a study on handwritten marathi word recognition
TRANSCRIPT

“A STUDY ON HANDWRITTEN MARATHI WORD RECOGNITION”
A THESIS SUBMITTED TO
BHARATI VIDYAPEETH UNIVERSITY, PUNE
FOR AWARD OF DEGREE OF
DOCTOR OF PHILOSOPHY
IN
COMPUTER SCIENCE UNDER THE
FACULTY OF SCIENCE
SUBMITTED BY
CHANDRASHEKHAR HIMMATRAO PATIL
UNDER THE GUIDANCE OF
PROF. DR. M. S. PRASAD
DEPARTMENT OF COMPUTER SCIENCE,
YASHWANTRAO MOHITE COLLEGE OF ARTS, SCIENCE AND COMMERCE,
BHARATI VIDYAPEETH DEEMED UNIVERSITY PUNE.
JULY 2015

CERTIFICATE
This is to certify that the work incorporated in the thesis entitled
“A STUDY ON HANDWRITTEN MARATHI WORD RECOGNITION” for
the degree of ‘Doctor of Philosophy’ in the subject of Computer Science
under the faculty of Science has been carried out by
Mr. Chandrashekhar Himmatrao Patil in the Department of Computer
Science at Bharati Vidyapeeth Deemed University, Yashwantrao Mohite College of Arts, Science and Commerce, Pune during the
period from August 2010 to July 2015 under the guidance of Dr. M. S. Prasad.
Place: Pune (Signature of Head of the Institute with seal)
Date : Principal / Director
Seal

CERTIFICATION OF GUIDE
This is to certify that the work incorporated in the thesis entitled
“A STUDY ON HANDWRITTEN MARATHI WORD RECOGNITION”
Submitted by Mr. Chandrashekhar Himmatrao Patil for the degree of
‘Doctor of Philosophy’ in the subject of Computer Science under the
faculty of Science has been carried out in the Department of Computer
Science, Bharati Vidyapeeth’s Yashwantrao Mohite College of Arts, Science and Commerce, Pune during the period from August 2010 to
July 2015, under my direct supervision/ guidance.
Place : Pune (Research Guide)
Date : (Prof. Dr. M. S. Prasad)

DECLARATION BY THE CANDIDATE
I hereby declare that the thesis entitled “A STUDY ON HANDWRITTEN MARATHI WORD RECOGNITION” submitted by me to the Bharati
Vidyapeeth University, Pune for the degree of Doctor of Philosophy (Ph.D.) in Computer Science under the Faculty of Science is original piece of work
carried out by me under the supervision of Dr. M. S. Prasad. I further
declare that it has not been submitted to this or any other university or
Institution for the award of any degree or Diploma.
I also confirm that all the material which I have borrowed from other sources
and incorporated in this thesis is duly acknowledged. If any material is not
duly acknowledged and found incorporated in this thesis, it is entirely my
responsibility. I am fully aware of the implications of any such act which
might have been committed by me advertently or inadvertently.
Place : Pune Date : /07/2015 Research Student
Chandrashekhar H. Patil

ACKNOWLEDGMENT
I wish to express my sincere gratitude to Dr. M. S. Prasad, Research guide, Bharati Vidyapeeth Deemed University, Pune for his continuous support, encouragement and valuable guidance during my research work. I benefited a lot from his constructive suggestions, dedication and efforts to accomplish timely completion of my research. I shall always remain indebted to him.
My heartfelt thanks to Principal, Dr. K. D. Jadhav, Yashwantrao Mohite college and Prof. S. S. Shukla, Head, Dept. of Computer Science extending necessary facilities to carry forward my research.
I also thank Prof. Dr. M.G. Bodhankar, Prof. Dr. S. R. Patil for their continuous support and encouragement to complete my work.
My heartfelt thanks to my colleague Prof. Dr. S. M. Mali, for his valuable guidance, suggestions and critical comments helped me to carry forward my research.
I am beholden to Principal Dr. T. N. More of MAEER’S Arts, Commerce and Science College, Pune and Management of MAEER for supporting me to pursue for Ph. D. degree in computer Science. I also thank Mr. Vilas Shinde and other colleagues in the college for their constant support in completing my work.
I thank Ms. Manisha Bharambe and all fellow research scholars for their active participation in the technical discussions and providing a lively atmosphere during the course of research.
Lastly and most importantly, words cannot express my deepest gratitude to my beloved parents, my wife Kirti, daughter Rutu, my family members, relatives and friends for their love, support, patience and being source of a inspiration during the course of work.
Chandrashekhar H. Patil

Dedicated
To
My
Late Mother Pramila Patil

CONTENTS List of Figures
List of Tables
List of Abbreviations
1. INTRODUCTION ... 1
1.1 Optical Character Recognition (OCR) ... 2
1.1.1 Types of OCR ... 2
1.1.2 Data collection ... 3
1.1.3 Pre-processing ... 4
1.1.4 Segmentation ... 4
1.1.5 Feature extraction ... 5
1.1.6 Classification ... 6
1.2 Literature Review ... 7
1.3 Motivation for the present work, Problem statement ... 14
1.4 Organization of the Thesis ... 15
2. OBJECTIVES AND PROPOSED SYSTEM … 17
2.1 Objectives … 17
2.2 Description of the proposed system for Handwritten
Marathi word recognition … 18
3. DEVELOPMENT OF A DATABASE OF
HANDWRITTEN MARATHI WORDS, ISOLATED
CHARACTERS AND PREPROCESSING
... 22
3.1 Introduction ... 23
3.2 Marathi characters ... 24
3.3 Formation of Marathi words ... 26
3.4 Database Development ... 28
3.4.1 Database development for handwritten
Marathi simple words ... 28
3.4.2 Database development for handwritten ... 31

Marathi compound words
3.4.3 Database development for isolated
handwritten Marathi characters ... 33
3.5 Pre-processing ... 34
4. SEGMENTATION ... 38
4.1 Introduction ... 38
4.2 Segmentation and Difficulties in Segmentation ... 39
4.3 Segmentation Methodology for simple words ... 42
4.4 Segmentation methodology for compound words ... 44
4.5 Discussion of Results ... 48
4.6 Analysis Of Results ... 58
5. MULTILEVEL CLASSIFICATION ... 60
5.1 Introduction ... 60
5.2 Multilevel Classification ... 61
5.3 Discussion of Results ... 69
6. FEATURE EXTRACTION ... 71
6.1 Introduction ... 71
6.2 Zone based symmetric density feature ... 72
6.3 Diagonal, Horizontal and Vertical features ... 76
6.4 Normalized chain code feature ... 81
6.5 Invariant moment feature ... 84
6.6 Zernike moment feature ... 87
6.7 Discrete wavelet transform ... 90
7. CLASSIFICATION AND RESULTS ... 94
7.1 Introduction ... 94
7.2 Support Vector Machine Classifier ... 95
7.3 k-NN Classifier ... 99
7.4 Discussion of Results ... 101
8. SUMMARY AND CONCLUSIONS ... 123

8.1 Conclusions ... 123
8.2 Scope for further research ... 133
PUBLICATIONS
BIBLIOGRAPHY

List of Figures
1.1 Steps in offline OCR ………………………………………………… 3
2.1 Proposed system for offline handwritten Marathi word Recognition... 19
3.1 First Group of Marathi Vowels………………………………………. 24
3.2 Second Group of Marathi Vowels…………………………………… 24
3.3 Three words contains remaining two vowels………………………... 25
3.4 Group of Marathi consonants……………………………………….. 25
3.5 Marathi vowels and consonant ……………………………………… 26
3.6 Consonants and its corresponding half consonant…………………… 27
3.7 Dataset of handwritten Marathi simple words……………………….. 29
3.8 Sample of sheets for collection of handwritten Marathi simple words 30
3.9 Sample handwritten Marathi simple words………………………….. 30
3.10 Dataset of handwritten Marathi compound words…………………… 31
3.11 Sample A4 sheet for Handwritten Compound words………………... 32
3.12 Sample handwritten Marathi compound words……………………… 32
3.13 Sample A4 sheet for isolated handwritten Marathi characters………. 33
3.14 Example of Median filtering……………………………………........ 34
4.1 Words where no ‘shirorekha’ written……………………………….. 40
4.2 Words having touching characters…………………………………… 41
4.3 Words having slanted characters…………………………………….. 41
4.4 Words having broken characters……………………………………... 41
4.5 Words having overlapping characters………………………………... 42
4.6 Marathi vowels………………………………………………………. 53
4.7 Five base characters for Marathi vowels…………………………...... 54
4.8 Marathi consonants…………………………………………………... 54
5.1 Phases in Multilevel classification…………………………………… 62
5.2 Bar character…………………………………………………………. 63
5.3 No bar character……………………………………………………… 64
5.4 Enclosed region character……………………………………………. 65

5.5 Not enclosed region character………………………………………... 65
5.6 Two component character……………………………………………. 66
5.7 One component character……………………………………………. 66
5.8 80% row contains at least one black pixels character………………... 67
5.9 less than 80% row contains at least one black pixels character……… 67
5.10 Consonants having bar and enclosed region…………………………. 68
5.11 Consonants having bar, enclosed region and having two components 68
5.12 Consonants having bar, enclosed region, one component and black
pixels…………………………………………………………………. 68
5.13 Consonants having bar, enclosed region, one component and not
black pixels…………………………………………………………... 68
5.14 Consonants does not have bar and having enclosed region………….. 68
5.15 Consonants does not have bar and enclosed region………………….. 69
6.1 Character image divided into n zones and feature value for
corresponding zone…………………………………………………... 75
6.2 Diagonal Features……………………………………………………. 78
6.3 Horizontal Features…………………………………………………... 79
6.4 Vertical Features……………………………………………………... 80
6.5 Eight directional Chain code………………………………………… 83
7.1 Hyperplanes separating two classes correctly……………………….. 96
7.2 Soft margin training allows some training examples to remain on the
wrong side of the separating hyperplane…………………………….. 98
7.3 Linear and non linear classification………………………………….. 99
7.4 Test sample for k=3 and k=5………………………………………… 100
7.5 Data flow diagram of the system…………………………………….. 103
8.1 Recognition rate (%) of Marathi handwritten Characters using SVM
and k-NN classifiers………………………………………………… 126

LIST OF TABLES
4.1 Segmentation result for handwritten Marathi simple words………… 49
4.2 Segmentation result for handwritten Marathi compound words……. 51
4.3 Marathi vowels grouped depending on their base character………… 53
4.4 Isolated full characters after applying segmentation algorithm on
handwritten Marathi words………………………………………….. 55
4.5 Half characters after applying segmentation algorithm on handwritten
Marathi words………………………………………………………… 56
4.6 Modifiers after applying segmentation algorithm on handwritten
Marathi words……………………………………………………….. 57
4.7 Segmentation result comparison with other researchers…………….. 58
5.1 Multilevel classification result from Phase I to Phase IV…………… 69
5.2 Outcome of Multilevel classification………………………………... 70
6.1 First eight order Zernike moments…………………………………... 89
7.1 Results for Subclass I using SVM Classifier………………………... 107
7.2 Results for Subclass I using k-NN Classifier………………………... 107
7.3 Results for Subclass II using SVM Classifier……………………….. 108
7.4 Results for Subclass II using k-NN Classifier………………………. 108
7.5 Results for Subclass III using SVM Classifier……………………… 109
7.5 Results for Subclass III using k-NN Classifier……………………… 109
7.7 Results for Subclass IV using SVM Classifier………………………. 110
7.8 Results for Subclass IV using k-NN Classifier……………………… 110
7.9 Results for Subclass V using SVM Classifier……………………….. 111
7.10 Results for Subclass V using k-NN Classifier………………………. 111
7.11 Results for Subclass VI using SVM Classifier………………………. 112
7.12 Results for Subclass VI using k-NN Classifier……………………… 112
7.13 Confusion Matrix for fold I Subclass I using Density and Normalized
chain code feature SVM classifier……………………………………. 113
7.14 Confusion Matrix for fold I Subclass I using Density and Normalized 113
chain code feature k-NN classifier……………………………………
7.15 Confusion Matrix for fold I Subclass II using Density and
Normalized chain code feature SVM classifier………………………. 112
7.16 Confusion Matrix for fold I Subclass II using Density and
Normalized chain code feature k-NN classifier……………………..... 114
7.17 Confusion Matrix for fold I Subclass III using Density and
Normalized chain code feature SVM classifier………………………. 114
7.18 Confusion Matrix for fold I Subclass III using Density and
Normalized chain code feature k-NN classifier……………………..... 114
7.19 Confusion Matrix for fold I Subclass IV using Density and
Normalized chain code feature SVM classifier………………………. 115
7.20 Confusion Matrix for fold I Subclass IV using Density and
Normalized chain code feature k-NN classifier……………………... 115
7.21 Confusion Matrix for fold I Subclass V using Density and
Normalized chain code feature SVM classifier……………………… 116
7.22 Confusion Matrix for fold I Subclass V using Density and
Normalized chain code feature k-NN classifier……………………... 116
7.23 Confusion Matrix for fold I Subclass VI using Density and
Normalized chain code feature SVM classifier……………………… 117
7.24 Confusion Matrix for fold I Subclass VI using Density and
Normalized chain code feature k-NN classifier……………………... 117
7.25 Highest recognition rate for 41 Marathi characters using SVM and k-
NN Classifier……………………………………………………… 118
7.26 Handwritten Marathi simple words Recognition using SVM
classifier………………………………………………………………. 118
7.27 Handwritten Marathi compound words recognition using SVM
classifier………………………………………………………………. 120
8.1 Comparison of recognition rates of proposed methods for subclass I. 128
8.2 Comparison of recognition rates of proposed methods for subclass II 128

8.3 Comparison of recognition rates of proposed methods for subclass
III…………………………………………………………………… 128
8.4 Comparison of recognition rates of proposed methods for subclass
IV……………………………………………………………………. 129
8.5 Comparison of recognition rates of proposed methods for subclass V 129
8.6 Comparison of recognition rates of proposed methods for subclass
VI…………………………………………………………………….. 129
8.7 Comparison of recognition rates for handwritten marathi characters
with other methods in literature……………………………………... 130
8.8 Comparison of recognition rates for handwritten Marathi words with
other methods in literature…………………………………………… 133
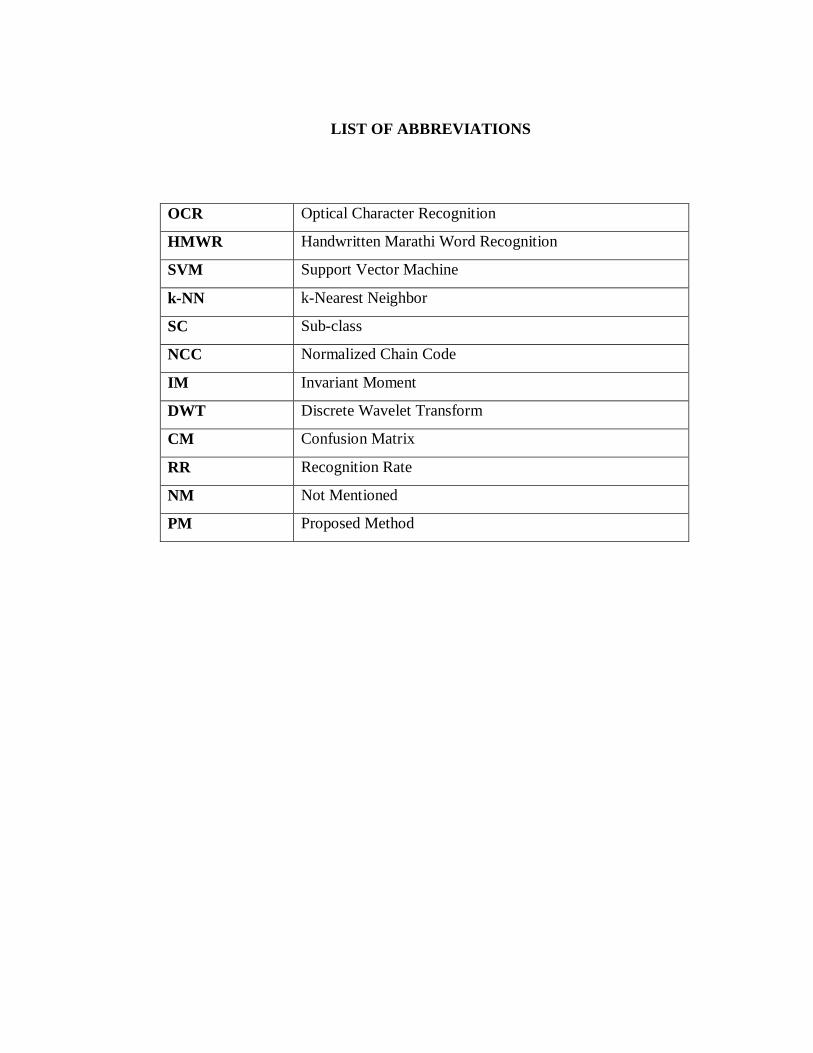
LIST OF ABBREVIATIONS
OCR Optical Character Recognition
HMWR Handwritten Marathi Word Recognition
SVM Support Vector Machine
k-NN k-Nearest Neighbor
SC Sub-class
NCC Normalized Chain Code
IM Invariant Moment
DWT Discrete Wavelet Transform
CM Confusion Matrix
RR Recognition Rate
NM Not Mentioned
PM Proposed Method

Chapter 1
Introduction
---------------------------------------------------------------------------------------------------
1.1 Optical Character Recognition (OCR) 1.1.1 Types of OCR 1.1.2 Data collection 1.1.3 Pre-processing 1.1.4 Segmentation 1.1.5 Feature extraction 1.1.6 Classification
1.2 Literature Review 1.3 Motivation for the present work, Problem Statement 1.4 Organization of Thesis
---------------------------------------------------------------------------------------------------
The thesis entitled 'A Study on Handwritten Marathi Word Recognition' presented
here is OCR for handwritten Marathi words. OCR is acronym for Optical
Character Recognition in which text images are converted into digital text
without human intervention. This technology converts read only documents into
digitized formats that can easily be retrieved, searched, and archived. Document
analysis and recognition are two challenging research areas in pattern
recognition. Although sufficient amount of research work is reported for printed
offline OCR, little research work exists for offline handwritten OCR due to the
diversified nature in handwritings. Handwritten Marathi word recognition is a
challenging task because the total number of characters present in Marathi large.
Also Marathi consists of various modifiers and different forms of compound
characters which complicate the design of OCR procedures. In this chapter, we

2 Chapter 1: Introduction
give a brief description of OCR, literature review, motivation for the present work
and problem statement.
---------------------------------------------------------------------------------------------------
1.1 Optical Character Recognition (OCR):
Optical Character Recognition (OCR) converts text images into digital
text without user intervention. Since OCR has numerous applications like postal
automation, automatic form processing, historical document preservation and
many more, OCR is an area of interest for researchers working in document
analysis and recognition. OCR can be broadly classified into two types: Online
OCR and Offline OCR.
1.1.1 Types of OCR:
Online OCR: Online OCR converts input text to digital text as it is entered on
the device. Device used for input text can be a mobile, PDA or any special
digitizer. Pen movement, strokes and pen up and downs are recorded by the
sensors which can be used for recognition purpose.
Offline OCR: Offline OCR converts printed/handwritten text images into digital
text. Printed/handwritten texts documents are scanned using a scanner and
converted into digital text so that computer understands and processes that text.
The important steps in offline OCR are shown in the Figure 1.1.
Offline OCR can be broadly classified into two types: Printed OCR and
Handwritten OCR.
Printed OCR Vs Handwritten OCR: Input for offline OCR is either printed
documents or handwritten documents. Offline OCR converts printed/handwritten
documents into digital text. Printed OCR is used to digitize historical documents,

3 Chapter 1: Introduction
Figure 1.1 Steps offline OCR
books and printed forms. Handwritten OCR is used to digitize handwritten
documents. Designing and developing handwritten OCR is more complicated and
challenging task than printed OCR. Printed text has specific font type and
specific size where as in handwritten text considerable variation exists as each
person has different writing styles. Also segmentation process is difficult in
handwritten OCR as compared to printed OCR. In handwritten OCR
segmentation of text into characters is complicated task and which further reduces
recognition accuracy. Major steps in offline OCR are discussed below:
1.1.2 Data Collection:
In order to develop offline handwritten OCR, database of handwritten
sample images is to be created. Database has to be large in vocabulary and
variations. There are standard databases such as CEDAR, NIST and CENPARMI
which are used for experimentation of offline handwritten OCR. But all these
databases are only for isolated English and Devanagari characters, but not for
words, that is, strings of characters.

4 Chapter 1: Introduction
1.1.3 Pre-processing:
Pre-processing and image enhancement operations on images are carried
out to improve the quality of image data and to remove distortions. We have to
analyze information in the image so as to improve the quality and reduce
distortions. First, image data is transformed to gray scale using Ostu’s threshold
technique then gray scale image is converted to black and white image using
binarization. Conversion from a gray-scale image to a black-and-white image
may cause some loss of information. Dilation and erosion operations can reduce
this loss of information. We can remove noise by using appropriate structuring
elements. Slant corrections can be made to improve recognition rate. Also, we
have to normalize images to a specified standard plane. Normalization is carried
out to reduce the interclass variation of the shapes of the images. To carry out
feature extraction and classification process, preprocessing and image
enhancement is to be executed correctly; otherwise it may degrade the quality of
image and important information may be lost.
1.1.4 Segmentation:
Segmentation divides an image into meaningful components called
segments. Segmentation is of two types: contextual segmentation and non
contextual segmentation. Contextual segmentation is more useful to differentiate
objects using the pixels belongs to that object. There are two types of contextual
segmentation depending on signal discontinuity and signal similarity. Cluster,
compression based methods, histograms, edge detection are widely used in
contextual segmentation. Non contextual segmentation differentiates the pixels
irrespective of their location. A simple method of non contextual segmentation is
thresholding. The accuracy of offline handwritten OCR recognition largely
depends on the success of the segmentation phase.

5 Chapter 1: Introduction
1.1.5 Feature extraction:
Feature extraction is an important phase in OCR which occurs prior to
classification. Recognition accuracy of OCR is largely depends on the extracted
features. In this phase unique characteristics (features) are stored in a feature
vector for all input images. Features are broadly classified into two types (i)
global features, and (ii) geometric and topological features based on their
characteristics:
Global Features:
Global features are also known as statistical features. Global features are
not affected by noise or distortions and can be detected easily. Some commonly
used global features are moments, zoning, projection, histogram, n-tuples,
crossing and distances.
Geometric and Topological Features:
Geometric and topological features may represent both global and local
properties, but are not affected by distortions or style variations. Object
components, structure of objects and their properties can be represented using
geometric and topological features. Geometric and topological representations
can be broadly grouped into four categories:
i) Topological structures like lines, curves, loops, end points, branch
points, T- point etc.
ii) Approximating geometric properties like aspect ratio, difference
between x and y coordinates etc are a kind of representation.
iii) Codings like freeman chain code, normalized chain code, regular
expressions are forms of another representation of geometric features.
iv) Graphs and trees are another type of representations, in which first
topological features are extracted and those features are represented in
graph or tree formats.

6 Chapter 1: Introduction
1.1.6 Classification:
Image classification assigns a label to an unknown object. Classification
is broadly categorized into two types: supervised classification and unsupervised
classification
Supervised classification:
In supervised classification training data is used where available
predefined class labels and features are used to assign labels to unknown objects.
Supervised classification is appropriate when sufficient amount of training data is
available.
Unsupervised classification:
Unsupervised classification is more appropriate when there is less
information for classification. In unsupervised classification classes or groups are
formed according to randomly sampled data called clusters and unknown objects
are classified into these clusters.
Using various decision rules, unknown objects are classified into
respective classes. Some commonly used classification techniques and decision
rules are discussed below:
Multilevel slice classifier:
Multilevel slice classifier decision rule is defined on the basis of lowest
and highest values of classes. This classifier is also known as parallelpiped
classifier is very simple and easy to understand. In this case classification
accuracy depends on the lowest and highest values of classes chosen.
Minimum distance classifier:
In minimum distance classifier unknown image is classified into a class
that minimizes the distance between the image and the class. Decision rule is

7 Chapter 1: Introduction
based on the distances of image from the classes. Generally, Euclidian distance
or Mahalanobis distance are used in minimum distance classifiers.
Maximum likelihood classifier:
Maximum likelihood classifier decision rule is based on the posterior
probability of a pixel belonging to the class.
Fuzzy set theory and expert system:
Fuzzy set theory uses a ‘membership function’. It is difficult to define an
appropriate membership function and boundaries of different classes for
classification. Fuzzy set theory based classifiers are useful for qualitative data.
Expert system classifiers use knowledge based on experiences.
For the present work support vector machine and k-NN classifiers are
considered.
1.2 Literature Review:
Handwriting recognition is one of the important research problems in the
field of document analysis and recognition. Document analysis and recognition is
challenging area in pattern recognition due to its varied applications. Many
systems have been proposed for recognition of printed as well as handwritten
characters, for Devanagari (Karwankar and Bhalchandra (2010); Desai and
Malik(2011); Desai et.al.(2011); Raj et.al.(2013); Holambe et.al.; Aggarwal
et.al.(2012); Malaviya et.al.(1996); Dhandra et.al.(2010); Bharath and
Madhvanath(2010); Shaw et. al.(2008); Singh et. al.(2011); Chavan et. al.(2013);
Koshti and Govilkar; Agrawal et. al.; Gohil et. al. (2012); Holambe et. al.(2010);
Rajput and Mishra; Malik and Deshpande (2009); Jangid(2011); Shukla et.
al.(2011); Mapari et. al.(2011); Sharma et. al.(2006); Garg et. al.(2011); Pratap
and Arya(2012); Sahu et. al.(2012); Murthy and Hanmandlu(2011); Ramana et.
al.(2012); Murthy and Hanmandlu(2011); Deshpande et. al. (2007;2008);

8 Chapter 1: Introduction
Mukherji and Rege(2008;2009); Patil and Ansari(2014); Kakde and Raut(2012);
Singh and Tyagi(2011); Ramteke(2010); Ramteke and Melhotra(2008);
Jayadevan et. al.(2011); Kapoor et. al.(2002); Kumar et. al.; Rathi et. al.(2012);
Khobragade(2013); Bajaj et. al.(2002); Arora et. al.(2008; 2009; 2011); Kamble
and Kamble ((2011); Kumar(2009; 2010); Kumar et. al. (2010;2012); Asthana et.
al.(2011); Kompalli et.al.(2009); Shelke and Apte(2011); Vaidya and
Bombade(2013); Bhattacharya and Chaudhuri(2005); Ladwani and Malik(2010);
Agnihotri(2012); Bansal and Sinha(2000); Kumar and Sengar(2010); Dongre and
Mankar(2010); Rani and Kumar(2013)), for Bengali (Sarkar and Biswas(2010);
Majumdar(2007); Das and Yasmin(2006); Shukla et. al.(2011); Parui et.
al.(2008); Bag and Harit(2013); Bhattacharya and Chaudhari(2005)), for
English (Talele et. al.(2011); Koerch et. al.(2010); Choudhary et. al. (2010);
Dhandra et. al.(2006); Romero et. al.(2007); Patel et. al.(2012); Pradeep et.
al.(2010); Hull et. al.(1990); Vaid and Gupta(2002); Prema and Reddy(2002);
Biswas and Parekh(2012); Sharma et. al.(2012); Asthana et. al.(2011)), for
Marathi (Ajmire and Warkhede (2010); Jane and Pund(2012); Mahender and
Kale(2011); Rajput and Mali(2010); Kale et. al.(2014); Tapkir and Shelke(2012);
Patil et. al.(2011); Ajmire et. Al.(2012); Jayadevan et. Al.(2011); Mali(2012);
Shelke and Apte(2010;2011); Pawar and Gaikwad(2014)), for Guajarati (Desai
(2012); Baheti et. al.(2011)), for Gurumukhi (Kumar and Jindal(2012); Singh and
Budhiraja(2012); Singh and Dhir(2012); Kumar and Sengar(2010)), for Kannada
(Dhandra et. al.(2009;2010;2011); Acharya et. al. (2008); Niranjan et. al.(2009);
Sangame et. al.(2009); Vaidya and Bombade(2013)), for Telugu (Dhandra et. Al.
(2009;2010); Jawahar et.al. (2003); Rao et.al.(2013); Rajashekararadhya and
Ranjan (2008); Asthana et.al.(2011)), for Malayalam (Chacko and Anto(2010);
Rajashekararadhya and Ranjan(2008)), for Hindi (Jawahar et.al.(2003);
Hanmandlu et.al.(2007); Garg et.al.(2010;2011;2013)), for Arabic (Chun
et.al.(2009);Abd(2007)), for Chinese (Liu et.al.(2010)), for Tamil (Aparna
et.al.(2004); Gandhi and Iyakutti(2010); Kannan and Prabhakar(2008);

9 Chapter 1: Introduction
Rajashekararadhya and Ranjan(2009); Asthana et.al.(2011)), for Farsi (Reza
et.al.(2011)), for Urdu (Asthana et.al.(2011)) and for Oriya (Bhattacharya and
Chaudhari(2005)). Also many systems have been proposed for numeral
recognition of different script (Holambe et.al.; Ashoka et.al.(2012); Aggarwal
et.al.(2012); Dhandra et.al.(2010); Romero et.al.(2007); Das and Yasmin(2006);
Rajput and Mali(2010)).
Pal and Chaudhari (2001) presented in their brief survey on Indian script
recognition sufficient amount of work is reported for printed and handwritten
character recognition. Also reported the status of present research and presented
scope for future work which consists of OCR for poor quality documents, multi
font OCR, multi script OCR, handwritten OCR and OCR for the visually
handicapped.
Aarti Desai et. al. (2011) proposed a system for handwritten Devanagari
character recognition. They have used minimum edit distance classifier and
combination of chain code, branch point and end point features. Using the
combination of these features is reported 87 recognition accuracy for 150
characters.
Chavan S. V. et. al. (2013) presented a system for recognition of
handwritten compound Devanagari characters. Moment base feature extraction
techniques are used to extract geometric features and Zernike moment features.
MLP and k-NN classifiers are used for classification and recognition accuracies
of 98.78% and 95.65% using MLP and k-NN classifier respectively are achieved
on a database of 27000 basic and compound characters.
Karbhari V. Kale et. al.(2014) presented a Zernike moment based feature
extraction technique for handwritten Marathi compound characters. Database of
9600 basic characters, 9000 compound characters and 3000 split characters has
been developed. Local structural classification and zone based zernike moment
features are extracted. Recognition is carried out by using SVM and k-NN

10 Chapter 1: Introduction
classifiers, where 98.37% recognition accuracy is achieved by SVM classifier and
95.82% accuracy by k-NN classifier.
Malik and Deshpande (2009) presented a novel approach for printed and
handwritten Devanagari characters by using regular expressions in finite state
models. Recognition accuracy reported for printed Devanagari characters is 100.
Shelke and Apte (2010, 2011) have suggested novel approach for
handwritten Devanagari compound character recognition consisting of multi-
feature and multi-classifier scheme. Database of 35000 character samples has
been developed. Structural classification, random transform, wavelet transform,
density, Euclidean distance, modified wavelet transforms are used as feature
extraction techniques. MLP and Neural network are used for classification.
Recognition accuracies reported are 94.22% when wavelet transform is used;
96.23% when modified wavelet transform is used, while for a combination of
modified wavelet transform, density and Euclidean distance gives 97.95%
recognition accuracy.
Bhattacharya and Chaudhari (2005) presented a brief survey on databases
for research on recognition of handwritten characters of Indian script. Databases
of 22556 samples of Devanagari numerals, 12938 samples of Bangala numerals,
5970 samples of Oriya numerals have been developed. Database of Devanagari
numerals is collected from 1049 users. Also 556 users have written Bangala and
Oriya numerals.
Sandhya Arora et. al. (2009, 2011) reported multiple feature and multi
classification approach for handwritten Devanagari character recognition.
Shadow features, view based features, chain code and moments are used as
features for recognition. Neural network classifier is used sequentially for
classification using multiple features. Recognition accuracy reported is 90.74%
when shadow features and chain code features are used.
Naresh Kumar Garg et. al.(2010) presented a segmentation method using
vertical and horizontal projection. Databases of 200 lines and 1380 words of

11 Chapter 1: Introduction
Hindi text were developed and results of 91.50% for line segmentation, 98.10%
for word segmentation, 79.12% for consonants segmentation and for modifiers
86% were reported.
Pal and Chaudhari (2001) presented a segmentation method for printed
and text line identification and the segmentation accuracy achieved 98.60%
accuracy.
Ajay Talele et. al. (2011) reported a system for handwritten legal amounts
written in English. Cavity and closed loop features are used for the recognition
purpose. They also have reported 92.50% recognition accuracy.
Alessandro L. Koerich et. al.(2013) proposed a system for verification of
unconstrained handwritten English words at character level. A database of 85092
English handwritten words is used for the experiments and recognition accuracy
is improved by 3.9%.
Bikash Shaw et. al. (2008) made significant contributions towards offline
handwritten Devanagari word recognition. They have developed a database of
39700 word samples for offline handwritten Devanagari words, consisting of 100
words. Both Holistic and segmentation based approaches are used for recognition
purpose. Chain code, 8 scaler, histogram and zone based features are are
extracted and HMM classifier is used for classification purpose. Using holistic
based approach 80.2% recognition accuracy is reported, while 81.63% recognition
accuracy is reported for segmentation based approach.
Brijmohan Singh et. al. (2011) proposed a novel approach for handwritten
Devanagari word recognition using curvelet transform. Database of 28500
samples for handwritten Devanagari word from 30 classes and database of 31860
samples for handwritten Devanagari characters from 46 classes were developed.
Curvelet transform and character geometry is used to extract features and
recognition accuracy is compared using SVM and k-NN classifier. Recognition
accuracy for words is 85.60% using SVM classifier and 93.21% using k-NN
classifier.

12 Chapter 1: Introduction
Gang Liu et. al. (2010) reported a novel approach for handwritten Chinese
words. Database of 44208 samples of words has been developed. Holistic
approach for recognition is used. LDA and MQDF classifiers are used for
classification purposes. Recognition accuracy reported for Chinese words is
91.96%.
R. Jayadevan et. al. (2011) presented a database and a recognition
approach for handwritten Devanagari legal amount words. A database of 26720
word samples is developed which contains all Devanagari legal amount words.
Gradient, structural features and cavity binary vector matching (BVM) is used for
recognition and achieved 80.65% recognition accuracy. A second approach using
vertical projection and dynamic time wraping (DTW) is reported with recognition
accuracy 76.69%.
Tapkir and Shelke (2012) reported OCR for handwritten Marathi script.
Projection methodology is used for line segmentation and word segmentation.
Density feature and Euclidean minimum edit distance classifier is used for
recognition. Reported result for line segmentation is 100% and for word
segmentation 98%. Recognition accuracy achieved is 92.77% for handwritten
Marathi script.
Veena Bansal and R.M.K. Sinha (2000) presented a complete Devanagari
OCR system and tested it with real-life printed documents of varying size and
font. Most of the documents used were photocopies of the originals. Recognition
accuracy reported is 90%.
Neha Avhad et. al. (2015) elaborated system for handwritten Devanagari
character recognition. The system addresses the segmentation of handwritten
Devnagari text document, the most popular script of Indian sub – continent into
lines, words and characters. They have used artificial neural network technique to
design to pre-process, segment and recognize Devanagari characters.

13 Chapter 1: Introduction
Priyanka Kulkarni (2015) et. al. presented brief review on Marathi and
Sanskrit word recognition using genetic algorithm. They have used dictionary
based approach and curvelet transform features are used for recognition purpose.
Kapil Bamne and Neha Sharma (2015) presented a system for offline
classifier for handwritten Devanagari script recognition. They have focused on
the recognition of offline handwritten Hindi characters that can be used in
common applications like commercial forms, bill processing systems ,bank
cheques, passport readers, offline document recognition generated by the
expanding technological society.
Snehal S.Patwardhan and R. R. Deshmukh (2015) reported a brief review
on offline handwritten recognition of Devanagari script. They have elaborated
detailed overview of different feature extraction and classification techniques for
recognition process Devanagari script by the researchers over the past few
decades.
From literature it has been observed that, due to non availability
benchmark database of handwritten words, experiments are performed on varied
number of samples. Very few experiments were performed on large databases.
Many researchers are considering holistic approach for word recognition, in
which dataset is limited. Analytical approach for word recognition is
segmentation based approach. There are many hazards in segmentation based
approach which reduces recognition accuracy. Also many characters are similar
in shape and presence of compound characters in some scripts complicates the
process of word recognition. It may be concluded that, development of
handwritten OCR is most challenging and fascinating task for researchers
working in pattern recognition.

14 Chapter 1: Introduction
1.3 Motivation for the present work, Problem statement:
Marathi is a well known language spoken by the people of Maharashtra. It
is written in Devanagari script which is third most widely used script in the world.
There are around 100 million speakers of Marathi language which is the fourth
largest number of native speakers in India.
Handwritten Marathi OCR has numerous applications like the reading
machines for blind and visually impaired, number plate recognition, for reading
invoices, postal automation, automated processing of bank cheque and bank
statements, digitization of 7/12 documents and ration cards, automated evaluation
of answer sheets, automated processing of admission forms and recommendation
forms.
Significant work has been reported for handwritten Devanagari/Marathi character
recognition and for printed Marathi OCR. However, handwritten Marathi word
OCR is not addressed satisfactorily in case of unconstrained handwritten Marathi
words. OCR for unconstrained handwritten Marathi word is very complex due to
many reasons as stated below:
1. Number of vowels and consonants in Marathi is large.
2. Word formation in Marathi is complex.
3. Vowels can be combined with consonants in forms.
4. Diacritic marks can be placed to the left or right or above or bottom of the
consonant.
5. Vocabulary is very large.
6. Marathi has fused characters also known as ‘Jodakshare’.
7. Number of ‘Jodakshare’s are more and are used frequently as compare to
other languages written in Devanagari script.
8. Some of the vowels and consonants are very similar in shapes and
structure.

15 Chapter 1: Introduction
9. Every consonant when it combined with consonant takes form of half
character.
10. Literature review shared that not much research is reported for
handwritten Marathi word recognition.
The goal of optical character recognition is to come up with a recognizer
which has best possible recognition accuracy. In this work we are designing such
type of recognizer. Hence the problem may be stated as: Given a character set
and a database of handwritten characters from the character set, design efficient
recognizer that recognizes all characters in the character set accurately.
Efficient recognizer is the recognizer which recognizes handwritten
characters using minimum number of features.
Accurate recognition can be defined as high recognition accuracy across
all handwritings.
For this problem we have chosen:
1. Character set consists of either Marathi character or Marathi words.
2. A Marathi word set is infinite since meaning of the words is not
considered in the present work.
1.4 Organization of thesis:
This thesis is organized into eight chapters.
In chapter 2, we are presenting objectives of the research work and brief
description of the proposed system to recognize handwritten Marathi word.
In chapter 3, we presented a brief description about Marathi; characters
used and the formation of Marathi words. The method of development of
database for handwritten Marathi words is elaborated. Also development of
database for handwritten Marathi simple words, compound words and isolated
characters is presented. Preprocessing techniques that were used to improve
quality of word images and to reduce noise are elaborated.

16 Chapter 1: Introduction
In chapter 4, the methodology for segmentation of handwritten Marathi
words was described. In this chapter we have described difficulties in
segmentation of handwritten Marathi word. Segmentation algorithms are
presented for handwritten Marathi simple and compound words and results are
compared with earlier work.
In chapter 5, we are presenting a multilevel classification technique which
categorized Marathi characters into six different groups depending upon their
special properties.
In chapter 6, feature extraction techniques are presented for handwritten
Marathi characters such as zone based symmetric density, moment invariant,
zernike moment, discrete wavelet transformations, diagonal, horizontal and
vertical features and normalized chain code. Finally we have discussed how to
create a knowledge base which contains feature vectors for every image and
corresponding class labels.
In chapter 7, classification process is described in detail. Methods used
for classification such as k-NN and SVM are described. For rigorous testing and
validation a fivefold cross validation technique is presented. A comparative study
of two the classifiers namely, k-NN and SVM is elaborated.
Finally, the chapter 8 contains summary, conclusions and future directions
of work carried out in this thesis. The results of all the methods proposed in this
thesis are compared. Further, the comparative study of proposed method and other
methods in literature is also carried out. Lastly, future directions for research
based on the present work are presented.

Chapter 2 OBJECTIVES AND PROPOSED SYSTEM

Chapter 2
Objectives and Proposed System
---------------------------------------------------------------------------------------------------
2.1 Objectives 2.2 Description of the proposed system for Handwritten Marathi
Word Recognition
---------------------------------------------------------------------------------------------------
In this chapter, we are presenting objectives of the system. Also description of the
proposed system for handwritten Marathi word recognition is elaborated.
---------------------------------------------------------------------------------------------------
2.1 Objectives:
The varied applications and challenging tasks in developing handwritten
Marathi word OCR motivated us to design and develop an efficient and robust
system for recognizing handwritten Marathi word of any length written in Marathi
by any writer. Thus, the main objectives of the thesis may be states as:
To design and develop a benchmark database for handwritten Marathi
words.
To design and develop segmentation methodology for handwritten
Marathi words.
To design appropriate and efficient feature extraction algorithms for
handwritten Marathi word recognition.
To use appropriate classification methodology so as to achieve significant
recognition accuracy.

18 Chapter 2: Objectives and Proposed System
The proposed system for isolated handwritten Marathi word OCR is
discussed in the next section.
2.2 Description of the proposed system for handwritten Marathi word
Recognition:
There are two approaches for Handwritten Marathi Word Recognition
(further handwritten Marathi word recognition will be abbreviated as
HMWR): Holistic approach and analytical approach.
In holistic approach the word is considered as a single entity for
recognition. Holistic word recognition is also known as segmentation free
approach. Holistic approach of word recognition is simple and widely used if
domain of the words is limited.
In analytical approach the word is divided into their indivisible isolated
characters. Analytical approach is also known as segmentation based handwritten
word recognition. If domain of words is very large then analytical approach is
preferred.
We have adopted analytical approach for HMWR. The proposed model
for HMWR is shown in Fig. 2.1.
The process of handwritten Marathi word recognition is broadly classified
into two phases: Training phase and testing phase as shown in Fig. 1.2. Tasks in
the training phase are as follows:
Handwritten word database development: Training phase begins with
development of a reasonably large database to carry out experiments.
Database of 50000 unconstrained handwritten Marathi words is developed
and stored in the database. In addition, database of 10000 isolated
handwritten Marathi characters is developed and used in training phase. Preprocessing: Second step in handwritten Marathi word recognition is
preprocessing. Preprocessing is performed on input images to improve the
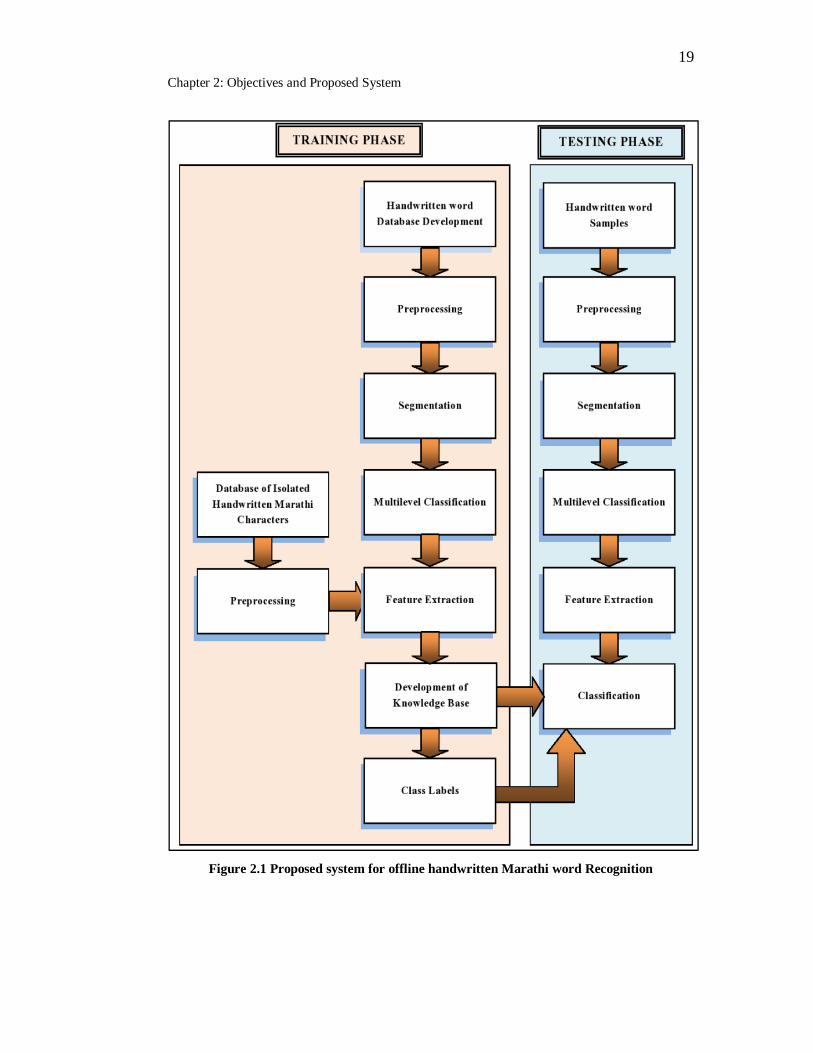
19 Chapter 2: Objectives and Proposed System
Figure 2.1 Proposed system for offline handwritten Marathi word Recognition

20 Chapter 2: Objectives and Proposed System
visual appearance and quality of image. Preprocessing operations like
image filtering, noise removal, morphological processing is performed.
Incorrect preprocessing may cause loss of information.
Segmentation: Third step in handwritten word recognition is
segmentation. Segmentation phase divides a word into meaningful
indivisible isolated characters. In handwritten word recognition system,
success of recognition largely depends on the effectiveness of
segmentation phase.
Multilevel classification: The multilevel classification technique is
developed for handwritten character categorization. In this, the character
set is divided into groups depending on specific properties of the
characters. The set of all Marathi characters are grouped into six classes
depending on their special properties.
Feature extraction: Feature is the property of input data to distinguish
objects uniquely. Feature extraction phase extracts features from input
image and is stored in a feature vector. In the proposed system features
are extracted from isolated characters as well as segmented characters and
stored in a feature vector.
Development of Knowledge base: Using the feature vectors of isolated
handwritten characters and feature vectors of segmented characters
knowledge base for handwritten Marathi word recognition is developed.
The knowledge base contains feature vectors for each image with their
class labels. The knowledge base developed in the training phase is
further for classification in the testing phase.
Tasks in testing phase are as follows:
In this phase tasks are similar to those in training phase such as
preprocessing, segmentation, multilevel classification and feature extraction as
shown in Fig. 1.2, are performed. In this phase some selected samples from the

21 Chapter 2: Objectives and Proposed System
database are used as input. Handwritten Marathi word input images are first
preprocessed, segmented, grouped into six groups using multilevel classification
and features are extracted from the segmented characters. In testing phase, the
segmented character is classified and recognized and a label is assigned to the
character. In the present work, two systems (OCR) are proposed for character
recognition based on SVM and k-NN methods respectively.
The input for the handwritten Marathi word recognition system is
handwritten Marathi word and the outcome of the system will be class labels for
every isolated character, half character and modifier present in the input word.
All the algorithms stated in this thesis are implemented in MATLAB Version 7.
In the next chapter development of database and preprocessing techniques
applied in this work are discussed.

Chapter 3 DEVELOPMENT OF A DATABASE OF
HANDWRITTEN MARATHI WORDS,
ISOLATED CHARACTERS AND
PREPROCESSING

Chapter 3
Development of a database of the handwritten Marathi
words, isolated characters and pre-processing ------------------------------------------------------------------------------------
3.1 Introduction
3.2 Marathi characters
3.3 Formation of Marathi words
3.4 Database Development 3.4.1 Database development for handwritten Marathi simple words
3.4.2 Database development for handwritten Marathi compound words
3.4.3 Database development for isolated handwritten Marathi characters
3.5 Pre-processing
------------------------------------------------------------------------------------
In this chapter, we are presenting brief description about Marathi language,
characters used in Marathi and formation of Marathi words. Also we have
presented the method for development of a database of the handwritten Marathi
isolated characters, simple words and compound words. Further pre-processing
techniques used to improve quality of word images and to reduce noise are
elaborated. Normalization is carried out for handwritten Marathi words and
isolated characters without disturbing aspect ratio.
--------------------------------------------------------------------------------------------------- Part of this has been chapter published in the Proceedings of National Conference on Challenging Research Areas in Computer Science and Information Technology - 2014, ISBN 978-93-83777-00-6.

23 Chapter 3: Development of database for handwritten Marathi words, characters and preprocessing
3.1 Introduction:
An overview of Marathi language, characters used in Marathi and various
word formations rule complicate the process handwritten Marathi word
recognition. The method of preparing the database for isolated handwritten
Marathi characters and isolated handwritten Marathi words is discussed in detail.
Pre-processing techniques helps to improve the quality and reduce the noise in the
images. Sufficient amount of work had been carried out and reported on isolated
Devanagari characters in the literature discussed below.
Bikash Shaw et. al. (2008) have reported a database of 39700 samples
using 100 classes from 436 writers for handwritten Devanagari words. Brijmohan
Singh et. al. (2011) has developed a database of 28500 word samples for 30
classes for handwritten Devanagari word from 950 writers. Laurent Guichard et.
al. (2010) have reported a database of 2000 samples for 10 classes of Devanagari
numerals written in word form from one to ten numerals. This database consists
of 10 classes and for each class 200 samples are stored. Naresh Kumar Garg et.
al. (2010, 2011, 2013) developed a database for handwritten Hindi text consisting
of 200 lines and 1380 words. R. Jayadevan et.al. (2011) developed a database of
26720 word samples for handwritten Marathi legal amounts consisting of 114
classes. G.G.Rajput et. al. (2010) used 100 blocks of handwritten Hindi script.
Rajiv Kumar et. al. [113] developed a database of 2,000 constrained and 2,000
unconstrained handwritten Devanagari words. Sandip N. Kamble et. al.(2011)
developed a database of 100 handwritten Devanagari words. Vijaya Rahul Pawar
et. al. (2014) developed a database of 3000 handwritten Marathi word.
It is observed from literature that experiments by researchers were
performed on databases various sizes ranging from 100 to 39700 having different
datasets. The method for database development and pre-processing techniques
applied are discussed in the next sections.

24 Chapter 3: Development of database for handwritten Marathi words, characters and preprocessing
Marathi language: Marathi is well known language spoken by people of
Maharashtra. Marathi belongs to the Indo-Aryan group of languages. Indo-
Aryan languages are originated from Sanskrit. Currently balbodh script is used
for Marathi language and is originated from Devanagari script. Marathi has
influence of other languages like Sanskrit, Kannada and Telugu. Also lots of
words are entered into Marathi from Persian, Turkish and Arabic as well as
Portuguese and the British have influenced Marathi through their words.
3.2 Marathi Characters:
Marathi consists of a total 53 characters out of which 16 are vowels and 37
are consonants.
Marathi vowels:
The 16 Marathi vowels are classified into two groups; the first group
contains 12 vowels as shown in Fig. 3.1 while the second group contains four
vowels as shown in Fig. 3.2.
Fig. 3.1: First Group of Marathi Vowels
Fig. 3.2: Second Group of Marathi Vowels
First group of vowels are commonly used where as second group of
vowels are very rarely used. Out of four vowels of the second group two vowels
( ) have never been used in Marathi and remaining two vowels are found
only in three words called 'kL^iptee', ‘R^ishI’, ‘R^itU’ as shown in Fig. 3.3.

25 Chapter 3: Development of database for handwritten Marathi words, characters and preprocessing
Fig. 3.3: Three words contains remaining two vowels
Since second group of Marathi vowels are not commonly used, we have
considered only first group of vowels for our study.
Marathi consonants:
The 37 consonants are broadly classified into six groups as shown in Fig. 3.4
according to their pronunciation.
Fig. 3.4 (a): First group of Marathi consonants Fig. 3.4 (b): Second group of Marathi consonants Fig. 3.4 (c): Third group of Marathi consonants Fig. 3.4 (d): Fourth group of Marathi consonants Fig. 3.4 (e): Fifth group of Marathi consonants Fig. 3.4 (f): Sixth group of Marathi consonants
Out of all 37 consonants first 25 consonants are classified into five groups
where each group contains five consonants. First group of consonants is called
‘Kantha’ because they are pronounced from the throat. Second group of
consonants is called 'Murdhanya' because they are pronounced by touching the
tongue to 'Murdhani' which is a part of the upper jaw between the roof and the
teeth. Third group of consonants is called 'Taalavya' because they are pronounced
by touching the tongue to the palate. Fourth group of consonants is called
'Dantya' because the tongue touches the teeth while pronouncing these. Fifth
group of consonants is called 'Aushthya' because they are pronounced by touching
the lips together. Sixth group consists of twelve remaining consonants which are
pronounced using combination of usage of tongue.

26 Chapter 3: Development of database for handwritten Marathi words, characters and preprocessing
In Marathi out of 37 consonants, 36 consonants are commonly used but
one consonant ( ) is rarely used hence only 36 consonants are considered in this
work.
Finally the total 48 characters in Marathi are considered in this work
which consists of 12 vowels and 36 consonants as shown in Fig. 3.5.
Fig. 3.5(a) Marathi vowels
Fig. 3.5(b) Marathi Consonants
3.3 Formation of Marathi Words:
In Marathi, word formation is a very complex system because number of
vowels and consonants are more than English. Also during word formation
vowels may be combined with consonants. Whenever vowels are combined with
consonants they will take different forms called diactric marks such as ‘Kana’,
’Matra’, ’Ukar’, ’Velanti’, ’Anuswar’ or ’Visarg’.
In addition to this Marathi has a complex system of compound or fused
characters where more than one consonant are combined called ‘Jodakshare’. In
‘Jodakshare’ first consonant converted into half form and second has its full
form. Also two different words are also combined when second word is starting
with vowel.
Following Fig. 3.6 shows full consonant and its corresponding half
consonant.

27 Chapter 3: Development of database for handwritten Marathi words, characters and preprocessing
Fig. 3.6(a): Group one consonants and its corresponding half consonant.
Fig. 3.6(b): Group two consonants and its corresponding half consonant.
Fig. 3.6(c): Group three consonants and its corresponding half consonant.
Fig. 3.6(d): Group four consonants and its corresponding half consonant.
According to their form half consonants are classified into 5 groups.
Group one contains those consonants are having vertical bar at the end and we get
corresponding half consonant form by removing vertical bar. Group two is
consonants not having vertical bar and we get corresponding half consonant form
by adding slanting line below the consonant. Group three contains only one
consonant with small vertical line on right-top end ( ) and we get half consonant
form by removing that small vertical line ( ). Group four contains two
consonants ( and ) having curve on the right side and formation of half
a b
c d

28 Chapter 3: Development of database for handwritten Marathi words, characters and preprocessing
consonant is obtained by removing half curve. Group five contains consonants
which take multiple forms depending on the next character ( and ).
3.4 Database development:
In order to develop a system for offline handwritten Marathi word
recognition sufficient amount of database is required. Database has to contain
large vocabulary and variations. No standard database is available for Marathi.
3.4.1 Database for Handwritten Marathi simple words:
It is observed from literature that experiments by researchers were
performed on databases various sizes ranging from 100 to 39700 having different
datasets. Also literature review indicates that benchmark database for handwritten
Marathi word is not available for carrying out experiments. Since a benchmark
database is not available [32] our first attempt was to develop a database for
handwritten Marathi words.
Marathi contains two types of words such as simple words and compound
words. Simple words do not have ‘Jodakshare’ while compound words have. To
develop a database for handwritten Marathi simple words, a dataset consisting of
50 commonly used Marathi words were selected as shown in Fig. 3.7. While
selecting simple words we have taken care that all possible combinations of vowel
modifiers and consonants will appear in the words.
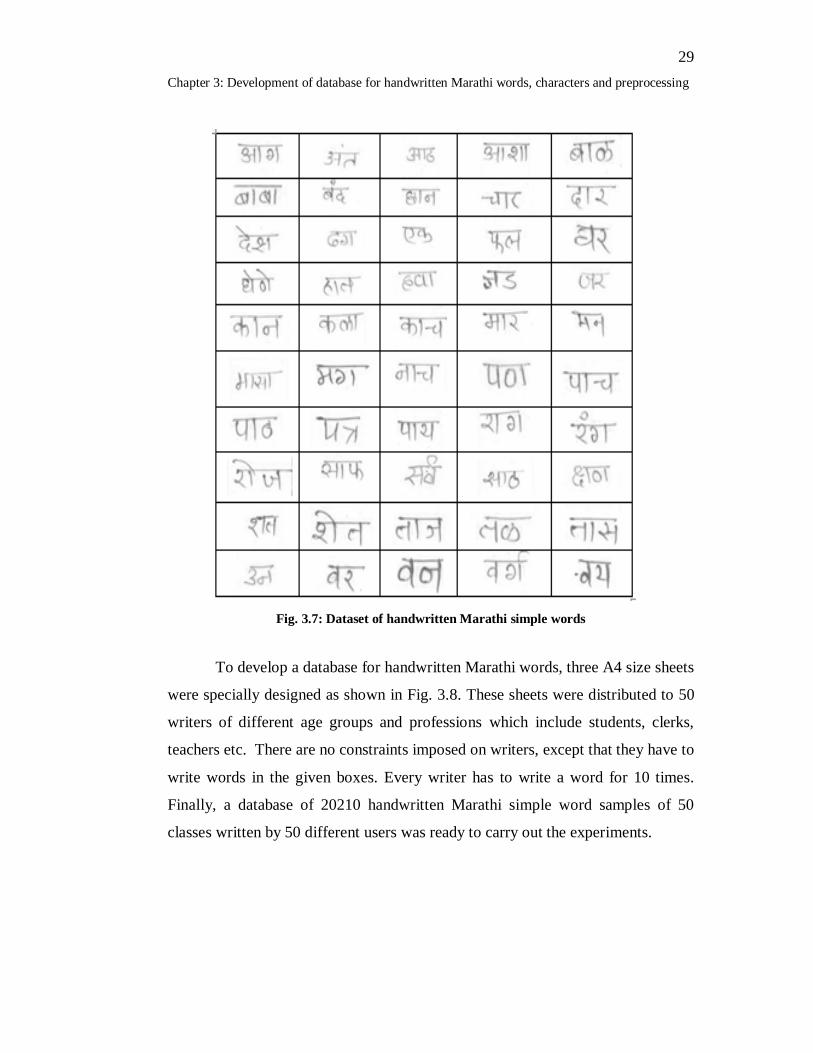
29 Chapter 3: Development of database for handwritten Marathi words, characters and preprocessing
Fig. 3.7: Dataset of handwritten Marathi simple words
To develop a database for handwritten Marathi words, three A4 size sheets
were specially designed as shown in Fig. 3.8. These sheets were distributed to 50
writers of different age groups and professions which include students, clerks,
teachers etc. There are no constraints imposed on writers, except that they have to
write words in the given boxes. Every writer has to write a word for 10 times.
Finally, a database of 20210 handwritten Marathi simple word samples of 50
classes written by 50 different users was ready to carry out the experiments.

30 Chapter 3: Development of database for handwritten Marathi words, characters and preprocessing
Fig. 3.8: Sample of sheets for collection of handwritten Marathi simple words
The handwritten data sheets were then scanned using a flat bed scanner at
a resolution of 1200 dpi and stored as gray scale images. Handwritten words
from the scanned gray scale images were manually cropped and stored in
respective class folders. The Fig. 3.9 shows some handwritten simple words in
gray scale cropped from the scanned image of a datasheet.
Fig. 3.9: Sample handwritten Marathi simple words

31 Chapter 3: Development of database for handwritten Marathi words, characters and preprocessing
3.4.2 Database for handwritten Marathi compound words:
As discussed in section 2.4.1 Marathi consists of compound words also
called as fused words. Compound word contains fused characters known as
‘Jodakshare’. Occurrences of compound characters in Marathi is more frequent
(11 to 12%) as compared to other languages written in Devanagari (5 to 6%)
Shelke and Apte (2010).
To develop a database for handwritten Marathi compound words, the
dataset consisting of 47 commonly used Marathi words are selected as shown in
Fig. 3.10. While selecting the compound words all possible combinations of
vowels, modifiers and consonant clusters are considered.
Fig. 3.10: Dataset of handwritten Marathi compound words
Also A4 size sheets were specially designed to collect handwritten
Marathi word from 50 different users as shown in Fig. 3.11.

32 Chapter 3: Development of database for handwritten Marathi words, characters and preprocessing
Fig. 3.11: Sample A4 sheet for Handwritten Compound words
We have adopted the same procedure for scanning, manually cropping
and storing in the respective class-folders as described in section 2.4.1. Finally, a
database of 16073 handwritten Marathi compound word samples of 47 classes
written by 50 users is ready for experiments. Sample handwritten compound
words are shown in Fig. 3.12.
Fig. 3.12: Sample handwritten Marathi compound words

33 Chapter 3: Development of database for handwritten Marathi words, characters and preprocessing
3.4.3 Database for isolated handwritten Marathi characters:
We have designed A4 size sheets for data collection of Marathi
handwritten Marathi characters and distributed the sheets amongst 20. We have
adopted same procedure for scanning, cropping and storing into respective class-
folders as described in Section 3.4.1. Finally, a database of 9600 isolated
handwritten Marathi characters of 48 classes, written by 20 persons is ready for
experiments.
Fig. 3.13: Sample A4 sheet for isolated handwritten Marathi characters

34 Chapter 3: Development of database for handwritten Marathi words, characters and preprocessing
3.5 Pre-processing:
Pre-processing refers to a number of operations that may be performed on
the input intensity images to obtain outputs with good quality intensity images.
The main objective of pre-processing is to remove noise from images, to enhance
quality of input images and to represent word images in standard plane.
3.5.1 Noise Removal:
Digital images contain noise due to various reasons such as movement in
acquisition process or inaccuracy in instrument for digitization. Noise removal is
an important step in preprocessing. There are several techniques for noise
removal like low-pass, high-pass, band-pass, spatial filtering, mean filtering,
median filtering. To reduce the blurring of word edges, suppress noise and
improve some features, the median filter is used. Median filter preserves edges
and removes noise. An example of the median filtering process on raw input
image is shown in Fig. 3.14.
Fig. 3.14 Example of Median filtering

35 Chapter 3: Development of database for handwritten Marathi words, characters and preprocessing
3.5.2 Binarization:
Binarization operation takes input as indexed, intensity or RGB images
and outputs binary images. Here gray scale image is converted into binary image
having values 0 and 1. Gray scale image values are converted to 0 and 1
depending upon a threshold. The threshold for the gray scale image is calculated
by using histogram-shape based image thresholding suggested by Otsu. Otsu’s
method reduces interclass variance.
Ostu’s method assumes two classes of pixels (foreground and background)
in input image and calculates the optimum threshold value for separating those
two classes. The output binary image contains 0 if values of pixels in input image
are less than the calculated threshold value and 1 for all other pixels.
Ostu’s Algorithm:
Input: Nandwritten Marathi word / character images.
Output: Pre-processed handwritten Marathi word / character
Procedure:
1. Compute the normalized histogram of the input image. Denote the
components of the histogram by Pi, i=0,1,2,…L-1.
2. Compute the cumulative sums, P1(k), for k=0,1,2,…,L-1, using
퐏ퟏ(퐤) = 퐏퐢
풌
풊 ퟎ
3. Compute the cumulative means, m(k), for k=0,1,2,…,L-1, using
퐦(퐤) = 퐢 ∗ 퐏퐢
풌
풊 ퟎ
4. Compute the global intensity mean, mG, using
퐦퐆 = 퐢 ∗ 퐏퐢
푳 ퟏ
풊 ퟎ

36 Chapter 3: Development of database for handwritten Marathi words, characters and preprocessing
5. Compute the between-class variance, 훔푩ퟐ(푲), for k=0,1,2,…,L-1, using
훔푩ퟐ(푲) =
[풎푮푷ퟏ(풌)− 풎(풌)]ퟐ
푷ퟏ(풌)[ퟏ − 푷ퟏ(풌)]
6. Obtain the Otsu threshold, k*, as the value of k for which 훔푩ퟐ (푲) is
maximum. If the maximum is not unique, obtain k* by averaging the
values of k corresponding to the various maxima detected.
7. Obtain the separability measure, η*, by evaluating
. 휼(푲) = 훔푩ퟐ (퐤∗)훔푮ퟐ
3.5.3 Normalization:
Handwritten words are varying in size and shape. We need to map these
word images onto a standard plane (with predefined size) so as to give a
representation of fixed dimensionality for classification. Normalization is
performed on the image to reduce the inter-class and intra-class variations of the
shapes of the words. Normalization operation facilitates segmentation process and
improves their segmentation accuracy. Linear normalization method is used to
standardize the word images. The standard plane is considered as a square of size
60 pixels x 90 pixels. The width and height ratio of the word image is not
disturbed due to normalization.
3.5.4 Thinning:
A morphological operation known as thinning, is also performed on word
images. The goal of character thinning is to remove pixels so that an object
without holes shrinks to a minimally connected stroke, and an object with holes
shrinks to a ring halfway between the hole and outer boundary. Thinning Marathi
words is very difficult task due to the presence of loops. This thinning operation
preserves Euler number. Thinning operation is related to hit-or-miss transform

37 Chapter 3: Development of database for handwritten Marathi words, characters and preprocessing
and is represented as follows. Thinning of a set A by a structuring element B, is
defined as follows in terms of hit-or-miss transforms
퐴퐵 = 퐴 − (퐴 퐵) = 퐴 ∩ (퐴 퐵)
In this process we have used a sequence of structuring elements as
follows:
In the next chapter algorithms for segmentation of words into isolated
characters are described and analyzed.
},...,,,{}{ 321 nBBBBB

Chapter 4 SEGMENTATION

Chapter 4
Segmentation -------------------------------------------------------------------------------
4.1 Introduction
4.2 Segmentation and Difficulties in Segmentation
4.3 Segmentation Methodology for simple words
4.4 Segmentation methodology for compound words
4.5 Discussion of Results
4.6 Analysis of Results --------------------------------------------------------------------------------------------------- In this chapter, we have presented a brief description about segmentation of
handwritten Marathi words and difficulties in segmentation. Segmentation
algorithms are proposed for handwritten Marathi simple words and compound
words. Proposed algorithms are rigorously tested on the database developed for
this research and results are reported.
---------------------------------------------------------------------------------------------------
4.1 Introduction:
There are two approaches for handwritten text recognition. The first one is
a holistic approach which is more useful if words are limited. In this approach
features are extracted directly from word samples and classified. But, since
Marathi consists of many words, this approach is not appropriate.
The second approach is a segmentation based approach in which
handwritten Marathi words are divided into isolated indivisible characters, and
then these indivisible characters are used for classification process.

39 Chapter 4: Segmentation
The problem of segmentation of words and difficulties in segmentation are
well studied and reported in the literature. The problem of segmenting the old
typewritten Gujarati documents' is considered by Apurva desai (2012) and has
achieved 65% segmentation accuracy by using vertical projection method.
Bikash Shaw et. al. (2008) and Brijmohan Singh et. al. (2011) also reported the
use of projection method for handwritten word recognition. Dipankar Das and
Rubaiyat Yasmin [47] reported best cut method for touching Bangala numerals
and achieved 89.7% segmentation accuracy. Naresh Kumar Garg et. al. (2010)
has considered the problem of segmentation of Hindi text and reported 79.12%
segmentation accuracy by using vertical projection method. Morphological
approach for segmentation of handwritten Devanagari text is reported by Sandip
N. Kamble and Megha Kamble (2011) and achieved 52% segmentation accuracy.
Suryaprakash Kompalli et. al. (2009) reported a graph based segmentation
approach, and achieved 85% segmentation accuracy.
It has been observed from the literature that experiments of segmentation
were performed on a number of samples. However, few experiments were
performed on large databases. There are many hazards in segmentation based
approach which reduces recognition accuracy. Also presence of compound
characters complicates the process of word segmentation. Hence, we conclude
that, there is a need to address the problem of segmentation of handwritten
Marathi words.
4.2 Segmentation and difficulties in segmentation:
Segmentation is the process that decomposes the image into multiple
meaningful subparts. Text segmentation process divides written text into words
and characters. Text segmentation is a non-trivial problem because some written
languages have explicit word boundary markers, such as in written English and
the distinctive initial, medial and final letter shapes in Arabic. Such delimiters are

40 Chapter 4: Segmentation
sometimes ambiguous and not present in all languages. Many techniques were
developed for image segmentation. These general techniques have to be
combined with domain knowledge to solve domain specific segmentation
problems. The general purpose segmentation methods are based on thresholding,
clustering, compression, histogram, edge detection, dual clustering, region
growing, partial differential equations and graphs. Segmentation of handwritten
Marathi word is a very difficult and challenging task because of various reasons
described below.
4.2.1. Shirorekha:
Marathi has a most prominent characteristic in every word called header
cap known as ‘Shirorekha’ which is written from left to right on the top of
characters in the words. Sometimes writers don’t write ‘Shirorekha’ or is broken
or slanted or is mixed with characters. Detecting the location of ‘Shirorekha’ is
an important part for segmentation process. If location of ‘Shirorekha’ is not
detected correctly segmentation of word fails which ultimately results in
misclassification of the word. Sample words without ‘Shirorekha’ and broken
‘Shirorekha’ are shown in Fig. 4.1.
Fig. 4.1: Words where no ‘shirorekha’ written
4.2.2. Touching characters:
Due to irregular handwritings it may happen that characters touch to each
other or connected to the modifiers of other characters. Touching characters
create problems during segmentation of words into isolated indivisible characters
that may lead to misclassification of words. Sample words with touching
characters are shown in Fig. 4.2.

41 Chapter 4: Segmentation
Fig. 4.2: Words having touching characters
4.2.3. Slanting characters:
Due to different handwriting styles or style of keeping paper it may
happen characters in the words are slanted. It is very difficult to detect the
location of ‘Shirorekha’ if slanted characters or slanted ‘shirorekha’ present in the
word, which hampers segmentation process. Sample words with slanted
characters are shown in Fig. 4.3.
Fig. 4.3: Words having slanted characters
4.2.4. Broken characters:
Due to various reasons such as pen not working properly, incorrect writing
style, poor quality paper or damaged paper may result in broken characters. If
characters are broken in the word, it may cause over segmentation of character.
Over segmentation reduces the recognition accuracy of a word. Sample words
with broken characters are shown in Fig. 4.4.
Fig. 4.4: Words having broken characters

42 Chapter 4: Segmentation
4.2.5. Overlapping characters:
It may happen that characters are overwritten due to improper writing
style or if writer is in hurry. Also modifiers are overwritten on characters. Due to
overlapping characters segmentation fails to segment isolated characters and
modifiers which lead to misclassification of words. Sample words with
overlapping characters are shown in Fig. 4.5.
Fig. 4.5: Words having overlapping characters
4.3 Segmentation methodology for simple words: An algorithm to segment simple Marathi words into characters is
described below.
Algorithm 1: Segmentation of Marathi simple words.
Input: Handwritten Marathi Word Image
Output: Segmented isolated indivisible characters.
1. Read input handwritten Marathi word image.
2. Perform pre-processing on input image.
3. Calculate horizontal projection for the word image.
4. Find out the row number which contains maximum number of white
pixel in horizontal projection label it as header_line (‘Shirorekha’).
5. Convert all white pixels to black pixels of the header_line identified in
step 4.
6. Divide word image into two parts. First part above ‘Shirorekha’
cropped from the word image labeled as top_strip of that word
contains top modifiers if any and second part labeled as core_area of
the word.

43 Chapter 4: Segmentation
7. Calculate vertical projection for the core_area of the word image.
8. Find number of segments present in the core_area of word by using
vertical projection label the number as no_of_isolated_characters.
9. Repeat steps from 10 to 15 for the no_of_isolated_characters.
10. Skip all zeros.
11. Find out first column location contains nonzero value labeled as
starting_point.
12. Skip all nonzero numbers till zero.
13. Assign column location - 1 to the end_point.
14. Crop the word image from starting_point to end_point column
numbers mark it as isolated_character.
15. Assign remaining image to the core_area of word image.
16. Segment top modifiers in top_strip and assign modifiers to respective
segmented character in core_area using Algorithm 2.
Algorithm 2: Segmentation of modifiers and assign to characters.
Input: Top strip image identified in step 6 Algorithm 1.
Output: Segmented top_modifiers and assign to core_area word segments.
1. Calculate vertical projection for the top_strip.
2. Find number of segments present in top_strip.
3. Repeat step 4 to 6 for number of segments.
4. Find end_point of the segment.
5. If end_point of segment is greater than starting_point and less than
ending point of any segment in core_area word image assign top_strip
segment to the segment of core_area.
6. Otherwise if end_point of segment is greater than core_area segments
end_point and less than starting_point of next segment then assign
top_strip segment to first segment of core_area.

44 Chapter 4: Segmentation
4.4 Segmentation of compound words:
Marathi consists of compound words, also known as fused words. A
compound word contains fused characters known as ‘Jodakshare’. Occurrences
of compound character in Marathi are about 11 to 12% where as in other
languages written in Devanagari is just 5 to 6% [145]. According to their form
half consonants are classified into 5 groups. Group one contains those consonants
that have vertical bar at the end for which we get corresponding half consonant
form is obtained by removing the vertical bar. Group two contains consonants
that do not have a vertical bar. In this case, corresponding half consonant form is
obtained by adding a slanting line below the consonant. Group three contains
only one consonant with small vertical line on right-top end ( ) and we get half
consonant form by removing that small vertical line ( ). Group four contains
two consonants ( and ) having curve on the right side and formation of half
consonant is obtained by removing the half curve. Group five contains
consonants take multiple forms depending on the next character ( and ).
A segmentation algorithm that depends on the groups mentioned above is
defined for compound words.
4.4.1 Segmentation methodology for compound words:
An algorithm to segment compound Marathi words into characters is
described below.
Algorithm 3: Compound word segmentation
Input: Handwritten Marathi Word Image
Output: Segmented isolated indivisible characters.
1. Read a handwritten Marathi word image as input.
2. Perform pre-processing on input image.
3. Find horizontal projection of the word image and label it as

45 Chapter 4: Segmentation
horizontal_projection.
4. Find row number from horizontal_projection which contains maximum
value and label it as header_line. Header_line is also known as
‘Shirorekha’ in Marathi which contains maximum number of white
pixel.
5. Convert all white pixels to black pixels of the header_line identified in
step 4.
6. Divide the input word image into two parts depending on header_line.
First part is above header_line cropped from the input word image
labeled as top_modifier of that word which contains top modifiers if
any. Second part is below header_line cropped from input word image
labeled as core_area of the word.
7. Calculate vertical projection for the core_area of the word image
labeled as ca_vertical_projection.
8. Find number of segments present in the ca_vertical_projection label it
as number_of_characters.
9. Repeat steps from I to VII for the number_of_characters.
I. Scan ca_vertical_projection and skip all zeros.
II. Find out first column location contains nonzero value labeled it as
starting_point.
III. Skip all nonzero numbers till zero in ca_vertical_projection.
IV. Assign column location - 1 to the end_point.
V. Crop the input image from column number starting_point to column
number end_point and label it as char.
VI. To check whether compound character is present or not in char call
Algorithm 4.
VII. Mark the char who contains lower modifier based on threshold_height
of character. Crop lower_modifier from core_area of the char and
assign lower_modifier to respective char using Algorithm 5.

46 Chapter 4: Segmentation
VIII.Assign remaining image of core_area to core_area.
10. Segment top_modifier and assign modifiers to respective segmented
character in core_area using Algorithm 6.
Algorithm 4: Check for compound character present or not and set cut point.
Input: Character image from step 10(vi) of Algorithm 3.
Output: Isolated indivisible characters.
1. Check if compound character is present or not.
if height(char) > width(char)
then
no compound character present;
return char image;
exit;
else
goto step 2;
end;
2. Find vertical_projection of char. Labled it as vp_char.
3. Check for vertical bar present or not.
for i=1 : 1 : number_of_columns
if vp_char(i) >= 42
then
vertical_bar=vertical_bar+1;
end;
end;
4. Set cut point for compound character segmentation.
if vertical_bar >= 2
then
difference=location_second_bar - location_first_bar;

47 Chapter 4: Segmentation
cut_point = location_first_bar + (difference * 0.25);
else
if lower modifier present
then
cut_point=(start_point+end_point)/2;
else
difference=end_point – start_point;
cut_point=start_point + diff *0.40;
end;
end;
half_char=crop(char,start_point,cut_point);
full_char=crop(char,cut_point,end_point);
5. Return (half_char, full_char)
Algorithm 5: Separate lower modifier from character.
Prerequisite: There are three possible relationships between character and lower
modifiers if present.
A. Weak joining: Lower modifier below a middle bar or end bar character has weak
joining. Also some non bar character having small vertical bar also forms weak
joining with lower modifier.
B. Thick Joining: lower modifiers may be connected to some characters at more than
one location.
C. Gap: Sometimes lower modifiers are not joined to characters.
Input: Suspected character that contains lower_modifier.
Output: Segment lower modifier and assign to character.
1. Calculate horizontal projection for the character image.
2. If C relationship is present then find the row which contains no white
pixel, use that row to separate lower modifiers from the character
image.
3. If A relationship then find the row which contains minimum number of

48 Chapter 4: Segmentation
pixels. Check if height (lower_modifier) >= (threshold_height * 0.20)
then crop char image from located row to bottom boundary. Otherwise
lower modifier is not present.
4. If B relationship then find row which contains minimum number of
pixels assigns to min_row_num below threshold_height, then set
cut_point = (min_row_num - threshold_height)/2. Crop char image
from cut_point to bottom boundary of character.
Algorithm 6: Segment Top_modifier and assign to respective character.
Input: Top strip image identified in step 6 Algorithm 1.
Output: Segmented top modifiers and assign to core_area word segments.
1. Calculate vertical projection for the top_strip.
2. Find number of segments present in top_strip.
3. Repeat step 4 to 6 for number of segments.
4. Find end point of the segment.
5. If end point of segment is greater than starting_point and less than
end_point of any segment in core_area word image, assign top_strip
segment to the segment of core_area.
6. Otherwise if end_point of segment is greater than core_area segments
end_point and less than starting_point of next segment then assign
top_strip segment to first segment of core area.
4.5 Discussion of results:
Segmentation algorithms proposed for simple words and compound words
are tested on the database. Database contains 20210 Marathi simple words and
16000 Marathi compound words. Segmentation results for simple words are
elaborated in Table 4.1 and for compound words are elaborated in Table 4.2.
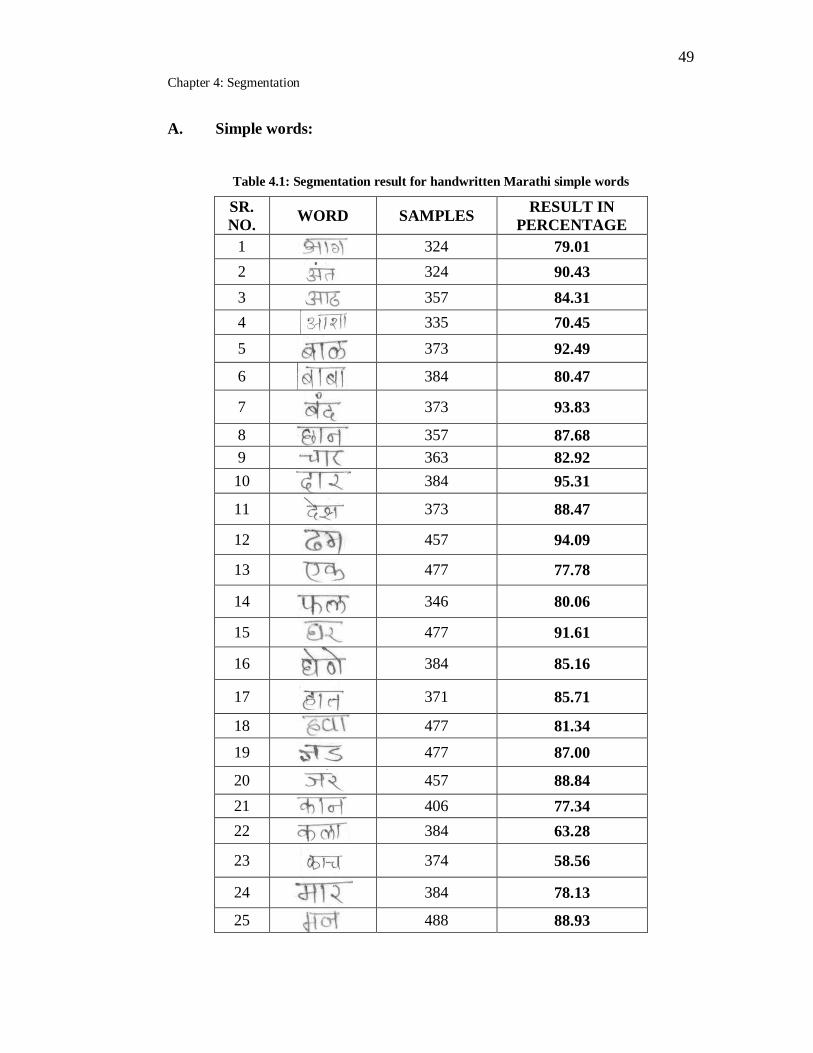
49 Chapter 4: Segmentation
A. Simple words:
Table 4.1: Segmentation result for handwritten Marathi simple words
SR. NO. WORD SAMPLES RESULT IN
PERCENTAGE 1 324 79.01 2 324 90.43 3 357 84.31 4 335 70.45 5 373 92.49
6 384 80.47
7
373 93.83
8 357 87.68 9 363 82.92 10 384 95.31
11 373 88.47
12 457 94.09
13 477 77.78
14
346 80.06
15 477 91.61
16
384 85.16
17
371 85.71
18 477 81.34 19 477 87.00
20 457 88.84 21 406 77.34 22 384 63.28
23
374 58.56
24 384 78.13
25 488 88.93
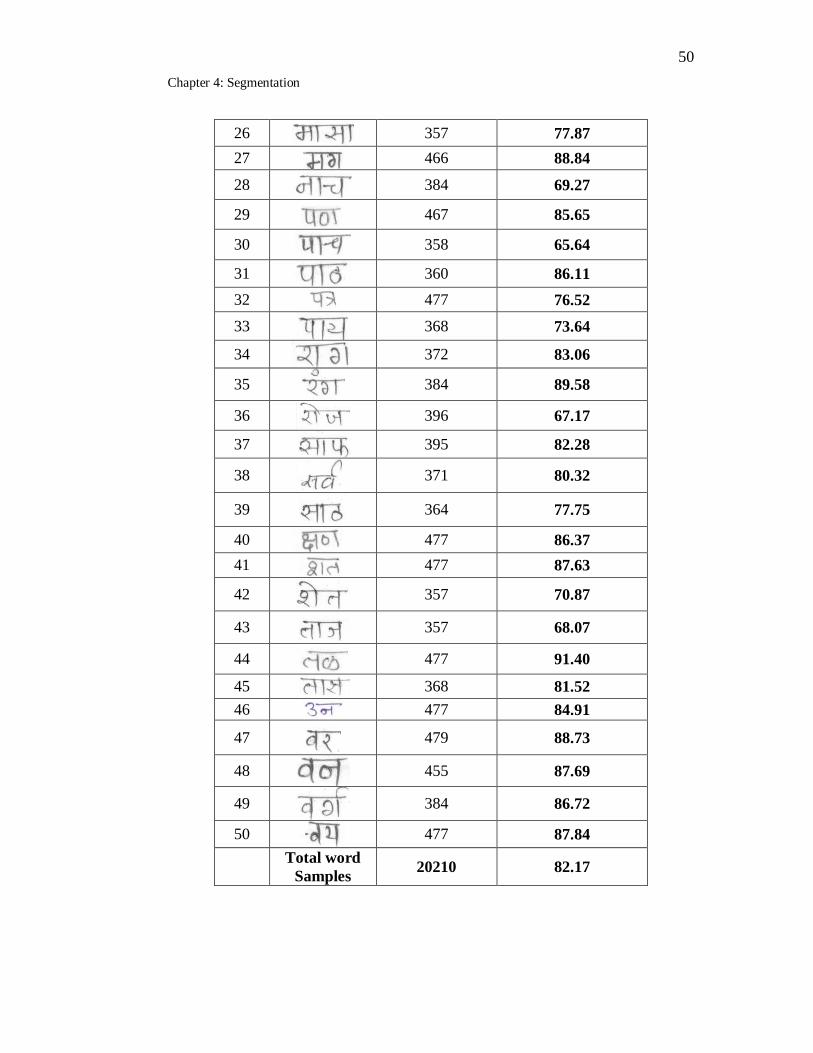
50 Chapter 4: Segmentation
26 357 77.87 27 466 88.84 28 384 69.27
29 467 85.65
30 358 65.64
31 360 86.11 32 477 76.52 33 368 73.64
34 372 83.06
35
384 89.58
36 396 67.17
37 395 82.28
38
371 80.32
39
364 77.75
40 477 86.37 41 477 87.63
42
357 70.87
43
357 68.07
44 477 91.40
45 368 81.52 46 477 84.91
47
479 88.73
48 455 87.69
49
384 86.72
50 477 87.84
Total word
Samples 20210 82.17
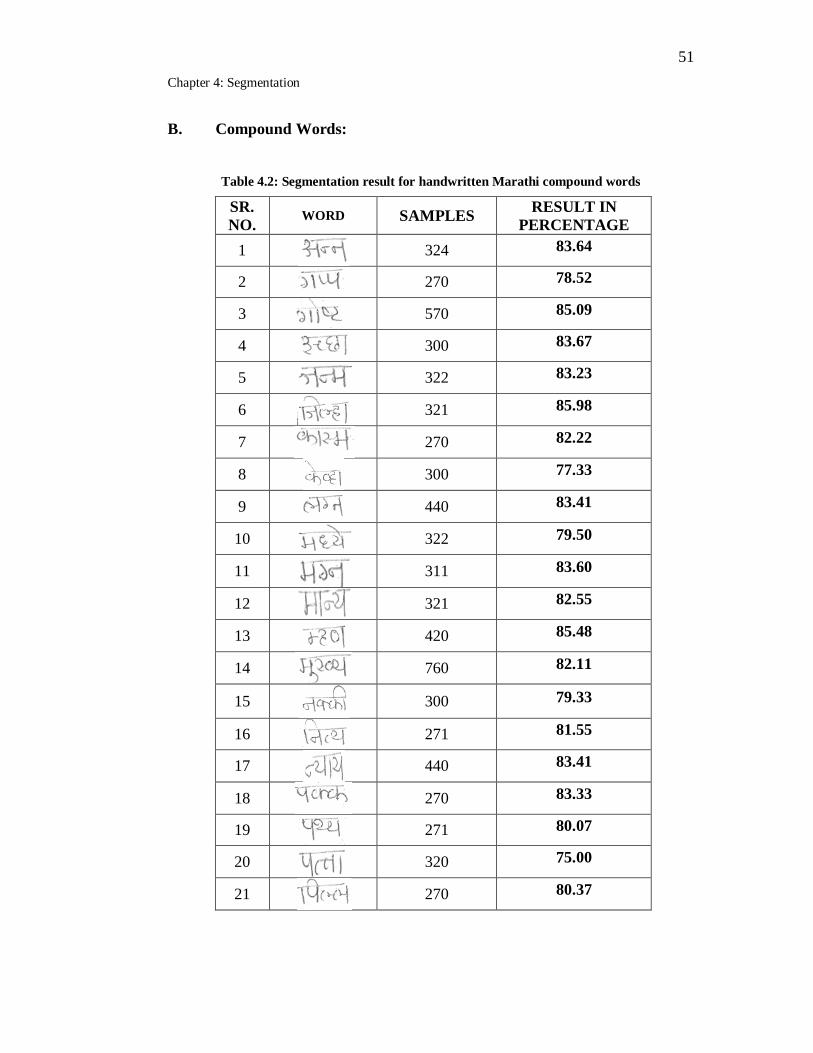
51 Chapter 4: Segmentation
B. Compound Words:
Table 4.2: Segmentation result for handwritten Marathi compound words
SR. NO. WORD SAMPLES RESULT IN
PERCENTAGE 1
324 83.64
2
270 78.52
3
570 85.09
4
300 83.67
5
322 83.23
6
321 85.98
7
270 82.22
8
300 77.33
9
440 83.41
10
322 79.50
11
311 83.60
12
321 82.55
13
420 85.48
14
760 82.11
15
300 79.33
16
271 81.55
17
440 83.41
18
270 83.33
19
271 80.07
20
320 75.00
21
270 80.37
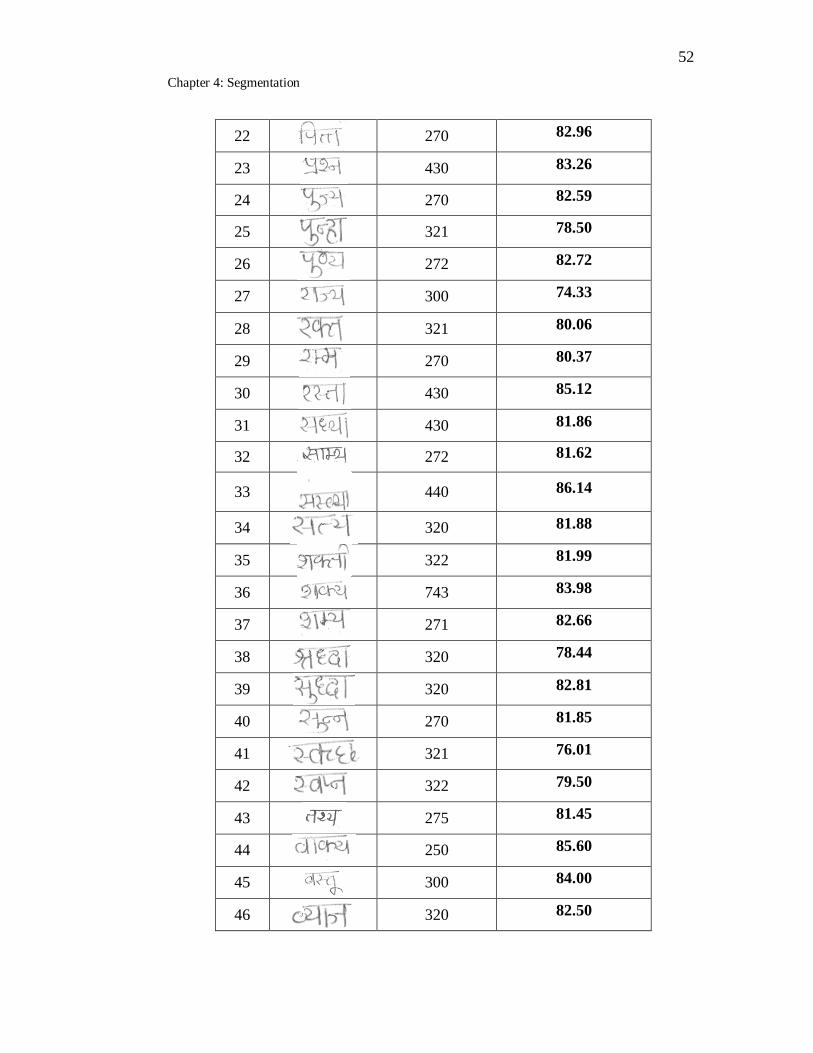
52 Chapter 4: Segmentation
22
270 82.96
23
430 83.26
24
270 82.59
25
321 78.50
26
272 82.72
27
300 74.33
28
321 80.06
29
270 80.37
30
430 85.12
31
430 81.86
32
272 81.62
33
440 86.14
34
320 81.88
35
322 81.99
36
743 83.98
37
271 82.66
38
320 78.44
39
320 82.81
40
270 81.85
41
321 76.01
42
322 79.50
43
275 81.45
44
250 85.60
45
300 84.00
46
320 82.50

53 Chapter 4: Segmentation
47
300 83.00
Total 16073 81.80
The outcome of segmentation process is isolated characters, top modifiers,
bottom modifiers and half characters. Marathi has 12 vowels as shown in Fig.
4.6.
Fig. 4.6: Marathi vowels
After segmentation above 12 vowels are grouped in to five groups based
on their base character as given below.
Table 4.3 : Marathi vowels grouped depending on their base character Group
No. Base
Character Vowels in the group
1.
2.
3.
4.
5.
Finally 12 Marathi vowels are based on only five base characters.
Therefore after segmentation process we are considering only five base characters

54 Chapter 4: Segmentation
instead of 12 vowels. These five base characters for Marathi vowels are shown in
Fig. 4.7.
Fig. 4.7: Five base characters for Marathi vowels
Also in addition to vowels Marathi consists of 36 consonants as shown in
Fig. 4.8.
Fig. 4.8: 36 Marathi consonants
Finally we have total 41 isolated characters after segmentation process,
which includes five base characters of vowels and 36 consonants. Table 4.4
shows isolated characters and number of samples we get after applying
segmentation algorithms on handwritten Marathi words. Table 4.5 shows half
characters and number of samples we get after applying segmentation algorithm
on handwritten Marathi words. Table 4.6 shows modifiers and number of
samples we get after applying segmentation algorithm on handwritten Marathi
words. Section 4.7 gives comparative study of segmentation reported by other
researchers.
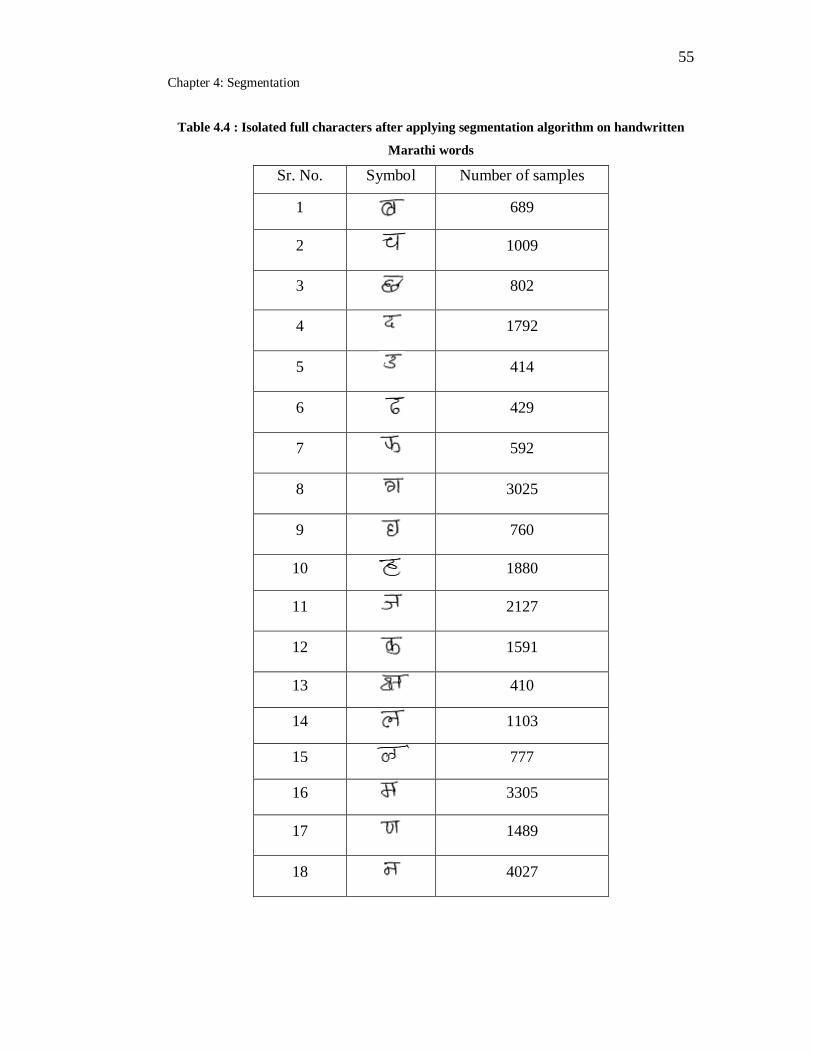
55 Chapter 4: Segmentation
Table 4.4 : Isolated full characters after applying segmentation algorithm on handwritten
Marathi words
Sr. No. Symbol Number of samples
1 689
2 1009
3 802
4 1792
5 414
6 429
7 592
8 3025
9 760
10 1880
11 2127
12 1591
13 410
14 1103
15 777
16 3305
17 1489
18 4027
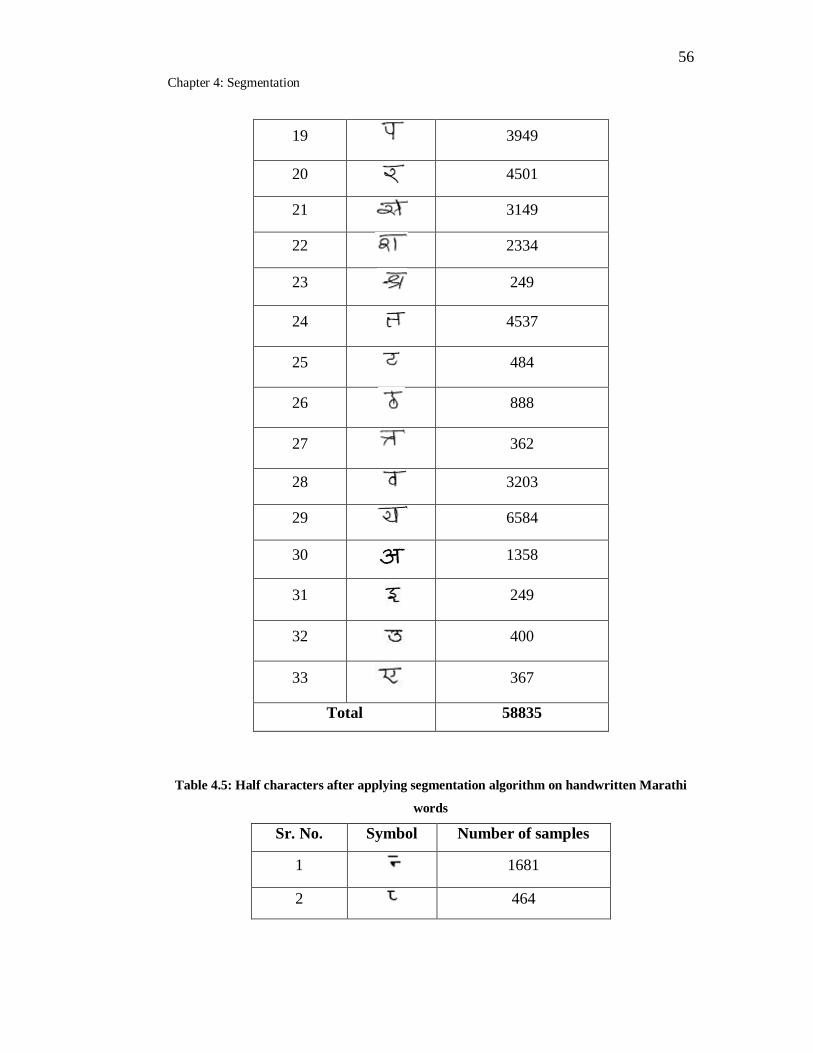
56 Chapter 4: Segmentation
19 3949
20 4501
21 3149
22 2334
23 249
24 4537
25 484
26 888
27 362
28 3203
29 6584
30 1358
31
249
32 400
33 367
Total 58835
Table 4.5: Half characters after applying segmentation algorithm on handwritten Marathi
words
Sr. No. Symbol Number of samples
1 1681
2 464
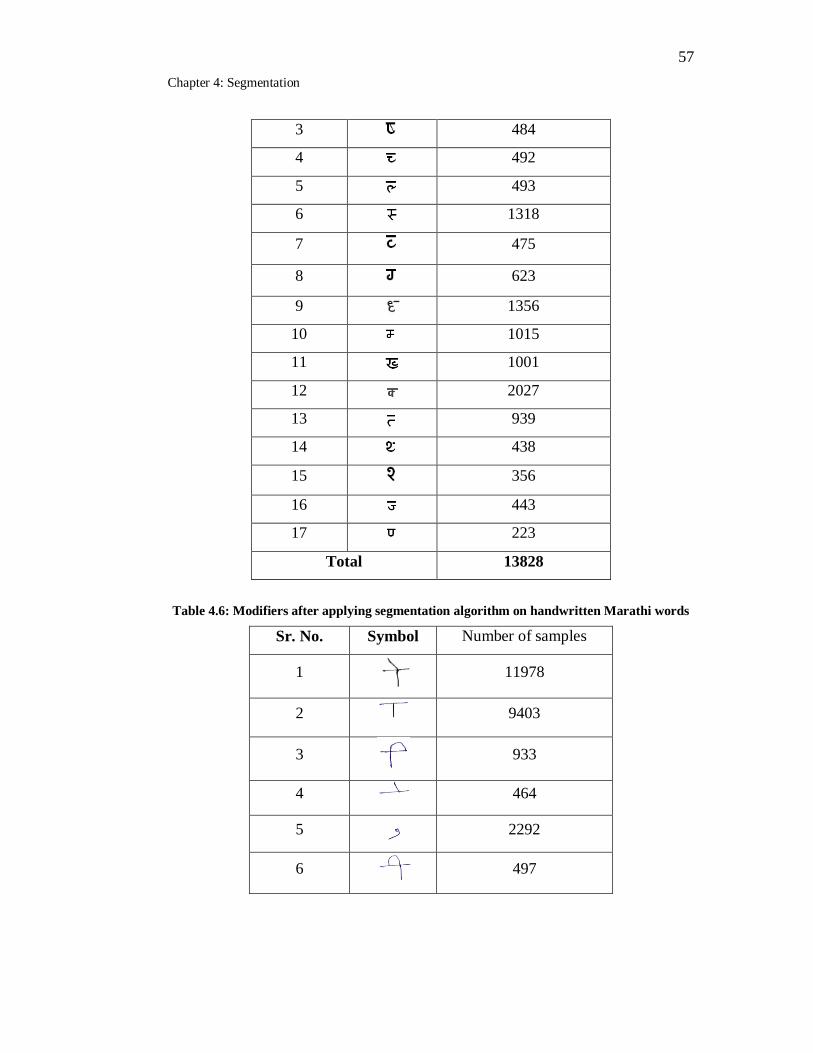
57 Chapter 4: Segmentation
3 484
4 492
5 493
6 1318
7 475
8 623
9 1356
10 1015
11 1001
12 2027
13 939
14 438
15 356
16 443
17 223
Total 13828
Table 4.6: Modifiers after applying segmentation algorithm on handwritten Marathi words
Sr. No. Symbol Number of samples
1
11978
2 9403
3
933
4 464
5 2292
6 497
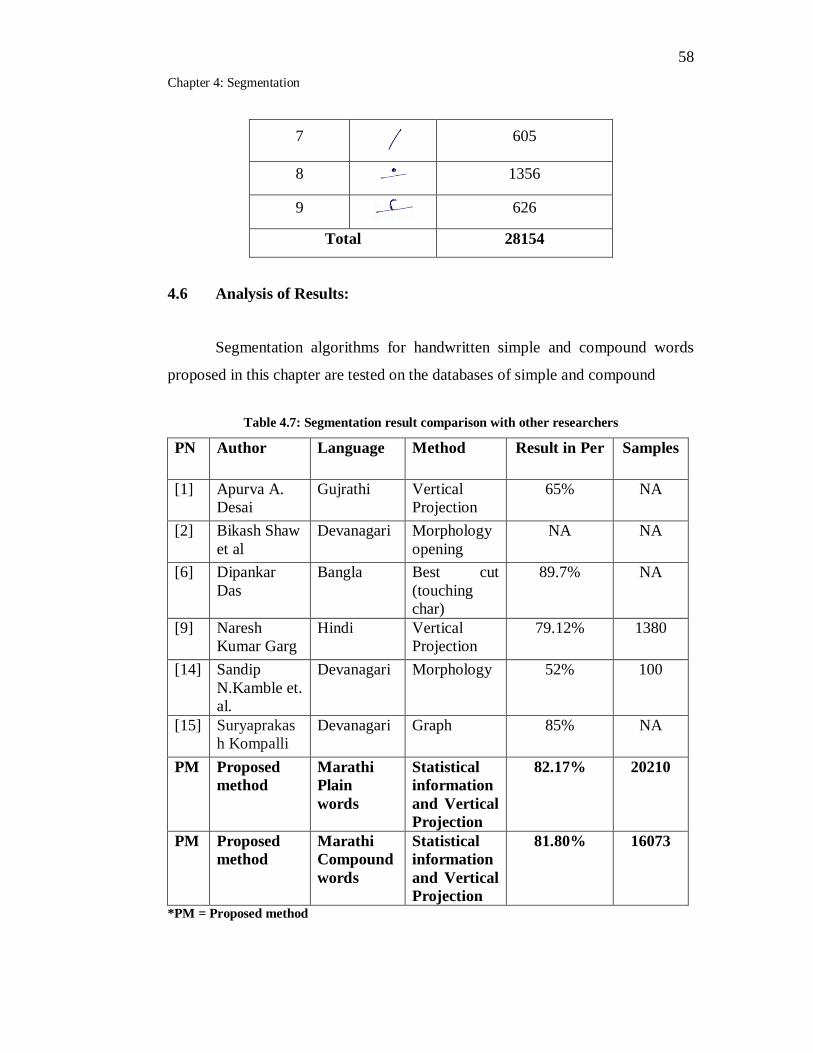
58 Chapter 4: Segmentation
7 605
8 1356
9 626
Total 28154
4.6 Analysis of Results:
Segmentation algorithms for handwritten simple and compound words
proposed in this chapter are tested on the databases of simple and compound
Table 4.7: Segmentation result comparison with other researchers
PN Author Language Method Result in Per Samples
[1] Apurva A. Desai
Gujrathi Vertical Projection
65% NA
[2] Bikash Shaw et al
Devanagari Morphology opening
NA NA
[6] Dipankar Das
Bangla Best cut (touching char)
89.7% NA
[9] Naresh Kumar Garg
Hindi Vertical Projection
79.12% 1380
[14] Sandip N.Kamble et. al.
Devanagari Morphology 52% 100
[15] Suryaprakash Kompalli
Devanagari Graph 85% NA
PM Proposed method
Marathi Plain words
Statistical information and Vertical Projection
82.17% 20210
PM Proposed method
Marathi Compound words
Statistical information and Vertical Projection
81.80% 16073
*PM = Proposed method

59 Chapter 4: Segmentation
words. It is observed from literature that database is quite large to carry out
segmentation results. The segmentation results are encouraging for simple as well
as compound handwritten Marathi words. Comparison of segmentation
methodology and results with other researchers is shown in Table 4.7.
In the next chapter we are elaborating novel multilevel classification
approach which groups 41 Marathi characters into six groups.

Chapter 5 MULTILEVEL CLASSIFICATION

Chapter 5
Multilevel classification
------------------------------------------------------------------------------------
5.1 Introduction
5.2 Multilevel Classification
5.3 Discussion of Results
------------------------------------------------------------------------------------ In this chapter, a multilevel classification approach is described for handwritten
Marathi character recognition. In this method we have divided the character set
into six groups depending on special properties of the characters. This process of
classification is carried out in four phases.
------------------------------------------------------------------------------------
5.1 Introduction:
Marathi characters have more interclass and intra-class similarities. By
experiment it has been observed that single feature is not sufficient for
classification because recognition rate using single feature is very low. Also
classifying and recognizing 41 characters is time consuming task. In multilevel
classification approach Marathi characters are sub-classified into six groups
depending on their special properties such as presence of bar, presence of
enclosed region, presence of one component etc. Marathi 41 characters are sub-
classified into six subclasses using four phases which takes tree structure and the

61 Chapter 5: Multilevel Classification
tree has four levels. Since the approach of sub-classification has four levels we
are calling it as multilevel classification.
Chavan S. V. et.al (2013) has reported pre-classification approach for
handwritten Devanagari character recognition based on location of vertical bar
and number of components present in the character. Kale K. V. et.al (2014) has
reported local structural sub-classification for Marathi compound character
recognition. M. Hanmandlu et. al.(2007) has reported coarse classification
approach for handwritten Hindi characters using presence of vertical bar, location
of vertical bar and character is open to right or left side. Sushma Shelke and
Shaila Apte (2011) has reported structural classification approach for handwritten
Marathi compound character recognition.
It has been observed from literature that using single feature for
classification of large number of classes is difficult. In the next section 4.2 we are
describing multilevel classification approach where total numbers of Marathi
characters are sub-classified into six subclasses using their special properties.
5.2 Multilevel classification:
The outcome of segmentation process is 41 isolated full characters, half
characters, top modifiers and lower modifiers. These 41 isolated characters are
further classified into six sub-classes in phase I to phase IV as shown in the Fig.
5.1.
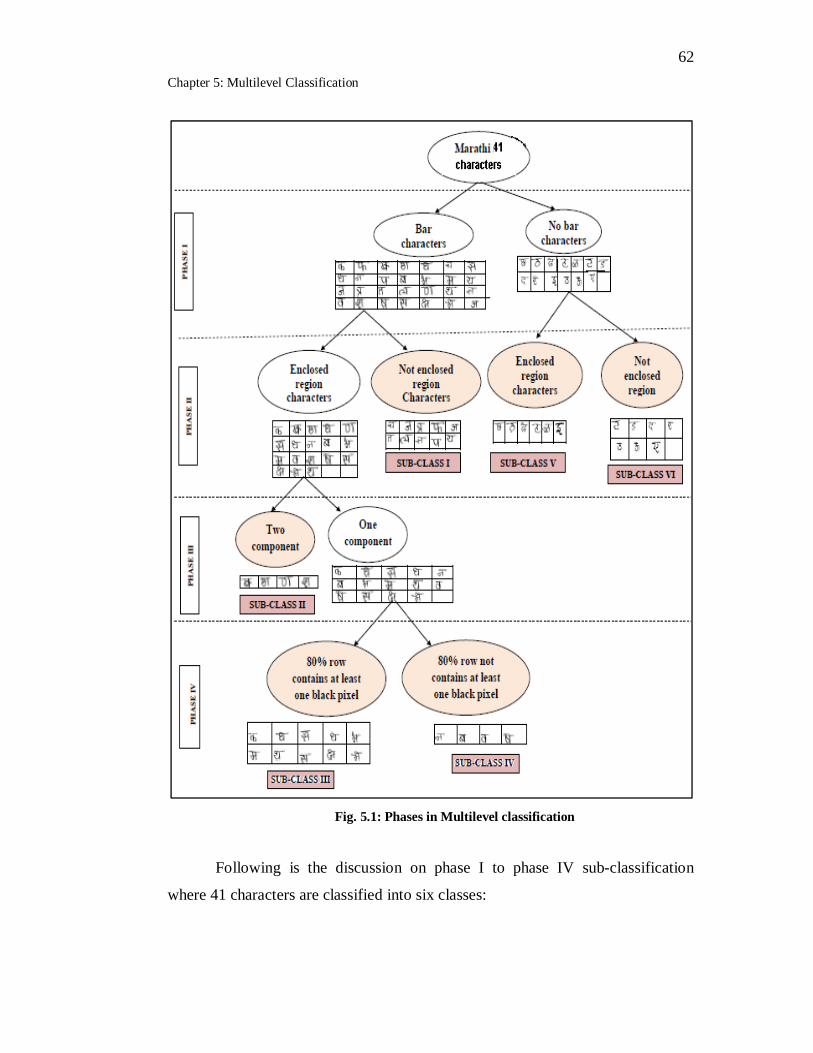
62 Chapter 5: Multilevel Classification
Fig. 5.1: Phases in Multilevel classification
Following is the discussion on phase I to phase IV sub-classification
where 41 characters are classified into six classes:
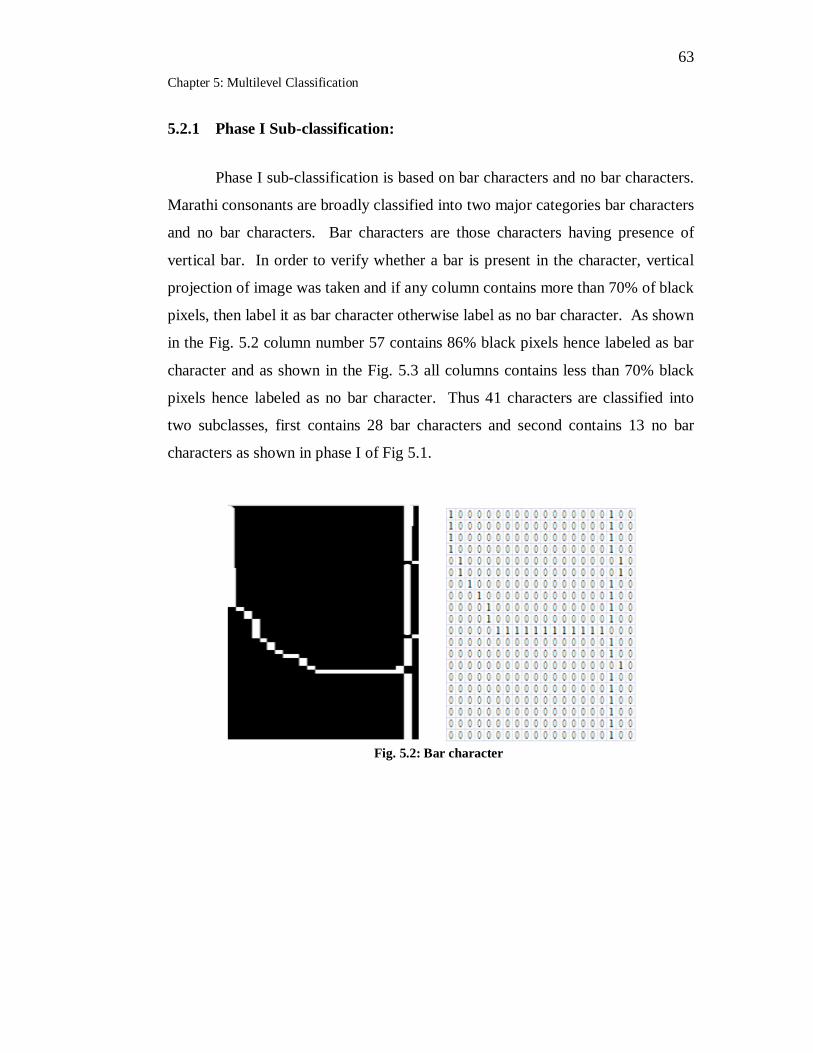
63 Chapter 5: Multilevel Classification
5.2.1 Phase I Sub-classification:
Phase I sub-classification is based on bar characters and no bar characters.
Marathi consonants are broadly classified into two major categories bar characters
and no bar characters. Bar characters are those characters having presence of
vertical bar. In order to verify whether a bar is present in the character, vertical
projection of image was taken and if any column contains more than 70% of black
pixels, then label it as bar character otherwise label as no bar character. As shown
in the Fig. 5.2 column number 57 contains 86% black pixels hence labeled as bar
character and as shown in the Fig. 5.3 all columns contains less than 70% black
pixels hence labeled as no bar character. Thus 41 characters are classified into
two subclasses, first contains 28 bar characters and second contains 13 no bar
characters as shown in phase I of Fig 5.1.
Fig. 5.2: Bar character

64 Chapter 5: Multilevel Classification
Fig. 5.3: No bar character
5.2.2 Phase II Sub-classification:
Phase II sub-classification is based on presence of enclosed region. In
phase II, 28 bar characters are broadly classified into two major categories having
enclosed region or not. To verify whether enclosed region is present, the numbers
of holes are counted in the character using eight connectivity as shown in the Fig.
5.4. If one or more than one enclosed region exists in the character then label it as
enclosed region character otherwise not enclosed region character as shown in
Fig. 5.5. Now 28 bar characters are sub-classified into 18 enclosed region bar
characters and 10 not enclosed region bar characters as shown in phase II of Fig.
5.1.
Similarly 13 no bar characters are classified into six enclosed region no
bar characters and seven not enclosed region no bar characters as shown in phase
II of Fig. 5.1.

65 Chapter 5: Multilevel Classification
Fig. 5.4: Enclosed region character
Fig. 5.5: Not enclosed region character
5.2.3 Phase III Sub-classification:
Phase III sub-classification is based on number of components present in
character. In phase III, 18 bar enclosed region characters are classified into two
subclasses, depending on whether number of component is one or more as shown
in Fig. 5.6 and Fig. 5.7. Presence of a component can be verified using region
properties for each labeled region.

66 Chapter 5: Multilevel Classification
In all 18 bar enclosed region characters are sub-classified into 14
characters having a component and four characters having two components as
shown in phase III of fig. 5.1.
Fig. 5.6: Two component character.
Fig. 5.7: One component character
5.2.4 Phase IV Sub-classification:
Phase IV sub-classification is based on number of rows containing at least
one black pixel. We have 14 bar enclosed region characters having one

67 Chapter 5: Multilevel Classification
component and further classified into two subclasses, depending on whether
character's 80% rows contains at least one black pixel in first 75% columns as
shown in phase IV of Fig. 5.1. Out of 14 bar enclosed region characters having
one component we get 10 characters satisfying above condition as shown in Fig.
5.8 and four characters does not satisfy the condition as shown in Fig. 5.9.
Fig. 5.8: 80% row contains at least one black pixels character
Fig. 5.9: less than 80% row contains at least one black pixels character.
Using above sub-classification method problem of handwritten Marathi
character recognition is simplified into six sub-classes as follows:

68 Chapter 5: Multilevel Classification
Sub-class I: Bar not enclosed region (10 characters)
Fig. 5.10: Consonants having bar and enclosed region
Sub-class II: Bar enclosed region with two components (4 characters)
Fig. 5.11: Consonants having bar, enclosed region and having two components.
Sub-class III: Bar enclosed region with one component and having 80% rows
contains at least one black pixel in first 75% columns (10 characters)
Fig. 5.12: Consonants having bar, enclosed region, one component and black pixels.
Sub-class IV: Bar enclosed region with one component and less than 80% rows
contains at least one black pixel in first 75% columns (4 characters)
Fig. 5.13: Consonants having bar, enclosed region, one component and not black pixels.
Sub-class V: No bar enclosed region (6 characters)
Fig. 5.14: Consonants does not have bar and having enclosed region.
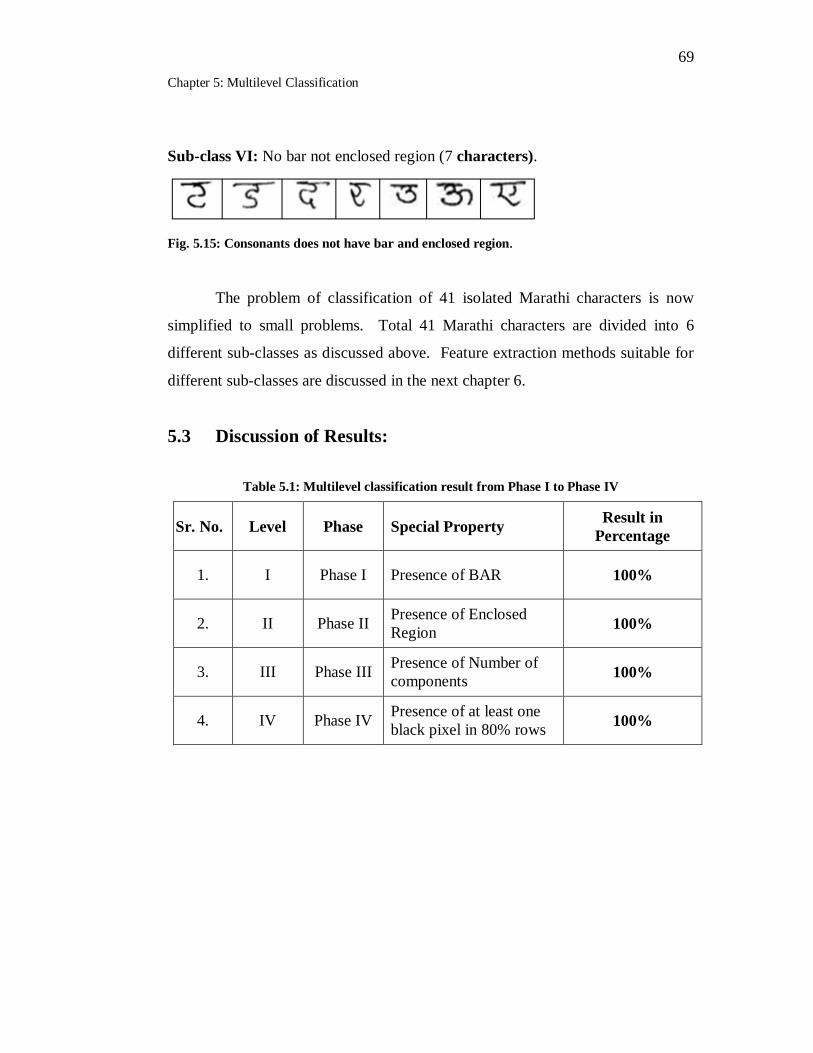
69 Chapter 5: Multilevel Classification
Sub-class VI: No bar not enclosed region (7 characters).
Fig. 5.15: Consonants does not have bar and enclosed region.
The problem of classification of 41 isolated Marathi characters is now
simplified to small problems. Total 41 Marathi characters are divided into 6
different sub-classes as discussed above. Feature extraction methods suitable for
different sub-classes are discussed in the next chapter 6.
5.3 Discussion of Results:
Table 5.1: Multilevel classification result from Phase I to Phase IV
Sr. No. Level Phase Special Property Result in Percentage
1. I Phase I Presence of BAR 100%
2. II Phase II Presence of Enclosed Region 100%
3. III Phase III Presence of Number of components 100%
4. IV Phase IV Presence of at least one black pixel in 80% rows 100%
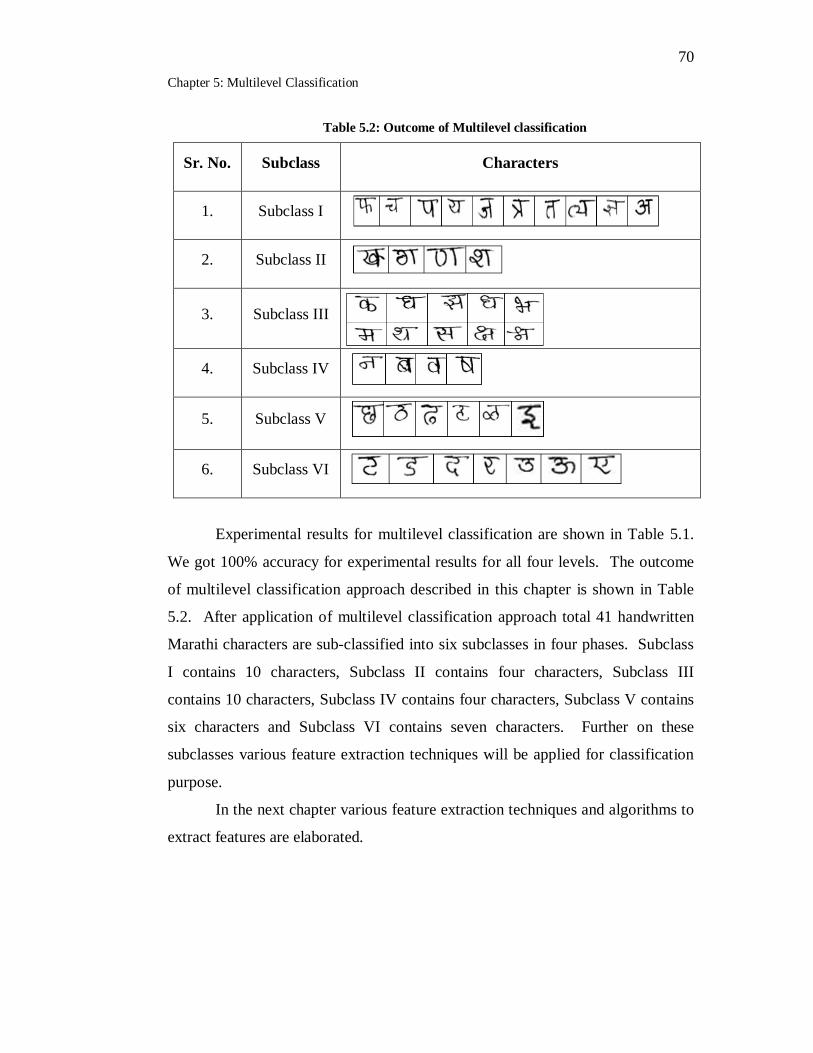
70 Chapter 5: Multilevel Classification
Table 5.2: Outcome of Multilevel classification
Sr. No. Subclass Characters
1. Subclass I
2. Subclass II
3. Subclass III
4. Subclass IV
5. Subclass V
6. Subclass VI
Experimental results for multilevel classification are shown in Table 5.1.
We got 100% accuracy for experimental results for all four levels. The outcome
of multilevel classification approach described in this chapter is shown in Table
5.2. After application of multilevel classification approach total 41 handwritten
Marathi characters are sub-classified into six subclasses in four phases. Subclass
I contains 10 characters, Subclass II contains four characters, Subclass III
contains 10 characters, Subclass IV contains four characters, Subclass V contains
six characters and Subclass VI contains seven characters. Further on these
subclasses various feature extraction techniques will be applied for classification
purpose.
In the next chapter various feature extraction techniques and algorithms to
extract features are elaborated.

Chapter 6 FEATURE EXTRACTION

Chapter 6
Feature Extraction -------------------------------------------------------------------------------
6.1 Introduction
6.2 Zone based symmetric density feature
6.3 Diagonal, Horizontal and Vertical features
6.4 Normalized chain code feature
6.5 Invariant moment feature
6.6 Zernike moment feature
6.7 Discrete wavelet transform
------------------------------------------------------------------------------------ In this chapter different feature extraction techniques are elaborated. The feature
extraction techniques are based on density, chain code, invariant moment,
Zernike moments and wavelet transform. Also we have presented different
algorithms to extract these features.
------------------------------------------------------------------------------------
6.1 Introduction
Feature extraction is important phase in OCR prior to classification. A
feature is a unique property that can describe image. The main objective of
feature extraction is to reduce the size of image and represent the image object
effectively in terms of a compact feature vector. Feature extraction takes image Part of this chapter has been published in the International Journal of Computer Applications (0975 – 8887) Volume 108 – No. 4, December 2014, ISSN 0975-8887. International Journal of Engineering Research & Technology (IJERT), Vol. 3 Issue 11, November-2014, ISSN: 2278-0181.

72 Chapter 6: Feature Extraction
as input, builds initial data and finally gives feature values which are non-
redundant and informative. Recognition accuracy of OCR largely depends on
features extracted in this phase. In this phase unique characteristics (features) of
an image are stored into feature vector for all input images which are further used
for recognition purpose.
Assigning handwritten Marathi character to predefined classes is very
difficult and challenging task due to interclass and intra-class similarities.
Sufficient amount of work is reported for isolated handwritten Devanagari
character recognition. Various feature extraction techniques like zone based
symmetric density, zone based diagonal, horizontal, vertical, normalized chain
code, moment invariant, Zernike moment and discrete wavelet transform are
reported. The major advantage zone based symmetric density, diagonal,
horizontal and vertical feature approach is that it is robust to small variations, easy
to implement and yields relatively high recognition rate. Many authors have
presented zoning mechanisms or regional decomposition methods to investigate
the recognition rates of patterns. Normalized chain code has several advantages
like it has compact representation and also translation invariant. Moment invariant
and Zernike moments are very important features they are rotation invariant,
independent of variability involved in the writing style of different individuals
and also thinning free. In the next sections we will elaborate all the feature
extraction techniques used in the present work.
6.2 Zone based symmetric density feature:
In this feature extraction technique hybrid zone based symmetric density
features are extracted. For correct classification of handwritten characters
suitable features should be extracted which are invariant with respect to shape.
The objective of this hybrid approach came from its robustness to small variation,
easy implementation and promising recognition accuracy. Zone based feature

73 Chapter 6: Feature Extraction
extraction method gives good recognition accuracy even when certain
preprocessing steps like filtering, smoothing and slant corrections are not
performed. In this section, we elaborate on this feature extraction technique and
the algorithm.
6.2.1 Review of earlier work:
Ashoka H. N. et. al.(2012) reported zone based feature extraction methods
for handwritten numeral recognition and achieved 100% recognition accuracy.
B.V. Dhandra et. al. (2011) reported zone based density feature for recognition of
handwritten and printed Kannada and English numerals, and reported recognition
accuracy for Kannada numerals 95.25% and for English numerals 97.05%. B.V.
Dhandra and M. Hangarge [26] reported density and density ratio features as one
of the features for identification of script at word level. B.V. Dhandra et. al.
(2009, 2010) reported direction density estimation feature for Kannada, Telugu
and Devanagari numeral recognition and achieved 99.40% recognition accuracy
for Kannada numerals, 99.60% recognition accuracy for Telugu numerals and
98.40% recognition accuracy for Devanagari numerals. B.V.Dhandra et. al.
(2011) reported directional density feature for Kannada numerals and achieved
98.04% recognition accuracy. Dinesh Acharya U. et. al. (2008) reported direction
code frequency for horizontal and vertical blocks and achieved 92.68%
recognition accuracy for printed Kannada characters. Mahesh Jangid (2011)
reported pixel density and zone density features for Devanagari character
recognition and achieved 94.89% recognition accuracy using SVM classifier.
Vinaya Tapkir and Sushma Shelke (2012) reported pixel density feature for four
zones and achieved a recognition accuracy of 92.77% for handwritten Marathi
script. O.V. Ramana Murthy and M. Hanmandlu (2011) reported pixel density
feature for recognition of Devanagari character recognition.

74 Chapter 6: Feature Extraction
It is observed from literature that for handwritten character recognition,
density feature is largely used by researchers and obtained significant recognition
accuracies. Structural features reflect the character’s structure information.
Statistical feature is the most relevant information extracted from the raw data,
which minimizes the inter-class distance and maximizes the between-class
distance. Density statistical feature is commonly used for character recognition.
Character’s structure feature method has a strong adaptability of character font
changes, so it can easily differentiate between similar characters, but its
computational complexity is large and its ability of anti-interference is bad.
Character’s statistical feature has advantage of anti-interference and simple
algorithm of classification and matching.
Hence, we have chosen zone based symmetric density feature for
handwritten character recognition. The feature extraction method that was used to
extract features and an algorithm is described in the following sections.
6.2.2 Feature extraction method:
To extract zone based symmetric density feature, the binary image
representing the handwritten character is pre-processed and is normalized to a size
of 60 x 60 pixels. The size-normalized image is divided into n equal zones. The
input image is divided into 4, 9, 16, 25 and 36 equal zones. For 4 equal zones,
one zone has 30 x 30 pixels; for 9 equal zones, one zone has 20 x 20 pixels; for 16
equal zones, one zone has 15 x 15 pixels; for 25 equal zones, one zone has 12 x
12 pixels and for 36 equal zones, one zone has 10 x 10 pixels. Therefore, features
are identified for n=4, 9, 16, 25 and 36 equal zones and they were stored in
feature vector for each image.
The density of each zone is computed by taking the ratio of total number
of object pixels to total number of pixels in that zone. This is carried out for every
zone in the image. Finally, 90 features are extracted from the image and feature

75 Chapter 6: Feature Extraction
vector stores these 90 features. Zone based symmetric density features were
calculated for n=4, 9, 16, 25, 36 are shown in Fig. 6.1 using Equation (1).
Density(Z) = h h
------------------------------------(1)
Fig. 6.1: Character image divided into n zones and feature value for corresponding zone
6.2.3. Algorithm:
Algorithm: Zone based symmetric density feature extraction algorithm. Input: Gray scale character image
Output: Feature vector of size 90.
1. Pre-process the input image and resize it to 60 x 60 standard plane.
2. Divide the input image into four equal zones; calculate the density of
each zone that will give four features as shown in Fig. 6.1(a) & (b).

76 Chapter 6: Feature Extraction
3. Divide the input image into nine equal zones; calculate the density of
each zone that will give nine features as shown in Fig. 6.1(c) & (d).
4. Divide the input image into 16 equal zones; calculate the density of each
zone that will give 16 features as shown in Fig. 6.1(e) & (f).
5. Divide the input image into 25 equal zones; calculate the density of each
zone that will give 25 features as shown in Fig. 6.1(g) & (h).
6. Divide the input image into 36 equal zones; calculate the density of each
zone that will give 36 features as shown in Fig. 6.1(i) & (j).
7. Store all features extracted in Step 2, 3, 4, 5 and 6 in feature vector.
Finally feature vector containing 90 features for each image is ready for
experimentation.
6.3 Diagonal, Horizontal and Vertical Features:
6.3.1 Review of earlier work:
J. Pradeep et.al.(2010) reported diagonal feature extraction method for
handwritten character recognition and reported 99% recognition accuracy using
69 features. Om Prakash Sharma et. al. (2012) reported zone based diagonal
features for handwritten Devanagari alphabets and obtained 98.50% recognition
accuracy. It is observed that diagonal, horizontal and vertical features are having
quite encouraging recognition results.
Zone based diagonal, horizontal and vertical features are statistical
features and gives most relevant information from the raw data, which minimize
the inner-class distance and maximize the between-class distance. Diagonal,
horizontal and vertical feature methods have a strong adaptability of character
font changes, so it can easily differentiate the similar characters and its

77 Chapter 6: Feature Extraction
computational complexity is large. Character’s statistical feature has advantage
of anti-interference and simple algorithm of classification and matching.
Hence we have decided to use a combination of diagonal, horizontal and
vertical features. Feature extraction technique used to extract these features and
algorithm is given in the next section.
6.3.2 Feature extraction method:
To extract diagonal, horizontal and vertical features the binary image
representing the handwritten character is pre-processed and is normalized to a size
of 50 x 50 pixels. The size-normalized image is divided into 25 equal zones where
one zone has 10 x 10 pixels. The procedure to find diagonal, horizontal and
vertical features is described below.
6.3.2.1 Diagonal Features:
To extract diagonal features from the binary image representing the
handwritten character is preprocessed and is normalized to a size of 50 x 50
pixels. The size-normalized image is divided into 25 equal zones each of size is
10 x 10 pixels as shown in Fig. 6.2(a). Each zone has 19 diagonal lines, each
diagonal line is summed to get a single sub-feature and thus 19 sub-features are
obtained from the each zone as shown in Fig. 6.2(b).
These 19 sub-features values are averaged to form a single feature value
and placed in the corresponding zone. This procedure is sequentially repeated for
the all the zones as shown in Fig. 6.2(c).
Finally, 25 features are extracted for each character. In addition, 10
features are obtained by averaging the values placed in zones row-wise and
column-wise, respectively. As a result; every character is represented by 25+10
features, that is, 35 features.

78 Chapter 6: Feature Extraction
Fig. 6.2: Diagonal Features
6.3.2.2 Horizontal Features:
To extract horizontal feature of the binary image representing the
handwritten character is first preprocessed and is normalized to size of 50 x 50
pixels. The size-normalized image is divided into 25 equal zones, each zone is of
size 10 x 10 as shown in Fig. 6.3(a). Each zone has 10 horizontal lines, each
horizontal line is summed to get a single sub feature and thus 10 sub-features are
obtained from the each zone as shown in Fig. 6.3(b).
These 10 sub-features values are averaged to form a single feature value
and assigned as horizontal feature to the corresponding zone. This procedure is
sequentially repeated for the all the zones. Finally, 25 features are extracted for 25
zones for each character as shown in Fig. 6.3(c). In addition, 10 features are
obtained by averaging the values placed in zones row-wise and column-wise
respectively. Finally every character is represented by 35 features, that is 25+10
features.

79 Chapter 6: Feature Extraction
Fig. 6.3: Horizontal Features
6.3.2.3 Vertical Features
To extract vertical features from the binary image representing the
handwritten character is preprocessed and is normalized to a size of 50 x 50
pixels. The size-normalized image is divided into 25 equal zones; each zone of
size is 10 x 10 as shown in Fig. 6.4(a). Each zone has 10 vertical lines, each
vertical line is summed to get a single sub-feature and thus 10 sub-features are
obtained from the each zone as shown in Fig. 6.4(b).
These 10 sub-features values are averaged to form a single feature value
and placed in the corresponding zone. This procedure is sequentially repeated for
the all the zones as shown in Fig. 6.4(c). Finally, 25 features are extracted for
each character. As a result every character is represented by 25 features. In
addition, 10 features are obtained by averaging the values placed in zones row-
wise and column-wise, respectively. Finally every character is represented by 35
features, that is 25+10 features.

80 Chapter 6: Feature Extraction
Fig. 6.4: Vertical Features
6.3.3 Algorithm:
Algorithm: Diagonal, Horizontal and Vertical feature extraction algorithm
Input: Gray scale character Image
Output: Diagonal, Horizontal and Vertical Features.
1. Pre-process the input Image and resize to 50 x 50 standard plane.
2. Divide the input image into 25 zones, each zone is of size 10 x 10 pixels.
3. Calculate diagonal feature value for each zone, repeat the process to find
diagonal features for 25 zones.
4. Calculate average values for row-wise diagonal features and column-
wise diagonal features, in all five row-wise and five column-wise values.
5. Feature vector of 35 diagonal features is prepared for each image.
6. Calculate horizontal feature value for each zone, repeat the process to
find horizontal features for 25 zones.
7. Calculate average values for row-wise horizontal features and column-
wise horizontal features, in all five row-wise and five column-wise
values.

81 Chapter 6: Feature Extraction
8. Feature vector of 35 horizontal features is prepared for each image.
9. Calculate vertical feature value for each zone, repeat the process to find
vertical features for 25 zones.
10. Calculate average values for row-wise vertical features and column-wise
vertical features, in all five row-wise and five column-wise values.
11. Feature vector of 35 vertical features is prepared for each image.
6.4 Normalized Chain Code:
Chain codes are the features which represents the boundary of a character.
There are several advantages of using normalized chain code feature extraction
listed below:
1. Compact representation of a character.
2. Feature values are not affected by translation of character.
6.4.1 Review of earlier work:
Aarti Desai et.al. (2011) reported chain code features for Devanagari
character recognition. They have divided a character image into 25 blocks and for
each block 8 chain code features are extracted, finally they have used 200 chain
code features for recognition and achieved 87% recognition accuracy. Bikash
Shaw et.al. (2008) reported directional chain code feature for handwritten
Devanagari word recognition and achieved 80.2% recognition accuracy. G.G.
Rajput and S.M. Mali (2010) reported freeman chain code features in combination
with fourier descriptor for handwritten Marathi numeral recognition and achieved
98.1% recognition accuracy. Gunvantsinh Gohil et.al. (2012) reported chain code
and holistic features for printed Devanagari script and achieved 66.35% and
80.55% using ANN and SVM classifier respectively. N. Sharma et.al. (2006)

82 Chapter 6: Feature Extraction
reported directional chain code feature extraction for 49 zones for handwritten
Devanagari characters and obtained 98.86% and 80.36% on Devanagari numerals
and characters respectively. Ravi Sheth et.al. (2011) reported normalized chain
code feature extraction technique for handwritten English character recognition
and obtained 92% recognition accuracy. S. Arora et.al. (2011) reported chain
code feature extraction method in combination with shadow and view based
features and obtained 98.61% recognition accuracy for handwritten Devanagari
characters. S. Arora et.al. [122] reported zone based chain code histogram feature
in combination with shadow features for recognition of non-compound
handwritten Devanagari character and obtained 90.74% recognition accuracy.
It is observed from literature review that chain code directional features
are having quite encouraging recognition results. Hence we have decided to use
normalized chain code features for recognition of handwritten characters. Feature
extraction technique used to extract these features and algorithm is elaborated in
next sections.
6.4.2 Feature extraction method:
To extract freeman chain codes first locate any boundary pixel, called as
starting pixel, and then move along the boundary of character either clockwise or
anticlockwise direction, find out next boundary pixel and allocate this new pixel
a number depending upon its direction from the previous pixel is called code for
that pixel. The process is repeated till starting pixel is not encountered. The codes
may be 4-directional or 8-directional depending upon 4-connectivity or 8-
connectivity of a pixel to its neighboring contour pixel. An 8-directional chain
coded image is given in Fig. 6.5.

83 Chapter 6: Feature Extraction
Fig. 6.5: Eight directional Chain code
The chain code extracted from above process is different for different
characters as length of each chain code depends on the size of the handwritten
characters.
Example shows Chain code extracted for the image shown in Fig. 5.5.
Chain code: [0 7 6 6 6 0 6 4 3 4 5 4 2 2 2 0 2 0 2]
V1= [0 7 6 6 6 0 6 4 3 4 5 4 2 2 2 0 2 0 2]
Compute the frequency of the codes 0, 1, 2, ….., 7. For vector V1 we have the
frequency vector V2 as below.
V2= [4 0 5 1 3 1 3 1]
The normalized frequency, represented by vector V3, is computed using the
formula
V3 =| |
, where |V1|=ΣV2
For the example considered above, we have
V3= [0.22 0 0.27 0.05 0.16 0.05 0.16 0.05]
Finally, V3 is the required feature vector of size 8.
6.4.3 Algorithm: Algorithm: Normalized chain code feature extraction algorithm
Input: Gray scale character image
Output: Normalized chain code feature vector for each image.
1. Pre-process the input Image and resize to 50 x 50 standard plane.

84 Chapter 6: Feature Extraction
2. Extract the boundary of the character image.
3. Resample the boundary in order to obtain a uniform resampling along the running arc length of the boundary.
4. Trace the boundary in counterclockwise direction and generate 8 directional chain codes 0 to 7.
5. Compute the frequency of the codes 0 to 7.
6. Divide frequency of each code by sum of the frequencies.
7. Store eight features in feature vector.
8. Finally feature vector of 8 features is ready for each input image.
6.5 Moment Invariant
Moment invariant features are based on statistical moments of characters.
They are traditional and widely-used tool for character recognition. Classical
moment invariants were introduced by Hu (1962) and they were successfully used
in numerous applications not only for character recognition. Hu invariants are
invariant under translation, rotation and scaling. Moment invariants features are
extracted for the image which contributes to improve the overall recognition
accuracy.
6.5.1 Review of earlier work:
Ajmire and Warkhede (2010) reported seven moment invariant features
for handwritten Marathi vowel recognition. They have computed mean and
standard deviation for each feature and these 14 features were used for
recognition using Gaussian distribution function. S.V.Chavan et.al.(2013)
reported geometric and Zernike moments for handwritten Devanagari compound
character recognition and achieved 98.78% recognition accuracy using MLP

85 Chapter 6: Feature Extraction
classifier and 95.56% recognition accuracy using k-NN classifier. Nilima Patil
et.al.(2011) reported moment invariant and affine moment invariant for
handwritten Marathi vowel recognition and obtained 75% recognition accuracy.
R. J. Ramteke (2010) reported invariant moment based feature extraction
technique for handwritten Devanagari vowels recognition using 3 different feature
sets by dividing image into four or two zones. R. J. Ramteke and S. C. Mehrotra
(2008) reported invariant moment based feature extraction technique for
handwritten Devanagari numerals recognition using 3 different feature sets by
dividing image into four or two zones and achieved 92% recognition accuracy
using 78 features. Reena Bajaj et.al.(2002) reported density and moment feature
extraction technique for Devanagari numeral recognition and obtained 63.4%
recognition accuracy for Devanagari numerals. S. Arora et.al.(2009) reported
chain code histogram and moment based features for handwritten Devanagari
character recognition and reported 98.03% recognition accuracy. S. M. Mali
(2012) reported moment and density features for handwritten Marathi numeral
recognition and reported 97.69% recognition accuracy.
It is observed from literature review that moment invariant features are
having quite encouraging recognition results in case of handwritten characters.
Hence we have decided to use moment invariant features for recognition of
handwritten characters. Feature extraction technique used to extract these
features and algorithm is elaborated in next sections.
6.5.2 Feature extraction Technique:
The method to calculate invariant moment is described below:
The two Dimensional moment of order (pique) of image is calculated as
follows
푚 = 푥 푦 푓(푥, 푦)

86 Chapter 6: Feature Extraction
Where p=0, 1,2,… and q=0,1,2….
Using 2D moments, central moment of order (p+q) can be calculated as follows
µ = (푥 − 푥̅) (푦 − 푦) 푓(푥, 푦)
For p=0,1,2,… and q=0,1,2…. Where 푥̅ = 푎푛푑 푦 =
Normalized central moments can be derived by using above central moments as
follows
휂 =µµ
Where
훾 =푝 + 푞
2 + 1
For p+q=2,3…
Set of seven invariant moments can be derived from second and third moments
ø = 휂 + 휂
ø = (휂 − 휂 ) + 4휂
ø = (휂 − 3휂 ) + (3휂 − 휂 )
ø = (휂 + 휂 ) + (휂 + 휂 )
ø = (휂 − 3휂 )(휂 + 휂 )[(휂 + 휂 ) − 3(휂 + 휂 ) ]
+ (3휂 − 휂 )(휂 + 휂 )[3(휂 + 휂 ) − (휂 + 휂 ) ]
ø = (휂 − 휂 )[(휂 + 휂 ) − (휂 + 휂 ) ] + 4휂 (휂 + 휂 )(휂 + 휂 ) ]
ø = (3휂 − 휂 )(휂 + 휂 )[(휂 + 휂 ) − 3(휂 + 휂 ) ]
+ (3휂 − 휂 )(휂 + 휂 )[3(휂 + 휂 ) − (휂 + 휂 ) ]

87 Chapter 6: Feature Extraction
6.5.3 Algorithm to compute moment invariant features: Algorithm: Moment Invariant feature extraction algorithm.
Input: Gray scale character image.
Output: Moment invariant features for each image.
1. Pre-process the input Image and resize to 50 x 50 standard plane.
2. Compute seven moment invariant feature for the whole image and store into feature vector.
3. Divide character image into four equal zones, each zone of size 25 x 25 pixels.
4. Compute moment invariant feature for each zone. Add these 28 features into feature vector.
5. Feature vector of size 35 is ready for each image.
6.6 Zernike Moment:
6.6.1 Review of earlier work:
K. V. Kale et. al. (2014) reported Zernike moment feature extraction
technique for handwritten Marathi compound character recognition. They had
extraction zone based first 8 order Zernike moments and achieved 98.37% and
95.82% recognition accuracy using SVM and k-NN classifier.
The Zernike moment were first proposed in 1934 by Zernike. Zernike
moments are complex numbers by which an image is mapped on to a set of two-
dimensional complex Zernike polynomials. The magnitude of Zernike moments is
used as a rotation invariant feature to represent a character image pattern. Zernike
moments are a class of orthogonal moments and have been shown effective in
terms of image representation. The orthogonal property of Zernike polynomials
enables the contribution of each moment to be unique and independent of

88 Chapter 6: Feature Extraction
information in an image. A Zernike moment does the mapping of an image onto a
set of complex Zernike polynomials. These Zernike polynomials are orthogonal to
each other and have characteristics to represent data with no redundancy and able
to handle overlapping of information between the moments. Due to these
characteristics, Zernike moments have been utilized as feature sets in applications
such as pattern recognition and content-based image retrieval. These specific
aspects and properties of Zernike moment are supposed to found to extract the
features of handwritten characters. Feature extraction technique and algorithm to
extract Zernike moments is elaborated in next sections.
6.6.2 Feature extraction method:
The Zernike moments introduce a set of complex polynomials which form
a complete orthogonal set over the interior of a unit circle, i.e., x2 + y2 ≤ 1.
Zernike moments are the projection of the image function on some orthogonal
basis functions. Let the set of these basis functions be denoted by Vn,m(x, y).
These polynomials are defined by Vn,m(x, y) = Vn,m(ρ, θ) = Rn,m(ρ)ejmρ (1)
where n is a non-negative integer, m is a non-zero integer subject to the following
constrain: n − |m| is even and |m| < n. Also, ρ is the length of the vector from
origin to the (x, y) pixel, θ is the angle between vector ρ and x axis in a counter-
clockwise direction, and Rn,m(ρ) is the Zernike radial polynomial. The Zernike
radial polynomials, Rn,m(ρ), are defined as :
Rn, m(ρ) =(−1) (n− s)!
s! n + |m|2 − s ! n − |m|
2 − s ! ρ
| |
Note that Rn,m(ρ) = Rn,−m(ρ). The Zernike moment of order n with repetition m
for a digital image is

89 Chapter 6: Feature Extraction
푍 , =n + 1π 푓(푥, 푦)푉 ,
∗ (푥, 푦)∆x∆y
where V∗n,m(x, y) is the complex conjugate of Vn,m(x, y).
To compute the Zernike moments of a given image, the image center of mass is
taken as the origin.
Table 6.1: First eight order Zernike moments
Order Dimension Zernike moment
0 1 Z0,0
1 2 Z1,1
2 4 Z2,0,Z2,2
3 6 Z3,1,Z3,3
4 9 Z4,0,Z4,2,Z4,4
5 12 Z5,1,Z5,3,Z5,5
6 16 Z6,0,Z6,2,Z6,4,Z6,6
7 20 Z7,1,Z7,3,Z7,5,Z7,7
6.6.3 Algorithm:
Algorithm: Zernike moment feature extraction algorithm.
Input: Gray scale character image
Output: First eight orders of Zernike moment features for each image.
1. Pre-process the input Image and resize to 50 x 50 standard plane.
2. Compute first eight orders Zernike moment feature for the whole image and store into feature vector.
3. Divide character image into four equal zones, each zone of size 25 x 25 pixels.

90 Chapter 6: Feature Extraction
4. Compute first eight orders Zernike moment feature for each zone and append into feature vector.
5. Feature vector containing first eight orders Zernike moment is ready for experiments.
6.7 Discrete Wavelet Transform:
6.7.1 Review of earlier work:
The Discrete Wavelet Transform (DWT) provides a decomposition of an
image into details having different resolutions and orientations; it is a bijection
from the image space onto the space of its coefficients. It has been mainly used
for image compression. Diego J. Romero et.al. (2007) has reported directional
continuous wavelet transformed for recognition of handwritten numerals.
G.G.Rajput and Anita H. B. (2010) has reported discrete cosine transform and
discrete wavelet transform for handwritten script recognition. Pritpal Singh and
Sumit Budhiraja (2012) has reported wavelet transformation for handwritten
Gurumukhi character recognition. Sushama Shelke and Shaila Apted (2010) has
reported discrete wavelet transform for the recognition of handwritten Marathi
compound character.
6.7.2 Feature extraction method:
Discrete wavelet transforms (DWT) are applied to discrete data sets and
produce discrete outputs. Transforming signals and data vectors by DWT is
a process that resembles the fast Fourier transform (FFT), the Fourier method
applied to a set of discrete measurements. Discrete wavelet transforms map data
from the time domain (the original or input data vector) to the wavelet
domain. The result is a vector of the same size. Wavelet transforms are linear and
they can be defined by matrices of dimension if they are applied to inputs

91 Chapter 6: Feature Extraction
of size . Depending on boundary conditions, such matrices can be either
orthogonal or ''close'' to orthogonal. When the matrix is orthogonal, the
corresponding transform is a rotation in in which the data (a -typle) is
a point in . The coordinates of the point in the rotated space comprise the
discrete wavelet transform of the original coordinates. The discrete wavelet
transform (DWT) has a large number of applications in computer science. It is
used for signal coding, to represent a discrete signal in a more redundant form,
often as a preconditioning for data compression. Practical applications can also be
found in signal processing of accelerations for gait analysis, in digital
communications and many others.
It is shown that discrete wavelet transform (DWT) is discrete in scale and
shift, and continuous in time. DWT is successfully implemented as analog filter
bank in biomedical signal processing for design of low-power pacemakers and
also in ultra-wideband (UWB) wireless communications. Wavelets are localized
basis functions which are translated and dilated versions of some fixed mother
wavelet. The decomposition of the image into different frequency bands is
obtained by successive low-pass and high-pass filtering of the signal and down-
sampling the coefficients after each filtering. Here various discrete wavelet
transforms Daubechies is used.
DWT Single-level discrete 1-D wavelet transform. Single-level one-
dimensional wavelet decomposition with respect to Daubechies wavelet transform
is used. It performs a multilevel one-dimensional wavelet analysis using
Daubechies wavelet and returns the wavelet decomposition of the signal. The
output decomposition structure contains the wavelet decomposition vector C and
the bookkeeping vector L. Compute the approximation coefficients using the
wavelet decomposition structure [C, L].

92 Chapter 6: Feature Extraction
The wavelet transform exhibits the features like separability, scalability,
translatability, orthogonality and multiresolution capability. The discrete wavelet
transform of an image f(x, y) of size MxN is
푊 (푗 ,푚,푛) =1
√푚푛푓(푥, 푦)휑 , , (푥, 푦)
푊 (푗,푚,푛) =1
√푚푛푓(푥, 푦) 훹 , , (푥,푦)
Where,
휑 , , = 2 휑 2 푥 −푚, 2 푦 − 푛
And,
훹 , , = 2 훹 2 푥 −푚, 2 푦 − 푛
are the two dimensional scaling and wavelet functions respectively and the index i
identifies the directional wavelets that takes the values H, V and D i.e. horizontal,
vertical and diagonal details respectively. j0 an arbitrary starting scale and the
푊 (푗 ,푚, 푛) coefficients define an approximation of f(x, y) at scale j0. The
푊 (푗,푚, 푛) coefficients add horizontal, vertical and diagonal details for scales j≥
j0. Normally, j0 = 0 N = M = 2J so that j = 0, 1, 2…, J-1 and m, n = 0, 1, 2,…, 2j-
1. The discrete wavelet transform can be implemented using digital filters and
down samplers. The high pass or detail component characterizes the image’s
high-frequency information with vertical orientation; the low-pass, approximation
component contains its low-frequency, vertical information. Both sub images are
then filtered column wise and down sampled to yield four quarter size output
images.

93 Chapter 6: Feature Extraction
6.7.3 Algorithm:
Algorithm: Discrete wavelet transforms feature extraction algorithm.
Input: Gray scale character image
Output: Eight discrete wavelet transform features for each image.
1. Pre-process the input Image and resize to 50 x 50 standard planes.
2. Number of black pixels along each row of the binarized image has been
counted to form a 50 sized vector.
3. The 1D discrete wavelet transform on row count vector at level 3 using
Daubechies db1 wavelet has been applied.
4. Compute approximation coefficients and add to these four values to
feature vector.
5. Number of black pixels along each column of the binarized image has
been counted to form a 50 sized vector.
6. The 1D discrete wavelet transform on column count vector at level 3
using Daubechies-db1 wavelet has been applied.
7. Compute approximation coefficients and add to these four values to
feature vector.
8. Feature vector containing eight discrete wavelet transformations is ready
for experiments.
All these feature extraction methods are used to extract the features and
the extracted features are further used for classification. In the next chapter SVM
and k-NN classifiers are discussed. Also results are presented for SVM and k-NN
classifier.

Chapter 7 CLASSIFICATION AND RESULTS

Chapter 7
Classification and Results ---------------------------------------------------------------------------------
7.1 Introduction
7.2 Support Vector Machine Classifier
7.3 k-NN Classifier
7.4 Discussion of Results
--------------------------------------------------------------------------------- In this chapter classification is elaborated. SVM and k-NN classifiers are
discussed and used for handwritten Marathi words recognition. Fivefold cross
validation technique is used to compute the results. Recognition rates for
handwritten Marathi simple and compound words are reported using SVM
classifier using combination of density and normalized chain code features. Also
recognition accuracy for isolated handwritten Marathi character is reported
using SVM and k-NN classifier. Recognition accuracy using SVM and k-NN
classifier is compared also results are compared with other researchers.
------------------------------------------------------------------------------------
7.1 Introduction:
Classification is a process in OCR that groups the individual items
depending on the similarity of item and groups properties. Different types of item
are distinguished in classification process. Image classification assigns label to
the unknown object. Classification broadly categorized into two types:
supervised classification and unsupervised classification

95 Chapter 7: Classification and Results
Supervised classification:
Supervised classification first applies knowledge and then classifies. In
supervised classification we use training data where predefined class labels and
features are available which are used to assign labels to unknown objects.
Supervised classification is useful when sufficient amount of training data is
available.
Unsupervised classification:
Unsupervised classification process first classifies and then applies
knowledge. Unsupervised classification is more useful where there is less
information is available for classification. In unsupervised classification classes
or groups are formed according to randomly sampled data called clusters and
unknown objects are classified into that clusters. Using various decision rules,
unknown objects are classified to respective class.
In the present work two supervised classifiers are used for classification
purpose namely support Vector Machine (SVM) and k-Nearest Neighbor (k-NN).
We are elaborating SVM and k-NN classifiers in the next sections.
7.2 Support vector machines:
Support vector machines are introduced in COLT-92 by Boser, Guyon &
Vapnik. Support vector machines are supervised classification method used for
classification. SVM has successful applications in the fields of bioinformatics,
text, image recognition etc. SVM is effective in high dimensional spaces; also
effective even if number of dimensions is greater than the number of samples. In
SVM different kernel functions can be specified for decision functions, also they
are memory efficient. SVM creates a hyper plane or set of hyper planes for
classification and uses it for classification. SVM correct classification can be
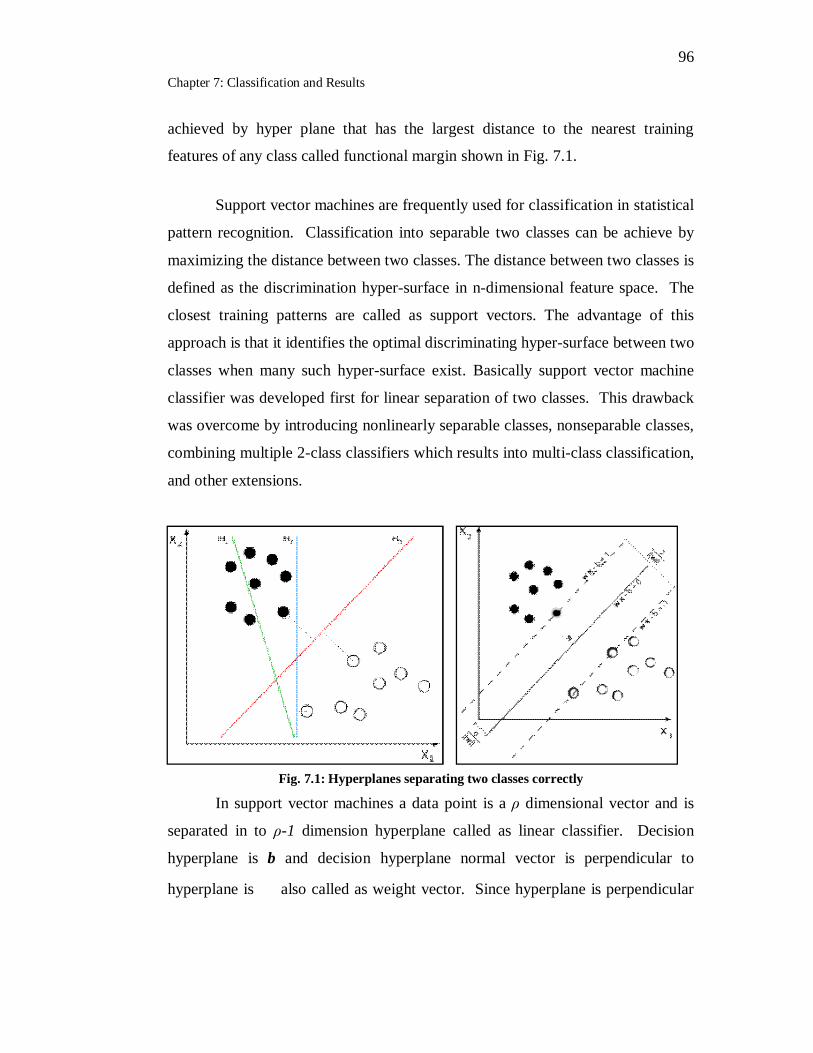
96 Chapter 7: Classification and Results
achieved by hyper plane that has the largest distance to the nearest training
features of any class called functional margin shown in Fig. 7.1.
Support vector machines are frequently used for classification in statistical
pattern recognition. Classification into separable two classes can be achieve by
maximizing the distance between two classes. The distance between two classes is
defined as the discrimination hyper-surface in n-dimensional feature space. The
closest training patterns are called as support vectors. The advantage of this
approach is that it identifies the optimal discriminating hyper-surface between two
classes when many such hyper-surface exist. Basically support vector machine
classifier was developed first for linear separation of two classes. This drawback
was overcome by introducing nonlinearly separable classes, nonseparable classes,
combining multiple 2-class classifiers which results into multi-class classification,
and other extensions.
Fig. 7.1: Hyperplanes separating two classes correctly
In support vector machines a data point is a ρ dimensional vector and is
separated in to ρ-1 dimension hyperplane called as linear classifier. Decision
hyperplane is b and decision hyperplane normal vector is perpendicular to
hyperplane is also called as weight vector. Since hyperplane is perpendicular

97 Chapter 7: Classification and Results
to normal vector, all the points on hyperplane → will satisfy 푤̇⃗ 푥⃗ = −푏̇ . Training
data set is 픻 = {(푥⃗ , 푦 )}, where 푥⃗ is a pair of points on hyperplane and 푦 are
class labels.
Then linear classifier푓(푥⃗) = 푠푖푔푛(푤̇⃗ 푥⃗ + 푏̇ ), returns -1 if 푓(푥⃗) < 0 and
+1 if 푓(푥⃗) ≥ 0 for different classes. Functional margin of 푥⃗ with respect to
hyperplane < 푤̇⃗ , b > is 푤̇⃗ 푥⃗ + 푏̇ . Functional margin can be increased by scaling
푤̇⃗ and 푏.
The discrimination function in terms of support vectors and multipliers is
given below:
푓(푥) = 훼 휔 (푥є
.푥) + 푏
Each of the Lagrange multipliers 훼 shares a corresponding training vector푥 .
Those vectors that contribute to the maximized margin have non zero 훼 are the
support vectors. Since remaining training vectors do not contribute to the final
discrimination function, summation is performed only for support vectors푥 .
The decision whether test vector belongs to which class +1 or -1 totally
depends on the support vectors associated with the maximum margin as identified
in the training phase. Hence the discrimination hyperplane in the feature space
can be obtained from the vectors in the input space and the dot products in the
feature space. Also training can be based on a small set of support vectors, even
in large training sets, thus limiting the computational complexity of the training
with explicitly represented feature vectors.
If a separating hyperplane cannot be found to partition the feature space
into two classes that is linear inseparability of the training patterns. Support vector
machines trains classifier in such non-separable sets, soft margin training allows
some training examples to remain on the wrong side of the separating hyperplane.
Support vector classifier splits these two class patterns as accurate as possible
with minimum number of patterns on the wrong side as shown in Fig. 7.2. Hence
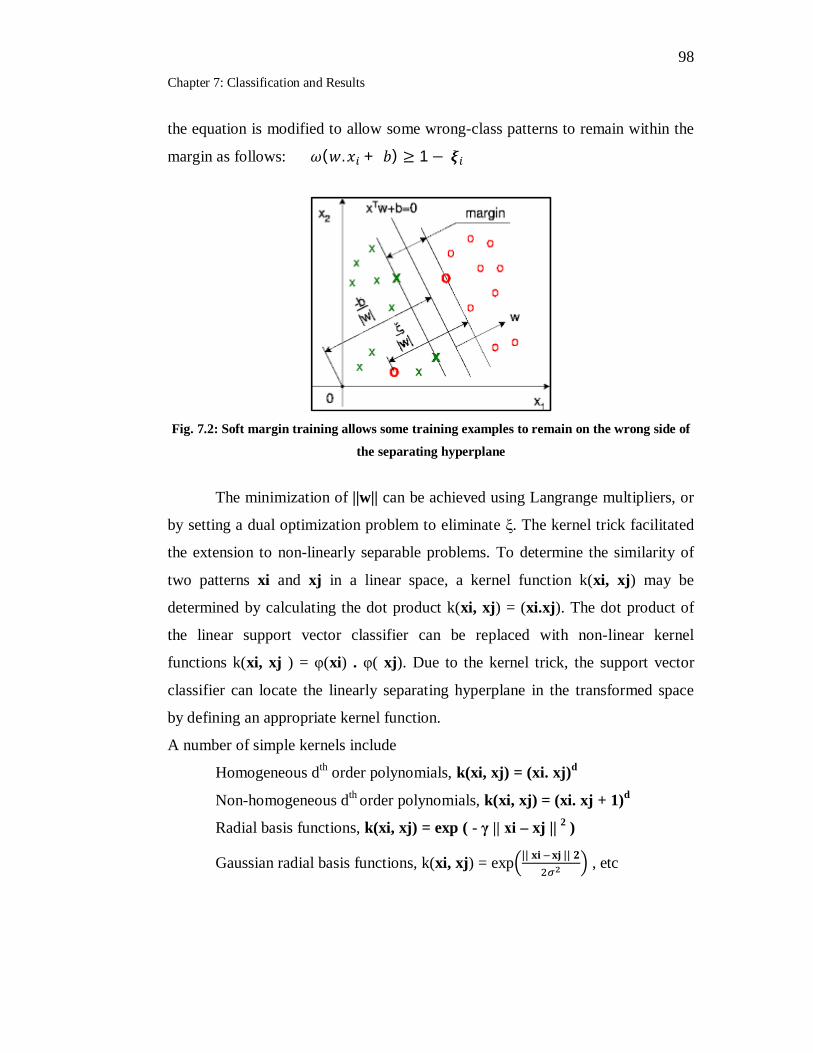
98 Chapter 7: Classification and Results
the equation is modified to allow some wrong-class patterns to remain within the
margin as follows: 휔(푤.푥 + 푏) ≥ 1 − 흃
Fig. 7.2: Soft margin training allows some training examples to remain on the wrong side of
the separating hyperplane
The minimization of ||w|| can be achieved using Langrange multipliers, or
by setting a dual optimization problem to eliminate ξ. The kernel trick facilitated
the extension to non-linearly separable problems. To determine the similarity of
two patterns xi and xj in a linear space, a kernel function k(xi, xj) may be
determined by calculating the dot product k(xi, xj) = (xi.xj). The dot product of
the linear support vector classifier can be replaced with non-linear kernel
functions k(xi, xj ) = φ(xi) . φ( xj). Due to the kernel trick, the support vector
classifier can locate the linearly separating hyperplane in the transformed space
by defining an appropriate kernel function.
A number of simple kernels include
Homogeneous dth order polynomials, k(xi, xj) = (xi. xj)d
Non-homogeneous dth order polynomials, k(xi, xj) = (xi. xj + 1)d
Radial basis functions, k(xi, xj) = exp ( - γ || xi – xj || 2 )
Gaussian radial basis functions, k(xi, xj) = exp || 퐱퐢 – 퐱퐣 || ퟐ , etc

99 Chapter 7: Classification and Results
Fig. 7.3: Linear and non linear classification
Multiple class classification can be achieved by combining N 2-class classifiers,
where each classifier will discriminate between a specific class and the rest of the
training set. During the classification stage, a pattern is assigned to the class with
the largest positive distance between the classified pattern and the individual
separating hyperplane for the N binary classifiers. Algorithm for support vector
machine learning and classification is given below.
1. Training:
1. Select an appropriate kernel function, k(xi, xj).
2. Minimize ||w|| subject to the constraint.
3. Store only the non zero αi‘s and the corresponding training vectors xi.
These are the support vectors.
2. Testing/Classification:
1. For each pattern x compute the discrimination function, using the
support vectors xi and the corresponding weights αi. The sign of the
function determines the classification of x.
7.3 K Nearest Neighbor classifier:
k-Nearest Neighbor (k-NN) algorithm is very simple to understand and has
numerous applications. k-NN is non parametric lazy algorithm, does not make
any assumptions on the data distribution. In k-NN algorithm no explicit training

100 Chapter 7: Classification and Results
phase or is minimum, but testing phase is costly in terms of time and memory. K-
NN algorithm can be used for classification, where if x is unlabeled data item then
find data closest to x if it is y then assign the label of y to x using nearest neighbor
algorithm. K-NN looks up for its k nearest points (for k an integer number) and
then label the new point according to which set contains the majority of its k
neighbours. The best value for k totally depends on the data. Large value
of k may reduce the effect of noise, but it creates very short boundaries between
distinct classes. A good k can be selected by various heuristic techniques. In case
where k = 1 is called the nearest neighbor algorithm.
Fig. 7.4: Test sample for k=3 and k=5
For example, in the above Fig. 7.4 there is a test sample shown by green
circle has to be classified into first class of blue squares or to the second class of
red triangles. Consider k = 3 indicated by solid line circle then unlabeled circle is
assigned to the second class because there are 2 triangles and only 1 square inside
the inner circle. If k = 5 shown by dashed line circle then unlabeled circle is
assigned to the first class because 3 squares vs. 2 triangles inside the outer circle.
An alternative to using the Euclidean distance are the city-block distance,
Minkowski distance, and the weighted Euclidean distance and the weighted city-
block distance. The k-nearest neighbor classifiers performs well when there are a
lot of training patterns. However, the more training patterns there are, the more

101 Chapter 7: Classification and Results
distance have to be calculated, and consequently the computation required
increases, thus slowing down the process of classification. But because of their
fairly high classification performance, they serve as good benchmarks for
evaluating other classifiers.
Algorithm:
1. Training set: (x1,y1), (x2,y2), …, (xn,yn)
2. Assume xi = (xi1, xi
2, …, xid) is a d-dimensional feature vector of real
numbers, for all i.
3. yi is a class label in {1…C}, for all i
4. Determine ynew for xnew
5. Find k closest training points to xnew w.r.t. Euclidean distance between x
and y defined as:
푑 = |푥 − 푦 |
= (푥 − 푦)(푥 − 푦)
6. Classify by yknn = majority vote among the k points.
7.4 Discussion of Results:
The input for handwritten Marathi word recognition system is handwritten
Marathi words and Marathi isolated characters. We have collected 9600 images
of isolated Marathi characters and 36283 handwritten Marathi words from
different users. In Marathi isolated characters we are considering five base
characters of vowels. Thus we obtained 8200 images for isolated Marathi
characters. The outcome of segmentation process is 58835 isolated Marathi
characters, along with 13828 half characters and 28154 modifiers. After
combining 8200 Marathi isolated characters and 58835 segmented isolated

102 Chapter 7: Classification and Results
characters, a database of 67035 images for 41 handwritten Marathi characters is
ready for experiments.
Now this database is fed to multilevel classification, where these 41
characters are grouped into six subclasses as discussed in chapter 5. The outcome
of multilevel classification is, sub-class I consist of 10 characters with 23621
images; sub-class II consist of four characters with 7648 images; sub-class III
consist of 10 characters with 11464 images; sub-class IV consist of four
characters with 8719 images; sub-class V consist of 6 characters with 6225
images and sub-class VI consist of 7 characters with 9358 images.
OCR for handwritten Marathi word recognition system is shown in
Fig.7.5.
The multilevel classification groups 41 Marathi characters into six sub-
classes. Now suitable feature extraction techniques discussed in chapter 5 are
used to extract features for all sub-classes. We found promising recognition
results for following features:
1. Zone based symmetric density (90 features)
2. Diagonal features (35 features)
3. Horizontal features (35 features)
4. Vertical features (35 features)
5. Normalized chain code (8 Features)
6. Invariant moment (35 features)
7. Zernike moment (16 features)
8. Discrete wavelet transformation (8 features)
9. Zone based symmetric density and Normalized chain code (98
features)
10. Diagonal and Zernike moment(51 features)
11. Horizontal and normalized chain code (43 features)
12. Horizontal and invariant moment (42 features)
13. Horizontal and Zernike moment (51 features)
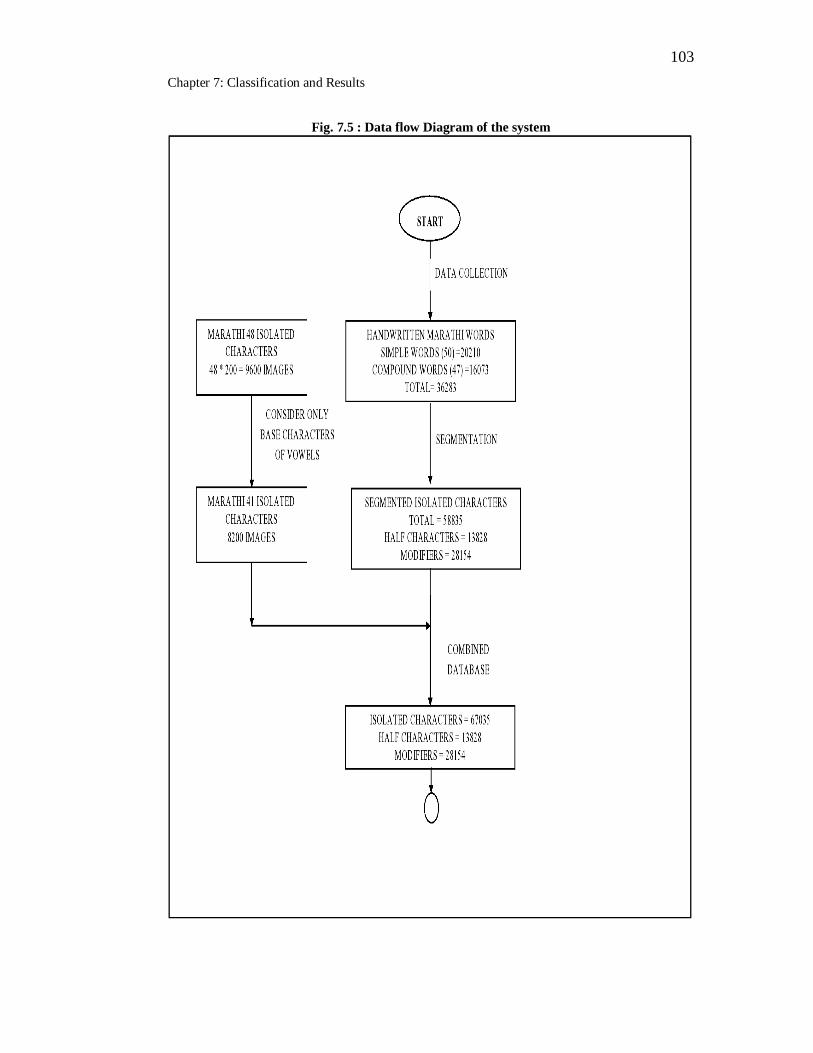
103 Chapter 7: Classification and Results
Fig. 7.5 : Data flow Diagram of the system
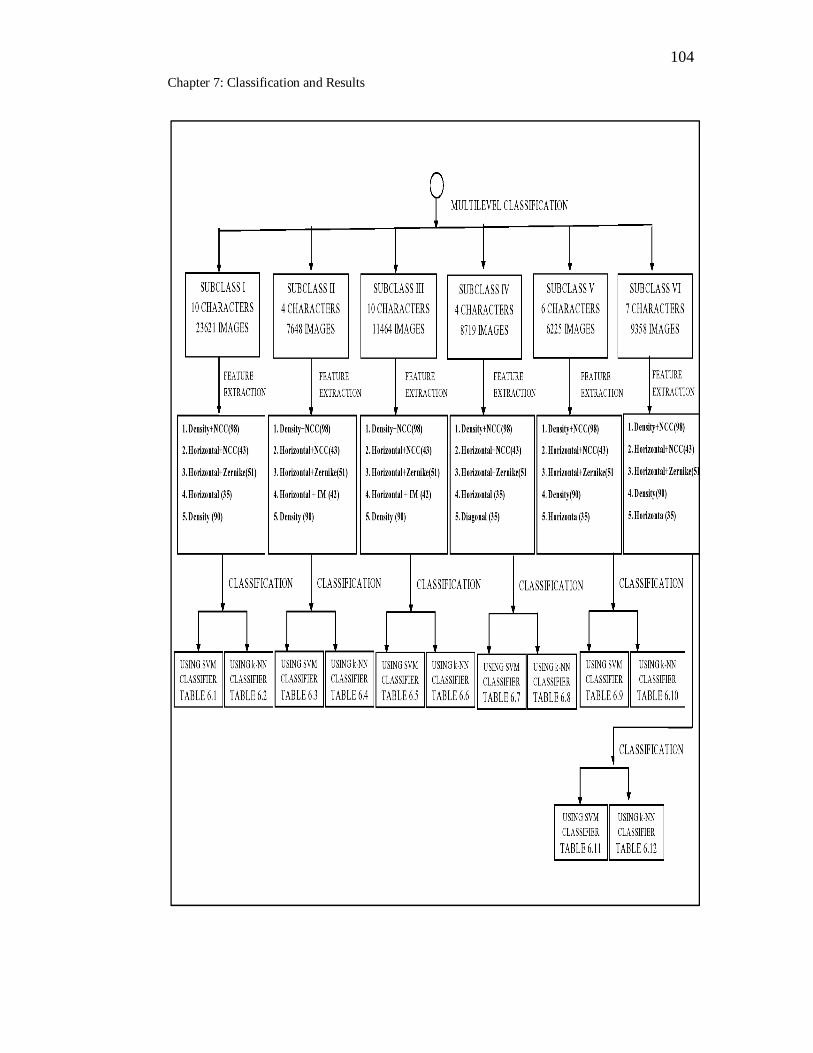
104 Chapter 7: Classification and Results

105 Chapter 7: Classification and Results
After extracting features for each sub-class separately we have used SVM
and k-NN classifiers for recognition. The experiments were performed on the
67035 samples of handwritten Marathi characters. We have used 5-fold cross
validation technique. In this method, five test subsets were created. Each subset
contains disjoint image samples. The 5-fold cross-validation involves the
determination of classification accuracy for multiple partitions of the input
samples used in training. The 5-fold cross-validation partitions available data into
5 sets. In each run 4 sets are used for training and the remaining 5th set is used for
testing. Finally, an average accuracy over 5 runs is obtained.
The experiments were performed on the sub-class I contains 10 characters
and 23621 image samples. Table 7.1 and Table 7.2 show recognition results for
sub-class I using SVM and k-NN classifier respectively. The highest average
recognition rate 91.85% achieved for combination of features symmetric density
and normalized chain code using SVM classifier. The highest average
recognition rate 89.10% achieved for combination of features symmetric density
and normalized chain code using k-NN classifier.
The experiments were performed on the sub-class II contains four
characters and 7648 image samples. Table 7.3 and Table 7.4 show recognition
results for sub-class II using SVM and k-NN classifier respectively. The highest
average recognition rate 94.72% achieved for combination of features symmetric
density and normalized chain code using SVM classifier. The highest average
recognition rate 90.00% achieved for combination of features symmetric density
and normalized chain code using k-NN classifier.
The experiments were performed on the sub-class III contains 10
characters and 11464 image samples. Table 7.5 and Table 7.6 show recognition
results for sub-class III using SVM and k-NN classifier respectively. The highest
average recognition rate 83.30% achieved for combination of features symmetric
density and normalized chain code using SVM classifier. The highest average

106 Chapter 7: Classification and Results
recognition rate 76.75% achieved for combination of features symmetric density
and normalized chain code using k-NN classifier.
The experiments were performed on the sub-class IV contains four
characters and 8719 image samples. Table 7.7 and Table 7.8 show recognition
results for sub-class IV using SVM and k-NN classifier respectively. The highest
average recognition rate 88.62% was achieved when symmetric density and
normalized chain code features were combined and SVM classifier was used.
The highest average recognition rate 82.62% achieved for combination of features
symmetric density and normalized chain code using k-NN classifier.
The experiments were performed on the sub-class V contains six
characters and 6225 image samples. Table 7.9 and Table 7.10 show recognition
results for sub-class V using SVM and k-NN classifier respectively. The highest
average recognition rate 92.83% achieved for combination of features symmetric
density and normalized chain code using SVM classifier. The highest average
recognition rate 89.75% achieved for combination of features symmetric density
and normalized chain code using k-NN classifier.
The experiments were performed on the sub-class VI contains seven
characters and 9358 image samples. Table 7.11 and Table 7.12 show recognition
results for sub-class VI using SVM and k-NN classifier respectively. The highest
average recognition rate 94.73% achieved for combination of features symmetric
density and normalized chain code using SVM classifier. The highest average
recognition rate 93.28% achieved for combination of features symmetric density
and normalized chain code using k-NN classifier.
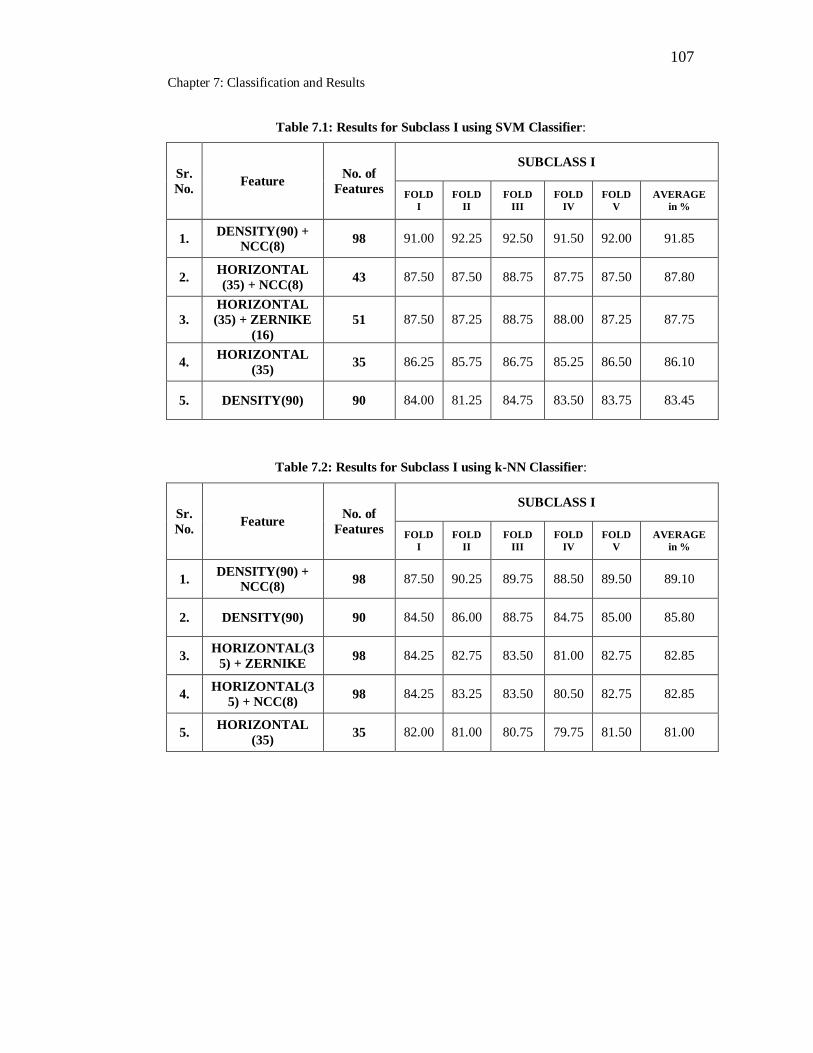
107 Chapter 7: Classification and Results
Table 7.1: Results for Subclass I using SVM Classifier:
Sr. No. Feature No. of
Features
SUBCLASS I
FOLD I
FOLD II
FOLD III
FOLD IV
FOLD V
AVERAGE in %
1. DENSITY(90) + NCC(8) 98 91.00 92.25 92.50 91.50 92.00 91.85
2. HORIZONTAL (35) + NCC(8) 43 87.50 87.50 88.75 87.75 87.50 87.80
3. HORIZONTAL (35) + ZERNIKE
(16) 51 87.50 87.25 88.75 88.00 87.25 87.75
4. HORIZONTAL (35) 35 86.25 85.75 86.75 85.25 86.50 86.10
5. DENSITY(90) 90 84.00 81.25 84.75 83.50 83.75 83.45
Table 7.2: Results for Subclass I using k-NN Classifier:
Sr. No. Feature No. of
Features
SUBCLASS I
FOLD I
FOLD II
FOLD III
FOLD IV
FOLD V
AVERAGE in %
1. DENSITY(90) + NCC(8) 98 87.50 90.25 89.75 88.50 89.50 89.10
2. DENSITY(90) 90 84.50 86.00 88.75 84.75 85.00 85.80
3. HORIZONTAL(35) + ZERNIKE 98 84.25 82.75 83.50 81.00 82.75 82.85
4. HORIZONTAL(35) + NCC(8) 98 84.25 83.25 83.50 80.50 82.75 82.85
5. HORIZONTAL (35) 35 82.00 81.00 80.75 79.75 81.50 81.00
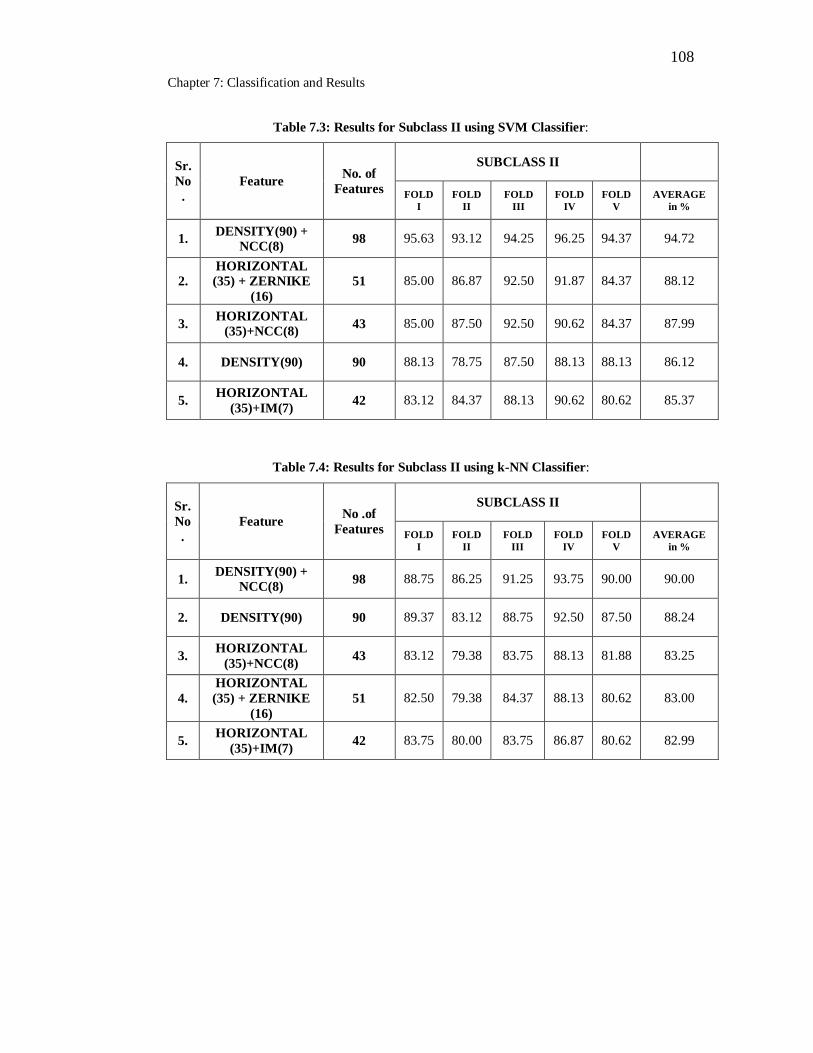
108 Chapter 7: Classification and Results
Table 7.3: Results for Subclass II using SVM Classifier:
Sr. No
. Feature No. of
Features
SUBCLASS II
FOLD I
FOLD II
FOLD III
FOLD IV
FOLD V
AVERAGE in %
1. DENSITY(90) + NCC(8) 98 95.63 93.12 94.25 96.25 94.37 94.72
2. HORIZONTAL (35) + ZERNIKE
(16) 51 85.00 86.87 92.50 91.87 84.37 88.12
3. HORIZONTAL (35)+NCC(8) 43 85.00 87.50 92.50 90.62 84.37 87.99
4. DENSITY(90) 90 88.13 78.75 87.50 88.13 88.13 86.12
5. HORIZONTAL (35)+IM(7) 42 83.12 84.37 88.13 90.62 80.62 85.37
Table 7.4: Results for Subclass II using k-NN Classifier:
Sr. No.
Feature No .of Features
SUBCLASS II
FOLD I
FOLD II
FOLD III
FOLD IV
FOLD V
AVERAGE in %
1. DENSITY(90) + NCC(8) 98 88.75 86.25 91.25 93.75 90.00 90.00
2. DENSITY(90) 90 89.37 83.12 88.75 92.50 87.50 88.24
3. HORIZONTAL (35)+NCC(8) 43 83.12 79.38 83.75 88.13 81.88 83.25
4. HORIZONTAL (35) + ZERNIKE
(16) 51 82.50 79.38 84.37 88.13 80.62 83.00
5. HORIZONTAL (35)+IM(7) 42 83.75 80.00 83.75 86.87 80.62 82.99
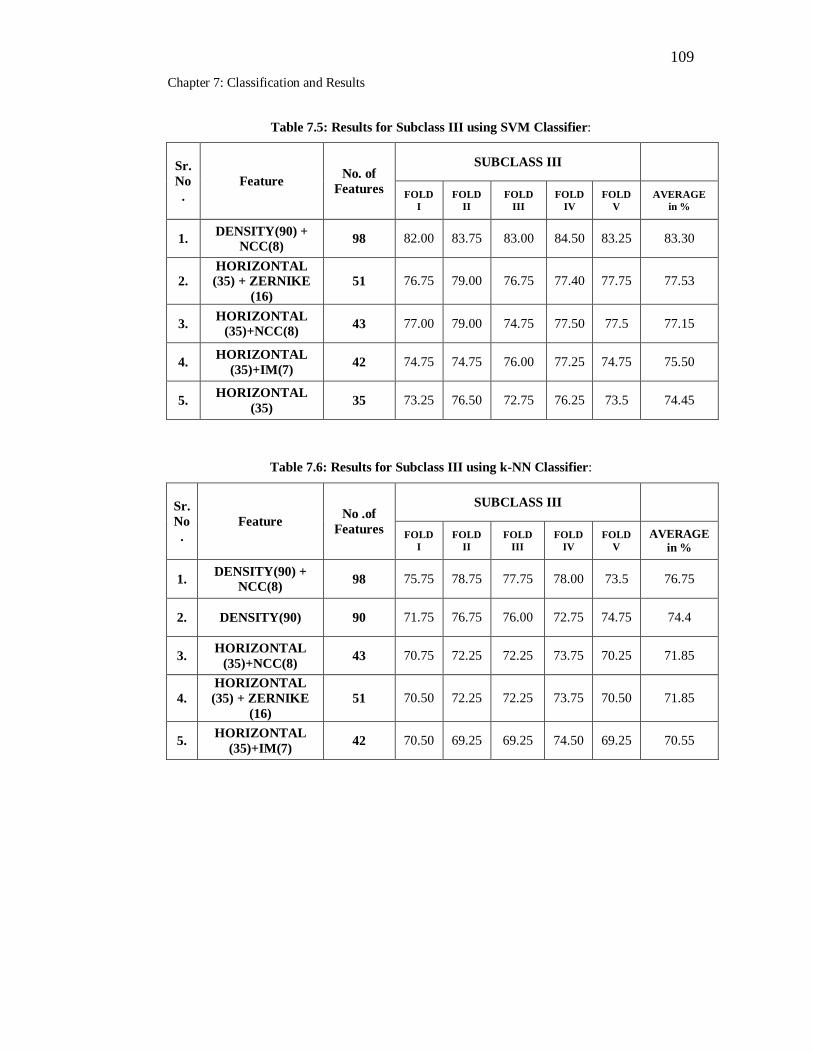
109 Chapter 7: Classification and Results
Table 7.5: Results for Subclass III using SVM Classifier:
Sr. No
. Feature No. of
Features
SUBCLASS III
FOLD I
FOLD II
FOLD III
FOLD IV
FOLD V
AVERAGE in %
1. DENSITY(90) + NCC(8) 98 82.00 83.75 83.00 84.50 83.25 83.30
2. HORIZONTAL (35) + ZERNIKE
(16) 51 76.75 79.00 76.75 77.40 77.75 77.53
3. HORIZONTAL (35)+NCC(8) 43 77.00 79.00 74.75 77.50 77.5 77.15
4. HORIZONTAL (35)+IM(7) 42 74.75 74.75 76.00 77.25 74.75 75.50
5. HORIZONTAL (35) 35 73.25 76.50 72.75 76.25 73.5 74.45
Table 7.6: Results for Subclass III using k-NN Classifier:
Sr. No
. Feature No .of
Features
SUBCLASS III
FOLD I
FOLD II
FOLD III
FOLD IV
FOLD V
AVERAGE in %
1. DENSITY(90) + NCC(8) 98 75.75 78.75 77.75 78.00 73.5 76.75
2. DENSITY(90) 90 71.75 76.75 76.00 72.75 74.75 74.4
3. HORIZONTAL (35)+NCC(8) 43 70.75 72.25 72.25 73.75 70.25 71.85
4. HORIZONTAL (35) + ZERNIKE
(16) 51 70.50 72.25 72.25 73.75 70.50 71.85
5. HORIZONTAL (35)+IM(7) 42 70.50 69.25 69.25 74.50 69.25 70.55
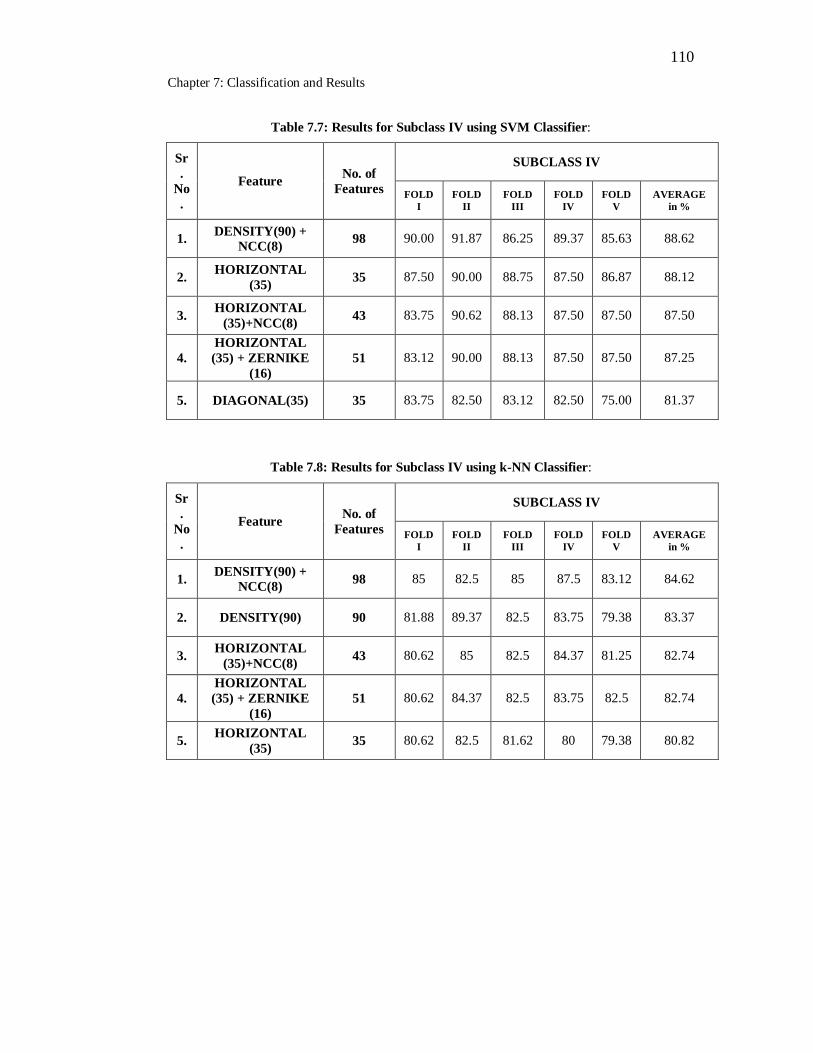
110 Chapter 7: Classification and Results
Table 7.7: Results for Subclass IV using SVM Classifier:
Sr.
No.
Feature No. of Features
SUBCLASS IV
FOLD I
FOLD II
FOLD III
FOLD IV
FOLD V
AVERAGE in %
1. DENSITY(90) + NCC(8) 98 90.00 91.87 86.25 89.37 85.63 88.62
2. HORIZONTAL (35) 35 87.50 90.00 88.75 87.50 86.87 88.12
3. HORIZONTAL (35)+NCC(8) 43 83.75 90.62 88.13 87.50 87.50 87.50
4. HORIZONTAL (35) + ZERNIKE
(16) 51 83.12 90.00 88.13 87.50 87.50 87.25
5. DIAGONAL(35) 35 83.75 82.50 83.12 82.50 75.00 81.37
Table 7.8: Results for Subclass IV using k-NN Classifier:
Sr.
No.
Feature No. of Features
SUBCLASS IV
FOLD I
FOLD II
FOLD III
FOLD IV
FOLD V
AVERAGE in %
1. DENSITY(90) + NCC(8) 98 85 82.5 85 87.5 83.12 84.62
2. DENSITY(90) 90 81.88 89.37 82.5 83.75 79.38 83.37
3. HORIZONTAL (35)+NCC(8) 43 80.62 85 82.5 84.37 81.25 82.74
4. HORIZONTAL (35) + ZERNIKE
(16) 51 80.62 84.37 82.5 83.75 82.5 82.74
5. HORIZONTAL (35) 35 80.62 82.5 81.62 80 79.38 80.82
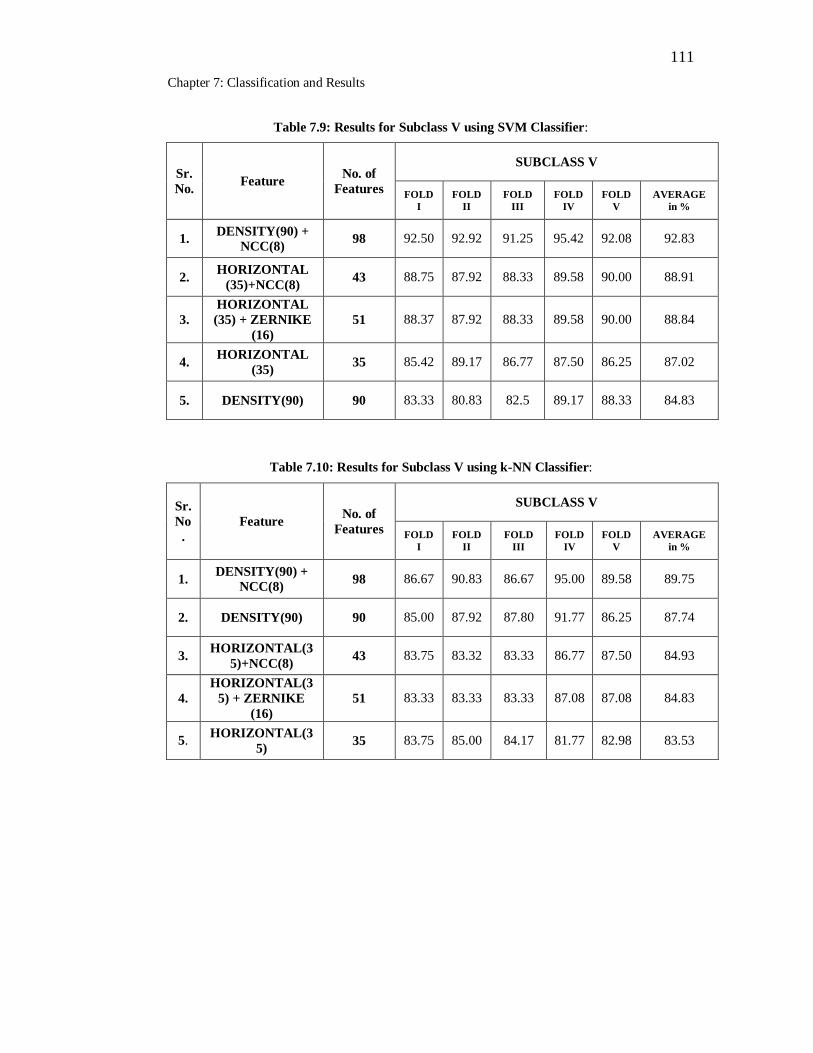
111 Chapter 7: Classification and Results
Table 7.9: Results for Subclass V using SVM Classifier:
Sr. No. Feature No. of
Features
SUBCLASS V
FOLD I
FOLD II
FOLD III
FOLD IV
FOLD V
AVERAGE in %
1. DENSITY(90) + NCC(8) 98 92.50 92.92 91.25 95.42 92.08 92.83
2. HORIZONTAL (35)+NCC(8) 43 88.75 87.92 88.33 89.58 90.00 88.91
3. HORIZONTAL (35) + ZERNIKE
(16) 51 88.37 87.92 88.33 89.58 90.00 88.84
4. HORIZONTAL (35) 35 85.42 89.17 86.77 87.50 86.25 87.02
5. DENSITY(90) 90 83.33 80.83 82.5 89.17 88.33 84.83
Table 7.10: Results for Subclass V using k-NN Classifier:
Sr. No
. Feature No. of
Features
SUBCLASS V
FOLD I
FOLD II
FOLD III
FOLD IV
FOLD V
AVERAGE in %
1. DENSITY(90) + NCC(8) 98 86.67 90.83 86.67 95.00 89.58 89.75
2. DENSITY(90) 90 85.00 87.92 87.80 91.77 86.25 87.74
3. HORIZONTAL(35)+NCC(8) 43 83.75 83.32 83.33 86.77 87.50 84.93
4. HORIZONTAL(3
5) + ZERNIKE (16)
51 83.33 83.33 83.33 87.08 87.08 84.83
5. HORIZONTAL(35) 35 83.75 85.00 84.17 81.77 82.98 83.53
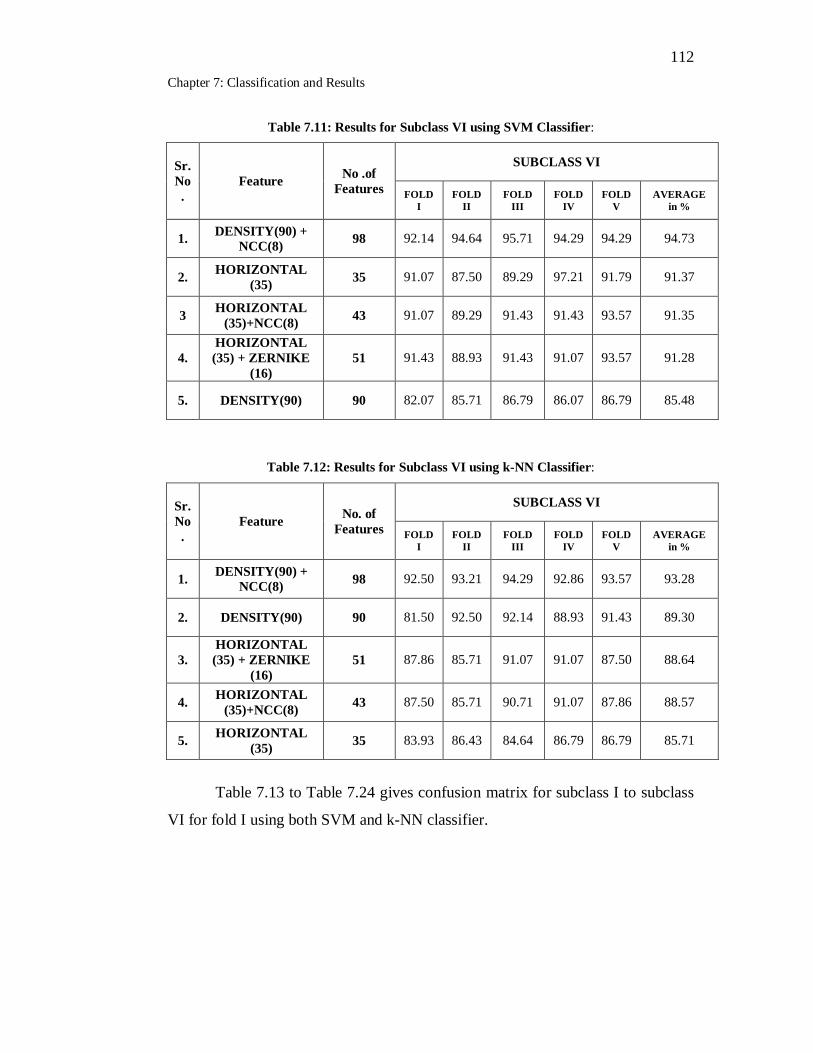
112 Chapter 7: Classification and Results
Table 7.11: Results for Subclass VI using SVM Classifier:
Sr. No.
Feature No .of Features
SUBCLASS VI
FOLD I
FOLD II
FOLD III
FOLD IV
FOLD V
AVERAGE in %
1. DENSITY(90) + NCC(8) 98 92.14 94.64 95.71 94.29 94.29 94.73
2. HORIZONTAL (35) 35 91.07 87.50 89.29 97.21 91.79 91.37
3 HORIZONTAL (35)+NCC(8) 43 91.07 89.29 91.43 91.43 93.57 91.35
4. HORIZONTAL (35) + ZERNIKE
(16) 51 91.43 88.93 91.43 91.07 93.57 91.28
5. DENSITY(90) 90 82.07 85.71 86.79 86.07 86.79 85.48
Table 7.12: Results for Subclass VI using k-NN Classifier:
Sr. No.
Feature No. of Features
SUBCLASS VI
FOLD I
FOLD II
FOLD III
FOLD IV
FOLD V
AVERAGE in %
1. DENSITY(90) + NCC(8) 98 92.50 93.21 94.29 92.86 93.57 93.28
2. DENSITY(90) 90 81.50 92.50 92.14 88.93 91.43 89.30
3. HORIZONTAL (35) + ZERNIKE
(16) 51 87.86 85.71 91.07 91.07 87.50 88.64
4. HORIZONTAL (35)+NCC(8) 43 87.50 85.71 90.71 91.07 87.86 88.57
5. HORIZONTAL (35) 35 83.93 86.43 84.64 86.79 86.79 85.71
Table 7.13 to Table 7.24 gives confusion matrix for subclass I to subclass
VI for fold I using both SVM and k-NN classifier.
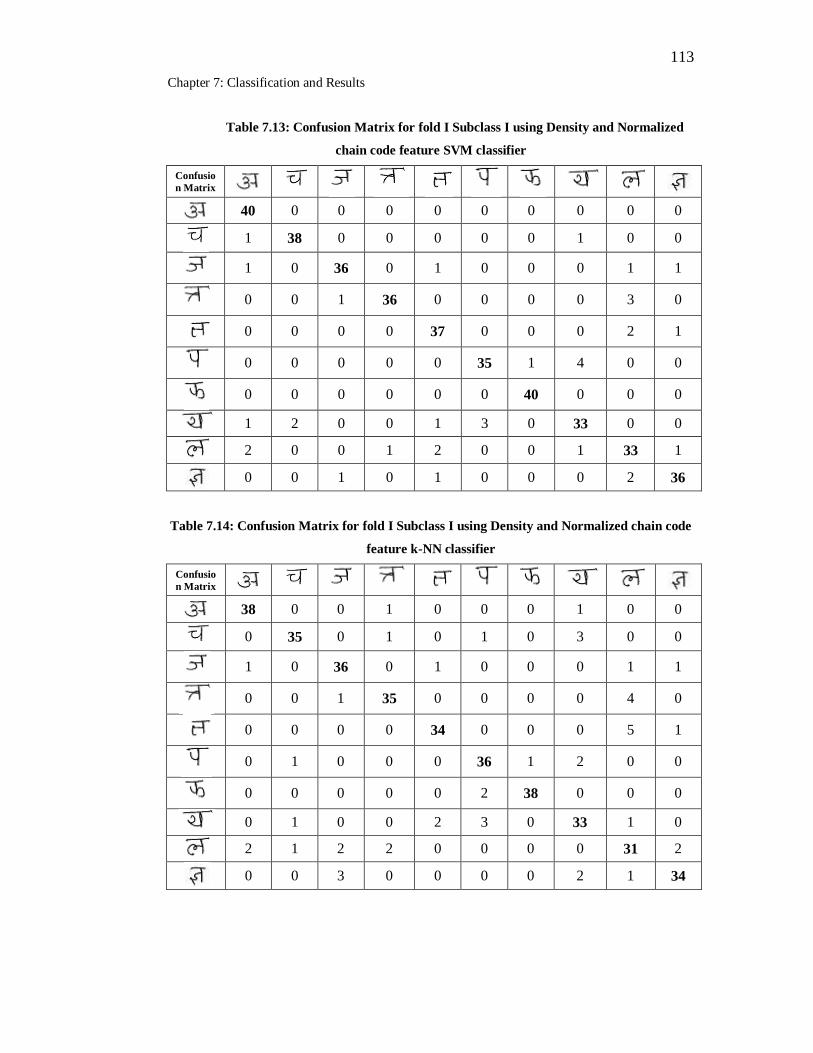
113 Chapter 7: Classification and Results
Table 7.13: Confusion Matrix for fold I Subclass I using Density and Normalized
chain code feature SVM classifier
Confusion Matrix
40 0 0 0 0 0 0 0 0 0
1 38 0 0 0 0 0 1 0 0
1 0 36 0 1 0 0 0 1 1
0 0 1 36 0 0 0 0 3 0
0 0 0 0 37 0 0 0 2 1
0 0 0 0 0 35 1 4 0 0
0 0 0 0 0 0 40 0 0 0
1 2 0 0 1 3 0 33 0 0
2 0 0 1 2 0 0 1 33 1
0 0 1 0 1 0 0 0 2 36
Table 7.14: Confusion Matrix for fold I Subclass I using Density and Normalized chain code
feature k-NN classifier
Confusion Matrix
38 0 0 1 0 0 0 1 0 0
0 35 0 1 0 1 0 3 0 0
1 0 36 0 1 0 0 0 1 1
0 0 1 35 0 0 0 0 4 0
0 0 0 0 34 0 0 0 5 1
0 1 0 0 0 36 1 2 0 0
0 0 0 0 0 2 38 0 0 0
0 1 0 0 2 3 0 33 1 0
2 1 2 2 0 0 0 0 31 2
0 0 3 0 0 0 0 2 1 34
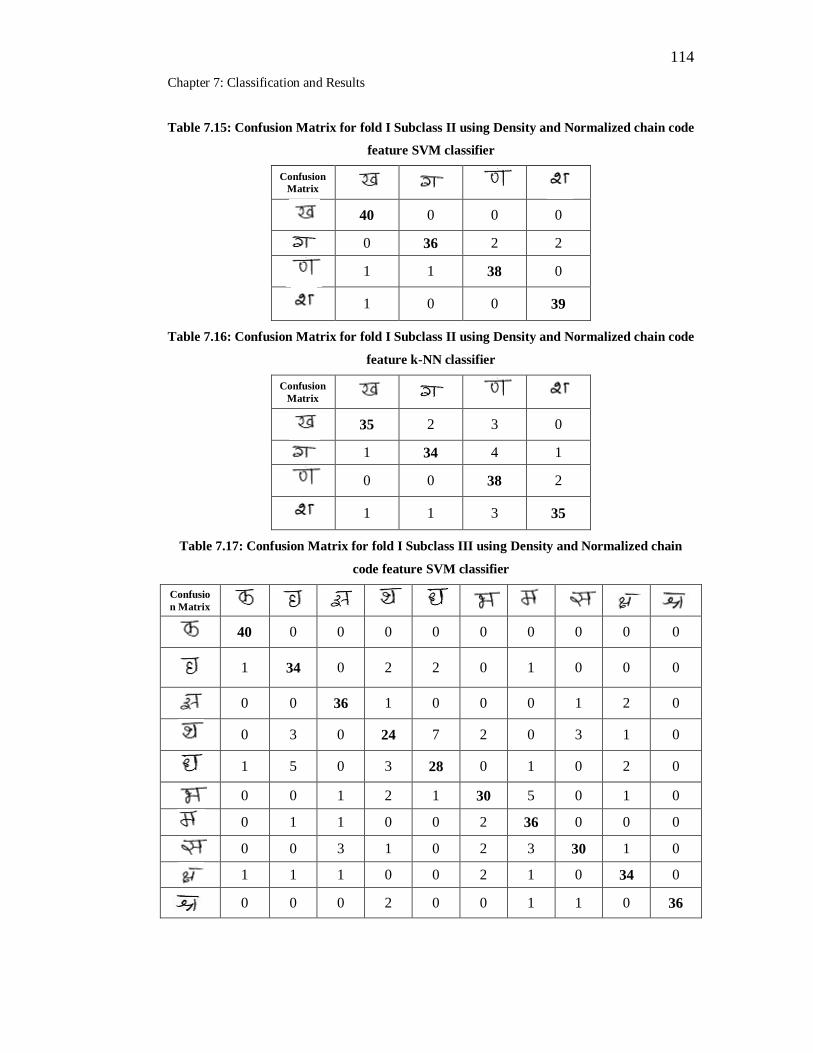
114 Chapter 7: Classification and Results
Table 7.15: Confusion Matrix for fold I Subclass II using Density and Normalized chain code
feature SVM classifier
Confusion Matrix
40 0 0 0
0 36 2 2
1 1 38 0
1 0 0 39
Table 7.16: Confusion Matrix for fold I Subclass II using Density and Normalized chain code
feature k-NN classifier
Confusion Matrix
35 2 3 0
1 34 4 1
0 0 38 2
1 1 3 35
Table 7.17: Confusion Matrix for fold I Subclass III using Density and Normalized chain
code feature SVM classifier
Confusion Matrix
40 0 0 0 0 0 0 0 0 0
1 34 0 2 2 0 1 0 0 0
0 0 36 1 0 0 0 1 2 0
0 3 0 24 7 2 0 3 1 0
1 5 0 3 28 0 1 0 2 0
0 0 1 2 1 30 5 0 1 0
0 1 1 0 0 2 36 0 0 0
0 0 3 1 0 2 3 30 1 0
1 1 1 0 0 2 1 0 34 0
0 0 0 2 0 0 1 1 0 36
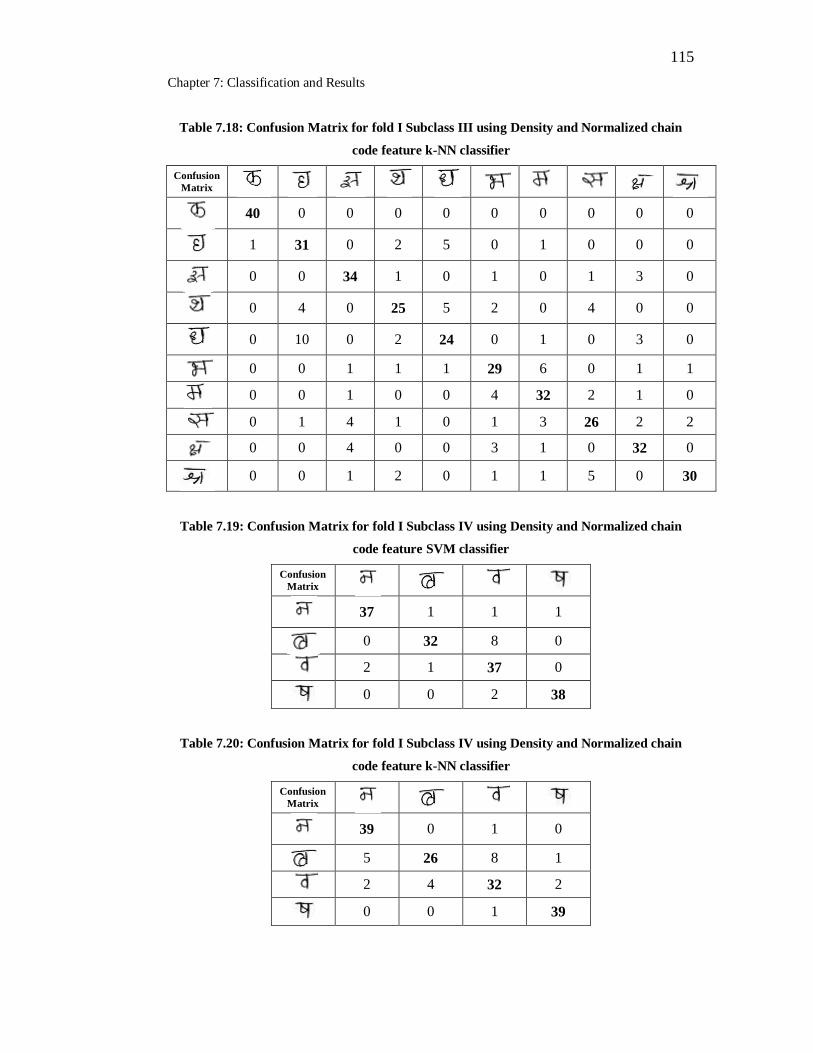
115 Chapter 7: Classification and Results
Table 7.18: Confusion Matrix for fold I Subclass III using Density and Normalized chain
code feature k-NN classifier
Confusion Matrix
40 0 0 0 0 0 0 0 0 0
1 31 0 2 5 0 1 0 0 0
0 0 34 1 0 1 0 1 3 0
0 4 0 25 5 2 0 4 0 0
0 10 0 2 24 0 1 0 3 0
0 0 1 1 1 29 6 0 1 1
0 0 1 0 0 4 32 2 1 0
0 1 4 1 0 1 3 26 2 2
0 0 4 0 0 3 1 0 32 0
0 0 1 2 0 1 1 5 0 30
Table 7.19: Confusion Matrix for fold I Subclass IV using Density and Normalized chain
code feature SVM classifier
Confusion Matrix
37 1 1 1
0 32 8 0
2 1 37 0
0 0 2 38
Table 7.20: Confusion Matrix for fold I Subclass IV using Density and Normalized chain
code feature k-NN classifier
Confusion Matrix
39 0 1 0
5 26 8 1
2 4 32 2
0 0 1 39
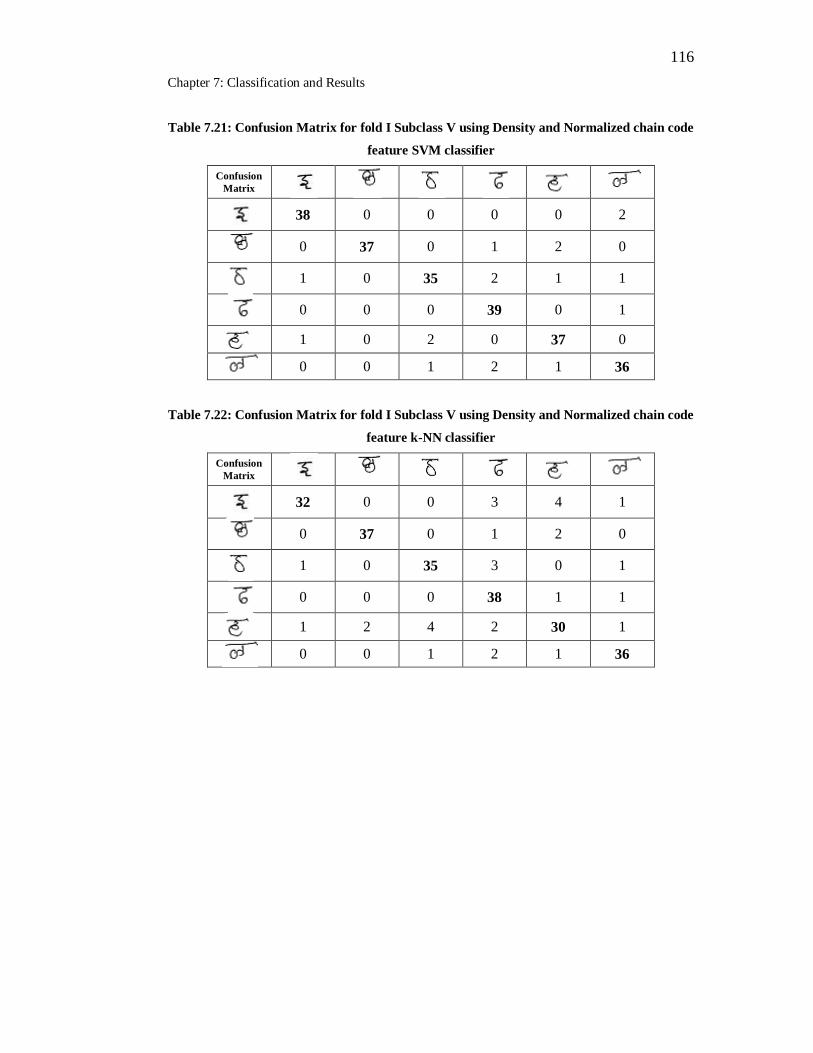
116 Chapter 7: Classification and Results
Table 7.21: Confusion Matrix for fold I Subclass V using Density and Normalized chain code
feature SVM classifier
Confusion Matrix
38 0 0 0 0 2
0 37 0 1 2 0
1 0 35 2 1 1
0 0 0 39 0 1
1 0 2 0 37 0
0 0 1 2 1 36
Table 7.22: Confusion Matrix for fold I Subclass V using Density and Normalized chain code
feature k-NN classifier
Confusion Matrix
32 0 0 3 4 1
0 37 0 1 2 0
1 0 35 3 0 1
0 0 0 38 1 1
1 2 4 2 30 1
0 0 1 2 1 36
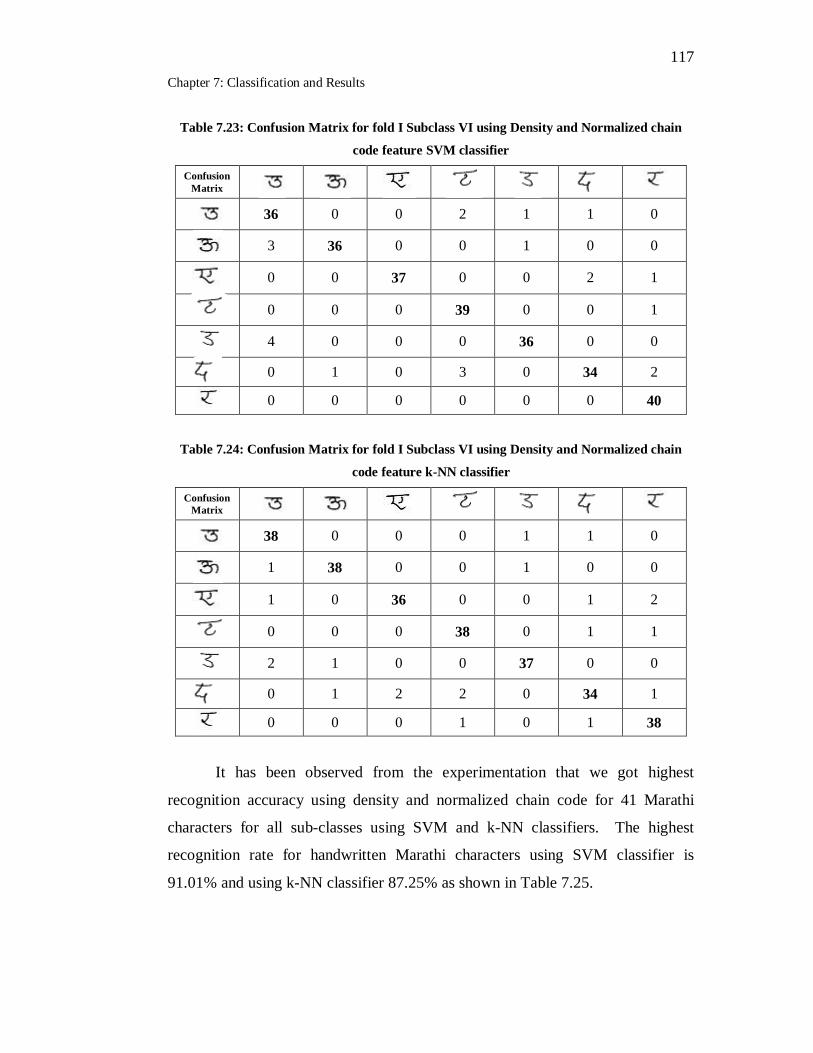
117 Chapter 7: Classification and Results
Table 7.23: Confusion Matrix for fold I Subclass VI using Density and Normalized chain
code feature SVM classifier
Confusion Matrix
36 0 0 2 1 1 0
3 36 0 0 1 0 0
0 0 37 0 0 2 1
0 0 0 39 0 0 1
4 0 0 0 36 0 0
0 1 0 3 0 34 2
0 0 0 0 0 0 40
Table 7.24: Confusion Matrix for fold I Subclass VI using Density and Normalized chain
code feature k-NN classifier
Confusion Matrix
38 0 0 0 1 1 0
1 38 0 0 1 0 0
1 0 36 0 0 1 2
0 0 0 38 0 1 1
2 1 0 0 37 0 0
0 1 2 2 0 34 1
0 0 0 1 0 1 38
It has been observed from the experimentation that we got highest
recognition accuracy using density and normalized chain code for 41 Marathi
characters for all sub-classes using SVM and k-NN classifiers. The highest
recognition rate for handwritten Marathi characters using SVM classifier is
91.01% and using k-NN classifier 87.25% as shown in Table 7.25.
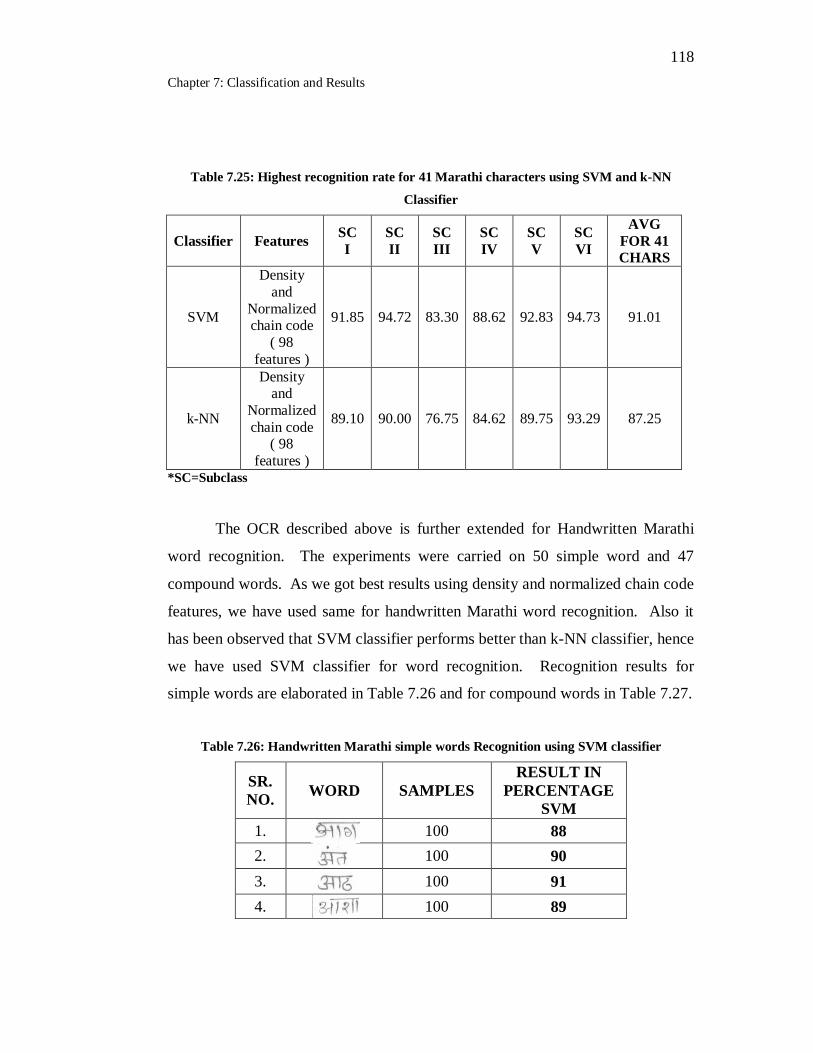
118 Chapter 7: Classification and Results
Table 7.25: Highest recognition rate for 41 Marathi characters using SVM and k-NN
Classifier
Classifier Features SC I
SC II
SC III
SC IV
SC V
SC VI
AVG FOR 41 CHARS
SVM
Density and
Normalized chain code
( 98 features )
91.85 94.72 83.30 88.62 92.83 94.73 91.01
k-NN
Density and
Normalized chain code
( 98 features )
89.10 90.00 76.75 84.62 89.75 93.29 87.25
*SC=Subclass
The OCR described above is further extended for Handwritten Marathi
word recognition. The experiments were carried on 50 simple word and 47
compound words. As we got best results using density and normalized chain code
features, we have used same for handwritten Marathi word recognition. Also it
has been observed that SVM classifier performs better than k-NN classifier, hence
we have used SVM classifier for word recognition. Recognition results for
simple words are elaborated in Table 7.26 and for compound words in Table 7.27.
Table 7.26: Handwritten Marathi simple words Recognition using SVM classifier
SR. NO. WORD SAMPLES
RESULT IN PERCENTAGE
SVM 1. 100 88 2. 100 90 3. 100 91 4. 100 89
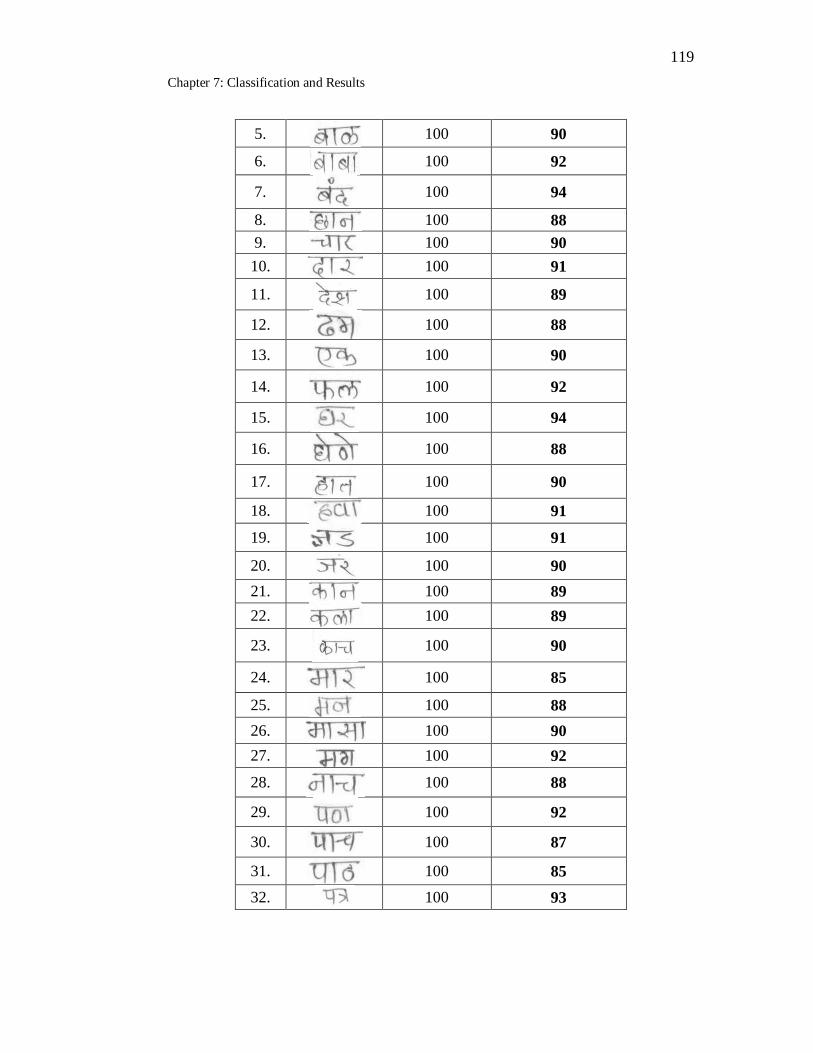
119 Chapter 7: Classification and Results
5. 100 90
6. 100 92
7.
100 94
8. 100 88 9. 100 90 10. 100 91
11. 100 89
12. 100 88
13. 100 90
14.
100 92
15. 100 94
16.
100 88
17.
100 90
18. 100 91 19. 100 91
20. 100 90 21. 100 89 22. 100 89
23.
100 90
24. 100 85
25. 100 88 26. 100 90 27. 100 92 28. 100 88
29. 100 92
30. 100 87
31. 100 85 32. 100 93
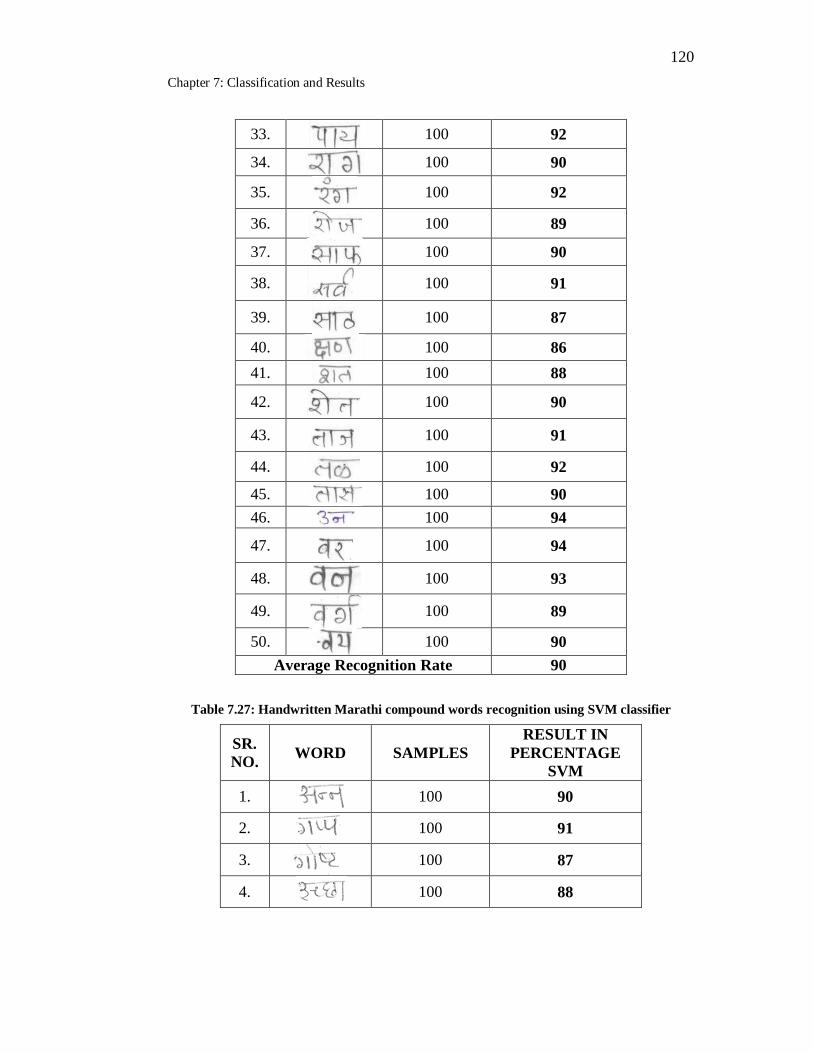
120 Chapter 7: Classification and Results
33. 100 92
34. 100 90
35.
100 92
36. 100 89
37. 100 90
38.
100 91
39.
100 87
40. 100 86 41. 100 88
42.
100 90
43.
100 91
44. 100 92
45. 100 90 46. 100 94
47.
100 94
48. 100 93
49.
100 89
50. 100 90 Average Recognition Rate 90
Table 7.27: Handwritten Marathi compound words recognition using SVM classifier
SR. NO. WORD SAMPLES
RESULT IN PERCENTAGE
SVM 1.
100 90
2. 100 91
3.
100 87
4. 100 88
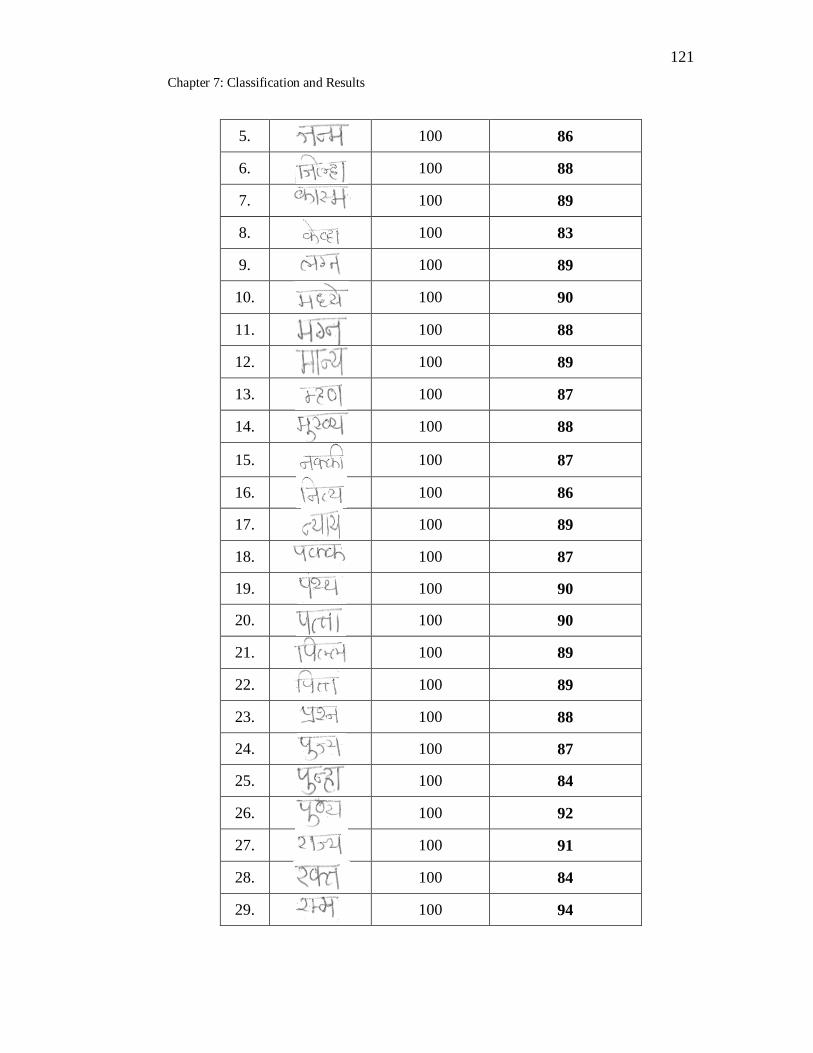
121 Chapter 7: Classification and Results
5.
100 86
6.
100 88
7.
100 89
8.
100 83
9.
100 89
10.
100 90
11.
100 88
12.
100 89
13.
100 87
14.
100 88
15.
100 87
16. 100 86
17.
100 89
18.
100 87
19. 100 90
20.
100 90
21.
100 89
22.
100 89
23.
100 88
24. 100 87
25. 100 84
26.
100 92
27.
100 91
28.
100 84
29.
100 94
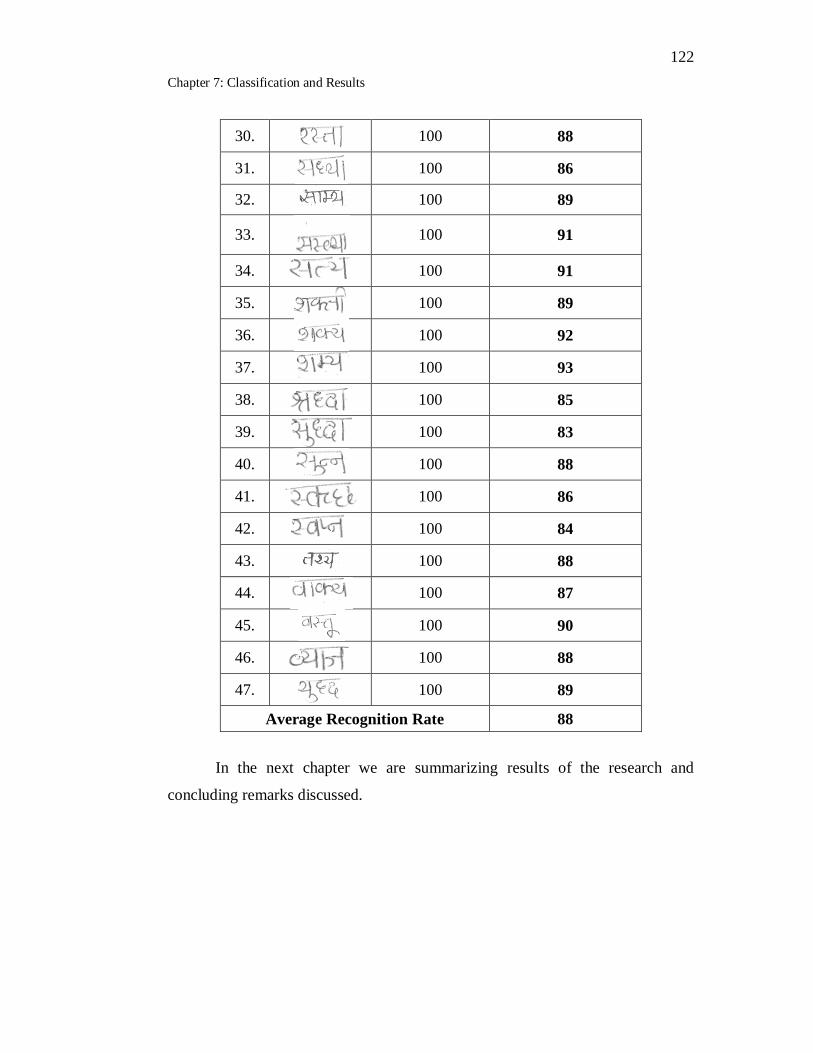
122 Chapter 7: Classification and Results
30.
100 88
31.
100 86
32. 100 89
33.
100 91
34.
100 91
35.
100 89
36.
100 92
37.
100 93
38.
100 85
39.
100 83
40.
100 88
41.
100 86
42.
100 84
43.
100 88
44.
100 87
45.
100 90
46.
100 88
47.
100 89
Average Recognition Rate 88
In the next chapter we are summarizing results of the research and
concluding remarks discussed.

Chapter 8
Summary and Conclusions
---------------------------------------------------------------------------------------------------
8.1 Conclusions
8.2 Scope for further research
---------------------------------------------------------------------------------------------------
In this chapter we present contributions and summary of the present research
work. A comparative study of the present work with research work reported in
literature is made. Limitations of the present work and scope for the further
research are discussed.
---------------------------------------------------------------------------------------------------
8.1 Conclusions:
The work presented in this thesis has addressed the problem of
handwritten Marathi word recognition. Approaches to recognition largely depend
on the nature of the data to be recognized. Since handwritten Marathi words
could be of various shapes and sizes, the recognition process needs to be much
efficient and accurate to recognize the words written by different users. The
present work has addressed this problem by a novel multilevel classification
approach that groups Marathi characters into six groups. In additions to this,
suitable features for different subclasses are extracted. Recognition accuracy for
handwritten Marathi characters are cross validated using fivefold method and
tested using two classifiers, viz. k-Nearest Neighbor and Support Vector Machine
classifier. The different feature sets used are:

124
Chapter 8: Summary and Conclusions
1. Symmetric density features based upon the zoning approach. The feature
vector size is 90.
2. Diagonal features based upon the zoning approach. The feature vector
size is 35.
3. Horizontal features based upon the zoning approach. The feature vector
size is 35.
4. Vertical features based upon the zoning approach. The feature vector size
is 35.
5. Normalized chain code features. The feature vector size is 8.
6. Invariant moment features. The feature vector size is 35.
7. Zernike moment features. The feature vector size is 16.
8. Discrete wavelet transformation features. The feature vector size is 8.
9. Combination of symmetric density features based upon the zoning
approach and normalized chain code. The feature vector size is 98.
10. Combination of diagonal features based upon the zoning approach and
Zernike moments. The feature vector size is 51.
11. Combination of horizontal features based upon the zoning approach and
normalized chain code features. The feature vector size is 43.
12. Combination of horizontal features based upon the zoning approach and
moment invariant features. The feature vector size is 42.

125
Chapter 8: Summary and Conclusions
13. Combination of horizontal features based upon the zoning approach and
Zernike moment features. The feature vector size is 51.
The effectiveness of the features proposed in the thesis is evaluated by
performing experiments on the database developed for the work. The database of
handwritten Marathi words contains 36283 images which are obtained from 100
writers belonging to different age groups and professions. In addition to this
database of isolated handwritten Marathi characters contains 9600 images which
are obtained from 20 writers belonging to different age groups and professions.
Since the data was collected in a preformatted paper the skew/slant was assumed
to be negligible and hence ignored in preprocessing stage. We adopted fivefold
cross validation technique, for performance evaluation of the classifier. With
fivefold cross-validation, all objects in the data set are used both as test objects as
well as training objects. This ensures that the classifier is tested on both rare and
common types of objects. The graphical presentation of recognition accuracy for
all subclasses using combination of zone based symmetric density and normalized
chain code feature is shown in the Figure 8.1 for both the classifiers SVM as well
as k-NN.
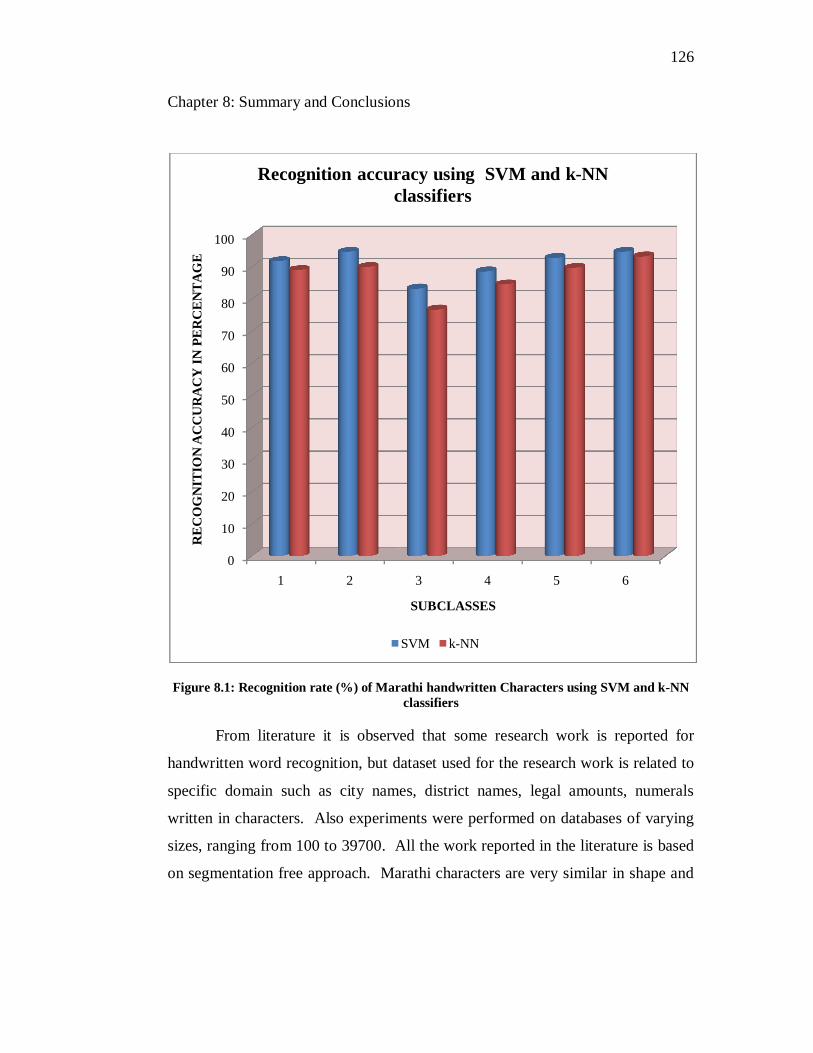
126
Chapter 8: Summary and Conclusions
Figure 8.1: Recognition rate (%) of Marathi handwritten Characters using SVM and k-NN classifiers
From literature it is observed that some research work is reported for
handwritten word recognition, but dataset used for the research work is related to
specific domain such as city names, district names, legal amounts, numerals
written in characters. Also experiments were performed on databases of varying
sizes, ranging from 100 to 39700. All the work reported in the literature is based
on segmentation free approach. Marathi characters are very similar in shape and
0
10
20
30
40
50
60
70
80
90
100
1 2 3 4 5 6
RE
CO
GN
ITIO
N A
CC
UR
AC
Y IN
PE
RC
EN
TA
GE
SUBCLASSES
Recognition accuracy using SVM and k-NN classifiers
SVM k-NN

127
Chapter 8: Summary and Conclusions
structure; hence large numbers of features are required to achieve good
recognition accuracy.
All these limitations are considered and resolved in this work. The
contributions of the present work may be summarised as follows:
1. Any handwritten word of any size can be recognized using the system
proposed in this thesis.
2. Database developed for handwritten Marathi words and isolatd characters
is large enough to carry out experiments in further work.
3. Segmentation algorithms are developed and tested on the developed
database.
4. A novel multilevel classification approach is proposed to reduce the
number of features and hence improved the recognition efficiency of
character classification.
5. The usual claim by researcher that SVM clasifier performs better than k-
NN classifier is verified from this work.
The recognition accuracy from subclass I to subclass VI is computed using
listed features for both the classifiers. The recognition rates are higher for all
subclasses using combination of zone based symmetric density and normalized
chain code features. Top five features and their recognition accuracies for all
subclasses using SVM and k-NN classifiers is given in Table 8.1 to Table 8.6.
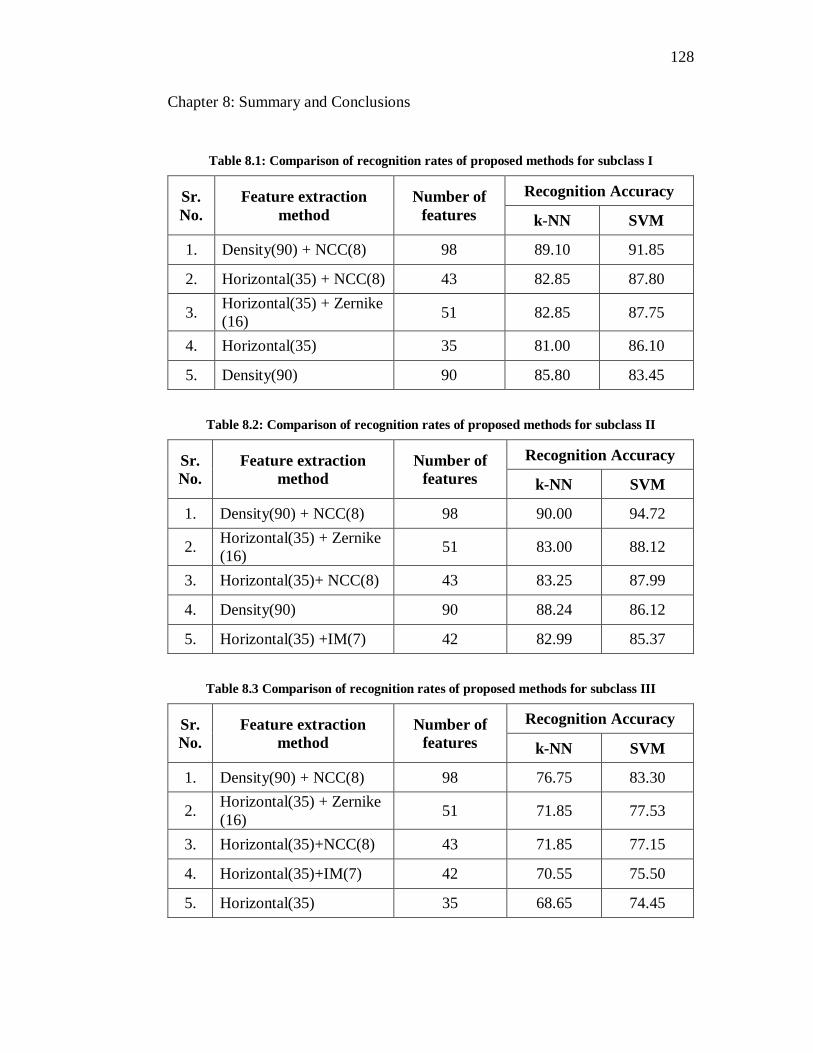
128
Chapter 8: Summary and Conclusions
Table 8.1: Comparison of recognition rates of proposed methods for subclass I
Sr. No.
Feature extraction method
Number of features
Recognition Accuracy
k-NN SVM
1. Density(90) + NCC(8) 98 89.10 91.85
2. Horizontal(35) + NCC(8) 43 82.85 87.80
3. Horizontal(35) + Zernike (16) 51 82.85 87.75
4. Horizontal(35) 35 81.00 86.10
5. Density(90) 90 85.80 83.45
Table 8.2: Comparison of recognition rates of proposed methods for subclass II
Sr. No.
Feature extraction method
Number of features
Recognition Accuracy
k-NN SVM
1. Density(90) + NCC(8) 98 90.00 94.72
2. Horizontal(35) + Zernike (16) 51 83.00 88.12
3. Horizontal(35)+ NCC(8) 43 83.25 87.99
4. Density(90) 90 88.24 86.12
5. Horizontal(35) +IM(7) 42 82.99 85.37
Table 8.3 Comparison of recognition rates of proposed methods for subclass III
Sr. No.
Feature extraction method
Number of features
Recognition Accuracy
k-NN SVM
1. Density(90) + NCC(8) 98 76.75 83.30
2. Horizontal(35) + Zernike (16) 51 71.85 77.53
3. Horizontal(35)+NCC(8) 43 71.85 77.15
4. Horizontal(35)+IM(7) 42 70.55 75.50
5. Horizontal(35) 35 68.65 74.45
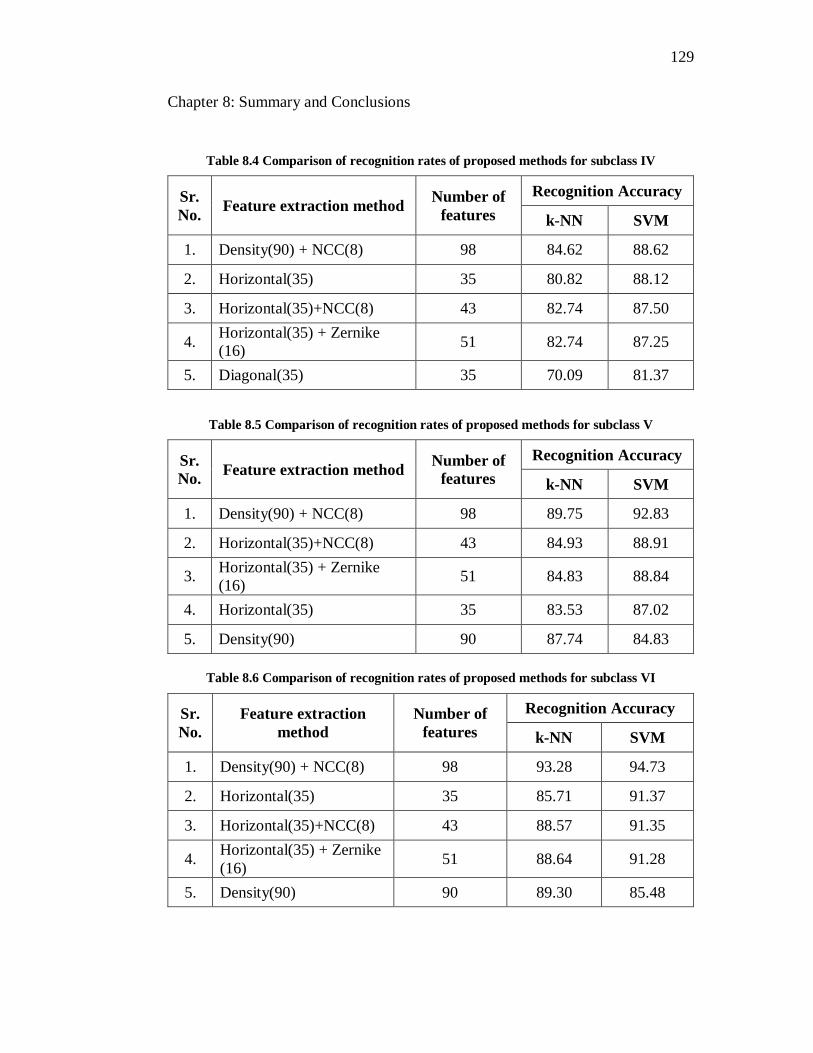
129
Chapter 8: Summary and Conclusions
Table 8.4 Comparison of recognition rates of proposed methods for subclass IV
Sr. No. Feature extraction method Number of
features Recognition Accuracy
k-NN SVM
1. Density(90) + NCC(8) 98 84.62 88.62
2. Horizontal(35) 35 80.82 88.12
3. Horizontal(35)+NCC(8) 43 82.74 87.50
4. Horizontal(35) + Zernike (16) 51 82.74 87.25
5. Diagonal(35) 35 70.09 81.37
Table 8.5 Comparison of recognition rates of proposed methods for subclass V
Sr. No. Feature extraction method Number of
features Recognition Accuracy
k-NN SVM
1. Density(90) + NCC(8) 98 89.75 92.83
2. Horizontal(35)+NCC(8) 43 84.93 88.91
3. Horizontal(35) + Zernike (16) 51 84.83 88.84
4. Horizontal(35) 35 83.53 87.02
5. Density(90) 90 87.74 84.83
Table 8.6 Comparison of recognition rates of proposed methods for subclass VI
Sr. No.
Feature extraction method
Number of features
Recognition Accuracy
k-NN SVM
1. Density(90) + NCC(8) 98 93.28 94.73
2. Horizontal(35) 35 85.71 91.37
3. Horizontal(35)+NCC(8) 43 88.57 91.35
4. Horizontal(35) + Zernike (16) 51 88.64 91.28
5. Density(90) 90 89.30 85.48
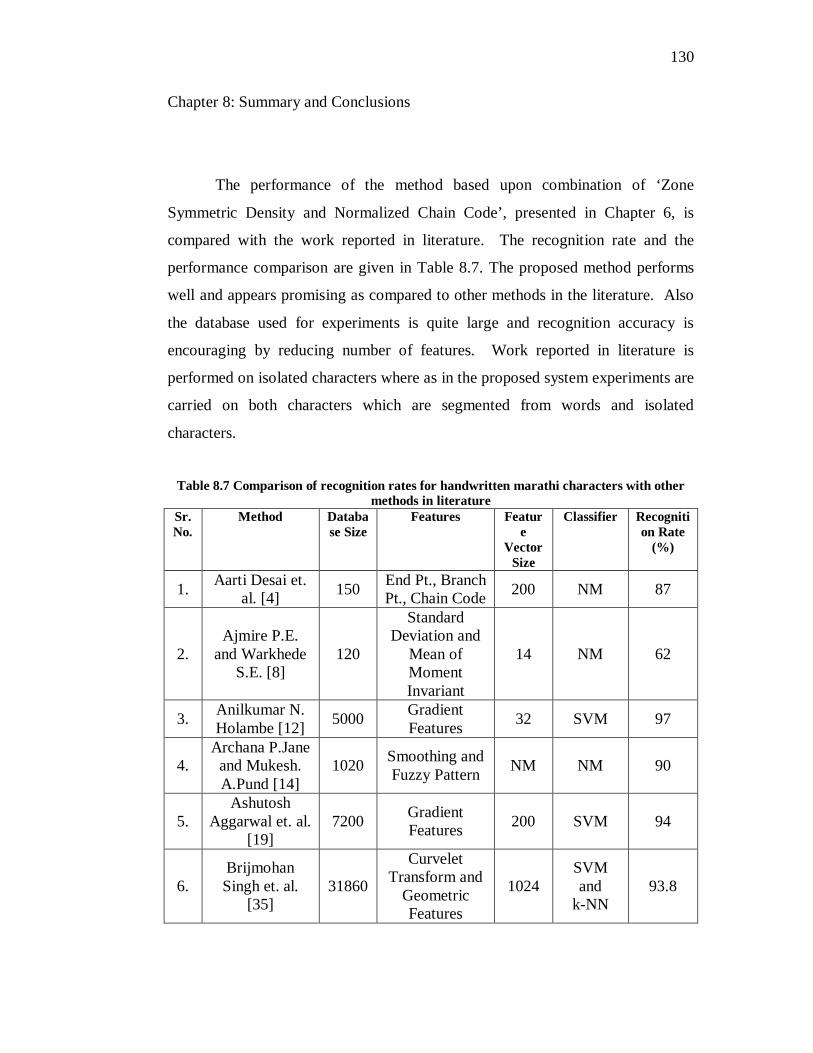
130
Chapter 8: Summary and Conclusions
The performance of the method based upon combination of ‘Zone
Symmetric Density and Normalized Chain Code’, presented in Chapter 6, is
compared with the work reported in literature. The recognition rate and the
performance comparison are given in Table 8.7. The proposed method performs
well and appears promising as compared to other methods in the literature. Also
the database used for experiments is quite large and recognition accuracy is
encouraging by reducing number of features. Work reported in literature is
performed on isolated characters where as in the proposed system experiments are
carried on both characters which are segmented from words and isolated
characters.
Table 8.7 Comparison of recognition rates for handwritten marathi characters with other methods in literature
Sr. No.
Method Database Size
Features Feature
Vector Size
Classifier Recognition Rate
(%)
1. Aarti Desai et. al. [4] 150 End Pt., Branch
Pt., Chain Code 200 NM 87
2. Ajmire P.E.
and Warkhede S.E. [8]
120
Standard Deviation and
Mean of Moment Invariant
14 NM 62
3. Anilkumar N. Holambe [12] 5000 Gradient
Features 32 SVM 97
4. Archana P.Jane
and Mukesh. A.Pund [14]
1020 Smoothing and Fuzzy Pattern NM NM 90
5. Ashutosh
Aggarwal et. al. [19]
7200 Gradient Features 200 SVM 94
6. Brijmohan Singh et. al.
[35] 31860
Curvelet Transform and
Geometric Features
1024 SVM and
k-NN 93.8
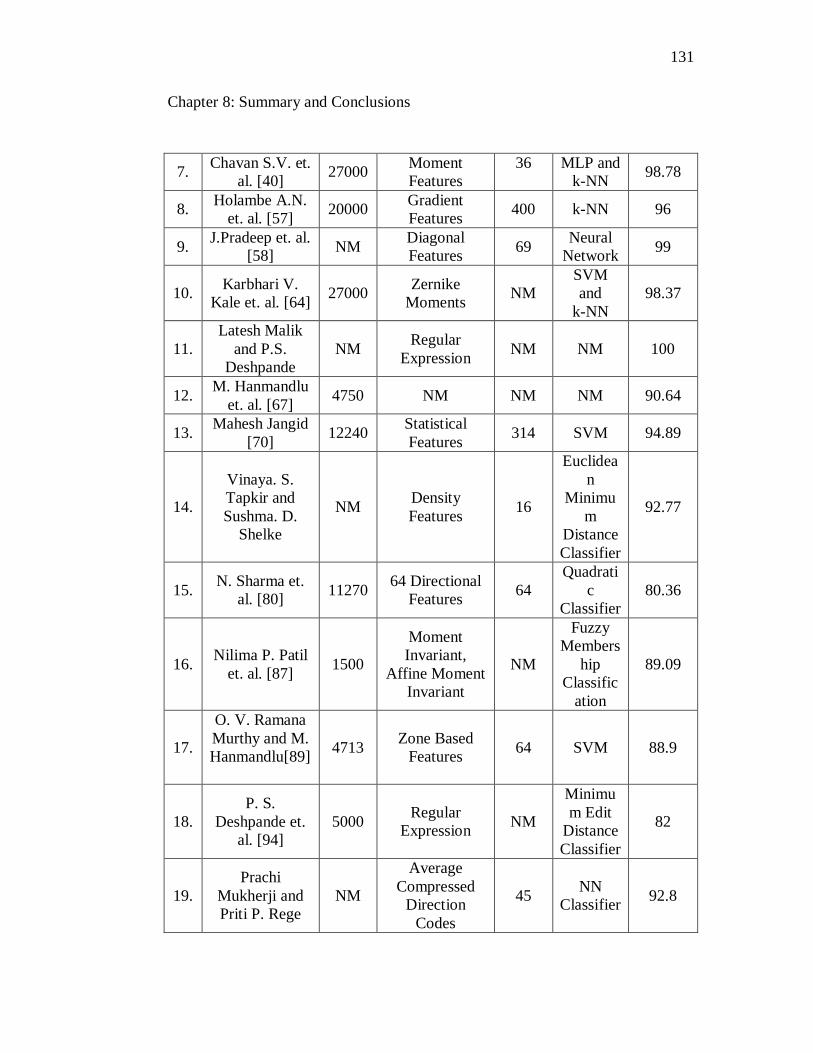
131
Chapter 8: Summary and Conclusions
7. Chavan S.V. et. al. [40] 27000 Moment
Features 36
MLP and
k-NN 98.78
8. Holambe A.N. et. al. [57] 20000 Gradient
Features 400 k-NN 96
9. J.Pradeep et. al. [58] NM Diagonal
Features 69 Neural Network 99
10. Karbhari V. Kale et. al. [64] 27000 Zernike
Moments NM SVM and
k-NN 98.37
11. Latesh Malik
and P.S. Deshpande
NM Regular Expression NM NM 100
12. M. Hanmandlu et. al. [67] 4750 NM NM NM 90.64
13. Mahesh Jangid [70] 12240 Statistical
Features 314 SVM 94.89
14.
Vinaya. S. Tapkir and Sushma. D.
Shelke
NM Density Features 16
Euclidean
Minimum
Distance Classifier
92.77
15. N. Sharma et. al. [80] 11270 64 Directional
Features 64 Quadrati
c Classifier
80.36
16. Nilima P. Patil et. al. [87] 1500
Moment Invariant,
Affine Moment Invariant
NM
Fuzzy Members
hip Classific
ation
89.09
17.
O. V. Ramana Murthy and M. Hanmandlu[89]
4713 Zone Based Features 64 SVM 88.9
18. P. S.
Deshpande et. al. [94]
5000 Regular Expression NM
Minimum Edit
Distance Classifier
82
19. Prachi
Mukherji and Priti P. Rege
NM
Average Compressed
Direction Codes
45 NN Classifier 92.8
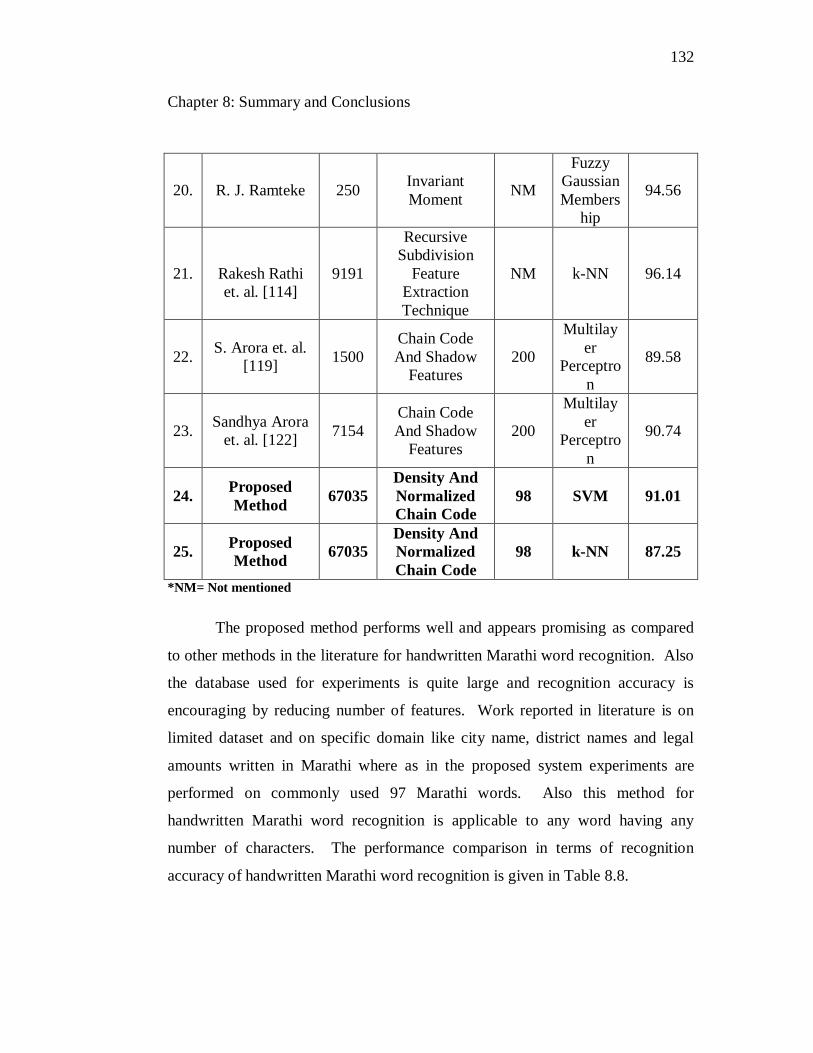
132
Chapter 8: Summary and Conclusions
20. R. J. Ramteke 250 Invariant Moment NM
Fuzzy Gaussian Members
hip
94.56
21.
Rakesh Rathi et. al. [114]
9191
Recursive Subdivision
Feature Extraction Technique
NM k-NN 96.14
22. S. Arora et. al. [119] 1500
Chain Code And Shadow
Features 200
Multilayer
Perceptron
89.58
23. Sandhya Arora et. al. [122] 7154
Chain Code And Shadow
Features 200
Multilayer
Perceptron
90.74
24. Proposed Method 67035
Density And Normalized Chain Code
98 SVM 91.01
25. Proposed Method 67035
Density And Normalized Chain Code
98 k-NN 87.25
*NM= Not mentioned
The proposed method performs well and appears promising as compared
to other methods in the literature for handwritten Marathi word recognition. Also
the database used for experiments is quite large and recognition accuracy is
encouraging by reducing number of features. Work reported in literature is on
limited dataset and on specific domain like city name, district names and legal
amounts written in Marathi where as in the proposed system experiments are
performed on commonly used 97 Marathi words. Also this method for
handwritten Marathi word recognition is applicable to any word having any
number of characters. The performance comparison in terms of recognition
accuracy of handwritten Marathi word recognition is given in Table 8.8.
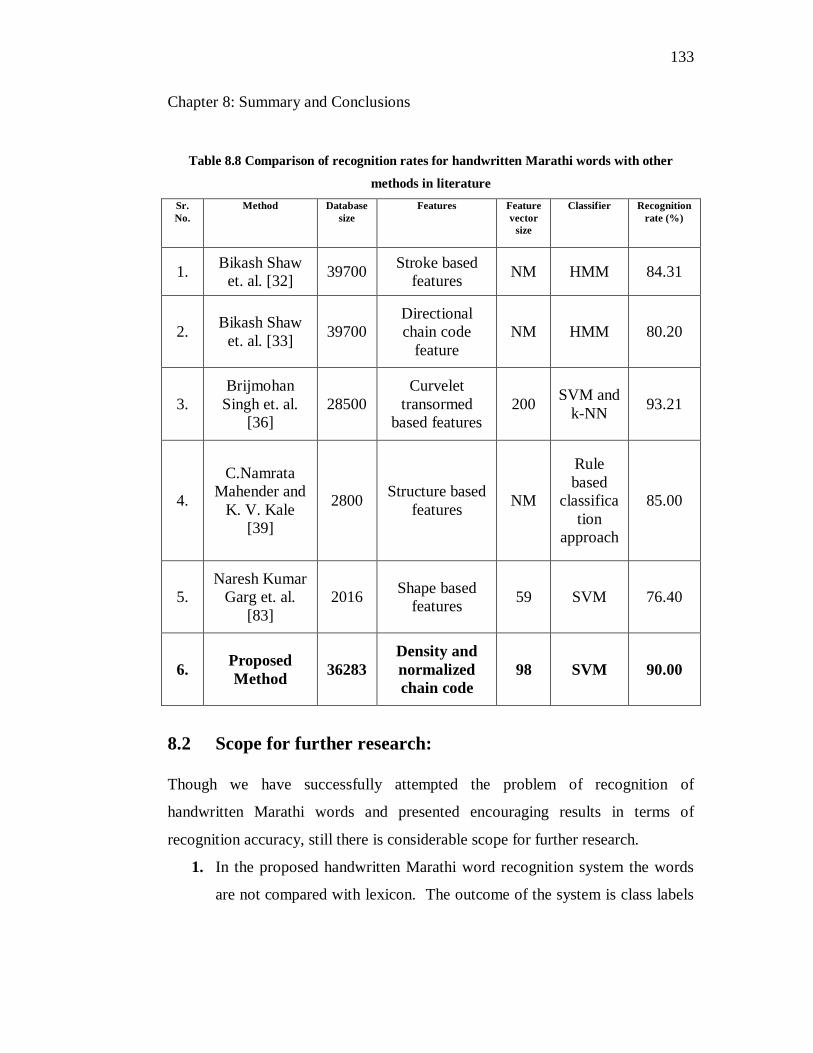
133
Chapter 8: Summary and Conclusions
Table 8.8 Comparison of recognition rates for handwritten Marathi words with other
methods in literature Sr. No.
Method Database size
Features Feature vector
size
Classifier Recognition rate (%)
1. Bikash Shaw et. al. [32] 39700 Stroke based
features NM HMM 84.31
2. Bikash Shaw et. al. [33] 39700
Directional chain code
feature NM HMM 80.20
3. Brijmohan
Singh et. al. [36]
28500 Curvelet
transormed based features
200 SVM and k-NN 93.21
4.
C.Namrata Mahender and
K. V. Kale [39]
2800 Structure based features NM
Rule based
classification
approach
85.00
5. Naresh Kumar
Garg et. al. [83]
2016 Shape based features 59 SVM 76.40
6. Proposed Method 36283
Density and normalized chain code
98 SVM 90.00
8.2 Scope for further research:
Though we have successfully attempted the problem of recognition of
handwritten Marathi words and presented encouraging results in terms of
recognition accuracy, still there is considerable scope for further research.
1. In the proposed handwritten Marathi word recognition system the words
are not compared with lexicon. The outcome of the system is class labels

134
Chapter 8: Summary and Conclusions
for every isolated character, half character and modifier. The performance
of the system may be improved by including lexicon.
2. The proposed feature extraction methods have been tested for handwritten
words collected in preformatted sheets. In real world situations, the words
are segmented out from a handwritten document and are input to the OCR
for recognition. Hence, there is a need to consider such words to test the
robustness of the proposed OCR system.
3. Though the data is collected in preformatted sheets, there is always some
slant in the written words. Including slant correction algorithms in
preprocessing stage may definitely increase the recognition rate of
handwritten Marathi words.
4. The characters in words obtained from old handwritten documents are
often disconnected. The proposed system takes care of disconnected
characters, where the disconnectivity is one or two pixels. Beyond that,
there is a need to consider other methods to take care of disconnected
characters.
5. For similar character symbols, the recognition rate can be improved by
combining multiple classifiers.
6. The proposed methods can be extended for recognition of words written in
other Indian scripts.

Publications
International Journals:
1. “Recognition of Handwritten Marathi Vowels using Zone based Symmetric
Density Features”, International Journal of Computer Applications (0975 –
8887) Volume 108 – No. 4, December 2014, ISSN 0975-8887. Impact factor-
0.715.
2. “Recognition of Handwritten Marathi Vowels using Combination of
Topological and Statistical Features”, International Journal of Engineering
Research & Technology (IJERT), Vol. 3 Issue 11, November-2014, ISSN: 2278-
0181. Impact factor-1.76
National:
1. “Isolated Handwritten Marathi Character Recognition”, Proceedings of
National Conference on Challenging Research Areas in Computer Science and
Information Technology - 2014, ISBN 978-93-83777-00-6.

Bibliography
1. A. L. Koerich, R. Sabourin, C. Y. Suen; 2003; Large vocabulary off-line
handwriting recognition:A survey; Springer Pattern Anal Applic (2003) 6: 97–121 DOI 10.1007/s10044-002-0169-3.
2. A. R. Karwankar, A.S. Bhalchandra; 2010; Stroke Pattern Identification in Devanagari Character Recognition; Published in International Journal of Advanced Engineering & Application, Jan. 2010.
3. Aarti Desai, Latesh Malik; 2011; A Novel Approach To Thinning Of Devnagari Characters; International Journal of Engineering Science and Technology (IJEST); ISSN : 0975-5462.
4. Aarti Desai, Latesh Malik, Rashmi Welekar; 2011; A New Methodology For Devnagari Character Recognition; JM academy of It & Management Volume -1 Issue 1; ISSN: 2229-6115.
5. Aditya Raj, Ranjeet Srivastava, Tushar Patnaik, Bhupendra Kumar; 2013; A Survey of Feature Extraction and Classification Techniques Used In Character Recognition for Indian Scripts; International Journal of Engineering and Advanced Technology (IJEAT) , Volume-2, Issue-3, February 2013; ISSN: 2249 – 8958.
6. Aisharjya Sarkar, Arindam Biswas; 2010; Word Segmentation and Baseline Detection in Handwritten Documents Using Isothetic Covers; 12th International Conference on Frontiers in Handwriting Recognition 978-0-7695-4221-8/10, 2010 IEEE.
7. Ajay K. Talele, Sanjay L. Nalbalwar, Milind E. Rane; 2011; Automatic Recognition and Verification of Handwritten Legal and Courtesy Amounts in English Language Present on Bank Cheques; International Journal of Computer Applications(0975–8887) Volume 21– No.8, May 2011.
8. Ajmire P. E., Warkhede S.E.; 2010; Handwritten Marathi character (vowel) recognition; Advances in Information Mining, ISSN: 0975–3265, Volume 2, Issue 2, 2010, PP-11-13.
9. Alessandro L. Koerich Alceu de S. Britto Jr. Luiz Eduardo S. de Oliveira; 2010; Verification of Unconstrained Handwritten Words at Character Level; 12th International Conference on Frontiers in Handwriting Recognition 978-0-7695-4221-8/10, 2010 IEEE.
10. Amit Choudhary, Rahul Rishi, Savita Ahlawat, Vijaypal Singh Dhaka; 2010; Totally Unconstrained Handwritten Character Recognition using Improved BP Neural Network; International Journal of Information Technology and Knowledge Management July-December 2010, Volume 2, No. 2, pp. 645-649.
11. Angshul Majumdar; 2007; Bangla Basic Character Recognition Using Digital Curvelet Transform; Journal of Pattern Recognition Research 1 (2007) 17-26.

137 Bibliography
12. Anilkumar N. Holambe, Ravinder C.Thool, Sushilkumar N. Holambe; Printed and Handwritten Character & Number Recognition of Devanagari Script using Gradient Features; Advances in Multimedia - An International Journal (AMIJ).
13. Apurva A. Desai; 2012; Segmentation of Characters from Old Typewritten Documents using Radon Transform; International Journal of Computer APPlications (0975–8887) Volume 37– No.9, January 2012.
14. Archana P. Jane, Mukesh A. Pund; 2012; Recognition of Similar Shaped Handwritten Marathi Characters Using Artificial Neural Network; Global Journal of Computer Science and Technology Neural & Artificial Intelligence Volume 12 Issue 11 Version 1.0 Year 2012; Online ISSN: 0975-4172 & Print ISSN: 0975-4350.
15. Ashish Ghosh, B. Uma Shankar, Saroj K. Meher; 2009; A novel approach to neuro-fuzzy classification; Elsevier Neural Networks 22 (2009) 100 109.
16. Ashoka H.N., Manjaiah D.H., Rabindranath Bera; 2012; Feature Extraction Technique for Neural Network Based Pattern Recognition; International Journal on Computer Science and Engineering (IJCSE) Vol. 4 No. 03; ISSN : 0975-3397.
17. Ashu Kumar, Simpel Rani Jindal; 2012; Segmentation of handwritten Gurmukhi text into lines; International Conference on Recent Advances and Future Trends in Information Technology (iRAFIT2012) Proceedings published in International Journal of Computer Applications (IJCA).
18. Ashutosh Aggarwal, Rajneesh Rani, Renu Dhir; 2012; Recognition of Devanagari Handwritten Numeralsusing Gradient Features and SVM; International Journal of Computer Applications (0975–888). Volume 48– No.8, June 2012.
19. Ashutosh Aggarwal, Rajneesh Rani, RenuDhir; 2012; Handwritten Devanagari Character Recognition Using Gradient Features; International Journal of Advanced Research in Computer Science and Software Engineering Volume 2, Issue 5; ISSN: 2277 128X.
20. Ashutosh Malaviya, Christoph Leja, Liliane Peters; 1996; Multi-Script Handwriting Recognition with FOHDEL; Published in the Proceedings of the Biennial Conference of North American Information Proecessing Society (NAFIPS’96), Berkeley, IEEE, PP. 147-151, 1996.
21. B. V. Dhandra, V. S. Malemath, Mallikarjun H. , Ravindra Hegadi; 2006; Skew Detection in Binary Image Documents Based on Image Dilation and Region labeling Approach; 0-7695-2521-0/06/2006 IEEE.
22. B. V. Dhandra, V. S. Malemath, Mallikarjun H., Ravindra Hegadi; 2006; Multi-font Numeral Recognition without Thinning based on Directional Density of Pixels; 1-4244-0682-X/06/2006 IEEE.
23. B.V. Dhandra, Gururaj Mukarambi, Mallikarjun Hangarge; 2011; Mixture Of Printed Kannada Numerals And Vowels Recognition System; World Journal of Science and Technology 2011,1(8):109-114 ISSN: 2231 – 2587.

138 Bibliography
24. B.V.Dhandra, Gururaj Mukarambi, Mallikarjun Hangarge; 2011; Kannada and English Numeral Recognition System; International Journal of Computer APPlications (0975–8887) Volume 26– No.9, July 2011.
25. B.V.Dhandra, Mallikarjun Hangarge; 2007; On Separation of English Numerals from Multilingual Document Images; Journal Of Multimedia, Vol. 2, No. 6.
26. B.V.Dhandra, Mallikarjun Hangarge; Morphological Reconstruction for Word Level Script Identification; International Journal of Computer Science and Security, Volume (1) : Issue (1).
27. B.V.Dhandra, P. Nagabhushan, Mallikarjun Hangarge, Ravindra Hegadi, V.S. Malemath; 2006; Script Identification Based on Morphological Reconstruction in Document Images; 0-7695-2521-0/06/2006 IEEE.
28. B.V.Dhandra, R.G.Benne, Mallikarjun Hangarge; 2010; Kannada, Telugu and Devanagari Handwritten Numeral Recognition with Probabilistic Neural Network: A Novel APProach; IJCA Special Issue on “Recent Trends in Image Processing and Pattern Recognition” RTIPPR, 2010.
29. Baheti M. J., Kale K.V., Jadhav M.E.; 2011; Comparison Of Classifiers For Gujarati Numeral Recognition; International Journal of Machine Intelligence ISSN: 0975–2927 & E-ISSN: 0975–9166, Volume 3, Issue 3, 2011, PP-160-163.
30. Benne R. G., Dhandra B. V., Mallikarjun Hangarge; 2009; Tri-scripts Handwritten Numeral Recognition: A Novel Approach; Advances in Computational Research, ISSN: 0975–3273, Volume 1, Issue 2, 2009, PP-47-51.
31. Bharath A., Sriganesh Madhvanath; 2010; On the Significance of Stroke Size and Position for Online Handwritten Devanagari Word Recognition: An Empirical Study; International Conference on Pattern Recognition; 1051-4651/10 2010 IEEE.
32. Bikash Shaw, Swapan Kr. Parui, Malayappan Shridhar; 2008; Offline Handwritten Devanagari Word Recognition: A Segmentation Based Approach; 978-1-4244-2175-6/08/2008 IEEE.
33. Bikash Shaw, Swapan Kr. Parui, Malayappan Shridhar; 2008; Offline Handwritten Devanagari Word Recognition: A holistic approach based on directional chain code feature and HMM; International Conference on Information Technology; IEEE ICIT 978-0-7695-3513-5/08 2008.
34. Binu P Chacko, Babu Anto P; 2010; Pre and Post Processing Approaches in Edge Detection for Character Recognition; 12th International Conference on Frontiers in Handwriting Recognition 978-0-7695-4221-8/10 2010 IEEE.
35. Brijmohan Singh, Ankush Mittal, Debashis Ghosh; 2011; An Evaluation of Different Feature Extractors and Classifiers for Offline Handwritten Devnagari Character Recognition; Journal of Pattern Recognition Research 2 (2011) 269-277.

139 Bibliography
36. Brijmohan Singh, Ankush Mittal, M. A. Ansari, Debashis Ghosh; 2011; Handwritten Devanagari Word Recognition: A Curvelet Transform Based Approach; International Journal on Computer Science and Engineering (IJCSE) Vol. 3 No. 4 ; ISSN : 0975-3397.
37. Brijmohan Singh, Nitin Gupta, Rashi Tyagi, Ankush Mittal, Debashish Ghosh; 2011; Parallel Implementation of Devanagari Text Line and Word Segmentation Approach on GPU; International Journal of Computer Applications (0975–8887) Volume 24– No.9, June 2011.
38. C. V. Jawahar, Pavan Kumar, S. S. Ravi Kiran; 2003; A Bilingual OCR for Hindi-Telugu Documents and its Applications; Proceedings of the Seventh International Conference on Document Analysis and Recognition (ICDAR 2003) 0-7695-1960-1/03 2003 IEEE.
39. C. Namrata Mahender, K.V.Kale; 2011; Structured based Feature Extraction of Handwritten Marathi Word; International Journal of Computer Applications (0975–8887) Volume 16– No.6, February 2011.
40. Chavan S. V., Kale K. V., Kazi M. M., Rode Y. S.; 2013; Recognition Of Handwritten Devanagari Compound Character A Moment Feature Based Approach; International Journal of Machine Intelligence ISSN: 0975-2927 & E-ISSN: 0975-9166, Volume 5, Issue 1, 2013, pp.-421-425.
41. Chun Lei He Louisa Lam Ching Y. Suen; 2009; A Novel Rejection Measurement in Handwritten Numeral Recognition Based on Linear Discriminant Analysis; 10th International Conference on Document Analysis and Recognition 978-0-7695-3725-2/09 IEEE.
42. Dhandra B. V., Benne R. G., Mallikarjun Hangarge; 2011; Printed And Handwritten Kannada Numerals Recognition using Directional Stroke And Directional Density With Knn; International Journal of Machine Intelligence ISSN: 0975–2927 & E-ISSN: 0975–9166, Volume 3, Issue 3, 2011, pp-121-125.
43. Diego J. Romero, Leticia M. Seijas, Ana M. Ruedin; 2007; Directional Continuous Wavelet Transform Applied to Handwritten Numerals Recognition Using Neural Networks; JCS&T Vol. 7 No. 1.
44. Dileep Kumar Patel, Tanmoy Som, Sushil Kumar Yadav, Manoj Kumar Singh; 2012; Handwritten Character Recognition Using Multiresolution Technique and Euclidean Distance Metric; Journal of Signal and Information Processing, 2012, 3, 208-214 doi:10.4236/jsip.2012.32028 Published Online May 2012.
45. Dinesh Achaya U., N. V. Subba Reddy and Krishnamoorthi; 2008; Hierarchical Recognition System for Machine Printed Kannada Characters; IJCSNS International Journal of Computer Science and Network Security, VOL.8 No.11.
46. Dipak V. Koshti, Sharvari Govilkar; Segmentation of Touching Characters in Handwritten Devanagari Script; UACEE International Journal of Computer Science and its Applications - Volume 2: Issue 2 [ISSN 2250 - 3765].

140 Bibliography
47. Dipankar Das, Rubaiyat Yasmin; 2006; Segmentation and Recognition of Unconstrained Bangla Numeral; Asian Journal of Information Technology 5(2).
48. Dipti Deodhare, NNR Ranga Suri R. Amit; 2005; Preprocessing and Image Enhancement Algorithms for a Form-based Intelligent Character Recognition System; International Journal of Computer Science & Applications Vol. II, No. II, PP. 131 - 144 2005.
49. Dipti Pawar; 2012; Extended Fuzzy Hyperline Segment Neural Network for Handwritten Character Recognition; Proceedings of the International MultiConference of Engineers and Computer Scientists 2012 Vol I;ISBN 978-988-19251-1-4 ISSN 2078-0958.
50. Edgar Erdfelder, Carolina E. Küpper-Tetzel, Sandra D. Mattern; 2011; Threshold models of recognition and the recognition heuristic; Judgment and Decision Making, Vol. 6, No. 1, February 2011, PP. 7–22.
51. G. G. Rajput, S. M. Mali; 2010; Fourier Descriptor based Isolated Marathi Handwritten Numeral Recognition; International Journal of Computer Applications (0975 – 8887) Volume 3 – No.4.
52. G. G. Rajput, Anita H. B.; 2010; Handwritten Script Recognition using DCT and Wavelet Features at Block Level; IJCA Special Issue on “Recent Trends in Image Processing and Pattern Recognition” RTIPPR, 2010.
53. G. G. Rajput, S. M. Mali; 2010; Isolated Handwritten Marathi Numerals Recognition Based upon Fourier Descriptors and Freeman Chain Code; International Journal of Computational Intelligence Research ISSN 0973-1873 Volume 6, Number 2 (2010), PP. 289–298.
54. Gang Liu, Lianwen Jin, Kai Ding, Hanyu Yan; 2010; A new approach for synthesis and recognition of large scale handwritten Chinese words; 12th International Conference on Frontiers in Handwriting Recognition 978-0-7695-4221-8/10 2010 IEEE.
55. Gaurav Agrawal, Kshitij, Amitabha Mukerjee, Nimit Kumar; Handwritten Devanagari Script Segmentation using Support Vector Machines.
56. Gunvantsinh Gohil, Rekha Teraiya, Mahesh Goyani; 2012; Chain Code And Holistic Features Based OCR System For Printed Devanagari Script Using ANN And SVM; International Journal of Artificial Intelligence & Applications (IJAIA), Vol.3, No.1, January 2012.
57. Holambe A. N., Thool R. C., Shinde U. B. and Holambe S. N.; 2010; Brief review of research on Devanagari script; International Journal of Computational Intelligence Techniques, ISSN: 0976–0466, Volume 1, Issue 2, 2010, PP-06-09.
58. J.Pradeep, E.Srinivasan, S.Himavathi; 2010; Diagonal Feature Extraction Based Handwritten Character System Using Neural Network; International Journal of Computer Applications(0975–8887) Volume 8– No.9, October 2010.
59. Jonathan J. Hull, Alan Commike, Tin-Kam HO; 1990; Multiple Algorithms for Handwritten Character Recognition; Int. Workshop on Frontiers in Handwriting Recognition, Montreal, Canada, April 2-3, 1990.

141 Bibliography
60. Jyotsna Vaid, Ashum Gupta; 2002; Exploring Word Recognition in a Semi-Alphabetic Script: The Case of Devanagari; 2002 Elsevier Science (USA) Brain and Language 81, 679–690 (2002).
61. K. V. Prema, N. V. Subba Reddy; 2002; Two-tier architecture for unconstrained handwritten character recognition; Sadhana Vol. 27, Part 5, PP. 585–594.
62. K. Y. Rajput, Sangeeta Mishra; Recognition and Editing of Devnagari Handwriting Using Neural Network; Proceedings of SPIT-IEEE Colloquium and International Conference, Mumbai, India Vol. 1.
63. K. H. Aparna, Vidhya Subramanian, M. Kasirajan, G. Vijay Prakash, V. S. Chakravarthy; 2004; Online Handwriting Recognition for Tamil; Proceedings of the 9th Int’l Workshop on Frontiers in Handwriting Recognition (IWFHR-9 2004) 0-7695-2187-8/04 2004 IEEE;
64. Kapil Bamne, Neha Sharma; 2015; Offline Classifier For Handwritten Devanagari Script Recognition; International Journal of Advanced Research in Electronics and Communication Engineering (IJARECE) Volume 4, Issue 2, February 2015; ISSN: 2278 – 909X.
65. Karbhari V. Kale, Prapti D. Deshmukh, Shriniwas V. Chavan, Majharoddin M. Kazi, Yogesh S. Rode; 2014; Zernike Moment Feature Extraction for Handwritten Devanagari (Marathi) Compound Character Recognition; (IJARAI) International Journal of Advanced Research in Artificial Intelligence,Vol. 3, No.1, 2014.
66. Latesh Malik, P.S. Deshpande; 2009; Recognition of Printed and Handwritten Devanagari Characters With Regular Expression in Finite State Models; Digital Technology Journal 2009, Vol. 2, PP. 1{7, ISSN 1802-5811 (print), ISSN 1802-582X (online).
67. Laurent Guichard Alejandro H. Toselli Bertrand Couasnon; 2010; Handwritten word verification by SVM-based hypotheses re-scoring and multiple thresholds rejection; 12th International Conference on Frontiers in Handwriting Recognition 978-0-7695-4221-8/10 2010 IEEE.
68. M. Hanmandlu, O.V. Ramana Murthy, Vamsi Krishna Madasu; 2007; Fuzzy Model based recognition of handwritten Hindi characters; Digital Image Computing Techniques and Applications 0-7695-3067-2/07 2007 IEEE DOI 10.1109/DICTA.2007.82 IEEE.
69. M. Omidyeganeh, S. Ghaemmaghami, S. Shirmohammadi; 2012; Application of 3D-wavelet statistics to video analysis; Multimed Tools Appl DOI 10.1007/ s11042-012-1012-5 Springer.
70. M.K. Jindal, R.K. Sharma, G.S. Lehal; 2007; Segmentation of Horizontally Overlapping Lines in Printed Indian Scripts;International Journal of computational Intelligence Research. ISSN 0973-1873 Vol.3, No.4 (2007), PP. 277–286.

142 Bibliography
71. Mahesh Jangid; 2011; Devanagari Isolated Character Recognition by using Statistical features; International Journal on Computer Science and Engineering (IJCSE) Vol. 3 No. 6 ;ISSN : 0975-3397.
72. Manoj Kumar Shukla, Tushar Patnaik, Shrikant Tiwari, Sanjay Kumar Singh; 2011; Script Segmentation of Printed Devnagari and Bangla Languages Document Images OCR; International Journal of Computer Sci ence and Technology Vol. 2, Issue 2,;ISSN:2229-4333(Print)|ISSN:0976-8491(Online).
73. Mansi Shah, Gordhan B Jethava; 2013; A Literature Review On Hand Written Character Recognition; Indian Streams Research Journal Vol -3 , ISSUE –2, March.2013 ISSN:-2230-7850.
74. Mehmmood Abdulla Abd; 2007; Effective Arabic Character Recognition using Support Vector Machines; Springer Innovations and Advanced Techniques in Computer and Information Sciences and Engineering, 7–11.
75. Mithun Biswas, Ranjan Parekh; 2012; Character Recognition using Dynamic Windows; International Journal of Computer Applications (0975 – 8887) Volume 41– No.15, March 2012.
76. Mohammad Reza, Jenabzade Reza Azmi , Boshra Pishgoo, Samanesadat Shirazi; 2011; Two Methods for Recognition of Hand Written Farsi Characters; International Journal of Image Processing (IJIP), Volume (5) : Issue (4) : 2011.
77. Mohit Mehta, Rupesh Sanchati, Ajay Marchya; 2010; Automatic Cheque Processing System; International Journal of Computer and Electrical Engineering, Vol. 2, No. 4, August, 2010 1793-8163;
78. Vinaya. S. Tapkir, Sushma. D. Shelke; 2012; OCR For Handwritten Marathi Script; International Journal of Scientific & Engineering Research Volume 3, Issue 8, August-2012 1; ISSN 2229-5518.
79. Mudit Agrawal, Ajay S Bhaskarabhatla and Sriganesh Madhvanath;Data Collection For Handwriting Corpus Creation In Indic Scripts.
80. N. B. Mapari, A. L. Telang, R. K. Rajbhure; 2011; A Study Of Devnagri Handwritten Character Recognition System; International Journal Of Computer Science And Applications Vol. 4, No. 2, June-July 2011 ISSN: 0974-1003.
81. N. Sharma, U. Pal, F. Kimura, S. Pal; 2006; Recognition of Off-Line Handwritten Devnagari Characters Using Quadratic Classifier; Springer ICVGIP 2006, LNCS 4338, PP. 805 – 816, 2006.
82. Naresh Kumar Garg, Lakhwinder Kaur, M. K. Jindal; 2010; Segmentation of Handwritten Hindi Text; 2010 International Journal of Computer Applications (0975 – 8887) Volume 1 – No. 4.
83. Naresh Kumar Garg, Lakhwinder Kaur, M. K. Jindal; 2011; The Hazards in Segmentation of Handwritten Hindi Text; International Journal of Computer Applications (0975 – 8887) Volume 29– No.2, September 2011.
84. Naresh Kumar Garg, Lakhwinder Kaur, M. K. Jindal; 2013; Recognition of Offline Handwritten Hindi Text Using SVM; International Journal of Image Processing (IJIP), Volume (7) : Issue (4) : 2013.

143 Bibliography
85. Nazih Ouwayed, Abdel Belaïd; 2011; A general approach for multi-oriented text line extraction of handwritten documents;Springer IJDAR DOI 10.1007/s10032-011-0172-6.
86. Neeraj Pratap, Shwetank Arya; 2012; A Review of Devnagari Character Recognition from Past to Future; International Journal of Computer Science and Telecommunications [Volume 3, Issue 6, June 2012].
87. Neha Avhad, Shraddha Darade,Neha Gawali, Apurva Matsagar; 2015; Handwritten Devnagari Character Recognition System; International Journal Of Engineering And Computer Science Volume 4 Issue 4 April 2015, Page No. 11233-11236; ISSN:2319-7242.
88. Neha Sahu, R. K. Rathy, Indu Kashyap; 2012; Survey and Analysis of Devnagari Character Recognition Techniques using Neural Networks; International Journal of Computer Applications (0975 – 888) Volume 47– No.15, June 2012.
89. Nilima P. Patil, K. P. Adhiya, Surendra P. Ramteke; 2011; A Structured Analytical Approach to Handwritten Marathi vowels Recognition; International Journal of Computer Applications (0975 – 8887) Volume 31– No.3, October 2011.
90. Niranjan S.K, Vijaya Kumar, Hemantha Kumar G, Manjunath Aradhya V N; 2009; FLD based Unconstrained Handwritten Kannada Character Recognition; International Journal of Database Theory and Application Vol. 2, No. 3, September 2009.
91. O. V. Ramana Murthy, M. Hanmandlu; 2011; Zoning based Devanagari Character Recognition; International Journal of Computer Applications (0975 – 8887) Volume 27– No.4, August 2011.
92. O. V. Ramana, Sujoy Roy, Vipin Narang, M. Hanmandlu; 2012; Devanagari Character Recognition in the Wild; International Journal of Computer Applications (0975 – 8887) Volume 38– No.4, January 2012.
93. O.V. Ramana Murthy, M. Hanmandlu; 2011; A Study on the Effect of Outliers in Devanagari Character Recognition; International Journal of Computer Applications (0975 – 8887) Volume 32– No.10, October 2011.
94. Om Prakash Sharma, M. K. Ghose, Krishna Bikram Shah; 2012; An Improved Zone Based Hybrid Feature Extraction Model for Handwritten Alphabets Recognition Using Euler Number; International Journal of Soft Computing and Engineering (IJSCE) ISSN: 2231-2307, Volume-2, Issue-2, May 2012.
95. P. Bhaskara Rao D.Vara Prasad Ch.Pavan Kumar; 2013; Feature Extraction Using Zernike Moments; International Journal of Latest Trends in Engineering and Technology (IJLTET) Vol. 2 Issue 2 March 2013; ISSN: 2278-621X.
96. P. S. Deshpande, Latesh Malik, Sandhya Arora; 2008; Fine Classification & Recognition of Hand Written Devnagari Characters with Regular Expressions & Minimum Edit Distance Method; Journal Of Computers, Vol. 3, No. 5.

144 Bibliography
97. P. S. Deshpande, Latesh Malik, Sandhya Arora; 2007; Recognition of Hand Written Devnagari Characters with Percentage Component Regular Expression Matching and Classification Tree; IEEE 1-4244-1272-2/07 2007.
98. P.E.Ajmire, R.V. Dharaskar, V. M. Thakare; 2012; A Comparative Study of Handwritten Marathi Character Recognition; National Conference on Innovative Paradigms in Engineering & Technology (NCIPET-2012) Proceedings published by International Journal of Computer Applications (IJCA).
99. Partha Pratim Roy, Umapada Pal, Josep Lladós; 2011; Text line extraction in graphical documents using background and foreground information;Springer IJDAR DOI 10.1007/s10032-011-0167-3.
100. Prachi Mukherji, Priti P. Rege; 2008; Fuzzy Stroke Analysis of Devnagari Handwritten Characters; WSEAS TRANSACTIONS on COMPUTERS Issue 5, Volume 7; ISSN: 1109-2750.
101. Prachi Mukherji, Priti P. Rege; 2009; Shape Feature and Fuzzy Logic Based Offline Devnagari Handwritten Optical Character Recognition; Journal of Pattern Recognition Research 4 (2009) 52-68.
102. Prachi Mukherji, Priti P. Rege; Stroke Analysis Of Devnagari Handwritten Characters; 6th Wseas International Conference On Circuits, Systems, Electronics, Control & Signal Processing, Cairo, Egypt, Dec 29-31, 2007.
103. Prachi Patil, Saniya Ansari; 2014; Online Handwritten Devnagari Word Recognition using HMM based Technique; International Journal of Computer Applications (0975 – 8887) Volume 95– No.17, June 2014.
104. Prashant M. Kakde, Vivek R. Raut; 2012; Performance Analysis Of Handwritten Devnagri Characters Recognition Through Machine Intelligence; International Journal of Emerging Technology and Advanced Engineering www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 7, July 2012).
105. Prerna Singh, Nidhi Tyagi; 2011; Radial Basis Function For Handwritten Devanagari Numeral Recognition; (IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 2, No. 5, 2011.
106. Pritpal Singh, Sumit Budhiraja; 2012; Handwritten Gurmukhi Character Recognition Using Wavelet Transforms;International Journal of Electronics, Communication & Instrumentation Engineering Research and Development (IJECIERD) ISSN 2249-684X Vol.2, Issue 3 Sep 2012 27-37.
107. Priyanka Kulkarni, Sonal Patil, Ganesh Dhanokar; 2015;Review On Marathi And Sanskrit Word Recognition Using Genetic Algorithm; International Journal of Informative & Futuristic Research ISSN (Online): 2347-1697, Volume 2 Issue 7 March 2015; ISSN (Online): 2347-1697.
108. R. C. Tripathi, Vijay Kumar; 2012; Character Recognition: A Neural Network Approach; National Conference on Advancement of Technologies – Information Systems & Computer Networks (ISCON – 2012) Proceedings published in International Journal of Computer Applications (IJCA).

145 Bibliography
109. R. Indra Gandhi, K.Iyakutti; 2010; A Technique for Segmentation over Overlapping Line of Uniform Sized Text on Non-Headline Based Distorted Tamil Scripts; Int. J. of Advanced Networking and Applications Volume: 02, Issue: 02, Pages: 491-495 (2010).
110. R. J. Ramteke ; 2010; Invariant Moments Based Feature Extraction for Handwritten Devanagari Vowels Recognition; International Journal of Computer Applications (0975 - 8887) Volume 1 – No. 18.
111. R. J. Ramteke, S. C. Mehrotra; 2008; Recognition Of Handwritten Devanagari Numerals; International Journal of Computer Processing of Oriental Languages;
112. R. Jagadeesh Kannan, R. Prabhakar; 2008; An Improved Handwritten Tamil Character Recognition System using Octal Graph; Journal of Computer Science 4 (7): 509-516, 2008;ISSN 1549-3636.
113. R. Jayadevan, S. R. Kolhe, P. M. Patil, U. Pal; 2011; Automatic Processing Of Handwritten Bank Cheque Images: A Survey; Springer IJDAR DOI 10.1007/ s10032-011-0170-8.
114. R. Jayadevan, S. R. Kolhe, P. M. Patil, Umapada Pal; 2011; Database Development and Recognition of Handwritten Devanagari Legal Amount Words; International Conference on Document Analysis and Recognition 1520-5363/11 2011 IEEE.
115. Rajiv Kapoor, Deepak Bagai, T. S. Kamal; 2002; Skew Angle Detection Of A Cursive Handwritten Devanagari Script Character Image; J. Indian Inst. Sci., May-Aug. 2002, 82, 161–175.
116. Rajiv Kumar, Amresh Kumar, Pervez Ahmed; A Benchmark Dataset for Devnagari Document Recognition Research; Recent Advances in Telecommunications, Signals and Systems; ISBN: 978-1-61804-169-2.
117. Rakesh Rathi, Ravi Krishan Pandey, Mahesh Jangid; 2012; Offline Handwritten Devanagari Vowels Recognition using KNN Classifier; International Journal of Computer Applications (0975 – 8887) Volume 49– No.23, July 2012.
118. Ratnashil N Khobragade, Nitin A. Koli, Mahendra S Makesar; 2013; A Survey on Recognition of Devnagari Script; International Journal of Computer Applications & Information Technology Vol. II, Issue I, January 2013 (ISSN: 2278-7720);
119. Ravi Sheth, N C Chauhan, Mahesh M Goyani, Kinjal A Mehta; 2011; Handwritten Character Recognition System using Chain code and Correlation Coefficient; International Conference on Recent Trends in Information Technology and Computer Science (IRCTITCS) 2011 Proceedings published in International Journal of Computer Applications (IJCA).
120. Reena Bajaj, Lipika Dey , Santanu Chaudhury; 2002; Devnagari numeral recognition by combining decision of multiple connectionist classifiers; Sadhana Vol. 27, Part 1, PP. 59–72.

146 Bibliography
121. Rohit Verma, Jahid Ali; 2012; A-Survey of Feature Extraction and Classification Techniques in OCR Systems; International Journal of Computer Applications & Information Technology Vol. I, Issue III, November 2012 (ISSN: 2278-7720).
122. S. Arora D. Bhattacharjee, M. Nasipuri, D.K. Basu, M.Kundu; 2011; Complementary Features Combined in a MLP-based System to Recognize Handwritten Devnagari Character;Journal of Information Hiding and Multimedia Signal Processing 2010 ISSN 2073-4212 Ubiquitous International Volume 2, Number 1, January 2011.
123. S. Arora, D. Bhattacharjee, M. Nasipuri, D.K. Basu, M.Kundu; 2009; Application of Statistical Features in Handwritten Devnagari Character Recognition; International Journal of Recent Trends in Engineering, Vol 2, No. 2, November 2009
124. S. Arora, D. Bhattacharjee, M. Nasipuri, D.K. Basu, M.Kundu, L.Malik; 2009; Study of Different Features on Handwritten Devnagari Character; Second International Conference on Emerging Trends in Engineering and Technology, ICETET-09.
125. S. Arora, D. Bhattacharjee, M. Nasipuri, D. K. Basu, M. Kundu; Recognition of Non-Compound Handwritten Devnagari Characters using a Combination of MLP and Minimum Edit Distance; International Journal of Computer Science and Security (IJCSS),Volume (4) : Issue (1).
126. S. K. Parui, K. Guin, U. Bhattacharya, B. B. Chaudhuri; 2008; Online Handwritten Bangla Character Recognition Using HMM; IEEE 978-1-4244-2175-6/08.
127. S. M. Mali; 2012; Moment And Density Based Hadwritten Marathi Numeral Recognition; Indian Journal of Computer Science and Engineering (IJCSE); ISSN : 0976-5166 Vol. 3 No.5 Oct-Nov 2012.
128. S.P.Kosbatwar , S.K.Pathan; 2012; Pattern Association for character recognition by Back-Propagation algorithm using Neural Network approach; International Journal of Computer Science & Engineering Survey (IJCSES) Vol.3, No.1, February 2012.
129. S.Ramasundaram, S.P.Victor ; 2010; Text Categorization by Backpropagation Network; International Journal of Computer Applications (0975 – 8887) Volume 8– No.6, October 2010.
130. S.V. Rajashekararadhya, P. Vanaja Ranjan; 2008; Efficient Zone Based Feature Extration Algorithm For Handwritten Numeral Recognition Of Four Popular South Indian Scripts; Journal of Theoretical and Applied Information Technology.
131. S.V. Rajashekararadhya, P. Vanaja Ranjan; 2009; A Novel Zone Based Feature Extraction Algorithm for Handwritten Numeral Recognition of Four Indian Scripts; Digital Technology Journal 2009, Vol. 2, PP. 41{51, ;ISSN 1802-5811 (print), ISSN 1802-582X (online).

147 Bibliography
132. Sandhya Arora, Debotosh Bhattacharjee, Mita Nasipuri, Dipak Kumar Basu, Mahantapas Kundu; 2008; Combining Multiple Feature Extraction Techniques for Handwritten Devnagari Character Recognition; IEEE Region 10 Colloquium and the Third ICIIS, Kharagpur, INDIA December 8-10.
133. Sandip N.Kamble, Megha Kamble; 2011; Morphological Approach for Segmentation of Scanned Handwritten Devnagari Text; International Journal of Computer Science & Technology Vol. 2, Issue 4; ISSN : 0976-8491 (Online) | ISSN : 2229-4333(Print).
134. Sang Sung Park, Won Gyo Jung, Young Geun Shin, Dong-Sik Jang;2008;Optical Character Recognition System Using BP Algorithm;IJCSNS International Journal of Computer Sci 118 ence and Network Security, VOL.8 No.12, ;
135. Sangame S.K., Ramteke R.J., Rajkumar Benne; 2009; Recognition of Isolated Handwritten Kannada Vowels; Advances in Computational Research, ISSN: 0975–3273, Volume 1, Issue 2, 2009, PP-52-55.
136. Satish Kumar; 2009; Performance Comparison of Features on Devanagari Hand-printed Dataset; International Journal of Recent Trends in Engineering, Vol. 1, No. 2.
137. Satish Kumar; 2010; An Analysis of Irregularities in Devanagari Script Writing – A Machine Recognition Perspective; (IJCSE) International Journal on Computer Science and Engineering Vol. 2, No. 2, 2010, 274-279;ISSN:0975-3397.
138. Shailedra Kumar, Shrivastava Sanjay, S. Gharde; 2010; Support Vector Machine for Handwritten Devanagari Numeral Recognition; International Journal of Computer Applications (0975 – 8887) Volume 7– No.11, October 2010.
139. Shailendra Kumar, Shrivastava Pratibha, Chaurasia; 2012; Handwritten Devanagari Lipi using Support Vector Machine; International Journal of Computer Applications (0975 – 8887) Volume 43– No.20, April 2012;
140. Shazia Akram Dr. Mehraj-Ud-Din Dar Aasia Quyoum; 2010; Document Image Processing - A Review; International Journal of Computer Applications (0975 – 8887) Volume 10– No.5, November 2010.
141. Shraddha V. Shelke, D. M. Chandwadkar; Automatic System for Recognition of Handwritten Character Using Multiscale Neural Network; International Journal of Computer Applications (0975 – 8887).
142. Snehal S.Patwardhan, R.R. Deshmukh; 2015; A Review on Offline Handwritten Recognition of Devnagari Script; International Journal of Computer Applications (0975 – 8887) Volume 117 – No. 19, May 2015.
143. Soumen Bag, Gaurav Harit; 2013; A survey on optical character recognition for Bangla and Devanagari scripts; Sadhana Vol. 38, Part 1, PP. 133–168. Indian Academy of Sciences.

148 Bibliography
144. Stuti Asthana, Farha Haneef, Rakesh K Bhujade; 2011; Handwritten Multiscript Numeral Recognition using Artificial Neural Networks; International Journal of Soft Computing and Engineering (IJSCE) ISSN: 2231-2307, Volume-1, Issue-1, March 2011.
145. Sukhpreet Singh, Renu Dhir; 2012; Recognition of Handwritten Gurmukhi Numeral using Gabor Filters;International Journal of Computer Applications (0975 – 8887) Volume 47– No.1, June 2012.
146. Suryaprakash Kompalli, Srirangaraj Setlur, Venu Govindaraju; 2009; Devanagari OCR using a recognition driven segmentation framework and stochastic language models; Springer IJDAR (2009) 12:123–138 DOI 10.1007/s10032-009-0086-8.
147. Sushama Shelke, Shaila Apte; 2011; Multistage Handwritten Marathi Compound Character Recognition Using Neural Networks; Journal of Pattern Recognition Research 2 (2011) 253-268.
148. Sushama Shelke, Shaila Apte; 2010; A Novel Multi-feature Multi-Classifier Scheme for Unconstrained Handwritten Devanagari Character Recognition; 12th International Conference on Frontiers in Handwriting Recognition 978-0-7695-4221-8/10 2010 IEEE.
149. Sushama Shelke, Shaila Apte; 2011; A Multistage Handwritten Marathi Compound Character Recognition Scheme using Neural Networks and Wavelet Features;International Journal of Signal Processing, Image Processing and Pattern Recognition Vol. 4, No. 1, March 2011.
150. Swapnil A. Vaidya, Balaji R. Bombade; 2013; A Novel Approach of Handwritten Character Recognition using Positional Feature Extraction; International Journal of Computer Science and Mobile Computing IJCSMC, Vol. 2, Issue. 6, June 2013, pg.179 – 186;ISSN 2320–088X.
151. T. Mondal, U. Bhattacharya, S. K. Parui, K. Das; 2010; On-line handwriting recognition of Indian scripts – the first benchmark; 2010 12th International Conference on Frontiers in Handwriting Recognition; 978-0-7695-4221-8/10 2010 IEEE.
152. U. Bhattacharya, B. B. Chaudhuri; 2005; Databases for Research on Recognition of Handwritten Characters of Indian Scripts; Proceedings of the 2005 Eight International Conference on Document Analysis and Recognition (ICDAR’05) 1520-5263/05 2005 IEEE.
153. U. Pal. B.B. Chaudhari; 2001; Machine Printed and handwritten text lines Identification;Elsevier Science Pattern Recognition Letters 22(2001) ;0167-8655/01.
154. U. Pal., B.B. Chaudhari; 2004; Indian Script Character Recognition : a Survey;Pattern Recognition (37) 2004.
155. V.N. Manjunath, Aradhya S.K., Niranjan G., Hemantha Kumar; 2010; Probabilistic Neural Network based Approach for Handwritten Character Recognition; Special Issue of IJCCT Vol.1 Issue 2, 3, 4; 2010 for International Conference [ACCTA-2010], 3-5 August 2010.

149 Bibliography
156. Vandana Korde, C Namrata Mahender; 2012; Text Classification And Classifiers: A Survey; International Journal of Artificial Intelligence & Applications (IJAIA), Vol.3, No.2, March 2012.
157. Vandana M. Ladwani, Latesh Malik; 2010; Survey Of Various Approches Towards Handwritten Devanagari Word Recognition; International Journal on Computer Engineering and Information Technology; ISSN 0974-2034
158. Ved Prakash Agnihotri; 2012; Offline Handwritten Devanagari Script Recognition; I.J. Information Technology and Computer Science, 2012, 8, 37-42.
159. Veena Bansal, R. M. K. Sinha; 2000; Integrating Knowledge Sources in Devanagari Text Recognition System; IEEE Transactions On Systems, Man, And Cybernetics—Part A: Systems And Humans, Vol. 30, No. 4, ;1083–4427.
160. Vijay Kumar, Pankaj K. Sengar; 2010; Segmentation of Printed Text in Devanagari Script and Gurmukhi Script; International Journal of Computer Applications (0975 – 8887) Volume 3 – No.8, June 2010.
161. Vijaya Rahul Pawar, Arun Gaikwad; 2014; Multistage Recognition Approach for Offline Handwritten Marathi Script Recognition; International Journal of Signal Processing, Image Processing and Pattern Recognition Vol.7, No.1 (2014), PP.365-378 http://dx.doi.org/10.14257/ijsip.2014.7.1.34.
162. Vikas J Dongre, Vijay H Mankar; 2010; A Review of Research on Devnagari Character Recognition; International Journal of Computer Applications (0975–8887) Volume 12– No.2, November 2010.
163. Vneeta Rani, Pankaj Kumar; 2013; Problems of Character Segmentation In Handwritten Text Documents written in Devnagari Script; International Journal of Advanced Research in Computer Engineering & Technology (IJARCET) Volume 2, Issue 3, March 2013;ISSN: 2278 – 1323.
164. Xian Wang, Venu Govindaraju, Sargur Srihari; 2000; Holistic recognition of handwritten character pairs; Elsevier Science Ltd Pattern Recognition 33 (2000) 1967}1973 0031-3203/00.
165 http://marathi.tripod.com/marathi.html 166 http://learnmarathithroughai.weebly.com/combining-consonants-in-marathi 167 http://mindurmarathi.com/marathi-vocabulary 168 http://marathi.tripod.com/marathi.html