gallop: the benefits of wide-area computing for parallel processing
TRANSCRIPT

File: DISTL1 148701 . By:GC . Date:13:10:98 . Time:11:35 LOP8M. V8.B. Page 01:01Codes: 4059 Signs: 2367 . Length: 58 pic 2 pts, 245 mm
journal of parallel and distributed computing 54, 183�205 (1998)
Gallop: The Benefits of Wide-Area Computing forParallel Processing1
Jon B. Weissman
Division of Computer Science, University of Texas at San Antonio, San Antonio, Texas 78249
E-mail: jon�cs.utsa.edu.
Received September 2, 1997; revised May 27, 1998; accepted July 27, 1998
Internet computing has emerged, as an attractive paradigm for manyapplications that require access to distributed resources such as telemedicine,collaboratories, and transaction systems. For applications that require highperformance, the Internet is assumed to be inappropriate. However, it ispossible to obtain high performance for parallel scientific applications in anInternet environment. A wide-area scheduling system called Gallop has beendeveloped to exploit opportunities for high performance using remote Inter-net resources for these applications. This paper describes the Gallop architec-ture and scheduling model, and performance results obtained for threeparallel applications. The initial results indicate that wide-area parallel pro-cessing can lead to better performance even with Internet technology, butthat current Internet bandwidth is a major bottleneck for file and binarytransfer. This overhead limits the class of suitable applications to those thatare large-grained or that will be run multiple times to amortize the transfercost. � 1998 Academic Press
1.0. INTRODUCTION
The conventional wisdom is that high performance computing and the Internetare incompatible. However, it is possible to achieve high performance for computa-tionally demanding applications in a wide-area Internet environment. High perfor-mance can be achieved in one of two ways: metacomputing and remote computing.Metacomputing aggregates the computation, memory, disk, and communicationresources of multiple wide-area sites providing the illusion of a single, powerful,metacomputer to the user. For the metacomputing paradigm to be feasible, high-speed wide-area networks must connect the sites. Small-scale high-speed wide-areanetworks are emerging to support metacomputing, but Internet-wide metacomputing
article no. PC981487
183 0743-7315�98 �25.00Copyright � 1998 by Academic Press
All rights of reproduction in any form reserved.
1 This work was partially funded by NSF ASC-9625000.

File: DISTL1 148702 . By:GC . Date:13:10:98 . Time:11:35 LOP8M. V8.B. Page 01:01Codes: 3669 Signs: 3271 . Length: 52 pic 10 pts, 222 mm
is not yet practical for most applications given current Internet communicationperformance. Remote computing is a special case of metacomputing in which theheterogeneity, ubiquity, and availability of Internet resources can be exploited tolocate the best intra-site resources for user applications. Remote computing selectsa single remote site for application execution and can be beneficial even withcurrent Internet technology. A software system called Gallop has been developed toexploit this opportunity.
Gallop provides a metacomputing abstraction to the user, but restricts applica-tion scheduling to run in the best site in a wide-area network. Gallop schedulesparallel applications including data parallel (SPMD) and task parallel pipelines(PP) to reduce application completion time. Gallop is built upon two establishedsoftware technologies, Mentat [9] and Prophet [21]. Mentat provides theprogramming environment for Gallop applications and the necessary run-timesupport for remote execution. Prophet provides local site scheduling for parallelapplications in shared, heterogeneous, workstation networks. Prophet runs in eachwide-area site and is used by the global Gallop scheduler.
The preliminary results are very promising. Gallop was able to exploit oppor-tunities for better performance using remote Internet sites for applications with awide range of granularities. Gallop is careful to avoid costly scheduling overhead inorder to obtain this performance benefit. The shortcomings of the Internet are alsoexposed: current Internet bandwidth limitations produce very high file and binarytransfer overhead. This overhead cannot be amortized unless the application is verylarge-grained, or will be run multiple times, or files are pre-installed at each site.However, the emergence of high-speed wide-area networks promises to remove thisobstacle.
The Gallop parallel application Model is described in Section 2.0. It specifies theinformation needed to select the best site for the application and to remotelyexecute the application, if necessary. Next, the Gallop wide-area computing modelis described in Section 3.0. This model includes the Gallop network architectureand the application scheduling algorithms. Finally, experimental results for parallelapplications executed in the Gallop network testbed are presented in Section 4.0.The paper concludes with related work and summary.
2.0. PARALLEL APPLICATION MODEL
The Gallop scheduling system assumes a parallel application model thatdescribes the application structure and important cost parameters. In this model,the parallel application is assumed to be decomposed into a set of tasks that com-pute and communicate over the course of the application. This application modelis a variant of the static-task graph (STG) model [3, 13, 17]. Scheduling theapplication requires two important types of information��application executioninformation (AEI ) and application structure information (ASI ). Application execu-tion information describes the run-time execution structure of the application. Thisinformation is used by the system to support application execution in any site.Application structure information quantitatively describes the computation and
184 JON B. WEISSMAN

communication cost structure of the parallel application. This information is usedto evaluate candidate resources offered by the local and remote sites. The ASImodel depends on the structure of the implementation, but it does not assume aparticular language or system implementation. It could be used to describe a PVM,Mentat, DataParallel C, or other parallel application. In contrast, the AEI modelis specific to a particular language implementation. An AEI for SPMD and taskparallel applications written in Mentat has been implemented in Gallop.
Mentat is an object-oriented parallel processing system based on C++ suitablefor medium- to coarse-grain parallel applications [9]. Mentat programs are writtenin an extended C++ language called MPL. The programmer specifies granularityinformation to the system by indicating that a class is a Mentat class. Instances ofMentat classes, called Mentat objects, are implemented by address-space disjointprocesses, and communicate via remote methods. Parallelism is expressed inMentat by defining a Mentat class that corresponds to a computation task andinstantiating some number of Mentat objects of this class. Separate Mentat objectsmay run in parallel, and Mentat class methods may in-turn be implemented inparallel via other Mentat objects. Mentat has been developed for LAN environ-ments and parallel computers and has recently been extended to support wide-areacomputing. These extensions are the precursor to a new wide-area system calledLegion [11]. Gallop uses one of these extensions, the Legion global name space,to allow sites to access remote application binaries and data files needed to supportremote execution.
The Mentat AEI consists of a front-end program, a master or main program, andone or more slave programs all written in MPL (Fig. 1). The front-end is respon-sible for constructing a list of application execution parameters and submitting theapplication for execution. The front-end is run by the end-user on a local computer.An example front-end is given in Appendix A. The main program is responsible forinstantiating the parallel computation represented by the slave programs and return-ing results to the front-end program. Once a scheduling decision is made, the mainprogram and the slave programs are run in the same site. The main program is
FIG. 1. Application execution structure.
185GALLOP: THE BENEFITS OF WIDE-AREA COMPUTING

FIG. 2. Main�prog�class specification.
encapsulated by a Mentat class main�prog�class (Fig. 2). The main programwill be ``launched'' by creating a Mentat object of this class on a computer in theselected site. Currently, the main�prog�class is used to encapsulate Mentatprograms. The application execution parameters assembled by the front-end includethe following.
v main program class file��file name of main�prog�class implementation
v slave binary files��binary file names for slave programs
v command-line arguments��any parameters needed by the application
v input files��input files needed by the application
v output files��output files produced by the application
v constraints��see below (not currently implemented)
v execution history��see below (not currently implemented)
The only mandatory parameter is the main program class file. If a remote site isselected, the system will transport input files, output files, and binaries, if necessary.Issues relating to binary recompilation and security, while important, are outsidethe scope of this paper. Constraints include application execution dependencies,such as the application is written in PVM and requires a PVM-aware site, orapplication resource dependencies, such as the application requires a specific typeof computer, or application deadline requirements, such as the application mustfinish in under t time units. Application execution history information can be usedto select or avoid sites based on prior performance.
An ASI model for two classes of tightly coupled parallel applications, medium-to coarse-grain data parallel (SPMD) and task, parallel pipelines (PP) has beencompleted. In the ASI model, parallel applications consist of computation and com-munication phases. Typically these phases are executed repeatedly for some numberof iterations or cycles. Within the application, the data domain is decomposed intoa number of primitive data units or PDUs, where the PDU is the smallest unit ofdata decomposition. The PDU is problem and application specific. For example,the PDU might be a row, column, or block of a matrix in a matrix-based SPMD
186 JON B. WEISSMAN

application. In a PP image-processing application, it might be an input image.Information about the computation and communication phase,s is provided by aset of functions called callbacks provided by the application programmer. For eachcomputation phase, the following information must be provided by the callbacks:
v numPDUs
v comp�complexity
v arch�cost
v cycles
The number of PDUs manipulated during a computation phase, numPDUs,depends on problem parameters (e.g., problem size). The amount of computation(in number of instructions) performed on a PDU in a single cycle is known as thecomputation complexity, comp�complexity. The architecture-specific execution costsassociated with comp�complexity are captured by arch�cost, provided in units of+s�instruction. The arch�cost contains an entry for each machine type in thenetwork. To obtain the arch�cost, the sequential code must be benchmarked oneach machine type. For each communication phase, the following information mustbe provided by the callbacks:
v topology
v comm�complexity.
The topology refers to the communication pattern of the application, e.g., 1-D,ring, tree, etc. The amount of communication between application tasks is knownas the communication complexity, comm�complexity. It is the number of bytestransmitted by a task in a single communication during a single cycle of the com-munication phase. For irregular applications, the callbacks are provided as anaverage. Among the computation and communication phases, two phases are dis-tinguished. The dominant computation phase has the largest computational com-plexity and the dominant communication phase has the largest communication com-plexity. For example, the call-backs for an SPMD application that uses a five-pointstencil to compute poissons equation on a N_N grid is shown in Fig. 3 (thearch�cost is omitted). This implementation uses a row decomposition of the gridwith the constituent tasks communicating in a 1-D pattern. The PDU is a row ofthe grid. This application consists of a dominant computation phase where eachtask updates its grid points in parallel, and a dominant communication phase
FIG. 3. Callbacks for 1-D stencil.
187GALLOP: THE BENEFITS OF WIDE-AREA COMPUTING

FIG. 4. Callback interface.
where each task transmits a border row containing 4-byte grid points, to its northand south neighbors.
The ASI callback information is contained in a C++ class called a domain(Fig. 4). The domain class consists of a set of member functions that correspond tothe callbacks. This class must be derived and tailored for each parallel application.However, a library of classes for common application types such as stencilproblems can be easily developed to simplify this task for the application program-mer. The domain class is used by the Prophet scheduling system [21], a softwarescheduler that runs at every site described in Section 3.3.
The AEI and ASI parameters are encapsulated by a class Job�class (Fig. 5).The Job�class is a Mentat class��an object of this class is created to run locallyby the front-end and accessed by Gallop. The contained information will be usedby Gallop as described in the next section.
FIG. 5. Job�class specification.
188 JON B. WEISSMAN

3.0. WIDE-AREA COMPUTING MODEL
3.1. Wide-Area System Architecture
Gallop represents the wide-area network as a collection of autonomous fully con-nected sites (Fig. 6). The connections indicate that all sites can communicatedirectly and schedule applications to each other. A flat organization has good faulttolerance properties (as compared with a hierarchical organization) and scaleswell for modest size testbeds of 10�100 sites. This size system would include allrecent metasystem testbeds such as I-Way�Gusto [7], Nile [14], and testbeds thatconnect the national laboratories, various universities, and corporate enterprises.
Within a site, resources are organized into processor clusters (Fig. 7). Processorclusters contain computers on separate subnetworks. Information about a site'scomputing resources is needed to evaluate potential scheduling decisions. Thesystem maintains the following information about each processor cluster within asite:
v processors
v aggregate power
v communication functions.
The processors include the number and type of the available computers andtheir load status. The aggregate power is the total Mflops and Mips available. Thecommunication functions predict the communication cost as a function of messagesize and number of processors for the cluster. Examples of communication functionsfor workstation-based clusters are provided in Section 3.3.
Each site runs a scheduling manager (SM) and a local scheduler (LS). The SM 'srun the wide-area scheduling algorithm discussed later in Section 3.2. The SM inter-faces to the site LS and to the other SM 's. The LS is responsible for managing thelocal site resources in a manner transparent to the SM. It is the LS that decides
FIG. 6. Wide-area system organization.
189GALLOP: THE BENEFITS OF WIDE-AREA COMPUTING

FIG. 7. Intra-site organization. A site containing 3 processor clusters, two connected via ethernetand the other via ATM.
what resources the site will make available for wide-area scheduling at any pointin time, thus providing site autonomy. The LS contains two components. Onecomponent is an interface to the SM and the other is an interface to a site-specificscheduling system (e.g., NQS, Condor, Prophet, etc.). As an example consider twosites as depicted in Fig. 8; site 1 contains a single parallel supercomputer (perhapsan Intel Paragon or IBM SP-2) and site 2 contains a workstation network. The LSfor site 1 uses NQS and the LS for site 2 uses Condor. NQS manages the super-computer partitions and Condor manages the workstations. For sites that containa multitude of resources, several LS 's may be used with a single representativedesignated to communicate with the site SM. The SM 's and LS 's are address-spacedisjoint, communicate via message-passing, and will run on one of host computerswithin each site. However, in some systems, the SM and LS may be configured asa single process. In this system prototype, the LS is the Prophet scheduler [21].The LS will explore and evaluate potential resource schedules within the site usingapplication information provided by the callbacks (Fig. 4) and the resource infor-mation described above.
The current system will schedule an application within a single site. Schedulingan application across multiple sites may be feasible for sites that have a high com-munication capacity between them (e.g., 45Mb�sec bandwidth or higher). Thisrequires a tighter integration of the site SM 's through the virtual site mechanism.A virtual site is composed of multiple sites with sufficient communication capacityto be considered as a single site by scheduling. As an example consider the I-Wayand Casa virtual sites as depicted in Fig. 9 (the virtual sites are the dotted boxes).A single application could be scheduled across the multiple sites connected on theI-Way given this organization. Loosely coupled meta-applications may be suitable
FIG. 8. Scheduling components.
190 JON B. WEISSMAN
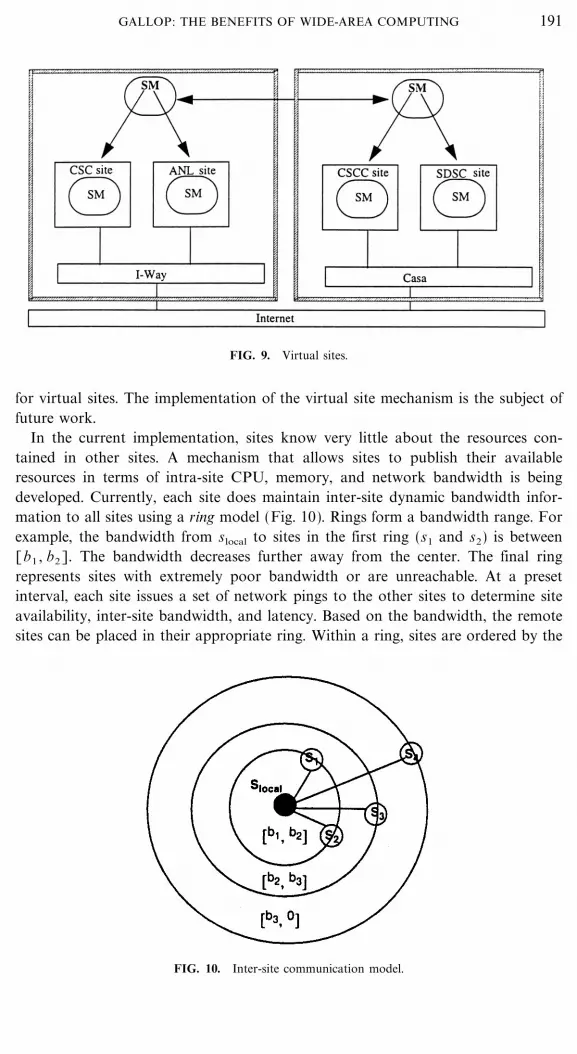
FIG. 9. Virtual sites.
for virtual sites. The implementation of the virtual site mechanism is the subject offuture work.
In the current implementation, sites know very little about the resources con-tained in other sites. A mechanism that allows sites to publish their availableresources in terms of intra-site CPU, memory, and network bandwidth is beingdeveloped. Currently, each site does maintain inter-site dynamic bandwidth infor-mation to all sites using a ring model (Fig. 10). Rings form a bandwidth range. Forexample, the bandwidth from slocal to sites in the first ring (s1 and s2) is between[b1 , b2]. The bandwidth decreases further away from the center. The final ringrepresents sites with extremely poor bandwidth or are unreachable. At a presetinterval, each site issues a set of network pings to the other sites to determine siteavailability, inter-site bandwidth, and latency. Based on the bandwidth, the remotesites can be placed in their appropriate ring. Within a ring, sites are ordered by the
FIG. 10. Inter-site communication model.
191GALLOP: THE BENEFITS OF WIDE-AREA COMPUTING

File: DISTL1 148710 . By:GC . Date:13:10:98 . Time:11:35 LOP8M. V8.B. Page 01:01Codes: 3853 Signs: 3296 . Length: 52 pic 10 pts, 222 mm
measured latency to the local site. At different times of the day, sites may movebetween rings as the network load changes. This inter-site communication informa-tion is used in estimating scheduling and remote execution overhead, and for siteselection, described in Section 3.2.
3.2. Wide-Area Scheduling
The wide-area scheduling process contains a global and local phase. The globalphase is initiated by the arrival of a scheduling request to a local site SM, producedby the front-end program (Appendix A). The SM is passed the Job�class objectto initiate scheduling of the application. The wide-area scheduling algorithm is adistributed algorithm that has two parts, the local site SM component and theremote site SM component (Fig. 11). The procedure calls across address-spaces(e.g., get�best) are remote procedure calls (RPC's). When an application requestfirst arrives at a local site SM, a set of candidate sites are selected (including thelocal site) and the Job�class object is sent to each remote site SM for bidding.Selecting the candidate sites (step 2) is done in the following manner. Sites ``closest''to the local site in terms of communication performance are given the greatestpriority since files, binaries, results, and scheduling control messages may have tobe transmitted between the local and a selected remote site.2 The closest sites arelocated on rings closest to the local site (Fig. 10). For most applications, it is tooexpensive to consider all available sites. An estimate of the scheduling overhead isused to constrain the number of sites under consideration. This overhead has twoterms, protocol overhead (Fig. 11) and file transfer overhead, in the event that aremote site is selected. The overhead estimate is computed using the ring latencyand bandwidth (for the RPC's in steps 3�6, Fig. 11a) to each site for the protocolitself and for file transfer, and the local scheduling overhead (steps 2�3, Fig. 11b).Fortunately, the local scheduling overhead is paid once as the sites run this algo-rithm in parallel. But the communication overhead for the protocol and file transferdominates.
The number of sites selected is constrained such that the estimated schedulingoverhead falls within 100 of the best execution time that can be achieved locally.Sites are selected based on their ring position from the center outward, until thepredicted overhead reaches this limit. The best local execution time is obtained byhaving the local LS run steps 2 and 3 (Fig. 11b). For small applications, perhapsno remote sites will be considered, but for larger applications that run longer, alarger number of remote sites will be selected. Currently, all sites within a ring areweighted equally since no information about intra-site resources is assumed. Whensites publish their available aggregate resources, a mechanism for ordering siteswithin a ring can be designed. This version is in development.
Once the candidate set of sites is determined, the algorithm proceeds as follows.Each selected remote SM contacts its LS to get a list of machines and when theyare available. The remote SM invokes the LS to run a local scheduling algorithm
192 JON B. WEISSMAN
2 History and constraint information will be used first in candidate site selection.

FIG. 11. Wide-area scheduling algorithm.
to search this set of machines to evaluate the possible schedules. The best scheduleand projected completion time are returned to the local site SM. Each SM locksthis schedule until the scheduling transaction is complete. The best schedule has thesmallest predicted completion time. The local site SM then selects the best site andinitiates the scheduling of the application on that site. This algorithm offers anopportunity to provide robust application scheduling��instead of a single site selec-tion, the system could redundantly schedule the application in multiple sites forfault tolerance. This possibility is being investigated [23].
When the local SM receives all of the bids, it selects the best schedule andinforms all of the remote sites of its decision. This information can be used by theother sites in making future scheduling decisions. For examples the other sites canavoid this site in the short-run since it is already running an application. Thiswould allow a Gallop system to implement load-sharing, if desired. At present, allscheduling decisions are based on what is best for the current application. Thechosen site SM passes the application (i.e., the Job�class object) to the local LSfor execution. Execution is accomplished by the LS which creates and launches themain�prog�class object. At this point, the other remote SM 's can release the
FIG. 12. Wide-area scheduling and execution.
193GALLOP: THE BENEFITS OF WIDE-AREA COMPUTING

FIG. 13. SPMD scheduling. The application is decomposed into a set of data regions (shaded rec-tangles) each assigned to a task (circle) which is placed on a processor (square). In this example, thetasks are arranged in a 1-D communication topology.
lock on their best candidate schedule. The interactions between the various systemcomponents are depicted in Fig. 12 (site SM2 is selected to run the application).Additional details may be found in [19].
3.3. Local Scheduling
The Prophet LS utilizes a cost-driven method for scheduling SPMD and PPapplications in heterogeneous workstation networks. Prophet makes resourcescheduling decisions that are predicted to produce reduced completion time for theapplication. Near-optimal scheduling results have been obtained for SPMDapplications [22]. Scheduling SPMD applications consists of two parts, partitioningand placement (Fig. 13). In partitioning, the application is decomposed across a setof potentially heterogeneous processors. The number of processors selected dependson the computation granularity��an application with a large computationgranularity may benefit by a large number of processors relative to a smaller one.Another factor in processor selection is the granularity supported by the networkresources. A faster network (e.g., ATM vs ethernet) may allow greater parallelismto be exploited. In placement, a task will be placed on each selected processor andassigned a piece of the data domain. Tasks are assigned to specific processors toreduce communication overhead induced by routing and contention. In the SPMDmodel, the tasks are identical and are parameterized to compute on their dataregion. The data domain is decomposed to give load balance��tasks onheterogeneous processors are given a portion of the data domain proportional tothe power of the processor. A number of PDUs will be assigned to each taskproportional to the power of the processor to which it is assigned.
FIG. 14. Image processing pipeline.
194 JON B. WEISSMAN

FIG. 15. Parallel pipelines.
For PP applications, a number of inputs are pumped into a pipeline with stagesoverlapped in execution. The archetype example is an image processing application(Fig. 14). The speedup is limited by the pipeline depth and maximum computationtime of the pipeline stages. To overcome this performance limitation, the pipelinecan be replicated and run in parallel (Fig. 15). In the PP model, each computationstage is a task that will be assigned to a processor. If the pipeline depth is k andthere are n pipelines, then kn processors are needed. Unlike SPMD applications,the computation tasks may be different. In-both PP and SPMD applications, asingle computation task is assigned per processor.
Prophet will determine the appropriate number of pipelines (i.e., processors) toapply to a PP application, and the placement of computation tasks to processors.Unlike the scheduling of SPMD applications, there is no need to partition the datadomain. The inputs are served to the initial stage of the pipelines when they becomeidle. For PP applications, the PDU is the input (e.g., an image). For each computa-tion stage, a comp�complexity and comm�complexity callback is defined. The numberof processors to use depends on the number of inputs (provided by the numPDUscallback), the computation granularity of the stages, and the amount of com-munication contention between the parallel pipelines.
Prophet exploits information about the parallel application and the networkresources in order to make scheduling decisions for SPMD and PP applications(Fig. 16). Prophet explores a set of candidate processor configurations to apply tothe application in order to minimize completion time. The details of this algorithmmay be found in [21]. Prophet first orders the processor clusters based upon theircomputation and communication capabilities for the application in order to con-strain the search process. The scheduling algorithm estimates the computation andcommunication rates using the cost functions given below:
TCT[SPMD]=cycles } (Tcomm +Tcomp )
TCT[PP]=num�inputs } k } (Tcomm +Tcomp )
Tcomp [PP]=(comp�complexity } arch�cost)
k } n } cpu�avail
Tcomp [SPMD]=comp�complexity }
linearch�cost } numPDUsp } cpu�avail
Tcomm [SPMD]=(c1 } p)+(c2 } p } comm�complexity)
bw�avail.
195GALLOP: THE BENEFITS OF WIDE-AREA COMPUTING

FIG. 16. Prophet system architecture.
Prophet constructs a cost function for application completion time TCT for eachcandidate schedule.3 Different processor configurations will have different TCT
values��the algorithm searches for a configuration that is predicted to give a mini-mum TCT . Tcomp is the average computation time spent by a processor or task inone cycle or iteration of execution. It is based on arch�cost, the average cost ofexecuting a PDU over all the selected processors, p. The term cpu�avail is theaverage CPU availability as a percentage (idle=1000 available) for all selectedprocessors. Since arch�cost reflects the peak execution time, it is scaled by cpu�availto give the true cost. The term bw�avail is the amount of bandwidth availablewithin the cluster as a percentage (idle network=1000 available). Tcomm is theaverage communication time spent by a processor or task in one iteration of execu-tion. The communication function shown is for SPMD applications on ethernetwhich is linear in the number of processors, p, and message size, given bycomm�complexity. The constants c1 and c2 depend on the application communica-tion topology and are determined off -line��c1 is a latency-dependent constant andc2 is a bandwidth-dependent constant. Since the communication parameters reflectthe peak communication rates, bw�avail is used to scale the bandwidth-dependentportion of Tcomm . The communication function for PP applications is more complexsince communications from different pipelines will contend for network bandwidthand is omitted. A model for PP communications is provided in [19].
The algorithm tries to minimize the sum of Tcomm and Tcomp , hence cycles is notrequired to minimize TCT [SPMD] since it is a constant.
4.0. RESULTS
An experimental Internet-based wide-area testbed containing sites at the Univer-sity of Virginia (UVA), University of Texas at San Antonio (UTSA), SouthwestResearch Institute (SWRI) in San Antonio, and Sandia National Laboratory inNew Mexico (HEAT) was used to demonstrate the benefits of Gallop. In thetestbed, each site contained four Sparc workstations of different power and networkconnection: UTSA contained four Sun SPARCstation-5s connected on 10 base-Tethernet, UVA contained four Sun SPARCServers-20�514s connected on 10 base-Tethernet, SWRI contained four Sun SPARCstation-5s connected by a Fore ATM
196 JON B. WEISSMAN
3 The algorithm tries to minimize the sum of Tcomm and Tcomp , hence cycles is not required to minimizeTCT[SPMD] since it is a constant.
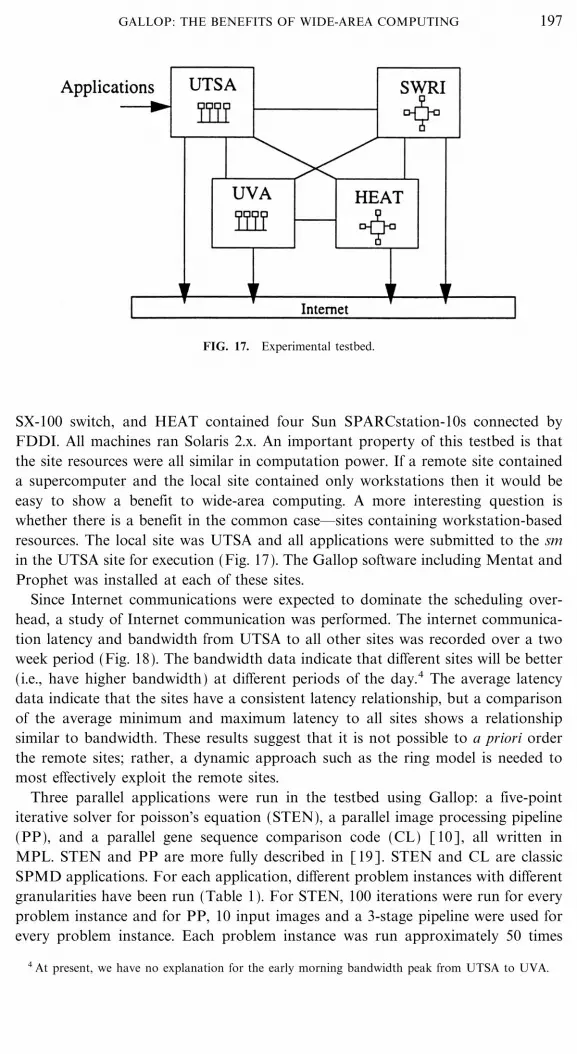
FIG. 17. Experimental testbed.
SX-100 switch, and HEAT contained four Sun SPARCstation-10s connected byFDDI. All machines ran Solaris 2.x. An important property of this testbed is thatthe site resources were all similar in computation power. If a remote site containeda supercomputer and the local site contained only workstations then it would beeasy to show a benefit to wide-area computing. A more interesting question iswhether there is a benefit in the common case��sites containing workstation-basedresources. The local site was UTSA and all applications were submitted to the smin the UTSA site for execution (Fig. 17). The Gallop software including Mentat andProphet was installed at each of these sites.
Since Internet communications were expected to dominate the scheduling over-head, a study of Internet communication was performed. The internet communica-tion latency and bandwidth from UTSA to all other sites was recorded over a twoweek period (Fig. 18). The bandwidth data indicate that different sites will be better(i.e., have higher bandwidth) at different periods of the day.4 The average latencydata indicate that the sites have a consistent latency relationship, but a comparisonof the average minimum and maximum latency to all sites shows a relationshipsimilar to bandwidth. These results suggest that it is not possible to a priori orderthe remote sites; rather, a dynamic approach such as the ring model is needed tomost effectively exploit the remote sites.
Three parallel applications were run in the testbed using Gallop: a five-pointiterative solver for poisson's equation (STEN), a parallel image processing pipeline(PP), and a parallel gene sequence comparison code (CL) [10], all written inMPL. STEN and PP are more fully described in [19]. STEN and CL are classicSPMD applications. For each application, different problem instances with differentgranularities have been run (Table 1). For STEN, 100 iterations were run for everyproblem instance and for PP, 10 input images and a 3-stage pipeline were used forevery problem instance. Each problem instance was run approximately 50 times
197GALLOP: THE BENEFITS OF WIDE-AREA COMPUTING
4 At present, we have no explanation for the early morning bandwidth peak from UTSA to UVA.
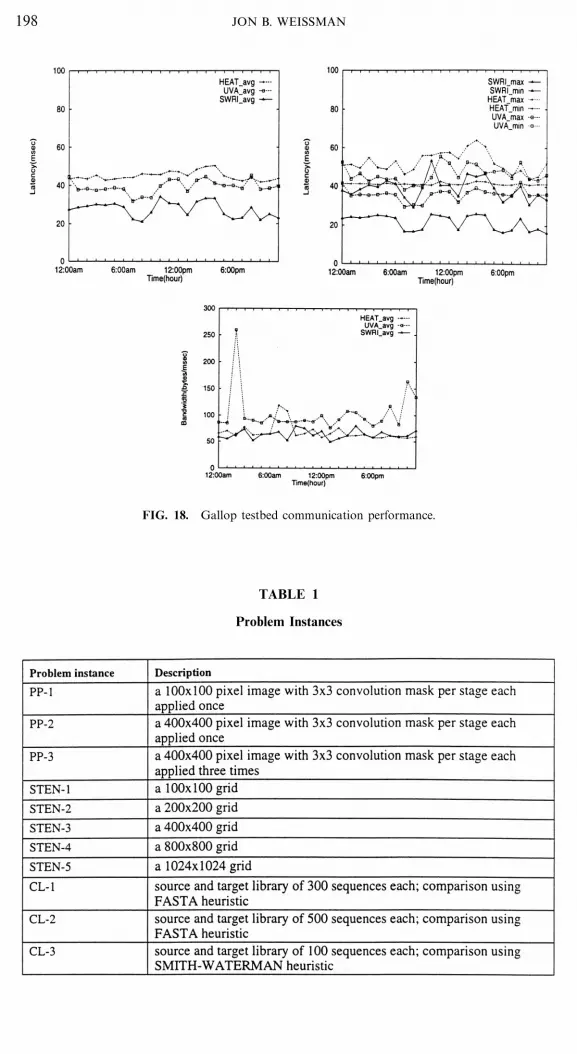
FIG. 18. Gallop testbed communication performance.
TABLE 1
Problem Instances
198 JON B. WEISSMAN
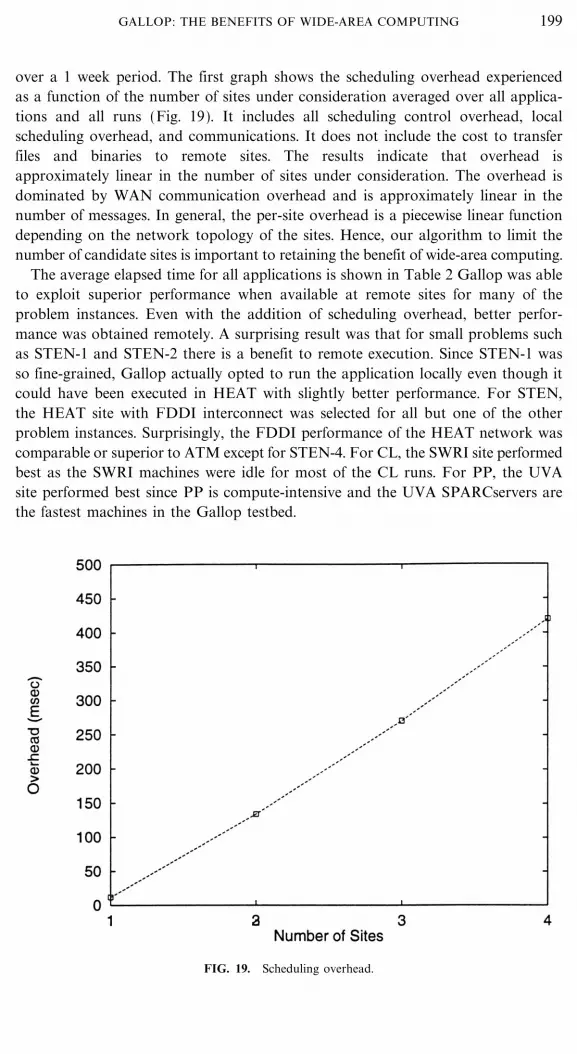
over a 1 week period. The first graph shows the scheduling overhead experiencedas a function of the number of sites under consideration averaged over all applica-tions and all runs (Fig. 19). It includes all scheduling control overhead, localscheduling overhead, and communications. It does not include the cost to transferfiles and binaries to remote sites. The results indicate that overhead isapproximately linear in the number of sites under consideration. The overhead isdominated by WAN communication overhead and is approximately linear in thenumber of messages. In general, the per-site overhead is a piecewise linear functiondepending on the network topology of the sites. Hence, our algorithm to limit thenumber of candidate sites is important to retaining the benefit of wide-area computing.
The average elapsed time for all applications is shown in Table 2 Gallop was ableto exploit superior performance when available at remote sites for many of theproblem instances. Even with the addition of scheduling overhead, better perfor-mance was obtained remotely. A surprising result was that for small problems suchas STEN-1 and STEN-2 there is a benefit to remote execution. Since STEN-1 wasso fine-grained, Gallop actually opted to run the application locally even though itcould have been executed in HEAT with slightly better performance. For STEN,the HEAT site with FDDI interconnect was selected for all but one of the otherproblem instances. Surprisingly, the FDDI performance of the HEAT network wascomparable or superior to ATM except for STEN-4. For CL, the SWRI site performedbest as the SWRI machines were idle for most of the CL runs. For PP, the UVAsite performed best since PP is compute-intensive and the UVA SPARCservers arethe fastest machines in the Gallop testbed.
FIG. 19. Scheduling overhead.
199GALLOP: THE BENEFITS OF WIDE-AREA COMPUTING
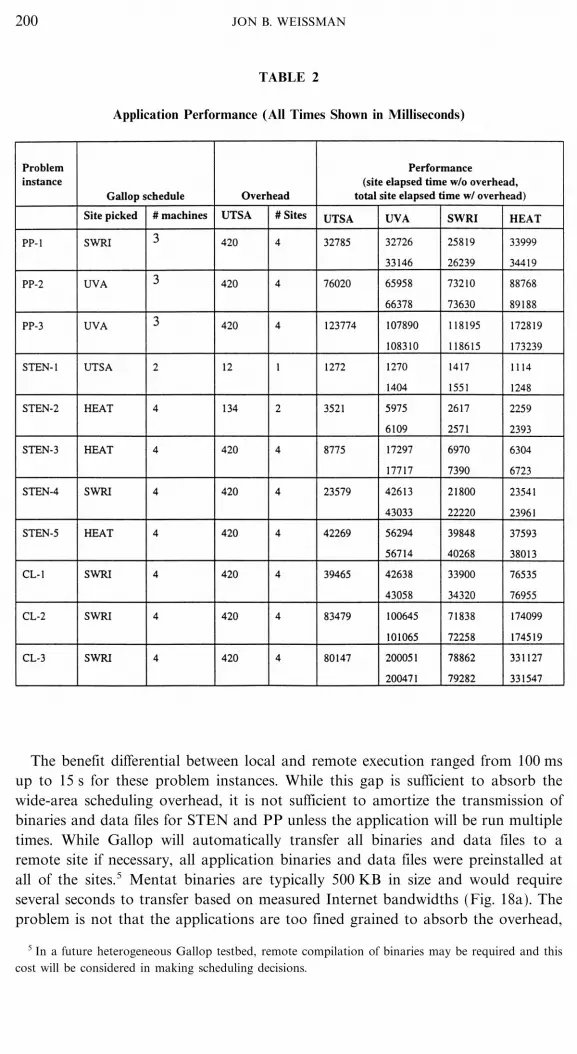
TABLE 2
Application Performance (All Times Shown in Milliseconds)
The benefit differential between local and remote execution ranged from 100 msup to 15 s for these problem instances. While this gap is sufficient to absorb thewide-area scheduling overhead, it is not sufficient to amortize the transmission ofbinaries and data files for STEN and PP unless the application will be run multipletimes. While Gallop will automatically transfer all binaries and data files to aremote site if necessary, all application binaries and data files were preinstalled atall of the sites.5 Mentat binaries are typically 500 KB in size and would requireseveral seconds to transfer based on measured Internet bandwidths (Fig. 18a). Theproblem is not that the applications are too fined grained to absorb the overhead,
200 JON B. WEISSMAN
5 In a future heterogeneous Gallop testbed, remote compilation of binaries may be required and thiscost will be considered in making scheduling decisions.

File: DISTL1 148719 . By:GC . Date:13:10:98 . Time:11:35 LOP8M. V8.B. Page 01:01Codes: 3704 Signs: 3286 . Length: 52 pic 10 pts, 222 mm
but that the gap between local and remote site performance is too small. The reasonthe gap is relatively small is that the sites are of comparable computation power.As the Gallop testbed grows to include more sites, some including supercomputers,this gap will widen for applications that can utilize supercomputing resources. Forthese applications, the cost of file and binary transfer and perhaps even remotecompilation is much more likely to be amortized. Large-scale scientific applicationsare the most likely candidates for supercomputing resources. Another solution tothis problem may be provided by wide-area gigabit networks [4] that wouldreduce transfer overhead by at least an order of magnitude. This would be sufficientfor most of the problem instances presented here. Gallop will be deployed on thesefuture networks as they become available. These networks also make it possible toconsider running a single application across multiple sites. The virtual sitemechanism (Fig. 9) will be used to exploit this opportunity. Current Internettechnology limits the class of applications that would benefit by such distri-bution.
In a future heterogeneous Gallop testbed, remote compilation of binaries may berequired and this cost will be considered in making scheduling decisions.
5.0. RELATED WORK
A number of other research projects are exploring the benefits of wide-areacomputing for user applications [1, 2, 5, 7, 8, 11, 14, 18]. The Legion projectis developing the interfaces and infrastructure for object-oriented wide-area middle-ware [11]. Since Legion does not mandate specific solutions for problems such asscheduling, Gallop will be integrated into Legion to provide support for schedulingparallel applications. The Globus project is a metacomputing framework designedfor applying distributed resources to scientific applications [7]. It relies on a high-speed WAN to interconnect all of the participating sites. Globus is a high-levelarchitecture for constructing metacomputing applications but also lacks schedulingsupport for parallel applications. A prototype system called GUSTO is in construc-tion. A Gallop GUSTO integration will also be investigated in the future.Infospheres is a framework for building applications that span wide-area systems[5]. It has several components including a distributed directory service needed tolocate wide-area resources. Infospheres is targeted to collaborative applications asopposed to high performance. It does not have any specific support for schedulingor resource management. IceT is a framework for collaborative and high-perfor-mance distributed computing based on Java [8]. In IceT, programs and data aremoved to the appropriate computational resources. In this respect IceT and Gallopare similar, but Gallop is not tied to a specific programming language such as Java.The Nile project is building a high-performance wide-area computing environmentfor high-energy physics applications. Nile applications number in the thousands perday and may be scheduled on machines located throughout the Nile network.Resource management in Nile is concerned more with job throughput than withapplication finishing time. The Responsive web computing (RWC) project is
201GALLOP: THE BENEFITS OF WIDE-AREA COMPUTING

File: DISTL1 148720 . By:GC . Date:13:10:98 . Time:11:35 LOP8M. V8.B. Page 01:01Codes: 3423 Signs: 2955 . Length: 52 pic 10 pts, 222 mm
exploring the use of the Web as a metacomputer [2]. The primary focus of thiswork is to reduce the variance of Web computing to support applications with real-time constraints. Specialized TCP protocols and resource management middlewareare the key components of the RWC system. However, no specific resource manage-ment algorithms have been implemented. Apples is a framework for user-levelscheduling of parallel applications in heterogeneous LANs and WANs [1]. InApples, a programmer-provided scheduling agent is responsible for scheduling andis tightly coupled to the application. While the Apples approach is very general, itrequires that the programmer write the scheduling agent, which may be a complextask. Apples is also targeted to LANs primarily. The Apples philosophy is verysimilar to that of Prophet which is to use application and resource information tomake application-centric scheduling decisions. VDCE is a system for executingtasks across processors that may span multiple sites. The emphasis in VDCE is onthe composition of parallel applications from library components.
6.0. CONCLUSION AND FUTURE WORK
The Gallop scheduling system shows that high performance and wide-area com-puting are not incompatible ideas. Gallop was able to exploit opportunities forbetter performance using remote Internet sites for applications with a range ofgranularities. Gallop uses resource and application knowledge to avoid costlyscheduling overhead when it would not be profitable. The experimental study alsorevealed that the bandwidth limitation of the current Internet is a problem whenlarge binaries and files must be transported to support remote execution. Thesecosts cannot be absorbed unless the remote site offers an order of magnitude betterperformance than the local site or the application will be run multiple times. Futurework includes deploying Gallop on a fast wide-area network testbed such asGUSTO to overcome this bandwidth bottleneck, and an implementation in theLegion wide-area computing environment [11]. A high-speed WAN such as thevBNS would allow a much wider range of applications to benefit from wide-areaexecution. An experimental evaluation of Gallop in this environment to test thishypothesis is planned. Future work also includes the development of a schedulingmodel that would allow single applications to be distributed across multiple sites.The benefit of multiple sites has been demonstrated by large-scale scientific applica-tions [15], but these applications are typically hand-scheduled. Extending Gallopto support the automatic scheduling of applications across multiple sites usingapplication and resource information is planned.
ACKNOWLEDGMENTS
The author acknowledges the following Internet sites that provided resources for our wide-areatestbed: University of Virginia Computer Science Department, Sandia National Laboratories, andSouthwest Research Institute.
202 JON B. WEISSMAN

File: DISTL1 148721 . By:GC . Date:13:10:98 . Time:11:35 LOP8M. V8.B. Page 01:01Codes: 2364 Signs: 1295 . Length: 52 pic 10 pts, 222 mm
APPENDIX A: FRONT-END FOR STENCIL APPLICATION
void main (int argc, char **argv)[
schedule *results;sm local�SM;stencil�Job�class *j=new stencil�Job�class;arg�list *Args;program�arg arg;arg�type idatafile, odatafile, ldatafile, lbfile;
local�SM.bind (SEARCH�SUBNIT); �� locate local schedulingmanager
Args=new (8) arg�list (8);��Package up Application Informationstrcpy (arg.arg, ``stencil�main�class'');arg.type=�main�;Args � append (6arg);strcpy (arg.arg, argv[1]);arg.type=�argv�;Args � append (6arg);strcpy (arg.arg, argv[2]);Args � append (6arg);
��Include grid input file and output file (omitted)�� ...��Include slave binary filestrcpy (arg.arg, ``sten�worker''); ��Binaries ...arg.type=�bfile�;��Register binaries in Legion name space to enable remote
copyingstrcpy (lbfile, ``�legion�'');strcat (lbfile, arg .arg);lreg�host (arg.arg, lbfile,
raw�host�id (SELF�ONAME .get�mmps�host()));strcpy (arg.arg, lbfile);Args � append (6arg);
j � create (0); �� create Job�class objectif (j � init�domain(Args) == 1); �� init domain object((Job�class*)j) � init�execution (Args);results=local�SM.WA�sched ((Job�class*)j); �� submit
application
�� Could log schedule if necessary ...fprintf (stderr, ``**********FE: stencil took 0f msec"n'',
(*results)[0] .etime�taken);j � destroy ();
]
203GALLOP: THE BENEFITS OF WIDE-AREA COMPUTING

File: DISTL1 148722 . By:GC . Date:13:10:98 . Time:11:35 LOP8M. V8.B. Page 01:01Codes: 8281 Signs: 3394 . Length: 52 pic 10 pts, 222 mm
REFERENCES
1. F. Berman and R. Wolski, Scheduling from the perspective of the application, in ``Proceedings of theFifth IEEE International Symposium on High Performance Distributed Computing, August1996.''
2. A. Bestavros et al., ``Responsive Web Computing: Resource Management, Protocol Techniques, andApplications,'' Boston University Computer Science technical report, 96-008 March 1996.
3. S. H. Bokhari, ``Assignment Problems in Parallel and Distributed Computing,'' Kluwer Academic,Dordrecht�Norwell, MA, 1987.
4. S. Chatterjee, Requirements for success in gigabit networking, Comm. of the ACM 40, No. 7(1997).
5. K. M. Chandy et al., A world-wide distributed system using java and the internet, in ``Proceedingsof the Fifth IEEE International on High Performance Distributed Computing HPDC-5, August1996.''
6. D. L. Eager, E. D. Lazowska, and J. Zahorjan, Adaptive load sharing in homogeneous distributedsystems, IEEE Trans. on Software Engrg. 12 (1986).
7. I. Foster and C. Kesselman, Globus: A metacomputing infrastructure toolkit, Intern. J. of Supercom-puting Appl., in press.
8. P. A. Gray and V. S. Sunderam, IceT: Distributed computing and java, in ``Cluster Computing Con-ference, Atlanta, GA, 1997.''
9. A. S. Grimshaw, Easy to use object-oriented parallel programming with mentat, IEEE Comput.(1993).
10. A. S. Grimshaw, E. A. West, and W. R. Pearson, No pain and gain! Experiences with mentat onbiological application, Concurrency: Practice Experience 5 (1993).
11. A. S. Grimshaw and W. A. Wulf, The legion vision of a worldwide virtual computer, Comm. of theACM 40, No. 1 (1997).
12. A. K. Jain, ``Fundamentals of Digital Image Processing,'' Prentice�Hall, New York, 1989.
13. V. M. Lo, Temporal communication graphs: Lamport's process-time graphs augmented for the pur-pose of mapping and scheduling, J. Parallel Distributed Comput. 16 (1992).
14. K. Marzullo et al., Nile: Wide-area computing for high energy physics, in ``Proceedings of theSeventh ACM SIGOPS European Workshop, 1996.''
15. C. R. Mechoso et al., Running a climate model in a heterogeneous distributed computer environ-ment, in ``Proceedings of the Third IEEE International on High-Performance Distributed Comput-ing, August 1994.''
16. N. Nedeljkovic and M. J. Quinn, Data-parallel programming on a network of heterogeneousworkstations, in ``Proceedings of the First IEEE International Symposium on High-PerformanceDistributed Computing, Sept. 1992.''
17. H. S. Stone, Multiprocessor scheduling with the aid of network flow algorithms, IEEE Trans. onSoftware Engrg. SE-3, No. 1 (1977).
18. H. Topcuoglu et al., The software architecture of a virtual distributed computing environment, in``Proceedings of the Sixth IEEE International Symposium on High-Performance Distributed Com-puting, August 1997.''
19. J. B. Weissman and X. Zhao, Run-time support for scheduling parallel applications in heterogeneousNOWs, in ``Proceedings of the Sixth IEEE International Symposium on High Performance Dis-tributed Computing, August 1997.''
20. J. B. Weissman and A. S. Grimshaw, A federated model for scheduling in wide-area systems, in``Proceedings of the Fifth IEEE International Symposium on High Performance Distributed Com-puting, August 1996.''
21. J. B. Weissman and A. S. Grimshaw, A framework for partitioning parallel computations inheterogeneous environments, Concurrency: Practice Experience 7, No. 5 (1995), 455�478.
204 JON B. WEISSMAN

File: DISTL1 148723 . By:GC . Date:13:10:98 . Time:11:35 LOP8M. V8.B. Page 01:01Codes: 1536 Signs: 461 . Length: 52 pic 10 pts, 222 mm
22. J. B. Weissman, ``Scheduling Parallel Computations in a Heterogeneous Environment,'' Ph.D. disser-tation, University of Virginia, August 1995.
23. J. B. Weissman and D. Womack, ``Fault Tolerant Scheduling in Distributed Networks,'' UTSAtechnical report, CS-96-10 October 1996.
24. X. Zhao and J. B. Weissman, ``The Design of a Dynamic Resource Monitor,'' UTSA technicalreport, CS-97-2 January 1997.
205GALLOP: THE BENEFITS OF WIDE-AREA COMPUTING