complex terminology extraction model from unstructured web text based linguistic and statistical...
TRANSCRIPT

IJIRR: International Journal of Information Retrieval Research. 2(3), 1-18, 2013.
Complex Terminology Extraction Model
from Unstructured Web Text based
Linguistic and Statistical Knowledge
Fethi Fkih and Mohamed Nazih Omri
MARS Research Unit, Faculty of sciences of Monastir,
University of Monastir, 5019 Monastir, Tunisia
ABSTRACT
Textual data remain the most interesting source of information in the web. In our research, we
focus on a very specific kind of information namely "complex terms". Indeed, complex terms are
defined as semantic units composed of several lexical units that can describe in a relevant and
exhaustive way the text content. In this paper, we present a new model for complex terminology
extraction (COTEM), which integrates linguistic and statistical knowledge. Thus, we try to focus
on three main contributions: firstly, we show the possibility of using a linear Conditional
Random Fields (CRF) for complex terminology extraction from a specialized text corpus.
Secondly, we prove the ability of a Conditional Random Field to model linguistic knowledge by
incorporating grammatical observations in the CRF’s features. Finally, we present the benefits
gained by the integration of statistical knowledge on the quality of the terminology extraction.
Keywords: Term; Collocation; Terminology Extraction; Linguistic knowledge; Conditional
Random Fields; Statistical measure.
1. INTRODUCTION
Data contained in the web are very
heterogeneous; we can find several types of
information: text, image, video, etc. The
textual content remains the most interesting.
As detailed in (Kwok, Etzioni & Weld, 2001;
Popescu & Etzioni, 2005), unstructured Web
text is characterized, compared to other types
of information, by several features: a huge
volume, difficulty of extraction, heterogeneity
of knowledge, wealth of useful information,
etc.
The textual information is the main base of
the process of information retrieval (IR). In
the information retrieval process, the indexing
task is very important. Indeed, poor indexing
of documents will necessarily lead to bad
results. Therefore it is important to improve
the quality of the extraction of indexes to
increase the efficiency of information retrieval
on the Web.
We define the problem of indexing as
follows: for a given document, how to present
its content in an exhaustive and unambiguous
way? Thus, the ultimate goal of indexing is to
select semantic and meaningful tokens that
can help with semantic modelling of
documents. In the literature of the Natural
Language Processing (NLP) field, these
semantic tokens are often called "terms".

IJIRR: International Journal of Information Retrieval Research. 2(3), 1-18, 2013.
The manual extraction of meaningful terms
from textual documents is very costly in time
and resources. So, it’s necessary to develop
methods for an automatic term extraction.
Former works in the information extraction
field focuses on exploiting structured and
semi-structured text (Chang, Hsu & Lui, 2003;
Zhai & Liu, 2006; Subhashini & Jawahar
Senthil Kumar, 2011). Recently, several
research works are directed towards the
extraction from unstructured Web text. We
cite, among others, the use of lexico-syntactic
patterns (Hearst, 1992), the use of generic
patterns and a bootstrap approach in order to
learn semantic relations from text
(Pennacchiotti & Pantel, 2006), the use of a
Relational Markov Network framework
(Bunescu, Mooney, 2004), etc.
In our research, we are interested in a
specific type of information, namely the
terminology, which owns its own linguistic,
statistical and semantic characteristics
(detailed in the remainder of this article).
In this context, we propose a new model
for terminology extraction. This hybrid model
combines linguistic and statistical knowledge;
it is composed of two main modules: linguistic
for extraction and statistical for filtering.
The linguistic module is based on
Conditional Random Fields (CRF) enriched
by shallow linguistic knowledge. Indeed,
probabilistic models and essentially the CRFs
have proven their contributions in several
application areas of Natural Language
Processing (NLP) such as text chunking,
Morphosyntactic annotation (Lafferty,
McCallum & Pereira, 2001) and Named
Entities Recognition (NER) (Okanohara,
Miyao, Tsuruoka & Tsujii, 2006). CRFs are
not yet applied for terminology extraction
from specialized text corpora. This may be
due to the extraction difficulty and complexity
of the relevant terms because of their
linguistic nature and semantic specificity.
Therefore, it is original to propose a model
based CRF using linguistic knowledge for
complex terminology extraction.
The statistical module is based on joint
frequency calculations of tokens in a fixed-
size window. The goal is to quantify the
strength of connection between the lexical
units. These statistical measures are
considered good indicators to decide whether
the coexistence of two lexical units is
significant or not (due to chance).
In our research, we focus on specialized
corpora (medical, biology, chemistry, etc.).
This kind of textual document is characterized
by a terminology reflecting specialized
language of the considered field. In fact, the
specialized language is rich in scientific and
technical terms making them more visible and
accessible and requiring no intervention of an
expert to identify them.
The remainder of this paper is structured as
follows. Section 2 presents the main
approaches of term extraction from text
documents. In section 3, we introduce our
approach for the complex terminology
extraction with a presentation of features used
to model different linguistic observations and
we focus on the theoretical principle of our
statistical filter. Section 4 is reserved for the
performance tests of our approach. Our
experimental study was carried out on the
standard test database MEDLARS and
compared with other powerful models.
2. RELATED WORKS
The notion of "term" is a central concept in the
indexing and documentary retrieval doctrine.
That’s why it is necessary to precisely define
it. Actually, there are several definitions which
are very unclear and fuzzy. In the early
thirties, Eugene Wüster based a general theory
of terminology that defines the term as the
linguistic representation of a concept in a
domain of knowledge (Felber, 1987). From
this perspective, a term is a scientific concept
label linked to other concepts in a primarily

IJIRR: International Journal of Information Retrieval Research. 2(3), 1-18, 2013.
taxonomic organization. This classic definition
lacks flexibility; it requires that the concept is
part of a unique and stable conceptual system
that characterizes a priori knowledge field.
Didier Bourigault in (Bourigault & Jacquemin,
2000) proposes a more flexible definition; they
maintains that the term is the result of a
terminology analysis process and a decision
made by a community of experts (researchers,
linguists, engineers ...). This definition can
cover some linguistic phenomena that may
appear while processing a big size corpus
where a term can vary between several
knowledge fields, or even within the same
field (such as polysemy and synonymy , for
example).
A term can be classified into two types:
simple or complex. Simple terms are formed
by a single full word and are easy to extract
but they present a semantic ambiguity, often
polysemic. By cons, the complex terms are
constituted by two full words at minimum,
and are difficult to extract but they have less
ambiguity. In this work, we focus on the
extraction of complex terms.
2.1 Complex terms variations
Each complex term admits a set of linguistic
changes that maintain its semantics and refer
to the same lexical referent. Complex terms
variations can be:
Graphics: This variation type relates to
changes in graphic (capitalization,
hyphen)
Inflectional: variations are related to
setting one or more words forming the
term plural,
Syntactic: it’s the change of the internal
structure of the term without changing
the grammatical class of content words,
Morphosyntactic: these variations affect
the internal structure of the base term
and the component words (grammatical
or full),
Paradigmatic: it’s to substitute one
or two full words by one of their
synonyms without changing the
morphosyntactic structure
Anaphoric: this type of variation
refers to a previous mention in the
text of the basic term.
For more details, see (Daille, 1994; Daille,
2002).
2.2 Terminology Extraction
Approaches
Researches interested in complex terms
extraction are recent and can be classified into
three main approaches: statistical (or
numerical) approach, linguistic (or symbolic)
approach, and a hybrid approach that’s both
statistical and linguistic.
2.2.1 Statistical approach
The statistical approach is used in general to
extract the binary terms (collocations), by
calculating for each pair of words a statistical
index. This index presents an association score
which measures the force of attachment
between the two words of the same couple.
Church and Hanks (Church & Hanks,
1990) in their work use the association score
which’s an adaptation of mutual information
on the terminology extraction field (Fano,
1961). In the same context, Frank Smadja in
(Smadja, 1993) presents a terminology
extraction system Xtract that uses the z-score
(Berry-Rogghe, 1973) for the bi-grams
identification.
The collocations extraction technique is
based on a simple principle: if two words
frequently appear together, then there’s a
chance that they form a meaningful lexical
sequence (or a relevant term). In practice, we
calculate a score that measures the attachment
force between two words in a given text. If
this force exceeds a threshold fixed a
priori, we conclude that the couple can
form a relevant term.

IJIRR: International Journal of Information Retrieval Research. 2(3), 1-18, 2013.
Before calculating the words joint
frequency we must, first, reduce them to a
canonical form. Stemming (or lemmatization)
can solve the terminological variation
problem. The terminological variation can be
graphical, inflectional or otherwise. In fact,
terminology variation can disrupt the results if
we consider two variations of the same token
as two different units. Example, the lexical
units "acids" and "Acid" are reduced to their
canonical form "acid" that will accumulate the
frequencies sum of all its variations.
Next, we apply a common statistical
technique presented by Kenneth Church in
(Church & Hanks, 1990) on the text. This
technique consists in moving a sliding
window of size T over the text (see Figure 1).
Figure 1. Example of a sliding window of
size 5
For each pair of lemma (w1,w2),
(w1,w2),…, (w1,wT) we increment its
occurrence frequency in the corpus. We
associate a contingency table with each couple
(wi,wj) (see table1).
Table 1. Contingency table
wj wj’ with j’≠j
wi A b
wi’ with i≠i’ C d
a = occurrences number of the pair of
lemma.
b = occurrences number of the pair of
lemma where a given lemma appears as
the first item of the pair.
c = occurrences number of the pair of
lemma where a given lemma appears as
the second item of the pair.
d = occurrences number of the pairs of
lemma that don’t contain one of the two
lemmas.
In the literature, we find several statistical
criteria to determine the reattachment force
between two words in a text. These measures
are used initially in the biology domain to
detect possible relationships between events
that occur together. We cite, inter alia, the
Loglikelihood (1) (Daille, Gaussier & Langé,
1998).
(1)
Roche in (Roche, Heitz, Matte-Tailliez &
Kodratoff, 2004) defines a new measure
(OccL) that combines Loglikelihood with joint
occurrence (2).
aLoglikeOccL (2)
Based on experimental studies, Roche in
(Roche, Azé, Kodratoff & Sebag, 2004) has
proved that OccL measure admits a higher
discriminative ability than other measures and
therefore offers the best result. That’s why; we
choose this measure to extract collocations in
our work.
The statistical approach based on the
sliding window allows extracting only binary
terms (collocations from size 2) but cannot
extract terms of size three, four or more. This
criterion is regarded as a major flaw in this
approach. To meet this need, Lebert in (Lebert
& Salem 1994) proposes the method of
repeated segments. This method involves
identifying sequences of words that are
repeated in the text and the frequencies of
which are calculated thereafter. This method
)log()(
)log()()log()(
)log()()log()(
)log( )log()log()log(Loglike
dcbadcba
dcdcdbdb
cacababa
ddccbbaa

IJIRR: International Journal of Information Retrieval Research. 2(3), 1-18, 2013.
gives very noisy results; it identifies
heterogeneous, fixed and uninteresting noun
phrases (Claveau, 2003).
The strengths of the statistical approach can
be summarized in the following points:
Independence from natural
languages
Independence from knowledge
areas
Ability to be easily automated.
These features make the statistical
approach flexible and portable between
different types of textual corpora.
Nevertheless, this approach is unable to
provide interpretable results and cannot detect
rare terms in the text. Indeed, this approach
considers the text as a "bag of words" while it
focuses on the statistics features of the words
and ignores any kind of linguistic or semantic
relationship between them.
In the next section, we present the linguistic
approach that uses the linguistic context for
the terminology extraction.
2.2.2 Linguistic approach
This approach uses the linguistic properties
(morphological or syntactic) to identify terms.
In general, the text is chunked into non-
recursive chunks using a rules system (or
grammar) to detect terms by identifying their
components or their contexts, based on the
morphosyntactic annotation (Daille, 2002).
Practically, we use two techniques: patterns or
borders. The patterns are regular expressions
using an alphabet composed of grammatical
categories and/or lexical units; the idea is to
extract any sequence of tokens matching a
pattern specified by an automaton.
Compound terms of a given knowledge
domain (sports, politics, medicine, biology,
etc...) belong to a finite set of syntactic
structures. These structures are frequent in the
specialized corpus and can be easily identified
by an expert. For example, we consider the
case of the medical field (in the English
language), we can detect the following
patterns:
Adjective + noun. Example: renal
amyloidosis
noun1 + noun2. Example: lung abscess
adjective1 + adjective2 + noun.
Example: autoimmune hemolytic anemia
noun1 + preposition + noun2. Example:
action of antimetabolites
Then we can construct finite state machines
for the extraction of these structures. The
alphabet of this automaton is made up of a
subset of grammatical tags and tokens. “Figure
2” presents an automaton that can identify the
structure noun1 noun2.
Figure 2. Pattern for the structure extraction
“noun1noun2”
This technique is used by Thierry Hamon
and Sophie Aubin for implementing YaTeA
(Aubin & Hamon, 2006). The extraction of
candidate terms is based on a hybrid strategy
in which the extraction from syntactic patterns
can be guided and corrected using existing
terminology resources.
Fkih, Omri and Toumia in (Fkih, Omri &
Toumia, 2012) implement a purely linguistic
model where they use a CRF to model the
linguistic knowledge provided by the syntactic
pattern.
The method of "natural borders" is based
on the identification of natural borders for the
noun phrases identification. For example in
the French language, a conjugated verb is
considered as one of the natural borders of the
nominal group.
This method is used by Didier Bourigault
for implementing LEXTER (Bourigault, 1994;
Bourigault, 1996). The accuracy of these
boundaries for delineating French nominal
groups can reach 95% (Bourigault, 1992).

IJIRR: International Journal of Information Retrieval Research. 2(3), 1-18, 2013.
Mollá Diego and his research group (2003)
proposed a new model for extracting answers
from technical texts (ExtrAns). This system
uses a linguistic module to identify and extract
the terms most relevant to a user query.
ExtrAns provided a good precision at the price
of a small recall.
In the same context, Abramowicz and
Wisniewski (2008) have proposed a novel
method for term extraction in ontology
learning from text that uses proximity context-
window based on multi-layered shallow
linguistic information. It should be noted that
the performance of this system is average and
needs improvement.
The linguistic approach presents a strong
dependence on treated language since each
natural language admits its own linguistic
characteristics that require a different
treatment. For example, the linguistic models
applied to extract the Chinese terminology
(Lang, Liang, Chong & Heyan, 2008) cannot
be integrally applied to the extraction of
Arabic terminology (Bounhas & Slimani,
2009). Also, the linguistic approach depends
on the syntactic (or grammatical) analysis
tools used for text tagging. Consequently, this
dependence will decrease the portability of
any application that uses this approach. In
addition, the performance of the syntactic
analysis tools affects the quality of results
provided by a system implementing this
approach.
On the other hand, the linguistic approach
offers the possibility to detect and to extract
complex terms in a very fine manner. So, it
increases the semantic aspect of the results by
making them more interpretable.
2.2.3 Hybrid approach
The hybrid approach combines statistical and
linguistic methods. We present three
techniques: the first one is the identifying by
linguistic methods and filtering by statistical
methods, the second one is the identification
by statistical methods and filtering by
linguistic methods and the third technique is a
parallel identification by statistical and
linguistic methods.
ACABIT, a system developed by Beatrice
Daille (Daille, 1994), applies primarily a
morphosyntactic analysis to identify the
different terminological variations. Then it
filters the candidate terms using statistical
methods. Note that the statistical filtering is
done only for the binary terms. The terms of a
size equal to 3 or more are extracted during
the linguistic phase using lexico-syntactic
patterns, and then they are not concerned by
the second phase (statistical).
Using a reverse technique, Oueslati, in his
system Mantex (Frath, Oueslati & Rousselot,
2000) applies primarily a statistical approach
then uses a linguistic approach. At the first
level he uses the “repeated segments” method
extraction (previously presented) and keeps
only the terms that exceed a certain frequency.
Secondly he filters the result by using
syntactic information.
Mathieu Roche (Roche, Heitz, Matte-
Tailliez & Kodratoff, 2004) implements a
system called EXIT that can extract complex
terms using a mixed method which makes
alternation between statistical and linguistic
processing. Indeed, He begins by extracting
two tokens using the same principle of binary
collocations extraction. During the extraction
process, the user will judge the relevance of
each found term: if a term is deemed relevant
then the two tokens will be concatenated
(separated by a hyphen "-") and re-injected
back into the corpus. The system repeats this
task several times. The high cost in execution
time is the main drawback of this approach.
Practically, to extract a term of size three the
corpus must be treated twice (three times for a
term of size four and so on). Consequently,
this task becomes almost impossible for large
corpora. In addition, this technique requires
the intervention of the user in the extraction
process. Therefore it cannot qualify as an
automatic approach.

IJIRR: International Journal of Information Retrieval Research. 2(3), 1-18, 2013.
2.2.4 Use of Machine Learning in
Information Extraction
The use of machine learning has become very
common in the information extraction field,
mainly for the recognition of named entities
(named entity recognition). In the literature,
we find a large variety of models based on
machine learning for knowledge extraction,
we cite: Hidden Markov Models (HMM)
(Cohen & Sarawagi, 2004; Fu & Luke, 2005),
Support Vector Machines (SVM) (Zhou,
Shen, Zhang, Su, Tan & Chew Lim, 2004),
Conditional Random Fields (McCallum & Li,
2003), semi-CRF (Okanohara, Miyao,
Tsuruoka & Tsujii, 2006). These models are
used to identify several types of entities such
as: personal and company names in the
newspapers, genes and proteins names in
biomedical publications, titles and authors in
unstructured texts, etc...
Recently, several studies have been geared
towards the use of Machine Learning for
terminology extraction. In this context, Liu
and Qi (2011) have used an annotated corpus
of nominal terms for learning a SVM. The
main disadvantage of this model is that it only
extracts nominal terms and ignores other types
of terminology.
The CRFs have proved their effectiveness
when they were applied to text chunking and
syntactic text annotation where they gave
good results (Sha & Pereira, 2003; Tsuruoka,
Tsujii & Ananiadou, 2009; Constant, Tellier
& Duchier, 2011). So far, we have not found
CRF-based models for complex terms
extraction from textual documents. This may
be due to the linguistic nature of complex
terms characterized by a specific semantic and
lexical richness.
3. COMPLEX TERMINOLOGY
EXTRACTION MODEL (COTEM)
The COTEM model that we propose (see
Figure 3) revolves around three main tasks:
Lemmatization and grammatical
annotation
Linguistic extraction based CRF
Statistical filtering
Figure 3. Overview of COTEM function
The lemmatization and annotation task is
performed by a program of syntactic
annotation (TreeTager1). Later in this paper,
we present only the second and the third steps:
linguistic extraction and statistical filtering.
3.1 Linguistic extraction based CRF
In the context of the linguistic approach, we
propose a model based on the integration of
grammar in a CRF
In practice, we want to make the CRF learn
the same linguistic knowledge used by the
“lexico-syntactic patterns” method for
terminology extraction. This knowledge is
built on observing the linguistic characteristics
of the relevant terms and their neighbors in the
text.
3.1.1 Conditional Random Fields
A conditional random field may be viewed
as an undirected graphical model (Figure 4). It
is used to annotate an observed sequence X=
(x1, x2… xn) by a sequence of a predefined
label Y= (y1, y2… yn).
1 http://www.ims.uni-stuttgart.de/projekte/corplex/TreeTagger/

IJIRR: International Journal of Information Retrieval Research. 2(3), 1-18, 2013.
Figure 4. Graphical structure of a sequential
CRF
Relation between observation and label (3)
is introduced by (Lafferty, McCallum &
Pereira, 2001):
(3)
With C being the set of cliques in the graph
and yc values set of the Y variables on the
clique c. A normalization coefficient Z(x) is
used to ensure that:
(4)
A set of features fk is defined within each
clique c. Each features fk takes two arguments
as input: the current observation and the
following state. fk often returns a binary value
(1 or 0). These features express some
characteristics based on empirical observations
built during the training phase (Wallach,
2003).
In general, features don’t have the same
degree of importance in the model. Therefore,
a real weight λk is assigned to each feature in
order to characterize its discriminating power.
These weights are estimated in the training
phase using a set of annotated examples and an
algorithm to maximize the log-likelihood
(Sutton & McCallum, 2006).
Unlike other probabilistic models, CRFs
offer a great opportunity for modeling long-
distance dependencies between observations.
For example, we can model the dependence
between the states yi, yi-3, yi+2 and the
observation xi+4. This property is very useful in
the terminology extraction field where the
words of a term are sometimes not adjacent but
distant and separated by undesirable words.
3.1.2 States and observations
In our work we propose the use of a sequential
CRF composed of the following states:
BSent: models the beginning of a
sentence.
ESent: models the end of a sentence.
Bterm: models the beginning of a term.
Eterm: models the end of a term.
The linguistic observations included in the
CRF are mainly grammatical, based on
grammatical labels provided by an automatic
part-of-speech tagger. In the remainder of our
article, we use “TreeTager” grammatical labels
for the English language. Example of
“TreeTager” labels:
IN: preposition.
JJ: adjective.
NN: Noun.
SENT: point.
To take into account the context of a term,
we prepare five lists:
PL (Punctuation List): contains
punctuation.
WBTT (True Words Before Terms):
contains the words or grammatical
categories that frequently come before
the relevant terms (e.g. a preposition).
TWBTT (Two Words Before True
Terms): contains terms composed of two
words that frequently come before the
relevant terms (e.g. exchange of).
WATT (After Words True Terms):
contains the words that come frequently
after the relevant terms.
)),,(exp()(
1)x\(
Cc k
cxcykfkxZyp
1)\( y xyp

IJIRR: International Journal of Information Retrieval Research. 2(3), 1-18, 2013.
DL (Definition List) contains
expressions that introduce a definition
(e.g. is, :).
The occurrence count of words in each list
must be greater or equal to a minimum
threshold frequency. In our experiment, we
take a threshold equal to 5.
In our terminology extraction approach, we
distinguish two lexical sequences types:
Relevant Terms: meaningful lexical
sequences, they can describe a given
knowledge field (biomedical in our case)
Irrelevant terms: lexical sequences
belonging to usual language (which are
common to all areas of knowledge), in
the following we refer to these types of
lexical sequences by "Others" (see
Figure 5 )
If we observe our list of relevant terms, we
can extract several linguistic relationships
useful for learning our CRF. In the following,
we present some examples of linguistic
observations integrated in CRF Features.
Observation 1:
Adjectives, in most cases, are followed by:
A name: renal<JJ>amyloidosis<NN>.
An adjective: para-aminohippuric <JJ>
acid <JJ> clearance<NN>
Observation 2:
Names are usually followed by:
Name: lung<NN> abscess<NN>
Adjective: starch<NN> gel<NN>
electrophoretic<JJ>
Preposition: inhalation<NN> of <IN>
nickel<JJ> carbonyl<NN>
Figure 5. Simplified structure of the CRF
model
Observation 3:
Prepositions are generally followed by a name:
toxicity<NN> of<IN> sulfur-35<NP>
Observation 3:
Relevant terms have a particular linguistic
context. Indeed, we observe the tokens that
precede and follow it. Example of lexical units
observed before the relevant terms:
Preposition (as, of, by, ...)
Verbs (reported, have, employed, is ...)
Punctuation (:)
This linguistic knowledge is used to build the
CRF (see Figure 5) and to learn the Features.
For more details, we refer you to our paper
(Fkih, Omri & Toumia, 2012).

IJIRR: International Journal of Information Retrieval Research. 2(3), 1-18, 2013.
3.1 Statistical filtering
If we observe the list of terms extracted by
the linguistic model, we find that most of the
terms classified by the system as "irrelevant"
are composed of "random" tokens, that is to
say, it is rare (statistically) to find these tokens
together in a fixed-size window.
In order to improve the performance of the
linguistic model, we propose the elimination of
each term admitting a rare composition (from a
statistical viewpoint) between the lexical units.
For this, we propose the following rule: An
extracted term is considered relevant if each
pair of tokens that compose it admits a force of
attachment that exceeds a threshold fixed a
priori.
Formally, the rule can be stated as follows:
Let T be a term of n tokens, T can be
represented (statistically) by the n-gram:
w1 w2 w3… wn, such that wi is the token
of rank i of the term T.
Let S be a statistical threshold fixed by
an expert.
T is considered relevant if for each pair
(wi, wi +1) we have M(wi, wi +1)> S, Such
that M is a statistical measure that
quantifies the strength of connection
between the two lemmas wi and wi+1 in a
fixed-size window.
Practically, we chose to use OccL as a
statistical measure (see formula 2). The
window size choice is a necessary task to
ensure a better performance for the term
extraction. According to (Fkih & Omri, 2012),
a window of size 4 tokens will be a suitable
choice for our application. Also, we used a
threshold equal to 3.5; this choice is made by
an expert.
4. EXPERIMENTAL STUDY AND
EVALUATION OF THE RESULTS
4.1 Corpus description
During this work, we used an extract from
the medical corpus MEDLAR2 for the training
and the experimentation phases (see Table 2).
An expert in the medical field (university
professor in medicine) manually prepared a list
of relevant terms extracted from the corpus.
This list contains 226 technical terms in the
medical field. Examples of terms existing in
the list: toxicity of inorganic selenium salts,
cancer of the liver, diabetic syndrome,
histological examination, etc.
Table 2. Corpus description
MEDLARS
Training data Test data
Documents
number
Terms
number
Documents
number
25 226 75
4.2 Experimental study
We divide our experimental study in two
phases: extraction by CRF based on purely
linguistic knowledge, then a filtering based on
statistical measures quantifying the strength of
connection between the lexical units.
4.2.1 Extraction based CRF
We use TreeTagger for the grammatical
annotation of the text. We finally obtain an
annotated text that will be the input of our
system (see Figure 6).
At the end of the first phase of extraction we
obtain a preliminary list of candidate terms. By
way of example, we choose two terms
belonging to the preliminary list:
Terme1: horse crystalline lens gel
Terme2 : corresponding malignant cell
2 ftp://ftp.cs.cornell.edu/pub/smart
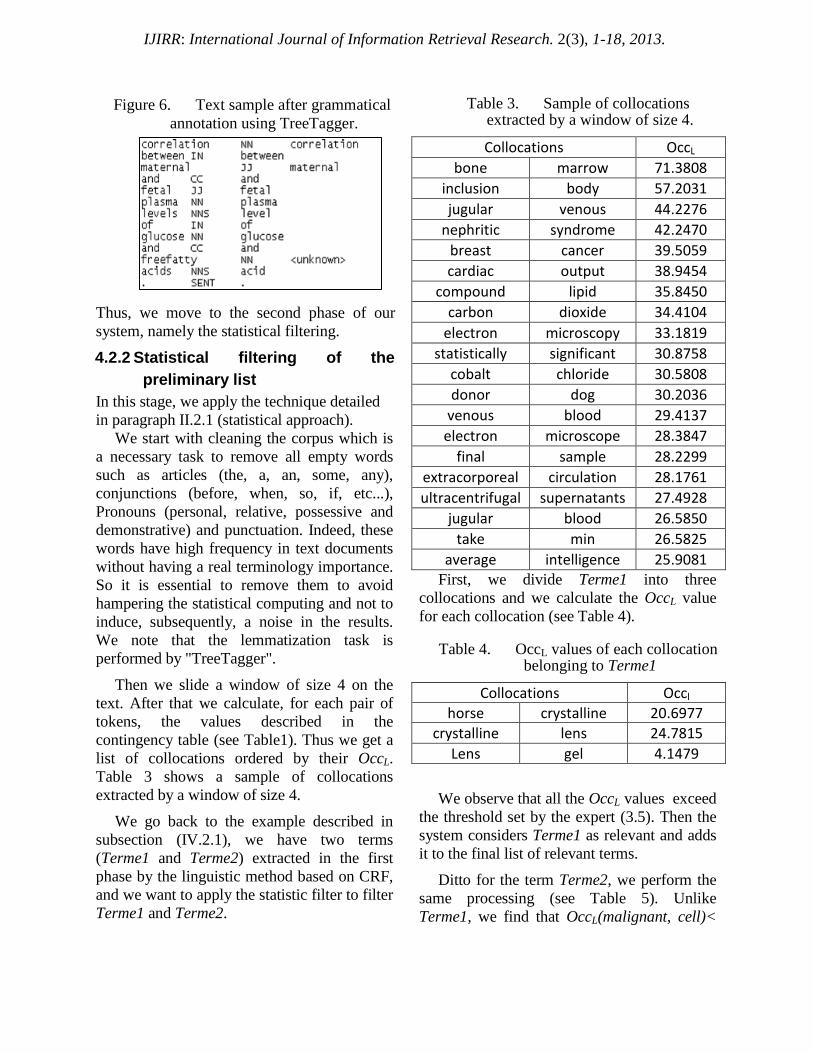
IJIRR: International Journal of Information Retrieval Research. 2(3), 1-18, 2013.
Figure 6. Text sample after grammatical
annotation using TreeTagger.
Thus, we move to the second phase of our
system, namely the statistical filtering.
4.2.2 Statistical filtering of the
preliminary list
In this stage, we apply the technique detailed
in paragraph II.2.1 (statistical approach).
We start with cleaning the corpus which is
a necessary task to remove all empty words
such as articles (the, a, an, some, any),
conjunctions (before, when, so, if, etc...),
Pronouns (personal, relative, possessive and
demonstrative) and punctuation. Indeed, these
words have high frequency in text documents
without having a real terminology importance.
So it is essential to remove them to avoid
hampering the statistical computing and not to
induce, subsequently, a noise in the results.
We note that the lemmatization task is
performed by "TreeTagger".
Then we slide a window of size 4 on the
text. After that we calculate, for each pair of
tokens, the values described in the
contingency table (see Table1). Thus we get a
list of collocations ordered by their OccL.
Table 3 shows a sample of collocations
extracted by a window of size 4.
We go back to the example described in
subsection (IV.2.1), we have two terms
(Terme1 and Terme2) extracted in the first
phase by the linguistic method based on CRF,
and we want to apply the statistic filter to filter
Terme1 and Terme2.
Table 3. Sample of collocations extracted by a window of size 4.
Collocations OccL
bone marrow 71.3808
inclusion body 57.2031
jugular venous 44.2276
nephritic syndrome 42.2470
breast cancer 39.5059
cardiac output 38.9454
compound lipid 35.8450
carbon dioxide 34.4104
electron microscopy 33.1819
statistically significant 30.8758
cobalt chloride 30.5808
donor dog 30.2036
venous blood 29.4137
electron microscope 28.3847
final sample 28.2299
extracorporeal circulation 28.1761
ultracentrifugal supernatants 27.4928
jugular blood 26.5850
take min 26.5825
average intelligence 25.9081 First, we divide Terme1 into three
collocations and we calculate the OccL value
for each collocation (see Table 4).
Table 4. OccL values of each collocation belonging to Terme1
Collocations Occl
horse crystalline 20.6977
crystalline lens 24.7815
Lens gel 4.1479
We observe that all the OccL values exceed
the threshold set by the expert (3.5). Then the
system considers Terme1 as relevant and adds
it to the final list of relevant terms.
Ditto for the term Terme2, we perform the
same processing (see Table 5). Unlike
Terme1, we find that OccL(malignant, cell)<

IJIRR: International Journal of Information Retrieval Research. 2(3), 1-18, 2013.
threshold. In this case the system will classify
Terme2 as irrelevant.
Table 5. OccL values of each collocation belonging to Terme2
Collocations Occl
corresponding malignant 6.1573
malignant Cell 2.4006
4.3 Evaluation of results
To evaluate Model performance, we make
a comparative study between our hybrid model
(COTEM) and three other models:
YaTe3: a linguistic model that is guided
and corrected using existing terminology
resources (Aubin & Hamon, 2006).
CRFGRA: a linguistic model based CRF
(Fkih, Omri & Toumia, 2012).
Model-based lexico-syntactic patterns
(Patterns Model) (Daille, 2002).
For our model implementation, we use
MAILLET4
a Java library used for natural
language processing, classification, extraction,
etc.
After application of the four models we
obtain the results described in the table below
(Table 6).
The COTEM can recover all 403 words of
which 213 are irrelevant. This noise reduction
is due to the integration of knowledge about
the context to better filtering terms before
extracting them.
The results show that COTEM reduced the
silence. Among 226 relevant terms, it recovers
190 terms. This result is due, among other
things, to the use of the “conjunction feature”.
This feature can extract terms related by a
conjunction. The Patterns Model can’t extract
3http://taln09.blogspot.com/2009/03/description-lextracteur-
de-termes-yatea.html 4 http://mallet.cs.umass.edu/
this kind of terms because it can only recover
the terms composed of adjacent words.
To evaluate COTEM performance we
considered two standard measures precision
and recall, which are defined as the ratio of
the number of relevant terms extracted
(NRET) by the Total Extracted Terms (TET)
and the Number of Extracted Terms (NET) by
the Total Number of Relevant Terms (TNRT)
in the corpus respectively.
(13)
In the field of terminology extraction, great
importance is attached to precision. For this
reason, we favor precision over recall. So, we
have chosen to highlight precision versus
recall in the F-Measure formula (15):
The table (Table 7) contains performance
measures that correspond respectively to our
model (COTEM), YaTeA, CRFGRA and
Patterns Model.
Figures 7, 8 and 9 show, respectively, the
precision, the recall and the F-measure for
each model.
Figure 7. Precision.
TET
NRETPrecision
TNRT
NETRecall
(15)
(14)
RecallPrecision*0.25
Recall)*(Precision*1.25
0.5MeasureF
0
0,1
0,2
0,3
0,4
0,5
COTEM YaTeA CRFGRA PatternsModel
Precision

IJIRR: International Journal of Information Retrieval Research. 2(3), 1-18, 2013.
Figure 8. Recall.
Figure 9. F-Measure.
The model COTEM provides a significant
improvement of precision by reducing the
number of irrelevant terms extracted by the
system. This improvement can be explained by
two factors:
The consideration of the linguistic
context of the terms which ensures a
more precise extraction.
The use of statistical knowledge to
eliminate terms of rare composition.
The recall provided by COTEM is
important, with a great advantage for YaTeA.
This result is due to the combining of different
linguistic knowledge (such as conjunction
detection) that can help to extract new relevant
terms which are ignored by other models.
It is clear that the precision which does not
reach 50% can be considered as the main
limitation of our model. We note that a
significant portion of noise in the results is
caused by the grammatical annotation and
lemmatization tools. In fact, a wrong
grammatical annotation of tokens will disrupt
the operation of the model. Similarly,
lemmatization errors will disturb the statistical
computing which admits a negative influence
on terms identification.
5. CONCLUSION AND FUTURE
WORKS
In this paper, we proposed a Complex
Terminology Extraction Model (COTEM)
from unstructured Web Text based on both
linguistic and statistic knowledge. The
originality of our model appears in two main
contributions. The first contribution is the
integration of shallow linguistic knowledge
(such as grammatical knowledge) in the CRF
features. And the second contribution is the
use of a statistical measure based filter.
We compared our model to three standard
models which are YaTeA, CRFGRA and
Patterns Model. The experimental study
showed that the performance of our model
according to different standard tests: precision,
recall and F-measure is better than the other
models.
In our next work, we will focus on
improving the performance of our model,
essentially precision. Indeed, the enrichment of
CRFs by deeper linguistic knowledge (i.e.
syntactic knowledge) and by statistical
knowledge about the context (the most
frequent words in the term neighbourhood)
will make the identification and the extraction
of relevant terms more precisely.
00,20,40,60,8
11,2
Recall
Recall
0
0,2
0,4
0,6
COTEM YaTeA CRFGRA PatternsModel
F-Measure
IJIRR: International Journal of Information Retrieval Research. 2(3), 1-18, 2013.
Table 6. Number of terms extracted for each model
Table 7. Performance Measures
Model Precision (P) Recall (R) F-Measure
COTEM 0.4714 0.8407 0.5168
YaTeA 0.1175 1 0.1427
CRFGRA 0.3203 0.8716 0.3667
Patterns
Model 0.1402 0.8097 0.1680
References
Abramowicz, W., & Wisniewski, M. (2008).
Proximity Window Context Method for
Term Extraction in Ontology Learning from
Text. 19th International Conference on
Database and Expert Systems Application,
(pp. 215-219).
Aubin, S., & Hamon, T. (2006). Improving
Term Extraction with Terminological
Resources. In Advances in Natural
Language Processing, 5th International
Conference on NLP (pp. 380-387),
FinTAL2006. Berlin: Springer-Verlag.
Berry-Rogghe, G. (1973). The Computation
of Collocations and their Relevance in
Lexical Studies. The computer and the
literary studies (pp. 103-112). Edinburgh:
Edinburgh University Press.
Bounhas, I., & Slimani, Y. (2009). A hybrid
approach for Arabic multi-word term
extraction. International Conference on
Natural Language Processing and
Knowledge Engineering NLP-KE (pp. 1-8).
Bourigault, D. (1992). Surface grammatical
analysis for the extraction of terminological
noun phrases. 14th International Conference
on Computational Linguistics, COLING’92
(pp. 977-981), Stroudsburg: Association for
Computational Linguistics.
Bourigault, D. (1994). LEXTER un Logiciel
d'EXtraction de TERminologie, Application
à l'extraction des connaissances à partir de
textes. Unpublished doctoral dissertation,
École des Hautes Études en Sciences
Sociales, Paris.
Model
Total
number of
extracted
terms
Number of relevant
terms extracted
Number of irrelevant
terms extracted
COTEM 403 190 213
YaTeA 1922 226 1696
CRFGRA 615 197 418
Patterns Model 1305 183 1122

IJIRR: International Journal of Information Retrieval Research. 2(3), 1-18, 2013.
Bourigault, D. (1996). LEXTER, a Natural
Language Processing tool for terminology
extraction. The 7th EURALEX International
Congress. Goteborg. Sweden.
Bourigault, D., & Jacquemin, C. (2000).
Construction de ressources terminologiques.
In Pierrel, J-M. (Ed.), Ingénierie des langues
(pp. 215-233), Paris: Hermès.
Bunescu, R., & Mooney, R. (2004).
Collective information extraction with
Relational Markov Networks. ACL '04
Proceedings of the 42nd Annual Meeting on
Association for Computational Linguistics
(pp. 439–446), Stroudsburg: Association for
Computational Linguistics.
Chang, C-H., Hsu, C-N., & Lui, S-C.
(2003). Automatic information extraction
from semi-structured Web pages by pattern
discovery. Decision Support Systems - Web
retrieval and mining, 35(1), 129-147.
Church, K., & Hanks,P. (1990). Word
association norms, mutual information and
lexicography. Computational Linguistics,
16(1), 22-29.
Claveau, V. (2003). Acquisition automatique
de lexiques automatiques sémantiques pour
la recherche d’information. Unpublished
doctoral dissertation. Université de Renne 1.
Cohen, W., & Sarawagi, S. (2004).
Exploiting Dictionaries in Named Entity
Extraction: Combining SemiMarkov
Extraction Processes and Data Integration
Methods. Proceeding KDD'04 Proceedings
of the tenth ACM SIGKDD international
conference on Knowledge discovery and
data mining (pp. 89-98), New York: ACM.
Constant, M., Tellier, I., & Duchier, D.
(2011). Intégrer des connaissances
linguistiques dans un CRF: application à
l’apprentissage d’un segmenteur-étiqueteur
du français. Natural language Processing
TALN 2011. Montpellier, France.
Daille, B. (1994). Approche mixte pour
l’extraction automatique de terminologie :
statistique lexicale et filtres linguistiques.
Unpublished doctoral dissertation,
Université Paris 7.
Daille, B., Gaussier, E., & Langé, J. (1998).
An evaluation of statistical scores for word
association. In (Ginzburg et al., 1998) (ed.),
Studies in Logic, Language and Information,
(pp. 177–188).
Daille, B. (2002). Découvertes linguistiques
en corpus. Unpublished doctoral
dissertation. Université de Nantes.
Fano, R. (1961). Transmission of
Information: A Statistical Theory of
Communications. Cambridge, MA : MIT
Press.
Felber, H. (1987). Terminology manual.
Unesco, International Information Centre for
Terminology (Austria), Paris.
Fkih, F., Omri, M.N., & Toumia, I. (2012).
A linguistic model for terminology
extraction based Conditional Random Field.
International Conference on Computer
Related Knowledge, ICCRK’2012, (pp. 38),
Sousse, Tunisia.
Fkih, F., & Omri, M.N. (2012). Learning the
Size of the Sliding Window for the
Collocations Extraction: a ROC-Based
Approach. In (H. Arabnia et al., 2012) (ed.),

IJIRR: International Journal of Information Retrieval Research. 2(3), 1-18, 2013.
The 2012 International Conference on
Artificial Intelligence, ICAI'12, (pp. 1071-
1077), Vol. 1. Las Vegas, USA: CSREA
Press.
Frath, P., Oueslati, R., & Rousselot, F.
(2000). Identification de relations
sémantiques par repérage et analyse de
cooccurrences de signes linguistiques. In
Charlet J., Zacklad M., Kassel G. et
Bourigault D. (Eds), Ingénierie des
connaissances : Évolutions récentes et
nouveaux défis (pp. 291-304), Paris:
Eyrolles.
Fu, G., & Luke, K. (2005). Chinese Named
Entity Recognition using Lexicalized
HMMs. Newsletter, ACM SIGKDD
Explorations Newsletter - Natural language
processing and text mining, Vol. 7 (pp. 19-
25), New York, USA: ACM.
Hearst, M. (1992). Automatic Acquisition of
Hyponyms from Large Text Corpora. The
14th International Conference on
Computational Linguistics (pp. 539–545),
Stroudsburg: Association for Computational
Linguistics.
Kwok, C., Etzioni, O., & Weld, D. (2001).
Scaling question answering to the web.
ACM Transactions on Information Systems
(TOIS), 19(3), 242 – 262.
Lafferty, J., McCallum, A., & Pereira, F.
(2001). Conditional Random Fields:
Probabilistic Models for Segmenting and
Labeling Sequence Data. ICML'01
Proceedings of the Eighteenth International
Conference on Machine Learning, (pp. 282-
289), San Francisco, CA, USA: Morgan
Kaufmann Publishers Inc.
Lang, Z., Liang, Z, Chong, F., & Heyan, H.
(2008). Extracting Chinese multi-word
terms from small corpus. International
Conference on Intelligent System and
Knowledge Engineering ISKE, (pp. 813-
818).
Lebart, L., & Salem, A. (1994). Statistique
textuelle. France: Dunod.
Liu, L., & Qi, Q. (2011). A Combined
Method for Automatic Domain-Specific
Terminology Extraction. Eighth
International Conference on Fuzzy Systems
and Knowledge Discovery (FSKD), (pp.
1734-1737).
McCallum, A., & Li, W. (2003). Early
results for named entity recognition with
conditional random fields, feature induction
and web-enhanced lexicons. Proceedings of
the seventh conference on Natural language
learning at HLT-NAACL 2003, CONLL’03,
(pp. 188-191). Stroudsburg, PA, USA:
Association for Computational Linguistics.
Mollá, D., Schwitter, R., Rinaldi, F.,
Dowdall, J., & Hess, M. (2003). ExtrAns:
Extracting answers from technical texts.
IEEE Intelligent Systems, 18(4), 12-17.
Okanohara, D., Miyao, Y., Tsuruoka, Y., &
Tsujii, J. (2006). Improving the Scalability
of Semi-Markov Conditional Random Fields
for Named Entity Recognition. ACL-44
Proceedings of the 21st International
Conference on Computational Linguistics
and the 44th annual meeting of the
Association for Computational Linguistics
(pp. 465-472). Stroudsburg, PA, USA:
Association for Computational Linguistics.

IJIRR: International Journal of Information Retrieval Research. 2(3), 1-18, 2013.
Pennacchiotti, M., & Pantel, P. (2006).
Espresso: Leveraging Generic Patterns for
Automatically Harvesting Semantic
Relations. ACL’44 Proceedings of the 21st
International Conference on Computational
Linguistics and the 44th annual meeting of
the Association for Computational
Linguistics, (pp. 113-120), Stroudsburg, PA,
USA: Association for Computational
Linguistics.
Popescu, A-M., & Etzioni, O. (2005).
Extracting product features and opinions
from reviews. HLT'05 Proceedings of the
conference on Human Language Technology
and Empirical Methods in Natural
Language Processing, (pp. 339-346),
Stroudsburg, PA, USA: Association for
Computational Linguistics.
Roche, M., Azé, J., Kodratoff, Y., & M.
Sebag, (2004). Learning Interestingness
Measures in Terminology Extraction A
ROC based approach. In Proceedings of
ROC Analysis in AI Workshop (ECAI 2004).
Valencia, Espagne.
Roche, M., Heitz, T. Matte-Tailliez, O. &
Kodratoff, Y. (2004). EXIT : Un système
itératif pour l’extraction de la terminologie
du domaine à partir de corpus spécialisés. In
Actes de JADT’04 (Les journées
internationales d'analyse statistique des
données textuelles), Louvain-la-Neuve,
Belgique.
Sha, F., & Pereira, F. (2003). Shallow
parsing with conditional random fields.
NAACL '03 Proceedings of the 2003
Conference of the North American Chapter
of the Association for Computational
Linguistics on Human Language (pp. 213–
220). Stroudsburg, PA, USA: Association
for Computational Linguistics.
Smadja, F. (1993). Retrieving collocations
from text: Xtract. Computational
Linguistics, Special issue on using large
corpora, 19(1), 134-141.
Subhashini, R., & Jawahar Senthil Kumar,
V. (2011). A Roadmap to Integrate
Document Clustering in Information
Retrieval. International Journal of
Information Retrieval Research (IJIRR).
1(1). 31-44.
Sutton, C., & McCallum, A. (2006). An
Introduction to Conditional Random Fields
for Relational Learning. In L. Getoor and B.
Taskar (Ed.), Introduction to Statistical
Relational Learning (pp. 1-35). USA: MIT
Press.
Tsuruoka, Y., Tsujii, J., & Ananiadou, S.
(2009). Fast full parsing by linear-chain
conditional random fields. In Proceedings of
the 12th Conference of the European
Chapter of the Association for
Computational Linguistics (EACL 2009)
(pp. 790–798). Stroudsburg, PA, USA:
Association for Computational Linguistics.
Wallach, H. (2003). Efficient Training of
Conditional Random Fields. In Proceedings
of the 6th Annual Computational Linguistics
U.K. Research Colloquium (CLUK 6).
Edinburgh, UK.
Zhai, Y., & Liu, B. (2006). Structured Data
Extraction from the Web Based on Partial
Tree Alignment. IEEE Transactions on
Knowledge and Data Engineering, 18(12),
1614–1628.

IJIRR: International Journal of Information Retrieval Research. 2(3), 1-18, 2013.
Zhou, G., Shen,D., Zhang, J., Su, J., Tan, S.,
& Chew Lim, T. (2004). Recognition of
Protein/Gene Names from Text using an
Ensemble of Classifiers and Effective
Abbreviation Resolution. Proceedings of the
EMBO Workshop 2004 on a critical
assessment of text mining methods in
molecular biology. Granada, Spain.