bab 2 tinjauan referensi 2.1 machine learning
TRANSCRIPT

7
BAB 2
TINJAUAN REFERENSI
2.1 Machine Learning
Machine learning merupakan sebuah gabungan antara ilmu dan seni
dari sebuah pemrograman komputer sehingga machine learning dapat belajar
dari data (G Aurelien, 2017). Menurut Aurelien Geron (2017) machine
learning tepat digunakan ketika:
• Masalah yang membutuhkan solusi dengan banyak rules code.
Machine learning dapat menyederhanakan code dan bahkan
menghasilkan performa yang lebih baik
• Masalah yang kompleks yang tidak ada solusinya ketika
menggunakan pendekatan tradisional. Dengan machine learning
dapat menemukan solusinya.
• Lingkungan yang berubah-ubah. Machine learning dapat
beradaptasi dengan data baru maupun data yang berjumlah besar
dan mendapatkan insight tentang masalah yang kompleks
Pendekatan machine learning dapat dikelompokkan menjadi tiga
kategori yaitu berdasarkan (G Aurelien, 2017):
• Training berdasarkan pengawasan manusia atau tidak (supervised,
unsupervised, semisupervised, reinforcement learning)
• Cara belajar, apakah dapat belajar secara bertahap atau tidak (online
atau batch learning)
• Cara mengeneralisasi, apakah bekerja dengan membandingkan titik
data baru dengan titik data yang diketahui, atau sebaliknya
mendeteksi pola dalam data pelatihan dan membangun model
prediksi (instance-based atau model-based)

8
2.1.1 Supervised Learning
Pada supervised learning data yang dimasukkan kedalam
algoritma machine learning merupakan data yang memiliki solusi di
dalamnya atau biasa disebut label. (G Aurelien, 2017)
Gambar 2.1 Data Yang Berlabel Untuk Dilatih
Sumber: Aurelien Geron, 2017
Gambar 2.1 menjelaskan tugas dari supervised learning
biasanya klasifikasi. Contohnya filter spam training dengan banyak
data email yang memiliki label spam dan bukan spam. Nantinya harus
dapat memprediksi sebuah email baru.
2.1.2 Unsupervised Learning
Pada unsupervised learning sebuah sistem belajar untuk
training tanpa menggunakan label atau belajar sendiri.
Gambar 2.2 Data Yang Tidak Berlabel Untuk Unsupervised Learning
Sumber: Aurelien Geron, 2017

9
Unsupervised learning memiliki contoh yaitu mengenai
pengunjung suatu blog. Gambar 2.2 menjalankan algoritma clustering
untuk mencoba mendeteksi kelompok pengunjung yang serupa namun
tanpa kita memberitahu algoritma menentukan grup mana pengunjung
berasal, nantinya ia akan menemukan koneksi antar pengunjung tanpa
bantuan manusia. (G Aurelien, 2017).
2.1.3 Semisupervised Learning
Pada semisupervised learning menggunakan sebagaian data
yang berlabel. Biasanya perbandingan data yang berlabel lebih sedikit
dibanding yang tidak berlabel. Contoh yang paling sederhana adalah
photo hosting service seperti Google Photos ketika kita mengupload
foto keluarga, ia dapat mengidentifikasi orang pada foto keluarga
terdapat di foto lainnya. Kebanyakan algoritma semisupervised
learning merupakan kombinasi dari algoritma unsupervised dan
supervised. Contohnya, deep belief network (DBN) didasarkan pada
komponen unsupervised yaitu restricted boltzman machine (RBM).
RBM dilatih secara berurutan dengan cara unsupervised learning, dan
seluruh sistem disesuaikan dengan menggunakan supervised learning
(G Aurelien, 2017).
2.1.4 Reinforcement Learning
Sistem pembelajaran, yang disebut agen dalam konteks ini,
dapat mengamati lingkungan, memilih dan melakukan tindakan.
Ketika agen memilih jalan yang salah akan mendapat penalty lalu ia
harus belajar dengan sendirinya, untuk mendapatkan reward (jika
memilih jalan yang benar) terbanyak dari waktu ke waktu. Suatu
policy menentukan tindakan apa yang harus dipilih agen ketika berada
dalam situasi tertentu (G Aurelien, 2017).
Sebagai contoh, DeepMind’s AlphaGo program menjadi berita
utama ketika mengalahkan juara dunia Lee Sedol dalam permainan
Go. AlphaGo belajar dengan cara menganalisis jutaan game, dan
kemudian melawan dirinya sendiri. Ketika dalam pertandingan

10
melawan juara dunia AlphaGo hanya bermain berdasarkan analisis
game yang telah dipelajarinya.
2.1.5 Batch Learning
Dalam batch learning, machine learning model dilatih
menggunakan seluruh dataset yang tersedia. Ketika sudah memiliki
model yang bagus dalam test set maka model sudah dapat digunakan.
Proses ini sering juga disebut offline learning. Namun jika ada
penambahan data maka sebuah model harus dilatih menggunakan
seluruh dataset ditambah data yang baru (B Ekaba, 2019).
Untungnya, seluruh proses pada machine learning dapat
diotomatiskan, sehingga batch learning pun dapat beradaptasi
terhadap perubahan yang ada. Training menggunakan banyak data
dapat memakan waktu yang lama, oleh karena itu jika menggunakan
batch learning, training untuk memperbarui data dilakukan sehari
atau seminggu sekali. Ketika memiliki data dengan jumlah yang besar
dan mengotomatiskan sistem untuk training dari awal setiap hari,
pada akhirnya akan menghabiskan resources. Sangat tidak mungkin
untuk menggunakan algoritma batch learning (B Ekaba, 2019).
2.1.6 Online Learning
Dalam online learning, data yang dilatih kedalam sistem
secara bertahap baik secara individu maupun kelompok kecil. Online
learning sangat cocok ketika data dihasilkan secara berkelanjutan dan
ketika kita membutuhkan data yang real-time untuk memprediksi
sebuah model (B Ekaba, 2019).
Online learning sangat bagus untuk sistem yang menerima
data secara berkelanjutan. Online learning merupakan opsi yang baik
ketika mempunyai sumber daya komputasi yang terbatas. Ketika
sebuah online learning telah mempelajari tentang data baru, maka
data tersebut dapat dibuang. Ini dapat menghemat banyak memori.
Algoritma online learning juga dapat digunakan untuk melatih sistem
pada kumpulan data besar yang tidak dapat ditampung dalam memori
utama (B Ekaba, 2019).

11
2.1.7 Instance Based Learning
Dalam instance based learning cara machine learning
mengeneralisasi adalah dengan menggunakan hati kemudian
mengeneralisasikannya kedalam kasus-kasus baru menggunakan
pengukuran kesamaan. Alih-alih hanya menandai email yang identik
dengan spam, filter spam dapat diprogram untuk juga menandai email
yang sangat mirip dengan email spam yang dikenal. Ini membutuhkan
parameter kesamaan antara dua email. Kesamaan antara dua email
bisa dilihat dari jumlah kata yang mereka miliki. Sistem akan
menandai email sebagai spam jika memiliki banyak kata yang sama
dengan email spam yang dikenal. Ini disebut instance based learning,
sistem mengeneralisasikan kasus baru dengan menggunakan
parameter kesamaan (G Aurelien, 2017).
2.1.8 Model Based Learning
Dengan menggunakan model based maka cara
mengeneralisasi yaitu dengan membangun model, lalu menggunakan
model tersebut untuk memprediksi (G Aurelien, 2017).
Gambar 2.3 Model Based Learning
Sumber: Aurelien Geron, 2017
Contoh, ketika kita ingin mengetahui apakah uang dapat
membuat orang bahagia, maka yang harus dilakukan adalah
mengunduh data better life index dari website OECD dan GDP per
12
kapita dari website IMF. Lalu gabungkan kedua data tersebut seperti
pada tabel 2.1
Table 2.1 Data Gabungan Antara GDP Per Kapita Dan Kesejahteraan
Hidup
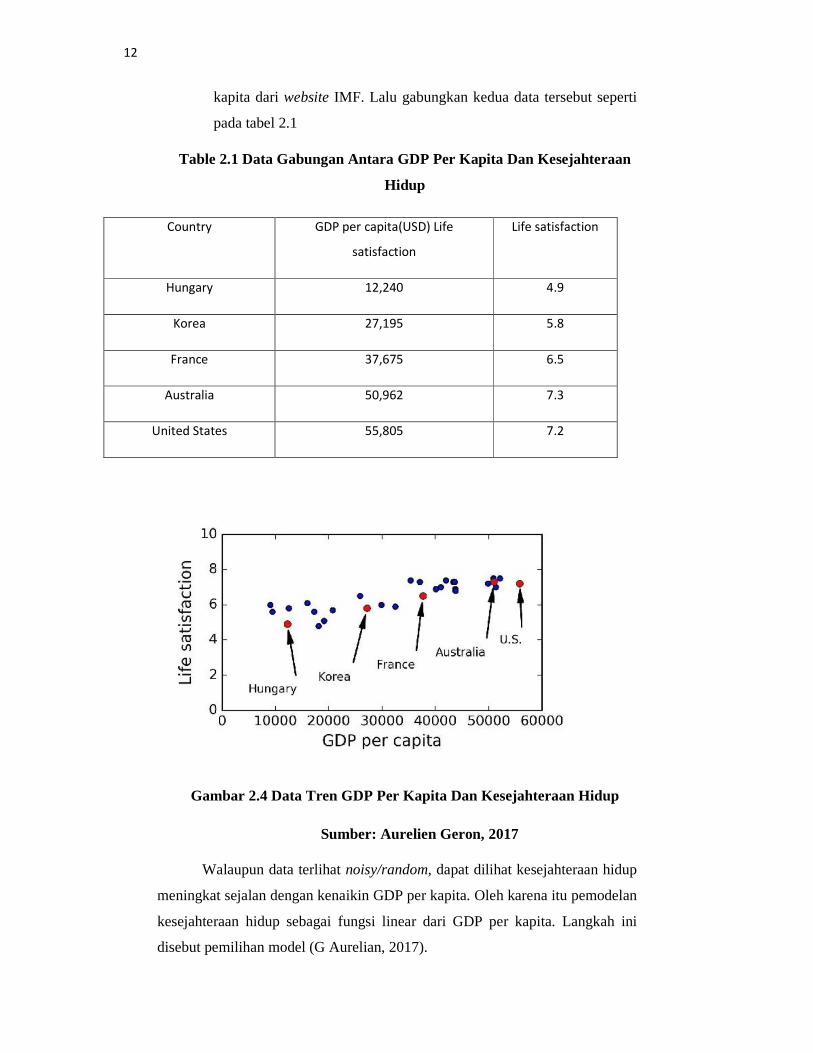
Gambar 2.4 Data Tren GDP Per Kapita Dan Kesejahteraan Hidup
Sumber: Aurelien Geron, 2017
Walaupun data terlihat noisy/random, dapat dilihat kesejahteraan hidup
meningkat sejalan dengan kenaikin GDP per kapita. Oleh karena itu pemodelan
kesejahteraan hidup sebagai fungsi linear dari GDP per kapita. Langkah ini
disebut pemilihan model (G Aurelian, 2017).
Country GDP per capita(USD) Life
satisfaction
Life satisfaction
Hungary 12,240 4.9
Korea 27,195 5.8
France 37,675 6.5
Australia 50,962 7.3
United States 55,805 7.2

13
2.2 Natural Language Processing
Natural language processing (NLP) merupakan serangkaian metode
untuk membuat bahasa manusia dapat diakses komputer. Tujuan dari NLP
adalah untuk merancang dan membuat aplikasi yang dapat memfasilitasi
interaksi antar manusia dengan mesin dan device lain melalui penggunaan
natural language. Terdapat beberapa sektor dalam kehidupan sehari-hari
yang telah mengimplementasikan natural language processing seperti:
google translate, klasifikasi email, mesin pencarian google, dan chatbot (E
Jacob, 2018). Pustejovsky dan Stubbs (2012) menjelaskan bahwa ada
beberapa area utama penelitian pada NLP, diantaranya:
• Question Answering Systems (QAS) adalah kemampuan sebuah
komputer dalam menjawab pertanyaan yang diberikan oleh
pengguna. Dibandingkan memasukkan kata kunci ke dalam
browser pencarian, dengan QAS, pengguna bisa langsung bertanya
dalam bahasa natural yang digunakannya, baik itu bahasa Inggris,
Mandarin, ataupun Indonesia.
• Summarization merupakan pembuatan ringkasan dari sekumpulan
konten dokumen atau email. Dengan menggunakan teknologi ini,
user dapat dengan mudah mengkonversikan dokumen teks
kedalam bentuk slide presentasi.
• Machine Translation merupakan sebuah aplikasi yang dapat
memahami bahasa manusia dan menterjemahkannya ke dalam
bahasa lain. Salah satunya, Google Translate yang
menterjemahkan bahasa secara real time.
• Speech Recognition merupakan cabang ilmu NLP. Bahasa yang
sering digunakan adalah berupa pertanyaan dan perintah.
• Document Classification adalah area penelitian NLP. Pekerjaan
yang dilakukan aplikasi ini adalah menentukan dimana tempat
terbaik dokumen yang baru dimasukkan ke dalam sistem.
Contohnya, pada aplikasi spam filtering, news article
classification, dan movie review.

14
2.3 Analisis Sentimen
Analisis sentimen meliputi analisis, deteksi, dan evaluasi pemikiran
manusia terhadap kejadian, layanan, masalah, dan kebutuhan lainnya. Pada
bidang tujuan utamanya adalah mendapatkan sentimen dan emosi
berdasarkan pada tanggapan-tanggapan yang didapatkan dari tulisan,
mimik wajab, cara bicara, musik, pergerakan, dan hal lainnya (Yadollahi,
Shahraki, Zaiane, 2017).
Analisis sentimen mengarah kepada proses dalam mengidentifikasi
suatu informasi penting dan subjektif berdasarkan tanggapan orang yang
mengandung informasi. Proses ini dapat diimplementasikan pada sumber
teks yang beragam serta pada tingkat perincian yang berbeda dimulai dari
dokumen hingga kalimat individu atau bahkan kata-kata. Secara khusus,
analisis sentimen bisa bisa dibagi menjadi beberapa kategori, teks yang
positif, negatif, dan kadang netral (Giatsoglou et al, 2017:8). Klasifikasi
sentimen merupakan suatu cara dalam mendeteksi apakah suatu teks
mengekspresikan opini yang positif atau negatif terhadap hasil ulasan
produk. Blog, artikel, partai politik, atau suatu kebijakan. (Martinez-
Camara et al dalam Nakov et al, 2016:1).
Analisis sentimen sudah menjadi bagian penting dalam aplikasi
pada umummnya dengan menyediakan beberapa keuntungan bagi sejumlah
domain yang berbeda-beda. Contohnya, analisis sentimen penting dalam
meningkatkan penjualan suatu produk serta menentukan strategi pemasaran
suatu produk, mengidentifikasi perubahan pandangan ideologis dan
menganalisis tren dalam perencanaan strategi politik, atau memprediksi
pergerakan pasar saham berdasarkan berita yang terdapat di media sosial.
(Giatsoglou et al., 2017).
Algoritma dalam analisis sentimen yaitu proses natural language
processing dengan menggunakan sumber tambahan seperti kamus
sentimen untuk merepresentasikan dokumen-dokumen yang ada. Fitur
dokumen penting dalam mengidentifikasi sentimen. Fitur-fitur yang
digunakan, seperti terms frequency, parts of speech, kata dan frasa yang
sudah dilabel opininya, dan keberadaan negasi dan kata-kata penting
(Giatsoglou et al., 2017). Kemudian, identifikasi sentimen dilanjutkan

15
dengan menandakan dokumen berdasarkan polaritas positif, negatif atau
netral. Berbagai teknik dapat digunakan untuk identifikasi sentimen, seperti
supervised dan unsupervised (Giatsoglou et al., 2017).
2.4 Recurrent Neural Network
Recurrent neural network adalah bagian dari neural network yang memproses
sejumlah data yang bersambung (sequential data). Secara umum, manusia tidak membuat
keputusan dari awal setiap saat. Manusia selalu memperhitungkan informasi masa lalu dalam
membuat keputusan. Seperti halnya manusia, Recurrent Neural Network menyimpan
informasi dari masa lalu dengan melakukan looping dalam arsitekturnya seperti yang terlihat
dalam gambar 2.5 yang secara otomatis membuat informasi dari masa lalu tetap tersimpan.
Gambar 2.5 Proses Perulangan Informasi Pada RNN
Sumber: Olah, 2015
Pada gambar 2.5, Xt sebagai input, Ht sebagai output dan terdapat alur perulangan
yang memungkinkan informasi dilewatkan dari satu langkah jaringan ke langkah berikutnya.
Recurrent Neural Network dapat dianggap sebagai banyak salinan dari jaringan yang sama.
Masing-masing jaringan mengirimkan pesan kepada jaringan berikutnya seperti terlihat pada
gambar 2.6.
Gambar 2.6 RNN Terdiri Dari Banyak Salinan Jaringan Yang Sama
Sumber: Olah, 2015

16
2.5 Long Short-Term Memory
Long Short-Term Memory (LSTM) merupakan salah satu variasi
dari Recurrent Neural Network yang dibuat untuk menghindari
ketergantungan mengingat dalam jangka waktu yang pendek pada Recurrent
Nueral Network (RNN). LSTM memiliki kelebihan dalam mengingat
informasi jangka panjang. Pada RNN perulangan jaringan hanya
menggunakan satu layer sederhana, yaitu tanh layer seperti pada gambar 2.7.
Gambar 2.7 Layer tanh Pada RNN
Sumber: Olah, 2015
Persamaan tanh diuraikan pada persamaan 2.1
tanh(�) = 2�(2�) – 1 (2.1)
Dimana:
� = fungsi aktivasi sigmoid
� = data input
Sedangkan, LSTM memiliki empat layer pada perulangan modelnya seperti pada
gambar 2.8
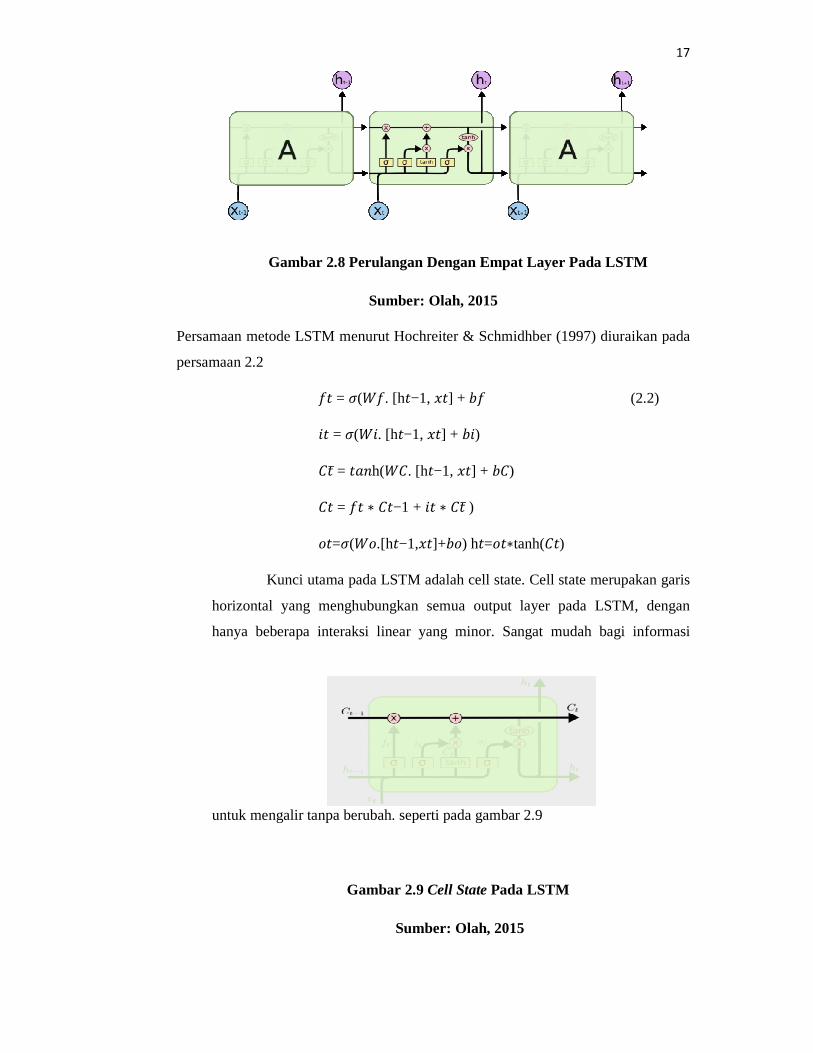
17
Gambar 2.8 Perulangan Dengan Empat Layer Pada LSTM
Sumber: Olah, 2015
Persamaan metode LSTM menurut Hochreiter & Schmidhber (1997) diuraikan pada
persamaan 2.2
�� = �(��. [h�−1, ��] + �� (2.2)
�� = �(��. [h�−1, ��] + ��)
��̅ = ��h(��. [h�−1, ��] + ��)
�� = �� ∗ ��−1 + �� ∗ ��̅ )
�=�(� .[h�−1,��]+� ) h�= �∗tanh(��)
Kunci utama pada LSTM adalah cell state. Cell state merupakan garis
horizontal yang menghubungkan semua output layer pada LSTM, dengan
hanya beberapa interaksi linear yang minor. Sangat mudah bagi informasi
untuk mengalir tanpa berubah. seperti pada gambar 2.9
Gambar 2.9 Cell State Pada LSTM
Sumber: Olah, 2015

18
LSTM memiliki kemampuan untuk menambah dan menghapus
informasi dari cell state. Kemampuan LSTM tersebut dinamakan gates. Gates
sebagai pintu dalam mengatur apakah informasi akan diteruskan atau
diberhentikan. LSTM terdapat 3 jenis gates yaitu forget gate, input gate, dan
output gate. Forget gate merupakan gate yang bertanggung jawab ketika
informasi akan dihapus dari cell. Input gate merupakan gate yang bertanggung
jawab ketika nilai dari input akan diperbarui pada state memori. Output gate
merupakan gate yang bertanggung jawab terhadap hasil output apakah sesuai
dengan input dan memori pada cell.
Gambar 2.10 Forget Gate Pada LSTM
Sumber: Olah, 2015
Langkah pertama dari LSTM adalah pada gambar 2.10 memutuskan
informasi apa yang akan kita buang dengan menggunakan sigmoid layer,
dapat juga disebut sebagai forget gate. Sigmoid Layer menghasilkan nilai 0
yang artinya mengabaikan elemen tersebut dan 1 artinya menyimpan elemen
tersebut.

19
Gambar 2.11 Input Gate Pada LSTM
Sumber: Olah, 2015
Setelah mendapatkan hasil dari forget gate dan input gate. Pada
gambar 2.11 input gate akan mengupdate pada bagian cell state yg dimana
akan melakukan perkalian pada bagian forget gate dengan konteks yang
lama. Dan juga pada bagian input gate bertugas untuk menghitung berapa
banyak informasi yang akan diteruskan ke cell state.
Gambar 2.12 Update Cell State Pada LSTM
Sumber: Olah, 2015
Pada langkah selanjutnya, pada gambar 2.12 hasil dari input dan
forget gate akan diperbaruhi kedalam cell state dengan informasi yang baru.

20
Gambar 2.13 Output Gate Pada LSTM
Sumber: Olah, 2015
Tahap selanjutnya merupakan penentuan hasil output. Pada gambar
2..13 terlihat bahwa output didasarkan pada nilai dalam konteks yang
dilewatkan ke suatu filter. Pertama informasi akan melewati ke sigmoid layer
yang dimana untuk memutuskan bagian-bagian mana dari konteks yang akan
dihasilkan. Kemudian akan dilewatkan ke tanh layer dan hasil dari tahn layer
akan dikalikan dengan sigmoid layer tadi sehingga akan menghasilkan bagian
mana yang ingin dijadikan output.
2.6 Dropout
Dropout adalah salah satu teknik regularisasi untuk mencegah
terjadinya overfitting dan juga mempercepat proses pelatihan. Overfitting
adalah kondisi dimana data yang telah melewati proses pelatihan mendapatkan
hasil akurasi yang baik tetapi terjadi ketidaksesuaian pada proses prediksi.
Dalam sistem kerja nya teknik yang digunakan pada Dropout adalah beberapa
neuron akan dipilih secara acak dan neuron tidak dipakai selama pelatihan atau
bisa dibilang dibuang secara acak.
Dapat dilihat pada gambar 2.14 (a) adalah standard neural network
dimana mempunyai 2 hidden layer yang belum di aplikasikan dengan dropout.
Tetapi di gambar 2.14 (b) dapat dilihat bahwa beberapa neuron tidak dipakai
lagi dalam proses. Sehingga data noise yang ada dalam proses pelatihan model
dapat diabaikan untuk mendapatkan hasil akurasi dan proses prediksi dengan
benar.

21
Gambar 2.14 Dropout
Sumber: cs231n.github.io
2.7 Word Embedding
Word embedding merupakan nama kolektif dari suatu model bahasa
dan teknik pembelajaran dari suatu fitur dalam pemrosesan bahasa dimana
kata-kata dari vocabulary yang disediakan akan dipetakan menjadi vektor
bilangan ril. Menurut penelitian (Yepes, 2017) menunjukan word embedding
meningkatkan performa akurasi dari suatu model dan memungkinkan juga
digunakan pada pengklasifikasian teks dengan LSTM. Terdapat dua metode
yang digunakan dalam penelitian ini yaitu Word2vec dan GloVe Embedding
yang akan dijelaskan pada 2.6.1 dan 2.6.2

22
2.6.1 Word2Vec
Word2Vec merupakan model yang populer digunakan, terdiri
atas dua jenis, yaitu Continuous Bag-of Words (CBOW) dan Skip-
Gram. Beda antara Skip-Gram dan CBOW terletak pada arsitektur
Neural Network dan cara pembentukan model dari masing-masing
jenis. Skip-Gram memberikan masukan kata dan meminta Neural
Network untuk menebak kata-kata yang muncul di sekitar kata
masukan. Untuk arsitektur CBOW, Neural Network digunakan untuk
menebak sebuah kata dengan masukan adalah kata sekitar dari kata
yang ditebak. Dapat dilihat pada gambar 2.10 dan gambar 2.11 untuk
arsitektur CBOW dan Skip-Gram
Gambar 2.10 Arsitektur CBOW
Pada gambar 2.10 input layer berisi kata yang berbentuk
vector. hidden layer berisi neuron sebanyak N dan output layer
merupakan panjang vector pada input layer dengan elemen berisi
softmax value.

23
Gambar 2.11 Arsitektur Skip-Gram
Pada gambar 2.11 terlihat seperti multiple-context pada
CBOW namun terbalik, kita memasukkan target kata ke dalam
jaringan. Model ini akan mengeluarkan distribusi probabilitas dari
suatu kata. Antara CBOW dan Skip-Gram memiliki kelebihan dan
kekurangannya masing-masing. Menurut Tomas Mikolov (2013)
Skip-Gram dapat bekerja dengan baik dengan data yang kecil
sedangkan CBOW dapat lebih cepat dalam komputasi untuk
merepresentasikan kata.
2.6.2 GloVe
GloVe termasuk algoritma unsupervised learning untuk
mendapatkan representasi vektor untuk kata-kata. Pelatihan dilakukan
pada agregat statistik gabungan kata-kata global gabungan dari sebuah
korpus, dan representasi yang dihasilkan menunjukan substruktur
linear dari vektor kata.

24
Tujuan utama yang mendasari model ini adalah pengamatan
sederhana bahwa rasio probabilitas kemunculan kata-kata memiliki
potensi untuk mengkodekan beberapa bentuk makna. Model GloVe
dilatih tentang entri dari matriks kata-kata global, mengenai seberapa
sering kata-kata muncul bersamaan satu sama lain dalam sebuah
corpus yang diberikan. Untuk mengisi matriks dalam GloVe
dibutuhkan satu kali melewati seluruh korpus untuk mengumpulkan
statistik. Untuk korpus besar, ketika melewati seluruh korpus dapat
membebani komputasi, tetapi ini hanya dilakukan satu kali.
2.8 Activation Function
Gambar 2.12 Neuron Pada Neural Network
Activation function merupakan sebuah fungsi yang
mengkombinasikan antara input pada z yang tertera pada gambar 2.12 lalu
menerapkan fungsi terhadap z lalu mengeluarkan output. Activation function
menentukan keadaan suatu neuron dengan menghitung fungsi aktivasi pada
input gabungan. Activation function dibutuhkan karena ketika jika nilai input
tidak dihitung dengan menggunakan activation function maka nilai output
akan menjadi infinity. Kedua jaringan pada neural network akan sia-sia
karena jaringan tidak akan belajar sama sekali, jika activation function adalah
linear function atau tidak ada activation function, maka turunan dari linear
25
function akan menjadi 0 yang akan menimbulkan masalah karena jika pada
saat training algoritma akan membantu memberikan feedback kepada network
jika ada kesalahan dalam mengklasifikasikan serta membantu neuron untuk
menyetal weights berdasarkan turunan dari linear function. Dapat
disimpulkan jika hasil dari turunan linear function adalah 0 maka sebuah
network akan kehilangan kemampuan dalam belajar artinya sama saja
memiliki 1 layer neural network dengan n layer neural network. Setidaknya
kita harus memiliki activation function pada setiap hidden layer yang kita
miliki agar jaringan dapat belajar dengan benar. Activation function yang
paling umum digunakan adalah sigmoid (M Jojo, 2019). Sigmoid akan
dijelaskan pada 2.7.1
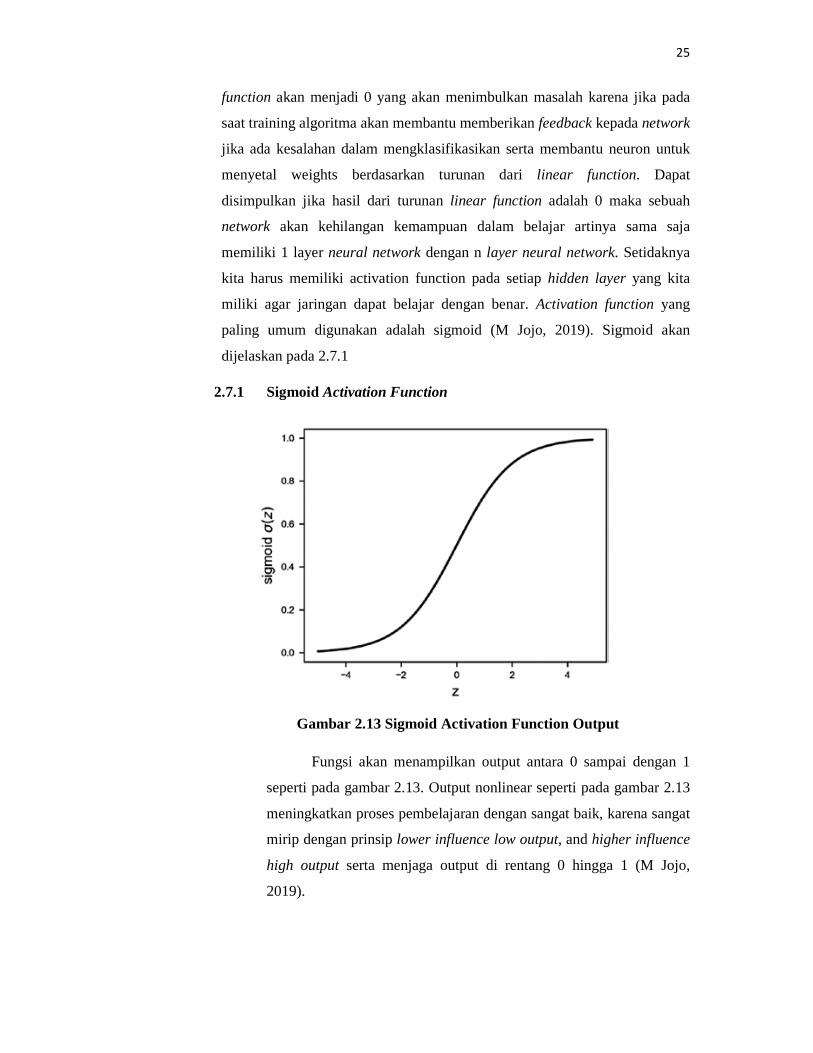
2.7.1 Sigmoid Activation Function
Gambar 2.13 Sigmoid Activation Function Output
Fungsi akan menampilkan output antara 0 sampai dengan 1
seperti pada gambar 2.13. Output nonlinear seperti pada gambar 2.13
meningkatkan proses pembelajaran dengan sangat baik, karena sangat
mirip dengan prinsip lower influence low output, and higher influence
high output serta menjaga output di rentang 0 hingga 1 (M Jojo,
2019).

26
2.9 Loss Function
Loss function merupakan metrik yang membantu jaringan memahami
apakah jaringan sudah belajar ke arah yang benar. Cara kerja loss function,
anggap sebagai nilai ujian yang dicapai dalam suatu ujian. Jika dalam beberapa
ujia pada subjek yang sama loss function mendapat skor 56, 60, 78, 90, dan 96
dari 100 dalam lima ujian berturut-turut. Maka akan terlihat dengan jelas
bahwa peningkatan skor ujian merupakan indikasi seberapa baik sebuah model
belajar. Seandainya nilai ujian menurun, maka keputusannya bahwa kinerja
model menurun dan model perlu mengubah metode belajar. Loss function
mengukur loss dari suatu target, dapat dikatakan ketika mengembangkan
sebuah model untuk memprediksi nilai mahasiswa apakah lulus atau tidak
lulus, maka kesempatan mahasiswa lulus atau tidak lulus ditentukan oleh
probabilitas. 1 menggambarkan lulus dan 0 menggambarkan tidak lulus. Model
belajar dari data dan memprediksi skor 0.87 untuk mahasiswa lulus maka nilai
loss adalah 1.00 – 0.87 = 0.13. Jika model mengulangi latihan dengan
memperbaruhi parameter lalu nilai loss menjadi 0.40 maka sebuah model
belajar bahwa perubahan yang dilakukan tidak memberikan efek. Sebaliknya
jika nilai loss menjadi 0.05 maka model belajar bahwa perubahan yang dibuat
memberikan efek. Terdapat beberapa pilihan untuk loss function yang
disediakan oleh Keras API salah satunya untuk menghasilkan output
kategorikal yaitu yes atau no maka menggunakan Binary cross-entrophy (M
Jojo, 2019).
2.10 Optimizer
Bagian terpenting dari pelatihan model adalah optimizer. Jika sebuah
model sudah mempelajari apakah perubahan parameter yang dilakukan selama
pelatihan mengarah baik atau buruk disini adalah perang loss function. Maka
langkah selanjutnya bagaiamana suatu model melakukan perubahan untuk
menimilasir model disini peran optimizer diperlukan. Dalam kalkulus untuk
melakukan perubahan bobot pada neuron diperlukan mengetahui berapa
banyak perubahan yang terdapat pada loss function (M Jojo, 2019).

27
2.9.1 Adam
Adam merupakan singkatan dari Adaptive Moment
Estimation, sejauh ini merupakan optimizer yang paling populer dan
banyak digunakan pada deep learning. Teknik optimisasi adam
menghitung tingkat pembelajaran adaptif untuk setiap parameter.
Dengan mendefinisikan momentum dan varians dari gradien loss dan
memanfaatkannya untuk memperbarui parameter weight. Momentum
dan varians membantu memperlancar kurva belajar dan secara efektif
meningkatkan proses pembelajaran (M Jojo, 2019).
2.11 Trip Advisor
Trip Advisor merupakan sebuah platform travel terbesar di dunia yang
membantu hampir 460 juta wisatawan setiap bulan. Wisatawan di seluruh
dunia menggunakan situs dan aplikasi Trip Advisor untuk menelusuri lebih
dari 830 juta ulasan dan opini meliputi 8,6 juta akomodasi, restoran,
pengalaman, maskapai penerbangan, dan kapal pesiar. Wisatawan beralih ke
Trip Advisor untuk membandingkan harga di hotel, penerbangan, dan kapal
pesiar. Serta membandingkan kepuasaan tur dan objek wisata populer
(TripAdvisor, 2020).
2.12 Python
Bahasa pemrograman Python merupakan sebuah urutan command
(statements) untuk dieksekusi oleh Python interpreter. Statements pada Python
meliputi seperti print output untuk ditampilkan ke layar, menerima input dari
pengguna, kalkulasi angka matematika, dan mengeksekusi statements yang
berurutan Python dikenal sebagai bahasa yang dinamis dan berorientasi pada
objek. Selain kemudahan yang terdapat pada bahasa pemrograman Python
memungkinkan programmer dapat dengan mudah membuat prototype.
Kumpulan library yang kuat membuatnya sangat cocok pada proyek rekayasa
perangkat lunak yang tingkat produksinya termasuk skala besar. John M Zelle
(2004).
Python mempunyai kelebihan yang dapat digunakan tanpa haru
berbayar, dan tersedia bagi semua platform dan semua orang yang ingin
menggunakannya. Selain itu, Python juga mudah untuk dipelajari dan

28
digunakan, karena tersedia banyak library, list, dan kamus yang dapat
membantu dalam mencapai tujuan masing-masing programmer. Python
memiliki struktur program yang mudah untuk dimengerti, sehingga sangat
mudah jika ingin melakukan debug terhadap program. (Colliau, T., Rogers, G.,
Hughes, Z., Ozgur, C.,2016).
2.13 NLTK
Natural Language Toolkit (NLTK) adalah library dalam Python, yang
menyediakan basis untuk pemrosesan dan klasifikasi teks. Operasi seperti
tokenization, filtering, manipulasi teks dapat dilakukan dengan menggunakan
NLTK (Gupta et al., 2017).
Library NLTK digunakan untuk membuat model bag-of word, yang
merupakan jenis model unigram untuk teks. Dalam model ini, jumlah
kemunculan setiap kata dihitung. Sehingga data setiap bobot kata yang
diperoleh dapat digunakan untuk melatih model classifier.
2.14 NumPy
NumPy adalah paket mendasar yang diperlukan untuk komputasi ilmiah
dengan menggunakan Python. Paket ini berisi:
• Objek array N-dimensi yang kuat
• Fungsi canggih (penyiaran)
• Fungsi aljabar linier dasar
• Transformasi Fourier dasar
• Kemampuan angka acak canggih
• Alat untuk mengintegrasikan kode Fortran
• Alat untuk mengintegrasikan kode C / C ++
Selain dalam penggunaan ilmiah, NumPy dapat digunakan sebagai
tempat untuk data generik multidimensi yang efisien. Dengan tidak
menginisialisasi tipe data NumPy dapat menentukannya oleh karena itu
NumPy dapat dengan cepat berintegrasi. NumPy merupakan penerus dari dua
library Python yang sebelumnya yaitu: Numeric dan Numarray (NumPy,2020).

29
Array NumPy merupakan sebuah kumpulan elemen multidimensi dan
homogen (yaitu, semua elemen menempati jumlah byte yang sama dalam
memori). Array dapat dilihat dari jenis elemen yang dikandungnya. Contohnya,
sebuah matriks dapat direpresentasikan sebagai larik dalam bentuk M × N yang
berisi angka, seperti floating-point atau bilangan kompleks. Tidak seperti
matriks, array NumPy dapat memiliki hingga 32 dimensi. Array NumPy
mungkin juga mengandung jenis elemen lain (atau bahkan kombinasi elemen),
seperti Boolean atau tanggal. Array NumPy hanya cara yang lebih mudah
dalam menggambarkan satu atau lebih blok memori komputer sehingga angka-
angka yang diwakilkan dapat dengan mudah dimanipulasi (Edwin S. S, Ricky
H, 2019).
2.15 Keras
Keras merupakan API jaringan saraf tingkat tinggi, ditulis dengan
Python dan mampu berjalan di TensorFlow, CNTK, atau Theano. Keras
dirancang untuk manusia, bukan mesin. Oleh karena itu user experience sangat
dikedepankan oleh Keras. Keras menawarkan API yang konsisten &
sederhana, meminimalkan jumlah tindakan pengguna yang diperlukan untuk
kasus penggunaan umum, dan memberikan feedback yang jelas terhadap user
error. Keras dikembangkan dengan fokus untuk eksperimen yang bersifat
cepat. Keras memiliki beberapa keuntungan yaitu (Keras, 2020):
• Memungkinkan untuk prototyping yang mudah dan cepat
• Mendukung jaringan convolutional dan recurrent networks, serta
kombinasi keduanya.
• Berjalan mulus di CPU dan GPU.
2.16 Accuracy
Accuracy merupakan pengukuran yang digunakan untuk menentukan
model mana yang paling baik dalam mengidentifikasi hubungan dan pola antar
variabel. Accuracy merupakan proporsi pengamatan yang diprediksi dengan
benar (A Chris, 2018):
(2.3)

30
• TP adalah jumlah kelas positif. Pengamatan yang merupakan bagian
dari kelas yang diprediksi positif
• TN adalah jumlah kelas negatif. Pengamatan yang merupakan
bagian dari kelas yang diprediksi negatif
• FP adalah jumlah kelas yang diprediksi positif namun sebenarnya
kelas negatif
• FN adalah jumlah kelas yang diprediksi negatif namun sebenarnya
kelas positif
2.17 Related Works
Penelitian mengenai pariwisata telah dilakukan oleh (G Jinfeng, Y
Ruxian, L Han, dan C Ting-Cheng, 2019) yang menganalisis komentar tourist
pada portal scenic spot. Penelitian ini menggunakan Jieba tokenizer dengan
metode Convolutional Neural Network (CNN) dan Long Short Term Memory
(LSTM) satu layer dengan penambahan layer dropout untuk mereduce over-
fitting serta dilakukan proses word embedding menggunakan google word2vec
menhasilkan akurasi 82,7% dan 82,5% pada CNN dan LSTM.
Berikutnya penelitian (L Pengfei, H Xiaxu, H Zhirui, N Duxian, Z
Weifeng, H Keijing) mengenai analisis sentimen terhadap komentar wisata
tiongkok dengan data yang telah dikumpulkan oleh Professor Tan Songbo dari
University of Chinese Academy of Sciences menggunakan metode LSTM
dengan menggunakan Boosting menghasilkan akurasi 90,5%. LSTM
menggunakan penambahan fitur Boosting sangat efisien pada data yang tidak
balance antara positif dan data negatif. Metode LSTM dengna Boosting lebih
akurat digunakan untuk emotional classification dan menghasilkan performa
lebih baik dibandingan traditional machine learning model. Ketika jumlah
iterasi meningkat, keakuratan prediksi model LSTM berdasarkan penambahan
Boosting terus meningkat, dan akurasi rata-rata akhirnya meningkat menjadi
lebih dari 90,5%. Namun, waktu pelatihan model yang sesuai akan meningkat.
Selain itu, mengingat bahwa kalimat ulasan online umumnya lebih pendek dan
panjang urutan memori lebih lama, waktu perhitungan lebih lama, makalah ini
menetapkan panjang urutan memori sebagai yang solid. Nilai tetap, dan tidak
31
secara bertahap menyesuaikan panjang untuk meningkatkan akurasi. Dalam
aplikasi praktis, panjang urutan yang wajar dapat diatur sesuai dengan situasi
aktual, sehingga kompromi antara keakuratan model dan waktu pelatihan dapat
diperoleh.
Berikutnya penelitian yang dilakukan oleh (P Subarno, Dr. Soumadip
Ghosha, Dr. N Amitava) menganalisis ulasan movie berdasarkan IMDB
dataset yang terdiri dari dari data positif dan negatif. Dengan metode
conventional LSTM, deep LSTM, dan bidirectional deep LSTM menghasilkan
akurasi masing-masing 81%, 81,3%, 83%.
Penelitian lain mengenai analisis sentimen komentar pada situs JD.com
dan Ctrip dengan membandingkan metode LSTM dan RNN. Metode yang
digunakan pada penelitian ini yaitu LSTM. Hasil klasifikasi analisis sentimen
dikategorikan menjadi 3 kategori, yaitu kategori positif, negatif dan netral.
Menghasilkan akurasi 88% pada RNN dan 90% pada LSTM.
Penelitian sejenis akan diuraikan pada tabel secara singkat pada tabel
2.2
Table 2.2 Tabel Related Works
No Judul, Nama Peneliti,
Tahun Penelitian
Metode Keterangan
1 Jinfeng Gao, Ruxian
Yao, Han Lai, Ting-
Cheng Chang
Convolutional Neural Network (CNN)
dan Long Short Term Memory (LSTM)
Menganalisis
komentar tourist pada
portal scenic spot dan
menghasilkan akurasi
dengan menggunakan
LSTM yaitu 82,5%
sedangkan dengan
menggunakan CNN
yaitu 82,7%
2 Pengfei Liu, Xiaxu He,
Zhirui Huang, Duxian
Nie, Weifeng Zhang,
Long Short Term Memory (LSTM)
dengan fitur Boosting
Menganalisis
komentar tourist yang
terdiri dari 10000 data
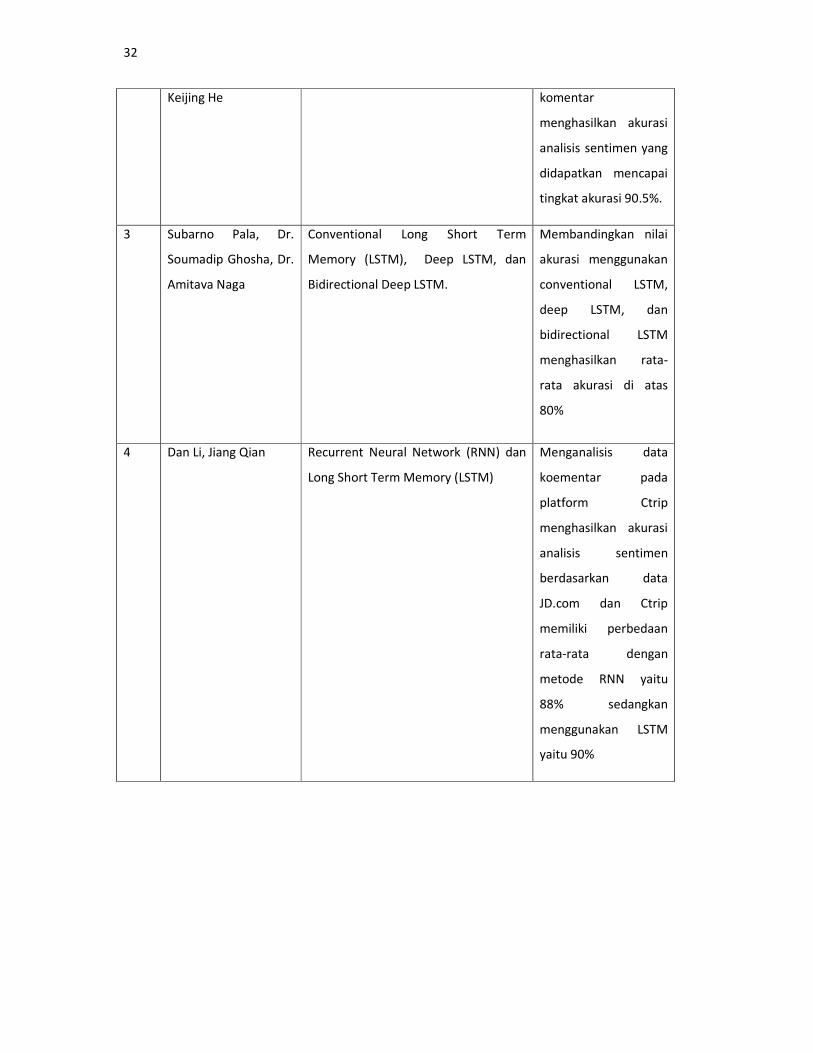
32
Keijing He komentar
menghasilkan akurasi
analisis sentimen yang
didapatkan mencapai
tingkat akurasi 90.5%.
3 Subarno Pala, Dr.
Soumadip Ghosha, Dr.
Amitava Naga
Conventional Long Short Term
Memory (LSTM), Deep LSTM, dan
Bidirectional Deep LSTM.
Membandingkan nilai
akurasi menggunakan
conventional LSTM,
deep LSTM, dan
bidirectional LSTM
menghasilkan rata-
rata akurasi di atas
80%
4 Dan Li, Jiang Qian Recurrent Neural Network (RNN) dan
Long Short Term Memory (LSTM)
Menganalisis data
koementar pada
platform Ctrip
menghasilkan akurasi
analisis sentimen
berdasarkan data
JD.com dan Ctrip
memiliki perbedaan
rata-rata dengan
metode RNN yaitu
88% sedangkan
menggunakan LSTM
yaitu 90%