abhidha: an extended wordnet for indo-aryan languages
TRANSCRIPT

Abstract – A lexical knowledge base is an important component of any intelligent information processing system. The WordNet developed at the Cognitive Systems Laboratories at Princeton has served as a lexical reference system for natural language processing activities. The Indian language based activities at our institute mainly in text-to-speech synthesis and natural language generation from iconic inputs require the inclusion of additional features in the lexical reference system like phonology, word roots and etymological information. Our initial efforts have been in Hindi and Bengali but commonality of Indo Aryan Languages and the importance of these extra features lead us to believe that it is a worthwhile effort to build-up a WordNet for other Indo-Aryan languages containing these features. In this paper we speak of the issues relating to the structured design and development of a generalized extended WordNet for Indo Aryan languages with special reference to Hindi and Bengali. 1. INTRODUCTION
The WordNets have long served as a lexicon for natural language processing and knowledge representation in Artificial Intelligence. “WordNet is an on–line lexical reference system whose design is inspired by current psychological theories of human lexical memory.” [1] The organization of the WordNet is based on the presumption that there is a mental thesaurus in which the words are organized under conceptual fields or
semantic domains. The WordNet aims to organize this lexical information as word meanings or concepts rather than word forms. It is more efficient and versatile than a paper thesaurus or dictionary and it is capable of bringing out the lexical relations.
In any WordNet, for each word the word meanings or the identifying lexical concepts are stored as synonym sets or synsets. This style of knowledge representation has evolved mainly due to the deficiencies in the traditional dictionaries. For example when one refers to a good Hindi dictionary for the various interpretations for a lexeme, he will find information such as spelling, definition, inflections, parts of speech, illustrative examples and figures, references, synonyms etc., which is not sufficient to draw the sense of a word. For example on referring to a word like sonA {ºÉÉäxÉÉ}, what one finds is some sort of a definition as eka prasidhda bahumUlya pIlI dhAtu jisake gahane Adi banate haiM {BE |ÉʺÉr ¤É½Ö¨ÉÚ±ªÉ {ÉÒ±ÉÒ vÉÉiÉÖ ÊVɺÉEä MɽxÉä +ÉÊn ¤ÉxÉiÉä ½é}{a famous and precious yellow colored metal, out of which ornaments are made} [5]. Such a definition may not convey any lexical concept to a machine, neither is it sufficient to infer that sonA means svarNa{º´ÉhÉÇ}{gold} in this sense whereas in another sense it may refer to asAvadhAna honA{+ºÉÉ´ÉvÉÉxÉ ½ÉäxÉÉ}{to be unaware}. This is where the concept of synonym sets or synsets arise. For instance, the synonym set {sonA, svarNa}{ºÉÉäxÉÉ, º´ÉhÉÇ} and {sonA, asAvadhAna honA}{ºÉÉäxÉÉ , +ºÉÉ´ÉvÉÉxÉ ½ÉäxÉÉ} serves as an unambiguous differentiator of the meanings of sonA {ºÉÉäxÉÉ} [4].
ABHIDHA: An Extended WordNet for Indo Aryan Languages
Monojit Choudhury Department of Computer Science & Engineering.
Indian Institute of Technology Kharagpur INDIA 721302
email: [email protected]
Anupam Basu Department of Computer Science & Engg. Indian Institute of Technology Kharagpur
INDIA 721302 email: [email protected]
Shireesh Reddy Annam Department of Electrical Engineering, Indian Institute of Technology Kanpur,
INDIA 208016 email: [email protected]
Sudeshna Sarkar Department of Computer Science & Engineering
Indian Institute of Technology Kharagpur INDIA 721302
email: [email protected]

The ideas propounded by Miller (1991) and Miller, et al. (1993) were used to develop the Princeton WordNet [1]. Later a lot of research underwent in the development of WordNets for different languages, resulting in Euro WordNet [2], German WordNet, and many others. In India, Bhattacharya, et al. developed the Indo WordNet [6,7] and Rajendran, et al. developed the Tamil WordNet [8] for Hindi and Tamil respectively belonging to Indo-Aryan and Dravidian group of languages. All these WordNets use synset as a word sense node, which is related by means of basic semantic relations such as Synonymy, Antonymy, Hypernymy–Hyponymy, Meronymy–Holonymy, Troponymy, Entailment, Gradation and similar relations serving to organize the lexical knowledge base. However the Indian Language based activities at our institute in Text-to-Speech systems and natural language sentence generation from icons and concepts call for certain semantic and linguistic information and relationships between the words or the synsets which are not present in the traditional WordNets. This led us to the design and development of an extended WordNet structure for Hindi and Bengali. Some of the extra features added are specific to Indo Aryan Languages and hence we this structure can be generalized for all the Indo Aryan Languages.
In this paper, we describe the issues related to
the structure and design of the Indo Aryan WordNet, which we call the ABHIDHA. This paper is organized as follows: section 2 describes the motivating factors behind the design of ABHIDHA. New features and relations introduced are explained in detail in section 3, with appropriate illustrations. Section 4 schemes through the implementation issues. Section 5 concludes this paper and discusses the current status of ABHIDHA and future works. 2. MOTIVATION FOR AN EXTENDED WORDNET People suffering from severe motor neuron disorders require special assistive technologies for learning and communication. We are involved in development of vernacular educational and communication tools for such segment of the Indian population. The tools consist of an iconic interface. The user selects a set of icons to express his/her feelings. The system interprets the icons and generates a natural language sentence (in Hindi and Bengali), which is then uttered by using Indian language TTS. Figure 1 shows the basic architecture of the system. As can be seen from the figure, all the modules in the system depend on the lexical knowledge base, which is the WordNet. In this section, the different modules and their lexical knowledge requirements have been described. We show that the
knowledge stored in traditional WordNets is insufficient for these applications and how we can overcome these deficiencies by adding certain extra features.
Figure 1. Architecture of the iconic communication system [The gray
coloured boxes represent input/outputs of the system]
2.1 Icon Interpretation An icon can mean different concepts under different circumstances. For example, an icon of a sun near the horizon can be interpreted as both morning and evening. If this icon is chosen along with the icons of school and going, then the most probable interpretation is “going to school in the morning” and not “in the evening”. However, using the features of the traditional WordNet, it is impossible to disambiguate the semantics of the icons based on their contextual dependencies, as in the case cited above. Though hypernymy-hyponymy and meronymy-holonymy relations can help in disambiguation in some cases, they are not sufficient for complex reasoning. One possible solution to this problem is to maintain a co-occurrence measure between different concepts or synsets. Some of the other relations which we found helpful in icon interpretation are
• Storing the properties of the verb synsets, like whether transitive or intransitive, possible auxiliary verbs that can be added to it etc.
• Adjective-noun relations like pertainymy. 2.2 Natural Language Generation Generation of a natural language sentence from a case-frame or semantic-frame like structure requires several lexical information, some of which can be elegantly stored in the WordNet such as
• Morphological Information: Morphological synthesis is one of the vital parts of any natural language generator. It has been seen that for
Icons Icon Interpreter
WordNet
Intermediate Representation
Natural Language Sentence Generator
Natural Language Sentence
TTS Speech

Hindi and Bengali, the inflected forms of a word depend on the etymology and the syllable structure of the word. Although the later can be extracted in situ, the former needs to be stored in the WordNet. Besides this, root information is also necessary for morphological synthesis.
• For Hindi, number, gender and person and for Bengali person information of the nouns and pronouns in a sentence is required for generation of a syntactically correct sentence. Accordingly, this can also be stored in the WordNet.
• Knowledge of the causative and compound forms of the verbs is also useful in sentence generation.
Hitherto none of these information is stored in the WordNets. As a result, other knowledge bases are required for storing those information, which increases the redundancy and time and space complexity of the system. 2.3 Speech Synthesis
As we shall see, all the Indo Aryan Languages have deviated from the strict pronunciation rules of Sanskrit. As a result, phonological modeling of these languages becomes necessary for speech synthesis. However, complete phonological modeling is cumbersome if not impossible and gives rise to lots of exceptions as well. One way out is to store the phonology information along with the word senses in the WordNet itself. 2.4 Other Issues Keeping in mind the restricted muscle movement of the target users, we plan to design virtual keyboards and intelligent navigation system which can reduce the time and effort spent on the part of the user while selecting the icons, by predicting the next possible choices of the user and proactively feeding the “more probable” ones. The co-occurrence measure between the different concepts provides one way of predicting the possible choices. Since this system is also developed as an educational tool, another issue is the selective use of words in a sentence depending on the level of the user. A beginner may be conversant with only some of the simpler synonyms of a concept, whereas an advanced learner may know many other uncommon synonyms. This calls for the classification of the words into different levels.
The WordNet is a rich lexical resource. Addition of these extra features will not only cater to our application specific needs but it will also help in design of a richer lexical resource, which can have a plethora of other usages. Moreover, as we shall see, though some of these proposed features are language independent, some of them are really language specific. Interestingly, these specific features are common to all Indo Aryan Languages. These provide enough reasons and motivation for development of an extended WordNet structure for all Indo Aryan Languages. 3. EXTENDED FEATURES OF THE INDO–ARYAN LEXICALNET In this section, we will describe the new features introduced to the Indo-Aryan LexicalNet. Each of these features, their need and applications will be discussed using suitable examples taken from Hindi and Bengali. Figure 2 shows the schematic of the WordNet structure.
Figure 2: Schematic of the features in ABHIDHA The extended features have been shown in bold font. Other relations
specific to certain part of speech category have not been shown 3.1 Phonology Information We seldom find the pronunciation of a word in the dictionary for any of the IALs. The reason is that in Sanskrit the phonology of a word can be unambiguously derived from its graphemes. Graphemes in Sanskrit and other IALs denote syllables and hence directly map to the pronunciation. Therefore, it seems that there is no need for any phonology information of the words. Although this is true for Sanskrit, but in course of evolution, many IALs have lost this property and pronunciation in many cases differs from that predicted by the graphemes. Schwa deletions [9] in Hindi and vowel height assimilation in Bengali are some of the phonetic factors leading to deviation from ideal phonology. Table 3.1 illustrates these issues.
Synset WordWord Sense
Hypernym Antonym Holonym
Hyponym Meronym Pertainym
Etymology Phonology Level_Category Root Gender/No.
Co-occurrence
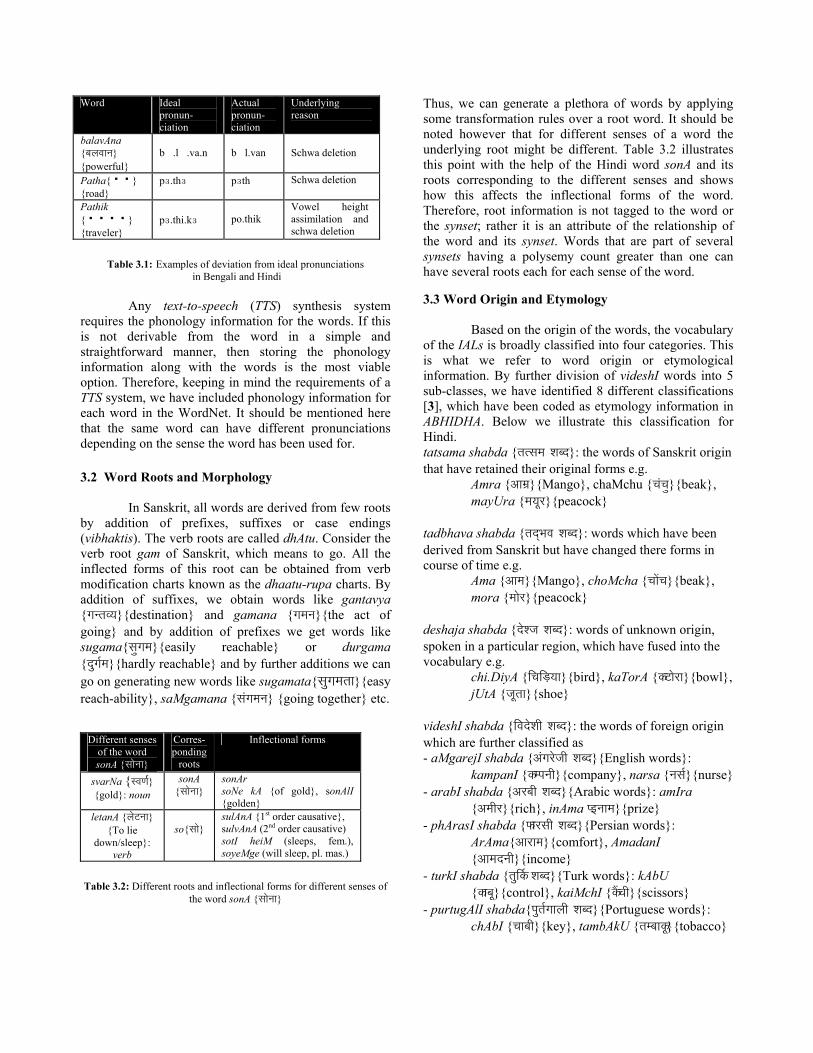
Table 3.1: Examples of deviation from ideal pronunciations
in Bengali and Hindi
Any text-to-speech (TTS) synthesis system requires the phonology information for the words. If this is not derivable from the word in a simple and straightforward manner, then storing the phonology information along with the words is the most viable option. Therefore, keeping in mind the requirements of a TTS system, we have included phonology information for each word in the WordNet. It should be mentioned here that the same word can have different pronunciations depending on the sense the word has been used for.
3.2 Word Roots and Morphology
In Sanskrit, all words are derived from few roots by addition of prefixes, suffixes or case endings (vibhaktis). The verb roots are called dhAtu. Consider the verb root gam of Sanskrit, which means to go. All the inflected forms of this root can be obtained from verb modification charts known as the dhaatu-rupa charts. By addition of suffixes, we obtain words like gantavya {MÉxiÉ´ªÉ}{destination} and gamana {MɨÉxÉ}{the act of going} and by addition of prefixes we get words like sugama{ºÉÙMɨÉ}{easily reachable} or durgama {nÖMÉÇ̈ É}{hardly reachable} and by further additions we can go on generating new words like sugamata{ºÉÖMɨÉiÉÉ}{easy reach-ability}, saMgamana {ºÉÆMɨÉxÉ} {going together} etc.
Table 3.2: Different roots and inflectional forms for different senses of
the word sonA {ºÉÉäxÉÉ}
Thus, we can generate a plethora of words by applying some transformation rules over a root word. It should be noted however that for different senses of a word the underlying root might be different. Table 3.2 illustrates this point with the help of the Hindi word sonA and its roots corresponding to the different senses and shows how this affects the inflectional forms of the word. Therefore, root information is not tagged to the word or the synset; rather it is an attribute of the relationship of the word and its synset. Words that are part of several synsets having a polysemy count greater than one can have several roots each for each sense of the word.
3.3 Word Origin and Etymology
Based on the origin of the words, the vocabulary of the IALs is broadly classified into four categories. This is what we refer to word origin or etymological information. By further division of videshI words into 5 sub-classes, we have identified 8 different classifications [3], which have been coded as etymology information in ABHIDHA. Below we illustrate this classification for Hindi. tatsama shabda {iÉiºÉ¨É ¶É¤n}: the words of Sanskrit origin that have retained their original forms e.g.
Amra {+É©É}{Mango}, chaMchu {SÉÆSÉÙ}{beak}, mayUra {¨ÉªÉÚ®}{peacock}
tadbhava shabda {iÉnÂ¦É´É ¶É¤n}: words which have been derived from Sanskrit but have changed there forms in course of time e.g.
Ama {+ɨÉ}{Mango}, choMcha {SÉÉåSÉ}{beak}, mora {¨ÉÉä®}{peacock}
deshaja shabda {nä¶VÉ ¶É¤n}: words of unknown origin, spoken in a particular region, which have fused into the vocabulary e.g.
chi.DiyA {ÊSÉÊcªÉÉ}{bird}, kaTorA {E]Éä®É}{bowl}, jUtA {VÉÚiÉÉ}{shoe}
videshI shabda {Ê´Énä¶ÉÒ ¶É¤n}: the words of foreign origin which are further classified as - aMgarejI shabda {+ÆMÉ®äVÉÒ ¶É¤n}{English words}:
kampanI {E¨{ÉxÉÒ}{company}, narsa {xɺÉÇ}{nurse} - arabI shabda {+®¤ÉÒ ¶É¤n}{Arabic words}: amIra
{+¨ÉÒ®}{rich}, inAma {<xÉɨÉ}{prize} - phArasI shabda {¡É®ºÉÒ ¶É¤n}{Persian words}:
ArAma{+ɮɨÉ}{comfort}, AmadanI {+ɨÉnxÉÒ}{income}
- turkI shabda {iÉÖÌE ¶É¤n}{Turk words}: kAbU {EɤÉÚ}{control}, kaiMchI {EéSÉÒ}{scissors}
- purtugAlI shabda{{ÉÖiÉÇMÉɱÉÒ ¶É¤n}{Portuguese words}: chAbI {SÉɤÉÒ}{key}, tambAkU {iɨ¤ÉÉEÚ}{tobacco}
Word Ideal pronun-ciation
Actual pronun-ciation
Underlying reason
balavAna {¤É±É´ÉÉxÉ} {powerful}
b�.l�.va.n�
b�l.van
Schwa deletion
Patha{পপ} {road}
pɜ.thɜ pɜth Schwa deletion
Pathik {পপপপ} {traveler}
pɜ.thi.kɜ
po.thik
Vowel height assimilation and schwa deletion
Different senses of the word sonA {ºÉÉäxÉÉ}
Corres-ponding
roots
Inflectional forms
svarNa {º´ÉhÉÇ} {gold}: noun
sonA {ºÉÉäxÉÉ}
sonAr soNe kA {of gold}, sonAlI {golden}
letanA {±Éä]xÉÉ} {To lie
down/sleep}: verb
so{ºÉÉä}
sulAnA {1st order causative}, sulvAnA (2nd order causative) sotI heiM (sleeps, fem.), soyeMge (will sleep, pl. mas.)

We propose to include the etymological information for each word precisely for developing morphological tools (both analyzer and synthesizer). Morphological synthesis is necessary for generation of natural language sentences from concepts. Similarly, morphological analysis is important for parsing and understanding point of view. This includes inflectional analysis, prefix-suffix, compound and conjugate word analysis. To illustrate how etymological information can help in morphological analysis, consider the Hindi word sahamaraNa {ºÉ½¨É®hÉ}. It is a compound Hindi/Bengali word with two possible decompositions: saha{ºÉ½} {tatsama, together} + maraNa {¨É®hÉ}{tatsama, death} or sahama {ºÉ½¨É} {videshi, to be afraid} + raNa{®hÉ}{tatsama, war}. Semantically both the decompositions make sense. However, since in the later decomposition, the two words are of two different origins, it is unlikely. Therefore, sahamaraNa invariably means to die together (with ones spouse, a rite of ancient India).
It is to be noted here that like word roots,
etymology of a word also depends on its sense. We illustrate this point in table 3.3 with the help of Hindi word Ama and Bengali word kalA.
Word Etymology Arts and Crafts tatsama kalA{পপপ
} (Bengali)
Banana tadbhava [from kadalI{পপপপ}]
Mango tadbhava [from Amra {+É©É}] Ama{+ɨÉ} (Hindi) Common videshi (Persian)
Table 3.3: Examples of different etymology for the same word based on
different senses of the word from Hindi and Bengali. 3.4 Pertainymy Pertainymy is a lexical relation relating descriptive adjectives with the particular noun that they pertain to. Though, adjectives can be established as a separate category in Hindi, there are many bound forms and root forms that are not purely adjectival in nature and they draw their origins from other parts-of-speech. Many adjectives in Hindi for instance, have their origin in nouns and so the adjectives will be morphologically similar to their respective nominative forms. For example, dhArmika {vÉĘ́ÉE}{religious} is related to its nominative form dharma {vɨÉÇ}{religion} [3]. This relational pointer has been included for computations in sentence generation. The icon which depicts a nominative concept such as dharma can be used in an iconic sentence to refer to the quality of dhArmika. The pertainymy information
helps us to extract the proper word and generate the sentence in such cases. 3.5 Gender and Number Information
The gender and number information of words plays an important role in syntactically correct sentence generation. For instance, in the sentence isa vidyAlaya meM kevala la.DakiyoM ko shikshAa dI jAtI hai {<ºÉ Ê´ÉvÉÉ±ÉªÉ ¨Éå Eä´É±É ±ÉcÊEªÉÉå EÉä ʶÉIÉÉ nÒ VÉÉiÉÒ ½è}{only girls are given education in this school}, the inflectional form jAtI {VÉÉiÉÒ}, which is present simple and feminine indicative, has been derived from the verb root jA{VÉÉ} {to go} based on the fact that the gender of the word shikshhA{ʶÉIÉÉ} (which is the theme in this sentence) is feminine. ABHIDHA includes the gender and number information for the different senses of a word. The gender information has been coded as masculine, feminine or neutral and number information as either plural or singular.
3.6 Verbs Verbs in IALs are varied in nature and in ABHIDHA we have tried to include the semantic and syntactic information of the verbs. The verb lexicon has been examined on the lines of semantic and syntactic domains and corresponding classifications have been proposed. All the verbs have been conceptualized into five sub domains simple, compound, causative, nominal and conjunct verbs. Table 3.4 gives examples of verbs from each of these domains for Hindi.
pa.DhanA {{ÉgxÉÉ}
{to read}
{ÉgxÉÉ – αÉJÉxÉÉ bidirectional “Compound”
likhanA {αÉJÉxÉÉ}
{to write}
sulAnA {ºÉÖ±ÉÉxÉÉ} {to make someone
sleep}
ºÉÖ±ÉÉxÉÉ – ºÉֱɴÉÉxÉÉ
unidirectional “Causative”
sulavAnA {ºÉֱɴÉÉxÉÉ} {to make
someone sleep by a third person}
hAtha {½ÉlÉ}
{hand}
½ÉlÉ – ½ÊlɪÉÉxÉÉ unidirectional
“Nominal”
hathiyAnA {½ÊlɪÉÉxÉÉ} {to steal}
dUra {nÚ®}
{far}
nÚ® – ½]xÉÉ bidirectional “Conjunct”
haTanA {½]xÉÉ}
{to move}
Table 3.4 Types of verb-verb relations in ABHIDHA
It should be noted that Hindi have causation in two levels
I
sonA {ºÉÉäxÉÉ} {to sleep}
sulAnA {ºÉÖ±ÉÉxÉÉ } {to make one sleep}
II
sulAnA {ºÉÖ±ÉÉxÉÉ } {to make one
sleep}
sulavAnA {ºÉֱɴÉÉxÉÉ} {to make someone
sleep by a third person}

and this WordNet has coded them correspondingly. For instance, Whereas in Bengali, the causation is at level 1only. For instance,
3.7 Level Categorization
This relation is not a semantic or lexical relation, but looking at the aim of developing this lexical data base as an NLP tool for language teaching system, we propose to include the concept of level categorization in ABHIDHA. This categorization is being done to match the proficiency level of the end–user. For instance, a word of level 1 is understood by all age groups but words of level 5 shall match the vocabulary of a more advanced user. In other words, a WordNet database belonging to a level 1 category forms a subset to the database of level 2 and levels higher up. While generating a sentence for a user of level say 3, the system tries to choose only those words of the synset which are of level 3 or below.
3.9 Co-occurrence Measure between Concepts Applications like adaptive navigation and icon-semantics disambiguation require complex reasoning on an extraordinarily rich domain knowledge. This makes both of these problems very hard to solve. One way to avoid this is to maintain a co-occurrence measure between two or more concepts. Co-occurrence is defined as occurrence of two concepts or words in the same sentence. A measure of this on a 0 to 1 scale is a function of the number of independent occurrences of the two concepts and the number of times they co-occur. The more the co-occurrence measure, the more is the number of times they occur in the same sentence. Co-occurrence can be measured between two concepts or in general a set of n concepts. Currently we are measuring the co-occurrence between two concepts only. By concept, here we refer to the synsets, because in the domain of icons, each icon represents a concept or set of concepts rather than words. The co-occurrence measures are obtained by analysis of the corpora. Apart from the above relations ABHIDHA also includes relations like antonymy, entailment, troponymy, gradation for adjectives, hypernymy, hyponymy, holonymy and meronymy. 4. IMPLEMENTATION
The design of ABHIDHA is based on the fact
that the basic relations and lexical links are between the synsets. The synset and semantic links are grouped in accordance with the part–of–speech categories like noun, verb, adjective, and adverb. Word forms and senses in ABHIDHA are given unique indices and correspondingly glosses have been provided for every sense entry, where the mapping is from the word-form index to sense index will be represented in a tabular form in the database.
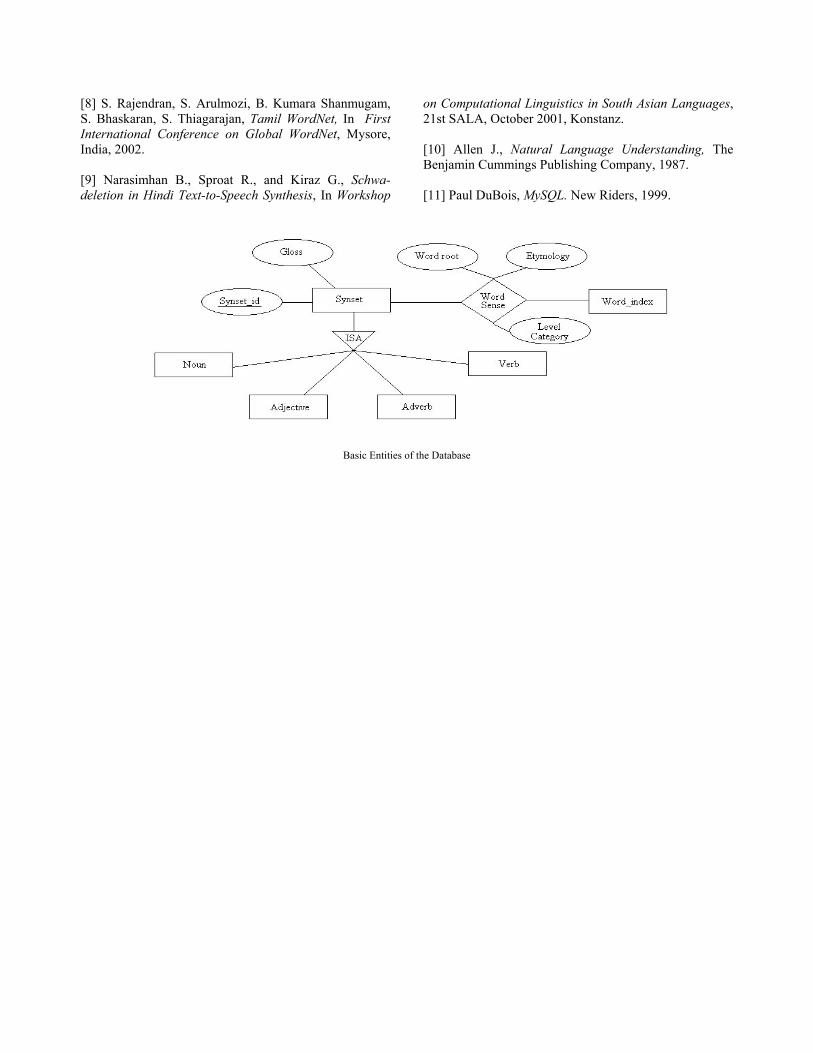
Thus all word-form entries corresponding to a particular sense entry will perforce define a synset. Relations, both binary and hierarchical, will be represented in a tabular format. A set of tables are created to store the lexical entities and the semantic links between them is grouped according to different grammatical categories such as noun, adjective, verb and adverb and are stored in separate tables. Figure 5 illustrates the database design of our generalized LexicalNet though an Entity–Relationship diagram. This self–explanatory ER Diagram establishes the various entities in our LexicalNet and the relationships that link them through. At present, the lexical entries and the relations are stored in files, which can be later imported to a MYSQL database [10] depending on the size and complexity of the system.
Proper interfaces have been developed in java
for entering data into the system and for retrieval of information as well. There are separate interfaces for entering verbs, nouns, adjectives and avyayas. Figure 4 shows screen shots of the data-entry interface. On entering a particular synset and the related relations, a log file is created for each synset entry. These log files are finally committed to the final database after checking several constraints and consistency of the whole system.
I shoYA {পপপপপ}
shoYAno {পপপপপপপপ}

Figure 4: The data–entry interface 5. CONCLUSION
This paper has presented the features of ABHIDHA, a generalized and extended WordNet structure for the IALs. After an initial study of the traditional WordNets, we found that the information stored in them are not enough to solve problems like grapheme to phoneme mapping for TTS, natural language sentence generation and icon interpretation. Accordingly, new relations like pertainymy for adjectives, phonology information, gender and number information, root information, word derivation information, verb categorizations, co-occurrence measure etc. has been introduced. In addition, we have shown how level categorization of the words helps in using ABHIDHA as a tool for learning and teaching language. It may be added here that the original Princeton WordNet [1] had mentioned about the possibility of including morphological relations, there has been no concrete attempts in identification and implementation of such relations. In this work, we have tried to identify the morphological relations for IALs and have included those features in ABHIDHA.
The basic structure of the databases and
interfaces for data entry and retrieval has already been implemented. Currently, it is being populated for Hindi and Bengali using standard dictionaries and thesauri for these languages [4,5,10]. Our initial target is 10,000 common words for each of these languages, which we expect to be completed very soon. The usefulness of the added features in practical applications and many NLP
activities and presence of these features in all the IALs lead us to believe that it is a worthwhile effort to develop extended WordNets for other IALs as well. We would like to take up that activity after we complete the building of ABHIDHA for Hindi and Bengali.
We are working on development of
morphological analyzer and synthesizers for Bengali and Hindi using the information stored in ABHIDHA. Successful attempts have also been made in simple sentence generation in Hindi and Bengali. ACKNOWLEDGMENT This research is partially supported by research grant from Media Lab Asia, India. We would like to thank Mrs. Samhita Deb for her valuable suggestions during the discussions that ensued along the length and breadth of the research work. We would also like to thank Arnab Bhattacharya and Ajay S. Bisht for putting in their time and effort in developing the graphical user interfaces, both for populating the database and for data retrieval. REFERENCES [1] Christiane D. Fellbum, WordNet: An Electronic Lexical Database. The MIT Press, 1998. [2] Piek Vossen, Euro WordNet General Document. University of Amsterdam, 1999. Available online at http://www.hum.uva.nl/~ewn [3] Vasudevanandan Prasad, Aadhunika Hindi Vakarana Aur Rachana (23rd Edition). Bharathi Bhavan, India, 1993. [4] Arvind Kumar and Kusum Kumar, Samantar Kosh. Vol. I & Vol. II, National Book Trust, India, 1997. [5] Arvind Varma and Badrinath Kapoor, Pramanika Hindi Kosh, Lokabharathi Prakashan, India, 1998. [6] Sanjay Kumar Jha, Dipak K. Narayan, Prabhakar Pandey, and Pushpak Bhattacharya, A Wordnet for Hindi, In Workshop On Lexical Resources in Natural Language Processing. Hyderabad, India, 2001. [7] Dipak Narayan, Debasri Chakrabarty, Prabhakar Pande and P. Bhattacharyya, Experiences in Building the Indo WordNet – A WordNet for Hindi, In First International Conference on Global WordNet, Mysore, India, 2002.
[8] S. Rajendran, S. Arulmozi, B. Kumara Shanmugam, S. Bhaskaran, S. Thiagarajan, Tamil WordNet, In First International Conference on Global WordNet, Mysore, India, 2002. [9] Narasimhan B., Sproat R., and Kiraz G., Schwa-deletion in Hindi Text-to-Speech Synthesis, In Workshop
on Computational Linguistics in South Asian Languages, 21st SALA, October 2001, Konstanz. [10] Allen J., Natural Language Understanding, The Benjamin Cummings Publishing Company, 1987. [11] Paul DuBois, MySQL. New Riders, 1999.
Basic Entities of the Database
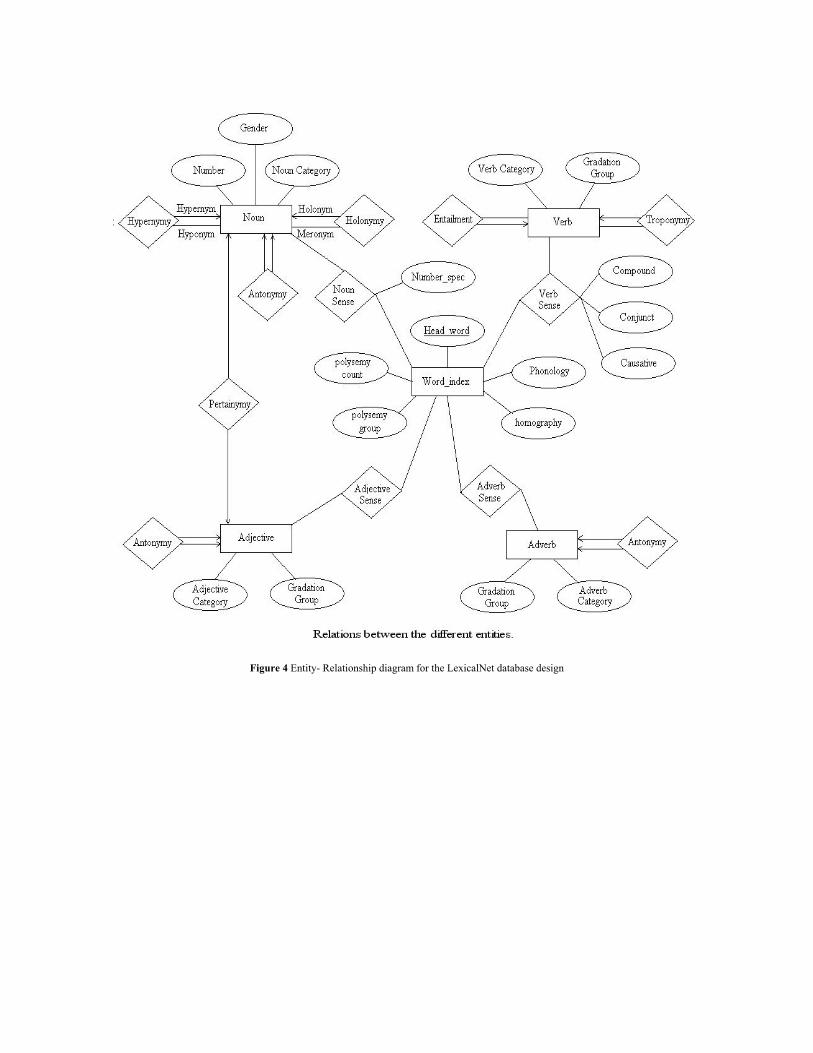
Figure 4 Entity- Relationship diagram for the LexicalNet database design