a three-layer privacy preserving cloud storage scheme based
TRANSCRIPT

DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING
A
PROJECT REPORT
ON
“A THREE-LAYER PRIVACY PRESERVING CLOUD STORAGE
SCHEME BASED ON COMPUTATIONAL INTELLIGENCE IN FOG
COMPUTING“
Submitted in partial fulfillment for the award of the degree of
BACHELOR OF ENGINEERING
IN
COMPUTER SCIENCE AND ENGINEERING
BY
SHARANYA IYER G S
1NH15CS121
Under the guidance of
Ms. RAJITHA NAIR
Assistant Professor 2,
Dept. of CSE, NHCE

DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING
CERTIFICATE
It is hereby certified that the project work entitled “A THREE-LAYER PRIVACY
PRESERVING CLOUD STORAGE SCHEME BASED ON COMPUTATIONAL INTELLIGENCE IN
FOG COMPUTING” is a bonafide work carried out by SHARANYA IYER G S (1NH15CS121)
in partial fulfilment for the award of Bachelor of Engineering in COMPUTER SCIENCE
AND ENGINEERING of the New Horizon College of Engineering during the year 2018-
2019. It is certified that all corrections/suggestions indicated for Internal Assessment
have been incorporated in the Report deposited in the departmental library. The project
report has been approved as it satisfies the academic requirements in respect of project
work prescribed for the said Degree.
………………………… ……………………….. ………………………………
Signature of Guide Signature of HOD Signature of Principal
(Ms. Rajitha Nair) (Dr. B. Rajalakshmi) (Dr. Manjunatha)
External Viva
Name of Examiner Signature with date
1. ………………………………………….. ………………………………….
2. …………………………………………… …………………………………..

I
ABSTRACT
Recent years witness the development of cloud computing technology. With the explosive
growth of unstructured data, cloud storage technology gets more attention and better
development. However, in current storage schema, user’s data is totally stored in cloud
servers. In other words, users lose their right of control on data and face privacy leakage
risk. Traditional privacy protection schemes are usually based on encryption technology,
but these kinds of methods cannot effectively resist attack from the inside of cloud server.
In order to solve this problem, we propose a three-layer storage framework based on fog
computing. The proposed framework can both take full advantage of cloud storage and
protect the privacy of data. Besides, Hash-Solomon code algorithm is designed to divide
data into different parts. Then, we can put a small part of data in local machine and fog
server in order to protect the privacy. Moreover, based on computational intelligence, this
algorithm can compute the distribution proportion stored in cloud, fog, and local machine,
respectively. Through the theoretical safety analysis and experimental evaluation, the
feasibility of our scheme has been validated, which is really a powerful supplement to
existing cloud storage scheme.

II
ACKNOWLEDGEMENT
The satisfaction and euphoria that accompany the successful completion of any task
would be impossible without the mention of the people who made it possible, whose
constant guidance and encouragement crowned our efforts with success.
I have great pleasure in expressing my deep sense of gratitude to Dr. Mohan
Manghnani, Chairman of New Horizon Educational Institutions for providing necessary
infrastructure and creating good environment.
I take this opportunity to express my profound gratitude to Dr. Manjunatha , Principal
NHCE, for his constant support and encouragement.
I am grateful to Dr.Prashanth C.S.R, Dean Academics, for his unfailing encouragement
and suggestions, given to me in the course of my project work.
I would also like to thank Dr. B. Rajalakshmi , Professor and Head, Department of
Computer Science and Engineering, for her constant support.
I express my gratitude to Ms. Rajitha Nair , Assistant Professor 2, my project guide, for
constantly monitoring the development of the project and setting up precise deadlines.
Her valuable suggestions were the motivating factors in completing the work.
Finally a note of thanks to the teaching and non-teaching staff of Dept of Computer
Science and Engineering, for their cooperation extended to me, and my friends, who
helped me directly or indirectly in the course of the project work.
SHARANYA IYER G S (1NH15CS121)

III
CONTENTS
ABSTRACT I
ACKNOWLEDGEMENT II
LIST OF FIGURES V
1. INTRODUCTION
1.1. OBJECTIVE 2
1.2. PROJECT STATEMENT 2
2. LITERARY SURVEY
2.1. OBJECTIVES 3
2.2. EXISTING SYSTEM 13
2.3. PROPOSED SYSTEM 14
3. REQUIREMENT ANALYSIS
3.1 FUNCTIONAL REQUIREMENTS 15
3.2 NON FUNCTIONAL REQUIREMENTS 16
3.3 REQUIREMENT SPECIFICATION 18
3.4 TOOLS 19
4 SYSTEM DESIGN ARCHITECTURE
4.1 DESIGN CONSIDERATION 22
4.2 SYSTEM ARCHITECTURE 23
4.3 DESIGN 24
5 IMPLEMENTATION
5.1 DOMAIN SELECTION 31
5.2 PLATFORM SELECTION 31
5.3 GUI DESIGN 33
5.4 MODULES 35
5.5 ALGORITHM 36

IV
6 TESTING
6.1 TYPES 40
6.2 TEST CASES 42
6.3 OUTPUT
7 CONCLUSION 47
REFERENCES 48

V
LIST OF FIGURES
Fig no. Fig.Name Page no.
6.3.1 Home Page 44
6.3.2 Login Page 45
6.3.3 File Upload 45
6.3.4 Hash Files 46
6.3.5 File Division 46

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 1
CHAPTER 1
INTRODUCTION
Cloud computing has attracted great attention from different sectors of society. Cloud computing
has gradually matured through so many people’s efforts. Then there are some cloud-based
technologies deriving from cloud computing. Cloud storage is an important part of them. With
the rapid development of network bandwidth, the volume of user’s data is rising geometrically.
User’s requirement cannot be satisfied by the capacity of local machine any more. Therefore,
people try to find new methods to store their data. Pursuing more powerful storage capacity, a
growing number of users select cloud storage. Storing data on a public cloud server is a trend in
the future and the cloud storage technology will become widespread in a few years. Cloud
storage is a cloud computing system which provides data storage and management service. With
a cluster of applications, network technology and distributed file system technology, cloud
storage makes a large number of different storage devices work together coordinately. Nowadays
there are a lot of companies providing a variety of cloud storage services, such as Dropbox,
Google Drive, iCloud, Baidu Cloud, etc. These companies provide large capacity of storage and
various services related to other popular applications, which in turn leads to their success in
attracting humorous subscribers. However, cloud storage service still exists a lot of security
problems. The privacy problem is particularly significant among those security issues. In history,
there were some famous cloud storage privacy leakage events. For example, Apples iCloud
leakage event in 2014, numerous Hollywood actresses private photos stored in the clouds were
stolen. This event caused an uproar, which was responsible for the users’ anxiety about the
privacy of their data stored in cloud server. Here, we propose a TLS scheme based on fog
computing model and design a Hash-Solomon code based on Reed-Solomon code. Fog
computing is an extended computing model based on cloud computing which is composed of a
lot of fog nodes. These nodes have a certain storage capacity and processing capability. In our
scheme, we split user’s data into three parts and separately save them in the cloud server, the fog
server and the user’s local machine. Besides, depending on the property of the Hash-Solomon
code, the scheme can ensure the original data cannot be recovered by partial data. On another
hand, using Hash-Solomon code will produce a portion of redundant data blocks which will be
used in decoding procedure. Increasing the number of redundant blocks can increase the

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 2
reliability of the storage, but it also results in additional data storage. By reasonable allocation of
the data, our scheme can really protect the privacy of user’ data. The Hash-Solomon code needs
complex calculation, which can be assisted with the Computational Intelligence (CI). Paradigms
of CI have been successfully used in recent years to address various challenges, for example, the
problems in Wireless sensor networks (WSNs) field. CI provides adaptive mechanisms that
exhibit intelligent behavior in complex and dynamic environments like WSNs. Thus in our
paper, we take advantage of CI to do some calculating works in the fog layer. Compared with
traditional methods, our scheme can provide a higher privacy protection from interior, especially
from the CSPs.
1.1 OBJECTIVE
The main objective is to provide the ideal cloud storage and protect the privacy of data by
introducing three-layer storage framework based on fog computing. We used Hash-Solomon
algorithm which designed to divide the data into different parts, later we can put small parts of
data into local machine and fog server in order to protect the privacy.
1.2 PROBLEM STATEMENT
With the exponential growth of unstructured data, the cloud storage gets more attentions since
it’s provided better security and privacy of data but the fact of the matter is the risk of sharing or
leaking the data is also begin to raise in other words user lose their right of control on data and
facing leakage risk. The privacy problem is particularly significant among those security issues.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 3
CHAPTER 2
LITERARY SURVEY
A literature survey or a literature review in a project report shows the various analyses and
research made in the field of interest and the results already published, taking into account the
various parameters of the project and the extent of the project.
A literature survey includes the following
• Existing theories about the topic which are accepted universally.
• Books written on the topic, both generic and specific.
• Research done in the field usually in the order of oldest to latest.
• Challenges being faced and on-going work, if available.
Literature survey describes about the existing work on the given project .It deals with the
problem associated with the existing system and also gives user a clear knowledge on how to
deal with the existing problems and how to provide solution to the existing problems .different
thing.
2.1 OBJECTIVES
• Learning the definitions of the concepts.
• Access to latest approaches, methods and theories.
• Discovering research topics based on the existing research
• Concentrate on your own field of expertise– Even if another field uses the same words, they
usually mean completely
• It improves the quality of the literature survey to exclude sidetracks– Remember to explicate
what is excluded.
2.1.1 Virtual Machine and Bandwidth Allocation in Software Defined Network (SDN) and
Cloud Computing Environments

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 4
An optimal algorithm was proposed for provisioning VMs and network bandwidth in a cloud
computing environment, enabled by software defined networking. The algorithm makes a
decision to reserve VMs and network bandwidth from certain cloud providers to minimize costs,
by trading off the cost of over provisioning against the cost of on-demand resources. They have
accounted for uncertain demand by formulating and solving a two-stage stochastic optimization
problem to optimally reserve VMs and bandwidth to minimize cost. They have observed that the
solution is optimal and outperforms alternative methods, achieving results close to those
achieved when demand is perfectly known.
Advantages:
The proposed solution minimizes users’ costs and provides superior performance.
Disadvantages:
Not scalable.
2.1.2 General Systematic Erasure Codes with Optimal Repair Bandwidth and Storage for
Distributed Storage Systems
A family repair-bandwidth-efficient erasure codes was proposed, called the Z codes for
distributed storage systems. The Z codes not only achieve the optimal repair bandwidth for
repairing a single data node’s failure, but also attain the minimum storage property as the RS and
CRS codes. The Z codes have many other beneficial properties that make them suitable for
distributed storage systems. The Z codes have comparable encoding and repairing performances
with the RS codes, and significantly outperform the CRS codes and FMSR codes.
Advantages:
Performance is high.
Efficient & effective.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 5
Disadvantages:
Not flexible.
Doesn't provide robustness.
2.1.3 Computational Intelligence in Wireless Sensor Networks
Wireless sensor networks (WSNs) are networks of distributed autonomous devices that can sense
or monitor physical or environmental conditions cooperatively. WSNs face many challenges,
mainly caused by communication failures, storage and computational constraints and limited
power supply. Paradigms of computational intelligence (CI) have been successfully used in
recent years to address various challenges such as data aggregation and fusion, energy aware
routing, task scheduling, security, optimal deployment and localization. CI provides adaptive
mechanisms that exhibit intelligent behavior in complex and dynamic environments like WSNs.
CI brings about flexibility, autonomous behavior, and robustness against topology changes,
communication failures and scenario changes. However, WSN developers are usually not or not
completely aware of the potential CI algorithms offer. On the other side, CI researchers are not
familiar with all real problems and subtle requirements of WSNs. This mismatch makes
collaboration and development difficult. This paper intends to close this gap and foster
collaboration by offering a detailed introduction to WSNs and their properties. An extensive
survey of CI applications to various problems in WSNs from various research areas and
publication venues is presented in the paper. Besides, a discussion on advantages and
disadvantages of CI algorithms over traditional WSN solutions is offered. In addition, a general
evaluation of CI algorithms is presented, which will serve as a guide for using CI algorithms for
WSNs.
Advantages:
Provides feasibility.
Disadvantages:
Provides high communication costs.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 6
Nodes in most WSNs have limited energy.
2.1.4 Privacy-Preserving Smart Semantic Search Based on Conceptual Graphs Over
Encrypted Outsourced Data
In this paper, the authors proposed a content-aware search scheme, which can make semantic
search more smart. Firstly, they introduce conceptual graphs (CGs) as a knowledge
representation tool. Then, they present our two schemes (PRSCG and PRSCG-TF) based on CGs
according to different scenarios. In order to conduct numerical calculation, they transfer original
CGs into their linear form with some modification and map them to numerical vectors. Second,
they employ the technology of multi-keyword ranked search over encrypted cloud data as the
basis against two threat models and raise PRSCG and PRSCG-TF to resolve the problem of
privacy-preserving smart semantic search based on CGs. Finally, they choose a real-world data
set: CNN data set to test our scheme. They also analyze the privacy and efficiency of proposed
schemes in detail.
The summarization of the paper is described briefly as follows:
1) The authors used Conceptual Graphs as a knowledge representation to substitute traditional
keywords and solve the problem of privacy-preserving smart semantic search based on
conceptual graphs over encrypted outsourced data. Compared with, it’s more secure and
efficient.
2) They creatively propose a modified linear form of conceptual graphs which makes
quantitative calculation on conceptual graphs possible. In a sense, we facilitate fuzzy retrieval on
conceptual graphs in semantic level.
3) They presented two practical schemes from different aspects to solve the problem of privacy-
preserving smart semantic search based on conceptual graphs over encrypted outsourced data.
They are both secure and efficient, but have their own focus on different aspects.
Advantages:
Secure & efficient.
Provides an effective searchable symmetric encryption scheme.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 7
Disadvantages:
Semantic search over encrypted cloud data is not possible.
2.1.5 A Secure and Dynamic Multi-keyword Ranked Search Scheme over Encrypted Cloud
Data
A secure tree-based search scheme over the encrypted cloud data, which supports multi-keyword
ranked search and dynamic operation on the document collection. Specifically, the vector space
model and the widely-used “term frequency (TF) × inverse document frequency (IDF)” model
are combined in the index construction and query generation to provide multi-keyword ranked
search. In order to obtain high search efficiency, the authors constructed a tree-based index
structure and proposed a “Greedy Depth-first Search” algorithm based on this index tree. Due to
the special structure of our tree-based index, the proposed search scheme can flexibly achieve
sub-linear search time and deal with the deletion and insertion of documents. The secure kNN
algorithm is utilized to encrypt the index and query vectors, and meanwhile ensure accurate
relevance score calculation between encrypted index and query vectors.
The contributions are summarized as follows:
1) The authors design a searchable encryption scheme that supports both the accurate multi-
keyword ranked search and flexible dynamic operation on document collection.
2) Due to the special structure of our tree-based index, the search complexity of the proposed
scheme is fundamentally kept to logarithmic. And in practice, the proposed scheme can achieve
higher search efficiency by executing our “Greedy Depth-first Search” algorithm. Moreover,
parallel search can be flexibly performed to further reduce the time cost of search process.
Advantages:
Enable secure, efficient, accurate and dynamic multi-keyword ranked search over
outsourced encrypted cloud data.
Achieve sub-linear search efficiency by exploring a special tree-based index and an
efficient search algorithm.
Disadvantages:

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 8
In the proposed scheme, the data owner is responsible for generating updating
information and sending them to the cloud server. Thus, the data owner needs to store the
unencrypted index tree and the information that are necessary to recalculate the IDF
values. Such an active data owner may not be very suitable for the cloud computing
model.
2.1.6 Privacy-Preserving Public Auditing for Secure Cloud Storage
A privacy-preserving public auditing system for data storage security in Cloud Computing. They
utilized the homomorphic linear authenticator and random masking to guarantee that the TPA
would not learn any knowledge about the data content stored on the cloud server during the
efficient auditing process, which not only eliminates the burden of cloud user from the tedious
and possibly expensive auditing task, but also alleviates the users’ fear of their outsourced data
leakage. Considering TPA may concurrently handle multiple audit sessions from different users
for their outsourced data files, they further extend our privacy-preserving public auditing
protocol into a multi-user setting, where the TPA canperform multiple auditing tasks in a batch
manner for better efficiency.
The contribution can be summarized as the following three aspects:
1) The authors motivated the public auditing system of data storage security in Cloud Computing
and provide a privacy-preserving auditing protocol, i.e., our scheme enables an external auditor
to audit user’s outsourced data in the cloud without learning the data content.
2) The proposed scheme is the first to support scalable and efficient public auditing in the Cloud
Computing. Specifically, the scheme achieves batch auditing where multiple delegated auditing
tasks from different users can be performed simultaneously by the TPA.
3) They proved the security and justify the performanceof our proposed schemes through
concrete experiments and comparisons with the state-of-the-art.
Advantages:
Public auditability: to allow TPA to verify the correctness of the cloud data on demand
without retrieving a copy of the whole data or introducing additional online burden to the
cloud users.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 9
Storage correctness: to ensure that there exists no cheating cloud server that can pass the
TPA’s audit without indeed storing users’ data intact.
Privacy-preserving: to ensure that the TPA cannot derive users’ data content from the
information collected during the auditing process.
Batch auditing: to enable TPA with secure and efficient auditing capability to cope with
multiple auditing delegations from possibly large number of different users
simultaneously.
Lightweight: to allow TPA to perform auditing with minimum communication and
computation overhead.
Disadvantages:
Not cost-efficient.
2.1.7 Security and privacy for storage and computation in cloud computing
SecCloud, a privacy-cheating discouragement and secure-computation auditing protocol for data
security in the cloud. They had defined the concepts of un-cheatable cloud computation and
privacy-cheating discouragement and proposed SecCloud to achieve the security goals. To
improve the efficiency, different users’ requests can be concurrently handled through the batch
verification. By the extensive security analysis and performance simulation in our developed
SecHDFS, it is showed that our protocol is effective and efficient for achieving a secure cloud
computing.
The contributions of this paper can be summarized as follows.
Firstly, the authors model the security problems in cloud computing and define the
concepts: uncheatable cloud computation and privacy cheating discouragement in our
cloud computing, which are our design goals.
Secondly, they proposed a basic protocol, SecCloud, to attain data storage security and
computation auditing security as well as privacy cheating discouragement and an
advanced protocol to achieve computation and communication efficiency improvement
through batch verification.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 10
Thirdly, they analyze and prove that SecCloud achieves our design goals and discuss how
to minimize the computation cost by choosing the optimal sampling size.
Finally, they develop a cloud computing experimental environment SecHDFS and
implement SecCloud as a test bed.
Advantages:
Efficient & effective.
Disadvantages:
Doesn't provide privacy and security.
2.1.8 Formulating a Security Layer of Cloud Data Storage Framework Based on Multi
Agent System Architecture
Investigating the problem of data security in cloud data storage, to ensure the correctness of
users’ data in cloud data storage; they proposed a security framework and MAS architecture to
facilitate security of cloud data storage. This security framework consists of two main layers as
agent layer and cloud data storage layer. The propose MAS architecture includes five types of
agents: UIA, UA, DERA, DRA and DDPA. In order to facilitate the huge amount of security,
our MAS architecture offered eleven security attributes generated from four main security
policies of correctness, integrity, confidentially and availability of users’ data in the cloud.
The contributions of the paper are two-fold.
First, this research shall contribute to the new proposed cloud data storage security
framework and would be documented for future use in facilitating cloud data security.
Second, formulate cloud data storage security framework and its architecture to facilitate
the security issues that are offered by MAS of cloud data storage.
Advantages:
Cloud Data Correctness: Ensuring that the cloud data is stored and secured properly.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 11
Cloud Data Confidentially: Ensuring that the cloud data is not disclosed to unauthorized
persons.
Cloud Data Integrity: Ensuring that the cloud data held in a system is a prior
representation of the cloud data and that it has not been modified by an unauthorized
person.
Cloud Data Availability: Ensuring that the cloud data processing resources are not
made unavailable by malicious action.
Disadvantages:
The data stored in the cloud may be frequently updated by the users.
2.1.9 Fog Computing and Its Role in the Internet of Things
Fog Computing is a highly virtualized platform that provides compute, storage, and networking
services between end devices and traditional Cloud Computing Data Centers, typically, but not
exclusively located at the edge of network. The authors had outlined the vision and defined key
characteristics of Fog Computing, a platform to deliver a rich portfolio of new services and
applications at the edge of the network. The motivating examples peppered throughout the
discussion range from conceptual visions to existing point solution prototypes. They envision the
Fog to be a unifying platform, rich enough to deliver this new breed of emerging services and
enable the development of new applications. They welcome collaborations on the substantial
body of work ahead:
1) Architecture of this massive infrastructure of compute, storage, and networking devices
2) Orchestration and resource management of the Fog nodes
3) Innovative services and applications to be supported by the Fog.
Some of the roles of fog computing are being mentioned below:
Edge location, location awareness, and low latency. The origins of the Fog can be traced
to early proposals to support endpoints with rich services at the edge of the network,

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 12
including applications with low latency requirements (e.g. gaming, video streaming,
augmented reality).
Geographical distribution. In sharp contrast to the more centralized Cloud, the services
and applications targeted by the Fog demand widely distributed deployments. The Fog,
for instance, will play an active role in delivering high quality streaming to moving
vehicles, through proxies and access points positioned along highways and tracks.
Large-scale sensor networks to monitor the environment, and the Smart Grid are other
examples of inherently distributed systems, requiring distributed computing and storage
resources. Very large number of nodes, as a consequence of the wide geo-distribution, as
evidenced in sensor networks in general, and the Smart Grid in particular.
Support for mobility. It is essential for many Fog applications to communicate directly
with mobile devices, and therefore support mobility techniques, such as the LISP
protocol, that decouple host identity from location identity, and require a distributed
directory system.
Real-time interactions. Important Fog applications involve real-time interactions rather
than batch processing.
Predominance of wireless access.
Heterogeneity. Fog nodes come in different form factors, and will be deployed in a wide
variety of environments.
Interoperability and federation. Seamless support of certain services (streaming is a good
example) requires the cooperation of different providers. Hence, Fog components must
be able to interoperate, and services must be federated across domains.
Support for on-line analytic and interplay with the Cloud. The Fog is positioned to play a
significant role in the ingestion and processing of the data close to the source.
2.1.10 Maximizing real-time streaming services based on a multi servers networking
framework
A novel framework was proposed based on multi servers to collaboratively provide services for
each end user.
This framework exploits the diversity of network and efficiently realize the real time
streaming and backup at the same time.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 13
Based on the proposed framework, they innovatively formulated a brand-new problem in
providing real-time streaming services: Maximum Services(MS).This problem aims to
maximize the total number of streaming flows and/or services.
For the real working applications of real-time streaming services, we innovatively
inserted a two-relay restriction into the framework, and there for simplified the MS
problem.
The authors designed an approximate algorithm with foreseeable performance bounds to
the optimal solution. Extensive simulations were carried out to validate the effectiveness
of the proposed methods for real working applications.
A new metric Possible Loss(PL)was introduced to evaluate the storage and backup
performance. An efficient storage algorithm is designed to achieve the minimized PL.
Advantages:
Provides high-quality services such as real-time streams delivery and storage.
Disadvantages:
Performance is poor.
Not cost-effective.
2.2 EXISTING SYSTEM
Cloud is semi-trusted and propose a framework for urban data sharing by exploiting the attribute-
based cryptography. The scheme they proposed is secure and can resist possible attacks.
Fu et al. propose a content-aware search scheme, which can make semantic search smarter. The
experiments results show that their scheme is efficient.
It is considered that in traditional situation, user’s data is stored through CSP, even if CSP is
trustworthy, attackers can still get user’s data if they control the cloud storage management node.
To avoid this problem, they propose an encrypted index structure based on an asymmetric
challenge-response authentication mechanism.
Feng points out that in paper, the burden of server will increase and data may leak during
transmission in cloud servers. Feng proposes a more concise scheme: encrypting data in closed
cloud environment.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 14
Disadvantages:
Not reliable.
Not completely secured.
Cannot resist internal attacks or prevent the CSP (Cloud Service Provider) from selling
user’s data to earn illegal profit.
The private data will be decoded once malicious attackers get it no matter how advanced
the encryption technologies.
2.3 PROPOSED SYSTEM
A new secure cloud storage scheme in this paper by dividing file with specific code and
combining with three-layer storage scheme based on fog computing model and design a Hash-
Solomon code based on Reed-Solomon code. Fog computing is an extended computing model
based on cloud computing which is composed of a lot of fog nodes. These nodes have a certain
storage capacity and processing capability. In our scheme, we split user’s data into three parts
and separately save them in the cloud server, the fog server and the user’s local machine. The
scheme can ensure the original data cannot be recovered by partial data.
Advantages:
This scheme can protect the image content and image features well from the semi-honest
cloud server.
It’s secure and can resist possible attacks.
It achieves high accuracy, security and efficient.
It enables to protect fine-grained secure of the data.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 15
CHAPTER 3
REQUIREMENT ANALYSIS
System Requirement Specification (SRS) is a central report, which frames the establishment of
the product advancement process. It records the necessities of a framework as well as has a
depiction of its significant highlight. A SRS is essentially an association's seeing (in composing)
of a client or potential customer's frame work necessities and conditions at a specific point in
time (generally) before any genuine configuration or improvement work. It's a two-way
protection approach that guarantees that both the customer and the association comprehend
alternate's necessities from that viewpoint at a given point in time.
The composition of programming necessity detail lessens advancement exertion, as
watchful audit of the report can uncover oversights, mistaken assumptions, and irregularities
ahead of schedule in the improvement cycle when these issues are less demanding to right. The
SRS talks about the item however not the venture that created it, consequently the SRS serves as
a premise for later improvement of the completed item.
The SRS may need to be changed, however it does give an establishment to proceed with
creation assessment. In straightforward words, programming necessity determination is the
beginning stage of the product improvement action. The SRS means deciphering the thoughts in
the brains of the customers – the information, into a formal archive – the yield of the prerequisite
stage. Subsequently the yield of the stage is a situated of formally determined necessities, which
ideally are finished and steady, while the data has none of these properties.
3.1 FUNCTIONAL REQUIREMENTS
Functional Requirement defines a function of software system and how the system must behave
when presented with specific inputs or conditions. These may include calculations, data
manipulation and processing and other specific functionality. The functional requirements of the
project are one of the most important aspects in terms of entire mechanism of modules.
The functional requirements here are:

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 16
The user is able to select the file and then encode the data.
After encoding, the data gets saved in the local machine.
Forward the data from the local machine to fog and then store it in the fog server.
Upload the data to the cloud server, allocate the data and save it in the main server.
Key is generated using Hash-Solomon code is so as to provide the encoding
and decoding completely and securely.
Cloud server receives the request and then prepare the data.
Fog server restores the data and then send it to the user.
The user receives the decoded data and then end the process.
3.2 NON-FUNCTIONAL REQUIREMENTS
In addition to the obvious features and functions that you will provide in your system, there are
other requirements that don't actually DO anything, but are important characteristics
nevertheless. These are called "non-functional requirements" or sometimes "Quality Attributes."
For example, attributes such as performance, security, usability, compatibility aren’t a "feature"
of the system, but are a required characteristic. You can't write a specific line of code to
implement them, rather they are "emergent" properties that arise from the entire solution. The
specification needs to describe any such attributes the customer requires. You must decide the
kind of requirements that apply to your project and include those that are appropriate.
Here are some Non-Functional Requirements:
Reliability
The framework ought to be dependable and solid in giving the functionalities. When a
client has rolled out a few improvements, the progressions must be made unmistakable by
the framework. The progressions made by the Programmer ought to be unmistakable both
to the Project pioneer and in addition the Test designer.
Security

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 17
Aside from bug following the framework must give important security and must secure
the entire procedure from smashing. As innovation started to develop in quick rate the
security turned into the significant concern of an association. A great many dollars are
put resources into giving security. Bug following conveys the greatest security accessible
at the most noteworthy execution rate conceivable, guaranteeing that unapproved clients
can't get to imperative issue data without consent. Bug following framework issues
diverse validated clients their mystery passwords so there are limited functionalities for
all the clients.
Maintainability
The framework observing and upkeep ought to be basic and target in its approach. There
should not be an excess of occupations running on diverse machines such that it gets hard
to screen whether the employments are running without lapses.
Performance
The framework will be utilized by numerous representatives all the while. Since the
framework will be facilitated on a solitary web server with a solitary database server out
of sight, execution turns into a noteworthy concern. The framework ought not succumb
when numerous clients would be utilizing it all the while. It ought to permit quick
availability to every last bit of its clients. For instance, if two test specialists are all the
while attempting to report the vicinity of a bug, then there ought not to be any irregularity
at the same time.
Portability
The framework should to be effectively versatile to another framework. This is obliged
when the web server, which s facilitating the framework gets adhered because of a few
issues, which requires the framework to be taken to another framework.
Scalability
The framework should be sufficiently adaptable to include new functionalities at a later
stage. There ought to be a typical channel, which can oblige the new functionalities.
Flexibility
Flexibility is the capacity of a framework to adjust to changing situations and
circumstances, and to adapt to changes to business approaches and rules. An adaptable

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 18
framework is one that is anything but difficult to reconfigure or adjust because of diverse
client and framework prerequisites. The deliberate division of concerns between the
trough and motor parts helps adaptability as just a little bit of the framework is influenced
when strategies or principles change.
3.3 REQUIREMENT SPECIFICATION
3.3.1 Hardware Requirements:
System : Intel i3 2.1 GHZ
Memory : 4GB.
Hard Disk : 40 GB.
Monitor : 15 VGA Color.
Mouse : Logitech.
3.3.2 Software Requirements:
Operating System : Windows 7 / 8.
Language : JAVA / J2EE
Database : MySQL
Tool : NetBeans, Navicat

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 19
3.4 TOOLS
3.4.1 NET BEANS IDE
NetBeans IDE is the official IDE for Java 8. With its editors, code analyzers, and
converters, you can quickly and smoothly upgrade your applications to use new Java 8 language
constructs, such as lambdas, functional operations, and method references. Batch analyzers and
converters are provided to search through multiple applications at the same time, matching
patterns for conversion to new Java 8 language constructs. With its constantly improving Java
Editor, many rich features and an extensive range of tools, templates and samples, NetBeans IDE
sets the standard for developing with cutting edge technologies out of the box. An IDE is much
more than a text editor. The NetBeans Editor indent lines, matches words and brackets, and
highlight source code syntactically and semantically. It also provides code templates, coding tips,
and refactoring tools. The editor supports many languages from Java, C/C++, XML and HTML,
to PHP, Groovy, Javadoc, JavaScript and JSP. Because the editor is extensible, you can plug in
support for many other languages. Keeping a clear overview of large applications, with
thousands of folders and files, and millions of lines of code, is a daunting task. NetBeans IDE
provides different views of your data, from multiple project windows to helpful tools for setting
up your applications and managing them efficiently, letting you drill down into your data quickly
and easily, while giving you versioning tools via Subversion, Mercurial, and Get integration out
of the box. When new developers join your project, they can understand the structure of your
application because your code is well-organized.
Design GUIs for Java SE, HTML5, Java EE, PHP, C/C++, and Java ME applications
quickly and smoothly by using editors and drag-and-drop tools in the IDE. For Java SE
applications, the NetBeans GUI Builder automatically takes care of correct spacing and
alignment, while supporting in-place editing, as well. The GUI builder is so easy to use and
intuitive that it has been used to prototype GUIs live at customer presentations. The cost of
buggy code increases the longer it remains unfixed. NetBeans provide static analysis tools,
especially integration with the widely used FindBugs tool, for identifying and fixing common
problems in Java code. In addition, the NetBeans Debugger lets you place breakpoints in your
source code, add field watches, step through your code, run into methods. The NetBeans Profiler
provides expert assistance for optimizing your application's speed and memory usage, and makes

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 20
it easier to build reliable and scalable Java SE, JavaFX and Java EE applications. NetBeans IDE
includes a visual debugger for Java SE applications, letting you debug user interfaces without
looking into source code. Take GUI snapshots of your applications and click on user interface
elements to jump back into the related source code.
Fig.: Snap Shot of Net Beans
3.4.2 MySQL
MySQL ("My Sequel") is (as of 2008) the world's most widely used open source
relational database management system (RDBMS) that runs as a server providing multi-user
access to a number of databases. The SQL phrase stands for Structured Query Language.
The MySQL development project has made its source code available under the terms of
the GNU General Public License, as well as under a variety of proprietary agreements. MySQL
was owned and sponsored by a single for-profit firm, the Swedish company MySQL AB, now
owned by Oracle Corporation.
MySQL is a popular choice of database for use in web applications, and is a central
component of the widely used LAMP open source web application software stack (and other
'AMP' stacks). LAMP is an acronym for "Linux, Apache, MySQL, Perl/PHP/Python." Free-
software-open source projects that require a full-featured database management system often use
MySQL.
MySQL is a relational database management system (RDBMS), and ships with no GUI
tools to administer MySQL databases or manage data contained within the databases. Users may

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 21
use the included command line tools, or use MySQL "front-ends", desktop software and web
applications that create and manage MySQL databases, build database structures, back up data,
inspect status, and work with data records. The official set of MySQL front-end tools, MySQL
Workbench is actively developed by Oracle, and is freely available for use.
MySQL, like most other transactional relational databases, is strongly limited by hard
disk performance. This is especially true in terms of write latency. Given the recent appearance
of very affordable consumer grade SATA interface Solid-state drives that offer zero mechanical
latency, a fivefold speedup over even an eight drive RAID array can be had for a smaller
investment.
3.4.3 NAVICAT PREMIUM
Navicat Premium is a multi-connections database administration tool allowing you to
connect to MySQL, MariaDB, SQL Server, and SQLite, Oracle and PostgreSQL databases
simultaneously within a single application, making database administration to multiple kinds of
database so easy.
Navicat Premium combines the functions of other Navicat members and supports most of
the features in MySQL, MariaDB, SQL Server, SQLite, Oracle and PostgreSQL including Stored
Procedure, Event, Trigger, Function, View, etc.
Navicat Premium enables you to easily and quickly transfer data across various database
systems, or to a plain text file with the designated SQL format and encoding. Also, batch job for
different kind of databases can also be scheduled and run at a specific time. Other features
include Import/ Export Wizard, Query Builder, Report Builder, Data Synchronization, Backup,
Job Scheduler and more. Features in Navicat are sophisticated enough to provide professional
developers for all their specific needs, yet easy to learn for users who are new to database server.
Establish a secure SSH session through SSH Tunnelling in Navicat. You can enjoy a
strong authentication and secure encrypted communications between two hosts. The
authentication method can use a password or public / private key pair. And, Navicat comes with
HTTP Tunnelling while your ISPs do not allow direct connections to their database servers but
allow establishing HTTP connections. HTTP Tunnelling is a method for connecting to a server
that uses the same protocol (http://) and the same port (port 80) as a webserver does.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 22
CHAPTER 4
SYSTEM DESIGN ARCHITECTURE
The one of the important feature of the project is designing the system. The design part provides
the different elements of the system such as, architecture and components. System design solves
the problem by splitting the components of the complex system into smaller components and will
perform and operate on each individual component. The framework configuration prepare
develops general structure building outline. Programming diagram incorporates addressing the
item system works in a shape that might be changed into at least one anticipates. The essential
demonstrated by the end customer must be placed in a systematically way. Diagram is a creative
system; an extraordinary design is the best approach to reasonable structure. The structure
"Layout" is portrayed as "The methodology of applying distinctive frameworks and guidelines
with the ultimate objective of describing a strategy or a system in sufficient purpose important to
permit its physical affirmation". Diverse design segments are taken after to add to the system.
The design detail depicts the segments of the system, the sections or segments of the structure
and their appearance to end-customers.
4.1 DESIGN CONSIDERATION
The explanation behind the plan is to orchestrate the course of action of the issue dictated by the
necessities report. This stage is the underlying stage in moving from issue to the game plan
space. All things considered, start with what is obliged; diagram takes us to work towards how to
satisfy those necessities. The design of the system is perhaps the most essential segment
affecting the way of the item and note worthily affects the later stages, particularly testing and
upkeep. System diagram delineates all the huge data structure, report game plan, yield and
genuine modules in the system and their Specification is picked.
4.1.1 HIGH LEVEL DESIGN
HLD - High Level Design (HLD) is the overall system design - covering the system architecture
and database design. It describes the relation between various modules and functions of the
system data flow, flow charts and data structures are covered under HLD.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 23
High Level Design gives the overall System Design in terms of Functional Architecture details
and Database design. This is very important for the ETL developers to understand the flow of the
system with function and database design wise. In this phase the design team, testers and
customers are plays a major role. Also it should have projects standards, the functional design
documents and the database design document also
A high-level design provides an overview of a solution, platform, system, product, service or
process. Such an overview is important in a multi project development to make sure that each
supporting component design will be compatible with its neighboring designs and with the big
picture.
The highest-level solution design should briefly describe all platforms, systems, products,
services and processes that it depends on and include any important changes that need to be
made to them. In addition, there should be brief consideration of all significant commercial,
legal, environmental, security, safety and technical risks, issues and assumptions.
The idea is to mention every work area briefly, clearly delegating the ownership of more detailed
design activity whilst also encouraging effective collaboration between the various project teams.
Today, most high-level designs require contributions from a number of experts, representing
many distinct professional disciplines. Finally, every type of end-user should be identified in the
high-level design and each contributing design should give due consideration to customer
experience.
4.2 SYSTEM ARCHITECTURE
The structural setup methodology is worried with working up a fundamental\ essential
framework for a system. It incorporates perceiving the genuine parts of the structure and
exchanges between these fragments. The starting design technique of perceiving these
subsystems and working up a structure for subsystem control and correspondence is called
development demonstrating plot and the yield of this framework method is a depiction of the
item basic arranging. The proposed design for this framework is given beneath. It demonstrates
the way this framework is outlined and brief working of the framework.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 24
Fig 4.2 : Three Layer Architecture
4.3 DESIGN
Low-level design (LLD) is a component-level design process that follows a step-by-step
refinement process. This process can be used for designing data structures, required software
architecture, source code and ultimately, performance algorithms. Overall, the data organization
may be defined during requirement analysis and then refined during data design work. Post-
build, each component is specified in detail.
4.3.1 Data Flow Diagram
The DFD is straightforward graphical formalism that can be utilized to speak to a framework as
far as the info information to the framework, different preparing did on this information and the
yield information created by the framework. A DFD model uses an exceptionally predetermined

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 25
number of primitive images to speak to the capacities performed by a framework and the
information stream among the capacities.
The principle motivation behind why the DFD method is so famous is most likely in light
of the way that DFD is an exceptionally basic formalism- It is easy to comprehend and
utilization. Beginning with the arrangement of abnormal state works that a framework performs,
a DFD display progressively speaks to different sub capacities. Actually, any various leveled
model is easy to get it.
The human personality is such that it can without much of a stretch see any progressive
model of a framework in light of the fact that in a various leveled model, beginning with an
extremely straightforward and unique model of framework, distinctive points of interest of a
framework are gradually presented through the diverse orders. A data-flow diagram (DFD) is a
graphical representation of the "stream" of information through a data framework. DFDs can
likewise be utilized for the perception of information handling.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 26
DATA FLOW DIAGRAM OF STORE PROCEDURE
Start
User select
the file
Encode the
data
Store in the
local machine
Upload the
data to fog
Encode the
information
Select the
server
Allocate the
data
Get the relevant
information
Storage Main
server
End the process

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 27
DATA FLOW DIAGRAM FOR DOWNLOAD PROCEDURE
Upload the
data to cloud
Store in fog
server
Cloud receives
request
Fog server
receives the data
Data from
cloud
Decoding
From local
machine
User receives
the data
Data
End the process
Prepare
data
Restore
the data

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 28
4.3.2 USE CASE DIAGRAM
A use case chart is a kind of behavioral graph made from a Use-case examination. Its
object is to present a graphical diagram of the usefulness gave by a framework regarding
performers, their objectives (spoke to as utilization cases), and any conditions between those
utilization cases. Use case chart gives us the data about how that clients and utilization cases are
connected with the framework. Use cases are used amid prerequisites elicitation and examination
to speak to the usefulness of the framework. Use cases concentrate on the conduct of the
framework from an outside perspective.
A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 29
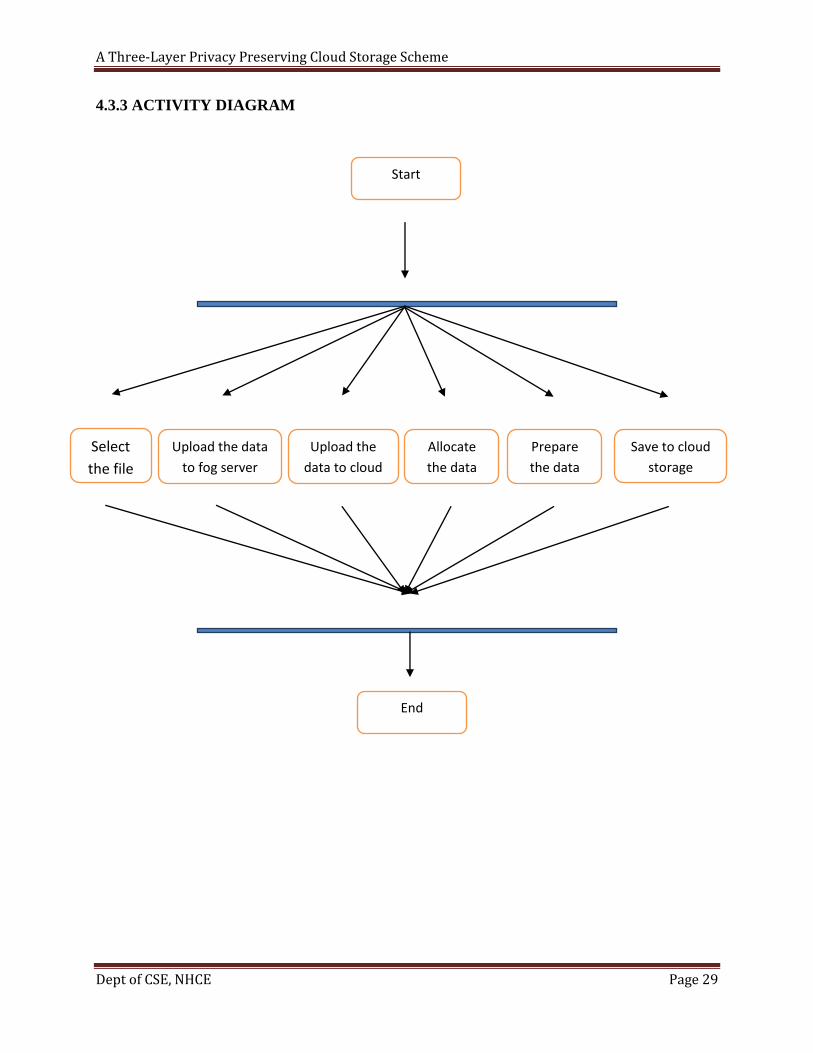
4.3.3 ACTIVITY DIAGRAM
Start
Select
the file
Upload the data
to fog server
Upload the
data to cloud
Save to cloud
storage
End
Allocate
the data
Prepare
the data

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 30
CHAPTER 5
IMPLEMENTATION
The implementation phase involves the actual materialization of the ideas, which are
expressed in the analysis document and developed in the design phase. Implementation should be
perfect mapping of the design document in a suitable programming language in order to achieve
the necessary final product. Often the product is ruined due to incorrect programming language
chosen for implementation or unsuitable method of programming. It is better for the coding
phase to be directly linked to the design phase in the sense if the design is in terms of object
oriented terms then implementation should be preferably carried out in a object oriented way.
The implementation involves:
1. Careful planning.
2. Investigation of the current system and the constraints on implementation.
3. Training of staff in the newly developed system.
Implementation of any software is always preceded by important decisions regarding
selection of the platform, the language used, etc. these decisions are often influenced by several
factors such as real environment in which the system works, the speed that is required, the
security concerns, and other implementation specific details. There are three major
implementation decisions that have been made before the implementation of this project. They
are as follows:
1. Selection of the platform (Operating System).
2. Selection of the programming language for development of the application.
3. Coding guideline to be followed.
The GUI is developed using Android Studio, which is the client side. Android Studio is
the official integrated development environment (IDE) for the Android platform. The server side
of the implementation is done using NetBeans. NetBeans is a software development platform

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 31
written in Java. The NetBeans Platform allows applications to be developed from a set of
modular software components called modules. Applications based on the NetBeans Platform,
including the NetBeans integrated development environment (IDE), can be extended by third
party developers. The NetBeans IDE is primarily intended for development in Java, but also
supports other languages, in particular PHP, C/C++ and HTML5.
The protocol implemented in this project is Light Weight Anonymous Authentication
Protocol. This protocol aims at providing Data Freshness, Authentication, Secure Localization
and Maintains Anonymity.
5.1 DOMAIN SELECTION
Java is a little, basic, safe, item situated, translated or rapidly improved, byte coded,
engineering, waste gathered, multithreaded programming dialect with a specifically exemption
taking care of for composing circulated and powerfully extensible projects.
With most programming dialects, you either accumulate or translate a project so you can run it
on your PC. The Java programming dialect is irregular in that a project is both accumulated and
deciphered. The stage autonomous codes deciphered by the mediator on the Java stage. The
mediator parses and runs every Java byte code guideline on the PC. Aggregation happens just
once; understanding happens every time the project is executed. The accompanying figure
delineates how this function You can consider Java byte codes as the machine code directions for
the Java Virtual Machine (Java VM). Each Java mediator, whether it’s an advancement device or
a Web program that can run applets, is an execution of the Java VM.
5.2 PLATFORM SELECTION
A platform is the hardware or software environment in which a program runs. As already
mentioned some of the most popular platforms like Windows 2000, Linux, Solaris, and MacOS.
Most platforms can be described as a combination of the operating system and hardware. The
Java platform differs from most other platforms in that it’s a software-only platform that runs on
top of other hardware-based platforms.
The Java platform has two components:
• The Java Virtual Machine (JVM)
• The Java Application Programming Interface (Java API)

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 32
We’ve already been introduced to the Java VM. It’s the base for the Java platform and is ported
onto various hardware-based platforms.
The Java API is a large collection of ready-made software components that provide many useful
capabilities, such as graphical user interface (GUI) widgets. The Java API is grouped into
libraries of related classes and interfaces; these libraries are known as packages.
The figure shown below depicts a program that’s running on the Java platform. As the figure
shows, the Java API and the virtual machine insulate the program from the hardware.
Native code is code that after you compile it, the compiled code runs on a specific hardware
platform. As a platform-independent environment, the Java platform can be a bit slower than
native code. However, smart compilers, well-tuned interpreters, and just-in-time byte code
compilers can bring performance close.
5.2.1 Input Design
The info outline is the connection between the client and data framework and creating particular
and strategies for information arrangement and those strides are important to put exchange
information into a usable structure for handling can be accomplished by investigating the PC to
peruse information from a composed or printed archive or it can happen by having individuals
entering the information specifically into the framework.
5.2.2 Output Design
A quality output is one, which meets the necessities of the end client and presents the data
obviously. In any framework consequences of preparing are conveyed to the clients and to other
framework through yields. In yield outline it is resolved how the data is to be dislodged for
prompt need furthermore the printed version yield. It is the most essential and direct source data
to the client. Productive and insightful yield outline enhances the framework's relationship to
help client choice making.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 33
5.3 GRAPHICAL USER INTERFACE DESIGN
Graphical user interface is a type of user interface that allows users to interact with
electronic devices using images rather than text commands, A GUI represents the information &
action available to a user through graphical icons & visual indicators such as secondary notation,
as opposed to text-based interfaces, type command labels or text navigation. The actions are
usually performed through direct manipulation of the graphical elements. A GUI uses a
combination of technologies & devices to provide a platform that the user can interact with, for
the tasks of gathering & producing information.
A series of elements confirming a visual language have evolved to represent information
stored in computers. This makes it easier for people with a few computer skills to work with and
use computer software.
Designing the visual composition & temporal behavior of a GUI is an important part of
software application programming in the area of human-computer interaction. Its goal is to
enhance the efficiency & ease of use for the underlying logical design of a stored program, a
design discipline known as usability. Methods of user-centered design are used to ensure that the
visual language introduced in the design is well tailored to the tasks.
5.3.1 OVERVIEW
Java was conceived by James Gosling, Patrick Naughton, Chris wrath, Ed Frank, and
Mike Sheridan at Sun Micro system. It is a platform independent programming language that
extends its features wide over the network. Java2 version introduces a new components than are
possible with AWT
• It’s a light weight package, as they are not implemented by platform-specific code.
• Related classes are contained in javax.swing and its sub packages, such as
javax.swing.tree
• Components explained in the swing have more capabilities than those of AWT.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 34
The Java programming language is a high-level language that can be characterized by all of
the following buzzwords
• Simple
• Architecture neutral
• Object oriented
• Portable
• Distributed
• High performance
• Interpreted
• Multithreaded
• Robust
• Dynamic
• Secure
With most programming languages, it either compile or interpret a program so that it can
run it on our computer. The Java programming language is unusual in that a program is both
compiled and interpreted. With the compiler, first it translate a program into an intermediate
language called Java byte codes.
Java byte codes are the platform-independent codes interpreted by the interpreter on the
Java platform. The interpreter parses and runs each Java byte code instruction on the computer.
Compilation happens just once; interpretation occurs each time the program is executed. The
following figure illustrates how this works.
We can think of Java byte codes as the machine code instructions for the Java Virtual
Machine (Java VM). Every Java interpreter, whether it’s a development tool or a Web browser
that can run applets, is an implementation of the Java VM. Java byte codes help make “write
once, run anywhere” possible. You can compile your program into byte codes on any platform
that has a Java compiler. The byte codes can then be run on any implementation of the Java VM.
That means that as long as a computer has a Java VM, the same program written in the Java
programming language can run on Windows 2000, a Solaris workstation, or on an iMac.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 35
5.4 MODULES:
5.4.1 Fog Computing
Our scheme is based on fog computing model, which an extension of cloud is computing.
Compared to highly concentrated cloud computing, fog computing is closer to edge network and
has many ad vantages as follows: broader geographical distributions, higher real-time and low
latency. In considering of these characters, fog computing is more suitable to the applications
which are sensitive to delay. Fog computing is usually a three-level architecture, the up-most is
cloud computing layer which has powerful storage capacity and compute capability. The next
level is fog computing layer. The fog computing layer serves as the middle layer of the fog
computing model and plays a crucial role in transmission between cloud computing layer and
sensor network layer. The fog nodes in fog computing layer has a certain storage capacity and
compute capability. The bottom is wireless sensor network layer. The main work of this layer is
collecting data and uploading it to the fog server. Besides, the transfer rate between fog
computing layer and other layers is faster than the rate directly between cloud layer and the
bottom layer. The introduction of fog computing can relief the cloud computing layer, improving
the work efficiency. In our scheme, we take advantage of the fog computing model, adopt three-
layer structure. Furthermore, we replace the WSNs layer by user’s local machine.
5.4.2 Three-Layer Privacy Preserving Cloud Storage Scheme Based on Fog
Computing Model
In order to protect user’s privacy, we propose a TLS frame-work based on fog computing
model. The TSL framework can give user a certain power of management and effectively protect
user’s privacy. As mentioned, the interior attack is difficult to resist. Traditional approaches
work well in solving outside at-tack, but when CSP itself has problems, traditional ways are all
invalid. Different from the traditional approaches, in our scheme, user’s data is divided into three
different-size parts with encoding technology. Each of them will lack a part of key information
for confidentiality. Combining with the fog computing model, the three parts of data will be
stored in the cloud server, the fog server and user’s local machine according to the order from
large to small. By this method, the attacker cannot recover the user’s original data even if he gets

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 36
all the data from a certain server. As for the CSP, they also cannot get any useful information
without the data stored in the fog server and local machine because both of the fog server and
local machine are controlled by users.
5.4.3 Implementation Detail of Workflow
i. Stored Procedure: When user wants to store his file to thecloud server, first of all, user’s file
will be encoded with Hash-Solomon code. And then, the file will be divided into several data
blocks and the system will also feedback encoding information simultaneously. Secondly, after
receiving the 99% data blocks from user’s machine, these data blocks will be encoded with
Hash-Solomon again. These data blocks will be divided into smaller data blocks and generates
new encoding information. Thirdly, after cloud server received the data blocks form fog side,
these data blocks will be distributed by cloud manage system. Finally, the storage procedure ends
when all the related information be recorded in different servers.
ii. Download Procedure: When user wants to download his file from the cloud server, firstly,
cloud server receives user’s request and then integrates the data in different distributed servers.
Secondly, the fog server receives the data from the cloud server. Then the fog server returns the
99% data to the user. Thirdly, the user receives the data from fog server. User can get the
complete data by repeating the above steps.
5.5 ALGORITHM
5.5.1 Hash-Solomon code algorithm:
Based on the Reed-Solomon code algorithm, we propose a Hash-Solomon code algorithm. The
Hash-Solomon encoding process is actually a matrix operation. As shown in the diagram below,
firstly we should do mapping transformation on the file which is prepared to be stored, so that
each word of the file corresponds to a number in GF(2ω ). After mapping transformation we get
file matrix O. Secondly we do hash transform on matrix O and get matrix X. Then we multiply
the transformed matrix X by the encoding matrix A. The multiplication will generate k data
blocks X1 to X6 and m redundant data blocks C (k = 6, m= 1). In the same figure below, we

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 37
prepare to save X1 to X5 in the Cloud and Fog, and store X6 and C in the local machine. The next
step is similar to the above operations, we do hash transform on X' and get file matrix Y. Then we
multiply the transformed matrix Y by the encoding matrix B. At last, we store Y1 to Y4 in the
cloud server and store Y5 and R in the fog server (k = 5, m = 1). The encoding matrix usually
consists of an identity matrix and a Vandermonde matrix or a Cauchy matrix.
Fig. Diagram of download procedure.
Hash-Solomon code has the following properties: in the k+m data blocks, if we have at least k
data blocks, we can recover the original data combining with the encoding matrix. But once the
number of data blocks is less than k, it cannot be recovered. Using the above properties in our
scheme, after each encoding, we store less than k parts of data blocks in the higher server and
store the remainder parts of data blocks in the lower server. With such reasonable allocation, the
cloud server, the fog server and user’s local machine independently store a certain percentage of
data blocks. It is impossible to recover the original data with any single server’s data. The TLS
framework largely solves the leakage of user’s privacy.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 38
5.5.2 Feasibility study
The feasibility of the project is analyzed in this phase and business proposal is put forth with
a very general plan for the project and some cost estimates. During system analysis the
feasibility study of the proposed system is to be carried out. This is to ensure that the
proposed system is not a burden to the company. For feasibility analysis, some
understanding of the major requirements for the system is essential.
5.5.3 Economical feasibility
This study is carried out to check the economic impact that the system will have on the
organization. The amount of fund that the company can pour into the research and development
of the system is limited. The expenditures must be justified. Thus the developed system as well
within the budget and this was achieved because most of the technologies used are freely
available. Only the customized products had to be purchased.
5.5.4 Technical feasibility
This study is carried out to check the technical feasibility, that is, the technical requirements of
the system. Any system developed must not have a high demand on the available technical
resources. This will lead to high demands on the available technical resources. This will lead to
high demands being placed on the client. The developed system must have a modest
requirement, as only minimal or null changes are required for implementing this system.
5.5.5 Social feasibility
The aspect of study is to check the level of acceptance of the system by the user. This
includes the process of training the user to use the system efficiently. The user must not feel
threatened by the system, instead must accept it as a necessity. The level of acceptance by the
users solely depends on the methods that are employed to educate the user about the system and
to make him familiar with it. His level of confidence must be raised so that he is also able to
make some constructive criticism, which is welcomed, as he is the final user of the system.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 39
CHAPTER 6
TESTING
Testing is an important phase in the development life cycle of the product. This is the
phase, where the remaining errors, if any, from all the phases are detected. Hence testing
performs a very critical role for quality assurance and ensuring the reliability of the software.
During the testing, the program to be tested was executed with a set of test cases and the
output of the program for the test cases was evaluated to determine whether the program was
performing as expected. Errors were found and corrected by using the below stated testing steps
and correction was recorded for future references. Thus, a series of testing was performed on the
system, before it was ready for implementation.
It is the process used to help identify the correctness, completeness, security, and quality
of developed computer software. Testing is a process of technical investigation, performed on
behalf of stake holders, i.e. intended to reveal the quality-related information about the product
with respect to context in which it is intended to operate. This includes, but is not limited to, the
process of executing a program or application with the intent of finding errors.
The quality is not an absolute; it is value to some person. With that in mind, testing can
never completely establish the correctness of arbitrary computer software; Testing furnishes a
‘criticism’ or comparison that compares the state and behaviour of the product against
specification. An important point is that software testing should be distinguished from the
separate discipline of Software Quality Assurance (SQA), which encompasses all business
process areas, not just testing.
There are many approaches to software testing, but effective testing of complex products
is essentially a process of investigation not merely a matter of creating and following routine
procedure.
Although most of the intellectual processes of testing are nearly identical to that of
review or inspection, the word testing is connoted to mean the dynamic analysis of the product-
putting the product through its paces. Some of the common quality attributes include capability,
reliability, efficiency, portability, maintainability, compatibility and usability.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 40
A good test is sometimes described as one, which reveals an error; however, more recent
thinking suggest that a good test is one which reveals information of interest to someone who
matters within the project community.
6.1 TYPES
6.1.1 Unit Testing
Individual component are tested to ensure that they operate correctly. Each component is
tested independently, without other system component. This system was tested with the set of
proper test data for each module and the results were checked with the expected output. Unit
testing focuses on verification effort on the smallest unit of the software design module. This is
also known as MODULE TESTING. This testing is carried out during phases, each module is
found to be working satisfactory as regards to the expected output from the module.
6.1.2 Integration Testing
Integration testing is another aspect of testing that is generally done in order to uncover errors
associated with flow of data across interfaces. The unit-tested modules are grouped together and
tested in small segment, which make it easier to isolate and correct errors. This approach is
continued unit I have integrated all modules to form the system as a whole.
6.1.3 System Testing
System testing is actually a series of different tests whose primary purpose is to fully exercise
the computer-based system. System testing ensures that the entire integrated software system
meets requirements. It tests a configuration to ensure known and predictable results. An example
of system testing is the configuration oriented system integration testing. System testing is based
on process description and flows, emphasizing pre-driver process and integration points
6.1.4 Performance Testing
The performance testing ensure that the output being produced within the time limits and time
taken for the system compiling, giving response to the users and request being send to the
system in order to retrieve the results.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 41
6.1.5 Validation Testing
The validation testing can be defined in many ways, but a simple definition is that. Validation
succeeds when the software functions in a manner that can be reasonably expected by the end
user.
6.1.6 Black Box testing
Black box testing is done to find the following
• Incorrect or missing functions
• Interface errors
• Errors on external database access
• Performance error
• Initialization and termination error
6.1.7 White Box Testing
This allows the tests to
• Check whether all independent paths within a module have been exercised at least
once
• Exercise all logical decisions on their false sides
• Execute all loops and their boundaries and within their boundaries
• Exercise the internal data structure to ensure their validity
• Ensure whether all possible validity checks and validity lookups have been
provided to validate data entry.
6.1.8 Acceptance Testing
This is the final stage of testing process before the system is accepted for operational use.
The system is tested within the data supplied from the system procurer rather than simulated data

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 42
6.2 TEST CASES
Sl # 3Test 3Case UTC-*1
Name3of3Test Saving data to the local machine
Expected3Result
The 1% data gets stored into local machine before uploading to
the cloud.
Actual3output Same3as3expected.
Remarks3 Successful
S2# 3Test 3Case UTC-*2
Name3of3Test Fog servers
Expected3Result After being forwarded the data from local machine it should
stores 5% of data and remaining should forward for cloud
storage.
Actual3output Same3as3expected.
Remarks3 Successful
S3# 3Test 3Case UTC-*3
Name3of3Test Cloud Servers
Expected3Result Eventually the remaining data gets stored into the cloud
server and 100% uploaded.
Actual3output 3Same3as3expected.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 43
Remarks3 3Successful
S4# 3Test 3Case UTC-*4
Name3of3Test Hash-Solomon code
Expected3Result The key should get passed with this code so as to provide
the encoding and decoding completely and securely
Actual3output Same3as3expected.
Remarks3 Successful
S5# 3Test 3Case UTC-*5
Name3of3Test Divide into chunks.
Expected3Result Divide the files into small chunks and save it to the sever
in different potions.
Actual3output Same3as3expected.
Remarks3 Successful
S6# 3Test 3Case UTC-*6
Name3of3Test View the file.
Expected3Result The user should be able to view the files that are saved in
the server.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 44
Actual3output 3Same3as3expected.
Remarks3 3Successful
S7# 3Test 3Case UTC-*7
Name3of3Test Download the file.
Expected3Result The files gets merged into a single unit and the user
should be able to download the merged file.
Actual3output 3Same3as3expected.
Remarks3 3Successful
6.3 OUTPUT
6.3.1 HOME PAGE

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 45
6.3.2 LOGIN PAGE
6.3.3 FILE UPLOAD

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 46
6.3.4 HASH FILES
6.3.5 FILE DIVISION

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 47
CHAPTER 7
CONCLUSION
The development of cloud computing brings us a lot of benefits. Cloud storage is a convenient
technology which helps users to expand their storage capacity. However, cloud storage also
causes a series of secure problems. When using cloud storage, users do not actually control the
physical storage of their data and it results in the separation of ownership and management of
data. In order to solve the problem of privacy protection in cloud storage, we propose a TLS
framework based on fog computing model and design a Hash-Solomon algorithm. in order to
achieve the maximum efficiency, and we also find that the Cauchy matrix is more efficient in
coding process.
In future, the theoretical safety analysis, the scheme is proved to be feasible. By allocating the
ratio of data blocks stored in different servers reasonably, we can ensure the privacy of data in
each server the experiment test, this scheme can efficiently complete encoding and decoding
without influence of the cloud storage efficiency.

A Three-Layer Privacy Preserving Cloud Storage Scheme
Dept of CSE, NHCE Page 48
References:
[1] P. Mell and T. Grance, “The NIST definition of cloud computing,” Nat.Inst. Stand. Technol.,
vol. 53, no. 6, pp. 50–50, 2009.
[2] H. T. Dinh, C. Lee, D. Niyato, and P. Wang, “A survey of mobile cloud computing:
Architecture, applications, and approaches,” Wireless Commun. Mobile Comput., vol. 13, no. 18,
pp. 1587–1611, 2013.
[3] J. Chase, R. Kaewpuang, W. Yonggang, and D. Niyato, “Joint virtual machine and bandwidth
allocation in software defined network (sdn) and cloud computing environments,” in Proc. IEEE
Int. Conf. Commun., 2014, pp. 2969–2974.
[4] H. Li, W. Sun, F. Li, and B. Wang, “Secure and privacy-preserving data storage service in
public cloud,” J. Comput. Res. Develop., vol. 51, no. 7, pp. 1397–1409, 2014.
[5] Y. Li, T.Wang, G.Wang, J. Liang, and H. Chen, “Efficient data collection in sensor-cloud
system with multiple mobile sinks,” in Proc. Adv. Serv. Comput., 10th Asia-Pac. Serv. Comput.
Conf., 2016, pp. 130–143.
[6] L. Xiao, Q. Li, and J. Liu, “Survey on secure cloud storage,” J. Data Acquis. Process., vol.
31, no. 3, pp. 464–472, 2016.
[7] R. J. McEliece and D. V. Sarwate, “On sharing secrets and reed-solomon codes,” Commun.
ACM, vol. 24, no. 9, pp. 583–584, 1981.
[8] J. S. Plank, “T1: Erasure codes for storage applications,” in Proc. 4th USENIX Conf. File
Storage Technol., 2005, pp. 1–74.
[9] R. Kulkarni, A. Forster, and G. Venayagamoorthy, “Computational intelligence in wireless
sensor networks: A survey,” IEEE Commun. Surv. Tuts., vol. 13, no. 1, pp. 68–96, First Quarter
2011.
[10] Z. Xia, X. Wang, L. Zhang, Z. Qin, X. Sun, and K. Ren, “A privacy preserving and copy-
deterrence content-based image retrieval scheme in cloud computing,” IEEE Trans. Inf. Forensics
Security, vol. 11, no. 11, pp. 2594–2608, Nov. 2016.
[11] J. Shen, D. Liu, J. Shen, Q. Liu, and X. Sun, “A secure cloud-assisted urban data sharing
framework for ubiquitous-cities,” Pervasive Mobile Comput., vol. 41, pp. 219–230, 2017.
[12] Z. Fu, F. Huang, K. Ren, J.Weng, and C.Wang, “Privacy-preserving smart semantic search
based on conceptual graphs over encrypted outsourced data,” IEEE Trans. Inf. Forensics
Security, vol. 12, no. 8, pp. 1874–1884, Aug. 2017.
[13] J. Hou, C. Piao, and T. Fan, “Privacy preservation cloud storage architecture research,” J.
Hebei Acad. Sci., vol. 30, no. 2, pp. 45–48, 2013.