electromagnetismo numerico
TRANSCRIPT

Resolucion numerica de campos
electromagneticos
Julian Barquın

ii

Prefacio
El proposito de este escrito es servir de apoyo al laboratorio de metodos numeri-cos de la asignatura de Electrotecnia I de la Escuela Tecnica Superior de Inge-nierıa Industrial de la Universidad Pontificia Comillas.
Por otra parte, se ha intentado incluir no solamente el material que se impar-te en esta asignatura, sino tambien material adicional que pueda ser de utilidaden cursos superiores. Se ha diferenciado estos dos tipos de materiales senalando-les como “basico” y “avanzado”.
En este texto no se trata de los aspectos fısicos de las ecuaciones tratadas, loque es, por supuesto, la preocupacion principal en la asignatura de Electrotec-nia I. En cambio, si que se incluye un capıtulo (el segundo) sobre la resolucionnumerica de sistemas lineales. Aunque este tema debiera serle familiar a losalumnos al finalizar el segundo curso, no lo es todavıa cuando comienza el labo-ratorio de metodos numericos, por lo que unas ligeras nociones preliminares sondeseables. Por otra parte, creo que es util que tengan una pequena descripcionde los algoritmos utiles en la resolucion de las ecuaciones de campo.
Tras este capıtulo, el tercero trata de la resolucion de la ecuacion de Poissonmediante diferencias finitas, y el cuarto mediante elementos finitos. En el quintose estudian otras ecuaciones elıpticas de interes en electromagnetismo.
El sexto capıtulo aborda el tratamiento de la ecuacion de difusion, y el ultimode su resolucion en regimen senoidal.
No se han tratado ecuaciones hiperbolicas. La razon es que estas ecuacionesno se tratan en la asignatura con el detenimiento de las elıpticas o las paraboli-cas, tanto por el (muy relativo) menor interes tecnico, como porque se estudiancon menos intensidad en segundo curso, debido, entre otras cosas, a que losalumnos todavıa no han visto analisis de Fourier.
Madrid, octubre de 1996.
iii

iv

Indice general
1 Introduccion 1
2 Resolucion de sistemas lineales 32.1 Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32.2 Metodo directo: la factorizacion LU . . . . . . . . . . . . . . . . . 5
2.2.1 Factorizacion LU de matrices llenas . . . . . . . . . . . . 52.2.2 Factorizacion LU de matrices ralas . . . . . . . . . . . . . 9
2.3 Metodos iterativos . . . . . . . . . . . . . . . . . . . . . . . . . . 112.3.1 Los metodos de Jacobi y Gauss-Seidel . . . . . . . . . . . 112.3.2 El metodo de la sobrerrelajacion sucesiva . . . . . . . . . 17
2.4 Metodos semidirectos: el gradiente conjugado . . . . . . . . . . . 19
3 Ecuaciones de Laplace y Poisson: diferencias finitas 273.1 Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273.2 Preliminares matematicos . . . . . . . . . . . . . . . . . . . . . . 283.3 Construccion de la malla y planteamiento de las ecuaciones . . . 293.4 El principio del maximo . . . . . . . . . . . . . . . . . . . . . . . 333.5 Errores y convergencia . . . . . . . . . . . . . . . . . . . . . . . . 34
3.5.1 Anexo: prueba del teorema . . . . . . . . . . . . . . . . . 363.6 Problemas con los contornos . . . . . . . . . . . . . . . . . . . . . 38
3.6.1 Condiciones de von Neumann no nulas . . . . . . . . . . . 383.6.2 Tratamiento de contornos curvos . . . . . . . . . . . . . . 39
3.7 Diferencias finitas en otros sistemas coordenados . . . . . . . . . 403.7.1 Diferencias finitas en coordenadas polares . . . . . . . . . 413.7.2 Diferencias finitas con simetrıa axial . . . . . . . . . . . . 41
4 Ecuaciones de Laplace y Poisson: elementos finitos 454.1 Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 454.2 Forma variacional de la ecuacion de Poisson . . . . . . . . . . . . 454.3 Aproximacion funcional . . . . . . . . . . . . . . . . . . . . . . . 48
4.3.1 Un ejemplo . . . . . . . . . . . . . . . . . . . . . . . . . . 514.4 Nomenclatura y propiedades . . . . . . . . . . . . . . . . . . . . . 544.5 El espacio de funciones admisibles . . . . . . . . . . . . . . . . . 554.6 Elementos finitos triangulares . . . . . . . . . . . . . . . . . . . . 58
v

vi INDICE GENERAL
4.7 Otros elementos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 644.8 Errores y convergencia . . . . . . . . . . . . . . . . . . . . . . . . 664.9 Elementos finitos y diferencias finitas . . . . . . . . . . . . . . . . 69
5 Otros problemas estaticos 715.1 Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 715.2 Corrientes estacionarias . . . . . . . . . . . . . . . . . . . . . . . 715.3 Magnetostatica en medios lineales . . . . . . . . . . . . . . . . . 725.4 Magnetostatica no lineal . . . . . . . . . . . . . . . . . . . . . . . 76
5.4.1 Planteamiento de la forma variacional . . . . . . . . . . . 765.4.2 Resolucion numerica de la forma variacional . . . . . . . . 78
6 La ecuacion de difusion 836.1 Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 836.2 La ecuacion de difusion en 1 dimension . . . . . . . . . . . . . . . 846.3 Resolucion de las ecuaciones . . . . . . . . . . . . . . . . . . . . . 86
6.3.1 Metodo explıcito clasico . . . . . . . . . . . . . . . . . . . 876.3.2 Metodo implıcito clasico . . . . . . . . . . . . . . . . . . . 886.3.3 Metodo de Crank-Nicholson . . . . . . . . . . . . . . . . . 89
6.4 Estabilidad de la solucion . . . . . . . . . . . . . . . . . . . . . . 916.5 Convergencia de los algoritmos . . . . . . . . . . . . . . . . . . . 946.6 Elementos finitos y la ecuacion de difusion . . . . . . . . . . . . . 97
7 Problemas armonicos 1017.1 Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1017.2 Notacion compleja . . . . . . . . . . . . . . . . . . . . . . . . . . 1027.3 Difusion magnetica e histeresis . . . . . . . . . . . . . . . . . . . 104

Capıtulo 1
Introduccion
Hace ya mas de 200 anos, Leonard Euler, de quien dicen que jamas dejabade calcular1, decidio abordar el problema del flujo del agua. El conocıa lasecuaciones de Newton, y sabıa como aplicarlas a partıculas o solidos rıgidos.En estos casos, el estado del sistema fısico esta descrito por un numero finitode cantidades: las posiciones y las velocidades de las partıculas, o la posicion yvelocidad del centro de masas junto con la orientacion del cuerpo y su velocidadangular. No ası con el agua: para definir su estado se necesita saber la velocidadde cada partıcula.
Matematicamente, su estado se puede representar mediante el campo develocidades v(x, y, z). Euler logro derivar una ecuacion que relacionaba el cambiode la velocidad con el tiempo con su cambio en el espacio, una ecuacion enderivadas parciales, o una ecuacion de campo.
100 anos despues, James Maxwell logro dar forma matematica a las ideasde Michel Farady sobre las leyes del campo electromagnetico. De nuevo se en-contro con ecuaciones en derivadas parciales, que en teorıa permitirıan calcularlos campos electrico E(x, y, z) y magnetico B(x, y, z).
Este fue, sin duda alguna2, el hecho mas importante del siglo XIX, el comien-zo de la era electrica. Durante los anos siguientes, el final del siglo XIX y el sigloXX, los ingenieros aplicarıan estas ecuaciones en un numero creciente de dispo-sitivos. Sin embargo, es curioso de que, salvo en raras ocasiones, no las resolvıan:las simplificaban. La razon, por supuesto, es que no se sabıa resolverlas, salvoen casos de una extrema idealizacion.
Hoy la situacion es distinta. La razon es que la aparicion de los ordenado-res (lejanos descendientes de Farady y Maxwell, por otra parte) permiten laresolucion de grandes sistemas de ecuaciones algebraicas. Este escrito trata, portanto, de la aproximacion de ecuaciones en derivadas parciales por ecuacionesalgebraicas.
En electromagnetismo, casi todas las ecuaciones de interes tienen un mismoaspecto: son ecuaciones de segundo orden. Por ejemplo, en dos dimensiones
1De hecho, murio rico.2Y que digan lo que quieran.
1

2 CAPITULO 1. INTRODUCCION
toman la forma:
a∂2φ
∂x2+ b
∂2φ
∂x∂y+ c
∂2φ
∂y2+ d
∂φ
∂x+ e
∂φ
∂y+ fφ + g = 0 (1.1)
donde a, b, c, d, e, f y g son funciones conocidas de x e y, y φ es la funcion (elcampo) a resolver. El caracter cualitativo de la solucion depende, sin embargo,de los coeficientes de los terminos de segundo orden: a, b y c. En concreto:
• b2 − 4ac < 0. Se llaman ecuaciones elıpticas. Describen situaciones deequilibrio, como el potencial electrico en problemas electrostaticos, o lastensiones mecanicas en una viga.
• b2−4ac = 0. Son ecuaciones parabolicas. Describen fenomenos de difusion,tales como la conduccion del calor, o el efecto pelicular en conductores.
• b2 − 4ac > 0. Se trata de las ecuaciones hiperbolicas. Describen camposque se propagan a una velocidad dada, tales como el sonido o la luz.
Es curioso constatar como comportamientos tan diferentes dependen de mo-dificaciones aparentemente tan pequenas en la ecuacion. De todas formas, aquı setrataran tan solo los dos primeros tipos de ecuaciones.

Capıtulo 2
Resolucion de sistemaslineales
5 Basico
2.1 Introduccion
La mayor parte de este escrito trata sobre la forma en que las ecuaciones decampo son aproximadas por sistemas de ecuaciones algebraicas. Estos sistemasson muy a menudo sistemas lineales. Cuando no son sistemas lineales, su reso-lucion suele requerir la de varios sistemas lineales. Por todo ello, las tecnicasnumericas de resolucion de estos sistemas son de una importancia crucial.
El tratamiento sistematico de estos procedimientos hace muy conveniente,de hecho casi imprescindible, el que estos sistemas lineales se planteen de formamatricial. Ası pues, se puede reescribir el parrafo anterior diciendo que estecapıtulo trata de la resolucion del sistema
Ax = b (2.1)
A, la matriz del sistema, es una matriz cuadrada que depende de la ecuaciona resolver y, naturalmente, del metodo escogido. El termino independiente bdepende del valor de las condiciones de contorno y de la densidad de carga (ode fuerzas volumetricas, o de generacion de calor) dentro del dominio. x es,naturalmente, la incognita, los valores del campo.
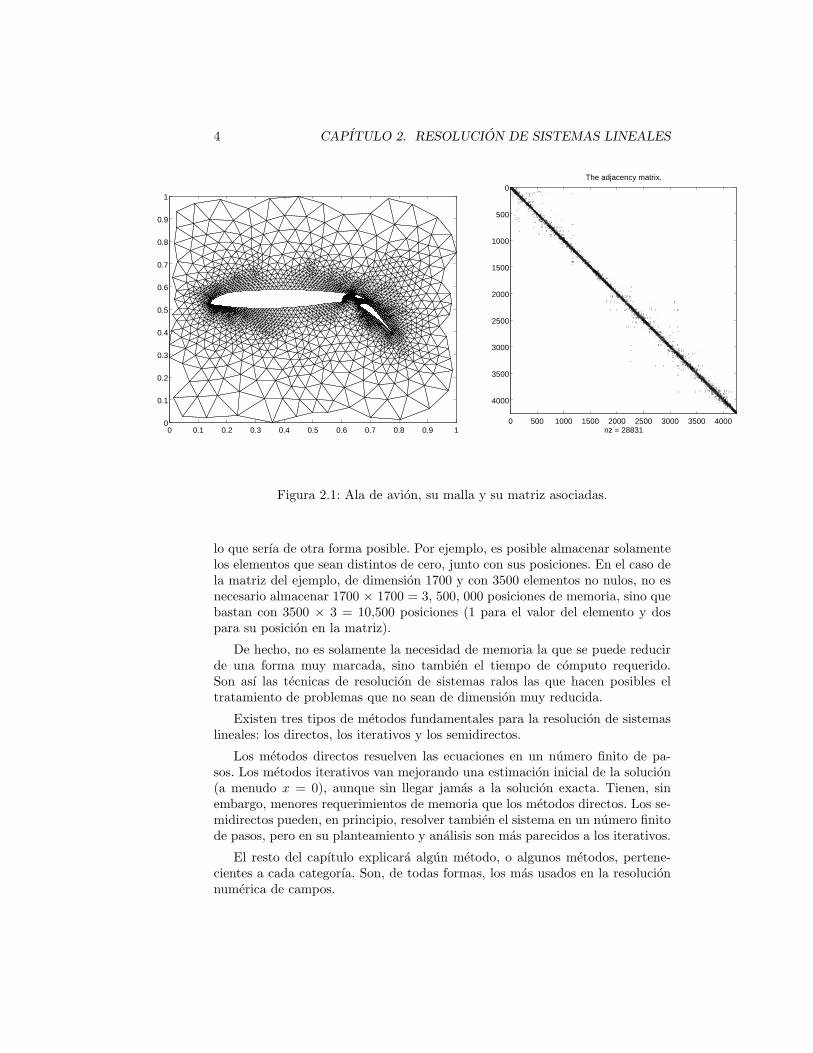
Una caracterıstica muy importante de la matriz A es que casi todos suselementos son nulos. Por ejemplo, la figura 2.1 muestra la malla de elementosfinitos utilizada para analizar el flujo alrededor del ala de un avion y la matrizA que tiene asociada. Se ha dibujado un punto en la posicion de todos loselementos de la matriz cuyo valor es distinto de cero. Observese que exiguaminorıa constituyen.
Una matriz con esta caracterıstica es llamada rala o cuasivacıa1. Esta carac-terıstica ofrece la posibilidad de tratar matrices de mucha mayor dimension de
1En ingles, sparse. Cierta similitud fonetica parece haber llevado en ocasiones a traducirlo(erroneamente) como dispersa.
3
4 CAPITULO 2. RESOLUCION DE SISTEMAS LINEALES
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 500 1000 1500 2000 2500 3000 3500 4000
0
500
1000
1500
2000
2500
3000
3500
4000
nz = 28831
The adjacency matrix.
Figura 2.1: Ala de avion, su malla y su matriz asociadas.
lo que serıa de otra forma posible. Por ejemplo, es posible almacenar solamentelos elementos que sean distintos de cero, junto con sus posiciones. En el caso dela matriz del ejemplo, de dimension 1700 y con 3500 elementos no nulos, no esnecesario almacenar 1700 × 1700 = 3, 500, 000 posiciones de memoria, sino quebastan con 3500 × 3 = 10,500 posiciones (1 para el valor del elemento y dospara su posicion en la matriz).
De hecho, no es solamente la necesidad de memoria la que se puede reducirde una forma muy marcada, sino tambien el tiempo de computo requerido.Son ası las tecnicas de resolucion de sistemas ralos las que hacen posibles eltratamiento de problemas que no sean de dimension muy reducida.
Existen tres tipos de metodos fundamentales para la resolucion de sistemaslineales: los directos, los iterativos y los semidirectos.
Los metodos directos resuelven las ecuaciones en un numero finito de pa-sos. Los metodos iterativos van mejorando una estimacion inicial de la solucion(a menudo x = 0), aunque sin llegar jamas a la solucion exacta. Tienen, sinembargo, menores requerimientos de memoria que los metodos directos. Los se-midirectos pueden, en principio, resolver tambien el sistema en un numero finitode pasos, pero en su planteamiento y analisis son mas parecidos a los iterativos.
El resto del capıtulo explicara algun metodo, o algunos metodos, pertene-cientes a cada categorıa. Son, de todas formas, los mas usados en la resolucionnumerica de campos.

2.2. METODO DIRECTO: LA FACTORIZACION LU 5
2.2 Metodo directo: la factorizacion LU 4 Basico
5 AvanzadoUn metodo directo es un metodo que alcanza la solucion tras un numero finitode pasos. De todos ellos, el mas empleado en el problema que aquı se trata es unageneralizacion del metodo de eliminacion de Gauss conocida como factorizacionLU.
En el resto de la seccion se explica la factorizacion de Gauss en el contextode las matrices llenas. Despues se exponen las modificaciones necesarias para suaplicacion a matrices ralas.
2.2.1 Factorizacion LU de matrices llenas
La eliminacion de Gauss (y la factorizacion LU) se basan en una observacionaparentemente trivial: es muy facil resolver un sistema lineal cuando la matrizA es triangular. En efecto, si se tiene un sistema como
2 0 0 03 1 0 0−4 0 3 07 1 0 −4
x1
x2
x3
x4
=
3−150
(2.2)
se puede resolver primero x1 de la primera ecuacion (la primera fila), conocido x1
se resuelve x2 de la segunda, conocidos x1 y x2 se puede resolver x3 de la tercera,y ası sucesivamente. Evidentemente, se puede proceder ası porque la matriz delsistema tiene elementos no nulos solamente por debajo de la diagonal principal(los elementos aij , con i ≥ j). Si la matriz fuera triangular superior (elementosno nulos solamente por encima de la diagonal superior) se podrıa proceder dela misma forma, salvo que se tendrıa que comenzar por la ultima componentede x, en vez de por la primera (¡compruebese!).
Esta observacion no dejarıa de ser trivial sino fuera por que toda matriz Ano singular se puede escribir como el producto de una matriz triangular inferiorpor una superior:
A = LU (2.3)
Es costumbre denotar al factor triangular inferior por L (del ingles lower) yal superior por U (de upper). La factorizacion LU es, esencialmente, el procedi-miento de calculo de estos dos factores a partir de la matriz A.
Supongase entonces que se ha logrado calcular L y U . Ahora la resoluciondel sistema Ax = b es inmediata. En efecto, este sistema es equivalente a
LUx = b (2.4)
Consideremos tambien el sistema
Ly = b (2.5)
Como este es un sistema triangular inferior, es facil de resolver. La soluciones y = L−1b. Ademas, de la ecuacion (2.4)

6 CAPITULO 2. RESOLUCION DE SISTEMAS LINEALES
Ux = L−1b = y (2.6)
¡Pero esto vuelve a ser una ecuacion con matriz triangular!. Como y esconocida (se ha resuelto (2.5)), es ahora facil calcular x.
En resumen, se han resuelto sucesivamente los sistemas
Ly = b (2.7)Ux = y (2.8)
El primer sistema es triangular inferior, luego las incognitas se resuelveniendo de la primera a la ultima. El segundo es triangular superior, en el que lasincognitas se resuelven de la ultima a la primera. Es por esto que el procedi-miento completo se conoce por la substitucion hacia delante y hacia atras.
El problema que queda es, naturalmente, el calculo de los factores L y U .Es esta la tarea, con mucho, mas complicada y costosa del procedimiento.
La tecnica consiste en ir eliminado sucesivamente los elementos de A que seencuentren por debajo de la diagonal. Quiza la forma mas sencilla de explicarloes mediante un ejemplo. Supongase ası que se desea factorizar la matriz
A =
3 1 0 11 4 2 00 2 5 21 0 2 6
(2.9)
Considerese el elemento (2,1) (segunda fila, primera columna). Este elemento(un 1) esta por debajo de la diagonal principal e impide, por tanto, que la matrizA sea diagonal superior. Para eliminar este elemento, se puede premultiplicarpor una triangular inferior:
1 0 0 0
−l2,1 1 0 00 0 1 00 0 0 1
3 1 0 11 4 2 00 2 5 21 0 2 6
=
3 1 0 1
1− l2,13 4− l2,1 2 −l2,1
0 2 5 21 0 2 6
(2.10)
El termino l2,1 se escoge de manera que anule al termino (2, 1) de la nuevamatriz, es decir
1− 3l2,1 = 0 ⇒ l2,1 =13
(2.11)
Luego,
1 0 0 0− 1
3 1 0 00 0 1 00 0 0 1
3 1 0 11 4 2 00 2 5 21 0 2 6
=
3 1 0 10 11
3 2 − 13
0 2 5 21 0 2 6
(2.12)

2.2. METODO DIRECTO: LA FACTORIZACION LU 7
Ahora, observese que
1 0 0 0− 1
3 1 0 00 0 1 00 0 0 1
−1
=
1 0 0 013 1 0 00 0 1 00 0 0 1
(2.13)
En realidad, es en general cierto para todas las matrices triangulares infe-riores formadas por una diagonal de 1’s y un solo elemento adicional debajo dela diagonal, que su inversa es ella misma salvo por el elemento adicional quecambia signo.
Se sigue ası de (2.12) que:
A =
3 1 0 11 4 2 00 2 5 21 0 2 6
=
1 0 0 013 1 0 00 0 1 00 0 0 1
3 1 0 10 11
3 2 − 13
0 2 5 21 0 2 6
= L1A1 (2.14)
La matriz A1 tiene todavıa un elemento en la primera columna por debajo dela diagonal distinto de 0: el 1 de la cuarta fila. Procediendo de manera analogaa la anterior se tiene:
A1 =
3 1 0 10 11
3 2 − 13
0 2 5 21 0 2 6
=
1 0 0 00 1 0 00 0 1 013 0 0 1
3 1 0 10 11
3 2 − 13
0 2 5 20 − 1
3 2 173
= L2A2
(2.15)Notese que la matriz L2 no afecta mas que a la cuarta fila de A2. Por tanto,
no puede cambiar los ceros de las filas segunda y tercera a algo no nulo. Estoes, naturalmente, lo que se pretende.
En todo caso, ya no hay elementos a eliminar en la primera columna de A2.En la segunda columna el elemento (3, 2) es distinto de cero (2). Ası, se tiene:
A2 =
3 1 0 10 11
3 2 − 13
0 2 5 20 − 1
3 2 173
=
1 0 0 00 1 0 00 6
11 1 00 0 0 1
3 1 0 10 11
3 2 − 13
0 0 4311
2411
0 − 13 2 17
3
= L3A3
(2.16)Hay que notar ahora que la matriz L3 no afecta a la primera columna de A3.
Es por esto que se ha comenzado por eliminar la primera columna, y por lo queuna vez que se elimine la segunda se comenzara por la tercera. Las matrices L’sque afectan a cada columna no pueden modificar las columnas anteriores.
En A3 el elemento (4, 2) es distinto de cero. Por tanto, se elimina:

8 CAPITULO 2. RESOLUCION DE SISTEMAS LINEALES
A3 =
3 1 0 10 11
3 2 − 13
0 0 4311
2411
0 − 13 2 17
3
=
1 0 0 00 1 0 00 0 1 00 1
11 0 1
3 1 0 10 11
3 2 − 13
0 0 4311
2411
0 0 2411
6211
= L4A4
(2.17)Finalmente, solo queda eliminar el termino (4, 3) de A4. De aquı resulta:
A4 =
3 1 0 10 11
3 2 − 13
0 0 4311
2411
0 0 2411
6211
=
1 0 0 00 1 0 00 0 1 00 0 24
43 1
3 1 0 10 11
3 2 − 13
0 0 4311
2411
0 0 0 2048473
= L5U
(2.18)U es una matriz triangular superior. Ahora, de todo lo anterior se sigue:
A = L1A1 = L1L2A2 = L1L2L3A3 = L1L2L3L4A4 = L1L2L3L4L5U (2.19)
Por otra parte, el producto de matrices triangulares inferiores es triangularinferior. Luego L1L2L3L4L5 es una triangular inferior que se llamara L. Es,ademas, muy facil de calcular. En efecto
L =
1 0 0 013 1 0 00 6
11 1 013
111
2443 1
(2.20)
Es decir, el efecto de cada Li es anadir su termino fuera de la diagonal.Esto es valido en general, para matrices Li como las que resultan del procesode factorizacion (una diagonal de 1’s mas un termino fuera de diagonal).
Notese que para calcular cada matriz Li hay que resolver la ecuacion
−li,(k,l)ai−1,(l,l) + ai−1,(k,l) = 0 (2.21)
siendo (k, l) el termino a eliminar. Para resolver esta ecuacion en (li,(k,l) espreciso que el termino de la diagonal ai−1,(l,l) 6= 0. Este termino es llamado elpivote. Caso de ser nulo, se puede intentar permutar la fila l-esima por otrasituada mas abajo. Esto equivale a reordenar las variables del sistema lineal. Sino hubiera ninguna permutacion que resolviera el problema (que todas dieranpivotes nulos) es que la matriz es singular y no hay, por tanto, solucion unica.
Por otra parte, en el ejemplo que se estudia, se puede comprobar que
U =
3 1 0 10 11
3 2 − 13
0 0 4311
2411
0 0 0 2048473
=
3 0 0 00 11
3 0 00 0 43
11 00 0 0 2048
473
1 13 0 1
30 1 6
11111
0 0 1 2443
0 0 0 1
= DLT
(2.22)

2.2. METODO DIRECTO: LA FACTORIZACION LU 9
Luego
A = LU = LDLT (2.23)
Esta expresion es conocida como la factorizacion triple LDLT . Es posiblellevarla a cabo si la matriz A es simetrica (¡pruebese!). Esta simetrıa se pre-senta a menudo en problemas de campos, y se puede explotar para mejorar elprocedimiento de factorizacion LU arriba explicado.
2.2.2 Factorizacion LU de matrices ralas
La factorizacion LU expuesta arriba tiene el inconveniente de que las operacionesse realizan sobre matrices llenas, es decir, sin tener en cuenta que la mayor partede los elementos de la matriz son nulos.
Esencialmente, la factorizacion LU con matrices ralas procede de la mismaforma que la factorizacion con matrices llenas. Las diferencias que existen sonlas siguientes:
1. Solamente se almacenan los elementos no nulos de las matrices, junto consu localizacion. Ası, por ejemplo, en Matlab, la matriz:
2 1 0 01 2 1 00 1 2 10 0 1 2
se almacena en tres vectores, un primero que almacena los valores nonulos, y otros dos que almacenan las posiciones (fila y columna) donde seencuentran:
( 2 1 1 2 1 1 2 1 1 2 )( 1 1 2 2 2 3 3 3 4 4 )( 1 2 1 2 3 2 3 4 3 4 )
Existen otras formas de codificar la posicion mas eficientes que la anterior,aunque mas complejas.
2. Existe una logica que determina las operaciones y sumas que es precisorealizar, saltandose todas las operaciones que consistan en multiplicar porcero, o sumar cero. Esto es posible porque se saben los elementos que sonnulos (los que no esten codificados en los vectores anteriores).
En cualquier caso, es claro que interesa conseguir que los factores LU queresulten tengan tantos elementos nulos como sea posible. En este sentido, elorden que adopten las variables y ecuaciones es de crucial importancia. Porejemplo, considerese la matriz

10 CAPITULO 2. RESOLUCION DE SISTEMAS LINEALES
A =
20 15 6 415 6 0 06 0 4 04 0 0 10
Al ser simetrica, admite una descomposicion LDLT . Es facil comprobar que
el factor L es 1 0 0 0
0,75 1 0 00,30 0,8571 1 00,20 0,5714 0,2264 1
Es decir, aun cuando la matriz original tenıa bastantes ceros, el factor L
tiene todos los elementos posibles (los de debajo de la diagonal) no nulos.En cambio, si se factoriza la matriz
B =
10 0 0 40 4 0 60 0 6 154 6 15 20
se obtiene el factor L
1 0 0 00 1 0 00 0 1 0
0,4 1,5 2,5 1
Notese que ahora el factor L tiene tantos ceros como la matriz B. Por otra
parte, las matrices A y B representan al mismo sistema lineal. En efecto, lo unicoque se ha hecho es cambiar el orden de ecuaciones (filas) y variables (columnas),de manera que la que antes era la primera es ahora la ultima, y viceversa.
Por tanto, es importante ordenar adecuadamente las ecuaciones y las varia-bles al formar la matriz del sistema lineal a resolver. “A grosso modo”, el mejorsitio para los ceros es al principio de las filas, antes de los elementos no nulos.Esto es porque al hacer la eliminacion de Gauss, estos elementos ya no requierenser eliminados.
Existen una serie de algoritmos que buscan el orden optimo en el que colo-car ecuaciones y variables. Matematicamente, este es un problema para el quetodavıa no se ha encontrado solucion, aunque la experiencia demuestra que al-gunos de los algoritmos propuestos son muy eficaces.
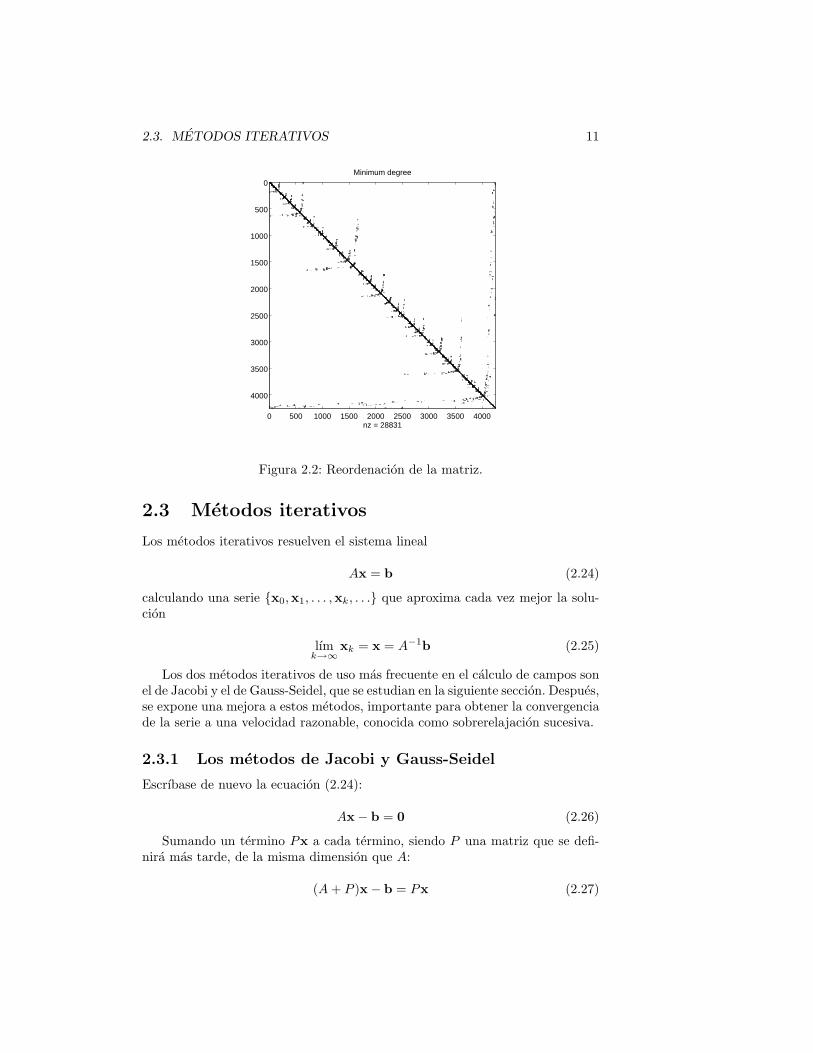
En el ejemplo anterior se ve como lo mas eficaz es colocar la fila con maselementos no nulos al final de la matriz. Esta es la idea subyacente al algoritmodel grado mınimo, quiza el mas popular de los algoritmos de reordenacion. Porejemplo, la figura 2.2 muestra la reordenacion que este algoritmo da para lamatriz de la figura 2.1. Observense las estructuras en forma de flecha que seforman, que recuerdan lo obtenido en el ejemplo.
2.3. METODOS ITERATIVOS 11
0 500 1000 1500 2000 2500 3000 3500 4000
0
500
1000
1500
2000
2500
3000
3500
4000
nz = 28831
Minimum degree
Figura 2.2: Reordenacion de la matriz.
2.3 Metodos iterativos
Los metodos iterativos resuelven el sistema lineal
Ax = b (2.24)
calculando una serie {x0,x1, . . . ,xk, . . .} que aproxima cada vez mejor la solu-cion
lımk→∞
xk = x = A−1b (2.25)
Los dos metodos iterativos de uso mas frecuente en el calculo de campos sonel de Jacobi y el de Gauss-Seidel, que se estudian en la siguiente seccion. Despues,se expone una mejora a estos metodos, importante para obtener la convergenciade la serie a una velocidad razonable, conocida como sobrerelajacion sucesiva.
2.3.1 Los metodos de Jacobi y Gauss-Seidel
Escrıbase de nuevo la ecuacion (2.24):
Ax− b = 0 (2.26)
Sumando un termino Px a cada termino, siendo P una matriz que se defi-nira mas tarde, de la misma dimension que A:
(A + P )x− b = Px (2.27)

12 CAPITULO 2. RESOLUCION DE SISTEMAS LINEALES
La serie {xk} se construye dando una estimacion inicial {x0} (muy a menudoun vector con todas las componentes nulas), y calculando, a partir de aquı, cadaxk a partir de la estimacion anterior xk−1. La regla para pasar de una estimaciona la siguiente es:
Pxk = (A + P )xk−1 − b (2.28)
En principio, no hay garantıa alguna de que la sucesion ası generada converjaa la solucion del sistema (2.24), salvo que la matriz P haya sido adecuadamenteescogida. Pero si la sucesion converge, en el lımite se cumple la ecuacion (2.27),que es equivalente a (2.24).
Para determinar en que condiciones la sucesion generada por la ley (2.28)converge, es conveniente analizar el comportamiento del error
ek = xk − xk−1 (2.29)
Si lımk→∞ xk = x, entonces lımk→∞ ek = 0. Ahora bien, de (2.28)
ek = P−1(A + P )xk−1 − b− P−1(A + P )xk−2 + b
= P−1(A + P )ek−1
= Gek−1 (2.30)
con la matriz de error G = P−1(A + P ) Se sigue entonces:
ek = Gek−1
= G2ek−2
= G3ek−3
= Gke0 (2.31)
Ası pues, lımk→∞ ek = 0 implica que lımk→∞Gk = 0.Para ver que significa esta condicion, supongase que G tiene n autovalores
distintos λi con autovectores asociados vi:
Gvi = λivi (2.32)
Como los autovectores forman una base, es posible escribir e0 como unacombinacion lineal de los mismos:
e0 =n∑
i=1
civi (2.33)
Entonces
Ge1 = Ge0 =n∑
i=1
Gcivi =n∑
i=1
ciλivi (2.34)

2.3. METODOS ITERATIVOS 13
Iterando el procedimiento, se obtiene:
Gek =n∑
i=1
ciλki vi (2.35)
El sumatorio solamente tendera a cero si todos los λki tienden a cero, es decir,
si ‖λi‖ < 1 ∀i. Definiendo el radio espectral de la matriz G como
ρ(G) = maxi‖λi‖ (2.36)
esta condicion se puede reescribir como que ρ(G) < 1.En resumen, se ha de escoger una matriz P tal que
1. ρ(P−1(A + P )) < 1
2. Los sistemas de la forma Pxk = (A + P )xk−1 − b, donde la incognita seaxk, sean faciles de resolver.
Desde el punto de vista de la primera condicion, la mejor P serıa −A. Enefecto, en este caso G = −A−1(A− A) = 0, y por tanto el error se anularıa enla primera iteracion (e1 = Ge0 = 0). El inconveniente es que, naturalmente, lamatriz A no da un sistema de facil solucion: si lo fuera se resolverıa directamenteel sistema Ax = b.
De todas formas, el parrafo anterior sugiere que la matriz P debiera serparecida a −A. Los metodos de Jacobi y Gauss-Seidel se basan en tomar suspartes diagonal o triangular. Concretando, descompongase A en
A = N + D + S (2.37)
donde N es la parte inferior, D la diagonal y S la superior. Por ejemplo, si
A =
2 1 0 01 2 1 00 1 2 10 0 1 2
(2.38)
Entonces
N =
0 0 0 01 0 0 00 1 0 00 0 1 0
D =
2 0 0 00 2 0 00 0 2 00 0 0 2

14 CAPITULO 2. RESOLUCION DE SISTEMAS LINEALES
S =
0 1 0 00 0 1 00 0 0 10 0 0 0
(2.39)
Entonces, se tiene que
• Jacobi hace P = −D. Por tanto, la iteracion de Jacobi es
−Dxk = (N + S)xk−1 − b (2.40)
• Gauss-Seidel hace P = −(D + N). Luego, la iteracion es
−(D + N)xk = Sxk−1 − b (2.41)
Ambas formulas son faciles de aplicar, pues la primera implica la resolucionde un sistema cuya matriz es diagonal, y la segunda la de una matriz triangu-lar inferior. Lo que es preciso es probar, ademas, que convergen, es decir queρ(D−1(N + S)) < 1 y que ρ((D + N)−1S) < 12.
En general estas desigualdades son falsas. Hay, sin embargo, un caso de granimportancia en que se verifican: cuando la matriz A es de diagonal dominante.Esto significa que los valores absolutos elementos de la diagonal son mayoresque la suma de los valores de los elementos fuera de la diagonal. Es decir
| Ai,i |≥∑j 6=i
| Ai,j | (2.42)
De hecho, las matrices que aparecen en el calculo de la ecuacion de Poisson,y en otras, verifican esta desigualdad.
Se probara ahora esta afirmacion para los dos metodos. Para ello es conve-niente introducir otras medidas del “tamano” de una matriz, analoga al radioespectrales: las normas matriciales. Para ello, considerese primero las normas(“longitudes” ) de un vector x. Una norma de un vector de n dimensiones esuna aplicacion de <n en < que verifica
1. ‖x‖ > 0 si x 6= 0, ‖x‖ = 0 si x = 0
2. ‖αx‖ =| α | ‖x‖, siendo α un escalar.
3. ‖x + y‖ ≤ ‖x‖+ ‖y‖
Existen varias de estas normas, tales como
• La norma euclıdea
‖x‖2 =√
x(1)2 + . . . + x(n)2 (2.43)2Es evidente que ρ(G) = ρ(−G), puesto que el radio espectral se define por los modulos de
los autovalores, que se limitan a cambiar de signo cuando la matriz cambia signo.

2.3. METODOS ITERATIVOS 15
• La norma-0
‖x‖0 =| x(1) | + . . .+ | x(n) | (2.44)
• La norma-∞
‖x‖∞ = maxk| x(k) | (2.45)
A cada una de estas normas vectoriales se les puede asociar una normamatricial. Por ejemplo, para la norma-∞
‖A‖∞ = max‖x‖=1
‖Ax‖∞ (2.46)
y de forma analoga para las demas normas. Notese que, a partir de esta defini-cion, si ‖x‖∞ = 1
‖Ax‖∞ ≤ ‖A‖∞‖x‖∞ (2.47)
Si ‖x‖∞ 6= 1, esta formula es tambien valida. En efecto, se ha de verificarpara el vector y = 1
‖x‖∞x
‖Ay‖∞ ≤ ‖A‖∞‖y‖∞ (2.48)
ya que ‖y‖∞ = 1. Multiplicando ahora por el escalar ‖x‖∞ se obtiene la expre-sion buscada.
Es ahora posible demostrar que una condicion suficiente (aunque no nece-saria) para que un algoritmo iterativo converja es que la norma de la matrizG = P−1(A + P ) sea menor que 1. En efecto, escribiendo la ecuacion de error,y teniendo en cuenta la desigualdad anterior
‖ek‖∞ = ‖Gek−1‖∞≤ ‖G‖∞‖ek−1‖∞≤ ‖G‖k
∞‖e0‖∞ (2.49)
Si ‖G‖∞ < 1, entonces lımk→∞ ‖ek‖ = 0. Si ‖G‖∞ = 1, se tiene al menos lagarantıa de que el error no puede crecer, y de hecho normalmente disminuira.Si ‖G‖∞ > 1, la serie podrıa ser, pese a todo, convergente.
Aunque el razonamiento anterior es valido para cualquier norma, ocurre quela norma-∞ es particularmente facil de calcular. En efecto, si G tiene dimensionn, se tiene que
‖G‖∞ = max1≤i≤n
n∑j=1
| Gij | (2.50)
Para probar este resultado, partimos de la definicion de norma (2.46). Te-niendo en cuenta que la componente i del vector Ge es
∑j Gijej , se tiene que

16 CAPITULO 2. RESOLUCION DE SISTEMAS LINEALES
‖G‖∞ = maxi|∑
j
Gijej | (2.51)
supuesto, claro esta, que ‖e‖∞ = 1. Pero esta igualdad significa que todaslas componentes de e estan comprendidas entre 1 y -1, y que una al menosalcanza este extremo. Teniendo esto en cuenta, es facil ver que la manera demaximizar la componente i, que es
∑j Gijej , es considerar un vector ej cuyas
componentes valgan 1 si Gij > 0, y -1 si Gij < 0. En este caso, se tiene que∑j Gijej =
∑j | Gij |, a partir de lo cual se deduce (2.50).
Es ahora posible probar la convergencia de los metodos de Jacobi y Gauss-Seidel para matrices diagonalmente dominantes.
• Jacobi. La matriz de la iteracion es
G = D−1(N + S) (2.52)
es decir
Gij =Aij
Aii, i 6= j, Gii = 0 (2.53)
Entonces
‖G‖∞ = maxi
∑j
| Aij || Aii |
≤ 1 (2.54)
donde la ultima desigualdad se sigue del hecho de que A es diagonalmentedominante.
• Gauss-Seidel. La matriz de iteracion es
G = (D + N)−1S (2.55)
Sea la ecuacion y = Gx. Esta ecuacion es equivalente a
(D + N)y = Sx (2.56)
Defınanse las matrices N = D−1N y S = D−1S. Los elementos de estasmatrices son:
Nij ={ Aij
Aiij < i
0 j ≥ i
Sij ={ Aij
Aiij > i
0 j ≤ i(2.57)

2.3. METODOS ITERATIVOS 17
Se tiene entonces que
y = Sx− Ny (2.58)
Sea entonces k la componente para la cual ‖y‖∞ = yk. De la ecuacionk-esima del sistema de ecuaciones anterior se sigue que:
yk = ‖y‖∞ ≤ sk‖x‖∞ + nk‖y‖∞ (2.59)
donde
si =n∑
j=i+1
| Aij || Aii |
ni =i−1∑j=1
| Aij || Aii |
(2.60)
Ası se tiene que
‖y‖∞ ≤ sk
1− nk‖x‖∞ (2.61)
Por otra parte, recuerdese la definicion de norma
‖G‖∞ = max‖x‖=1
‖Gx‖ (2.62)
Como y = Gx, es claro que
‖G‖∞ ≤ sk
1− nk(2.63)
Y como, al ser A diagonalmente dominante, sk+nk ≤ 1, luego sk ≤ 1−nk,y por tanto
‖G‖∞ ≤ 1 (2.64)
2.3.2 El metodo de la sobrerrelajacion sucesiva
Se ha visto en la seccion anterior que los metodos de Jacobi y Gauss-Seidel sonconvergentes cuando se cumple que la matriz A es diagonalmente dominante.Sin embargo, las matrices que aparecen tıpicamente en los problemas de campospresentan estan dominadas “por los pelos” (se cumple el = pero no el < en ladefinicion de dominancia), por lo que cabe temer que la convergencia sea lenta.Este temor se confirma en la practica.
Existe una forma sencilla de modificar estos metodos que a menudo mejorasubstancialmente su velocidad de convergencia. Por ejemplo, consideremos laiteracion de Jacobi

18 CAPITULO 2. RESOLUCION DE SISTEMAS LINEALES
xk = −D−1(N + S)xk−1 + D−1b = xk−1 + rk−1 (2.65)
siendo por tanto
rk−1 = −xk−1 −D−1(N + S)xk−1 + D−1b = −D−1Axk−1 + D−1b (2.66)
El residuo rk−1 es la cantidad en que corregimos xk−1 para intentar obtenerla solucion. Los residuos son cada vez mas pequenos, y tienden a cero conformenos acercamos a la solucion.
El metodo de la sobrerrelajacion sucesiva de Jacobi viene dado por la ecua-cion
xk = xk−1 + ωrk−1 (2.67)
siendo ω un numero que, como se vera mas adelante, esta comprendido entre 0y 2. Por supuesto, si ω = 1 se recupera el metodo de Jacobi.
El metodo de Jacobi es tambien conocido como metodo de relajacion deJacobi. Como normalmente ω > 1, al metodo propuesto se le llama metodo desobrerrelajacion de Jacobi.
Existe tambien un metodo de sobrerrelajacion de Gauss- Seidel, dado porla misma formula, pero donde rk−1 es el residuo que resulta de la iteracion deGauss-Seidel
rk−1 = −(D + N)−1Axk−1 + (D + N)−1b (2.68)
Es esta segunda version la que es utilizada con mas frecuencia. La iteracionsobrerrelajada de Gauss-Seidel se puede escribir, substituyendo la expresion delresiduo en (2.67), como:
xk = (I − ω(D + N)−1A)xk−1 + ω(D + N)−1b (2.69)
En estos algoritmos el error ek = ωrk. Por otra parte, la matriz de errorpara este algoritmo es
Gω = (I − ω(D + N)−1A) (2.70)
Utilizando las matrices N = D−1N y S = D−1S, se tiene que
Gω = I − ω(D + N)−1A
= I − ω(I + N)−1D−1A
= I − ω(I + N)−1D−1(I + N + S)= I − ω(I + N)−1(I + N + S)= (I + N)−1((I + N)− ω(I + N + S)= (I + N)−1((1− ω)(I + N)− ωS) (2.71)

METODOS SEMIDIRECTOS 19
Por otra parte, recuerdese que el determinante de una matriz es, por unaparte, el producto de sus autovalores; y por otra el producto de los elementosde la diagonal. N y S son matrices inferior y superior, con elementos nulos enla diagonal. Por tanto
det(Gω) = Πni=1λ
Gi
= det(I + N)−1 det((1− ω)(I + N)− ωS)= (1− ω)n (2.72)
Por consiguiente
ρ(G) = maxi| λG
i |≥| 1− ω | (2.73)
Y como es condicion necesaria para que el algoritmo converja que el radioespectral sea menor que 1, se sigue que 0 ≤ ω ≤ 2.
Se puede demostrar tambien que para matrices simetricas y positivas defini-das, el metodo converge para todo ω entre 0 y 2. Por otra parte, existen algunasmatrices para los que los valores optimos de ω son conocidos. En el caso de lasmatrices que resultan al aplicar el metodo de diferencias finitas a la ecuacion deLaplace, un valor de ω ligeramente por encima de 1 (1.1 por ejemplo) suele darbuenos resultados.
2.4 Metodos semidirectos: el gradiente conjuga-do
Los metodos semidirectos permiten, en principio, como los directos, resolver elsistema lineal Ax = b en un numero finito de pasos. Sin embargo, tanto ensu implantacion como en su comportamiento practico son mas similares a lositerativos.
De entre todos ellos, el que tiene mas predicamento es el metodo del gradienteconjugado. Tiene sin embargo una limitacion: solamente se aplica a matrices Aque sean simetricas definidas positivas. Sin embargo, este es muy a menudo elcaso en problemas de campos.
Recuerdese que A es positiva definida cuando se cumple que
xT Ax > 0 ∀x (2.74)
De la ecuacion anterior se sigue que la funcion
F (x) =12xT Ax− xT b (2.75)
tiene un mınimo para
x∗ = A−1b (2.76)

20 CAPITULO 2. RESOLUCION DE SISTEMAS LINEALES
En efecto, escrıbase x = x∗ + ∆x. Entonces
F (x) =12(x∗ + ∆x)T A(x∗ + ∆x)− (x∗ + ∆x)T b
=12x∗T Ax∗ + ∆xT Ax∗ +
12∆xT A∆x− x∗T b−∆xT b
=12x∗T Ax∗ − x∗T b + +∆xT (Ax∗ − b) +
12∆xT A∆x
=12x∗T Ax∗ − x∗T b +
12∆xT A∆x
= F (x∗) +12∆xT A∆x ≥ F (x∗) (2.77)
Se ha empleado el hecho de que A es simetrica para pasar de la primera ala segunda ecuacion, y el hecho de que es positiva definida para poder escribirla desigualdad en la ultima.
Se ha reducido, pues, el problema de resolver un sistema lineal al de encontrarel mınimo de una funcion. Una algoritmo popular para encontrar el mınimo esel algoritmo del gradiente. Reuerdese que el gradiente de una funcion indica ladireccion de maxima pendiente. Parece pues razonable escoger esta direccionpara minimizar F . En el caso presente, el gradiente de F en el punto x es
∇F = Ax− b = g (2.78)
y un posible algoritmo serıa
xk+1 = xk − αkgk (2.79)
La cantidad αk se calcula de forma que el decremento sea tan grande comosea posible. Pero
F (xk+1) = F (xk − αkgk)
=12
(xk − αkgk)TA (xk − αkgk)− (xk − αkgk)T b
=12α2
k
(gT
k Agk
)− αk
(gT
k Axk − gTk b)
+
12xT
k Axk − xT b (2.80)
Como xk y gk ya estan fijos, el αk optimo se encuentra buscando el mınimode esta expreson respecto a αk e igualando a 0. Luego
αk =
(gT
k Axk − gTk b)(
gTk Agk
) =gT
k (Axk − b)(gT
k Agk
) =gT
k gk(gT
k Agk
) (2.81)
Ası pues, el algoritmo tomarıa la forma

METODOS SEMIDIRECTOS 21
gk = Axk − b
αk =gT
k gTk(
gTk Agk
)xk+1 = xk − αkgk (2.82)
siendo necesaria, por supuesto, alguna estimacion inicial x0 (por ejemplo, x0 =0).
El algoritmo anterior (el algoritmo del gradiente) converge, aunque, en ge-neral, de una manera mas bien lenta. Una forma de acelerar la convergencia esmodificarlo de la siguiente manera:
gk = Axk − b
βk =dT
k−1Agk
dTk−1Adk−1
dk = gk − βkdk−1
αk =dT
k gk(dT
k Adk
)xk+1 = xk − αkdk (2.83)
La diferencia basica es que, en lugar de actualizar xk segun el gradiente gk,se baja a lo largo de una direccion modificada dk, egun se observa en la ultimaecuacion. Esta direccion se calcula a partir del gradiente y de la direccion que seutilizo en la iteracion anterior: dk = gk − βkdk−1. El numero βk se ha caluladode forma que dT
k−1Adk = 0 (¡compruebese!). El valor αk se calcula segun elmismo procediento que ya se empleo en el algoritmo del gradiente.
Es de importancia basica para comprender la eficacia del algoritmo el quese verifica que
gTi gj = 0 ∀i 6= j (2.84)
Para demostrar este hecho es preciso obtener unos resultados previos:
• gk = gk−1 − αk−1Adk−1
Esta formula se obtiene reescribiendo la definicion de gk
gk = Axk − b
= A [xk−1 − αk−1dk−1]− b
= [Axk−1 − b]− αk−1Adk−1
= gk−1 − αk−1Adk−1 (2.85)

22 CAPITULO 2. RESOLUCION DE SISTEMAS LINEALES
• dTk−1gk = 0
Esta condicion viene exigida por el hecho de que el punto xk se calculacomo el punto de la recta (el valor de α) x = xk−1 − αdk−1 que hacemınimo a F . Pero en este punto mınimo, el gradiente de F (es decir, gk)debe ser perpendicular a la recta, cuyo vector director es dk−1.
Con estos resultados, el algoritmo puede resumirse en cuatro ecuaciones:
gk = gk−1 − αk−1Adk−1 (2.86)dk = gk − βkdk−1 (2.87)
dTk Adk−1 = 0 (2.88)gT
k dk−1 = 0 (2.89)
De hecho, a partir de estas formulas se pueden despejar los valores de αk yβk.
Se empezara por demostrar que gTk gk−1 = 0. Naturalmente esto es lo mismo
que gTk gk+1 = 0. Para ello, primero hay que ver que
gTk dk−1 = 0
= (gk+1 + αkAdk)T dk−1
= gTk+1dk−1
= gTk dk−2 (2.90)
donde se ha usado el hecho de que AT = A. Pero, por otra parte
gTk dk−1 = 0
= gTk (gk−1 − βk−2dk−2)
= gTk gk−1 (2.91)
Con esto, ya se ha probado que el gradiente obtenido en una iteracion esperpendicular a los que se obtienen en la iteracion anterior y posterior. Peroademas
Agk = Adk + βkAdk−1
=1αk
(gk − gk+1) +βk
αk−1(gk−1 − gk)
= − 1αk
gk+1 +(
1αk
− βk
αk−1
)gk +
βk
αk−1gk−1
= ak+1gk+1 + bkgk + ck−1gk−1 (2.92)

METODOS SEMIDIRECTOS 23
Es esta formula de 3 terminos, junto con la simetrıa de A, lo que permiteasegurar la ortogonalidad de los vectores gk. Se empezara por comprobar quegT
k−2gk = 0. Para ello, se necesita probar una formula recursiva para el productogT
k gk. Premultiplicando dk = gk − βkdk−1 por gTk−1:
gTk−1dk = −βkgT
k−1dk−1
= −βkgTk−1 (gk−1 − βk−1dk−2)
= −βkgTk−1gk−1 (2.93)
Por otra parte
gTk−1dk = (gk + αk−1Adk−1)
T dk
= gTk dk
= gTk (gk − βkdk−1)
= gTk gk (2.94)
Por lo tanto, se concluye que
gTk gk = −βkgT
k−1gk−1 (2.95)
Premultiplicando ahora la formula de tres terminos (2.92) por gTk−1, se ob-
tiene
gTk−1Agk = − 1
αkgT
k−1gk+1 +βk
αk−1gT
k−1gk−1 (2.96)
Es claro que tambien es valida la formula
Agk−1 = − 1αk−1
gk +(
1αk−1
− βk−1
αk−2
)gk−1 +
βk−1
αk−1gk−2 (2.97)
Premultiplicando por gTk :
gTk Agk−1 = − 1
αk−1gT
k gk +βk−1
αk−1gT
k gk−2 (2.98)
Como la matriz A es simetrica, gTk−1Agk = gT
k Agk−1, y por tanto
− 1αk
gTk−1gk+1 +
βk
αk−1gT
k−1gk−1 = − 1αk−1
gTk gk +
βk−1
αk−1gT
k gk−2 (2.99)
Y teniendo en cuenta (2.95):
− 1αk
gTk−1gk+1 = +
βk−1
αk−1gT
k gk−2 (2.100)

24 CAPITULO 2. RESOLUCION DE SISTEMAS LINEALES
Ahora bien, considerese la primera iteracion del algoritmo. Se parte de x1 =0. Entonces g1 = −b. Ahora, al ir a escoger la direccion d1, no existe d0 dealguna iteracion anterior. Por tanto, es natural hacer d1 = g1 = −b. Con estaseleccion se tiene que
gT3 g1 = gT
3 d1 = 0 (2.101)
como se demuestra en (2.90). Pero entonces, se puede usar la expresion (2.100)para demostrar, por induccion, que
gTk+2gk = 0 ∀k (2.102)
Se probara ahora que gTi gj = 0 ∀i, j. Para ello supongase que gT
i gj = 0 sii, j ≤ k (es una prueba por induccion). De hecho, ya sabemos que, por lo menos,se cumplira para las primeras iteraciones: i, j = 1, 2, 3 o k = 3. Entonces, sii ≤ k − 2
gTi (Agk) = (Agi)T gk = (ai+1gi+1 + bigi + ci−1gi−1)T gk = 0 (2.103)
puesto que los productos escalares gTi−1gk = gT
i gk = gTi+1gk = 0. Pero, de la
formula de tres terminos
ak+1gk+1 = Agk − bkgk − ck−1gk−1 (2.104)
Premultiplicando por gTi i < k−1, y teniendo en cuenta (2.103) se sigue que
gTi gk+1 = 0 i < k − 1 (2.105)
Como ya se habıan probado los casos i = k − 1 e i = k, queda demostradoque los vectores gk son ortogonales. Ahora bien, si la dimension de la matriz Aes n, solamente puede haber n vectores ortogonales no nulos. Esto significa que,a mas tardar para i = n + 1, se ha tenido que cumplir que gi = 0. Pero comog = Ax− b, esto es lo mismo que decir que el algoritmo converge en, a lo mas,n + 1 iteraciones.
De hecho a menudo la situacion es todavıa mas favorable. En efecto, observe-se que
xk+1 = xk − αkdk = x1 −k∑
i=1
αidi = −k∑
i=1
αidi (2.106)
ya que x1 = 0. Ahora bien, el algoritmo tiende a calcular los mayores di enlas primeras iteraciones, dejando los mas pequenos para el final. Por lo tanto, amenudo se llegan a precisiones razonables con muchas menos iteraciones que n.
La restriccion de que x1 = 0 no es tan seria como parece. Por ejemplo,supongase que se tiene una solucion aproximada x desde la que se desea iniciarelalgoritmo. Entonces, se puede escribir la solucion exacta x como:
x = x + ∆x (2.107)

METODOS SEMIDIRECTOS 25
La ecuacion Ax = b es equivalente entonces a
A (x + ∆x) = b⇒ A∆x = b−Ax = b (2.108)
siendo ya razonable resolver este sistema por ∆x1 = 0.

26 CAPITULO 2. RESOLUCION DE SISTEMAS LINEALES

Capıtulo 3
Ecuaciones de Laplace yPoisson: diferencias finitas
5 Basico
3.1 Introduccion
Las ecuaciones de Laplace y Poisson aparecen con frecuencia en el estudio desituaciones estaticas, de situaciones de equilibrio. Por ejemplo, la ecuacion querige la distribucion del campo electrostatico en el vacıo es
ε0∆V = −ρ (3.1)
donde V es el potencial electrico y ρ la densidad de carga. La ecuacion anterior,escrita de una forma menos compacta, serıa:
ε0(∂2
∂x2+
∂2
∂y2+
∂2
∂z2)V (x, y, z) = −ρ(x, y, z) (3.2)
Esta ecuacion es la ecuacion de Poisson en tres dimensiones. Frecuentementese requiere su resolucion en dos, o incluso una dimension. Esto significa que enla ecuacion anterior no se considera la coordenada z, o la y y la z. Por ejemplo,la ecuacion de Poisson en 2 dimensiones es:
ε0(∂2
∂x2+
∂2
∂y2)V (x, y) = −ρ(x, y) (3.3)
Sin embargo, se utilizara el operador laplaciano ∆ para indicar tambien eloperador diferencial en dos dimensiones ∂2
∂x2 + ∂2
∂y2 . De hecho, la dimension deloperador denotado por ∆ sera determinada por el contexto.
La ecuacion de Poisson no sirve solamente para calcular el campo elec-trostatico. De hecho, es preciso resolver la misma ecuacion para determinarel campo gravitacional en la teorıa de Newton, la distribucion estacionaria detemperaturas en los cuerpos, la velocidad con que fluyen los lıquidos ideales, olas tensiones que aparecen en una barra sometida a torsion.
27

28 DIFERENCIAS FINITAS
���
bb
∂V∂n
∆V = f
V
Figura 3.1: Dominio de la ecuacion de Poisson
Un caso particular de gran interes es cuando la funcion ρ es nula. En tal casose tiene la ecuacion de Laplace:
∆V = 0 (3.4)
En este capıtulo se expondra como resolver estas ecuaciones mediante elmetodo de las diferencias finitas. El proximo abordara su resolucion medianteel metodo de los elementos finitos.
3.2 Preliminares matematicos
Antes de proceder a explicar cualquier procedimiento numerico, es preciso quelas ecuaciones a resolver hayan sido planteadas de una forma matematicamentecorrecta. En el caso de la ecuacion de Poisson, el problema a resolver es determi-nar el potencial V en el interior de un determinado dominio D. En la frontera dedicho dominio se da, o el propio potencial V o su derivada respecto a la normalde la superficie ∂V
∂n (ver figure 3.1)En el caso de problemas electrostaticos, el campo electrico es el gradiente del
potencial (E = −∇V ), por lo que la derivada normal a la superficie no es mas quela componente normal del campo (En = −∂V
∂n ). Es esta, de hecho, una condicionnatural en problemas electrostaticos. Por ejemplo, si se esta intentando calcularla resistencia de una determinada pieza, sabemos que no puede salir corrientepor la superficie no conectada a electrodos (ver figura 3.2). Ası, jn = 0. Perocomo, por la ley de Ohm, j = σE, se tiene tambien que En = 0. O dicho de otraforma ∂V
∂n = 0.

CONSTRUCCION DE LA MALLA 29
I
I
j=0
V=0
V=10
Figura 3.2: Una resistencia
En otro tipo de problemas (termicos, hidraulicos, ...) esta condicion sueletener tambien un sentido fısico bastante claro. Ademas, y en cualquier caso,aparece tambien cuando se consideran ejes de simetrıa en la configuracion deestudio, como se vera mas adelante.
De cualquier manera, se tiene el siguiente problema matematico:
∆V = f en D (3.5)sujeto a V = g en ∂D1 (3.6)
∂V∂n = h en ∂D2 (3.7)
donde f(x, y, z) = − ρε0
(definida en todo D), g(x, y, z) (definida solo en ∂D1)y h(x, y, z) (definida solo en ∂D2) son funciones conocidas, y V es la funcionincognita, a determinar en D.
Las condiciones V = g en ∂D1 y ∂V∂n = h en ∂D2 son colectivamente cono-
cidas como condiciones de contorno. El primer tipo (V = g) es conocido comocondicion de Dirichlet, y el segundo como condicion de von Neumann. Note-se que entre la dos han de cubrir todo el contorno, pero que su dominio dedefinicion no se puede superponer (∂D1 ∩ ∂D2 = ∅).
3.3 Construccion de la malla y planteamiento delas ecuaciones
En el metodo de las diferencias finitas se intenta calcular el valor de la funcionV en una serie finita de puntos, situados en las intersecciones de una red o malla(ver figura 3.3). Por regla general, esta es una red cuadrada (en 2 dimensiones)o cubica (en 3 dimensiones), aunque otros tipos de red (rectangular, hexagonal,...) son tambien posibles y se utilizan ocasionalmente.
30 DIFERENCIAS FINITAS
Figura 3.3: Dominio mallado
En el resto de esta seccion se estudiaran problemas bidimensionales en re-des cuadradas. La generalizacion a otras dimensiones y redes es sencilla, y seestudiaran algunos casos en otras secciones.
La ecuacion de Poisson es una ecuacion diferencial. Sin embargo, de lo unicoque se dispone es del valor de V en una serie discreta de puntos, por lo que espreciso aproximar las derivadas por diferencias. De ahı el nombre del metodo.
Por ejemplo, considerese el punto P de la figura 3.4. Como la malla tieneanchura h, el punto P se encuentra situado en las coordenadas (ih, jh). Parasimplificar la notacion, se escribira:
V (ih, jh) = Vi,j (3.8)
El valor de V en el punto (i + 1, j) puede relacionarse con el que tiene en elpunto (i, j) mediante la serie de Taylor:
Vi+1,j = Vi,j +∂V
∂x|i,jh +
12
∂2V
∂x2|i,jh2 +
16
∂3V
∂x3|i,jh3 +
124
∂4V
∂x4|ξ1,jh
4 (3.9)
Donde x(i) < ξ1 < x(i + 1). Analogamente, se pueden relacionar el valor deV en el punto (i− 1, j) con el de (i, j):
Vi−1,j = Vi,j −∂V
∂x|i,jh +
12
∂2V
∂x2|i,jh2 − 1
6∂3V
∂x3|i,jh3 +
124
∂4V
∂x4|ξ2,jh
4 (3.10)
Sumando las ecuaciones (3.9) y (3.10) se obtiene:
Vi+1,j + Vi−1,j = 2Vi,j +∂2V
∂x2|i,jh2 +
124
(∂4V
∂x4|ξ1,j +
∂4V
∂x4|ξ2,j
)h4 (3.11)

CONSTRUCCION DE LA MALLA 31
O h
h
P
ih
jhi, j
i, j + 1
i, j − 1
i + 1, ji− 1, j
Figura 3.4: La malla, de cerca
= 2Vi,j +∂2V
∂x2|i,jh2 + O(h4) (3.12)
donde O(h4) denota terminos de grado cuarto o mayor en h. Suponiendo queestos terminos son despreciables (lo que sucedera si h es lo bastante pequeno)se tiene:
∂2V
∂x2|i,j =
Vi+1,j + Vi−1,j − 2Vi,j
h2(3.13)
De forma similar se obtiene que:
∂2V
∂y2|i,j =
Vi,j+1 + Vi,j−1 − 2Vi,j
h2(3.14)
Luego
(∂2V
∂x2+
∂2V
∂y2)|i,j =
Vi+1,j + Vi−1,j + Vi,j+1 + Vi,j−1 − 4Vi,j
h2(3.15)
Ahora bien, el termino izquierdo de esta ecuacion es precisamente el opera-dor diferencial ∆ (el laplaciano), luego el termino derecho es la aproximacionbuscada que solo involucra el valor de V en los nodos de la red. De esta manera,la ecuacion de Poisson en el punto (i, j) se puede aproximar mediante la formulaen diferencias finitas:
Vi+1,j + Vi−1,j + Vi,j+1 + Vi,j−1 − 4Vi,j
h2= fi,j (3.16)

32 DIFERENCIAS FINITAS
Figura 3.5: Problema electrostatico
Ası se tiene ya una ecuacion para todos los puntos internos a la malla.Los nodos que esten en el contorno, o proximos a el, requieren un tratamientoespecial. La situacion se simplifica notablemente si la malla es escogida de talforma que se adapte al contorno. Esto es lo que se supondra en esta seccion,dejando el caso mas general para mas adelante.
Por ejemplo, supongase que se desea calcular el potencial electrostatico en elespacio entre los dos conductores que se muestran en la figura 3.5. El conductorinterno esta a un potencial V = 100 y el externo a V = 0. En el espaciointermedio se verifica la ecuacion de Laplace:
∆V = 0 (3.17)
Es tambien claro que, debido a la simetrıa de la configuracion, basta conresolver un octavo. En concreto, se tienen las siguientes ecuaciones:
2Vb + 0 + 100− 4Va = 0 punto a (3.18)Va + Vc + 0 + 100− 4Vb = 0 punto b (3.19)Vb + Vd + Ve + 0− 4Vc = 0 punto c (3.20)
2Vc + 2 ∗ 0− 4Vd = 0 punto d (3.21)2Vc + 2 ∗ 100− 4Ve = 0 punto e (3.22)
Notese que los nodos de la red donde se dan condiciones de Dirichlet (losconductores) no son incognitas, puesto que, por definicion, se conocen allı losvalores de los potenciales. Hay ademas dos nodos internos (b y c) y otros tresen el contorno (a, d y e).
En este caso, debido a la simetrıa de la configuracion, se puede suponerque estos tres nodos son internos, puesto que sabemos como se relacionan lospotenciales de los nodos que estan a ambos lados de la lınea de simetrıa (ası, por

3.4. EL PRINCIPIO DEL MAXIMO 33
ejemplo, en el caso del nodo a los valores de las tensiones a derecha e izquierdason iguales, que es por lo que ambos nodos se han denotado como b).
Pero hay otra forma de considerar este problema. Notemos que sobre la lıneade simetrıa se ha de verificar la anulacion de la derivada normal:
∂V
∂n= 0 en linea simetria (3.23)
En efecto, siendo las cargas simetricas a ambos lados de la lınea de simetrıa,no puede haber campo electrico normal a la lınea. Ası, en particular, se ha deverificar
∂V
∂x|a = 0 (3.24)
puesto que en el punto a no puede haber componente del campo Ex, ya queambas mitades “ tiran ” lo mismo.
Por lo tanto, en general una lınea de simetrıa implica la anulacion de laderivada normal. Pero es esta una condicion de contorno de von Neumann. Porlo tanto, las condiciones de contorno nulas de von Neumann ∂V
∂n = 0 puedentratarse anadiendo nodos adicionales por fuera del dominio simetricos a losnodos internos. El caso de condiciones no nulas se vera en una seccion posterior.
Las ecuaciones (3.18-3.22) se pueden escribir tambien en forma matricial:−4 2 0 0 01 −4 1 0 00 1 −4 1 10 0 2 −4 00 0 2 0 −4
Va
Vb
Vc
Vd
Ve
=
−100−100
00
−200
(3.25)
O, en notacion mas compacta
AV = b (3.26)
En esta ecuacion tanto la matriz A como el vector b son conocidos, por loque puede resolverse para determinar V. Notese que los valores concretos delas condiciones de contorno estan ıntegramente incluidos en el termino indepen-diente b. Ası, si se cambian el valor de los potenciales (por ejemplo, haciendoque el potencial del conductor interior valga 17, y el del exterior -313), lo unicoque serıa preciso modificar serıa el vector b, pero no la matriz A.
Existen diversos metodos para resolver la ecuacion lineal (3.26). Notese quelas ecuaciones que resultan del metodo de diferencias finitas (!y de otros muchos!)tienen matrices A con un gran numero de ceros, o sea, son matrices ralas ocuasivacıas. Su resolucion se ha abordado en el capıtulo anterior.
3.4 El principio del maximo4 Basico
5 AvanzadoConsiderese de nuevo la ecuacion (3.16), valida para puntos en el interior de lamalla:

34 DIFERENCIAS FINITAS
Vi+1,j + Vi−1,j + Vi,j+1 + Vi,j−1 − 4Vi,j
h2= fi,j (3.27)
En el caso de la ecuacion de Laplace, el termino de la derecha fi,j es nulo.Ası pues, se puede escribir:
Vi,j =14
(Vi+1,j + Vi−1,j + Vi,j+1 + Vi,j−1) (3.28)
Es decir, el valor del potencial en el centro es la media de los cuatro quetiene alrededor. Esto significa que el valor central Vi,j no puede ser ni el maxi-mo ni el mınimo, ya que la media se encuentra entre estos valores. Como estaconclusion es valida para todos los puntos en el interior del dominio, se sigueque el valor maximo y el mınimo de V se tienen que dar en puntos del contorno.Este resultado es conocido como el principio del maximo.
El parrafo anterior se refiere a los valores de V que resultan de resolver lasecuaciones en diferencias. Ahora bien, la misma conclusion se puede establecerpara los valores de V solucion de la ecuacion diferencial. En efecto, conforme vadisminuyendo la anchura de la malla h la solucion en diferencias va tendiendo ala solucion de la ecuacion diferencial (se da una prueba en la seccion siguiente).Por tanto, como la solucion de la ecuacion diferencial es el lımite de la ecuacionen diferencias, y para todas estas se verifica el principio del maximo, se sigueque tambien se cumple para la ecuacion diferencial.
Existe una extension del principio del maximo que sera de utilidad masadelante. Sea la ecuacion de Poisson
∆V = f (3.29)
con f > 0. Entonces se tiene, de la formula de diferencias finitas que
Vi,j =14
(Vi+1,j + Vi−1,j + Vi,j+1 + Vi,j−1 −
1h2
fi,j
)(3.30)
Es decir, V en el nodo central ha de ser menor que en al menos uno delos que le rodean. Por tanto, el maximo de V ha de alcanzarse en el contorno(aunque nada puede decirse del mınimo en este caso).
3.5 Errores y convergencia
En la seccion anterior se ha derivado una ecuacion algebraica con la que seespera aproximar la ecuacion diferencial que se desea resolver. Sin embargo,serıa interesante contar con alguna idea del error cometido, y de como este errordisminuye cuando la anchura de la malla h disminuye tambien.
Se va a realizar este analisis para un problema particular: el problema purode Dirichlet en dos dimensiones:

3.5. ERRORES Y CONVERGENCIA 35
(∂2
∂x2+
∂2
∂y2
)V = f en D (3.31)
sujeto a V = g en ∂D (3.32)
siendo D el rectangulo definido por 0 < x < a, 0 < y < b.Las ideas basicas de este analisis son, sin embargo, generalizables a otros
casos; y las conclusiones que se obtengan tambien.Para resolver las ecuaciones (3.31,3.32) por diferencias finitas se crearıa una
malla, que definiremos por la interseccion de las lıneas verticales xi = ih, i =1 . . .m y las lıneas horizontales yj = jh, j = 1 . . . n. Se supondra ademas quemh = a y nh = b, de forma que la malla se adapta perfectamente al dominioD. Denotemos ademas por Dh el conjunto de nodos interiores al dominio y por∂Dh el conjunto de nodos en la frontera del dominio.
La aproximacion a la ecuacion de Poisson dentro del dominio es
1h2
(vi+1,j + vi−1,j + vi,j+1 + vi,j−1 − 4vi,j) = fi,j (3.33)
En esta seccion se denotara por V la solucion de la ecuacion diferencial ypor v la solucion de la ecuacion en diferencias. El problema en diferencias sepuede escribir por tanto como
Lvi,j = fi,j en Dh (3.34)sujeto a vi,j = gi,j en ∂Dh (3.35)
siendo L es operador en diferencias
Lvi,j =1h2
(vi+1,j + vi−1,j + vi,j+1 + vi,j−1 − 4vi,j) (3.36)
Considerese ahora el error ei,j en los nodos de la malla entre la solucion dela ecuacion diferencial Vi,j y la de la ecuacion en diferencias vi,j :
Lei,j = LVi,j − Lvi,j (3.37)= LVi,j − fi,j (3.38)= Ti,j (3.39)
El error de truncacion Ti,j puede estimarse a partir del desarrollo de Taylorde V . En efecto, de la formula de Taylor (3.11) se sigue que:
Ti,j =124
h2
(∂4V
∂x4|ξ1,j +
∂4V
∂x4|ξ2,j +
∂4V
∂y4|i,η1 +
∂4V
∂y4|i,η2
)(3.40)
Denotese por D la union de D y ∂D. Entonces, defınase una constante Mmediante la ecuacion

36 DIFERENCIAS FINITAS
M = max(
maxD|∂
4V
∂x4|,max
D|∂
4V
∂y4|)
(3.41)
Ası pues, puede escribirse
maxDh
|Ti,j | ≤16h2M (3.42)
Y por tanto
maxDh
|Lei,j | = maxDh
|Ti,j | ≤16h2M (3.43)
Ahora lo que se necesita es algun resultado que relacione ei,j con Lei,j . En elanexo de esta seccion se prueba que en el rectangulo D definido por 0 < x < ay 0 < y < b se tiene para cualquier funcion u definida en la malla
maxDh
|u| ≤ max∂Dh
|u|+ 14(a2 + b2) max
Dh
|Lu| (3.44)
Aplicando este teorema el error ei,j se tiene que
maxDh
|ei,j | ≤ max∂Dh
|ei,j |+14(a2 + b2)max
Dh
|Lei,j | (3.45)
Pero, en la frontera ∂Dh, ei,j = 0 ya que se estan cumpliendo las condicionesde contorno. Luego
maxDh
|ei,j | ≤124
(a2 + b2)h2M (3.46)
Este resultado muestra que, si la solucion tiene derivada cuarta, el error sereduce conforme la anchura de la malla se reduce. Prueba ademas que el errores de orden h2, informacion de utilidad para varios metodos de mejora de lasolucion.
En el caso mas general, se obtienen formulas semejantes, con errores propor-cionales a h2. El paso mas complicado suele ser el de buscar una relacion entreei,j y Lei,j . Sin embargo, existen algunas pocas situaciones peligrosas donde esimposible encontrar cotas de error como la anterior. La mas importante es sihay esquinas con angulos internos mayores de 180 grados. En estos casos, hayque desconfiar de la solucion cerca de estos puntos1.
3.5.1 Anexo: prueba del teorema
Si u es cualquier funcion definida en el conjunto de los nodos Dh = Dh ∪ ∂Dh
de la region rectangular 0 ≤ x ≤ a, 0 ≤ y ≤ b, se verifica
maxDh
|u| ≤ max∂Dh
|u|+ 14(a2 + b2) max
Dh
|Lu| (3.47)
1Cosa logica, por otra parte. Recuerdese que en una punta el campo tiende a infinito

3.5. ERRORES Y CONVERGENCIA 37
siendo
Lui,j = ui+1,j + ui−1,j + ui,j+1 + ui,j−1 − 4ui,j (3.48)
Prueba
Defınase la funcion φi,j mediante la ecuacion:
φi,j =14(i2 + j2
)h2, (i, j) ∈ Dh (3.49)
Claramente
0 ≤ φi,j ≤14(a2 + b2
)∀(i, j) ∈ Dh (3.50)
Ademas, en todos los puntos (i, j) ∈ Dh
Lφi,j =14((i + 1)2 + j2 + (i− 1)2 + j2 + i2
+(j + 1)2 + i2 + (j − 1)2 − 4i2 − 4j2)
(3.51)= 1 (3.52)
Defınanse ahora las funciones w+ y w− mediante
w+ = u + Nφ y w− = u−Nφ (3.53)
donde
N = maxDh
|Lui,j | (3.54)
Operando en las ecuaciones (3.53) con L y usando (3.52) se obtiene que:
Lw±i,j = ±Lui,j + N ≥ 0 ∀(i, j) ∈ Dh (3.55)
donde la desigualdad se sigue de la definicion de N . Pero, por la extension delprincipio de maximo expuesta al final de la seccion anterior, se sigue de estaultima inecuacion que w± alcanza su maximo en el contorno. Ası pues
maxDh
w±i,j ≤ max∂Dh
w±i,j (3.56)
= max∂Dh
(±vi,j + Nφi,j) (3.57)
≤ max∂Dh
|vi,j |+ max∂Dh
N |φi,j | (3.58)
≤ max∂Dh
|vi,j |+14(a2 + b2
)N (3.59)
donde, para dar el ultimo paso, se utiliza la expresion (3.50). Por otra parte,como w± = u±Nφ, y Nφ ≥ 0, se sigue que ±ui,j ≤ w±i,j . Luego, por (3.53)

38 DIFERENCIAS FINITAS
Figura 3.6: Condiciones de von Neumann no nulas
maxDh
±ui,j ≤ max∂Dh
|vi,j |+14(a2 + b2
)N (3.60)
Es decir
maxDh
|ui,j | ≤ max∂Dh
|ui,j |+14(a2 + b2) max
Dh
|Lui,j | (3.61)
3.6 Problemas con los contornos4 Avanzado
5 BasicoEn esta seccion se estudian algunos problemas que se pueden presentar en loscontornos. Especıficamente, se estudia el tratamiento de condiciones de vonNeumann no nulas y que hacer cuando la malla no se adapta bien al contorno.Existe, por supuesto, otros problemas distintos a estos que se tratan. Las formu-las a aplicar en estos casos suelen ser bastante complicadas, aunque, despues deleer esta seccion, el estudiante interesado no debiera tener dificultades en esta-blecerlas.
3.6.1 Condiciones de von Neumann no nulas
Considerese la figura 3.6. Se desea encontrar una formula de diferencias finitasque aproxime la condicion de Dirichlet
∂V
∂x= g(y) en x = x0 (3.62)
Para obtener la ecuacion en el punto O existen varias posibilidades. Una deellas es introducir un punto “fantasma” F de forma que la ecuacion en O sereduzca a la formula habitual

3.6. PROBLEMAS CON LOS CONTORNOS 39
1h2
(vF + vA + vB + vC − 4vO) = fO (3.63)
Ahora se tiene una variable mas: el potencial en el nudo “fantasma” F .Ası pues, se necesita una ecuacion adicional para este nudo, que debiera estarrelacionada con la condicion de von Neumann, que no se ha usado todavıa. Paraello, considerese de nuevo los desarrollos de Taylor expuestos en la seccion 3.3:
Vi+1,j = Vi,j +∂V
∂x|i,jh +
12
∂2V
∂x2|i,jh2 +
16
∂3V
∂x3|i,jh3 +
124
∂4V
∂x4|ξ1,jh
4 (3.64)
Donde x(i) < ξ1 < x(i + 1). Analogamente,
Vi−1,j = Vi,j −∂V
∂x|i,jh +
12
∂2V
∂x2|i,jh2 − 1
6∂3V
∂x3|i,jh3 +
124
∂4V
∂x4|ξ2,jh
4 (3.65)
Si las dos ecuaciones anteriores se restan se obtiene:
Vi+1,j − Vi−1,j = 2∂V
∂x|i,jh + O(h3) (3.66)
siendo O(h3) terminos de orden cubico o superior. Despreciando estos terminos,se obtiene:
∂V
∂x|i,j =
1h
(Vi+1,j − Vi−1,j) (3.67)
o, en nuestro caso
∂V
∂x|0 = gO =
1h
(VA − VF ) (3.68)
que es la ecuacion adicional buscada.
3.6.2 Tratamiento de contornos curvos
Considerse una malla cuadrada pero con la frontera curva como en la figura 3.7.Se desea determinar que ecuacion en diferencias finitas hay que aplicar al
nodo O. Aplicando de nuevo el teorema de Taylor:
VA = VO + hθ1∂V
∂x|O + h2θ2
1
∂2V
∂x2|O + O(h3) (3.69)
V3 = VO − h∂V
∂x|O + h2 ∂2V
∂x2|O + O(h3) (3.70)
Eliminando ∂V∂x |O se sigue que:
∂2V
∂x2|O =
1h2
(2
θ1(1 + θ1)VA +
2(1 + θ1)
V3 −2θ1
VO
)(3.71)

40 DIFERENCIAS FINITAS
Figura 3.7: Contorno curvo
Realizando cuentas similares en la direccion y, se obtiene la aproximacion ala ecuacion de Poisson:
2VA
θ1(1 + θ1)+
2VB
θ2(1 + θ2)+
2V3
(1 + θ1)+
2V4
(1 + θ2)= −2
(1θ1
+1θ2
)VO = h2fO
(3.72)
3.7 Diferencias finitas en otros sistemas coorde-nados
En este capıtulo se ha venido tratando el analisis de problemas bidimensionalesen coordenadas cartesianas. Hay, sin embargo, circunstancias en que es precisotratar problemas de mas dimensiones o en sistemas coordenados no cartesianos.
El establecimiento de las ecuaciones tridimensionales en coordenadas carte-sianas es bastante trivial: lo unico que hay que hacer es repetir lo que se ha hechoanadiendo la coordenada z. En particular, con una malla cubica se obtiene laaproximacion a la ecuacion de Laplace:
Vi+1,j,k + Vi−1,j,k + Vi,j+1,k + Vi,j−1,k + Vi,j,k+1 + Vi,j,k+1 − 6Vi,j,k = 0 (3.73)
en que de nuevo se ve que el potencial central es la media de los adyacentes.En el caso de coordenadas no cartesianas el analisis es tambien similar. Se
parte de la ecuacion diferencial, cuyas derivadas se aproximan por diferenciasfinitas a partir de desarrollos de Taylor en las coordenadas utilizadas. Los dossiguientes apartados realizan estas aproximaciones, de forma somera, para doscasos particulares de cierta relevancia. Otros casos se tratarıan de forma similar.

OTROS SISTEMAS COORDENADOS 41
Figura 3.8: Diferencias finitas en polares
3.7.1 Diferencias finitas en coordenadas polares
En configuraciones con contornos circulares, el uso de coordenadas polares puedeestar indicado. Considerese, por ejemplo, la ecuacion de Laplace:
∂2V
∂r2+
1r
∂V
∂r+
1r2
∂2V
∂θ2= 0 (3.74)
Defınanse los nodos de la malla en el plano r - θ por las intersecciones delos cırculos r = ih, (i = 1, 2, . . .) y las lıneas rectas θ = jl, (j = 0, 1, 2, . . .) (verla figura 3.8)
La ecuacion de Laplace puede aproximarse entonces por:
(Vi+1,j − 2Vi,j + Vi−1,j)h2
+1ih
(Vi+1,j − Vi−1,j)2h
+1
(ih)2(Vi,j+1 − 2Vi,j + Vi,j−1)
l2= 0
(3.75)Reordenando terminos
(1− 1
2i
)Vi−1,j +
(1 +
12i
)Vi+1,j − 2
(1 +
1(il)2
)Vi,j
+1
(il)2Vi,j−1 +
1(il)2
Vi,j+1 = 0 (3.76)
Observese que tambien en este caso el potencial central es la media de los quehay alrededor. Por otra parte, el planteamiento de las condiciones de contornoes similar al del caso cartesiano.
3.7.2 Diferencias finitas con simetrıa axial
Existen configuraciones que presentan simetrıa respecto a un eje. En estos casos,el uso de coordenadas cilındricas esta indicado. Por ejemplo, la ecuacion de
42 DIFERENCIAS FINITAS
r
z
h
l
Figura 3.9: Diferencias finitas con simetrıa axial
Laplace en coordenadas cilındricas es:
∂2V
∂r2+
1r
∂V
∂r+
∂2V
∂z2= 0 (3.77)
donde se han anulado las derivadas respecto a θ, debido a la simetrıa axial dela configuracion.
Considerese la malla en el plano r - z por las intersecciones de las lıneasr = ih, (i = 0, 1, 2, . . .) y las lıneas rectas z = jl, (j = 0, 1, 2, . . .) (ver la figura3.9)
Una aproximacion en diferencias finitas a esta ecuacion viene dada por:
(Vi+1,j − 2Vi,j + Vi−1,j)h2
+1ih
(Vi+1,j − Vi−1,j)2h
+(Vi,j+1 − 2Vi,j + Vi,j−1)
l2= 0
(3.78)Reordenando terminos
1h2
(1− 1
2i
)Vi−1,j +
1h2
(1 +
12i
)Vi+1,j − 2
(1h2
+1l2
)Vi,j
+1l2
Vi,j−1 +1l2
Vi,j+1 = 0 (3.79)
Esta ecuacion no es valida en los puntos del eje, donde i = 0. No obstante,se pueda aplicar a estos nodos la ecuacion de Laplace en cartesianas, puesto quela malla alrededor de estos nodos en 3 dimensiones en nada se diferencia de unamalla cartesiana (ver figura 3.10). Luego se tiene

OTROS SISTEMAS COORDENADOS 43
Figura 3.10: La malla en el eje
4h2
Vi+1,j −(
4h2
+2l2
)Vi,j +
1l2
Vi,j−1 +1l2
Vi,j+1 = 0 (3.80)
para los puntos del eje.

44 DIFERENCIAS FINITAS

Capıtulo 4
Ecuaciones de Laplace yPoisson: elementos finitos
5 Basico
4.1 Introduccion
En la seccion anterior se estudio una manera de aproximar ecuaciones diferen-ciales en derivadas parciales mediante un sistema de ecuaciones algebraicas: elmetodo de las diferencias finitas.
Existe otro metodo importante para efectuar la discretizacion de las ecua-ciones en diferencias finitas: el metodo de los elementos finitos. El proposito deeste capıtulo es exponer sus fundamentos.
No obstante, antes de comenzar, dos comentarios parecen oportunos. El pri-mero es que estos dos metodos, aunque sean los mas importantes, no son losunicos. El segundo es que ambos tienen ventajas e inconvenientes, y que cadauno esta indicado en diferentes circunstancias. Mas sobre esto sera dicho al finaldel presente capıtulo.
4.2 Forma variacional de la ecuacion de Poisson
La base del metodo de los elementos finitos se basa en la posibilidad de replan-tear el problema de Poisson:
∇ (ε∇V ) = f en Dsujeto a V = g en ∂D1
ε∂V∂n = h en ∂D2 (4.1)
como un problema de optimizacion. En efecto, considerese el siguiente problema:
mınV
F =12
∫∫∫D
ε (∇V )2 dv −∫∫∫
DfV dv −
∫∫∂D2
hV ds
45

46 ELEMENTOS FINITOS
sujeto a V = g en ∂D1 (4.2)
Es este un problema de optimizacion funcional: se trata de encontrar lafuncion V (x, y, z) que cumpla la restriccion y minimice el funcional1 F (V ). Esdecir, para cada V que cumpla ser igual a g en la frontera ∂D1, se puede calcularun numero real F (ya que f y h son datos). Despues se escoge la V que de el Fmas pequeno. El resto de esta seccion se empleara en demostrar que la funcionbuscada V verifica la ecuacion de Poisson.
Sea V ∗ la solucion de la ecuacion de Poisson (4.1). Cualquier funcion V enla ecuacion (4.2) puede escribirse como
V = V ∗ + δV (4.3)
Por supuesto, tanto V como V ∗ tienen que cumplir la restriccion
V = V ∗ = g en ∂D1 (4.4)
Por tanto
V ∗ + δV = V ∗ = gen ∂D1 (4.5)
Luego
δV = 0 en ∂D1 (4.6)
Escrıbase el funcional F (V ) como la suma de tres terminos
F (V ) = F1(V ) + F2(V ) + F3(V ) (4.7)
F1(V ) =12
∫∫∫D
ε (∇V )2 dv (4.8)
F2(V ) =∫∫∫
DfV dv (4.9)
F3(V ) =∫∫
∂D2
hV ds
(4.10)
Se estudian ahora cada uno de los tres terminos
• F1(V ). Se tiene que
F1(V ) =12
∫∫∫D
ε (∇V )2 dv (4.11)
=12
∫∫∫D
ε (∇(V ∗ + δV ))2 dv (4.12)
1Un funcional es una ”funcion”que asigna a una funcion un numero.

4.2. FORMA VARIACIONAL DE LA ECUACION DE POISSON 47
=12
∫∫∫D
ε (∇V ∗)2 dv +12
∫∫∫D
ε (∇δV )2 dv +∫∫∫D
(ε∇V ∗) (∇δV ) dv (4.13)
=12
∫∫∫D
ε (∇V ∗)2 dv +12
∫∫∫D
ε (∇δV )2 dv +∫∫∫D∇ (δV ε∇V ∗) dv −
∫∫∫D
δV∇ (ε∇V ∗) dv (4.14)
=12
∫∫∫D
ε (∇V ∗)2 dv +12
∫∫∫D
ε (∇δV )2 dv +
©∫∫
∂D(δV ε∇V ∗) ds−
∫∫∫D
δV f dv (4.15)
=12
∫∫∫D
ε (∇V ∗)2 dv +12
∫∫∫D
ε (∇δV )2 dv −∫∫∂D2
δV ε∂V ∗
∂nds−
∫∫∫D
δV f dv (4.16)
=12
∫∫∫D
ε (∇V ∗)2 dv +12
∫∫∫D
ε (∇δV )2 dv −∫∫∂D2
δV h−∫∫∫
DδV f dv (4.17)
Para realizar este desarrollo se ha aplicado para pasar de (4.13) a (4.14)la formula de integracion por partes2; para pasar de (4.14) a (4.15), elteorema de Gauss y el hecho de que V ∗ verifica la ecuacion de Poisson;para pasar de (4.15) a (4.16) la condicion de contorno de que δV se ha deanular en ∂D1; y por ultimo, para pasar de (4.16) a (4.17), la condicionde contorno que verifica V ∗ en ∂D2.
• F2(V ). En este caso
F2(V ) =∫∫∫
DfV dv (4.18)
=∫∫∫
DfV ∗ dv +
∫∫∫D
fδV dv (4.19)
• Finalmente F3(V )
F3(V ) =∫∫
∂D2
hV ds (4.20)
=∫∫
∂D2
hV ∗ ds +∫∫
∂D2
hδV ds (4.21)
2O sea, ∇ (A∇B) = ∇(A)∇(B) + A∆B. Para probar esta formula, basta con escribir losoperadores diferenciales en, por ejemplo, cartesianas y operar.

48 ELEMENTOS FINITOS
Sumando ahora F1, F2 y F3:
F (V ) = F1(V ) + F2(V ) + F3(V ) (4.22)
=12
∫∫∫D
ε (∇V ∗)2 dv +12
∫∫∫D
ε (∇δV )2 dv −∫∫∂D2
δV h−∫∫∫
DδV f dv +∫∫∫
DfV ∗ dv +
∫∫∫D
fδV dv +∫∫∂D2
hV ∗ ds +∫∫
∂D2
hδV ds
=12
∫∫∫D
ε (∇V ∗)2 dv +∫∫∫D
fV ∗ dv +∫∫
∂D2
hV ∗ ds +
12
∫∫∫D
ε (∇δV )2 dv (4.23)
= F (V ∗) +12
∫∫∫D
ε (∇δV )2 dv (4.24)
Se observa que F tiene un mınimo para V = V ∗, ya que la segunda integrales positiva para cualquier δV 6= 0 puesto que ε > 0. Pero esto es equivalentea decir que la solucion a la ecuacion de Poisson (4.1) es la misma que la delproblema (4.2).
Al llegar aquı, se hace necesario introducir alguna nomenclatura. Las ecuacio-nes (4.1) y (4.2) son, como se ha visto, esencialmente la misma. Ası, la ecuacion(4.1) es conocida como la forma fuerte, y la (4.2) como la forma debil de la ecua-cion. Hay tambien dos tipos de condiciones iniciales. Unas (en este caso, las deDirichlet) tienen que ser introducidas como una restriccion adicional en la formadebil. Estas condiciones de contorno son conocidas como condiciones esencia-les. Existen otras (en el caso presente, las de von Neumann) que se introducenen la forma debil dentro del funcional F (V ) a minimizar. Estas condiciones seconocen como naturales.
En general, cuando se consigue reformular un problema de campos comola minimizacion de determinado funcional, se dice que se ha obtenido la formavariacional de problema. En nuestro caso particular, se puede comprobar que elfuncional F tiene dimensiones de energıa. De hecho, lo unico que se ha hecho esestablecer el principio de trabajos virtuales para este problema particular.
4.3 Aproximacion funcional
La forma debil (4.2) es la base para el desarrollo del metodo de los elementosfinitos. Sin embargo, esta expresion da la solucion como el mınimo sobre el

4.3. APROXIMACION FUNCIONAL 49
conjunto de todas las funciones3. Este es, por supuesto, un conjunto infinito. Loque se hace entonces es aproximar la funcion V como una suma de funcionesconocidas, preestablecidas:
V (x, y, z) = V0(x, y, z) +∑
i
aiVi(x, y, z) (4.25)
En esta expresion, las funciones V0 y Vi son conocidas, y lo que se va aintentar es encontrar los coeficientes, los numeros reales ai, que mejor aproximenla funcion solucion V ∗.
La funcion V0 se diferencia de las funciones Vi en lo siguiente: V0 verifica lascondiciones de contorno esenciales:
V0 = g en ∂D1 (4.26)
mientras que las Vi verifican condiciones nulas en el mismo contorno
Vi = 0 en ∂D1 (4.27)
Es claro, por tanto, que V verifica las condiciones esenciales. Substituyendola aproximacion en el funcional a minimizar se obtiene:
F (V ) =12
∫∫∫D
ε (∇V )2 dv −∫∫∫
DfV dv −
∫∫∂D2
hV ds (4.28)
=12
∫∫∫D
ε
(∇(V0 +
∑i
aiVi)
)2
dv −∫∫∫D
(V0 +∑
i
aiVi)f dv −∫∫
∂D2
(V0 +∑
i
aiVi)h ds (4.29)
=12
∫∫∫D
ε (∇V0)2
dv +∑
i
ai
∫∫∫D
ε (∇V0∇Vi) dv +
12
∑i
∑j
aiaj
∫∫∫D
ε∇Vi∇Vj dv −∫∫∫D
V0f dv −∑
i
ai
∫∫∫D
Vif dv −∫∫∂D2
V0h ds−∑
i
ai
∫∫∂D2
Vih ds (4.30)
=12
∑i
∑j
aiaj
∫∫∫D
ε∇Vi∇Vj dv +
3O mas bien, las funciones derivables que sean ademas integrables en D, para que la formadebil tenga sentido. Aunque la caracterizacion rigurosa del conjunto de funciones admisibleses importante para demostrar la consistencia matematica del esquema, aquı se adoptara unpunto de vista menos riguroso, y se supondra que todas las funciones consideradas se puedenderivar e integrar sin problemas.

50 ELEMENTOS FINITOS
∑i
ai
(∫∫∫D
ε∇V0∇Vi dv −∫∫∫
DVif dv −
∫∫∂D2
Vih ds)
+(12
∫∫∫D
ε (∇V0)2
dv −∫∫∫
DV0f dv −
∫∫∂D2
V0h ds)
(4.31)
=12
∑i
∑j
aiajKi,j
+
(∑i
aibi
)+ c (4.32)
donde, en la ultima lınea, se han definido las cantidades:
Ki,j =∫∫∫
Dε∇Vi∇Vj dv (4.33)
bi =(∫∫∫
Dε (∇V0∇Vi) dv −
∫∫∫D
Vif dv −∫∫
∂D2
Vih ds)
(4.34)
c =(
12
∫∫∫D
ε (∇V0)2
dv −∫∫∫
DV0f dv −
∫∫∂D2
V0h ds)
(4.35)
En forma matricial, la ecuacion (4.32) puede escribirse como
F =12aT Ka + bT a + c (4.36)
donde es claro que a es el vector columna de componentes ai, b el de compo-nentes bi, K la matriz cuyos elementos son Ki,j y el superındice T denota latransposicion.
F es una funcion de a, ya que las cantidades K, b y c solamente dependendel problema y de las funciones V0 y Vi, que son conocidas. Por otra parte,sabemos que la solucion de la ecuacion de Poisson es la funcion que minimizaF . Por tanto, los coeficientes ai buscados seran aquellos que minimicen F , esdecir, que se ha de cumplir:
∂F
∂ai= 0 ∀i (4.37)
o, en forma matricial
Ka + b = 0 (4.38)
Luego los a+i buscados seran
a+ = −K−1b (4.39)
y la solucion
V + = V0 +∑
i
a+i Vi (4.40)

4.3. APROXIMACION FUNCIONAL 51
La solucion aproximada V + no es la solucion exacta V ∗, ya que esta ultimaes el mınimo sobre todas las funciones que cumplen las condiciones de contornoesenciales, mientras que V + es el mınimo sobre un subconjunto de estas: las quese pueden generar con V0 y las Vi. Sin embargo, si el conjunto de funciones Vi
es lo bastante grande, la solucion aproximada V + no sera muy distinta de lasolucion V ∗.
4.3.1 Un ejemplo
Sea el problema de Poissond2Vdx2 = x(1− x) x ∈ [0, 1]V (0) = 0V (1) = 1
(4.41)
Este es un problema en una sola dimension. El dominio D es el segmento[0, 1], y la “superficie” que lo encierra los dos puntos x = 0 y x = 1, donde senos dan condiciones de contorno esenciales. La teorıa explicada anteriormente seaplica tambien a este caso, sin mas que substituir las integrales de volumen porintegrales de lınea, y las integrales de superficie por los valores de las funcionesen los puntos extremos del intervalo4.
De todas formas, para el problema (4.41) es facil encontrar una solucionanalıtica integrando la ecuacion diferencial. Se obtiene ası:
V (x) = − 112
x4 +16x3 +
1112
x (4.42)
Se va ahora a obtener una solucion aproximada por el metodo variacional.Se ha de desarrollar V como
V = V0 +∑
i
aiVi (4.43)
V0 ha de cumplir las condiciones de contorno esenciales. Una posibilidadsencilla es:
V0(x) = x (4.44)
En efecto V0(0) = 0 y V0(1) = 1, que son las condiciones esenciales. Por otraparte, las Vi han de tener condiciones esenciales nulas. Se escogen ası:
Vi(x) = sin (iπx) (4.45)
ya que Vi(0) = Vi(1) = 0.Ahora se puede proceder al calculo de la matriz K y del vector b. Recuerdese
que se obtuvo que
4De todas formas, el lector interesado puede rehacer los desarrollos anteriores para el casomonodimensional, mas sencillo.

52 ELEMENTOS FINITOS
Ki,j =∫∫∫
Dε∇Vi∇Vj dv (4.46)
Luego
Ki,j =∫ 1
0
dVi
dx
dVj
dxdx
=∫ 1
0
(d
dxsin(πix)
)(d
dxsin(πjx)
)dx
=∫ 1
0
πi sin(πix)πj sin(πjx)dx
=12δijπ
2i2 (4.47)
donde δij denota el sımbolo de Kronecker (δij = 1 si i = j, deltaij = 0 si i 6= j).Por otra parte, se obtuvo antes que
bi =(∫∫∫
Dε (∇V0∇Vi) dv −
∫∫∫D
Vif dv −∫∫
∂D2
Vih ds)
(4.48)
En este ejemplo, se tiene pues
bi =∫ 1
0
(d
dxx
)(d
dxsin(πix)
)dx−
∫ 1
0
x(1− x) sin(πix) dx
=∫ 1
0
πi cos(πix) dx−∫ 1
0
x(1− x) sin(πix) dx
= −∫ 1
0
x(1− x) sin(πix) dx
= − 2(πi)3
(1− (−1)i
)(4.49)
Ahora la ecuacion
Ka+ = −b (4.50)
da ∑j
Ki,ja+j = −bi (4.51)
O sea ∑j
12δijπ
2i2a+j =
2(πi)3
(1− (−1)i
)(4.52)
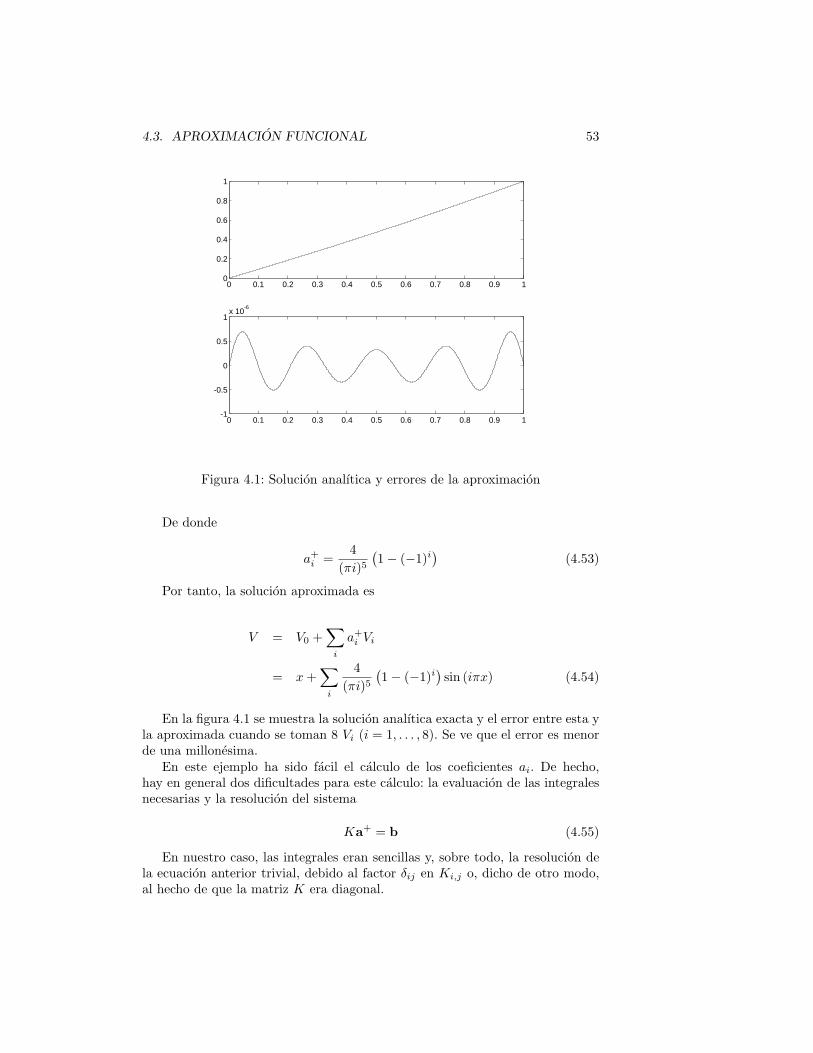
4.3. APROXIMACION FUNCIONAL 53
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.2
0.4
0.6
0.8
1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1-1
-0.5
0
0.5
1x 10
-6
Figura 4.1: Solucion analıtica y errores de la aproximacion
De donde
a+i =
4(πi)5
(1− (−1)i
)(4.53)
Por tanto, la solucion aproximada es
V = V0 +∑
i
a+i Vi
= x +∑
i
4(πi)5
(1− (−1)i
)sin (iπx) (4.54)
En la figura 4.1 se muestra la solucion analıtica exacta y el error entre esta yla aproximada cuando se toman 8 Vi (i = 1, . . . , 8). Se ve que el error es menorde una millonesima.
En este ejemplo ha sido facil el calculo de los coeficientes ai. De hecho,hay en general dos dificultades para este calculo: la evaluacion de las integralesnecesarias y la resolucion del sistema
Ka+ = b (4.55)
En nuestro caso, las integrales eran sencillas y, sobre todo, la resolucion dela ecuacion anterior trivial, debido al factor δij en Ki,j o, dicho de otro modo,al hecho de que la matriz K era diagonal.

54 ELEMENTOS FINITOS
Funciones que llevan a matrices K diagonales se llaman ortogonales. Unagran parte de los metodos “ clasicos” de resolucion de ecuaciones de campo estanrelacionados con la determinacion de estas funciones. El encontrarlas analıtica-mente es, en general, una tarea nada trivial y, a menudo, imposible. Solamenteen configuraciones especiales (cilindros, esferas, ...) es ello posible5.
Por contra, el metodo de los elementos finitos busca matrices K no diago-nales, pero si “sencillas”, utilizando funciones tambien sencillas.
4.4 Nomenclatura y propiedades
La matriz K es conocida como matriz de rigidez, mientras que el vector b recibeel nombre de vector de fuerzas. Los nombres tienen su origen en problemasmecanicos, de elasticidad, que fueron para los que se desarrollo originariamenteel metodo.
A partir de la definicion de la matriz de rigidez
Ki,j =∫∫∫
Dε∇Vi∇Vj dv (4.56)
se observa que es simetrica (Ki,j = Kj,i). Ademas, ha de ser positiva definida.Recuerdese que una matriz K es positiva definida si verifica que
xT Kx > 0 ∀x (4.57)
Supongamos entonces que K no es positiva definida. Entonces, existe alguny tal que
yT Ky ≤ 0 (4.58)
Hay pues dos posibilidades: que se verifique el signo < o el =. Supongaseprimero que
yT Ky < 0 (4.59)
Considerese entonces el valor del funcional a minimizar
F (αy) = α2yT Ky + αyT b + c (4.60)
Es claro que F puede hacerse tan negativo como se quiera sin mas queescoger un α lo suficientemente grande. Algo similar pasa si es valido el signoigual. Entonces
F (αy) = αyT b + c (4.61)
de manera que F puede hacerse tan negativo como se quiera escogiendo α � 0si bT y > 0, o α � 0 en caso contrario.
5Para los cilindros se han de emplear funciones de Bessel, y para las esferas armonicosesfericos.

4.5. EL ESPACIO DE FUNCIONES ADMISIBLES 55
En cualquier caso, F puede hacerse tan negativo como se quiera. Pero esteF esta acotado inferiormente, puesto que no es mas que una aproximacion alfuncional que se obtiene cuando se consideran todas las funciones posibles, queadquiere su valor mınimo cuando se le da como argumento la solucion de laecuacion de Poisson. Esta contradiccion prueba que K es definida positiva.
En particular, como K es positiva definida, K−1 existe siempre.
4.5 El espacio de funciones admisibles
Poco se ha dicho hasta aquı de cuales deben ser las caracterısticas que hande cumplir las funciones Vi. Por una parte, se sabe que la solucion V ∗ de laforma fuerte (4.1) debe ser dos veces derivable6, por lo que al menos debieranincluirse como posibles Vi las funciones con dos derivadas bien definidas. Peropor otra parte, en la forma debil (4.2) solamente aparecer derivadas primeras,lo que sugiere que el espacio de posibles funciones Vi debiera ampliarse hastalas funciones que tienen primera derivada, aun cuando no tengan bien definidala segunda.
No existe aquı el proposito de definir con rigor la naturaleza del espacio defunciones Vi admisibles. Sin embargo, si se justificara la posibilidad de usar unaclase particular de funciones: las funciones continuas que ademas tienen derivadasegunda a trozos7.
La idea es dividir el dominio de definicion de Vi en varias piezas. Por ejemplo,en 1 dimension en intervalos, en 2 en un teselado de polıgonos, en tres en unconjunto de poliedros. Ahora, dentro de cada intervalo, polıgono o poliedro,Vi tiene que ser 2 veces derivable, aunque puede haber discontinuidades en lasegunda derivada al pasar de un intervalo, polıgono o poliedro a otro. La funcionVi tiene que ser, de todas formas, continua en todo el dominio del problema.
Por ejemplo, la figura 4.2 muestra una de estas funciones para el caso uni-dimensional:
f(x) ={
0 x ≤ 0x x > 0 (4.62)
Esta funcion es, en efecto, continua y tiene definidas las derivadas primera ysegunda en todas partes, salvo en x = 0, es decir, tiene definidas las dos primerasderivadas a trozos.
4 Basico
5 AvanzadoEsta funcion f podrıa ser utilizada como una posible funcion Vi para calcular,
por ejemplo, los elementos de la matriz de rigidez (4.33). Sin embargo, no tienederivada en x = 0, con lo que el procedimiento puede parecer sospechoso8.
Sin embargo, se puede transformas f en una funcion f que tiene todas lasderivadas que se requieran en todos los puntos, y es por tanto ciertamente
6Supuesto que ε es una vez derivable7“piecewise” en ingles8Notese que se demostro la equivalencia entre las formas fuerte y la debil usando ciertas
operaciones diferenciales (integracion por partes, etc.) que requieren que la funcion V tengael numero adecuado de derivadas en todos los puntos.
56 ELEMENTOS FINITOS
x
f
δ
Figura 4.2: Una funcion admisible
admisible, uniendo los dos tramos de f mediante un empalme suave (ver figura4.2) de anchura δ. El punto importante es que δ puede ser tan pequeno como sedesee. Pero, los elementos de K o b calculados con f o f difieren en cantidadesde orden δ, y por tanto son a todos los efectos equivalentes.
Por ejemplo, supongase que D es el intervalo [−1, 1], y que se desea calcularla integral que aparece en la definicion de la matriz de rigidez
I(f) =∫ 1
−1
(df
dx
)2
dx =12
(4.63)
Si se calcula esta integral con f se obtiene:
I(f) =∫ 1
−1
(df
dx
)2
dx
=∫ −δ
−1
(df
dx
)2
dx +∫ δ
−δ
(df
dx
)2
dx +∫ 1
δ
(df
dx
)2
dx
=12(1− δ2
)+∫ δ
−δ
(df
dx
)2
dx (4.64)
Por otra parte, en el intervalo [−δ, δ]
4.5. EL ESPACIO DE FUNCIONES ADMISIBLES 57
x
f
δ
Figura 4.3: Una funcion no admisible
0 ≤ df
dx≤ 1 (4.65)
Por tanto
0 ≤∫ δ
−δ
(df
dx
)2
dx ≤ 2δ (4.66)
Luego
12(1− δ2
)≤ I(f) ≤ 1
2(1 + 4δ + δ2
)(4.67)
Finalmente
|I(f)− I(f)| ≤ 2δ +12δ2 (4.68)
Como δ puede ser tan pequeno como se quiera, es claro que ambas integralesson esencialmente iguales, y por lo tanto los elementos correspondientes de lamatriz de rigidez. Por otra parte, el argumento es de un caracter general, validopara todos los elementos de K y b, por lo que queda demostrado que la claseconsiderada de funciones definidas a trozos es admisible.
El argumento que se acaba de indicar no es, sin embargo, valido con funcionesdiscontinuas, que no son admisibles. Por ejemplo, considerese la funcion escalonde la figura 4.3:

58 ELEMENTOS FINITOS
f(x) ={
0 x ≤ 01 x > 0 (4.69)
Esta funcion puede aproximarse mediante la funcion admisible
f(x) =
0 x ≤ −δ12 + 1
2δ x −δ < x ≤ δ1 x > δ
(4.70)
f es una funcion admisible, ya que es continua y tiene derivada segunda atrozos. Por otra parte, es claro que aproxima a f como δ va tendiendo a cero.Sin embargo, ahora se tiene
I(f) =∫ 1
−1
(df
dx
)2
dx
=∫ −δ
−1
(df
dx
)2
dx +∫ δ
−δ
(df
dx
)2
dx +∫ 1
δ
(df
dx
)2
dx
=∫ δ
−δ
(df
dx
)2
dx
=12δ
(4.71)
Ahora la integral I, y por tanto el elemento correspondiente de la matriz derigidez K (y, en general, todos aquellos elementos de K y b donde intervengaf) no estan definidos, tienden a infinito conforme δ tiende a cero. Por tanto, fno es una funcion Vi admisible.
4.6 Elementos finitos triangulares4 Avanzado
5 BasicoHa llegado ya el momento de escoger unas funciones Vi concretas. Estas fun-ciones deberan dar una matriz de rigidez K que sea “sencilla”. Esto significa,basicamente, que debera tener muchos ceros, es decir, debera ser una matrizrala. Por otra parte, las propias funciones Vi deberan ser tambien sencillas, parapoder calcular facilmente los valores Ki,j y bi, que resultan de hacer integralescon estas funciones.
Una forma sencilla de cumplir estos requisitos en dos dimensiones, aunquemuy a menudo eficaz, es la utilizacion de los llamados elementos triangulares.En esta seccion se estudiaran estos elementos.
Ante todo es necesario triangularizar el dominio donde queremos resolver laecuacion, es decir, dividirlo en triangulos tal como muestra la figura 4.4, a laderecha. Se requiere para las triangularizaciones admisibles que cada triangulono tenga mas nodos de la red que sus vertices.

4.6. ELEMENTOS FINITOS TRIANGULARES 59
Figura 4.4: Triangularizaciones admisibles e inadmisibles.
Figura 4.5: Funcion Vi
Las funciones Vi son piramides. Cada piramide tiene su vertice encima deun nodo de la red, mientras que su base esta formada por todos los triangulosque coinciden en el vertice. La altura de la piramide es 1. La figura 4.5 muestrauna de estas Vi. Por supuesto, puede considerarse que Vi fuera del polıgono queforma la base de la piramide vale 0, con lo que Vi es una funcion continua conderivada segunda a trozos en todo el dominio D.
El potencial se aproxima mediante una serie
V =m∑
i=1
aiVi (4.72)
En este caso, las ai tienen ademas un significado sencillo: es el valor de V enel vertice i-esimo. En efecto, en este vertice todas las V ’s salvo la i-esima valen0. Es por ello, que las ai son llamadas variables nodales.
De entre todos los vertices, existiran un subconjunto que se encontraran en

60 ELEMENTOS FINITOS
el contorno donde se aplican condiciones de contorno esenciales. En estos nodosel valor de V , y por lo tanto el valor de los ai correspondientes es conocido.Dividanse entonces los nodos en dos conjuntos: uno formado por n nodos dondeno existen condiciones de contorno esenciales, y por tanto las ai son incognita;y otro formado por los m−n nodos restantes en el contorno esencial. Entonces:
V =n∑
i=1
aiVi +m∑
i=n+1
aiVi (4.73)
=n∑
i=1
aiVi + V0 (4.74)
V0 es conocido, puesto que se conocen las ai correspondientes. Se podrıa, apartir de aquı, calcular la matriz K y el vector b. Sin embargo, es mas conve-niente hacer estas operaciones de una forma menos directa.
Considerese, entonces, cada uno de los triangulos que forman la red. Cadauno de ellos se llamara un elemento, y se denotara al i-esimo elemento Ti. Sihay en total N elementos, se tiene que
∫∫∫D
. . . dv =N∑
i=1
∫∫∫Ti
. . . dv (4.75)
Dentro de cada elemento, las piramides son planos. Esto permite calcular lasintegrales de forma muy eficaz.
4 Basico
5 Avanzado
Especıficamente: sean (x, y)1, (x, y)2 y (x, y)3 las coordenadas de los tresvertices del elemento Ti. Sea Vj1 la piramide cuyo vertice esta en el punto 1.Entonces, la funcion Vj1 restringida al elemento Ti es
Vj1|Ti = Tj1
=1
(x1 − x2)(y1 − y3)− (x1 − x3)(y1 − y2)[(y2 − y3)x− (x2 − x3)y+ (4.76)12
((y2 + y3)(x2 − x3)− (x2 + x3)(y2 − y3))]
(4.77)
Esta ecuacion se ha deducido de la siguiente manera: dado que es un planotiene que ser de la forma Tj1 = ax + by + c. Por otra parte, Tj1 vale 1 en elnodo 1( el vertice de la piramide ), y 0 en los nodos 2 y 3, que estan en la basede la piramide. Estas tres condiciones permiten despejar a, b y c, resultando laecuacion anterior. De manera analoga se calculan Tj2 y Tj3.
Cada funcion Tj es llamada funcion de forma. Con su ayuda es ya facilcalcular la matriz de rigidez y el vector de fuerzas. En efecto, aplicando lasecuaciones (4.56 y (4.75):

4.6. ELEMENTOS FINITOS TRIANGULARES 61
Ki,j =∫∫D
ε∇Vi∇Vj ds
=N∑
k=1
∫∫Tk
ε∇Vi∇Vj ds (4.78)
(4.79)
Dentro de cada elemento solamente hace falta considerar 3 Vi’s: las trespiramides con vertice en cada uno de los tres vertices del elemento. En efecto,el resto de las piramides valen 0 en ese elemento. Entonces, la matriz de rigidezelemental
Kki,j =
∫∫Tk
ε∇Vi∇Vj ds (4.80)
es, esencialmente, una matriz de 3 × 3 (o, si se quiere, una matriz n × n peroque solo tiene elementos no nulos en la submatriz correspondiente a los tresvertices del elemento). Mas aun, las funciones Vi restringidas al elemento sonlas funciones de forma. Ası pues, se tiene por ejemplo que
Kki1,i2 =
∫∫Tk
ε∇Ti1∇Ti2 ds (4.81)
y de forma analoga los elementos Kki1,i1,K
ki1,i3, etc.
Las funciones de forma son funciones lineales, por lo que sus derivadas sonconstantes. Ası pues, la integracion es simplemente una constante por el areadel triangulo. Especıficamente:
Kki1,i2 =
∫∫Tk
ε
(∂Ti1
∂x
∂Ti2
∂x+
∂Ti1
∂y
∂Ti2
∂y
)ds
=∫∫Tk
ε1
(x1 − x2)(y1 − y3)− (x1 − x3)(y1 − y2)×
1(x2 − x3)(y2 − y1)− (x2 − x1)(y2 − y3)
×
((y2 − y3)(y3 − y1) + (x2 − x3)(x3 − x1)) ds
=1
(x1 − x2)(y1 − y3)− (x1 − x3)(y1 − y2)×
1(x2 − x3)(y2 − y1)− (x2 − x1)(y2 − y3)
×
((y2 − y3)(y3 − y1) + (x2 − x3)(x3 − x1))× (4.82)∫∫Tk
ε ds
=1
(x1 − x2)(y1 − y3)− (x1 − x3)(y1 − y2)×

62 ELEMENTOS FINITOS
1(x2 − x3)(y2 − y1)− (x2 − x1)(y2 − y3)
×
((y2 − y3)(y3 − y1) + (x2 − x3)(x3 − x1))×
ε12
((x1 − x2)(y1 − y3)− (x1 − x3)(y1 − y2))
=ε
2(y2 − y3)(y3 − y1) + (x2 − x3)(x3 − x1)(x2 − x3)(y2 − y1)− (x2 − x1)(y2 − y3)
(4.83)
Se ha supuesto que ε es constante en todo el elemento, lo que suele serhabitual. Si no lo fuera, habrıa que calcular la integral teniendo en cuenta estadependencia.
Se tiene ya calculada la matriz de rigidez elemental Kk para cada elemento.Es ahora preciso juntar estas matrices elementales a fin de obtener la matriz derigidez total K. Esto se realiza empleando la expresion (4.79):
Ki,j =N∑
k=1
∫∫Tk
ε∇Vi∇Vj ds =N∑
k=1
Kki,j (4.84)
Recuerdese que cada matriz Kk se puede interpretar como una matriz quesolo tiene elementos no nulos en las posiciones que corresponden a las variablesnodales del elemento k. Supongase, entonces, que se tiene una lista de elementostal como:
Elemento 1 Vertices 3,1,2Elemento 2 Vertices 3,4,2. . . . . .Elemento N Vertices 4,5,n
Al combinar las matrices Kk correspondientes a estos elementos se ob-tendra una matriz de rigidez de la forma:
K1 + K2 + KN =
1 1 1 . . .1 1 + 2 1 + 2 2 . . .1 1 + 2 1 + 2 2 . . .
2 2 2 + N N . . . NN N . . . N
......
......
.... . .
...N N . . . N
(4.85)
donde los numeros indican las posiciones donde aparecen terminos provenientesde cada Kk.
El ensamblaje del vector de fuerzas se realiza de una forma similar. Re-cuerdese que

4.6. ELEMENTOS FINITOS TRIANGULARES 63
bi =(∫∫
Dε (∇V0∇Vi) ds−
∫∫D
Vif ds−∫
∂D2
Vih dl)
(4.86)
=N∑
k=1
(∫∫Tk1
ε (∇V0∇Vi) ds−∫∫Tk
Vif ds−∫
∂Tk2
Vih dl)
(4.87)
=N∑
k=1
bki (4.88)
En esta expresion se han denotado por Tk2 los elementos que tienen algunlado en un contorno natural y por ∂Tk2 el contorno natural del elemento k. Puedehaber elementos tengan ambos tipos de contornos. Conocidas las funciones V0,f y h, pueden evaluarse todas las integrales por algun procedimiento numerico.
En el caso de tener una malla lo suficientemente fina, las funciones h y fse pueden considerar constantes, que salen por tanto fuera de la integral. Estosimplifica mucho el calculo del vector de fuerzas, puesto que queda tan solounas integrales sobre las funciones Vi asociadas al elemento, que son sencillasde calcular. En particular∫∫
Tk
Vi ds =12superficie elemento (4.89)
y ∫∂Tk2
Vi dl12longitud lado (4.90)
Por otra parte, la funcion V0 en la integral (4.87) puede ser escrita como
V0 = (ai1Vi1 + ai2Vi2)|Tk(4.91)
= (aj1Ti1 + ai2Ti2) (4.92)
donde i1 y i2 son los dos vertices que limitan el segmento del elemento k quecae sobre el contorno esencial, y Ti1 y Ti2 las respectivas funciones de forma.Las constantes ai1 y ai2 son el valor de V en los nodos i1 e i2, que es conocido.
Es claro que la unica Vi que entra en la integral (4.87) es la que correspondeal tercer vertice del elemento: Vj3. Por tanto
∫∫Tk1
ε (∇V0∇Vj3) ds = (4.93)
aj1
∫∫Tk1
ε (∇Tj1∇Tj3) ds + aj2
∫∫Tk1
ε (∇Tj1∇Tj3) ds (4.94)
Las dos integrales de la segunda lınea se evaluan como en (4.83).

64 ELEMENTOS FINITOS
Figura 4.6: Elemento triangular cuadratico
Con esto, se han calculado ya la matriz K y el vector b, y queda por resolverla ecuacion
Ka = b (4.95)
4.7 Otros elementos
Los elementos que se acaban de estudiar son elementos triangulares lineales. Sepueden generar otra serie de elementos para problemas planos substituyendo lostriangulos por otros polıgonos o las funciones lineales por polinomios de mayorgrado.
Una opcion es, por ejemplo, seguir utilizando triangulos pero utilizar comofunciones de forma, en vez de planos, funciones cuadraticas. Un elemento cuadrati-co general tiene la expresion
a + bx + cy + dx2 + exy + fy2 (4.96)
por lo que existen 6 coeficientes a identificar (a, b, c, d, e, f). En el caso de loselementos lineales, solamente existıan tres coeficientes. Tambien habıa tres va-riables nodales por elemento: los valores de V en cada uno de los vertices. Dehecho, cada funcion de forma valıa 1 en “su” vertice y 0 en los otros dos. Estose puede generalizar al caso cuadratico, pero ahora es preciso escoger 6 vertices.Lo adecuado es escoger los tres vertices y los tres puntos medios de los lados,tal como se muestra en la figura 4.6.
Para cada nodo, es posible conseguir un polinomio cuadratico que valga 1en el nodo considerado y 0 en los demas, ya que esto nos da 6 ecuaciones paralas 6 incognitas a, b, c, d, e, f . Las funciones de forma son estos polinomios.
En el caso del elemento triangular lineal, las funciones de forma estabancoordinadas porque cada variable nodal (cada vertice) esta compartida por tres

4.7. OTROS ELEMENTOS 65
Figura 4.7: Elemento cuadrilatero bilineal
elementos. Juntando las tres funciones de forma que confluıan en cada vertice seobtenıan funciones Vi en forma de piramide. En el caso cuadratico las cosas sonmuy similares. Cada variable nodal esta compartida por dos o tres elementos, loque junta las funciones de forma para crear Vi que tienen forma de “piramides”con las caras alabeadas.
Al construir, de la misma manera que antes, las matrices de rigidez elemen-tales se obtienen matrices de 6× 6, de forma analoga a como antes se obtenıande 3× 3. El ensamblamiento de estas matrices es analogo al estudiado antes.
La teorıa es ahora generalizable a polinomios de mayor grado. Se hace preci-so, eso sı, introducir un mayor numero de variables nodales. Por otra parte, lasmatrices elementales son tambien de dimension cada vez mayor. Esto significaque la matriz de rigidez total tiene cada vez un numero de ceros menor. Por lotanto, elementos de un orden elevado tienen una utilidad muy limitada, al nodar lugar a matrices lo suficientemente ralas.
Otra posibilidad es cambiar la forma del elemento. En dos dimensiones,ademas de triangulos, tan solo se usan, normalmente, rectangulos. La posibilidadmas sencilla es usar como variables nodales los cuatro vertices. Esto significa queno se pueden usar funciones de forma lineales, que tienen tres coeficientes y portanto se quedan “cortas”, ni cuadraticas, que con seis se “pasan”. La soluciones usar polinomios bilineales
a + bx + cy + dxy (4.97)
Estos polinomios se llaman bilineales porque son lineales en x e y separada-mente. De nuevo, es posible encontrar para cada vertice un polinomio bilinealque valga 1 en el vertice considerado y 0 en el resto.
Se pueden ahora generalizar la teorıa a elementos bicuadraticos, bicubicos,etc, en rectangulos anadiendo el numero adecuado de variables nodales. Es tam-bien posible combinar elementos triangulo y rectangulo.

66 ELEMENTOS FINITOS
Notese que se esta utilizando siempre como coeficientes ai del desarrollo V =V0 +
∑i aiVi el valor de V en determinados nodos. Es importante hacerlo ası,
ya que esto facilita muchısimo el asegurarse de que las funciones Vi construidasa partir de las funciones de forma de cada elemento son admisibles9.
En tres dimensiones la teorıa es muy parecida. Los elementos triangulo pasana ser tetraedros, pudiendo ser tambien lineales, cuadraticos, cubicos, etc. Losrectangulos se transforman en paralelepıpedos bilineales, bicuadraticos, bicubi-cos, etc.
Mencion especial merecen los elementos usados en problemas con simetrıaaxial, conocidos como elementos axisimetricos. En estos casos es conveniente uti-lizar coordenadas cilındricas, con el eje de simetrıa como coordenada z. Ademasexisten las coordenadas r y φ, siendo la derivada respecto a φ nula debido a lasimetrıa axial.
En estos casos, el problema queda reducido a un problema en dos dimensionesen el plano z − r. Puede utilizarse cualquier elemento plano, pero modificandoadecuadamente las integrales que definen K y b. Por ejemplo, se tiene que
Ki,j =∫∫∫
Dε∇Vi∇Vj dv
=∫∫∫
D3
ε1r2
(∂
∂r(rVi) +
∂
∂z(zVi)
)(∂
∂r(rVj) +
∂
∂z(zVj)
)dr dz rdφ
= 2π
∫∫D2
ε1r
(∂
∂r(rVi) +
∂
∂z(zVi)
)(∂
∂r(rVj) +
∂
∂z(zVj)
)dr dz
La ultima lınea es la integral que se hace en el plano r−z, pudiendose utilizarlas funciones Vi vista en el caso bidimensional.
4.8 Errores y convergencia
Sea V ∗ la solucion de la ecuacion de Poisson. Se sabe que V ∗ minimiza elfuncional F que se define como
F (V ) =12
∫∫∫D
ε (∇V )2 dv −∫∫∫
DfV dv −
∫∫∂D2
hV ds
sujeto a V = g en ∂D1 (4.98)
Por tanto, al ser V ∗ el minimizador, se ha de cumplir para cualquier funcionV que cumpla las condiciones de contorno esenciales
F (V ∗) ≤ F (V ) ⇒ F (V )− F (V ∗) > 0 (4.99)
9No obstante, es tambien frecuente, para algunos elementos de orden elevado, usar losvalores de las derivadas de V en ciertos nodos como coeficientes del desarrollo. La razonultima de hacerlo ası suele ser similar a la dada.

4.8. ERRORES Y CONVERGENCIA 67
La cantidad E = F (V )−F (V ∗) mide ası la bondad de V como aproximacionde la solucion. En el caso de la ecuacion de Poisson E admite una expresionparticularmente sencilla. En efecto
F (V )− F (V ∗) =12
∫∫∫D
ε (∇V )2 dv −∫∫∫
DfV dv −
∫∫∂D2
hV ds−
12
∫∫∫D
ε (∇V ∗)2 dv −∫∫∫
DfV ∗ dv −
∫∫∂D2
hV ∗ ds (4.100)
=12
∫∫∫D
ε (∇(V − V ∗))2 dv −∫∫∫
Df(V − V ∗) dv −
∫∫∂D2
h(V − V ∗) ds +∫∫∫D
ε∇V∇V ∗ dv (4.101)
=12
∫∫∫D
ε (∇(V − V ∗))2 dv −∫∫∫
Df(V − V ∗) dv −
∫∫∂D2
h(V − V ∗) ds +∫∫∫D∇(V∇V ∗) dv −
∫∫∫D
εV ∆V ∗ dv (4.102)
=12
∫∫∫D
ε (∇(V − V ∗))2 dv −∫∫∫
Df(V − V ∗) dv −
∫∫∂D2
h(V − V ∗) ds +
©∫∫
∂DV∇V ∗ ds +
∫∫∫D
V f dv (4.103)
=12
∫∫∫D
ε (∇(V − V ∗))2 dv +∫∫∫
DfV ∗ dv −
∫∫∂D2
h(V − V ∗) ds +∫∫∂D1
V∇V ∗ ds +∫∫
∂D2
V h ds (4.104)
=12
∫∫∫D
ε (∇(V − V ∗))2 dv +∫∫∫
DfV ∗ dv +∫∫
∂D2
hV ∗ ds +∫∫
∂D1
g∇V ∗ ds (4.105)
Ası pues
F (V )− F (V ∗) = E(V ) =12
∫∫∫D
ε (∇(V − V ∗))2 dv + C (4.106)
siendo la constante C (no depende de V )
C =∫∫∫
DfV ∗ dv +
∫∫∂D2
hV ∗ ds +∫∫
∂D1
g∇V ∗ ds (4.107)
Por otra parte E(V ∗) = F (V ∗)− F (V ∗) = 0. Como
12
∫∫∫D
ε (∇(V ∗ − V ∗))2 dv = 0 (4.108)

68 ELEMENTOS FINITOS
se sigue que C = 0.Se ve entonces que el error E no es mas que como el error cuadratico, total
o medio(si se divide por∫D ε dv) a la solucion. Por otra parte, la cantidad
E(V ) tiene dimensiones de energıa. Es por ello que se suele llamar la energıa detension10.
Considerese ahora la aproximacion a la solucion obtenida con elementosfinitos V +. Se puede escribir como
V + = V0 +∑
i
aiVi (4.109)
y se considera tambien otra combinacion de las Vi
V a = V0 +∑
i
biVi (4.110)
El metodo de los elementos finitos minimiza F (v). Luego
F (V +) ≤ F (V a) ∀V a (4.111)
Se sigue entonces que
F (V +)− F (V ∗) ≤ F (V a)− F (V ∗) ⇒ E(V +) ≤ E(V a) (4.112)
Es decir, el metodo de los elementos finitos calcula la combinacion de fun-ciones Vi que tiene la menor diferencia cuadratica media a la solucion. En estesentido, es un metodo “optimo”.
Ahora ya es muy facil demostrar que la solucion aproximada de elementosfinitos converge a la solucion del problema conforme se consideran mallas masfinas. En efecto, considerese que ahora V a no es una aproximacion arbitrariasino la aproximacion que cumple que es igual a V ∗ en los nodos de la malla. Detodas formas, se seguira verificando que E(V +) ≤ E(V a), luego en un sentidomedio V + aproxima mejor que V a a la solucion V ∗, aunque en los nodos lo hagapeor. Conforme la malla se va haciendo mas tupida, V a va aproximando cadavez mejor a V ∗.
Considerese entonces una serie de mallas cada vez mas finas. Sea h la mayoranchura del mayor elemento de la malla, y V +h y V ah las soluciones de ele-mentos finitos y la solucion igual a V ∗ en los nodos para la malla de anchurah, respectivamente. Claramente, cuando h tienda a 0, V ah tendera, de algunaforma, a V ∗, y por tanto
lımh→0
E(V ah) = 0 (4.113)
Y como E(V +h) ≤ E(V ah)
lımh→0
E(V +h) = 0 (4.114)
Es decir, la solucion aproximada V +h tiende a la solucion V .10En ingles “strain”.

4.9. ELEMENTOS FINITOS Y DIFERENCIAS FINITAS 69
4.9 Elementos finitos y diferencias finitas 4 Avanzado
5 BasicoEl metodo de los elementos finitos se ha impuesto, para un gran numero deproblemas de resolucion de campos, como el metodo de resolucion por excelencia.De hecho, en ecuaciones para las que es posible encontrar una forma variacional,suele ser el metodo mas recomendable. Esto es debido a que permite utilizarmallas muy irregulares, en geometrıas con diferentes materiales, sin que estosuponga esfuerzos adicionales a la hora de establecer el sistema de ecuacionesalgebraico y sin preocuparse por problemas de convergencia. Por contra, endiferencias finitas, el uso de mallas irregulares y distintos materiales lleva aecuaciones en diferencias complicadas, no siendo siempre facil establecer erroresy propiedades de convergencia para las soluciones obtenidas.
Sin embargo, el metodo de diferencias finitas tiene a su favor su mayor gene-ralidad, ya que parte directamente de la ecuacion diferencial. En cambio, no essiempre posible encontrar una forma variacional para una ecuacion diferencialdada.
En terminos generales, los problemas estaticos, en los que no interviene eltiempo, suelen tener forma variacional. Sin embargo, los problemas dinamicosen los que se pretende estudiar la evolucion de un cierto campo inicial, no suelentenerla. Es en estos problemas donde el metodo de las diferencias finitas tienemas predicamento.
Por ultimo, es preciso comentar que existen metodos que combinan ideasprocedentes de ambas tecnicas, ası como otros metodos basados en diferentesprincipios.

70 ELEMENTOS FINITOS

Capıtulo 5
Otros problemas estaticos
5 Basico
5.1 Introduccion
El objeto de este capıtulo es exponer la forma de resolver otros problemas estati-cos del electromagnetismo. En concreto, se abordara la resolucion por elementosfinitos de los problemas de corrientes estacionarias y de magnestostatica en me-dios lineales y no lineales.
5.2 Corrientes estacionarias
La ecuacion de continuidad para la corriente reza:
∇j =∂ρ
∂t(5.1)
En situaciones estacionarias, la densidad de carga permanece constante, ypor tanto
∇j = 0 (5.2)
La ley de Ohm establece que la corriente es proporcional al campo electri-co: j = σE. Por otra parte, el campo electrico a menudo se puede considerarirrotacional: E = −∇V . Por tanto, se obtiene la ecuacion:
∇ (σ∇V ) = 0 (5.3)
Esta ecuacion es la ecuacion de Laplace que se vio en el capıtulo anterior,substituyendo ε por σ. Mas aun, tambien las condiciones de contorno son delmismo tipo. En efecto, un conductor tiene algunos de sus lados a potencialesconocidos (condiciones de Dirichlet o esenciales) y otros aislados, por los queno se escapa corriente. Matematicamente esto significa que, en este ultimo caso,la componente normal de la densidad de corriente es nula: jn = 0 o, comoj = −σ∇V , ∂V
∂n = 0 (condiciones de von Neumann o naturales).
71

72 CAPITULO 5. OTROS PROBLEMAS ESTATICOS
Si se desea resolver este problema por elementos finitos, podemos escribirdirectamente el funcional de optimizacion a partir de los resultados del capıtuloanterior:
F =12
∫∫∫D
σ (∇V )2 dv
=12
∫∫∫D
jE dv (5.4)
Es decir, la distribucion de corrientes que realmente se da es aquella que escompatible con las condiciones de contorno y que minimiza el calor producido.
5.3 Magnetostatica en medios lineales
Las ecuaciones de campo para campos magnetostaticos son
∇B = 0 (5.5)∇×H = j (5.6)
La anulacion de la divergencia de B permite escribir que
B = ∇×A (5.7)
En medios lineales, existe una relacion entre B y H del tipo:
B = µH (5.8)
donde µ es una constante que depende del material, pero es independiente delcampo magnetico al que esta sometido.
Es preciso, ademas, especificar las condiciones de contorno. En la mayorparte de los casos solamente hay que considerar dos tipos de condiciones decontorno:
• El campo B no cruza el contorno, es decir, Bn = 0, siendo Bn la compo-nente normal al contorno.
• El campo B cruza perpendicularmente al contorno. Esta condicion se pue-de escribir Bt = 0, siendo Bt las dos componentes de B tangentes alcontorno.
Con las condiciones de contorno que se acaban de prescribir, las ecuacionespueden derivarse de un principio variacional, de forma analoga a la ecuacion dePoisson. En efecto, considerese el problema

5.3. MAGNETOSTATICA EN MEDIOS LINEALES 73
∇B = 0∇×H = j
B = µH
sujeto a Bn = 0 en ∂Dn
Bt = 0 en ∂Dt (5.9)
En este problema son datos la densidad de corriente j y las condiciones decontorno. La solucion puede obtenerse como la solucion del problema:
mınF =12
∫∫∫D
HB dv −∫∫∫
DjA dv
sujeto a At = 0 en ∂Dn (5.10)
Notese que el funcional de optimizacion es, de forma analoga al caso elec-trostatico, la energıa del campo menos la energıa asociada a las corrientes. Porotra parte, la condicion de que B sea perpendicular al contorno es una condicionnatural, es decir, no requiere la introduccion de restricciones en el problema deoptimizacion.
4 Basico
5 AvanzadoLa forma de demostrar este resultado es analoga a la que se empleo en el
caso electrostatico. No obstante, ahora hay que emplear el potencial vector Aen vez del potencial escalar V .
Sea entonces A∗ la solucion de (5.10). Consideremos otras posibles soluciones
A = A∗ + δA (5.11)
Estas posibles soluciones verifican la condicion de contorno de (5.10), es decir
At = 0 en ∂Dn ⇒ δAt = 0 en ∂Dn (5.12)
Notese que esta condicion garantiza que Bn = 0. En efecto, supongase queel eje normal al contorno coincide con el eje z. Entonces Bn = Bz. Pero
Bz =∂Ay
∂x− ∂Ax
∂y(5.13)
Como las componentes tangenciales son, en este caso, x e y, que son cons-tantes (iguales a 0) en el contorno (es decir, el plano x − y), se sigue que lasderivadas, y por tanto Bz, se anulan. El caso general, en funcion de las compo-nentes tangenciales y normales, se sigue de este resultado.
Volviendo al problema variacional, se procede a evaluar F para cualquier Aadmisible, es decir
F (A) = F (A∗ + δA) (5.14)
F es la suma de dos terminos

74 CAPITULO 5. OTROS PROBLEMAS ESTATICOS
F =12
∫∫∫D
HB dv −∫∫∫
DjA dv (5.15)
Se comienza por el primer sumando
12
∫∫∫DHB dv =
12
∫∫∫D
1µB2 dv =
12
∫∫∫D
1µ (∇×A)2 dv =
12
∫∫∫D
1µ (∇× (A∗ + δA))2 dv =
12
∫∫∫D
1µ (∇×A∗)2 dv +
∫∫∫D
1µ (∇×A∗) (∇× δA) dv+
12
∫∫∫D
1µ (∇× δA)2 dv (5.16)
El segundo sumando puede transformarse aplicando la formula del analisisvectorial, valida para dos campos a y b cualesquiera:
b (∇× a) = a (∇× b) +∇ (a× b) (5.17)
Aplicando esta expresion al segundo sumando de (5.16):
∫∫∫D
1µ (∇×A∗) (∇× δA) dv =∫∫∫
D δA∇×[
1µ (∇×A∗)
]dv −
∫∫∫D∇
[δA× 1
µ (∇×A∗)]
dv =∫∫∫D δA∇×H dv −©
∫∫∂D (δA×H) ds =∫∫∫
D δA∇×H dv −∫∫
∂Dt(δA×H) ds (5.18)
El ultimo paso se ha dado porque en ∂Dn las componentes tangenciales deδA son nulas, por lo que δA es paralelo a ds, y por tanto
δA×H ds = (ds× δA)H = 0 (5.19)
Por otra parte, se tiene que∫∫∫D
jA dv =∫∫∫
DjA∗ dv +
∫∫∫D
jδA dv (5.20)
Ası pues, se obtiene finalmente
F =12
∫∫∫D
1µ
(∇×A∗)2 dv −∫∫∫
DjA∗ dv +∫∫∫
DδA∇×H dv −
∫∫∫D
jδA dv −∫∫∂Dt
(δA×H) ds +
12
∫∫∫D
1µ
(∇× δA)2 dv (5.21)

5.4. MAGNETOSTATICA NO LINEAL 75
Ahora bien, puesto que el mınimo de F se alcanza para A = A∗, los terminosque son lineales en δA se han de anular. En efecto, tanto δA como −δA sonfunciones admisibles, puesto que verifican las condiciones de contorno (5.12).Pero si los terminos que multiplican δA fuesen distintos de cero, tendrıa signosdistintos para δA y −δA. Escogiendo el signo negativo, se tendrıa un F queserıa menor que el F en A∗, lo que contradice que el mınimo de F se alcanceen A∗1. Ası pues se ha de verificar:
∫∫∫D
δA∇×H dv −∫∫∫
DjδA dv = 0∫∫
∂Dt
(δA×H) ds = 0 (5.22)
Estas ecuaciones se han de cumplir para cualquier δA que cumpla las con-diciones de contorno (5.12). La primera ecuacion implica que
∇×H = j (5.23)
como se puede ver tomando funciones δA que sean no nulas en pequenos do-minios interiores a D. Por otra parte, la segunda ecuacion se puede escribircomo
∫∫∂Dt
(H× ds) δA = 0 (5.24)
En ∂Dt, δA puede, en principio, valer cualquier cosa. Por tanto, la unicaforma de que se anule la integral es que H× ds = 0, o lo que es lo mismo, queH no tenga mas componente que la normal al contorno.
Es importante notar que el problema variacional (5.10) esta escrita de formavectorial. Ası pues, es posible ahora escoger las coordenadas que mas convenganpara resolver el problema.
En casos en dos dimensiones (por ejemplo, cuando se estudian configura-ciones muy largas o con simetrıa cilındrica) se ha de utilizar un potencial Aque tenga tan solo una componente no nula. En este caso, la similaridad con laecuacion de Poisson es particularmente marcada.
En cualquier caso, la resolucion del problema por elementos finitos se planteade la misma forma que en el capıtulo anterior. Las tres componentes de Ase escriben como una suma finitas de las funciones de forma estudiadas en elcapıtulo anterior, y se calculan la matriz analoga a la matriz de rigidez K yel vector analogo al vector de fuerzas b, resolviendo posteriormente el sistemalineal resultante.

76 CAPITULO 5. OTROS PROBLEMAS ESTATICOS
5.4 Magnetostatica no lineal4 Avanzado
5 Basico5.4.1 Planteamiento de la forma variacional
Practicamente la totalidad de los aparatos que utilizan campos magneticos tie-nen partes de hierro. El hierro es empleado porque amplifica enormemente elcampo magnetico. Sin embargo, desde el punto de vista analıtico, complicagrandemente el problema debido a la existencia de fenomenos de histeresis ysaturacion.
Muy a menudo, los efectos de la histeresis pueden despreciarse. En efecto,son muchos los aparatos que utilizan hierros con ciclos muy estrechos, a fin deminimizar perdidas. Incluso en casos en que la histeresis no sea despreciable,esta aproximacion da una primera solucion util.
En este caso, existe una dependencia funcional entre B y H. En efecto, puedeescribirse que
B = B(H) (5.25)
donde B(H) es una funcion no lineal de H que tiende a saturarse, es decir, queverifica
lımH→∞
∂B(H)∂H
= µ0 (5.26)
mientras que, muy a menudo, ∂B(H)∂H |H=0 tiene un valor mucho mas alto (por
ejemplo, 1500µ0).La presencia de histeresis harıa imposible determinar esta relacion funcional,
ya que a cada valor de H le corresponderıa mas de uno de B.Puede verificarse que B(0) 6= 0. Los materiales con esta caracterıstica son
imanes permanentes, que crean campo en ausencia de corriente.En lo que sigue, se supondra que la dependencia funcional entre B y H puede
describirse mediante una relacion del tipo:
H = H0 +B(H)
BB (5.27)
El termino H0 es la fuerza coercitiva, que existe tan solo en imanes per-manentes, y resulta de la imanacion permanente del iman. El segundo terminoexpresa que, en la parte del campo no atribuible a la imanacion permanente(toda, salvo en imanes permanentes), los campos H y B son paralelos.
Esta relacion es falsa si a un iman se le aplica un campo externo muy intenso,ya que en este caso B y H acabaran siendo paralelos. Sin embargo, es aplicablea la mayor parte de los casos de interes, en los que en el interior del iman elprimer termino suele ser claramente mayor que el segundo.
Es fundamental entonces el hecho de que las ecuaciones de campo:
1Los terminos cuadraticos en δA pueden despreciarse eligiendo δA lo bastante pequeno.

5.4. MAGNETOSTATICA NO LINEAL 77
∇B = 0∇×H = j
B = B(H)sujeto a Bn = 0 en ∂Dn
Bt = 0 en ∂Dt (5.28)
son equivalentes al problema variacional:
mınF =∫∫∫
D
(∫ B
0
H dB
)dv −
∫∫∫D
jA; dv
sujeto a At = 0 en ∂Dn (5.29)
El funcional es identico al del problema lineal, salvo por el termino cuadraticoen el campo. De hecho, la integral∫ B
0
H dB (5.30)
ha de interpretarse a partir de la substitucion de (5.27):∫ B
0
H dB = H0B +∫ B
0
H(B) dB (5.31)
Notese que en el caso lineal H = 1µB, H0 = 0, y por tanto∫ B
0
H(B) dB =∫ B
0
1µ
B dB =12µ
B2 =12BH =
12BH (5.32)
con lo que el funcional se reduce al del apartado anterior.
4 Basico
5 AvanzadoLa demostracion de la igualdad entre las formas fuerte (5.28) y debil (5.29)
de las ecuaciones de campo se demuestra de una manera muy similar a la delcaso lineal. Sea ası A∗ y B∗ la solucion del problema (5.29), y se consideranperturbaciones δA, y por tanto δB = ∇ × δA al mismo, que cumplan lascondiciones de contorno esenciales del problema (5.29). Naturalmente, se ha decumplir que
F (A∗) ≤ F (A∗ + δA) ∀δA (5.33)
Ahora bien, se tiene que;
F (A∗ + δA)− F (A∗) =∫∫∫D
(∫ B∗+δB
0
H dB
)dv −
∫∫∫D
j (A∗ + δA) dv −

78 CAPITULO 5. OTROS PROBLEMAS ESTATICOS
∫∫∫D
(∫ B∗
0
H dB
)dv −
∫∫∫D
jA∗ dv =
∫∫∫D
(∫ B∗+δB
B∗H dB
)dv −
∫∫∫D
jδA dv =∫∫∫D
HδB dv −∫∫∫
DjδA dv (5.34)
donde el ultimo paso se ha podido dar debido a la suposicion de que δB espequeno. Entonces
F (A∗ + δA)− F (A∗) =∫∫∫
DH∇× δA dv −
∫∫∫D
jδA dv (5.35)
Aplicando las formulas (5.17):
F (A∗ + δA)− F (A∗) =∫∫∫D
H∇× δA dv −∫∫∫
DjδA dv =∫∫∫
DδA∇×H dv −
∫∫∫D∇ (HδA) dv −
∫∫∫D
jδA dv =∫∫∫D
δA∇×H dv −©∫∫
∂DHδA dv −
∫∫∫D
jδA dv (5.36)
Esta expresion coincide con la que se obtenıa en el caso lineal (ver ecuacion(5.18)). A partir de este punto, el resto del analisis es identico: la anulacion delos terminos lineales en δA (que son los unicos que existen cuando δA es lobastante pequeno), exigida por la condicion de que F (A∗) es mınimo, lleva alas ecuaciones (5.28).
5.4.2 Resolucion numerica de la forma variacional
Volviendo de nuevo a las ecuaciones (5.29), que se vuelven a reproducir a con-tinuacion:
mınF =∫∫∫
D
(∫ B
0
H dB
)dv −
∫∫∫D
jA dv
sujeto a At = 0 en ∂Dn (5.37)
es preciso establecer un proceso numerico para su resolucion. De forma analoga acomo se hacıa en el capıtulo, o en la seccion, anteriores se desarrolla el potencialvector en una suma finita de funciones conocidas:

5.4. MAGNETOSTATICA NO LINEAL 79
Ak = Ak0 +N∑
i=1
akiAki (5.38)
donde k = x, y, z, o k = r, θ, φ, u otras posibilidades segun el sistema de coor-denadas utilizado. Las funciones Aki son funciones conocidas, y las incognitasson los coeficientes aki. Por lo tanto
F (A) ≈ F (aki) (5.39)
Encontrar el mınimo de F es resolver el sistema de ecuaciones
∂F
∂aki= 0 ∀aki (5.40)
En el caso lineal (la ecuacion de Poisson o las ecuaciones de la magnetostaticalineal), el funcional F es una una funcion cuadratica de los coeficientes aki. Porlo tanto, la ecuacion anterior es una ecuacion lineal, cuya resolucion ya se haabordado.
En el caso no lineal, el funcional F no es una funcion cuadratica de los aki.En efecto, en el termino ∫∫∫
D
(∫ B
0
H dB
)dv (5.41)
B es una funcion lineal de aki, puesto que B depende linealmente de A (B =∇×A) y A depende linealmente de aki; pero H no es funcion lineal de aki, yaque la funcion H(B) no es lineal en este caso. Por tanto, la ecuacion (5.40) noes lineal.
Existen varios metodos para resolver problemas no lineales. En los programasde elementos finitos el mas utilizado es el metodo de Newton-Raphson. Estemetodo, para resolver el sistema de ecuaciones
f(x) = 0 (5.42)
plantea la iteracion
xl+1 = xl −(
∂f∂x
)−1
f(xl) (5.43)
donde xl es la estimacion de la solucion en la iteracion l-esima.Supongase entonces que, para simplificar la notacion2, existe una sola com-
ponente del potencial A, como sucede, por ejemplo, en problemas cartesianosde 2 dimensiones o en problemas con simetrıa cilındrica. Entonces
A = A0k +N∑
i=1
aiAik (5.44)
2Aunque el caso general se trata de la misma manera.

80 CAPITULO 5. OTROS PROBLEMAS ESTATICOS
para el caso cartesiano con el campo B con solamente componentes x e y. k esel vector unitario en la direccion z. En el caso de simetrıa cilındrica habrıa quesubstituir k por uφ. Aplicando el algoritmo de Newton-Raphson a la ecuacion(5.40) se obtiene que
al+1i = al
i −∑
j
(∂2F
∂ai∂aj
)−1(∂F
∂aj
)|ai=al
i(5.45)
Ası pues, es preciso evaluar la matriz
Kij =∂2F
∂ai∂aj(5.46)
y el vector
bj =∂F
∂aj(5.47)
El calculo de estas cantidades se realiza de una manera muy similar a lavista en el capıtulo anterior. Por ejemplo, para calcular la matriz Kij es precisocalcular dos terminos:
Kij =∂2
∂ai∂aj
{∫∫∫D
(∫ B
0
H(al) dB
)dv −
∫∫∫D
j
(A0 +
N∑i=1
aiAi
); dv
}
=∂2
∂ai∂aj
{∫∫∫D
(∫ B
0
H(al) dB
)dv
}(5.48)
La derivada segunda se puede hacer en dos pasos. Se calculara primero laderivada primera ∂
∂ai. Sea
FB =∫∫∫
D
(∫ B
0
H(al) dB
)dv (5.49)
Entonces, por la definicion de derivada, si se considera un incremento pe-queno de las cantidades ai, el incremento de FB se calculara por la formula:
δFB =∑
i
∂FB
∂aiδai (5.50)
Notese que δaiAi es simplemente δA. Comparando con (5.36)
∫∫∫D
δA∇×H dv −©∫∫
∂DHδA =∫∫∫
DδA∇×H dv =∫∫∫
DδaiAik∇×H dv =
∑i
∂FB
∂aiδai (5.51)

5.4. MAGNETOSTATICA NO LINEAL 81
El paso de la primera a la segunda lınea se ha podido dar porque las pertur-baciones consideradas δA tienen condiciones de contorno nulas (recuerdese queA0 lleva toda la informacion sobre las condiciones de contorno). Como los δai
son arbitrarios, se sigue que
∂FB
∂ai=∫∫∫
DAik∇×H dv (5.52)
Ası pues, la segunda derivada se calcula como
∂2FB
∂ai∂aj=∫∫∫
DAik∇×
∂H∂aj
dv (5.53)
Pero, escribiendo
H = H0 +H(B)
BB (5.54)
se obtiene
∂H∂aj
= (5.55)
∂
∂aj
(H(B)
BB)
= (5.56)
B∂
∂aj
(H(B)
B
)+
H(B)B
∂B∂aj
= (5.57)
B∂B
∂aj
∂
∂B
(H(B)
B
)+
H(B)B
∂B∂aj
(5.58)
Ahora, como B = ∇×A = ∇× (A0 +∑
i aiAi)k, las derivadas de B y deB con respecto a ai son faciles de evaluar. Conociendo B (es decir, el Bl queresultare de la estimacion l en el algoritmo de Newton-Raphson), tambien sepuede calcular ∂
∂B
(H(B)
B
). Por lo tanto, la expresion anterior es calculable.
Supongase ademas que las Ai son funciones piramidales como las del capıtuloanterior. Es entonces facil de comprobar que ∂H
∂ajes distinto de cero solamente
en los elementos que se juntan en el vertice j. Por tanto, la matriz Kij , que secalcula mediante la formula (5.53), solamente tendra elementos no nulos si i yj son vertices vecinos, o el mismo vertice. Es decir, sera tan cuasivacıa como lade la ecuacion de Poisson. Esto es muy importante, puesto que en el algoritmode Newton-Raphson hace falta invertir esta matriz.
El calculo del vector b, mas sencillo, se deja al lector interesado.

82 CAPITULO 5. OTROS PROBLEMAS ESTATICOS

Capıtulo 6
La ecuacion de difusion
5 Basico
6.1 Introduccion
La ecuacion de difusion es una de las mas sencillas ecuaciones de sistemas queevolucionan en el tiempo. Esta ecuacion es:
∂u
∂t= ∇(κ∇u)
sujeto a u ∈ D × [0, T ]u(x, 0) = f(x)u(x, t) = g(x, t) x ∈ ∂D1
∂u(x,t)∂n = h(x, t) x ∈ ∂D2 (6.1)
Es decir, la ecuacion de difusion iguala la laplaciana de una determinadafuncion en un cierto dominio a la derivada parcial de dicha funcion respecto altiempo. Como en el caso de la ecuacion de Poisson, existen tambien condicionesde contorno de Dirichlet y Neumann, que en este caso pueden tambien dependerdel tiempo. Ademas, se da el valor de la funcion para el instante inicial t = 0.El problema es calcular la funcion u(x, t) para todos los instantes hasta undeterminado tiempo maximo T .
Se puede apreciar que esta es una ecuacion aparentemente muy similar a lade Poisson. Sin embargo, sus propiedades y comportamiento son completamentediferentes, y los metodos de resolucion numerica, aunque aparentemente simila-res, tienen tambien propiedades muy diferentes a los estudiados hasta ahora.
En este capıtulo se estudiara con especial atencion la ecuacion de difusioncon una sola dimension espacial. Esta ecuacion ya presenta la mayor parte delos nuevos problemas y fenomenos. Mas adelante, se estudiara su generalizaciona varias dimensiones.
83

84 CAPITULO 6. LA ECUACION DE DIFUSION
6.2 La ecuacion de difusion en 1 dimension
En 1 dimension, la ecuacion de difusion se reduce a
∂u
∂t=
∂
∂x
(κ
∂u
∂x
)(6.2)
mas las condiciones de contorno. El dominio D es ahora un intervalo, que sepuede tomar de la forma D = [0, L]. La constante κ puede en principio dependerde la posicion. En esta seccion se considerara el caso en que κ sea constante.Por tanto, la ecuacion anterior se reduce a
∂u
∂t= κ
∂2u
∂x2(6.3)
Esta ecuacion puede ser simplificada aun mas definiendo las nuevas variables
x =x
L(6.4)
t =κt
L2(6.5)
Si se hace esta substitucion se obtiene que (6.3) se transforma en:
∂u
∂t=
∂2u
∂x2x ∈ [0, 1] (6.6)
Por lo tanto, se estudiara, sin perdida de generalidad, la ecuacion (6.6) (aun-que se omitira la tilde sobre las variable). El procedimiento que se ha aplicado esconocido como normalizacion, y es conveniente llevarlo a cabo, aun en los casosen que no se simplifique la ecuacion, para que el ordenador maneje numeros entorno a la unidad.
Considerense ahora las condiciones de contorno. Tras la normalizacion, elcontorno de D son los puntos 0 y 1. Por tanto, las condiciones de contorno seranel valor u(0) o el valor ∂u
∂x |x=0 para el punto x = 0, y similarmente para x = 1.Para concretar, supongase que se impone una condicion de Dirichlet en x = 0
y una de Neumann en x = 1. Entonces, el problema es
∂u
∂t=
∂2u
∂x2
sujeto a u(x, t) ∈ [0, 1]× [0, T ]u(0, t) = g(t)
∂u(x,t)∂x |x=1 = h(t)u(x, 0) = f(x) (6.7)
Para resolver numericamente el problema, el primer paso es discretizar elespacio. Ası pues, en vez de considerar los valores de u para todos los puntos de

6.2. LA ECUACION DE DIFUSION EN 1 DIMENSION 85
1 2 3 4 N-1 N
Figura 6.1: Malla unidimensional.
x, se va a considerar en los puntos de una malla de anchura h, tal como muestrala figura 6.1.
En los puntos internos de la malla, la laplaciana se puede aproximar pordiferencias finitas:
∂ui
∂t=
∂2u
∂x2|x=xi
≈ ui+1 + ui−1 − 2ui
h2(6.8)
Cada ui es, naturalmente, una funcion del tiempo. La condicion de contornode Dirichlet es
u0(t) = g(t) (6.9)
La condicion de contorno de Neumann se puede aproximar introduciendo unnodo auxiliar imaginario en x = 1 + 1
h . Este sera el nodo N + 1. Entonces, en elultimo nodo N se aproxima la laplaciana mediante
∂uN
∂t=
∂2u
∂x2|x=1 ≈
uN+1 + uN−1 − 2uN
h2(6.10)
Por otra parte, se tiene que la condicion de Neumann
∂u
∂x|x=1 = h(t) ≈ uN+1 − uN−1
2h(6.11)
Luego
uN+1 = uN−1 + 2hh(t) (6.12)
Substituyendo esta expresion en (6.10)
∂uN
∂t=
∂2u
∂x2|x=1 ≈
2uN−1 − 2uN
h2+
2h(t)h
(6.13)
Las ecuaciones (6.8,6.9,6.13) pueden combinarse en el sistema

86 CAPITULO 6. LA ECUACION DE DIFUSION
d
dt
u1
u2
u3
...uN−1
uN
=
1h2
−2 1 0 . . . 0 01 −2 1 . . . 0 00 1 −2 . . . 0 0...
......
. . ....
...0 0 0 . . . −2 10 0 0 . . . 2 −2
u1
u2
u3
...uN−1
uN
+
g(t)h2
00...0
2h(t)h
(6.14)
En forma compacta
d
dtu(t) = Au(t) + b(t) (6.15)
6.3 Resolucion de las ecuaciones
En general, la ecuacion de difusion lleva a ecuaciones diferenciales lineales dela forma anterior, donde la matriz A es la discretizacion de la ecuacion deLaplace en el dominio considerado y el vector b contiene informacion sobrelas condiciones de contorno. La solucion se puede obtener de la expresion:
u(t2) = exp [A(t2 − t1)]u(t1) +∫ t2
t1
exp [A(t2 − s)]b(s) ds (6.16)
donde el exponencial de una matriz se define por la serie
exp [Aτ ] = I + Aτ +12!
A2τ2 +13!
A3τ3 + . . . (6.17)
Se puede comprobar que (6.16) es la solucion mediante su substitucion di-recta en (6.15), substituyendo las exponenciales por sus series definitorias.
En principio, la ecuacion (6.16) permite la resolucion directa del problema,sin mas que hacer t1 = 0 y substituir t2 por el tiempo (o tiempos) para el cual sedesea la solucion. Sin embargo, el calculo del exponencial de una matriz grande(que surgen si el mallado del espacio es estrecho) es una tarea numericamentecompleja.
La solucion es mallar tambien el tiempo, de forma que se evalua la solucionen los instantes tj = j ∗ l, siendo l el intervalo temporal. Si l es lo bastantepequeno, puede sustituirse la exponencial por una aproximacion de calculo massencillo. Esto permite obtener una formula sencilla para pasar del instante tj altj+1. Algunas posibilidades son:
• Metodo explıcito clasico
exp [Al] ≈ I + Al (6.18)

6.3. RESOLUCION DE LAS ECUACIONES 87
• Metodo implıcito clasico
exp [Al] ≈ (I −Al)−1 (6.19)
• Metodo de Crank-Nicholson
exp [Al] ≈I + 1
2Al
I − 12Al
(6.20)
Se analizan ahora estas posibilidades.
6.3.1 Metodo explıcito clasico
La aproximacion empleada (6.18) resulta de cortar la serie definitoria de laexponencial (6.17) a partir del segundo termino. Por tanto, aproximara bien laexponencial si l es lo bastante pequeno. Aplicando la formula (6.16) entre losinstantes tj y tj+1, y utilizando la aproximacion (6.18)
uj+1 = exp [A(tj+1 − tj)]uj +∫ tj+1
tj
exp [A(tj+1 − s)]b(s) ds
= exp [Al]uj +∫ tj+1
tj
exp [A(tj+1 − s)]b(s) ds
≈ [I + Al]uj +∫ l
0
[I + As] dsbj+1 + bj
2
≈ [I + Al]uj +[l + A
l2
2
]bj+1 + bj
2≈ [I + Al]uj + cj (6.21)
La gran ventaja de este metodo es que permite calcular la solucion uj+1
a partir de la solucion uj sin hacer nada mas que unas multiplicaciones. Eneste sentido, podrıa parecer que presenta una carga computacional baja. Sinembargo, se vera que esto es mas apariencia que realidad, ya que se requiere unl muy pequeno para que el metodo funcione bien.
Antes de estudiarlo, es conveniente mirar con mas atencion la estructura dela ecuacion (6.21). Por ejemplo, para el caso monodimensional, la actualizaciondel valor de u en la posicion espacial i interior al dominio es
ui,j+1 = ui,j +1h2
(ui+1,j − 2ui,j + ui−1,j) l (6.22)
No aparece ningun termino proveniente de cj porque este vector tiene compo-nentes nulas para los nodos interiores. En efecto, b solamente tiene componentesno nulas en los nodos de frontera, y c, que resulta de una composicion de b yAb, solamente puede tenerlos en los nodos de frontera y en sus vecinos.
La ecuacion anterior se puede reescribir como

88 CAPITULO 6. LA ECUACION DE DIFUSION
ui,j+1 − ui,j
l=
1h2
(ui+1,j − 2ui,j + ui−1,j) (6.23)
Comparando con la ecuacion de difusion ∂u∂t = ∂2u
∂x2 , se comprueba que se hadiscretizado la ecuacion mediante las aproximaciones
∂u
∂t|i,j =
ui,j+1 − ui,j
l(6.24)
∂2u
∂x2|i,j =
1h2
(ui+1,j − 2ui,j + ui−1,j) (6.25)
La aproximacion de las derivadas respecto al espacio es la misma que seutilizo al estudiar la ecuacion de Poisson, y se puede justificar de la mismaforma. En cambio, la aproximacion de la derivada respecto al tiempo es unadiferencia retrasada, ya que estima el valor de la derivada a partir del valor dela funcion en un instante posterior.
6.3.2 Metodo implıcito clasico
La aproximacion de la exponencial utilizada en este metodo puede desarrollarseen serie
(I −Al)−1 = I + Al + A2l2 + A3l3 + . . . (6.26)
en el supuesto de que la serie del lado derecho converja. La formula puededemostrarse, en este caso, sin mas que multiplicar la serie por I −Al. Se puedecomprobar que la convergencia se produce si l es lo bastante pequeno1.
Comparando esta expresion con la serie que define la exponencial se puedeapreciar que en este caso se comete un error principal por exceso de 1
2A2l2,comparado con el error por defecto de la misma cantidad que se tenıa en elmetodo explıcito.
Utilizando esta aproximacion, se obtiene que
uj+1 = exp [A(tj+1 − tj)]uj +∫ tj+1
tj
exp [A(tj+1 − s)]b(s) ds
= exp [Al]uj +∫ tj+1
tj
exp [A(tj+1 − s)]b(s) ds
≈ [I −Al]−1 uj +∫ l
0
[I −As]−1ds
bj+1 + bj
2
≈ [I −Al]−1 uj +∫ l
0
[I + As] dsbj+1 + bj
2
1Especıficamente, debe ser lo bastante pequeno como para que todos los autovalores de Altengan un modulo inferior a 1.

6.3. RESOLUCION DE LAS ECUACIONES 89
≈ [I −Al]−1 uj +[Il + A
l2
2
]bj+1 + bj
2
≈ [I −Al]−1 uj + cj (6.27)
El metodo parece mas trabajoso que el metodo implıcito, puesto que hay quese observa la inversa de una matriz. La manera eficiente de tratar este problemaes reescribir la ecuacion como
[I −Al]uj+1 = uj + [I −Al] cj (6.28)
y resolver el sistema lineal para calcular uj+1 a partir de los valores conocidosde uj y cj . Como la matriz que aparece es siempre la misma en todos los pasosdel problema, de j = 1 hasta el ultimo, lo mas eficaz es calcular al principio delalgoritmo la factorizacion LU de I −Al, y utilizarla en adelante. Esta factoriza-cion inicial es la mayor diferencia, en terminos de coste computacional, entre elmetodo explıcito y el implıcito. Sin embargo, a menudo queda compensada porel hecho de que en el metodo implıcito se puede utilizar pasos l mucho mayoresque en el explıcito, por razones que se veran mas adelante.
La ecuacion (6.28) se puede escribir, para nodos del interior, como
ui,j+1 −1h2
(ui+1,j+1 − 2ui,j+1 + ui−1,j+1) l = ui,j (6.29)
Reordenando terminos
ui,j+1 − ui,j
l=
1h2
(ui+1,j+1 − 2ui,j+1 + ui−1,j+1) (6.30)
Comparando con la ecuacion diferencial, se comprueba que se han realizadolas aproximaciones
∂u
∂t|i,j+1 =
ui,j+1 − ui,j
l(6.31)
∂2u
∂x2|i,j+1 =
1h2
(ui+1,j+1 − 2ui,j+1 + ui−1,j+1) (6.32)
Es decir, se estan utilizando derivadas temporales adelantadas, en compara-cion con las retrasadas utilizadas en el metodo explıcito.
6.3.3 Metodo de Crank-Nicholson
En este caso, la exponencial queda aproximada mediante la matriz(I − 1
2Al
)−1(I +
12Al
)(6.33)
Desarrollando en serie la matriz inversa, se obtiene

90 CAPITULO 6. LA ECUACION DE DIFUSION
(I − 1
2Al
)−1(I +
12Al
)=(
I +12Al +
14A2l2 +
18A3l3 + . . .
)(I +
12Al
)=
I + Al +12A2l2 +
14A3l3 + . . . (6.34)
Comparando con la serie que define la exponencial, se observa que el errorprincipal es de 1
12A3l3. Es un termino de orden cubico, en vez de cuadraticocomo en los casos anteriores, por lo que, en principio, el metodo debiera ser masexacto.
Procediendo como en los casos anteriores, se encuentra que
uj+1 = exp [A(tj+1 − tj)]uj +∫ tj+1
tj
exp [A(tj+1 − s)]b(s) ds
= exp [Al]uj +∫ tj+1
tj
exp [A(tj+1 − s)]b(s) ds
≈[I − 1
2Al
]−1 [I +
12Al
]uj +∫ l
0
[I − 1
2As
]−1 [I +
12As
]ds
bj+1 + bj
2
≈[I − 1
2Al
]−1 [I +
12Al
]uj +∫ l
0
[I + As +
12As2
]ds
bj+1 + bj
2
≈[I − 1
2Al
]−1 [I +
12Al
]uj +
[l +
12Al2 +
16Al3]
bj+1 + bj
2
≈[I − 1
2Al
]−1 [I +
12Al
]uj + cj (6.35)
Como en el anterior metodo implıcito, aparece la inversa de una matriz. Esteproblema se trata de forma semejante, calculado la factorizacion LU de I− 1
2Alal principio del procedimiento.
La ecuacion anterior se puede escribir tambien como[I − 1
2Al
]uj+1 =
[I +
12Al
]uj + cj (6.36)
Para puntos del interior, esto es lo mismo que

6.4. ESTABILIDAD DE LA SOLUCION 91
ui,j+1 −1h2
(ui+1,j+1 − 2ui,j+1 + ui−1,j+1) l =
ui,j +1h2
(ui+1,j − 2ui,j + ui−1,j) l (6.37)
Reordenando terminos
ui,j+1 − ui,j
l=
12
[1h2
(ui+1,j+1 − 2ui,j+1 + ui−1,j+1) +1h2
(ui+1,j − 2ui,j + ui−1,j)]
(6.38)
Se puede considerar que se han hecho las aproximaciones
∂u
∂t|i,j+ 1
2=
ui,j+1 − ui,j
l(6.39)
∂2u
∂x2|i,j+ 1
2=
12
[1h2
(ui+1,j+1 − 2ui,j+1 + ui−1,j+1) +
1h2
(ui+1,j − 2ui,j + ui−1,j)]
(6.40)
Es decir, se han empleado diferencias centradas para aproximar las derivadas,tanto en el tiempo como en el espacio.
6.4 Estabilidad de la solucion
Todos los metodos expuestos se pueden escribir como
uj+1 = Guj + cj (6.41)
La matriz G depende del metodo escogido, siendo I + Al para el metodoexplıcito, (I − Al)−1 para el implıcito clasico y (I − 1
2Al)−1(I + Al) para elCrank-Nicholson. Esta ecuacion se resuelve empezando desde j = 0 y calculandopara valores sucesivos de j.
Esta ecuacion sera inutil si no es robusta frente a los errores. En efecto, esinevitable que se introduzcan errores al resolver la ecuacion, aunque solamentesea debido a errores de redondeo. Los errores producidos en el paso j causanerrores en el (se propagan al) paso j + 1, y de allı a los pasos sucesivos. Siestos errores propagados no disminuyen, sino que crecen conforme avanza elalgoritmo, la solucion que se obtenga sera de escasa utilidad.
Un algoritmo que tenga la propiedad de hacer que el efecto de los erroresdisminuya al avanzar la solucion se llama estable.
Supongamos entonces que en el instante j la solucion obtenida uj tiene unerror ej . O sea,

92 CAPITULO 6. LA ECUACION DE DIFUSION
uj = uj + ej (6.42)
Si se aplica el algoritmo (6.41) se obtiene, suponiendo que no haya erroresadicionales que
uj+1 = uj+1 + ej+1 = Guj = Guj + Gej + cj (6.43)
Comparando con la ecuacion original (6.41) se obtiene la ecuacion del error
ej+1 = Gej (6.44)
Es decir, la ecuacion del error es la misma que la de la solucion, salvo quedesaparece el termino independiente.
En general se tiene que
ej+k = Gkej (6.45)
Ası pues, si el error se ha de anular cuando k →∞, se debe verificar que
lımk→∞
Gk → 0 (6.46)
Esta ecuacion se cumple si todos los autovalores de G tienen modulo menorque 1. Por otra parte, los autovalores de G son funcion de los autovalores de A,ya que G es funcion de A. Los autovalores de A son las soluciones de la ecuacion
Avi = λAi vi (6.47)
Para el metodo explıcito clasico, G = I + Al
Gvi = (I + Al)vi =(1 + λA
i
)vi (6.48)
Ası pues, los autovalores de G para este caso son
λECi = 1 + λA
i l (6.49)
Analogamente, se encuentra para el metodo implıcito clasico
λICi =
11− λA
i l(6.50)
Para el de Crank-Nicholson
λCNi =
1 + 12λA
i l
1− 12λA
i l(6.51)
Se puede demostrar que los autovalores de A estan, para el caso monodi-mensional, entre 0 y − 4
h2 .Ası pues, la condicion de que el modulo de los autovalores de G sea menor
que 1 es

6.4. ESTABILIDAD DE LA SOLUCION 93
• Metodo explıcito clasico: lh2 < 1
2
• Metodo implıcito clasico: vale cualquier l y h. Se dice que el metodo esincondicionalmente estable.
• Metodo de Crank-Nicholson: es la misma situacion que antes. El metodoes incondicionalmente estable.
Se observa que en el metodo explıcito el uso de mallas espaciales pequenas(h pequenas) obliga al uso de pasos temporales muy cortos (h2 extremadamentepequenas). Es por esto por lo que este metodo no es muy usado, a pesar de susencillez.
4 Basico
5 AvanzadoLa demostracion anterior, aunque muy general, no es quiza muy transpa-
rente. Para analizar con mas precision la situacion puede utilizarse el llamadometodo de Neumann.
Este metodo parte de imponer un error de estructura particular. En concreto
ei,0(k) = sin (πki) (6.52)
o
fi,0(k) = cos (πki) (6.53)
La constante k es un numero real. Si todos los senos y cosenos definidos deesta manera dan lugar a un error que decrece, tambien decrecera un error inicialarbitrario. En efecto, un error arbitrario se puede escribir como suma de senosy cosenos.
Para analizar la estabilidad del metodo explıcito se escribe la ecuacion aso-ciada al i-esimo nodo:
ei,j+1(k) = ei,j(k) +1h2
(ei+1,j(k)− 2ei,j(k) + ei−1,j(k)) l (6.54)
Analogamente se tiene
fi,j+1(k) = fi,j(k) +1h2
(fi+1,j(k)− 2fi,j(k) + fi−1,j(k)) l (6.55)
El sımbolo denota la unidad imaginaria. Sea entonces
gi,j(k) = fi,j(k) + ei,j(k) (6.56)
Entonces,
gi,j+1(k) = gi,j(k) +1h2
(gi+1,j(k)− 2gi,j(k) + gi−1,j(k)) l (6.57)
Por otra parte

94 CAPITULO 6. LA ECUACION DE DIFUSION
gi,0(k) = fi,0(k) + ei,0(k)= cos (πki) + sin (πki)= exp (πki)
Por otra parte, aplicando (6.57)
gi,1(k) = gi,0(k) +1h2
(gi+1,0(k)− 2gi,0(k) + gi−1,0(k)) l
= exp (πki) +1h2
(exp (πk(i + 1))− 2 exp (πki) + exp (πk(i− 1))) l
= exp (πki)[1 +
l
h2exp (πk)− 2l
h2+
l
h2exp (−πk)
]= exp (πki)
[1− 2l
h2+
2l
h2cos (πk)
]= exp (πki) G(k)= G(k)gi,0
(6.58)
Ası pues, los senos y cosenos con un k dados resultan multiplicados por elfactor (real) G(k). Si los errores van a disminuir, se requiere que | G(k) |< 1. Elk mas desfavorable es aquel para el que cos (πk) = −1. En este caso
G(k) = 1− 4l
h2> −1 → l
h2<
12
(6.59)
que coincide con la condicion deducida anteriormente.Incidentalmente, el calculo demuestra que los errores que crecen mas rapido
son los senos y cosenos con k’s para los cuales cos (πk) = −1. Estas funcionescambian signo de un nodo i al vecino (i + 1 o i − 1). La figura 6.2 muestrala evolucion del algoritmo para pasos temporales por encima y por debajo delvalor crıtico.
En concreto, se simulo el caso monodimensional con 10 nodos y h = 1. Elcontorno de la izquierda era de Dirichlet, con potencial nulo; y el de derecha deNeumann, con derivada nula. La simulacion estable, mostrada a la izquierda,se hizo con un paso temporal l = 0,4. La de la derecha, inestable, con l = 0,6.Se observa, en el caso inestable, como crecen los errores del tipo indicado en elparrafo anterior.
Los algoritmos implıcito clasico y de Crank-Nicholson se analizan de formasimilar.
6.5 Convergencia de los algoritmos
En las secciones precedentes se ha analizado de que manera es posible discretizarla ecuacion diferencial de forma que sea resoluble en un ordenador. Es de esperar
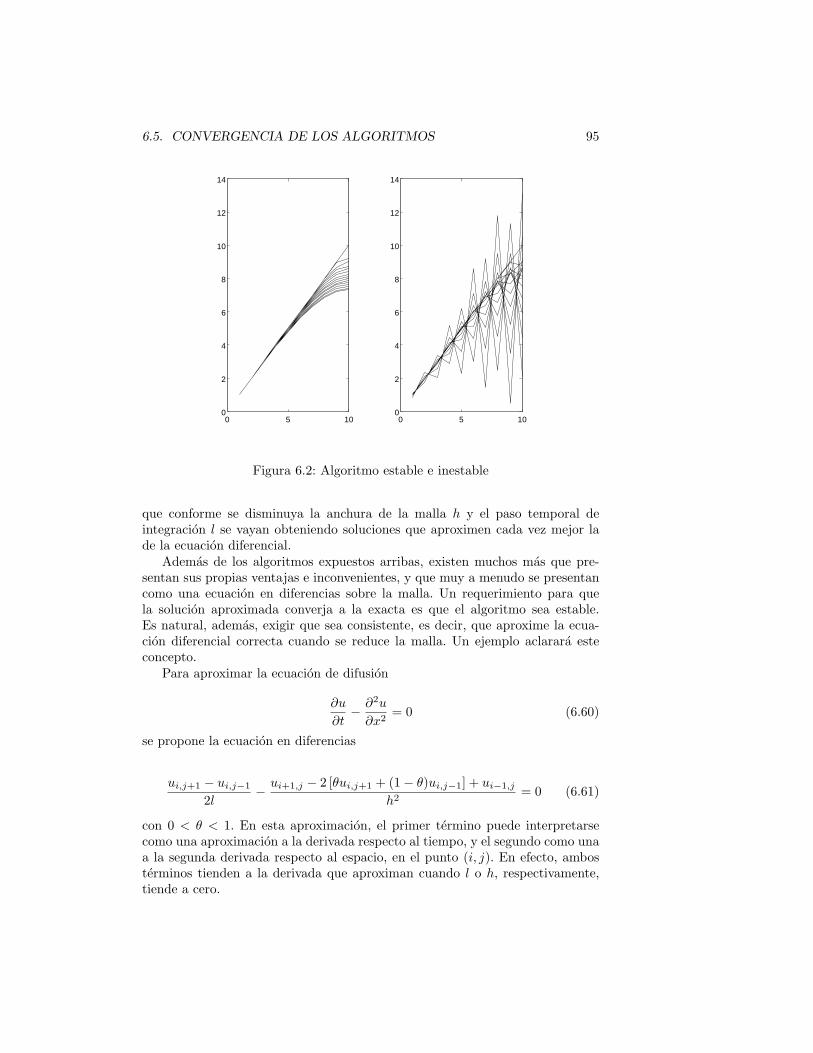
6.5. CONVERGENCIA DE LOS ALGORITMOS 95
0 5 100
2
4
6
8
10
12
14
0 5 100
2
4
6
8
10
12
14
Figura 6.2: Algoritmo estable e inestable
que conforme se disminuya la anchura de la malla h y el paso temporal deintegracion l se vayan obteniendo soluciones que aproximen cada vez mejor lade la ecuacion diferencial.
Ademas de los algoritmos expuestos arribas, existen muchos mas que pre-sentan sus propias ventajas e inconvenientes, y que muy a menudo se presentancomo una ecuacion en diferencias sobre la malla. Un requerimiento para quela solucion aproximada converja a la exacta es que el algoritmo sea estable.Es natural, ademas, exigir que sea consistente, es decir, que aproxime la ecua-cion diferencial correcta cuando se reduce la malla. Un ejemplo aclarara esteconcepto.
Para aproximar la ecuacion de difusion
∂u
∂t− ∂2u
∂x2= 0 (6.60)
se propone la ecuacion en diferencias
ui,j+1 − ui,j−1
2l− ui+1,j − 2 [θui,j+1 + (1− θ)ui,j−1] + ui−1,j
h2= 0 (6.61)
con 0 < θ < 1. En esta aproximacion, el primer termino puede interpretarsecomo una aproximacion a la derivada respecto al tiempo, y el segundo como unaa la segunda derivada respecto al espacio, en el punto (i, j). En efecto, ambosterminos tienden a la derivada que aproximan cuando l o h, respectivamente,tiende a cero.

96 CAPITULO 6. LA ECUACION DE DIFUSION
Es facil comprobar, de hecho, que para una funcion arbitraria u(x, t)
ui,j+1 − ui,j−1
2l|i,j =
∂u
∂t|i,j +
l2
6∂3u
∂t3
+O(l4) (6.62)ui+1,j − 2 [θui,j+1 + (1− θ)ui,j−1] + ui−1,j
h2=
∂2u
∂x2+
h2
12∂4u
∂x4−
(2θ − 1)2l
h2
∂u
∂t+
l2
h2
∂2u
∂t2+
O(h4,l3
h2) (6.63)
Restando una ecuacion de la otra se obtiene
ui,j+1 − ui,j−1
2l−
ui+1,j − 2 [θui,j+1 + (1− θ)ui,j−1] + ui−1,j
h2=
∂u
∂t− ∂2u
∂x2+
l2
6∂3u
∂t3− h2
12∂4u
∂x4+
(2θ − 1)2l
h2
∂u
∂t+
l2
h2
∂2u
∂t2+
O(h4,l3
h2, l4) (6.64)
Para aproximar con mas precision la ecuacion diferencial hace falta que tantoh como l tiendan a cero. Ademas, por razones de estabilidad, conviene hacer queel cociente entre l y h2 permanezca constante. Por tanto, se supondra que entodas las mallas k = rh2, siendo r alguna constante real que asegure estabilidad.Entonces, cuando la anchura de la malla tiende a cero, la ecuacion anteriormuestra que el lımite de la ecuacion en diferencias es:
∂u
∂t− ∂2u
∂t2+ 2(2θ − 1)r
∂u
∂t(6.65)
Esta ecuacion solamente coincide con la ecuacion de difusion original si θ =12 . En este caso se dice que la ecuacion en diferencias es consistente. En losdemas casos, en el que el lımite no es igual a la ecuacion diferencial, se dice quela ecuacion es inconsistente.
Es importante resaltar que el concepto de consistencia requiere alguna es-pecificacion de como se reduce la anchura de la malla. Ademas, el que se tenga

6.6. ELEMENTOS FINITOS Y LA ECUACION DE DIFUSION 97
una formula que aproxime correctamente cada derivada por separado no es su-ficiente para asegurar la consistencia, sino que es preciso examinar la ecuacioncompleta.
Estabilidad y consistencia son, por tanto, dos condiciones necesarias paraasegurar que la ecuacion en diferencias converja a la ecuacion diferencial con-forme se reduce la anchura de malla. Existe un resultado, conocido como elteorema de Lax, que garantiza que en el caso de ecuaciones lineales es tambiensuficiente.
6.6 Elementos finitos y la ecuacion de difusion
La ecuacion (6.1) se puede tambien resolver mediante el metodo de elementosfinitos. Sin embargo, dado que no es posible derivar esta ecuacion de un principiovariacional, es preciso obtener la forma debil en la que se basa el metodo de loselementos finitos de alguna otra manera.
Recuerdese que la ecuacion de difusion tiene la forma:
∂u
∂t= ∇(κ∇u)
sujeto a u ∈ D × [0, T ]u(x, 0) = f(x)u(x, t) = g(x, t) x ∈ ∂D1
∂u(x,t)∂n = h(x, t) x ∈ ∂D2 (6.66)
Escrıbase la funcion u como una serie
u = v0 +∑
i
aivi (6.67)
donde, como es habitual en el metodo de elementos finitos, v0 cumple las con-diciones de contorno esenciales, mientras que las vi se anulan en el contornoesencial ∂D1.
De la ecuacion (6.66) se sigue que∫∫∫D
(∂u
∂t−∇(κ∇u)
)φ dv = 0 (6.68)
para cualquier funcion φ. En particular, para las funciones vi:
∫∫∫D
(∂u
∂t−∇(κ∇u)
)vi dv =
∫∫∫D
∂[v0 +
∑j ajvj
]∂t
−∇(κ∇
v0 +∑
j
ajvj
)
vi dv =

98 CAPITULO 6. LA ECUACION DE DIFUSION∫∫∫D
∂v0
∂tvi dv
∑j
∫∫∫D
∂ajvj
∂tvi dv
−∫∫∫
∇(κ∇v0)vi dv −∑
j
aj∇(κ∇vj)vi dv =
0 ∀i (6.69)
Es costumbre tomar las funciones vi independientes del tiempo, aunque lafuncion v0 puede ser variable si las condiciones de contorno esenciales lo son.En este caso, en el desarrollo u = v0 +
∑i aivi los coeficientes ai son variables,
y la ecuacion anterior se simplifica a:
∫∫∫D
(∂u
∂t−∇(κ∇u)
)vi dv =∫∫∫
D
∂v0
∂tvi dv +
∑j
daj
dt
∫∫∫D
vjvi dv
−∫∫∫
∇(κ∇v0)vi dv −∑
j
aj
∫∫∫∇(κ∇vj)vi dv =
∑j
daj
dtMj,i − ci +
∑j
Ij,i = 0 ∀i (6.70)
La matriz definida por
Mi,j =∫∫∫
Dvjvi dv (6.71)
es conocido como matriz de masas. En cuanto a la matriz Ij,i puede escribirsede un modo mas familiar utilizando la formula de Green:
∫∫∫∇(κ∇vj)vi dv =∫∫∫
∇ (viκ∇vj) dv −∫∫∫
κ∇vj∇vi dv =
©∫∫
∂Dviκ
∂vj
nds−
∫∫∫κ∇vj∇vi dv =∫∫
∂D2
viκ∂vj
nds−
∫∫∫κ∇vj∇vi dv =
dj,i + Kj,i (6.72)
donde Ki,j es la matriz de rigidez introducida en el capıtulo 4. Substituyendoen la ecuacion base∑
j
[Mi,j
daj
dt−Ki,jaj − (di,jaj + ci)
]= 0 (6.73)

6.6. ELEMENTOS FINITOS Y LA ECUACION DE DIFUSION 99
Por otra parte
∑j
di,jaj + ci =
∑j
aj
∫∫∂D2
viκ∂vj
∂nds +
∫∫∫∇(κ∇v0)vi dv =
∫∫∂D2
viκ
∑j aj∂vj + ∂v0
∂nds+ =∫∫
∂D2
viκ∂u
∂nds+ =∫∫
∂D2
vih ds = bi (6.74)
notese que este es el coeficiente que aparece como termino independiente en elcapıtulo 4. Finalmente, se obtiene∑
j
Mi,jdaj
dt= −
∑j
Ki,jaj + bi (6.75)
o, en forma matricial
Mdadt
= −Ka + b (6.76)
Esta ecuacion diferencial puede integrarse para obtener la solucion apro-ximada a la ecuacion original. Las condiciones iniciales vienen dadas por laaproximacion a la condicion inicial u(x, 0) = f(x).
La matriz de rigidez K es positiva definida, segun se demostro en el capıtulo4. Tambien lo es la matriz de masas M . Por tanto, la matriz M−1K que apareceen el sistema
dadt
= −M−1Ka + M−1b (6.77)
es positiva definida. Por tanto, el algoritmo de Crank-Nicholson, aplicado a estaecuacion debe ser estable. Es por ello que es una opcion muy popular pararesolver este sistema. La matriz del algoritmo es
G =(
I − 12M−1A
)(I +
12M−1A
)−1
=(
M − 12A
)(M +
12A
)−1
(6.78)
(6.79)
Por lo tanto, solamente es preciso factorizar la matriz M − 12A.

100 CAPITULO 6. LA ECUACION DE DIFUSION

Capıtulo 7
Problemas armonicos
7.1 Introduccion
Es frecuente que en problemas dependientes del tiempo las condiciones de con-torno y las densidades de carga o de corriente tengan una dependencia senoidal(o cosenoidal) del tiempo. Por ejemplo, la ecuacion de difusion toma a menudola forma particular:
∂u
∂t= ∇(κ∇u)
sujeto a u ∈ D × [0, T ]u(x, 0) = f(x)
u(x, t) = g0(x) cos (ωt + φg(x)) x ∈ ∂D1
∂u(x,t)∂n = h0(x) cos (ωt + φh(x)) x ∈ ∂D2 (7.1)
La constante ω es la frecuencia del problema. Notese que aunque se han utili-zado funciones coseno para describir la dependencia temporal de las condicionesde contorno, podrıan haberse utilizado igualmente bien funciones seno, sin masque cambiar las fases φ∗(x) por φ∗(x) + pi
2 .La solucion de esta ecuacion es la suma de un termino transitorio, que se
va amortiguando conforme el tiempo final T tiende a infinito, y un terminopermanente, que presenta una dependencia cosenoidal del tiempo. Una de lasmaneras mas sencillas de demostrar este hecho es utilizar la ecuacion de difusiondiscretizada (6.15):
d
dtu(t) = Au(t) + b(t) (7.2)
Recuerdese que la matriz A representa el operador laplaciano, y es cons-tante; mientras que el vector b(t) lleva la informacion sobre las condiciones decontorno. Como estas son cosenoidales, es facil ver que
101

102 CAPITULO 7. PROBLEMAS ARMONICOS
bi(t) = b0i cos (ωt + φi) (7.3)
Por otra parte, la solucion de (7.2) es
u(t) = exp [At]u(0) +∫ t
0
exp [A(t− s)]b(s) ds (7.4)
El primer termino tiende a cero cuando t tiende a infinito. En efecto, comose comento en la seccion 6.4, los autovalores de A son negativos, por lo que quela matriz exp [At] tiende a cero cuando t tiende a infinito. Esto significa queel efecto de las condiciones iniciales, que estan representadas en el vector u(0),tiende a desaparecer conforme el tiempo crece, siendo el estado al cabo de untiempo largo independiente de la manera en que se origino, lo que cabe esperarpor razones fısicas. Tambien significa que la solucion u(t) permanece acotada:si los autovalores de A fueran positivos la exponencial crecerıa sin lımite, lo quees fısicamente absurdo. En cualquier caso, se obtiene para tiempos grandes:
u(t) =∫ t
0
exp [A(t− s)]b(s) ds (7.5)
7.2 Notacion compleja
La integral anterior puede resolverse de una forma particularmente sencilla uti-lizando numeros complejos. En efecto,
bi(t) = b0i cos (ωt + φi) (7.6)= < [b0i exp (ωt + φi)] (7.7)= <(b0i exp ωt) (7.8)
En este capıtulo se seguira la conveccion de que es la unidad imaginaria,z un numero complejo, z∗ su complejo conjugado y < e = las partes real eimaginaria respectivamente. Entonces
b(t) = <(b0eωt) (7.9)
=12
(b0e
ωt + b∗0e−ωt
)(7.10)
(7.11)
Utilizando este resultado para calcular la integral
u(t) =∫ t
0
exp [A(t− s)]b(s) ds
=∫ t
0
exp [A(t− s)]12
(b0e
ωs + b∗0e−ωs
)ds

7.2. NOTACION COMPLEJA 103
=∫ t
0
12
(b0 exp [A(t− s) + ωs] + b∗0 exp [A(t− s)− ωs]
)ds
=−12
(b0 [A− ω]−1 [
eωt − eAt]
+
b∗0 [A + ω]−1 [e−ωt − eAt
])(7.12)
Como eAt tiende a cero cuando t tiende a infinito, para tiempos grandes estaexpresion se puede simplificar a:
u(t) =−12
(b0 [A− ω]−1
eωt + b∗0 [A + ω]−1e−ωt
)(7.13)
=12(u0e
ωt + u∗0e−ωt
)(7.14)
= <(u0e
ωt)
(7.15)
siendo
u0 = −b0 [A− ω]−1 (7.16)
De otra forma
ωu0 = Au0 + b0 (7.17)
Comparando con la ecuacion original (7.2),
d
dtu(t) = Au(t) + b(t) (7.18)
se observa que para pasar de la una a la otra se han hecho los siguientes cambios:
1. Se han substituido la funcion del tiempo b(t) por el vector de numeroscomplejos b0. Estos numeros complejos se calculan mediante las ecuacio-nes (7.6,7.7,7.8). Analogamente con la funcion u(t) y el vector u0.
2. Se ha substituido la derivada respecto al tiempo por el producto por ω.
Estas reglas son generales para obtener la respuesta permanente en regimensenoidal de ecuaciones diferenciales lineales.
4 Basico
5 AvanzadoPor ejemplo, en el caso de que se prefiriera resolver la ecuacion de difusion
mediante elementos finitos, habrıa que pasar de
Mda(t)
dt= −Ka(t) + b(t) (7.19)
a
ωM a0 = −Ka0 + b0 (7.20)

104 CAPITULO 7. PROBLEMAS ARMONICOS
7.3 Difusion magnetica e histeresis
Un problema frecuente es el calculo de campos magneticos y electricos en cir-cunstancias donde las corrientes de desplazamiento son despreciables. La cuartaecuacion de Maxwell es entonces:
∇×H = j (7.21)Aplicando la ley de Ohm
∇×H = σE (7.22)
= σ
(∇V − ∂A
∂t
)(7.23)
= js − σ∂A∂t
(7.24)
El termino js son las corrientes impuestas por el potencial V , que suele serdato del problema. Por otra parte, como B = µH,
∇×(
1µ∇×A
)= js − σ
∂A∂t
(7.25)
En medios ferromagneticos, el numero µ no es una constante, sino que de-pende del propio campo B, debido a la existencia de fenomenos de saturacion ehisteresis. Esto causa que, aun cuando el campo H tenga una dependencia se-noidal del tiempo, el campo B (y por tanto A) no lo tenga, haciendo imposiblela aplicacion de los metodos de la seccion anterior, que se basa en que todas lasmagnitudes tengan dependencia senoidal.
Existe, no obstante, una forma aproximada de tratar el problema de lahisteresis. Esta consiste en la substitucion del ciclo real de histeresis por unciclo aproximado elıptico (ver figura 7.1). Esta aproximacion es equivalente a lautilizacion de una constante µ compleja.
En efecto, supongase que H presenta una dependencia senoidal del tiempo
H(x, t) = H0(x) cos (ωt + φH(x)) (7.26)De acuerdo con los metodos de la seccion anterior, se puede asociar a este
campo, el campo complejo no dependiente del tiempo:
H0 = H0eφH (7.27)
Se puede calcular ahora el campo B0 multiplicando por la constante complejaµ:
B0 = µH0 (7.28)= µeφµH0e
φH (7.29)= µH0e
(φµ+φH) (7.30)= B0e
φB (7.31)

7.3. DIFUSION MAGNETICA E HISTERESIS 105
H
B
Figura 7.1: Ciclos de histeresis real y aproximado
Este campo complejo tiene asociado el campo real dependiente del tiempo
B(x, t) = B0(x) cos (ωt + φB(x)) (7.32)
Ahora, a partir de (7.26) y (7.32)
B(x, t) = B0 cos (ωt + φB)= µH0 cos (ωt + (φµ + φH))= µH0 cos (ωt + φH) cos φµ − µH0 sin (ωt + φH) sinφµ
= µH0H
H0cos φµ − µH0
√1−
(H
H0
)2
sinφµ (7.33)
Luego
µH0 sinφµ
√1−
(H
H0
)2
= µH cos φµ −B
µ2H20 sin2 φµ
(1−
(H
H0
)2)
= µ2H2 cos2 φµ + B2 − 2µHB cos φµ
Ya que al ser los vectores B y H son paralelos, BH = BH. Ası pues:

106 CAPITULO 7. PROBLEMAS ARMONICOS
µ2H20 sin2 φµ − µ2H2 sin2 φµ = µ2H2 cos2 φµ + B2 − 2µHB cos φµ
µ2H2 + B2 − 2µHB cos φµ = µ2H20 sin2 φµ (7.34)
que es claramente la ecuacion de una elipse en el pano B −H. Pero esto es loque se querıa demostrar.
Notese que con este metodo se ha modelado la histeresis, pero no la satu-racion. En efecto, al aumentar H0, tambien aumenta proporcionalmente B0 =µH0, en vez de aumentar a un ritmo menor al saturarse el material.
Con estas cualificaciones, la ecuacion (7.25) se transforma en
∇×(
1µ∇× A0
)= js0 − σA0 (7.35)
Ahora, no queda mas que considerar las condiciones de contorno en A0, dis-cretizar las derivadas respecto al espacio, y resolver la ecuacion lineal complejaresultante.

Bibliografıa
La bibliografıa existente sobre la resolucion de ecuaciones de campo es suma-mente extensa, y ciertamente no existe aquı el proposito de presentarla de unaforma exhaustiva1, sino mas bien indicar algunos textos en los que el lectorinteresado puede ampliar conocimientos.
Un libro excelente de introduccion a la resolucion moderna (como contra-puesta a la de preguerra) de sistemas lineales es:
• “Linear Algebra and its Applications”, G. Strang, Saunders College Pu-blishing.
Y para los mas exigentes, la referencia es:• “Matrix Computations”, G. H. Golub and C. F. van Loan, John Hopkins
University Press.Una buena introduccion a las diferencias finitas, con un gran numero de
ejemplos trabajados:• “Numerical Solution of Partial Differetial Equations: Finite Difference Met-
hods”, G. D. Smith, Oxford University Press.Uno de los autores de la primera referencia tambien tiene escrita una intro-
duccion muy clara a la teorıa matematica de los elementos finitos:• “An Analysis of the Finite Element Method”, G. Strang and G. J. Fix,
Pretince-Hall.Mas completo (o mas pesado), tanto desde el aspecto matematico (cubre
elementos y diferencias finitas, y otras cosas) como del algorıtmico, es:• “Numerical Approximation of Partial Differential Equations”, A. Quarte-
roni and A. Valli, Springer-Verlag.Desde el punto de vista de las aplicaciones a problemas de ingenierıa, es
entretenido:• “What Every Engineer should know about Finite Element Analysis”, J.
R. Brauer, Marcel Dekker.
1Tarea para la que, por otra parte, el autor no se siente capacitado.
107