hacia atrás o hacia adelante.
4
La segunda posibilidad es añadir otra hoja de cálculo donde se ponga en cada renglón
el nombre corto de las variables y a su derecha una descripción detallada de esa
variable y los valores que contiene.
1.3. Importación de datos en SPSS
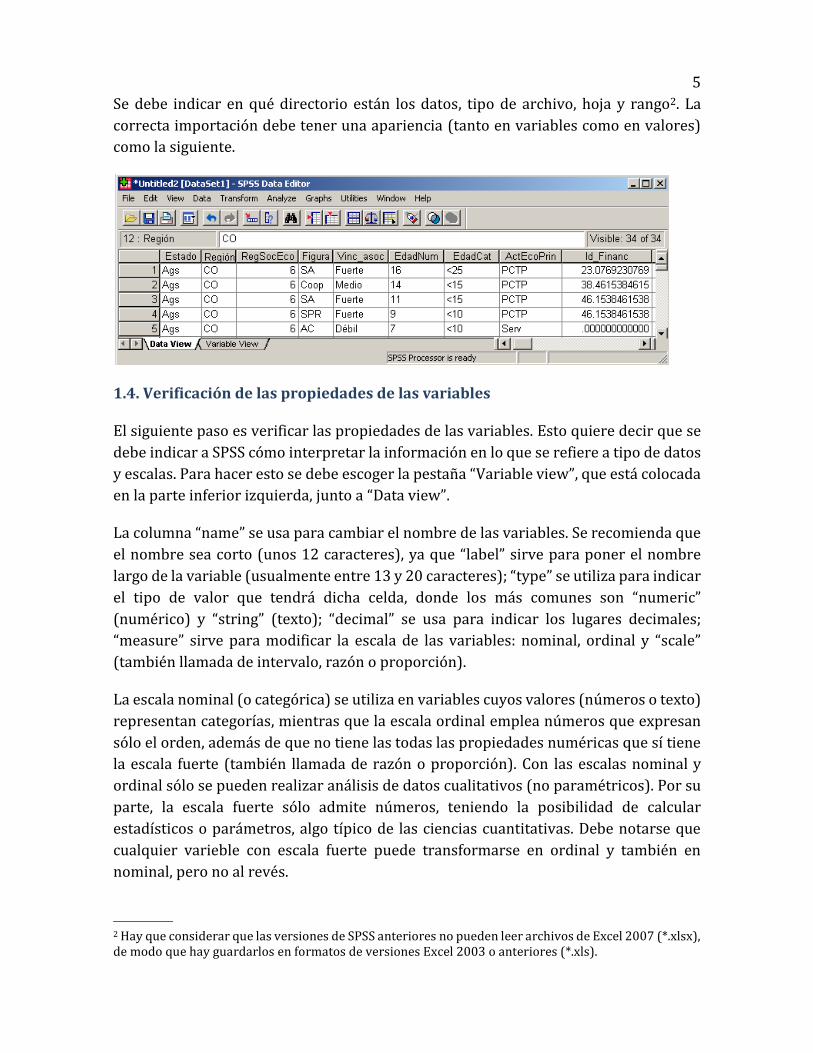
En las versiones nuevas de SPSS los datos se pueden pegar desde el Portapapeles de
Windows (copiar y pegar). Sin embargo, en versiones anteriores, como la 17, pegar los
datos produce resultados indeseados. Por ejemplo, no asigna correctamente los
nombres de las variables, tampoco interpreta bien las escalas de medida ni los valores.
Para ilustrar esto, observe la siguiente figura.
Para evitar esto, es mejor usar el procedimiento para importar datos. La secuencia de
pasos para abrir un conjunto de datos es esta: File / Open / Data.
5
Se debe indicar en qué directorio están los datos, tipo de archivo, hoja y rango2. La
correcta importación debe tener una apariencia (tanto en variables como en valores)
como la siguiente.
1.4. Verificación de las propiedades de las variables
El siguiente paso es verificar las propiedades de las variables. Esto quiere decir que se
debe indicar a SPSS cómo interpretar la información en lo que se refiere a tipo de datos
y escalas. Para hacer esto se debe escoger la pestaña “Variable view”, que está colocada
en la parte inferior izquierda, junto a “Data view”.
La columna “name” se usa para cambiar el nombre de las variables. Se recomienda que
el nombre sea corto (unos 12 caracteres), ya que “label” sirve para poner el nombre
largo de la variable (usualmente entre 13 y 20 caracteres); “type” se utiliza para indicar
el tipo de valor que tendrá dicha celda, donde los más comunes son “numeric”
(numérico) y “string” (texto); “decimal” se usa para indicar los lugares decimales;
“measure” sirve para modificar la escala de las variables: nominal, ordinal y “scale”
(también llamada de intervalo, razón o proporción).
La escala nominal (o categórica) se utiliza en variables cuyos valores (números o texto)
representan categorías, mientras que la escala ordinal emplea números que expresan
sólo el orden, además de que no tiene las todas las propiedades numéricas que sí tiene
la escala fuerte (también llamada de razón o proporción). Con las escalas nominal y
ordinal sólo se pueden realizar análisis de datos cualitativos (no paramétricos). Por su
parte, la escala fuerte sólo admite números, teniendo la posibilidad de calcular
estadísticos o parámetros, algo típico de las ciencias cuantitativas. Debe notarse que
cualquier varieble con escala fuerte puede transformarse en ordinal y también en
nominal, pero no al revés.
2 Hay que considerar que las versiones de SPSS anteriores no pueden leer archivos de Excel 2007 (*.xlsx), de modo que hay guardarlos en formatos de versiones Excel 2003 o anteriores (*.xls).

6
La figura anterior muestra varios errores en las propiedades de la variable EdadNum
(edad de la organización), ya que SPSS la considera “texto” y le asignó una escala
nominal (debe ser numérica y con escala de intervalo, razón o proporción).
La siguiente figura muestra los cambios realizados en la variable EdadNum, donde se
cambió el tipo (de “String” a “Numeric”); también se añadió su descripción completa en
la columna “Label”; después, en la columna “Measure” el cambio fue de “Nominal” a
“Scale”.
A veces se requiere añadir una descripción de los valores que adoptan las variables
cualitativas. Un ejemplo es cuando la variable tiene valores 0 y 1 para indicar “Sí”, “No”,
“Masculino”, “Femenino”, y así por el estilo. La siguiente figura muestra cómo usar el
procedimiento “Values” en la misma hoja de propiedades de las variables (Variable
view”), ahí donde se cambia la escala y los lugares de decimales.
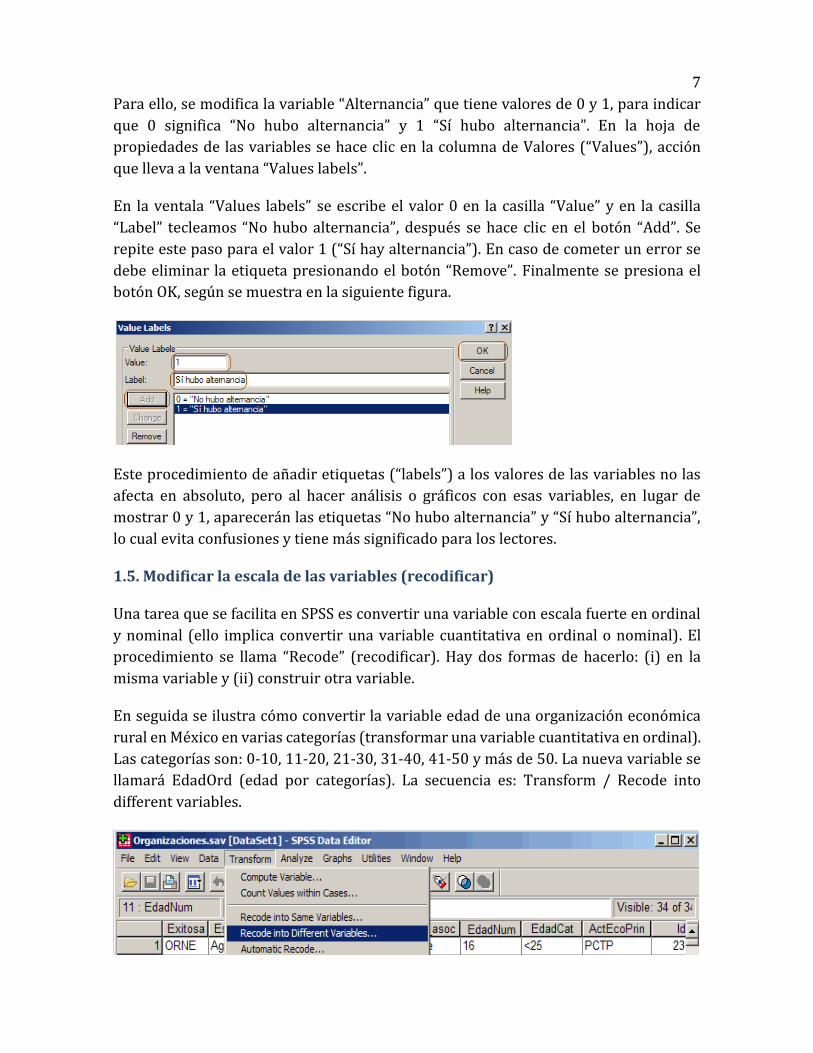
7
Para ello, se modifica la variable “Alternancia” que tiene valores de 0 y 1, para indicar
que 0 significa “No hubo alternancia” y 1 “Sí hubo alternancia”. En la hoja de
propiedades de las variables se hace clic en la columna de Valores (“Values”), acción
que lleva a la ventana “Values labels”.
En la ventala “Values labels” se escribe el valor 0 en la casilla “Value” y en la casilla
“Label” tecleamos “No hubo alternancia”, después se hace clic en el botón “Add”. Se
repite este paso para el valor 1 (“Sí hay alternancia”). En caso de cometer un error se
debe eliminar la etiqueta presionando el botón “Remove”. Finalmente se presiona el
botón OK, según se muestra en la siguiente figura.
Este procedimiento de añadir etiquetas (“labels”) a los valores de las variables no las
afecta en absoluto, pero al hacer análisis o gráficos con esas variables, en lugar de
mostrar 0 y 1, aparecerán las etiquetas “No hubo alternancia” y “Sí hubo alternancia”,
lo cual evita confusiones y tiene más significado para los lectores.
1.5. Modificar la escala de las variables (recodificar)
Una tarea que se facilita en SPSS es convertir una variable con escala fuerte en ordinal
y nominal (ello implica convertir una variable cuantitativa en ordinal o nominal). El
procedimiento se llama “Recode” (recodificar). Hay dos formas de hacerlo: (i) en la
misma variable y (ii) construir otra variable.
En seguida se ilustra cómo convertir la variable edad de una organización económica
rural en México en varias categorías (transformar una variable cuantitativa en ordinal).
Las categorías son: 0-10, 11-20, 21-30, 31-40, 41-50 y más de 50. La nueva variable se
llamará EdadOrd (edad por categorías). La secuencia es: Transform / Recode into
different variables.

8
En la parte izquierda de la figura aparece una lista de todas las variables. Observe que
las de tipo texto (“string”) tienen la apariencia de esferas junto a una letra, las que son
ordinales se asemejan a una escalera y las numéricas parecen una cinta de medir. Eso
facilita la identificación de los tipos de variables existentes, escoger la técnica de
análisis apropiada y el tipo de gráficos que se puede hacer.
Se selecciona la variable “Edad de la organización” y se presiona el botón flecha derecha
para que dicha variable ingrese en la sección “Input Variable -> Output variable”,
mientras que en la sección “Output variable” se escribe en la casilla “Name” el nombre
corto que tendrá la nueva variable y en la casilla “Label” su descripción completa. En
seguida se presiona el botón “Change”. Observe que en la parte central ya existía la
variable “EdadNum --> ?”, que ahora aparece como “EdadNum --> EdadOrd”. Después
se hace clic en el botón “Old and new values”.
Se usa la opción “Range” para indicar que a todos los valores de cero a diez años los
agrupe en una categoría que se llame “1. De 0-10”, y así sucesivamente. Para crear las
categorías los pasos a seguir son los siguientes: (1) en la sección “Range” se escribe el
valor menor en la primera celda y el valor mayor en la celda “through”; (2) se hace clic
en la casilla “Output variables are strings” para indicar que el nombre de la categoría
serán caracteres alfanuméricos (letras, números y guiones); (3) se escribe el nuevo
nombre o valor que tendrá esa categoría en “New value”; (4) después se presiona el
botón “Add”. Se hace esto mismo para todos los grupos de edad; (5) en la casilla “Width”
se pone un valor mayor de 8 para que los nombres de las categorías no salgan
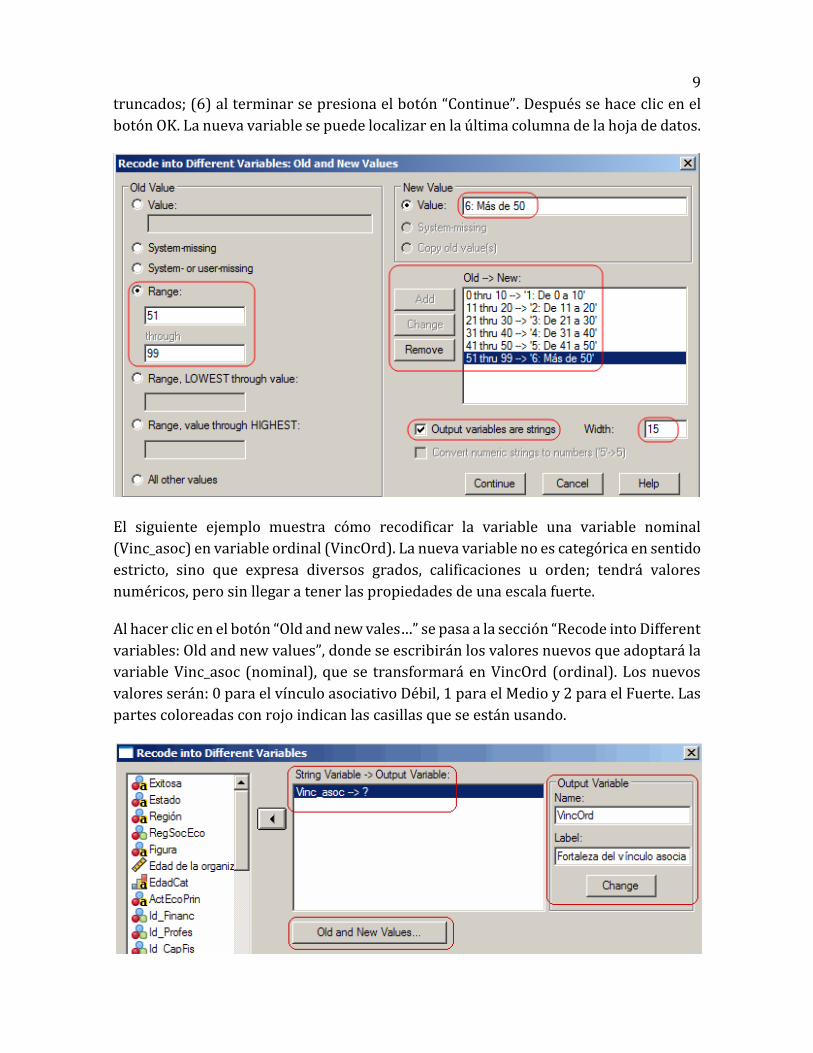
9
truncados; (6) al terminar se presiona el botón “Continue”. Después se hace clic en el
botón OK. La nueva variable se puede localizar en la última columna de la hoja de datos.
El siguiente ejemplo muestra cómo recodificar la variable una variable nominal
(Vinc_asoc) en variable ordinal (VincOrd). La nueva variable no es categórica en sentido
estricto, sino que expresa diversos grados, calificaciones u orden; tendrá valores
numéricos, pero sin llegar a tener las propiedades de una escala fuerte.
Al hacer clic en el botón “Old and new vales…” se pasa a la sección “Recode into Different
variables: Old and new values”, donde se escribirán los valores nuevos que adoptará la
variable Vinc_asoc (nominal), que se transformará en VincOrd (ordinal). Los nuevos
valores serán: 0 para el vínculo asociativo Débil, 1 para el Medio y 2 para el Fuerte. Las
partes coloreadas con rojo indican las casillas que se están usando.
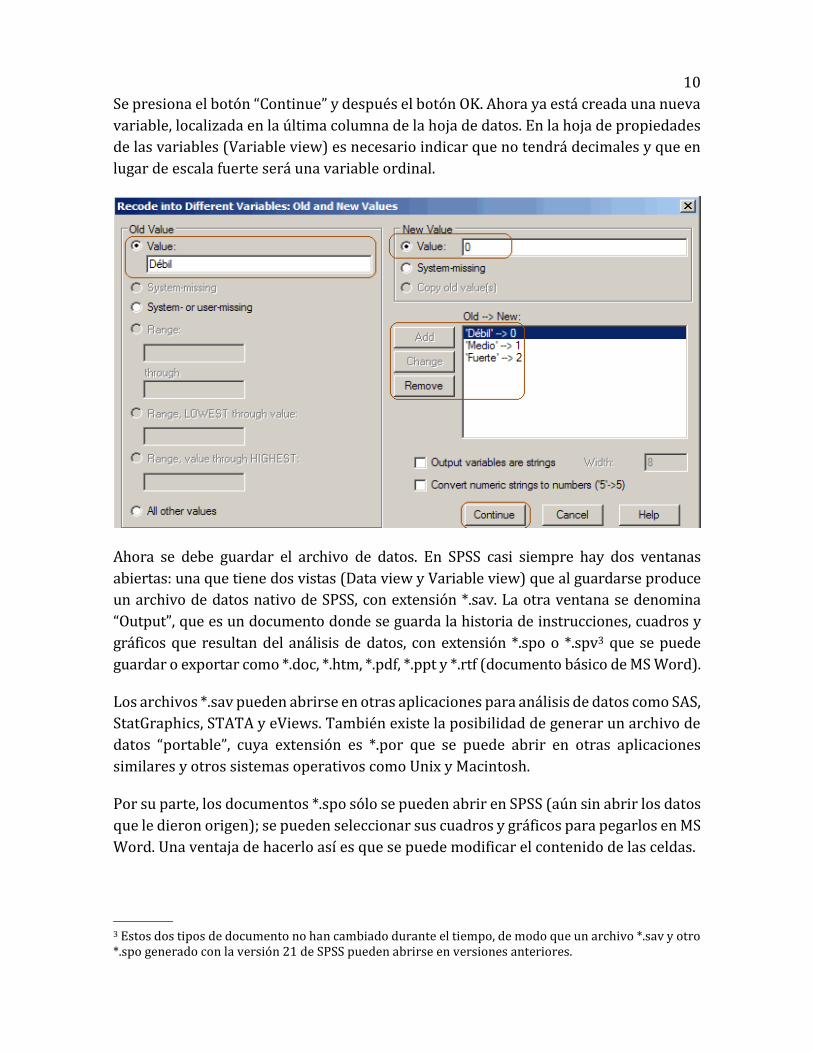
10
Se presiona el botón “Continue” y después el botón OK. Ahora ya está creada una nueva
variable, localizada en la última columna de la hoja de datos. En la hoja de propiedades
de las variables (Variable view) es necesario indicar que no tendrá decimales y que en
lugar de escala fuerte será una variable ordinal.
Ahora se debe guardar el archivo de datos. En SPSS casi siempre hay dos ventanas
abiertas: una que tiene dos vistas (Data view y Variable view) que al guardarse produce
un archivo de datos nativo de SPSS, con extensión *.sav. La otra ventana se denomina
“Output”, que es un documento donde se guarda la historia de instrucciones, cuadros y
gráficos que resultan del análisis de datos, con extensión *.spo o *.spv3 que se puede
guardar o exportar como *.doc, *.htm, *.pdf, *.ppt y *.rtf (documento básico de MS Word).
Los archivos *.sav pueden abrirse en otras aplicaciones para análisis de datos como SAS,
StatGraphics, STATA y eViews. También existe la posibilidad de generar un archivo de
datos “portable”, cuya extensión es *.por que se puede abrir en otras aplicaciones
similares y otros sistemas operativos como Unix y Macintosh.
Por su parte, los documentos *.spo sólo se pueden abrir en SPSS (aún sin abrir los datos
que le dieron origen); se pueden seleccionar sus cuadros y gráficos para pegarlos en MS
Word. Una ventaja de hacerlo así es que se puede modificar el contenido de las celdas.
3 Estos dos tipos de documento no han cambiado durante el tiempo, de modo que un archivo *.sav y otro *.spo generado con la versión 21 de SPSS pueden abrirse en versiones anteriores.

11
Como ejercicio final de esta sección 1, el estudiante debe hacer las transformaciones
necesarias, tanto en MS Excel y como en SPSS para lograr los resultados que se
muestran en el siguiente cuadro. Los valores que deberán adoptan las variables son:
Variable Descripción de la variable Escala Valores que adopta la variable
Exitosa Si la organizaciónes exitosa
Nominal ORE: Organización rural exitosa; ORNE: Organización rural no exitosa
Estado Estado de la república Nominal No aplica
RegSocEco Región socioeconómica del INEGI Ordinal 1: Chs, Gro, Oax; 2: Cam, Hgo, Pue, SLP, Tab, Ver; 3: Dgo, Gto, Mic, Tla, Zac; 4: Col, Méx, Mor, Nay, QR, Qro, Sin, Yuc; 5: BCN, BCS, Son, Tam; 6: Ags, Chh, Coa, Jal, NL; 7: DF
Figura Figura legal de la organización Nominal No aplica
Vinc_asoc Grado del vínculo asociativo Nominal Débil, Medio, Fuerte
EdadNum Edad de la organización (años) Razón / Proporción 0-100
ActEcoPrin Actividad económica principal Nominal 0: PCTP; 1: Serv; 2: IRNA
Id_Financ Índice de desarrollo financiero Razón / Proporción 0-100%
Id_Profes Índice de desarrollo profesional Razón / Proporción 0-100%
Id_CapFis Índice de desarrollo capital físico Razón / Proporción 0-100%
Id_Inform Índice de desarrollo informático Razón / Proporción 0-100%
Id_Estrat Índice de desarrollo estratégico Razón / Proporción 0-100%
Id_ValSoc Índice de desarrollo valor entregado a sus socios
Razón / Proporción 0-100%
Id_Comer Índice de desarrollo comercial Razón / Proporción 0-100%
Id_General Índice de desarrollo general (promedio de los anteriores)
Razón / Proporción 0-100%
PIB_2003 Participación del PIB del sector agropecuario en el estado
Razón / Proporción 0-100%
Compet_global Índice global de competitividad global Ordinal 0: Bajo, 1: Medio, 2: Alto Compet_econo Indice de competivitidad económica Ordinal 0: Bajo, 1: Medio, 2: Alto Compet_caphu Indice de capital humano Ordinal 0: Bajo, 1: Medio, 2: Alto Compet_infra Indice de infraestructura Ordinal 0: Bajo, 1: Medio, 2: Alto Compet_marreg Indice de marco regulatorio Ordinal 0: Bajo, 1: Medio, 2: Alto Compet_opiemp Indice de opinión empresarial Ordinal 0: Bajo, 1: Medio, 2: Alto Compet_mejreg Indice de mejora regulatoria Ordinal 0: Bajo, 1: Medio, 2: Alto Compet_rapape Indice de rapidez apertura empresas Ordinal 0: Bajo, 1: Medio, 2: Alto Compet_pagext Indice de pagos extraordinarios Ordinal 0: Bajo, 1: Medio, 2: Alto Compet_procjus Indice de procuración de justicia Ordinal 0: Bajo, 1: Medio, 2: Alto Compet_projuez Indice de probidad de los jueces Ordinal 0: Bajo, 1: Medio, 2: Alto Compet_rapjm Indice de rapidez de un juicio Ordinal 0: Bajo, 1: Medio, 2: Alto Compet_efisen Indice de aplicación de sentencias Ordinal 0: Bajo, 1: Medio, 2: Alto Compet_aplirec Indice de aplicación de recursos Ordinal 0: Bajo, 1: Medio, 2: Alto Autoconsumo Proporción de alimentos destinada al
autoconsumo en el estado en 2003 Razón / Proporción 0-100%
Alternancia Si hubo un gobernador postulado por un partido político distinto
Nominal 0: No, 1: Sí
EdadCat Edad de la organización por categorías Ordinal 1: 0-10, 2: 11-20, 3: 21-30, 4: 31-40, 5: 41-50, 6: Más de 50
Vinc_asoc Grado del vínculo asociativo Ordinal 0: Débil, 1: Medio, 2: Fuerte
1.6. Exploración de datos
La primera tarea que debe realizar un analista es hacer un diagnóstico exploratorio de
los datos. Esto es diferente de lo que se hace en la auditoría, donde lo que se busca es
12
que los datos estén “limpios” o capturados sin errores. Con la exploración lo que se
pretende es obtener la estadística descriptiva de esos datos a fin de descubrir algunos
patrones o relaciones estadísticas.
En SPSS hay dos tres opciones para ello: (1) Frecuencias, (2) Estadísticos descriptivos
y (3) Tabulaciones cruzadas. Casi siempre nos interesa conocer la media, la desviación
estándar, el valor mínimo, el valor máximo, el rango, la asimetría y la curtosis.
Adicionalmente interesa averiguar si los datos se ajustan a una distribución normal.
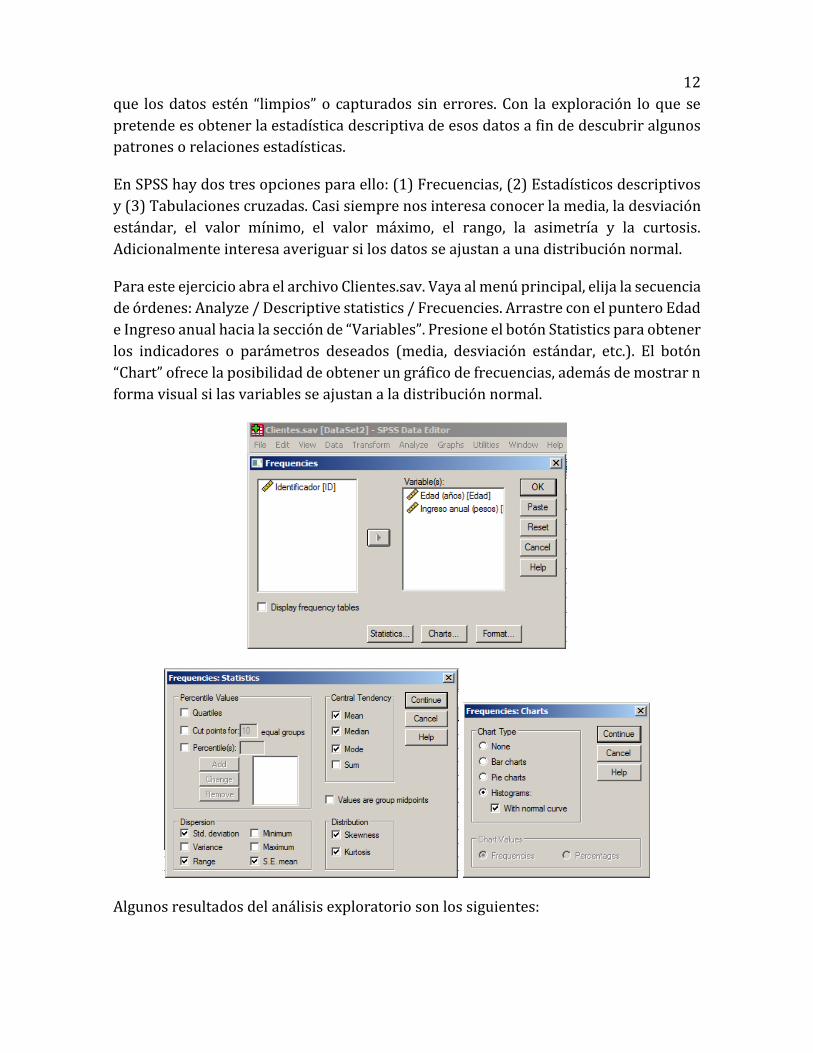
Para este ejercicio abra el archivo Clientes.sav. Vaya al menú principal, elija la secuencia
de órdenes: Analyze / Descriptive statistics / Frecuencies. Arrastre con el puntero Edad
e Ingreso anual hacia la sección de “Variables”. Presione el botón Statistics para obtener
los indicadores o parámetros deseados (media, desviación estándar, etc.). El botón
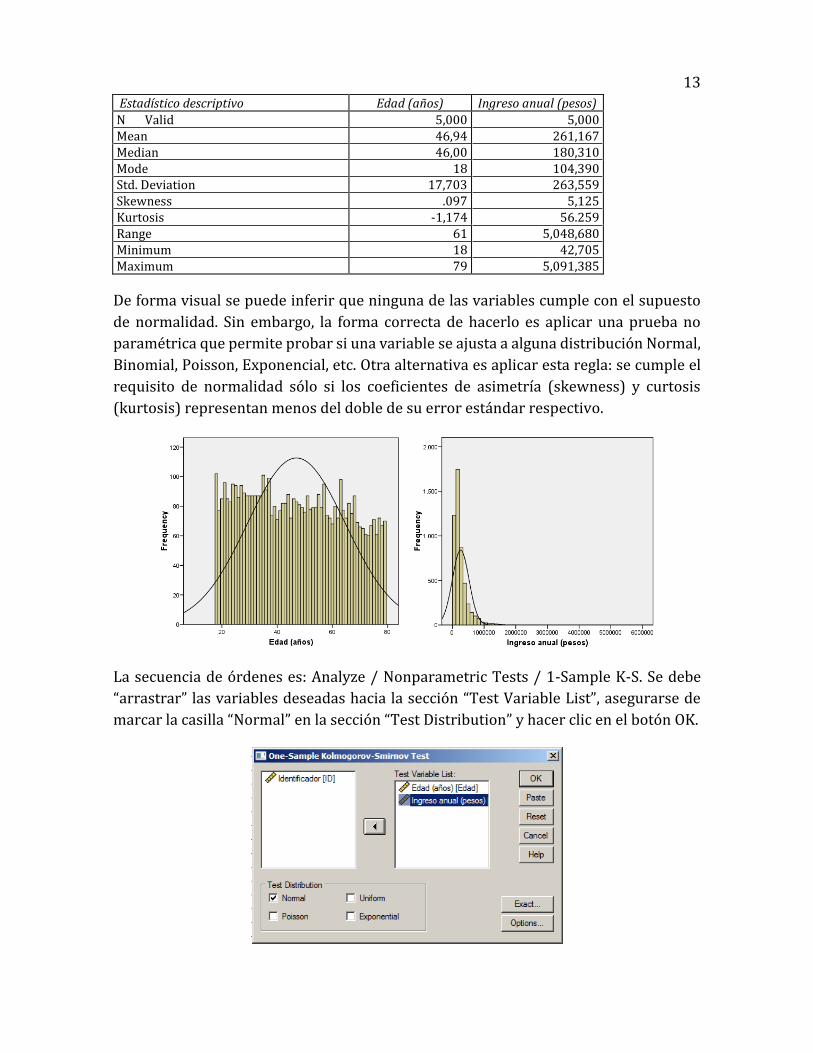
“Chart” ofrece la posibilidad de obtener un gráfico de frecuencias, además de mostrar n
forma visual si las variables se ajustan a la distribución normal.
Algunos resultados del análisis exploratorio son los siguientes:
13
Estadístico descriptivo Edad (años) Ingreso anual (pesos)
N Valid 5,000 5,000 Mean 46,94 261,167 Median 46,00 180,310 Mode 18 104,390 Std. Deviation 17,703 263,559 Skewness .097 5,125 Kurtosis -1,174 56.259 Range 61 5,048,680 Minimum 18 42,705 Maximum 79 5,091,385
De forma visual se puede inferir que ninguna de las variables cumple con el supuesto
de normalidad. Sin embargo, la forma correcta de hacerlo es aplicar una prueba no
paramétrica que permite probar si una variable se ajusta a alguna distribución Normal,
Binomial, Poisson, Exponencial, etc. Otra alternativa es aplicar esta regla: se cumple el
requisito de normalidad sólo si los coeficientes de asimetría (skewness) y curtosis
(kurtosis) representan menos del doble de su error estándar respectivo.
La secuencia de órdenes es: Analyze / Nonparametric Tests / 1-Sample K-S. Se debe
“arrastrar” las variables deseadas hacia la sección “Test Variable List”, asegurarse de
marcar la casilla “Normal” en la sección “Test Distribution” y hacer clic en el botón OK.
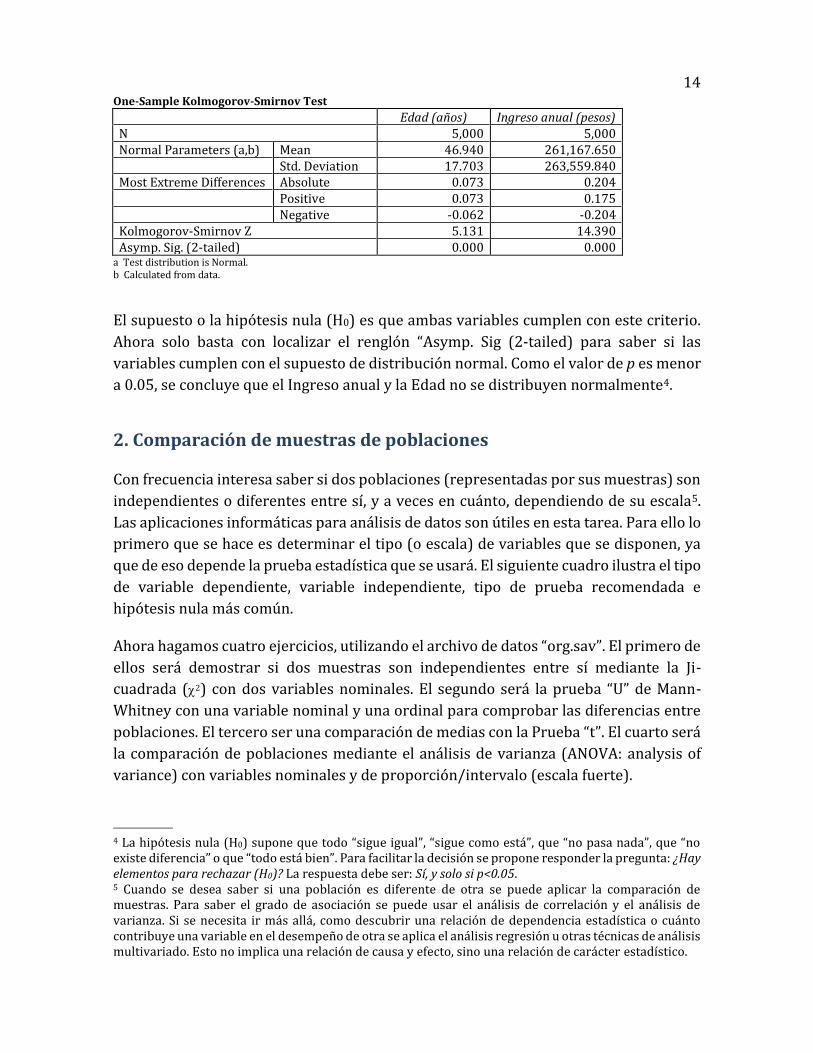
14 One-Sample Kolmogorov-Smirnov Test
Edad (años) Ingreso anual (pesos) N 5,000 5,000 Normal Parameters (a,b) Mean 46.940 261,167.650 Std. Deviation 17.703 263,559.840 Most Extreme Differences Absolute 0.073 0.204 Positive 0.073 0.175 Negative -0.062 -0.204 Kolmogorov-Smirnov Z 5.131 14.390 Asymp. Sig. (2-tailed) 0.000 0.000
a Test distribution is Normal. b Calculated from data.
El supuesto o la hipótesis nula (H0) es que ambas variables cumplen con este criterio.
Ahora solo basta con localizar el renglón “Asymp. Sig (2-tailed) para saber si las
variables cumplen con el supuesto de distribución normal. Como el valor de p es menor
a 0.05, se concluye que el Ingreso anual y la Edad no se distribuyen normalmente4.
2. Comparación de muestras de poblaciones
Con frecuencia interesa saber si dos poblaciones (representadas por sus muestras) son
independientes o diferentes entre sí, y a veces en cuánto, dependiendo de su escala5.
Las aplicaciones informáticas para análisis de datos son útiles en esta tarea. Para ello lo
primero que se hace es determinar el tipo (o escala) de variables que se disponen, ya
que de eso depende la prueba estadística que se usará. El siguiente cuadro ilustra el tipo
de variable dependiente, variable independiente, tipo de prueba recomendada e
hipótesis nula más común.
Ahora hagamos cuatro ejercicios, utilizando el archivo de datos “org.sav”. El primero de
ellos será demostrar si dos muestras son independientes entre sí mediante la Ji-
cuadrada (2) con dos variables nominales. El segundo será la prueba “U” de Mann-
Whitney con una variable nominal y una ordinal para comprobar las diferencias entre
poblaciones. El tercero ser una comparación de medias con la Prueba “t”. El cuarto será
la comparación de poblaciones mediante el análisis de varianza (ANOVA: analysis of
variance) con variables nominales y de proporción/intervalo (escala fuerte).
4 La hipótesis nula (H0) supone que todo “sigue igual”, “sigue como está”, que “no pasa nada”, que “no existe diferencia” o que “todo está bien”. Para facilitar la decisión se propone responder la pregunta: ¿Hay elementos para rechazar (H0)? La respuesta debe ser: Sí, y solo si p<0.05. 5 Cuando se desea saber si una población es diferente de otra se puede aplicar la comparación de muestras. Para saber el grado de asociación se puede usar el análisis de correlación y el análisis de varianza. Si se necesita ir más allá, como descubrir una relación de dependencia estadística o cuánto contribuye una variable en el desempeño de otra se aplica el análisis regresión u otras técnicas de análisis multivariado. Esto no implica una relación de causa y efecto, sino una relación de carácter estadístico.
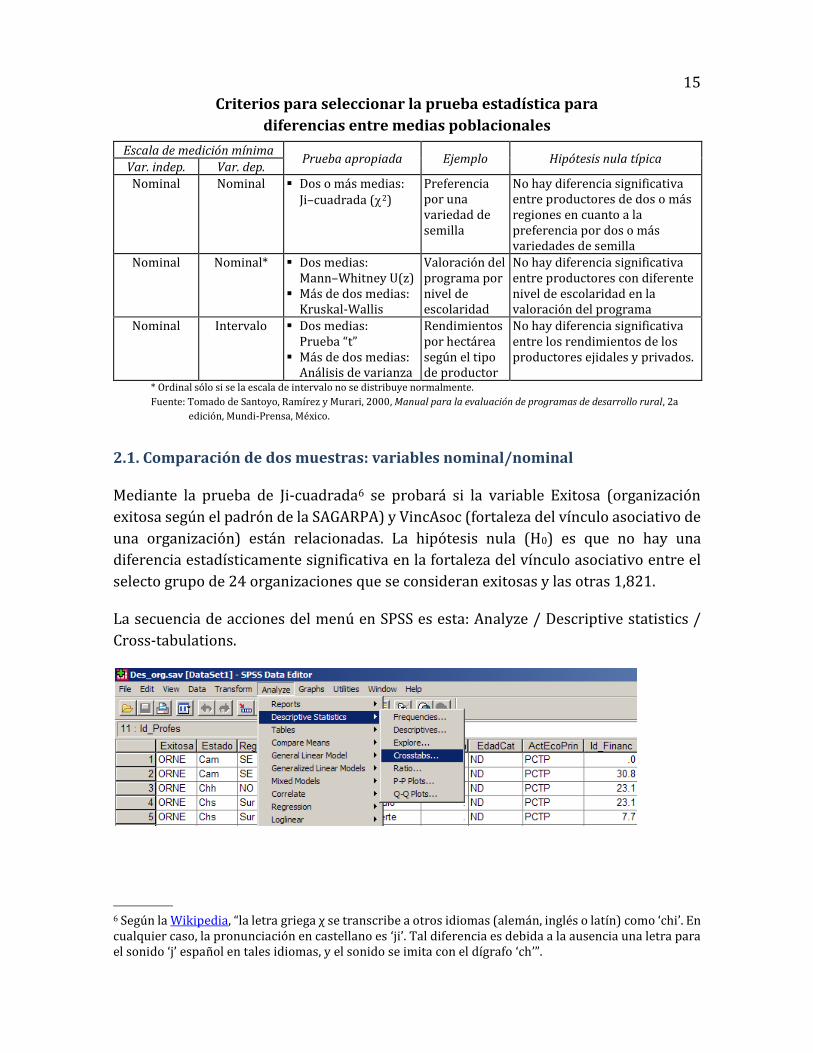
15
Criterios para seleccionar la prueba estadística para
diferencias entre medias poblacionales
Escala de medición mínima Prueba apropiada Ejemplo Hipótesis nula típica
Var. indep. Var. dep.
Nominal Nominal Dos o más medias: Ji–cuadrada (2)
Preferencia por una variedad de semilla
No hay diferencia significativa entre productores de dos o más regiones en cuanto a la preferencia por dos o más variedades de semilla
Nominal Nominal* Dos medias: Mann–Whitney U(z)
Más de dos medias: Kruskal-Wallis
Valoración del programa por nivel de escolaridad
No hay diferencia significativa entre productores con diferente nivel de escolaridad en la valoración del programa
Nominal Intervalo Dos medias: Prueba “t”
Más de dos medias: Análisis de varianza
Rendimientos por hectárea según el tipo de productor
No hay diferencia significativa entre los rendimientos de los productores ejidales y privados.
* Ordinal sólo si se la escala de intervalo no se distribuye normalmente.
Fuente: Tomado de Santoyo, Ramírez y Murari, 2000, Manual para la evaluación de programas de desarrollo rural, 2a
edición, Mundi-Prensa, México.
2.1. Comparación de dos muestras: variables nominal/nominal
Mediante la prueba de Ji-cuadrada6 se probará si la variable Exitosa (organización
exitosa según el padrón de la SAGARPA) y VincAsoc (fortaleza del vínculo asociativo de
una organización) están relacionadas. La hipótesis nula (H0) es que no hay una
diferencia estadísticamente significativa en la fortaleza del vínculo asociativo entre el
selecto grupo de 24 organizaciones que se consideran exitosas y las otras 1,821.
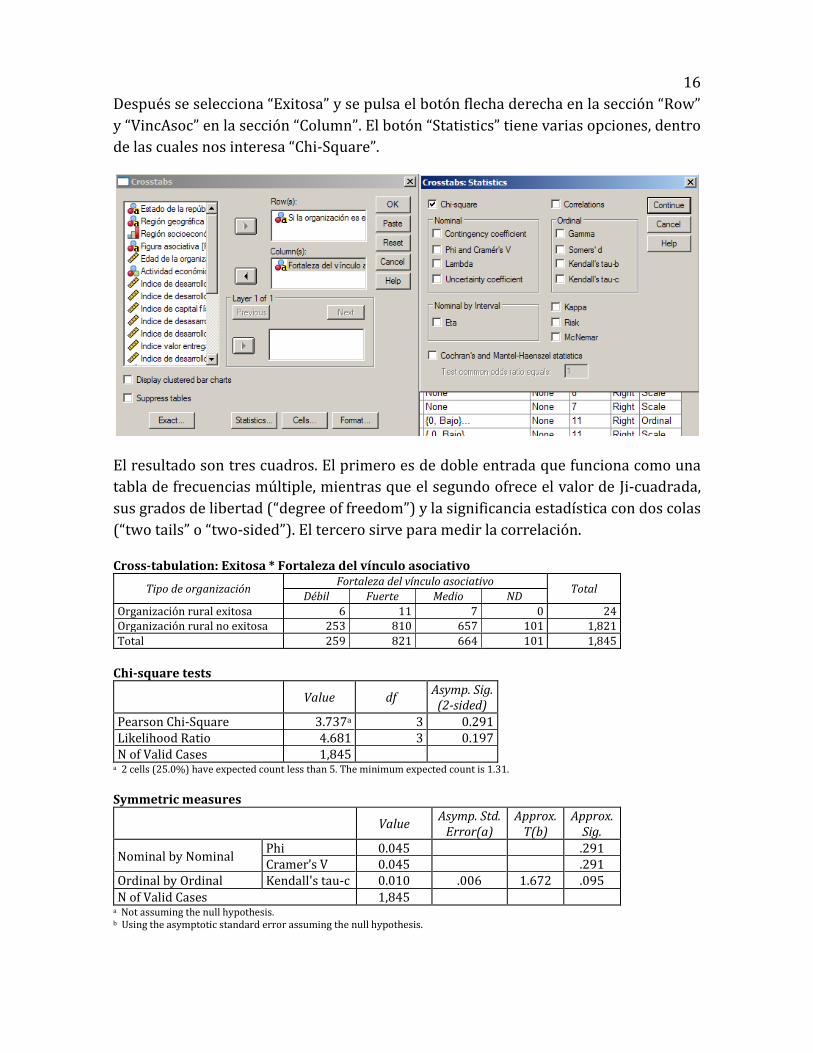
La secuencia de acciones del menú en SPSS es esta: Analyze / Descriptive statistics /
Cross-tabulations.
6 Según la Wikipedia, “la letra griega χ se transcribe a otros idiomas (alemán, inglés o latín) como ‘chi’. En cualquier caso, la pronunciación en castellano es ‘ji’. Tal diferencia es debida a la ausencia una letra para el sonido ‘j’ español en tales idiomas, y el sonido se imita con el dígrafo ‘ch’”.
16
Después se selecciona “Exitosa” y se pulsa el botón flecha derecha en la sección “Row”
y “VincAsoc” en la sección “Column”. El botón “Statistics” tiene varias opciones, dentro
de las cuales nos interesa “Chi-Square”.
El resultado son tres cuadros. El primero es de doble entrada que funciona como una
tabla de frecuencias múltiple, mientras que el segundo ofrece el valor de Ji-cuadrada,
sus grados de libertad (“degree of freedom”) y la significancia estadística con dos colas
(“two tails” o “two-sided”). El tercero sirve para medir la correlación.
Cross-tabulation: Exitosa * Fortaleza del vínculo asociativo
Tipo de organización Fortaleza del vínculo asociativo
Total Débil Fuerte Medio ND
Organización rural exitosa 6 11 7 0 24 Organización rural no exitosa 253 810 657 101 1,821
Total 259 821 664 101 1,845
Chi-square tests
Value df Asymp. Sig.
(2-sided)
Pearson Chi-Square 3.737a 3 0.291 Likelihood Ratio 4.681 3 0.197 N of Valid Cases 1,845
a 2 cells (25.0%) have expected count less than 5. The minimum expected count is 1.31.
Symmetric measures
Value Asymp. Std.
Error(a) Approx.
T(b) Approx.
Sig.
Nominal by Nominal Phi 0.045 .291 Cramer’s V 0.045 .291
Ordinal by Ordinal Kendall's tau-c 0.010 .006 1.672 .095
N of Valid Cases 1,845 a Not assuming the null hypothesis. b Using the asymptotic standard error assuming the null hypothesis.

17
Interpretación: Como el valor calculado de p = 0.291 para la Ji-cuadrada de Pearson
(2) es mayor al valor crítico de p < 0.05, no hay elementos para rechazar la hipótesis
nula (H0) de que las muestras son iguales. En pocas palabras: ambas muestras son
estadísticamente iguales, ya que p > 0.05.
2.2 Comparación de dos muestras: variables nominal/ordinal
Para probar la diferencia entre dos muestras con una variable nominal y otra ordinal se
puede utilizar la prueba “U” de Mann-Whitney. Para este caso se usará como variable
nominal “Alternancia” y como ordinal “RegSocEco” para probar que el desarrollo
socioeconómico regional (donde 1 es pobre y 7 es más desarrollado) no tiene que ver
con la alternancia política (elección de gobernador de diferente partido).
La secuencia de opciones del menú es esta: Analyze / Non parametric tests / 2
indepentent-sample tests. No hay que marcar ninguna otra casilla, puesto que la casilla
para “U” está marcada por defecto. Sólo resta indicar cuáles son los grupos o categorías
en que se divide la variable independiente (Alternancia): 0 para “No” y 1 para “Sí” en el
botón “Grouping variable”, haciendo clic en el botón “Define groups”.
Los resultados de la prueba Mann-Whitney para probar la relación de una variable
nominal y una ordinal son los siguientes:
Ranks
Variable Gobernador de
diferente partido N
Mean Rank
Sum of Ranks
Región socioeconómica del INEGI
No hubo alternancia 1,081 867.44 937,701.50 Sí hubo alternancia 764 1,001.61 765,233.50
Total 1,845

18 Test statistics (a)
Estadístico Región socioeconómica INEGI
Mann-Whitney U 352,880.500 Wilcoxon W 937,701.500 Z -5.419 Asymp. Sig. (2-tailed) .000
a Grouping Variable: Gobernador de diferente partido.
Interpretación: La prueba “U” de Mann-Whitney tiene una p menor al valor crítico
(< 0.05), por lo hay elementos para rechazar la hipótesis nula (H0) de que ambas
muestras son iguales. En pocas palabras: la elección de un gobernador distinto sí tiene
relación con el desarrollo regional donde se ubica la organización.
2.3. Comparación de muestras: variables nominal/razón (proporción)
Cuando se comparan una muestra nominal y otra de razón (proporción) se usa la
Prueba “t”. Se utilizará la variable “Alternancia” con “Id_CapFis” para probar que la
costumbre de “bajar” subsidios no se ve reducida con el cambio de gobernador.
La secuencia del menú es esta: Analyze / Compare means / Independet sample T tests.
La variable Id_CapFis se coloca en la sección “Test variables”, mientras que en la sección
Grouping variable se coloca la variable “Alternancia” para distinguir a las muestras, que
adoptan los valores de 0 y 1 (“No” y “Sí”).
Independent samples test
Variable Supuesto
Levene’s Test for Equality of Variances
t-test for Equality of Means
F Sig. t df Sig. (2-tailed)
Mean Difference
Std. Error Difference
95% Confidence Interval of the
Difference
Lower Upper
Índice de capital físico
Equal variances assumed
.488 .485 .548 1,843 .584 .929 1.697 -2.39 4.25
Equal variances not assumed
.547 1,629 .585 .929 1.701 -2.40 4.26

19
Interpretación: La prueba de Levene indica que las varianzas son homogéneas (la H0
supone que “que no pasa nada”) porque su significancia es de 0.485 (mayor a 0.05);
además, “t” tiene un valor de p = 0.584 (mayor al valor crítico de p < 0.05), por lo se
acepta la hipótesis nula (H0) que no hay diferencia entre las medias de ambas muestras.
O sea, que no existe una reducción en “bajar” subsidios y el cambio de gobernador de
distinto partido político. Esta práctica existe con o sin alternancia política.
Por otra parte, se aplica el análisis de varianza cuando se comparan muestras de varias
poblaciones. El ANOVA de una vía sólo indica si hay diferencia entre las muestras, pero
no dice cuáles ni en cuánto se diferencian. Por ello se añadieron a esta prueba los
“contrastes” que clasifican las medias según sus diferencias. Uno de los contrastes más
conocidos es el de Tukey, pero hay otros más como el de Scheffe.
A continuación se ilustra si existe variabilidad o diferencia entre el índice de capital
físico (Id_CapFis) y el desarrollo socioeconómico regional (RegSocEco). Se supone que
entre más desarrollada esté una región está menos acostumbrada a “bajar” los apoyos
o subsidios gubernamentales y se rige por criterios profesionales (en vez de políticos).
La secuencia del menú es esta: Analyze / Compare means / One-way ANOVA. La
variable Id_CapFis (escala de proporción) se coloca en la sección “Dependent list”,
mientras que en la sección de “Factor” se pone “RegSocEco” (escala ordinal, que en este
caso particular trataremos como nominal). Dentro de las comparaciones Post Hoc
elegiremos “Scheffe”, y dentro de las opciones se escogerán las estadísticas descriptivas
y la prueba de homogeneidad de varianza. La hipótesis nula es que no hay diferencia
del índice de capital físico entre las regiones socioeconómicas.
Test of homogeneity of variances: Indice de capital físico
Levene Statistic df1 df2 Sig.
21.146 6 1,838 .000
ANOVA: Índice de capital físico
Sum of Squares df Mean Square F Sig.
Between Groups 97,879.559 6 16,313.260 13.156 .000 Within Groups 2,279,028.602 1,838 1,239.950
Total 23,769,08.160 1,844
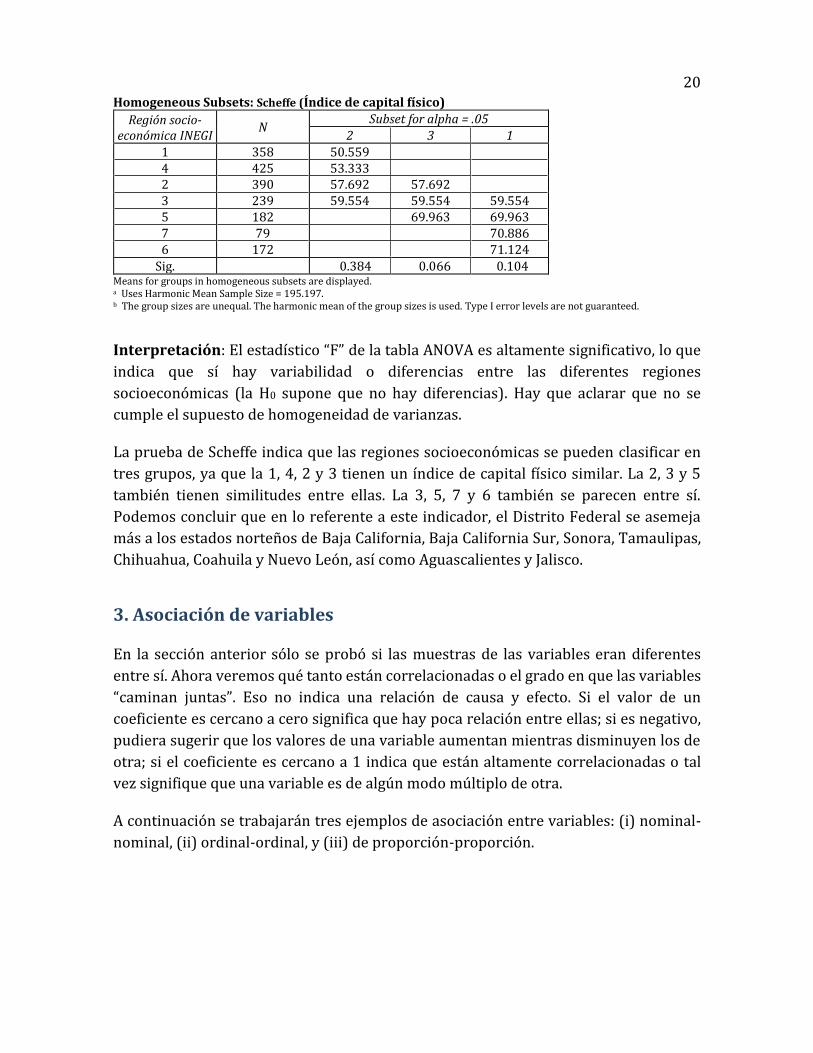
20 Homogeneous Subsets: Scheffe (Índice de capital físico)
Región socio-económica INEGI
N Subset for alpha = .05
2 3 1
1 358 50.559 4 425 53.333 2 390 57.692 57.692 3 239 59.554 59.554 59.554 5 182 69.963 69.963 7 79 70.886 6 172 71.124
Sig. 0.384 0.066 0.104 Means for groups in homogeneous subsets are displayed. a Uses Harmonic Mean Sample Size = 195.197. b The group sizes are unequal. The harmonic mean of the group sizes is used. Type I error levels are not guaranteed.
Interpretación: El estadístico “F” de la tabla ANOVA es altamente significativo, lo que
indica que sí hay variabilidad o diferencias entre las diferentes regiones
socioeconómicas (la H0 supone que no hay diferencias). Hay que aclarar que no se
cumple el supuesto de homogeneidad de varianzas.
La prueba de Scheffe indica que las regiones socioeconómicas se pueden clasificar en
tres grupos, ya que la 1, 4, 2 y 3 tienen un índice de capital físico similar. La 2, 3 y 5
también tienen similitudes entre ellas. La 3, 5, 7 y 6 también se parecen entre sí.
Podemos concluir que en lo referente a este indicador, el Distrito Federal se asemeja
más a los estados norteños de Baja California, Baja California Sur, Sonora, Tamaulipas,
Chihuahua, Coahuila y Nuevo León, así como Aguascalientes y Jalisco.
3. Asociación de variables
En la sección anterior sólo se probó si las muestras de las variables eran diferentes
entre sí. Ahora veremos qué tanto están correlacionadas o el grado en que las variables
“caminan juntas”. Eso no indica una relación de causa y efecto. Si el valor de un
coeficiente es cercano a cero significa que hay poca relación entre ellas; si es negativo,
pudiera sugerir que los valores de una variable aumentan mientras disminuyen los de
otra; si el coeficiente es cercano a 1 indica que están altamente correlacionadas o tal
vez signifique que una variable es de algún modo múltiplo de otra.
A continuación se trabajarán tres ejemplos de asociación entre variables: (i) nominal-
nominal, (ii) ordinal-ordinal, y (iii) de proporción-proporción.
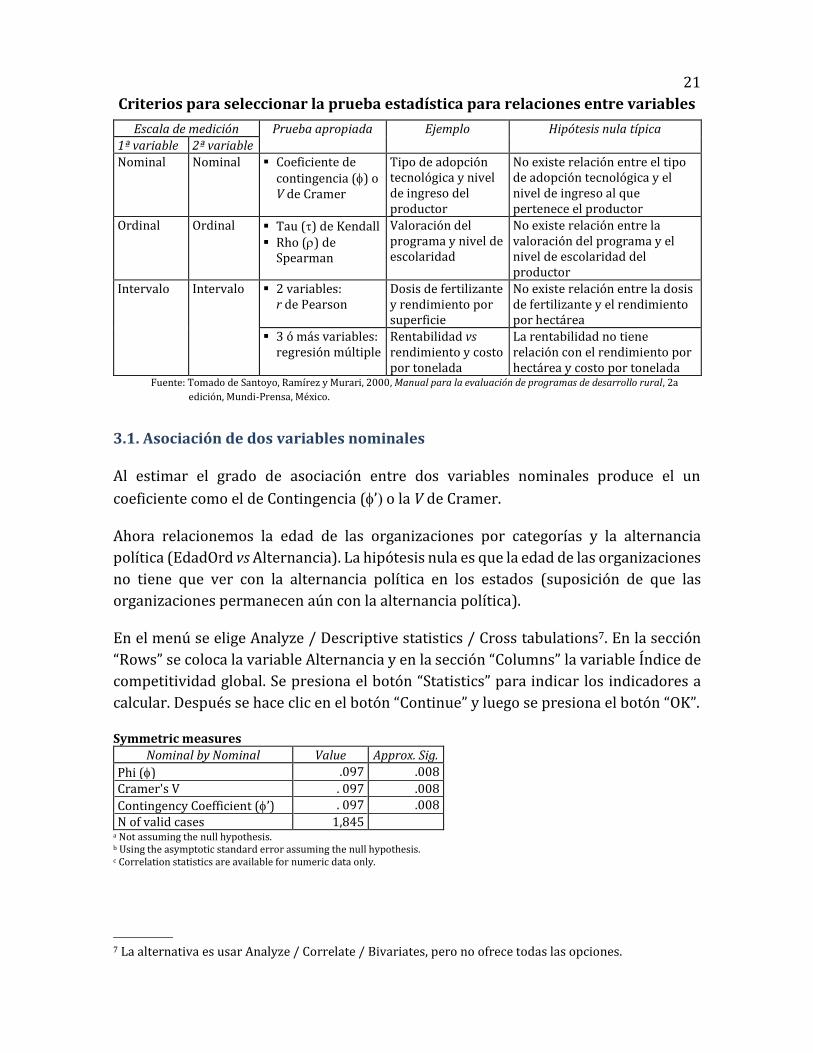
21
Criterios para seleccionar la prueba estadística para relaciones entre variables
Escala de medición Prueba apropiada Ejemplo Hipótesis nula típica
1ª variable 2ª variable
Nominal Nominal Coeficiente de contingencia () o V de Cramer
Tipo de adopción tecnológica y nivel de ingreso del productor
No existe relación entre el tipo de adopción tecnológica y el nivel de ingreso al que pertenece el productor
Ordinal Ordinal Tau () de Kendall Rho () de
Spearman
Valoración del programa y nivel de escolaridad
No existe relación entre la valoración del programa y el nivel de escolaridad del productor
Intervalo Intervalo 2 variables: r de Pearson
Dosis de fertilizante y rendimiento por superficie
No existe relación entre la dosis de fertilizante y el rendimiento por hectárea
3 ó más variables: regresión múltiple
Rentabilidad vs rendimiento y costo por tonelada
La rentabilidad no tiene relación con el rendimiento por hectárea y costo por tonelada
Fuente: Tomado de Santoyo, Ramírez y Murari, 2000, Manual para la evaluación de programas de desarrollo rural, 2a
edición, Mundi-Prensa, México.
3.1. Asociación de dos variables nominales
Al estimar el grado de asociación entre dos variables nominales produce el un
coeficiente como el de Contingencia (’ o la V de Cramer.
Ahora relacionemos la edad de las organizaciones por categorías y la alternancia
política (EdadOrd vs Alternancia). La hipótesis nula es que la edad de las organizaciones
no tiene que ver con la alternancia política en los estados (suposición de que las
organizaciones permanecen aún con la alternancia política).
En el menú se elige Analyze / Descriptive statistics / Cross tabulations7. En la sección
“Rows” se coloca la variable Alternancia y en la sección “Columns” la variable Índice de
competitividad global. Se presiona el botón “Statistics” para indicar los indicadores a
calcular. Después se hace clic en el botón “Continue” y luego se presiona el botón “OK”.
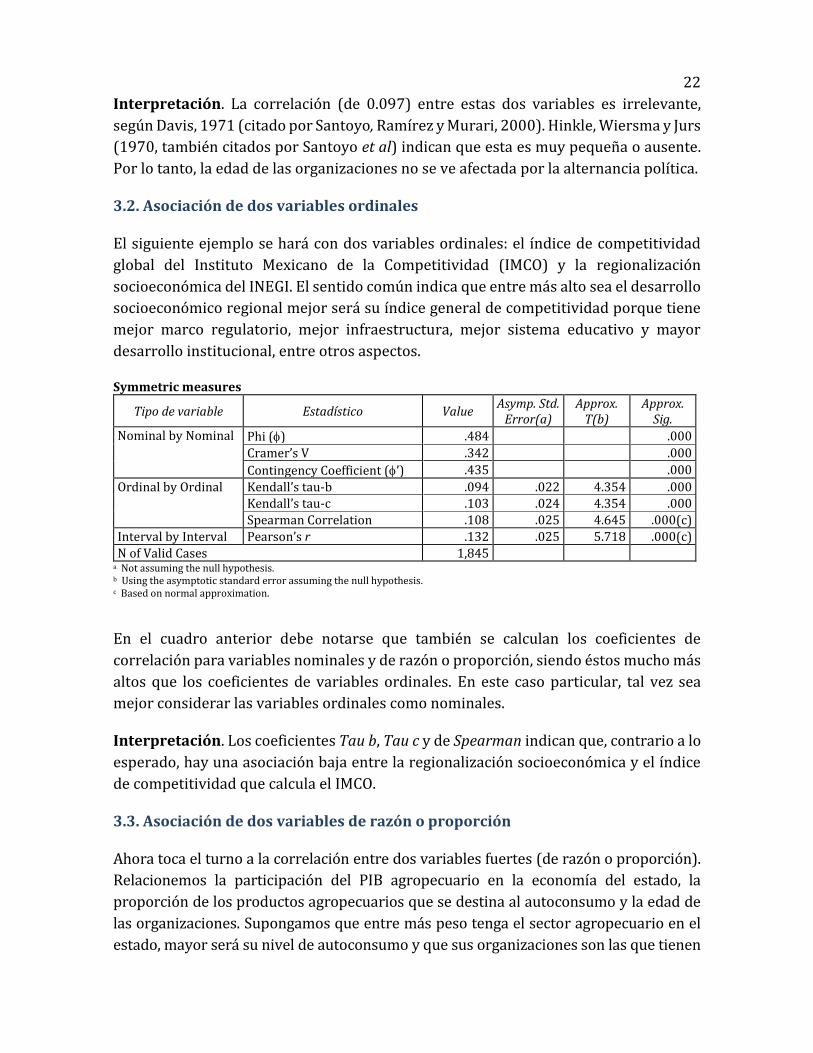
Symmetric measures
Nominal by Nominal Value Approx. Sig.
Phi () .097 .008
Cramer's V . 097 .008
Contingency Coefficient (’) . 097 .008
N of valid cases 1,845 a Not assuming the null hypothesis. b Using the asymptotic standard error assuming the null hypothesis. c Correlation statistics are available for numeric data only.
7 La alternativa es usar Analyze / Correlate / Bivariates, pero no ofrece todas las opciones.
22
Interpretación. La correlación (de 0.097) entre estas dos variables es irrelevante,
según Davis, 1971 (citado por Santoyo, Ramírez y Murari, 2000). Hinkle, Wiersma y Jurs
(1970, también citados por Santoyo et al) indican que esta es muy pequeña o ausente.
Por lo tanto, la edad de las organizaciones no se ve afectada por la alternancia política.
3.2. Asociación de dos variables ordinales
El siguiente ejemplo se hará con dos variables ordinales: el índice de competitividad
global del Instituto Mexicano de la Competitividad (IMCO) y la regionalización
socioeconómica del INEGI. El sentido común indica que entre más alto sea el desarrollo
socioeconómico regional mejor será su índice general de competitividad porque tiene
mejor marco regulatorio, mejor infraestructura, mejor sistema educativo y mayor
desarrollo institucional, entre otros aspectos.
Symmetric measures
Tipo de variable Estadístico Value Asymp. Std.
Error(a) Approx.
T(b) Approx.
Sig. Nominal by Nominal Phi () .484 .000
Cramer’s V .342 .000
Contingency Coefficient (’) .435 .000
Ordinal by Ordinal Kendall’s tau-b .094 .022 4.354 .000 Kendall’s tau-c .103 .024 4.354 .000
Spearman Correlation .108 .025 4.645 .000(c)
Interval by Interval Pearson’s r .132 .025 5.718 .000(c)
N of Valid Cases 1,845 a Not assuming the null hypothesis. b Using the asymptotic standard error assuming the null hypothesis. c Based on normal approximation.
En el cuadro anterior debe notarse que también se calculan los coeficientes de
correlación para variables nominales y de razón o proporción, siendo éstos mucho más
altos que los coeficientes de variables ordinales. En este caso particular, tal vez sea
mejor considerar las variables ordinales como nominales.
Interpretación. Los coeficientes Tau b, Tau c y de Spearman indican que, contrario a lo
esperado, hay una asociación baja entre la regionalización socioeconómica y el índice
de competitividad que calcula el IMCO.
3.3. Asociación de dos variables de razón o proporción
Ahora toca el turno a la correlación entre dos variables fuertes (de razón o proporción).
Relacionemos la participación del PIB agropecuario en la economía del estado, la
proporción de los productos agropecuarios que se destina al autoconsumo y la edad de
las organizaciones. Supongamos que entre más peso tenga el sector agropecuario en el
estado, mayor será su nivel de autoconsumo y que sus organizaciones son las que tienen
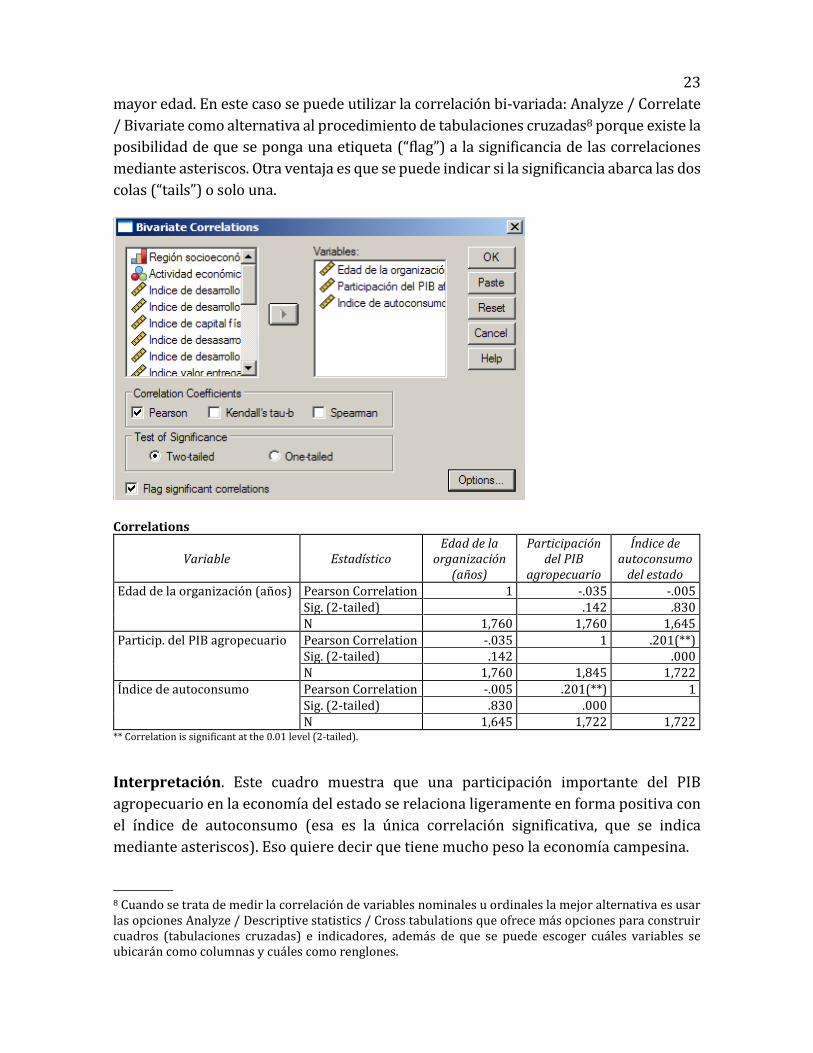
23
mayor edad. En este caso se puede utilizar la correlación bi-variada: Analyze / Correlate
/ Bivariate como alternativa al procedimiento de tabulaciones cruzadas8 porque existe la
posibilidad de que se ponga una etiqueta (“flag”) a la significancia de las correlaciones
mediante asteriscos. Otra ventaja es que se puede indicar si la significancia abarca las dos
colas (“tails”) o solo una.
Correlations
Variable Estadístico Edad de la
organización (años)
Participación del PIB
agropecuario
Índice de autoconsumo
del estado
Edad de la organización (años) Pearson Correlation 1 -.035 -.005 Sig. (2-tailed) .142 .830 N 1,760 1,760 1,645
Particip. del PIB agropecuario Pearson Correlation -.035 1 .201(**) Sig. (2-tailed) .142 .000 N 1,760 1,845 1,722
Índice de autoconsumo Pearson Correlation -.005 .201(**) 1 Sig. (2-tailed) .830 .000 N 1,645 1,722 1,722
** Correlation is significant at the 0.01 level (2-tailed).
Interpretación. Este cuadro muestra que una participación importante del PIB
agropecuario en la economía del estado se relaciona ligeramente en forma positiva con
el índice de autoconsumo (esa es la única correlación significativa, que se indica
mediante asteriscos). Eso quiere decir que tiene mucho peso la economía campesina.
8 Cuando se trata de medir la correlación de variables nominales u ordinales la mejor alternativa es usar las opciones Analyze / Descriptive statistics / Cross tabulations que ofrece más opciones para construir cuadros (tabulaciones cruzadas) e indicadores, además de que se puede escoger cuáles variables se ubicarán como columnas y cuáles como renglones.
24
3.4. Análisis de regresión lineal
El análisis regresión es muy amplio. Tan es así que es frecuente que en la licenciatura
se imparta primero un curso de “Estadística”, y después uno o dos cursos de
“Econometría”, así como otro de “Series de tiempo”.
En esta sección se mostrará la contribución estadística que tiene una variable sobre
otra. Mientras la correlación indica el grado de asociación entre variables (“que
caminan juntas”), el análisis de regresión intenta descubrir una relación causal
estadística entre ellas. El análisis de regresión pretende estimar el comportamiento de
una variable dependiente en función del comportamiento de las independientes.
A continuación se ilustra un ejemplo de regresión, utilizando para ello la variable Índice
general de desarrollo organizacional, el nivel de autoconsumo, la edad de las
organizaciones y la participación del PIB del sector agropecuario en la economía del
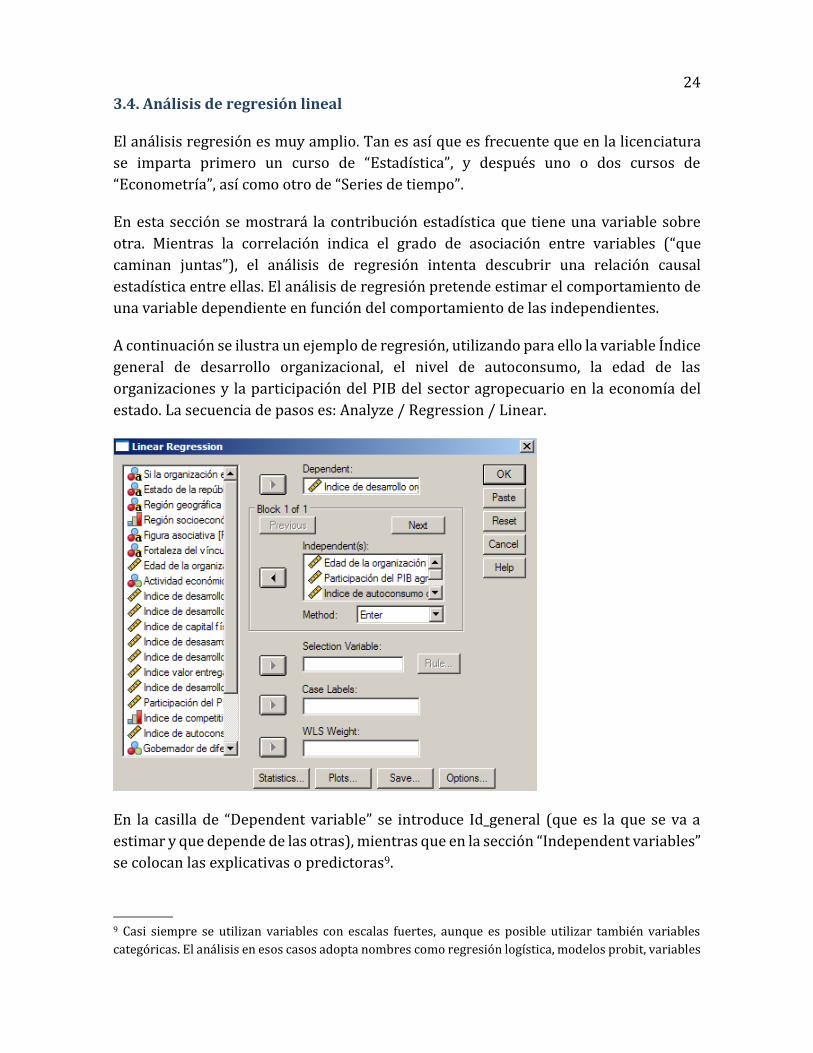
estado. La secuencia de pasos es: Analyze / Regression / Linear.
En la casilla de “Dependent variable” se introduce Id_general (que es la que se va a
estimar y que depende de las otras), mientras que en la sección “Independent variables”
se colocan las explicativas o predictoras9.
9 Casi siempre se utilizan variables con escalas fuertes, aunque es posible utilizar también variables
categóricas. El análisis en esos casos adopta nombres como regresión logística, modelos probit, variables
25 ANOVA(b)
Sum of Squares df Mean
Square F Sig.
Regression 7,043.210 3 2,347.737 5.449 .001(a) Residual 707,040.339 1,641 430.859 Total 714,083.549 1,644
a Predictors: (Constant), Índice de autoconsumo del estado, Edad de la organización (años), Participación del PIB agropecuario. b Dependent Variable: Índice de desarrollo organizacional.
Coefficients(a)
Unstandardized
Coefficients Standardized Coefficients t
Sig. Std. Error
B Std. Error Beta
Intercepto (Constant) 32.729 1.259 25.999 .000 Edad de la organización (años) .083 .042 .049 1.991 .047 Participación del PIB agropecuario .317 .091 .087 3.479 .001 Índice de autoconsumo del estado .003 .037 .002 .082 .934
a Dependent Variable: Índice de desarrollo organizacional.
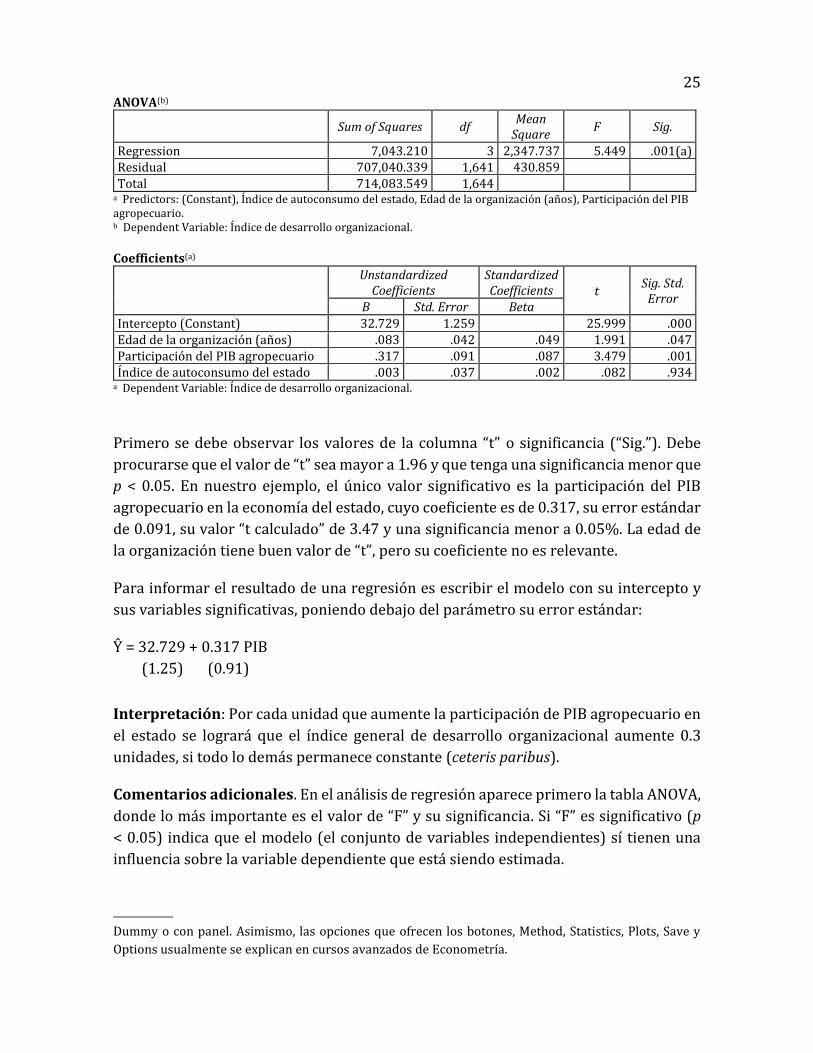
Primero se debe observar los valores de la columna “t” o significancia (“Sig.”). Debe
procurarse que el valor de “t” sea mayor a 1.96 y que tenga una significancia menor que
p < 0.05. En nuestro ejemplo, el único valor significativo es la participación del PIB
agropecuario en la economía del estado, cuyo coeficiente es de 0.317, su error estándar
de 0.091, su valor “t calculado” de 3.47 y una significancia menor a 0.05%. La edad de
la organización tiene buen valor de “t”, pero su coeficiente no es relevante.
Para informar el resultado de una regresión es escribir el modelo con su intercepto y
sus variables significativas, poniendo debajo del parámetro su error estándar:
Ŷ = 32.729 + 0.317 PIB
(1.25) (0.91)
Interpretación: Por cada unidad que aumente la participación de PIB agropecuario en
el estado se logrará que el índice general de desarrollo organizacional aumente 0.3
unidades, si todo lo demás permanece constante (ceteris paribus).
Comentarios adicionales. En el análisis de regresión aparece primero la tabla ANOVA,
donde lo más importante es el valor de “F” y su significancia. Si “F” es significativo (p
< 0.05) indica que el modelo (el conjunto de variables independientes) sí tienen una
influencia sobre la variable dependiente que está siendo estimada.
Dummy o con panel. Asimismo, las opciones que ofrecen los botones, Method, Statistics, Plots, Save y
Options usualmente se explican en cursos avanzados de Econometría.

26
El segundo cuadro contiene los coeficientes o parámetros individuales, algunos de los
cuales pueden tener una influencia pobre o nula sobre la variable dependiente, no
obstante que el modelo completo contenido en la tabla ANOVA así lo indique. Aquí es
donde cobra relevancia el valor del estadístico “t”. Este cuadro ofrece para cada variable
independiente el valor del parámetro (), su error estándar, el coeficiente Beta
normalizado, el estadístico “t” y su significancia individual.
El valor de R2 (“coeficiente de determinación”) tiene relevancia en las ciencias
biológicas (no es lo mismo que el coeficiente de correlación r de Pearson). Sin embargo,
en las ciencias sociales este coeficiente tiene poca importancia. Eso es así porque un
valor alto de R2 indica que el modelo global sirve para estimar muy bien la variable
dependiente, pero es posible que los parámetros individuales no sean significativos.
Por esta razón es mejor centrarse en los valores individuales de “t”, que se calcula
dividiendo el valor del parámetro entre su error estándar. El criterio de decisión es
que dicho valor sea mayor a 2.0, ya que el valor de “t de tablas” para 20 observaciones
con una significancia de p < 0.05 es de 1.96. En pocas palabras: “t calculado” debe ser
mayor que el valor crítico (“t de tablas”).
Una regla para el análisis de regresión es utilizar variables con escalas fuertes (a menos
que se trate de modelos logit, probit, con variables Dummy o en panel). También se
requiere tener al menos 20 observaciones para cada variable. Además, las aplicaciones
modernas para análisis estadístico incluyen muchas herramientas y procedimientos
para hacer diagnósticos de multicolinealidad, heterocedasticidad y autocorrelación. Así
que se recomienda profundizar en estos temas porque muchos de los modelos que se
estiman frecuentemente están mal diseñados.
Los problemas de heterocedasticidad aparecen cuando se analizan muestras pequeñas,
se analizan datos heterogéneos o cuando hay deficiencias en la captura de datos, por lo
que no se cumplen los supuestos de la distribución normal. La multicolinealidad se
presenta cuando se construye un modelo con variables que “caminan juntas” o que
“casi” son múltiplos unas de otras. Por su parte, la autocorrelación se produce cuando
se analizan variables con observaciones que dependen de datos anteriores (por
ejemplo, los presupuestos muchas veces dependen de la inflación del año anterior).
4. Uso de gráficos
Aunque en el mercado hay muchas aplicaciones para producir gráficos, el programa
informático SPSS tiene muchas ventajas por su facilidad de uso, la calidad, versatilidad
y sofisticación de las figuras que se pueden elaborar.

27
Abra el documento “Graficos1.xls” que contiene datos de la participación del PIB del
sector agropecuario en la economía durante 2003, así como el índice de autoconsumo
de la producción de ese sector en ese mismo año. Las variables son: Edo, PIB y IAC. El
archivo “Graficos2.xls” contiene algunos estados para las mismas variables anteriores.
Una opción para construir gráficos en SPSS es usar el “Chart Builder”, el cual permite
arrastrar o mover (“drag”) las variables con el puntero del ratón hacia los ejes del
gráfico y él área de leyendas. Lo primero que se hace es escoger un tipo de gráfico de la
galería y después arrastrar o colocar las variables en la sección correspondiente.
En este Taller se construirán dos gráficos. El primero ilustra las bondades de SPSS con
los gráficos “scatter dot” (diagrama de dispersión) para mostrar texto en lugar de los
datos de las variables. El segundo enriquecerá el análisis de datos mediante gráficos de
caja (“box plot”).
4.1. Construcción de gráficos en cajas
Para construir una figura de cajas que muestre los estados en lugar de los valores de las
variables, se escoge la opción “Simple boxplot”. Se arrastra ese tipo de gráfico hacia el
área de dibujo. Luego se “arrastra” la variable categórica hacia el eje de las X y la
variable cuantitativa hacia el eje Y.

28
Este tipo de gráficos muestra los valores mínimos y máximos que adoptan las variables,
al mismo tiempo que muestran otros elementos interesantes. Observe la figura
anterior. La longitud de la caja se llama “rango intercuartil”. Los valores superiores a
1.5 veces el rango intercuartil se conocen como observaciones no regulares (“outliers”).
Las obervaciones entre 1.5 y 3.0 veces el rango intercuartil son los datos extremos.
4.2. Construcción de diagramas de dispersión
En el Chart Builder se debe escoger el tipo “grouped scatter dot” de la galería,
arrastrarlo hacia el área de gráficos, arrastrar las variables y presionar el botón OK. Esto
permitirá alterar los atributos de los marcadores.
Estado
NLJalDFChhBCNAgs
Id_G
ener
al
100
80
60
40
20
0
29
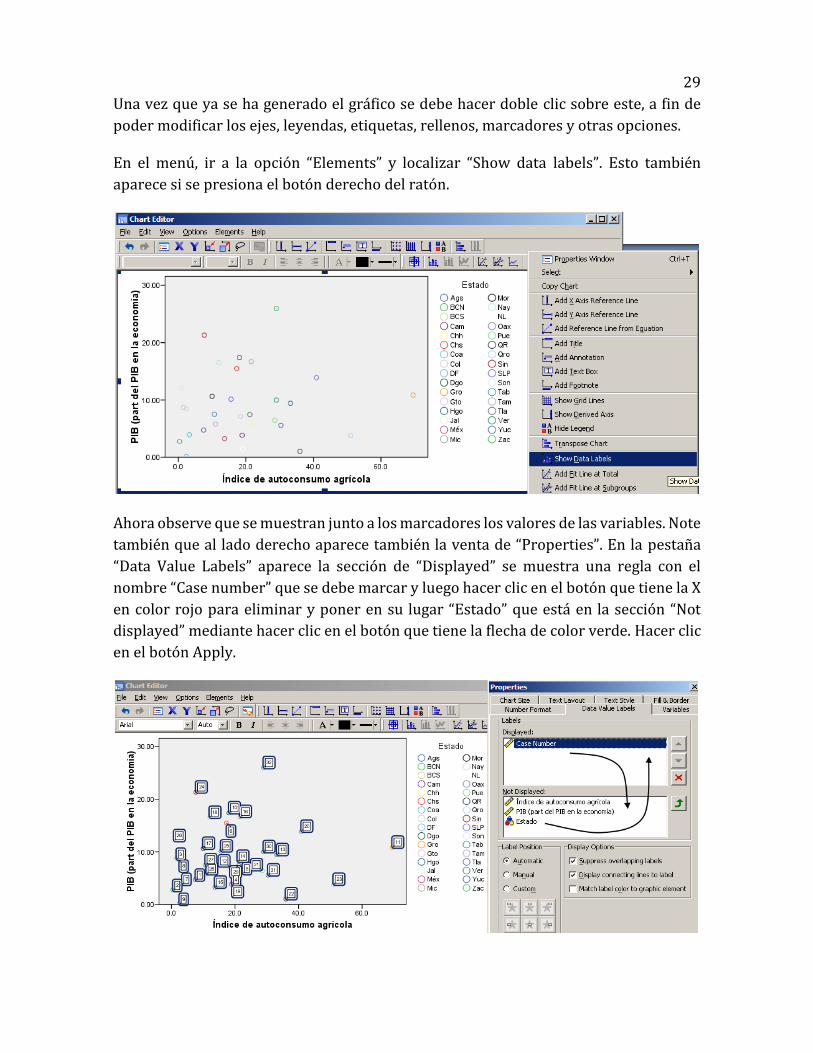
Una vez que ya se ha generado el gráfico se debe hacer doble clic sobre este, a fin de
poder modificar los ejes, leyendas, etiquetas, rellenos, marcadores y otras opciones.
En el menú, ir a la opción “Elements” y localizar “Show data labels”. Esto también
aparece si se presiona el botón derecho del ratón.
Ahora observe que se muestran junto a los marcadores los valores de las variables. Note
también que al lado derecho aparece también la venta de “Properties”. En la pestaña
“Data Value Labels” aparece la sección de “Displayed” se muestra una regla con el
nombre “Case number” que se debe marcar y luego hacer clic en el botón que tiene la X
en color rojo para eliminar y poner en su lugar “Estado” que está en la sección “Not
displayed” mediante hacer clic en el botón que tiene la flecha de color verde. Hacer clic
en el botón Apply.

30
En lugar mostrar los datos de las variables ahora se muestran los estados, encerrados
en un cuadro. En la ventana “Properties” que está al lado derecho se debe indicar que
no se desea relleno (“fill”) ni línea de contorno (“border”) mediante hacer clic en sus
respectivos botones y luego marcar la casilla que tiene una raya diagonal en color rojo.
El objetivo es lograr que tanto “Fill” y “Border” tengan una diagonal roja. Hecho esto se
puede borrar la leyenda de los estados que se localiza al lado derecho.