advanced sql performance tips for big data - wordpress.com
TRANSCRIPT

Advanced SQL Performance Tips
for Big DataBY DAVE BEULKE

D a v e @ d a v e b e u l k e . c o mMember of the inaugural IBM Db2 Information ChampionsOne of 40 IBM Db2 Gold Consultant Worldwide President of DAMA-NCRPast President of International Db2 Users Group - IDUGBest speaker at CMG conference & former TDWI instructor
Former Co-Author of certification tests
Db2 DBA Certification tests
IBM Business Intelligence certification test
Former Columnist for IBM Data Management Magazine
Extensive experience in Big Data systems, DW design and performance
Working with Db2 on z/OS since V1.2
Working with Db2 on LUW since OS/2 Extended Edition
Designed/implemented first data warehouse in 1988 for E.F. Hutton
Syspedia for data lineage and data dependencies since 2001 –- Find, understand and integrate your data faster!
2
Proven Performance Tips: www.DaveBeulke.com
Consulting Security Audit & ComplianceDb2 Performance ReviewCPU MLC Demand Reduction Analytics & Database Design ReviewDb2 12 Migration Assistance Java Application Performance Tuning
Educational Seminars Java Security for Application DevelopersDb2 Version 12 TransitionDb2 Performance for Java DevelopersData Warehousing Designs for PerformanceHow to Do a Java Performance Review

Advance SQL Techniques Faster Elapsed Time Run with less CPU cost Big Data is no problem

4
SQL Tips –Start with the basics 1. Only SELECT the columns needed because it optimizes
the I/O between Db2 and your program. *
2. Only SELECT rows needed for the process or transaction and use FETCH FIRST x ROWS ONLY whenever possible. *
3. Code WHERE clauses with indexed columns that have unique or good indexes. *
4. Reference only tables that are absolutely necessary for getting the data. *
5. Code as many WHERE column clauses as possible because the Db2 engine filters data faster than any application code. *
DON’T DO THIS:SELECT * FROM BEULKE.TBL1 WHERE COL1 = ?
OR
SELECT COL1,COL2,COL3,COL4,COL5FROM BEULKE.TBL1 WHERE COL4 = ?ORDER BY COL1, COL2, COL3
DO THIS:SELECT COL5FROM BEULKE.TBL1 WHERE COL4 = ?ORDER BY COL1, COL2, COL3

5
SQL Tips –Start with the basics
6. Prioritize the WHERE column clauses to maximize their effectiveness. First code the WHERE column clauses that reference indexed keys, than the WHERE column clauses that most restrictive/limit the most data, than WHERE clauses on all columns that can filter the data further. *
7. Code SQL JOINs instead of singular SQL access whenever possible. A single SQL JOIN is always faster than two SQL statements within an application program comparing and filtering the result set data. *
8. Code SQL tables JOINs when there is a common indexed column or columns shared by both or all of the JOINed tables. If a common column is not indexed talk to a DBA and make a new index if possible. *
9. When coding JOINs make sure to code the most restrictive JOIN tables first and provide as many indexed and restrictive WHERE clauses as possible to limit the amount of data that needs to be JOINed to the second or subsequent tables. *
10. Use Db2 OLAP Db2 functions to optimize your Db2 SQL answer result sets. Using these SQL Db2 OLAP functions is usually much faster than application code summing, totaling and calculations over your data. *
DON’T DO THIS:SELECT COL1,COL2,COL3,COL4,COL5FROM BEULKE.SALESWHERE CUST_ID = ?
AND TRN_NBR = ?…then later in the java codeSELECT COL5,COL6,COL7,COL8FROM BEULKE.SPOILSWHERE ACCT_ID = ?
AND TRN_NBR = ?
5
DO THIS:SELECT S.COL1,S.COL2, S.COL3,S.COL4,SUM(S.COL5), SUM(R.COL5), R.COL6, R.COL7, R.COL8FROM BEULKE.SALES S,
BEULKE.SPOILS RWHERE S.TRN_NBR=R.TRN_NBR
AND S.CUST_ID = ?AND R.ACCT_ID = ?

6
SQL Tips –Start with the basics 11. Leverage Db2 functions appropriately. Analyze the SQL to determine the need for
the various Db2 functions. Report writers generate SQL with multiple, duplicate or unnecessary Db2 functions. AVG, SUM etc... *
12. Examine the data columns and tables SELECTed in the SQL. Many of these new big data report writers have nice GUI interfaces that allow the users to point and click on anything. Sometimes they include unnecessary columns double check.
13. Verify the Db2 table joins for improving your Db2 SQL performance. Evaluate table indexes’ uniqueness, cardinality, relationship to the table partitioning or column frequencies. *
14. Eliminate data translations. Sometime the report writer generated SQL uses many CAST, SUBSTR, CASE statements, constants, or formulas in the SQL. The generated SQL may also have math formulas compared to columns within the SQL. Check the SQL rewrite these formulas for index-usage. *
15. Understand the order of JOINs access. By making sure the JOIN of the smaller table drives the data SELECTed from the big data Db2 table, your Db2 SQL should eliminate/minimize as much data as possible in the first JOIN. Also minimize SQL such as ORDER BY, GROUP BY, DISTINCT, UNION, or JOIN predicates that do not leverage the clustering order of the table, because they will require a Db2 sort. *
DON’T DO THIS:SELECT S.COL1,S.COL2, S.COL3,S.COL4,SUM(S.COL5), SUM(R.COL5), SUM(A.COL5), R.COL6, R.COL7, R.COL8FROM BEULKE.ADJSTMNTS A,
BEULKE.SPOILS R, BEULKE.SALES S
WHERE S.CUST_ID = ?AND R.ACCT_ID = ?AND S.TRN_NBR = R.TRN_NBR AND S.TRN_NBR = A.TRN_NBR
ORDER BY S.CUST_ID
DO THIS:SELECT S.COL1,S.COL2, S.COL3,S.COL4,SUM(S.COL5+R.COL5+A.COL5), R.COL6, R.COL7, R.COL8FROM BEULKE.ADJSTMNTS A,
BEULKE.SPOILS R, BEULKE.SALES S
WHERE A.TRN_NBR = R.TRN_NBR AND A.TRN_NBR = S.TRN_NBRAND S.CUST_ID = ?AND R.ACCT_ID = ?
ORDER BY S.TRN_NBR

7
SQL Tips –Start with the basics 16. Understand all SQL phrases that results in a SORT. Db2 SQL workloads
Sorts are one of the most expensive operations especially with Big Data. i.e. usage of Distinct, Order by, UNION etc. *
17. Verify Scalar function is index-able. Back in Db2 V11 many scalar function became index-able not all of them like DATE(timestamp-column).
18. Remove all math from the WHERE Clause if possible. Calculations in WHERE clauses sometime disrupts the data type comparisons and precision. Pre-calculate math variables before the SQL statement and always verify index-ability of any formulas that are in doubt. *
19. Minimize and optimize any WHERE ‘OR’ clauses. Rewrite them into a correlated sub-query if possible. Make sure that the ‘OR’ does not make the entire WHERE clause become a table scan.
20. Understand the number of trips to the database. Use multi-row SELECT and INSERT operations whenever possible to access or to the add the database.

8
21. SELECT from INSERT, UPDATE whenever possible. Especially useful for getting IDENTITY, sequence, and any other database column keys values in one trip. Avoids multiple trips to the database and minimize network traffic.
22. Use MERGE to reference the database and make sure the data is there and updated. Avoid complex program logic to perform the data checking and then update.
23. Create indexes on all WHERE clause expressions that are not already index-able. Companies have unique situations and data types. Create Indexes on Expressions that are used in your daily SQL processing. *
24. Use Common Table Expression (CTEs) whenever possible because they can get the data so that the result set can be used repeatedly and efficiently. **
25. Use Db2 TEMP tables for all data that is referenced more than threetimes in the flow of daily business. It is more efficient to get the TEMP result set working instead of repeated redundant data access. Remember they can also be set up as NOT LOGGED. *
SQL Tips –Start with the basics
Cus
tom
ers
Ord
ers
Pro
duc
ts
CTEOrders Today

9
Understand the EXPLAINfeedback tables 26. Use Db2 Virtual Indexes to model your potential Indexes. Model
INCLUDE column(s), Index on Expression, Uniqueness and other new index definition possibilities.
27. Use Optimizer Filter Factor Hints to give full information. JOIN Skew/Correlation, accurate statistics, complex predicates and host variables and special register information.
28. Analyze the SYSSTATFEEDBACK table contents to understand your SQL Access Path results better. Also can be used to generate better RUNSTATS input.
29. Leverage EXCLUDE NULL when creating indexes to reduce index size. Verify that the NULL-ability is not within the application WHERE clauses. Avoids NULLs in indexes!
30. Overriding predicate selectivity with the DSN_PREDICAT_% tables. Populate these tables with the details of the selectivity of the tables’ uniqueness to improve optimizer knowledge for better access paths and improved performance.

10
Optimize physical Database Design 31. Maximize parallelism by leveraging CPU, storage/channels,
buffer pools and I/O hardware capabilities. Understand TS BP Parallel reserves
32. Define hundreds or thousands of partitions to influence SQL parallelism through your database and tables designs
33. Use multiple Db2 data sharing members to parallelize your SQL processing execution, optimize Sort work areas and memory utilization. *
34. Understand OS (z/OS or LUW), Initiators, Job class, WLM, zIIP, storage, Java and Db2 system limitation settings and parameters. *
35. Optimize UNION ALL occurrences within each SQL statement to maximize parallelism and CPU utilization.*
NOTE: Db2 does not consider the use of CP parallelism if you declare a cursor as WITH HOLD and bind the application with RR or RS isolation.
Verify: BPool VPPSEQT Values CURRENT DEGREE=‘ANY’ PARAMDEG subsystem
parm

11
RUNSTATs36. Collect frequency and cardinality statistics on any column group
when running RUNSTATS TABLESPACE - use the COLGROUP option.
37. Collect frequency and cardinality statistics on any single column, multi-column frequency and cardinality statistics on all the leading concatenated columns of an index.
38. Do not allow any users to manually update the statistic columns in the Db2 catalog. Unpredictable SQL access paths can occur from manually updates to the statistic columns.
39. Always try to collect inline statistics with any utility execution to avoid the cost of running stand-alone RUNSTATS utility jobs
40. Collect RUNSTATS information on ALL tablespaces, partitions, tables, indexes, index column groups
Orders
CustomersProducts
12
Special data types need extra performance attention 41. Pay special attention to LOB, XML and other special needs
tablespaces or tables. Make sure their access keys are COLGROUPed and detailed for value frequencies (FREQVAL) and uniqueness.
42. Define Lean XML indexes –read “Db2 pure XML Cookbook”
43. Search 2 topics -a) “IBM Db2 Best practices for XML performance” b) “XML data indexing”
44. Extend SQL CTEs to use UNION ALL along partition ranges to drive parallelism. Drive from the smallest to largest data populated partitions.
45. Use multiple jobs that executed the single CTE with multiple UNION ALL SQL statements across the entire tablespace partitions’ ranges
46. Run the jobs across your Db2 data sharing members and different hardware LPARs.
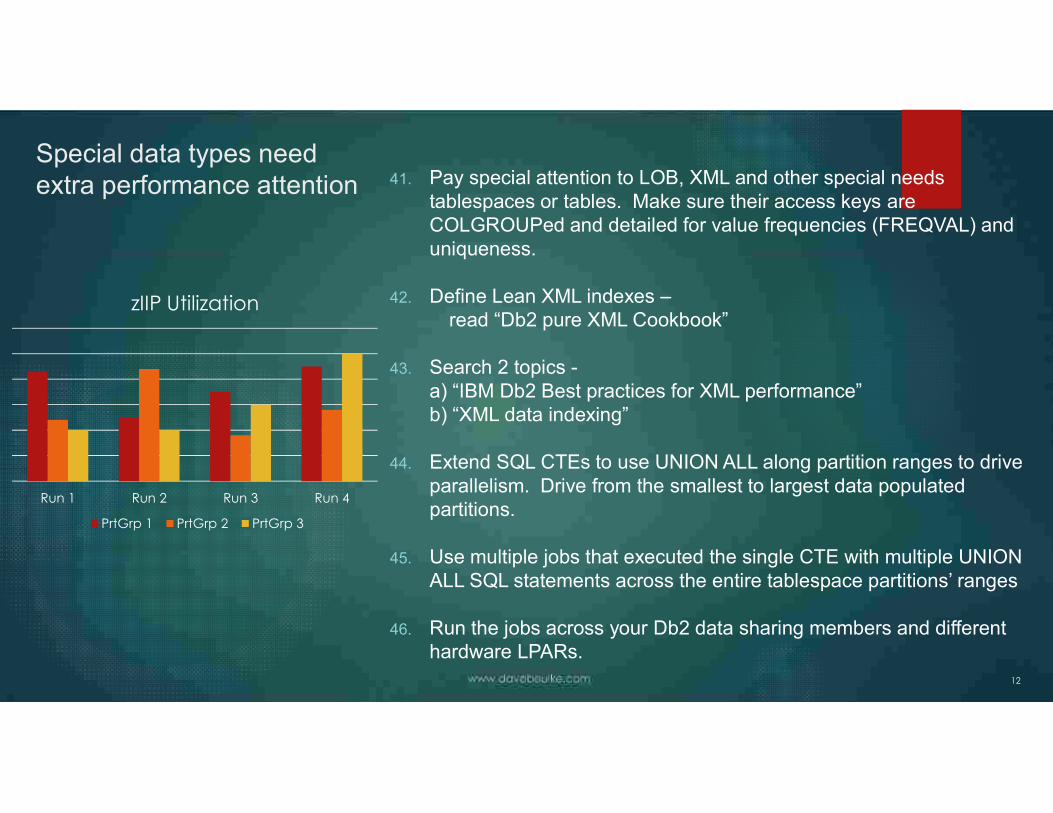
Run 1 Run 2 Run 3 Run 4
zIIP Utilization
PrtGrp 1 PrtGrp 2 PrtGrp 3

13
More ideas on how to tune your SQLBy Tony Andrews
50+ additional tips!

14
Cookbook Step 1 Tables Research all the table(s) necessary for the process
Note the biggest to the smallest
Verify all their statistics
Create TESTDB with production statistics
Understand the table clustering sequence
Know their partitioning scheme and range limits
Know their availability & maintenance schedules
Statistics
Table space statistics
Statistic sampling percentage/level
Table partition level statistics
Table – Column Distribution
Index – Index full
Index COLGROUP

15
Cookbook Step 2 - Columns Understand the data types needed – any conversions?
Understand tables’ indexed JOIN key columns
Minimize the large CHAR, VARCHAR & LONGVARCHAR columns
Verify & understand column encoding used
Understand the limits of the numeric columns
SMALLINT, INTeger, and BIGINT
Understand the difference between the Result Set and WHERE clause criteria columns required
Understand the uniqueness of columns
Best table for referencing unique column
Understand partitioning columns and partition limit key values
EBCDIC = ASCII

16
Cookbook Step 3 Indexes Understand Indexes on each table referenced
Uniqueness is very important
Make sure to understand INCLUDED columns
Realize the columns and cardinality
Verify statistics – COLGROUP statistics
UNIQUE columns unique indexes
Emphasize partitioning columns reflected in indexes
Indexes that align with partitioning
Understand NPIs versus DPSIs differences
Parallelism is better with DPSIs
Understand if any NULLs are within indexes
CREATE INDEX BEULKE.XDB2ORDR01ON BEULKE.CUST_ORDR
(COL1 ASC,COL2 ASC,COL3 ASC)
PARTITIONEDUSING STOGROUPPRIQTY xxx,xxx SECQTY -1FREEPAGE 30 PCTFREE 25NOT CLUSTERINCLUDE NULL KEYS(PARTITION 1,PARTITION …PARTITION 1000)
BUFFERPOOL BP7CLOSE YESCOPY YESDEFER NODEFINE YES)

17
Cookbook Step 4 - Where Criteria What is the business criteria for the data needed?
How many columns involved?
How many duplicate rows or restrictions?
What columns are necessary?
Calculate the Result Set number of rows
Calculate the sum of Result Set of column bytes
Fits within 4K page size?
How much space to sort it?
Determine most restrictive WHERE criteria
Simplify the WHERE clauses criteria
Give Index-able WHERE criteria priority
Most restrictive WHERE clause first
Use standard WHERE columns = criteria whenever possible
Use most restrictive WHERE criteria first!!!! – again!!!!
Know WHERE criteria filter(s) Each filter has #Rows reduction figures!

18
Cookbook Step 5 Join Criteria JOIN smallest table to biggest
Through index-able JOIN columns
First JOIN is the most important
Create smallest Result Set for subsequent query blocks
JOINs only use two sets of data at a time
Most of the big data SQL JOIN 5+ tables
JOIN group of tables with alike indexed keys
Filter JOINs on index columns if possible
Reference table related to business issue first
Relate non-indexes data in first QB if possible
Reduce # Rows immediately In first QB if possible

19
Cookbook Step 6 - Filter Priorities Most restrictive first JOIN – smallest result set!!!! -again
Use indexed columns as much as possible in filters
Filter data when accessed or JOINed
Filter every column possible in SQL
Use good SQL WHERE Clauses
Understand query block sequence
Know # of rows impact through every filter
Know the #Rows passed through each QB
Ultimate filter is to avoid any access possible

20
Cookbook Step 7 Sort Avoidance Know the SQL Key phrases that cause Sorts
Use these phrases only when required
GROUP BY or HAVING (without index)
ORDER BY (without index)
DISTINCT (without index)
UNION (except UNION ALL)
EXISTS (subselect)
Most math functions – SUM, COUNT, AVG etc..
Know if or how much data is sorted in each Query block
Leverage table clustering sequence
Avoid sort by ORDER BY clustering sequence
Delay/avoid SORTs early in SQL query block sequence
Sort the smallest amount of data possible
ANY (subselect)
SOME (subselect)
ALL (subselect)
Some joins

21
Cookbook Step 8 Good/Bad Filters Filter using definitive WHERE clauses
Know you data
Good
Use =, >, < against numeric data
Use = against full size CHAR columns
Country_Name =‘USA ‘
Avoid VARCHAR comparisons whenever possible
Avoid using SUBSTR
If must use SUBSTR make sure to start with first byte
SUBSTR(<column>,1,8) =
Avoid using column calculations in WHERE filters
Avoid any data conversions in WHERE filters
Avoid TIMESTAMP conversions in filters
For example: DATE(Timestamp-column)
Avoid XMLPARSEing or XML materialization
Sort

22
Cookbook Step 9 CTE Capable Common Table Expressions (CTEs) can help
minimize data
CTEs can help establish SQL query blocks
CTEs can be effective for establishing data groups
CTEs to establish JOIN group
For example,
CTE for all the product based dataCTE for all the customer based datathen JOIN of those CTE filtered sets
via Statevia Product categoriesvia Product priceVia Order Amount
CTE

23
Cookbook Step 10 Table Space, Index & Table Attributes
Know your database business representations
Know populations of all database tables
Identify table space definition types for all tables involved in SQL
Understand all indexes, their uniqueness, index columns, column groups and Included columns
Understand all Referential Integrity definitions
Know data ratios of main tables to related tables
Know partitioning definition limits keys
Align partitioning keys whenever possible
--GET PARTITIONING LIMIT KEYS/RANGESSELECT DBNAME, SUBSTR(TSNAME, 1, 8) AS TSNAME, SUBSTR(IXNAME, 1, 32) AS IXNAME,PARTITION, LIMITKEYFROM SYSIBM.SYSTABLEPARTWHERE DBNAME =? AND TSNAME = ? WITH UR;
---Or for older partitioningSELECT A.DBNAME,SUBSTR(A.CREATOR, 1, 12) AS CREATOR,SUBSTR(A.TBNAME, 1, 32) AS TBNAME,SUBSTR(A.NAME, 1, 12) AS IXNAME,A.UNIQUERULE, A.CLUSTERING,D.PARTITION, D.LIMITKEYFROM SYSIBM.SYSINDEXES A,SYSIBM.SYSINDEXPART DWHERE A.NAME = ?AND A.CREATOR = D.IXCREATORAND A.NAME = D.IXNAMEORDER BY DBNAME, TBNAME, IXNAME, PARTITION WITH UR;

24
IX2
IX2
IX2
Cookbook Step 11 Buffer pool & DASD Attributes
SQL to extract BPs to TSs--- THIS QUERY SHOWS THE MAPPING OF THE TABLES TO
--- THE VARIOUS BPS AND THEIR SPACE ALLOCATION
SELECT DISTINCT SUBSTR(T.NAME,1,30) AS TABLE_NAME,
SUBSTR(TS.NAME,1,8) AS TSPACE_NAME,PARTITION, TS.PGSIZE,
TS.BPOOL, CAST (TS.NACTIVEF AS BIGINT) AS TS_ACTIVE_PAGES,
BIGINT(TP.SPACEF) AS DEF_SPACE,
TS.MEMBER_CLUSTER,TP.STATSTIME
FROM SYSIBM.SYSTABLESPACE TS, SYSIBM.SYSTABLEPART TP,
SYSIBM.SYSTABLES T
WHERE TS.DBNAME = ‘BEULKE'
AND TS.DBNAME = TP.DBNAME AND TP.TSNAME = T.TSNAME
AND TS.DBNAME = T.DBNAME AND TS.NAME = T.TSNAME
AND T.TSNAME = TP.TSNAME AND TS.NAME NOT LIKE ‘BEULDS%'
AND T.NAME NOT LIKE '%MAP‘ AND T.NAME NOT LIKE '%MAP_'
ORDER BY TABLE_NAME, BPOOL WITH UR;
Fun answers
TS7
TS7
TS7
TS5
TS5
TS5
TS5
TS5
TS1
TS1
TS1
TS1

25
Cookbook Step 11 Buffer pool & DASD Attributes
SQL to extract BPs to indexes
--- THIS QUERY SHOWS THE MAPPING OF THE INDEXES TO THE
--- VARIOUS BPS AND THEIR SPACE ALLOCATION
SELECT DISTINCT DBNAME,
SUBSTR(I.TBNAME,1,35) AS TABLE_NAME,
SUBSTR(I.NAME,1,35) AS INDEX_NAME, I.PGSIZE, I.BPOOL,
BIGINT(I.SPACEF) AS SPACEF, BIGINT(I.SPACE) AS SPACE
FROM SYSIBM.SYSINDEXPART IS, SYSIBM.SYSINDEXES I
WHERE I.DBNAME LIKE ‘BEULKE'
AND IS.IXCREATOR = I.CREATOR AND IS.IXNAME = I.NAME
AND I.TBNAME NOT LIKE '%MAP‘
AND I.TBNAME NOT LIKE '%MAP_'
ORDER BY I.BPOOL, SPACEF DESC, TABLE_NAME, INDEX_NAME
WITH UR;

26
Cookbook Step 12 DSNDB07 & Sort Requirements
Determine the Sort limits for your Db2 System
For each specific Db2 Data Sharing member
How much parallelism is your Sort space set up for?
Small sorts Db2 does in memory
Bigger sorts go to the Sort work area
Biggest amount of data that can be sorted which QB?
Under 4k row size # of result set rows
> 4k row size # of result set rows
Calculate the amount of sort space
How many parallel sorts from you SQL can be done?

27
Cookbook Step 13 Validate z/OS Settings &
Determine WLM settings for:
Pushing multiple jobs across LPARs & Db2 systems
Validate zIIPs availability for each LPAR & Db2
Validate in schedule – timing and dependencies
Know Process – SQL - TCB - SRB subtask limits
Validate Db2 member parallelism settings/limits
How many parallel streams can be done
Limits on parallel sorts
zIIP processors available
Sort pool overflows/abends
Understand z/OS configuration matters - z15 or z14?
Processor Core Types: CP / IFL / ICF / zIIP* / Standard SAP(s) / Additional/Optional SAP(s) / Spares
z15 - at 5.2GHz processor frequency, offers 8TB memory per CPC drawer for up to 40TB per machine, 85 partitions, and up to 190 cores to configure
z14 five different configurations
z14 – 170 cores - zIIP to CPs to be 2:1
Start with the Capacity Planners are the best sources for this information

28
Cookbook Step 14 Validate z/OS Settings
Start with the Capacity Planners, they are the best sources for this information
Know the LPAR processors, configuration availability to your jobs/SQL
Source: z Systems –WSC Performance Team by John Burg

29
Cookbook Step 15 Avoid Spring Batch!Db2 can do it faster? but if you must consider it
Architecture – Read, Process, Write concept
Know your database partitioning ranges
Calculate result set size (#Rows * Column width)
Align JVM/Chunk with partitioning
Realize updates lock – isolate all locking appropriately
Adjust minimize JVM settings per chunk
Runtime Memory allocations appropriate
Optimize the Chunk Size
Must have a CPU processor per JVM
Chunk size determined by
One chunk “read” at time processes
Logical Read Process Write

30
Cookbook Step 17 Runtime environment characteristics
Getting started with z/OS Container Extensions and Docker
IBM Redbook SG24-8457-00
Architecture and setup is key for your Cloud/Kubernetes Configuration
Loosely coupled model to your Db2 system & database partitioning scheme
Translating Linux Kubernetes to Db2 z/OS
One Node per LPAR
Need zIIPs to leverage/manage the Kubernetes Node
Node deploys to both/either LPAR Db2 members
Again one zIIP Docker process per database partition (group)
Maximize zIIPs across all the partitions
IBM Strategic Direction – z/OS 2.4
z/CX same Linux - Ubuntu
Secure Services Containers – SSC
z/Platform for Docker deployments
z/OS z/CX Docker deploy Windows images coming?

Parallel Linux Environment Linux infrastructure reflective of the z/Os
environment
4 LPARs – 8-way DS
Need reflective Linux SSC Kubernetes configuration
Kubernetes reflective of the target database partitioned environment
Configuration encourages parallelism while minimizing deadlock exposures
Requested 8 zIIP per LPAR Db2 member - 8 * 8 = 64 zIIPs
8-way parallelism
Need 8 Dockers JVMs per Db2 member - 8 * 8 = 64 zIIPs
128 zIIPs to replicate existing z/OS performance utilization

33
Cookbook Step 18 query block order
Understand the Query Block order
Verify QBs continue to restrict data
Follow query blocks to understand
Business issues addressed in each block
Always reflect efficient indexed access if possible
Understand each QB sort requirements
Understand the QB access type
Use the most efficient access method for data
Is there a more efficient JOIN method for two tables?
CTE SQLTABLE JOINSOUTER JOINS -ADDITIONAL TABLE(S) FILTERS
WHERE JOIN CRITERIAWHERE BUSINESS FILTERSORDER BY CLUSTERING
-AVOID UNNECESSARY SORTS

34
Cookbook Step 19 Verify usable result set
Result set is understandable and usable
Report appropriate level of details
Understand next steps based on Result Set
Business rules are clearly reflected
Verify repeatability of run time environment
Scheduling analyzed for resource availability
zIIP processors
Sort pool utilization
Parallelism possibilities
MASTER CTECTE SQL1 TABLE JOINSOUTER JOINS -ADDITIONAL TABLE(S) FILTERSWHERE JOIN PART RANGE1 WHERE JOIN CRITERIAWHERE BUSINESS FILTERS
UNION ALLCTE SQL2 TABLE JOINSOUTER JOINS -ADDITIONAL TABLE(S) FILTERSWHERE JOIN PART RANGE2 WHERE JOIN CRITERIAWHERE BUSINESS FILTERS
UNION ALLCTE SQL3 TABLE JOINSOUTER JOINS -ADDITIONAL TABLE(S) FILTERSWHERE JOIN PART RANGE3 WHERE JOIN CRITERIAWHERE BUSINESS FILTERS
UNION ALLCTE SQL4 TABLE JOINSOUTER JOINS -ADDITIONAL TABLE(S) FILTERSWHERE JOIN PART RANGE4 WHERE JOIN CRITERIAWHERE BUSINESS FILTERS
ORDER BY CLUSTERING
35
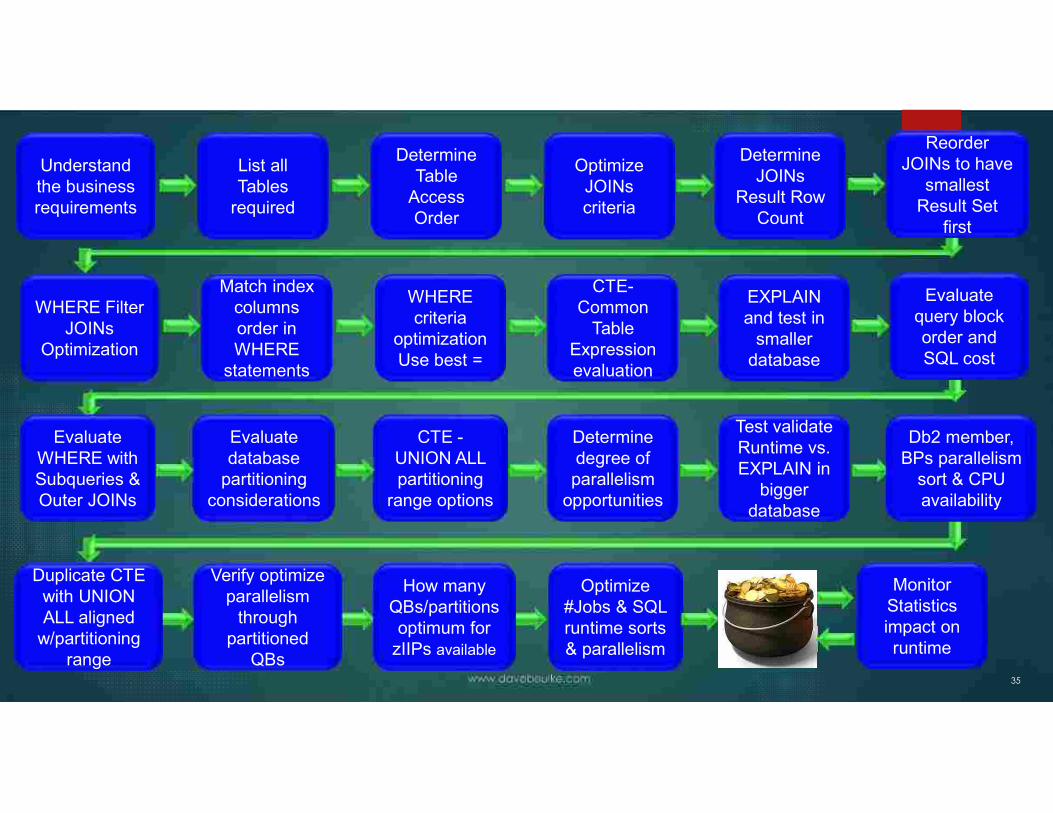
Understand the business requirements
List all Tables
required
Determine Table
Access Order
Optimize JOINs criteria
Determine JOINs
Result Row Count
Reorder JOINs to have
smallest Result Set
first
WHERE Filter JOINs
Optimization
Match index columns order in WHERE
statements
WHERE criteria
optimizationUse best =
CTE-Common
Table Expression evaluation
EXPLAIN and test in
smaller database
Evaluate query block order and SQL cost
Evaluate database
partitioning considerations
CTE -UNION ALL partitioning
range options
Evaluate WHERE with Subqueries &Outer JOINs
Determine degree of parallelism
opportunities
Test validate Runtime vs. EXPLAIN in
bigger database
Db2 member, BPs parallelism
sort & CPU availability
Verify optimize parallelism
through partitioned
QBs
How many QBs/partitions optimum for
zIIPs available
Duplicate CTE with UNION ALL aligned
w/partitioning range
Optimize #Jobs & SQL runtime sorts & parallelism
Monitor Statistics impact on runtime

36
Model – Keep it simple• Start with SQL as simple as possible
• Add all WHERE business filters
• Know sort and work space created
• Know the size of the work space
• Know DSNDB07 #-rows created and utilized
• Complexity kills performance• Know the smallest of the big tables
• Clear I/O streaming • Leverage pre-fetch
• Leverage buffer pools
• Leverage Index only
• Count query blocks
• Understand different types of SQL Access
Reiterate
Rewrite
Reorder
Reconfigure
Retest
Reward/Reiterate

Dave BeulkeDave@ D a v e B e u l k e . C o m Twitter @DBeulkeLinkedIn www.linkedin.com/in/davebeulke
Thank you!