coarse-grained speculative parallelism and optimization
TRANSCRIPT

Coarse-grained Speculative Parallelismand Optimization
by
Kirk Kelsey
Submitted in Partial Fulfillment
of the
Requirements for the Degree
Doctor of Philosophy
Supervised by
Dr. Chen Ding
Department of Computer ScienceArts, Sciences and Engineering
Edmund A. Hajim School of Engineering and Applied Sciences
University of RochesterRochester, New York
2011

ii
To Ellen:
Always Hopes,
Always Perseveres

iii
Curriculum Vitae
The author was born in New Haven, Connecticut on March 3rd, 1979. He
attended Vanderbilt University from 1997 to 2003, and graduated with a Bachelor
of Science degree in 2001 followed by a Master of Science degree in 2003. He came
to the University of Rochester in the Fall of 2003 and began graduate studies
in Computer Science. He pursued his research in software speculative parallelism
under the direction of Professor Chen Ding and received a Master of Science degree
from the University of Rochester in 2005.

iv
Acknowledgments
More than any other factor, I have to contribute so much to the unyielding
support of my wife, Ellen. This certainly extends well beyond the time spent
working towards a thesis, but so few pursuits offer the opportunity for a formal
acknowledgment. If I had the words, my thanks would dwarf this document. My
parents, also, deserve my heart-felt appreciation for many more years of support,
as well as for providing early models of scholarship.
I am deeply thankful to my adviser, Chen Ding, for guiding me through a
marathon process. Chen has been a constant through the many stages of graduate
education and study. Ultimately, he helped me develop a direction in research and
reminded me that we are measured not by the information we consume, but by the
knowledge we create. I owe a sincere debt to the members of my thesis committee
for their advice during the development of ideas that has led to this work, and for
the broader education they provided within the department.
My cohort of fellow aspiring researchers were an invaluable source of insight,
inspiration, humility and support. I’d like to thank other students in the compiler
and systems groups who have helped to show the way ahead of me — specifically
Yutao Zhong and Xipeng Shen — and kept me motivated, especially Mike Spear
and Chris Stewart. From a broader standpoint, I have appreciated time spent
with Ashiwin Lall, Chris Stewart, Ben Van Durme and Matt Post immensely.
My friends outside of the department helped to take my mind off computer
science from time; Jason and Ana stand out specifically in that regard. Finally,

v
I’d like to thank the staff of the computer science department for their help in
innumerable ways. Jo Marie Carpenter, Marty Gunthner, Pat Mitchell and Eileen
Pullara keep a lot of things running around the department and I’m happy to be
included among them.

vi
Abstract
The computing industry has long relied on computation becoming faster through
steady exponential growth in the density of transistors on a chip. While the
growth in density has been maintained, factors such as thermal dissipation have
limited the increase in clock speeds. Contemporary computers are rapidly becom-
ing parallel processing systems in which the notion of computer power comes from
multi-tasking rather than “speed”. A typical home consumer is now more likely
than not to get a parallel processor when purchasing a desktop or laptop.
While parallel processing provides an opportunity for continued growth in
mainstream computational power, it also requires that programs be built to use
multiple threads of execution. The process of writing parallel programs is ac-
knowledged as requiring a significant level of skill beyond general programming,
relegating parallel programming to a small class of expert programmers. The dif-
ficulty of parallel programming is only compounded when attempting to modify
an existing program. Given that the vast majority of existing programs have not
been written to use parallelism, a significant amount of code could benefit from
an overhaul.
An alternative to explicitly encoding parallelism into a program is to use spec-
ulative parallelism of some form. Speculative parallelism removes the burden of
guaranteeing the independence of parallel threads of execution, which greatly sim-
plifies the process of parallel program development. This is especially true when

vii
retrofitting existing programs because the programmer is less likely to have a
complete understanding of the code base.
In many cases, the safety of the parallelism can be speculative. There are also
cases in which it makes sense to parallelize tasks that are inherently speculative.
One may wish to speculate about the result of some computation, the safety of ap-
plying an optimization, or the best heuristics to use when searching for a solution.
This style of speculative parallelism is referred to as speculative optimization.
In this work I describe a speculative parallelism system based on POSIX pro-
cesses and communication. The system comprises a set of run-time libraries and
compiler support for easily generating a speculatively parallel program. The im-
plementation is designed to be general and portable, and the programming inter-
face is designed to minimize the programmer effort needed to effectively parallelize
a program. There are two variants on the run-time system intended for different
forms of parallelism. Both of these general forms of speculative parallelism are
generally applicable to many different problems.

viii
Table of Contents
Curriculum Vitae iii
Acknowledgments iv
Abstract vi
List of Tables xiii
List of Figures xiv
List of Algorithms xvi
Foreword 1
1 Introduction 2
1.1 Explicit Parallel Programing . . . . . . . . . . . . . . . . . . . . . 4
1.2 Speculative Execution . . . . . . . . . . . . . . . . . . . . . . . . 6
1.3 Road Map . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2 Background 9
2.1 Thread Representation . . . . . . . . . . . . . . . . . . . . . . . . 9
2.1.1 Data Sharing . . . . . . . . . . . . . . . . . . . . . . . . . 9

ix
2.1.2 Message Passing . . . . . . . . . . . . . . . . . . . . . . . 12
2.2 Speculative Threads . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2.1 Ancillary Tasks . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2.2 Run-Ahead . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3 Fork and Join . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3.1 Futures . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3.2 Cilk . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.3.3 Sequential Semantics . . . . . . . . . . . . . . . . . . . . . 21
2.4 Pipelining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.4.1 Decoupling . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.5 Support Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.5.1 Operating System . . . . . . . . . . . . . . . . . . . . . . . 26
2.5.2 Compiler . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.5.3 Race Detection . . . . . . . . . . . . . . . . . . . . . . . . 31
2.6 Correctness Checking . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.6.1 Heavyweight . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.6.2 Hardware Techniques . . . . . . . . . . . . . . . . . . . . . 33
2.6.3 Monitoring . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3 Process-Based Speculation 36
3.1 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.1.1 Creation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.1.2 Monitoring . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.1.3 Verification . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.1.4 Abort . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39

x
3.1.5 Commit . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.2 Advantages . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.3 Disadvantages . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.4 Special Considerations . . . . . . . . . . . . . . . . . . . . . . . . 41
3.4.1 Input and Output . . . . . . . . . . . . . . . . . . . . . . . 41
3.4.2 Memory Allocation . . . . . . . . . . . . . . . . . . . . . . 42
3.4.3 System Signals . . . . . . . . . . . . . . . . . . . . . . . . 43
4 Speculative Parallelism 44
4.1 Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.1.1 Lead and Spec Processes . . . . . . . . . . . . . . . . . . . 45
4.1.2 Understudy: Non-speculative Re-execution . . . . . . . . . 47
4.1.3 Expecting the Unexpected . . . . . . . . . . . . . . . . . . 48
4.2 Programming Interface . . . . . . . . . . . . . . . . . . . . . . . . 51
4.2.1 Region Markers . . . . . . . . . . . . . . . . . . . . . . . . 51
4.2.2 Post-Wait . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.2.3 Feedback . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.3 Run-Time System . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
4.3.1 Creation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
4.3.2 Monitoring . . . . . . . . . . . . . . . . . . . . . . . . . . 57
4.3.3 Verification . . . . . . . . . . . . . . . . . . . . . . . . . . 71
4.3.4 Commit . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.3.5 Abort . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
4.4 Types Of Speculative Parallelism . . . . . . . . . . . . . . . . . . 78
4.4.1 Data-Parallel . . . . . . . . . . . . . . . . . . . . . . . . . 80

xi
4.4.2 Task-Parallel . . . . . . . . . . . . . . . . . . . . . . . . . 80
4.5 Comparison to Other Approaches . . . . . . . . . . . . . . . . . . 81
4.5.1 Explicit Parallelism . . . . . . . . . . . . . . . . . . . . . . 81
4.5.2 Fine-Grained Techniques . . . . . . . . . . . . . . . . . . . 82
4.6 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
4.6.1 Implementation and Experimental Setup . . . . . . . . . . 84
4.6.2 Application Benchmarks . . . . . . . . . . . . . . . . . . . 85
5 Speculative Optimization 95
5.1 Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
5.1.1 Fast and Normal Tracks . . . . . . . . . . . . . . . . . . . 96
5.1.2 Dual-track . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
5.2 Programming Interface . . . . . . . . . . . . . . . . . . . . . . . . 97
5.3 Run-time Support . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
5.3.1 Creation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
5.3.2 Monitoring . . . . . . . . . . . . . . . . . . . . . . . . . . 99
5.3.3 Verification . . . . . . . . . . . . . . . . . . . . . . . . . . 101
5.3.4 Abort . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
5.3.5 Commit . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
5.3.6 Special Considerations . . . . . . . . . . . . . . . . . . . . 107
5.4 Compiler Support . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
5.5 Uses of Fast Track . . . . . . . . . . . . . . . . . . . . . . . . . . 115
5.5.1 Unsafe Program Optimization . . . . . . . . . . . . . . . . 115
5.5.2 Parallel Memory-Safety Checking . . . . . . . . . . . . . . 117
5.6 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118

xii
5.6.1 Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
5.6.2 Experimental Results . . . . . . . . . . . . . . . . . . . . . 122
6 Conclusion 131
6.1 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
6.2 Future Directions . . . . . . . . . . . . . . . . . . . . . . . . . . . 132
6.2.1 Automation . . . . . . . . . . . . . . . . . . . . . . . . . . 132
6.2.2 Composability . . . . . . . . . . . . . . . . . . . . . . . . . 133
6.2.3 Further Evaluation . . . . . . . . . . . . . . . . . . . . . . 135
A Code Listings 137
A.1 BOP Code . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
A.2 Fast Track Code . . . . . . . . . . . . . . . . . . . . . . . . . . . 146
A.3 Common Code . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
Bibliography 166

xiii
List of Tables
4.1 Speculation actions for unexpected behavior . . . . . . . . . . . . 49
4.2 Three types of data protection . . . . . . . . . . . . . . . . . . . . 65
4.3 Comparisons between strong and weak isolation . . . . . . . . . . 70
4.4 XLisp Private Variables . . . . . . . . . . . . . . . . . . . . . . . 85
4.5 XLisp Checked Variables . . . . . . . . . . . . . . . . . . . . . . . 85
4.6 Execution times for various speculation depths . . . . . . . . . . . 87
4.7 The size of various protection groups in training runs . . . . . . . 88
4.8 Execution times of bop GZip . . . . . . . . . . . . . . . . . . . . 89

xiv
List of Figures
4.1 Sequential and speculative execution of three ppr instances . . . . 46
4.2 Example of matching ppr markers . . . . . . . . . . . . . . . . . 54
4.3 The states of the sequential and parallel execution . . . . . . . . . 66
4.4 State diagram of bop . . . . . . . . . . . . . . . . . . . . . . . . . 79
4.5 The effect of speculative processing on Parser . . . . . . . . . . . 90
4.6 Solving 8 systems of linear equations with Intel MKL . . . . . . . 93
5.1 State diagram of FastTrack processes. . . . . . . . . . . . . . . . . 106
5.2 FastTrack resource allocation state diagram . . . . . . . . . . . . 127
5.3 Analytical results of the FastTrack system . . . . . . . . . . . . . 128
5.4 The effect of FastTrack Mudflap on four spec 2006 benchmarks. . 129
5.5 FastTrack application to sorting routines . . . . . . . . . . . . . . 130
5.6 FastTrack on synthetic benchmarks . . . . . . . . . . . . . . . . . 130

xv
List of Algorithms
2.4.1 Listing of pipeline loop. . . . . . . . . . . . . . . . . . . . . . . . . 24
2.4.2 Interleaved iterations of pipelined loop. . . . . . . . . . . . . . . . 24
4.2.1 Example use of bop to mark a possibly parallel region of code
within a loop. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.2.2 Example use of bop including EndPPR marker. . . . . . . . . . . . 52
4.2.3 Example use of bop in a non-loop context. . . . . . . . . . . . . . 53
4.2.4 Example of a pipelined loop body. . . . . . . . . . . . . . . . . . . 55
4.2.5 Example use of bop post/wait. . . . . . . . . . . . . . . . . . . . 56
4.3.1 Listing of ppr creation. . . . . . . . . . . . . . . . . . . . . . . . 58
4.3.2 Examples of shared, checked, and private data . . . . . . . . . . . 59
4.3.3 Listing of bop termination routine . . . . . . . . . . . . . . . . . 73
4.3.4 Listing of ppr commit in the speculative process . . . . . . . . . 75
4.3.5 Listing ppr commit in the understudy process . . . . . . . . . . . 76
4.3.6 Listing of ppr commit in the main process . . . . . . . . . . . . . 77
4.3.7 Listing of ppr commit finalization routine . . . . . . . . . . . . . 78
5.2.1 Example listing of FastTrack loop optimization . . . . . . . . . . 98
5.2.2 Unsafe function optimization using fast track . . . . . . . . . . . . 98
5.3.1 Listing of FastTrack creation. . . . . . . . . . . . . . . . . . . . . 100
5.3.2 Listing of FastTrack monitoring. . . . . . . . . . . . . . . . . . . . 101
5.3.3 Listing of FastTrack verification routine FT CheckData . . . . . . 103
5.3.4 Listing of slow track commit routine. . . . . . . . . . . . . . . . . 105

xvi
5.3.5 Listing of FastTrack exit point handler. . . . . . . . . . . . . . . . 110
5.6.1 Pseudo code of the synthetic search program . . . . . . . . . . . . 125
6.2.1 Example of FastTrack self-composition . . . . . . . . . . . . . . . 135

1
Foreword
Chapters 4 and 5 of this dissertation are based on collaborative work. Chap-
ter 4 of my dissertation was co-authored with Professor Chen Ding, and with fellow
students Xipeng Shen, Chris Tice, Ruke Huang, and Chengliang Zhang. I con-
tributed the implementation of the computational system, and the experimental
analysis. It has been published in Proceedings of the ACM SIGPLAN Conference
on Programming Language Design and Implementation, 2007. An early prototype
of the run-time system was created by Xipeng Shen, which was rewritten for our
publication, and again for ongoing work. Rule Huang contributed compiler sup-
port, and Chris Tice worked on the MKL benchmark. Chengliang Zhang helped
with system testing.
I am the primary author of Chapter 5, on which I collaborated with Profes-
sor Chen Ding and with fellow graduate student Tongxin Bai. This chapter has
been published in Proceedings of the International Symposium on Code Gener-
ation and Optimization, March 2009. My contribution is the implementation of
the computational system, construction of the experimental frameworks, and the
experimental analysis. Tongxin Bai contributed design ideas, and assisted with
testing.

2
1 Introduction
Since the introduction of the Intel 4004 microprocessor, the number of transistors
on commercial integrated circuits has doubled roughly every two years. This
trend was famously noted by Gordon Moore in 1965 and has continued to the
present [40]. During this period of time the growing number of transistors typically
corresponded with an increase in the clock rate, from 740 kHz for the 4004 chipset
to 3.8 GHz for Intel’s Pentium 4 processor in 2004.
Since the release of the Pentium 4 processor, clock rates have actually de-
creased slightly. Currently, the highest clock rate available on an Intel micro-
processor is 3.33 Ghz. The primary reason for this stagnation and decline is the
problem of thermal dissipation. Each transistor on a chip uses some amount of
power in two forms: constant leakage and per state switch. Increasing the chip
clock rate directly increases the power consumption due to switching, but also re-
quires a reduction in the size of components (to reduce signal propagation time).
This miniaturization increases the density of the transistors, which increases the
amount of power consumed in any given chip area. Increased power consumption
leads to increased heat consumption. The two factors — increased switching and
concentration of components — compound on one another.
On the consumer front, we’ve reached the limits of air cooling a computer

3
sitting a room-temperature environment. Air cooling can be extended by moving
processing into areas with colder ambient temperature, and liquid cooling tech-
niques provide an alternative solution. Even with more sophisticated approaches
to ensure the integrity of a running processor, at some point a significant amount
of power must be used to cool the chip. In contemporary data centers it is com-
mon for the power demands of the cooling systems to surpass the power used to
actually perform computation. The continued growth in power consumption has
been recognized to be unsustainable both technologically and commercially, as
consumers recognize the ancillary costs of their processors.
With the skyward increase in clock rates stalled, the choice has been to expand
processors horizontally. Computers are no longer made “faster” with increasing
clock rates, but instead are made more powerful with multiple processing cores.
We have reached the multicore era in which it is typical to find a multiprocessor
in consumer desktops, laptops, and even mobile devices.
Although computers are now parallel, the same cannot broadly be said of the
programs running on them. The majority of programs, both existing programs
and those being written today, are not designed to take advantage of parallel
processing. One reason for this is the relative scarcity of parallel computers in
the past — particularly in the home consumer arena. Another reason is that
programmers are trained to think about the problems they are solving in an
explicitly sequential way.
The result is a large body of programs that must be retrofitted to take ad-
vantage of parallel processing systems. There are a few significant reasons that
parallel programming is difficult, and many of these are only exacerbated when
attempting to modify an existing code base.

4
1.1 Explicit Parallel Programing
While the general public may recognize that programming requires a certain level
of expertise, parallel programming has largely been relegated to a select group of
programmers. Programmers are typically taught to think explicitly in series —
to write an imperative program as a series of steps that depend on one another.
This can make the transition to parallel programming difficult for programmers,
but more importantly it has led to a legacy of programs that are truly serial by
design.
Finding Parallelism
Identifying portions of a program that can safely run in parallel with one another
is perhaps the most difficult aspect of parallel programming. This task is often
made more difficult by attempts by programmers to optimize their code for the
sequential execution. Once the parallel regions have been identified, the program-
mer must ensure the correctness of each region interacting with all others. This
is most commonly done using locks, which must be correctly associated with the
same collection of data in every case where that data may be modified by multiple
threads. The problems involved in correctly writing a parallel program are exac-
erbated when attempting to update an existing program. Without a familiarity
with the code in question, the programmer is less likely to recognize side effects
of functions or identify poorly isolated data. Currently, no tool exists that can
automatically identify parallelism in an arbitrary program, and it is not possible
to do so in every case.
Ensuring Progress
One of the most well known problems encountered in parallelism, whether de-
signing a single program with multiple threads of execution, or scheduling multi-

5
ple programs with shared resources in an operating system, is deadlock. Of the
four conditions necessary for deadlock to exist identified in [12], three are easily
achieved using locks: mutual exclusion (only one thread can hold a lock), lack
of preemption (a thread cannot steal a lock), and hold and wait (a thread can
acquire locks one after another). The only condition that needs to be added by a
programmer is circular waiting, where a group of multiple threads each wait on a
lock held by another member of the group.
In addition to deadlock, a few other problems can arise that prevent a system
from making progress. Livelock is similar to deadlock in that threads do not make
progress collectively because of interference with one another. The difference being
that each thread is active, typically trying to coordinate with another livelocked
thread. Livelock is a specific example of resource starvation, which describes a
situation in which a thread cannot make progress because it lacks access to some
resource. The distinction from deadlock is that progress is made by the thread
holding the resource. When the resource is released, it is allocated to some thread
other than the starving one.
Guaranteeing Correctness
In the context of parallel programming, correctness is defined to mean that the ob-
servable behavior of the program is maintained. If the program acts as a function,
mapping input to output, then the function must be preserved. In the context of
parallelizing a sequential program, the original serialization of observable points in
the execution implied by that program must be maintained, ruling out deadlock.
To guarantee correctness, the programmer must ensure that all accesses to shared
data are properly guarded. This requires identifying all shared data, identifying
all accesses to that data, and finally creating an association between data objects
and the primitives used to synchronize their access. Particularly in the case of
parallelizing an inherited code base, the programmer may have difficulty simply

6
identifying what data objects are shared. Assuming that using a single global lock
will not allow acceptable performance, the programmer will also be responsible for
determining which data need to be protected collectively because their common
state needs to be consistent.
Debugging
One of the more common problem in parallel programming is the occurrence of
a data race, which is the case of two threads accessing the same data without
synchronization between the accesses (at least one of which must be a write).
The result of a race (i.e., the value that is ultimately attributed to the data)
depends on the sequence and timing of events in both threads leading up to their
accesses. Because the scheduling of threads may depend on other processes in
the system at large, the error is effectively non-deterministic. Generally, we want
to reproduce the conditions under which a bug occurs to isolate it. Because the
problem may appear very intermittently, the conditions for the error are effectively
random. Running the program in a debugger can force a particular serialization,
which ensures a certain outcome of the race, potentially making the debug session
useless for finding the problem.
1.2 Speculative Execution
Speculative parallelism — running some portions of a program in parallel with
the rest on the assumption they will be useful and correct — can extract useful
coarse-grained parallelism from existing programs in several ways. The speculative
execution systems outlined in Section 1.3 directly address the problems of explicit
parallel programming raised in Section 1.1.

7
Finding Parallelism The first-order problem of explicitly parallelizing code is
to identify which portions of a program can safely be executed simultaneously.
The other problems are largely the result of the solutions used once the parallel
regions of the program have been identified. Using a speculative system allows a
programmer to indicate parallel regions without the responsibility of preserving
run-time dependencies, which the system guarantees will not be violated.
Ensuring Progress Ensuring progress is trivial because there is no potential
for deadlock. The programmer does not introduce any serialization primitives
such as locks. This means that the speculative run-time system cannot introduce
a circular waiting condition. It may be tempting to qualify the previous statement
such as “where one did not already exist,” but clearly there cannot have been a
circular dependency in a sequential program. Likewise, there is no potential for
introducing livelock or resource starvation.
Debugging The speculative execution system depends on the ability to dis-
card the speculative portion of execution and follow only the sequential flow of
execution. The intent of this fallback is that the speculatively parallel program
maps directly back to the sequential execution. In this case, there is no need to
explicitly debug a speculatively parallel program because the user can debug the
sequential program with the same effect.
1.3 Road Map
In Chapter 2 I cover the extensive existing literature on speculative execution
related to both sequential programs and optimization. In Chapter 3 I describe
the fundamental aspects of an implementation for a process-based speculative
run-time system. Chapter 4 describes a run-time system intended for speculative

8
execution of program regions ahead of time. In Chapter 5 I describe a software-
only speculation system that enables unsafe optimization of sequential code. I
conclude with a discussion of the limitations of the current speculative execution
system, and of future directions to address, in Chapter 6.

9
2 Background
2.1 Thread Representation
2.1.1 Data Sharing
Because programs written in imperative languages progress by writing to and later
reading from data objects, eventually using their values to represent their result,
data sharing is a natural extension. By allowing multiple processes to share some
of the data they are modifying, the syntax of each process can remain largely the
same. On a surface level, the semantics of each process also remain largely the
same except that the value of a data object may change between being written
and later being read.
Rather than considering a single program and its state represented by data, in
the context of shared data we have to consider all processes and all of their data
as a single state. The problem that arises is guaranteeing that state is always
consistent. A classic example of such consistency is a shared buffer into which
multiple processes may add or remove data. In order to know where new data
should be inserted, or the position from which is should be read, a process must
update an indication of the size of the buffer. If the value is entered first, another
process may overwrite it before the position is updated. If the position is updated

10
first then a reader may attempt to read the buffer and receive garbage.
In order to guarantee a process always sees a consistent view of the global state,
there must be some mechanism to indicate that the data should not be accessed.
This is typically done by introducing a lock, which requires a hardware guarantee
that all processes see the flag consistently and cannot access it simultaneously.
Implementations typically rely on an atomic read-modify-write operation that
only sets the value of a data object if its current value matches what is expected.
Such systems are more efficient if multiple locks are used so that distinct parts
of the shared state can be modified simultaneously. One of the difficulties is
ensuring that the relationship between a lock and the data it is meant to protect
is well defined — that no access to the data is made without first acquiring the
lock. In this way, a portion of the shared state is used to protect the consistency
of the shared state.
An alternative to locking regions of memory to provide protection is to create
the illusion that modifications are made atomically. This typically involves intro-
ducing additional redirection to encapsulated data that must be keep consistent.
By modifying a local (or private) copy of the data, one process can ensure that
no others will read inconsistent state. Once the modifications are complete, the
single point of redirection can be atomically updated to refer to the new (and no
longer private) version of the data.
This sort of redirection can be expanded to be applied to general memory
access in transactional memory systems. These systems indicate that specific
regions of the program should appear atomically. By tracking all of the reads
and writes that a process makes, it is possible to ensure that none of the memory
involved was changed by another transacting simultaneously.
Transactional memory was originally proposed as a hardware mechanism to
support non-blocking synchronization (by extending cache coherence protocols) [26]
and several software implementations are built for existing hardware. Transaction

11
semantics, which require a serializable result, is less restrictive than speculative
parallelization, which requires observational equivalence or the same result as the
original sequential execution. Because transactions have the potential to conflict
with one another, they do not guarantee parallelism. Inserting transactions does
affect the semantic meaning of a program because they alter the serial execution
it performs. The techniques I describe in Chapter 4 do not change the program
in this way, and are easier to use for a user or a tool to parallelize an unfamiliar
program.
At the implementation level, serializibility checking requires the monitoring of
both data reads and writes, so it is more costly than the run-time dependence
checking. Current transactional memory systems monitor data accesses rather
than values for conflict detection. The additional flexibility is useful for supporting
parallel reduction, but it is not strictly necessary for parallelization, as it is for
concurrency problems such as on-line ticket booking.
In most thread-level speculation schemes (e.g., speculative DOALL) the entire
body of a loop constitutes a transaction. When we consider a parallelization
technique like decoupled software pipelining described in Section 2.4.1 the loop
body is spread across multiple threads. In order to introduce speculation to such
pipelines a multi-threaded transaction (mtx) is necessary, which had depended
on hardware support. The work in [51] introduces a software only multi-threaded
transaction system.
The software mtx gives the threads within a transaction the effect of a pri-
vate memory space for their work. Each mtx representing a loop iteration is
divided into sub-transactions that are each executed on a separate thread. Each
sub-transaction forwards the uncommitted values it has computed to the next
through a shared queue during execution, and the final sub-transaction has the
responsibility of committing the transaction as a whole.

12
2.1.2 Message Passing
The other typical way to express synchronization between parallel processes is
through message passing. The most basic form of message passing is through
matched pairs of send and receive statements by which one process explicitly
passes data to another process that has expressly made an attempt to acquire
it. This point-to-point communication can be synchronous or asynchronous, and
may be related to allow unmatched pairs of communication primitives. In com-
parison to data sharing as a synchronization mechanism, message passing benefits
in encouraging local data storage in systems with non-uniform memory access.
Attempting to model message passing as a global, shared state is non-trivial
because of the complexities resulting from delays as message are passed between
processes. Message passing does not have a clear analog to an imperative se-
quential programming, though it clearly translates to client-server models typical
of networking. Such systems are often event based, where a processes’ state is
directly affected by signals given to it, rather than polling a data location or
explicitly receiving a message.
2.2 Speculative Threads
2.2.1 Ancillary Tasks
Past work has suggested specifically using speculative execution to treat some
portion of the program’s work as a parallel task. Such tasks include the addition of
memory error and leak checking, performing user defined assertions, and profiling.
In [48] the authors suggest creating a “shadow” version of a program to address
these ancillary tasks specifically, although they do not address how the shadow
process might be generated.

13
By pruning computation that is not necessary to determine the control flow,
the shadow process creates some slack with which it can instead perform the addi-
tional work. It is not clear however if typical programs contain enough unnecessary
computation to be removed and compensate for extra work.
It is not always possible for a shadow process to determine all of the values
necessary for control flow. These values could be dictated by interactive input or
system calls that the shadow cannot safely reproduce. As a result, the control
flow within the shadow process may depend on values communicated from the
primary process once it has computed them. Additionally, there is a trade off to
be made between having the shadow compute values and having the main process
communicate those values to the shadow.
A limitation of the shadow processing system is composability; there is no
good way to handle multi-threaded or multi-process tasks. There is a limit to the
availability of signal handlers. The shadow process is generated once and runs
in parallel to the entirety of the original process. Empirical results found the
shadow process typically finishing after the serial process. As a result, there is
no mechanism for the shadow process to provide feedback to the original process.
This is acceptable in some use cases, such as error checking, where a report can
be generated after program execution, but prevents shadow processing from being
applicable for accelerating processes in general.
The limitation of shadow processing is addressed in later work by periodically
spawning a new shadow process [41]. The objective in this case is specifically to
make execution profiling more tolerable, described as “shadow profiling”. A new
profiling process is created each time a timer interrupt is triggered1.
Program instrumentation is added using the Pin tool [36] by having the shadow
process switch to a just-in-time rewriting mode within the Pin runtime after it has
forked. Moseley et al. [41] additionally address some of the problems that arise
1By default the SIGPROF timer is used, but this is customizable.

14
even when using copy-on-write protection. Writes to shared memory segments or
memory mapped files cannot be completely protected and trigger a fault in the
child profiling process. The shadow profiling process can choose to skip the trou-
blesome instruction, or it can terminate and allow a new shadow profile process
to be created.
System calls are also a problem for speculative execution, and Moseley et al.
[41] attempt to categorize them into groups: benign, output, input, miscellaneous,
and unsafe. If call is encountered that is not known explicitly to be safe, the
shadow simply aborts and allows a new profiler to begin.
Because the profiling system is only intended to be an instrumentation sample
the shadow profiling can safely afford to abort in many cases. It is also not neces-
sary for the execution performed in the shadow profile to be deterministic. While
allowing the control flow in the speculative process to deviate from the original
program reduces the accuracy of the profile, it does not affect the correctness of
the program. This flexibility is not acceptable for general purpose speculative ex-
ecution, and again precludes shadow processing from being used for accelerating
process in the general case.
Newer work has moved beyond parallelizing memory checking to placing dy-
namic memory management in a parallel task, which is referred to as the memory
management thread (mmt) [58]. If the memory allocation and deallocation sub-
system includes safety checks such as invalid frees then these checks can also be
placed in the memory management thread.
One of the difficulties in moving dynamic memory management into a separate
thread is ensuring that the memory management can be wrapped with minimal
modification to the application and memory management library. Another signifi-
cant difficulty is the overhead of thread synchronization, which the authors note is
comparable to the cost of the memory management itself. These two problems are
addressed by allowing the mmt to run as a server and only requiring synchroniza-

15
tion for memory allocation. When memory objects are released, the program can
essentially issue the deallocation asynchronously and continue without waiting for
memory management to complete.
The synchronous memory requests still have a communication delay in addition
to the period of time needed to actually service the request. This is alleviated by
having the mmt speculative preallocate objects, which can be provided without
delay if the size is right. Delays are further reduced by batching deallocation
requests to the mmt, and symmetrically by providing the client with multiple
preallocated objects.
Although the mmt technique can extract some memory safety checks into a
separate thread, not all types of memory checks are isolated in the allocation or
deallocation routines. Checks such as array over-flow are must be performed in
the context of the memory access.
Some of these limitations are addressed in the approach taken in the Speck
(Speculative Parallel Check) system [45]. The Speck system is intended to decou-
ple the execution of security checking from the execution of the program at large.
During program execution a set of instrumented systems call potentially create an
addition instance of the application that includes the security checks. Like earlier
work, some of the overhead is removed by only entering the instrumented code
path periodically.
The primary focus of the Speck work is on security checks such as virus scan-
ners and taint analysis, though it could be applied to simpler checking for safe
memory access. The limitation of the Speck system is its dependence on the use
of a modified Linux kernel designed to support efficient distributed file system
interaction, called Speculator [44]. This support is necessary to allow for unsafe
actions performed by an application to be rolled back if one of the security checks
were to fail. An addition feature of their operating system support is the ability
to ensure that certain system functionality operates identically in both processes,

16
and that signals are delivered at the same point in the execution of each.
Another recent approach to minimizing the overhead of memory safety check-
ing with thread-level speculation did so by parallelizing an existing memory check-
ing library [31]. Because of the tight synchronization needed by the accesses to the
data structures used by the library, adapting it for use with TLS requires detailed
analysis of the library itself and the manual insertion of source level pragmas to
denote parallel regions. The annotated code was then passed through a paralleliz-
ing compiler which extracts each parallel task. Ultimately, the authors assume
that some form of hardware support will guarantee the ordering of the tasks to
guarantee the sequential semantics of the original program. The system also relies
on the presence of a mechanism to explicitly synchronize access to the library’s
data structures which is not provided.
2.2.2 Run-Ahead
An approach related to the techniques used to off-load ancillary tasks to unused
processing units is to create a second thread of execution to precompute some
values for the primary process. Rather than performing additional work, thus
lagging behind the original program, these processes run ahead of the primary
process in order for it to execute more quickly.
There are a number of methods for producing a run-ahead process, relying on
various kinds of support. The ‘Slipstream’ technique presented in [57] monitors
the original program to detect operations which are redundant at run time. The
operations that are found to be redundant can be speculatively elided from the
leading process when they are next encountered. As a result, the leading process
can run faster because many operations are removed entirely. The trailing process
is also able to execute more quickly because of side-effects from the first process:
memory prefetching and improved branch prediction. The end result is that the

17
two processes together (one of which is the original program) complete faster than
either would independently.
Because the leading process is not performing all of the operations of the
original program, its execution may deviate from the correct execution, which
is always computed by the trailing process. In order to recover from incorrect
speculation, and to generate the lead process, the Slipstream technique requires
a number of additional hardware components. The lead process must have a
program counter that is modified to skip past some instructions by recording
previous traces through the program execution. The address of memory locations
modified by the lead process are recorded to allow for recovery by updating those
values from the memory state of the trailing process2.
The suggested mechanism for determining which operations may be good can-
didates for speculative removal is based on a small data flow graph built in re-
verse as instructions are retired. Operations that write to memory (or registers)
are recorded as being the producer of the value stored there, and a bit denotes
the value as valid. A subsequent write with the same value is redundant, while
a different value updates the producer. A reading operation sets a bit indicat-
ing a location has been referenced, which allows an old producer operation to be
removed if the value was unused.
Another related idea used in hardware systems is to extract a fast version of
sequential code to run ahead while the original computation follows. It is used to
reduce memory load latency with run-ahead code generated in software [33], and
recently to reduce hardware design complexity [19].
A third, more recent idea is speculative optimization at fine granularity, which
does not yet make use of multiple processors [43]. All of these techniques re-
quire modifications to existing hardware. Similar special hardware support has
been used to parallelize program analysis such as basic block profiling, memory
2Additionally, the register file is copied.

18
checking [46], data watch-points [66].
Loop-level software speculation was pioneered by the lazy privatizing doall
(LPD) test [52]. The LPD technique works in two separate phases: a marking
phase executes the loop and records access to shared arrays in a set of shadow
arrays. A later analysis phase then checks for dependence between any two itera-
tions of the loop by analyzing the shadow values. Later techniques speculatively
make shared arrays private to allow avoid falsely detecting dependencies, and com-
bine the marking and checking phases to guarantee progress [11, 14, 22]. Previous
systems also address issues of parallel reduction [22, 52] and different strategies
of loop scheduling [11]. A weaker type of software speculation is used for disk
prefetching, where only the data access of the speculation needs to be protected
(through compiler-inserted checks) [9].
2.3 Fork and Join
2.3.1 Futures
A future is a mechanism to indicate that the result of some computation will be
needed by the process — referred to as the continuation — at some point in the
future. Originally introduced in Multilisp [24], the contents of the future com-
putation are independent of the invoking computation. A system implementing
futures is free to schedule the future computation at any point before the result of
the computation is needed. Support for futures exists in the Java programming
language through its concurrency utilities package. Unlike functional languages
like Multilisp, Java and other imperative languages make frequent modification of
shared state. In its implementation of futures, the Java run-time system does not
make any guarantees about the synchronization of the future with its continua-
tion. The programmer is still responsible for ensuring that access to shared data

19
is protected.
Work on a Java implementation of futures that are “safe” in terms of main-
taining their sequential semantics has been done through modifications to the
run-time virtual machine [63]. In order to ensure the effects of a future are not
intermixed with data accesses of its continuation, each is run in a separate thread
with a local write buffer implemented by chaining multiple versions of an object
together. Reads to the object must traverse a list of versions to location the cor-
rect one for the context of the thread. Each thread must also maintain a read
and write map of data accesses, which is used to detecting read-write violations
between the threads. Despite the name, the future should conceptually complete
its data accesses before the continuation.
The implementation of safe futures depends heavily on the fact that Java is a
managed language in which objects have metadata and are accessed by reference,
simplifying the redirection needed to protect access. The additional work needed
to monitor data access is added to existing read and write barriers designed for
garbage collection, and the rollback routine is based on the virtual machine’s
exception handling.
Recent work has sought to automatically insert synchronization for Java fu-
tures using compiler support [42]. This support determines statically when a
future first accesses a shared data object and inserts a special form of barrier
statement called allowed. The allowed statement is not released in a continua-
tion until all of its futures have granted access with an explicitly matched grant
statement. A list of futures is built as they are spawned, and cleared after they
have granted access to the data. Because the insertion of the grant and allowed
operations is based on static analysis, it is more conservative than what could
be achieved with a system using run time analysis. The static analysis has the
advantage of significantly lower overhead during execution.

20
2.3.2 Cilk
One representation of fork-join style parallel programming is provided by the Cilk
programming language, which an extension of the C programming language us-
ing an additional set of annotations [6, 18]. Cilk allows a programmer to expose
parallelism using a set of language-specific keywords, which can be removed to
return to a valid C program. Because the programmer is responsible for dis-
tinguishing sequential and parallel code, the two portions of a program can be
clearly delineated and the programmer is forced to consider the overheads in the
sequential portion. The code that occurs within the cilk procedures is considered
to be “work” while the code outside these procedures is referred to as the “critical
path”. This distinction is directly analogous to the relationship expressed earlier
as Amdahl’s Law [2, 23].
The original implementation of Cilk required that invocation points distinguish
between threads that produce a value and the continuation that consumes that
value. The first thread would be created using spawn, while the consumer (or
“successor”) had to be created with spawn next. In order to pass the value to the
consumer, the send argument keyword would be used to explicitly place the result,
potentially allowing the waiting thread to begin. The keyword thread was used in
the way that cilk is now to represent code that contains Cilk specific code. The
use of spawn next and send argument is now handled automatically by the runtime
when the sync keyword is used. This improvement removes a requirement that all
Cilk threads (functions with the cilk keyword) be non-blocking.
In addition to the source code annotations, the Cilk programming language
depends on a sophisticated run-time system. The cornerstone of the system is
a work-stealing scheduler that seeks to balance the load between the available
processing units. The scheduler moves Cilk tasks (threads) from the processor
where they were spawned to processors that are idle. All of the overheads of the

21
system (e.g., spawning and moving tasks) are placed on the critical-path, which
is a design decision not shared by all systems.
2.3.3 Sequential Semantics
Although fork-join style semantics for parallelism makes explicit the point at which
parallel computation is needed, as mentioned in Section 2.3.1 there is no implicit
guarantee of atomicity or progress. A programmer is still responsible for guarding
shared data accesses to preserve object consistency and inserting synchronization
to prevent race conditions. Recent work using a run-time system called Grace
converts a program with fork-join parallel threads into a sequentially consistent
program [4].
Guaranteeing sequential consistency requires the effect of operations appear in
a specific order. This sequence is defined by the semantics of the source program
code. By assuming that threads should be serialized in the order they are created,
the sequential semantics of a fork become the same as a simple function call.
Allowing the run-time system to ensure thread ordering and atomicity, locks can
be elided and the program viewed semantically as though it were serial.
The Grace system does this by converting each thread into a heavy-weight
process with isolated (copy-on-write) memory. Heap and global data that would
have originally been available to all threads are placed in a memory mapped
file and each process maintains a local mapping of the same data for privatized
writes. Using a versioning scheme for the memory, and logging accesses during
execution, the run-time system can determine whether the processes execution
is correct. Assuming correct execution, the process must wait until all logically
prior processes complete before committing its local writes to the global map.
Although the process corresponds to a thread in the original program, Grace
intends to detect violations of the sequential semantics to guard against improper

22
parallel implementations.
Somewhat earlier work suggested two ways in which sequential semantics could
be relaxed intuitively to remove common points of misspeculation [8]. They argue
that sequential semantics may be overly restrictive in many cases in which some
portions of execution do not need to be explicitly ordered, and a program may
have multiple valid outputs. The primary suggestion is that groups of functions
be annotated to indicate a commutative relationship if their internal state does
not need to be ordered but does need to be accessed atomically. Put another
way, these functions have side effects that are only visible to one another. This
kind of behavior is common for dynamic memory management, which maintains
metadata that is not accessed externally.
The programmer is still responsible for identifying all functions accessing the
same state. Although this is significantly easier than identifying all functions that
access shared state and subsequently grouping them, it does allow for failures the
speculation system would otherwise prevent. Additionally, it requires atomicity
guards within the functions, which the authors ignore. There is an additional
requirement that commutative functions operate outside the scope of speculation
itself. If a transactional memory system is being used, the functions must use
non-transactional memory. This complicates cases where some state is internal
to the commutative group, while other state is global and also implies that these
functions must have an explicit inverse function because the rollback mechanism
of the speculation system will not protect them. This limits to applicability of
commutative annotations, or requires significantly more programmer effort that
initially suggested.

23
2.4 Pipelining
The general approach of parallelizing a loop — executing each instance of the
loop body separately — is not possible if there are dependencies carried from one
iteration of the loop to the next. There may still be cases in which such a loop
can still be parallelized, if it can successfully be pipelined. By breaking the loop
into a sequence of individual stages, we may find that dependencies are carried
from one stage to the next within an iteration, and one iteration of a stage to the
same stage in the next iteration, but that no dependencies are carried from a late
stage to an early stage in the next iteration.
A pipelined loop is analogous to a manufacturing pipeline in which a product
is created in stages. Each individual widget mirrors an instance of the loop body:
just as only one item can be painted or packaged at once, subsequent instances
of the first stage of the loop cannot execute concurrently. Likewise, just as the
widget must be painted before it is packaged, stages of the loop must be executed
in order. In such cases, the iterations of the loop can be performed in parallel by
skewing successive instances by one stage.
Given the code in Listing 2.4, the first three skewed iterations would appear as
depicted in Listing 2.4. Note that the first stage to be executed on each processor
is stalled until the stage is completed on the previous processor3. There is also
a stall between loop iterations because the number of stages does not align with
the number of processors.
2.4.1 Decoupling
In a traditional software pipeline, the thread on one processor executes an entire
instance of the loop body. Once the instruction carrying a dependency has been
executed (the dependent stage of the pipeline), the next iteration of the loop begins
3The correctness of this pipeline relies on the memory coherence of the architecture.

24
Algorithm 2.4.1 Listing of pipeline loop.
i n t A[ ] , B [ ] , C [ ] , D[ ] ;
fo r ( i n t i =0; i < N; ++i ) {B[ i ] = f (A [ i ] ) ;C [ i ] = g (B[ i ] ) ;D[ i ] = h (C [ i ] ) ;
}
Algorithm 2.4.2 Interleaved iterations of pipelined loop.
Processor 1 Processor 2 Processor 3 Processor 4B[1] = f(A[1]);
C[1] = g(B[1]); B[2] = f(A[2]);
D[1] = h(C[1]); C[2] = g(B[2]); B[3] = f(A[3]);
D[2] = h(C[2]); C[3] = g(B[3]); B[4] = f(A[4]);B[5] = f(A[5]); D[3] = h(C[3]); C[4] = g(B[4]);C[5] = g(B[5]); B[6] = f(A[6]); D[4] = h(C[4]);
on another processor. One seeks to align the loop structure and processor count
so that the first processor completes its loop iteration just as the last processor
completes the dependent stage of the loop. In this case there are no bubbles in
this pipeline and the processors can be maximally utilized.
The above scenario assumes there is no delay between completing the depen-
dent stage one on processor and initiating it on another. In reality, there will likely
be communication latency between the processors causes the later iterations to
stall slightly. Multiple stalls will accumulate over time and propagate through
later iterations.
The reason this problem arises is that communication is flowing cyclically
through all of the processors. Decoupling breaks the communication cycle so the
dependency communication only flows in one direction [47]. In a decoupled soft-
ware pipelined loop, after the dependent stage is executed on the first processor
the remainder of the loop is dispatched to another processor while the first pro-
cessor begins the next dependent stage. The result is that any communications

25
delay applies equally in all cases. The second processor is effectively skewed by
that delay.
The processes of scheduling a decoupled software pipeline involves constructing
a dependence graph of the loop instructions. The instructions represented by a
strongly connected component (scc) in the graph must be scheduled collectively in
a thread (though a thread may compute multiple components). These components
limit possible parallelism in two ways: there can be no more pipeline stages than
there are scc’s, and the size of the largest scc is the minimum size of the all
pipeline stages.
By introducing speculation into the decoupled software pipelined loop it is
possible to break some of the dependencies [60]. Breaking graph edges allows for
a reduction in the size of scc’s and an increase in their number. The specula-
tion temporarily removes dependencies that are highly predictable, schedules the
pipeline normally, then replaces edges that do not cross threads or flow normally
from early threads to later ones.
The implementation presented in [60] relies on compiler support for trans-
formations and versioned memory to enable rollback of misspeculation. Each
loop iteration involves advancing the memory version and sending checkpoint in-
formation to a helper thread, as well as speculation status. The dependence
on additional hardware support can be overcome using software multi-threaded
transactions as described in Section 2.1.1.
2.5 Support Systems
In order for parallel programming — and particularly speculative parallel pro-
gramming — to be possible, there is a number of ways the task of generating
the program must be supported. The initial problem is determining how the pro-
grammer should express the parallelism. The actual implementation of the parallel

26
constructs can be built for an existing language using a new library and program-
ming interface, or may be built around a language explicitly designed for parallel
programming. In the later case, the language compiler may be equipped with
additional analysis techniques to determine whether the parallel execution will be
valid. Below the programming language, the operating system must provide some
form of support. This OS support must at the very least include scheduling for
multiple tasks, but may also provide additional isolation or monitoring. At the
lowest level, the hardware must again provide multiple processing cores.
2.5.1 Operating System
Adding support for speculation at the operating system level provides a broad form
of support for applications. It is however generally limited to use by heavy-weight
processes, while light-weight thread implementations may need to multiplex what
the operating system supports.
One way for the operating system to enable parallel programming is by forcing
sequential semantics on the processes within the system much like the run-time
system described in Section 2.3.3. One way to achieve this is by building a message
based system in which processes only execute in response to receiving a message,
generating output to be passed to another process. Conceptually, only the old-
est message in the system can be consumed, which serialize the computation by
forcing the causality to flow linearly through the virtual time of the system.
The Time Warp operating system (twos) takes this approach and extends it
by speculatively allowing multiple processes to execute simultaneously [27]. twos
is motivated by distributed systems in which synchronization between processes
is impeded by varying latencies between parts of the system. A process cannot
quickly determine whether it may receive a message in future that should have
been handled before those currently waiting in its queue. For this reason, allowing

27
a process to proceed speculatively is also advantageous.
To allow for rolling back incorrect speculation each process periodically gener-
ates check a point, which is enqueued and assigned to the process’ current virtual
time. The virtual time value is incremented on (and assigned to) each sent mes-
sage, while received messages update the virtual time. If the incoming message is
labeled with a time in the virtual past then the process has consumed a message
that should have been processed before it, indicating misspeculation and causing
rollback.
The dependency, or causality, between processes is managed using anti-messages
that annihilate their matching message. Whenever a twos process creates a mes-
sage a matching anti-message is created as well. While the original message is
sent the anti-message is kept in the output buffer. After a process has rolled back
to a checkpoint, it will begin by consuming the oldest message (which just arrived
and caused the misspeculation). As the process proceeds it will often generate
many of the same outgoing messages, which will annihilate the matching message
waiting in the output buffer. If the anti-message is not matched it will be sent to
the original recipient of the message, where it will either cancel a pending mes-
sage in that processes input queue or cause another rollback. Irrevocable messages
(i.e., output to the user) are held in buffers until all messages that were issued
before them in virtual time have been consumed. The condition determines when
anti-message can be expunged from output buffers.
The twos has a number of limitations that make it inappropriate for use
as a general purpose operating system resulting from its intended purpose as a
platform for simulation. One complaint leveraged by later work is that twos
processes must be deterministic. In reality, processes can use a random number
generation as long as it is reproducible. Truly non-deterministic execution is
generally not desirable. twos does not allow for the use of dynamic memory
allocation, which is quite limiting. The operating system is designed only to run

28
in single user mode and on a static set of processes, though as long as processes
are not communicating with one another the principles of twos remain valid.
The Speculator system introduces support for explicitly tracking speculative
processes by extending the Linux operating system kernel [44]. As with all spec-
ulation systems, Speculator implements detection of and recovery from misspec-
ulation and guarantees that speculative processes do not perform irrevocable op-
erations.
Because speculation is performed on heavy-weight processes, rollback of in-
correct speculation is handled by terminating the process and restarting from a
checkpoint. The checkpointing routine is based on extensions to the standard
fork call. The processes is duplicated, but the new child is not made available to
the scheduler and retains the same identifiers as the original process. Additionally,
any pending signals are recorded and file descriptors are saved. The memory of
the process is marked for copy-on-write just as when a normal fork call is made.
During execution of the speculative process the use of output operations are
buffered for playback when the speculation is determined to be correct. Inter-
process communication is generally allowed, but the processes receiving the com-
munication is made to checkpoint and become speculative as well. The depen-
dency between the two processes is tracked so misspeculation will cause a series
of rollbacks to occur. Outside of the kernel, the speculative state of a process is
indeterminate.
2.5.2 Compiler
Any language with support for parallel programming will need some form of com-
piler support, even if it simply interprets a trivial syntax extension as a call to a
run-time library. More powerful analysis by a compiler can allow some degree of
automatic parallelization. The Mitosis compiler implements a form of run-ahead

29
speculation like those described in Section 2.2.2 by automatically selecting and
reducing speculative regions [50].
The objective of the Mitosis compiler is to insert spawn points in a program and
determining a corresponding point to which another thread should speculatively
jump. To enable the speculative thread, the region between the spawn and jump
points is reduced into a pre-computation slice (p-slice) that should evaluate the
state needed by the thread. The compiler estimates the length of the speculative
execution, and traces back through the control-flow graph from the point it should
complete. Any values that are found to live into the region between the jump point
and the assumed end point are required. By continuing past the jump point to
the spawn point, the instructions needed to compute those values are identified
and added to the p-slice.
The Mitosis compiler uses profile information to speculatively optimize the
p-slice in several ways. Branches that are infrequently taken, and write-read
dependencies that occur infrequently are elided. Additionally, control flow that
cannot reach the jump point is removed entirely. The profile information is also
used to select the most effective pairs of spawn and jump points based on the
length of the p-slice and speculative region as well as the likely-hood of the path
being take and correctly speculated. The Mitosis system relies on the underlying
hardware to detect misspeculation and handle recovery.
While the Mitosis system is build on a research system (the Open Research
Compiler), contemporary work implemented similar compiler support for in the
production gcc compiler [35]. Rather than generating p-computation slices,
POSH relies on profile information to select tasks that are likely to speculate
correctly. Tasks are initially created for every loop body and subroutine (and the
continuations of both) and then expanded or pruned to meet size restrictions —
large enough to overcome the cost of creation and small enough to be manageable4.
4Hardware TLS support is inherently limited to tracking a finite number of accesses.

30
Like the Mitosis system, POSH relies on hardware support for detection of vi-
olations of the sequential semantics of the program. In both cases, the assumption
is that threads are explicitly spawned. While POSH specifies that the architecture
provides a spawn instruction, Mitosis leaves the architecture details completely un-
specified. In a departure from the fork/join notation, POSH assumes the spawned
task will explicitly commit, while the parent task does nothing to explicitly re-
claim the child. If the parent attempts to read results from the child before it is
complete, misspeculation will occur.
Rather than inserting spawn and commit, a compiler could automatically gen-
erate the synchronization necessary to guarantee sequential ordering. Past work
has used data-flow analysis to insert wait and signal statements similar to the
grant and allow instructions introduced in Section 2.3.1 [64] to pipeline loop bod-
ies. The precise semantics of the instructions only indicate that access to a par-
ticular variable is guarded (equivalent to introducing a lock) and ordered (version
numbered). It must be assumed that instructions to initiate and finalize tasks are
also generated.
Zhai et al. only consider loop bodies as candidates for parallelization. The
naive placement of the synchronization would place the request at the beginning
of the task (loop body) and the release at the end, encapsulating the entire loop
in a single state. The region of code between the wait and signal represents the
critical section in which only the current task can access the variable, and like any
critical section is should be made as small as possible. To optimize the interleaving
of the tasks, the wait statement should be placed as late as possible while still
preceding all accesses to the variable. Likewise, the signal should be as early as
possible as long as no further writes follow it.
To further reduce the size of the critical section, instructions may be reordered
along with the synchronization instructions. By treating a signal instruction as
a read and following the dependence chain up through a control flow graph, the

31
entire sequence of instructions can be hoisted to a point at which dependency
cannot to determined (e.g., due to aliasing). Like the later Mitosis and POSH
systems, Zhai et al. consider profile information to achieve further optimization.
In cases where branches are highly predictable, synchronization may be hoisted out
of the hot path at the expense of misspeculation due to access in the uncommon
case.
2.5.3 Race Detection
Race detection is concerned with determining whether two task can be run in
parallel or need to be performed in series. One way this can be done is by moni-
toring threads during execution to maintain a representation of their relationship
in terms of being inherently serial or possibly parallel. During specific run-time
operations the representation can be queried to determine if a serial relationship
has been violated [17]. For example, when threads access shared data the order
of accesses must match the order of serial threads.
During execution a tree is maintained to represent threads. The leaves of
the tree represent threads, while the internal nodes indicate either a series or
parallel relationship. To determine the relationship between two threads, their
least common ancestor holds appropriate marker. For a given execution tree, the
leaves are numbered with a depth first traversal, and given a second number by
traversing the parallel nodes in the opposite order. Given these values, two nodes
are in series if the values indicate the same order, while the nodes are executing
in parallel if the values are in opposite orders.
Early implementations required that the reverse ordering of nodes be main-
tained at run time, requiring computation on order with the depth of the tree. The
approach in [3] allows for parallel maintenance of and queries to the series/parallel
information in linear time.

32
The process of data race detection can be made more efficient by reducing the
number of objects that need to be monitored at compile time. The eraser anal-
ysis tool achieves this using a number of deep analysis techniques [38]. Initially,
all accesses within a target Fortran program are assumed to require annotation
(including not just recording of access, but initialization and cleanup of metadata
to allow such recording). Using dependence analysis eraser prunes annotation
around statements without dependencies. With intra-procedural analysis, includ-
ing alias, modification, and reference information as well as whether a procedure
is ever used in a parallel construct, annotation for a procedure’s parameters may
be removed as well. After pruning as much annotation as possible, remaining
checks are handled using calls into an associated run-time library to track data
access during execution.
2.6 Correctness Checking
2.6.1 Heavyweight
Recently three software systems use multi-processors for parallelized program pro-
filing and correctness checking. All use heavyweight processes, and all are based
on Pin, a dynamic binary rewriting tool [36]. SuperPin uses a signature-checking
scheme and strives to divide the complete instrumented execution into time slices
and executing them in parallel [62]. Although fully automatic, SuperPin is not
foolproof since in theory the slices may overlap or leave holes in their coverage.
The speculative execution system I describe in Chapter 5 is not designed for
fully automatic program analysis, although I describe a use case in which auto-
matic analysis is enabled with some manual effort. The resulting system guar-
antees the complete and unique coverage during parallel error checking using a
programming interface that allows selective checking. This is useful when check-

33
ing programs that contain unrecoverable operations on conventional operating
systems. Because the runtime operates at the program level it requires source
code and cannot instrument externally or dynamically linked libraries. On the
other hand, it benefits from full compiler optimization across original and instru-
mented code. This is especially useful for curbing the high cost of memory-safety
checking. For example it takes a minute for gcc to optimize the instrumented
code of 458.sjeng, and the optimized code runs over 20% faster in typical cases.
Unlike the earlier systems that automatically analyze the full execution, a system
that is designed specifically for speculative optimization can provide a program-
ming interface for selecting program regions, the ability for a checking process to
roll back the computation from the last correct point, and a throttling mechanism
for minimizing useless speculation.
2.6.2 Hardware Techniques
Fast track is closely related to several ideas explored in hardware research. One
is thread-level speculative parallelization, which divides sequential computation
into parallel tasks while preserving their dependencies. The dependencies may be
preserved by stalling a parallel thread as in the Superthreaded architecture [59]
or by extracting dependent computations through code distillation [67] and com-
piler scheduling for reducing critical forwarding path [64]. These techniques aim
to only reorganize the original implementation rather than to support any type
of alternative implementation. Fast track is not fully automatic, but it is pro-
grammable and can be used by both automatic tools and manual solutions. The
run-time system checks correctness differently. The previous hardware techniques
check dependencies or live-in values, while fast track checks result values or some
user-defined criterion.
Hardware-based thread-level speculation is among the first to automatically
exploit loop-level and method-level parallelism in integer code. In most tech-

34
niques, the states of speculative threads are buffered and checked by monitoring
the data accesses in earlier threads either through special hardware additions to
a processor [54], bus snooping [10], or an extended cache coherence protocol [56].
Since speculative states are buffered in hardware, the size of threads is usually no
more than thousands of instructions. A recent study classifies existing loop-level
techniques as control, data, or value speculation and shows that the maximal
speedup is 12% on average for SPEC2Kint assuming no speculation overhead and
unlimited computing resources [28]. The limited potential at the loop level sug-
gests that speculation needs to be applied at larger granularity to fully utilize
multi-processor machines.
2.6.3 Monitoring
Correct data monitoring is essential for speculative parallelism techniques, and is
of the major sources of run-time overhead. For large programs using complex data,
per-access monitoring causes slowdowns often in integer multiples. The problem of
data monitoring is closely related to data breakpoints in the realm of debugging,
which must monitor program memory accesses and subsequently perform some
user defined action. Also related is to on-the-fly data race detection, which seeks
to detect inconsistencies in data accesses between threads of the same program.
Past work focused on reducing the overhead of data breakpoints5 has ap-
proached that problem using compile time data-flow analysis to identify accesses
which do not need to be explicitly monitored, and by instrumenting the program
with checks with simplified address calculations [61]. Within a debugger there
are two approaches to handling a break point for a particular memory location:
watch the location itself, or check each operation that could modify the loca-
tion. Typically, many instructions can be statically determined not to require
5Data breakpoints are also known as watch points, as opposed to control breakpoints.

35
monitoring.
Another approach to reducing the overhead of debugging is to use sampling
over a large number of runs. One such technique introduces code instrumentation
to record a number of boolean predicates based on run-time program behavior [34].
The predicates represent possible control flow (e.g., was a branch taken), return
value from functions (if it is positive, negative, zero), and the relationship be-
tween variables in the same scope (if one is greater than, less than, or equal to
the other). The total number of predicates is extremely large and so is the over-
head of potentially recording all of them. This cost is limited by evaluating the
predicate instrumentation infrequently based on random choice at each instance.
By additionally recording whether each predicate was ever observed, it is possible
to evaluate the probability that a given predicate can be used to predict program
failure. Although the approach that Liblit et al. discusses allows for useful analysis
of crash reports from deployed programs, it is not a general solution to program
debugging due to the number of samples needed before a bug can be isolated. For
the same reason, such sampling techniques are not applicable to the monitoring
needed by speculative execution.

36
3 Process-Based Speculation
Process based speculation consists of a run-time system and a programming in-
terface. The run-time system is built as a code library with which a programmer
might link their program. The programming interface defines how the program-
mer would invoke calls into the run-time library. In this chapter I describe the
implementation of the core run-time system. Descriptions of the programming
interface and details of the runtime for particular types of speculative parallelism
are addressed in Chapters 4 and 5.
3.1 Implementation
Speculative program execution requires mechanisms for:
• dividing a sequential execution into a series of possibly parallel tasks.
• spawning a speculative task in addition to the existing sequential execution.
• monitoring the execution of tasks.
• managing access to one or more speculative versions of data.
• determining whether the speculative execution is correct.

37
• terminating the speculative execution and reverting any effects it may have
had.
In the remainder of this chapter I will describe how process-based speculation
achieves each of these goals.
3.1.1 Creation
Process based speculation addresses the problem of creating a speculative task
using the operating system’s fork call. The fork call is advantageous in that
all POSIX operating systems support it, making its use highly portable. Prior
to calling fork, the speculative run-time system establishes the communication
systems needed to ensure correctness (described in Section 3.1.3). After the fork
call has been made, two paths of execution exist. Before returning from the run-
time creation block, each process configures its own correctness routines.
3.1.2 Monitoring
In order to determine whether the execution of a speculative task is correct, the
speculative run-time system must ensure that the state of the speculative execu-
tion corresponds with the state of the non-speculative execution. Because each
task’s execution is sequestered in its own process the state is defined by the mem-
ory contents of each process.
Because the speculative task is forked from the sequential task we know that
the initial state of the two processes is identical. As a result, we need only track
the changes made in each process and compare that subset of memory. Because
the two tasks are executed with processes we can monitor those changes using two
operating system constructs: memory access protection and signal handlers.

38
The signal handler routine has three basic responsibilities: to ensure the vio-
lation is a result of the run-time system monitoring, to record the access for later
reference, and to remove the restriction.
The operating system detects memory access violations in the normal course
of operation in order to protect processes. Because a process might access regions
of memory in violation of the operating systems typical restrictions the run-time
system must ensure such accesses are not allowed to pass. The runtime must dif-
ferentiate between access to memory regions that it has restricted, and access the
program should never be permitted to make. The signal itself identifies whether
the access was made to a memory location that is not mapped (maperr) or to a
region of memory to which the process does not have access (accerr).
Once the location of the access has been deemed legitimate, the run-time
system must record the access for later reference. The speculative run-time system
uses an access bitmap to represent each block of memory. One bit for each page
equals one word for every 32 pages. With a page size of 4096 bytes the access map
uses one byte to record accesses on 131,072 bytes. Because much of the access
map will be zeros, and most of it will not be modified, the OS will typically be
able to map several of these pages to the same zero-filled data.
Once the access has been recorded the process must be allowed to continue
its operation. Additionally, there is no reason to record future access to the same
block. The run-time system can safely remove memory protection for the current
block.
3.1.3 Verification
Once the sequential process has advanced far enough the run-time system must
verify that the speculative execution is correct. Such verification requires an
analysis of the access maps for both processes, but without special consideration

39
each process would only have access to its own map. The run-time system can
facilitate the access map analysis in two ways. One option is to push a copy of
one of the maps using a POSIX pipe established during the spawning process as
indicated in Section 3.1.1. In practice it is only necessary to transfer the non-zero
portions of the map. The second option is to create the maps in a segment of
memory that has been explicitly shared between the two processes.
The details of verification — notably the precise point at which it can be
performed and which types of accesses need to be validated — depend on the
type of speculation being performed. These details are discussed in Sections 4.3.3
and 5.3.3.
3.1.4 Abort
Speculative execution requires a mechanism for unrolling or aborting the specula-
tive portion of a process when the speculation proved to be incorrect. In order to
abort speculative execution that has proven incorrect, process-based speculation
can simply kill the running process. Because the Linux kernel protects the mem-
ory space of running processes from access by other processes, it is not possible for
the speculative process to directly affect the non-speculative portion of execution.
As a result, once the speculative execution is killed the non-speculative process
continues as it would in the sequential case.
3.1.5 Commit
The approach for committing a speculative task amounts to terminating the non-
speculative process and allowing execution to continue based on what was com-
puted speculatively. In addition, the meta-data used to track memory accesses
must be updated to reflect the fact that the speculative process is no longer spec-
ulative.

40
3.2 Advantages
Using processes for speculative parallelism has a major advantage over other
thread based approaches. Perhaps the most significant of these is portability.
By using POSIX constructs the speculative run-time system can be built for any
POSIX operating system. The system does not rely on any specific hardware
architecture or features. The run-time system and compiler support presented in
this work have been built and executed on Linux and Mac OS X.
The access monitoring used by thread based approaches relies on instrumen-
tation to data accesses. This instrumentation must be explicitly applied to both
program code and any libraries used during execution. The process-based system
does not require any attention to external libraries to perform correctly. This
flexibility also improves the portability of the run-time system because only the
annotated source code needs to be recompiled.
Process based memory access monitoring also has the advantage of incurring a
constant cost for each location accessed, rather than a cost at every single access
as in a thread based system. Additionally, because the monitoring is done at the
page level, this cost can be amortized for large tasks with multiple accesses to the
same page.
In addition to monitoring the locations of data accesses, the process-based
system compares the data values for conflicts. Using value based checking guar-
antees that identical changes to the same data will not be reported as a conflict,
a problem known as false sharing. In order to support value based checking, a
run-time system must maintain multiple copies of the data. While the process-
based run-time system gains this for free through the operating system’s virtual
memory system, thread based systems need to introduce additional data copies.
Additionally, these multiple copies must be explicitly managed to differentiate
access and guarantee that rollback is possible.

41
3.3 Disadvantages
The process-based protection has a high overhead. However, much of this over-
head is inherently unavoidable for a software scheme to support unpredictable
computations. A major goal of this thesis is to show that general protection can
be made cost effective by three techniques. The first is programmable speculation.
Since the overhead depends on the size of (write) accessed data rather then the
length of the ppr region, it can be made negligible if the size of the parallel task
is large enough.
Second, most overheads—starting, checking, and committing—are off the crit-
ical path, so the non-speculative execution is almost as fast as the unmodified
sequential execution. Moreover, a race is run in every parallel region, where the
correct speculative result is used only when the speculation finishes faster than
the would-be sequential execution. The overhead of determining the winner of
this race is placed in the speculative execution, off the critical path.
Last, the run-time system uses value-based checking, which is more general
than dependence-based checking, and satisfies the Bernstein conditions [5]. Value-
based checking permits parallel execution in the presence of true dependencies
and it is one of the main differences between process-based system and existing
thread-based systems (as discussed in Section 4.3.2).
3.4 Special Considerations
3.4.1 Input and Output
To ensure that the output of a program running with speculative parallelism
support is correct, we ensure output is produced only by a non-speculative process
or by a speculative process that is known to be correct and is serialized in the

42
correct order. Until a speculative process has confirmed that its initialization and
execution was correct (i.e., that all previous speculation was correct), it buffers all
terminal output and file writes. Given correct execution, any output the process
produces will be the same as what the sequential program would have generated.
Program output buffering is established by creating a temporary file in which
to buffer the output that would otherwise be sent to the standard output. Such
a file is created by the run-time system each time a new speculative process is
created. At link time, we use a linker option1 to replace calls to the known input
and output functions with wrappers included with the run-time library. These
wrappers send file output to the redirection temporary file (in the case of printf)
or abort the speculative process (in all other cases). Although it should be possible
to detect writes to the standard error output using fprintf, such support has not
been implemented.
The task of committing the redirected output is addressed by rewinding to
the beginning of the redirection temporary file, reading it in blocks, and writing
those blocks to the standard output. If the speculative process is aborted, the
temporary redirection file is closed and deleted.
3.4.2 Memory Allocation
Dynamic memory allocation can potentially pose a problem for speculative exe-
cution because, unlike stack allocation, its implementation is library based and
the mechanism is not known in advance. The root of the problem for specula-
tive execution is that the implementation may not return the same sequence of
memory locations when the same sequence of requests are made. Even in cases
where the speculative and non-speculative are performing exactly the same com-
putations, the value of some of their pointers may differ because the dynamic
1The gnu linker supports a --wrap option.

43
allocation return a different location. Additionally, comparing the changes the
processes have made is complicated by the need to recognize that different areas
of memory should be treated as though they were the same.
3.4.3 System Signals
The speculative parallel run-time system uses operating system signals to indicate
or initiate state changes among the running processes. The total number of avail-
able signals is limited, and the user program that is being extended may be relying
on some of the same signals. Some of the signals we’re using are slightly reinter-
preted (for example special action may be taken on termination) while others have
no default meaning.
The run-time system does not attempt to preserve any existing signal handlers
installed by the user program, but it would be extended to identify them. The
user installed signal handler can be stored and invoked from within the runtime’s
handler. While using signals would still provide a means to actively alert another
process, we would also need to differentiate signals initiated by the run-time sys-
tem from those of the user program. This could be accomplished using a shared
flag, which the run-time system would consult before either dispatching the signal
to the original handler or processing it.
Ultimately, it is not possible to guarantee that the user program does not install
a new signal handler during execution, over-writing the run-time system’s handler
functions. One solution would be to replace or wrap the handler installation
functions to ensure the run-time system’s handlers are preserved, while any new
handlers are indirectly dispatched. Because the signals the run-time system is
using are intended for user programs, this change could be performed during
compilation.

44
4 Speculative Parallelism
Introduction
In this chapter I describe a type of process-based speculative execution referred
to as Behavior Oriented Parallelism (or bop). The bop system is designed to
introduce parallelism into sequential applications. Many sequential applications
are difficult to parallelize because of problems such as unpredictable data access,
input-dependent parallelism, and custom memory management. These difficulties
motivated the development of a system for behavior-oriented parallelization, which
allows a program to be parallelized based on partial information about program
behavior. Such partial information would be typical of a user reading just part of
the source code, or a profiling tool examining a small number of inputs.
The bop style of speculative parallelism allows for some portions of code to
be marked as potentially safe for parallel execution. I refer to these regions of
code as possibly parallel regions, abbreviated ppr. The goal of bop is to allow a
programmer or an analysis tool to provide hints about parallel execution without
needing to guarantee that the parallelism is safe in all cases.
In Section 4.2 I describe the programmatic way in which code is annotated for
bop. The burden on the programmer is intended to be minimal, and the interface

45
to be a natural extension of the existing program. In Section 4.3 I describe how
the run-time system manages the speculative execution. In Section 4.6 I show
an evaluation of performance gains using the bop system, which has improved
the whole-program performance by integer factors for a Lisp interpreter, a data
compressor, a language parser, and a scientific library on a multicore personal
computer.
4.1 Design
The bop system uses concurrent executions to hide the speculation overhead off
the critical path, which determines the worst-case performance where all specula-
tion fails and the program runs sequentially.
4.1.1 Lead and Spec Processes
The execution starts as the lead process, which continues to execute the program
non-speculatively until the program exits. At a pre-specified speculation depth k,
up to k processes are used to execute the next k ppr instances. For a machine
with p available processors, the speculation depth is set to p− 1 to make the full
use of the CPU resource.
Figure 4.1 illustrates an example run-time setup of either the sequential execu-
tion or the speculative execution of three ppr instances. As shown in Part 4.1(b),
when the lead process reaches the start marker mbP , it forks the first spec process
and continues to execute the ppr instance P . The first spec jumps to the end
marker of P and executes the next ppr instance Q. At mbQ, it forks the second
spec process, which jumps ahead to execute the third ppr instance R.
At the end of P , the lead process becomes the understudy process, which re-
executes the next ppr instance non-speculatively. In addition, it starts a parallel
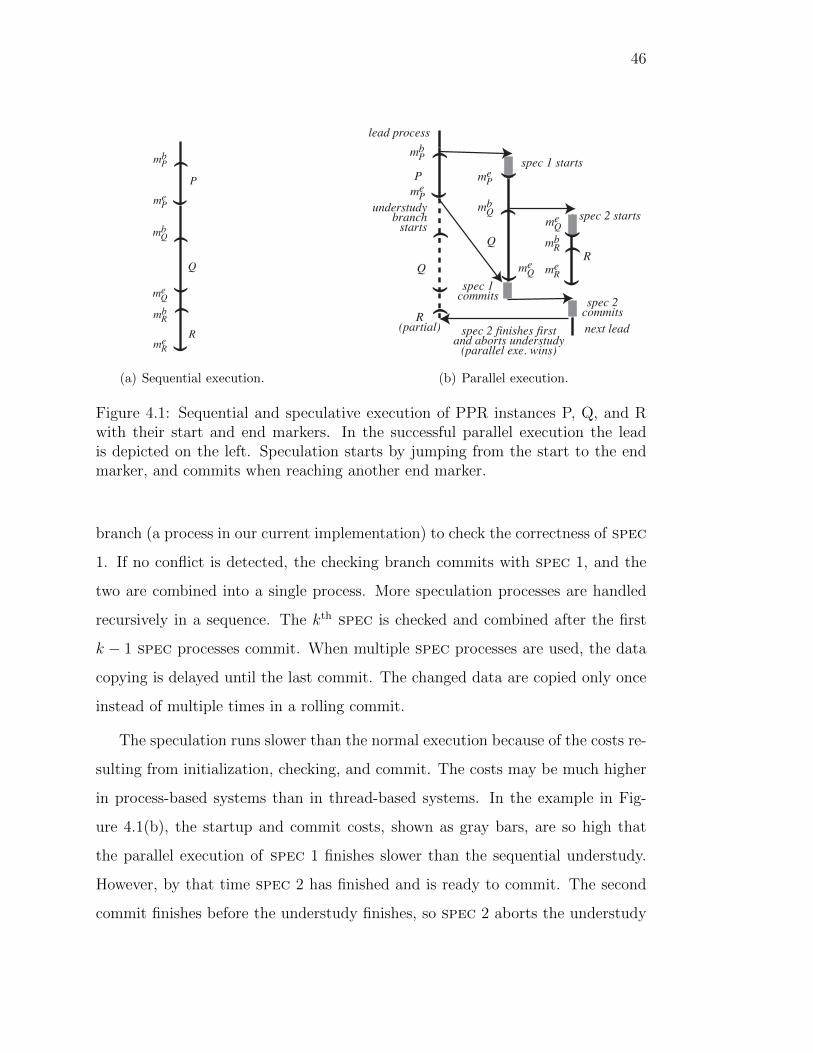
46
27
P
Q
R
mbP
meP
mbQ
meQ
mbR
meR
P
Q
Q
R(partial)
R
mbP
meP
mbQ
meQ
meP
meQ me
R
spec 1 starts
spec 2 starts
spec 1commits
(b) A successful parallel execution, with lead on the left, spec 1 and 2 on the right.
Speculation starts by jumping from the start to the end marker. It commits when
reaching another end marker.
(a) Sequential execution of PPR
instances P, Q, and R and their start and
end markers.
(
(
(
(
(
(
(
(
(
(
(
((
spec 2 finishes firstand aborts understudy
(parallel exe. wins)(
(
(
(spec 2
commits
mbR
understudybranch
starts
lead process
next lead
(a) Sequential exe-cution.
P
Q
R
mbP
meP
mbQ
meQ
mbR
meR
P
Q
Q
R(partial)
R
mbP
meP
mbQ
meQ
meP
meQ me
R
spec 1 starts
spec 2 starts
spec 1commits
(b) A successful parallel execution, with lead on the left, spec 1 and 2 on the right.
Speculation starts by jumping from the start to the end marker. It commits when
reaching another end marker.
(a) Sequential execution of PPR
instances P, Q, and R and their start and
end markers.
(
(
(
(
(
(
(
(
(
(
(
(
(
spec 2 finishes firstand aborts understudy
(parallel exe. wins)
(
(
(
(
spec 2commits
mbR
understudybranch
starts
lead process
next lead
(b) Parallel execution.
Figure 4.1: Sequential and speculative execution of PPR instances P, Q, and Rwith their start and end markers. In the successful parallel execution the leadis depicted on the left. Speculation starts by jumping from the start to the endmarker, and commits when reaching another end marker.
(a) Sequential execution.
P
Q
R
mbP
meP
mbQ
meQ
mbR
meR
P
Q
Q
R(partial)
R
mbP
meP
mbQ
meQ
meP
meQ me
R
spec 1 starts
spec 2 starts
spec 1commits
(b) A successful parallel execution, with lead on the left, spec 1 and 2 on the right.
Speculation starts by jumping from the start to the end marker. It commits when
reaching another end marker.
(a) Sequential execution of PPR
instances P, Q, and R and their start and
end markers.
(
(
(
(
(
(
(
(
(
(
(
(
(
spec 2 finishes firstand aborts understudy
(parallel exe. wins)
(
(
(
(
spec 2commits
mbR
understudybranch
starts
lead process
next lead
(b) Parallel execution.
Figure 4.1: Sequential and speculative execution of PPR instances P, Q, and Rwith their start and end markers. In the successful parallel execution the leadis depicted on the left. Speculation starts by jumping from the start to the endmarker, and commits when reaching another end marker.
branch (a process in our current implementation) to check the correctness of spec
1. If no conflict is detected, the checking branch commits with spec 1, and the
two are combined into a single process. More speculation processes are handled
recursively in a sequence. The kth spec is checked and combined after the first
k − 1 spec processes commit. When multiple spec processes are used, the data
copying is delayed until the last commit. The changed data are copied only once
instead of multiple times in a rolling commit.
The speculation runs slower than the normal execution because of the costs re-
sulting from initialization, checking, and commit. The costs may be much higher
in process-based systems than in thread-based systems. In the example in Fig-
ure 4.1(b), the startup and commit costs, shown as gray bars, are so high that
the parallel execution of spec 1 finishes slower than the sequential understudy.
However, by that time spec 2 has finished and is ready to commit. The second
commit finishes before the understudy finishes, so spec 2 aborts the understudy

47
and becomes the next lead process.
bop executes ppr instances in a pipeline and shares the basic property of
pipelining: if there is an infinite number of pprs, the average finish time is de-
termined by the starting time not the length of each speculation. In other words,
the parallel speed is limited only by the speed of the initialization and the size
of the sequential region outside ppr. The delays during and after speculation do
not affect the steady-state performance. This may be counter intuitive at first
because the commit time does not matter even though it is done sequentially. In
the example in Figure 4.1(b), spec 2 has similar high startup and commit costs
but they overlap with the costs of spec 1. In experiments with real programs, if
the improvement jumps after a small increase in the speculation depth, it usually
indicates a high speculation overhead.
4.1.2 Understudy: Non-speculative Re-execution
bop assumes that the probability, the size, and the overhead of parallelism are all
unpredictable. The understudy provides a safety net not only for correctness when
the speculation fails, but also for performance when speculation is slower than
the sequential execution. For performance, bop holds a two-way race between the
non-speculative understudy and the team of speculative processes.
The non-speculative team represents the worst-case performance along the
critical path. If all speculation fails, it sequentially executes the program. As I
will explain below, the overhead for the lead process consists only of the page-based
write monitoring for the first ppr instance. The understudy runs as the original
code without any monitoring. As a result, if the granularity of ppr instance is
large or when the speculation depth is high, the worst-case running time should
be almost identical to that of the unmodified sequential execution. On the other
hand, whenever the speculation finishes faster than the understudy, it means a

48
performance improvement over the would-be sequential execution.
The performance benefit of understudy comes at the cost of potentially re-
dundant computation. However, the cost is at most one re-execution for each
speculatively executed ppr, regardless of the depth of the speculation.
Using the understudy, the worst-case parallel running time is equal to the
best-case sequential time. One may argue that this can be easily done by running
the sequential version side by side in a sequential-parallel race. The difference is
that the bop system is running a relay race for every group of ppr instances. At
the whole-program level it is sequential-parallel collaboration rather than compe-
tition because the winners of each relay are joined together to make the fastest
time. Every improvement in time counts when speculation runs faster, and no
penalty is incurred when it runs slower. In addition, the parallel run can benefit
from sharing read-only data in cache and memory, while multiple sequential runs
cannot. Finally, running two instances of a program is not always possible for
a utility program, since the communication with the outside world often cannot
be undone. In bop, unrecoverable I/O and system calls are placed outside the
parallel region.
4.1.3 Expecting the Unexpected
Figure 4.1 shows the expected behavior when an execution of pprs runs from
BeginPPR to EndPPR. In general, the execution may reach an exit (normal or
abnormal) or an unexpected ppr marker. Table 4.1 shows the actions taken by
the lead process, its understudy branch, and spec processes when encountering
an exit, error, or unexpected ppr markers.
The abort by spec in Table 4.1 is conservative. It is possible for, speculation
to reach a program exit point during correct execution, so an alternative scheme
might delay the abort and salvage the work if it turns out to be correct. We favor

49
Table 4.1: Speculation actions for unexpected behaviorbehavior prog. exit or error unexpected ppr markers
lead exit continueunderstudy exit continuespec abort speculation continue
the conservative design for performance. Although it may recompute useful work,
the checking and commit cost will never delay the critical path.
The speculation process may also allocate an excessive amount of memory
and attempt permanent changes through I/O and other OS or user interactions.
The latter cases are solved by aborting the speculation upon file reads, system
calls, and memory allocation exceeding a pre-defined threshold. The file output is
managed by buffering and is either written out or discarded at the commit point.
The current implementation supports stdout and stderr for the pragmatic purpose
of debugging and verifying the output. Additional engineering effort could add
support for regular file I/O.
Strong Isolation
I describe the bop implementation as having strong isolation because the inter-
mediate results of the lead process are not made visible to speculation processes
until the lead process finishes the first ppr. Strong isolation comes naturally with
process-based protection. It is a basic difference between bop and thread-based
systems, where the updates of one thread are visible to other threads, which I
describe as weak isolation.I discuss the control aspect of the difference here and
complete the rest of comparisons in Section 4.3.2 after describing the data pro-
tection.
Weak isolation allows opportunistic parallelism between two dependent threads,
if the source of the dependency happens to be executed before the sink. In the

50
bop system, such parallelism can be made explicit and deterministic using ppr
directives by placing dependent operations outside the ppr region. As an exam-
ple, the code outside ppr in Figure 4.1 executes sequentially. At the loop level,
the most common dependency comes from the update of the loop index variable.
With ppr, the loop control can be easily excluded from the parallel region and
the pipelined parallelism is definite instead of opportunistic.
The second difference between strong and weak isolation is that strong isola-
tion does not need synchronization during the parallel execution but weak isolation
needs to synchronize between the lead and the spec processes when communi-
cating the updates between the two. Since the synchronization delays the non-
speculative execution, it adds visible overheads to the thread-based systems when
speculation fails. bop does not suffer this overhead.
Although strong isolation delays data updates, it detects speculation failure
and success before the speculation ends. Like systems with weak isolation, strong
isolation detects conflicts as they happen because all access maps are visible to all
processes for reads (each process can only update its own map during the parallel
execution). After the first ppr, strong isolation can check for correctness before
the next speculation finishes by stopping the speculation, checking for conflicts,
and communicating data updates. As a design choice, bop does not abort spec-
ulation early because of the property of pipelined parallelism, explained at the
end of Section 4.1.1. The speculation process may improve the program speed,
no matter how slowly it executes, when enough of them are working together.

51
4.2 Programming Interface
In addition to the ppr markers, the bop programming interface two other im-
portant components. First, the programmer may provide a list of global and
static variables that are privatizable within each parallel process. By specifying
where the variables are initialized, the system can treat their data as shared until
the initialization and as private thereafter. The third component is described in
Section 4.2.3.
4.2.1 Region Markers
The bop programming interface allows a programmer to indicate what portions of
code are candidates for parallelism. The primary component of the bop program-
ming interface is the BeginPPR function that denotes the beginning of a parallel
region. The return value of BeginPPR is a Boolean value where truth corresponds
to execution of the speculative code path. Put in terms of the run-time system,
the speculative process receives a non-zero return value while the non-speculative
process receives a return value of zero.
A call to BeginPPR is typically wrapped in a conditional statement to control
the flow of execution through the two paths of execution. Listing 4.2.1 illustrates
an example use of a ppr to parallelize a loop. Each iteration of the loop computes
the value to fill one element of a table based on the corresponding index. If one
assumes that the function compute is free of side-effects, then each iteration of the
loop can be executed in parallel with the others. Using ppr guarantees correct
execution even when the assumption about compute’s purity is not valid.
As counterpart to the BeginPPR marker used to indicate the start of a possible
parallel region, the bop interface provides an EndPPR marker to finalize the region.

52
Algorithm 4.2.1 Example use of bop to mark a possibly parallel region of codewithin a loop.
fo r ( i n t i = 0 ; i < N; ++i ) {i f ( ! BeginPPR (0 ) ) {
tab [ i ] = compute ( i ) ;} EndPPR ( 0 ) ;
}
These two functions both accept a single scalar value that identifies the region to
ensure the markers are properly matched, which allows for nesting. Using the
identifier, an incorrectly matched marker can be safely ignored on the assumption
that another marker matches it and is also ignored.
Algorithm 4.2.2 Example use of bop including EndPPR marker.
fo r ( i n t i = 0 ; i < N; ++i ){i f ( ! BeginPPR ( ) ) {
tab [ i ] = compute ( i ) ;}
}EndPPR ( ) ;agg r ega t e ( tab ) ;
In the loop body example shown in Listing 4.2.1, there is little meaning to
the else branch of the BeginPPR conditional. One can view the second branch as
containing any execution until the next ppr marker of any kind. In straight-line
code it may be more clean to explicitly enclose a block of code within an else
branch to place it in juxtaposition to the speculative path. The code in List-
ing 4.2.3 represents a case in which the else branch is explicitly used to demarcate
distinct paths of execution that may be processed in parallel. Note that there is
no reason that a simple pair of if/else must be used, and in the listing a nest
of conditions is used.

53
Algorithm 4.2.3 Example use of bop in a non-loop context.
i f ( ! BeginPPR ( ) ){f ( tab1 ) ;
} e l se i f ( ! BeginPPR ( ) ){f ( tab2 ) ;
} e l se {f ( tab3 ) ;
}EndPPR ( ) ;
Explicitly Matched Markers
While multiple BeginPPR(p) invocations may exist in the code, a EndPPR(p) must
be unique for the same p, and the matching markers must be inserted into the
same function. The exact code sequence in C is as follows:
BeginPPR if (BeginPPR(p)) goto EndPPR p;
EndPPR EndPPR(p); EndPPR p:;
In the presence of unpredictable control flow, there is no guarantee that a start
marker will be correctly followed by its end marker, or that the matching markers
are executed the same number of times. For example, a longjmp in the middle
of a parallel region may cause the execution to back out and re-enter.
The bop system constructs a sequence of zero or more non-overlapping ppr
instances at run time using a dynamic scope. At any point t, the next ppr instance
starts from the first BeginPPR start marker operation after t and then ends at the
first EndPPR end marker operation after the BeginPPR. For example, assume the
program has two ppr regions P and Q, which are marked by the pairs {BP , EP}
and {BQ, EQ} respectively. If the program executes from the start t0, invoking
the markers six times from t1 to t6 as in Figure 4.2(a), then the two dynamic ppr
instances are depicted in Figure 4.2(b). The ppr range from t1 to t3 and from t4

54
BP
t0 t1 t2 t3 t4 t5 t6
BP BQEP EP EQ
t0 t1 t3 t4 t6
PPRP PPRQ
(a) Sequential execution
BP
t0 t1 t2 t3 t4 t5 t6
BP BQEP EP EQ
t0 t1 t3 t4 t6
PPRP PPRQ(b) Parallel execution
Figure 4.2: Example of matching ppr markers
to t6, and will be run in parallel. The other fragments of the execution will be
run sequentially, although the portion from t3 to t4 will be speculative.
Compared to the static and hierarchical scopes used by most parallel con-
structs, the dynamic scope lacks the structured parallelism to model complex
task graphs and data flows. While it is not a good fit for static parallelism, it is
a useful solution for the extreme case of dynamic parallelism in unfamiliar code.
A coarse-grain task often executes thousands of lines of code, communicates
through dynamic data structures, and has non-local control flows. Functions may
be called through indirect pointers, so parallel regions may be interleaved instead
of being disjoint. Some forms of non-local error handling or exceptions may be
frequent, for example when an interpreter encounters a syntax error. Some forms
are rare, as found in the error checking and abnormal exit found in the commonly
used gzip program’s compression code. Although no error has ever happened
in our experience, if one cannot prove the absence of error in such software of
this size, the dynamic scopes implemented by a ppr can be used to parallelize
the common cases while guarding against unpredictable or unknown entries and
exits.
Since the ppr markers can be inserted anywhere in a program and executed
in any order at run time, the system tolerates incorrect marking of parallelism,
which can easily happen when the region is marked by a profiling tool based on
a few inputs or given by a user unfamiliar with the code. The markers, like other
aspects of the interface, are programmable hints where the quality of the hints

55
affects the parallelism but not the correctness or the worst-case performance.
4.2.2 Post-Wait
The basic ppr structure allows for regions of code to be executed in parallel if
there are no dependencies carried from one to another. In many cases a loop body
may have carried dependencies, but be parallelizable if care is taken. Consider
a loop that is structured in stages so that some stages carry a dependency, but
the dependency is consumed by the same stage in the next iteration. In such a
scenario, the stages of the loop body can be viewed as stages of a pipeline.
Post-Wait is an extension of the basic ppr mechanism provided by the bop
system to allow for pipelining portions of the possibly parallel region. Using the
post-wait interface the speculative processes can be synchronized so that the writes
in the earlier process occur before the corresponding reads during run time.
Algorithm 4.2.4 Example of a pipelined loop body.
fo r ( i n t i = 0 ; i < N; ++i ) {B[ i ] = f (A [ i ] ) ;C [ i ] = g (A[ i ] ) ;D[ i ] = h (B[ i ] , C [ i ] ) ;
}
4.2.3 Feedback
The third component of the bop interface is run-time feedback to the user. When
speculation fails, the system generates output indicating the cause of the failure,
particularly the memory page on which receives conflicting accesses occurred. In
our current implementation, global variables are placed on separate memory pages
by the compiler. As a result, the system can output the exact name of the global
variable when it causes a conflict. A user can then examine the code and remove

56
Algorithm 4.2.5 Example use of bop post/wait.
fo r ( i n t i = 0 ; i < N; ++i ) {i f ( ! BeginPPR ( ) ) {B[ i ] = f (A [ i ] ) ;BOP post ( ‘B ’ ) ;C [ i ] = g (A[ i ] ) ;BOP wait ( ‘B ’ ) ;D[ i ] = h (B[ i ] , C [ i ] ) ;
}EndPPR ( ) ;
}
the conflict by marking the variable privatizable or moving the dependency out
of the parallel region.
Three features of the API are especially useful for working with large, unfa-
miliar code. First, the user does not write a parallel program and never needs
parallel debugging. Second, the user parallelizes a program step by step as hid-
den dependencies are discovered and removed one by one. Finally, the user can
parallelize a program for a subset of inputs rather than all inputs. The program
can run in parallel even if it has latent dependencies.
4.3 Run-Time System
4.3.1 Creation
On the first instance of BeginPPR the run-time system initializes the signal han-
dlers and memory protection used by all of the subsequent process. The beginning
of a possibly parallel region is marked by a call to the system fork function. The
fork function creates a new operating system process which will act as the spec-
ulative process. This new process is considered to be the child of the preexisting
process, which is non-speculative. The original process returns immediately and

57
continues execution in non-speculative state.
4.3.2 Monitoring
The bop system guarantees that if the speculation succeeds the same user vis-
ible output is produced as in the sequential execution. bop partitions the ad-
dress space of a running program into three disjoint groups: shared, checked,
and private. More formally, Dall = Dshared + Dchecked + Dprivate, and any two of
Dshared, Dchecked, and Dprivate do not overlap.
For the following discussion we consider two concurrent processes — the lead
process that executes the current ppr instance, and the spec process that executes
the next ppr instance and the code in between. The cases for k (k > 1) speculation
processes can be proved by induction since they commit in a sequence in the bop
system.
Three types of data protection
Page-based protection of shared data All program data are shared at the
BeginPPR marker by default, and are protected at the memory page granularity.
During execution, the system records all global variables and the range of dy-
namic memory allocation. At BeginPPR, the system turns off write permission
for the lead process and read/write permission for the spec processes. It installs
customized page-fault handlers that loosen the permission for read or write upon
the first read or write access. At the same time, the handler records which type
of access each process has to each page. At commit time, each spec process is
checked in increasing order based on creation. The kth process fails if and only if
a page is written by the lead process and the previous k − 1 spec processes but
read by spec k. If speculation succeeds, the modified pages are merged into a
single address space at the commit point.

58
Algorithm 4.3.1 Listing of ppr creation.
i n t BOP PrePPR( i n t i d ) {i f ( mySpecOrder == specDepth ) return 0 ;
switch ( myStatus ) {defau l t : return 0 ; // ignore nested PPRs (status = MAIN)
case CTRL : // CRTL is the initial statememset ( accMapPtr , 0 , ACC MAP SIZE ) ;myStatus = MAIN ;mySpecOrder = 0 ;
// signal handlers for monitoringSP se tupAct i on ( BOP SegvHandler , SIG MEMORY FAULT ) ;// signals for sequential−parallel race arbitrationSP se tupAct i on ( BOP RaceHandler , SIGUSR1 ) ;SP se tupAct i on ( BOP UndyTermHandler , SIGUSR2 ) ;
// fall throughcase SPEC :
ppr ID = i d ; // record identifier of this PPR
i n t f i d = f o r k ( ) ;i f (−1 == f i d ) return 0 ; // fork failurei f ( f i d > 0) { // the MAIN or older SPEC
specP id = f i d ; // track the SPEC process ’ IDi f ( myStatus==MAIN) BOP se tPro tec t i on (PROT READ) ;return 0 ;
} // the newer SPEC continues here
specP id = 0 ;myStatus = SPEC ;mySpecOrder++;
s e t p g i d (0 , SP gpid ) ;SP Red i r ec tOutput ( ) ;
i f ( mySpecOrder==1) // set this up only onceBOP setPro tec t i on (PROT NONE) ;
return 1 ;}
}

59
Algorithm 4.3.2 Examples of shared, checked, and private data
sha r ed = GetTable ( ) ;. . .whi le ( . . . ) {
. . .BeginPPR (1). . .i f ( . . . )
checked = checked + Search ( shared , x )I n s e r t ( p r i v a t e , new Node ( checked ) )
. . .i f ( ! e r r o r ) Rese t ( checked ). . .EndPPR(1). . .
}
By using Unix processes for speculation, the bop system eliminates all anti-
dependencies and output dependencies through the replication of the address
space, and detects true dependencies at run time. An example is the variable
shared in Figure 4.3.2, which may point to some large dictionary data structure.
Page-based protection allows concurrent executions as long as a later ppr does
not need the entries produced by a previous ppr. The overwrites by a later ppr
are fine even if the entries are used concurrently by a previous ppr.
The condition is significantly weaker than the Bernstein condition [5], which
requires that no two concurrent computations access the same data if at least
one of the two writes to it. The additional parallelism is possible because of
the replication of modified data, which removes anti-dependencies and output
dependencies. The write access by spec k never causes failure in previous spec
processes. As an additional optimization, the last spec process is only monitored
for data reads. In fact, when the system is limited to only one spec process, a
case termed co-processing, the lead process is monitored only for writes and the
spec only for reads.

60
Page-based protection has been widely used for supporting distributed shared
memory [29, 32] and many other purposes including race detection [49]. While
these systems enforce parallel consistency among concurrent computations, the
bop system checks for dependence violation when running a sequential program.
A common problem in page-level protection is false-positive alerts. We allevi-
ate this problem by allocating global variables on separate memory page. Writes
to different parts of a page may be detected by checking the difference at the end
of ppr, as in [29]. In addition, the shared data are never mixed with checked and
private data on the same page, although at run time newly allocated heap data
are private at first and then converted to shared data at EndPPR.
Value-based checking Typical dependence checking is based on data access
rather than data value. Although this type of checking is sufficient for correctness,
it is not necessary. Consider the variable checked in Figure 4.3.2, which causes
true dependencies because both the current and next ppr instances may read and
modify it. On the other hand, the reset statement at the end may re-install the
old value that checked had at the beginning of the ppr. The parallel execution is
still correct at run time despite the true dependence violation. This case is called
a silent dependence [53].
There is often no guarantee that the value of a variable is reset by EndPPR. In
the above example, the reset depends on a flag, so the “silence” is conditional.
Even after a reset, the value could be modified by pointer indirection in the general
case. Finally, the reset operation may assign different values at different times.
Hence run-time checking is necessary.
For global variables, the size is statically known, so the bop system allo-
cates checked variables in a contiguous region, makes a copy of their value at the
BeginPPR of the lead process, and checks their value at the EndPPR. For dynamic
data, the system needs to know the range of addresses and performs the same

61
checking steps. Checked data can be determined through profiling analysis or
identified by the user as described in more detail in Section 4.2.3. Since the values
are checked, incorrect hints would not compromise correctness. In addition, a
checked variable does not have to return to its initial value in every ppr instance.
Speculation still benefits if the value remains constant for just two consecutive
ppr instances.
Most silent dependencies come from implicit re-initialization of a variable.
Some examples are incrementing and decrementing a scope level when a compiler
compiles a function, setting and clearing traversed bits of the nodes in a graph
during a depth-first search, and filling then clearing the work-list in a scheduling
pass. Such variables that may take the same value at BeginPPR and EndPPR are
classified as checked data. In other words, the ppr execution may have no visible
effect on the checked data variable.
The shared data and checked data have a significant overlap, which is the set
of data that are either read only or untouched by the parallel processes. Data in
this set are classified as checked if their size is small; otherwise, they are shared.
A problem arises when different parts of a structure or array require different
protection schemes. Structure splitting, when possible, may alleviate the problem.
The correctness of checked data is not obvious because their intermediate
values may be used to compute other values that are not checked. I will present
a formal proof of the correctness to show how the three protection schemes work
together to cast a complete shield against concurrency errors.
Likely private data The third class of objects is private data, which is initial-
ized before being used and therefore causes no conflict. In Figure 4.3.2, if private
is always initialized before it is used, the access in the current ppr cannot affect
the result of the next ppr, so any true dependency caused by it can be ignored.
Private data come from three sources. The first is the program stack, which

62
includes local variables that are either read-only in the ppr, or always initialized
before use. Intra-procedure dataflow analysis is capable of identifying such data
for most programs. When the two conditions of safely cannot be guaranteed by
compiler analysis, for example due to unknown control flow or the escape of a local
variable’s address into the program heap, we redefine the local variable to be a
global variable and classify it as shared data. Recursive functions are not handled
specially, but could be managed either using a stack of pages or by disabling the
ppr.
The second source of private data is global variables and arrays that are al-
ways initialized before the use in the ppr. The standard technique to detect this
is inter-procedural kill analysis [1]. In general, a compiler may not always ascer-
tain all cases of initialization. For global data whose access is statically known
in a program, the compiler automatically inserts calls after the initialization as-
signment or loop to classify the data as private at run time. Any access by the
speculation process before the initialization causes it to be treated as shared data.
For (non-aggregate) data that may be accessed by pointers, the system places it
on a single page and treats it as shared until the first access. Additionally, we
allow the user to specify the list of variables that are known to be written before
read in ppr. These variables are reinitialized to zero at the start of a ppr instance.
Since we cannot guarantee write-first access in all cases, we call this group likely
private data.
The third type of private date is newly allocated data in a ppr instance. Before
BeginPPR, the lead process reserves regions of memory for speculation processes.
Speculation would abort if it allocates more than the capacity of the region. The
main process does not allocate into the region, so at EndPPR, the newly allocated
data can be merged with the data from the speculation process. For programs that
use garbage collection, we encapsulate the heap region of spec processes, which
we will describe when discussing the test of a lisp interpreter. Another solution is

63
to ignore garbage collection, which will cause speculation to fail if it is initiated
during a ppr instance because of the many changes it makes to the shared data.
A variable is marked by bop private if its value is assigned before it is used
within a ppr task. Because the first access is a write, the variable does not
inherit value from prior tasks. Verifying the suggestion requires capturing the
first access to a variable, which can be costly if the variable is an array or a
structure. For efficiency we use a compromise. We insert code at the start of
the ppr to write a constant value in all variables that are marked bop private. If
the suggestion is correct, the additional write adds a small extra cost but does
not change the program semantics. If the suggestion is wrong, the program may
not execute correctly, but the sequential version has the same error, and the error
can be identified using conventional debugging tools. Under this implementation,
bop private is a directive rather than a hint, unlike other bop primitives.
Overheads on the critical path The three data protection schemes are sum-
marized and compared in Table 4.2. Most of the overhead of speculation — the
forking of speculation processes, the change of protection, data replication and
read and write monitoring, the checking of access maps for conflicts, the merging
of modified pages, and the competition between the understudy and the spec pro-
cesses — are off the critical path. Therefore, the relation between the worst-case
running time Tmaxparallel and the time of unmodified sequential program Tseq is
Tmaxparallel = Tsequential + c1 ∗ (Sshared/Spage) + c2 ∗ (Smodified by 1st ppr + Schecked)
The two terms after Tseq are the cost from data monitoring and copying on the
critical path, as explained below.
For monitoring, at the start of ppr, the lead process needs to set and reset
the write protection and the access map for shared data before and after the first
ppr instance. The number of pages is the size of shared data Sshared divided
by the page size Spage plus a constant cost c1 per page. During the instance, a

64
write page fault is incurred for every page of shared data modified in the first ppr
instance. The constant per page cost is negligible compared to the cost of copying
a modified page.
Two types of copying costs may appear on the critical path. The first is for
pages of shared data modified by the lead process in the first ppr instance and
(among those) pages modified again by the understudy. The second cost is taking
the snapshot of checked data. The cost in the above formula is the worst case,
though the copy-on-write mechanism in modern OS may completely hide both
costs.
Data copying may hurt locality across ppr boundaries, although the locality
within is preserved. The memory footprint of a speculative run is larger than the
sequential run as modified data are replicated. However, the read-only data are
shared by all processes in main memory and in shared cache, which is physically
indexed. As a result, the footprint may be much smaller than running k copies of
a program.
A Formal Proof of Correctness
It is sufficient to prove the correctness for a single instance of the parallel execution
between two ppr instances. An abstract model of an execution is defined by:
Vx : a set of variables. Vall represents all variables in memory.
St : the content of V at time t.
Stx : the state of Vx at t.
rx : an instruction. The instructions we consider are the markers of the two pprs,
P and Q, P b, P e, Qb, and Qe (corresponding to mbP , me
P , mbQ, and me
Q in
Section 4.2.1). P and Q can be the same region.

65
Table 4.2: Three types of data protectionshared data
protection: Not written by lead and read by specgranularity: page/elementsupport: compiler, profiler, run-timecritical path overhead: 1 fault per modified page
checked dataprotection: Value at BeginPPR is the same at EndPPR in lead.
Concurrent read/write allowed.granularity: elementsupport: compiler, profiler, run-timecritical path overhead: copy-on-write
private dataprotection: no read before 1st write in spec. Concurrent read-
/write allowed.granularity: elementsupport: compiler (run-time)critical path overhead: copy-on-write
〈rx, StV 〉 : a point in execution where in terms of instruction and state.
〈r1, St1all〉
p=⇒ 〈r2, St2
all〉 : execution of a process p from one point to another.
Figure 4.3 shows the parallel execution and the states of the lead and the spec
processes at various times. If a parallel execution passes the three data protection
schemes, all program variables in our abstract model can be partitioned into the
following categories:
• Vwf : variables whose first access by spec is a write. wf stands for write first.
• Vexcl lead: variables accessed only by lead when executing the first ppr
instance P .
• Vexcl spec: variables accessed only by spec.

66
(a) sequential execution (b) parallel execution by three processes
main process(main)
(rb
, S init)
(re , Smid)
(re , Sseq)
(rb
, S init) (re , S init)
(re , Sspec)
(re , Smain) (re
, Smain)
(re , Sundy)
understudy process(undy)
speculation process(spec)
Figure 4.3: The states of the sequential and parallel execution
• Vchk: the remaining variables. chk stands for checked.
Vchk = Vall − Vwf − Vexcl lead − Vexcl spec
Examining Table 4.2, we see that Dshared contains data that are either accessed
by only one process (Vexcl lead and Vexcl spec), written before read in spec (Vwf ),
read only in both processes or not accessed by either (Vchk). Dprivate contains data
either in Vwf or Vchk. Dchecked is a subset of Vchk. In addition, the following two
conditions are met upon a successful speculation.
1. lead process reaches the end of P at P e, and the spec process, after leaving
P e, executes the two markers of Q, Qb and then Qe.
2. the state of Vchk is the same at the two ends of P (but it may change in the
middle), that is, Sinitchk = Slead
chk .

67
To analyze correctness, examine the states of the sequential execution, Sinit
at P b and Sseq at Qe of the sequential process seq, and the states of the parallel
execution, Sinit at P b, Slead at P e of the lead process and Sinit at P e and Sspec at
Qe of the spec process. These states are illustrated in Figure 4.3.
The concluding state of the parallel execution, Sparallel at Qe, is a combination
of Slead and Sspec after the successful speculation. To be exact, the merging step
copies the modified pages from the lead process to the spec process, so
Sparallel = Sspecall−excl lead + Slead
excl lead
In the following proof, each operation rt is defined by its inputs and outputs,
which all occur after the last input. The inputs are the read set R(rt). The out-
puts include the write set W (rt) and the next instruction to execute, rt+1. For
clarification, an operation is an instance of a program instruction. For the sim-
plicity of the presentation, symbol rx is overloaded as both the static instruction
and its dynamic instances. To distinguish in the text, former is referred to as an
instruction and the latter as an operation, so there may be only one instruction
rx but any number of operations rx.
Theorem:
If the spec process reaches the end marker of Q, and the protection in Table 4.2
passes, the speculation is correct, because the sequential execution would also
reach Qe with a state Sseq = Sparallel, assuming that both the sequential and the
parallel executions start with the same state, Sinit at P b.
Proof:
Consider the speculative execution, (P e, Sinit)spec=⇒ (Qe, Sspec), for the part of the
sequential execution, (P e, Smid)seq
=⇒ (Qe, Sseq). The correct sequential execution
is denoted as pe, r1, r2, · · ·, and the speculative execution as pe, r′1, r′2, · · ·. Proving
the above theorem must show that every operation r′t in the speculative execution,

68
and the corresponding operation rt in the sequential execution must:
1. map to the same instruction as rt
2. read and write the same variables with the same values
3. move to the same next instruction rt+1
Which is done through contradiction.
Assume the two sequences are not identical and let r′t be the first instruction
that produces a different value than rt, either by modifying a different variable,
the same variable with a different value, or moving next to a different instruction.
Since rt and r′t are the same instruction, the difference in output must be due to
a difference in the input.
Suppose rt and r′t read a variable v but see different values v and v′. Since the
values cannot differ if the last writes do not exist, let rv and r′v be the previous
write operations that produce v and v′. The operation r′v can occur either in spec
before r′t or in the lead process as the last write to v. The contradiction depends
on showing neither of these two cases is possible.
First, if r′v happens in spec, then it must produce the same output as rv per
our assumption that r′t is the first instruction to deviate. Second, r′v is part of
lead and produces a value not visible to spec. Consider the only way v can be
accessed. Given that r′v is the last write, v is read before being modified in spec,
and so it does not belong to Vwf or Vexcl lead. Neither is it in Vexcl spec since it is
modified in the lead process. The only case left is for v to belong to Vchk. Since
V leadchk = V init
chk , after the last write the value of v is restored to the beginning state
where spec starts and consequently cannot cause r′t in spec to see a different value
as rt does in the sequential run. Therefore rt and r′t cannot have different inputs
and produce different outputs, and the speculative and sequential executions must
be identical.

69
Since spec reads and writes correct values, Vwf , Vexcl spec, and the accessed
part of Vchk are correct. Vexcl lead is also correct because of the copying of the
their values at commit time. The remaining part of Vchk is not accessed by lead
or spec and still holds the same value as Sinit. It follows that the two states
Sparallel and Sseq are identical, which means that Sparallel is correct.
�
The above proof is similar to that of the Fundamental Theorem of Dependence
(Sec. 2.2.3 in [1]). While the proof in the book deals with statement reordering,
the proof here deals with region reordering and value-based checking. It rules
out two common concerns. First, that the intermediate values of checked data
never lead to incorrect results in unchecked data. Second, the data protection
always ensures the correct control flow by speculation. In bop, the three checking
schemes work together to ensure these strong guarantees.
Comparisons
Strong and weak isolation as discussed in Section 4.1.3 is a basic difference between
process-based bop and thread-based systems that include most hardware and
software speculation and transactional memory techniques. The previous section
discussed the control aspect, while the data protection and system implementation
are discussed below. The comparisons are summarized in Table 4.3.
Weak isolation needs concurrent access to both program data and system data,
as well as synchronization to eliminate race conditions between parallel threads
and between the program and the run-time system. The problem is complicated
if memory operations may be reordered by the compiler or by hardware, and
the hardware uses weak memory consistency, which does not guarantee correct
results without explicit synchronization. In fact, concurrent threads lack a well-
defined memory model [7]. A recent loop-level speculation system avoids race
conditions and reduces the number of critical sections (to 1) by carefully ordering
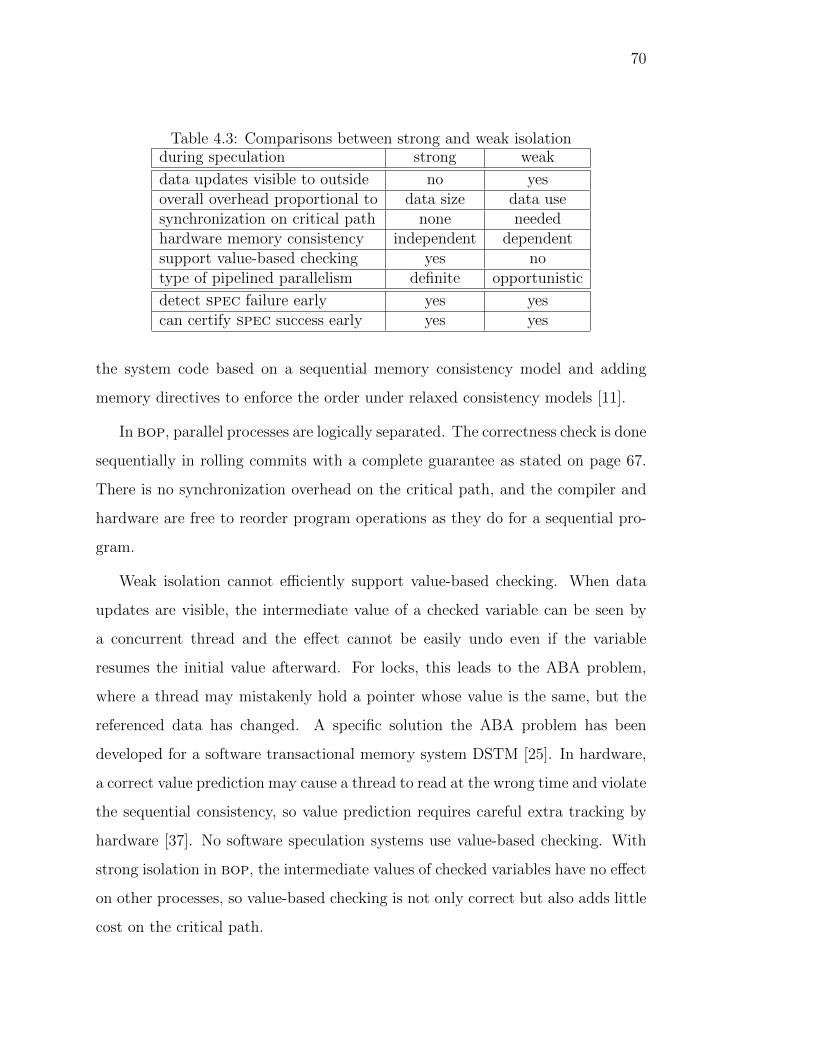
70
Table 4.3: Comparisons between strong and weak isolationduring speculation strong weak
data updates visible to outside no yesoverall overhead proportional to data size data usesynchronization on critical path none neededhardware memory consistency independent dependentsupport value-based checking yes notype of pipelined parallelism definite opportunistic
detect spec failure early yes yescan certify spec success early yes yes
the system code based on a sequential memory consistency model and adding
memory directives to enforce the order under relaxed consistency models [11].
In bop, parallel processes are logically separated. The correctness check is done
sequentially in rolling commits with a complete guarantee as stated on page 67.
There is no synchronization overhead on the critical path, and the compiler and
hardware are free to reorder program operations as they do for a sequential pro-
gram.
Weak isolation cannot efficiently support value-based checking. When data
updates are visible, the intermediate value of a checked variable can be seen by
a concurrent thread and the effect cannot be easily undo even if the variable
resumes the initial value afterward. For locks, this leads to the ABA problem,
where a thread may mistakenly hold a pointer whose value is the same, but the
referenced data has changed. A specific solution the ABA problem has been
developed for a software transactional memory system DSTM [25]. In hardware,
a correct value prediction may cause a thread to read at the wrong time and violate
the sequential consistency, so value prediction requires careful extra tracking by
hardware [37]. No software speculation systems use value-based checking. With
strong isolation in bop, the intermediate values of checked variables have no effect
on other processes, so value-based checking is not only correct but also adds little
cost on the critical path.

71
Value-based checking is different from value-specific dynamic compilation (for
example in DyC [20]), which finds values that are constant for a region of the
code rather than values that are the same at specific points of an execution (and
can change arbitrarily between these points). It is different from a silent write,
which writes the same value as the previous write to the variable. The bop run-
time software checking happens once per ppr for a global set of data, and the
correctness is independent of the memory consistency model of the hardware.
Most previous techniques monitor data at the granularity of array elements,
objects, and cache blocks; bop uses pages for heap data and padded variables
for global data. Paging support is more efficient for monitoring unknown data
structures but it takes more time to set up the permissions. It gives rise to
false sharing. The cost of page-based monitoring is proportional to the size of
accessed data (for the overhead on the critical path it is the size of modified data)
rather than the number of accesses as in thread-based systems, making page-based
protection especially suitable for coarse-grain parallelism.
4.3.3 Verification
In the case of speculative parallelism through pprs, verifying correct execution is
primarily the handled by the run-time monitoring. Any conflict between the main
and speculative processes will be detected when it occurs and does not require
additional analysis after the pprs complete.
In addition to verifying the correctness of the in-flight ppr executions, it is im-
portant to handle cases where one of the processes attempts to terminate (whether
or not the termination is the result of correct execution). It is always safe for the
non-speculative main process to exit. The nature of the main process is such that
a speculative processes must be running as well1, which must be terminated. It is
1The identifier main only exists within the context of a ppr.

72
worth noting that these speculative process are performing useless computation,
but there is no other useful ppr related work that could have been scheduled.
Reaching a program exit point in the understudy process is equivalent doing so
in the main process, except that buffered output must be committed.
If a speculative process reaches a program exit point it cannot be permitted to
commit normally. The current bop system simply forces the speculative process
to abort, which allows the corresponding understudy to eventually reach the exit
point and complete. If the speculative process is the child of another speculative
process, that process is notified of the failure, which allows it to change directly
to control status and elide any further coordination with the terminal speculative
process. An alternative is for the speculative process to treat the exit as the
end marker of the current ppr. This would cause the speculative process to
synchronize with the main process once it reaches its own end marker, after which
the process will potentially commit and exit without delaying until the understudy
reaches the same point.
4.3.4 Commit
The bop commit routine is invoked when a process reaches a EndPPR marker.
The functionality is dependent on the state of the process; sequential and control
processes are ignored, while the other states are handled specifically. If the iden-
tifier parameter does not match the current ppr identifier, then the end marker
is ignored.
The commit routine for the speculative process involves synchronizing with the
non-speculative processes, as well as maintaining order among the other specula-
tive processes. The actual tasks are provided in Listing 4.3.4 but can be summa-
rized as follows: We first pass our token to the next waiting speculative process.
We then wait for the previous speculative process to indicate that it has completed

73
Algorithm 4.3.3 Listing of bop termination routine
void a t t r i b u t e ( ( d e s t r u c t o r ) ) BOP End ( void ) {s t a t i c short f i n i s h e d = 0 ;i f ( f i n i s h e d ) return ;f i n i s h e d = 1 ;
switch ( myStatus ) {case SPEC :
// Tell the parent to start early termination .i f ( mySpecOrder > 1)
k i l l ( g e t pp i d ( ) , SIGUSR1 ) ;e x i t (EXIT SUCCESS ) ;
case UNDY:// Commit any buffered output.SP CommitOutput ( ) ;// (fall through)
case MAIN : case CTRL : case SEQ:BOP pipeClose ( ) ;
// Kill all run−time processes ( including self)k i l l ( SP gpid , SIGTERM) ;// Wait until signal propagates .pause ( ) ;e x i t (EXIT SUCCESS ) ;break ;
defau l t :e x i t ( EXIT FAILURE ) ;
}}

74
(assuming we are not the first). If this process is the first member of a group of
speculative processes then it must also wait for the previous group to have com-
mitted. Once the order among the speculative processes is confirmed the process
verifies the access maps are correct and copies the data changes it has made to
the next speculative process. Synchronization with the understudy is handled
by determining its process identifier, signaling the understudy, and waiting for
confirmation. Finally, the speculative process commits its output.
The commit routine for the understudy process is fairly simple. This is because
the understudy is considered to be on the critical path and much of the burden of
work has been placed elsewhere. Additionally, the understudy is not speculative.
As depicted in Listing 4.3.4, the understudy keeps a count of each EndPPR marker it
reaches. Because the speculative processes are placed into groups, the understudy
must complete all of the work of one group in order to succeed. The understudy
officially beats the speculative processes once it blocks the signal they would use to
declare completion. After this point the understudy can safely change its status to
control (which is not to be confused with being the lead process). The speculative
processes are killed, and output from the understudy committed.
The commit routine for the lead process (MAIN) is somewhat anomalous in
that it does not actually commit anything. The main process is responsible for
spawning the understudy process, and for synchronizing with the first speculative
process by passing its own data changes.
4.3.5 Abort
The abort routine basically just amounts to the speculative process exiting. Be-
cause the output has been buffered, and the operating system virtual memory
isolates any changes made, the process has no outside impact unless it is ex-
plicitly committed. The run-time system is structured so that if the speculative

75
Algorithm 4.3.4 Listing of ppr commit in the speculative process
void PostPPR spec ( void ) {i n t token ;s i z e t s i z e = s i z eo f ( token ) ;//remove the restrictive protections from memory pagesBOP setPro tec t i on (PROT READ |PROT WRITE ) ;// set the segfault handler back to the defaults i g n a l (SIG MEMORY FAULT , SIG DFL ) ;
i f ( myStatus==SPEC) // wait for main doneSP sync r ead ( l oH iP i p e s [ mySpecOrder ] [ 0 ] , &token , s i z e ) ;
i f ( BOP compareMaps ( ) ) e x i t ( 0 ) ; // access conflict
// If I am not the last spec task in the batchi f ( mySpecOrder < specDepth && ! e a r l yT e rm i n a t i o n ) {
PostPPR commit ( ) ; // never returnsreturn ;
}
// copy all updates to the last SPEC task (mySpecOrder)fo r ( i n t k = 0 ; k < specDepth ; k++)
SP Pul lDataAccordingToMap (WRITEMAP(mySpecOrder ) ,updateP ipe [ 0 ] , f a l s e ) ;
// clear the access mapmemset ( accMapPtr , 0 , ( specDepth+1)∗BIT MAP SIZE ) ;
// reset early termination flage a r l yT e rm i n a t i o n = f a l s e ;
// read the PID of the understudySP sync r ead ( undyCreatedP ipe [ 0 ] , &token , s i z e ) ;k i l l ( token , SIGUSR1 ) ; // tell understudy of our progress// wait for acknowledgement from the understudySP sync r ead ( undyConcedesPipe [ 0 ] , &token , s i z e ) ;// spec wins
myStatus = CTRL ;
SP CommitOutput ( ) ;}

76
Algorithm 4.3.5 Listing ppr commit in the understudy process
// BOP PostPPR for the understudyvoid PostPPR undy ( void ) {++undyWorkCount ;
// UNDY must catch SPECsi f ( undyWorkCount < specDepth ) return ;
// ignore notices from the SPEC (the UNDY has won)s i gp rocmask (SIG BLOCK , &sigMaskUsr1 , NULL ) ;myStatus=CTRL ;undyWorkCount = 0 ;
memset ( accMapPtr , 0 , ( specDepth+1)∗BIT MAP SIZE ) ;mySpecOrder = 0 ;
// Indicate the success of the understudy.k i l l (−SP gpid , SIGUSR2 ) ;// Explicitly kill the first SPEC process .k i l l ( specPid , SIGKILL ) ;
s i gp rocmask (SIG UNBLOCK , &sigMaskUsr1 , NULL ) ;
SP CommitOutput ( ) ;}

77
Algorithm 4.3.6 Listing of ppr commit in the main process
void PostPPR main ( void ) {
i f ( e a r l yT e rm i n a t i o n ) {// Speculation has failed . Restart the next round.myStatus = CTRL ;e a r l yT e rm i n a t i o n = f a l s e ;return ;
}
// open page protection for understudyBOP setPro tec t i on (PROT READ |PROT WRITE ) ;
// start the understudyi n t f i d = f o r k ( ) ;switch ( f i d ) {case −1: a s s e r t ( 0 ) ;case 0 : // the understudy
myStatus = UNDY;s e t p g i d (0 , SP gpid ) ;mySpecOrder = −1;
SP Red i r ec tOutput ( ) ;
// tell spec that undy i s readyp i d t c u r r e n t p i d = ge t p i d ( ) ;w r i t e ( undyCreatedP ipe [ 1 ] , &c u r r e n t p i d , s i z eo f ( i n t ) ) ;break ;
defau l t : // main continuesPostPPR commit ( ) ;break ;
}}

78
Algorithm 4.3.7 Listing of ppr commit finalization routine
void PostPPR commit ( void ) {i n t token , s i z e = s i z eo f ( token ) ;
// send ”main i s done” to specw r i t e ( l oH iP i p e s [ mySpecOrder ] [ 1 ] , &mySpecOrder , s i z e ) ;
i f ( myStatus == SPEC)SP sync r ead ( l oH iP i p e s [ mySpecOrder −1 ] [ 0 ] , &token , s i z e ) ;
SP PushDataAccordingToMap (WRITEMAP(mySpecOrder ) ,updateP ipe [ 1 ] ) ;
// send copy donew r i t e ( l oH iP i p e s [ mySpecOrder ] [ 1 ] , &mySpecOrder , s i z e ) ;e x i t ( 0 ) ;
}
process aborts it means that either the understudy has finished the parallel region
first, or that there is an error indicated in the access maps. In either of these cases
the understudy process becomes the control process and continues running. If the
understudy process is aborting then it must be the case that the spec process has
succeeded. Because the understudy is useless at that point it simply exists.
4.4 Types Of Speculative Parallelism
The bop system can be used to express parallelism in several ways. At the pro-
gram level, parallelism can be broken into three categories: instruction level, data,
and task. The coarse-grained nature of process-based speculative parallelism does
cannot take advantage of instruction level improvements, but it does address both
data and task parallelism.
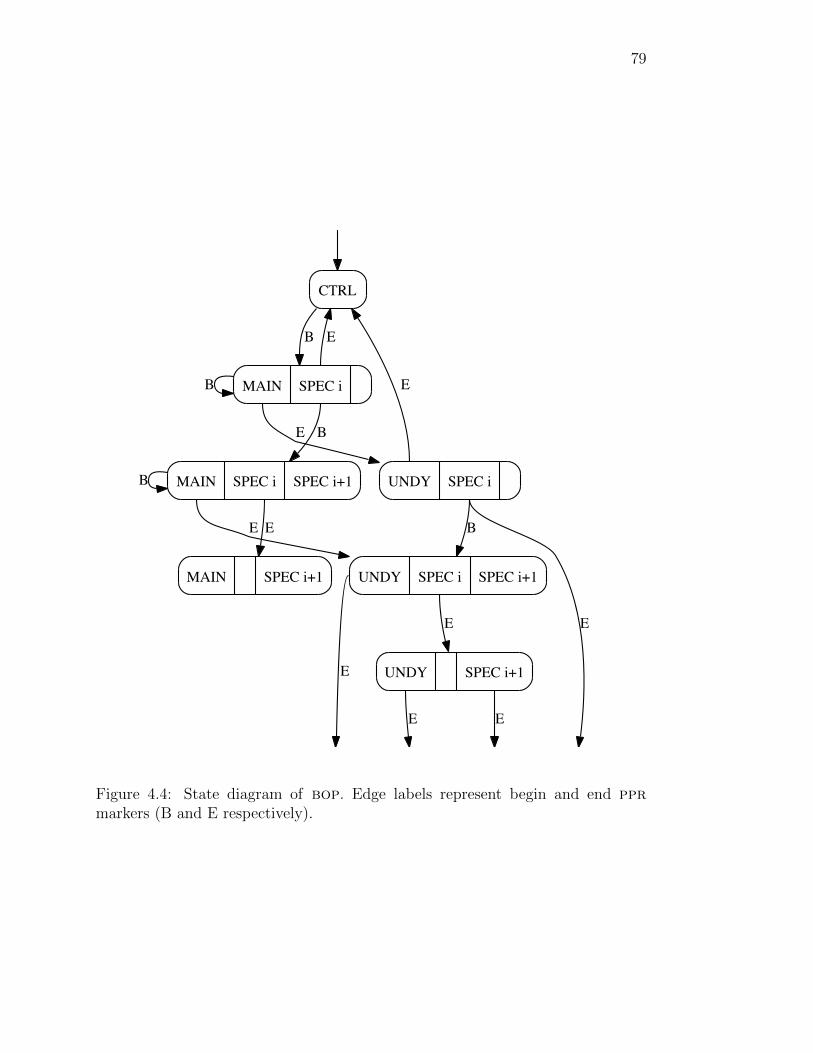
79
START
CTRL
MAIN SPEC i
B E
B
MAIN SPEC i SPEC i+1
B
UNDY SPEC i
E
B
UNDY SPEC i SPEC i+1
E
MAIN SPEC i+1
E
E
B
END1
E
UNDY SPEC i+1
E
END4
E
END2
E
END3
E
Figure 4.4: State diagram of bop. Edge labels represent begin and end pprmarkers (B and E respectively).

80
4.4.1 Data-Parallel
Data parallelism is possible when the same operation can be performed on many
data elements. This form of parallelism is often expressed in a loop, and the con-
version from a sequential program will often focus there. It is not necessary that
all instance of the parallel region perform exactly the same sequence of instruc-
tions, and so control flow can change within the region. This is not the case in the
simplest SIMD (single instruction multiple data) style parallelism. Other system
may offer an explicitly parallel loop, for example the DOALL construct available in
Fortran, or the parallel for directive in OpenMP, in which a loop is marked
are parallel. The same effect is achieved with bop by making the loop body con-
ditional on a BeginPPR marker and placing the EndPPR marker at the end of the
loop body.
4.4.2 Task-Parallel
Task parallelism exists when separate portions of the execution can be performed
independently. This can be implemented with the bop system by placing one
portion of otherwise straight-line code in a conditional block based on the return of
BeginPPR and finalized with a EndPPR marker. At some later point, and additional
EndPPR marker indicates that the speculative process needs the results of the
parallel task. At run time, the main process will execute the code within the ppr
block and spawn its understudy at its conclusion. The speculative process will skip
the conditional block, eventually synchronizing when it reaches the end marker. If
the understudy reaches the marker first, it will terminate the speculative process.
This arrangement is semantically similar to fork-join execution where the sec-
ond end marker represents the join point. One can view the conditional block of
code in terms of a future that is explicitly consumed at the end marker. If the
code block were to be placed in a separate function, the syntax would even be

81
quite similar. This setup can be generalized to multiple parallel tasks by treating
each task as described above. Because only a newly created speculative process
receives a unique return value from BeginPPR the understudy will double check
all of the tasks.
The series of ppr markers is necessary to guarantee that each task is not
dependent on the computation of earlier tasks. If the programmer knows that
the work a task is performing is ancillary to final results, then any data modified
within the task can be ignored by the bop run-time system.
4.5 Comparison to Other Approaches
4.5.1 Explicit Parallelism
In order to explicitly parallelism a program it must be proved the program will
execute correctly in parallel in all cases. Perhaps the most significant advantage
of using bop over an explicit technique is the guarantee of correct execution even
if the region markers are incorrect. Using a ppr to guard a region of an execution
is significantly easier than determine what data are modified within the region
and appropriately protecting it.
In comparison to using locks when explicitly parallelizing a program, one does
not need to ensure the association between the protection (the lock) and the data
are correct. If this association is not correct then the lock fails to serve its purpose.
If one were to implement something like a ppr with locks, it would be necessary to
protect the body of the ppr with a lock and acquire the lock immediately before
attempting to access (either read or write) any of the data accessed within the
ppr.
Attempting to debug a parallel program, particularly in the face of race con-
ditions, relies on the non-deterministic interleaving of the executions. A program

82
running with the bop runtime will behave the same as if it were to be executed
sequentially, which largely obviates the need for debugging it. If errors in the
sequential program need to be diagnosed, the bop markers can be easily disabled
(become a non-operation) and the program run sequentially.
Even if locks are used correctly to synchronize parallel execution, these uses
cannot be composed into more general cases. The use of locks for parallel pro-
gramming has a significant advantage over the bop system in their efficiency.
Locks introduce the least overhead of any synchronization technique, and can use
used in fine-grained cases for which a ppr would not be appropriate.
Attempting to implement something analogous to pprs using a message pass-
ing representation would face many of the same problems as locking. Because
message passing generally requires an explicit receive statement, it must be placed
before the first potential access of any type to any of the data potentially modified
within the ppr. Additionally, the message would need to carry all data modified
in the ppr. Because the members of this set cannot generally be known until run
time, a conservative implementation would need to gather all data modified in the
ppr.
4.5.2 Fine-Grained Techniques
bop is not as efficient as thread-level techniques because of the overhead of general
protection and the problem of false sharing. Speculation also causes unnecessary
computations and by nature cannot handle general forms of I/O and other opera-
tions with unrecoverable side effects (inside a ppr). However, the main advantage
is ease of programming. bop can parallelize a program based on only partial in-
formation. It requires little or no manual changes to the sequential program and
no parallel programming or debugging. The overhead of the system can be hidden
when there is enough parallelism. bop uses unmodified, fully optimized sequential

83
code while explicit threading and its compiler support are often restrained due to
concerns over the weak memory consistency on modern processors. With these
features, bop addresses the scalability of a different sort—to let large, existing
software benefit from parallel execution.
Any technique that does not use heavy-weight processes can be considered fine-
grained. Such techniques are inherently unable to utilize operating system copy-
on-write memory protection. Without hardware support, speculative parallelism
techniques must employ some other mechanism for the roll-back of speculative
writes.
In addition to lacking the operating system mechanism for protecting mem-
ory stores, fine-grained techniques face distinct challenges with regard to logging
memory loads. While the page level read/write access can be manipulated as
in the Fast Track system, this approach is non-viable. The time spent handling
the operating system level signal is far too high in proportion to the duration of
the parallel work. Additionally, the run-time system must do more work than
a system such as Fast Track to determine which thread performed the memory
access.
The more common approach is for the run-time system to instrument mem-
ory loads and stores to allow for logging (and subsequent roll-back or replay).
Excluding systems replying on hardware support, such instrumentation amounts
to expensive additional operations surrounding all memory accesses. These ad-
ditional operations introduce overheads measured as multiples of the execution
time.

84
4.6 Evaluation
4.6.1 Implementation and Experimental Setup
Compiler support is implemented with a modified version of the GNU Compiler
Collection (gcc) 4.0.1 at the intermediate language level. After high-level pro-
gram optimization passes but before machine code generation, the compiler con-
verts global variables to use dynamic allocation for proper protection. We did not
implement the compiler analysis for local variables. Instead the system privatizes
all stack data. All global and heap data are protected. Each global variable is
allocated on separate page(s) to reduce false sharing.
Also based on gcc 4.0.1 are an instrumentor and a behavior analyzer. The
instrumentor collects complete program traces with unique identifiers for instruc-
tions, data accesses, and memory and register variables, so the behavior analyzer
can track all data dependencies and identify ppr.
The bop runtime is implemented as a statically linked library. Shared memory
is used for storing snapshots, access maps, and for copying data at a commit.
Most communication is done by signals, and no locks are used. Two similar
systems have been implemented in the past within our research group using binary
instrumentors. These system do not require program source but offer no easy way
of relocating global data, tracking register dependencies, or finding the cause of
conflicts at the source level.
In bop, the lead process may die long before the program ends, since each
successful speculation produces a new lead (see Figure 4.1 for an example). Now
each parallelized program starts with a timing process that forks the first lead
process and waits until the last process is over (when a lead process hits a program
exit). Instead of collecting user and system times for all processes, the wall-
clock time of the timing process is used, which includes os overheads in process

85
Table 4.4: XLisp Private Variablesbuf : for copying string constants
gsprefix : for generated name stringsxlfsize : for counting the string length in a print call
xlsample : the vestige of a deleted feature called oscheckxltrace : intermediate results for debugging
Table 4.5: XLisp Checked Variablesxlstack : current stack pointer, restored after an evaluation
xlenv : current environment, restored after an evaluationxlcontext : the setjump buffer for exception handling
xlvalue : would-be exception valuexlplevel : parenthesis nesting level, for command prompt
scheduling. Experiments use multiple runs on an unloaded system with four dual-
core Intel 3.40 GHz Xeon processors, with 16MB of shared L3 cache. Compilation
is done with gcc 4.0.1 with “-O3” flag for all programs.
4.6.2 Application Benchmarks
XLisp Interpreter v1.6 by D. M. Betz
The XLisp code, which is available as part of the SPEC 1995 benchmark suite,
has 25 files and 7616 lines of C code. The main function has two control loops,
one for reading expressions from the keyboard and the other for batch processing
from a file. The body of the batch loop is marked by hand as a ppr. Through the
programming interface described in Section 4.2.3, 5 likely privatizable variables are
identifiable (listed in Table 4.6.2), along with 5 checked variables (Table 4.6.2) and
one reduction variable, gccalls, which counts the number of garbage collections.
We do not know much about the rest of the 87 global variables (including function
pointers) except that they are all monitored by bop.
The speculatively parallelized version of XLisp runs successfully until the
garbage collection routine is activated. Because of the extensive changes the

86
collector makes to the memory state, it always kills the speculation. To solve this
problem, the mark-sweep collector implementation is revised for bop as described
briefly here. The key idea is to insulate the effect of garbage collection so it can
be done concurrently, without causing unnecessary conflicts. Each ppr uses a
separate page-aligned memory region. At the beginning of a ppr instance (after
forking but before data protection) the garbage collector performs a marking pass
over the entire heap to record all reachable objects in a start list. New objects are
allocated inside the pre-allocated region during the execution of the ppr. When
the garbage collection is invoked, it marks only objects inside the region but tra-
verses the start list as an additional set of root pointers. Likewise, only objects
within the region that are unmarked are freed. At the end of the ppr, the garbage
collector is run again, so only the pages with live objects are copied at the commit.
The code changes to implement this region-based garbage collection comprise the
introduction of three new global variables and 12 additional statements, most of
which are for collecting and traversing the start list and resetting the MARK flags
in its nodes.
The region-based mark-sweep has non-trivial costs at the beginning and end
of pprs. Within the ppr the collector may not be as efficient because it may fail
to reclaim all garbage because some nodes in the start list would have become
unreachable in the sequential run. The extent of these costs depends on the
input. In addition, the memory regions will accumulate long-live data, which
leads to more unnecessary alerts from false sharing. The lisp evaluation may
trigger an exception leading to an early exit from within a ppr, so the content
of checked variables may not be restored even for parallel expressions. Therefore,
one cannot decide a priori whether the chance of parallelism and its likely benefit
would outweigh the overhead. However, these are the exact problems that bop is
designed to address with its streamlined critical path and the on-line sequential-
parallel race.

87
SerialSpeculative
1 3 7
Times (s)2.25 1.50 0.95 0.68
2.27 1.48 0.94 0.68
2.26 1.47 0.94 0.68
Speedup 1.00 1.53 2.39 3.31
Table 4.6: Execution times for various speculation depths
The N–Queens input from spec95 benchmark suite, which computes all po-
sitions of n queens on an n × n chess board in which no attacks are possible,
is used as a test case of the bop-lisp interpreter. Four lines of the original five
expression lisp program are modified, resulting in 13 expressions, of which 9 are
parallelized in a ppr. When n is 9, the sequential run takes 2.36 seconds using the
base collector and 2.25 seconds using the region-based collector (which effectively
has a larger heap but still needs over 4028 garbage collections for nine 10K-node
regions). The results of testing three speculation depths are listed in Table 4.6.2.
The last row of Table 4.6.2 shows that the speedup, based on the minimum
time of from three runs, is a factor of 1.53 with 2 processors, 2.39 with 4 processors,
and 3.31 with 8 processors. The table does not list the additional cost of failed
speculations, which accounts for 0.02 seconds of the execution.
GZip v1.2.4 by J. Gailly
GZip takes one or more files as input and compresses them one by one using the
Lempel-Ziv coding algorithm (LZ77). This case is based on version 1.2.4, which
available from the spec 2000 benchmark suite. Much of the 8616-line C code
performs bit-level operations, some through in-line assembly. The kernel is based
on a well worn implementation originally written for 16-bit machines. During
testing the program is not instructed to act as a “spec” and behaves as a normal
compressor rather than a benchmark program (which artificially lengthens the

88
Table 4.7: The size of various protection groups in training runsData Groups GZip Parser
Shared Dataobject count 33 35size (bytes) 210K 70Kaccesses 116M 343M
Checked Dataobject count 78 117size (bytes) 2003 5312accesses 46M 336M
Private Data (likely)object count 33 16size (bytes) 119K 6024accesses 51M 39M
input by replication).
Table 4.7 shows the results of the bop analyzer, which identifies 33 variables
and allocation sites as shared data, 78 checked variables (many of which not used
during compression), and 33 likely private variables. Behavior analysis detected
flow dependencies between compressions because the original GZip failed to com-
pletely reinitialize parts of its internal data structure before starting compression
on another new file. The values would have been zeroed if the file was the first
to be compressed, and in this test the code has been changed to reinitialize these
variables. Compression returns identical results in all test inputs.
The sequential GZip code compresses buffered blocks of data one at a time, and
stores the results until an output buffer is full. pprs are manually placed around
the buffer loop and the set of likely private variables are specified through the
program interface described in Section 4.2.3. In this configuration the program
returned correct results, but speculation continually failed because of conflicts
caused by two variables, unsigned short bi buf and int bi valid, as detected by the
run-time monitoring.
The two variables are used in only three short functions. After inspecting the
original source code it became clear that the compression produces bits rather
than bytes, and the two variables stored the partial byte of the last buffer. This

89
SequentialSpeculative
1 3 7
Times (s)8.46 8.56 7.29 7.71 5.38 5.49 4.80 4.478.50 8.51 7.32 7.47 4.16 5.71 4.49 3.108.53 8.48 5.70 7.02 5.33 5.56 2.88 4.88
Average Time 8.51 7.09 5.27 4.10Average Speedup 1.00 1.20 1.61 2.08
Table 4.8: Execution times of bop GZip
dependency was hidden below layers of code and among 104 global variables, but
the run-time analyzer enabled quick discovery of the hidden dependency. The
byte cannot simply be filled (as is done for the final byte) if the resulting file is
to be decompressed with the stock Gunzip. A single extra or error bit will render
the output file meaningless to the decompressor. The solution is to compress
individual data buffers in parallel and concatenate the compressed bits afterward.
The intra-file compression permits single-file compression to use multiple pro-
cessors. The bop version of GZip is testing using a single 84MB file (the gcc 4.0.1
tar file). Table 4.8 shows the comparison between the running time of the unmod-
ified sequential code and the bop version running at three speculation depths.
Although the execution time is stable in sequential runs, it varies by as much as
67% in parallel runs, so in the following table we include the result of six con-
secutive tests of each version is used, and the computed speedup is based on the
average time.
With 2, 4, and 8 processors, the parallel compression gains speedups of 1.20,
1.61, and 2.08. The 8-way GZip is twice as fast and it is slightly faster than data
decompression by Gunzip, whose time is between 4.40 and 4.73 seconds in 6 runs.
The critical path of bopGZip, when all speculation fails, runs slightly faster than
the sequential version because of the effect of prefetching by the speculation. Intra-
file speculation uses additional memory mostly for spec to buffer the compressed
data for the input used. In addition, the program has 104 global variables, so the
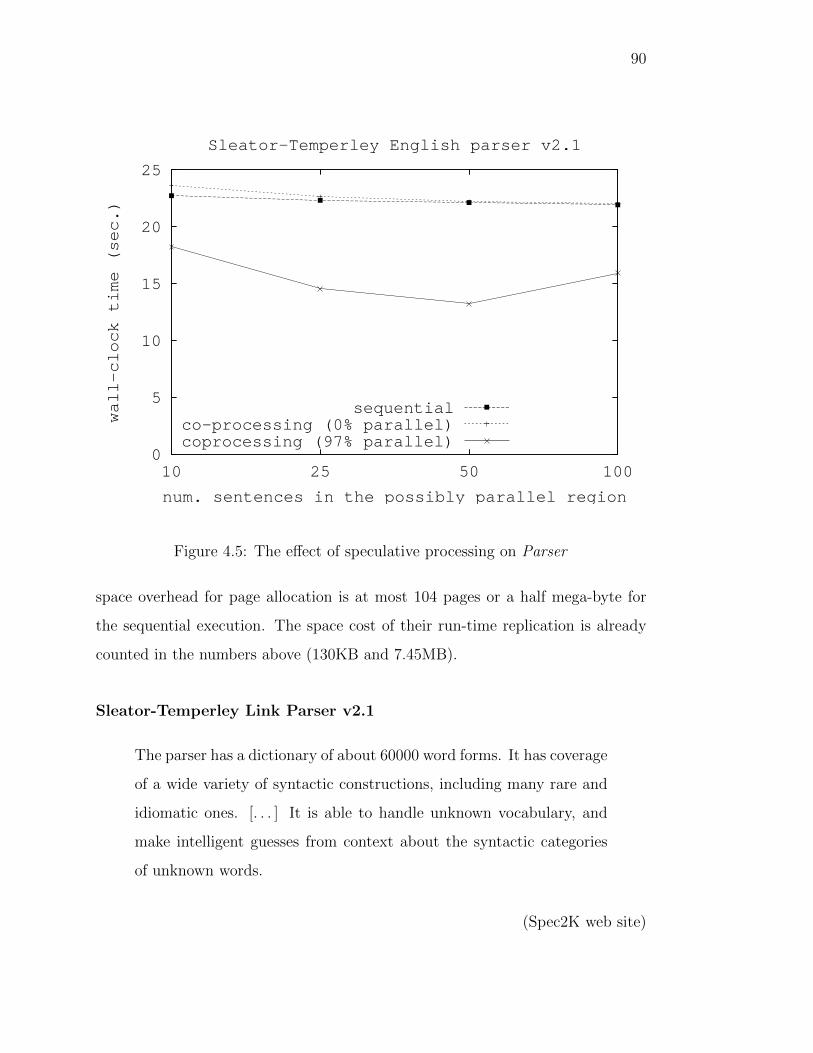
90
0
5
10
15
20
25
100502510
wall-clock time (sec.)
num. sentences in the possibly parallel region
Sleator-Temperley English parser v2.1
sequentialco-processing (0% parallel)coprocessing (97% parallel)
Figure 4.5: The effect of speculative processing on Parser
space overhead for page allocation is at most 104 pages or a half mega-byte for
the sequential execution. The space cost of their run-time replication is already
counted in the numbers above (130KB and 7.45MB).
Sleator-Temperley Link Parser v2.1
The parser has a dictionary of about 60000 word forms. It has coverage
of a wide variety of syntactic constructions, including many rare and
idiomatic ones. [. . . ] It is able to handle unknown vocabulary, and
make intelligent guesses from context about the syntactic categories
of unknown words.
(Spec2K web site)

91
SequentialSpeculative
1 3 7
Times (s)11.35 10.06 7.03 5.3411.37 10.06 7.01 5.3511.34 10.07 7.04 5.34
Speedup 1.00 1.13 1.62 2.12
It is not immediately clear from the documentation — or from the 11,391 lines
of its C code — whether the Seatlor–Temperley Link Parser handles sentences in
parallel, but in fact they are not. If a ppr instance parses a command sentence
which changes the parsing environment, e.g., turning on or off the echo mode, the
next ppr instance cannot be speculatively executed. This is a typical example of
dynamic parallelism.
The bop parallelism analyzer identifies the sentence-parsing loop. We man-
ually strip-mine the loop to create a larger ppr. The data are then classified
automatically as shown in Table 4.7. During the training run, 16 variables are
always written first by the speculation process during training, 117 variables al-
ways have the same value at the two ends of a ppr instance, and 35 variables are
shared.
The test input for the parallel version of the parser uses 1022 sentences ob-
tained by replicating the spec95 training input twice. When each ppr includes
the parsing of 10 sentences, the sequential run takes 11.34 second, and the parallel
runs show speedup of 1.13, 1.62 and 2.12 with a few failed speculations due to the
dynamic parallelism.
The right-hand side of Figure 4.5 shows the performance on an input with 600
sentences. Strip-mine sizes ranging from 10 sentences to 100 sentences are tested
in each group, and the group size has mixed effects on program performance.
For sequential and spec fail, the largest group size leads to the lowest overhead,
3.1% and 3.6% respectively. Speculative processing improves performance by 16%,
46%, 61%, and 33% for the four group sizes. The best performance occurs with the

92
medium group size. When the group size is small, the relative overhead is high;
when the group size is large, there are fewer ppr instances and they are more
likely to unevenly sized. Finally, the space overhead of speculation is 123KB,
100KB of which is checked data. This space overhead does not seem to change
with the group size.
Comparison with Threaded Intel Math Kernel Library
The Intel Math Kernel Library 9.0 (mkl) provides highly optimized, processor-
specific, and multi-threaded routines specifically for Intel processors. The li-
brary includes Linear Algebra Package (LAPACK) routines used for, among other
things, solving systems of linear equations. In this experiment the performance of
solving eight independent systems of equations using the dgesv routine is used for
comparison. mkl exploits thread-level parallelism within, but not across, library
calls. The number of threads used is defined by setting the OMP NUM THREADS
environment variable. bop, on the other hand, can speculatively solve the sys-
tems of equations in parallel even when it uses an unparallelized library, and so the
value OMP NUM THREADS is set to one for bop executions. Since the program
data are protected, bop guarantees program correctness if speculation succeeds.
Math Kernel Library experiments were conducted on systems of equations
with a number of equations ranging from 500 to 4500 in increments of 500. For
each system of equations mkl-only implementation is tested with the number of
threads set to 1, 2, 4, and 8. For the bop and mkl implementation the level
of speculation tested was correspondingly set to 0, 1, 3, and 7. Results for the
single-threaded mkl run and zero-speculation bop run are not shown.As shown
in Figure 4.6, bop-mkl depth 1 and omp-mkl thread 2 perform similarly, with the
mkl-only implementation achieving at most an 18% increase in operations per
second for 1000 equations. For bop-mkl depth 3 and bop-mkl depth 7, the run-time
overhead of bop prevents the system from achieving speedups for systems with
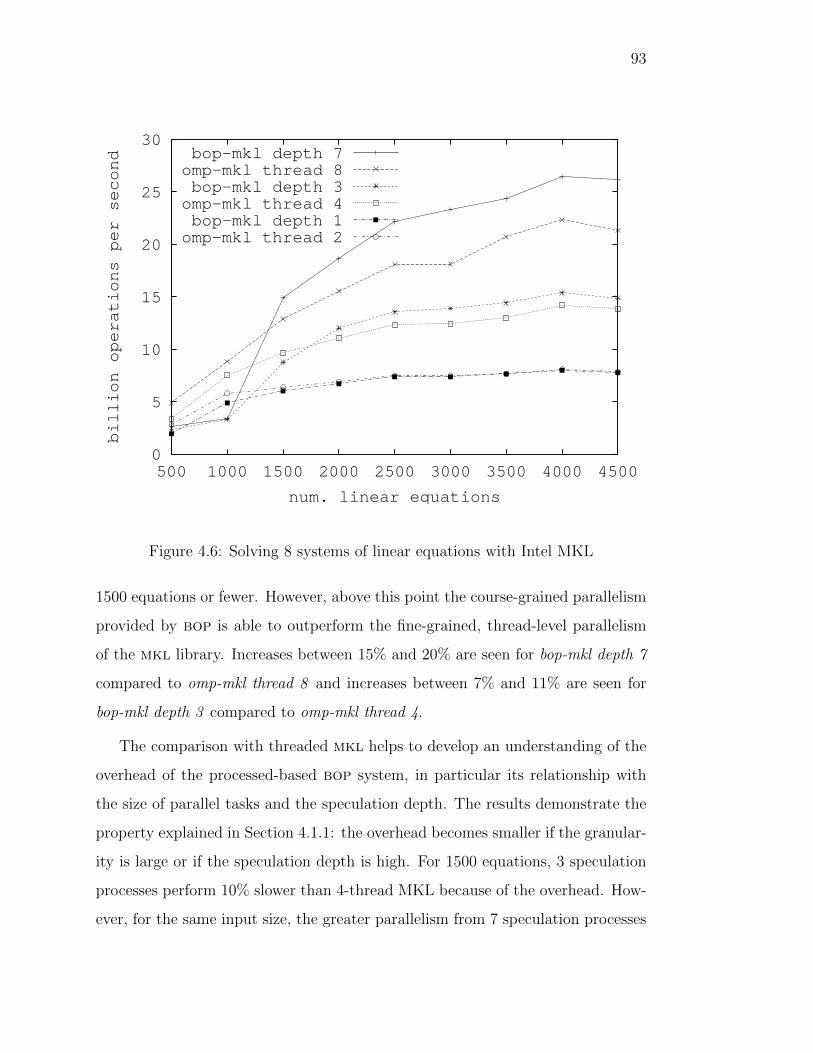
93
0
5
10
15
20
25
30
45004000350030002500200015001000500
billion operations per second
num. linear equations
bop-mkl depth 7omp-mkl thread 8bop-mkl depth 3
omp-mkl thread 4bop-mkl depth 1
omp-mkl thread 2
Figure 4.6: Solving 8 systems of linear equations with Intel MKL
1500 equations or fewer. However, above this point the course-grained parallelism
provided by bop is able to outperform the fine-grained, thread-level parallelism
of the mkl library. Increases between 15% and 20% are seen for bop-mkl depth 7
compared to omp-mkl thread 8 and increases between 7% and 11% are seen for
bop-mkl depth 3 compared to omp-mkl thread 4.
The comparison with threaded mkl helps to develop an understanding of the
overhead of the processed-based bop system, in particular its relationship with
the size of parallel tasks and the speculation depth. The results demonstrate the
property explained in Section 4.1.1: the overhead becomes smaller if the granular-
ity is large or if the speculation depth is high. For 1500 equations, 3 speculation
processes perform 10% slower than 4-thread MKL because of the overhead. How-
ever, for the same input size, the greater parallelism from 7 speculation processes

94
more than compensates for the overhead and produces an improvement of 16%
over 8-thread mkl. Similar experiments pitting bop against another scientific li-
brary, the threaded automatically tuned linear algebra software (atlas), shows
similar results.

95
5 Speculative Optimization
Introduction
In this chapter I present a variation on process-based speculative execution called
Fast Track. The Fast Track system is based on the infrastructure for speculative
execution described in Chapter 3 but is applicable for a wholly different set of
uses from those in Chapter 4. Fast Track allows the use of unsafely optimized
code, while leaving the tasks of error checking and recovery to the underlying
implementation. The unsafe code can be implemented by a programmer or by a
compiler or other automated tool, and the program regions to be optimized can be
indicated manually or determined during execution by the run-time system. As
before, the system uses coarse-grain tasks to amortize the speculation overhead
and does not require special hardware support.
The shift in processor technology toward multicore, multi-processors opens
new opportunities for speculative optimization, where the unsafely optimized code
marches ahead speculatively while the original code follows behind to check for
errors and recover from mistakes. In the past, speculative program optimization
has been extensively studied both in software and hardware as an automatic
technique. The level of improvement, although substantial, is limited by the

96
ability of both the static and run-time analyzes. In fact, previous techniques
primarily targeted individual loops and only considered transformations based on
value and dependency information.
One may question the benefit of this setup: suppose the fast code gives correct
results, would we not still need to wait for the normal execution to finish to know
it is correct? The reason for the speed improvement is the overlapping of the
normal tracks. Without fast track, the next normal track cannot start until the
previous one fully finishes. With fast track, the next one starts once the fast code
for the previous normal track finishes. In other words, although the checking is as
slow as the original code, it is now done in parallel. If the fast code has an error
or occasionally runs slower than the normal code, the program would execute the
normal code sequentially and will not be delayed by a strayed fast track.
In Section 5.2 I describe the programming interface for Fast Track. This inter-
face can be used an automated too, or in a natural way by a human programmer
with little effort. In Section 5.3 I describe the ways in which the Fast Track
run-time system extends the basic runtime described in Section 3.1.
5.1 Design
5.1.1 Fast and Normal Tracks
The FastTrack system represents two alternative methods of execution for some
portion of a program. At run time both of the methods are executed in parallel.
One of the two is identified a priori to be the canonical method, while the other is
assumed to potentially be unsafe in some cases. The unsafe execution is expected
to complete more quickly and is referred to as the “fast track” while the correct
computation is called the “normal track”.

97
5.1.2 Dual-track
In addition to the fast and normal track notation, the FastTrack run-time system
allows for a pair of parallel executions that are considered to be indistinguishable.
In this usage, both of the executions are referred to as “Dual Tracks”. Here,
whichever of the dual tracks can complete first leads to the continuing sequential
execution. The track which finishes more slowly will then confirm the results of the
first. If the two tracks are known with certainty to compute the same information
(but at unpredictable rates) the verification can be disabled.
5.2 Programming Interface
The FastTrack programming interface allows a programmer to optimize code at
the semantic level to select competing algorithms at run time, or to insert on-line
analysis modules such as locality profiling or memory-leak detection. Figures 5.2.1
and 5.2 show example uses of FastTrack to enable unsafely optimized loop and
function execution. If the fast tracks are correct, they will constitute the critical
path of the execution. The original loop iterations and function executions, which
we refer as normal tracks, will be carried out in parallel, “on the side.” The use
of FastTrack allows multiprocessors to improve the speed of sequential tasks.
A fast-track region contains a beginning branch if (FastTrack()), the con-
tents of two tracks, and an ending statement EndDualTrack(). An execution of
the code region is called a dual-track instance, in which the two tracks are the fast
track and the normal track. A program execution consists of a sequence of dual-
track instances along with any computations that occur before, between, or after
these instances. Any region of code whose beginning dominates the end in control
flow can be made a dual-track region. Nesting of regions is allowed by maintaining
the type of the track. When a inner dual-track region is encountered, the outer
fast track will take the inner fast track, while the outer normal track will take the

98
Algorithm 5.2.1 Unsafe loop optimization using fast track. Iterations offast fortuitous will execute sequentially. Iterations of safe sequential willexecute in parallel with one another, checking the correctness of the fast iterations.
while ( . . . ){
. . .i f ( FastTrack ( ) ) {
f a s t f o r t u i t o u s ( ) ; // unsafely optimized} e l se {
s a f e s e q u e n t i a l ( ) ; // safe code}EndDualTrack ( ) ;. . .
}
Algorithm 5.2.2 Unsafe function optimization using fast track. Routinesfast step 2 and step 2 can start as soon as fast step 1 completes. They arelikely to run in parallel with step 1.
. . .i f ( FastTrack ( ) ){
f a s t s t e p 1 ( ) ; // optimized} e l se {
s t e p 1 ( ) ; // safe code}. . .i f ( FastTrack ( ) ){
f a s t s t e p 2 ( ) ; // optimized} e l se {
s t e p 2 ( ) ; // safe code}

99
inner normal track. Statements with side effects that would be visible across the
processor boundary, such as system calls and file input and output, are prohibited
inside a dual-track region. The amount of memory that a fast instance may allo-
cate is bounded so that an incorrect fast instance will not stall the system through
excessive consumption. Figure 5.2.1 in the previous section shows an example of
a fast track that has been added to the body of a loop. The dual-track region can
include just a portion of the loop body, multiple dual-track regions can be placed
back-to-back in the same iteration, or a region can be used in straight-line code.
Figure 5.2 shows the use of fast track on two procedure calls, with . . . standing in
for any other statements in between. Multiple dual-track regions do not have to
be arranged in a straight sequence. One might be used only within a conditional
branch, while another could be in loop.
5.3 Run-time Support
5.3.1 Creation
In addition to the general creation process described in Section 3.1.1 the FastTrack
run-time variant must enable state comparison between the fast and regular tracks.
Within the FT BeginFastTrack run-time hook, prior to spawning a normal track,
the system allocates a shared memory space for two access maps, and a shared
data pipe. The use of these objects is described in Section 5.3.2.
5.3.2 Monitoring
During execution, memory pages are protected so that any write access will trigger
a segmentation fault. Both the fast and normal tracks use a signal handler to catch
the faults and record the access in a bit map.

100
Algorithm 5.3.1 Listing of FastTrack creation.
// Returns 1 when entering the fast track, 0 otherwise .i n t FT BeginFastTrack ( void ) {
i n t s e n p i p e [ 2 ] ;
// If we are currently in a fast track, finish it .i f ( FT ac t i v e ) FT PostDualTrack ( ) ;
// the number of processors used i s specDepth + 1i f ( FT maxSpec < 1) return 0 ;i f (SEQ == myStatus ) return 0 ;
// Setup memory access handler to watch pages modification .i f ( SP se tupAct i on ( FT SegvHandler , SIG MEMORY FAULT) )
return FT errorOnBeg in ( ) ;
// Setup communication channel for data updating .i f ( p i p e ( updateP ipe ) ) return FT errorOnBeg in ( ) ;
// Setup new access maps for the fast and normal tracks .i f ( FT setupMaps ( ) ) return FT errorOnBeg in ( ) ;
// Setup pipe for indication track seniority .i f ( p i p e ( s e n p i p e ) ) return FT errorOnBeg in ( ) ;
++FT order ; // Record serial number of the new normal track.
// Enqueue order to readyQueuei f ( FT order > FT maxSpec )
w r i t e ( readyQ−>p i p e [ 1 ] , &FT order , s i z eo f ( FT order ) ) ;
i n t PID = f o r k ( ) ;i f (−1 == s e t p g i d (0 , SP gpid ) )
p e r r o r ( ” f a i l e d to s e t p r o c e s s group ” ) ;
switch (PID ) {case −1:
return FT errorOnBeg in ( ) ;case 0 :
return FT in t e rna lBeg i nNo rma l ( s e n p i p e ) ;defau l t :
return FT i n t e r n a lB e g i nF a s t ( s e n p i p e ) ;}
}

101
In order to compare the memory modifications of the two track, the fast track
must provide the normal track with a copy of any changes it has made. At the
end of each dual track region, the fast track evaluates its access map to determine
what pages have been modified. Each page flagged in the access map is pushed
over a shared pipe, and consumed by the normal track, which then compares the
data to its own memory page.
Algorithm 5.3.2 Listing of FastTrack monitoring.
s t a t i c void FT SegvHandler ( i n t s i g , s i g i n f o t ∗ i n f o ,u c o n t e x t t ∗ con t e x t )
{a s s e r t (SIG MEMORY FAULT == s i g ) ;a s s e r t ( c on t e x t ) ;
// access to pages that are not mapped are true faultsi f ( i n f o−>s i c o d e == SEGV MAPERR)
i f (−1 == k i l l ( SP gpid , SIGALRM))p e r r o r ( ” f a i l e d to k i l l the t ime r ” ) ;
i f ( !WRITEOPT( con t e x t ) ) return ;
// record the page and remove the restrictionvoid∗ f au l tAdd = in f o−>s i a d d r ;SP recordAccessToMap ( fau l tAdd , FT accMap ) ;i f ( mprotect (PAGESTART( f au l tAdd ) , 1 ,PROT WRITE |PROT READ)){
p e r r o r ( ” f a i l e d to change memory a c c e s s p e rm i s s i o n .\ n” ) ;abo r t ( ) ;
}}
5.3.3 Verification
To guarantee that the speculative execution is correct, the memory state of the
fast and normal tracks are compared at the end of the dual track region. If the
fast track reached the same state as the normal track, then the initial state of the

102
next normal track must be correct. Typically, the next normal track was started
well before its predecessor finished, and it will know only in hindsight that it was
correctly initialized.
The normal track is responsible for comparing the writes made by both itself
and the fast track. The memory state comparison is performed once the normal
track has finished the dual track region because this is the first point at which
verification is possible. The comparison first determines if the set of writes made
by the two tracks is identical, which is handled by a simple memcmp on the access
map of each of the two tracks. The process then compares the writes themselves
using the FT CheckData run-time call as in Listing 5.3.3. Verification will fail if
either the set or contents differ, or if the fast track has not yet completed the dual
track region.
Once verification has been completed successfully, the two process are know
to have made identical changes to the same memory locations. From that point
forward, the execution of the two process would be identical. Given this, one of
the tracks is superfluous. Because the fast track is aborted if it does not reach
the end of the dual track region first, we assume that it has continued past that
point and completed other useful work. The normal track is thus useless (since
it would be recomputing exactly what the fast track has already computed) and
aborts.
It is worth noting that although multiple dual track regions (i.e., multiple pairs
of fast and normal tracks) may exist simultaneously, a single process will have at
most one fast access map and one normal access map. Because the normal track
is responsible for performing the verification routine, the fast track can abandon
the access map it had been using for a region once the region is complete. The
normal track will still have access to that map. Once the map has been analyzed,
the normal track will abort or transition to the fast state.

103
Algorithm 5.3.3 Listing of FastTrack verification routine FT CheckData
i n t FT CheckData ( void ) {unsigned long page = 0 ;char b u f f e r [ PAGESIZE ] ;i n t count , c ;
while ( page < PAGECOUNT) {// Returns true if the bitmap i s set for this page.i f ( SP checkMap ( ( void ∗ ) ( page ∗ PAGESIZE ) , FT accMap )){
count = 0 ;// Read a full page into a local buffer .while ( count < PAGESIZE) {
c = read ( updateP ipe [ 0 ] , b u f f e r ,PAGESIZE ) ;i f (−1 == c ) {
p e r r o r ( ” f a i l e d to read from p i p e ” ) ;} e l se {
i f (0 == c ) return UINT MAX ;e l se count += c ;
}}// compare our memory page to the buffered pagei f (0 != memcmp ( bu f f e r , ( void ∗ ) ( page∗PAGESIZE ) ,
PAGESIZE ) ){
return page + 1 ; // non−0 indicates failure}
}page++;
}
return 0 ; // 0 indicates success}

104
5.3.4 Abort
The FastTrack abort routine is handled almost entirely by the normal track. The
normal track first waits to receive a notification that all of the preceding normal
tracks have completed, at which point it commits any buffered output and per-
forms the verification routine. If the fast track needs to be aborted for any of the
reasons indicated in Section 5.3.3 the process executing the fast track is termi-
nated. Because the normal track performs the verification, all cases in which the
fast track is terminated pass through the same code path. The normal path pro-
cess explicitly signals the process running the fast track, which handles the signal
by simply closing the communications pipes and exiting. The steps taken by the
normal track after completing the dual track region are provided in Listing 5.3.5.
The normal track will continue executing until the next dual-track region is
encountered, or a program exit point is reached. Depending on the difference
in execution speed between the fast and normal track, the fast track may have
reached other dual track regions. In this case the abort of the fast track is followed
by the normal track sending a flag through the floodgates as an indication to
any waiting normal tracks that they should abort. Any normal tracks that have
already been released from the floodgate will run through their dual track region.
At the end of the region the process will synchronize by waiting to receive a flag
through the inheritance pipe indicating that it is the oldest running normal track.
In the case of an error in an earlier normal track, that synchronization flag will
indicate that the current process should also abort.
5.3.5 Commit
If the normal track verifies the correct execution of the dual track region, it clean
up and aborts. The fast track is free to continue execution, possibly entering more
FastTrack regions and creating further normal tracks.

105
Algorithm 5.3.4 Listing of slow track commit routine.
s t a t i c void FT slowTakesOver ( void ) {i n t token = −1;i n t pp id = ge tpp i d ( ) ; // (parent i s the fast track)k i l l ( ppid , SIGABRT ) ; // kill the fast track// Tell running slow tracks to abort on completion .SP s yn c w r i t e ( bequest , &token , s i z eo f ( token ) ) ;// Flush processes waiting at floodgates .FT c l e a r F l o odg a t e s ( ) ;FT s lowCleanup ( ) ;FT i n i t ( ) ; // setup meta datamyStatus = FAST ; // become FAST track
}
void FT PostSlow ( void ) {FT becomeOldest ( ) ; // wait for inheritance tokenSP CommitOutput ( ) ;
i f (memcmp( FT fastAccMap , FT slowAccMap , ACC MAP SIZE)| | FT CheckData ( ) ) // true if data changes differ
{FT slowTakesOver ( ) ;return ;
}// pass the inheritance tokenw r i t e ( bequest , &FT order , s i z eo f ( FT order ) ) ;// let a process leave the floodgateFT re l ea s eNex tS l ow ( ) ;FT s lowCleanup ( ) ;e x i t ( 1 ) ;
}
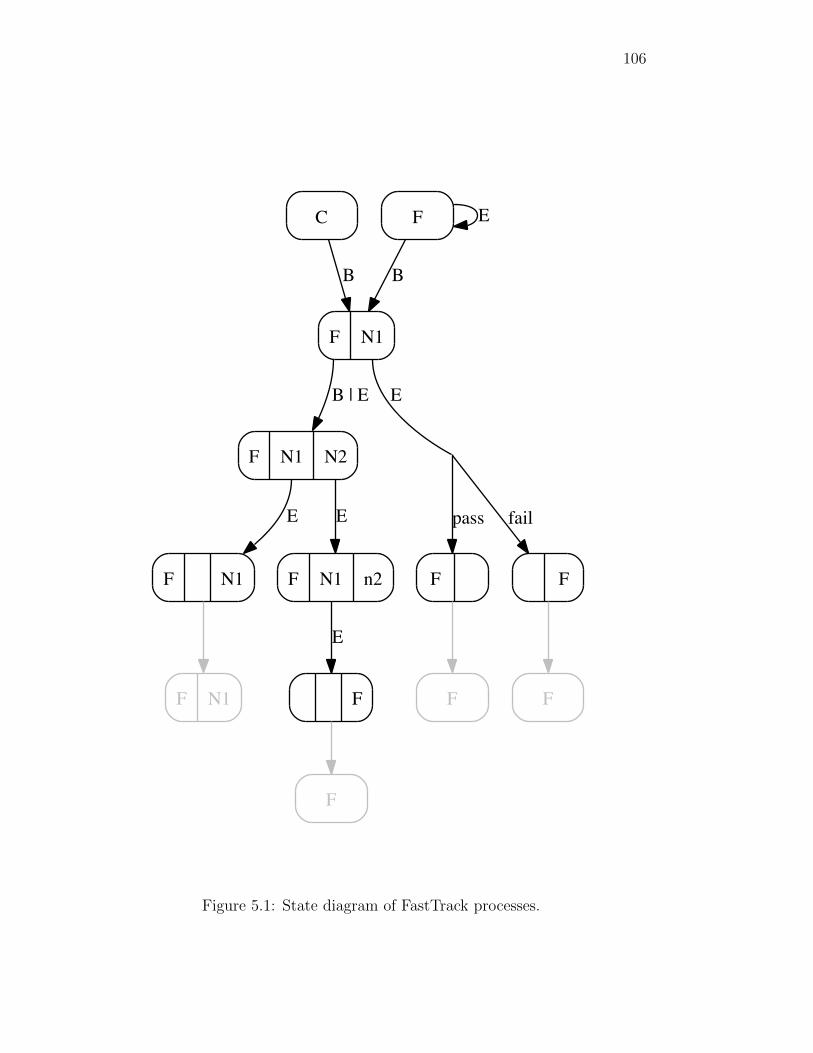
106
F
pass
F
fail
C
F N1
B
F E
B
E
F N1 N2
B | E
F F F
F
F N1
E
F N1 n2
E
F N1
E
Figure 5.1: State diagram of FastTrack processes.

107
5.3.6 Special Considerations
There are a number of corner cases of which the Fast Track system must take
account.
Seniority Control
Because the fast track may spawn multiple normal tracks, which may then run
concurrently, each normal track must know when all of its logical predecessors
have completed. Before a normal track terminates, it waits on a flag to be set by
its predecessor, and then signals its successor when complete. If there is an error
in speculation, the normal track uses the same mechanism to lazily terminate
normal tracks that are already running once they reach the end of their FastTrack
region.
Output buffering
To ensure that the output of a program running with FastTrack support is correct,
we ensure output is produced only by a normal track that is known to be correct
and is serialized in the correct order. Until a normal track has confirmed that
its initialization was correct (i.e., that all previous speculation was correct), it
buffers all terminal output and file writes. Once all previous normal tracks have
been committed the normal track is considered to be the “oldest,” and we can
be certain that its execution is correct. Given correct execution, any output the
process produces will be the same as what the sequential program would have
generated. The fast track never produces any output to the terminal nor does it
write to any regular file.

108
Implicit End Markers
The FastTrack end point can be indicated explicitly using the FT PostDualTrack
programming interface, but it is also handled implicitly in several cases. This
flexibility makes the job of the programmer easier by reducing the amount of
additional code they must write. Implicitly determining the end of the dual track
region also helps ensure correctness by catching cases where the user neglected to
correctly mark the end of the region. It should be noted that explicitly marking
the end of the region reduces the system overhead by pruning one of the system
process earlier.
There are two ways in which the end of a dual track region is determined
implicitly. This first is when the beginning of a dual track region is encountered.
Any process that is currently executing a dual track region (in any state) records
a flag to indicate its active participation. The first step the run-time system
takes when entering the FT BeginFastTrack or FT BeginDualTrack routines is to
check this activity flag and, if it is set, invoke the FT PostDualTrack routine. This
activity flag is distinct from the identifying state of the process (i.e., “FAST”),
which remains in effect.
The other implicit end marker point is a bit more subtle: we must capture
all program exit points in both the fast and normal tracks. This guarantees that
incorrect speculation does not direct a normal track to perform computation that
leads to a spurious exit from the program. In addition to ensuring correctness
in all cases, capturing all of the program exit points allows for correct program
termination to occur within the scope of a dual track region.
In the normal track we are ensuring that the same computation was performed
as in the fast track. In the fast track we must capture the program exit point and
wait for all normal tracks to finish. This may mean that they complete their dual
track region, or that the normal track has also reached the program exit. Because

109
the normal tracks are serialized, the fast track only needs to wait for the last
normal track it spawned to complete. This is achieved using the same mechanism
the normal tracks use to order themselves: the fast track waits on the inheritance
token. Note that the fast track is not necessarily waiting for the normal track to
reach the same program exit point, but the state of two will agree.
Whether or not we are within the scope of a dual track region, the correctness of
the fast track is not known until the verifying normal tracks complete. Although
we could terminate the fast track and allow the normal track to simply do its
work, the normal track may be predicated on the results of other normal tracks.
Keeping the state of the fast track allows the earlier normal tracks to validate.
The alternative would be to abort all but the oldest normal track, potentially
wasting work.
Processor Utilization
The objective of speculative execution is for execution to occur as quickly as
possible. In order to make this happen, the run-time system should use the
available processing cores as wisely as possible. In a naive approach the fast
track would run until it exits the program, spawning normal tracks along the way.
Each normal track would compute its own version its dual track region and verify
correct computation.
Although execution of the normal tracks (with the exception of the oldest) is
speculative based on the correctness of the fast track, they are taking advantage
of otherwise unused resources. However, if we spawn too many normal tracks,
they may begin contend for hardware resources. Ultimately the normal tracks are
performing the real computation, and delaying their execution would be wasteful.
This is true either if we allow a “more speculative” process to be scheduled in
favor of an older one, or if it merely interferes with it.

110
Algorithm 5.3.5 Listing of FastTrack exit point handler.
void a t t r i b u t e ( ( d e s t r u c t o r ) ) FT ex i tHand l e r ( void ) {i n t token ;
i f ( FT ac t i v e ) FT PostDualTrack ( ) ;
switch ( myStatus ) {
case FAST :c l o s e ( readyQ−>p i p e [ 0 ] ) ;c l o s e ( readyQ−>p i p e [ 1 ] ) ;// wait for the last normal trackSP sync r ead ( i n h e r i t a n c e , &token , s i z eo f ( i n t ) ) ;c l o s e ( i n h e r i t a n c e ) ;k i l l ( SP gpid , SIGTERM) ;break ;
case SLOW:i f ( FT order > 1) // wait to be the oldest
SP sync r ead ( i n h e r i t a n c e , &token , s i z eo f ( token ) ) ;SP CommitOutput ( ) ; // commit outputk i l l ( SP gpid , SIGTERM) ; // terminate speculationbreak ;
defau l t :break ;
}
}

111
The FastTrack system mitigates the interference between normal tracks by
limiting the number of tracks active at any one time (below). There is no action
take to encourage the operating system to schedule the normal tracks with respect
to one another, but modifying the scheduling priority of the processes would be
a simple way to further improve the efficiency of the system. The impact of such
scheduling is open for further exploration.
Fast-track Throttling The fast track has thus far been described as specula-
tively running ahead of the normal tracks, constrained only by program termina-
tion or a terminal signal from one of the normal tracks. There are two reasons
why it is undesirable for the fast track to run arbitrarily far ahead. The first prob-
lem is the potential resource demand of the waiting normal tracks. The second
problem is that, should there be an error in the speculation detected in one of the
normal tracks, the processing done by the fast track is essentially wasted. The
FastTrack run-time system implements a throttling mechanism to keep the fast
track running far enough ahead to supply normal tracks and keep the processing
cores utilized, while minimizing potentially wasted resources.
The throttling strategy is to pause the fast track and give the processor to
a normal track, as shown by the middle diagram in Figure 5.2. When the next
normal track finishes, it re-activates fast track. The word “next” is critical for
two reasons. First, only one normal track should activate fast track when it
waits, effectively returning the processor after “borrowing” it. The time of the
activation must be exact. If it is performed by a track to early there will be too
many processes. One track later and there would be under-utilization.
Consider a system with p processors running fast track and p−1 normal tracks
until the fast track becomes too fast and suspends execution giving the processor
to a waiting normal track. Suppose that three normal tracks finish in the order n1,
n2, and n3, and fast track suspends after n1 and before n2. The proper protocol

112
is for n2 to activate fast track so that before and after n2 we have p and only p
processes running concurrently. Activation before and after n2 would lead to less
than or more than p processes.
In order to ensure that suspension and activation of the fast track is timed
correctly with respect to the completion of the normal tracks FastTrack maintains
some extra state. The value of waitlist length indicates the number of normal-track
processes waiting in the ready queue. A flag ft waiting represents whether the fast
track has been paused.
The fast track is considered to be too fast when waitlist length exceeds p. In
this case, the fast track activates the next waiting process in the ready queue, sets
the ft waiting flag, and then yields its processor by. When a normal track finishes,
it enters the critical section and determines which process to activate based on the
flag: if ft waiting is on, it clears ft waiting and reactivates the fast track; otherwise,
it activates the next normal track and updates the value of waitlist length.
A problem arises when there are no normal tracks waiting to start, which can
happen when the fast track is too slow. If a normal track waits inside the critical
section to start its successor, then the fast track cannot enter to add a new track
to the queue. The bottom graph in Figure 5.2 shows this case, where one or more
normal track processes are waiting for fast track to fill the queue.
Resource Allocation Assuming we are executing on a system with N proces-
sors, and that the fast track is executing on one of the processors, the run-time
system should allow at most N − 1 normal processes to execute simultaneously.
The exception is when the fast track has been throttled, allowing an N th normal
track process. In addition to limiting the number of normal tracks, the FastTrack
system should guarantee that the N − 1 oldest (or, least speculative) processes
are allotted hardware resources. The FastTrack run-time system implements these
constraints using a token passing system such that only a process holding a token

113
is released from the FT BeginFastTrack run-time call.
Once a normal track process has been spawned and initialized, it waits to
receive a token by attempting to read from a pipe we refer to as the floodgate.
Although conceptually each normal track needs its own floodgate, we know that
the maximum number of normal tracks is bounded and a pool of floodgates can be
used (implemented as an array with circular access). The system inserts the set of
tokens into the floodgates at initialization, and whenever resetting the floodgates
due to miss-speculation. The whole set of floodgates is available to all processes.
In order to open the floodgates in the correct order, a normal track must iden-
tify to whom it should pass the token it currently holds. The track makes this
determination by reading the identifier from the ready queue. The fast track is re-
sponsible for enqueuing the normal tracks when they are created. Because there is
a single producer into the ready queue (the fast track) and it enqueues the normal
tracks in their sequential order, the normal tracks are guaranteed to be released in
the correct sequential order. This is true regardless of the order in which normal
tracks complete. It is worth noting that the normal tracks commit in sequential
order in any case, however the floodgate is opened before the synchronization is
performed.
Allowing the normal tracks to finish out of order allows the run-time system to
better absorb differences in the computational cost of various dual track regions.
The steady state of the run-time system’s resource allocation control is shown by
the top diagram in Figure 5.2. The execution rate of fast track is the same as
the combined rate of N − 1 normal tracks. When their speeds do not match, the
ready queue may become empty or may continue growing until the fast track is
throttled.
With activity control and fast-track throttling, the FastTrack run-time system
utilizes the available processors as efficiently as possible. Processing resources are
completely utilized unless there is a lack of parallelism and the fast track runs

114
too slowly. When there is enough parallelism, the fast track is constrained to
minimize potentially useless speculative computation.
Memory Usage The FastTrack run-time system relies on the operating sys-
tem implementation of copy-on-write, which lets processes share memory pages
to which they do not write. In the worst case where every dual-track instance
modifies every data page, the system needs d times the memory needed by the
sequential run, where d is the fast-track depth. The memory overhead can be
controlled by abandoning a fast track instance if it modifies more pages than a
empirical constant threshold h. This bounds the memory increase to be no more
than d×h×M , where M is the virtual memory page size. The threshold h can be
adjusted based on the available memory in the system. Memory usage is difficult
to estimate since it depends on the demands of the operating system and other
running processes. Earlier work has shown that on-line monitoring can effectively
adapt memory usage by monitoring the page-fault indicators from Linux [21, 65].
Experimental test cases have never indicated that memory expansion will be a
problem, so I do not consider memory resource further.
Running two instances of the same program would double demand for off-chip
memory bandwidth, which is a limiting factor for modern processors, especially
chip multiprocessors. In the worst case if a program is completely memory band-
width bound, no fast track can reduce the overall memory demand or improve
program performance. However, experience with small and large applications on
recent multicore machines, which are detailed later, is nothing but encouraging.
In FastTrack, the processes originate from the same address space and share read-
only data. Their similar access patterns help to prefetch useful data and keep
it in cache. For the two large test applications used, multiple processes in Fast-
Track ran almost the same speed as that of a single process. In contrast, running
multiple separate instances of a program always degrades the per-process speed.

115
5.4 Compiler Support
The FastTrack system guarantees that it produces the same result as the sequen-
tial execution. By using Unix processes, FastTrack eliminates any interference
between parallel executions through the replication of the address space. During
execution, it records which data are changed by each of the normal and fast in-
stances. When both instances finish, it checks whether the changes they made are
identical. Program data can be divided into three parts: global, stack, and heap
data. The stack data protection is guaranteed by the compiler, which identifies
the set of local variables that may be modified through inter-procedural MOD
analysis [30] and then inserts checking code accordingly. Imprecision in compiler
analysis may lead to extra variables being checked, but the conservative analysis
does not affect correctness. The global and heap data are protected by the op-
erating system’s paging support. At the beginning of a dual-track instance, the
system turns off write permission to global and heap data for both tracks. It then
installs custom page-fault handlers that record which page has been modified in
an access map and re-enables write permission.
5.5 Uses of Fast Track
5.5.1 Unsafe Program Optimization
In general, the fast code can be any optimization inserted by either a compiler
or a programmer; for example memoization, unsafe compiler optimizations or
manual program tuning. The performance of the system is guaranteed against
slow or incorrect fast track implementations. The programmer can also specify two
alternative implementations and let the system dynamically select the faster one.
Below I discuss four types of optimizations that are good fits for fast track because

116
they may lead to great performance gains but their correctness and profitability
are difficult to ensure.
Memoization For any procedure the past inputs and outputs may be recorded.
Instead of re-executing the procedure in the future, the old result can be reused
when given the same input. Studies dated back to at least 1968 [39] show dramatic
performance benefits when using memoization, for example to speed up table look-
up in transcoding programs. Memoization must be conservative about side-effects
and can provide only limited coverage for generic use in C/C++ program [15].
With FastTrack, memoization does not have to be correct in all cases and therefore
can be more aggressively used to optimize the common case.
Semantic optimization Often, different implementation options may exist at
multiple levels, from the basic data structures used such as a hash table, to the
choice of algorithms and their parameters. A given implementation is often more
general than necessary for a program, allowing for specialization. Current pro-
gramming languages do not provide a general interface for a user to experiment
with an unsafely simplified algorithm or to dynamically select the best choice
among alternative solutions.
Manual program tuning A programmer can often identify performance prob-
lems in large software and make changes to improve the performance on test in-
puts. However, the most radical solutions are often the most difficult to verify in
terms of correctness, or to ensure good performance on other inputs. As a result,
many creative solutions go unused because an automatic compiler cannot possibly
achieve them.
Monitoring and safety checking It is often useful to instrument a program
to collect run-time statistics such as frequently executed instructions or accessed

117
data, or to report memory leaks or out-of-bound memory accesses. In such cases,
the original uninstrumented code can serve as the fast track, and the instrumented
code can run in parallel to reduce the monitoring overhead.
5.5.2 Parallel Memory-Safety Checking
To test fast track on real-world applications, it has been applied to the paralleliza-
tion of a memory-safety checking tool called Mudflap [16]. Mudflap is bundled
with the widely used GNU compiler collection (gcc), adding checks for array
range (over or under flow) and validity of pointer dereferences to any program
gcc compiles. Common library routines that perform string manipulation or di-
rect memory access are also guarded. Checks are inserted at compile time and
require that a run-time library be linked into the program.
The Mudflap compilation has two passes: memory recording, which tracks all
memory allocation by inserting mf register and mf unregister calls, and access
checking, which monitors all memory access by inserting mf check calls and
inlined operations. The recording cost is proportional to the frequency of data
allocation and recollection, and the checking cost is proportional to the frequency
of data access.
To fast track the Mudflap checking system we introduced a new compiler pass
that clones all functions in the program. The second Mudflap pass is instructed
to ignore the clones while instrumenting the program. The result is an executable
with the original code fully checked while the clone just records data allocation
and free. The instrumentation of the clones is necessary to maintain the same
allocation and meta data of memory as those of the original code. We create a
Fast Track version of programs by using the fully checked version of the program
to verify the memory safety of the unchecked fast track.

118
5.6 Evaluation
5.6.1 Analysis
Throughout he remainder of this section I use the following notation to represent
the basic parameters of the system:
• Dual track computations are identified ri.
• Interleaving computation regions are uj.
• The program execution E is a sequence of u0r1u1r2 . . . rnun.
• The running time of a region is denoted by T ().
• The number of available processors is p > 1.
• Each ri has a success rate α (0 ≤ α ≤ 1).
• A fast instance takes a fraction x (0 ≤ x ≤ 1) of the time the normal
instance takes
• The dual-track execution has a time overhead qc (qc ≥ 0) per instance and
is slowed down by a factor of qe (qe ≥ 0) because of the monitoring for
modified pages.
Analytical Model
The original execution time is T (E) = T (u0) +∑n
i=1 T (riui). By reordering
the terms leads to T (E) =∑n
i=1 T (ri) +∑n
i=0 T (ui). Name the two components
Er = r1r2 . . . rn and Eu = u0u1 . . . un. The time T (Eu) is not changed by fast-track
execution because any ui takes the same amount of time regardless of whether it
is executed with a normal or a fast instance.

119
Focusing on T (Er) and in particular the average time taken per ri, tr = T (Er)n
,
and how this time changes as a result of FastTrack. Since we would like to derive
a closed formula to examine the effect of basic parameters, consider a regular case
where the program is a loop with n equal length iterations. A part of the loop
body is a FastTrack region. Let T (ri) = tc be the (constant) original time for
each instance of the region. The analysis can be extended to the general case
where the length of each ri is arbitrary and tc is the average. The exact result
would depend on assumptions about the distribution of T (ri). In the following,
we assume T (ri) = tc for all i.
With FastTrack, an instance may be executed by a normal track in time ts =
(1 + qe)tc + qc or by a fast track in time tpf , where qc and qe are overheads. In the
best case, all fast instances are correct (α = 1) and the machine has unlimited
resources p =∞. Each time the fast track finishes an instance, a normal track is
started. Thus, the active normal tracks form a pipeline if considering only dual-
track instances (the component T (Er) in T (E)). The first fast instance is verified
after ts. The remaining n − 1 instances finish at a rate of t∞f = (1 + qe)xtc + qc,
where x is the speedup by fast track and qc and qe are overheads.
Using the superscript to indicate the number of processors, the average time
and the overall speedup are
t∞f =(ts + (n− 1)t∞f )
n
speedup∞ =original time
fast track time=
ntc + T (Eu)
nt∞f + T (Eu)
In the steady state tct∞f
dual-track instances are run in parallel. For simplicity
the equation does not show the fixed lower bound of fast track performance.
Since a fast instance is aborted if it turns out to be slower than the normal
instance, the worst-case is t∞f = ts = (1 + qe)tc + qc, and consequently speedup =
ntc+T (Eu)n((1+qe)tc+qc)+T (Eu)
. While this is slower than the original speed (speedup ≤ 1),

120
the worst-case time is bounded only by the overhead of the system and not by the
quality of fast-track implementation (factor x).
As a normal instance for ri finishes it may find the fast instance incorrect,
canceling the on-going parallel execution, and restarting the system from ri+1.
This is equivalent to a pipeline flush. Each failure adds a cost of ts − t∞f , so the
average time with a success rate α is (1− α)(ts − t∞f ) + tpf .
For the sake of illustration, assume no fast-track throttling when considering
the limited number of processors. With p processors, the system can have a fast
track execution depth d of at most d = min(p−1, tst∞f
) dual-track instances running
concurrently. Because d is an average it may take a non-integral value. When
α = 1, p− 1 dual-track instances take ts + (p− 2)t∞f (p ≥ 2) time. Therefore the
average time (assuming p− 1 | n) is
tpf =ts + (d− 1)t∞f
d
When α < 1, the cost of restarting has the same effect as in the infinite-processor
case. The average time and the overall speedup are
tpf = (1− α)(ts − t∞f ) +ts + (d− 1)t∞f
d
speedupp =ntc + T (Eu)
ntpf + T (Eu)
Finally consider FastTrack throttling. As p − 1 dual-track instances execute
and when the last fast instance finishes, the system start the next normal instance
instead of waiting for the first normal instance to finish (and start the next normal
and fast instances together). Effectively it finishes d+ (ts− dt∞f ) instances, hence
the change to the denominator. Augmenting the previous formula we have
tpf = (1− α)(ts − t∞f ) +ts + (d− 1)t∞fd+ ts − dt∞f

121
After simplification, FastTrack throttling may seem to increase the per instance
time rather than decreasing it. But it does decrease the time because d ≤ tst∞f
.
The overall speedup (bounded from below and n ≥ 2) is as follows, where all the
basic factors are modeled.
speedupp = max
(ntc + T (Eu)
nts + qc + T (Eu),ntc + T (Eu)
ntpf + T (Eu)
)
Simulation Results
By translating the above formula into actual speedup numbers the effect of major
parameters can be examined. Of interest are the speed of the fast track, the
success rate, the overhead, and the portion of the program executed in dual-track
regions. The four graphs in Figure 5.3 show their effect for different numbers of
processors ranging from 2 to 10 in a step of 1. The fast-track system has no effect
on a single-processor system.
All four graphs include the following setup where the fast instance takes
10%the time of the normal instance (x=0.1), the success rate (α) is 100%, the
overhead (qc and qe) adds 10% execution time, and the program spends 90% of the
time in dual-track regions. The performance of this case is shown by the second
highest curve in all but graph 5.3(a), in which it is shown by the highest curve.
FastTrack improves the performance from a factor of 1.60 with 2 processors to a
factor of 3.47 with 10 processors. The maximal possible speedup for this case is
3.47. When we change the speed of the fast instance to vary from 0% to 100%
the time of the normal instance, the speedup changes from 1.80 to 1.00 with 2
processors and from 4.78 to 1.09 with 10 processors, as shown by graph 5.3(a).
When the success rate is reduced from 100% to 0%, the speedup changes from
1.60 to 0.92 (8% slower because of the overhead) with 2 processors and from
3.47 to 0.92 with 16 processors, as shown by the graph in 5.3(a). Naturally the
performance hits the worst case when the success rate is 0%.

122
When the overhead is reduced from 100% to 0% of the running time, the
speedup increases from 1.27 to 1.67 with 2 processors and from 2.26 to 3.69 with
16 processors, as shown by graph 5.3(c). Note that with 100% overhead the
fast instance still finishes in 20% the time of the normal instance, although the
checking needs to wait twice as long.
Finally, when the coverage of the fast-track execution increases from 10% to
100%, the speedup increases from 1.00 to 1.81 with 2 processors and from 1.08
to 4.78, as shown by the graph 5.3(d). If the analytical results are correct, it is
not overly difficult to obtain a 30% improvement with 2 processors, although the
maximal gain is limited by the time spent outside dual-track regions, the speed
of the fast instance, and the overhead of fast-track.
The poor scalability is not a surprise given the program is inherently sequential
to begin with. Two final observations from the simulation results are important.
First, FastTrack throttling is clearly beneficial. Without it there can be no im-
provement with 2 processors. It often improves the theoretical maximum speedup,
although the increase is slight when the number of processors is large. Second, the
model simplifies the effect of FastTrack system in terms of four parameters, which
we have not validated with experiments on a real system. On the other hand,
if the four parameters are the main factors, they can be efficiently monitored at
run time, and the analytical model may be used as part of the on-line control to
adjust the depth of fast-track execution with the available resources.
5.6.2 Experimental Results
Implementation and Experimental Setup
Compiler support for FastTrack is implemented in gcc 4.0.1’s intermediate lan-
guage, GIMPLE (based on static-single assignment [13]). The transformation is
applied after high-level program optimization passes but before machine code gen-

123
eration. The main transformation is converting global variables to use dynamic
allocation, so the run-time support can track them and set appropriate access
protection. The modified compiler allocates a pointer for each global (and file
and function static) variable, inserts an initialization function in each file that
allocates heap memory for variables (and assigns initial values) defined in the file,
and redirects all accesses through the global pointer. The indirection causes only
marginal slowdown because most global-variable accesses have been removed or
converted to (virtual) register access by earlier optimization passes.
Compiler analysis for data protection of local variables has not been imple-
mented. Stack data are not checked, but global and heap variables are protected.
The run-time system is implemented as a statically linked library using shared
memory only for storing access maps. The design guarantees forward progress,
which means no deadlocks or starvation provided that the operating system does
not permanently stall any process.
Parallel Memory Safety Checking
A FastTrack version of Mudflap has been generated for the C-language bench-
marks 401.bzip2, 456.hmmer, 429.mcf, and 458.sjeng from the spec 2006 suite[55].
These benchmarks represent computations in pattern matching, mathematical op-
timization, chess playing, and data compression. The number of program lines
ranges from a few thousand to over ten thousand. All four programs show sig-
nificant improvement, up to a factor of 2.7 for 401.bzip2, 7.1 for 456.hmmer, and
2.2 for 429.mcf and 458.sjeng. The factors affecting the parallel performance are
the coverage of FastTrack and the relative speed of the fast track as discussed in
our analytical model. One factor not tested here is the overhead of correctness
checking and error recovery. The running times with and without Mudflap over-
head, as given in the captions in Figure 5.4, show that memory-safety checking
delays the execution by factors of 5.4, 15.0, 8.6, and 67.4. By utilizing multiple

124
processors, FastTrack reduces the delay to factors of 2.0, 2.1, 3.7, and 28.8, which
are more tolerable for long-running programs.
The code change in 429.mcf includes replicating the call of price out impl in
function global opt in file mcf.c. Similar to the code in the FastTrack example in
the introduction, the original call is placed in the normal track and the call to the
clone, clone price out impl, in the fast track. For 458.sjeng, the call of search in
function search root in file search.c is similarly changed to use clone search in the
fast track and search in the normal track. In both cases, merely four lines of code
need to be modified.
Memory safety checking by Mudflap more than triples the running time of
mcf. FastTrack improves the speed of checking by over 30%. The running time
of fast track is within half a second of a dual track implication, which shows that
FastTrack runs with little overhead. The cost of safety checking for 458.sjeng is
a factor of 200 slowdown—it takes 24 minutes to check the original execution of
7.3 seconds. FastTrack is able to reduce the checking time to 13 minutes, a factor
of two reduction. A dual track style execution without verification runs faster,
finishing in under 9 minutes without the overhead of checking every memory
access.
Results of Sort and Search Tests
The following two tests are intended to measure the performance of FastTrack
use for the support of unsafe optimizations as executed with two Intel dual-core
Xeon 3Ghz processors. Compilation is done using the modified FastTrack version
of gcc using the optimizations specified by the -O3 flag. The first test is a
simple sorting program that repeatedly sorts an array of 10,000 elements. In a
specified percentage of iterations the array contents are randomized. The array
sort is performed with either a short-circuited bubble sort, a quick sort, or by
running both in a FastTrack environment. The results of these tests are shown in

125
Figure 5.5. The quick sort performs consistently and largely independent of the
input array. One can see that the bubble sort quickly detects when the array is
sorted, but performs poorly in cases in which the contents have been randomized.
The FastTrack approach is able to out-perform either of the individual sorting
algorithms. These results illustrate the utility of Fast-Track in cases where both
solutions are correct, knowing which is actually faster is not possible in advance.
In cases where the array is always sorted or always unsorted, the overhead of using
FastTrack will cause it to lose out. Although FastTrack is not a better solution
compared to an explicitly parallel sorting approach, this example motivates the
utility of automatically selecting the faster of multiple sequential approaches.
Algorithm 5.6.1 Pseudo code of the synthetic search program
for i = 1 to n doVi ← random
end forfor 1 to T do
if normal track thenfor i = 1 to n doVi ← f(Vi)
end form← max(v : v ∈ V )
else {fast track}R← S random samples from Vfor j = 1 to S doR← f(Ri)
end form← max(r : r ∈ R)
end ifrandomly modify N1 elements
end forprint m
The second program is a simple search to test the effect of various parameters,
for which the basic algorithm is given in Figure 5.6.1. The program repeatedly
updates some elements of a vector and finds the largest result from certain com-
putations. By changing the size of the vectors, the size of samples, and the

126
frequency of updates, we can effect different success rates by the normal and the
fast instances. Figure 5.6(a) shows the speedups over the base sequential execu-
tion, which takes 3.33 seconds on a 4-CPU machine. The variation between times
of three trials is always smaller than 1 millisecond.
The sampling-based fast instance runs in 2.3% the time of the normal instance.
When all fast instances succeed, they improve the performance by a factor of 1.73
on 2 processors, 2.78 on 3 processors, and 3.87 on four processors. When the
frequency of updates is reduced the success rate drops. At 70%, the improvement
is a factor of 2.09 on 3 processors and changes only slightly when the fourth
processor is added. This drop is because the chance of four consecutive fast
instances succeeding is only 4%. When the success rate is further reduced to
30%, the chance for three consecutive successful fast tracks drops to 2.7%. The
speedup from 2 processors is 1.29 and no improvement is observed for more than 2
processors. In the worst case when all fast instances fail, we see that the overhead
of forking and monitoring the normal track adds 6% to the running time.
The results in Figure 5.6(b) show interesting trade-offs when the fast track
is tuned by changing the size of samples. On one hand, a larger sample size
means more work and slower speed for the fast track. On the other hand, a
larger sample size leads to a higher success rate, which allows more consecutive
fast tracks succeed and consequently more processors utilized. The success rate
is 70% when the sample size is 100, which is the same configuration as the row
marked “70%” in Figure 5.6(a). The best speedup for 2 processors is found when
the sample size is 200 but adding more processors does not help as much (2.97
speedup) as when the sample size is 300, where 4 processors lead to a speedup
of 3.78. The second experiment shows the significant effect of tuning when using
unsafely optimized code. Experience has shown that the automatic support and
analytical model have made tuning much less labor intensive.
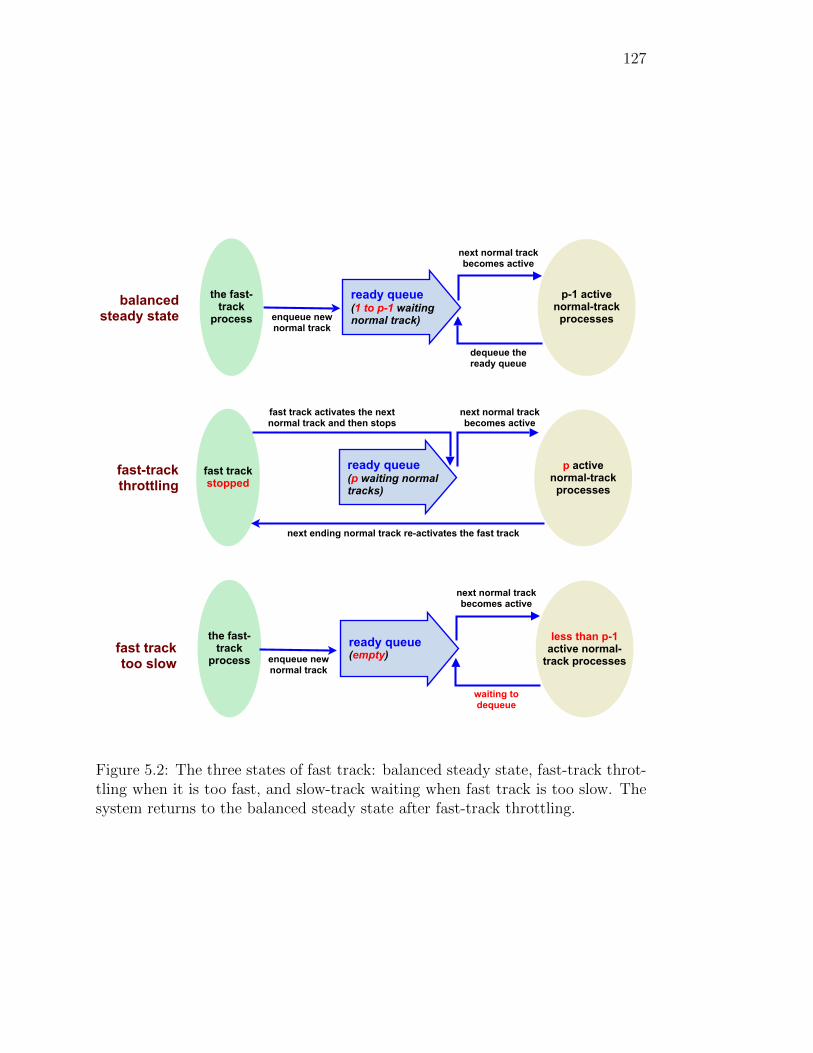
127
enqueue new normal track
p-1 active normal-track processes
the fast-track
process
ready queue(1 to p-1 waiting normal track)
dequeue the ready queue
next normal track becomes active
balancedsteady state
less than p-1 active normal-
track processes
the fast-track
process
ready queue(empty)
waiting to dequeue
enqueue new normal track
next normal track becomes active
fast tracktoo slow
p active normal-track processes
fast track stopped
ready queue(p waiting normal tracks)
next normal track becomes active
next ending normal track re-activates the fast track
fast track activates the next normal track and then stops
fast-trackthrottling
Figure 5.2: The three states of fast track: balanced steady state, fast-track throt-tling when it is too fast, and slow-track waiting when fast track is too slow. Thesystem returns to the balanced steady state after fast-track throttling.
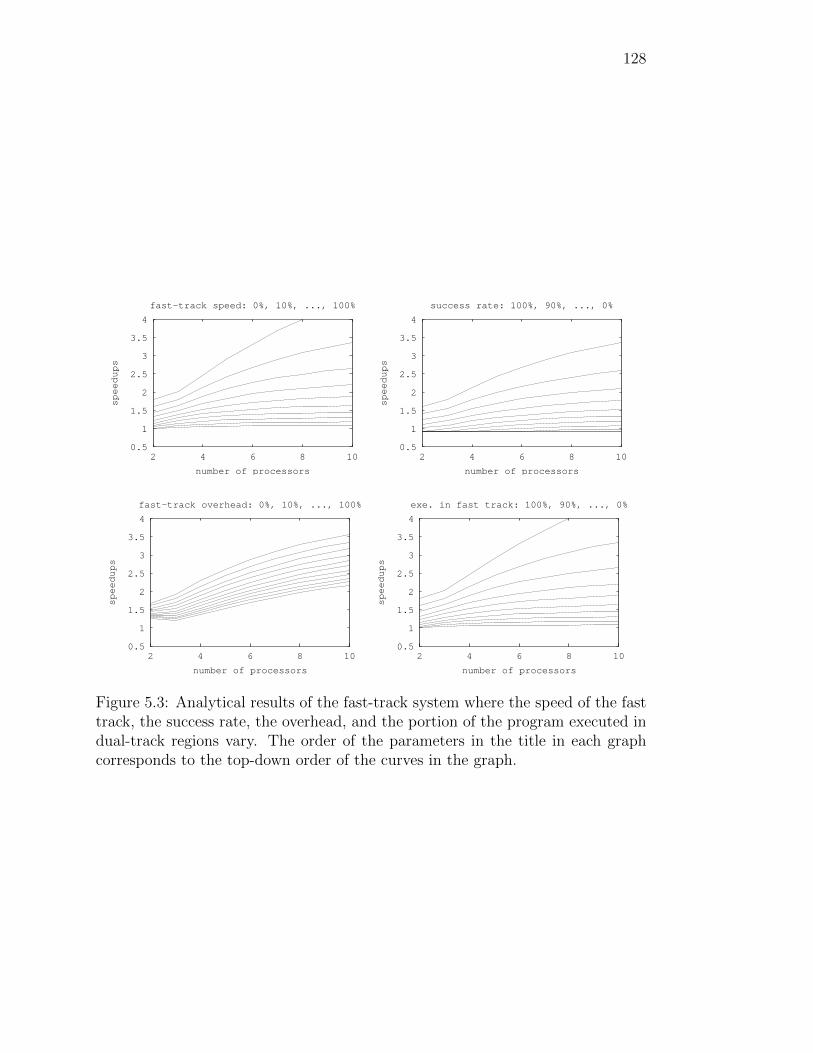
128
0.5
1
1.5
2
2.5
3
3.5
4
108642
speedups
number of processors
fast-track speed: 0%, 10%, ..., 100%
0.5
1
1.5
2
2.5
3
3.5
4
108642
speedups
number of processors
success rate: 100%, 90%, ..., 0%
0.5
1
1.5
2
2.5
3
3.5
4
108642
speedups
number of processors
fast-track overhead: 0%, 10%, ..., 100%
0.5
1
1.5
2
2.5
3
3.5
4
108642
speedups
number of processors
exe. in fast track: 100%, 90%, ..., 0%
Figure 5.3: Analytical results of the fast-track system where the speed of the fasttrack, the success rate, the overhead, and the portion of the program executed indual-track regions vary. The order of the parameters in the title in each graphcorresponds to the top-down order of the curves in the graph.
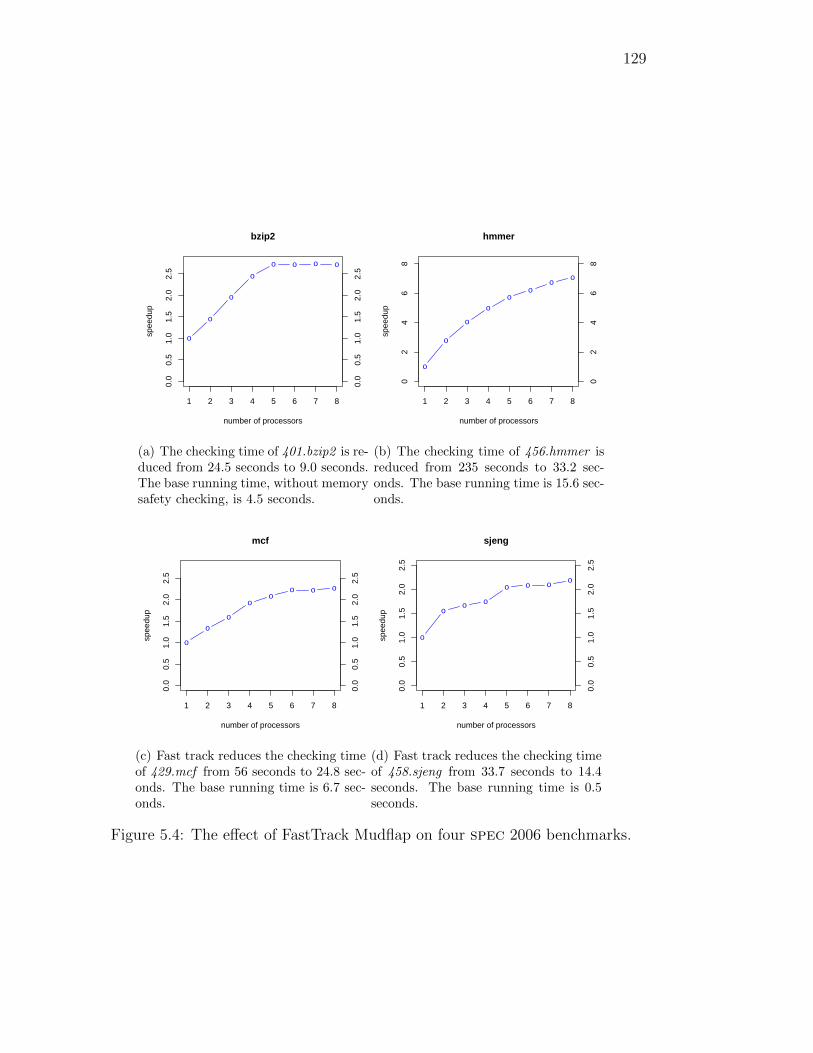
129
1 2 3 4 5 6 7 8
0.0
0.5
1.0
1.5
2.0
2.5
bzip2
number of processors
spee
dup
o
o
o
o
o o o o
0.0
0.5
1.0
1.5
2.0
2.5
(a) The checking time of 401.bzip2 is re-duced from 24.5 seconds to 9.0 seconds.The base running time, without memorysafety checking, is 4.5 seconds.
1 2 3 4 5 6 7 80
24
68
hmmer
number of processors
spee
dup
o
o
o
oo
oo
o
02
46
8
(b) The checking time of 456.hmmer isreduced from 235 seconds to 33.2 sec-onds. The base running time is 15.6 sec-onds.
1 2 3 4 5 6 7 8
0.0
0.5
1.0
1.5
2.0
2.5
mcf
number of processors
spee
dup
o
oo
oo
o o o
0.0
0.5
1.0
1.5
2.0
2.5
(c) Fast track reduces the checking timeof 429.mcf from 56 seconds to 24.8 sec-onds. The base running time is 6.7 sec-onds.
1 2 3 4 5 6 7 8
0.0
0.5
1.0
1.5
2.0
2.5
sjeng
number of processors
spee
dup
o
oo o
o o o o0.
00.
51.
01.
52.
02.
5
(d) Fast track reduces the checking timeof 458.sjeng from 33.7 seconds to 14.4seconds. The base running time is 0.5seconds.
Figure 5.4: The effect of FastTrack Mudflap on four spec 2006 benchmarks.
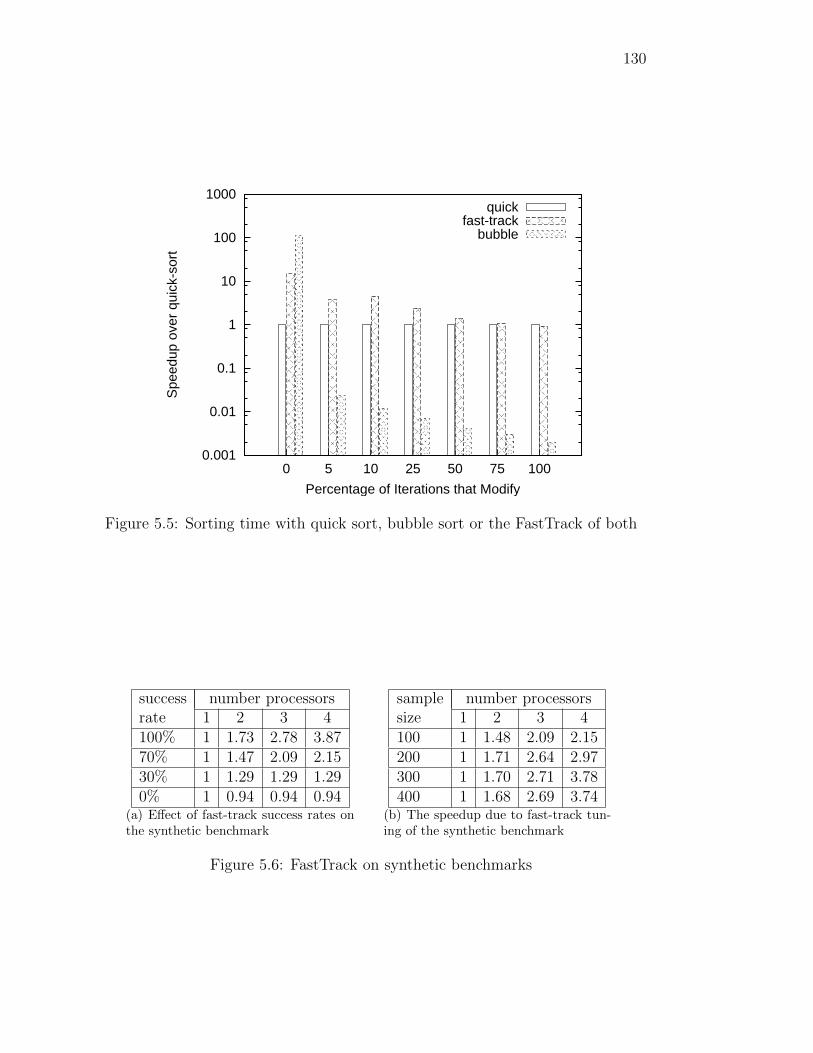
130
0.001
0.01
0.1
1
10
100
1000
0 5 10 25 50 75 100
Spe
edup
ove
r qu
ick-
sort
Percentage of Iterations that Modify
quickfast-track
bubble
Figure 5.5: Sorting time with quick sort, bubble sort or the FastTrack of both
success number processorsrate 1 2 3 4100% 1 1.73 2.78 3.8770% 1 1.47 2.09 2.1530% 1 1.29 1.29 1.290% 1 0.94 0.94 0.94
(a) Effect of fast-track success rates onthe synthetic benchmark
sample number processorssize 1 2 3 4100 1 1.48 2.09 2.15200 1 1.71 2.64 2.97300 1 1.70 2.71 3.78400 1 1.68 2.69 3.74
(b) The speedup due to fast-track tun-ing of the synthetic benchmark
Figure 5.6: FastTrack on synthetic benchmarks

131
6 Conclusion
6.1 Contributions
I have presented two systems for implementing speculative parallelism in exist-
ing programs. For each system I have implemented a complete working system
including compiler and run-time support. The first system, bop, provides a pro-
grammer with tools to introduce traditional types of parallelism in cases where
program dependencies cannot be statically evaluated or guaranteed. I have shown
the use of bop to effectively extract parallelism from utility programs.
I have also presented FastTrack, a system that supports unsafely optimized
code and can also be used to off-loaded safety checking and other program anal-
ysis. The key features of the systems include a programmable interface, compiler
support, and a concurrent run-time system that includes correctness checking, out-
put buffering, activity control, and fast-track throttling. I have used the system
to parallelize memory safety checking for sequential code, reducing the overhead
by up to a factor of seven for four large size applications running on a multicore
personal computer. We have developed an analytical model that shows the effect
from major parameters including the speed of the fast track, the success rate, the
overhead, and the portion of the program executed in fast-track regions. We have

132
used our system and model in speculatively optimizing a sorting and a search
program. Both analytical and empirical results suggest that fast track is effective
at exploiting today’s multi-processors for improving program speed and safety.
6.2 Future Directions
6.2.1 Automation
Automating the insertion of bop region markers requires identifying pprs auto-
matically, which is similar to identifying parallelism — a major open problem.
Because pprs are only hints at parallelism, it’s not necessary for them to be cor-
rect. In addition to inserting the ppr markers automatically, the system could be
simplified by allowing the EndPPR marker to be optional. The difficulty in doing
this comes in handling the final instance of the ppr. Without an end marker,
the speculative task will continue until it reaches a program exit point. The non-
speculative will execute the ppr, and subsequently repeat the same execution as
the speculative task. Such duplicated work is certainly wasteful, but may be ac-
ceptable if there is no other useful work that could be offloaded to the additional
processing unit.
In order to automate the use of the FastTrack system, markers can be inserted
at various points throughout the code using compiler instrumentation. We can
choose dynamically whether to initiate a new dual-track region based on the past
success rate and the execution time since the start of the last region. A region
can begin at an arbitrary point in execution, as long as the other track makes
the same decision at that point. We can identify the point with a simple shared
counter each track increments every time it passes a marker. The fast track makes
its increments atomically, and when it creates a new normal track it begins a new
counter (leaving the old one for the previous normal track). As the normal tracks

133
pass marks they compare their counter to the fast track’s to identify the mark at
which verification needs to be performed. If the two processes did not follow the
same execution path then the state verification will fail.
A significant problem is ensuring that the fast path includes all of the markers
the normal track has. This is directly related to where the markers are placed, and
how the two tracks are generated. In a case like the fast mudflap implementation
described in Chapter 5 the markers will be consistent as long as they are not
placed in the mudflap routines. In any case where code is similarly inserted to
create the normal track, it will suffice to simply not insert markers with that code.
In a case where the fast track is created by removing optimizations from existing
code, we must ensure that markers are not removed, and that any function calls
are not directly removed because they might contain further markers.
6.2.2 Composability
One of the major problems in parallel programming — particularly when dis-
cussing explicit parallel programming with locks — is the composability of various
operations. The intuition behind composability is that the combination of multi-
ple components should not break correctness.
Lack of composability is a significant weakness of lock based components, and
is one of the strengths of transactional memory systems. Because the speculative
parallelism run-time systems are intended to be a simple way to extend existing
programs, the bop and FastTrack system should seek to compose correctly. There
are several general questions to ask about the composability of these systems: do
each compose with itself, do they compose with one another, and do they compose
with existing parallel programming techniques.
Self-Composition The question of self-composition is whether the run-time
system properly handles entering a speculative region when one is already active.

134
Cases where disjoint regions of the program use speculation compose trivially. The
bop run-time system does correctly compose with itself. The implementation is
designed to that nested use of pprs are not allowed, but are detected and handled
correctly. If a piece of code (for example a library) is built to use pprs, and that
is invoked from within another ppr, the inner regions will be ignored. Although
this maintains semantic correctness — which is the primary concern — it may
not be the most effective solution.
The FastTrack run-time system also maintains semantic correctness when it is
composed with itself. When the FastTrack system encounters a nested fast track
region, the runtime will treat it like any other dual track region. If the fast track is
the first to reach the nested region it will spawn a new normal track. Eventually
the normal track will encounter the end of the original dual track region, and
speculation will fail. Although semantic correctness is maintained, performance
will suffer because speculation over the entire outer region will always fail. This
failure could potentially be avoided if fast track regions were given identifiers. The
run-time system would also need a mechanism to match the identifier the normal
track encounters at the end of its region to the fast track. Additionally, the fast
track would need to abandon the inner normal tracks and to reacquire the changes
it made starting at the beginning of the outer region (which are otherwise simply
left for the inner normal track to verify).
If the normal track reaches a nested region then it will assume that the fast
track has miss-speculated, or is otherwise delayed, and that it has simply com-
pleted executing the region first. As in any case where the normal track wins the
race, it will terminate the fast track. The normal track will then assume the role
of fast track and spawn a new normal track to handle the inner region. From a
performance standpoint this is not likely to be the most effective solution because
only the smaller inner region will be fast tracked. Nevertheless, it is a better out-
come than the case above, and it does maintain semantic correctness. In the case

135
that both tracks encounter a nested dual track region, the result is very much like
the above case in which only the normal track encounters the inner region.
Algorithm 6.2.1 Example of FastTrack self-composition
void ou t e r ( void ) {i f (FT\ Beg inFas tTrack ( ) ) {
i n n e r f a s t ( ) ;} e l se {
i n n e r n o rma l ( ) ;}
}
void i n n e r f a s t ( void ) {i f (FT\ Beg inFas tTrack ( ) ) {
. . .} e l se {
. . .}
}
6.2.3 Further Evaluation
One of the major issues in contemporary computing is power consumption. This is
true for mobile systems drawing from a battery, to high performance computing
systems and data centers built on massive numbers of processors. Because so
much power drawn by a computer ends up as waste heat, even more power must be
drawn to cool the system. As such, the power utilization of speculative parallelism
must be considered. Although there will always be a demand for the ability to
complete tasks more quickly, the power costs to do so have to be put in balance.
One way to frame the energy consumption question is to consider the com-
parable energy necessary to gain the same speed increase using a uni-processor.
Conversely, if the speculative parallelism system can allow a program to be com-

136
pleted as quickly on two or more processors running at a slower clock rate, an
energy savings may be found.
As processor vendors produce systems with higher numbers of cores, they face
the reality that often many of these cores are not utilized. The two largest chip
makes have both introduced schemes to allow some of the cores on the multi-core
systems, which they refer to as “turbo boost” (Intel) and “dynamic speed boost”
(AMD). Evaluating the energy consumption of speculatively parallelized programs
on such systems would provide empirical data to address such a hypothesis.

137
A Code Listings
Included here are source code fragments not found earlier in this dissertation.
Where relevant, a reference to the earlier source is included. The inclusion of
system header files and standard pre-processor include guards have been omitted
for brevity.
A.1 BOP Code
Listing A.1: Private Header
s t a t i c i n t specDepth ; // Between 1 and MaxSpecDepth.
s t a t i c i n t specP id ; // Process ID of SPEC.
s t a t i c i n t undyWorkCount ; // Work done by UND
s t a t i c i n t pprID ; // User assigned region ID.
s t a t i c i n t mySpecOrder = 0 ; // Serial number.
// For Data update .
s t a t i c i n t updateP ipe [ 2 ] ;
// For termination of the understudy .
s t a t i c i n t undyCreatedP ipe [ 2 ] ;

138
s t a t i c i n t undyConcedesPipe [ 2 ] ;
// loHiPipes control information flow. The main process
// takes the 0th slot to send MainDone and MainCopyDone.
s t a t i c i n t l oH iP i p e s [MAX SPEC DEPTH∗2+1 ] [ 2 ] ;
// Flag set if the next speculation fails .
s t a t i c v o l a t i l e char e a r l yT e rm i n a t i o n = f a l s e ;
// Signal sets masking SIGUSR1, SIGUSR2, and both
s t a t i c s i g s e t t s igMaskUsr1 , s igMaskUsr2 , s igMaskUsr12 ;
s t a t i c void BOP AbortSpec ( void ) ;
s t a t i c void BOP AbortNextSpec ( void ) ;
Listing A.2: Access Map Handling
// Implementation depends on maps of single byte units .
char ∗useMap ;
char ∗accMapPtr ;
// Record access of the given type in my access map.
void BOP recordAccess ( void ∗ page add r e s s , AccessType a c c e s s ) {
i n t mapId = mySpecOrder==0 ? 0 : MYRESOURCE(mySpecOrder ) ;
char∗ map = NULL ;
switch ( a c c e s s ){
case READ:
map = accMapPtr + (mapId ∗ 2 ∗ BIT MAP SIZE ) ;
break ;
case WRITE :
map = accMapPtr + ( ( ( mapId ∗ 2) + 1) ∗ BIT MAP SIZE ) ;
break ;
}

139
SP recordAccessToMap ( page add r e s s , map ) ;
}
void BOP setPro tec t i on ( i n t p ro t ) {
unsigned long page ;
unsigned long l a s t = 0 , f i r s t = 0 ;
// Look at each position in the map.
f o r ( page = 0 ; page < PAGECOUNT; page++) {
i f ( SP checkMap ( ( void ∗ ) ( page ∗ PAGESIZE ) , useMap ) ) {
i f ( page == l a s t +1) l a s t ++;
e l s e {
i f ( l a s t > 0) SP pro tec tPages ( f i r s t , l a s t , p r o t ) ;
l a s t = f i r s t = page ;
}
}
}
i f ( l a s t > 0) SP pro tec tPages ( f i r s t , l a s t , p r o t ) ;
}
// Returns zero if the there are no conflicts in the maps .
s t a t i c i n t BOP compareMaps ( void ) {
char∗ p r e vWr i t e s ;
i f ( mySpecOrder == 1)
p r e vWr i t e s = WRITEMAP( 0 ) ;
e l s e /∗ the union map ∗/
p r e vWr i t e s = READMAP(mySpecOrder − 1 ) ;
char∗ cu rWr i t e s = WRITEMAP(mySpecOrder ) ;
char∗ curReads = READMAP(mySpecOrder ) ;
f o r ( unsigned i = 0 ; i < BIT MAP SIZE ; i++) {
i f ( p r e vWr i t e s [ i ] & ( curReads [ i ] | cu rWr i t e s [ i ] ) ) return 1 ;
/∗ compute the union map in place ∗/

140
curReads [ i ] = p r e vWr i t e s [ i ] | cu rWr i t e s [ i ] ;
}
return 0 ;
}
Listing A.3: Signal Handlers
void BOP RaceHandler ( i n t s i gno , s i g i n f o t ∗ i n f o , u c o n t e x t t ∗ cn t x t ) {
a s s e r t ( SIGUSR1 == s i gno ) ;
a s s e r t ( c n t x t ) ;
// Committing Spec seeing its signal , SIGUSR1. No action .
i f ( i n f o−>s i p i d == ge t p i d ( ) ) return ;
// SOS: the next process has a conflict . Start early termination .
// (set myself as the last process of the group) .
i f ( myStatus == SPEC) {
BOP AbortNextSpec ( ) ;
return ;
}
i f ( myStatus != UNDY) return ;
// Sending a symbolic value .
w r i t e ( undyConcedesPipe [ 1 ] , &mySpecOrder , s i z eo f ( i n t ) ) ;
e x i t ( 0 ) ;
}
// Spec or main gets a segmentation fault .
void BOP SegvHandler ( i n t num , s i g i n f o t ∗ i n f o , u c o n t e x t t ∗ cn t x t ) {
void ∗ f au l tAdd = in f o−>s i a d d r ;
// This should only be the handler for SEGV signals , and we
// only handle the case of permission violations .
a s s e r t (num == SIG MEMORY FAULT ) ;
i f ( i n f o−>s i c o d e != SEGV ACCERR) {

141
whi le (1 ) pause ( ) ;
a s s e r t ( 0 ) ;
}
// Check if the predecessor wrote to this page .
// A more complete check i s done after this and pred complete .
unsigned mapID = MYRESOURCE(mySpecOrder − 1 ) ;
char∗ mapPtr = accMapPtr + (mapID ∗ 2 + 1) ∗ BIT MAP SIZE ;
unsigned a c c e s s = SP checkMap ( fau l tAdd , mapPtr ) ;
i f ( myStatus==SPEC && ac c e s s ) BOP AbortSpec ( ) ;
i f (WRITEOPT( cn t x t ) ) { // A write access .
BOP AbortNextSpec ( ) ;
BOP recordAccess ( fau l tAdd , WRITE ) ;
i f ( mprotect (PAGESTART( fau l tAdd ) , 1 , PROT WRITE |PROT READ) )
e x i t ( e r r n o ) ;
} e l s e { // A read access .
BOP recordAccess ( fau l tAdd , READ) ;
i f ( mprotect (PAGESTART( fau l tAdd ) , 1 , PROT READ) )
e x i t ( e r r n o ) ;
}
}
void BOP UndyTermHandler ( i n t num , s i g i n f o t ∗ i n f o , u c o n t e x t t ∗ cn t x t )
{
a s s e r t ( SIGUSR2 == num ) ;
a s s e r t ( c n t x t ) ;
i f ( i n f o−>s i p i d == ge t p i d ( ) ) return ; /∗ Must be Undy ∗/
e x i t ( 0 ) ;
}
// See Listing 4.3.1 for BOP PrePPR implementation .

142
s t a t i c i n t BOP pipeClose ( void ) {
i n t i = 0 , h a sE r r o r =0;
f o r ( i =0; i<=MAX SPEC DEPTH∗2 ; i++) {
ha sE r r o r |= c l o s e ( l oH iP i p e s [ i ] [ 0 ] ) ;
h a sE r r o r |= c l o s e ( l oH iP i p e s [ i ] [ 1 ] ) ;
}
ha sE r r o r |= c l o s e ( undyCreatedP ipe [ 0 ] ) ;
h a sE r r o r |= c l o s e ( undyCreatedP ipe [ 1 ] ) ;
h a sE r r o r |= c l o s e ( undyConcedesPipe [ 0 ] ) ;
h a sE r r o r |= c l o s e ( undyConcedesPipe [ 1 ] ) ;
i f ( h a sE r r o r ) {
p e r r o r ( ” f a i l e d to c l o s e p i p e s ” ) ;
myStatus = SEQ;
return 0 ;
}
e l s e return 1 ;
}
// See Listing 4.3.3 for BOP End implementation .
// See Listing 4.3.4 for PostPPR commit implementation .
// See Listing 4.3.4 for PostPPR main implementation .
// See Listing 4.3.4 for PostPPR spec implementation .
// See Listing 4.3.4 for PostPPR undy implementation .
s t a t i c i n t BOP Pipe In i t ( void ){
i n t i , h a sE r r o r = 0 ;
f o r ( i =0; i<=MAX SPEC DEPTH∗2 ; i++)
ha sE r r o r |= p ipe ( l oH iP i p e s [ i ] ) ;
h a sE r r o r |= p ipe ( undyCreatedP ipe ) ;
h a sE r r o r |= p ipe ( undyConcedesPipe ) ;

143
i f ( h a sE r r o r ) {
p e r r o r ( ” update p i p e c r e a t i o n f a i l e d : ” ) ;
myStatus = SEQ;
return 0 ;
}
e l s e return 1 ;
}
s t a t i c void BOP timerAlarmExit ( i n t s i g no ) {
( void ) s i g no ;
k i l l ( 0 , SIGKILL ) ;
}
s t a t i c void BOP timerTermExit ( i n t s i g no ) {
a s s e r t (SIGTERM == s i gno ) ;
s i g n a l (SIGTERM, SIG IGN ) ;
k i l l ( 0 , SIGTERM) ;
e x i t ( 0 ) ;
}
// Allocates the shared data and installs the timer process .
void BOP In i t ( )
{
s t a t i c i n t i n i t d o n e = 0 ;
i f ( i n i t d o n e ) return ;
i n i t d o n e = 1 ;
char ∗ curPnt = mmap(NULL , ALLOC MAP SIZE + ACC MAP SIZE ,
PROT READ | PROT WRITE,
MAP ANONYMOUS | MAP SHARED, −1, 0 ) ;
a s s e r t ( curPnt ) ;
useMap = curPnt ;
accMapPtr = curPnt + ALLOC MAP SIZE ;

144
// Setup BOP process group.
SP gpid = ge t p i d ( ) ;
s e t p g i d (0 , SP gpid ) ;
// Prepare signal handlers .
s i g n a l ( SIGINT , BOP timerAlarmExit ) ;
s i g n a l ( SIGQUIT , BOP timerAlarmExit ) ;
s i g n a l ( SIGUSR1 , SIG DFL ) ;
s i g n a l ( SIGUSR2 , SIG DFL ) ;
// Pre−made for signal blocking and unblocking
s i g emp t y s e t (&s igMaskUsr1 ) ;
s i g a d d s e t (&sigMaskUsr1 , SIGUSR1 ) ;
s i g emp t y s e t (&s igMaskUsr2 ) ;
s i g a d d s e t (&sigMaskUsr2 , SIGUSR2 ) ;
s i g emp t y s e t (&s igMaskUsr12 ) ;
s i g a d d s e t (&sigMaskUsr12 , SIGUSR1 ) ;
s i g a d d s e t (&sigMaskUsr12 , SIGUSR2 ) ;
// Prepare post/wait
BOP Pipe In i t ( ) ;
// Create the timer process , which waits for the whole
// speculative precessing team to complete .
i n t f i d = f o r k ( ) ;
switch ( f i d ) {
case −1:
myStatus = SEQ;
return ;
case 0 : // The child i s the new control .
myStatus = CTRL ;
s e t p g i d (0 , SP gpid ) ;
return ;
defau l t :

145
// Setup SIGALRM
s i g n a l (SIGALRM , BOP timerAlarmExit ) ;
s i g n a l (SIGTERM, BOP timerTermExit ) ;
whi le (1 ) pause ( ) ; // Timer waits for the program to end .
}
}
void BOP PostPPR( i n t i d ) {
// Ignore a PPR ending if it doesn ’t match the PPR we started
i f ( i d != pprID ) return ;
ppr ID = −1;
switch ( myStatus ) {
case UNDY:
return PostPPR undy ( ) ;
case SPEC :
return PostPPR spec ( ) ;
case MAIN :
return PostPPR main ( ) ;
case SEQ:
case CTRL :
return ; // No action .
defau l t :
a s s e r t ( 0 ) ;
}
}
s t a t i c void BOP AbortSpec ( void ) {
a s s e r t ( myStatus == SPEC ) ;

146
// With no earlier SPEC, just let UNDY take over .
i f ( mySpecOrder == 1) e x i t ( 0 ) ;
// Initiate early termination in the parent .
k i l l ( g e t pp i d ( ) , SIGUSR1 ) ;
e x i t ( 0 ) ;
}
s t a t i c void BOP AbortNextSpec ( void ) {
e a r l yT e rm i n a t i o n = t r u e ;
// Kill any following SPEC
i f ( specP id !=0) k i l l ( specPid , SIGKILL ) ;
}
A.2 Fast Track Code
Listing A.4: Public Header File
i n t FT BeginFastTrack ( void ) ;
i n t FT BeginDualTrack ( void ) ;
void FT PostDualTrack ( void ) ;
Listing A.5: Private Header File
s t a t i c boo l FT ac t i v e ; // True during a dual−track region .
// The maximum number of speculation processes allowed.
s t a t i c unsigned FT maxSpec = 2 ;
// Access maps used by each fast/normal pair :
s t a t i c char∗ FT fastAccMap ; // Fast track
s t a t i c char∗ FT slowAccMap ; // Slow track
s t a t i c char∗ FT accMap ; // Alias to local map

147
// Queue for waiting slow tracks .
typedef s t ruc t {
i n t p i p e [ 2 ] ;
sem t sem ;
v o l a t i l e unsigned r e c e n t ; // Newest activte track.
v o l a t i l e boo l wa i t i n g ; // True when the FT yields .
} readyQueue ;
s t a t i c readyQueue ∗ readyQ ;
// Communication channels :
// Channel for passing data updates after verification .
s t a t i c i n t updateP ipe [ 2 ] ;
// File descriptors for assigning seniority . Each slow track reads
// from inheritance pipe and writes to the bequest .
s t a t i c i n t i n h e r i t a n c e , beques t ;
// Slow tracks ”open” a floodgate of another waiting slow track.
#def ine FLOODGATESIZE (2 ∗ (MAX SPEC DEPTH + 1))
s t a t i c i n t f l o o d g a t e s [ FLOODGATESIZE ] [ 2 ] ;
// Unique identifier for speculative processes .
s t a t i c unsigned FT order = 0 ;
Listing A.6: Utility Functions
s t a t i c void ∗ FT sharedMap ( s i z e t l e n g t h ) {
return mmap(NULL , l eng th ,
PROT READ | PROT WRITE,
MAP ANONYMOUS | MAP SHARED, −1 , 0 ) ;
}
/// Transitions to error state and returns 0.
s t a t i c char FT errorOnBeg in ( void ) {
myStatus = SEQ;
return 0 ;
}

148
s t a t i c i n t FT getDepthFromEnv ( void ) {
char∗ c v a l ;
s t a t i c const i n t de f = 2 ; // Default value
i n t depth = de f ;
c v a l = getenv ( ”BOP SpecDepth” ) ;
i f ( c v a l != NULL) depth = a t o i ( c v a l ) ;
// Must be in the range [0 , MAX]
i f ( depth < 0 | | depth > MAX SPEC DEPTH) depth = de f ;
return depth ;
}
/// Returns zero on success .
s t a t i c char FT setupMaps ( void ) {
// Allocate two access maps contiguously .
char∗ accMap = FT sharedMap (ACC MAP SIZE ∗ 2 ) ;
i f (MAP FAILED == accMap ) return 1 ;
FT fastAccMap = accMap ;
FT slowAccMap = accMap + ACC MAP SIZE ;
return 0 ;
}
Listing A.7: Floodgate Control
s t a t i c i n l i n e i n t ∗ FT f loodGateFor ( i n t specOrde r ) {
return f l o o d g a t e s [ specOrde r%FLOODGATESIZE ] ;
}
/// Synchronously reads a single token from the floodgate
/// associated with the current process .

149
s t a t i c i n l i n e i n t FT readFloodGate ( void ) {
i n t token ;
i n t ∗ gate = FT f loodGateFor ( FT order ) ;
SP sync r ead ( gate [ 0 ] , &token , s i z eo f ( token ) ) ;
return token ;
}
/// Opens the floodgate for track.
s t a t i c i n l i n e void FT openFloodGate ( i n t t r ack , i n t token ) {
i n t ∗ gate = FT f loodGateFor ( t r a c k ) ;
w r i t e ( gate [ 1 ] , &token , s i z eo f ( token ) ) ;
}
/// Tell any processes waiting on a floodgate to give up .
s t a t i c void FT c l e a r F l o odga t e s ( void ) {
f d s e t r e a d s e t ;
const i n t token = −1;
s t ruc t t ime v a l z e r o t ime = {0 ,0} ;
i n t n fd s = readyQ−>p i p e [ 0 ] + 1 ;
i n t nex t s l ow ;
FD ZERO(& r e a d s e t ) ;
FD SET( readyQ−>p i p e [ 0 ] , &r e a d s e t ) ;
i f (−1 == s e l e c t ( nfds , &r ead s e t , NULL , NULL , &ze r o t ime ) )
p e r r o r ( ” s e l e c t i n g ready queue” ) ;
whi le ( FD ISSET ( readyQ−>p i p e [ 0 ] , &r e a d s e t ) ) {
i f (−1 == read ( readyQ−>p i p e [ 0 ] , &next s low , s i z eo f ( n ex t s l ow ) ) )
p e r r o r ( ” read from ready queue” ) ;
FT openFloodGate ( next s low , token ) ;
i f (−1 == s e l e c t ( nfds , &r ead s e t , NULL , NULL , &ze r o t ime ) )
p e r r o r ( ” s e l e c t i n g ready queue” ) ;
}

150
}
s t a t i c void FT re l ea s eNex tS low ( void ) {
whi le (0 != sem wai t (&( readyQ−>sem ) ) ) ;
i f ( readyQ−>wa i t i n g ) {
// restart the fast
a s s e r t (FAST != myStatus ) ;
FT s lowCleanup ( ) ;
readyQ−>wa i t i n g = f a l s e ;
sem post (&( readyQ−>sem ) ) ;
e x i t ( 1 ) ;
} e l s e {
i n t s l ow t r a c k = 0 ;
// Read from ready queue until a value i s returned .
SP sync r ead ( readyQ−>p i p e [ 0 ] , &s l owt r a ck , s i z eo f ( s l ow t r a c k ) ) ;
i f ( s l ow t r a c k > 0) readyQ−>r e c e n t = s l ow t r a c k ;
sem post (&( readyQ−>sem ) ) ;
// If we got a slowtrack from the ready queue , start it .
i f ( s l ow t r a c k ) FT openFloodGate ( s l owt r a ck , FT order ) ;
}
}
// If the fast track gets too far ahead (a lot of slow tracks are
// waiting) it will yield to let some slow tracks get work done.
s t a t i c void FT cont i nueOrY i e l d ( void ) {
i f ( FT order > readyQ−>r e c e n t + FT maxSpec ) {
// Continuing after yielding to slow track
FT re l ea s eNex tS low ( ) ;
readyQ−>wa i t i n g = t r u e ;
whi le ( readyQ−>wa i t i n g ) pause ( ) ;
}
}
s t a t i c void FT becomeOldest ( void )

151
{
i n t token ;
// Wait until we are the most senior slow instance
SP sync r ead ( i n h e r i t a n c e , &token , s i z eo f ( token ) ) ;
i f ( token == −1) {
// Upstream error . Propagate and abort.
SP s yn c w r i t e ( bequest , &token , s i z eo f ( token ) ) ;
e x i t ( 1 ) ;
}
// Now the oldest slow track.
c l o s e ( i n h e r i t a n c e ) ;
}
Listing A.8: Finalization
s t a t i c i n l i n e void FT fas tC l eanup ( void ) {
i n t i ;
f o r ( i =0; i < FLOODGATESIZE ; i++) {
c l o s e ( f l o o d g a t e s [ i ] [ 0 ] ) ;
c l o s e ( f l o o d g a t e s [ i ] [ 1 ] ) ;
}
}
// Closes everything the slow track normally has open .
s t a t i c i n l i n e void FT slowCleanup ( void ) {
i n t i ;
c l o s e ( updateP ipe [ 0 ] ) ;
c l o s e ( beques t ) ;
c l o s e ( readyQ−>p i p e [ 0 ] ) ;
f o r ( i =0; i < FLOODGATESIZE ; i++) {
c l o s e ( f l o o d g a t e s [ i ] [ 0 ] ) ;
c l o s e ( f l o o d g a t e s [ i ] [ 1 ] ) ;
}
}

152
// See Listing 5.3.3 for FT CheckData implementation
#i fnde f FT AUTOMARKPOINT
#def ine FT AUTOMARKPOINT 0
#end i f
s t a t i c void FT StartAutoMarkPointTimer ( void ) ;
s t a t i c void FT In i tAutoMarkPo int ( void ) ;
s t a t i c void a t t r i b u t e ( ( c o n s t r u c t o r ) ) FT i n i t ( void ) {
i n t i ;
i n t s e n p i p e [ 2 ] ;
/∗ Shared floodgate pipes ∗/
f o r ( i =0; i<=MAX SPEC DEPTH∗2 ; i++)
i f ( p i p e ( f l o o d g a t e s [ i ] ) != 0) {
p e r r o r ( ” a l l o c a t i n g f l o o d g a t e s ” ) ;
abo r t ( ) ;
}
readyQ = FT sharedMap ( s i z eo f ( readyQueue ) ) ;
readyQ−>wa i t i n g = f a l s e ;
i f (0 != p ip e ( readyQ−>p i p e ) ) {
p e r r o r ( ” a l l o c a t i n g ready queue” ) ;
abo r t ( ) ;
}
i f (−1 == s em i n i t (&( readyQ−>sem ) , 1 , 1 ) ) {
p e r r o r ( ” unab l e to i n i t i a l i z e semaphore ” ) ;
abo r t ( ) ;
}
// Create the first seniority pipe .
i f (0 != p ip e ( s e n p i p e ) ) {
p e r r o r ( ” unab l e to i n i t i a l i z e s e n i o r i t y p i p e ” ) ;

153
abo r t ( ) ;
}
// Ensure the first slow track will know it i s the oldest .
w r i t e ( s e n p i p e [ 1 ] , &FT order , s i z eo f ( FT order ) ) ;
c l o s e ( s e n p i p e [ 1 ] ) ;
// Keep the read end open .
i n h e r i t a n c e = s e n p i p e [ 0 ] ;
FT maxSpec = FT getDepthFromEnv ( ) ;
FT ac t i v e = f a l s e ;
SP Red i r ec tOutput ( ) ;
i f (FT AUTOMARKPOINT) FT In i tAutoMarkPo int ( ) ;
}
// Automatic branch point insertion
s t a t i c unsigned FT AM count = 0 ;
s t a t i c boo l FT AM active = f a l s e ;
s t a t i c unsigned∗ FT AM joinPoint ;
s t a t i c void FT i t ime rHand l e r ( i n t s i g no ) {
a s s e r t ( s i g no == SIGALRM ) ;
FT AM active = t r u e ;
}
s t a t i c void FT A l l o c a t e J o i nPo i n t e r ( void ) {
FT AM joinPoint = FT sharedMap ( s i z eo f ( FT AM joinPoint ) ) ;
∗FT AM joinPoint = 0 ;
}
s t a t i c void FT StartAutoMarkPointTimer ( void ) {
s t ruc t t ime v a l i n t e r v a l = {0 ,500000} ;
s t ruc t i t i m e r v a l t ime r = { i n t e r v a l , i n t e r v a l } ;

154
i f ( SIG ERR == s i g n a l (SIGALRM , FT i t ime rHand l e r ) )
p e r r o r ( ” s e t t i n g s i g n a l ” ) ;
i f (0 > s e t i t i m e r ( ITIMER REAL,& t imer ,NULL) )
p e r r o r ( ” s e t t i n g t ime r ” ) ;
}
s t a t i c void FT In i tAutoMarkPo int ( void ) {
i f ( !FT AUTOMARKPOINT) return ;
FT StartAutoMarkPointTimer ( ) ;
FT A l l o c a t e J o i nPo i n t e r ( ) ;
}
i n t FT AutoMarkPoint ( void ) {
i f ( !FT AUTOMARKPOINT) return 0 ;
FT AM count++;
i f ( ! FT AM active ) return 0 ;
i f (SLOW == myStatus ){
// If the slow track has already passed the join point , then it
// i s running ahead of the fast track (or the timer didn ’t fire
// soon enough) . Slow Wins.
i f ( FT AM count > ∗FT AM joinPoint ) FT slowTakesOver ( ) ;
// If we have reached the indicated joint point , cleanup .
e l s e i f ( FT AM count == ∗FT AM joinPoint ) FT PostDualTrack ( ) ;
} e l s e i f (FAST == myStatus | | CTRL == myStatus ) {
// reset the activation
FT AM active = f a l s e ;
// indicate where the branch/join i s
∗FT AM joinPoint = FT AM count ;
munmap( FT AM joinPoint , s i z eo f ( FT AM joinPoint ) ) ;
// Setup a new joinpoint record for the next slow track.
FT A l l o c a t e J o i nPo i n t e r ( ) ;
return FT BeginFastTrack ( ) ;

155
}
return 0 ;
}
// See Listing 5.3.5 for FT PostSlow and FT slowTakesOver.
// See Listing 5.3.5 for FT exitHandler implementation
// The slow track kills fast with SIGABRT.
s t a t i c void FT s igAbo r tFa s t ( i n t s i g ) {
a s s e r t (SIGABRT == s i g ) ;
FT fa s tC l eanup ( ) ;
e x i t ( 1 ) ;
}
// Handler for the fast track to recognize a child has aborted .
s t a t i c void FT s i gCh i l dAbo r t ed ( i n t s i g ) {
i n t p id ;
i n t f l a g s = WNOHANG | WUNTRACED | WCONTINUED;
a s s e r t (SIGCHLD == s i g ) ;
// Clean up any and all dead children .
whi le (0 < ( p i d = wa i t p i d (−1 , NULL , f l a g s ) ) ) ;
}
/// Returns 1 on success (fast track started ) .
char FT i n t e r n a lB e g i nFa s t ( i n t s e n i o r i t y [ 2 ] ) {
myStatus = FAST ;
FT ac t i v e = t r u e ;
FT accMap = FT fastAccMap ;
// We need to be able to abort if necessary
s i g n a l (SIGABRT , FT s i gAbo r tFa s t ) ;
// Keep track of what FAST’ s children do.
s i g n a l (SIGCHLD , FT s i gCh i l dAbo r t ed ) ;

156
// Seniority based ordering
c l o s e ( s e n i o r i t y [ 1 ] ) ; // We don ’t need the ’read ’ side .
c l o s e ( i n h e r i t a n c e ) ; // SLOW is responsible for old ’write ’ side .
i n h e r i t a n c e = s e n i o r i t y [ 0 ] ; // We have a new ’write ’ pipe .
FT cont i nueOrY i e l d ( ) ;
return 1 ;
}
char FT in t e rna lBeg inNorma l ( i n t s e n i o r i t y [ 2 ] ) {
myStatus = SLOW;
beques t = s e n i o r i t y [ 1 ] ;
// Stop using handlers from past fast tracks .
s i g n a l (SIGABRT , SIG DFL ) ;
// specDepth control via waiting by the floodgate
i f ( FT order > FT maxSpec ) {
i f ( FT readFloodGate ( ) == −1) {
// An error occurred earlier .
FT slowCleanup ( ) ;
e x i t ( 1 ) ;
}
}
c l o s e ( readyQ−>p i p e [ 1 ] ) ;
c l o s e ( s e n i o r i t y [ 0 ] ) ;
FT accMap = FT slowAccMap ;
c l o s e ( updateP ipe [ 1 ] ) ;
i f ( SIG ERR == s i g n a l (SIGABRT , SIG DFL ) )
p e r r o r ( ” f a i l e d to c l e a r abo r t h and l e r ” ) ;

157
SP Red i r ec tOutput ( ) ;
FT ac t i v e = t r u e ;
i f (FT AUTOMARKPOINT) FT StartAutoMarkPointTimer ( ) ;
return 0 ;
}
// See Listing 5.3.2 for FT SegvHandler implementation
// See Listing 5.3.1 for FT Begin implementation
s t a t i c i n t dua lP id ; // The other dual (not−fast/slow) track.
s t a t i c i n l i n e void FT PostDual ( void ) {
// Just kill the other and move on.
i f (−1 == k i l l ( dua lP id , SIGABRT) )
p e r r o r ( ” f a i l e d to abo r t p a r a l l e l t r a c k ” ) ;
myStatus = CTRL ;
SP CommitOutput ( ) ;
}
i n t FT BeginDualTrack ( void )
{
// Make sure we’re currently running sequentially .
i f ( myStatus != CTRL ) return 0 ;
// Don’t bother if there can ’t be parallelism
i f ( FT maxSpec < 1) return 0 ;
i n t PID= f o r k ( ) ;
i f (−1 == s e t p g i d (0 , SP gpid ) ) {
p e r r o r ( ” f a i l e d to s e t p r o c e s s group ” ) ;
abo r t ( ) ;
}
switch (PID ){
case −1:
myStatus = SEQ;

158
PID = 0 ;
break ;
case 0 :
myStatus = DUAL;
dua lP id = ge tpp i d ( ) ;
break ;
defau l t :
myStatus = DUAL;
dua lP id = PID ;
break ;
}
SP Red i r ec tOutput ( ) ;
return PID ;
}
s t a t i c i n l i n e void FT PostFast ( void ) {
SP PushDataAccordingToMap ( FT fastAccMap , updateP ipe [ 1 ] ) ;
i f (munmap( FT fastAccMap , ACC MAP SIZE) == −1)
p e r r o r ( ”unmapping a c c e s s map” ) ;
i f (munmap( FT slowAccMap , ACC MAP SIZE) == −1)
p e r r o r ( ”unmapping a c c e s s map” ) ;
c l o s e ( updateP ipe [ 0 ] ) ;
c l o s e ( updateP ipe [ 1 ] ) ;
}
void FT PostDualTrack ( void )
{
switch ( myStatus ) {
case SLOW:
FT PostSlow ( ) ;
break ;
case FAST :

159
FT PostFast ( ) ;
break ;
case DUAL:
FT PostDual ( ) ;
break ;
defau l t :
f p r i n t f ( s t d e r r , ” unexpected p r o c e s s s t a t e %d” , myStatus ) ;
abo r t ( ) ;
}
FT ac t i v e = f a l s e ;
}
A.3 Common Code
Listing A.9: Common Header File
#def ine PAGESIZE 4096 // memory page size
#def ine PAGECOUNT (UINT MAX / PAGESIZE)
// The size of any single memory bitmap in bytes .
#def ine BIT MAP SIZE ( (PAGECOUNT) >> 3)
// ALLOCMAP SIZE defines the size of the allocation (use) map
#def ine ALLOC MAP SIZE BIT MAP SIZE
#def ine MAX SPEC DEPTH 16
// The total size of the access maps .
// Dual maps the map pair for specOrder 0 i s reused for unions
#def ine ACC MAP SIZE ( (MAX SPEC DEPTH + 1 ) ∗ 2 ∗ BIT MAP SIZE )
// Write operations are type 2 , and register 13 stores the type info .
#i f d e f i n e d ( MACH )
#def ine SIG MEMORY FAULT SIGBUS

160
#def ine MAPANONYMOUS MAP ANON
#def ine WRITEOPT( cn t x t ) ( ( c n t x t )−>uc mcontext−> e s . e r r & 2)
#el se
#def ine SIG MEMORY FAULT SIGSEGV
#def ine WRITEOPT( cn t x t ) ( ( c n t x t )−>uc mcontext . g r e g s [ 1 3 ] & 2)
#end i f
typedef enum {
CTRL, MAIN,
SPEC , // a speculation process
UNDY, // the understudy
SEQ, // a sequential process
FAST , // a fast track
SLOW, // a slow track
DUAL // either of two equal options
} SP Status ;
v o l a t i l e SP Status myStatus ; // Current processes status .
i n t SP gpid ; // The process group.
#def ine PAGESTART( x ) ( ( void ∗ ) ( ( ( unsigned long ) x/PAGESIZE)∗PAGESIZE ) )
#def ine MYRESOURCE( a ) ( ( a)==0? 0 : ( ( ( a)−1)%MAX SPEC DEPTH)+1)
#def ine WRITEMAP( a ) ( accMapPtr + (MYRESOURCE( a )∗2+1)∗BIT MAP SIZE )
#def ine READMAP( a ) ( accMapPtr + MYRESOURCE( a )∗2∗BIT MAP SIZE )
Listing A.10: IO Capture Header
void SP Red i r ec tOutput ( ) ;
void SP CommitOutput ( ) ;
Listing A.11: Utility Functions Header
typedef enum {
READ,
WRITE
} AccessType ;

161
// Returns map ’ s bit for address .
i n t SP checkMap ( void ∗ page add r e s s , char∗ map ) ;
// Applies the protection prot to any memory pages that
// are marked as in use according to the useMap.
void SP s e tP r o t e c t i o n ( i n t p ro t ) ;
// Call read until it succeeds .
void SP sync r ead ( i n t fd , void ∗buf , s i z e t count ) {
whi le ( r ead ( fd , buf , count ) == −1);
}
// Call write until it succeeds .
void SP s yn c w r i t e ( i n t fd , const void ∗buf , s i z e t count ) {
whi le ( w r i t e ( fd , buf , count ) == −1);
}
Listing A.12: Utility Function Implementations
s t a t i c i n l i n e void
SP pro tec tPages ( unsigned long f i r s t , unsigned long l a s t , i n t p ro t )
{
void ∗ page = ( void ∗) ( f i r s t ∗ PAGESIZE ) ;
s i z e t l e n = ( ( l a s t − f i r s t + 1) ∗ PAGESIZE ) ;
// Try to set the protection all at once .
i f (0 == mprotect ( page , l en , p r o t ) ) return ;
p e r r o r ( ” ” ) ;
f o r ( unsigned long i = f i r s t ; i <= l a s t ; i++) {
i f ( mprotect ( ( void ∗ ) ( i ∗ PAGESIZE ) , PAGESIZE , p r o t ) )
p e r r o r ( ” ” ) ;
}
}
// Sets a bit in map to indicate that page i s accessed .

162
void SP recordAccessToMap ( void ∗ page add r e s s , char∗ map) {
i n t byte , b i t , page ;
page = ( ( unsigned long ) p ag e add r e s s ) / PAGESIZE ;
by te = page >> 3 ; //byte = page / 8
b i t = page & 7 ; //bit = page % 8;
map [ byte ] |= (1 << b i t ) ;
}
i n t SP checkMap ( void ∗ page add r e s s , char∗ map){
i n t page = ( ( unsigned long ) p ag e add r e s s ) / PAGESIZE ;
i n t byte = page >> 3 ;
i n t b i t = page % 8 ;
char mapvalue = map [ byte ] ;
return ( mapvalue >> b i t ) & 0x1 ;
}
// Writes num memory pages to pipeid starting with the i ’th page .
void SP PushPageToPipe ( unsigned long i , i n t p i p e i d , unsigned num) {
unsigned wr i t e c o u n t = 0 ;
whi le ( w r i t e c o u n t < (num ∗ PAGESIZE ) ) {
i n t r e s u l t = w r i t e ( p i p e i d ,
( void ∗ ) ( ( i ∗PAGESIZE) + w r i t e c o u n t ) ,
(num∗PAGESIZE) − wr i t e c o u n t ) ;
i f ( r e s u l t == −1) {
p e r r o r ( ” f a i l e d to w r i t e i n t o p i p e ” ) ;
abo r t ( ) ;
} e l s e {
wr i t e c o u n t += r e s u l t ;
}
}
}
i n t SP PushDataAccordingToMap ( char ∗map , i n t p i p e i d ) {

163
unsigned bchar , b i t , i ;
i n t page count =0;
f o r ( bchar=0; bchar< BIT MAP SIZE ; bchar++) {
i f (map [ bchar ]==0) continue ;
i f (˜map [ bchar ]==0) {
SP PushPageToPipe ( bchar ∗8 , p i p e i d , 8 ) ;
page count += 8 ;
continue ;
}
f o r ( b i t =0; b i t <8; b i t++) {
i f ( (map [ bchar ]>> b i t ) & 0x1 ) {
i = bchar∗8+ b i t ;
SP PushPageToPipe ( i , p i p e i d , 1 ) ;
page count++;
}
}
}
return page count ;
}
// Read a page from pipe and write it to the i ’th page of memory.
s t a t i c void
SP CopyPageFromPipe ( unsigned long i , i n t p ipe , char p r o t e c t e d ) {
unsigned r e ad coun t = 0 ;
i n t i n c r ement ;
i f ( p r o t e c t e d )
mprotect ( ( void ∗ ) ( i ∗PAGESIZE ) , PAGESIZE , PROT WRITE ) ;
whi le ( r e ad coun t < PAGESIZE) {
// read the remaining portion of the page from the pipe .
// The location to read to i s page i offset by the amount
// already read in .
i n c r ement = read ( p ipe ,
( void ∗ ) ( ( i ∗PAGESIZE)+ read coun t ) ,
PAGESIZE−r e ad coun t ) ;

164
i f (−1 == inc r ement ) {
p e r r o r ( ” e r r o r code ” ) ;
e x i t ( 0 ) ;
}
r e ad coun t += inc r ement ;
}
i f ( p r o t e c t e d )
mprotect ( ( void ∗ ) ( i ∗PAGESIZE ) , PAGESIZE , PROT NONE) ;
}
// If we are reading pages into protected space (protected==true) ,
// we’ ll need to first open the protection and then close it .
i n t SP Pul lDataAccordingToMap ( char ∗map , i n t p ipe , char p r o t e c t e d ) {
unsigned bchar , b i t , i ;
i n t page count =0;
f o r ( bchar=0; bchar < BIT MAP SIZE ; ++bchar ) {
i f (map [ bchar ]==0) continue ;
f o r ( b i t =0; b i t <8; ++b i t ) {
i f ( (map [ bchar ]>> b i t ) & 0x1 ) {
i = bchar∗8+ b i t ;
SP CopyPageFromPipe ( i , p ipe , p r o t e c t e d ) ;
++page count ;
} // if map[ bint ] . . .
} //for bit
} //for map
return page count ;
}
/// Returns 0 on success .
char SP se tupAct i on ( void (∗ hand l e r ) ( int , s i g i n f o t ∗ , u c o n t e x t t ∗ ) ,
i n t s i g n a l )
{
s t ruc t s i g a c t i o n a c t i o n ;

165
s i g f i l l s e t (& a c t i o n . sa mask ) ;
a c t i o n . s a f l a g s = SA SIGINFO ;
a c t i o n . s a s i g a c t i o n = ( void ∗) h and l e r ;
i f (−1 == s i g a c t i o n ( s i g n a l , &ac t i on , NULL) ) {
p e r r o r ( ” f a i l e d to s e t ’ f a u l t ’ h and l e r ” ) ;
return 1 ;
}
return 0 ;
}

166
Bibliography
[1] Allen, Randy and Ken Kennedy. 2001. Optimizing Compilers for Modern
Architectures: A Dependence-based Approach. Morgan Kaufmann Publishers.
[2] Amdahl, Gene M. 1967. Validity of the single processor approach to achieving
large scale computing capabilities. In AFIPS ’67 (Spring): Proceedings of the
April 18-20, 1967, spring joint computer conference, pages 483–485. ACM,
New York, NY, USA.
[3] Bender, Michael A., Jeremy T. Fineman, Seth Gilbert, and Charles E. Leiser-
son. 2004. On-the-fly maintenance of series-parallel relationships in fork-join
multithreaded programs. In Proceedings of the ACM Symposium on Paral-
lelism in Algorithms and Architectures, pages 133–144.
[4] Berger, Emery D., Ting Yang, Tongping Liu, and Gene Novark. 2009. Grace:
safe multithreaded programming for C/C++. In Proceedings of the ACM
SIGPLAN Conference on Object oriented programming systems and applica-
tions, pages 81–96. ACM, New York, NY, USA.
[5] Bernstein, A. J. 1966. Analysis of programs for parallel processing. IEEE
Transactions on Electronic Computers, 15(5):757–763.
[6] Blumofe, Robert D., Christopher F. Joerg, Bradley C. Kuszmaul, Charles E.
Leiserson, Keith H. Randall, and Yuli Zhou. 1995. Cilk: an efficient multi-
threaded runtime system. SIGPLAN Not., 30(8):207–216.

167
[7] Boehm, Hans-Juergen. 2005. Threads cannot be implemented as a library.
In Proceedings of the ACM SIGPLAN Conference on Programming language
design and implementation, pages 261–268.
[8] Bridges, Matthew, Neil Vachharajani, Yun Zhang, Thomas Jablin, and David
August. 2007. Revisiting the sequential programming model for multi-core.
In Proceedings of the International Symposium on Microarchitecture, pages
69–84. IEEE Computer Society, Washington, DC, USA.
[9] Chang, Fay W. and Garth A. Gibson. 1999. Automatic i/o hint generation
through speculative execution. In Proceedings of the Symposium on Operating
System Design and Implementation.
[10] Chen, Michael K. and Kunle Olukotun. 2003. The Jrpm system for dy-
namically parallelizing Java programs. In 30th International Symposium on
Computer Architecture, pages 434–445.
[11] Cintra, Marcelo and Diego Llanos. 2005. Design space exploration of a soft-
ware speculative parallelization scheme. IEEE Transactions on Parallel and
Distributed Systems, 16(6):562–576.
[12] Coffman, Edward G., M. J. Elphick, and Arie Shoshani. 1971. System dead-
locks. ACM Computing Surveys, 3(2):67–78.
[13] Cytron, Ron, Jeanne Ferrante, Barry Rosen, Mark Wegman, and F. Kenneth
Zadeck. 1991. Efficiently computing static single assignment form and the
control dependence graph. ACM Transactions on Programming Languages
and Systems, 13(4):451–490.
[14] Dang, Francis, Hao J. Yu, and Lawrence Rauchwerger. 2002. The R-LRPD
test: Speculative parallelization of partially parallel loops. In IEEE Interna-
tional Parallel and Distributed Processing Symposium on, pages 20–29. Ft.
Lauderdale, FL.

168
[15] Ding, Yonghua and Zhiyuan Li. 2004. A compiler scheme for reusing inter-
mediate computation results. In Proceedings of the International Symposium
on Code Generation and Optimization.
[16] Eigler, Frank Ch. 2003. Mudflap: Pointer use checking for C/C++. In GCC
Developers’ Summit, pages 57–69.
[17] Feng, Mingdong and Charles E. Leiserson. 1997. Efficient detection of de-
terminacy races in cilk programs. In Proceedings of the ACM Symposium on
Parallelism in Algorithms and Architectures, pages 1–11. ACM, New York,
NY, USA.
[18] Frigo, Matteo, Charles E. Leiserson, and Keith H. Randall. 1998. The imple-
mentation of the cilk-5 multithreaded language. In Proceedings of the ACM
SIGPLAN Conference on Programming language design and implementation,
pages 212–223. ACM, New York, NY, USA.
[19] Garg, Alok and Michael C. Huang. 2008. A performance-correctness
explicitly-decoupled architecture. In 41st International Symposium on Mi-
croarhictecutre.
[20] Grant, Brian K., M. Philipose, Marcus U. Mock, Craig D. Chambers, and
S. J. Eggers. 1999. An evaluation of staged run-time optimizations in DyC.
In Proceedings of the ACM SIGPLAN Conference on Programming language
design and implementation. Atlanta, Georgia.
[21] Grzegorczyk, Chris, Sunil Soman, Chandra Krintz, and Rich Wolski. 2007.
Isla vista heap sizing: Using feedback to avoid paging. In Proceedings of
the International Symposium on Code Generation and Optimization, pages
325–340. IEEE Computer Society, Washington, DC, USA.

169
[22] Gupta, Manish and Rahul Nim. 1998. Techniques for speculative run-time
parallelization of loops. In Proceedings of the ACM/IEEE conference on
Supercomputing, pages 1–12.
[23] Gustafson, John L. 1988. Reevaluating amdahl’s law. Commun. ACM,
31(5):532–533.
[24] Halstead, Robert H., Jr. 1985. MULTILISP: A language for concurrent sym-
bolic computation. ACM Transactions on Programming Langguage Systems,
7(4):501–538.
[25] Herlihy, Maurice, Victor Luchangco, Mark Moir, and William N. Scherer III.
2003. Software transactional memory for dynamic-sized data structures. In
Proceedings of the ACM Symposium on Principles of Distributed Computing,
pages 92–101. Boston, MA.
[26] Herlihy, Maurice and J. E. Moss. 1993. Transactional memory: Architectural
support for lock-free data structures. In Proceedings of the International
Symposium on Computer Architecture. San Diego, CA.
[27] Jefferson, David R., Brian R. Beckman, Frederick Wieland, L. Blume, and
M. Diloreto. 1987. Time warp operating system. In SOSP ’87: Proceedings
of the ACM Symposium on operating systems principles, pages 77–93. ACM,
New York, NY, USA.
[28] Kejariwal, Arun, Xinmin Tian, Wei Li, Milind Girkar, Sergey Kozhukhov,
Hideki Saito, Utpal Banerjee, Alexandru Nicolau, Alexander V. Veidenbaum,
and Constantine D. Polychronopoulos. 2006. On the performance potential
of different types of speculative thread-level parallelism. In ICS ’06: Proceed-
ings of the 20th annual international conference on Supercomputing, page 24.
ACM, New York, NY, USA.

170
[29] Keleher, Peter J., Allen L. Cox, Sandhya Dwarkadas, and Willy Zwaenepoel.
1994. TreadMarks: Distributed shared memory on standard workstations and
operating systems. In Proceedings of the 1994 Winter USENIX Conference.
[30] Kennedy, Andrew and Claudio V. Russo. 2005. Generalized algebraic data
types and object-oriented programming. In Proceedings of the ACM SIG-
PLAN Conference on Object oriented programming systems and applications,
pages 21–40.
[31] Lee, Sanghoon and James Tuck. 2008. Parallelizing Mudflap using thread-
level speculation on a CMP. Presented at the Workshop on the Parallel Ex-
ecution of Sequential Programs on Multi-core Architecture, co-located with
ISCA.
[32] Li, Kai. 1986. Shared Virtual Memory on Loosely Coupled Multiprocessors.
Ph.D. thesis, Dept. of Computer Science, Yale University, New Haven, CT.
[33] Liao, Shih-Wei, Perry H. Wang, Hong Wang, John Paul Shen, Gerolf
Hoflehner, and Daniel M. Lavery. 2002. Post-pass binary adaptation for
software-based speculative precomputation. In Proceedings of the ACM SIG-
PLAN Conference on Programming language design and implementation,
pages 117–128.
[34] Liblit, Ben, Mayur Naik, Alice X. Zheng, Alex Aiken, and Michael I. Jordan.
2005. Scalable statistical bug isolation. In Proceedings of the ACM SIGPLAN
Conference on Programming language design and implementation, pages 15–
26. ACM Press, New York, NY, USA.
[35] Liu, Wei, James Tuck, Luis Ceze, Wonsun Ahn, Karin Strauss, Jose Renau,
and Josep Torrellas. 2006. Posh: A TLS compiler that exploits program
structure. In Proceedings of the ACM SIGPLAN Symposium on Principles
and Practice of Parallel Programming.

171
[36] Luk, Chi-Keung, Robert Cohn, Robert Muth, Harish Patil, Artur Klauser,
Geoff Lowney, Steven Wallace, Vijay Janapa Reddi, and Kim Hazelwood.
2005. Pin: building customized program analysis tools with dynamic instru-
mentation. In Proceedings of the ACM SIGPLAN Conference on Program-
ming language design and implementation, pages 190–200. ACM, New York,
NY, USA.
[37] Martin, Milo M. K., Daniel J. Sorin, Harold W. Cain, Mark D. Hill, and
Mikko H. Lipasti. 2001. Correctly implementing value prediction in micro-
processors that support multithreading or multiprocessing. In Proceedings of
the International Symposium on Microarchitecture.
[38] Mellor-Crummey, John. 1993. Compile-time support for efficient data race
detection in shared-memory parallel programs. In PADD ’93: Proceedings of
the 1993 ACM/ONR workshop on Parallel and distributed debugging, pages
129–139. ACM Press, New York, NY, USA.
[39] Michie, Donald. 1968. Memo functions and machine learning. Nature, 218:19–
22.
[40] Moore, Gordon E. 1965. Cramming more components onto integrated cir-
cuits, Electronics. Electronics Magazine, 19:114–117.
[41] Moseley, Tipp, Alex Shye, Vijay Janapa Reddi, Dirk Grunwald, and Ramesh
Peri. 2007. Shadow profiling: Hiding instrumentation costs with parallelism.
In Proceedings of the International Symposium on Code Generation and Op-
timization, pages 198–208.
[42] Navabi, Armand, Xiangyu Zhang, and Suresh Jagannathan. 2008. Quasi-
static scheduling for safe futures. In Proceedings of the ACM SIGPLAN
Symposium on Principles and Practice of Parallel Programming.

172
[43] Neelakantam, Naveen, Ravi Rajwar, Suresh Srinivas, Uma Srinivasan, and
Craig Zilles. 2007. Hardware atomicity for reliable software speculation. In
Proceedings of the International Symposium on Computer Architecture.
[44] Nightingale, Edmund B., Peter M. Chen, and Jason Flinn. 2005. Speculative
execution in a distributed file system. In Proceedings of the twentieth ACM
symposium on Operating systems principles, pages 191–205. ACM, New York,
NY, USA.
[45] Nightingale, Edmund B., Daniel Peek, Peter M. Chen, and Jason Flinn.
2008. Parallelizing security checks on commodity hardware. In Proceedings
of the International Conference on Architectural Support for Programming
Languages and Operating Systems, pages 308–318.
[46] Oplinger, Jeffrey T. and Monica S. Lam. 2002. Enhancing software reliability
with speculative threads. In Proceedings of the International Conference on
Architectural Support for Programming Languages and Operating Systems,
pages 184–196.
[47] Ottoni, Guilherme, Ram Rangan, Adam Stoler, and David I. August. 2005.
Automatic thread extraction with decoupled software pipelining. In Proceed-
ings of the International Symposium on Microarchitecture, pages 105–118.
[48] Patil, Harish and Charles Fischer. 1995. Efficient run-time monitoring using
shadow processing. In Mireille Ducasse, editor, International Workshop on
Automated and Algorithmic Debugging, pages 119–132.
[49] Perkovic, Dejan and Peter J. Keleher. 2000. A protocol-centric approach
to on-the-fly race detection. IEEE Transactions on Parallel and Distributed
Systems, 11(10):1058–1072.
[50] Quinones, Carlos Garcıa, Carlos Madriles, Jesus Sanchez, Pedro Marcuello,
Antonio Gonzalez, and Dean M. Tullsen. 2005. Mitosis compiler: An in-

173
frastructure for speculative threading based on pre-computation slices. In
Proceedings of the ACM SIGPLAN Conference on Programming language
design and implementation.
[51] Raman, Arun, Hanjun Kim, Thomas R. Mason, Thomas B. Jablin, and
David I. August. 2010. Speculative parallelization using software multi-
threaded transactions. In Proceedings of the International Conference on
Architectural Support for Programming Languages and Operating Systems,
volume 38, pages 65–76. ACM.
[52] Rauchwerger, Lawrence and David Padua. 1995. The LRPD test: Speculative
run-time parallelization of loops with privatization and reduction paralleliza-
tion. In Proceedings of the ACM SIGPLAN Conference on Programming
language design and implementation. La Jolla, CA.
[53] Shen, Xipeng and Chen Ding. 2005. Parallelization of utility programs based
on behavior phase analysis. In Proceedings of the International Workshop
on Languages and Compilers for Parallel Computing. Hawthorne, NY. Short
paper.
[54] Sohi, Gurindar S., Scott E. Breach, and T. N. Vijaykumar. 1995. Multiscalar
processors. In Proceedings of the International Symposium on Computer Ar-
chitecture.
[55] SPEC. 2010. Standard performance evaluation corporation (SPEC).
http://www.spec.org/.
[56] Steffan, J. Gregory, Christopher B. Colohan, Antonia Zhai, and Todd C.
Mowry. 2005. The STAMPede approach to thread-level speculation. ACM
Transactions on Computer Systems, 23(3):253–300.

174
[57] Sundaramoorthy, Karthik, Zach Purser, and Eric Rotenberg. 2000. Slip-
stream processors: improving both performance and fault tolerance. SIG-
PLAN Not., 35(11):257–268.
[58] Tiwari, Devesh, Sanghoon Lee, James Tuck, and Yan Solihin. 2010. Mmt:
Exploiting fine-grained parallelism in dynamic memory management. IEEE
Transactions on Parallel and Distributed Systems.
[59] Tsai, Jenn-Yuan, Zhenzhen Jiang, and Pen-Chung Yew. 1999. Compiler tech-
niques for the superthreaded architectures. International Journal of Parallel
Programming, 27(1):1–19.
[60] Vachharajani, Neil, Ram Rangan, Easwaran Raman, Matthew J. Bridges,
Guilherme Ottoni, and David I. August. 2007. Speculative decoupled soft-
ware pipelining. In Proceedings of the International Conference on Parallel
Architectures and Compilation Techniques, pages 49–59. IEEE Computer So-
ciety, Washington, DC, USA.
[61] Wahbe, Robert, Steven Lucco, and Susan L. Graham. 1993. Practical data
breakpoints: design and implementation. In Proceedings of the ACM SIG-
PLAN Conference on Programming language design and implementation.
[62] Wallace, Steven and Kim Hazelwood. 2007. Superpin: Parallelizing dynamic
instrumentation for real-time performance. In Proceedings of the Interna-
tional Symposium on Code Generation and Optimization, pages 209–220.
[63] Welc, Adam, Suresh Jagannathan, and Antony L. Hosking. 2005. Safe futures
for Java. In Proceedings of the ACM SIGPLAN Conference on Object oriented
programming systems and applications, pages 439–453.
[64] Zhai, Antonia, Christopher B. Colohan, J. Gregory Steffan, and Todd C.
Mowry. 2002. Compiler optimization of scalar value communication between

175
speculative threads. In Proceedings of the International Conference on Archi-
tectural Support for Programming Languages and Operating Systems, pages
171–183.
[65] Zhang, Chengliang, Kirk Kelsey, Xipeng Shen, Chen Ding, Matthew Hertz,
and Mitsunori Ogihara. 2006. Program-level adaptive memory management.
In Proceedings of the International Symposium on Memory Management. Ot-
tawa, Canada.
[66] Zhou, Pin, Feng Qin, Wei Liu, Yuanyuan Zhou, and Josep Torrellas. 2004.
iWatcher: Efficient architectural support for software debugging. In Pro-
ceedings of the International Symposium on Computer Architecture, pages
224–237.
[67] Zilles, Craig and Gurindar S. Sohi. 2002. Master/slave speculative paralleliza-
tion. In Proceedings of the International Symposium on Microarchitecture,
pages 85–96. IEEE Computer Society Press, Los Alamitos, CA, USA.